







原文:Mastering Numerical Computing With NumPy
译者:飞龙
一、使用 NumPy 数组
科学计算是一个多学科领域,其应用跨越数值分析,计算金融和生物信息学等学科。
让我们考虑一下金融市场的情况。 当您考虑金融市场时,会有巨大的相互联系的互动网络。 政府,银行,投资基金,保险公司,养老金,个人投资者和其他人都参与了这种金融工具的交换。 您不能简单地模拟市场参与者之间的所有互动,因为参与金融交易的每个人都有不同的动机和不同的风险/回报目标。 还有其他因素会影响金融资产的价格。 即使为一个资产价格建模也需要您做大量工作,并且不能保证成功。 用数学术语来说,这没有封闭形式的解决方案,这为利用科学计算提供了一个很好的案例,您可以在其中使用高级计算技术来解决此类问题。
通过编写计算机程序,您将有能力更好地了解正在使用的系统。 通常,您将要编写的计算机程序将是某种模拟,例如蒙特卡洛模拟。 通过使用诸如蒙特卡洛的模拟,您可以对期权合约的价格进行建模。 仅仅由于金融市场的复杂性,对金融资产进行定价是进行模拟的良好材料。 在进行计算时,所有这些数学计算都需要一个功能强大,可扩展且方便的数据结构(大多数为矩阵形式)。 换句话说,您需要比列表更紧凑的结构,以简化您的任务。 NumPy 是高效向量/矩阵运算的理想选择,其广泛的数学运算库使数值计算变得简单而高效。
在本章中,我们将涵盖以下主题:
- NumPy 的重要性
- 关于向量和矩阵的理论和实践信息
- NumPy 数组操作及其在多维数组中的用法
问题是,我们应该从哪里开始练习编码技能? 在本书中,由于 Python 在科学界的广泛应用,您将在使用它,并且您将主要使用名为 NumPy 的特定库(它代表数字 Python)。
技术要求
在本书中,我们将使用 Jupyter 笔记本。 我们将通过网络浏览器编辑和运行 Python 代码。 这是一个开源平台,您可以按照此链接中的说明进行安装。
本书将使用 Python 3.x,因此在打开新笔记本时,应选择 Python 3 内核。 另外,也可以使用 Anaconda(Python 版本 3.6)安装 Jupyter 笔记本。 您可以按照此链接中的说明进行安装。
为什么我们需要 NumPy?
Python 最近成为一种摇滚明星的编程语言,不仅因为它具有友好的语法和可读性,而且因为它可以用于多种用途。 各种库的 Python 生态系统使程序员相对容易进行各种计算。 堆栈溢出是程序员最受欢迎的网站之一。 用户可以通过标记与之相关的编程语言来提问。 下图通过计算这些标签显示了主要编程语言的增长,并绘制了多年来主流编程语言的流行程度。 通过 Stack Overflow 进行的研究可以通过其官方博客链接进行进一步分析:
主要编程语言的发展
NumPy 是 Python 中科学计算的最基本软件包,也是许多其他软件包的基础。 由于 Python 最初并不是为数字计算而设计的,因此在 90 年代后期开始出现这种需求时,Python 开始在需要更快的向量运算的工程师和程序员中流行。 从下图可以看到,许多流行的机器学习和计算包都使用了 NumPy 的某些功能,最重要的是它们在其方法中大量使用了 NumPy 数组,这使 NumPy 成为科学项目的基本库。
该图显示了一些使用 NumPy 功能的知名库:
NumPy 栈
对于数值计算,您主要处理向量和矩阵。 您可以通过使用一系列数学函数以不同的方式来操作它们。 NumPy 非常适合此类情况,因为它允许用户有效地完成其计算。 尽管 Python 列表很容易创建和操作,但它们不支持向量化操作。 Python 在列表中没有固定的类型元素,例如,for循环效率不高,因为在每次迭代中都需要检查数据类型。 但是,在 NumPy 数组中,数据类型是固定的,并且还支持向量化运算。 与 Python 列表相比,NumPy 在多维数组操作中不仅效率更高。 它还提供了许多数学方法,您可以在导入后立即应用它们。 NumPy 是用于科学 Python 数据科学堆栈的核心库。
SciPy 与 NumPy 有着密切的关系,因为它使用 NumPy 多维数组作为其线性代数,优化,插值,积分,FFT,信号,图像处理和其它的科学函数的基础数据结构。 SciPy 建立在 NumPy 数组框架之上,并凭借其先进的数学函数提升了科学编程能力。 因此,NumPy API 的某些部分已移至 SciPy。 在许多情况下,与 NumPy 的这种关系使 SciPy 更便于进行高级科学计算。
综上所述,我们可以总结出 NumPy 的优势如下:
- 它是开源的,零成本
- 这是一种具有用户友好语法的高级编程语言
- 比 Python 列表更有效
- 它具有更高级的内置函数,并与其他库很好地集成在一起
谁使用 NumPy?
在学术界和商业界,您都会听到人们谈论他们在工作中使用的工具和技术。 根据环境和条件,您可能需要使用特定技术。 例如,如果您的公司已经投资了 SAS,则需要在适合您问题的 SAS 开发环境中进行项目。
但是,NumPy 的优点之一是它是开源的,在您的项目中使用它无需花费任何成本。 如果您已经使用 Python 编写过代码,那么它非常容易学习。 如果您关心性能,则可以轻松嵌入 C 或 Fortran 代码。 此外,它将为您介绍其他完整的库集,例如 SciPy 和 Scikit-learn,您可以使用它们来解决几乎所有问题。
由于数据挖掘和预测分析在最近变得非常重要,因此数据科学家和数据分析师等角色在 21 世纪最热门的工作中被提及,例如《福布斯》,彭博社, 等等。 需要处理数据并进行分析,建模或预测的人员应该熟悉 NumPy 的用法及其功能,因为它将帮助您快速创建原型并测试您的想法。 如果您是专业工作人员,那么您的公司很可能希望使用数据分析方法,以使其领先于竞争对手。 如果他们能够更好地理解他们拥有的数据,那么他们就可以更好地理解业务,这将使他们做出更好的决策。 NumPy 在这里起着至关重要的作用,因为它能够执行各种操作,并使您的项目及时有效。
向量和矩阵简介
矩阵是一组数字或元素,它们以矩形数组的形式排列。 矩阵的行和列通常按字母索引。 对于n x m矩阵,n表示行数,m表示列数。 如果我们有一个假设的n×m矩阵,则其结构如下:
如果n = m,则称为称为方阵:
向量实际上是具有多于一个元素的一行或一列的矩阵。 也可以将其定义为1 x m或n x 1矩阵。 您可以将向量解释为m维空间中的箭头或方向。 通常,大写字母表示矩阵,例如X;小写字母带有下标,例如x[11],表示矩阵X的元素。
此外,还有一些重要的特殊矩阵:零矩阵(空矩阵)和恒等矩阵。0表示零矩阵,它是所有0的矩阵(MacDufee 1943 p.27)。 在0矩阵中,添加下标是可选的:
由I表示的单位矩阵及其对角线元素为1,其他元素为0:
将矩阵X与单位矩阵相乘时,结果将等于X:
单位矩阵对于计算矩阵的逆非常有用。 当您将任何给定矩阵与其逆矩阵相乘时,结果将是一个单位矩阵:
让我们简要地看一下 NumPy 数组上的矩阵代数。 矩阵的加减法运算与具有普通单数的数学方程式相似。 举个例子:
标量乘法也非常简单。 例如,如果将矩阵X乘以4,则唯一要做的就是将每个元素乘以4值,如下所示:
开始时矩阵处理看似复杂的部分是矩阵乘法。
假设您有两个矩阵,分别为X和Y,其中X是 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/42a4db1c-64a7-46dd-8263-54d675e077f2.png 矩阵,Y是 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/172c79a3-53ed-4890-86ae-be57c1cea263.png 矩阵:
这两个矩阵的乘积将如下所示:
因此,乘积矩阵的每个元素的计算方式如下:
如果您不了解该符号,请不要担心。 以下示例将使事情变得更清楚。 您有矩阵X和Y,目标是获得这些矩阵的矩阵乘积:
基本思想是X的i行与Y的j列的乘积将成为结果矩阵的第i, j个元素。 乘法将从X的第一行和Y的第一列开始,因此它们的乘积将为Z[1, 1]:
您可以使用以下四行代码轻松地交叉检查结果:
In [1]: import numpy as np
x = np.array([[1,0,4],[3,3,1]])
y = np.array([[2,5],[1,1],[3,2]])
x.dot(y)
Out[1]: array([[14, 13],[12, 20]])
先前的代码块只是演示如何使用 NumPy 计算两个矩阵的点积。 在后面的章节中,我们将更深入地研究矩阵运算和线性代数。
NumPy 数组对象的基础
如上一节所述,使 NumPy 与众不同的是使用称为ndarrays的多维数组。 所有ndarray项目都是同类的,并且在内存中使用相同的大小。 让我们首先导入 NumPy,然后通过创建数组来分析 NumPy 数组对象的结构。 您可以通过在控制台中键入以下语句来轻松导入该库。 您可以使用任何命名约定代替np,但是在本书中,将使用np作为标准约定。 让我们创建一个简单的数组,并说明 Python 在幕后所具有的属性作为所创建数组的元数据,即所谓的属性:
In [2]: import numpy as np
x = np.array([[1,2,3],[4,5,6]])
x
Out[2]: array([[1, 2, 3],[4, 5, 6]])
In [3]: print("We just create a ", type(x))
Out[3]: We just create a <class 'numpy.ndarray'>
In [4]: print("Our template has shape as" ,x.shape)
Out[4]: Our template has shape as (2, 3)
In [5]: print("Total size is",x.size)
Out[5]: Total size is 6
In [6]: print("The dimension of our array is " ,x.ndim)
Out[6]: The dimension of our array is 2
In [7]: print("Data type of elements are",x.dtype)
Out[7]: Data type of elements are int32
In [8]: print("It consumes",x.nbytes,"bytes")
Out[8]: It consumes 24 bytes
如您所见,我们对象的类型是 NumPy 数组。x.shape返回一个元组,该元组为您提供数组的维度作为输出,例如(n, m)。 您可以使用x.size获得数组中元素的总数。 在我们的示例中,我们总共有六个元素。 知道形状和大小等属性非常重要。 您了解的越多,您对计算的适应就越多。 如果您不知道数组的大小和大小,那么开始使用数组进行计算就不明智了。 在 NumPy 中,您可以使用x.ndim来检查数组的维数。 还有其他属性,例如dtype和nbytes,这些属性在检查内存使用情况并验证应该在数组中使用哪种数据类型时非常有用。 在我们的示例中,每个元素的数据类型为int32,总共消耗 24 个字节。 您还可以在创建数组时强制使用其中某些属性,例如dtype。 以前,数据类型是整数。 让我们将其切换为float,complex或uint(无符号整数)。 为了查看数据类型更改的作用,让我们分析一下字节消耗量,如下所示:
In [9]: x = np.array([[1,2,3],[4,5,6]], dtype = np.float)
print(x)
Out[9]: print(x.nbytes)
[[ 1\. 2\. 3.]
[ 4\. 5\. 6.]]
48
In [10]: x = np.array([[1,2,3],[4,5,6]], dtype = np.complex)
print(x)
print(x.nbytes)
Out[10]: [[ 1.+0.j 2.+0.j 3.+0.j]
[ 4.+0.j 5.+0.j 6.+0.j]]
96
In [11]: x = np.array([[1,2,3],[4,-5,6]], dtype = np.uint32)
print(x)
print(x.nbytes)
Out[11]: [[ 1 2 3]
[ 4 4294967291 6]]
24
如您所见,每种类型消耗不同数量的字节。 假设您有一个如下矩阵,并且您正在使用int64或int32作为数据类型:
In [12]: x = np.array([[1,2,3],[4,5,6]], dtype = np.int64)
print("int64 consumes",x.nbytes, "bytes")
x = np.array([[1,2,3],[4,5,6]], dtype = np.int32)
print("int32 consumes",x.nbytes, "bytes")
Out[12]: int64 consumes 48 bytes
int32 consumes 24 bytes
如果使用int64,则内存需求将增加一倍。 向自己问这个问题; 哪种数据类型就足够了? 在您的数字大于 2,147,483,648 且小于 -2,147,483,647 之前,使用int32就足够了。 假设您有一个大小超过 100MB 的巨大数组。 在这种情况下,这种转换对性能起着至关重要的作用。
正如您在上一个示例中可能已经注意到的那样,当您更改数据类型时,每次都在创建一个数组。 从技术上讲,创建数组后无法更改dtype。 但是,您可以做的是再次创建它,或者使用新的dtype和astype属性复制现有的文件。 让我们使用新的dtype创建数组的副本。 下面是一个示例,说明如何使用astype属性也可以更改dtype:
In [13]: x_copy = np.array(x, dtype = np.float)
x_copy
Out[13]: array([[ 1., 2., 3.],
[ 4., 5., 6.]])
In [14]: x_copy_int = x_copy.astype(np.int)
x_copy_int
Out[14]: array([[1, 2, 3],
[4, 5, 6]])
请记住,使用astype属性时,即使将其应用于x_copy,它也不会更改x_copy的dtype。它保留x_copy,但创建一个x_copy_int:
In [15]: x_copy
Out[15]: array([[ 1., 2., 3.],
[ 4., 5., 6.]])
假设有一个案例,您正在一个研究小组中工作,该研究小组试图确定和计算每个患癌症患者的风险。 您有 100,000 条记录(行),其中每一行代表一位患者,每位患者具有 100 个特征(某些测试的结果)。 结果,您有(100000, 100)的数组:
In [16]: Data_Cancer= np.random.rand(100000,100)
print(type(Data_Cancer))
print(Data_Cancer.dtype)
print(Data_Cancer.nbytes)
Data_Cancer_New = np.array(Data_Cancer, dtype = np.float32)
print(Data_Cancer_New.nbytes)
Out[16]: <class 'numpy.ndarray'>
float64
80000000
40000000
从前面的代码中可以看到,仅通过更改dtype即可将它们的大小从 80MB 减小到 40MB。 我们得到的回报是小数点后的精度较低。 除了精确到 16 位小数点外,您将只有 7 位小数。 在某些机器学习算法中,精度可以忽略不计。 在这种情况下,您应该随意调整dtype,以最大程度地减少内存使用量。
NumPy 数组操作
本节将指导您使用 NumPy 创建和处理数字数据。 让我们从列表中创建一个 NumPy 数组开始:
In [17]: my_list = [2, 14, 6, 8]
my_array = np.asarray(my_list)
type(my_array)
Out[17]: numpy.ndarray
让我们用标量值做一些加法,减法,乘法和除法:
In [18]: my_array + 2
Out[18]: array([ 4, 16, 8, 10])
In [19]: my_array - 1
Out[19]: array([ 1, 13, 5, 7])
In [20]: my_array * 2
Out[20]: array([ 4, 28, 12, 16, 8])
In [21]: my_array / 2
Out[21]: array([ 1\. , 7\. , 3\. , 4\. ])
在列表中执行相同的操作要困难得多,因为该列表不支持向量化操作,并且您需要迭代其元素。 创建 NumPy 数组的方法有很多,现在您将使用这些方法之一来创建一个充满零的数组。 稍后,您将执行一些算术运算,以查看 NumPy 在两个数组之间的按元素运算中的行为:
In [22]: second_array = np.zeros(4) + 3
second_array
Out[22]: array([ 3., 3., 3., 3.])
In [23]: my_array - second_array
Out[23]: array([ -1., 11., 3., 5.])
In [24]: second_array / my_array
Out[24]: array([ 1.5 , 0.21428571, 0.5 , 0.375 ])
就像我们在前面的代码中所做的那样,您可以创建一个充满np.ones的数组或一个充满np.identity的标识数组,并执行与之前相同的代数运算:
In [25]: second_array = np.ones(4) + 3
second_array
Out[25]: array([ 4., 4., 4., 4.])
In [26]: my_array - second_array
Out[26]: array([ -2., 10., 2., 4.])
In [27]: second_array / my_array
Out[27]: array([ 2\. , 0.28571429, 0.66666667, 0.5 ])
它可以通过np.ones方法按预期工作,但是当您使用单位矩阵时,计算将返回(4, 4)数组,如下所示:
In [28]: second_array = np.identity(4)
second_array
Out[28]: array([[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])
In [29]: second_array = np.identity(4) + 3
second_array
Out[29]: array([[ 4., 3., 3., 3.],
[ 3., 4., 3., 3.],
[ 3., 3., 4., 3.],
[ 3., 3., 3., 4.]])
In [30]: my_array - second_array
Out[30]: array([[ -2., 11., 3., 5.],
[ -1., 10., 3., 5.],
[ -1., 11., 2., 5.],
[ -1., 11., 3., 4.]])
这是从second_array的第一列的所有元素和第二列的second_element的所有元素中减去my_array的第一个元素,依此类推。 同样的规则也适用于除法。 请记住,即使形状不完全相同,也可以成功执行数组操作。 在本章的后面,您将了解当两个数组由于形状不同而无法进行计算时的广播错误:
In [31]: second_array / my_array
Out[31]: array([[ 2\. , 0.21428571, 0.5 , 0.375 ],
[ 1.5 , 0.28571429, 0.5 , 0.375 ],
[ 1.5 , 0.21428571, 0.66666667, 0.375 ],
[ 1.5 , 0.21428571, 0.5 , 0.5 ]])
创建 NumPy 数组最有用的方法之一是arange。 这将在起始值和结束值之间的给定间隔内返回一个数组。 第一个参数是数组的起始值,第二个参数是终止值(在该位置它不再创建值),第三个参数是间隔。 您可以选择将dtype定义为第四个参数。 默认间隔值为 1:
In [32]: x = np.arange(3,7,0.5)
x
Out[32]: array([ 3\. , 3.5, 4\. , 4.5, 5\. , 5.5, 6\. , 6.5])
当您无法确定间隔应该是多少时,还有另一种方法可以在起点和终点之间创建具有固定间隔的数组,但是您应该知道数组应该有多少个拆分:
In [33]: x = np.linspace(1.2, 40.5, num=20)
x
Out[33]: array([ 1.2 , 3.26842105, 5.33684211, 7.40526316, 9.47368421,
11.54210526, 13.61052632, 15.67894737, 17.74736842, 19.81578947,
21.88421053, 23.95263158, 26.02105263, 28.08947368, 30.15789474,
32.22631579, 34.29473684, 36.36315789, 38.43157895, 40.5 ])
有两种用法相似的不同方法,但由于它们的基本尺度不同,它们返回不同的数字序列。 这意味着数字的分布也将不同。 第一个是geomspace,它以几何级数返回对数刻度上的数字:
In [34]: np.geomspace(1, 625, num=5)
Out[34]: array([ 1., 5., 25., 125., 625.])
