






目录
1.概述:
我们在开发用户画像的标签系统的模型的时候,需要从Hbase里面读取数据,编写HbaseTool工具类,HbaseTool里提供两个方法:read 和 write ,其用处就是传递参数读写表的数据。但是,我们是否能够实现向SparkSQL那样读写MYSQL数据库表的数据呢?
SparkSQL读写MYSQL数据:
// load:加载数据
val jdbcDF = spark.read
.format("jdbc") // 指定数据源
.option("driver", "com.mysql.jdbc.Driver") // 参数
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load() // 加载数据
// save: 保存数据
jdbcDF.write
.format("jdbc") // 指定数据源
.option("driver", "com.mysql.jdbc.Driver") // 参数
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save() // 保存数据
今天就来讲一讲如何实现像SparkSQL 一样读写外部的数据源。
2.External DataSource
从Spark1.3开始,SparkSQL开始正式支持外部数据源。SparkSQL开放了一系列可操作的外部数据源接口,可供开发者去使用。其接口在org.apache.spark.sql.sources包下的:interfaces.scala。
其主要有两个类:BaseRelation 和 RelationProvider
如果要实现一个外部数据源,比如hbase数据源,支持Spark SQL操作HBase数据库。那么就必须定义HBaseRelation来继承BaseRelation,同时也要定义DefaultSource实现一个
RelationProvider。
(1)BaseRelation:
代表了一个抽象的数据源;
该数据源由一行行有着已知schema的数据组成(关系表)
展示从DataFrame中产生的底层数据源的关系或者表;
定义如何产生schema信息
(2)RelationProvider:
根据用户提供的参数(parameters)返回一个数据源(BaseRelation)
一个Relation的提供者,创建BaseRelation
2.1BaseRelation
BaseRelation是Spark SQL中外部数据源的抽象,它主要定义了如何与外部数据源进行交互。
abstract class BaseRelation{
def sqlContext: SQLContext
def schema: StructType
}
// 如果自定义Relation,必须重写schema,就是必须描述对于外部数据源的Schema。
SparkSQL从外部数据源加载(读取)数据和保存(写入)数据时,提供不同接口实现:
(1)加载数据接口:
提供4种 Scan 策略,加载数据:

一般来说只会用TableScan,TableScan实现其中方法buildScan,其作用是定义如何查询外部数据源。
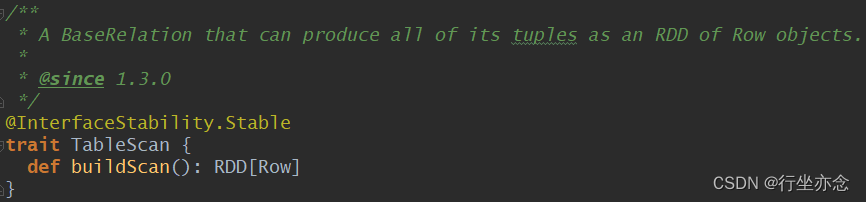
其他的Scan作用:
PrunedScan:提供列裁剪的数据扫描服务,可以传入指定的列,不需要的列不会从外部数据源加载。
PrunedFilteredScan :提供列裁剪和过滤下推的数据扫描服务,在列裁剪的基础上,并且加入Filter机制,在加载数据也的时候就进行过滤,而不是在客户端请求返回时做Filter。
CatalystScan :它负责将SQL查询转换为高效的物理执行计划。Catalyst的支持传入expressions来进行Scan,支持列裁剪和Filter.
