







机器学习+城市规划 第六期:利用 SHAP 实现空间地理可视化 —— XGBoost 与 GeoPandas 的结合实战
在前几期中,我们探索了机器学习在城市规划中的多种应用方式,例如碳排放预测、指标评估等。本期教程将进入 可解释性建模与空间可视化的深度结合实践:
🧠 目标:借助 SHAP(SHapley Additive exPlanations)揭示模型的“黑箱”,并将其与地理数据联动,实现空间层面的可视化解释。
📌 本期学习内容:
- 如何基于 XGBoost 训练区域碳排放致因分析模型
- 如何用 SHAP 分析特征对模型输出的影响
- 如何将 SHAP 值与地理空间数据(GeoJSON)结合,实现空间地图可视化
- 基于空间可视化SHAP分析碳排放的空间区域异质性
- 一套完整的 机器学习 + 地理信息系统(GIS) 分析流程
一、环境准备与库导入
import xgboost as xgb
import shap
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pandas as pd
import geopandas as gpd
import os
二、读取数据函数定义
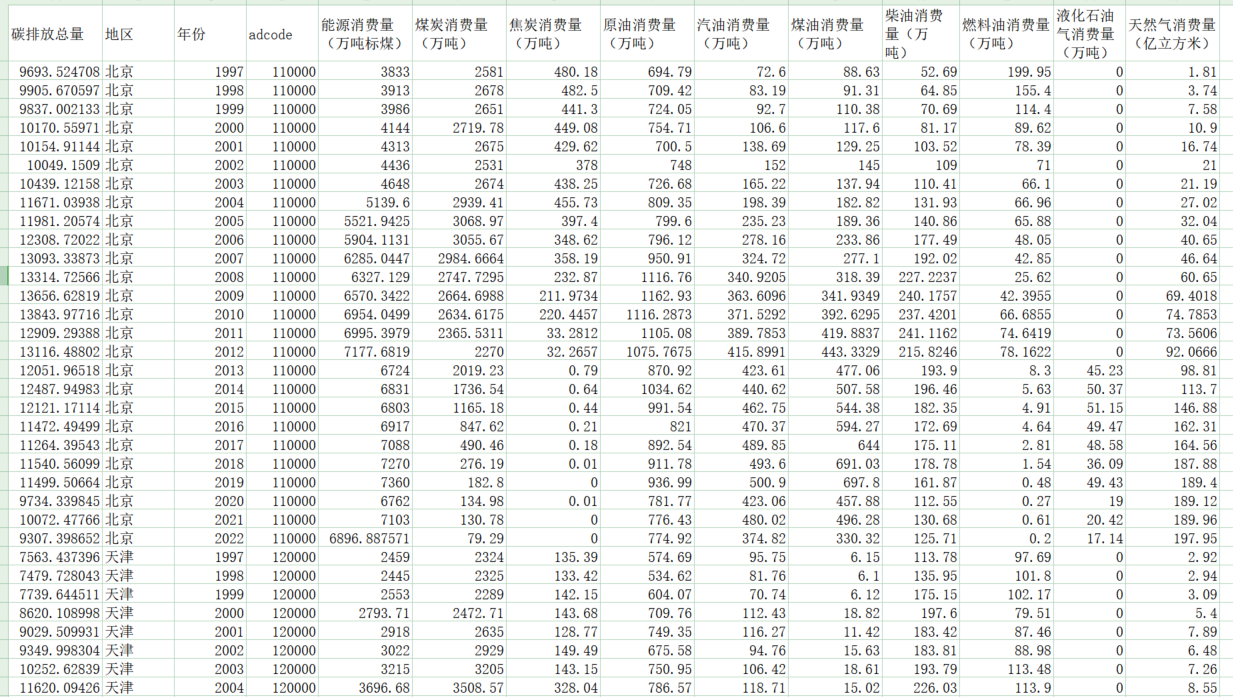
我们读取两个文件:
.csv:碳排放与相关变量数据.json:GeoJSON 行政边界数据(如市/区的边界)
# 读取数据的函数
def load_data(csv_path, json_path):
df = pd.read_csv(csv_path, encoding='ANSI')
df = df.iloc[:, [0, 3] + list(range(4, 14))]
df.columns = ['碳排放总量', 'adcode'] + [f'var_{i}' for i in range(10)]
gdf = gpd.read_file(json_path)
return df, gdf
数据示例:
三、训练 XGBoost 模型预测碳排放
# 模型训练
def train_xgboost(df):
X = df.drop(['碳排放总量', 'adcode'], axis=1)
y = df['碳排放总量']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = xgb.XGBRegressor(
objective='reg:squarederror',
learning_rate=0.1,
max_depth=5,
n_estimators=300
)
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f'模型RMSE: {mean_squared_error(y_test, pred, squared=False):.2f}')
return model
说明:
- 删除
碳排放总量和adcode作为输入特征 - 模型目标是最小化平方误差,使用
XGBoost的回归器 - 打印 RMSE 衡量模型效果
四、计算 SHAP 值并聚合为区域级别
# 计算 SHAP 值
def process_shap(model, df):
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(df.drop(['碳排放总量', 'adcode'], axis=1))
shap_df = pd.DataFrame(shap_values, columns=[f'shap_{col}' for col in df.columns[2:]], index=df.index)
df = df.reset_index(drop=True)
shap_df = shap_df.reset_index(drop=True)
full_shap = pd.concat([df[['adcode']], shap_df], axis=1)
print("✅ full_shap 列名:", full_shap.columns)
region_shap = full_shap.groupby('adcode').mean().reset_index()
