






 本文介绍了DiT,一种结合了扩散模型的加噪去噪特性与Transformer强大自注意力机制的新型架构。DiT通过使用Transformer模块替代U-Net,解决了传统模型的缺陷,尤其是在生成图片质量上有显著提升。关键组件如In-ContextConditioning和adaLN-Zero展示了如何有效地融合条件信息。
本文介绍了DiT,一种结合了扩散模型的加噪去噪特性与Transformer强大自注意力机制的新型架构。DiT通过使用Transformer模块替代U-Net,解决了传统模型的缺陷,尤其是在生成图片质量上有显著提升。关键组件如In-ContextConditioning和adaLN-Zero展示了如何有效地融合条件信息。
DiT:基于transformer架构的扩散模型。
paper:[2212.09748] Scalable Diffusion Models with Transformers (arxiv.org)
有空看
1. 介绍
对于扩散模型来说,自2020年DDPM诞生以来,连续3年的工作仍然延续最初的经典U-Net架构,在网络结构设计上仍依赖早期的研究经验,有着很大的提升空间;
而Transformer一直被诟病的则是其“错误累积”问题,简单来说,错误扩散来源于Transformer“预测下一个词”的生成模式,如果说前面生成的词出现了错误,那么模型在生成后续的词时会“将错就错”,进而导致误差的累积,扩散模型由于同时对所有的像素去除噪声(这种范式我们称为非自回归,non-autoregressive),从生成范式上规避了这一问题。
如何同时解决好二者的存在的缺陷,成为了一个很好的研究课题。扩散模型基于早期工作的经验,在网络结构设计上仍有很大的提升空间。而这篇工作在隐空间扩散模型范式的启发下,成功将扩散模型中经典的U-Net结构替换成了Transformer,在进一步提升网络架构复杂度的前提下,能够显著提升生成图片的质量。
2. 方法
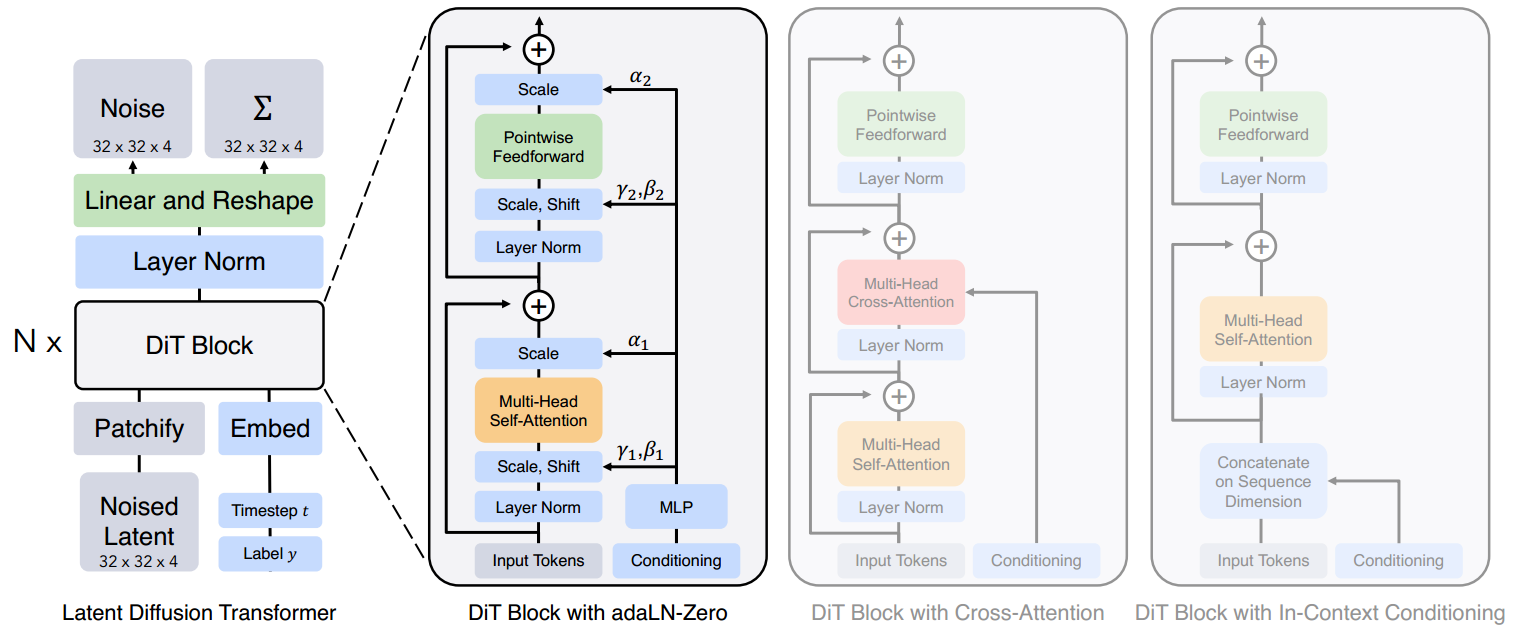
图3。DiT架构。左:我们训练条件潜在DiT模型。输入潜信号被分解成小块,并由多个DiT块进行处理。右:DiT块的详细信息。我们尝试了各种标准的变压器模块,这些模块通过自适应层规范、交叉注意和额外的输入令牌结合了条件反射。自适应层规范效果最好。
DiT既有着扩散模型对图片加噪、去噪的特殊机制,又同时有Transformer强大的自注意力机制,以及Transformer“预测下一个词”的特点。给定输入图片时,DiT首先通过扩散模型标准的加噪过程对图像压缩后的特征进行污染,将带噪特征、条件特征、ground truth对应的特征拼接在一起输入Transformer后输出结果,完成一次DiT的前传过程。
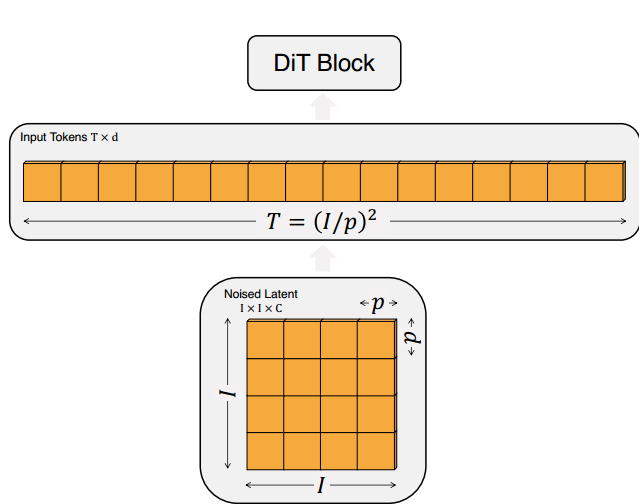
- DiT模块:在完成“块化”的操作之后,下一步要做的就是输入DiT进行相应的运算。DiT由DiT 模块的基本单元构成,其中,DiT模块中的大多数元素类似于标准的Transformer模块,包括多头自注意力机制(Multi-Head Self-Attention)、Layer Normalization、Feed Forward Layer等等。其中,为了融合外部的条件控制,DiT有三种变种形式,分别与In-Context Conditioning、Cross-Attention、adaLN-Zero相组合,它们都用于融合外部的标签条件,对应Diffusion Transformer模型架构图中由右到左的顺序:
