






历史情况
传统的线性模型(如 ARIMA、VAR 模型)在数据稀疏期已发挥重要作用,但面对当今非线性、非平稳且复杂交织的海量数据,传统方法的适应性和预测精度面临挑战。自 21 世纪初以来,以机器学习和深度学习为代表的数据驱动方法迅速崛起,LSTM、GRU、Transformer 等新型神经网络结构不断涌现,并在处理长序列依赖、捕捉非线性关系方面表现出明显优势。如北京航空航天大学的 Zhou等人在经典的 Transformer 编码器-解码器结构的基础上提出了 Informer 模型来弥补Transformer 类深度学习模型在应用于长序列时间预测问题时的不足1,在此之前,解决预测一个长序列的任务往往采用多次预测的方法,而 Informer 模型可以一次给出想要的长序列结果。Informer 提出了稀疏自注意力机制、自注意力蒸馏操作和生成式解码器。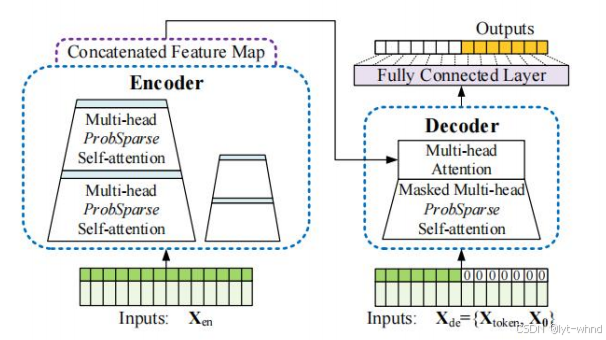
WuH等人虽然稀疏注意力机制解决了二次复杂度问题,但是限制了信息利用率2。而且在长时预测中由于复杂的时间模式,自注意力机制难以捕获可靠依赖,2021年Wu等人提出了用长期预测的自相关分解Transformer模型Autoformer。虽然稀疏注意力机制解决了二次复杂度问题,但是限制了信息利用率。而且在长时预测中由于复杂的时间模式,自注意力机制难以捕获可靠依赖。Autoformer引入了一种进阶的时间序列分解机制,将时间序列分解为趋势和季节性成分,以应对复杂的时间模式。这一分解架构嵌入在模型的内部操作中,使得模型能够逐步从预测过程中提取和聚合长期趋势信息,并设计了自相关机制,基于时间序列的周期性来发现子序列的依赖关系,并进行信息聚合。这种机制相比于传统的点对点自注意力机制,更加高效,且能更好地利用序列中的周期性信息。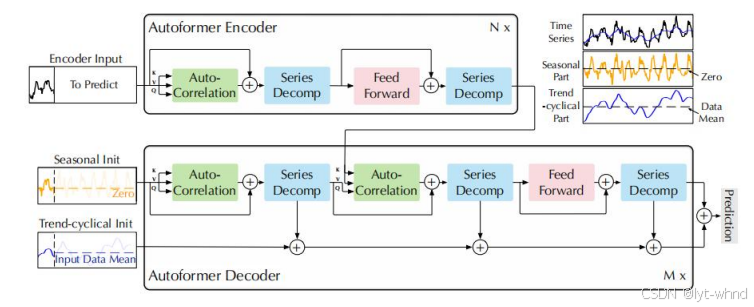
面临的问题
传统的机器学习或者深度学习在研究时序预测总是将一段序列当作是平稳的状态,即未来的数据分布不会发生变化但是实际的时序序列通常会随着时间而发生漂移,如概念漂移,概念漂移是(Concept Drift)是指在机器学习中,数据分布或数据生成过程随时间发生变化的现象。当发生概念漂移时,原先训练好的模型可能无法适应新的数据分布,导致预测性能下降。概念漂移对机器学习算法的性能和稳定性产生重要影响。如果忽视概念漂移,模型将无法准确预测新的数据实例。
前沿技术发展
在上面的情况下,我们想从时间序列中学到序列中不变的特征,传统的Transformer,如Informer,autoformer,FEDformer3等都是将时间戳作为一个token进行预测。这种建模并不能很好的捕捉序列的相关性,因为时间不对等事件会导致会产生会多噪声从而影响预测,并且也难以捕捉到序列间的潜在特征。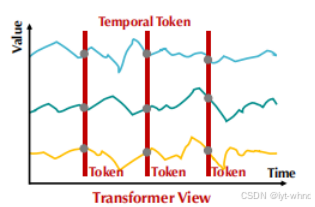
现在的Transformer考虑到这个问题,采用了一种新的token建模方式,将每个变量作为token的单位,如Nie等人提出了PatchTST,将时间按照补丁进行建模token4,Liu等人提出了反转Transformer的方式进行token的建模[5],这种通道独立的方式可以很有效的减少通道间的影响。
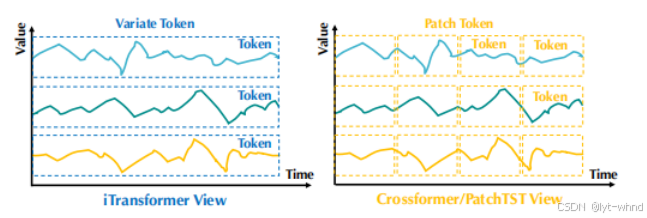
这种方式不仅可以很好解决通道之间混合之后产生的时间不对等事件产生的噪声,并且提高了模型的泛化能力,让模型可以学习更好的序列表示,为建立大模型更提升了一步。
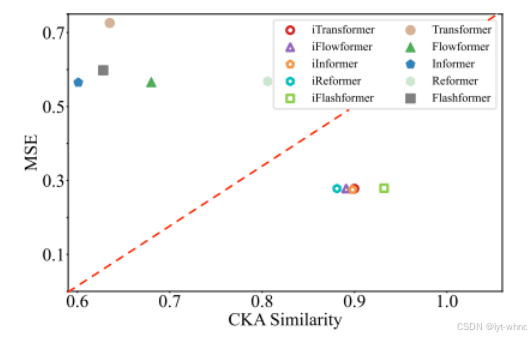
但是上述方式没有考虑因果关系,通道独立反而会学习不到通道之间的相关性,虽然对每个变量的序列有更好的建模,但是站在人思考的角度,比如要进行光伏发电预测的时候,我们需要考虑温度、湿度、太阳辐射度等因素综合考虑,如物理方法。Wang等人提出了一种外生变量影响内生变量的形式,用协变量辅助预测[6],更加考虑了因果关系。
