







机器学习+城市规划第四期:XGB-SHAP框架连续变量回归实战
本期教程是机器学习与城市规划系列课程的第四期。在上一期中,我们学习了如何使用XGBoost和SHAP框架处理离散型变量的分类任务。本期我们将扩展到回归任务,尤其是针对连续型变量的分析。通过使用XGBoost回归模型与SHAP可解释性分析,我们能够更好地理解连续变量对预测结果的贡献,并进行更精确的回归任务预测。
练习数据下载:https://pan.baidu.com/s/1Bk_e-h7-jarCj0dQ0H7lFg?pwd=ecqj
环境设置
与之前的版本一样,本期课程需要以下几个Python库:pandas,sklearn,xgboost,matplotlib 和 shap。如果尚未安装这些库,可以使用以下命令进行安装:
pip install pandas scikit-learn xgboost matplotlib shap
数据准备
我们使用的数据集为连续数据集,在群内已经给大家进行了分享,同时大家还可以通过网盘来进行下载,包含了若干自变量(如温度、湿度等)和一个因变量(事故延误时间),数据来源于US-Accident数据集。假设我们的目标是通过自变量预测目标变量。
载入数据集并进行预处理
首先激活必要的库,载入数据集并进行数据预处理。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
import matplotlib.pyplot as plt
import shap
# 载入数据集
df = pd.read_csv("连续数据.csv", encoding="utf-8")
data = df.iloc[:, 1:6] # 自变量,选择第1列到第6列(共5列)
target = df.iloc[:, 0] # 因变量,选择第0列
数据划分
接下来,将数据划分为训练集和测试集。我们使用train_test_split函数将数据分为80%的训练集和20%的测试集。
# 将数据集划分为训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.2, random_state=7)
模型训练
在模型训练中,我们将使用XGBoost回归模型来进行预测。设置适当的参数后,我们开始训练模型。
XGBoost回归模型设置
# 模型初始化和设置
dtrain = xgb.DMatrix(train_x, label=train_y)
dtest = xgb.DMatrix(test_x)
watchlist = [(dtrain, 'train')]
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror', # 回归任务
'eval_metric': 'rmse', # 均方根误差
'max_depth': 5,
'lambda': 10,
'subsample': 0.75,
'colsample_bytree': 0.75,
'min_child_weight': 2,
'eta': 0.025,
'seed': 0,
