







机器学习+城市规划第二期:XGBoost-SHAP模型学习与论文解读
在城市规划学中,很多研究目的是分析城市空间结构或城市建成环境对某种城市特征的影响,包括城市空间结构对城市容量的影响,城市建成环境对城市居民出行兴趣的影响,城市建成环境对地表温度LST的影响。而对于这些研究,利用机器学习技术能够很好的达成我们的目的。因此这期我们选择具体的机器学习模型进行学习。
首先我们选择的就是XGB-SHAP这一经典框架,XGB是一个基于梯度提升的树模型,其作用广泛,可以用来进行分类预测,回归预测,以及影响因素排序。这是一种机器学习模型,SHAP是一种机器学习可解释机制,在我们研究某种现象的时候,SHAP可以解释发生这种现象的机理
XGB框架学习
以下讲述部分参考了陈天奇教授的Introduction to Boosted TreesPPT,链接:
https://xgboost.readthedocs.io/en/latest/tutorials/model.html
https://cugtyt.github.io/blog/intv/190811.html
XGBoost,全称是eXtreme Gradient Boosting,简称XGB,是GBDT算法的一个变种。它是一种监督算法,是boost算法的一种,也属于集成学习,是一种伸缩性强、便捷的可并行构建模型的Gradient Boosting算法。它高效地实现了GBDT算法并进行了算法和工程上的许多改进,可用于分类、回归,排序问题。
XGB建模
- 生成一棵树
XGBoost和GBDT两者都是boosting方法,除了工程实现、解决问题上的一些差异外,最大的不同就是目标函数的定义。因此,本文我们从目标函数开始探究XGBoost的基本原理。
- 学习第 t 棵树
XGBoost是由
k
k
k个基模型组成的一个加法模型,假设我们第t次迭代要训练的树模型是
f
t
(
x
)
f_t(x)
ft(x),则有:

- 定义一棵树
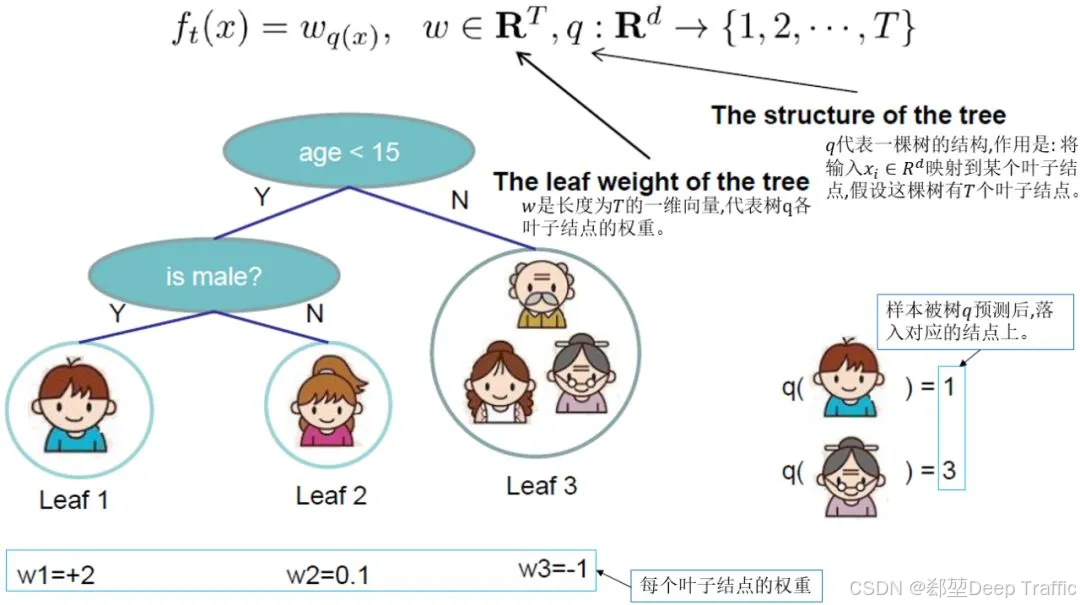
我们可以重新定义一棵决策树,其包括两个部分:
叶子节点的权重向量 ω ω ω,
实例样本到叶子节点的映射关系
q
q
q(实际上是树的分支结构)
G
x
+
1
2
H
x
2
,
H
>
0
Gx+ \begin{array} {c}1 \\ 2 \end{array}Hx^2,H>0
Gx+12Hx2,H>0
- 定义树的复杂度
决策树的复杂度 Ω Ω Ω可由叶子数 T T T组成,叶子节点越少模型越简单,此外叶子节点也不应该含有过高的权重 ω ω ω(类比 LR 的每个变量的权重),所以目标函数的正则项由生成的所有决策树的叶子节点数量,和所有节点权重所组成的向量的 L 2 L_2 L2范式共同决定。
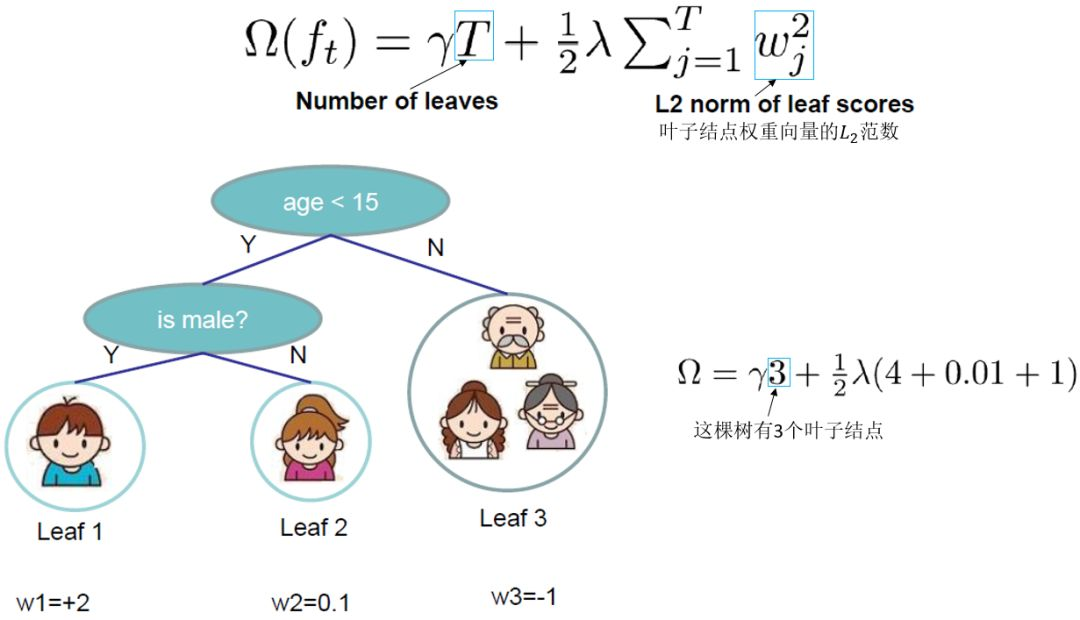
- 叶子结点归组
我们将属于第 j j j个叶子结点的所有样本 x i x_i xi划入到一个叶子结点的样本集合中,数学表示为: I j = { i ∣ q ( x i ) = j } I_j=\{i|q(x_i)=j\} Ij={i∣q(xi)=j},那么XGBoost的目标函数可以写成:
L ( ∅ ) = ∑ i l ( y i , y ^ i ) + ∑ k Ω ( f k ) \mathcal{L}(\emptyset)=\sum_{i}l(y_{i},\widehat{y}_{i})+\sum_{k}\Omega(f_{k}) L(∅)=i∑l(yi,y i)+k∑Ω(fk)
将 f t ( x i ) = w q ( x i ) f_t(x_i)=w_{q(x_i)} ft(xi)=wq(xi)(这个公式指的是定义的树)代入目标函数可以得到:
L ( t ) = ∑ i = 1 n [ g i w q ( x i ) + 1 2 h i w q ( x i ) 2 ] + γ T + λ 1 2 ∑ j = 1 T w j 2 \mathcal{L}^{(t)}=\sum_{i=1}^{n}\left[g_{i}w_{q(x_{i})}+\frac{1}{2}h_{i}w_{q(x_{i})}{}^{2}\right]+\gamma T+\lambda\frac{1}{2}\sum_{j=1}^{T}w_{j}{}^{2} L(t)=i=1∑n[giwq(xi)+21hiwq(xi)2]+γT+λ21j=1∑Twj2
将所有的训练样本按照叶子节点进行分组得:
L ( t ) = ∑ j = 1 T [ ( ∑ i ϵ I j g i ) w j + 1 2 ( ∑ i ϵ I j h i + λ ) w j 2 ] + γ T \mathcal{L}^{(t)}=\sum_{j=1}^{T}\left[\left(\sum_{i\epsilon I_{j}}g_{i}\right)w_{j}+\frac{1}{2}\left(\sum_{i\epsilon I_{j}}h_{i}+\lambda\right)w_{j}{}^{2}\right]+\gamma T L(t)=j=1∑T iϵIj∑gi wj+21 iϵIj∑hi+λ wj2 +γT
