




YOLOV8 网络模型以及代码讲解
1.YOLO系列背景
YOLO(You Only Look Once)系列从2016年的YOLOv1发展至今,经历了多个版本的迭代,每一代都在速度、精度和功能上不断优化。Joseph Redmon 是YOLO系列的主要创始人,他在华盛顿大学进行研究工作时提出了 YOLO 的概念,YOLOV1到YOLOV3都是由其提出。想要查看YOLO最先提出的论文,点击:论文地址。
YOLO将目标检测转化为回归问题,通过将输入图像划分为网格,每个网格预测固定数量的边界框及其类别。相比于传统的双阶段检测器(如R-CNN系列),YOLO只需一次前向传播即可完成检测,显著提升了检测速度。
从v1开始一直到今天要介绍的v8,以下是YOLO系列的主要特点和发展历程:
YOLOv1(2016年):首次提出单阶段检测框架,检测速度快,但对小目标检测效果较差。
YOLOv2(2016年):引入锚框、多尺度训练和高分辨率分类器,提升了小目标检测能力。
YOLOv3(2018年):采用Darknet-53骨干网络,支持多尺度检测,改进分类器为逻辑回归。
YOLOv4(2020年):引入CSPDarknet53、PANet和CIOU损失函数,进一步优化速度与精度。
YOLOv5(2020年):转向PyTorch框架,支持自适应锚框和多种模型尺寸,便于开发与部署。
YOLOv6(2022年):针对工业应用优化,采用无锚框设计和EfficientRep结构。
YOLOv7(2022年):通过级联模型缩放策略提升性能,适用于实时检测。
YOLOv8(2023年):引入模块化设计,支持检测、分割和跟踪任务,采用Anchor-Free检测头。
2. YOLOv8网络模型
YOLOv8是Ultralytics公司推出的Yolo系列目标检测算法,可以用于图像分类、物体检测和实例分割等任务。根据官方描述,YOLOv8是一个SOTA模型,它建立在YOLO系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