(2)保存数据接口:
InsertableRelation :保存数据的 Relation。

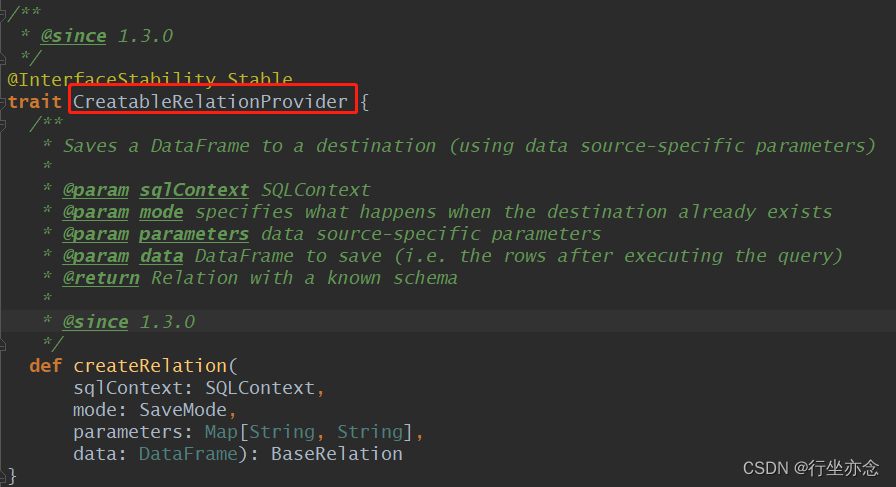
2.2.RelationProvider
RelationProvider是BaseRelation的一个提供者。RelationProvider获取参数列表,返回一个BaseRelation对象。要实现这个接口需要接受传入的参数 ,来生成对应的External Relation,就是 一个反射生产外部数据源Relation的接口 ,接口定义:
trait RelationProvider{
def createRelation(
sqlContext: SQLContext, parameters: Map[String, String]
): BaseRelation
}加载数据构建的Provider与保存数据的Provider基本上一致:
于是实现自定义数据源从Hbase表读取数据需要创建的文件以及包结构如下:
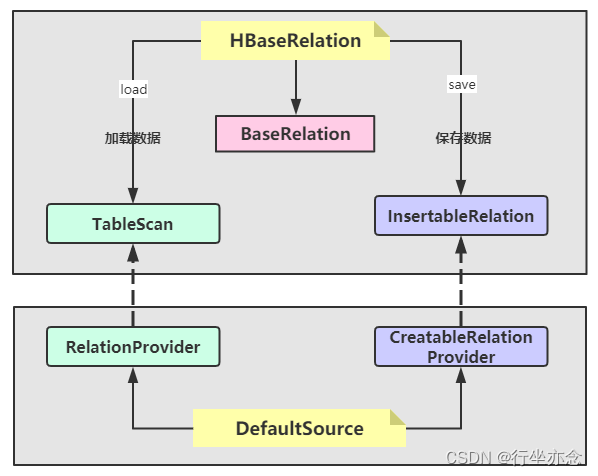
HBaseRelation继承TableScan、BaseRelation、InsertableRelation
而DefaultSource需要继承RelationProvider、CreatableRelationProvider
2.3自定义HBaseRelation
自定义 HBaseRelation 类,除了继承 BaseRelation 、 TableScan 和 InsertableRelation ,此外实现序列化接口 Serializable ,所有类声明如下,其中实现 Serializable 接口为了保证对象可以被序列化和反序列化。
将读写HBase表数据时参数属性定义为常量:
// 连接接HBase数据库的属性名称
val HBASE_ZK_QUORUM_KEY: String = "hbase.zookeeper.quorum"
val HBASE_ZK_QUORUM_VALUE: String = "zkHosts"
val HBASE_ZK_PORT_KEY: String = "hbase.zookeeper.property.clientPort"
val HBASE_ZK_PORT_VALUE: String = "zkPort"
val HBASE_TABLE: String = "hbaseTable"
val HBASE_TABLE_FAMILY: String = "family"
val SPERATOR: String = ","
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val HBASE_TABLE_ROWKEY_NAME: String = "rowKeyColumn"HBaseRelation具体代码如下:
package com.rison.tag.spark.hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Put, Result, Scan}
import org.apache.hadoop.hbase.filter.{FilterList, SingleColumnValueFilter}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.sql.sources.{BaseRelation, InsertableRelation, TableScan}
import org.apache.spark.sql.types.{HIVE_TYPE_STRING, StructType}
/**
* 自定义外部数据源:从HBase表加载数据和保存数据值HBase表
*/
class HBaseRelation(context: SQLContext, params: Map[String, String], userSchema: StructType) extends BaseRelation with TableScan with InsertableRelation with Serializable {
// 连接HBase数据库的属性名称
val HBASE_ZK_QUORUM_KEY: String = "hbase.zookeeper.quorum"
val HBASE_ZK_QUORUM_VALUE: String = "zkHosts"
val HBASE_ZK_PORT_KEY: String = "hbase.zookeeper.property.clientPort"
val HBASE_ZK_PORT_VALUE: String = "zkPort"
val HBASE_TABLE: String = "hbaseTable"
val HBASE_TABLE_FAMILY: String = "family"
val SPERATOR: String = ","
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val HBASE_TABLE_ROWKEY_NAME: String = "rowKeyColumn"
val HBASE_TABLE_FILTER_CONDITIONS: String = "filterConditions"
/**
* SQLContext 实例对象
*
* @return
*/
override def sqlContext: SQLContext = context
/**
* DataFrame 的 schema 信息
*
* @return
*/
override def schema: StructType = userSchema
/**
* 如何从HBase表中读取数据,返回RDD[Row]
*
* @return
*/
override def buildScan(): RDD[Row] = {
//设置HBase中Zookeeper集群信息
val conf = new Configuration()
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_KEY))