print("✅ region_shap 列名:", region_shap.columns)
return region_shap
说明:
- SHAP 值揭示了每个特征对模型输出的影响(正向 or 负向)
- 将 SHAP 值按
adcode聚合,即按区域计算平均贡献度 - 得到
region_shap,每一行代表一个区域的特征解释
五、SHAP 空间可视化地图绘制
# 可视化 SHAP 值
def visualize_shap(region_shap, gdf):
if 'adcode' not in region_shap.columns:
print("⚠️ `adcode` 不在 `region_shap` 列中,尝试重置索引")
region_shap = region_shap.reset_index()
region_shap['adcode'] = region_shap['adcode'].astype(str)
gdf['adcode'] = gdf['adcode'].astype(str)
# **合并地理数据,未匹配区域设为 NaN**
merged_gdf = gdf.merge(region_shap, on='adcode', how='left')
print("✅ 合并成功!")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# **使用 Spectral 颜色映射**
cmap = 'Spectral' # 颜色匹配图片的蓝-绿-黄-红渐变
fig, axs = plt.subplots(3, 4, figsize=(24, 18))
axs = axs.flatten()
for i, col in enumerate(region_shap.columns[1:]): # 跳过 `adcode` 列
# **先绘制 SHAP 值地图**
merged_gdf.plot(column=col,
cmap=cmap,
legend=True,
missing_kwds={"color": "lightgrey", "label": "无数据"}, # 未赋值区域显示为灰色
ax=axs[i],
legend_kwds={'label': f"{col} SHAP值",
'orientation': "horizontal"})
# **再叠加黑色边界**
gdf.boundary.plot(ax=axs[i], edgecolor="black", linewidth=1.5)
axs[i].set_title(col)
plt.tight_layout()
plt.savefig('shap_map.png', dpi=300, bbox_inches='tight')
说明:
- 将 SHAP 值与 GeoDataFrame 合并
- 每张图展示一个变量的 SHAP 值在地图上的空间分布
- 使用
Spectral渐变色展示贡献大小,灰色为无数据区域 - 保存输出地图为
shap_map.png
六、主程序入口
# 主程序
if __name__ == "__main__":
csv_path = "data.csv"
json_path = "china.json"
df, gdf = load_data(csv_path, json_path)
if df is None or gdf is None:
print("❌ 数据加载失败,程序终止!")
exit()
print("✅ 数据读取成功!")
print("df 列名:", df.columns)
print("gdf 列名:", gdf.columns)
model = train_xgboost(df)
region_shap = process_shap(model, df)
visualize_shap(region_shap, gdf)
region_shap.to_csv('regional_shap.csv', index=False)
print("✅ 处理完成,结果已保存为 shap_map.png 和 regional_shap.csv")
七、城市规划中的应用展望
那么,这样的空间 SHAP 可视化能为城市规划带来哪些启发?