此外,YOLOv8还有一个特点就是可扩展性,ultralytics没有直接将开源库命名为Yolov8,而是直接使用"ultralytics",将其定位为算法框架,而非某一个特定算法。这也使得YOLOv8开源库不仅仅能够用于YOLO系列模型,而且能够支持非YOLOv8模型以及分类分割姿态估计等各类任务。
获取有关YOLOv8源码可点击:YOLOv8源码地址。下面我将分模块详细讲述YOLOv8的网络模型以及源码。(说明:本博客中用到图出自csdn博主,bilibili up主:炮哥带你学,有详情可以狠狠的看他的博客和B站视频)
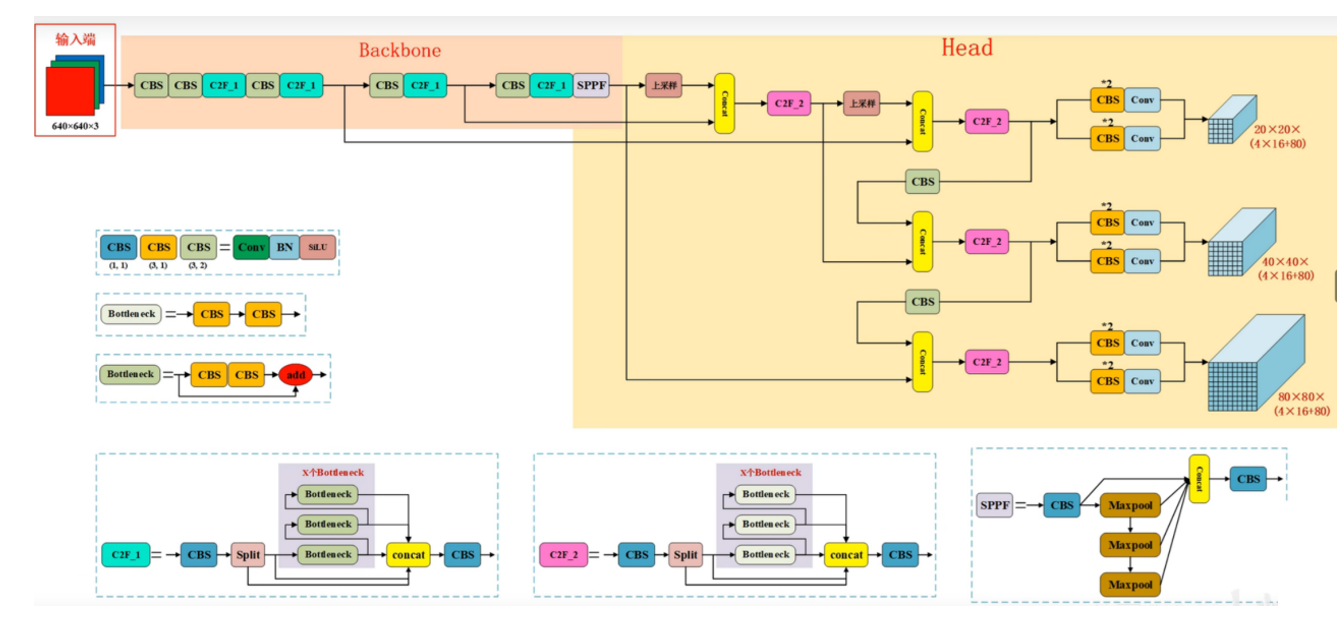
模型整体结构
如图,是YOLOv8模型的整体结构,从其中清晰明了的能够看到作者将他分成了两个主要部分:BackBone和Head。学过YOLO之前系列的同学会发现,这里的Head就是之前系列的Neck+Head,这里作者把二者合二为一,并且可以观察到:不同于之前的Head,之前输出的检测头格式如YOLOv5输出(76×76×255,38×38×255,19×19×255),之前的输出就是将图像划分成n×n个grid cell,然后每个grid cell输出[(x,y,w,h,c)+80个分类概率]×anchor个数。但是在v8当中都是按照n×n×(4×16+80)的格式进行输出,这也是v8和之前的系列改进最大的一点,也是整个v8当中最为重要的一点。BackBone就是整个网路的主干部分,作用在于对输入图像进行特征提取;Head中利用了FPN+PAN结构进行特征融合,最后输出检测结果。
在图中,能看到作者将每一层网络都当成一个小模块进行处理,例如:CBS模块、C2F_N模块,SPPF模块等等。接下来,我们就以此先讲解这些小模块原理以及代码。
CBS模块
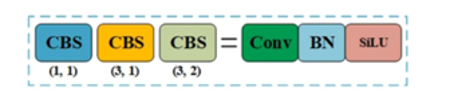
如上图,CBS模块是一个非常简单的模块,其实就是一次Conv+Batch Norm+SiLu激活函数。你能看到,有蓝色的CBS,黄色的CBS,浅绿色的CBS通过下面括号中的数字就能看出来,他们之前的区别在于进行卷积操作时,卷积核的大小和以及滑动步数的不同。而在CBS模块中,我觉得可能让大家不熟悉的地方在于Silu激活函数,它与Relu和LeakyRelu这些激活函数有什么不同呢?
