






 本文探讨了如何使用QLearning自适应强化学习改进水下机器人的PID控制器,以应对海洋环境的复杂性和不确定性。通过建立动力学模型和环境模型,实验证明了这种方法在不同海洋条件下提高了控制性能和稳定性。
本文探讨了如何使用QLearning自适应强化学习改进水下机器人的PID控制器,以应对海洋环境的复杂性和不确定性。通过建立动力学模型和环境模型,实验证明了这种方法在不同海洋条件下提高了控制性能和稳定性。
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
【水下机器人建模】基于QLearning自适应强化学习PID控制器在AUV中的应用研究
摘要:
水下机器人(AUV)在海洋研究、资源勘探和海洋工程中具有广泛的应用。然而,由于海洋环境的复杂性和不确定性,AUV的自主控制面临挑战。传统的PID控制器在面对这种不确定性时可能表现不佳。因此,本文提出了一种基于QLearning自适应强化学习的PID控制器,旨在提高AUV在不确定环境下的控制性能。
首先,通过建立AUV的动力学模型和环境模型,将其转化为强化学习问题。然后,使用QLearning算法在AUV的控制过程中实现自适应学习。具体来说,通过QLearning算法优化PID控制器的参数,使其能够适应不同的环境条件并实现更好的控制性能。