XGBoost的损失函数
损失函数可由预测值 y ^ i \hat{y}_i y^i与真实值 y i y_i yi进行表示, n n n为样本量
L = ∑ i = 1 n l ( y i , y ^ i ) L=\sum_{i=1}^nl(y_i,\hat{y}_i) L=i=1∑nl(yi,y^i)
其中, n n n为样本的数量。
目标函数
- 求目标函数
最后,合并一次项系数
定义两个函数:
G j = ∑ i ϵ I j g i G_j=\sum_{i\epsilon I_j}g_i Gj=iϵIj∑gi
H j = ∑ i ϵ I j h i H_j=\sum_{i\epsilon I_j}h_i Hj=iϵIj∑hi
其中:
G
j
G_j
Gj:叶子节点
j
j
j所包含的一阶偏导数累加之和,是一个常数
H j H_j Hj:叶子节点 j j j所包含的二阶偏导数累加之和,是一个常数
将 G j G_j Gj与 H j H_j Hj代入目标函数得到:
L ( t ) = ∑ j = 1 T [ G j w j + 1 2 ( H j + λ ) w j 2 ] + γ T \mathcal{L}^{(t)}=\sum_{j=1}^{T}\left[G_{j}w_{j}+\frac{1}{2}\left(H_{j}+\lambda\right)w_{j}{}^{2}\right]+\gamma T L(t)=j=1∑T[Gjwj+21(Hj+λ)wj2]+γT
这个就是XGB的最终目标函数
- XGB目标函数解
XGB的目标函数解的过程是构建星入一元二次方程形式,求最优值。我们已经事先知道,XGB的目标函数是:
L ( t ) = ∑ j = 1 T [ G j w j + 1 2 ( H j + λ ) w j 2 ] + γ T \mathcal{L}^{(t)}=\sum_{j=1}^{T}\left[G_{j}w_{j}+\frac{1}{2}\left(H_{j}+\lambda\right)w_{j}{}^{2}\right]+\gamma T L(t)=j=1∑T[Gjwj+21(Hj+λ)wj2]+γT
则每个叶子节点 j j j的目标函数是:
f ( w j ) = G j w j + 1 2 ( H j + λ ) w j 2 f(w_j)=G_jw_j+\frac{1}{2}\left(H_j+\lambda\right)w_j{}^2 f(wj)=Gjwj+21(Hj+λ)wj2
其是 w j w_j wj的的一元二次函数:
( H j + λ ) > 0 (H_j+\lambda)>0 (Hj+λ)>0,则 f ( w j ) f(w_j) f(wj)在 w j = − G j H j + λ w_{j}=-\frac{G_{j}}{H_{j}+\lambda} wj=−Hj+λGj处取得最小值,最小值为 = − 1 2 G j 2 H j + λ =-\frac{1}{2}\frac{G_{j}^{2}}{H_{j}+\lambda} =−21Hj+λGj2。
目标值Obj最小,则树结构最好,此时即是目标函数的最优解
XGB目标函数的各个叶子节点的目标式子是相互独立的,即每个叶子节点的式子都达到最值点,整个目标函数也达到最值点,那么每个叶子节点的权重 w j ∗ w_j^* wj∗及此时达到最优的 O b j Obj Obj目标值:
w j ∗ = − G j H j + λ w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda} wj∗=−Hj+λGj
O b j = − 1 2 ∑ j = 1 T G j 2 H j + λ + γ T Obj=-\frac{1}{2}\sum_{j=1}^{T}\frac{{G_{j}}^{2}}{H_{j}+\lambda}+\gamma T Obj=−21j=1∑THj+λGj2+γT

最后得到:目标值Obj最小,则树结构最好,此时即是目标函数的最优解
SHAP机理解释机制
在城市规划研究中,机器学习模型能够帮助我们预测和分析城市特征,但一个关键问题是如何解释这些模型的预测结果。XGBoost虽然能提供强大的预测能力,但其复杂性使得单纯依靠特征重要性(如特征分数、增益等)难以揭示特征对预测结果的具体影响。为了解决这一问题,我们引入 SHAP(Shapley Additive Explanations),它是一种基于Shapley值的可解释性方法,可以用来衡量每个特征对模型预测结果的贡献。
SHAP 作为一种基于 Shapley 值的解释方法,为 XGBoost 模型的可解释性提供了强有力的工具。在城市规划研究中,我们可以利用 SHAP 量化各个特征对预测结果的贡献,帮助我们理解复杂的城市系统如何影响城市发展、居民行为等。结合 SHAP 的可视化工具,我们能够更加透明、清晰地解释模型的预测结果,从而提高研究的可信度和实用性。
