






训练过程
步骤:
- 配置环境
- pip install ultralytics
- 下载数据集
- 按照下图所示顺序创建目录
- test:测试集
- train:训练集
- valid:验证集
- iamges:图像
- labels:每一张图像的参数
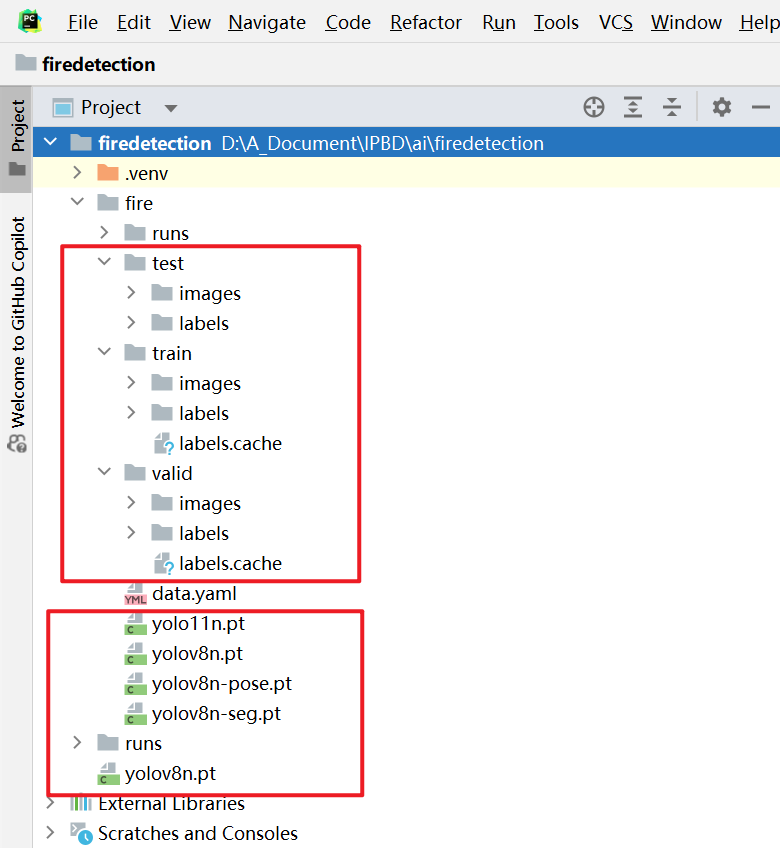
- 创建data.yaml文件(见下面)
- 运行命令,可以规定epoch
yolo task=detect mode=train model=yolov8n.pt data=data.yaml epochs=500 imgsz=416 patience=0 plots=True
patience=100意味着如果连续 100 个 epoch 中模型在验证集上的性能(如 mAP)没有提升,训练会自动停止 , 如果不希望提前停止,可以设置patience=0,则训练将运行完整的 500 个 epoch。
label文件作用
在 YOLO 模型中,labels 文件用于存储每张图片中目标对象的位置和类别标签。每张图片对应一个同名的 labels 文件,用于告诉模型图片中有哪些目标对象、这些对象的类别是什么,以及它们的位置。
YOLO labels 文件的内容格式
labels 文件通常是一个 .txt 文件,格式如下:
<class_id> <x_center> <y_center> <width> <height>
其中:
<class_id>:目标的类别 ID,从 0 开始编号,表示当前目标属于哪个类别。<x_center>** 和 **<y_center>:目标边界框的中心点坐标,通常是相对于图片宽度和高度的归一化值,范围在 0 到 1 之间。<width>** 和 **<height>:目标边界框的宽度和高度,同样是相对于图片宽度和高度的归一化值,范围在 0 到 1 之间。
示例
假设 labels 文件名为 image1.txt,内容如下:
0 0.5 0.5 0.2 0.3
1 0.7 0.3 0.1 0.1
解释:
- 第一行:目标类别为
0,中心点位于图片中点(0.5, 0.5),宽度为0.2,高度为0.3。 - 第二行:目标类别为
1,中心点位于图片的(0.7, 0.3),宽度为0.1,高度为0.1。
labels 文件在训练中的作用
在训练中,模型会通过 labels 文件中的信息找到目标对象的边界框和类别,进行目标检测的训练。模型学习如何根据图片中的像素特征来预测目标对象的边界框和类别标签。
data.yaml文件作用
在 YOLOv8 中,data.yaml 文件用于定义数据集的路径和类别信息,是训练和验证模型的重要配置文件。它帮助 YOLOv8 知道在哪里找到训练、验证、测试数据以及要检测的类别。
- 指定数据集路径:告诉模型训练、验证、测试数据集所在的文件夹路径。
- 定义类别:提供目标检测任务中的类别名称和数量,以便模型正确地识别不同的目标。
data.yaml 文件的基本结构
一个典型的 data.yaml 文件包含以下内容:
train: path/to/train/images # 训练集图片文件夹路径
val: path/to/val/images # 验证集图片文件夹路径
test: path/to/test/images # 测试集图片文件夹路径(可选)
nc: 3 # 类别数量,例如检测火焰时有火焰、烟雾和其他的标签
names: ["fire", "smoke", "background"] # 每个类别的名称列表
关键字段说明
train:指定训练集图片的文件夹路径。文件夹中应包含images文件夹和labels文件夹。val:指定验证集图片的文件夹路径。test(可选):指定测试集图片的文件夹路径,训练时一般不使用,但可以在模型评估阶段使用。nc:(number of classes)目标检测任务的类别数量,即模型将检测的不同对象类型数量。names:一个字符串列表,定义每个类别的名称,模型会使用这些名称识别不同的目标。
示例
假设项目目录结构如下:
project/
├── data.yaml
├── train/
│ ├── images/
│ └── labels/
├── val/
│ ├── images/
│ └── labels/
└── test/
├── images/
└── labels/
对应的 data.yaml 文件可以写成:
train: project/train/images
val: project/val/images