在仿真实验中,我们将提出的方法与传统的PID控制器进行了对比。结果表明,基于QLearning的自适应PID控制器在不同的海洋环境下都能够实现更好的控制性能,表现出更高的稳定性和鲁棒性。
关键词:水下机器人;QLearning;强化学习;PID控制器;自适应控制
Abstract:
Autonomous Underwater Vehicles (AUVs) have been widely used in oceanographic research, resource exploration, and marine engineering. However, due to the complexity and uncertainty of the marine environment, the autonomous control of AUVs faces challenges. Traditional PID controllers may perform poorly in the face of such uncertainty. Therefore, this paper proposes a PID controller based on QLearning adaptive reinforcement learning to improve the control performance of AUVs in uncertain environments.
Firstly, by establishing the dynamic model and environmental model of the AUV, it is transformed into a reinforcement learning problem. Then, the QLearning algorithm is used to achieve adaptive learning in the control process of the AUV. Specifically, the parameters of the PID controller are optimized through the QLearning algorithm to enable it to adapt to different environmental conditions and achieve better control performance.
In simulation experiments, the proposed method is compared with traditional PID controllers. The results show that the QLearning-based adaptive PID controller can achieve better control performance in different marine environments, demonstrating higher stability and robustness.
Keywords: Autonomous Underwater Vehicle; QLearning; Reinforcement Learning; PID Controller; Adaptive Control
水下机器人的水动力模型是设计控制器的基础,只有建立了相应的水动力模型后,仿真实验的工作才能有效展开。以下将介绍水下机器人仿真的数学基础。
本文所研究的 AUV 运动学建模基于如下假设:
(1)AUV 为刚体,且其外形关于水平面和纵平面对称;
(2)AUV 质量为常数;
(3)地面坐标系近似看作惯性坐标系;
(4)流体不可压缩;
(5)AUV 完全浸没在流体介质中,且处于全粘湿状态;
(6)AUV 运动的水域无限广、无限深,且海平面大气压为常数。