1. SHAP 的基本概念
SHAP 的核心思想源自合作博弈论中的 Shapley 值,其用于衡量某个特征在不同特征组合下对预测结果的贡献。具体来说,SHAP 计算的是 某个特征在多个不同的特征子集中的边际贡献的平均值,确保了公平性和一致性。其主要特点包括:
- 一致性(Consistency):如果增加某个特征的贡献,SHAP 重要性不会降低。
- 局部准确性(Local Accuracy):SHAP 值的总和等于模型的预测输出,即:
f ( x ) = ϕ 0 + ∑ i = 1 M ϕ i f(x) = \phi_0 + \sum_{i=1}^{M} \phi_i f(x)=ϕ0+i=1∑Mϕi
其中:
- f ( x ) f(x) f(x)是模型的预测值,
- ϕ 0 \phi_0 ϕ0是基准值(如数据集中所有样本的平均预测值),
- ϕ i \phi_i ϕi是特征 i i i的 SHAP 值(即其贡献)。
2. SHAP 在 XGBoost 解释中的应用
在 XGBoost 模型中,SHAP 可以用来分析各个特征对最终预测值的贡献。一般来说,我们可以通过 SHAP 值 来解释:
- 全局解释(Global Explanation):观察不同特征对整体预测的影响,例如哪个特征对预测最重要。
- 局部解释(Local Explanation):对于某个具体样本,分析哪些特征驱动了其预测结果。
SHAP 在 XGBoost 解释中的主要应用方式包括:
- 特征重要性分析:使用 SHAP 均值衡量特征在整体数据集上的贡献。
- SHAP 值可视化:使用 SHAP Summary Plot、Dependence Plot、Force Plot 等方式展示 SHAP 值的分布及其影响。
- 个体样本解释:针对某个特定样本,分析具体特征的 SHAP 贡献,帮助研究人员理解个体预测的驱动因素。
3. SHAP 计算方法
SHAP 计算特征贡献的方法可以分为几种:
- Kernel SHAP(基于采样的方法,适用于任意黑箱模型)
- Tree SHAP(针对树模型的高效计算方法,适用于 XGBoost、LightGBM 等)
- Deep SHAP(用于深度学习模型)
对于 XGBoost,我们通常采用 Tree SHAP,它能够在多项式时间复杂度内计算 SHAP 值,相较于经典 Shapley 值计算的指数复杂度更高效。
4. SHAP 可视化分析
为了更直观地解释 SHAP 计算的结果,我们可以使用以下可视化方法:
(1) SHAP Summary Plot
SHAP Summary Plot 展示了所有特征的 SHAP 值分布情况,可以看出哪些特征对模型预测贡献最大。
summary plot是针对全部样本预测的解释,有两种图,一种是取每个特征的shap values的平均绝对值来获得标准条形图,这个其实就是全局重要度,另一种是通过散点简单绘制每个样本的每个特征的shap values,通过颜色可以看到特征值大小与预测影响之间的关系,同时展示其特征值分布。
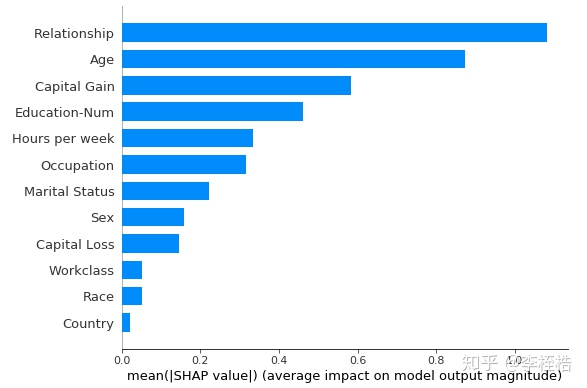
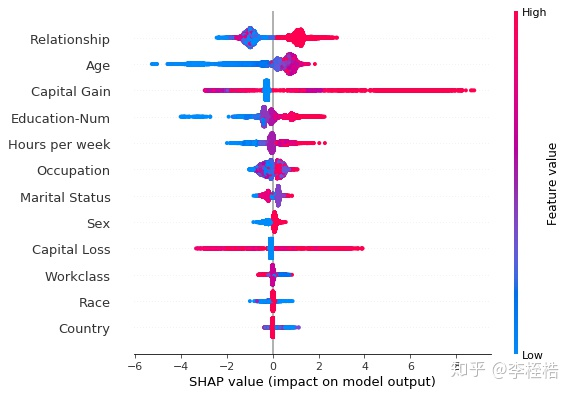
两个图都可以看到Relationship全局重要度是最高的,其次是Age。第一个图可以看到各个特征重要度的相对关系,虽然Capital Gain是第三,但是重要度只有Relationship的60%,而第二个图由颜色深浅则可以看到Relationship和Age都是值越大,个人年收入超过5万美元的可能性越大。
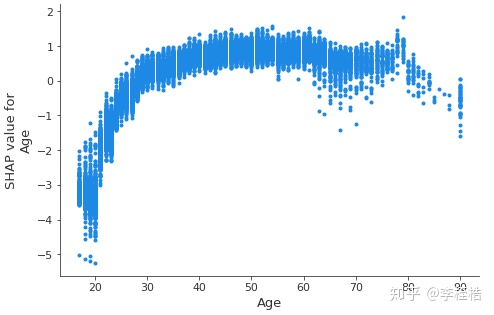
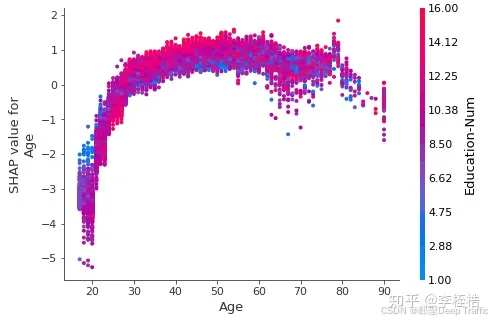
(2) SHAP Dependence Plot
SHAP Dependence Plot 用于分析单个特征的 SHAP 值与其取值的关系,观察特征的非线性效应。
如果要看特征值大小与预测影响之间的关系使用dependence plot更合适,dependence plot清楚地展示了单个特征是如何影响模型的预测结果的,dependence plot同样有多种使用方式,一种是查看某个特征是如何影响到模型预测结果的,另一种是一个特征是如何和另一个特征交互影响到模型预测结果的。
(3) SHAP Force Plot
SHAP Force Plot 可以解释某个特定样本的 SHAP 值贡献,显示哪些特征推动了预测值上升或下降。
force plot是针对单个样本预测的解释,它可以将shap values可视化为force,每个特征值都是一个增加或减少预测的force,预测从基线开始,基线是解释模型的常数,每个归因值是一个箭头,增加(正值)或减少(负值)预测。