test: project/test/images
nc: 2
names: ["fire", "smoke"]
data.yaml 文件的作用总结
- 训练路径配置:为 YOLO 模型提供数据集路径。
- 类别信息:定义模型所需的类别,使得模型在训练和检测时知道每个类别的含义。
有了 data.yaml 文件,YOLOv8 就能正确地定位数据集、加载类别信息,并根据指定的训练和验证集路径进行训练和测试。
实际案例
names:
- Fire
- default
- smoke
nc: 3
roboflow:
license: CC BY 4.0
project: fire-wrpgm
url: https://universe.roboflow.com/custom-thxhn/fire-wrpgm/dataset/8
version: 8
workspace: custom-thxhn
#test: D:\A_Document\IPBD\ai\firedetection1\fire_data\test\images
train: D:\A_Document\IPBD\ai\firedetection1\fire_data\train\images
val: D:\A_Document\IPBD\ai\firedetection1\fire_data\valid\images
这个 yaml 文件是一个 YOLOv8 模型的配置文件,用于定义数据集的信息,包括类别、路径和其他元数据。让我们逐行解释:
配置项解析
names:
- Fire
- default
- smoke
names:定义了模型要检测的目标类别名称列表。
类别列表的顺序从 0 开始,即 Fire 的类别 ID 为 0,default 为 1,smoke 为 2。
- `Fire`:类别名称,可能表示火焰。
- `default`:类别名称,这通常是一个通用类别名称,可能表示默认的非火焰物体或背景。
- `smoke`:类别名称,表示烟雾。
nc: 3
nc:类别数量。此处为3,表示数据集中有 3 个不同的检测类别,与names列表一致。
roboflow:
license: CC BY 4.0
project: fire-wrpgm
url: https://universe.roboflow.com/custom-thxhn/fire-wrpgm/dataset/8
version: 8
workspace: custom-thxhn
roboflow:包含数据集的元数据信息,表明此数据集可能是从 Roboflow 平台导出的。license:数据集的许可证类型,CC BY 4.0表示该数据集遵循 Creative Commons Attribution 4.0 许可协议,允许共享和修改,需注明出处。project:数据集项目名称fire-wrpgm。url:数据集的 URL,指向 Roboflow 平台上的项目链接。version:数据集的版本号,表明当前数据集是第8版。workspace:Roboflow 平台上的工作区名称custom-thxhn。
#test: D:\A_Document\IPBD\ai\firedetection1\fire_data\test\images
train: D:\A_Document\IPBD\ai\firedetection1\fire_data\train\images
val: D:\A_Document\IPBD\ai\firedetection1\fire_data\valid\images
test(已注释掉):定义测试集图片路径,当前被注释掉,表明在训练阶段不会使用测试集。如果需要在训练后对测试集评估,可以取消注释。train:训练集图片路径,D:\A_Document\IPBD\ai\firedetection1\fire_data\train\images指向训练数据图片文件夹。val:验证集图片路径,D:\A_Document\IPBD\ai\firedetection1\fire_data\valid\images指向验证数据图片文件夹。
总结
此配置文件定义了 YOLO 模型的类别名称、类别数量、训练和验证数据路径以及数据集元数据信息。模型会基于 train 和 val 路径进行训练和验证,类别信息将用于检测任务中的目标分类。


















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