另一个重要的方法是logspace,您可以在其中返回起点和终点的值,这些值在以下位置均匀缩放:
In [35]: np.logspace(3, 4, num=5)
Out[35]: array([ 1000\. , 1778.27941004, 3162.27766017, 5623.4132519 ,
10000\. ])
这些参数是什么? 如果起始点为3,结束点为4,则这些函数将返回比初始范围大得多的数字。 实际上,您的起点默认设置为10,终点也设置为10。 因此,从技术上讲,在此示例中,起点为10**3,终点为10**4。 您可以避免这种情况,并使起点和终点与在方法中将其用作参数时相同。 诀窍是使用给定参数的以 10 为底的对数:
In [36]: np.logspace(np.log10(3) , np.log10(4) , num=5)
Out[36]: array([ 3\. , 3.2237098 , 3.46410162, 3.72241944, 4\. ])
到目前为止,您应该熟悉创建具有不同分布的数组的不同方法。 您还学习了如何对它们进行一些基本操作。 让我们继续您在日常工作中肯定会使用的其他有用函数。 大多数时候,您将不得不使用多个数组,并且需要非常快速地比较它们。 NumPy 对这个问题有很好的解决方案。 您可以像比较两个整数一样比较数组:
In [37]: x = np.array([1,2,3,4])
y = np.array([1,3,4,4])
x == y
Out[37]: array([ True, False, False, True], dtype=bool)
比较是逐个元素进行的,无论元素是否在两个不同的数组中匹配,它都会返回一个布尔向量。 此方法在小大小数组中效果很好,以及也为您提供了更多详细信息。 您可以从输出数组中看到以False表示的值,这些索引值在这两个数组中不匹配。 如果数组很大,则还可以选择对问题的单个答案,即元素是否在两个不同的数组中匹配:
In [38]: x = np.array([1,2,3,4])
y = np.array([1,3,4,4])
np.array_equal(x,y)
Out[38]: False
在这里,您只有一个布尔输出。 您只知道数组不相等,但是您不知道哪些元素完全不相等。 比较不仅限于检查两个数组是否相等。 您还可以在两个数组之间进行逐元素的上下比较:
In [39]: x = np.array([1,2,3,4])
y = np.array([1,3,4,4])
x < y
Out[39]: array([False, True, True, False], dtype=bool)
当需要进行逻辑比较(AND,OR和XOR)时,可以在数组中使用它们,如下所示:
In [40]: x = np.array([0, 1, 0, 0], dtype=bool)
y = np.array([1, 1, 0, 1], dtype=bool)
np.logical_or(x,y)
Out[40]: array([ True, True, False, True], dtype=bool)
In [41]: np.logical_and(x,y)
Out[41]: array([False, True, False, False], dtype=bool)
In [42]: x = np.array([12,16,57,11])
np.logical_or(x < 13, x > 50)
Out[42]: array([ True, False, True, True], dtype=bool)
到目前为止,已经介绍了诸如加法和乘法之类的代数运算。 我们如何将这些运算与指数函数,对数函数或三角函数之类的超越函数一起使用?
In [43]: x = np.array([1, 2, 3,4 ])
np.exp(x)
Out[43]: array([ 2.71828183, 7.3890561 , 20.08553692, 54.59815003])
In [44]: np.log(x)
Out[44]: array([ 0\. , 0.69314718, 1.09861229, 1.38629436])
In [45]: np.sin(x)
Out[45]: array([ 0.84147098, 0.90929743, 0.14112001, -0.7568025 ])
矩阵的转置呢? 首先,您将reshape函数与arange一起使用以设置所需的矩阵形状:
In [46]: x = np.arange(9)
x
Out[46]: array([0, 1, 2, 3, 4, 5, 6, 7, 8])
In [47]: x = np.arange(9).reshape((3, 3))
x
Out[47]: array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [48]: x.T
Out[48]: array([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
您转置了3 * 3数组,因此形状不会改变,因为两个大小均为3。 让我们看看没有平方数组时会发生什么:
In [49]: x = np.arange(6).reshape(2,3)
x
Out[49]: array([[0, 1, 2],
[3, 4, 5]])
In [50]: x.T
Out[50]: array([[0, 3],
[1, 4],
[2, 5]])
转置将按预期工作,并且大小也会切换。 您还可以从数组中获取摘要统计信息,例如均值,中位数和标准差。 让我们从 NumPy 提供的用于计算基本统计信息的方法开始:
| 方法 | 说明 |
|---|---|
np.sum | 返回数组所有值沿指定轴的总和 |
np.amin | 返回数组所有值或沿指定轴的最小值 |
np.amax | 返回数组所有值或沿指定轴的最大值 |
np.percentile | 返回数组所有值或沿指定轴的第 n 个的给定百分数 |
np.nanmin | 与np.amin相同,但忽略数组中的 NaN 值 |
np.nanmax | 与np.amax相同,但忽略数组中的 NaN 值 |
np.nanpercentile | 与np.percentile相同,但忽略数组中的 NaN 值 |
以下代码块给出了前面的 NumPy 统计方法的示例。 这些方法非常有用,因为您可以根据需要在整个数组中或轴向操作这些方法。 您应该注意,由于 SciPy 使用 NumPy 多维数组作为数据结构,因此可以在 SciPy 中找到这些方法的功能更完善的更好的实现:
In [51]: x = np.arange(9).reshape((3,3))
x
Out[51]: array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [52]: np.sum(x)
Out[52]: 36
In [53]: np.amin(x)
Out[53]: 0
In [54]: np.amax(x)
Out[54]: 8
In [55]: np.amin(x, axis=0)
Out[55]: array([0, 1, 2])
In [56]: np.amin(x, axis=1)
Out[56]: array([0, 3, 6])
In [57]: np.percentile(x, 80)
Out[57]: 6.4000000000000004
axis参数确定此函数将要作用的大小。 在此示例中,轴= 0代表第一个轴,即x轴,轴= 1代表第二个轴,即y。 当我们使用常规amin(x)时,我们返回单个值,因为它会计算所有数组中的最小值,但是当我们指定轴时,它将开始沿轴方向计算函数并返回一个数组,该数组显示每行或列的结果。 想象一下,您有很多人。 您可以使用amax找到最大值,但是如果您需要将此值的索引传递给另一个函数,将会发生什么? 在这种情况下,argmin和argmax可以提供帮助,如以下代码片段所示:
In [58]: x = np.array([1,-21,3,-3])
np.argmax(x)
Out[58]: 2
In [59]: np.argmin(x)
Out[59]: 1
让我们继续更多的统计函数:
| 方法 | 说明 |
|---|---|
np.mean | 返回数组所有值或沿特定轴的平均值 |
np.median | 返回数组所有值或沿特定轴的中值 |
np.std | 返回数组所有值或沿特定轴的标准差 |
np.nanmean | 与np.mean相同,但忽略数组中的 NaN 值 |
np.nanmedian | 与np.nanmedian相同,但忽略数组中的 NaN 值 |
np.nonstd | 与np.nanstd相同,但忽略数组中的 NaN 值 |
以下代码提供了 NumPy 的先前统计方法的更多示例。 这些方法在数据发现阶段中大量使用,您可以在其中分析数据特征和分布:
In [60]: x = np.array([[2, 3, 5], [20, 12, 4]])
x
Out[60]: array([[ 2, 3, 5],
[20, 12, 4]])
In [61]: np.mean(x)
Out[61]: 7.666666666666667
In [62]: np.mean(x, axis=0)
Out[62]: array([ 11\. , 7.5, 4.5])
In [63]: np.mean(x, axis=1)
Out[63]: array([ 3.33333333, 12\. ])
In [64]: np.median(x)
Out[64]: 4.5
In [65]: np.std(x)
Out[65]: 6.3944420310836261
处理多维数组
本节将通过执行不同的矩阵运算使您对多维数组有一个简要的了解。
为了在 NumPy 中进行矩阵乘法,您必须使用dot()而不是*。 让我们看一些例子:
In [66]: c = np.ones((4, 4))
c*c
Out[66]: array([[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.]])
In [67]: c.dot(c)
Out[67]: array([[ 4., 4., 4., 4.],
[ 4., 4., 4., 4.],
[ 4., 4., 4., 4.],
[ 4., 4., 4., 4.]])
使用多维数组时,最重要的主题是堆栈,即如何合并两个数组。hstack用于水平(列方式)堆叠数组,vstack用于垂直(行方式)堆叠数组。 您还可以使用hsplit和vsplit方法拆分列,方法与堆叠它们相同:
In [68]: y = np.arange(15).reshape(3,5)
x = np.arange(10).reshape(2,5)
new_array = np.vstack((y,x))
new_array
Out[68]: array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]])
In [69]: y = np.arange(15).reshape(5,3)
x = np.arange(10).reshape(5,2)
new_array = np.hstack((y,x))
new_array
Out[69]: array([[ 0, 1, 2, 0, 1],
[ 3, 4, 5, 2, 3],
[ 6, 7, 8, 4, 5],
[ 9, 10, 11, 6, 7],
[12, 13, 14, 8, 9]])
这些方法在机器学习应用中非常有用,尤其是在创建数据集时。 堆叠数组后,可以使用Scipy.stats检查其描述性统计信息。 假设有一个100记录,并且每个记录都具有10个特征,这意味着您有一个 2D 矩阵,其中包含100行和10列。 下面的示例说明如何轻松获取每个特征的一些描述性统计信息:
In [70]: from scipy import stats
x= np.random.rand(100,10)
n, min_max, mean, var, skew, kurt = stats.describe(x)
new_array = np.vstack((mean,var,skew,kurt,min_max[0],min_max[1]))
new_array.T
Out[70]: array([[ 5.46011575e-01, 8.30007104e-02, -9.72899085e-02,
-1.17492785e+00, 4.07031246e-04, 9.85652100e-01],
[ 4.79292653e-01, 8.13883169e-02, 1.00411352e-01,
-1.15988275e+00, 1.27241020e-02, 9.85985488e-01],
[ 4.81319367e-01, 8.34107619e-02, 5.55926602e-02,
-1.20006450e+00, 7.49534810e-03, 9.86671083e-01],
[ 5.26977277e-01, 9.33829059e-02, -1.12640661e-01,
-1.19955646e+00, 5.74237697e-03, 9.94980830e-01],
[ 5.42622228e-01, 8.92615897e-02, -1.79102183e-01,
-1.13744108e+00, 2.27821933e-03, 9.93861532e-01],
[ 4.84397369e-01, 9.18274523e-02, 2.33663872e-01,
-1.36827574e+00, 1.18986562e-02, 9.96563489e-01],
[ 4.41436165e-01, 9.54357485e-02, 3.48194314e-01,
-1.15588500e+00, 1.77608372e-03, 9.93865324e-01],
[ 5.34834409e-01, 7.61735119e-02, -2.10467450e-01,
-1.01442389e+00, 2.44706226e-02, 9.97784091e-01],
[ 4.90262346e-01, 9.28757119e-02, 1.02682367e-01,
-1.28987137e+00, 2.97705706e-03, 9.98205307e-01],
[ 4.42767478e-01, 7.32159267e-02, 1.74375646e-01,
-9.58660574e-01, 5.52410464e-04, 9.95383732e-01]])
NumPy 有一个很棒的模块numpy.ma,用于屏蔽数组元素。 当您要在计算时屏蔽(忽略)某些元素时,它非常有用。 当 NumPy 数组被屏蔽时,它将被视为无效,并且不考虑计算:
In [71]: import numpy.ma as ma
x = np.arange(6)
print(x.mean())
masked_array = ma.masked_array(x, mask=[1,0,0,0,0,0])
masked_array.mean()
2.5
Out[71]: 3.0
在前面的代码中,您有一个数组x = [0,1,2,3,4,5]。 您要做的是屏蔽数组的第一个元素,然后计算平均值。 当一个元素被屏蔽为1(True)时,数组中的关联索引值将被屏蔽。 在替换 NAN 值时,此方法也非常有用:
In [72]: x = np.arange(25, dtype = float).reshape(5,5)
x[x<5] = np.nan
x
Out[72]: array([[ nan, nan, nan, nan, nan],
[ 5., 6., 7., 8., 9.],
[ 10., 11., 12., 13., 14.],
[ 15., 16., 17., 18., 19.],
[ 20., 21., 22., 23., 24.]])
In [73]: np.where(np.isnan(x), ma.array(x, mask=np.isnan(x)).mean(axis=0), x)
Out[73]: array([[ 12.5, 13.5, 14.5, 15.5, 16.5],
[ 5\. , 6\. , 7\. , 8\. , 9\. ],
[ 10\. , 11\. , 12\. , 13\. , 14\. ],
[ 15\. , 16\. , 17\. , 18\. , 19\. ],
[ 20\. , 21\. , 22\. , 23\. , 24\. ]])
在前面的代码中,我们通过放置一个带有索引的条件将前五个元素的值更改为nan。x[x<5]指的是索引为 0、1、2、3 和 4 的元素。然后,我们用每列的平均值覆盖这些值(nan值除外)。 为了帮助您的代码更简洁,数组操作中还有许多其他有用的方法:
| 方法 | 说明 |
|---|---|
np.concatenate | 连接列表中的给定数组 |
np.repeat | 沿特定轴重复数组的元素 |
np.delete | 返回一个带有删除的子数组的新数组 |
np.insert | 在指定轴之前插入值 |
np.unique | 在数组中查找唯一值 |
np.tile | 通过以给定的重复次数重复给定的输入来创建数组 |
索引,切片,重塑,调整大小和广播
当您在机器学习项目中使用大量数组时,通常需要索引,切片,调整形状和调整大小。
索引是数学和计算机科学中使用的一个基本术语。 一般而言,索引可帮助您指定如何返回各种数据结构的所需元素。 下面的示例显示列表和元组的索引:
In [74]: x = ["USA","France", "Germany","England"]
x[2]
Out[74]: 'Germany'
In [75]: x = ('USA',3,"France",4)
x[2]
Out[75]: 'France'
在 NumPy 中,索引的主要用途是控制和操纵数组的元素。 这是一种创建通用查找值的方法。 索引包含三个子操作,分别是字段访问,基本切片和高级索引。 在字段访问中,只需指定数组中元素的索引即可返回给定索引的值。
NumPy 在索引和切片方面非常强大。 在许多情况下,您需要在数组中引用所需的元素,然后对该切片区域执行操作。 您可以对数组进行索引,类似于对元组或带有方括号的列表进行索引。 让我们从字段访问和使用一维数组的简单切片开始,然后继续使用更高级的技术:
In [76]: x = np.arange(10)
x
Out[76]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [77]: x[5]
Out[77]: 5
In [78]: x[-2]
Out[78]: 8
In [79]: x[2:8]
Out[79]: array([2, 3, 4, 5, 6, 7])
In [80]: x[:]
Out[80]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [81]: x[2:8:2]
Out[81]: array([2, 4, 6])
索引从0开始,因此在创建带有元素的数组时,第一个元素被索引为x[0],与最后一个元素x[n-1]相同。 如您在前面的示例中看到的,x[5]指的是第六个元素。 您也可以在索引中使用负值。 NumPy 将这些值理解为倒数第n个。 像示例中一样,x[-2]指倒数第二个元素。 您还可以通过声明开始索引和结束索引来选择数组中的多个元素,也可以通过将增量级别作为第三个参数声明来创建顺序索引,如代码的最后一行所示。
到目前为止,我们已经看到了一维数组中的索引和切片。 逻辑不会改变,但是为了演示起见,我们也对多维数组进行一些练习。 当您拥有多维数组时,唯一发生变化的就是只有更多的轴。 您可以在以下代码中将 n 维数组切片为[x 轴切片,y 轴切片]:
In [82]: x = np.reshape(np.arange(16),(4,4))
x
Out[82]: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [83]: x[1:3]
Out[83]: array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
In [84]: x[:,1:3]
Out[84]: array([[ 1, 2],
[ 5, 6],
[ 9, 10],
[13, 14]])
In [85]: x[1:3,1:3]
Out[85]: array([[ 5, 6],
[ 9, 10]])
您按行和列对数组进行了切片,但没有以更加不规则或更具动态性的方式对元素进行切片,这意味着您始终以矩形或正方形的方式对其进行切片。 想象一下我们要切片的4 * 4数组,如下所示:
为了获得前面的切片,我们执行以下代码:
In [86]: x = np.reshape(np.arange(16),(4,4))
x
Out[86]: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [87]: x[[0,1,2],[0,1,3]]
Out[87]: array([ 0, 5, 11])
在高级索引中,第一部分指示要切片的行的索引,第二部分指示相应的列。 在前面的示例中,您首先切片了第一,第二和第三行([0,1,2]),然后切片第一,第二和第四列。
整形和调整大小方法似乎很相似,但是这些操作的输出有所不同。 重新排列数组的形状时,只是输出会临时更改数组的形状,但不会更改数组本身。 调整数组大小时,它将永久更改数组的大小,如果新数组的大小大于旧数组的大小,则新数组元素将填充旧数组的重复副本。 相反,如果新数组较小,则新数组将从旧数组中获取元素,并按索引顺序填充新数组。 请注意,相同的数据可以由不同的ndarray共享。这意味着一个ndarray可以是另一个ndarray的视图。 在这种情况下,对一个数组进行的更改将对其他视图产生影响。
下面的代码给出了一个示例,说明当大小大于或小于原始数组时如何填充新数组元素:
In [88]: x = np.arange(16).reshape(4,4)
x
Out[88]: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [89]: np.resize(x,(2,2))
Out[89]: array([[0, 1],
[2, 3]])
In [90]: np.resize(x,(6,6))
Out[90]: array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 0, 1],
[ 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13],
[14, 15, 0, 1, 2, 3]])
本小节的最后一个重要术语是广播,它解释了当 NumPy 具有不同形状时在数组的算术运算中如何表现。 NumPy 有两个广播规则:数组的大小相等或其中之一为 1。如果不满足以下条件之一,则将得到以下两个错误之一:frames are not aligned或operands could not be broadcast together:
In [91]: x = np.arange(16).reshape(4,4)
y = np.arange(6).reshape(2,3)
x+y
--------------------------------------------------------------- ------------
ValueError Traceback (most recent call last)
<ipython-input-102-083fc792f8d9> in <module>()
1 x = np.arange(16).reshape(4,4)
2 y = np.arange(6).reshape(2,3)
----> 3 x+y
12
ValueError: operands could not be broadcast together with shapes (4,4) (2,3)
您可能已经看到可以将两个矩阵的形状分别为(4, 4)和(4,)或(2, 2)和(1, 2)。 第一种情况满足具有一维的条件,因此乘法成为向量*数组,这不会引起任何广播问题:
In [92]: x = np.ones(16).reshape(4,4)
y = np.arange(4)
x*y
Out[92]: array([[ 0., 1., 2., 3.],
[ 0., 1., 2., 3.],
[ 0., 1., 2., 3.],
[ 0., 1., 2., 3.]])