红色的为正贡献,蓝色为负贡献,对于第一个样本的模型预测值0.0128,由上图可以解释为特征Education-Num=13的正贡献最大,其次是Age=39,但是Capital Gain=2174的负贡献很大,其次是Relationship=0,意思是没有家庭,在所有特征的综合影响下,该样本个人年收入超过5万美元的可能性只有0.0128。
5. SHAP 在城市规划中的应用示例
在城市规划的研究中,SHAP 可以用于解释 XGBoost 模型的预测结果。例如:
- 分析城市建成环境对居民出行模式的影响:通过 SHAP 值可以量化不同城市特征(如道路密度、公交可达性、建筑混合度等)对出行行为预测的贡献。
- 评估城市空间结构对城市热岛效应的影响:使用 SHAP 分析不同环境变量(如绿地覆盖率、建筑密度等)对地表温度(LST)预测的贡献。
- 城市功能区划分的影响分析:利用 SHAP 解释 XGBoost 预测的城市功能类型分类结果,找出关键的影响因素。
XGB-SHAP实际案例
在上一小节,我们学习了XGB模型的基本原理,我们可以知道XGB模型的主要作用是影响因素排序和预测两个功能,在本小节,我们学习一下XGB模型的具体案例:
案例1:基于 XGBoost 模型的城市建成环境对网约车碳排放影响
该案例来自于:
尹超英,葛耀霞,陈文栋,王晓全,邵春福.基于 XGBoost 模型的城市建成
环境对网约车碳排放影响[J/OL].北京交通大学学报.https://link.cnki.net/urlid/11.5258.U.20250103.1628.015
- 北京交通大学学报,中国科协高质量期刊目录铁路运输类T1期刊,北京建筑大学A3类期刊(5分)
**摘 要:**为探究建成环境与网约车碳排放之间的互动关系,以南京市网约车订单运营数据为基础,从土地利用、房价等方面刻画建成环境指标,建立将出行起终点建成环境因素同时考虑在内的极端梯度提升树模型(XGBoost),以揭示二者之间非线性影响及变量交互效应。研究结果显示:XGBoost 模型拟合效果优于传统梯度提升决策树模型(GBDT),其 R2、MAE、RMSE 分别为 0.541、0.364、0.275。相对重要度方面,发现网约车出行起终点距市中心距离变量贡献度较大,分别为 20.544%和 29.127%。依据非线性关系可知,各变量的反馈机制不同。其中,起终点距地铁站点距离对网约车碳排放量的反馈机制相反,表明距地铁站点距离对碳排放影响存在非对称性;起终点距市中心距离与网约车碳排放非线性关系均呈现 U 型分布,在 7 km 和 20 km 处具有显著阈值效应;起点距市中心距离与起点道路密度等变量对网约车碳排放存在明显的交互作用。研究有助于为城市规划提供理论依据,加快碳达峰和碳中和目标的实现。
- XGB的应用目的,影响因素排序
在这项研究中,挖掘的是城市建成环境与网约车碳排放的关系,他们利用城市建成环境的各类数据,探寻这些建成环境因素对网约车碳排放的影响。实际上在这个任务中,XGB所进行的是对影响网约车碳排放的因素进行重要性排序,探寻重要的影响因素与不重要的影响因素。在实际应用中,针对重要的影响因素进行改善,可以有效控制城市网约车的碳排放。探寻城市建成环境对城市的作用,是城市规划的重要研究内容。
- 原始数据
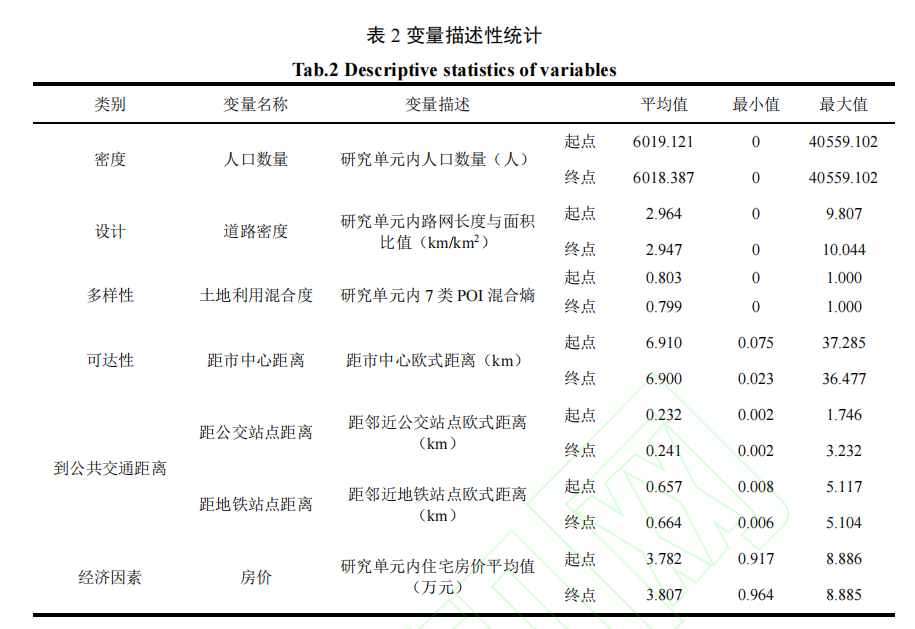
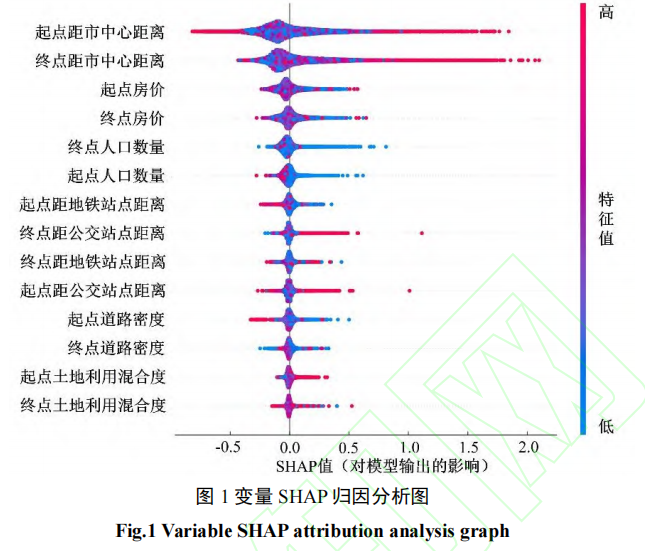
- 实验与结果
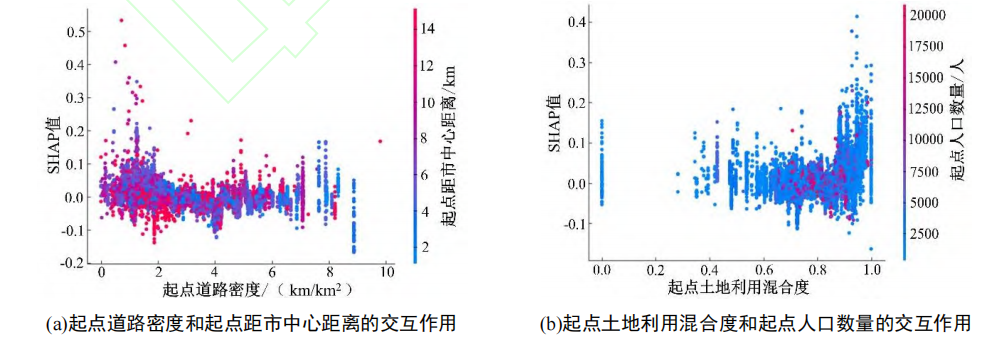
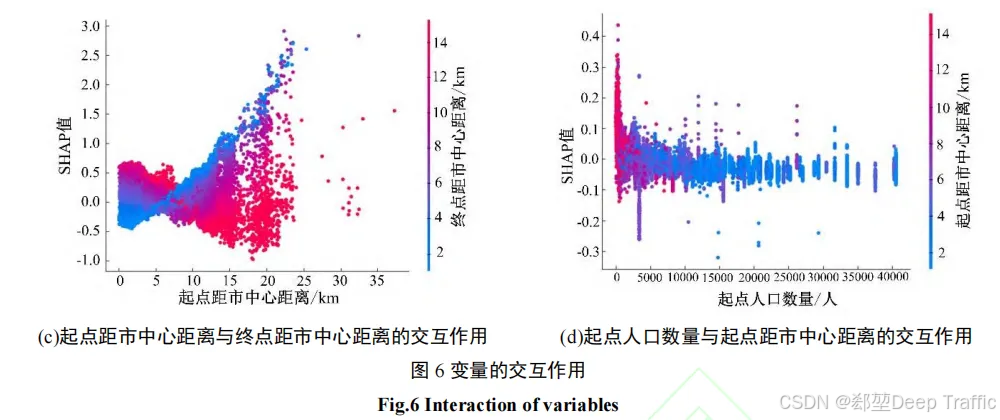
- 研究结果
SHAP 归因分析的结果表明,各变量对网约车碳排放的反馈机制存在差异。其中,起终点人口密度和起点道路密度等变量为负反馈机制;起终点距公交站点距离为正反馈机制;起终点距市中心距离、起终点房价和起点土地利用混合度等变量对网约车出行碳排放的正负反馈机制不显著;起点距地铁站点距离与终点距地铁站点距离对网约车碳排放的反馈机制相反,表明起终点距地铁站点距离对碳排放影响存在非对称性。该反馈机制结果提示城市管理者需提高公交站点的覆盖率和便捷性,以减少居民对网约车的依赖性,促进绿色低碳出行。
起终点距市中心距离、起终点房价等变量与网约车碳排放之间存在显著的非线性关系和阈值效应。起点距市中心距离与起点道路密度等变量间对网约车碳排放量存在明显的交互作用。依据阈值和变量间的交互作用结果,可确定各建成环境因素促进网约车节能减排的最佳取值,合理配置建成环境资源,进而有效控制和减少网约车碳排放。
案例2:探究高密度城市块状环境特征对地表温度及其空间异质性的影响
该案例来自于:
Wan Y, Du H, Yuan L, et al. Exploring the influence of block environmental characteristics on land surface temperature and its spatial heterogeneity for a high-density city[J]. Sustainable Cities and Society, 2025, 118: 105973.
