






FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
重点回顾下这篇论文中筛选重要特征的经典做法SeNet。
提出背景
之前的一些工作聚焦在特征交叉上面,像Hadamard product、Inner product,对特征重要性关注较少。
其实SeNet的做法就是对特征做attention操作,动态找出重要的特征,可以说是判别特征重要性的神器。
实际的推荐系统,有大量的特征Embedding因为样本数据极度稀疏,没法学习的很好比如大量低活用户的ID特征、大量长尾的物料ID特征、长尾的一些tag特征等,他们出现的次数很少,想要学习出一个靠谱的Embedding几乎不可能。如果我们一股脑把所有特征都作为输入塞进炼丹炉,那必然会引入噪音导致推荐效果不佳。在炼丹之前,如果能对炼丹材料各个特征Embedding进行挑选,对特征Embedding做重要性打分,然后根据重要程度来加大重要的特征的权重输入,同时抑制不重要特征的输入,效果必然会有所提升。
以DSSM双塔为例,SeNet的结构如下:
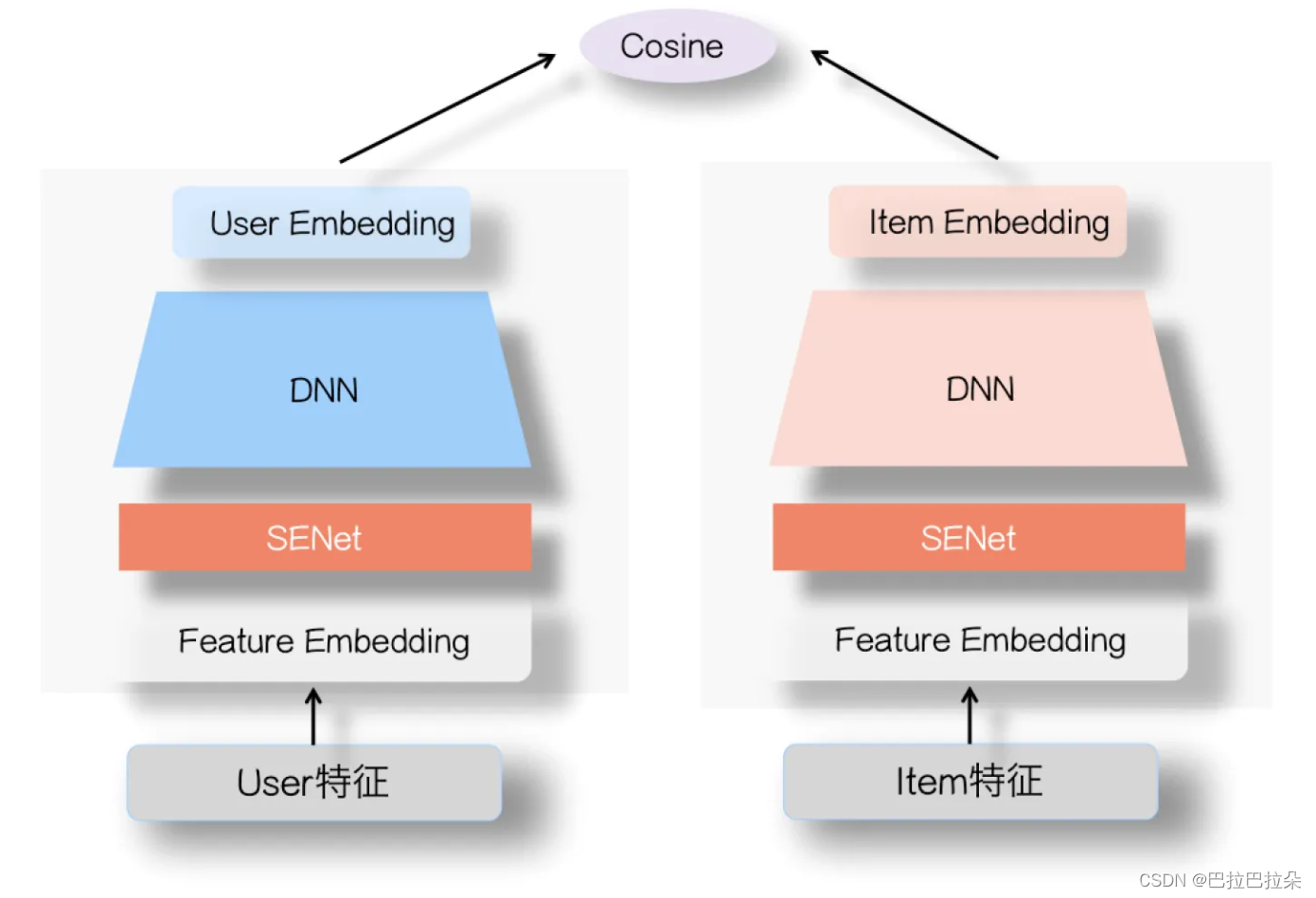
详细做法
整体结构如下
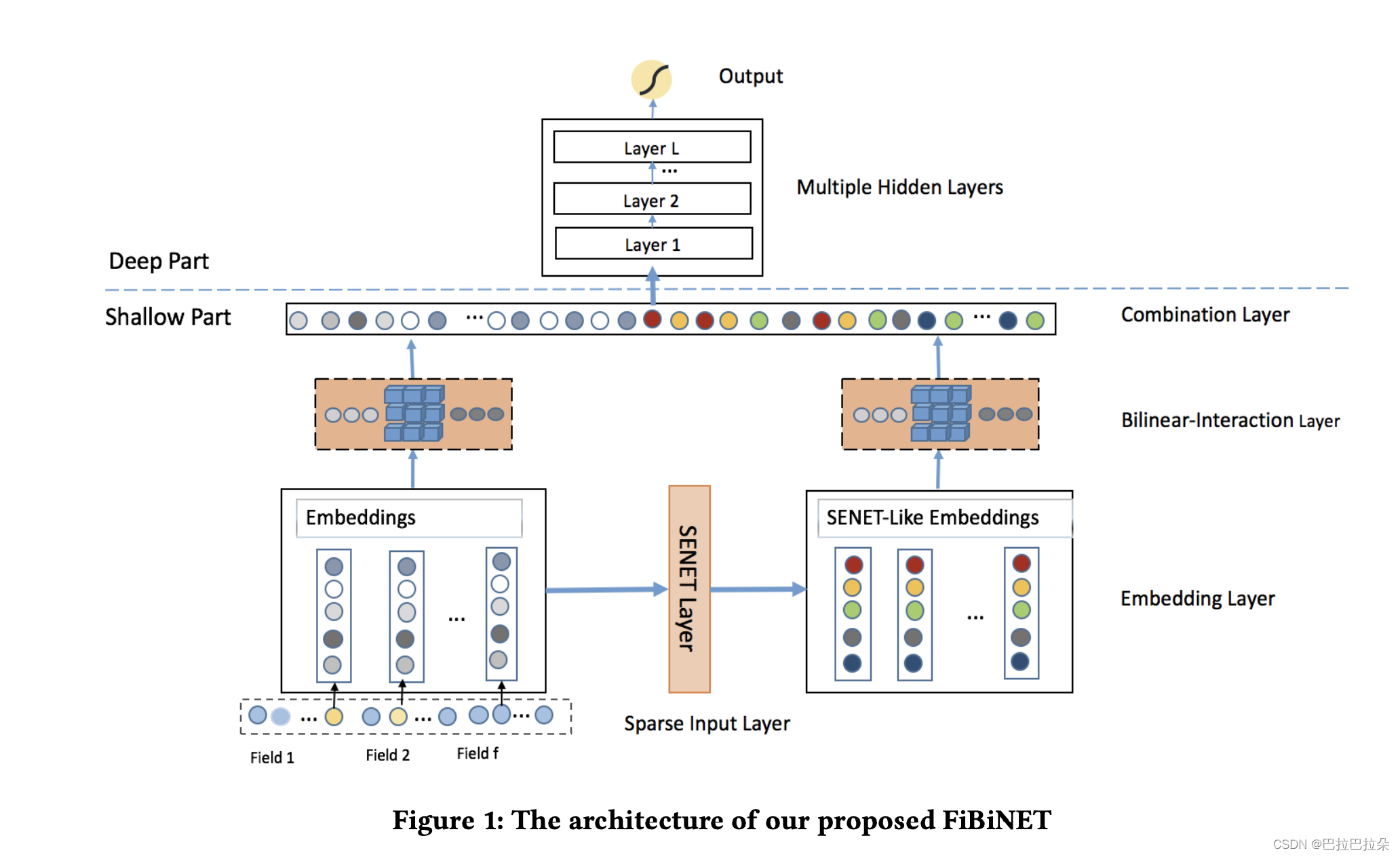
其中的SENet结构如下
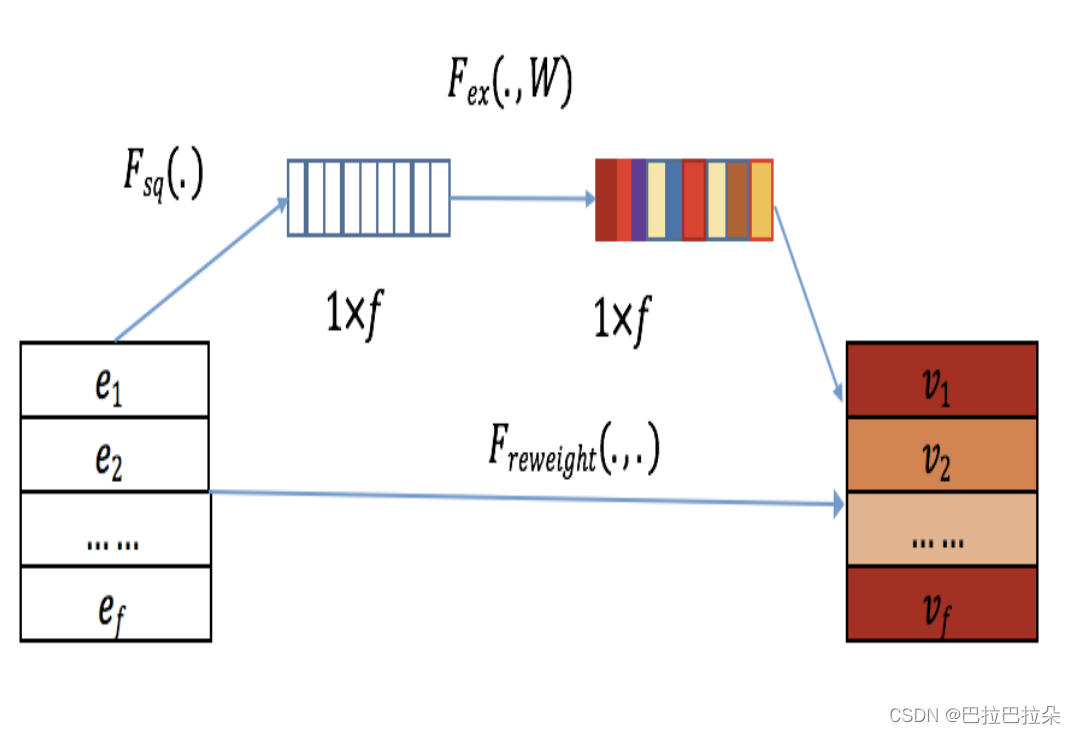
分为三步,整体是用两个全连接层操作(不过实际运用可以只用一个)
Squeeze
用户的
f
f
f个特征对应的Embedding集合
E
=
(
e
1
,
e
2
,
.
.
.
,
e
f
)
T
∈
R
f
×
d
\mathbf E = (\mathbf e_1, \mathbf e_2, ..., \mathbf e_f)^T \in R^{f \times d}
E=(e1,e2,...,ef)T∈Rf×d,讲每个特征Embedding取平均,相当于取到代表每个特征Embedding的精华
z
i
=
F
s
q
u
e
e
z
e
(
e
i
)
=
∑
j
=
1
k
e
i
j
z_i = F_{squeeze}(\mathbf e_i) = \sum_{j=1}^k e_{ij}
zi=Fsqueeze(ei)=j=1∑keij
得到向量
z
=
[
z
1
,
z
2
,
.