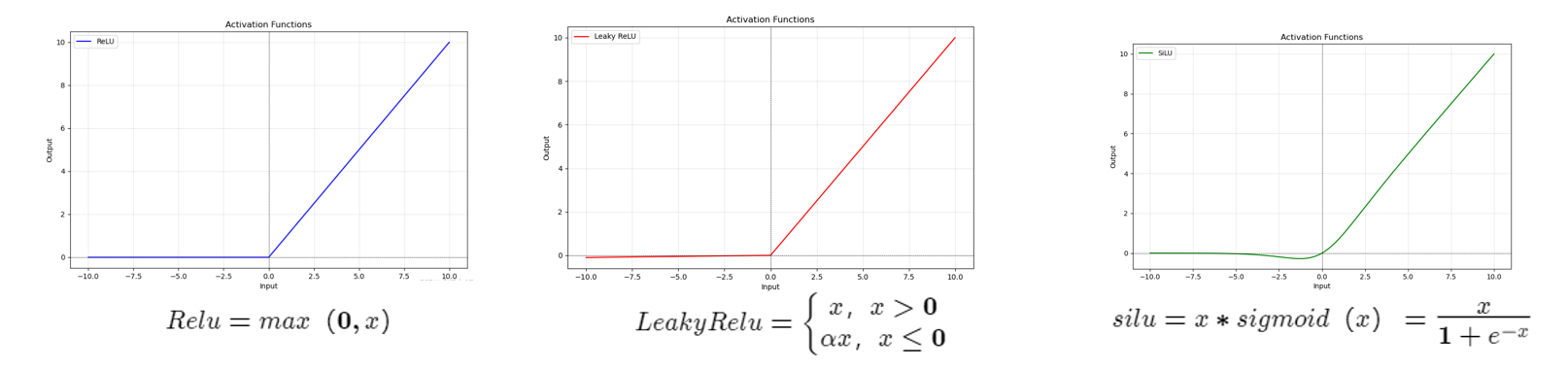
上图分别是Relu、LeakyRelu、Silu激活函数的函数图像以及函数表达式,可以看到Relu激活函数在输入≤0时,输出值为0;而在输入>0时,输出值则等于输入值,对于Relu激活函数而言一个老生常谈的问题就是,在输入≤0时,输出值为0 很容易导致神经元失活问题。所以Geoff Hinton基于这个问题提出了LeakyRelu激活函数:在输入≤0时引入一个十分小的缩放因子,让输出值接近于0但是不等于0,从图中就可以看到,当输入<0且距离原点越来越远时函数图像距离x轴是有一个明显的偏移的。但是,我们知道在CBS模块中,激活函数的输入是Batch Norm的输出,Batch Norm的输出结果是均值为0,方差为1的一组数据,所以极大可能经过Batch Norm的结果会在零点附近,而通过LeakyRelu函数图像可以看到,在零点的左侧也是无限的接近于0,甚至可以看作是等于0的,也会有可能出现神经元失活的问题。所以,进入了Silu激活函数。
Google公司提出了Silu激活函数,引入sigmoid函数,在零点附近函数图像是有明显起伏,解决了LeakyRelu可能出现的问题。Silu激活函数可以说是彻底解决了神经元失活这个问题,所以我觉得这也是作者使用它的原因。
下面是实现CBS模块的源码,对于有深度学习的一点点基础的同学来说,这这段代码应该也是十分简单的,我就不多讲述。
#CBS模块——>conv
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))#CBS,卷积+batch norm+silu
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
BottleNeck模块
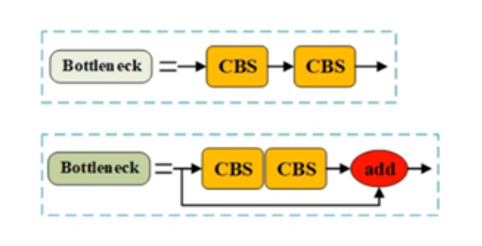
该模块是使用在下面的C2F模块中的一部分。通过上图可以看到,在v8的网络结构当中是有两种BottleNeck的,一种仅仅是两次CBS模块,另一种是两次CBS模块+一次add操作。这也区分出来了后文中的两种C2F模块。
两种BottleNeck的结构是清晰明了的,十分的简单。在这里想给大家区分一下add和concat两种十分经典的特征融合的方式。
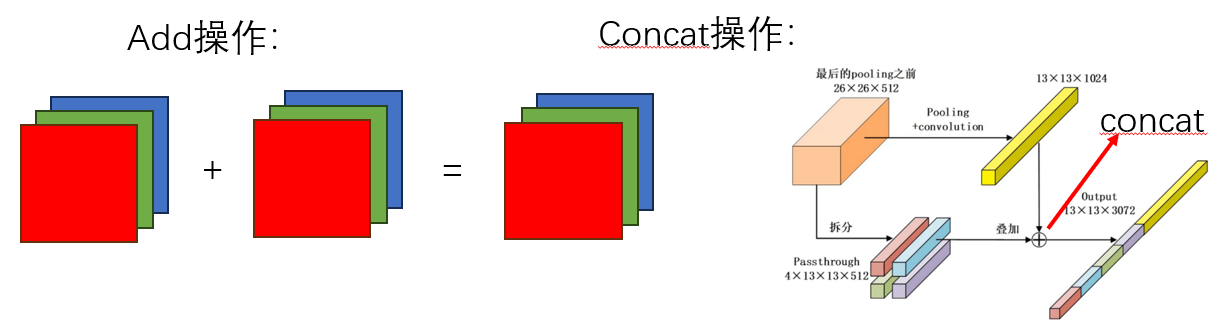
从上图中其实可以明显的看出两种操作的区别:Add操作是直接将两种图像对应通道的各个像素直接一一对应相加,所以这就必须保证相加的两张图像必须大小相同,通道数也要相同,不然就无法完成Add操作;而Concat操作是将两张图像直接在通道方向上进行相加,例如:有一张H×W×C1的图像,一张H×W×C2的图像,那么它们进行一次Concat操作,结果就为H×W×(C1+C2)图像,所以,对于Concat操作而言,仅需保证两张图像大小相同即可。