- Sustainable Cities and Society,中科院一区TOP,规划顶刊,IF10.5
摘要:深入了解城市化背景下地表温度的空间变化趋势及其驱动机制是制定有效的城市热岛效应缓解策略的前提。本研究以中国高密度城市深圳的建成区为分析单元。利用多源数据集计算了44个环境特征指标,涵盖4类。为了综合分析各环境特征指标对地表温度和空间异质性的影响,构建了MLR、XGBoost和MGWR模型。在此基础上,利用SHAP方法分析了各变量之间的非线性关系。结果表明,MGWR和XGBoost模型的预测效果明显优于MLR模型。森林覆盖率、平均高程、NDVI、额面积指数和建筑高度标准差是影响地表温度的主要因素。这些因素对地表温度分布的解释约占52%。大部分景观格局、建筑形态和街景指标对地表温度的影响呈现空间异质性。此外,各指标对地表温度也表现出非线性模式和阈值效应。这些发现为改善城市热环境,特别是在高密度的城市地区提供了有价值的见解。
- XGB的应用目的,影响因素排序,地标温度预测
在这项研究中,作者运用了包含XGB在内的多个模型,进行城市地表温度的预测。而运用XGB的优势是因为XGB可以在预测过程中分析每种影响因素的重要程度,以便在预测过程中分析地表温度高低的主要致因。同时作者在利用XGB分析地表温度致因的过程中,引入SHAP方法对地表温度进行形成机理分析,从而挖掘出每个因素对地表温度高低的动态影响,对为改善城市热环境,特别是在高密度的城市地区的工作提供更详细的数据支撑。
