






本文学习自华南理工大学龙胆也大佬,融入自己的思考和理解总结得到!
MPC三要素:
1、模型
2、预测
3、滚动优化
4、误差补偿
该模型与其它主流算法的对比:

总结:MPC适合大部分没有精确模型,或者阶次很高、非线性很强、约束很多的模型。
注意
MPC基于的模型不止一种。有传递函数,状态空间方程,也有数值模型,例如脉冲响应和阶跃响应。
本文主要讲阶跃响应序列。
正文
MPC里面滚动优化的核心是二次规划
二次规划的目标函数为二次多项式:
二次多项式的画法要不就是开口向上或者开口向下。
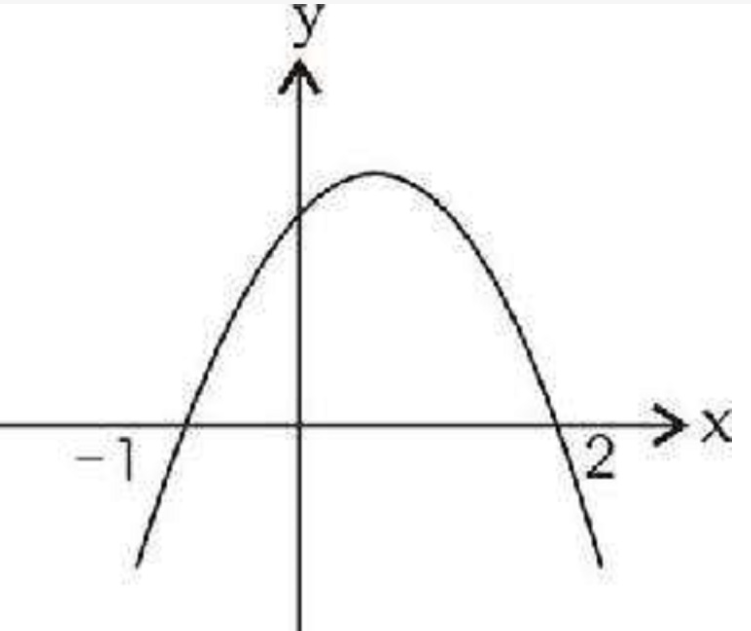
拐弯点即极值点,就是二次规划目标函数的最优解。
为了找最优解,需要求导数为零的时候。
P是预测步长。假如K是当前时刻,可以往后面去预测 y(K+1) , y(K+2) ..... y(K+P),P可以从1开始到无穷大。
而M是控制步长,我们只能控制当前时刻的输入,因为现在永远早于预测,否则就不叫预测了。
即Δu(K),Δu(K + 1)....... Δu(K + M - 1)
如何理解MPC模型?
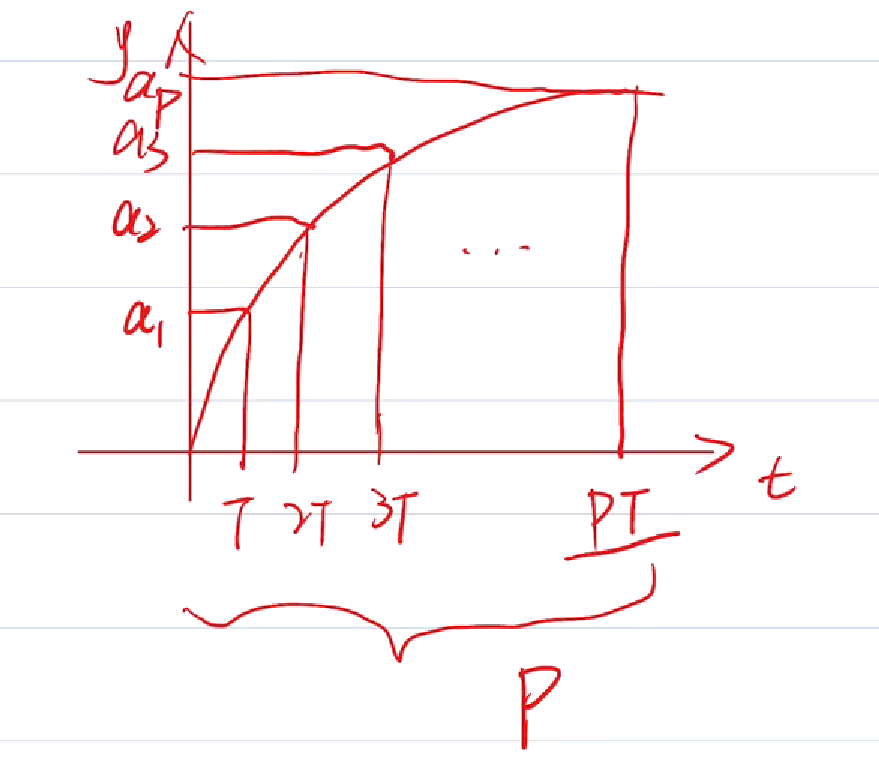
P个时间周期的数据,直至PT时刻。
然后每个时刻都采集输出,y(a1),y(aP)。
根据线性系统的叠加原理:
ps:K代表某时刻。
我们把上面这个公式写成增量式:
可能会疑问,为什么最后是,因为我们能控制的只有当下,也就是M个步长可以控制,而不是P,因为P = M + 1
如何理解MPC的预测?