In [93]: x = np.arange(4).reshape(2,2)
x
Out[93]: array([[0, 1],
[2, 3]])
In [94]: y = np.arange(2).reshape(1,2)
y
Out[94]: array([[0, 1]])
In [95]: x*y
Out[95]: array([[0, 1],
[0, 3]])
前面的代码块提供了第二种情况的示例,其中在计算过程中,小数组迭代通过大数组,并且输出扩展到整个数组。 这就是为什么有(4, 4)和(2, 2)输出的原因:在乘法过程中,两个数组都以较大的大小广播。
总结
在本章中,您熟悉了 NumPy 数组操作的基础知识,并刷新了有关基本矩阵操作的知识。 NumPy 是用于 Python 科学堆栈的极其重要的库,它具有用于数组操作的广泛方法。 您已经学习了如何使用多维数组,并涵盖了重要的主题,例如索引,切片,整形,调整大小和广播。 本章的主要目的是让您简要了解有关数字数据集的 NumPy 的工作方式,这将对您的日常数据分析工作有所帮助。
在下一章中,您将学习线性代数的基础知识以及使用 NumPy 完整的实际示例。
二、NumPy 线性代数
数学的主要分类之一是代数,尤其是线性代数专注于线性方程和映射线性空间(即向量空间)。 当我们在向量空间之间创建线性映射时,实际上是在创建称为矩阵的数据结构。 线性代数的主要用途是求解联立线性方程,但也可用于非线性系统的近似。 想象一下您要理解的复杂模型或系统,将其视为非线性模型。 在这种情况下,您可以将问题的复杂的非线性特征简化为联立的线性方程,并且可以在线性代数的帮助下求解它们。
在计算机科学中, 线性代数在机器学习(ML)应用中大量使用。 在 ML 应用中,您处理的是高维数组,可以轻松地将其转换为线性方程式,您可以在其中分析给定空间中要素的相互作用。 想像一下您正在从事图像识别项目并且您的任务是从 MRI 图像中检测出大脑中的肿瘤的情况。 从技术上讲,您的算法应该像医生一样工作,在其中扫描给定的输入并检测大脑中的肿瘤。 医生的优势在于能够发现异常情况。 人类的大脑已经进化了数千年,以解释视觉输入。 无需付出太多努力,人类就可以直观地捕获异常。 但是,对于执行相似任务的算法,您应该尽可能详细地考虑此过程,以了解如何正式表达它,以便机器可以理解。
首先,您应该考虑 MRI 数据如何存储在仅处理 0 和 1 的计算机中。 计算机实际上将像素强度存储在称为矩阵的结构中。 换句话说,您将 MRI 转换为大小为N2的向量,其中每个元素均由像素值组成。 如果此 MRI 大小为512 x 512,则每个像素将是 262,144 像素中的一个点。 因此,您将在此矩阵中进行的任何计算操作都极有可能会使用线性代数原理。 如果该示例不足以证明 ML 中的线性代数的重要性,那么让我们看一下深度学习中的一个流行示例。 简而言之,深度学习是一种算法,该算法使用神经网络结构通过不断更新各层之间神经元连接的权重来学习所需的输出(标签)。 一个简单的深度学习算法的图形表示如下:
神经网络存储各层之间的权重和矩阵中的偏差值。 由于这些参数是您尝试调整到深度学习模型中以最小化损失函数的参数,因此您不断进行计算并更新它们。 通常,机器学习模型需要大量计算,并且需要针对大型数据集进行训练以提供有效的结果。 这就是为什么线性代数是 ML 的基本部分的原因。
在本章中,我们将使用 numpy 库,但请注意,大多数线性代数函数也是通过 scipy 导入的,它们更恰当地属于它。 理想情况下,在大多数情况下,您都可以导入这两个库并执行计算。 scipy 的一个重要特征是拥有功能齐全的线性代数模块。 在本章中,我们强烈建议您阅读 scipy 文档并使用与 scipy 相同的操作进行练习。 这是 scipy 的线性代数模块的链接。
在本章中,我们将介绍以下主题:
- 向量和矩阵数学
- 什么是特征值?我们如何计算它?
- 计算范数和行列式
- 求解线性方程
- 计算梯度
向量和矩阵运算
在上一章中,您练习了向量和矩阵的入门操作。 在本节中,您将练习在线性代数中大量使用的更高级的向量和矩阵运算。 让我们记住关于矩阵操作的点积透视图,以及当您具有 2D 数组时如何使用不同的方法来完成。 以下代码块显示了执行点积计算的替代方法:
In [1]: import numpy as np
a = np.arange(12).reshape(3,2)
b = np.arange(15).reshape(2,5)
print(a)
print(b)
Out[1]:
[[ 0 1]
[ 2 3]
[ 4 5]]
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
In [2]: np.dot(a,b)
Out[2]: array([[ 5, 6, 7, 8, 9],
[15, 20, 25, 30, 35],
[25, 34, 43, 52, 61]])
In [3]: np.matmul(a,b)
Out[3]: array([[ 5, 6, 7, 8, 9],
[15, 20, 25, 30, 35],
[25, 34, 43, 52, 61]])
In [4]: a@b
Out[4]: array([[ 5, 6, 7, 8, 9],
[15, 20, 25, 30, 35],
[25, 34, 43, 52, 61]])
内积和点积在 ML 算法(如监督学习)中非常重要。 让我们回到有关肿瘤检测的示例。 想象我们有三张图像(MRI):第一张图像有肿瘤(A),第二张图像无肿瘤(B),第三张图像是您要标记为肿瘤或无肿瘤的未知 MRI。下图显示了向量a和b的点积的几何表示:
作为一个非常简单的例子,点积将向您显示这两个向量之间的相似性,因此,如果您未知的 MRI 方向接近向量 A,则您的算法将被归类为具有肿瘤的 MRI。 否则,它将分类为无肿瘤。 如果要在一个函数中乘以两个或多个数组,linalg.multi_dot()非常方便。 进行此操作的另一种方法是将np.dot()嵌套的数组相乘,但您需要知道哪个计算顺序最快,因为在linalg.multi_dot()中此优化是自动进行的。 如前所述,以下代码块使用不同的方法执行相同的点积运算:
In [5]: from numpy.linalg import multi_dot
a = np.arange(12).reshape(4,3)
b = np.arange(15).reshape(3,5)
c = np.arange(25).reshape(5,5)
multi_dot([a, b, c])
Out[5]: array([[ 1700, 1855, 2010, 2165, 2320],
[ 5300, 5770, 6240, 6710, 7180],
[ 8900, 9685, 10470, 11255, 12040],
[12500, 13600, 14700, 15800, 16900]])
In [6]: a.dot(b).dot(c)
Out[6]: array([[ 1700, 1855, 2010, 2165, 2320],
[ 5300, 5770, 6240, 6710, 7180],
[ 8900, 9685, 10470, 11255, 12040],
[12500, 13600, 14700, 15800, 16900]])
如下面的代码所示,即使使用三个小型矩阵,multi_dot()方法也将运行时间减少了 40%。 如果矩阵数量和大小增加,则该时间间隔会大大增加。 因此,您应该使用multi_dot()方法以确保最快的求值顺序。 以下代码将比较这两种方法的执行时间:
In [7]: import numpy as np
from numpy.linalg import multi_dot
import time
a = np.arange(120000).reshape(400,300)
b = np.arange(150000).reshape(300,500)
c = np.arange(200000).reshape(500,400)
start = time.time()
multi_dot([a,b,c])
ft = time.time()-start
print ('Multi_dot tooks', time.time()-start,'seconds.')
start_ft = time.time()
a.dot(b).dot(c)
print ('Chain dot tooks', time.time()-start_ft,'seconds.')
Out[7]:
Multi_dot tooks 0.14687418937683105 seconds.
Chain dot tooks 0.1572890281677246 seconds.
NumPy 的线性代数库中还有另外两种重要的方法,即outer()和inner()。outer方法计算两个向量的外积。inner方法的行为取决于所采用的参数。 如果您有两个向量作为参数,它将产生一个普通的点积,但是当您具有一个更高维的数组时,它会像tensordot()一样返回最后一个轴的积的和。您将在本章后面看到tensordot()。 现在,让我们首先关注outer()和inner()方法。 以下示例将帮助您了解这些函数的作用:
In [8]: a = np.arange(9).reshape(3,3)
b = np.arange(3)
print(a)
print(b)
Out[8]:
[[0 1 2]
[3 4 5]
[6 7 8]]
[0 1 2]
In [9]: np.inner(a,b)
Out[9]: array([ 5, 14, 23])
In [10]: np.outer(a,b)
Out[10]: array([[ 0, 0, 0],
[ 0, 1, 2],
[ 0, 2, 4],
[ 0, 3, 6],
[ 0, 4, 8],
[ 0, 5, 10],
[ 0, 6, 12],
[ 0, 7, 14],
[ 0, 8, 16]])
在上述inner()方法的示例中,数组的第i行与向量产生标量积,总和成为输出数组的第i个元素,因此输出数组的构造如下:
[0x0 + 1x1 + 2x2, 0x3 + 1x4 + 2x5, 0x6 + 1x7 + 2x8] = [5, 14, 23]
在下面的代码块中,我们对同一数组但具有一维执行outer()方法。 如您所见,结果与我们对二维数组所做的完全相同:
In [11]: a = np.arange(9)
np.ndim(a)
Out[11]: 1
In [12]: np.outer(a,b)
Out[12]: array([[ 0, 0, 0],
[ 0, 1, 2],
[ 0, 2, 4],
[ 0, 3, 6],
[ 0, 4, 8],
[ 0, 5, 10],
[ 0, 6, 12],
[ 0, 7, 14],
[ 0, 8, 16]])
outer()方法计算向量的外积,在我们的示例中为 2D 数组。 这不会改变方法的功能,而是将 2D 数组展平为向量并进行计算。
在进行分解之前,本小节介绍的最后一件事是tensordot()方法。 在数据科学项目中,我们通常处理需要进行发现和应用 ML 算法的 n 维数据。 以前,您了解了向量和矩阵。 张量是向量和矩阵的通用数学对象,可以将向量的关系保持在高维空间中。tensordot()方法用于两个张量的收缩; 换句话说,它通过将指定轴上两个张量的乘积相加来减小维数(张量级)。 以下代码块显示了两个数组的tensordot()操作示例:
In [13]: a = np.arange(12).reshape(2,3,2)
b = np.arange(48).reshape(3,2,8)
c = np.tensordot(a,b, axes =([1,0],[0,1]))
print(a)
print(b)
Out[13]:
[[[ 0 1]
[ 2 3]
[ 4 5]]
[[ 6 7]
[ 8 9]
[10 11]]]
[[[ 0 1 2 3 4 5 6 7]
[ 8 9 10 11 12 13 14 15]]
[[16 17 18 19 20 21 22 23]
[24 25 26 27 28 29 30 31]]
[[32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47]]]
In [14]: c
Out[14]: array([[ 800, 830, 860, 890, 920, 950, 980, 1010],
[ 920, 956, 992, 1028, 1064, 1100, 1136, 1172]])
什么是特征值,我们如何计算?
特征值是特征向量的系数。 根据定义,特征向量是一个非零向量,在应用线性变换时仅会按标量因子进行更改。 通常,将线性变换应用于向量时,其跨度(穿过其原点的线)会移动,但是某些特殊向量不受这些线性变换的影响,而是保留在自己的跨度上。 这些就是我们所说的特征向量。 线性变换仅在将向量与标量相乘时才通过拉伸或挤压它们来影响它们。 该标量的值称为特征值。 假设我们有一个 A 矩阵,该矩阵将用于线性变换。 我们可以用以下数学表达式表示特征值和特征向量:
在这里,https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/5bb72e21-92d3-44e2-8b9b-b096407781c2.png 是特征向量,https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0d8c932d-e857-4256-a918-c9845c8996d9.png 是特征值。 在等式的左侧,向量通过矩阵进行变换,结果只是同一向量的标量形式。 另外,请注意,左侧实际上是矩阵向量乘法,而右侧是标量向量乘法。 为了使边的乘法类型相同,我们可以将 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0d8c932d-e857-4256-a918-c9845c8996d9.png 与恒等矩阵相乘,这不会改变右侧。 但是将 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0d8c932d-e857-4256-a918-c9845c8996d9.png 从标量更改为矩阵,并且两边都是矩阵向量乘法:
如果我们减去右侧并分解为 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/89730e46-aa7f-4a55-ab70-9863fafac4bc.png,您将具有以下等式:
因此,我们的新矩阵将如下所示:
如您所知,您正在尝试计算0以外的特征向量的特征值; (如果 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/7360bfbd-2cce-4c74-810b-1c60981ad34b.png = 0,则没有意义),因此特征向量(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/55451371-dc34-4251-b721-cb4d1f1552c3.png)不能为0。 因此,您正在尝试求解以下等式:
前面的公式正在计算矩阵的行列式,因为只有一个条件,即非零矩阵等于0,即矩阵的行列式等于零。 给定矩阵的行列式为零意味着使用该矩阵进行的转换会将所有内容压缩为较小的维度。 在下一部分中,您将详细了解行列式。 此处的真正目的是找到使行列式为零并将空间压缩为较小维度的 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0d8c932d-e857-4256-a918-c9845c8996d9.png。 找到 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0d8c932d-e857-4256-a918-c9845c8996d9.png 后,我们可以根据以下公式计算特征向量(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/7818d6b6-5b66-4d9d-a919-d1a190f820f3.png):
在 ML 算法中,您需要处理大量维度。 主要问题不是规模很大,而是算法与它们的兼容性和性能。 例如,在 PCA(主成分分析)中,您尝试发现大小最有意义的线性组合。 PCA 的主要思想是减少数据集的规模,同时最大程度地减少信息丢失。 此处的信息丢失实际上是您特征的差异。 假设您具有五个特征,并且具有五个示例的类标签,如下所示:
| 特征 1 | 特征 2 | 特征 3 | 特征 4 | 特征 5 | 类别 |
|---|---|---|---|---|---|
| 1.45 | 42 | 54 | 1.001 | 1.05 | 狗 |
| 2 | 12 | 34 | 1.004 | 24.1 | 猫 |
| 4 | 54 | 10 | 1.004 | 13.4 | 狗 |
| 1.2 | 31 | 1 | 1.003 | 42.1 | 猫 |
| 5 | 4 | 41 | 1.003 | 41.4 | 狗 |
在上表中,在特征 4 中,类别标签是狗还是猫实际上并没有明显的区别。 在我的分析中,此特征将是多余的。 这里的主要目标是使各个类之间的特征保持很大的差异,因此特征值在我的决定中起着重要的作用。
在以下示例中,我们将使用一个名为scikit-learn的附加库,以便加载数据集并通过使用该库来执行 PCA。 Scikit-learn 是一个免费的 python 机器学习库,它基于 SciPy 构建。 它具有用于许多机器学习算法(例如分类,回归,聚类)的许多内置函数和模块。 SVM,DBSCAN,K 均值等。
Scikit-learn 与 numpy,scipy 和 pandas 具有很好的兼容性。 您可以将sklearn中的 numpy 数组用作数据结构。 此外,您还可以使用sklearn_pandas将 scikit-learn 管道输出转换为 pandas 数据帧。 Scikit-learn 还通过auto_ml和auto-sklearn库支持自动化机器学习算法。sklearn是在 python 中键入 scikit-learn 名称的一种方法。 这就是为什么在导入 skicit-learn 和使用函数时使用sklearn的原因。
现在是时候进行实际练习,以了解特征值和特征向量在 PCA 中的用法和重要性。 在下面的代码中,您将 PCA 与 NumPy 一起导入并应用,然后将您的结果与sklearn是用于验证的内置方法进行比较。 您将使用 sklearn 数据集库中的乳腺癌数据集。 让我们先导入所需的库和数据集,然后再对数据进行标准化。 标准化非常重要,有时甚至对于 scikit-learn 之类的某些 ML 库中的估计器来说也是必需的。 在我们的示例中,使用StandardScaler()方法来标准化特征; 主要目的是具有标准正态分布数据中的特征(均值= 0和单位方差)。fit_transform()方法用于转换原始数据,其形式为分布的平均值为 0,标准差为 1。它将计算所需的参数并应用转换。 当我们使用StandardScaler()时,此参数将为 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/6b4f4ba1-e6b5-4d3d-a706-535db7b4a91f.png 和 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/49736463-aa50-4ceb-acf3-5dce84f2d4a6.png。 请记住,标准化不会从我们的原始数据集中产生正态分布的数据。 只是重新缩放了数据,我们的平均值为零,标准差为 1:
In [15]: import numpy as np
from sklearn import decomposition, datasets
from sklearn.preprocessing import StandardScaler
data = datasets.load_breast_cancer()
cancer = data.data
cancer = StandardScaler().fit_transform(cancer)
cancer.shape
Out[15]: (569, 30)
在前面的代码中检查数据形状时,它显示数据由569行和30列组成。 您也可以在标准化开始和标准化之后比较数据,以便更清楚地了解原始数据是如何转换的。 以下代码块为您展示了癌症数据中列转换的示例:
In [16]: before_transformation = data.data
before_transformation[:10,:1]
Out[16]: array([[ 17.99],
[ 20.57],
[ 19.69],
[ 11.42],
[ 20.29],
[ 12.45],
[ 18.25],
[ 13.71],
[ 13\. ],
[ 12.46]])
In [17]: cancer[:10,:1]
Out[17]: array([[ 1.09706398],
[ 1.82982061],
[ 1.57988811],
[-0.76890929],
[ 1.75029663],
[-0.47637467],
[ 1.17090767],
[-0.11851678],
[-0.32016686],
[-0.47353452]])
从结果中可以看到,原始数据已转换为标准化版本的形式。 通过以下公式计算得出:
- https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0769fb03-5594-4756-9829-04748f2139c9.png:正在标准化的值(原始数据中的值)
- https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/c0dff95e-8033-4a9b-b8bc-9cf7833c23dc.png:分布的平均值
- https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/d9ffbbc2-5700-4fdc-9f09-5677e549439b.png:分布的标准差
- https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/fa8a85d1-da83-4b63-b229-100538c5147c.png:标准化值
转换数据后,您将如下计算协方差矩阵,以便使用np.linalg.eig()方法计算特征值和特征向量,然后将其用于分解:
In [18]: covariance_matrix = np.cov(cancer,rowvar=False)
covariance_matrix.shape
Out[18]: (30, 30)
In [19]: eig_val_cov, eig_vec_cov = np.linalg.eig(covariance_matrix)
eig_pairs = [(np.abs(eig_val_cov[i]), eig_vec_cov[:,i]) for i in
range(len(eig_val_cov))]
正如您在前面的代码中已经注意到的那样,我们计算为所有要素构造的协方差矩阵。 由于我们在数据集中具有 30 个特征,因此协方差矩阵是形状为(30, 30)的 2D 数组。 以下代码块按降序对特征值进行排序:
In [20]: sorted_pairs = eig_pairs.sort(key=lambda x: x[0], reverse=True)
for i in eig_pairs:
print(i[0])
Out[20]:
13.3049907944
5.70137460373
2.82291015501
1.98412751773
1.65163324233
1.2094822398
0.676408881701
0.47745625469
0.417628782108
0.351310874882
0.294433153491
0.261621161366
0.241782421328
0.157286149218
0.0943006956011
0.0800034044774
0.0595036135304
0.0527114222101
0.049564700213
0.0312142605531
0.0300256630904
0.0274877113389
0.0243836913546
0.0180867939843
0.0155085271344
0.00819203711761
0.00691261257918
0.0015921360012
0.000750121412719
0.000133279056663
您需要以降序对特征值进行排序,以确定要降低维度工作空间要删除的特征向量。 正如您在前面的排序列表中所看到的那样,具有较高特征值的前两个特征向量具有有关数据分布的最多信息。 因此,其余的将针对低维子空间删除:
In [21]: matrix_w = np.hstack((eig_pairs[0][1].reshape(30,1), eig_pairs[1] [1].reshape(30,1)))
matrix_w.shape
transformed = matrix_w.T.dot(cancer.T)
transformed = transformed.T
transformed[0]
Out[21]: array([ 9.19283683, 1.94858307])
In [22]: transformed.shape
Out[22]: (569, 2)
在前面的代码块中,前两个特征向量将水平堆叠,因为它们将用于矩阵乘法,以将新维度的数据转换到新的子空间上。 最终数据从(569,30)转换为(569,2)矩阵,这意味着28特征在 PCA 过程中下降了:
In [23]: import numpy as np
from sklearn import decomposition
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
pca = decomposition.PCA(n_components=2)
x_std = StandardScaler().fit_transform(cancer)
pca.fit_transform(x_std)[0]
Out[23]: array([ 9.19283683, 1.94858307])
另一方面,其他库中有内置函数可以执行与您相同的操作。 在 scikit-learn 中,有许多内置方法可用于 ML 算法。 如您在前面的代码块中看到的,同一 PCA 是通过三行代码和两种方法执行的。 不过,本示例的目的是向您展示特征值和特征向量的重要性,因此,本书展示了使用 NumPy 进行 PCA 的普通方法。
计算范数和行列式
本小节将介绍线性代数中的两个重要值,即范数和行列式。 简而言之,范数给出向量的长度。 最常用的范数是 L2 范数,也称为欧几里得范数。 正式地,Lp 的范数计算如下:
L0 范数实际上是向量的基数。 您可以通过仅计算非零元素的总数来计算它。 例如,向量A = [2,5,9,0]包含三个非零元素,因此||A||[0] = 3。 以下代码块显示了与 numpy 相同的范数计算:
In [24]: import numpy as np
x = np.array([2,5,9,0])
np.linalg.norm(x,ord=0)
Out[24]: 3.0
在 NumPy 中,您可以使用linalg.norm()方法来计算向量的范数。 第一个参数是输入数组,而ord参数用于范数的顺序。 L1 范数也称为出租车范数或曼哈顿范数。 它通过计算直线距离来计算向量的长度,因此||A||[1] = (2 + 5 + 9),如此||A||[1] = 16。以下代码块显示了相同的 numpy 范数计算:
In [25]: np.linalg.norm(x,ord=1)
Out[25]: 16.0
L1 范数的用途之一是用于计算平均绝对误差(MAE),如下式所示:
L2 范数是最受欢迎的范数。 它通过应用勾股定理来计算向量的长度,因此||A||[2] = https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/1027f89e-45fc-4a53-a4d3-1ec12876346b.png,所以||A||[2] = 10.48:
In [26]: np.linalg.norm(x,ord=2)
Out[26]: 10.488088481701515
L2 范数的众所周知的应用之一是均方误差(MSE)计算。 类似地,由于矩阵由向量组成,因此范数给出了长度或大小,但解释和计算略有不同。 在前面的章节中,您学习了向量矩阵乘法。 在结果中将矩阵与向量相乘时,将拉伸向量。 矩阵的范数揭示了该矩阵可以拉伸向量的程度。 让我们看看如何为矩阵A计算 L1 和 L∞ 范数的模数:
假设您有一个m x n矩阵。||A||[1]的计算如下:
因此结果将如下所示:
||A||[1] = max(3 + |-2| + 1; 7 + |-5| + 3; 6 + 4 + |-14|) = max(6, 15, 24) = 24
让我们使用linalg.norm()方法,用 NumPy 计算同一数组的范数:
In [27]: a = np.array([3,7,6,-2,-5,4,1,3,-14]).reshape(3,3)
In [28]: a
Out[28]: array([[ 3, 7, 6],
[ -2, -5, 4],
[ 1, 3, -14]])
In [29]: np.linalg.norm(a, ord=1)
Out[29]: 24.0
In [30]: np.linalg.norm(a, np.inf)
Out[30]: 18.0
在前面的计算中||A||[1]首先按列计算最大元素,并在所有列中给出最大结果,这将是一阶矩阵的范数。 对于 L∞ 元素计算按行执行,并在所有获得无穷范数范数矩阵的行中给出最大值。 计算结果如下:
||A||[∞] = max(3 + 7 + 6; |-2| + |-5| + 4; 1 + 3 + |-14|) = max(16, 11, 18) = 18
为了验证和使用 NumPy 函数,与我们在向量范数计算中所做的一样,使用linalg.norm()方法进行了相同的计算。 一阶和无限阶的计算比 Lp 范数(其中p > 2)的常规计算相对更直接,例如欧几里德/弗罗宾纽斯范数(其中p = 2)。 下面的公式显示了p范数的形式公式,只需将p替换为 2,就可以为给定数组制定欧几里得/弗罗比纽斯范数:
对于p = 2的特殊情况,它变为:
以下代码块显示了数组a的 L2 范数计算:
In [31]: np.linalg.norm(a, ord=2)
Out[31]: 15.832501006406099
在 NumPy 中,可以通过在linalg.norm()方法中将order参数设置为 2 来计算欧几里德/弗罗比纽斯范数,如您在前面的代码中所见。 在 ML 算法中,特征在特征空间的距离计算中大量使用。 例如,在模式识别中, 范数计算用于 K 最近邻算法(KNN),以便为连续变量或离散变量创建距离度量。 同样,范数对于 K 均值聚类中的距离度量也非常重要。 最受欢迎的顺序是曼哈顿范数和欧几里得范数。
线性代数中的另一个重要概念是计算矩阵的行列式。 根据定义,行列式是线性变换中给定矩阵的比例因子。 在上一节中,当您计算特征值和特征向量时,将给定矩阵乘以特征向量,并假定它们的行列式将为零。 换句话说,您假设将特征向量乘以矩阵后,会将矩阵展平为较低的维度。2 x 2和3 x 3矩阵的行列式如下:
在 NumPy 中,您可以使用linalg.det()方法来计算矩阵的行列式。 让我们用上式计算一个2 x 2和3 x 3矩阵行列式的示例,然后用 NumPy 交叉验证我们的结果:
因此计算如下:
对于我们有3 x 3矩阵的情况,它变为:
让我们使用linalg.det()方法,用 NumPy 计算相同数组的行列式:
In [32]: A= np.array([2,3,1,4]).reshape(2,2)
In [33]: A
Out[33]: array([[2, 3],
[1, 4]])
In [34]: np.linalg.det(A)
Out[34]: 5.0
In [35]: B= np.array([2,3,5,1,4,8,5,6,2]).reshape(3,3)
In [36]: B
Out[36]: array([[2, 3, 5],
[1, 4, 8],
[5, 6, 2]])
In [37]: np.linalg.det(B)
Out[37]: -36.0
转换的决定因素实际上显示了将扩展或压缩多少体积的因素。 如果矩阵的行列式等于2,则意味着此矩阵的变换将使体积增加2。 如果要进行链乘法,则还可以计算变换后音量的变化量。 假设您将两个矩阵相乘,这意味着将有两个转换。 如果det(A)= 2并且det(B)= 3,则总转换因子将乘以 6 作为det(AB) = det(A)det(B)。
最后,本章将为您的 ML 模型介绍一个非常有用的值,该值称为迹。 根据定义,迹线是矩阵对角线元素的总和。 在 ML 模型中,大多数情况下,您将使用几种回归模型来解释数据。 这些模型中的某些很有可能在某种程度上解释了您的数据质量,因此在这种情况下,您总是倾向于使用更简单的模型。 每当您必须进行权衡时,跟踪值对于量化复杂性就变得非常有价值。 以下代码块显示了使用 numpy 进行 2D 和 3D 矩阵的跟踪计算:
In [38]: a = np.arange(9).reshape(3,3)
In [39]: a
Out[39]: array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [40]: np.trace(a)
Out[40]: 12
In [41]: b = np.arange(27).reshape(3,3,3)
In [42]: b
Out[42]: array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
In [43]: np.trace(b)
Out[43]: array([36, 39, 42])
在 NumPy 中,可以使用trace()方法来计算矩阵的跟踪值。 如果您的矩阵是二维的,那么轨迹就是对角线的总和。 如果矩阵的维数大于2,则迹线是沿对角线的和数组。 在前面的示例中,矩阵B具有三个维度,因此跟踪数组的构造如下:
在本小节中,您学习了如何在 ML 算法中计算范数,行列式,跟踪和用法。 主要目的是学习这些概念并熟悉 NumPy 线性代数库。
求解线性方程
在本节中,您将学习如何使用linalg.solve()方法求解线性方程。 当您有线性方程要求解时,例如形式 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/0e3b6a5c-7f67-4ab8-aea6-cde4b3521b35.png ,在简单情况下,您只需计算A的反函数即可。然后将其乘以B即可得到解,但是当A具有高维数时,这使得计算起来很难进行计算A的倒数。 让我们从具有三个未知数的三个线性方程式的示例开始,如下所示:
因此,这些方程式可以用矩阵形式化如下:
然后,我们的问题是解决 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/6be36489-de17-4e8a-b83a-79a6708912de.png。 我们可以不使用linalg.solve(),而使用普通 NumPy 计算解决方案。颠倒A矩阵后,您将与B相乘以获得x的结果。在下面的代码块中,我们计算A和B的逆矩阵的点积,以便计算 https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/master-num-comp-numpy/img/8831a01b-8325-482a-8e28-31ebc3e92107.png:
In [44]: A = np.array([[2, 1, 2], [3, 2, 1], [0, 1, 1]])
A
Out[44]: array([[2, 1, 2],
[3, 2, 1],
[0, 1, 1]])
In [45]: B = np.array([8,3,4])
B
Out[45]: array([8, 3, 4])
In [46]: A_inv = np.linalg.inv(A)
A_inv
Out[46]: array([[ 0.2, 0.2, -0.6],
[-0.6, 0.4, 0.8],
[ 0.6, -0.4, 0.2]])
In [47]: np.dot(A_inv,B)
Out[47]: array([-0.2, -0.4, 4.4])
最后,得到a = -0.2,b = -0.4和c = 4.4的结果。 现在,让我们使用linalg.solve()执行相同的计算,如下所示:
In [48]: A = np.array([[2, 1, 2], [3, 2, 1], [0, 1, 1]])
B = np.array([8,3,4])
x = np.linalg.solve(A, B)
x
Out[48]: array([-0.2, -0.4, 4.4])
为了检查我们的结果,我们可以使用allclose()函数,该函数用于按元素比较两个数组:
In [49]: np.allclose(np.dot(A, x), B)
Out[49]: True
linalg.lstsq()方法是求解线性方程组的另一个重要函数,它返回最小二乘解。 此函数将返回回归线的参数。 回归线的主要思想是最小化每个数据点到回归线的距离平方和。 距离的平方和实际上量化了回归线的总误差。 距离越大,误差越大。 因此,我们正在寻找可以最大程度减少此误差的参数。 为了可视化我们的线性回归模型,我们将使用一个非常流行的 Python 二维绘图库matplotlib。 以下代码块在矩阵中运行最小二乘解,并返回权重和偏差:
In [50]: from numpy import arange,array,ones,linalg
from pylab import plot,show
x = np.arange(1,11)
A = np.vstack([x, np.ones(len(x))]).T
A
Out[50]: array([[ 1., 1.],
[ 2., 1.],
[ 3., 1.],
[ 4., 1.],
[ 5., 1.],
[ 6., 1.],
[ 7., 1.],
[ 8., 1.],
[ 9., 1.],
[ 10., 1.]])
In [51]: y = [5, 6, 6.5, 7, 8,9.5, 10, 10.4,13.1,15.5]
w = linalg.lstsq(A,y)[0]
w
Out[51]: array([ 1.05575758, 3.29333333])
In [52]: line = w[0]*x+w[1]
plot(x,line,'r-',x,y,'o')
show()
前面代码的输出如下:
上图给出了适合我们数据的回归线拟合结果。 该模型生成可用于预测或预测的线性线。 尽管线性回归有很多假设(恒定方差,误差的独立性,线性等),但它仍然是建模数据点之间线性关系的最常用方法。
计算梯度
当您有一条直线时,您可以使用导数,以便导数显示该线的斜率。 当函数中有多个变量时,梯度是导数的泛化,因此,梯度的结果实际上是向量函数,而不是导数中的标量值。 ML 的主要目标实际上是找到适合您数据的最佳模型。 您可以通过将损失函数或目标函数最小化来求值最佳均值。 梯度用于查找系数或函数,以最大程度地减少损失或成本函数。 查找最佳点的一种众所周知的方法是采用目标函数的导数,然后将其设置为零以找到模型系数。 如果系数不止一个,则它将成为梯度而不是导数,并且将成为向量方程式而不是标量值。 您可以在每个点上将梯度解释为向量,该梯度将指向函数的下一个局部最小值。 有一种非常流行的优化技术,可以通过计算每个点的梯度并沿该方向移动系数来寻找函数的最小值,以寻求最小值。 该方法称为梯度下降。 在 NumPy 中,gradient()函数用于计算数组的梯度:
In [53]: a = np.array([1,3, 6, 7, 11, 14])
gr = np.gradient(a)
gr
Out[53]: array([ 2\. , 2.5, 2\. , 2.5, 3.5, 3\. ])
让我们看看如何计算此梯度:
gr[0] = (a[1]-a[0])/1 = (3-1)/1 = 2
gr[1] = (a[2]-a[0])/2 = (6-1)/2 = 2.5
gr[2] = (a[3]-a[1])/2 = (7-3)/2 = 2
gr[3] = (a[4]-a[2])/2 = (11-6)/2 = 2.5
gr[4] = (a[5]-a[3])/2 = (14-7)/2 = 3.5
gr[5] = (a[5]-a[4])/1 = (14-11)/1 = 3
在前面的代码块中,我们计算了一维数组的梯度。 让我们添加另一个维度,并查看计算如何更改,如下所示:
[54]: a = np.array([1,3, 6, 7, 11, 14]). reshape(2,3)
gr = np.gradient(a)
gr
Out[54]: [array([[ 6., 8., 8.],
[ 6., 8., 8.]]), array([[ 2\. , 2.5, 3\. ],
[ 4\. , 3.5, 3\. ]])]
对于二维数组,与前面的代码一样,按列和按行计算梯度。 因此,结果将是两个数组的返回。 第一个数组代表行方向,第二个数组代表列方向。
总结
在本章中,我们介绍了线性代数的向量和矩阵运算。 我们研究了高级矩阵运算,尤其是特征点运算。 您还了解了的特征值和特征向量,然后在主成分分析(PCA)中实践了它们的用法。 此外,我们介绍了范数和行列式计算,并提到了它们在 ML 中的重要性和用法。 在最后两个小节中,您学习了如何将线性方程式转换为矩阵并求解它们,并研究了梯度的计算和重要性。
在下一章中,我们将使用 NumPy 统计数据进行解释性数据分析,以探索 2015 年美国住房数据。
三、使用 NumPy 统计函数对波士顿住房数据进行探索性数据分析
探索性数据分析(EDA)是数据科学项目的重要组成部分(如图数据科学过程所示)。 尽管在将任何统计模型或机器学习算法应用于数据之前这是非常重要的一步,但许多从业人员经常忽略或低估了它:
John Wilder Tukey 于 1977 年通过他的著作探索性数据分析促进了探索性数据分析。 在他的书中,他指导统计学家通过使用几种不同的视觉手段对统计数据集进行统计分析,这将帮助他们制定假设。 此外,在确定关键数据特征并了解有关数据的哪些问题后,EDA 还可以用于为高级建模准备分析。 在较高的层次上,EDA 是对您的数据的无假设探索,它利用了定量方法,使您可以可视化结果,从而可以识别模式,异常和数据特征。 在本章中,您将使用 NumPy 的内置统计方法执行探索性数据分析。
本章将涵盖以下主题:
- 加载和保存文件
- 探索数据集
- 查看基本统计量
- 计算平均值和方差
- 计算相关性
- 计算直方图
加载和保存文件
在本节中,您将学习如何加载/导入数据并保存。 加载数据的方式有很多,正确的方式取决于您的文件类型。 您可以加载/导入文本文件,SAS/Stata 文件,HDF5 文件以及许多其他文件。 HDF(分层数据格式)是一种流行的数据格式,用于存储和组织大量数据,并且在处理多维同构数组时非常有用。 例如,Pandas 库有一个非常方便的类,名为HDFStore,您可以在其中轻松使用 HDF5 文件。 在从事数据科学项目时,您很可能会看到许多这类文件,但是在本书中,我们将介绍最受欢迎的文件,例如 NumPy 二进制文件,文本文件(.txt)和逗号分隔值(.csv)文件。
如果内存和磁盘上有大量数据要管理,则可以使用bcolz库。 它提供了列式和压缩数据容器。 bcolz对象称为chunks,您在其中将整个数据压缩为位,然后在查询时部分解压缩。 压缩数据后,它会非常高效地使用存储。bcolz对象也提高了数据获取性能。 如果您对该库的性能感兴趣。 您可以在其官方 GitHub 存储库 上检查查询和速度比较。
使用数组时,通常在完成使用后将它们另存为 NumPy 二进制文件。 原因是您还需要存储数组形状和数据类型。 重新加载数组时,您希望 NumPy 记住它,并且您可以从上次中断的地方继续工作。 此外,即使您在具有不同架构的另一台计算机上打开文件, NumPy 二进制文件也可以存储有关数组的信息。 在 NumPy 中,load(),save(),savez()和savez_compressed()方法可帮助您加载和保存 NumPy 二进制文件,如下所示:
In [1]: import numpy as np
In [2]: example_array = np.arange(12).reshape(3,4)
In [3]: example_array
Out[3]: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
In [4]: np.save('example.npy',example_array)
In [5]: d = np.load('example.npy')
In [6]: np.shape(d)
Out[6]: (3, 4)
In [7]: d
Out[7]: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
在前面的代码中,我们执行以下步骤来练习将数组保存为二进制文件,以及如何在不影响其形状的情况下将其加载回:
- 创建形状为
(3, 4)的数组 - 将数组另存为二进制文件
- 加载回数组
- 检查形状是否仍然相同
同样,您可以使用savez()函数将多个数组保存到单个文件中。 如果要将文件另存为压缩的 NumPy 二进制文件,则可以按以下方式使用savez_compressed():
In [8]: x = np.arange(10)
y = np.arange(12)
np.savez('second_example.npz',x, y)
npzfile = np.load('second_example.npz')
npzfile.files
Out[8]: ['arr_0', 'arr_1']
In [9]: npzfile['arr_0']
Out[9]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [10]: npzfile['arr_1']
Out[10]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
In [11]: np.savez_compressed('compressed_example.npz', first_array = x , second_array = y)
npzfile = np.load('compressed_example.npz')
npzfile.files
Out[11]: ['first_array', 'second_array']
In [12]: npzfile['first_array']
Out[12]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [13]: npzfile['second_array']
Out[13]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
当您将多个数组保存在单个文件中时,如果您提供关键字参数如first_array=x,则将使用该名称保存数组。 否则,默认情况下,您的第一个数组将被赋予一个变量名,例如arr_0。 NumPy 具有称为loadtxt()的内置函数,用于从文本文件加载数据。 让我们加载一个.txt文件,该文件由一些整数和一个标头组成,该标头是文件顶部的字符串:
在前面的代码中,由于无法将字符串转换为浮点数,因此会出现误差,这实际上意味着您正在读取非数字值。 这样做的原因是该文件在顶部包含作为标题的字符串以及数值。 如果知道标题有多少行,则可以使用skiprows参数跳过这些行,如下所示:
In [15]: a = np.loadtxt("My_file.txt", delimiter='\t', skiprows=4)
a
Out[15]: array([ 0., 1., 2., 3., 4., 5., 6., 7., 8.,
9., 10., 11., 12., 13., 14., 15., 16., 17.,
18., 19., 20., 21., 22., 23., 24., 25., 26.,
27., 28., 29., 30., 31., 32., 33., 34., 35.,
36., 37., 38., 39., 40., 41., 42., 43., 44.,
45., 46., 47., 48., 49., 50., 51., 52., 53.,
54., 55., 56., 57., 58., 59., 60., 61., 62.,
63., 64., 65., 66., 67., 68., 69., 70., 71.,
72., 73., 74., 75., 76., 77., 78., 79., 80.,
81., 82., 83., 84., 85., 86., 87., 88., 89.,
90., 91., 92., 93., 94., 95., 96., 97., 98.,
99., 100., 101., 102., 103., 104., 105., 106., 107.,
108., 109., 110., 111., 112., 113., 114., 115., 116.,
117., 118., 119., 120., 121., 122., 123., 124., 125.,
126., 127., 128., 129., 130., 131., 132., 133., 134.,
135., 136., 137., 138., 139., 140., 141., 142., 143.,
144., 145., 146., 147., 148., 149., 150., 151., 152.,
153., 154., 155., 156., 157., 158., 159., 160., 161.,
162., 163., 164., 165., 166., 167., 168., 169., 170.,
171., 172., 173., 174., 175., 176., 177., 178., 179.,
180., 181., 182., 183., 184., 185., 186., 187., 188.,
189., 190., 191., 192., 193., 194., 195., 196., 197.,
198., 199., 200., 201., 202., 203., 204., 205., 206.,
207., 208., 209., 210., 211., 212., 213., 214., 215.,
216., 217., 218., 219., 220., 221., 222., 223., 224.,
225., 226., 227., 228., 229., 230., 231., 232., 233.,
234., 235., 236., 237., 238., 239., 240., 241., 242.,
243., 244., 245., 246., 247., 248., 249.])