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_KEY))
//设置Hbase表的名称
conf.set(TableInputFormat.INPUT_TABLE, params(HBASE_TABLE))
//设置读取列簇和列的名称
val scan = new Scan()
//设置列簇
val familyBytes: Array[Byte] = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
scan.addFamily(familyBytes)
//设置列的名称
val fields: Array[String] = params(HBASE_TABLE_SELECT_FIELDS).split(SPERATOR)
fields.foreach(
field => scan.addColumn(familyBytes, Bytes.toBytes(field))
)
//优化 添加过滤条件格式为:modified[GE]20190601,modified[LE]20191201
val filterConditions: String = params.getOrElse(HBASE_TABLE_FILTER_CONDITIONS, null)
if (null != filterConditions && filterConditions.length > 0) {
//构建FilterList对象
val filterList = new FilterList()
//依据条件语句创建Filter对象
filterConditions.split(SPERATOR).foreach {
filterCondition =>
//解析Filter clause
val condition: Condition = Condition.parseCondition(filterCondition)
//创建SingleColumnValueFilter对象
val filter = new SingleColumnValueFilter(
familyBytes, //列簇
Bytes.toBytes(condition.field), //列名
condition.compare, //比较操作符
Bytes.toBytes(condition.value) // 比较值
)
//将过滤的列加入到选择的列中
scan.addColumn(familyBytes, Bytes.toBytes(condition.field))
//添加到FilterList
filterList.addFilter(filter)
}
scan.setFilter(filterList)
}
//设置scan过滤
conf.set(
TableInputFormat.SCAN,
Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray)
)
//调用底层API , 读取 HBase表的数据
val datasRDD: RDD[(ImmutableBytesWritable, Result)] = sqlContext.sparkContext
.newAPIHadoopRDD(
conf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
//转换为RDD[Row]
val rowsRDD: RDD[Row] = datasRDD.map {
case (_, result) =>
val values: Array[String] = fields.map {
field =>
Bytes.toString(result.getValue(familyBytes, Bytes.toBytes(field)))
}
Row.fromSeq(values)
}
rowsRDD
}
/**
* 将数据【dataFrame】保存到Hbase中
*
* @param data 数据集
* @param overwrite 保存模式
*/
override def insert(data: DataFrame, overwrite: Boolean): Unit = {
//数据转换
val columns: Array[String] = data.columns
val putsRDD: RDD[(ImmutableBytesWritable, Put)] = data.rdd.map {
row =>
//获取RowKey
val rowKey: String = row.getAs[String](params(HBASE_TABLE_ROWKEY_NAME))
//构建Put对象
val put = new Put(Bytes.toBytes(rowKey))
//每列数据加入到Put中
val familyBytes: Array[Byte] = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
columns.foreach(
column =>
put.addColumn(
familyBytes,
Bytes.toBytes(column),
Bytes.toBytes(row.getAs[String](column))
)
)
//返回二元组
(new ImmutableBytesWritable(put.getRow), put)
}
//设置HBase中Zookeeper集群信息
val conf = new Configuration()
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_KEY))
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_KEY))
//设置Hbase表的名称
conf.set(TableInputFormat.INPUT_TABLE, params(HBASE_TABLE))
// 4. 保存数据到表
putsRDD.saveAsNewAPIHadoopFile(
s"/apps/hbase/${params(HBASE_TABLE)}-" +
System.currentTimeMillis(),