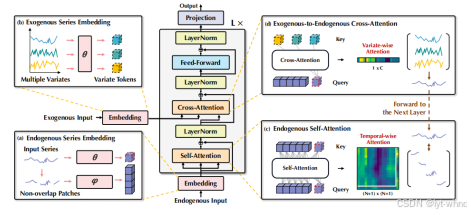
该模型更好的融入了其他序列变量的影响,并提高了整体的预测性能。
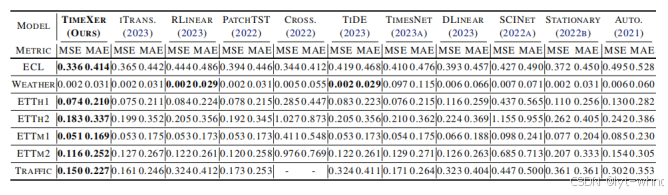
(上述是公共时序数据集的结果,所有的结果都是以历史窗口为96的预测的平均结果,-代表内存不足)
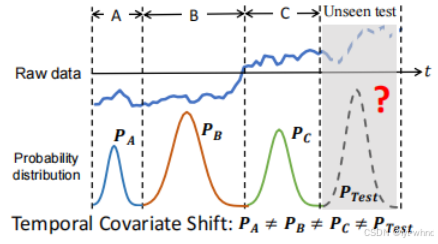
尽管上述方式通过滑动窗口的机制,并且通过归一化的方式能够对轻微漂移有一定的作用,但是这并不能很好的解决漂移问题。Du等人提出了一种自适应RNN算法专门来考虑漂移的问题,该方法基于领域泛化[8],如下图所示的数据情况。数据分布P(x)在不同的阶段A,B,C均不同。特别地,对于未知的测试数据而言,其分布与训练数据的分布也不相同。条件概率分布P(y/x)通常被认为是不变的。例如,在股票预测问题中,市场的波动导致边缘概率分布P(x)发生改变;而经济规律P(y/x)通常是不会变的。
为解决时序分布漂移的问题,AdaRNN方法设计了如下图所示的两个重要的步骤:
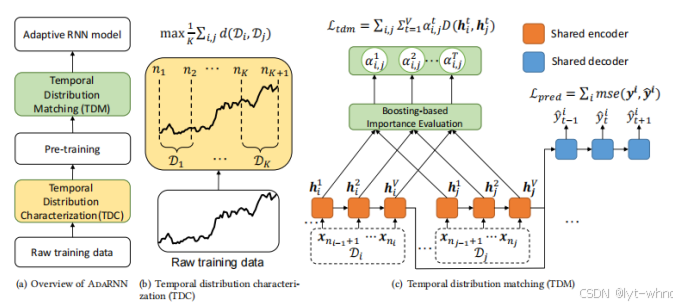
(1)时序相似性量化(Temporal distribution characterization,TDC)将时间序列中连续的数据分布情形进行量化以将其分为K段分布最不相似的序列。其假设是如果模型能减小K段最不相似的序列的分布差异,则模型将具有最强的泛化能力。因此对于未知的数据预测效果会更好。(2)时序分布匹配(Temporal distribution matching,TDM)为上述K段时间序列构建迁移学习模型以学习一个具有时序不变性的模型。AdaRNN方法并提出了基于Boosting的方法来学习模型参数。这个方法根据最大化分布差异的方法来自适应的更新参数,让模型更加适应漂移,但是该方法没有特被充分考虑时间的因素,现实世界中大部分的数据漂移都是随时间渐进漂移[7],Bai等人提出了一个以时间为更新漂移的DARIN方法,该方法将漂移与时间因素完全结合在一起,强调时间的重要性[9]。
该模型提出了一个贝叶斯通过贝叶斯框架联合建模数据和模型动态的关系,并通过动态图模型来存储参数,并且随着时间来更新参数。通过时间来划分不同的区域,该时间是一个超参数,可以根据先验知识设定。
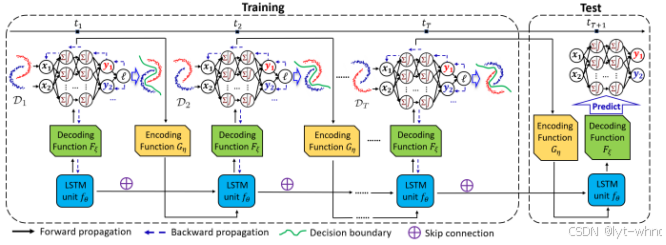
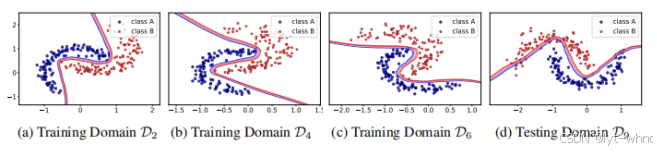
根据前面离散时间点的模型更新随时间变化的参数从而预测不同时间的参数,下面是该模型预测的关于时间的分类实验结果,数据集是2-moons数据集,可以看出根据不同的时间域能够很好的分类,很好的检测出漂移并且自适应的更新参数。
但是这个方法只考虑了离散的时间点,并没有考虑连续的情况,并且如果有某些时间的数据点缺失了并不能很好的预测出来。Cai等人提出一个连续的时间泛化域的情况,目标是处理连续时间和不规则时间点的数据分布[10]。该方法使用动力学方程进行建模,通过微分方程和优化策略,确保模型参数随时间连续演化。并且利用Koopman算子将复杂动态映射到低维线性空间,过损失函数确保预测模型在数据动态、模型动态和Koopman空间之间的协调一致。
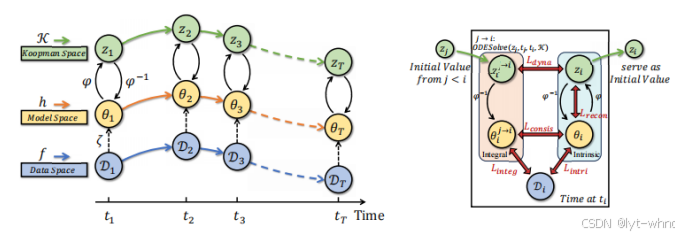
结果表明在连续有缺失值的情况下该方法仍然能够得到一个很好的结果。
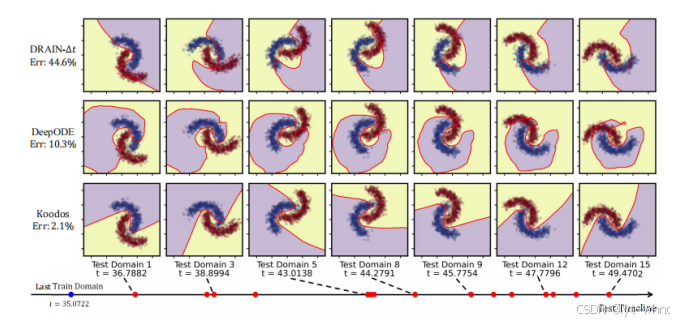
相反如果时间点是不连续的,上一个方法就显然不能很好的处理这种情况。该方法也是第一个提出连续的时间域泛化问题,该领域尚没有多少人进行探索。
参考文献