另外,您可以使用genfromtxt()并将标头的转换默认设置为nan。 然后,您可以检测到标题占用了多少行,并使用skip_header参数跳过它们,如下所示:
In [16]: b = np.genfromtxt("My_file.txt", delimiter='\t')
b
Out[16]: array([ nan, nan, nan, nan, 0., 1., 2., 3., 4.,
5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19., 20., 21., 22.,
23., 24., 25., 26., 27., 28., 29., 30., 31.,
32., 33., 34., 35., 36., 37., 38., 39., 40.,
41., 42., 43., 44., 45., 46., 47., 48., 49.,
50., 51., 52., 53., 54., 55., 56., 57., 58.,
59., 60., 61., 62., 63., 64., 65., 66., 67.,
68., 69., 70., 71., 72., 73., 74., 75., 76.,
77., 78., 79., 80., 81., 82., 83., 84., 85.,
86., 87., 88., 89., 90., 91., 92., 93., 94.,
95., 96., 97., 98., 99., 100., 101., 102., 103.,
104., 105., 106., 107., 108., 109., 110., 111., 112.,
113., 114., 115., 116., 117., 118., 119., 120., 121.,
122., 123., 124., 125., 126., 127., 128., 129., 130.,
131., 132., 133., 134., 135., 136., 137., 138., 139.,
140., 141., 142., 143., 144., 145., 146., 147., 148.,
149., 150., 151., 152., 153., 154., 155., 156., 157.,
158., 159., 160., 161., 162., 163., 164., 165., 166.,
167., 168., 169., 170., 171., 172., 173., 174., 175.,
176., 177., 178., 179., 180., 181., 182., 183., 184.,
185., 186., 187., 188., 189., 190., 191., 192., 193.,
194., 195., 196., 197., 198., 199., 200., 201., 202.,
203., 204., 205., 206., 207., 208., 209., 210., 211.,
212., 213., 214., 215., 216., 217., 218., 219., 220.,
221., 222., 223., 224., 225., 226., 227., 228., 229.,
230., 231., 232., 233., 234., 235., 236., 237., 238.,
239., 240., 241., 242., 243., 244., 245., 246., 247.,
248., 249.])
同样,您可以使用loadtxt(),genfromtxt()和savetxt()函数加载和保存.csv文件。 您唯一需要记住的是使用逗号作为定界符,如下所示:
In [17]: data_csv = np.loadtxt("MyData.csv", delimiter=',')
In [18]: data_csv[1:3]
Out[18]: array([[ 0.21982, 0.31271, 0.66934, 0.06072, 0.77785, 0.59984,
0.82998, 0.77428, 0.73216, 0.29968],
[ 0.78866, 0.61444, 0.0107 , 0.37351, 0.77391, 0.76958,
0.46845, 0.76387, 0.70592, 0.0851 ]])
In [19]: np.shape(data_csv)
Out[19]: (15, 10)
In [20]: np.savetxt('MyData1.csv',data_csv, delimiter = ',')
In [21]: data_csv1 = np.genfromtxt("MyData1.csv", delimiter = ',')
In [22]: data_csv1[1:3]
Out[22]: array([[ 0.21982, 0.31271, 0.66934, 0.06072, 0.77785, 0.59984,
0.82998, 0.77428, 0.73216, 0.29968],
[ 0.78866, 0.61444, 0.0107 , 0.37351, 0.77391, 0.76958,
0.46845, 0.76387, 0.70592, 0.0851 ]])
In [23]: np.shape(data_csv1)
Out[23]: (15, 10)
加载.txt文件时,它们会默认返回带有值的numpy数组,如后面的代码中所示:
In [24]: print (type(a))
print (type(b))
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
您可以使用tolist()方法将数据从数组更改为列表,然后使用savetxt()使用不同的分隔符将其保存为新文件,如下所示:
In [25]: c = a.tolist()
c
Out[25]: [0.0,
1.0,
2.0,
3.0,
4.0,
5.0,
6.0,
7.0,
8.0,
9.0,
10.0,
11.0,
12.0,
13.0,
14.0,
15.0,
16.0,
17.0,
18.0,
...
In [26]: np.savetxt('My_List.txt',c, delimiter=';')
In [27]: myList = np.loadtxt("My_List.txt", delimiter=';')
type(myList)
Out[27]: numpy.ndarray
将列表保存到My_List.txt后,可以使用loadtxt()加载此文件,它将再次作为numpy数组返回。 如果要返回数组的字符串表示形式,可以使用array_str(),array_repr()或array2string()方法,如下所示:
In [28]: d = np.array_str(a,precision=1)
d
Out[28]: '[ 0\. 1\. 2\. 3\. 4\. 5\. 6\. 7\. 8\. 9\. 10\. 11.\n 12\. 13\. 14\. 15\. 16\. 17\. 18\. 19\. 20\. 21\. 22\. 23.
24\. 25\. 26\. ... ]'
即使array_str()和array_repr()看起来一样,array_str()返回数组内部数据的字符串表示形式,而array_repr()实际上返回数组的字符串表示形式。 因此,array_repr()返回有关数组类型及其数据类型的信息。 这两个函数在内部都使用array2string(),这实际上是字符串格式化函数最灵活的版本,因为它具有更多可选参数。 以下代码块使用load_boston()方法加载波士顿房屋数据集:
In [29]: from sklearn.datasets import load_boston
dataset = load_boston()
dataset
在本章中,您将对sklearn.datasets包中的示例数据集进行探索性数据分析。 该数据集是关于波士顿房价的。 在前面的代码中,load_boston()函数是从sklearn.datasets包中导入的,如您所见,它返回具有属性DESCR,data,feature_names和target的类似字典的对象 ]。 这些属性的详细信息如下:
| 属性 | 解释 |
|---|---|
DESCR | 数据集的完整描述 |
data | 特征列 |
feature_names | 特征名称 |
target | 标签数据 |
在本节中,您学习了如何使用numpy函数加载和保存文件。 在下一部分中,您将探索波士顿住房数据集。
探索我们的数据集
在本节中,您将探索数据集并对其进行质量检查。 您将检查数据形状是什么,以及它的数据类型,所有缺失值/ NaN,拥有多少个特征列以及每个列代表什么。 让我们开始加载数据并进行探索:
In [30]: from sklearn.datasets import load_boston
dataset = load_boston()
samples,label, feature_names = dataset.data , dataset.target , dataset.feature_names
In [31]: samples.shape
Out[31]: (506, 13)
In [32]: label.shape
Out[32]: (506,)
In [33]: feature_names
Out[33]: array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'],
dtype='<U7')
在前面的代码中,您加载了数据集并解析了数据集的属性。 这表明我们拥有具有13函数的506样本,并且具有506标签(回归目标)。 如果要阅读数据集的描述,可以使用print(dataset.DESCR)。 由于此代码的输出太长,无法放置在此处,因此您可以在以下屏幕截图中查看各种特征及其描述:
如第一章所示,您可以使用dtype检查数组的数据类型。 如下面的代码所示,示例的每一列中都有一个数字float64数据类型和一个标签。 检查数据类型是非常重要的一步,您可能会意识到类型和列描述之间存在一些不一致,或者,如果您认为使用不太精确的目标值仍然可以实现,则可以通过更改其数据类型来减少数组的内存大小:
In [35]: print(samples.dtype)
print(label.dtype)
float64
float64
缺失值处理在 Python 软件包中略有不同。numpy库没有缺失值。 如果您的数据集中缺少值,则导入后它们将转换为NaN。 NumPy 中非常常见的方法是使用掩码数组以忽略NaN值,这在第一章中已向您展示:
In [36]: np.isnan(samples)
Out[36]: array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]], dtype=bool)
In [37]: np.isnan(np.sum(samples))
Out[37]: False
In [38]: np.isnan(np.sum(label))
Out[38]: False
要针对数据中的NaN值逐元素进行测试,可以使用isnan()方法。 此方法将返回一个布尔数组。 对于大型数组而言,检测它是否返回true可能很麻烦。 在这种情况下,您可以将数组的np.sum()用作isnan()的参数,这样它将为结果返回单个布尔值。
在本节中,您将深入研究数据并进行常规质量检查。 在下一节中,我们将继续进行基本统计。
查看基本统计量
在本节中,您将从统计分析的第一步开始,计算数据集的基本统计信息。 即使 NumPy 的内置统计函数有限,我们也可以将其与 SciPy 结合使用。 在开始之前,让我们描述一下我们的分析将如何进行。 所有特征列和标签列都是数字,但您可能已经注意到 Charles River 虚拟变量(CHAS)列具有二进制值(0, 1),这意味着它实际上是根据分类数据编码的。 分析数据集时,可以将列分为Categorical和Numerical。 为了一起分析它们,应将一种类型转换为另一种类型。 如果您具有分类值,并且想要将其转换为数字值,则可以通过将每个类别转换为数字值来实现。 该过程称为编码。 另一方面,可以通过将数值转换为类别对应物来执行装箱,类别对应物是通过将数据分成间隔来创建的。
我们将通过逐一探讨其特征来开始分析。 在统计中,此方法称为单变量分析。 单变量分析的目的主要围绕描述。 我们将计算最小值,最大值,范围,百分位数,均值和方差,然后绘制一些直方图并分析每个特征的分布。 我们将介绍偏度和峰度的概念,然后看一下修剪的重要性。 完成单变量分析后,我们将继续进行双变量分析,这意味着同时分析两个特征。 为此,我们将探索两组特征之间的关系:
In [39]: np.set_printoptions(suppress=True, linewidth=125)
minimums = np.round(np.amin(samples, axis=0), decimals=1)
maximums = np.round(np.amax(samples, axis=0), decimals=1)
range_column = np.round(np.ptp(samples, axis=0), decimals=1)
mean = np.round(np.mean(samples, axis=0), decimals=1)
median = np.round(np.median(samples, axis=0), decimals=1)
variance = np.round(np.var(samples, axis=0), decimals=1)
tenth_percentile = np.round(np.percentile(samples, 10, axis=0), decimals = 1)
ninety_percentile = np.round(np.percentile(samples, 90 ,axis=0), decimals = 1)
In [40]: range_column
Out[40]: array([ 89\. , 100\. , 27.3, 1\. , 0.5, 5.2, 97.1, 11\. , 23\. , 524\. , 9.4, 396.6, 36.2])
在前面的代码中,我们首先使用set_printoptions()方法设置打印选项,以便查看四舍五入的小数位数,并且其线宽足以容纳所有列。 要计算基本统计信息,我们使用numpy函数,例如amin(),amax(),mean(),median(),var(),percentile()和ptp()。 所有计算都是按列进行的,因为每一列都代表一个要素。 最终的数组看起来有点草率且无用,因为您看不到哪行显示了哪些统计信息:
为了打印对齐的 numpy 数组,可以使用zip()函数添加行标签并在数组之前打印列标签。 在 SciPy 中,您可以使用更多统计函数来计算基本统计信息。 SciPy 提供describe()函数,该函数返回给定数组的一些描述性统计信息。 您可以使用一个函数来计算点,最小值,最大值,均值,方差,偏度和峰度,然后分别解析它们,如下所示:
以下代码块分别计算基本统计信息并将其堆叠到最终数组中:
In [45]: minimum = arr.minmax[0]
maximum = arr.minmax[1]
mean = arr.mean
median = np.round(np.median(samples,axis = 0), decimals = 1)
variance = arr.variance
tenth_percentile = stats.scoreatpercentile(samples, per = 10, axis = 0)
ninety_percentile = stats.scoreatpercentile(samples, per =90, axis = 0)
rng = stats.iqr(samples, rng = (20,80), axis = 0)
np.set_printoptions(suppress = True, linewidth = 125)
Basic_Statistics1 = np.round(np.vstack((minimum,maximum,rng, mean,median,variance,tenth_percentile,ninety_percentile)), Basic_Statistics1.shape
Out[45]: (8, 13)
In [46]: stat_labels1 = ['minm', 'maxm', 'rang', 'mean', 'medi', 'vari', '50%t', '90%t']
与 NumPy 相比,我们可以使用iqr()函数来计算范围。 此函数计算沿指定轴和范围(rng参数)的数据的四分位数范围。 默认情况下,rng = (25, 75),这意味着该函数将计算数据的第 75 和第 25 个百分位数之间的差。 为了返回与numpy.ptp()函数相同的输出,可以使用rng = (0, 100),因为这将计算所有给定数据的范围。 我们使用stat.scoreatpercentile()作为与numpy.percentile()方法的等效物,来计算特征的第 10 个和第 90 个百分位值。 如果您看一眼结果,您会发现几乎每个特征的差异都很大。 您可以看到,由于我们通过将参数传递为(20,80)来限制范围计算,因此范围值显着减小。 它也向您展示了我们在分布式要素的两侧都有许多极值。 从我们的结果可以得出结论,对于大多数特征,平均值均高于中位数,这表明我们这些特征的分布偏向右侧。 在下一节中,当我们绘制直方图然后深入分析这些特征的偏度和峰度时,您将清楚地看到这一点。
计算直方图
直方图是数字数据分布的直观表示。 一百多年前,卡尔·皮尔森(Karl Pearson)首次提出了这一概念。 直方图是一种用于连续数据的条形图,而条形图直观地表示类别变量。 第一步,您需要将整个值范围划分为一系列间隔(仓位)。 每个桶必须相邻,并且它们不能重叠。 通常,桶大小相等,要包含的桶数量的经验法则是 5–20。 这意味着,如果您有 20 个以上的容器,则图形将很难阅读。 相反,如果您的箱数少于 5 个,则您的图形将很少了解数据的分布:
In [48]: %matplotlib notebook
%matplotlib notebook
import matplotlib.pyplot as plt
NOX = samples[:,5:6]
plt.hist(NOX,bins ='auto')
plt.title("Distribution nitric oxides concentration (parts per 10 million)")
plt.show()
在前面的代码中,我们绘制了特征NOX的直方图。 箱柜计算自动完成,如下所示:
您可以通过将切片数组作为第一个参数,使用pyplot.hist()绘制直方图。 y 轴显示数据集中每个间隔(桶)中有多少值的计数, x 轴表示其值。 通过设置normed=True,您可以看到箱柜的百分比,如下所示:
In [49]: plt.hist(NOX,bins ='auto', normed = True)
plt.title("Distribution nitric oxides concentration (parts per 10 million)")
plt.show()
当您查看直方图时,可能很难计算每个桶及其边界的大小。 当pyplot.hist()返回包含此信息的元组时,您可以轻松地获得这些值,如下所示:
In [50]: import matplotlib.pyplot as plt
NOX = samples[:,5:6]
n, bins, patches = plt.hist(NOX, bins='auto')
print('Bin Sizes')
print(n)
print('Bin Edges')
print(bins)
在前面的代码中,我们打印出每个桶中包含多少个数字,以及桶的边界是什么,如下所示:
让我们解释一下前面的输出。 第一个桶的大小为1,这意味着此桶中仅存在一个值下降。 第一仓的间隔在3.561和3.74096552之间。 为了使它们更整洁,可以使用以下代码块,该代码块有意义地堆叠了这两个数组(bin_interval,bin_size):
In [51]: bins_string = bins.astype(np.str)
n_string = n.astype(np.str)
lists = []
for i in range(0, len(bins_string)-1):
c = bins_string[i]+ "-" + bins_string[i+1]
lists.append(c)
new_bins = np.asarray(lists)
Stacked_Bins = np.vstack((new_bins, n_string)).T
Stacked_Bins
确定桶的数量及其宽度非常重要。 一些理论家对此进行试验以确定最佳拟合。 下表显示了最受欢迎的估计器。 您可以将估计器设置为numpy.histogram()中的bins参数,以相应地更改桶计算。 这些方法由pyplot.hist()函数隐式支持,因为其参数传递给numpy.histogram():
IQR = 四分位间距
g[1] = 分布的估计三阶偏度
所有这些方法都有不同的优势。 例如,Strurges 公式对于高斯数据是最佳的。 Rice 的规则是 Sturges 公式的简化版本,并假定近似正态分布,因此,如果数据不是正态分布,则可能效果不佳。 Doane 的公式是 Sturges 公式的改进版本,尤其是在具有非正态分布的情况下。 Freedman–Diaconis 估计器是 Scott 规则的修改版本,他用IQR=2代替了 3.5 个标准差,这使公式对异常值的敏感性降低。 平方根选择是一种非常常见的方法,许多工具都以其快速简便的方式使用它。 在numpy.histogram()中,还有一个名为'auto'的选项,它为我们提供了最大的 Sturges 和 Freedman–Diaconis 估计器方法。 让我们看看这些方法将如何影响直方图:
In [52]: fig, ((ax1, ax2, ax3),(ax4,ax5,ax6)) = plt.subplots(2,3,sharex=True)
axs = [ax1,ax2,ax3,ax4,ax5,ax6]
list_methods = ['fd','doane', 'scott', 'rice', 'sturges','sqrt']
plt.tight_layout(pad=1.1, w_pad=0.8, h_pad=1.0)
for n in range(0, len(axs)):
axs[n].hist(NOX,bins = list_methods[n])
axs[n].set_title('{}'.format(list_methods[n]))
在前面的代码中,我们编译了六个直方图,它们全部共享相同的 x 轴,如下所示:
所有直方图都表示相同的特征,但具有不同的合并方法。 例如,fd方法显示数据看起来接近其正态分布,而另一方面,doane方法看起来更像学生的 T 分布。 另外,sturges方法会创建两个小容器,因此很难分析数据。 当我们查看基本统计数据时,我们指出大多数特征的均值均高于其中位数,因此他们将数据向右倾斜。 但是,如果您查看sturges,rice和sqrt方法,则很难这么说。 但是,当我们使用自动箱绘制直方图时,这是显而易见的:
In [53]: import numpy as np
samples_new = np.delete(samples, 3 , axis=1)
samples_new.shape
Out[53]: (506, 12)
In [54]: %matplotlib notebook
%matplotlib notebook
import matplotlib.pyplot as plt
fig,((ax1, ax2 , ax3),(ax4, ax5, ax6), (ax7, ax8, ax9), (ax10, ax11, ax12)) = plt.subplots(4,3, figsize = (10,15))
axs =[ax1, ax2 , ax3, ax4, ax5, ax6, ax7, ax8, ax9, ax10, ax11, ax12]
feature_names_new = np.delete(feature_names,3)
for n in range(0, len(axs)):
axs[n].hist(samples_new[:,n:n+1], bins ='auto', normed = True)
axs[n].set_title('{}'.format(feature_names[n]))
在前面的代码中,我们在单个布局中编译所有特征直方图。 这将帮助我们轻松比较它们。 前面代码的输出如下:
在前面的代码中,我们删除了CHAS,因为它包含二进制值,这意味着直方图将无助于我们进一步了解此特征。 我们还从特征列表中取出了特征名称,以便正确绘制其余特征。
