







机器学习+城市规划第三期:XGBoost-SHAP分类模型实战
本次为第三次课程,在之前的课中大家进行了PyCharm和Anaconda软件的安装,Anaconda虚拟环境的搭建,这些已经是运行代码的基础了。同时我们进行了XGBoost模型的基本讲解,以及在城市规划学中的具体应用。已经学会这些,我们就可以进行实战了
本期实验数据获取链接如下:
通过网盘分享的文件:XGB-SHAP分类实战数据
链接: https://pan.baidu.com/s/1rf4iLQzljrUPN0dElJB8iw?pwd=w4yd 提取码: w4yd
XGB模型实战
环境设置
激活必要的环境,在本工作中包含pandas,sklearn,xgboost,matplotlib四个运行环境
import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn.model_selection import train_test_split
import xgboost as xgb
import matplotlib.pyplot as plt
设置绘图
# 绘图设置
plt.rcParams["axes.unicode_minus"] = False # 使用 ASCII "-"
plt.rcParams['font.sans-serif'] = ['Arial', 'DejaVu Sans', 'SimHei'] # 选择兼容的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
利用pandas工具来导入所使用的数据集
# 导入数据集
df = pd.read_csv("./data/diabetes.csv")
target = df.iloc[:, 0] # 因变量
data = df.iloc[:, 1:6] # 自变量(特征)
# 切分训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(data,target,test_size=0.2,random_state=7)
模型训练
机器学习模型训练的过程,大致分为这样几步:
1首先是对原始数据进行切割,划分为训练集和测试集两个数据子集,训练集是用来对模型进行训练,让模型在数据中学习所隐含的特征。而学习到这种隐含特征再进行预测,测试集就是与数据的预测值进行对比,评价模型的预测效果好坏。
2其次是模型超参数设置,超参数设置是控制模型训练的重要环节,合理的超参数设置可以有效提升模型的预测性能。具体来说,超参数设置能够约束模型对数据特征的学习,约束模型对预测结果的拟合程度,是预测值更加接近测试集的真实值。
#分类标签设置
# XGBoost 初始化设置
dtrain = xgb.DMatrix(train_x, label=train_y)
dtest = xgb.DMatrix(test_x)
watchlist = [(dtrain, 'train')]
# 设定 XGBoost 多分类任务参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 适用于三分类
'num_class': 4, # 三个类别
'eval_metric': 'mlogloss', # 多分类对数损失
'max_depth': 5,
'lambda': 10,
'subsample': 0.75,
'colsample_bytree': 0.75,
'min_child_weight': 2,
'eta': 0.025,
'seed': 0,
'nthread': 8,
'gamma': 0.15,
'learning_rate': 0.01
}
# 训练 XGBoost 多分类模型
bst = xgb.train(params, dtrain, num_boost_round=50, evals=watchlist)
# 进行预测(multi:softmax 直接输出类别)
ypred = bst.predict(dtest)
结果输出
首先设置模型的评价指标,用来描述模型预测的性能
同时利用matplotlab工具来进行图像绘制,通过数值的可视化来描述模型预测的结果,同时我们利用到plt.rcParams['font.sans-serif'] = ['SimHei']命令行来进行中文图片的显示。
# 计算分类指标
print('Classification Report:\n', metrics.classification_report(test_y, ypred))
print('Confusion Matrix:\n', metrics.confusion_matrix(test_y, ypred))
