







💖🏆🏆欢迎来到本博客🌞🌞🌞
📝个人主页:wlz249
🎉点赞➕评论➕收藏 == 养成习惯(一键三连)😋⚡希望大家多多支持🤗~一起加油 😁
⛳️座右铭:越努力,越幸运。
目录
📋1 概述
消除贫困、改善民生、逐步实现共同富裕,是社会主义的本质要求,是我们党的重要使命。党的十八大以来,国家把扶贫开发工作纳入“四个全面”战略布局,作为实现第一个百年奋斗目标的重点工作,摆在更加突出的位置。为了更好的激励各帮扶单位提高扶贫效率,扶真贫,真扶贫。五年前,国家启动了脱贫帮扶绩效评价机制。某科研团队接受任务后,对全国 32165 个需要帮扶的贫困村进行了初步的贫困调查。从居民收入(记为 SR)、产业发展(记为 CY)、居住环境(记为 HJ)、文化教育(记为 WJ)、基础设施(记为 SS)等五个评价指标给出了评分。以此为依据,将被帮扶的村庄划分为 160 个集合,每个集合指定帮扶单位(标记为 0-159)进行帮扶。这 160 个帮扶单位按照单位属性(如国企还是民营企业等)标记为 0-5 等 6 个类型。2020 年,研究团队再次进行了调研,得到了被帮扶的这些村庄居民收入、产业发展、居住环境、文化教育、基础设施等五个方面的评分数据以及总分数据。为了便于比较和研究,所有数据都进行了标准化处理(标准化后的数值越大表示
评分越高)。绩效评价,不能仅以最后的得分作为依据,需要考虑各个评价指标的进步幅度。因为这样才能公正的评判帮扶的效果,就能鼓励更多的帮扶单位愿意花精力去帮助非常贫困的地区。
问题:
每个帮扶单位在扶贫上有不同的工作特色,如有些单位在提高居民 收入上效果很好,而有些帮扶单位可能在改善基础设施上帮助的效果不错。请问, 哪些帮扶单位分别在居民收入、产业发展、居住环境、文化教育、基础设施等评价指标上帮扶业绩明显?请列出各单项评价指标前五名的帮扶单位编号。
📝2 运行结果
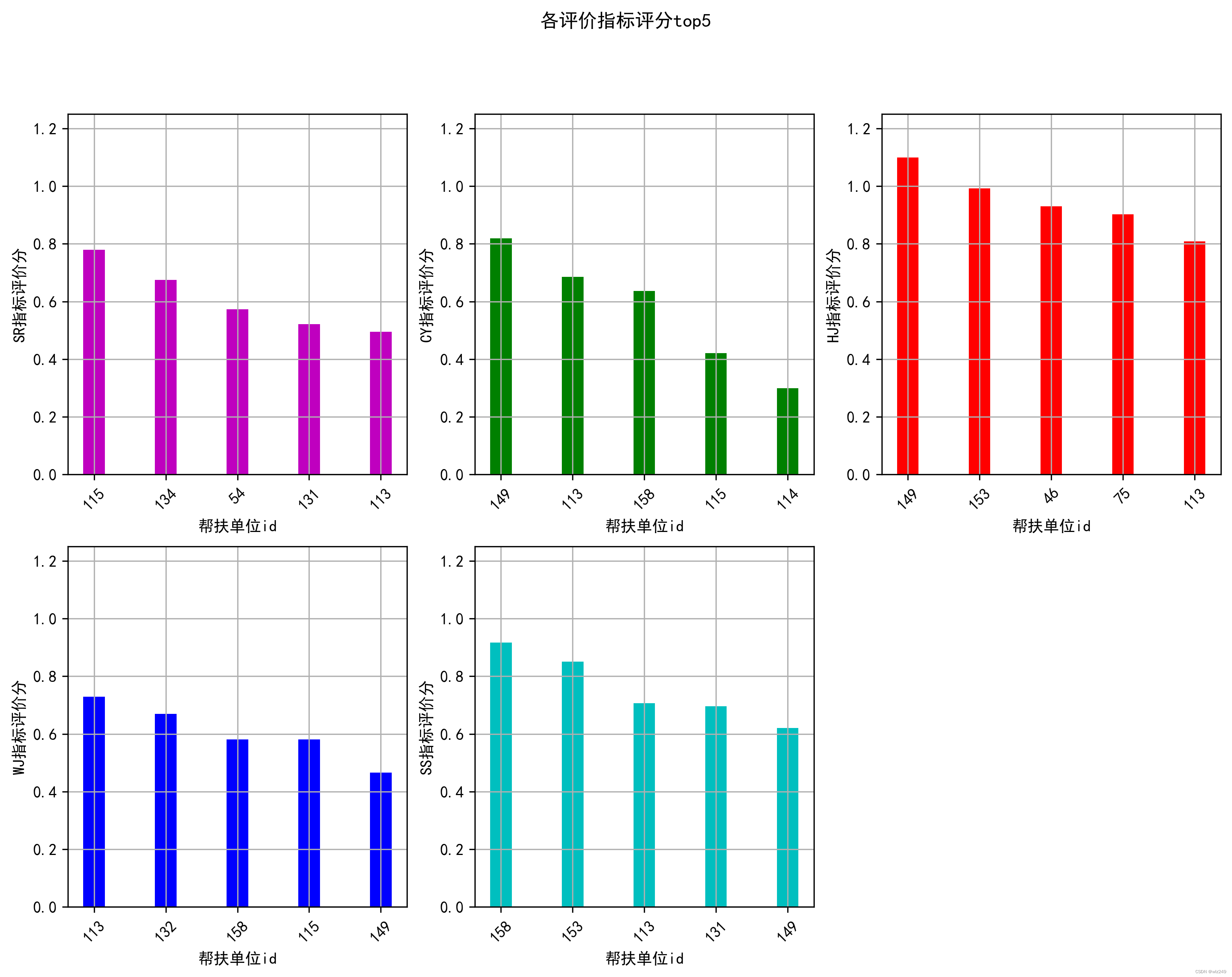
📋3 Python代码实现
# -*- coding: utf-8 -*-
import warnings
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings("ignore")
# 原始数据的问题
file_path = r'附件 C题数据.xlsx'
shuju = pd.read_excel(file_path)
biao_qian = ['SR', 'CY', 'HJ', 'WJ', 'SS']
dic = {'SR': '居民收入', 'CY': '产业发展', 'HJ': '居住环境', 'WJ': '文化教育', 'SS': '基础设施'}
for v in biao_qian:
shuju[v] = shuju['2020 %s' % v] - shuju['2015 %s' % v]
print(shuju[v])
vot = pd.pivot_table(shuju, index=['帮扶单位(0-159)'], values=biao_qian, aggfunc='mean')
print(vot)
plt.figure(figsize=(13, 9), dpi=300)
#Counter() 是 collections 库中的一个函数,可以用来统计一个 python 列表、字符串、元组等可迭代对象中每个元素出现的次数,并返回一个字典。
for n, v in enumerate(biao_qian):