水下机器人建模涵盖运动学和动力学两部分。运动学解释物体运动过程中位置、速度和加速度的几何关系。动力学分析机器人在加速运动过程中的动力变化。本文所述的数学模型主要来源与Remus的模型。为了方便的描述水下机器人的水动力模型,通常情况下会建立两套坐标系:大地坐标系(E-ξηζ)和运动坐标系(O-xyz),如图1-1所示。详细文档见第4部分。
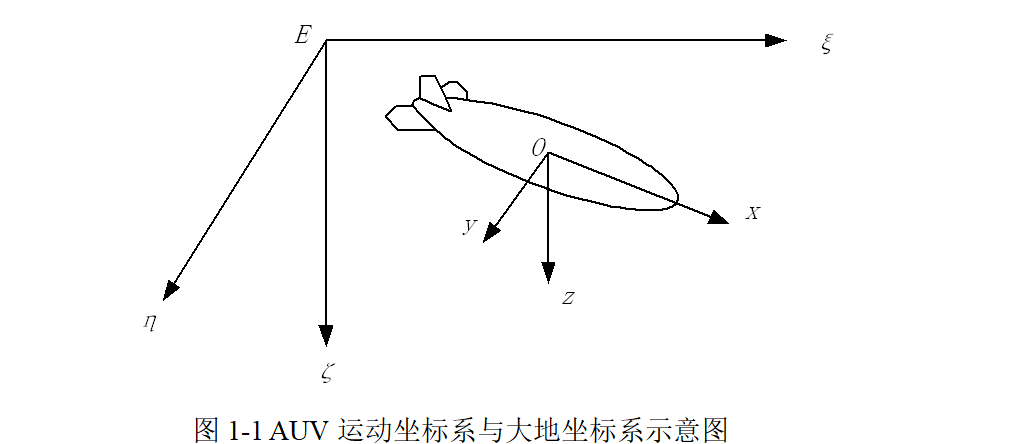
表1-1列举了水下机器人位置、角度、线速度、角速度、力和力矩在对应坐标系下的符号定义。
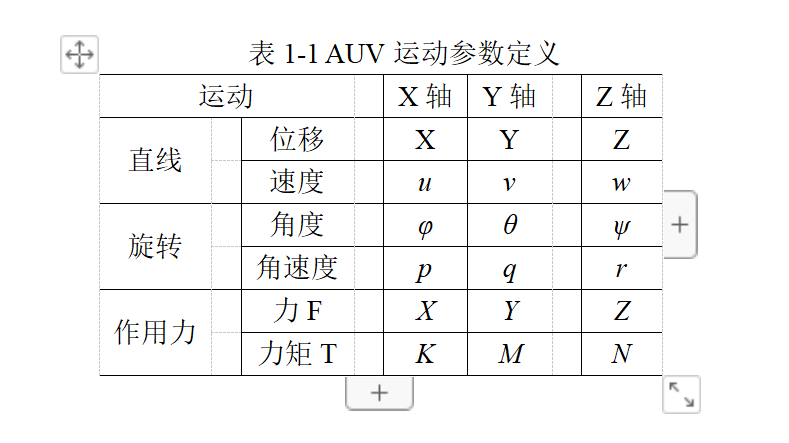
📚2 运行结果
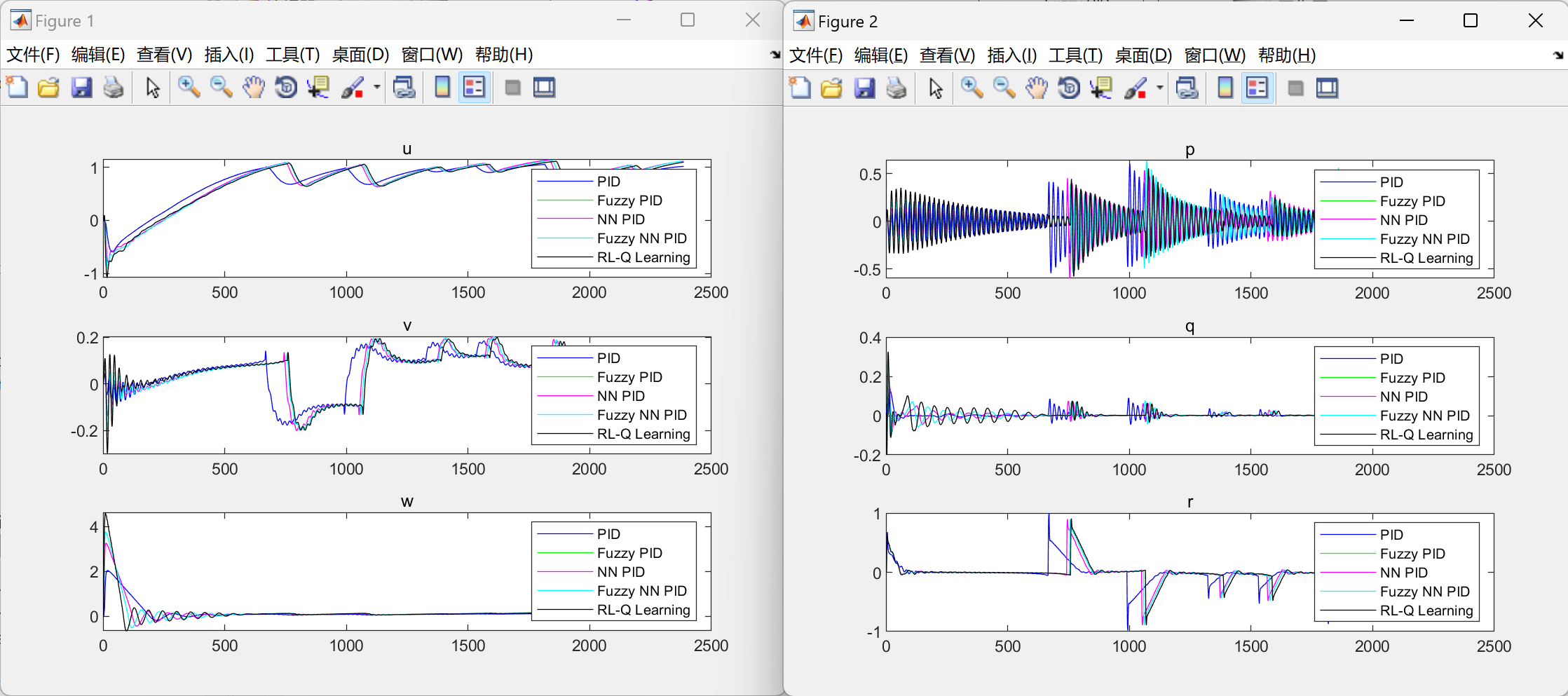
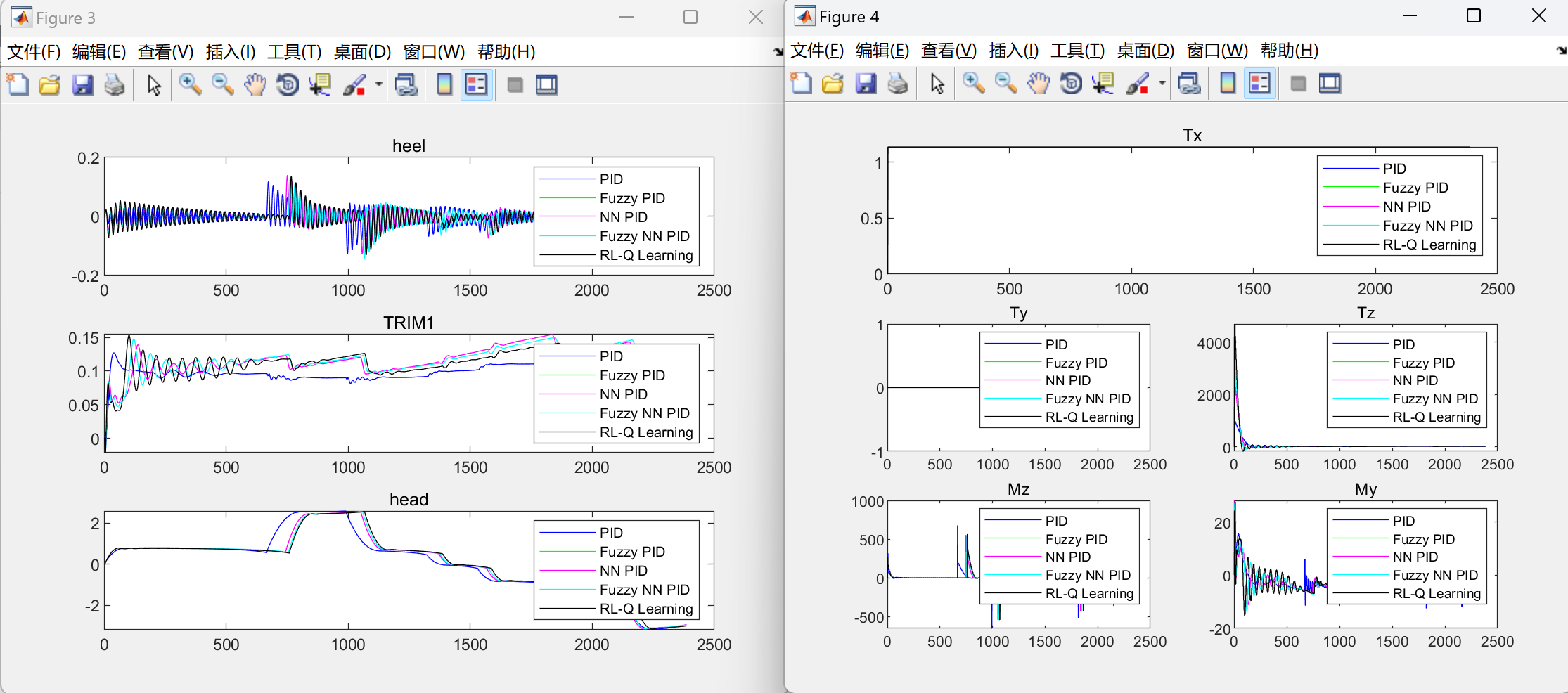
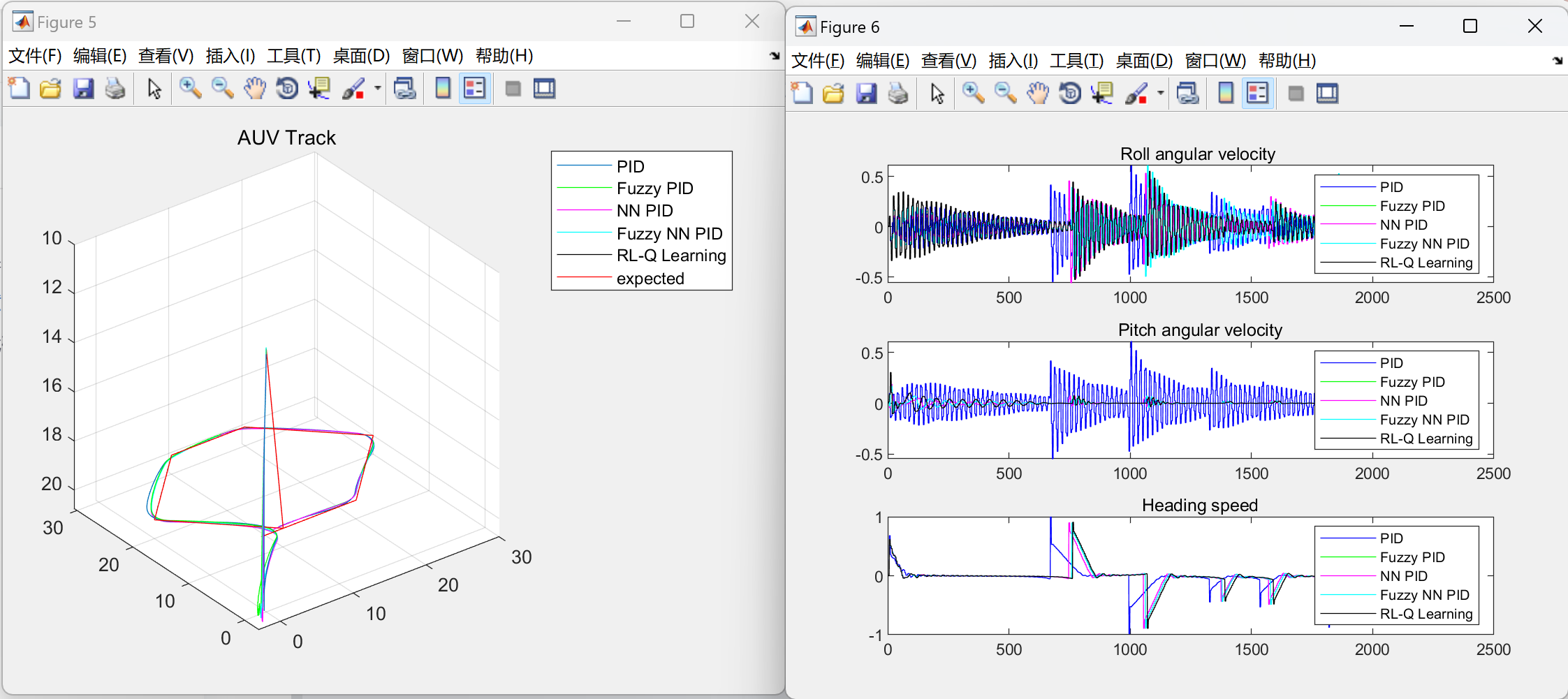
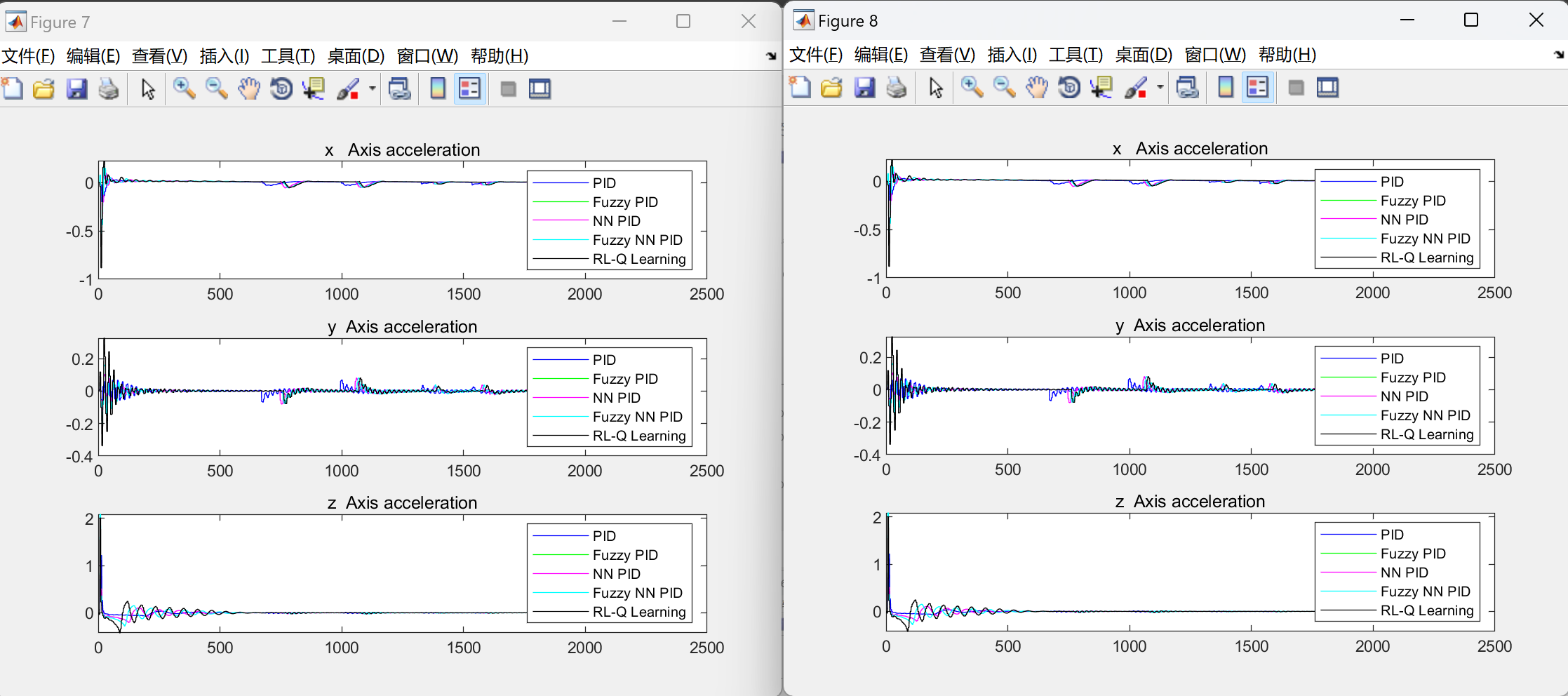
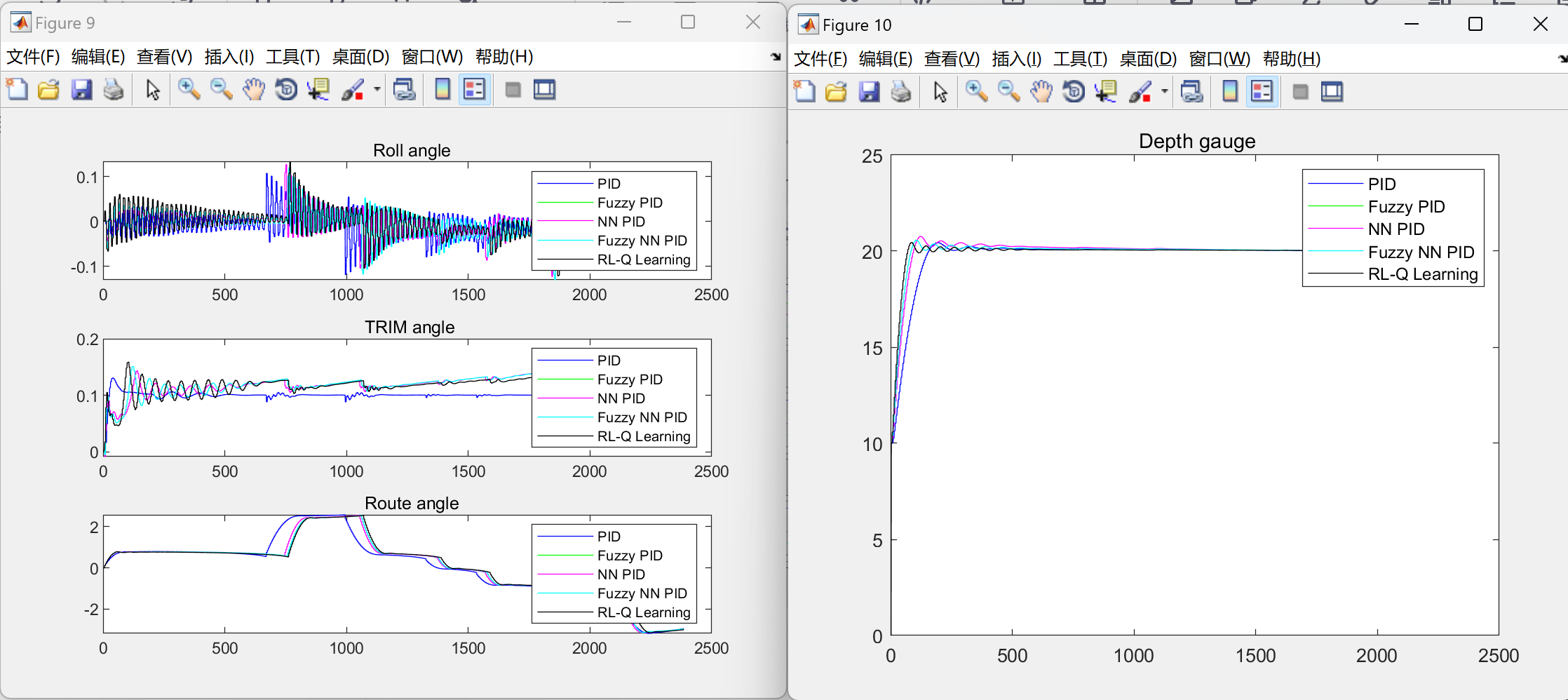
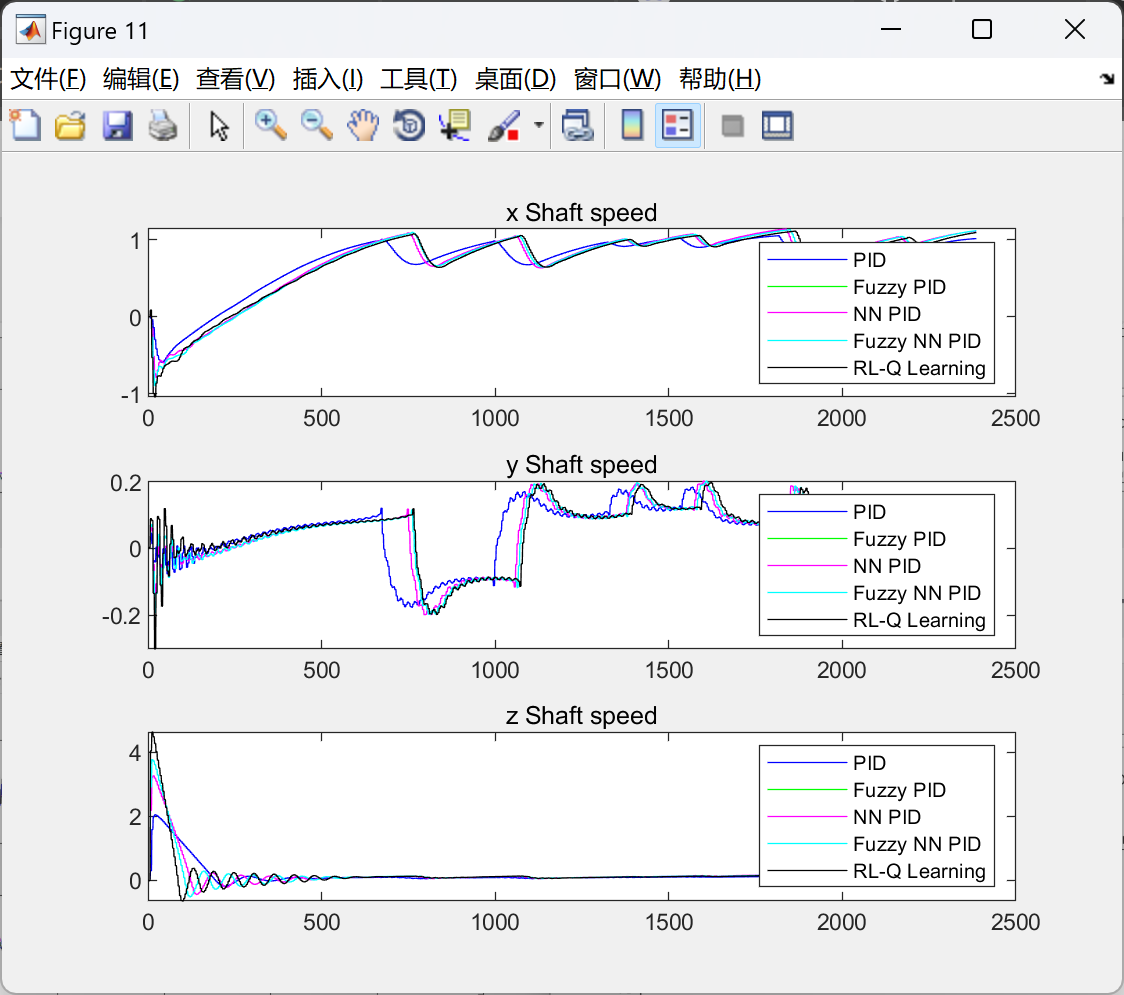
部分代码:
figure(1);
subplot(311);
plot(Mfile.iii,Mfile.pidresults(Mfile.iii,1),'b');
