







总体学习规划:2021/2022年的课程内容学完——》2023年的生成式AI也就是LLM随时补充
也就是按照B站网课视频学完21/22+23年的内容,
然后追更24年的生成式AI
从今天起开一个新坑:
就是李宏毅的深度学习课程,为了参考资料的完整性,主要是参考2021/2022 SPRING时期的网课,
实际视频中为了补全资料之间的完整性以及整个学习体系的结构性,很多视频不仅仅限制于21以及22年的课件,也补充了很多李宏毅老师之前的课件,主要是2021/22的spring以及2017的fall,可以找到该视频中大部分对应内容的课件:
https://speech.ee.ntu.edu.tw/~hylee/ml/2022-spring.php
所以在实际自学过程中,可以完全按照视频的内容顺序进行,然后在台大网站上找到对应课件资料即可(一般补充视频的课件资料大都是几年前的课程)
总之此处以22年spring的课件大纲为主线,然后作业homework以及原始代码的话都可以在原网页中找到:
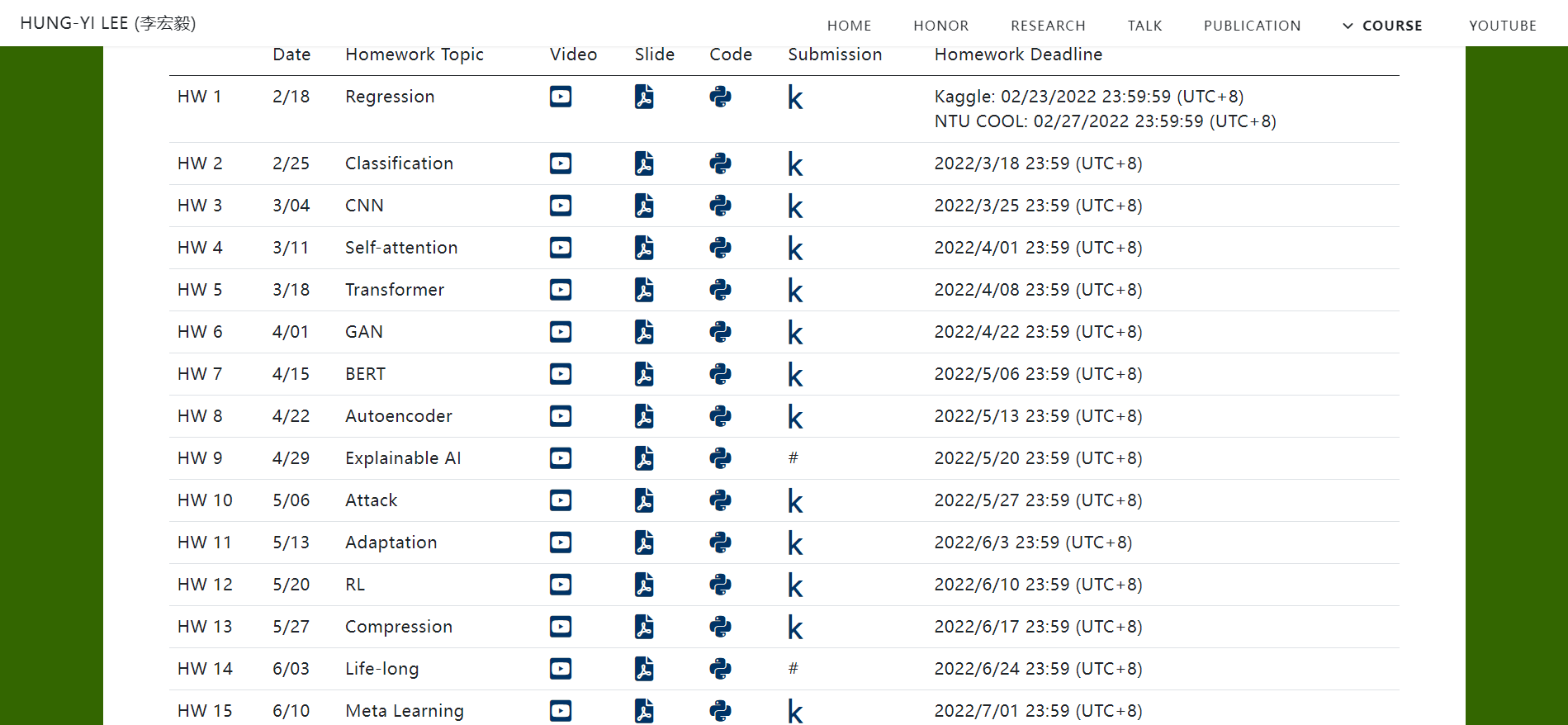
HW1的代码参考课件官网中的网址为:
https://colab.research.google.com/drive/1FTcG6CE-HILnvFztEFKdauMlPKfQvm5Z#scrollTo=YdttVRkAfu2t
另外注释:

https://github.com/ga642381/ML2021-Spring/blob/main/HW01/HW01.ipynb
github中脚本代码是原始参考,官网中给出的脚本代码是HW1的修改基础(也就是蓝图)
所有的操作都是基于官网给出的代码,但是在修改微调的时候可以参考github中的原始脚本
HW1的任务:
简单来说是个regression回归任务


构建模型过程中其实完全不用考虑test测试集,所以只要看train训练集即可;
train训练集中提供了2688名sample(人)x每sample118个feature的数据,
这118个feature包括第1列的ID列,37个state的one-hot编码,5天的阳性率检测相关数据(每天有上面ppt中4+8+3的表型数据feature共15列,然后阳性率的1列,即每天都有16个feature检测,然后每个样本一共检测了5天)
在实际训练过程中,实际上每个样本只获取其前117个feature进行train,即第5天的最后一列feature阳性率作为label不纳入train中,用于label-expected value来计算loss,优化模型架构;
然后train数据中5天数据训练出来的模型,最后用于评估test数据集中第5天的阳性率(test测试集同样只提供了前117维feature,同时注意train和test是完全不一样的数据,ID列具有迷惑性但是不是同一数据,总之就是完全不相关)


1,首先是对于模型数据的查看:包括训练集以及测试集
训练集:
实际上经过检查(有数据id缺失)是2699x118,
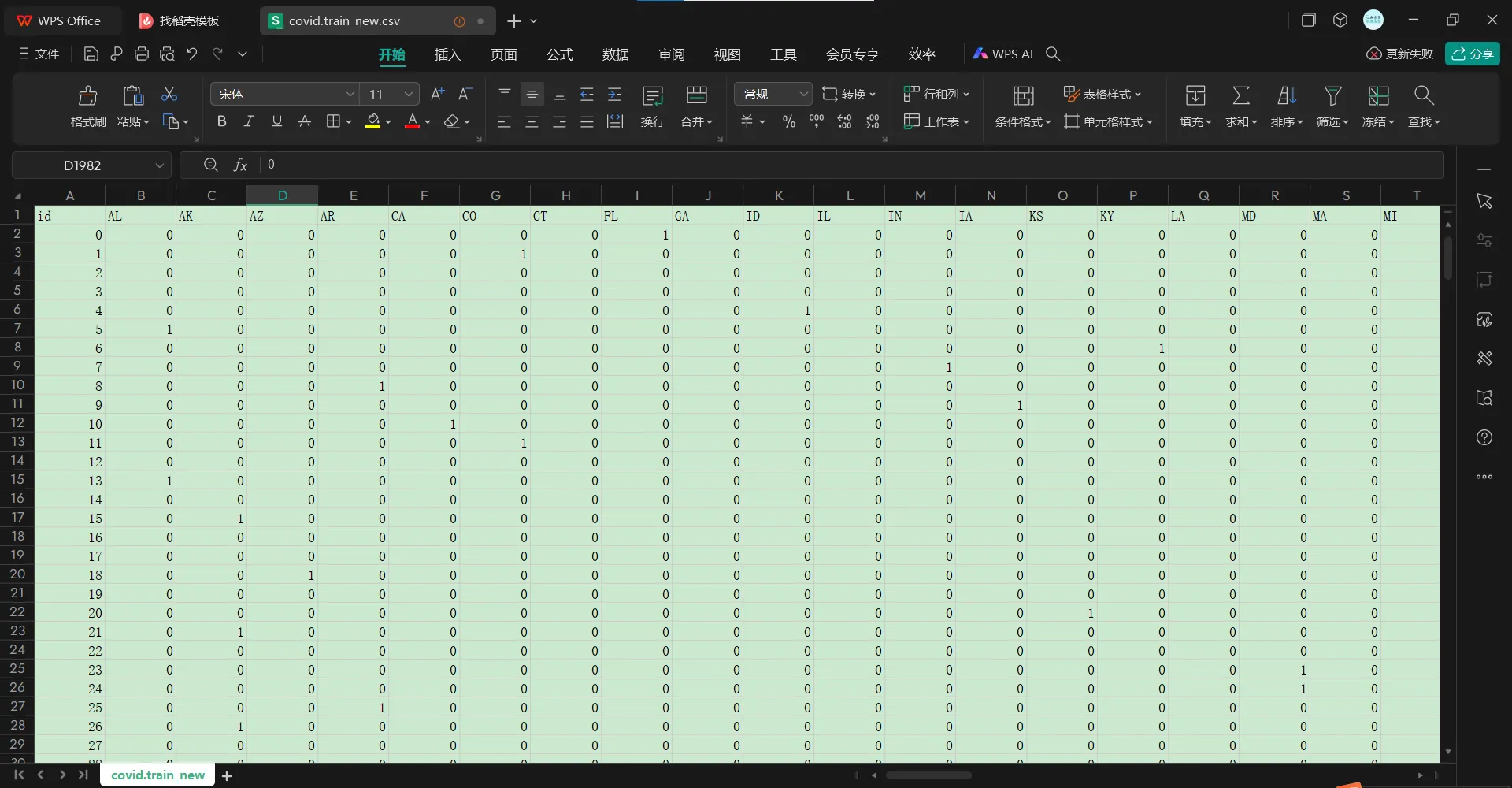
然后在列上:

第1列是id,紧接着是所在美国state所在地的one-hot编码,
one-hot之后是其他的一些feature,然后这些feature重复了5轮,实际上就是5天的data

每轮最后一列其实就是label值,也就是感染的阳性率
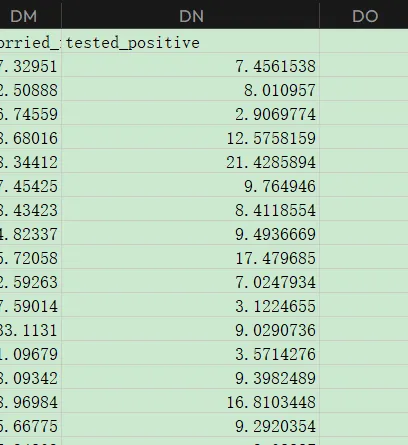
至于测试集:
实际上只有1078x117,也就是样本数少了,feature的话同样是给出了这些ID的前4天label值,但是第5天缺省label
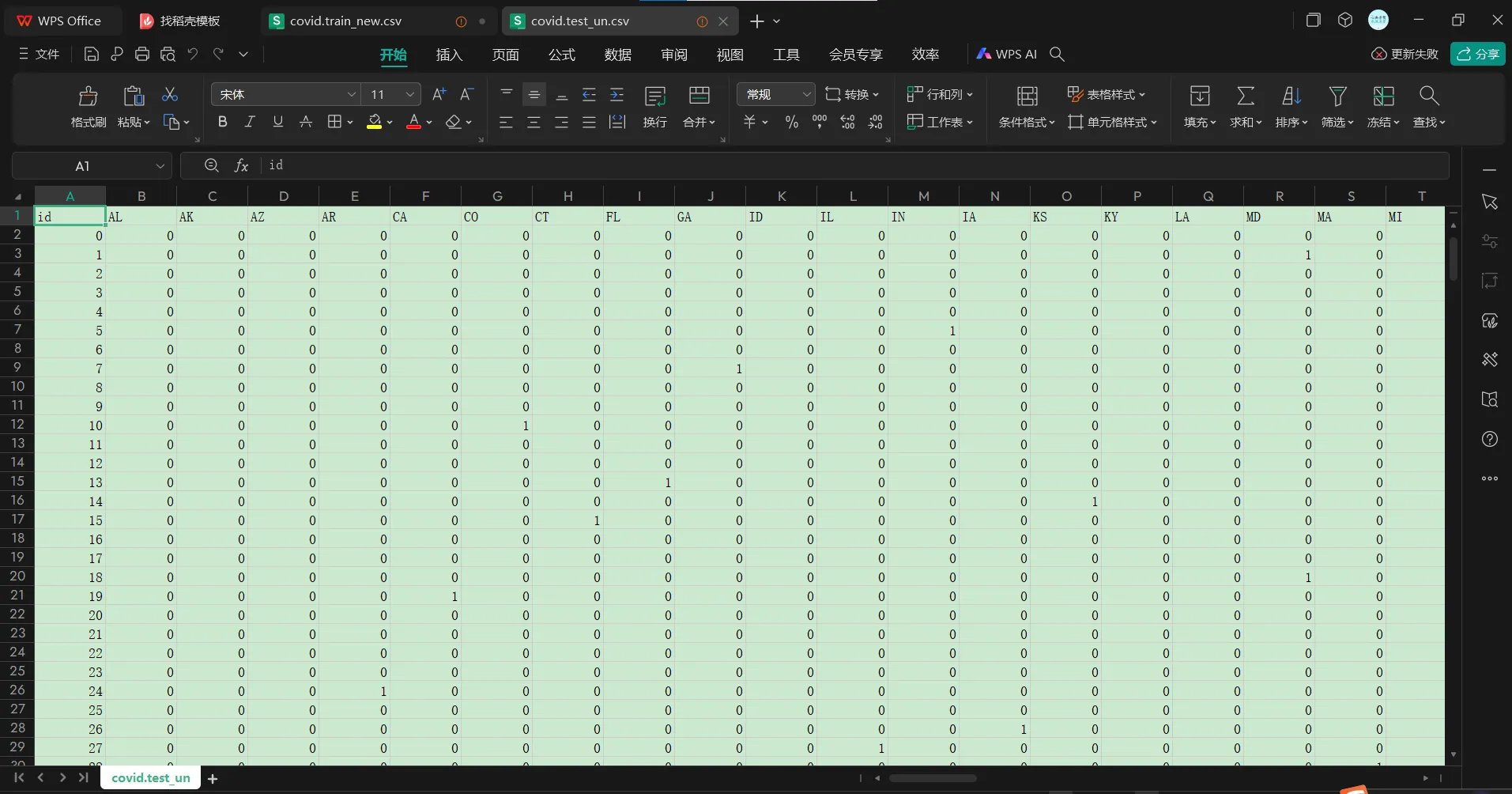
注意到虽然ID这一列很有迷惑性,但是ID相同的行实际上其他数据完全不一样,也就是说train和test是完全不同的数据,并没有11对应的关系
2,colab上代码实际执行过程中:因为训练的时间比较长,可能在训练过程中会中断,所以参考一些java脚本操作来保证运行过程中模型训练不会中断:
参考:
https://blog.csdn.net/Thebest_jack/article/details/124565741
以及https://gist.github.com/e96031413/80a633f6a07c150b431639a4e3c606a8
主要是参考前者
当然实际执行过程中如果神经网络已经训练完成,那么colab连接也会中断(所以情况主要是用于模型训练比较花费时间的过程)
3,如果不改动助教的代码过程,即按照原始的脚本执行过程:
如果使用tensorboard查看train以及valid过程中的loss就是:
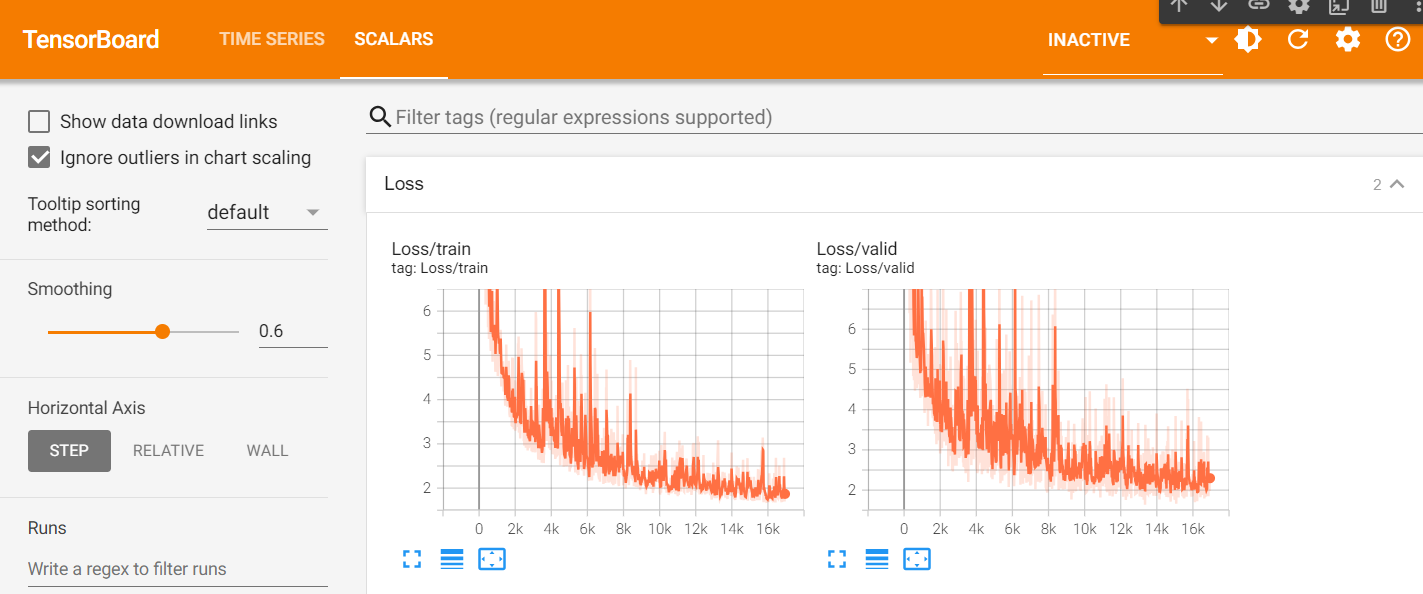
train维持在1.8左右,valid维持在2.0左右
最后对test数据集进行预测就是:
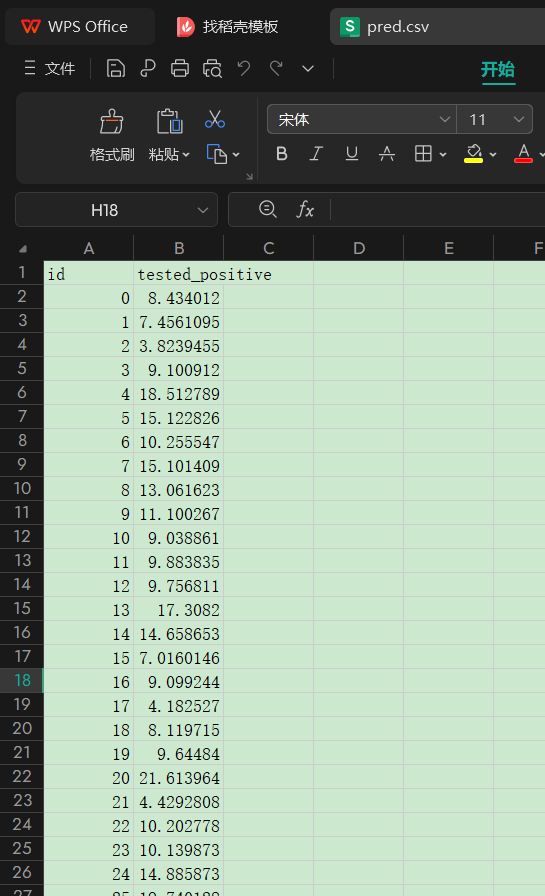
也就是1078个人的第5天的label
4,所有的ipynb脚本保存到github上:
*官网上的脚本是_original
官网参考过的脚本是*_official
自己注释过的是*_annotated
然后大佬复现学习的脚本就按照*_medium等等级来记录**
每个作业,官方的脚本仅仅作为baseline(实际上就是所有作业代码的base)
2021的官方脚本参考https://github.com/ga642381/ML2021-Spring
2022的官方脚本参考https://github.com/virginiakm1988/ML2022-Spring
然后改进/修改的方向,也就是各位开源贡献者大佬的代码,是用于复现以及内化吸收的部分:
主要参考来源:
(1)https://github.com/yaoweizhang/LHY2022-SPRING/tree/main 120stars
主要是其中的各个层级的baseline(都要看看)——>按照修改的顺序进行内化学习
也就是simple——》medium——》strong——》boss baseline的顺序