'nthread': 8,
'gamma': 0.15,
'learning_rate': 0.01
}
# 模型训练和预测:50棵树
bst = xgb.train(params, dtrain, num_boost_round=50, evals=watchlist)
ypred = bst.predict(dtest)
模型评估
使用均方误差(MSE)和决定系数(R-squared)来评估模型的性能。
# 回归指标输出
print('均方误差: %.4f' % mean_squared_error(test_y, ypred))
print('R-squared: %.4f' % r2_score(test_y, ypred))
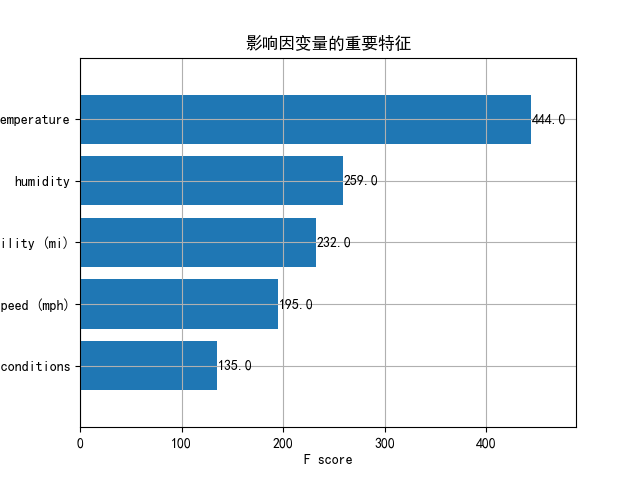
重要性排序图
输出特征的重要性排序图
# 特征重要性可视化
xgb.plot_importance(bst, height=0.8, title='影响因变量的重要特征', ylabel='特征')
plt.rc('font', family='Arial Unicode MS', size=14)
plt.show()
自变量与因变量关系图
我们可以利用matplotlib来绘制某个变量对因变量的作用关系,来清晰挖掘单因素变化下,因变量取值的变化。
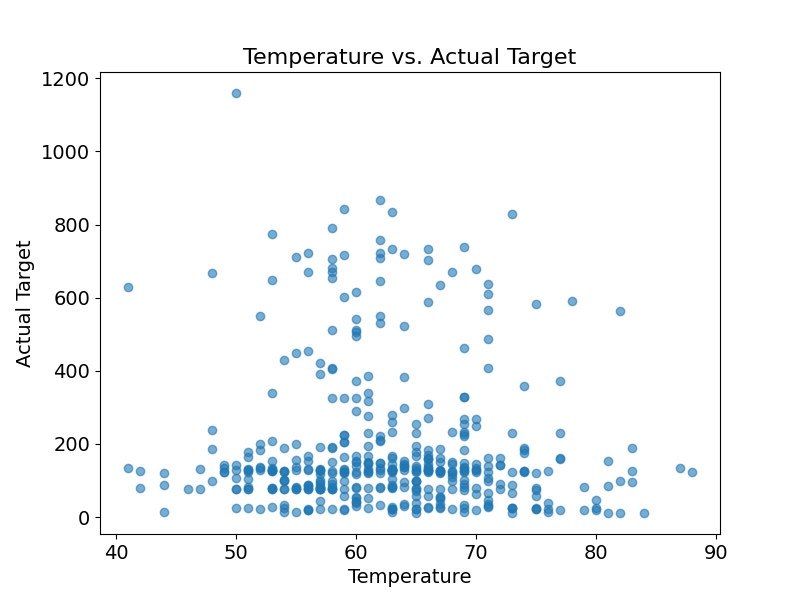
# 使用 matplotlib 绘制 自变量 与因变量之间的关系
plt.figure(figsize=(8, 6))
plt.scatter(test_x["temperature"], test_y, alpha=0.6)
plt.title("Temperature vs. Actual Target", fontsize=16)
plt.xlabel("Temperature", fontsize=14)
plt.ylabel("Actual Target", fontsize=14)
plt.show()
SHAP 可解释性分析
SHAP(Shapley Additive Explanations)可以帮助我们理解每个特征对预测结果的贡献。通过SHAP值的可视化,我们能够看到各个特征如何影响模型的预测。
计算SHAP值
在回归任务中,我们使用TreeExplainer来计算SHAP值。
# 创建 SHAP 解释器
explainer = shap.TreeExplainer(bst) # 使用 TreeExplainer 来处理 XGBoost 模型
shap_values = explainer.shap_values(test_x) # 计算 SHAP 值
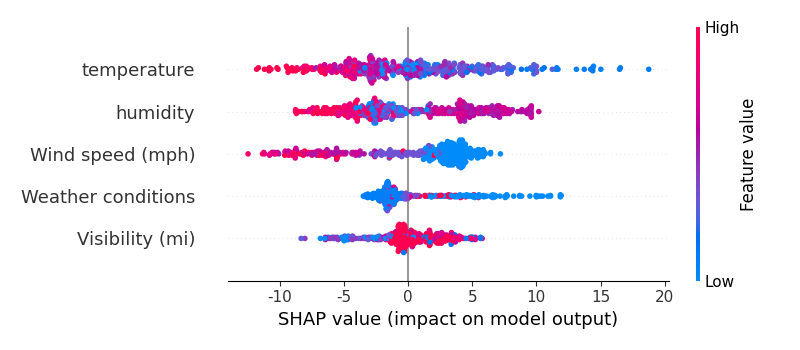
SHAP Summary图
SHAP总结图(Summary Plot)显示了所有特征的SHAP值分布情况,帮助我们理解哪些特征对预测的贡献最大。
# SHAP summary plot
shap.summary_plot(shap_values, test_x)
