






Scalable Diffusion Models with Transformers
本文介绍一篇发表于2023年国际计算机视觉大会(ICCV)的研究论文,该论文提出了一种基于Transformer架构的扩散模型,称为Diffusion Transformers (DiTs)。 通过用Transformer替代传统的U-Net架构,训练了一种作用于潜在图像块的扩散模型。 DiTs在大规模图像生成任务中展现出卓越的性能,成功实现了在ImageNet 256x256和512x512图像生成任务中的性能突破,表明了Transformer在扩散模型中的巨大潜力。
原文:W. Peebles and S. Xie, “Scalable Diffusion Models with Transformers,” 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023, pp. 4172-4182, doi: 10.1109/ICCV51070.2023.00387.
Introduction
近年来,基于大规模数据集的深度学习模型训练显著推动了图像生成和处理领域的发展。特别是Transformer架构,凭借其在自然语言处理和高层次视觉任务中的成功,被迅速应用于生成模型领域。然而,现有扩散模型通常采用U-Net作为主干网络,对生成质量和扩展性存在一定限制。
本篇论文提出了一种基于Transformer的新型扩散模型,称为Diffusion Transformers (DiTs),旨在突破传统方法的瓶颈。该模型通过用Transformer替代U-Net,在潜在图像空间中直接建模,实现了以下创新与突破:
-
卓越的生成质量:在ImageNet 256×256类别条件生成基准测试中,最优模型DiT-XL/2取得了当前最优的Fréchet Inception Distance (FID)值2.27;
-
良好的扩展性:研究表明,通过增加Transformer深度/宽度或输入Token数量,模型的生成质量随着Gflops(前向计算复杂度)的提升而显著提高;
-
高效的计算性能:相比传统U-Net架构扩散模型,DiTs在计算成本更低的情况下达到了更优质的图像生成效果。
本论文的研究不仅验证了Transformer架构在低层次图像生成任务中的潜力,还为未来在大规模生成模型(如文本到图像生成)的应用提供了新的设计思路。
Diffusion Transformers
DiT架构总览
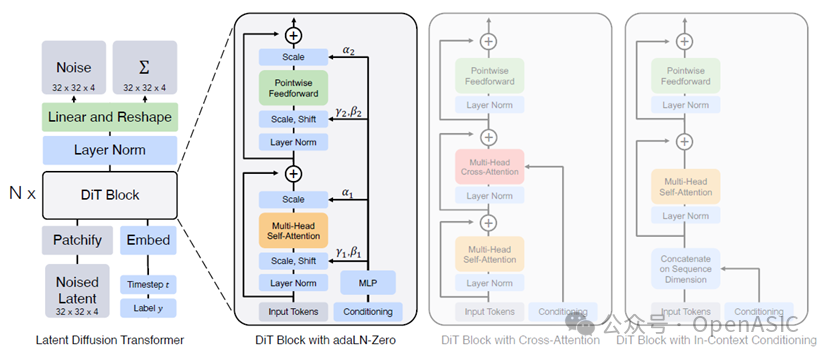
DiT整体架构
图中展示了**Diffusion Transformer (DiT)**的整体设计架构及其核心模块。
-
左侧部分:展示了完整的潜变量扩散模型(Latent Diffusion Transformer)流程,输入的潜变量首先通过patchify模块切分为小块,并转换为Token序列,随后通过多个DiT块进行处理,最终通过线性解码器恢复出噪声预测结果。
-