(2)https://github.com/Hoper-J/HUNG-YI_LEE_Machine-Learning_Homework 121stars
(3)https://github.com/wolfparticle/machineLearningDeepLearning 530stars

但这里主要是2021年的,所以仅仅作为参考,略
(4)https://github.com/sotaBrewer824/LHY_MLDL/tree/main 15stars
**之后作业代码的训练都以(1),(2),(4)为主要参考,(3)略
以及每一个HW在simple、medium、strong、boss baseline上都要试一试**
5,对model进行的优化
主要参考上面的(1),即https://github.com/yaoweizhang/LHY2022-SPRING/tree/main/Hw01/answer
之后的代码优化参考主要都以(1)为主!!!
然后就是具体的优化目标:各个baseline


(1)medium baseline:
主要就是依据domain knowledge精挑细选一些有用的feature
即https://delphi.cmu.edu/covidcast/survey-results/?date=20210221与https://cmu-delphi.github.io/delphi-epidata/api/covidcast-signals/fb-survey.html#mental-health-indicators,
主要就是对feature的一些解读,
此处主要是修改一些feature:
simple中是使用了全部的feature(包括ID列)
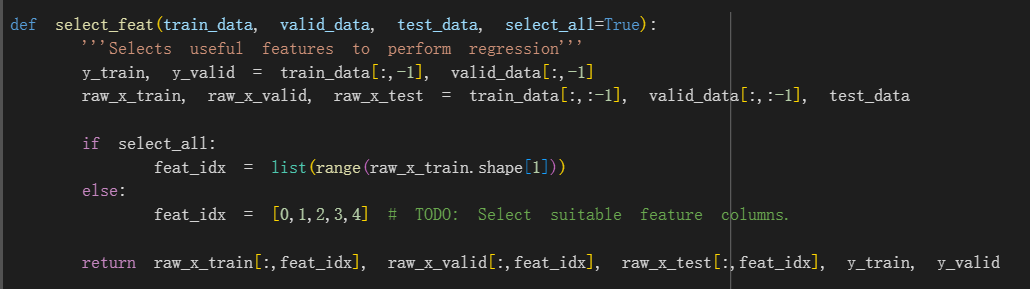
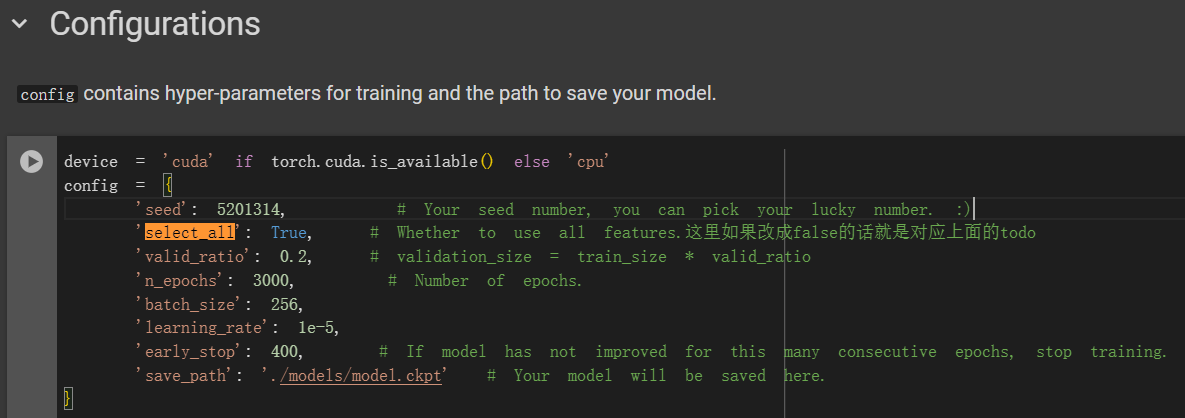
medium中并没有使用全部的feature列,也就是false循环分支,但是直接使用原本的[0,1,2,3,4]列也未免太过于随意,
实际上就是选了id列+前4个state名字
而medium baseline中改为了