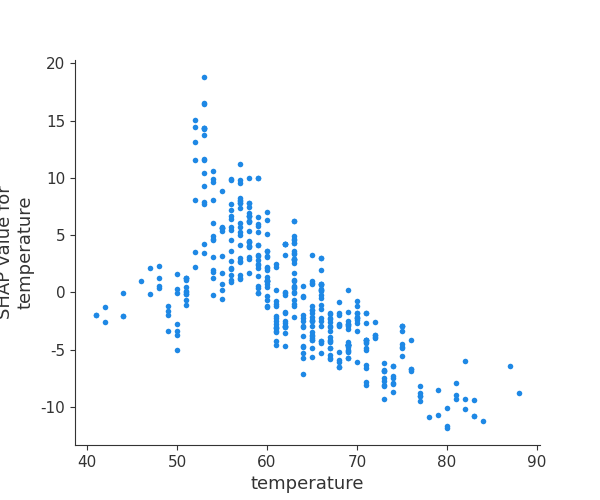
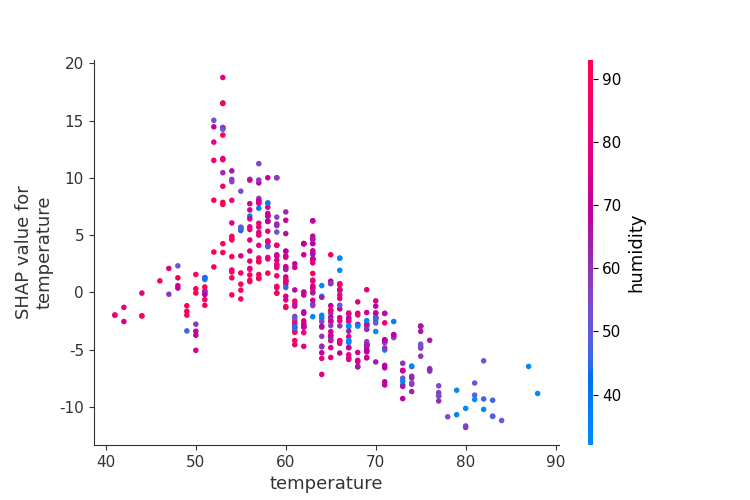
SHAP Dependence图
SHAP依赖图(Dependence Plot)用于分析特征对因变量的影响,并展示特征之间的交互作用。
我们首先生成单个因素对因变量影响的依赖图。
# SHAP dependence plot (每个特征对因变量的贡献)
shap.dependence_plot("temperature", shap_values, test_x, interaction_index=None)
同时我们也可以设置双因素进行交互分析,来输出两种因素的交互作用下对因变量的影响。通过shap.dependence_plot,分析特征之间的交互作用。例如,查看温度与湿度对目标变量的交互影响。
# 交互特征图,输出张量为(自变量,SHAP值,测试集,交互变量)
shap.dependence_plot("temperature", shap_values, test_x, interaction_index="humidity")
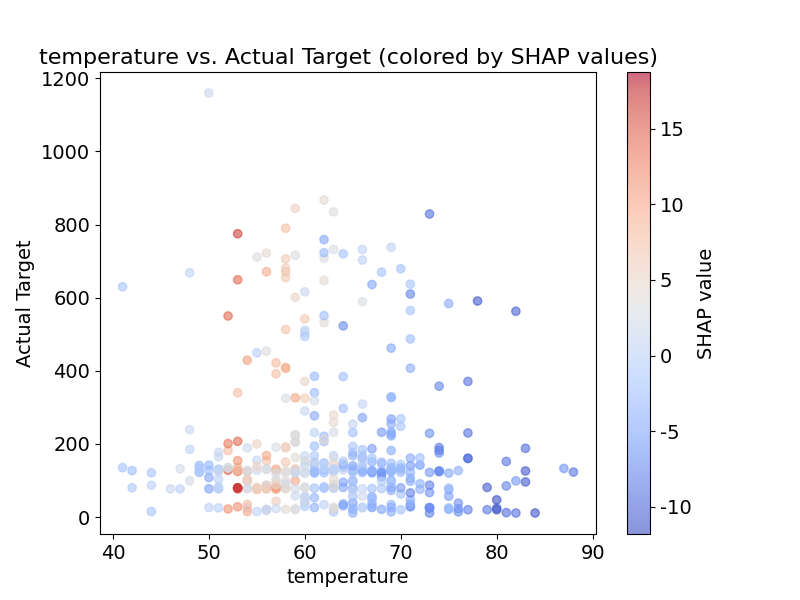
自变量与因变量关系图
我们使用matplotlib绘制自变量与因变量之间的关系,并通过SHAP值进行着色,便于理解特征的贡献。
# 使用 matplotlib 绘制 Drawingvolume 与因变量之间的关系,并通过 SHAP 值着色
Drawingvolume = "temperature"#因素选择
shap_values_temp = shap_values[:, test_x.columns.get_loc(Drawingvolume)]
plt.figure(figsize=(8, 6))
plt.scatter(test_x[Drawingvolume], test_y, c=shap_values_temp, cmap="coolwarm", alpha=0.6)
plt.title(f"{Drawingvolume} vs. Actual Target (colored by SHAP values)", fontsize=16)
plt.xlabel(Drawingvolume, fontsize=14)
plt.ylabel("Actual Target", fontsize=14)
plt.colorbar(label="SHAP value")
plt.show()
总结
通过本期教程,我们学习了如何使用XGBoost回归模型和SHAP框架进行连续变量的回归任务。我们通过SHAP值可视化分析了各个特征对模型预测结果的贡献,同时深入理解了特征之间的交互作用。掌握这些技术后,我们可以更好地解释回归模型的预测结果,并为城市规划等领域的决策提供数据支持。
原创声明:本教程由课题组内部教学使用,利用CSDN平台记录,不进行任何商业盈利。

















 2254
2254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