✅ 区域决策支持
可视化图清晰显示各变量在不同区域的影响强度,辅助政府进行差异化调控与资源分配。
✅ 精准治理与因地制宜
一些变量对特定区域影响更大,可以基于 SHAP 分析实施精准治理、定向优化政策。
✅ 模型透明度与解释性提升
通过地图化展示模型“因果路径”,提高城市规划模型的透明度与公众信任。
✅ 反馈闭环机制构建
可结合规划实施前后数据进行 SHAP 对比,实现模型与政策之间的反馈闭环。
八、实验结果分析
我们运行上述代码后,成功生成了 SHAP 空间可视化地图,如下图所示:
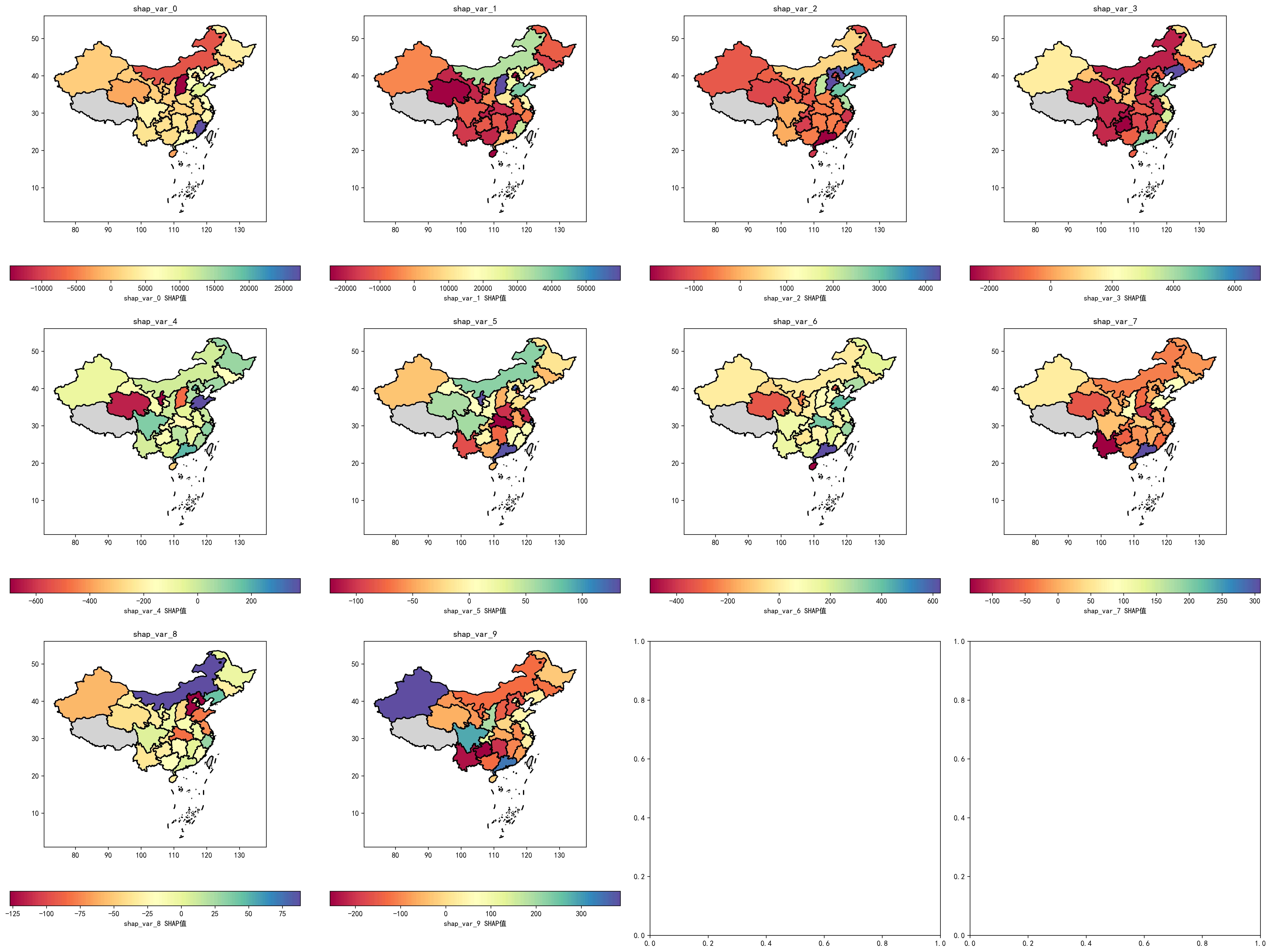
从结果中,我们可以观察到以下几个关键点:
1️⃣ SHAP 贡献度在不同区域的空间分布
- 每张子图代表一个特征对碳排放预测的 SHAP 贡献度(影响大小)。
- 颜色映射使用 Spectral 渐变色,其中:
- 红色/深色区域 表示该特征对碳排放贡献度较高(正向影响)。
- 蓝色/绿色区域 表示该特征对碳排放的贡献度较低(负向影响)。
- 灰色区域 为缺失数据或未匹配地区。
2️⃣ 变量在不同区域的重要性不同
- 部分变量在东部沿海地区 SHAP 值较高,表明工业密集、交通排放等因素对碳排放有较大影响。
- 中西部地区部分变量 SHAP 值较低或负向,与地广人稀、绿化率较高等因素有关。
- 例如,
shap_var_5在某些地区 SHAP 值极高,而shap_var_8在北部地区 SHAP 贡献较大。
3️⃣ SHAP 值的空间异质性
- 某些变量(如