- 研究框架

- 数据变量

- 实验与结果
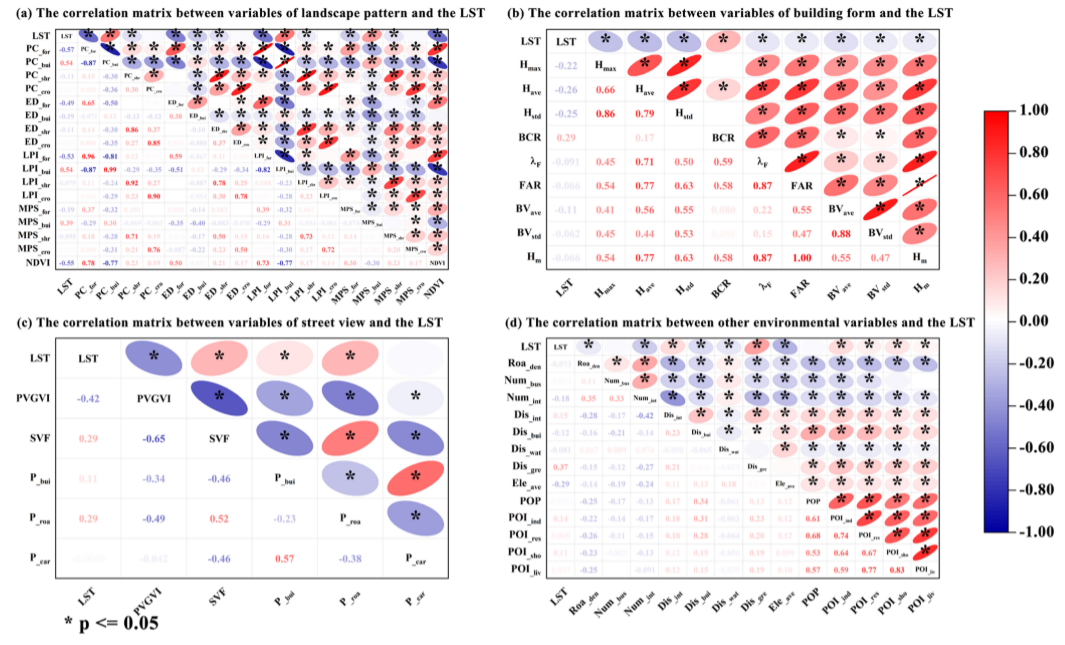
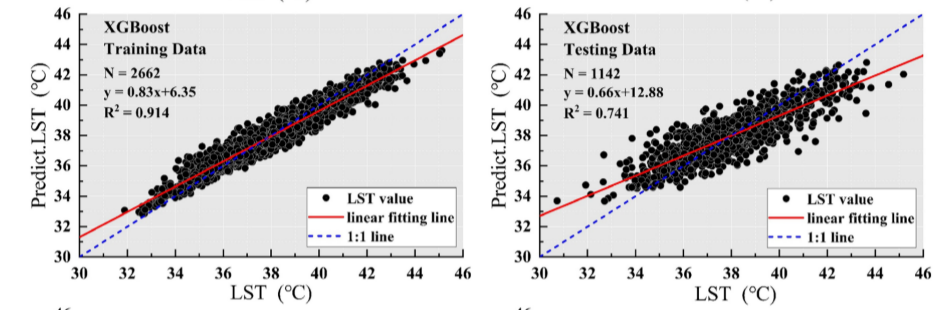
XGB影响因素分析
XGB对地表温度LST的预测结果
XGB对地表温度LST高低的致因分析与SHAP机理挖掘
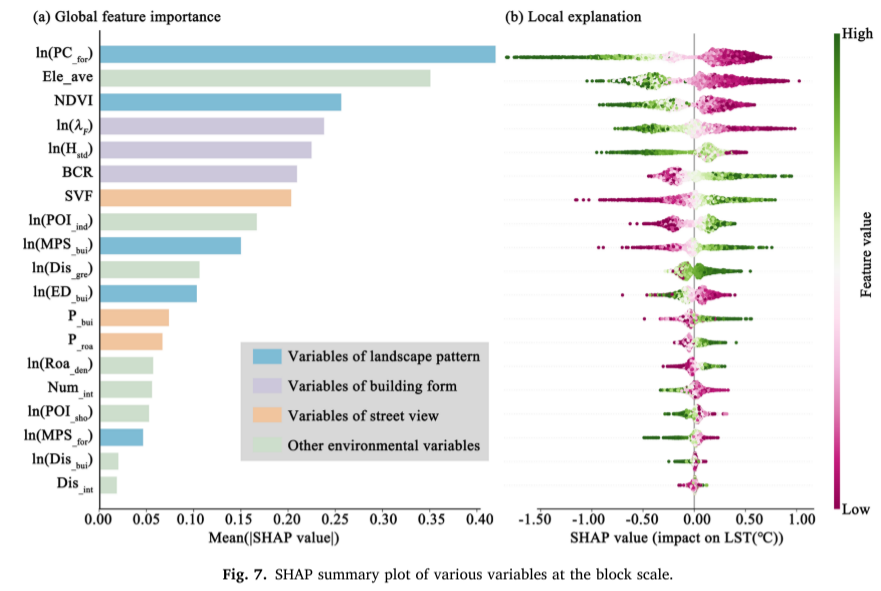
XGB对地表温度LST高低的致因的双因素交互分析
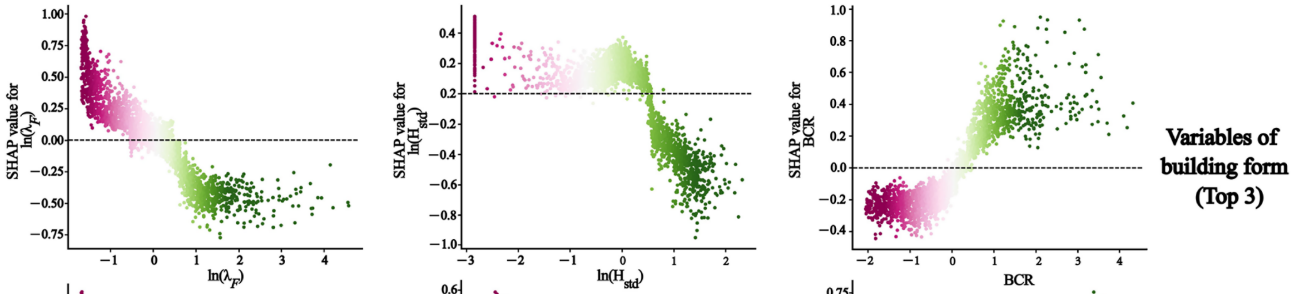
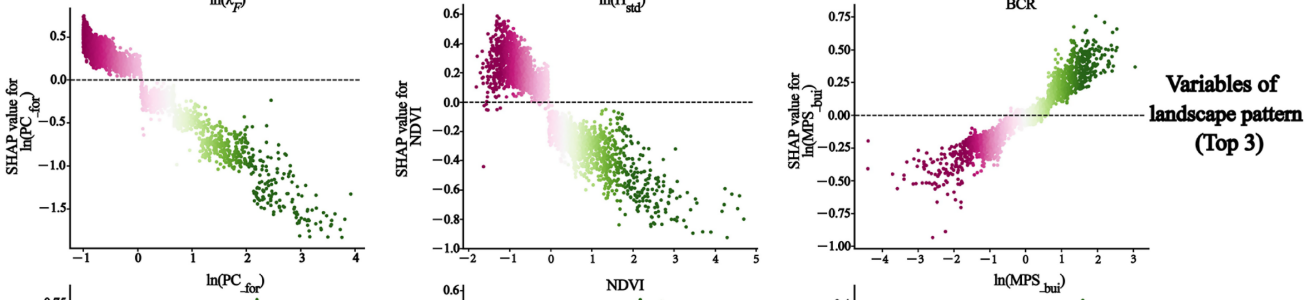
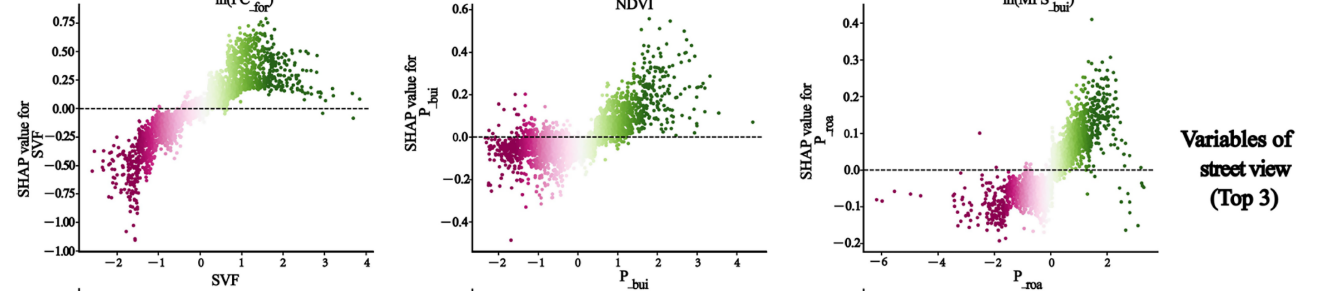
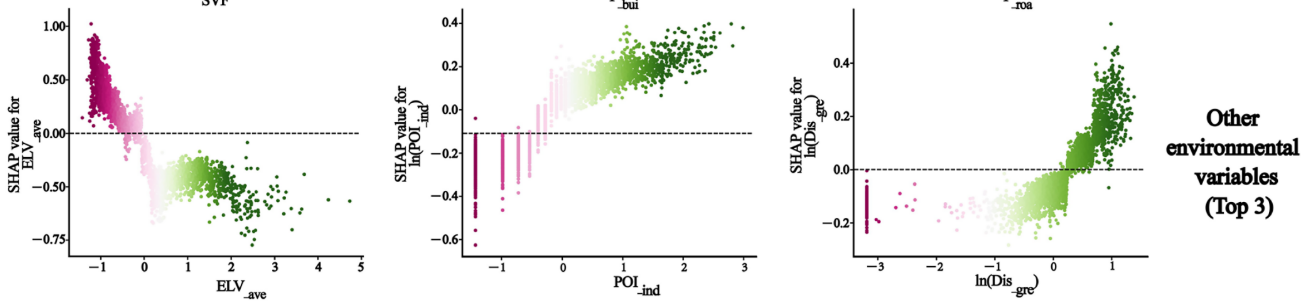
单因素对地表温度LST的影响在空间异质性的分析
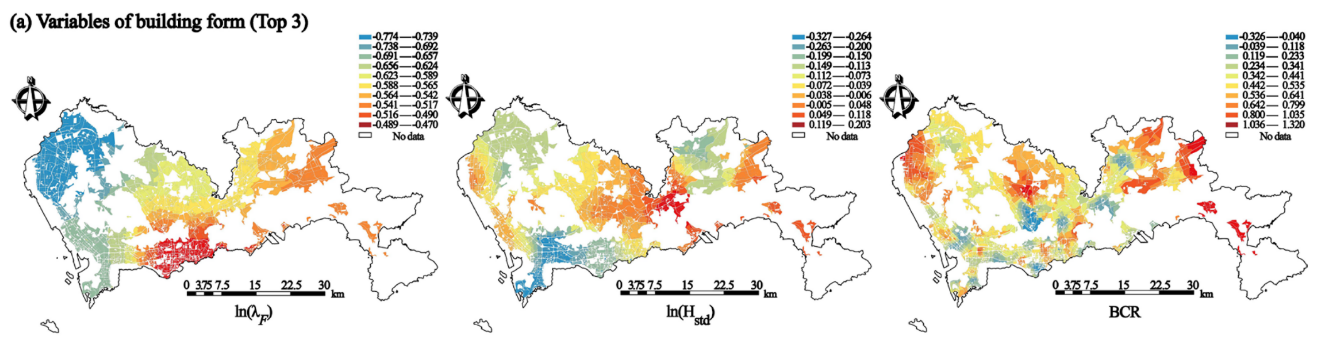
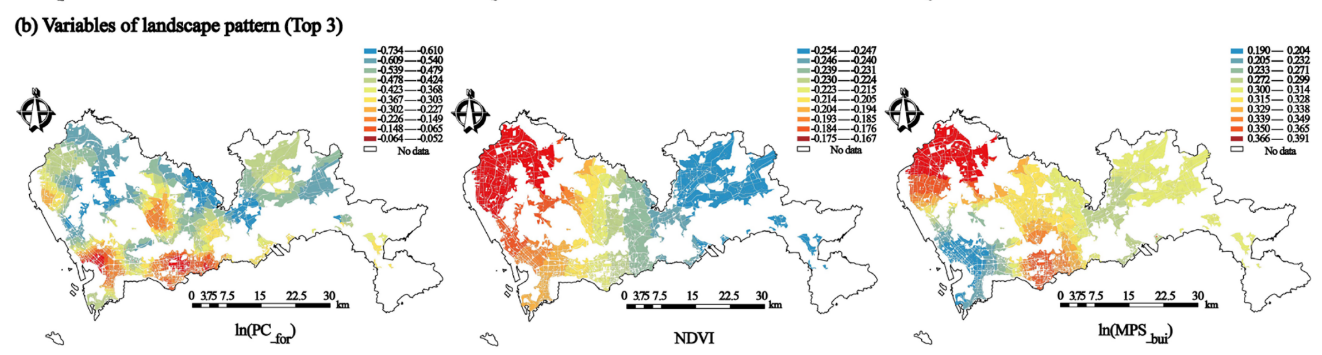
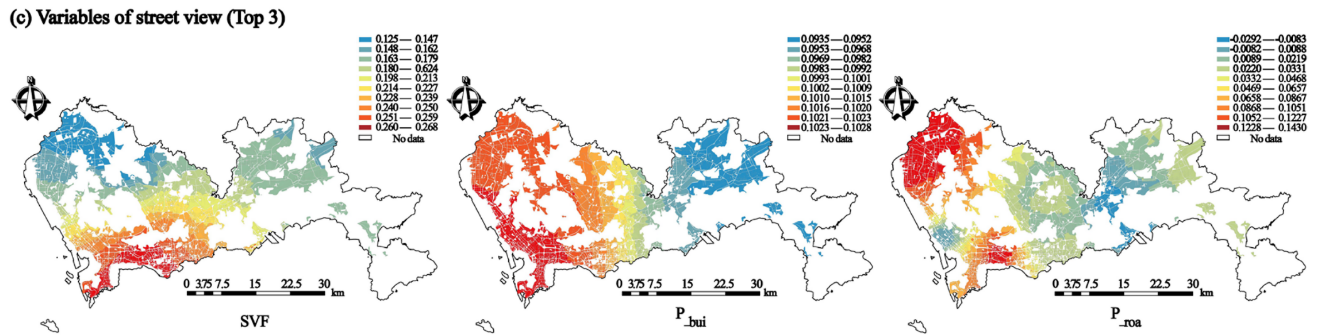