右侧部分:详细展示了不同类型的DiT块,包括自适应层归一化(adaLN-Zero)、交叉注意力(Cross-Attention)、以及上下文条件输入(In-Context Conditioning)三种变种的内部结构。
1.从输入到Token化:Patchify 模块
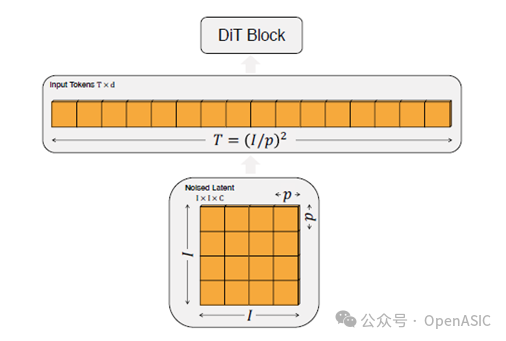
输入
Diffusion Transformer (DiT) 的输入是一组多通道潜变量特征图(Noised Latent),通常大小为 32×32×4。这些潜变量由前一时间步的噪声预测生成。在进入Transformer模型之前,潜变量需要经过Patchify模块的处理。
Patchify 模块的核心在于将图像或特征分割成小块(Patch),类似将一幅画分割成小块拼图。每个Patch大小由参数 p 决定,例如8×8或16×16。随后,这些Patch通过线性变换(Embed)被转化为一维Token序列,供Transformer进一步处理。
此外,时间步信息(Timestep ttt)和类别标签(Class Label ccc)作为条件信息,通过嵌入操作转化为向量Token,并直接拼接到输入Token序列中,为模型提供额外的上下文信息。
通过这种方式,Patchify 实现了从图像空间到序列空间的高效转换,为后续的Transformer建模奠定了基础。
2.DiT模块设计:条件信息的高效建模
在Diffusion Transformer中,DiT模块承担了条件信息融合和序列建模的核心任务。为了实现更灵活、更高效的条件建模,论文提出了四种模块设计:
-
上下文条件模块(In-context Conditioning) 这一设计最为直接,将条件信息(时间步 ttt 和类别标签 ccc)的向量嵌入作为额外的Token拼接到输入序列中,并与图像Token一并通过标准Transformer块处理。在最终输出前,这些条件Token会被移除。这种方法计算开销最低,但对复杂条件信息的表达能力相对有限。
-
交叉注意力模块(Cross-attention Block) 在这一设计中,条件信息被编码为独立的Token序列,与图像Token序列分离。Transformer块在多头自注意力(Multi-head Self-Attention)层后加入了一个多头交叉注意力层(Cross-attention),用于深度融合条件信息和主序列特征。尽管这种设计显著增强了条件信息的建模能力,但它也增加了约15%的计算复杂度。
-
自适应层归一化模块(adaLN Block) adaLN模块通过自适应层归一化动态调整每个维度的缩放和偏移参数 γ\gammaγ 和 β\betaβ,这些参数由条件信息向量的和回归而来。该模块在不增加太多计算开销的情况下,显著提高了条件信息的利用效率,是生成质量最佳的选择。
-
零初始化自适应层归一化模块(adaLN-Zero Block) 在adaLN的基础上,增加了零初始化策略:将残差连接之前的缩放参数初始化为零。这一改动使得每个残差块在初始阶段接近恒等映射,从而显著优化了训练的收敛速度。 通过这四种设计,DiT模块能够在生成质量和计算效率之间实现灵活权衡,并适应不同的任务需求。