从这些图表我们可以得出结论,在大多数城镇中,人均犯罪率非常低,但是在某些城镇中,这一比例非常高。 通常,住宅用地面积低于 25,000 英尺。在许多情况下,非零售业务用地所占土地不到整个城镇的 10% 。 另一方面,我们可以看到许多城镇的非零售业务用地约为 20% 。 一氧化氮的浓度非常偏斜,尽管此处存在一些离平均值很远的异常值。 每个住宅的平均房间数在 5 至 7 间之间。 在 1940 年之前建造的架构物中,超过 50% 的架构物被其所有者占用。 他们中的大多数人离波士顿的就业中心都不远。 超过 10% 的人无法轻松到达径向公路。 对于相当多的人来说,财产税很高。 通常,教室规模为 15 至 20 个孩子。 大多数城镇中居住的黑人比例非常相似。 大多数城镇居民的经济地位较低。 通过查看这些直方图,您可以得出许多其他结论。 如您所见,直方图在描述数据的分布方式时非常有用,并且可以看到平均值,方差和离群值。 在下一节中,我们将重点介绍偏度和峰度。
解释偏度和峰度
在统计分析中,力矩是一种定量度量,用于描述距参考点的预期距离。 如果期望参考点,则将其称为中心矩。 在统计中,中心矩是与均值相关的矩。 第一个和第二个矩分别是平均值和方差。 平均值是您的数据点的平均值。 方差是每个数据点与平均值的总偏差。 换句话说,方差表明您的数据如何与均值分散。 第三个中心矩是偏度,它测量均值分布的不对称性。 在标准正态分布中,偏度是对称的,因此等于零。 另一方面,如果均值
In [55]: %matplotlib notebook
%matplotlib notebook
from scipy.stats import skewnorm
fig, (ax1, ax2, ax3) = plt.subplots(1,3 ,figsize=(10,2.5))
x1 = np.linspace(skewnorm.ppf(0.01,-3), skewnorm.ppf(0.99,-3),100)
x2 = np.linspace(skewnorm.ppf(0.01,0), skewnorm.ppf(0.99,0),100)
x3 = np.linspace(skewnorm.ppf(0.01,3), skewnorm.ppf(0.99,3),100)
ax1.plot(skewnorm(-3).pdf(x1),'k-', lw=4)
ax2.plot(skewnorm(0).pdf(x2),'k-', lw=4)
ax3.plot(skewnorm(3).pdf(x3),'k-', lw=4)
ax1.set_title('Left Skew')
ax2.set_title('Normal Dist')
ax3.set_title('Right Skew')
您可以使用skewnorm()函数轻松创建具有偏斜度的正态分布。 如您在前面的代码中看到的,我们生成一个具有 100 个值的百分点函数(与累积分布函数百分位数相反),然后创建具有不同偏斜度的线。 您不能直接得出结论,左偏斜比右偏斜好,反之亦然。 当分析数据的偏斜度时,您需要考虑这些尾巴会导致什么。 例如,如果您正在分析股票收益的时间序列,并将其绘制后看到一个正确的偏斜,则不必担心获得比预期更高的收益,因为这些离群值不会给您的股票带来任何风险。 交易策略。 当您分析服务器的响应时间时,可能会出现类似的示例。 当您绘制响应时间的概率密度函数时,您对左尾巴并不真正感兴趣,因为它们代表了快速的响应时间。
关于均值的第四个中心矩是峰度。 峰度描述了与分布曲线的平坦程度或变薄程度有关的尾部(离群值)。 在正态分布中,峰度等于 3。峰度主要有三种类型:Leptokurtic(薄),Mesokurtic和Platykurtic(平坦):
In [56]: %matplotlib notebook
%matplotlib notebook
import scipy
from scipy import stats
import matplotlib.pyplot as plt
fig, (ax1, ax2, ax3) = plt.subplots(1, 3 , figsize=(10,2))
axs= [ax1, ax2, ax3]
Titles = ['Mesokurtic', 'Lebtokurtic', 'Platykurtic']
#Mesokurtic Distribution - Normal Distribution
dist = scipy.stats.norm(loc=100, scale=5)
sample_norm = dist.rvs(size = 10000)
#leptokurtic Distribution
dist2 = scipy.stats.laplace(loc= 100, scale= 5)
sample_laplace = dist2.rvs(size= 10000)
#platykurtic Distribution
dist3 = scipy.stats.cosine(loc= 100, scale= 5)
sample_cosine = dist3.rvs(size= 10000)
samples = [sample_norm, sample_laplace, sample_cosine]
for n in range(0, len(axs)):
axs[n].hist(samples[n],bins= 'auto', normed= True)
axs[n].set_title('{}'.format(Titles[n]))
print ("kurtosis of" + Titles[n])
print(scipy .stats.describe(samples[n])[5])
在前面的代码中,您可以更清楚地看到分布形状的差异。 所有峰度值均使用stats.describe()方法进行归一化,因此正态分布的实际峰度值约为 3,而归一化版本为 0.02。 让我们快速检查一下我们特征的偏度和峰度值是什么:
In [57]: samples,label, feature_names = dataset.data , dataset.target , dataset.feature_names
for n in range(0, len(feature_names_new)):
kurt = scipy.stats.describe(samples[n])[5]
skew = scipy.stats.describe(samples[n])[4]
print (feature_names_new[n] + "-Kurtosis: {} Skewness: {}" .format(kurt, skew))
CRIM-Kurtosis: 2.102090573040533 Skewness: 1.9534138515494224
ZN-Kurtosis: 2.8706349006925134 Skewness: 2.0753333576721893
INDUS-Kurtosis: 2.9386308786131767 Skewness: 2.1061627843164086
NOX-Kurtosis: 3.47131446484547 Skewness: 2.2172838215060517
RM-Kurtosis: 3.461596258869246 Skewness: 2.2086627738768234
AGE-Kurtosis: 3.395079726813977 Skewness: 2.1917520072643533
DIS-Kurtosis: 1.9313625761956317 Skewness: 1.924572804475305
RAD-Kurtosis: 1.7633603556547106 Skewness: 1.8601991629604233
TAX-Kurtosis: 1.637076772210217 Skewness: 1.8266096199819994
PTRATIO-Kurtosis: 1.7459544645159752 Skewness: 1.8679592455694167
B-Kurtosis: 1.7375702020429316 Skewness: 1.8566444885400044
LSTAT-Kurtosis: 1.8522036606250456 Skewness: 1.892802610207445
从结果中可以看出,所有特征都具有正偏度,这表明它们向右偏斜。 就峰度而言,它们都具有正值,尤其是 NOX 和 RM,它们具有非常高的色氨酸。 我们可以得出结论,它们全都是瘦腿型的,这表明数据更加集中在均值上。 在下一节中,我们将着重于数据修整并使用修整后的数据计算统计数据。
整理统计量
正如您在上一节中已经注意到的那样,我们特征的分布非常分散。 处理模型中的异常值是分析中非常重要的部分。 当您查看描述性统计数据时,它也非常重要。 由于这些极端值,您很容易混淆并曲解分布。 SciPy 具有非常广泛的统计函数,可以计算有关修剪数据的描述性统计数据。 使用调整后的统计数据的主要思想是删除异常值(尾部),以减少其对统计计算的影响。 让我们看看如何使用这些函数,以及它们如何影响我们的特征分布:
In [58]: np.set_printoptions(suppress= True, linewidth= 125)
samples = dataset.data
CRIM = samples[:,0:1]
minimum = np.round(np.amin(CRIM), decimals=1)
maximum = np.round(np.amax(CRIM), decimals=1)
variance = np.round(np.var(CRIM), decimals=1)
mean = np.round(np.mean(CRIM), decimals=1)
Before_Trim = np.vstack((minimum, maximum, variance, mean))
minimum_trim = stats.tmin(CRIM, 1)
maximum_trim = stats.tmax(CRIM, 40)
variance_trim = stats.tvar(CRIM, (1,40))
mean_trim = stats.tmean(CRIM, (1,40))
After_Trim = np.round(np.vstack((minimum_trim,maximum_trim,variance_trim,mean_trim)), decimals=1)
stat_labels1 = ['minm', 'maxm', 'vari', 'mean']
Basic_Statistics1 = np.hstack((Before_Trim, After_Trim))
print (" Before After")
for stat_labels1, row1 in zip(stat_labels1, Basic_Statistics1):
print ('%s [%s]' % (stat_labels1, ''.join('%07s' % a for a in row1)))
Before After
minm [ 0.0 1.0]
maxm [ 89.0 38.4]
vari [ 73.8 48.1]
mean [ 3.6 8.3]
要计算调整后的统计信息,我们使用了tmin(),tmax(),tvar()和tmean(),如前面的代码所示。 所有这些函数都将极限值作为第二个参数。 在CRIM函数中,我们可以在右侧看到很多尾巴,因此我们将数据限制为(1, 40),然后计算统计信息。 在修整值之前和之后,您可以通过比较计算的统计信息来观察差异。 作为tmean()的替代方法,如果要从两侧按比例分割数据,可以使用trim_mean()函数。 您可以看到我们的均值和方差在修剪数据后如何显着变化。 当我们删除了 40 至 89 之间的许多极端离群值时,方差显着减小。相同的修整对均值有不同的影响,此后均值增加了一倍以上。 原因是先前的分布中有很多零,并且通过将计算限制在 1 和 40 的值之间,我们删除了所有这些零,这导致了更高的平均值。 请注意,上述所有函数只是在计算这些值时即时修剪数据,因此CRIM数组不会被修剪。 如果要从两侧修剪数据,则可以在一侧使用trimboth()和trim1()。 在这两种方法中,应该使用比例作为参数,而不是使用极限值。 例如,如果您传递proportiontocut =0.2,它将把您最左边和最右边的值切成 20% :
In [59]: %matplotlib notebook
%matplotlib notebook
import matplotlib.pyplot as plt
CRIM_TRIMMED = stats.trimboth(CRIM, 0.2)
fig, (ax1, ax2) = plt.subplots(1,2 , figsize =(10,2))
axs = [ax1, ax2]
df = [CRIM, CRIM_TRIMMED]
list_methods = ['Before Trim', 'After Trim']
for n in range(0, len(axs)):
axs[n].hist(df[n], bins = 'auto')
axs[n].set_title('{}'.format(list_methods[n]))
从两侧修剪掉 20% 的值后,我们可以更好地解释分布,实际上可以看到大多数值在 0 到 1.5 之间。 仅查看左方的直方图就很难获得这种见解,因为极值主导了直方图,并且我们只能看到 0 周围的一条线。因此,trimmed函数在探索性数据分析中非常有用。 在下一部分中,我们将重点讨论箱形图,它们对于数据的描述性分析和异常值检测非常有用且非常流行。
箱形图
探索性数据分析中的另一个重要视觉效果是箱形图,也称为箱须图。 它基于五位数摘要建立,该摘要是最小值,第一四分位数,中位数,第三四分位数和最大值。 在标准箱形图中,这些值表示如下:
这是比较几种分布的一种非常方便的方法。 通常,情节的胡须通常延伸到极限点。 或者,您可以将其切入 1.5 个四分位范围。 让我们检查一下CRIM和RM函数:
In [60]: %matplotlib notebook
%matplotlib notebook
import matplotlib.pyplot as plt
from scipy import stats
samples = dataset.data
fig, (ax1,ax2) = plt.subplots(1,2, figsize =(8,3))
axs = [ax1, ax2]
list_features = ['CRIM', 'RM']
ax1.boxplot(stats.trimboth(samples[:,0:1],0.2))
ax1.set_title('{}'.format(list_features[0]))
ax2.boxplot(stats.trimboth(samples[:,5:6],0.2))
ax2.set_title('{}'.format(list_features[1]))
正如您在前面的代码中看到的那样,RM 值一直沿最小值和最大值连续分散,以便胡须看起来像一条线。 您可以轻松地检测到中位数几乎位于第一和第三四分位数之间的中间位置。 在CRIM中,极值不会沿着最小值继续; 它们更像是单个外围数据点,因此表示就像一个圆圈。 您可以看到这些离群值大多位于第三个四分位数之后,并且中位数非常接近第一个四分位数。 由此,您还可以得出结论,分布是右偏的。 因此,箱形图是直方图的非常有用的替代方法,因为您可以轻松分析分布并一次比较多个分布。 在下一节中,我们将继续进行双变量分析,并研究标签数据与要素的相关性。
计算相关性
本节专门用于双变量分析,您可以在其中分析两列。 在这种情况下,我们通常研究这两个变量之间的关联,这称为相关性。 相关性显示两个变量之间的关系,并回答一些问题,例如,如果变量 B 增加 10% ,变量 A 将会发生什么? 在本节中,我们将说明如何计算数据的相关性并以二维散点图表示它。
通常,相关是指任何统计依赖性。 相关系数是计算相关度量的定量值。 您可以将相关性和相关系数之间的关系视为湿度计和湿度之间的相似关系。 相关系数最流行的类型之一是皮尔逊积矩相关系数。 相关系数的值在 +1 和 -1 之间,其中 -1 表示两个变量之间的强负线性关系,而 +1 表示两个变量之间的强正线性关系。 在 NumPy 中,我们可以使用corrcoef()方法来计算系数相关矩阵,如下所示:
In [61]: np.set_printoptions(suppress= True, linewidth = 125)
CorrelationCoef_Matrix = np.round(np.corrcoef(samples, rowvar= False), decimals= 1)
CorrelationCoef_Matrix
Seaborn 是一个基于 matplotlib 的统计数据可视化库,您可以使用它创建非常吸引人的美观统计图形。 它是一个非常受欢迎的库,具有精美的可视化效果,并且与流行的软件包(尤其是 Pandas)具有完美的兼容性。 您可以使用seaborn程序包中的热图来形象化相关系数矩阵。 当您具有数百种特征时,它对于检测高相关系数非常有用:
In [62]: CorrelationCoef_Matrix1 = np.round(np.corrcoef(samples, rowvar= False), decimals= 1)
CorrelationCoef_Matrix1
import seaborn as sns; sns.set()
ax = sns.heatmap(CorrelationCoef_Matrix1, cmap= "YlGnBu")
在这里,我们具有标签列特征的相关系数。 您可以在corrcoef()函数中添加其他变量集作为第二个参数,就像我们对label列所做的那样,如下面的屏幕快照所示。 只要形状相同,该函数将在最后堆叠此列并计算相关系数矩阵:
如您所见,除了F13之外,大多数特征都具有弱或中等的负线性关系。 另一方面,F6具有很强的正线性关系。 让我们绘制此特征并用散点图查看这种关系。 以下代码块借助matplotlib显示了三个不同的特征散点图(RM,DIS和LSTAT)和一个标签列:
In [64]: %matplotlib notebook
%matplotlib notebook
import matplotlib.pyplot as plt
from scipy import stats
fig, (ax1, ax2, ax3) = plt.subplots(1,3 ,figsize= (10,4))
axs =[ax1,ax2,ax3]
feature_list = [samples[:,5:6], samples[:,7:8], samples[:,12:13]]
feature_names = ["RM", "DIS", "LSTAT"]
for n in range(0, len(feature_list)):
axs[n].scatter(label, feature_list[n], edgecolors=(0, 0, 0))
axs[n].set_ylabel(feature_names[n])
axs[n].set_xlabel('label')
在前面的代码中,RM 和标签值分散为一条正线性线,这与相关系数值为 0.7 一致,如前面的屏幕快照所示。 散点图表明样品的 RM 值越高,标签的值越高。 在中间的散点图中,您可以看到系数相关性等于 0.25 的位置。 这显示出非常弱的正线性相关性,这在散点图中也可以看到。 我们可以得出结论,由于值分散在各处,因此没有明确的关系。 第三个散点图显示了强大的线性关系,相关系数为 -0.7。 随着LSTAT下降,标签值开始增加。 所有这些相关矩阵和散点图均使用未修剪的数据对此进行了计算。 让我们看看如何针对每个要素和标签从两侧修剪数据 10% 来改变数据集的线性关系结果:
In [65]: %matplotlib notebook
%matplotlib notebook
import matplotlib.pyplot as plt
from scipy import stats
fig, (ax1, ax2, ax3) = plt.subplots(1,3 ,figsize= (9,4))
axs = [ax1, ax2, ax3]
RM_tr = stats.trimboth(samples[:,5:6],0.1)
label_tr = stats.trimboth(label, 0.1)
LSTAT_tr = stats.trimboth(samples[:,12:13],0.1)
DIS_tr = stats.trimboth(samples[:,7:8],0.1)
feature_names = ["RM", "DIS", "LSTAT"]
feature_list = [RM_tr, DIS_tr, LSTAT_tr]
for n in range(0, len(feature_list)):
axs[n].scatter(label_tr,feature_list[n], edgecolors=(0, 0, 0))
axs[n].set_ylabel(feature_names[n])
axs[n].set_xlabel('label')
修剪数据后,您可以看到所有特征都与标签具有很强的正线性相关性,尤其是DIS和LSTAT的相关性,其中标签发生了巨大变化。 这显示了修剪的力量。 如果您不知道如何处理异常值,则很容易误解您的数据。 离群值可以更改分布的形状以及其他变量之间的相关性,最终它们可以影响模型的性能。
总结
在本章中,我们介绍了使用 NumPy,SciPy,matplotlib 和 Seaborn 软件包进行探索性数据分析的过程。 首先,我们学习了如何加载和保存文件以及探索数据集。 然后,我们解释并计算了重要的统计中心矩,例如均值,方差,偏度和峰度。 四个重要的可视化分别用于单变量和变量分析的图形表示; 这些是直方图,箱形图,散点图和热图。 还通过示例强调了数据修整的重要性。
在下一章中,我们将更进一步,并开始使用线性回归预测房价。
四、使用线性回归预测房价
在本章中,我们将通过实现线性回归来介绍监督学习和预测建模。 在上一章中,您了解了探索性分析的知识,但尚未研究建模。 在本章中,我们将创建一个线性回归模型来预测房地产市场价格。 广义上讲,我们将借助目标变量与其他变量的关系来预测目标变量。 线性回归被广泛使用,并且是监督机器学习算法的简单模型。 本质上是关于为观察到的数据拟合一条线。 我们将从解释监督学习和线性回归开始我们的旅程。 然后,我们将分析线性回归的关键概念,例如自变量和因变量,超参数,损失和误差函数以及随机梯度下降。 对于建模,我们将使用与上一章相同的数据集。
本章将介绍以下主题:
- 监督学习和线性回归
- 自变量和因变量
- 超参数
- 损失和误差函数
- 为单个变量实现我们的算法
- 计算随机梯度下降
- 使用线性回归建模房价
监督学习和线性回归
机器学习使计算机系统无需显式编程即可学习。 监督学习是最常见的机器学习类型之一。 监督学习由一组不同的算法组成,这些算法提出学习问题并通过使用历史数据映射输入和输出来解决它们。 该算法分析输入和相应的输出,然后将它们链接在一起以找到关系(学习)。 最后,对于新的给定数据集,它将使用此学习来预测输出。
为了区分监督学习和非监督学习,我们可以考虑基于输入/输出的建模。 在监督学习中,将对计算机系统的每组输入数据使用标签进行监督。 在无监督学习中,计算机系统将仅使用没有任何标签的输入数据。
例如,假设我们有 100 万张猫和狗的照片。 在监督学习中,我们标记输入数据并声明给定的照片是猫还是狗。 假设每张照片(输入数据)有 20 个特征。 标有照片的计算机系统将知道照片是猫还是狗(输出数据)。 当我们向计算机系统显示一张新照片时,它将通过分析新照片的 20 个特征来确定它是猫还是狗,并根据其先前的学习进行预测。 在无监督学习中,我们将只拥有 100 万张猫和狗的照片,而没有任何标签说明是猫还是狗的照片,因此该算法将在没有我们监督的情况下通过分析其特征来对数据进行聚类。 聚类完成后,会将新照片输入到无监督学习算法中,系统会告诉我们该照片属于哪个聚类。
在这两种情况下,系统都将具有简单或复杂的决策算法。 唯一的区别是是否有任何初始监督。 监督学习方法的概述方案如下:
监督学习可以分为分类和回归两种类型,如上图所示。 分类模型预测标签。 例如,可以将前面的示例视为监督分类问题。 为了执行分类,我们需要训练分类算法,例如支持向量分类器(SVC),随机森林, K 近邻(KNN),依此类推。 基本上,分类器是指用于对数据进行分类(分类)的算法。
当我们的目标变量是分类变量时使用分类方法,而当我们的目标变量是连续变量时,则应用回归模型,因为目标是预测数值而不是类别。
考虑一下我们在上一章中使用的数据集:波士顿房屋价格数据集。 在该数据集中,我们的目的是对特征值进行统计分析,因为我们需要了解特征值的分布方式,其基本统计量以及之间的相互关系。 最后,我们想知道每个特征如何导致房价上涨。 它对正面,负面还是根本没有影响? 如果特征 x 与房屋价格 A 之间存在潜在的影响(关系),则该关系的强弱是多少?