.
.
.
,
z
f
]
\mathbf z = [z_1, z_2, ...., z_f]
z=[z1,z2,....,zf]
Excitation
对每个特征的精华值进行非线性变换,得到每个特征的重要性得分
a
=
F
e
x
c
i
t
a
t
i
o
n
(
z
)
=
σ
2
(
W
2
σ
1
(
W
1
z
)
)
\mathbf a = F_{excitation}(\mathbf z) = \sigma_2(\mathbf W_2 \sigma_1(\mathbf W_1 \mathbf z))
a=Fexcitation(z)=σ2(W2σ1(W1z))
Re-Weight
根据重要性对特征Embedding做attention操作
V
=
F
r
e
w
e
i
g
h
t
(
a
,
z
)
=
[
a
1
e
1
,
a
2
e
2
,
.
.
.
,
a
f
e
f
]
\mathbf V = F_{reweight}(\mathbf a, \mathbf z) = [a_1 \mathbf e_1, a_2 \mathbf e_2, ..., a_f \mathbf e_f]
V=Freweight(a,z)=[a1e1,a2e2,...,afef]
简单有效
实现
# input [batch_size, feature_num * emb_size]
def se_block(input, feature_num, emb_size, name):
hidden_size == (feature_num * emb_size)
w = tf.get_variable(name='w_se_block_%s' % name, shape=[hidden_size, feature_num], dtype=tf.float32)
b = tf.get_variable(name='b_se_block_%s' % name, shape=[1, feature_num], dtype=tf.float32)
cur_layer = tf.matmul(input, w) + b # [batch_size, feature_num]
cur_layer = tf.layers.batch_normalization(cur_layer, axis=1)
weight = tf.nn.sigmoid(cur_layer) # [batch_size , feature_num]
input = tf.reshape(input, [-1, feature_num, emb_size])
input = input * tf.expand_dims(weight, axis=2) # [batch_size , column_size , emb_size]
output = tf.layers.flatten(input) # [batch_size , hidden_size]
return output
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
提出背景
新用户冷启存在的问题:
- 用户行为稀疏,训练数据较少