3.模型规模:探索性能与效率的极限
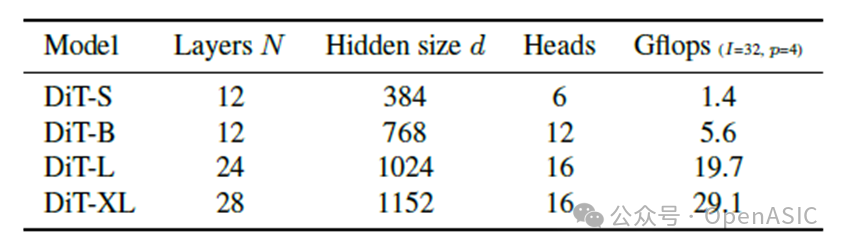
model size
DiT 的设计空间还涵盖了模型规模的调整。具体来说,模型通过调整Transformer块的数量 NNN、隐藏维度大小 ddd 和注意力头数,实现对性能和复杂度的控制。
论文中提供了四种模型配置:DiT-S(小型)、DiT-B(中型)、DiT-L(大型) 和 DiT-XL(超大型)。这些配置的计算复杂度(FLOPs)范围从 0.3 Gflops 到 118.6 Gflops,覆盖了从轻量级任务到高分辨率生成的广泛需求。
实验表明,随着模型规模的扩大,生成质量显著提升,但计算开销也相应增加。
4. Transformer 解码器:从Token到清晰图像
在经过Transformer模块的处理后,Token序列需要还原为完整的图像。这一过程由线性解码器(Linear Decoder)完成。具体来说,解码器对每个Token应用线性变换,将其映射为大小为 p×p×2C的张量,其中 C 是输入图像的通道数。解码后的Token会被重新排列为原始的空间布局,从而生成噪声预测(Noise Prediction)和协方差预测(Covariance Prediction)。
在扩散过程中,模型逐步减少图像中的噪声,直到还原出高清图像。这一解码过程高度依赖于条件信息和Transformer模块的高质量建模,使得生成的每一帧都与输入条件信息保持一致。
Experiments
为了验证 Diffusion Transformer (DiT) 模型的性能和扩展性,论文设计了一系列实验,涵盖从不同模块设计到模型规模与计算效率的综合评估。以下是实验的详细分析与结果。
DiT模块设计性能对比
论文首先评估了四种不同的DiT模块设计(In-context Conditioning、Cross-attention、adaLN 和 adaLN-Zero)的性能。实验选择了最高复杂度的 DiT-XL/2 模型(118.6 Gflops)进行测试,并通过生成质量指标 FID-50K 随训练迭代的变化进行对比。
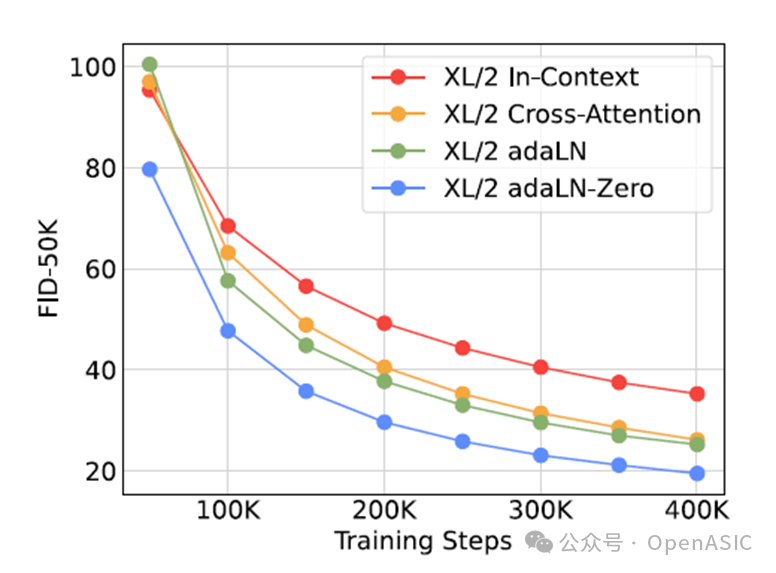
质量指标跟迭代次数关系
实验结果表明:
-
adaLN-Zero 模块的表现最佳,其生成质量显著优于其他设计。在400K训练步数时,adaLN-Zero的FID值几乎是In-context Conditioning的一半。
-
Cross-attention 虽然增强了条件信息融合能力,但计算复杂度增加了15%。
-
In-context Conditioning 是最轻量级的设计,但对复杂条件的表达能力有限。
这些结果进一步证明了条件输入机制对生成质量的关键作用,而 adaLN-Zero 模块由于其高效的初始化策略(残差块初始为恒等映射)成为性能最佳的选择。