(1)Zhou, Haoyi, et al. “Informer: Beyond efficient transformer for long sequence time-series forecasting.” Proceedings of the AAAI conference on artificial intelligence. Vol. 35. No. 12. 2021.
(2)Wu, Haixu, et al. “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting.” Advances in neural information processing systems 34 (2021): 22419-22430.
(3)Zhou, Tian, et al. “Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting.” International conference on machine learning. PMLR, 2022.
(4)Nie, Yuqi, et al. “A Time Series is Worth 64 Words: Long-term Forecasting with Transformers.” The Eleventh International Conference on Learning Representations.
(5)Liu, Yong, et al. “iTransformer: Inverted Transformers Are Effective for Time Series Forecasting.” The Twelfth International Conference on Learning Representations.
(6)Wang, Yuxuan, et al. “Timexer: Empowering transformers for time series forecasting with exogenous variables.” arXiv preprint arXiv:2402.19072 (2024).
(7)Li, Wendi, et al. “Ddg-da: Data distribution generation for predictable concept drift adaptation.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 36. No. 4. 2022.
(8)Du, Yuntao, et al. “Adarnn: Adaptive learning and forecasting of time series.” Proceedings of the 30th ACM international conference on information & knowledge management. 2021.
(9)Guangji Bai, Chen Ling, and Liang Zhao. Temporal domain generalization with drift-aware dynamic neural networks. In The Eleventh International Conference on Learning Representations, 2023.
(10)Cai, Zekun, et al. “Continuous Temporal Domain Generalization.” arXiv preprint arXiv:2405.16075 (2024).

















 4570
4570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