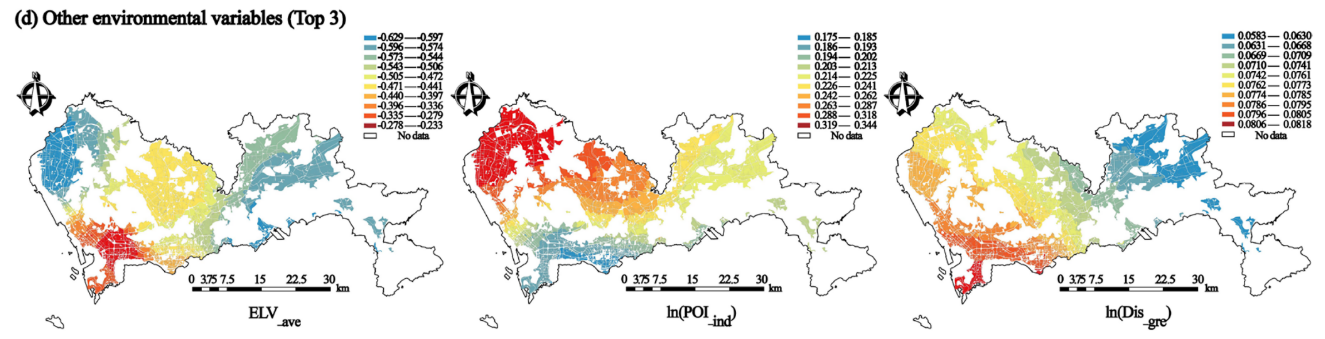
案例3:探究高密度城市块状环境特征对地表温度及其空间异质性的影响
该案例来自于:
杨东峰,王晓萌,韩瑞娜.建成环境对街道活力的非线性影响和交互效应:以沈阳为例[J].城市规划学刊,2023,(05):93-102.
- 城市规划学刊:城乡规划学科顶刊
摘要:营造有活力的街道空间需要对建成环境进行精细优化。运用机器学习及其可解释性方法,基于街道活力的复杂性内涵,以东北老工业基地沈阳市为例,探究建成环境与街道活力的非线性关系和建成环境要素间的交互效应,并对不同街道活力类型进行解读。研究发现:街道可达性是促进街道活力的主导建成环境特征;建成环境的非线性效应可分为积极影响、消极影响和其他不规律影响;不同维度街道环境要素间存在交互作用,且街道接近度与建筑密度在交互中处主导地位;街道类型按活力预测值大小排序依次为:高活力—密度驱动型、高活力—交通便捷型、低活力—设计欠佳型和低活力—综合不足型,且每种类型的街道活力形成机制存在显著差异。针对研究结果提出相关规划建议,以期为以活力提升为导向的街道更新设计提供思路借鉴。
- XGB的应用目的,影响因素排序