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf //
)
}
}
2.4自定义DefaultSource
自定义类 DefaultSource 也一样,除了需要继承那两个类为了更好序列化反序列化需要再继承Serializable:
package com.rison.tag.spark.hbase
import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode}
import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, DataSourceRegister, RelationProvider}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
/**
* 自定义外部数据源HBase,提供BaseRelation对象,用于加载数据和保存数据
*/
class DefaultSource extends RelationProvider with CreatableRelationProvider with DataSourceRegister with Serializable {
/**
* 参数信息
*/
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val SPERATOR: String = ","
/**
* 返回BaseRelation实例对象,提供加载数据功能
* @param sqlContext SQLContext 实例对象
* @param parameters 参数信息
* @return
*/
override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = {
//定义schema信息
val schema: StructType = StructType(
parameters(HBASE_TABLE_SELECT_FIELDS).split(SPERATOR).map(
field => StructField(field, StringType, nullable = true)
)
)
//创建HBaseRelation对象
val relation = new HBaseRelation(sqlContext, parameters, schema)
relation
}
/**
* 返回BaseRelation实例对象,提供保存数据功能
* @param sqlContext SQLContext
* @param mode 保存模式
* @param parameters 参数
* @param data 数据集
* @return
*/
override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String], data: DataFrame): BaseRelation = {
//创建HBaseRelation对象
val relation = new HBaseRelation(sqlContext, parameters, data.schema)
//插入数据
relation.insert(data, overwrite = true)
//返回对象
relation
}
/**
* 数据源使用简短名称
* @return
*/
override def shortName(): String = "hbase"
}
2.5编写测试主类
在Hbase中建表:
create "tbl_users", "info"
编写MAIN主类,测试上述自定义外部数据源实现从HBase表读写数据接口:
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object HBaseSQLTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.serializer",
"org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
import spark.implicits._
// 读取数据
val usersDF: DataFrame = spark.read
.format("cn.itcast.tags.spark.sql")
.option("zkHosts", "bigdata-cdh01.itcast.cn")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_tag_users")
.option("family", "detail")
.option("selectFields", "id,gender")
.load()
usersDF.printSchema()
usersDF.cache()
usersDF.show(10, truncate = false)
// 保存数据
usersDF.write
.mode(SaveMode.Overwrite)
.format("cn.itcast.tags.spark.sql")
.option("zkHosts", "bigdata-cdh01.itcast.cn")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_users")
.option("family", "info")
.option("rowKeyColumn", "id")
.save()
spark.stop()
}
}
通过查询数据库发现id已经加载进去,这样就完成自定义外部数据源的开发了。
总结:
传统的数据源编写像HbaseTools需要编写的代码复杂,不利于代码的规范化,而SparkSQL给予的接口使得用户可以自定义外部数据源从而实现了代码的规范化,而且对于数据的加载以及保存提供了更方便的操作。
(以上部分资料来自黑马程序员,自用笔记,侵删。)















 2544
2544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