print('Accuracy: %.4f' % metrics.accuracy_score(test_y, ypred))
# 预测每个样本在每棵树上的叶子节点
ypred_leaf = bst.predict(dtest, pred_leaf=True)
print("测试集每棵树所属的节点数:\n", ypred_leaf)
# 预测特征贡献度
ypred_contribs = bst.predict(dtest, pred_contribs=True)
print("特征的重要性:\n", ypred_contribs)
# 绘制特征重要性
xgb.plot_importance(bst, height=0.8, title='影响分类的重要特征', ylabel='特征')
plt.rc('font', family='Arial Unicode MS', size=14)
plt.show()
实验
在实验中,给大家提供了两份数据,分别是离散数据和连续数据两类,我们选择了美国US-Accident数据集,并且进行了一定的处理。大家可以在文件夹中看到,有离散数据和离散数据1两个数据集,我们选择离散数据1进行实验。
首先修改自己的目录,将pd函数索引到自己的数据集上,我是这样索引的
df = pd.read_csv(r"C:\Users\郄堃\Desktop\祝贺老师Python学习\第二课实战\离散数据1.csv", encoding="ANSI")
因为我的数据集中列名称都是用中文来命名的,所以我的解码器设置为ANSI。(注:如果大家选择的是“离散数据”数据集,这个数据集的列名称是英文,用UTF-8进行解码即可)
然后右键代码,运行模型
运行结果如下图所示:
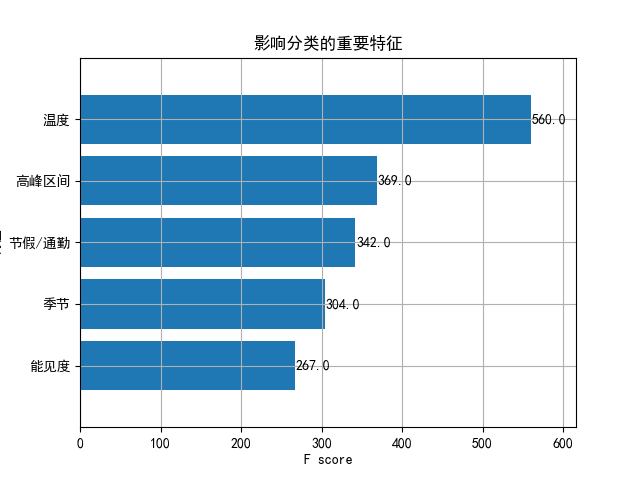
从这张图像中我们能够看出,温度对事故严重程度的影响是最大的,而能其他集中自然环境因素对事故严重程度的影响类似,能见度对事故的影响最低。同时根据模型分类的结果,可以看到:
Classification Report:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 1 | 0.44 | 0.41 | 0.42 | 2489 |
| 2 | 0.42 | 0.55 | 0.48 | 2331 |
| 3 | 0.50 | 0.30 | 0.38 | 1529 |
| accuracy | 0.44 | 6349 | ||
| macro avg | 0.45 | 0.42 | 0.43 | 6349 |
| weighted avg | 0.45 | 0.44 | 0.43 | 6349 |
从中能够看到,模型拟合效果很好,因为我们是一个三分类问题,大于0.33的基线准值就表示模型的结果是好结果。
SHAP因素机理分析
利用XGB模型分析出的实验结果,可以让我们知道不同的影响因素对交通事故严重程度的影响程度,同时对不同因素进行重要性排序。然而在这种情况下我们只能够得到,不同因素对交通事故的影响程度,但是无法挖掘到交通事故的内在影响机理。因此我们需要引入SHAP机制,利用结果因素的贡献情况,来进行事故发生机理的可解释性分析。
模型定义更新
在原本的XGB模型中,我们利用的是softmax激活函数,他的原理是利用分类标签来进行的。然而对于SHAP来说,依照变量选择的概率设置,因此我们需要选择softprob激活函数,计算多分类中样本特征的选择概率,因此需要重新构建XGB模型。
# XGB概率输出
# XGBoost 初始化设置
dtrain = xgb.DMatrix(train_x, label=train_y)
dtest = xgb.DMatrix(test_x)
watchlist = [(dtrain, 'train')]
params = {
'booster': 'gbtree',
'objective': 'multi:softprob', # 多分类类别概率
'num_class': 4, # **三分类任务**
'eval_metric': 'mlogloss',
'max_depth': 5,
'lambda': 10,
'subsample': 0.75,
'colsample_bytree': 0.75,
'min_child_weight': 2,
'eta': 0.025,
'seed': 0,
'nthread': 8,
'gamma': 0.15,
'learning_rate': 0.01
}
# 训练模型
bst = xgb.train(params, dtrain, num_boost_round=50)
# 进行预测
ypred_proba = bst.predict(dtest) # 预测概率