在这项研究中,作者运用了LightGBM的方法(大家可以将XGB视为这个方法的变种),分析城市建成环境对街道活力的非线性耦合影响,运用GBM模型分析建成换的影响因素,探讨对街道活力具有重要影响的因素,并利用SHAP机制进行对街道活力影响因素的动态机理挖掘,分析不同类型的建成环境对不同类型的街道活力形成机理的异质性,探讨街道间的差异性。
- 研究框架
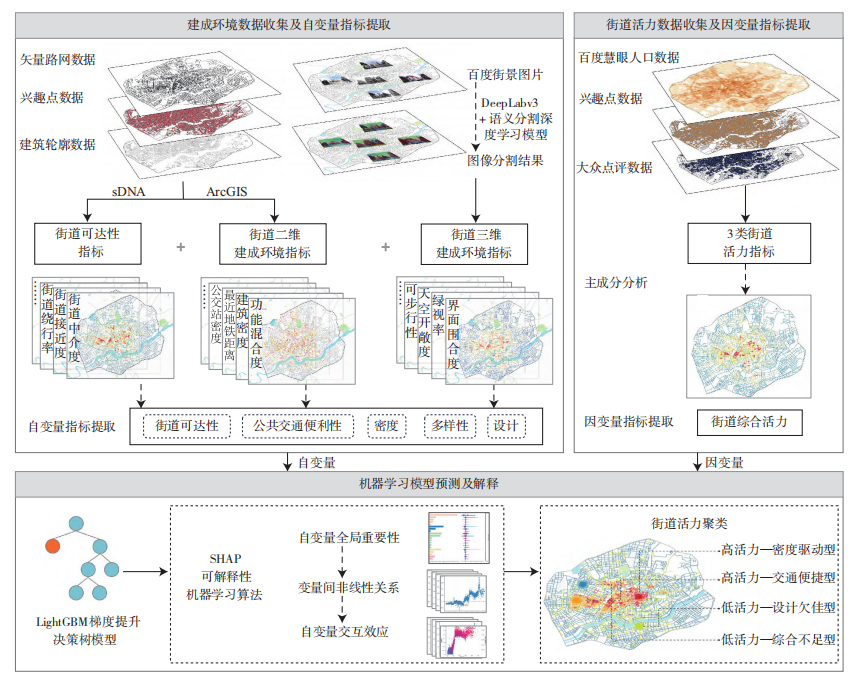
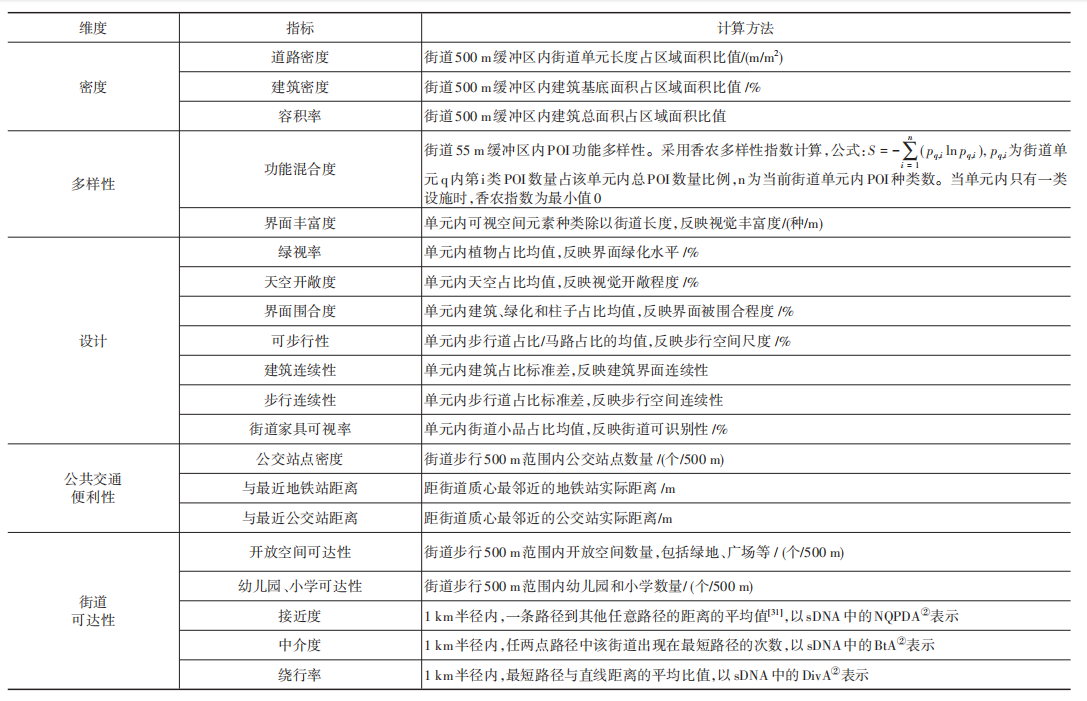
- 数据变量
- 实验与结果
建成环境因素对街道活力影响的重要性与内在机理
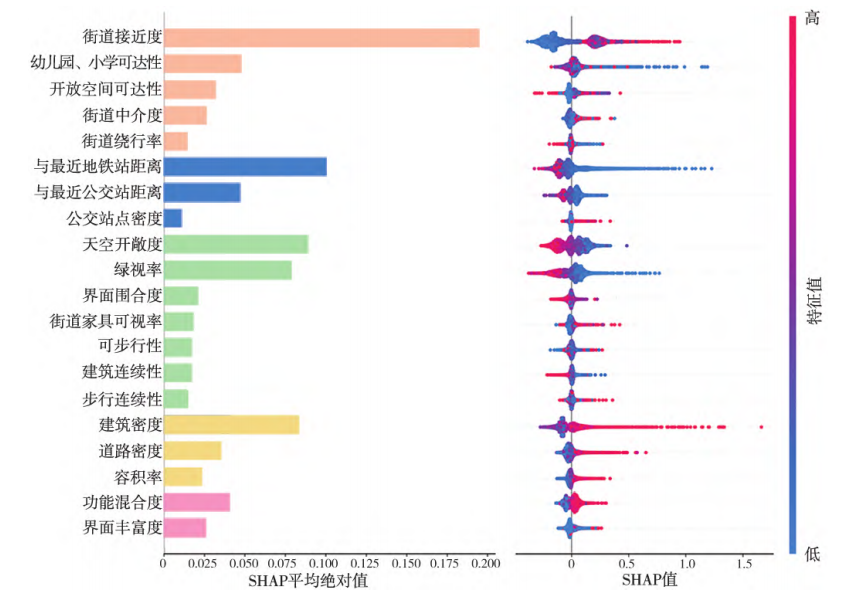
建成环境对街道影响的交互性分析
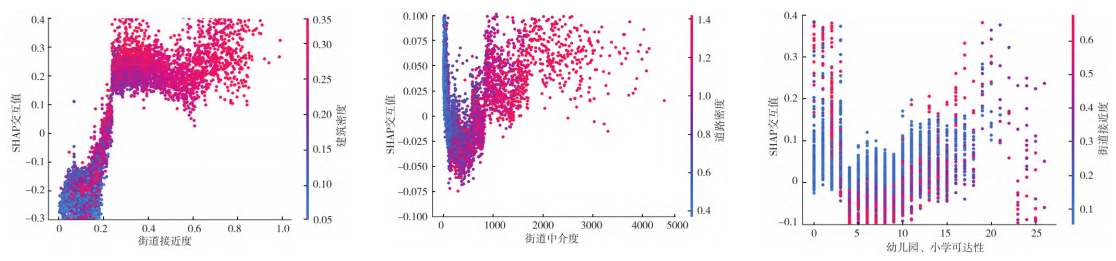
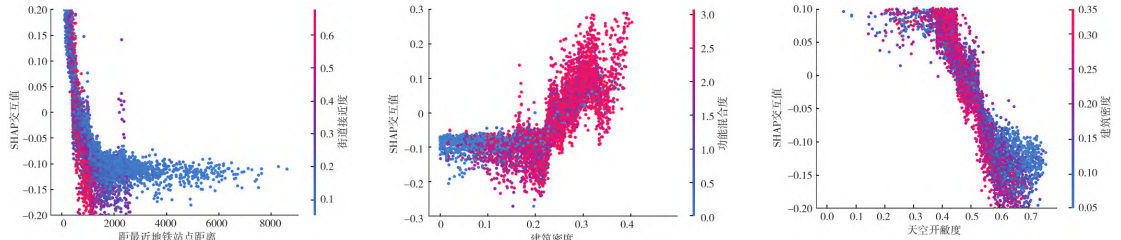

@原创声明:
本教程由课题组内部教学使用,利用CSDN平台记录,不进行任何商业盈利。
本次教程参考了CSDN中“python机器学习建模”的帖子,以及陈天奇教授Introduction to Boosted Trees的PPT

















 2374
2374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