经过上述的对比过后,我们来看看BottleNeck的源码:
#Bottleneck模块
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1) #第一个cbs
self.cv2 = Conv(c_, c2, k[1], 1, g=g) #第二个cbs
self.add = shortcut and c1 == c2 #是否有add操作
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
其实从整个yolov8的源码看下来,ultralytics公司发布的源码是十分优美、简单易懂的。就这段BottleNeck的代码,一行代码即区分了两种不一样的BottleNeck。正是因为使用add操作,需要通道数相同,所以它以此为判断条件,在forward前向传播中区分了两种BottleNeck。
C2F模块
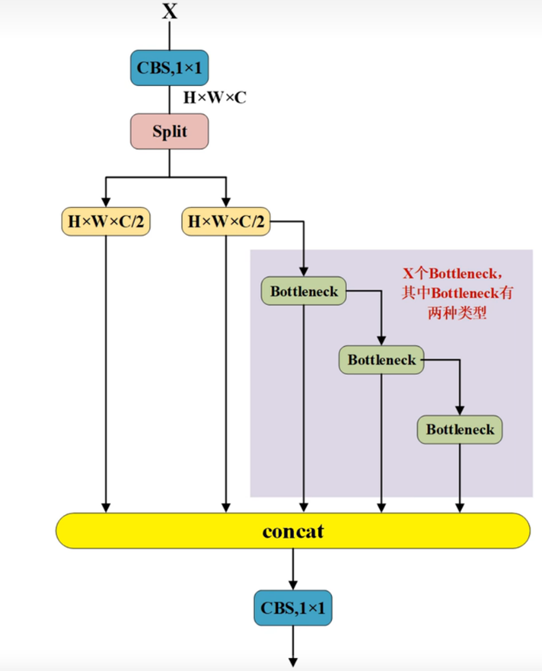
yolov8当中的C2F模块是源自于v7中的ELAN模块的,其作用是在进行多尺度的特征融合操作。在图像进入该模块后,首先会经过一个CBS模块操作得到结果后经过Split操作,Split操作就是将图像在通道方向上一分为二,在图中能清晰的看到:若输入图像为H×W×C,那么经过split操作就会得到两个H×W×C/2的图像。然后,其中一个H×W×C/2的图像会循环经过多个BottleNeck模块,最后将每一个结果整体进行一次concat操作以及一次CBS。而在这里,BottleNeck模块的种类以及个数则区分出来了C2F模块的不同。
在最上面的整体图中,能看到对于C2F模块有两种:C2F_1_X,C2F_2_X,其中X都代表了该C2F模块中BottleNeck的数量,而C2F_1则代表了其中的BottleNeck是带有add操作的,反之C2F_2则代表是了没有add操作的。
在YOLOv8中较之于之前的系列,新提出的也就是这个C2F模块,虽然它是源自于v7中的ELAN模块,在其基础之上做了改变,但是这个改变更好的进行了多尺度特征融合操作。同时,ultralytics实现的该模块的源码我觉得也是十分值得学习的部分,简洁易懂,几行代码就编写了这个模块,同时还将两种不一样的C2F进行了区分。
#C2f模块————最后的特征图大小是不变的
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









