






FLDA(Fisher's Linear Discriminant Analysis)是一种常用的模式识别和特征提取方法。它基于线性代数的原理,通过将数据投影到低维空间,使得不同类别的样本在投影后的空间中更好地分离开来。FLDA可用于分类、特征选择和降维等任务。
FLDA的核心思想是最大化类间散布矩阵与最小化类内散布矩阵之比的值。通过求解广义特征值问题,可以得到最优投影方向。FLDA在许多模式识别和机器学习领域都有广泛的应用,如人脸识别、文本分类等。
FLDA是一种经典且有效的方法,但也有一些限制。例如,FLDA在处理高维数据时可能面临维数灾难的问题,同时它也假设数据满足高斯分布的条件。因此,在应用FLDA时需要根据具体问题进行适当的调整和优化。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import warnings
warnings.filterwarnings("ignore") # 忽略警告
# 设置字体为中文字体
plt.rcParams['font.family'] = 'SimHei' # 使用微软雅黑或其他中文字体的名称
'''
Af:
触角X 翅膀长度Y
0 1.24 1.27
1 1.36 1.74
2 1.38 1.64
3 1.38 1.82
4 1.38 1.90
5 1.40 1.70
6 1.48 1.82
7 1.54 1.82
8 1.56 2.08
Apf:
触角X 翅膀长度Y
0 1.14 1.78
1 1.18 1.96
2 1.20 1.86
3 1.26 2.00
4 1.28 2.00
5 1.30 1.96
'''
class1_data = np.array([[1.24, 1.27],
[1.36, 1.74],
[1.38, 1.64],
[1.38, 1.82],
[1.38, 1.9],
[1.4, 1.7],
[1.48, 1.82],
[1.54, 1.82],
[1.56, 2.08]])
class2_data = np.array([[1.14, 1.78],
[1.18, 1.96],
[1.2, 1.86],
[1.26, 2.0],
[1.28, 2.0],
[1.3, 1.96]])
# 创建对应的类别标签
class1_labels = np.zeros(len(class1_data)) # 用0表示第一类数据
class2_labels = np.ones(len(class2_data)) # 用1表示第二类数据
# 将两类数据合并成一个数据集
X_train = np.vstack((class1_data, class2_data))
y_train = np.hstack((class1_labels, class2_labels))
# 初始化FLDA模型
lda = LinearDiscriminantAnalysis(n_components=1)
# 拟合FLDA模型
X_lda = lda.fit_transform(X_train, y_train)
# 创建新的数据点进行预测
new_data_points = np.array([[1.24, 1.80],
[1.28, 1.84],
[1.40, 2.04]]) # 三组新数据点
# 使用模型进行预测
predicted_classes = lda.predict(new_data_points)
# 输出预测结果
for i, predicted_class in enumerate(predicted_classes):
if predicted_class == 0:
print(f"第{i + 1}组数据预测为类别 1 (AF)")
else:
print(f"第{i + 1}组数据预测为类别 2 (APF)")
# 画出原始数据点
# 获取FLDA学习到的最佳投影线的参数
slope = lda.coef_[0][0] # 斜率
intercept = lda.intercept_[0] # 截距
# 绘制原始数据分布
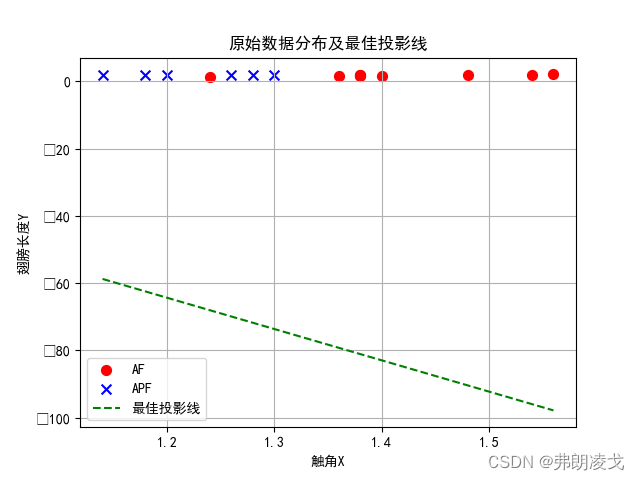
plt.scatter(class1_data[:, 0], class1_data[:, 1], label="AF", color='red', marker='o', s=50)
plt.scatter(class2_data[:, 0], class2_data[:, 1], label="APF", color='blue', marker='x', s=50)
# 绘制最佳投影线
x_line = np.array([min(X_train[:, 0]), max(X_train[:, 0])])
y_line = slope * x_line + intercept
plt.plot(x_line, y_line, color='green', linestyle='--', label="最佳投影线")
plt.xlabel("触角X")
plt.ylabel("翅膀长度Y")
plt.legend()
plt.title("原始数据分布及最佳投影线")
plt.grid(True)
plt.show()


















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