因为我们永远只能基于当下和之前来预测未来
![]()
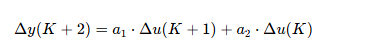
预测第三个状态时,我们要基于第一次和第二次的经验。
直到...
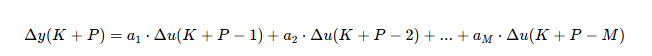
最后我们用求和公式:
总结一下:
新的预测输出 = Δ输出 + 原有预测输出
个人理解,主要是为了对比预测输出,一个是准确的预测输出,一个是根据以前的预测输出得到的预测输出。
写成
如何理解MPC的滚动优化?
一、目标函数
二、目标函数的求解
可以用matlab
也可以求导为0(基于这个二次多项式),得到最优解
但是这个是矩阵。我们选择矩阵中第一个数据为当前时刻的输入增量即可
滚动优化首先我们要知道它的期望轨迹。
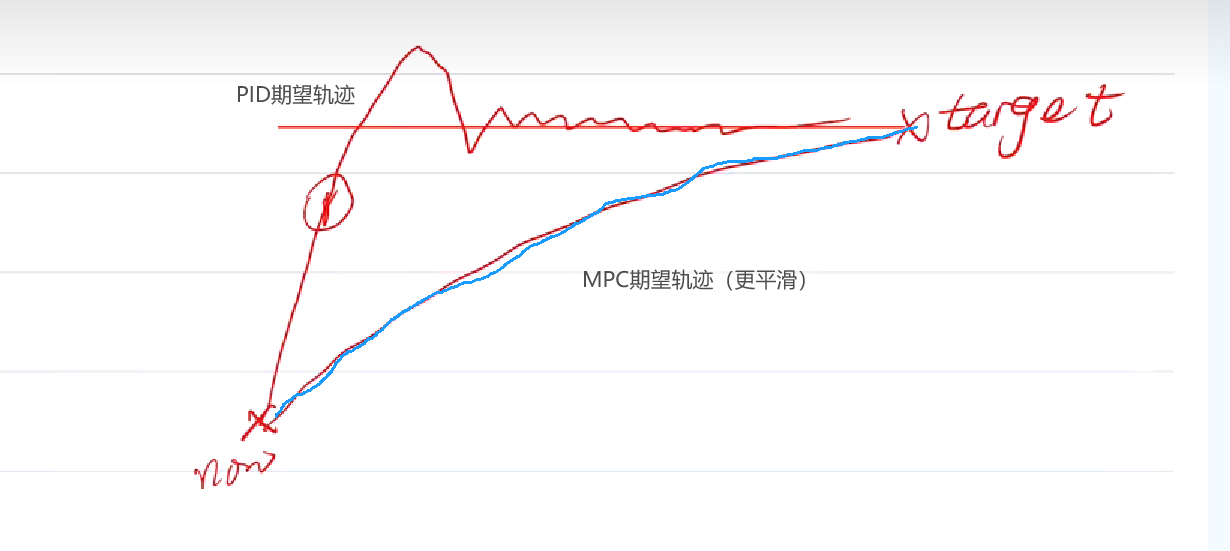
可以用一阶滤波去模拟期望轨迹,即:
ps:是目标值,
是当前值
约束条件 0< <1
越小,则期望轨迹越陡;
越大,则期望轨迹越缓慢
滚动优化第二步我们要如何设计目标函数J
目标函数设计原则
1、目标一:离目标越近越好
我们用一个求和函数,求P次,当前时刻的预测值与当前时刻期望的预测值偏离多远,然后用平方是为了把正负给取消掉。
所以这个公式意味着我希望系统的预测与期望的轨迹接近。
2、目标二:能量越小越好
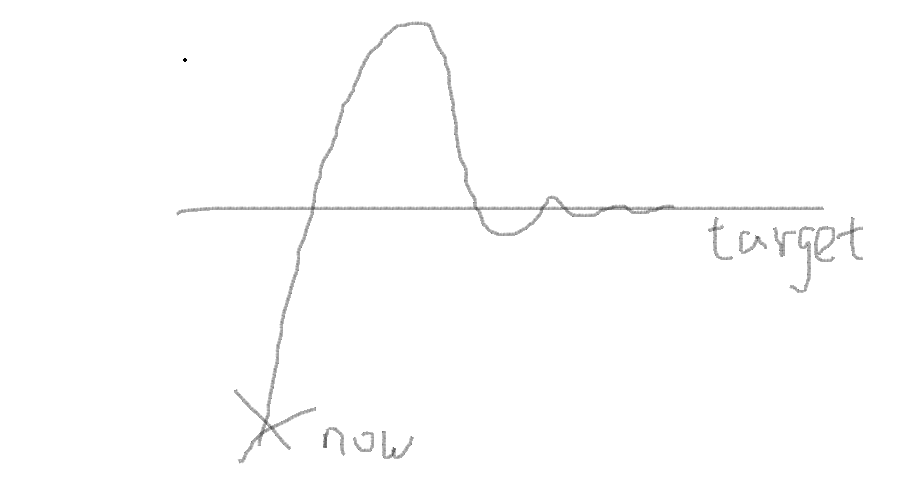
比如这个图,我肯定不希望系统绕个大弯去接近target。而是应该就近原则快速到达目标位置。