- In-Context Conditioning:从字面意思上来看,In-Context Conditioning可以翻译为”上下文条件化“。其实就是将条件拼接在输入词的后面。前面我们说到,Transformer的输出过程其实是在做“预测下一个词”,而in-context conditioning其实是给这一过程加上了一个前缀,在“预测下一个词”的过程中,模型会持续收到这个前缀的作用。具体来说,在DiT这篇工作的设定中,这个条件对应ImageNet中图片的类别,在模型生成图片“词”的时候,模型就会在知道生成图片的类别的前提之下完成输出过程。从技术层面上来看,这个设计跟ViT中的
clstoken大同小异。 - Cross-Attention:跨注意力机制其实很简单,类似于经典latent diffusion models中U-Net的跨注意力机制,将条件对应的特征作为注意力机制的K和V,以图片特征作为Q进行运算,从而达到将条件融入图片生成过程中的效果。
- adaLN-Zero:这个模块是这篇工作中的另一创新点,是针对Transformer原本layer normalization在图像生成任务上的一个创新。具体做法抛弃了layer norm原来直接学习增益(scale)和偏置(shift)的做法,而是通过自适应地学习加权系数(图中的 α1,α2,β1,β2),加权系数将输入条件的特征处理后,再加到每层layer norm的增益和偏置中去,以此完成条件的融合。
- 这里adaLN-Zero的设计其实感觉跟SPADE[6]的思路类似。SPADE的提出是为了融合分割图的条件输入而提出了,其做法是将分割图处理成可学习的增益和偏置,再将增益和偏置加权到图像特征上,完成条件的融合。可以看到,SPADE和adaLN-Zero的异曲同工之妙,说明增益和偏置是融入条件信号是一个有效的方式。
- In-Context Conditioning:从字面意思上来看,In-Context Conditioning可以翻译为”上下文条件化“。其实就是将条件拼接在输入词的后面。前面我们说到,Transformer的输出过程其实是在做“预测下一个词”,而in-context conditioning其实是给这一过程加上了一个前缀,在“预测下一个词”的过程中,模型会持续收到这个前缀的作用。具体来说,在DiT这篇工作的设定中,这个条件对应ImageNet中图片的类别,在模型生成图片“词”的时候,模型就会在知道生成图片的类别的前提之下完成输出过程。从技术层面上来看,这个设计跟ViT中的
参考:Diffusion Transformer Family:关于Sora和Stable Diffusion 3你需要知道的一切 - 知乎 (zhihu.com)

















 2663
2663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