vot.sort_values(v, ascending=False, inplace=True)
df = vot[v].head(5)
x = [str(i) for i in df.index]
y = df.values
colors = ['m', 'g', 'r', 'b', 'c']
plt.subplot(2, 3, n + 1)
plt.bar(x, y, width=0.3,color=colors[n])
plt.grid()
plt.xticks(rotation=45)
plt.ylim(0, 1.25)
plt.xlabel('帮扶单位id')
plt.ylabel('%s指标评价分' % v)
plt.suptitle('各评价指标评分top5')
plt.savefig('可视化/3.png', dpi=300, bbox_inches="tight")
plt.show()
# -*- coding: utf-8 -*-
import warnings
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings("ignore")
# 原始数据的问题
file_path = r'附件 C题数据.xlsx'
shuju = pd.read_excel(file_path)
biao_qian = ['SR', 'CY', 'HJ', 'WJ', 'SS']
dic = {'SR': '居民收入', 'CY': '产业发展', 'HJ': '居住环境', 'WJ': '文化教育', 'SS': '基础设施'}
for v in biao_qian:
shuju[v] = shuju['2020 %s' % v] - shuju['2015 %s' % v]
print(shuju[v])
vot = pd.pivot_table(shuju, index=['帮扶单位(0-159)'], values=biao_qian, aggfunc='mean')
print(vot)
plt.figure(figsize=(13, 9), dpi=300)
#Counter() 是 collections 库中的一个函数,可以用来统计一个 python 列表、字符串、元组等可迭代对象中每个元素出现的次数,并返回一个字典。
for n, v in enumerate(biao_qian):
vot.sort_values(v, ascending=False, inplace=True)
df = vot[v].head(5)
x = [str(i) for i in df.index]
y = df.values
colors = ['m', 'g', 'r', 'b', 'c']
plt.subplot(2, 3, n + 1)
plt.bar(x, y, width=0.3,color=colors[n])
plt.grid()
plt.xticks(rotation=45)
plt.ylim(0, 1.25)
plt.xlabel('帮扶单位id')
plt.ylabel('%s指标评价分' % v)
plt.suptitle('各评价指标评分top5')
plt.savefig('可视化/3.png', dpi=300, bbox_inches="tight")
plt.show()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