这里求和函数是M次,能量就是跟控制量有关,这里是能量的变化大小。那么平方就是不管是正负它也是在消耗能量。
最后,我们把完整的目标函数写出来。

根据你的需求,更看重目标一还是目标二,你可以自己去调整它们的相对大小。
最好还是q + r = 1
比如我q为0.1,r为0.9。说明我希望能量小更重要。
如果q为0.9,r为0.1。说明我希望它靠近目标更快一点。
我们再把它写成矩阵的形式
![]()
得到这个公式,解得ΔU。(这个公式跟代码有很重要的关系,一定要搞懂!)
![]()
ΔU是一个Mx1的矩阵,我们控制增量取当前时刻的加到系统的输入量里面就可以了
MPC反馈矫正,补偿误差
K作为当前时刻,要预测P个,从下一时刻K+1开始:
在K+1时刻,![]() 这个是实际值的输出
这个是实际值的输出
所以,误差 = 下一时刻实际值 - 当前时刻预测值
很容易理解,一个是从K时刻预测K+1的输出,一个是真真切切到达K+1时刻通过传感器等得到的输出。
那么有误差我们肯定要做补偿。
补偿值 = 预测输出值 + 误差值
ps:h作为补偿系数设为0.5
为什么补偿是,就是因为现在是K时刻在做预测,我们要预测K+1,K+2 ... K+P,相当于一次性预测完。
然后K+1时刻时,我们预测K+2 ... K+P+1,那么到时补偿就变为
K时刻:
把他写成矩阵的形式
![]()
那K+1时刻,预测值变为:
,S是移位矩阵

















 5674
5674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