- 新用户耐心差,对推荐结果敏感,推荐不精准就容易流失,试错成本很低
已有对新用户冷启的方法
- 元学习的方法:产生一个比较好的模型初始化参数,基于这个初始化参数进行微调
- 通过一些其他存在的特征产生新用户的ID Embedding
这些方法的问题是个性化不足:即使把用于区分不同用户群体的个性化特征加入进来,这些特征还是会淹没在严重不平衡的样本中,无法起效。
新用户与正常用户在vv、时长、点赞、完播等各个维度差异非常明显,如果将正常用户的各维度值设为原点,可以看到新用户的巨大差异。
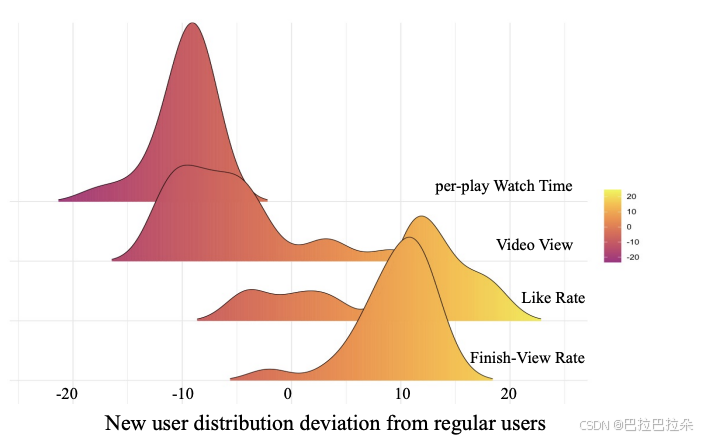
怎么验证加一个“是否是新用户”的特征的效果呢,对于同样一个训练好的模型,给一批用户的输入,统计靠近输出的激活层的各个神经元的输出均值,然后mask掉是否是新用户这个特征,对比mask掉用户的country属性特征,再统计两者靠近输出的激活层后的各个神经元的输出,和原来不mask的做diff,会发现对于严重不平衡的特征(是否是新用户)输出没差差异,对于相对平衡的特征差异非常明显。因为是否是新用户这个特征在样本不足5%,很容易淹没在模型中,对模型整体的参数贡献非常微弱。

POSO对每个用户群体学习个性化模型,从模型层面加强对不均衡的特征的学习。
详细方案
通过gate网络学习各个用户群体的偏好,同时gate网络的输入就是能区分用户群体的特征。
x
^
=
C
∑
i
N
[
g
(
x
p
c
)
]
i
f
(
i
)
(
x
)
\mathbf {\hat x} = C \sum_i^N[g(\mathbf x^{pc})]_if^{(i)}(\mathbf x)
x^=Ci∑N[g(xpc)]if(i)(x)
其中C是修正因子,gate求和没有做归一化的约束,期望存在缩放和偏移。 x ∈ R d i n \mathbf x \in R^{d^{in}} x∈Rdin, x ^ ∈ R d o u t \mathbf {\hat x} \in R^{d^{out}} x^∈Rdout
如果是最简单的线性模型 f ( x ) = W x f(\mathbf x) = \mathbf W \mathbf x f(x)=Wx,则变成
x ^ = C ∑ i N [ g ( x p c ) ] i W ( i ) x \mathbf {\hat x} = C \sum_i^N[g(\mathbf x^{pc})]_i \mathbf W^{(i)} \mathbf x x^=Ci∑N[g(xpc)]iW(i)x
x
^
\mathbf {\hat x}
x^的第
p
p
p维计算如下
x
^
p
=
C
∑
i
N
∑
q
=
1
d
i
n
[
g
(
x
p
c
)
]
i
W
p
,
q
(
i
)
x
q
\mathbf {\hat x}_p = C \sum_i^N \sum_{q=1}^{d^{in}} [g(\mathbf x^{pc})]_i \mathbf W^{(i)}_{p,q} \mathbf x_q
x^p=Ci∑Nq=1∑din[g(xpc)]iWp,q(i)xq
这里简化处理下,让
N
=
d
o
u