shap_var_0、shap_var_3)在东部和中部区域 SHAP 贡献高,而西部较低,反映经济发展模式的不同。 - 部分变量(如
shap_var_9)在部分省份 SHAP 贡献极高,而其他地区基本无影响,暗示了部分 政策、产业或土地利用类型的区域依赖性。
4️⃣ 可视化效果与改进方向
- 未来可以优化 动态子图布局(如
ncols计算方式)来适应不同变量数量,或者直接采用交互式地图(如folium或plotly)。 - 进一步的改进可以使用 地理加权回归(GWR) 或 深度学习可解释性方法(如 LIME、Grad-CAM) 进行补充分析。
九、城市规划的实践价值
✅ 区域政策优化
- 通过 SHAP 空间分析,我们可以 量化各个变量对碳排放的具体影响,进而调整不同区域的碳中和政策。
- 比如在 SHAP 贡献高的区域,可以加强排放监管、产业升级,而在贡献低或负向的区域,可以更侧重经济发展与扶持。
✅ 智慧城市与精细化管理
- 将 SHAP 地图与实时数据(如卫星遥感、空气质量监测)结合,可以 动态监测碳排放的关键驱动因素,提高城市治理精度。
✅ 土地利用规划
- 结合 SHAP 影响因子,我们可以在 城市扩张、产业布局、绿地规划等领域 做出更科学的决策。
- 例如:
- 高 SHAP 影响区域适合推行 低碳产业引导,或增加碳汇(如森林、湿地)。
- SHAP 贡献不均的区域,可以 优化交通基础设施布局,减少碳排放增量。
原创声明:本教程由课题组内部教学使用,利用CSDN平台记录,不进行任何商业盈利。

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