ypred = np.argmax(ypred_proba, axis=1) # 取最大概率对应的类别
环境设置与基本配置
激活必要的环境,激活SHAP功能组件
import shap
激活SHAP组件中,我们需要在XGB的预测过程中配置SHAP值的计算
# 创建 SHAP 解释器
explainer = shap.TreeExplainer(bst, feature_perturbation="tree_path_dependent")
shap_values = explainer.shap_values(test_x) # 计算 SHAP 值
shap_values_list = explainer.shap_values(test_x)
# 解决 SHAP 结果格式问题(对所有类别求和)
shap_values_sum = np.sum(shap_values, axis=0) # 对所有类别 SHAP 值求和
shap_values_sum1 = np.sum(np.array(shap_values_list), axis=0)
以上就完成了SHAP的基本设置,没错非常简单,与其说SHAP是一个可解释机制,更不如说他和matplotlab一样是一个Python的可视化工具,对一些机器学习模型的预测过程的机理进行可视化。
SHAP机理可视化
设置完SHAP所需要的基本框架后,遍可以对特征的影响机理进行分析了,我们分别选择前一次课所提到的SHAP Summary Plot,SHAP Dependence Plot,SHAP Force Plot三种图像进行可视化。
SHAP Summary Plot
SHAP Summary Plot 展示了所有特征的 SHAP 值分布情况,可以看出哪些特征对模型预测贡献最大。代码设置如下:
# SHAP 汇总图(Summary Plot)
plt.figure()
shap.summary_plot(shap_values_sum, test_x) # 传入修正后的 SHAP 值
plt.show()
以上为SHAP Summary Plot所需的代码,运行后便能够得到所有特征的贡献情况:
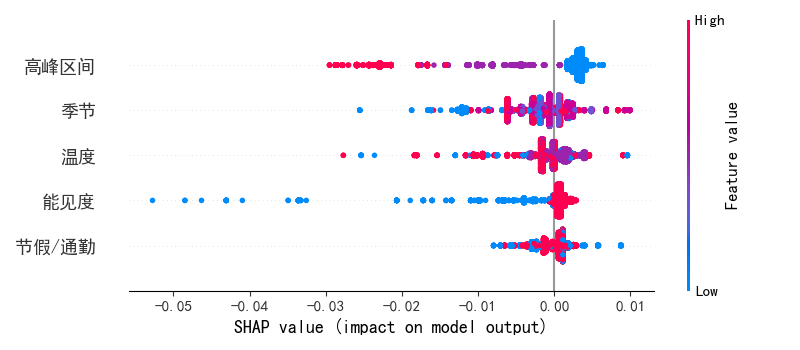
SHAP Dependence Plot
SHAP Dependence Plot 用于分析单个特征的 SHAP 值与其取值的关系,观察特征的非线性效应。
# 获取特征名称,指定要绘制交互作用的因素
feature_names = test_x.columns
factor_1_name = feature_names[1] # 能见度
factor_2_name = feature_names[4] # 高峰区间
# 使用 SHAP 交互作用绘图(注意数据必须和 SHAP 计算时保持一致)
shap.dependence_plot(
ind=factor_1_name, # 主要因素
interaction_index=factor_2_name, # 交互因素
shap_values=shap_values_sum1,
features=test_x # **必须和 SHAP 计算时的数据一致**
)
print(f"\n🔍 交互作用分析: {factor_2_name} 与 {factor_5_name} 对 “事故严重程度” 的影响")
以上为SHAP Dependence Plot所需的代码,运行后便能够得到双因素特征交互情况下对因变量的影响
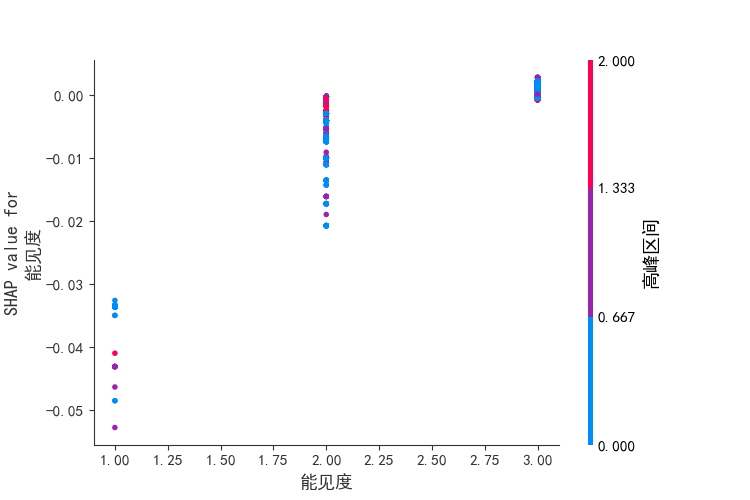
值得一提的是,为了让大家更清晰的选择不同的特征,我在代码中设置了一给特征选择,在factor_1_name = feature_names[1]中[1]为变量的选择,代表的是第几列变量。
SHAP Force Plot
SHAP Force Plot 可以解释某个特定样本的 SHAP 值贡献,显示哪些特征推动了预测值上升或下降。代码如下:
#查看所有类别的综合 SHAP 值
shap_values_avg = np.mean(np.abs(shap_values), axis=0) # 取绝对值后求均值
shap.summary_plot(shap_values_avg, train_x)
以上为SHAP Force Plot所需的代码,运行后便能够得到因素见的贡献情况的贡献情况:

以上为本次课程的内容,目的是让大家能够按照教程实现XGB-SHAP框架的应用,分析城市规划角度的问题。
@原创声明:本教程由课题组内部教学使用,利用CSDN平台记录,不进行任何商业盈利。

















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