t
,
W
p
,
q
(
i
)
=
W
p
,
q
∀
p
,
q
w
h
e
n
i
=
p
,
a
n
d
W
p
,
q
≡
0
f
o
r
a
n
y
i
≠
p
N=d^{out},\mathbf W^{(i)}_{p,q}=\mathbf W_{p,q} \forall p,q\ when i=p,and \ \mathbf W_{p,q} \equiv0\ for\ any \ i \neq p
N=dout,Wp,q(i)=Wp,q∀p,q wheni=p,and Wp,q≡0 for any i=p
变成了
x
^
p
=
C
×
[
g
(
x
p
c
)
]
p
∑
q
=
1
d
i
n
W
p
,
q
x
q
\mathbf {\hat x}_p = C \times [g(\mathbf x^{pc})]_p \sum_{q=1}^{d^{in}} \mathbf W_{p,q} \mathbf x_q
x^p=C×[g(xpc)]pq=1∑dinWp,qxq
等价就是
x
^
=
C
×
[
g
(
x
p
c
)
]
⊙
W
x
\mathbf {\hat x} = C \times [g(\mathbf x^{pc})] \odot \mathbf W \mathbf x
x^=C×[g(xpc)]⊙Wx
那就是gate网络的结果和线性输出的结果直接元素级点乘
对于MLP来讲,也是如此
x
^
=
C
×
[
g
(
x
p
c
)
]
⊙
σ
(
W
x
)
\mathbf {\hat x} = C \times [g(\mathbf x^{pc})] \odot \sigma( \mathbf W \mathbf x)
x^=C×[g(xpc)]⊙σ(Wx)
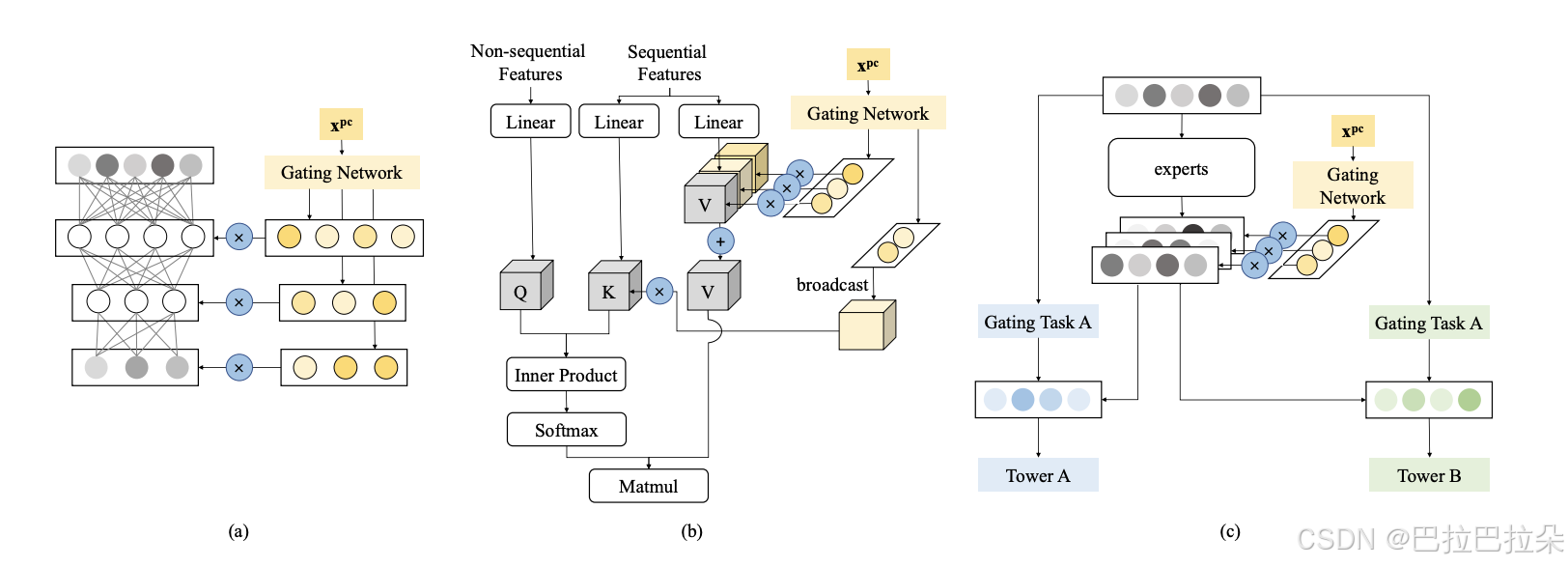
对于MMoE来讲
x
^
=
C
∑
i
N
[
g
(
x
p
c
)
]
i
(
∑
j
N
e
x
p
e
r
t
[
g
t
a
s
k
(
x
)
]
j
e
(
j
)
(
x
)
)
\mathbf {\hat x} = C \sum_i^N [g(\mathbf x^{pc})]_i ( \sum_j^{N_{expert}} [g^{task}(\mathbf x)]_j e^{(j)} (\mathbf x) )
x^=Ci∑N[g(xpc)]i(j∑Nexpert[gtask(x)]je(j)(x))
x ^ = C ∑ i N [ g ( x p c ) ] i [ g t a s k ( x ) ] i e ( i ) ( x ) \mathbf {\hat x} = C \sum_i^N [g(\mathbf x^{pc})]_i [g^{task}(\mathbf x)]_i e^{(i)} (\mathbf x) x^=Ci∑N[g(xpc)]i[gtask(x)]ie(i)(x)
POSO接入MLP、Multi-Head Attention、MMoE的结构如下图

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