我们试图通过建立模型来预测具有给定特征的房价来回答这些问题。 结果,在为模型提供新特征后,我们期望模型将输出变量生成为连续值(150k,120,154 美元等)。 让我们看一个非常基本的工作流程:
如上图所示,分析从为模型准备数据开始。 在此阶段,我们应该清理数据,处理缺失的值,并提取将要使用的特征。 数据干净后,我们应该将其分为训练数据和测试数据两部分,以测试模型的性能。
模型验证中的重要部分是过拟合的概念。 用外行的术语来说,过度拟合意味着从训练数据集中学到太多,因此我们的模型过度拟合并为训练数据集产生近乎完美的结果。 但是,对于从未见过的数据,它的灵活性不足以产生良好的结果,因此无法很好地泛化。
可以将数据集分为训练,验证(强烈推荐)和测试数据集来解决此问题。 训练数据是算法最初学习算法参数(权重)并在其中将误差最小化的地方建立模型的地方。 当您有几种算法并且需要调整超参数时,或者当算法中有许多参数并且需要调整参数时,平移数据集非常有用。 测试数据集用于性能评估。
简而言之,您可以使用训练数据来训练算法,然后在验证数据集中微调算法的参数或权重,最后一步,在测试数据集中测试调整后的算法的性能。
与过度拟合相反的情况是欠拟合,这意味着该算法从数据中学习得更少,并且我们的算法与我们的观察结果不太吻合。 让我们以图形方式查看过度拟合,欠拟合和最佳拟合的样子:
您可能已经注意到,在上图中,即使过度拟合看起来非常合适,它也会生成一个回归线,该回归线对于该数据集非常独特,并且无法正确捕获特征。 第二个图,即欠拟合图,实际上无法捕获数据的形状。 当我们的数据是非线性的时,它没有从中学习并产生了线性回归线。 第三个图是我们的最佳拟合图,拟合得很好,掌握了分布特征并产生了一条曲线。 我们可以预期,对于此数据集的延续,它不会有令人失望的性能指标。
在本章中,我们将使用线性回归作为有监督的学习方法。 我们将首先解释非常重要的概念,例如自变量和因变量,超参数以及损失和误差函数。 我们还将介绍线性回归的实际示例。 在下一章中,我们将介绍线性回归模型的最重要组成部分:独立变量和因变量。
自变量和因变量
正如我们在前面的小节中提到的,线性回归用于基于其他变量来预测变量的值。 我们正在研究输入变量X与输出变量Y之间的关系。
在线性回归中,因变量是我们要预测的变量。 之所以称其为因变量,是因为线性回归背后的假设。 该模型假设这些变量取决于方程另一侧的变量,这些变量称为独立变量。
在简单回归模型中,模型将解释因变量如何基于自变量而变化。
例如,假设我们要分析基于给定产品的价格变化如何影响销售值。 如果您仔细阅读此句子,则可以轻松检测出我们的因变量和自变量。 在我们的示例中,我们假设销售值受价格变化的影响,换句话说,销售值取决于产品的价格。 结果,销售值是从属值,价格是独立的值。 这不一定意味着给定产品的价格不依赖于任何东西。 当然,它取决于许多因素(变量),但是在我们的模型中,我们假设价格是给定的,并且给定的价格会改变销售值。 线性回归线的公式如下:
哪里:
Yi = 估计值或因变量
B0 = 截距
B1 = 斜率
Xi = 自变量或探索变量:
线性回归线的斜率(B1)实际上显示了这两个变量之间的关系。 假设我们将斜率计算为 0.8。 这意味着自变量增加 1 个单位可能会使估计值增加 0.8 个单位。 前面的线性回归线仅生成估计,这意味着它们仅是给定X的Y的预测。 如下图所示,每个观测值和线性线之间有一段距离。 该距离称为误差,这是预期的,在回归线拟合和模型评估中也非常重要:
拟合线性回归线的最常见方法是使用最小二乘方法。 该方法通过最小化这些误差的平方和来拟合回归线。 计算公式如下:
这些误差均方根的原因是我们不希望负误差和正误差彼此抵消。 在模型评估中,使用 R 平方,F 检验和均方根误差(RMSE)。 他们都使用平方和(SST)和平方和误差(SSE)作为基本度量。 如您所见,在 SSE 中,我们再次计算预测值和实际值之间的差,取平方并求和,以评估回归线对数据的拟合程度。
如前所述,最小二乘方法旨在最小化平方误差(残差),并找到最适合数据点的斜率和截距值。 由于这是一种封闭形式的解决方案,因此您可以轻松地手动计算它,以便在后台查看此方法的作用。 让我们使用一个包含少量数据集的示例:
| 牛奶消耗量(每周升) | 身高 |
|---|---|
| 14 | 175 |
| 20 | 182 |
| 10 | 170 |
| 15 | 185 |
| 12 | 164 |
| 15 | 173 |
| 22 | 181 |
| 25 | 193 |
| 12 | 160 |
| 13 | 165 |
假设我们有 10 个观察值,如上表所示,用于每周食用牛奶和食用牛奶的人的身高值。 如果我们绘制这些数据,我们可以看到每日牛奶消耗量与身高之间存在正相关:
现在,我们要使用最小二乘法拟合线性回归线,该方法通过对斜率和截距使用以下公式来完成:
然后,我们需要创建一个表格来帮助我们进行计算,例如x,y,xy,x^2和y^2的总和:
x(牛奶消耗量) | y(高度) | xy | x^2 | y^2 | |
|---|---|---|---|---|---|
| 1 | 14 | 175 | 2,450 | 196 | 30,625 |
| 2 | 20 | 182 | 3,640 | 400 | 33,124 |
| 3 | 10 | 170 | 1,700 | 100 | 28,900 |
| 4 | 15 | 185 | 2,775 | 225 | 34,225 |
| 5 | 12 | 164 | 1,968 | 144 | 26,896 |
| 6 | 15 | 173 | 2,595 | 225 | 29,929 |
| 7 | 22 | 181 | 3,982 | 484 | 32,761 |
| 8 | 25 | 193 | 4,800 | 625 | 37,249 |
| 9 | 12 | 160 | 1,920 | 144 | 25,600 |
| 10 | 13 | 165 | 2,145 | 169 | 27,225 |
| ∑ | 158 | 1,748 | 27,975 | 2,712 | 306,534 |
B0 = (1748*2712) - (158*27975) / (10*2712) - (158)^2 = 320526/2156 = 148.66
B1 = (10*27975) - (158*1748) / (10*2712) - (158)^2 = 1.65
然后,我们可以将回归线公式如下:
在本小节中,我们提到了自变量和因变量,并介绍了线性回归线和拟合方法。 在下一节中,我们将介绍超参数,这些参数在回归模型调整中非常有用。
超参数
在开始之前,也许最好解释一下为什么我们称它们为超参数而不是参数。 在机器学习中,可以从数据中学习模型参数,这意味着在训练模型时,您可以拟合模型的参数。 另一方面,我们通常在开始训练模型之前先设置超参数。 为了举例说明,您可以将回归模型中的系数视为模型参数。 以超参数为例,我们可以说许多不同模型中的学习率或 K 均值聚类中的聚类数(k)。
另一个重要的事情是模型参数和超参数之间的关系,以及它们如何塑造我们的机器学习模型,换句话说,就是我们模型的假设。 在机器学习中,参数用于配置模型,此配置将为我们的数据集专门定制算法。 我们需要处理的是如何优化超参数。 另外,如上所述,可以在验证期间执行该优化。 在许多情况下,优化超参数将带来性能提升。
您还可以将超参数视为模型参数之上的高级参数。 想象一下您使用无监督学习的 K 均值聚类的情况。 如果您使用误差的群集号(K)作为超参数,则可以确保您的数据不适合。
现在,您应该问的是,如果在训练模型之前手动设置超参数,我们该如何调整它们。 有几种方法可以调整超参数。 此优化的底线是使用一组不同的超参数测试算法,并在选择性能更好的超参数集之前针对每种情况计算误差函数或损失函数。
在本节中,我们简要介绍了参数,超参数及其差异。 在下一节中,我们将介绍损失和误差函数,这对于超参数优化非常重要。
损失和误差函数
在前面的小节中,我们解释了有监督和无监督的学习。 无论使用哪种机器学习算法,我们的主要挑战都是关于优化的问题。 在优化函数中,我们实际上是在尝试使损失函数最小化。 设想一下您试图优化每月储蓄的情况。 在关闭状态下,您要做的就是最小化支出,换句话说,将损失函数最小化。
建立损失函数的一种非常常见的方法是从预测值与实际值之差开始。 通常,我们尝试估计模型的参数,然后进行预测。 我们可以用来评估我们的预测水平的主要度量包括计算实际值之间的差:
在不同的模型中,使用了不同的损失函数。 例如,您可以在回归模型中使用均方误差,但是将其用作分类模型的损失函数可能不是一个好主意。 例如,您可以按以下方式计算均方误差:
其中回归模型如下:
有许多不同的损失函数可用于不同的机器学习模型。 以下是一些重要的说明,并简要说明了它们的用法:
| 损失函数 | 解释 |
|---|---|
| 交叉熵 | 这用于分类模型,其中模型的输出为 0-1 之间的概率。 这是对数损失函数,也称为对数损失。 当理想的模型的概率接近 1.0 时, 交叉熵损失降低。 |
| MAE(L1) | 计算误差绝对值的均值。 由于它仅使用绝对值,因此不会将较大误差的权重放大。 当较大误差与较小误差相比可以容忍时,这很有用。 |
| MSE(L2) | 计算误差的平方根的均值。 放大较大误差的权重。 当不希望出现较大误差时,这很明智。 |
| Hinge | 这是用于线性分类器模型(例如支持向量机)的损失函数。 |
| Huber | 这是回归模型的损失函数。 它与 MSE 非常相似,但对异常值不敏感。 |
| Kullback-Leibler | Kullback-Leibler 散度衡量两个概率分布之间的差异 。 KL 损失函数在 T 分布随机邻居嵌入算法中大量使用。 |
在机器学习算法中,损失函数在更新变量权重时至关重要。 假设您使用反向传播训练神经网络。 在每次迭代中,都会计算出总误差。 然后,权重被更新以便最小化总误差。 因此,使用正确的损失函数会直接影响您的机器学习算法的性能,因为它直接影响模型参数。 在下一章中,我们将从住房数据中的单个变量开始简单的线性回归。
使用梯度下降的单变量线性回归
在本小节中,我们将为波士顿住房数据集实现单变量线性回归,该数据已在上一章中用于探索性数据分析。 在拟合回归线之前,让我们导入必要的库并按以下方式加载数据集:
In [1]: import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
%matplotlib inline
In [2]: from sklearn.datasets import load_boston
dataset = load_boston()
samples , label, feature_names = dataset.data, dataset.target, dataset.feature_names
In [3]: bostondf = pd.DataFrame(dataset.data)
bostondf.columns = dataset.feature_names
bostondf['Target Price'] = dataset.target
bostondf.head()
Out[3]: CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT Target Price
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33 36.2
与上一章相比,我们使用 Pandas 数据帧代替了 numpy 数组,以便向您展示数据帧的用法,因为它也是一个非常方便的数据结构。 从技术上讲,在大多数情况下,如果仅将数值存储在 numpy 数组或 Pandas 数据帧中,则没有任何区别。 让我们将目标值添加到数据框中,并使用散点图查看RM函数与目标值之间的关系:
In [4]: import matplotlib.pyplot as plt
bostondf.plot(x='RM', y='Target Price', style= 'o')
plt.title('RM vs Target Price')
plt.ylabel('Target Price')
plt.show()
从该图可以看出,每个住宅的平均房间数(RM)与房价之间存在正相关,正如预期的那样。 现在,我们将看到这种关系的强度,并尝试使用这种关系来预测房价。
想象一下,您对线性回归的了解非常有限。 假设您只是熟悉方程式,但不知道误差函数是什么,为什么我们需要迭代,什么是梯度下降,以及为什么要在线性回归模型中使用它。 在这种情况下,您要做的就是简单地开始传递系数的一些初始值,并在计算预测值之前截取方程。
在计算了几个预测值之后,您可以将它们与实际值进行比较,看看您与实际情况有多远。 下一步将是更改系数或截距,或者同时进行这两项操作,以查看是否可以使结果更接近实际值。 如果您对此过程感到满意,这就是我们的算法将以更智能的方式进行的操作。
为了更好地理解线性回归模型步骤,我们将代码分成几个块。 首先,让我们创建一个函数,该函数作为回归线的结果返回预测值:
In [5]: def prediction(X, coefficient, intercept):
return X*coefficient + intercept
前面的函数计算线性回归模型如下:
然后,我们需要一个成本函数,该函数将在每次迭代中进行计算。 作为cost_function,我们将使用均方误差,它是预测值与实际值之间总平方差的平均值:
In [6]: def cost_function(X, Y, coefficient, intercept):
MSE = 0.0
for i in range(len(X)):
MSE += (Y[i] - (coefficient*X[i] + intercept))**2
return MSE / len(X)
我们的最后一个代码块将用于更新权重。 当我们讨论权重时,不仅涉及自变量的系数,还涉及截距。 拦截也称为偏差。 为了逻辑上更新权重,我们需要一种迭代优化算法,该算法可以找到给定函数的最小值。 在此示例中,我们将使用梯度下降方法来最小化每次迭代中的损失函数。 让我们一步一步地发现梯度下降的作用。
首先,我们应该初始化权重(截距和系数)并计算均方误差。 然后,我们需要计算梯度,这意味着查看当改变权重时均方误差如何变化。
为了以更智能的方式更改权重,我们需要了解我们必须更改系数和截距的方向。 这意味着我们在更改权重时应计算误差函数的梯度。 我们可以通过对系数和截距采用损失函数的偏导数来计算梯度。
在单变量线性回归中,我们只有一个系数。 在计算偏导数之后,该算法将调整权重并重新计算均方误差。 此过程将重复进行,直到更新的权重不再减小均方误差为止:
In [7]: def update_weights(X, Y, coefficient, intercept, learning_rate):
coefficient_derivative = 0
intercept_derivative = 0
for i in range(len(X)):
coefficient_derivative += -2*X[i] * (Y[i] - (coefficient*X[i] + intercept))
intercept_derivative += -2*(Y[i] - (coefficient*X[i] + intercept))
coefficient -= (coefficient_derivative / len(X)) * learning_rate
intercept -= (intercept_derivative / len(X)) * learning_rate
return coefficient, intercept
前面的代码块定义了更新权重的函数,然后返回更新的系数并进行拦截。 此函数中的另一个重要参数是learning_rate。 学习速度将决定变化的幅度:
在上图中,您可以看到我们的损失函数为x = y^2的形状,因为它是平方误差的总和。 通过梯度下降,我们试图找到最小损耗,如图所示,其中偏导数非常接近零。 如前所述,我们通过初始化权重来开始算法,这意味着我们从远离最小值的点开始。 在每次迭代中,我们将更新权重,从而减少损失。 这意味着给定足够的迭代次数,我们将收敛到全局最小值。 学习速度将决定这种融合发生的速度。
换句话说,当我们更新权重时,高学习率看起来就像是从一个点到另一个点的巨大跳跃。 低学习率将慢慢接近全局最小值(所需的最小损失点)。 由于学习率是一个超参数,因此我们需要在运行它之前进行设置:
那么,我们需要设定学习率的大还是小? 答案是我们应该找到最佳速率。 如果我们设定较高的学习率,我们的算法将超出最小值。 我们很容易错过最小值,因为这些跳跃永远不会让我们的算法收敛到全局最小值。 另一方面,如果我们将学习率设置得太小,则可能需要进行大量迭代才能收敛。
具有先前的代码块,是时候编写主函数了。 主函数应遵循我们前面讨论的流程:
然后,主函数的代码块应如下所示:
In [8]: def train(X, Y, coefficient, intercept, LearningRate, iteration):
cost_hist = []
for i in range(iteration):
coefficient, intercept = update_weights(X, Y, coefficient, intercept, learning_cost = cost_function(X, Y, coefficient, intercept)
cost_hist.append(cost)
return coefficient, intercept, cost_hist
现在,我们已经定义了所有代码块,并且可以运行单变量模型了。 在运行train()函数之前,我们需要设置系数和截距的超参数和初始值。 您可以创建变量,设置值,然后将这些变量作为函数的参数,如下所示:
In [9]: learning_rate = 0.01
iteration = 10001
coefficient = 0.3
intercept = 2
X = bostondf.iloc[:, 5:6].values
Y = bostondf.iloc[:, 13:14].values
coefficient, intercept, cost_history = train(X, Y, coefficient, intercept, learning_rate, iteration)
或者,可以在调用函数时将这些值作为关键字参数传递:
coefficient, intercept, cost_history = train(X, Y, coefficient, intercept = 2, learning_rate = 0.01, iteration = 10001)
我们的主函数将返回两个数组,这将为我们提供拦截和系数的最终值。 此外,主函数将返回损失值列表,这是每次迭代的结果。 这些是每次迭代中均方误差的结果。 拥有此列表以跟踪每次迭代中损耗的变化非常有用:
In [10]: coefficient
Out[10]: array([8.57526661])
In [11]: intercept
Out[11]: array([-31.31931428])
In [12]: cost_history
array([54.18545801]),
array([54.18036786]),
array([54.17528017]),
array([54.17019493]),
array([54.16511212]),
array([54.16003177]),
array([54.15495385]),
array([54.14987838]),
array([54.14480535]),
array([54.13973476]),
array([54.13466661]),
array([54.12960089]),
array([54.12453761]),
array([54.11947677]),
array([54.11441836]),
array([54.10936238]),
array([54.10430883]),
...]