DiT模型扩展性能分析:模型规模与Patch大小的影响
为了研究模型规模和输入Patch大小对生成质量的影响,论文训练了12个不同配置的DiT模型,涵盖 DiT-S、DiT-B、DiT-L 和 DiT-XL 四种规模,以及Patch大小为 8、4、2 的组合。
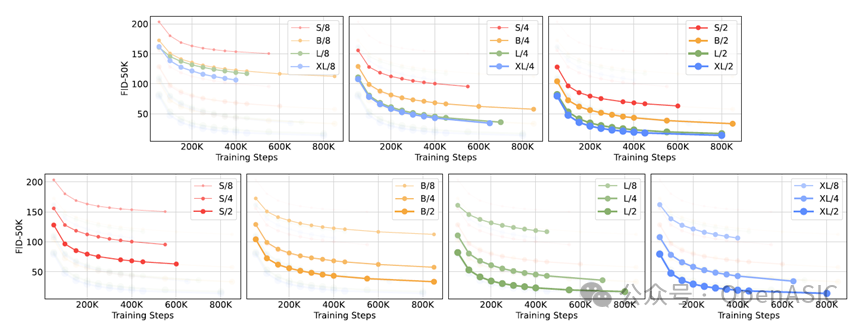
扩展性能分析
实验结果总结如下:
-
模型规模扩展:如图上半部分所示,在保持Patch大小不变的情况下,随着模型规模从DiT-S逐渐增加到DiT-XL,生成质量(FID)在所有训练阶段均显著提升。
-
Patch大小缩小:如图下半部分所示,在保持模型规模不变的情况下,减小Patch大小(即增加Token数量)同样显著提升了生成质量。
可视化扩展效果
论文通过对比不同DiT模型的生成图像,直观展示了扩展模型规模和计算复杂度的效果。

图像样本质量
在400K训练步数时,所有模型使用相同的噪声和类别标签生成样本。结果显示:
-
增加模型深度和宽度,或增加输入Token数量,均能显著提升生成图像的视觉质量。
-
生成样本在细节和纹理上更加逼真,体现了模型扩展的有效性。
与现有先进方法的对比
论文进一步在ImageNet 256×256和512×512数据集上评估了DiT-XL/2模型的性能,并与当前最先进的生成模型进行对比。
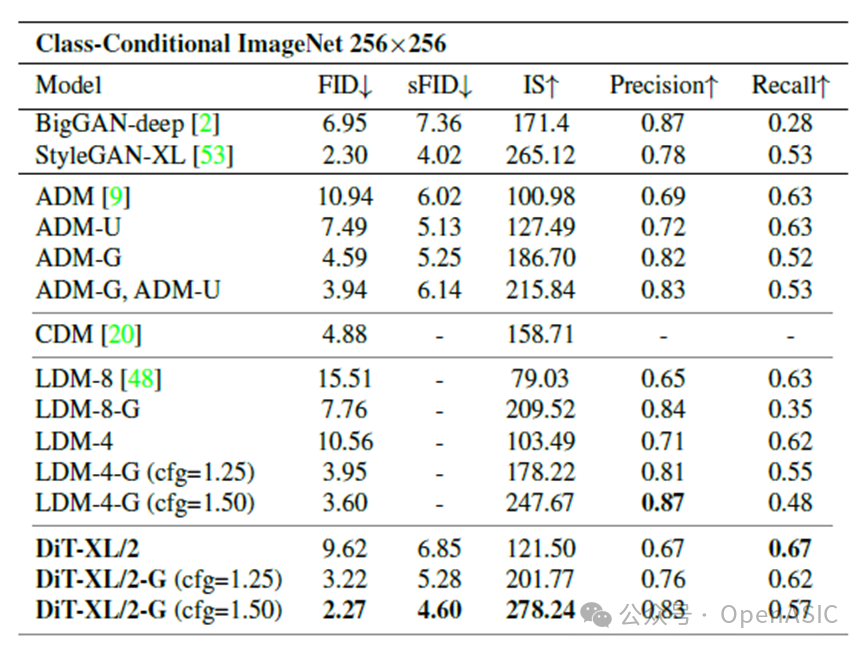
ImageNet 256×256
- 在ImageNet 256×256基准测试中,DiT-XL/2-G(cfg=1.50)实现了 2.27 FID,显著优于之前的最佳方法(LDM-4-G, FID=3.60)。
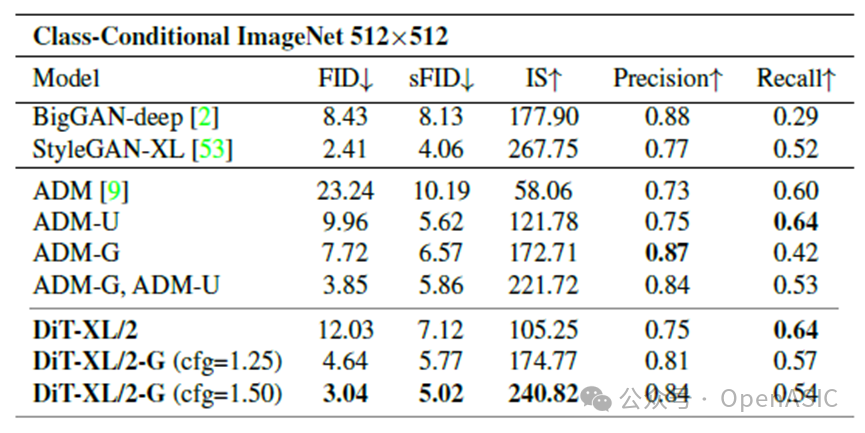
ImageNet 512 * 512
- 在ImageNet 512×512分辨率下,DiT-XL/2-G(cfg=1.50)的FID为 3.04,同样超越了所有先前模型,包括StyleGAN-XL和ADM。
实验结果表明,DiT-XL/2不仅生成质量优于基于U-Net的扩散模型,还具有更高的计算效率。例如,在相同任务中,DiT-XL/2的计算复杂度仅为524.6 Gflops,而ADM模型的计算复杂度高达1983 Gflops。
Conclusion
本文提出了 Diffusion Transformers (DiTs),一种基于Transformer的扩散模型主干网络。相比传统的U-Net模型,DiT展现出更强的性能,同时继承了Transformer架构在扩展性上的显著优势。
实验表明,DiT能够在多种生成任务中显著提升生成质量,并具备在更大模型规模和更多Token数量下持续提升性能的潜力。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 2672
2672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