hold on;
plot(Mfile.iii,Mfile.ffresults(Mfile.iii,1),'g');
hold on;
plot(Mfile.iii,Mfile.nnresults(Mfile.iii,1),'m');
hold on;
plot(Mfile.iii,Mfile.nfresults(Mfile.iii,1),'c');
hold on;
plot(Mfile.iii,Mfile.QLresults(Mfile.iii,1),'k');
title('u');
legend('PID','Fuzzy PID','NN PID','Fuzzy NN PID','RL-Q Learning');
hold off;
subplot(312);
plot(Mfile.iii,Mfile.pidresults(Mfile.iii,2),'b');
hold on;
plot(Mfile.iii,Mfile.ffresults(Mfile.iii,2),'g');
hold on;
plot(Mfile.iii,Mfile.nnresults(Mfile.iii,2),'m');
hold on;
plot(Mfile.iii,Mfile.nfresults(Mfile.iii,2),'c');
hold on;
plot(Mfile.iii,Mfile.QLresults(Mfile.iii,2),'k');
hold off;
title('v');
legend('PID','Fuzzy PID','NN PID','Fuzzy NN PID','RL-Q Learning');
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]李想.基于强化学习的汽车协同式自适应巡航控制技术研究[D].吉林大学,2019.
[2]徐昕.增强学习及其在移动机器人导航与控制中的应用研究[D].国防科学技术大学,2002.DOI:10.7666/d.y480233.
[3]闫敬,李文飚,杨晛,等.融合Q学习与PID控制器的AUV跟踪控制[J].水下无人系统学报, 2021.DOI:10.11993/j.issn.2096-3920.2021.05.008.
[4]徐莉.Q-learning研究及其在AUV局部路径规划中的应用[D].哈尔滨工程大学,2004.DOI:10.7666/d.y670628.
















 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