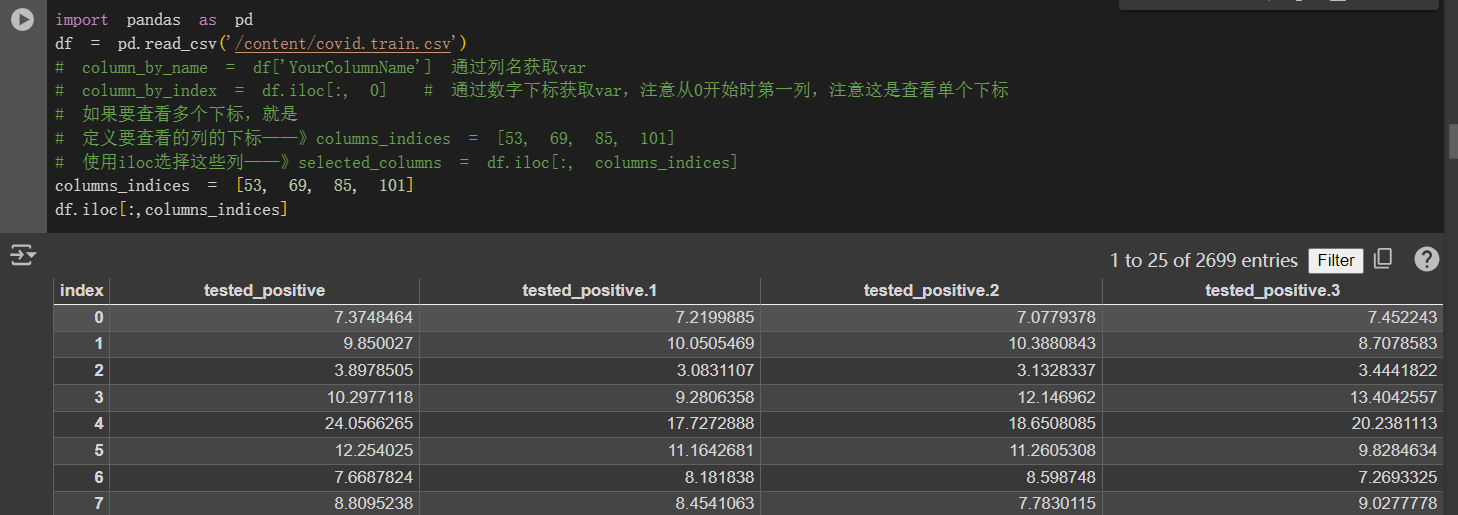
也就是说该medium baseline认为前4天的阳性率是比较重要的feature,对于预测第5天的阳性率有用(当然我们可以修改为其他的feature,比如说第5天的一些表型数据+前4天的阳性率数据等,这个在后面的其他更高级的baseline中也有所修改)
实际操作的时候:
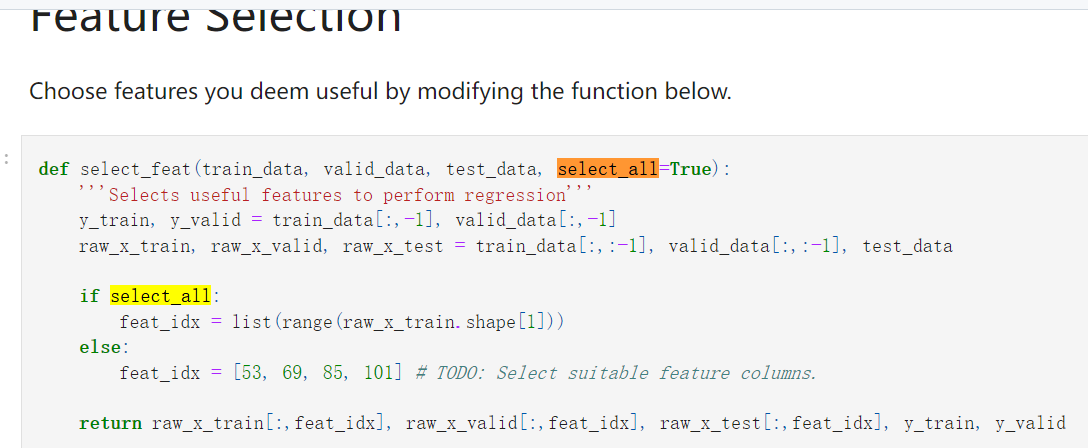
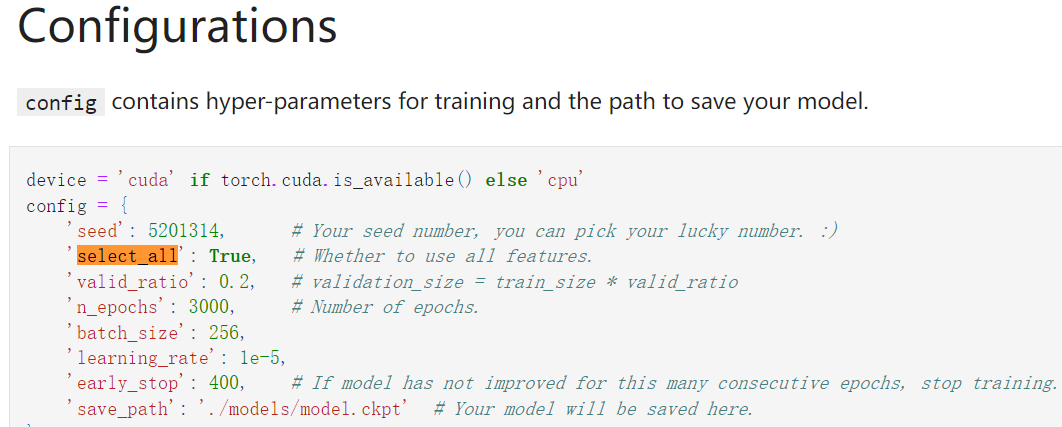
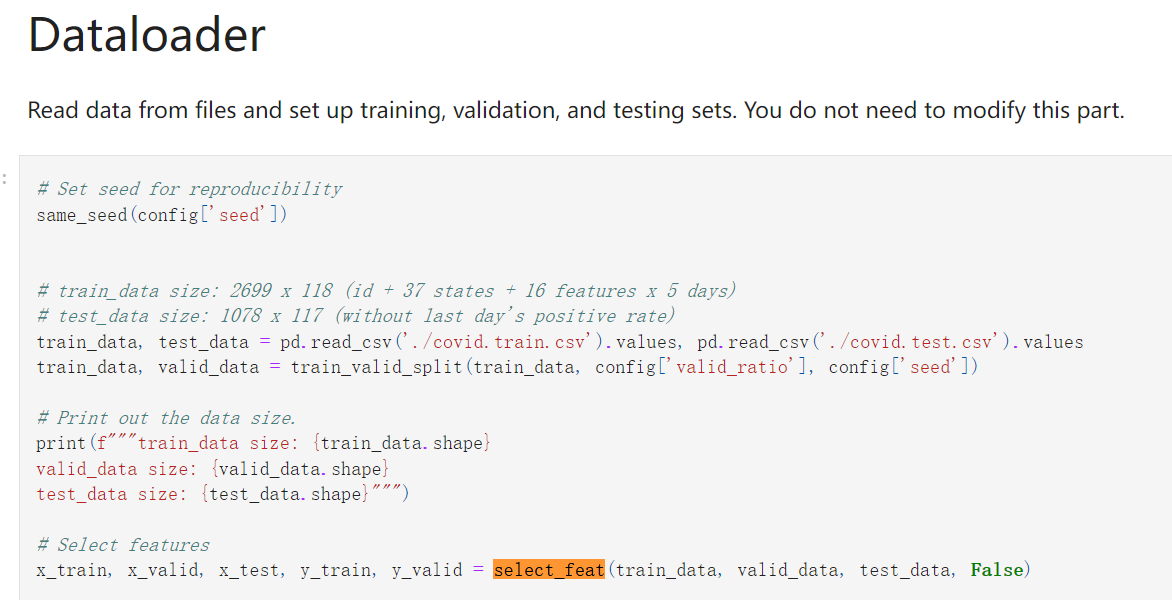
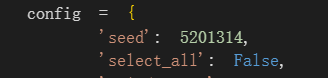
**我们知道是select_feat函数的select_all参数要决定使用全部feature还是自己挑出来的feature,
而这个参数可以在config中修改,通过config[‘select_all’]在data加载时传入;也可以不修改config,直接在data加载时在select_feat函数中直接定义False值;
个人建议在config中修改,这样与其他的参数配置统一化**
示例中medium并没有在config中修改,而是直接传入false参数


本人同理修改如下:

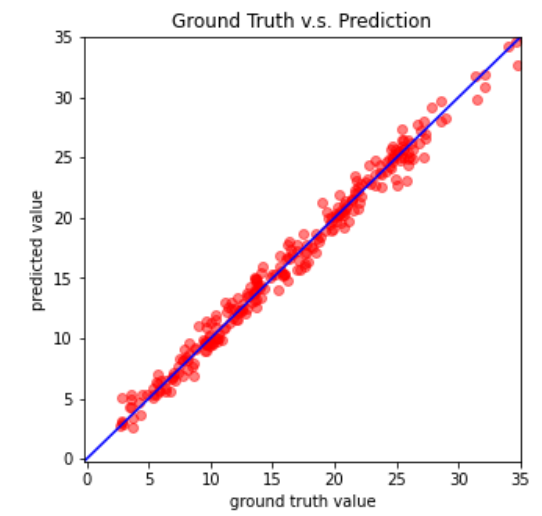
最后训练结果:
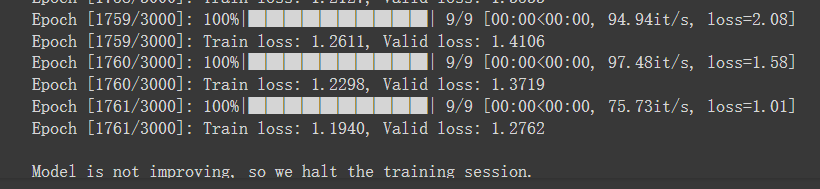
可以看得出来train和valid的loss相比较simple都下降了不少
train维持在1.2左右,valid维持在1.3左右
与参考一致:

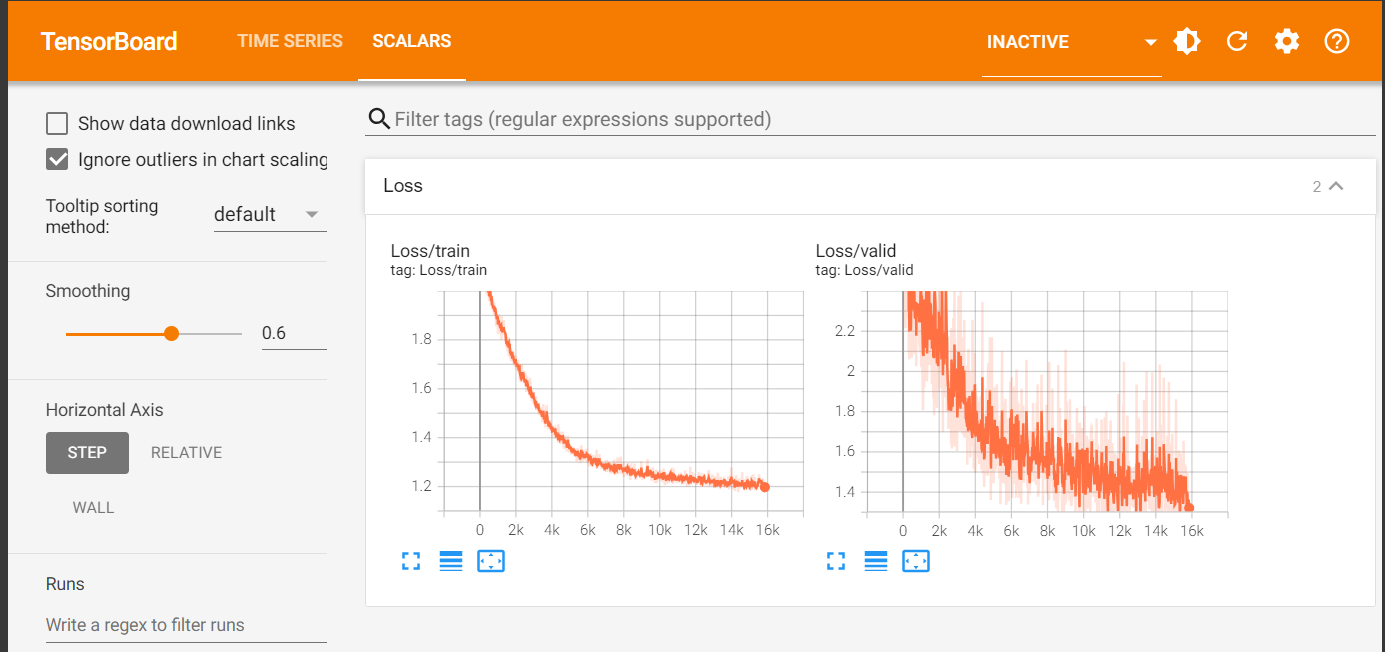
但是每次都是分开的图,查看实在是太不直观了,里路上train以及valid是可以放在一起比较的,可视化效果也更好,而且实际操作也就是折线图叠加(没什么技术难度)
即参考https://github.com/ga642381/ML2021-Spring/blob/main/HW01/HW01.ipynb
**todo:
将train、valid的loss整合在同一幅图中比较可视化;
valid中label与expected_value预测值的比较**
(2)strong baseline:
依据参考主要是在nn网络结构上优化,以及使用除了SGD随机梯度下降之外其他的优化算法;
首先是nn网络结构的修改,将
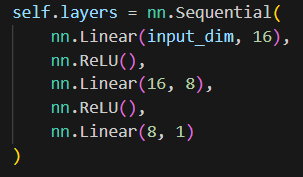
修改为

也就是换了激活函数,将ReLU换成了LeakyReLU,
后者参考https://pytorch.org/docs/stable/generated/torch.nn.LeakyReLU.html
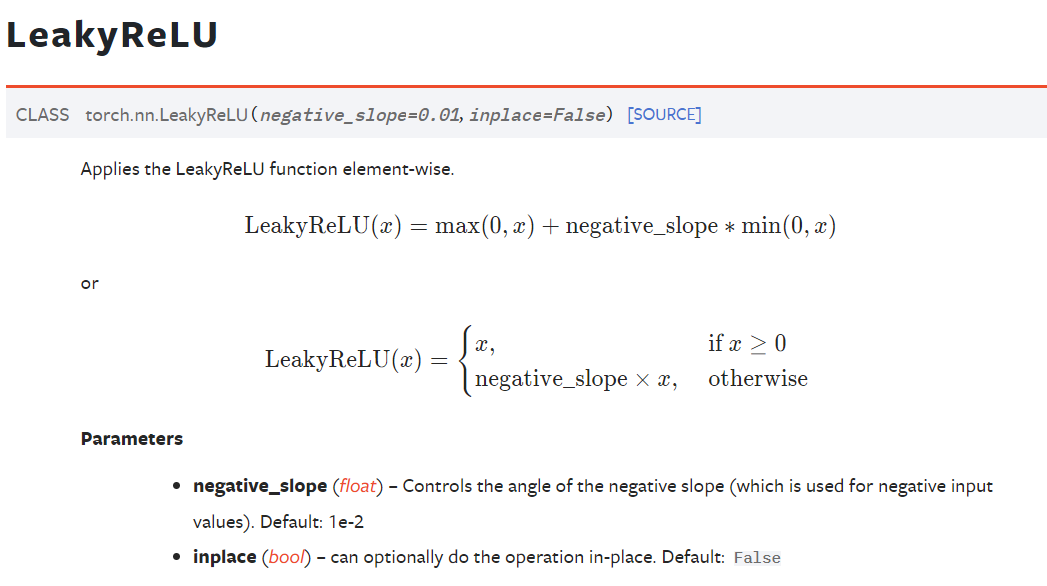
实际上ReLU是max(0,x),而LeakyReLU则是在负分段处换成了另外一个函数
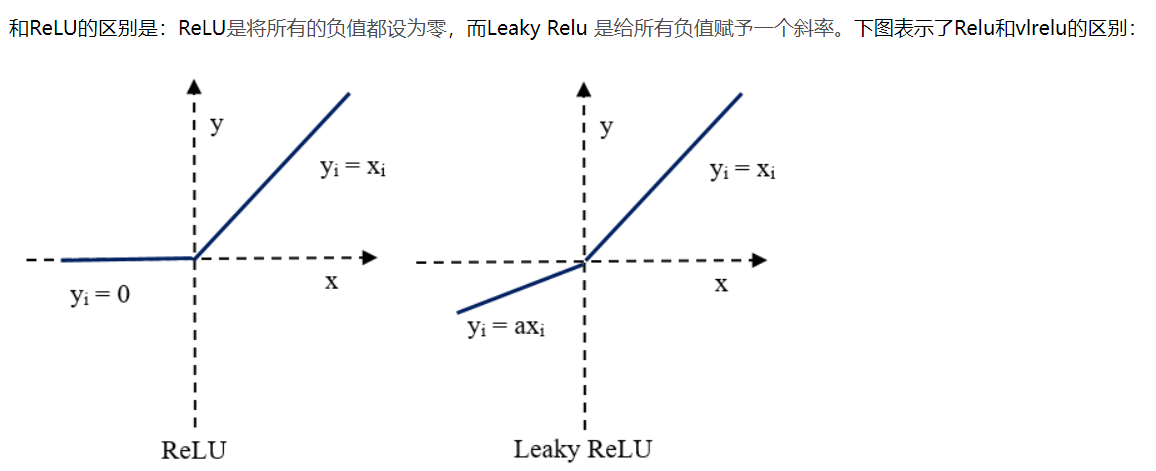

如何理解dead neuron




todo:理解dead neuron以及ReLU训练的缺点
另外的网络优化器中使用了SGD之外的其他算法,参考提示
 https://pytorch.org/docs/stable/optim.html,提供了一些优化算法
https://pytorch.org/docs/stable/optim.html,提供了一些优化算法

该strong示例中将SGD修改为了Adam算法,

(至于learning rate还是那句话,可以直接在config中修改,所以不必写成*10这种)
此处暂时不修改learning rate:

可能是该参考例子中认为strong baseline的lr太低,导致参数更新慢,所以修改了x10
如果不修改的话那门效果如下:

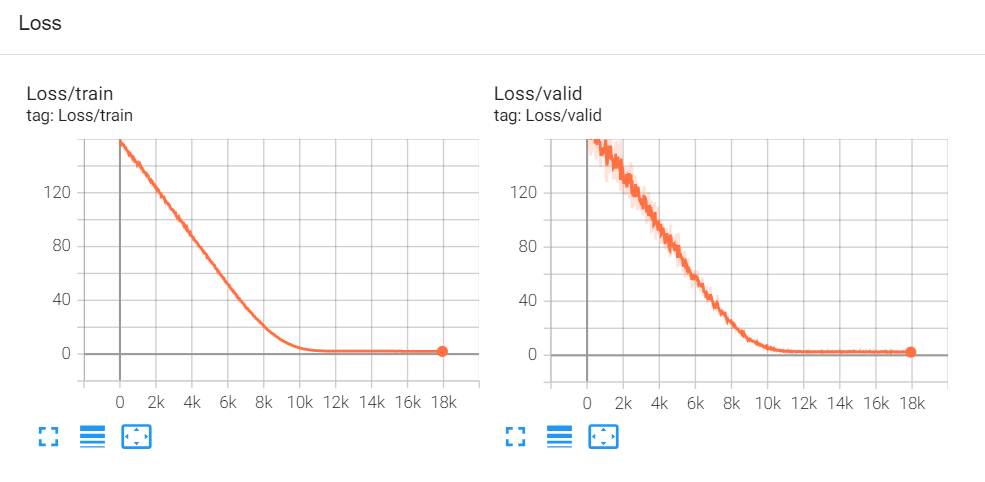
可以看到loss在后面基本上没有变化,
修改了之后


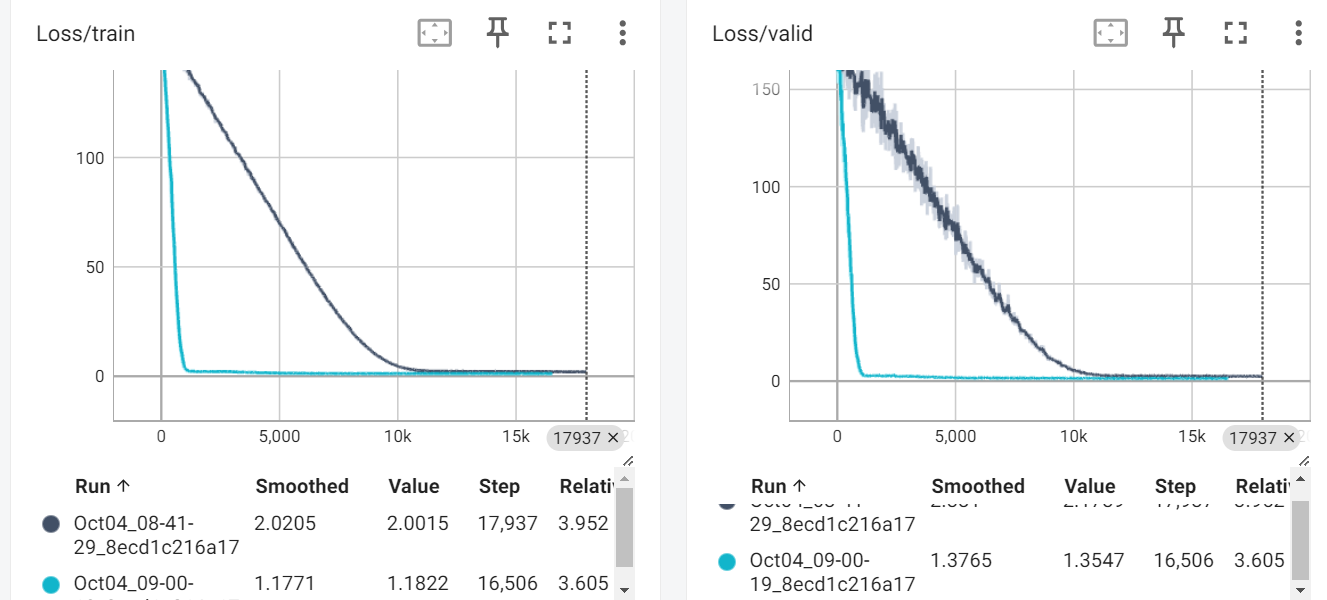
实际上处理之后蓝色线条是现在的,墨黑色线条是之前的,
可以看出收敛速度快了很多,但是后面又变平了
总而言之,效果勉勉强强

然后就是train以及test集上的数据应该更关注哪个:


所以此处我对代码进行了一些可视化的修改,主要是在tensorboard中的loss的统一可视化;
在Training Loop阶段:



其实主要是将原来分散的writer.add_scalar现在整合在了一起(原本分别计算train以及valid,现在合并在一起记录,提供词典dict)
(3)boss baseline:
首先是修改网络架构:
从strong的

修改为:

主要修改内容解读如下:



即修改后的:

网络架构的修改包括网络包括哪些层,以及每一层中的网络neuron的数目
也就是深度deep以及宽度fat方向的修改,前者修改什么层连接什么层,后者修改每一层中神经元的数目等。
前者在网络架构上主要是加入了batchNorm以及dropout操作,也就是这两层(其余的全连接层、激活层等都没有修改) ,所谓的BN层以及Dropout层


可以参考https://blog.csdn.net/m0_63007797/article/details/128742638
其中batchnorm1d函数可以参考https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm1d.html
当然还有一个问题就是什么时候使用这些层:什么时候使用批量归一化(Batch Normalization)和Dropout层操作?
暂时借助gpt的参考作为思考方向,内容正误未知:





所以该示例中的boss baseline也仅仅作为参考,至于batchNorm以及Dropout层要添加在网络的什么地方另外考虑
总之我们目前修改了网络的架构,在deep方向上增加了BN以及Dropout两层网络(至于什么地方/时候要加,分别加多少层暂定),**至少我们从经验上能够学习到要优化NN可以加这两层。
另外修改的部分是feature select部分:主要是使用ML方法选feature
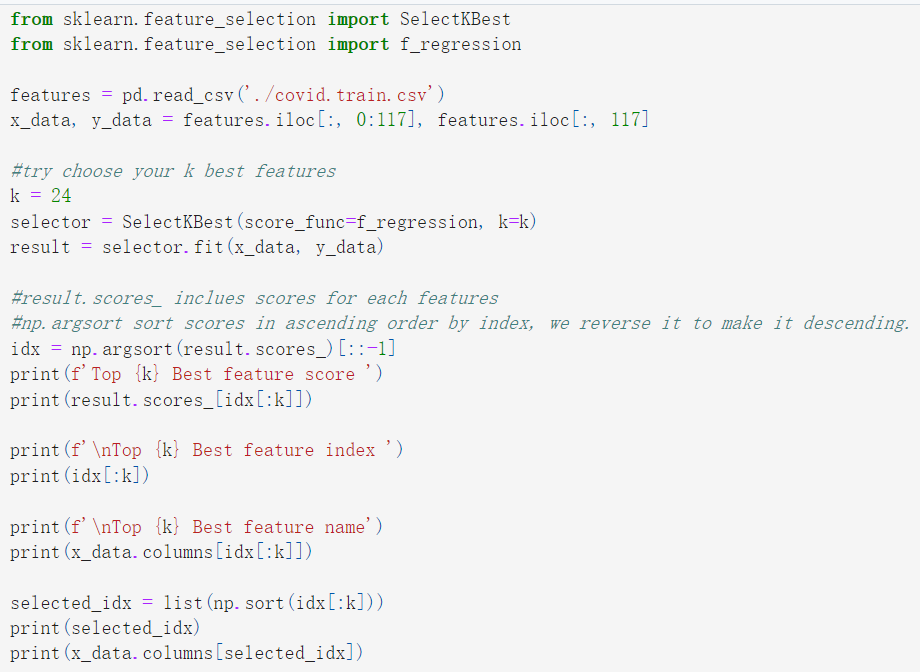
主要解读:



可以参考https://github.com/Hoper-J/HUNG-YI_LEE_Machine-Learning_Homework/tree/master/HW01
同样使用机器学习ML的方法来选取feature,同样是使用sklearn.feature_selection.SelectKBest 来进行特征选择

另外参考:https://github.com/sotaBrewer824/LHY_MLDL/blob/main/hw01/hw01.ipynb

实际基本上完全是boss baseline中的思路以及代码,只不过修改了超参数k=17个feature
k这一部分我们稍后可以自行修改,可以依据自己的理解来选取使用哪些feature
前面的feature修改了,那么后面select_feat函数也要修改:

然后就是对优化器(优化算法)的修改,还是采用Adam优化器,但是修改了参数,以及对于learning rate的参数也进行了设置




如果使用了scheduler来调整学习率,需要在适当时机调用
一般是在train的每个阶段即每个epoch训练之后使用scheduler

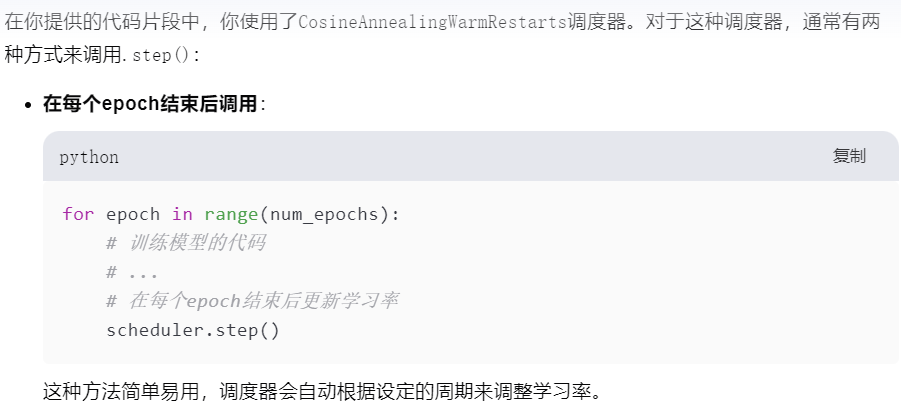
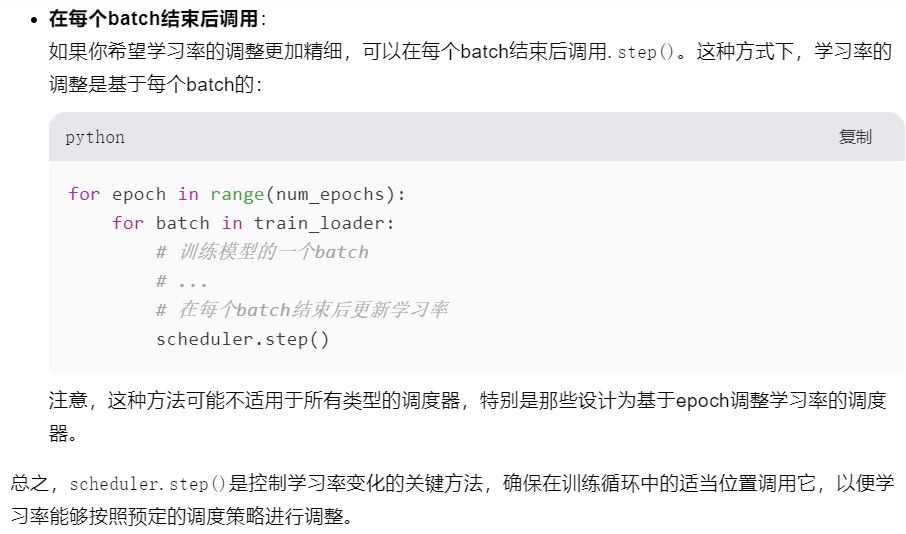
参考资料中是使用基于epoch的学习率调整,所以在参考例子中
是在epoch处理之后、valid之前调用
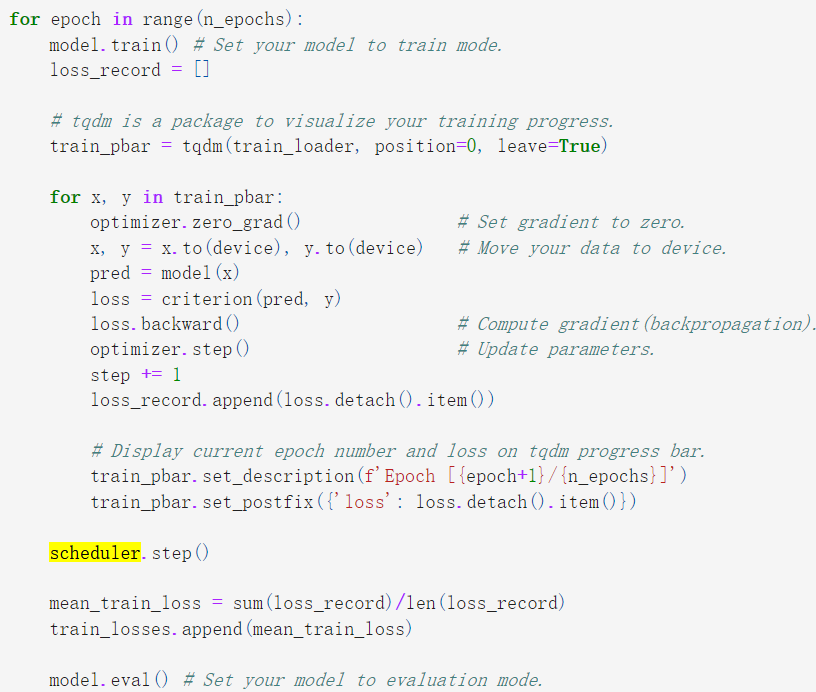
另外参考https://github.com/sotaBrewer824/LHY_MLDL/blob/main/hw01/hw01.ipynb
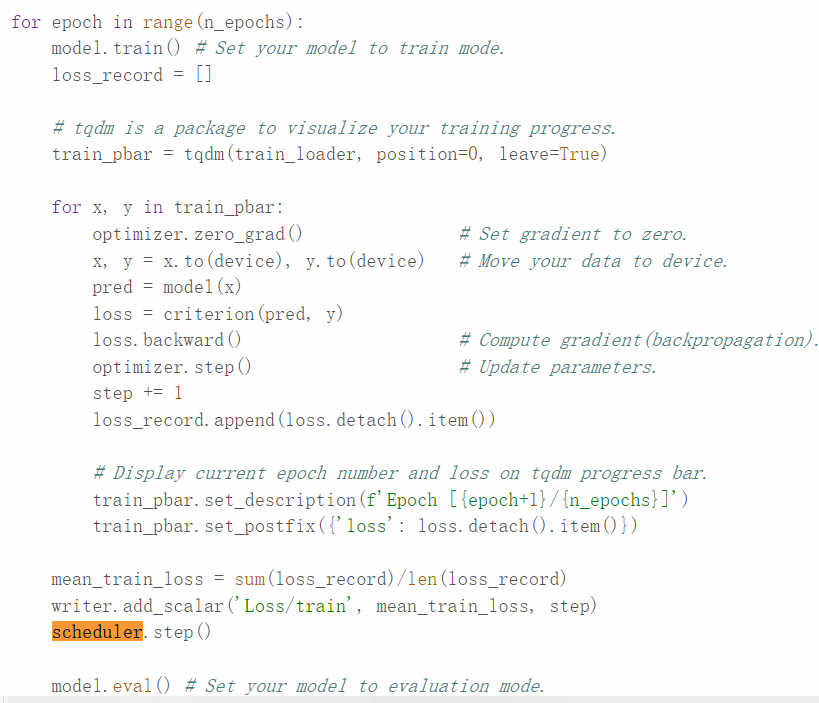
本质上也是在train的epoch之后、valid之前(其实与loss的记录没有顺序关系影响)
其余修改的地方影响也不是很大:
主要是训练epoch数目的延长,以及learning rate的修改(可以在前面optimizer中修改)
以及修改了一个early stop
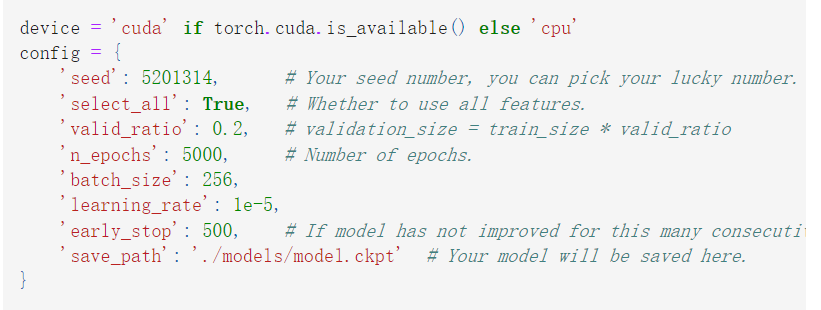
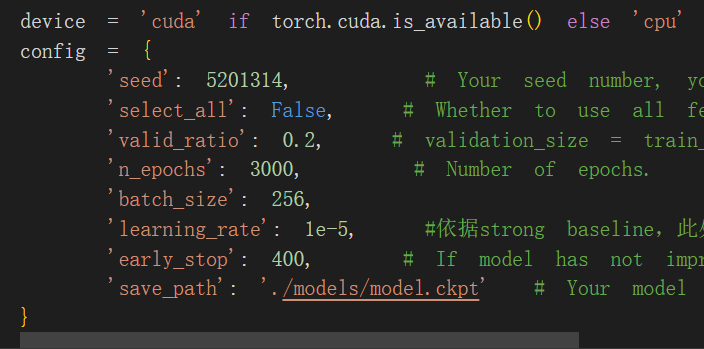
参考资料中对于early stop进行的操作与原来strong baseline中的没有区别


本质上都是超过early stop数目之后会执行终止(break或者return)
另外参考资料中使用了train_losses,valid_losses来记录训练以及valid过程中的loss,所以后面绘制loss曲线的时候没有使用tensorboard,而是自己使用记录的数据用matplotlib进行了绘制;
这一部分此处我不做改动,还是使用原来的tensorboard。
另外参考部分还对输入数据进行了修改:

其实主要是norm归一化,和前面的batchnorm类似

此处不执行。
实际执行过程中:

很显然之前选择的前4天的阳性率也是高相关的feature,排在top4。
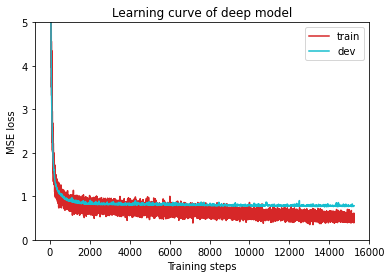
实际执行过程:
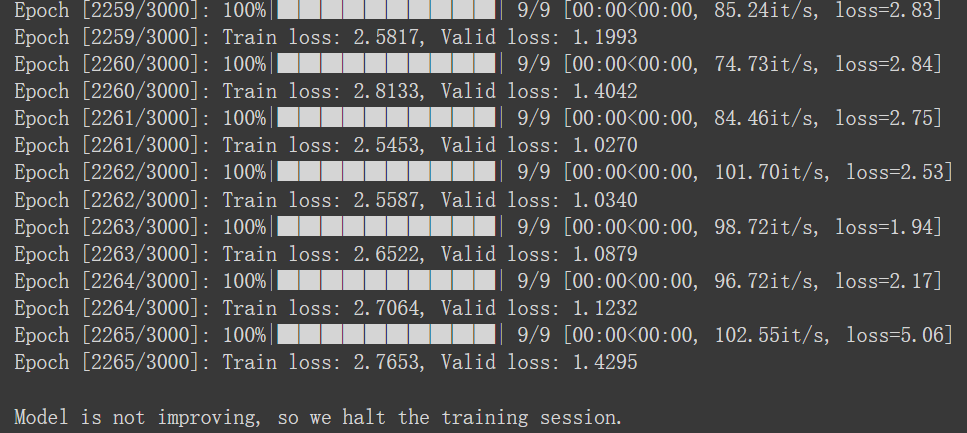
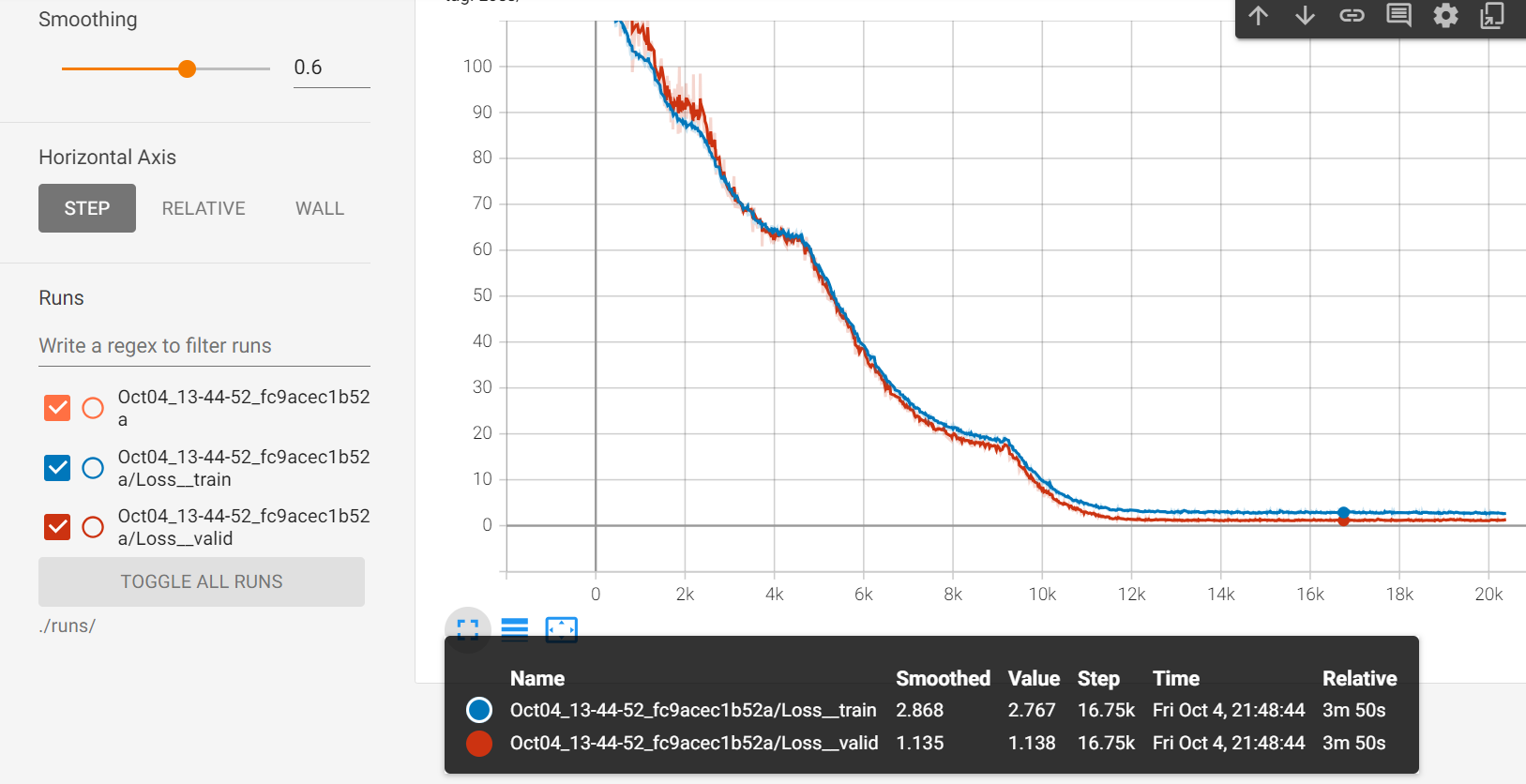
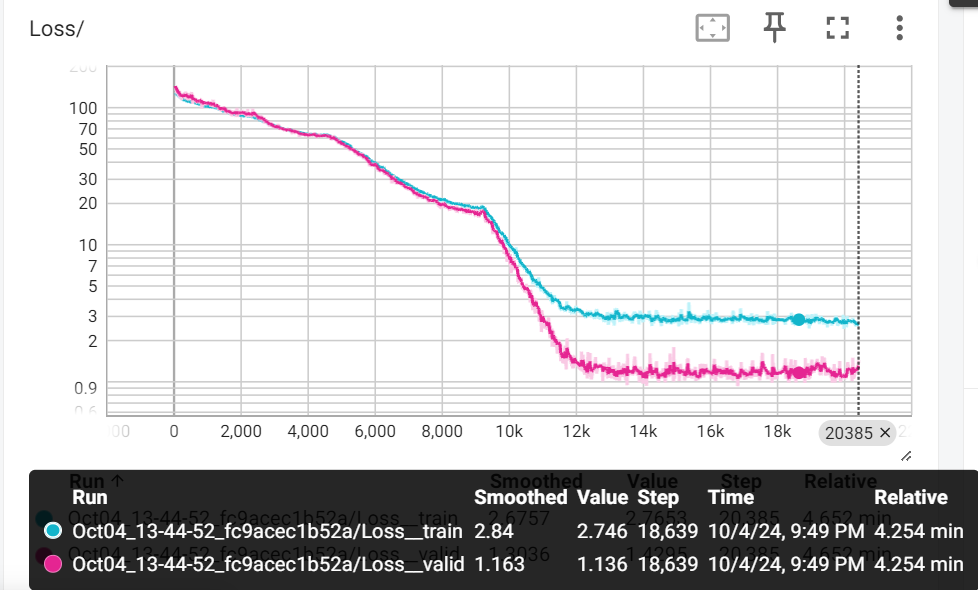
曲线是合并在了一起,可以方便的查看
valid在train下面,loss也还行
6,所有代码都上传到github中:
https://github.com/MaybeBio/Deep_learning/tree/main/Li_Hong_Yi_2021_2022/HW1
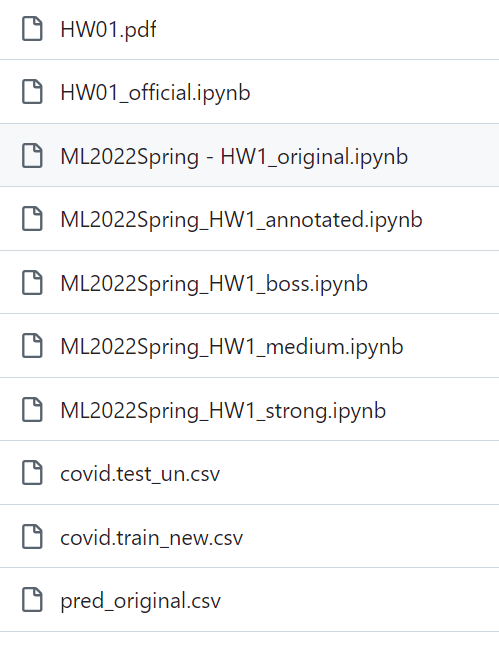
只保留:
*官网上的脚本(也就是simple baseline)是_original
官网参考过的脚本是*_official,自己注释过的是*_annotated(当然都是simple baseline)
然后参考github大佬复现学习的脚本就按照*_medium、_strong、_boss等等级来记录**

















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









