







深度学习阅读笔记(1) chapter 6
Learning a Conditional Probability Model
我们可以定义一个损失函数对应一个条件log似然函数,也就是负log似然函数损失函数为:
LNLL(fθ(x),y)=−logP(y=y|x=x;θ)
该条件对应于最小化KL离散变换,在模型
P(y|x)
和数据产生分布Q。
minimizing this negative log-likelihood is therefore equivalent to minimizing the squared error loss. Once we understand this principle, we can readily generalize it to other distributions, as appropriate.
Softmax
当
y
为离散且为有限整数值域时,伯努利分布拓展为multinoulli分布,softmax 函数
另外可以得到
如果预测正确,这是梯度接近0。
如果预测失败, pj≈1 ,这是会有较强的push降低 aj 。
如此以此类推。
对于平方误差损失
损失的梯度相对于输入向量为
所以如果模型对正确的类别给出很低的概率预测,i.e. py=pj≈1 ,这时给正确类别的分没有被优化器拉高。所以使用者正喜欢使用负log似然函数with softmax非线性,而不是应用平方损失。
softmax的另一个有用的性质为他的输出对加一个常量具有不变形。
这个性质可以用来实现数值稳定不变性。这使得我们计算softmax的时候只存在于很小的数值误差。
softmax输出的和总为1。
当一个战胜其他时,winner-take-all.
对于任意的参数概率分布 p(y|ω) ,可以构造一个条件分布 p(y|x) 通过构造 ω 为一个参数函数of x ,并学习函数: p(y|ω=fθ(x))
另一个神经网络的输出分布为混合模型
网络包含三个输出 p(c=i|x) , μi(x) 以及 Σi(x)
Multiple Output Variables
最简单的办法是假设 yi 之间是相互独立的。i.e.
(yi,x) 可以联系不同的学习任务。另外可以使用概率图模型对联合分布建模。
Cost Functions for Neural Networks
除了负log似然函数可以增加一些正则项。
Optimization step
NN的优化很困难以至于优化过程和建模过程交织在一起。也就是说我们经常设计优化过程比较简单的模型。
BP算法
The basic idea of the back-propagation algorithm is that the partial derivative of the cost J with respect to parameters
θ can be decomposed recursively by taking into consideration the composition of functions that relate θ to J , via intermediate quantities that mediate that influence, e.g., the activations of hidden units in a deep neural network.
缺点
- 反向传播算法很难调试得到正确结果,尤其是当实现程序存在很多难于发现的bug时。举例来说,索引的缺位错误(off-by-one error)会导致只有部分层的权重得到训练,再比如忘记计算偏置项。这些错误会使你得到一个看似十分合理的结果。
L_BFGS
L-BFGS算法我们以后会有论述(另一个例子是共轭梯度算法)。你将在编程练习里使用这些算法中的一个。使用这些高级优化算法时,你需要提供关键的函数:即对于任一个
Newton算法在计算时需要用到Hessian矩阵
H
, 计算Hessian矩阵非常费时, 所以研究者提出了很多使用方法来近似Hessian矩阵, 这些方法都称作准牛顿算法, BFGS就是其中的一种, 以其发明者Broyden, Fletcher, Goldfarb和Shanno命名.
BFGS算法使用以下方法来近似Hessian矩阵, Bk≈Hk
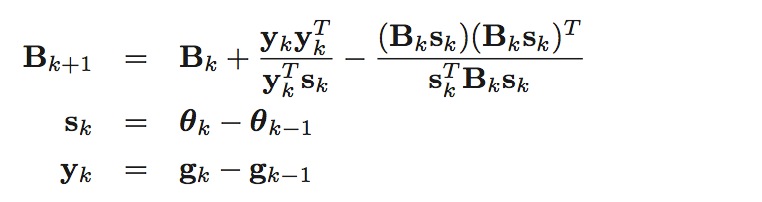
初始时可以取 B0=I
因为Hessian矩阵的大小为
O(D2)
, 其中D为参数的个数, 所以有时Hessian矩阵会比较大, 可以使用L-BFGS(Limited-memory BFGS)算法来进行优化.
detail















 4217
4217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