从系数值中可以看出,RM的每增加 1 单位,住房价格就会升至 8,575 美元左右。 现在,让我们通过将计算出的截距和系数注入回归公式中来计算预测值。 然后,我们可以绘制线性回归线并查看其如何拟合我们的数据:
In [13]: y_hat = X*coefficient + intercept
plt.plot(X, Y, 'bo')
plt.plot(X, y_hat)
plt.show()
在本节中,我们通过选择一个变量来应用单变量模型。 在以下小节中,我们将通过在模型中添加更多自变量来执行多元线性回归模型,这意味着我们将有多个系数可进行优化以实现最佳拟合。
使用线性回归建模房价
在本节中,我们将对同一数据集执行多元线性回归。 与上一节相反,我们将使用 sklearn 库向您展示执行线性回归模型的几种方法。 在开始线性回归模型之前,我们将使用trimboth()方法从两侧按比例修剪数据集。 通过这样做,我们将消除异常值:
In [14]: import numpy as np
import pandas as pd
from scipy import stats
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LinearRegression
In [15]: from sklearn.datasets import load_boston
dataset = load_boston()
In [16]: samples , label, feature_names = dataset.data, dataset.target, dataset.feature_names
In [17]: samples_trim = stats.trimboth(samples, 0.1)
label_trim = stats.trimboth(label, 0.1)
In [18]: print(samples.shape)
print(label.shape)
(506, 13)
(506,)
In [19]: print(samples_trim.shape)
print(label_trim.shape)
(406, 13)
(406,)
正如您在前面的代码块中看到的那样,由于我们将左右数据修剪了 10% ,每个属性和标签列的样本量从 506 减少到 406:
In [20]: from sklearn.model_selection import train_test_split
samples_train, samples_test, label_train, label_test = train_test_split(samples_trim, In [21]: In [21]: print(samples_train.shape)
print(samples_test.shape)
print(label_train.shape)
print(label_test.shape)
(324, 13)
(82, 13)
(324,)
(82,)
In [22]: regressor = LinearRegression()
regressor.fit(samples_train, label_train)
Out[22]: LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
In [23]: regressor.coef_
Out[23]: array([ 2.12924665e-01, 9.16706914e-02, 1.04316071e-01, -3.18634008e-14,
5.34177385e+00, -7.81823481e-02, 1.91366342e-02, 2.81852916e-01,
3.19533878e-04, -4.24007416e-03, 1.94206366e-01, 3.96802252e-02,
3.81858253e-01])
In [24]: regressor.intercept_
Out[24]: -6.899291747292615
然后,我们使用train_test_split()方法将数据集拆分为训练和测试。 这种方法在机器学习算法中非常普遍。 您将数据分为两组,然后让模型训练(学习),然后再使用数据的另一部分测试模型。 使用这种方法的原因是为了减少验证模型时的偏差。 每个系数代表当我们将这些样本增加一个单位时,预期目标值将改变多少:
In [25]: label_pred = regressor.predict(samples_test)
In [26]: plt.scatter(label_test, label_pred)
plt.xlabel("Prices")
plt.ylabel("Predicted Prices")
plt.title("Prices vs Predicted Prices")
plt.axis("equal")
Out[26]: (11.770143369175626, 34.22985663082437, 10.865962968036989, 34.20549738482051)
让我们在前面的代码块中测试我们的模型。 为了在数据集上运行我们的模型,我们可以使用predict()方法。 此方法将在模型上运行给定的数据集并返回结果。 理想情况下,我们期望该点以x = y线形分布,换言之,例如具有 45 度角的直线。 这是一个完美的一对一匹配预测。 我们不能说我们的预测是完美的,但是仅通过查看散点图,我们可以得出结论,该预测不是一个坏的预测。 我们可以查看有关模型性能的两个重要指标,如下所示:
In [27]: from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
mse = mean_squared_error(label_test, label_pred)
r2 = r2_score(label_test, label_pred)
print(mse)
print(r2)
2.032691267250478
0.9154474686142619
第一个是均方误差。 您可能已经注意到,当我们在模型中添加更多自变量时,它会大大降低。 第二个是 R 方,它是确定系数,或者换句话说,是回归得分。 确定系数可以解释您的自变量解释了因变量有多少方差。 在我们的模型中,结果为 0.91,这说明我们的 13 个特征可以解释 91% 的房价差异。 如您所见,sklearn 具有许多有用的线性回归内置函数,这些函数可以加快模型构建过程。 另一方面,您也可以仅使用 numpy 轻松构建线性回归模型,这可以为您提供更大的灵活性,因为您可以控制算法的每个部分。
总结
线性回归是对连续变量之间的关系进行建模的最常用技术之一。 这种方法的应用在工业上非常广泛。 我们开始对本书的一部分进行线性回归建模,这不仅是因为它非常流行,还因为它是一种相对简单的技术,并且包含了几乎每种机器学习算法都具有的大多数要素。
在本章中,我们了解了监督学习和无监督学习,并使用波士顿房屋数据集建立了线性回归模型。 我们谈到了不同的重要概念,例如超参数,损失函数和梯度下降。 本章的主要目的是为您提供足够的知识,以便您可以建立和调整线性回归模型并逐步了解它的作用。 我们研究了两个使用单变量和多元线性回归的实际案例。 您还体验了 numpy 和 sklearn 在线性回归中的用法。 我们强烈建议您对不同的数据集进行进一步练习,并检查更改超参数时结果如何变化。
在下一章中,我们将学习聚类方法,并通过批发分销商数据集上的示例进行实践。
五、使用 NumPy 对批发分销商的客户进行聚类
通过查看 NumPy 在各种使用案例中的使用,您肯定可以提高自己的技能。 本章介绍的分析类型与迄今为止所见不同。 聚类是一种无监督的学习技术,用于理解和捕获数据集中的各种形式。 由于您没有标签来监督您的学习算法,因此在很多情况下,可视化是关键,这就是为什么您也会看到各种可视化技术的原因。
在本章中,我们将介绍以下主题:
- 无监督学习和聚类
- 超参数
- 扩展简单算法来聚类批发分销商的客户
无监督学习和聚类
让我们用一个例子快速回顾一下监督学习。 在训练机器学习算法时,您可以通过提供标签来观察和指导学习。 考虑下面的数据集,其中每一行代表一个客户,每一列代表一个不同的特征,例如年龄,性别,收入,职业 ,任期和城市。 看看这个表:
您可能需要执行不同类型的分析。 其中一项可能是预测哪些客户可能会离开,即客户流失分析。 为此,您需要根据每个客户的历史记录为其标记标签,以指示哪些客户已离开或留下,如下表所示:
您的算法将根据客户的标签了解客户的特征。 算法将学习离开或留下的客户的特征,并且,当您希望根据这些特征为新客户评分时,算法将根据该学习进行预测。 这称为监督学习。
关于此数据集可能要问的另一个问题可能是:此数据集中存在多少个客户组,以便其组中的每个客户都与其他客户相似,而与属于其他组的客户不同。 流行的聚类算法(例如 K 均值)可以帮助您解决这一问题。 例如,一旦 K 均值将客户分配到不同的集群,则一个集群可以大体上包括 30 岁以下且以 IT 作为职业的客户,而另一个集群可以大体上包括 60 岁以上的客户并且职业为老师。 您无需标记数据集即可执行此分析,因为算法足以查看记录并确定它们之间的相似性。 由于没有监督,因此这种学习称为无监督学习。
进行此类分析时,首先可视化数据集会很有帮助。 您可以从可用的数据集开始构建您的处理和建模工作流程。 以下代码段显示了如何使用plotly可视化三维数据集。plotly是一个库,可让您绘制许多不同的交互式图表以进行探索性分析,并使数据探索更加容易。
首先,您需要使用以下代码段安装必要的库:
## Installing necessary libraries with pip
!pip install plotly --user
!pip install cufflinks -user
然后,使用以下代码导入必要的库:
## Necessary imports
import os
import sys
import numpy as np
import pandas
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.plotly as py
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import cufflinks as cf
import plotly.graph_objs as go
init_notebook_mode(connected=True)
sys.path.append("".join([os.environ["HOME"]]))
您将使用sklearn.datasets模块中可用的iris数据集,如下所示:
from sklearn.datasets import load_iris
iris_data = load_iris()
iris数据具有四个特征; 它们如下:
iris_data.feature_names
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
首先,让我们检查一下前两个特征:
x = [v[0] for v in iris_data.data]
y = [v[1] for v in iris_data.data]
创建一个trace,然后创建数据和图形,如下所示:
trace = go.Scatter(
x = x,
y = y,
mode = 'markers'
)
layout= go.Layout(
title= 'Iris Dataset',
hovermode= 'closest',
xaxis= dict(
title= 'sepal length (cm)',
ticklen= 5,
zeroline= False,
gridwidth= 2,
),
yaxis=dict(
title= 'sepal width (cm)',
ticklen= 5,
gridwidth= 2,
),
showlegend= False
)
data = [trace]
fig= go.Figure(data=data, layout=layout)
plot(fig)
如下图所示,这将为您提供以下输出:
您可以继续查看其他变量,但是要更好地理解一张图表中要素之间的关系,可以使用scatterplot矩阵。 创建pandas.DataFrame与plotly结合使用会更加方便:
import pandas as pd
df = pd.DataFrame(iris_data.data,
columns=['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)'])
df['class'] = [iris_data.target_names[i] for i in iris_data.target]
df.head()
使用plotly图形工厂,可以绘制scatterplot矩阵,如下所示:
import plotly.figure_factory as ff
fig = ff.create_scatterplotmatrix(df, index='class', diag='histogram', size=10, height=800, width=800)
plot(fig)
这将为您提供以下图表,如下图所示:
乍一看,花瓣长度,花瓣宽度和萼片长度似乎是建模的不错选择。 您可以通过以下代码使用 3D 图表进一步检查该数据集:
## Creating data for the plotly
trace1 = go.Scatter3d(
# Extracting data based on label
x=[x[0][0] for x in zip(iris_data.data, iris_data.target) if x[1] == 0],
y=[x[0][2] for x in zip(iris_data.data, iris_data.target) if x[1] == 0],
z=[x[0][3] for x in zip(iris_data.data, iris_data.target) if x[1] == 0],
mode='markers',
marker=dict(
size=12,
line=dict(
color='rgba(217, 217, 217, 0.14)',
width=0.5
),
opacity=0.8
)
)
trace2 = go.Scatter3d(
# Extracting data based on label
x=[x[0][0] for x in zip(iris_data.data, iris_data.target) if x[1] == 1],
y=[x[0][2] for x in zip(iris_data.data, iris_data.target) if x[1] == 1],
z=[x[0][3] for x in zip(iris_data.data, iris_data.target) if x[1] == 1],
mode='markers',
marker=dict(
color='rgb(#3742fa)',
size=12,
symbol='circle',
line=dict(
color='rgb(204, 204, 204)',
width=1
),
opacity=0.9
)
)
trace3 = go.Scatter3d(
# Extracting data based on label
x=[x[0][0] for x in zip(iris_data.data, iris_data.target) if x[1] == 2],
y=[x[0][2] for x in zip(iris_data.data, iris_data.target) if x[1] == 2],
z=[x[0][3] for x in zip(iris_data.data, iris_data.target) if x[1] == 2],
mode='markers',
marker=dict(
color='rgb(#ff4757)',
size=12,
symbol='circle',
line=dict(
color='rgb(104, 74, 114)',
width=1
),
opacity=0.9
)
)
data = [trace1, trace2, trace3]
## Layout settings
layout = go.Layout(
scene = dict(
xaxis = dict(
title= 'sepal length (cm)'),
yaxis = dict(
title= 'petal length (cm)'),
zaxis = dict(
title= 'petal width (cm)'),),
)
fig = go.Figure(data=data, layout=layout)
plot(fig)
这将为您提供以下交互式图表,如下图所示:
Interactive plotting of petal length, petal width, and sepal length
使用这些图表,您可以更好地理解数据并为建模做准备。
超参数
超参数可以被视为确定模型各种属性之一的高级参数,例如复杂性,训练行为和学习率。 这些参数自然与模型参数有所不同,因为它们需要在训练开始之前设置。
例如,K 均值或 K 最近邻中的 k 是这些算法的超参数。 K 均值中的 K 表示要找到的聚类数,K 最近邻中的 k 表示用于进行预测的最近记录数。
调整超参数是任何机器学习项目中提高预测性能的关键步骤。 有多种调优技术,例如网格搜索,随机搜索和贝叶斯优化,但这些技术不在本章范围之内。
让我们通过以下屏幕快照快速浏览 scikit-learn 库中的 K 均值算法参数:
如您所见,有许多参数可以使用,并且至少应查看算法的函数签名,以查看运行算法之前的选项。
让我们一起玩吧。 基线模型将与样本数据一起使用,几乎具有默认设置,如下所示:
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=20, centers=3, n_features=3, random_state=42)
k_means = KMeans(n_clusters=3)
y_hat = k_means.fit_predict(X)
y_hat保留集群的成员身份信息,这与原始标签相同,如您在此处看到的:
y_hat
## array([0, 2, 1, 1, 1, 0, 2, 0, 0, 0, 2, 0, 1, 2, 1, 2, 2, 1, 0, 1],
dtype=int32)
y
## array([0, 2, 1, 1, 1, 0, 2, 0, 0, 0, 2, 0, 1, 2, 1, 2, 2, 1, 0, 1])
您可以使用不同的选项来查看它如何影响训练和预测。
损失函数
损失函数通过测量误差来帮助算法在训练过程中更新模型参数,这是预测性能的指标。 损失函数通常表示为:
其中L测量预测值与实际值之间的差。 在训练过程中,此误差被最小化。 不同的算法具有不同的损失函数,迭代次数将取决于收敛条件。
例如,K 均值的损失函数使点与最接近的簇均值之间的平方距离最小化,如下所示:
您将在以下部分中看到详细的实现。
为单个变量实现我们的算法
让我们为单个变量实现 K 均值算法。 您将从一维向量开始,该向量具有 20 条记录,如下所示:
data = [1,2,3,2,1,3,9,8,11,12,10,11,14,25,26,24,30,22,24,27]
trace1 = go.Scatter(
x=data,
y=[0 for x in data],
mode='markers',
name='Data',
marker=dict(
size=12
)
)
layout = go.Layout(
title='1D vector',
)
traces = [trace1]
fig = go.Figure(data=traces, layout=layout)
plot(fig)
如下图所示,将输出以下图表:
我们的目标是找到在数据中可见的3簇。 为了开始实施 K 均值算法,您需要通过选择随机索引来初始化集群中心,如下所示:
n_clusters = 3
c_centers = np.random.choice(X, n_clusters)
print(c_centers)
## [ 1 22 26]
接下来,您需要计算每个点与聚类中心之间的距离,因此请使用以下代码:
deltas = np.array([np.abs(point - c_centers) for point in X])
deltas
array([[ 7, 26, 10],
[ 6, 25, 9],
[ 5, 24, 8],
[ 6, 25, 9],
[ 7, 26, 10],
[ 5, 24, 8],
[ 1, 18, 2],
[ 0, 19, 3],
[ 3, 16, 0],
[ 4, 15, 1],
[ 2, 17, 1],
[ 3, 16, 0],
[ 6, 13, 3],
[17, 2, 14],
[18, 1, 15],
[16, 3, 13],
[22, 3, 19],
[14, 5, 11],
[16, 3, 13],
[19, 0, 16]])
现在,可以使用以下代码来计算集群成员资格:
deltas.argmin(1)
## array([0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1])
现在,您需要使用以下代码来计算记录和群集中心之间的距离:
c_centers = np.array([X[np.where(deltas.argmin(1) == i)[0]].mean() for i in range(3)])
print(c_centers)
## [ 3.625 25.42857143 11.6 ]
这是一次迭代; 您可以继续计算新的群集中心,直到没有任何改善为止。
您可以编写一个函数来包装所有这些功能,如下所示:
def Kmeans_1D(X, n_clusters, random_seed=442):
# Randomly choose random indexes as cluster centers
rng = np.random.RandomState(random_seed)
i = rng.permutation(X.shape[0])[:n_clusters]
c_centers = X[i]
# Calculate distances between each point and cluster centers
deltas = np.array([np.abs(point - c_centers) for point in X])
# Get labels for each point
labels = deltas.argmin(1)
while True:
# Calculate mean of each cluster
new_c_centers = np.array([X[np.where(deltas.argmin(1) == i)[0]].mean() for i in range(n_clusters)])
# Calculate distances again
deltas = np.array([np.abs(point - new_c_centers) for point in X])
# Get new labels for each point
labels = deltas.argmin(1)
# If there's no change in centers, exit
if np.all(c_centers == new_c_centers):
break
c_centers = new_c_centers
return c_centers, labels
c_centers, labels = Kmeans_1D(X, 3)
print(c_centers, labels)
## [11.16666667 25.42857143 2.85714286] [2 2 2 2 2 2 0 0 0 0 0 0 0 1 1 1 1 1 1 1]
让我们使用以下代码绘制集群中心的图表:
trace1 = go.Scatter(
x=X,
y=[0 for num in X],
mode='markers',
name='Data',
marker=dict(
size=12
)
)
trace2 = go.Scatter(
x = c_centers,
y = [0 for num in X],
mode='markers',
name = 'Cluster centers',
marker = dict(
size=12,
color = ('rgb(122, 296, 167)')
)
)
layout = go.Layout(
title='1D vector',
)
traces = [trace1, trace2]
fig = go.Figure(data=traces, layout=layout)
plot(fig)
看下图。 给定的代码将输出以下内容:
您可以清楚地看到,可以为每个元素分配一个聚类中心。
修改我们的算法
现在,您已经了解了单个变量的 K 均值内部,可以将该实现扩展到多个变量,并将其应用于更实际的数据集。
本节中使用的数据集来自 UCI 机器学习存储库,它包括批发分销商的客户信息。 有 440 个具有八项特征的客户。 在下面的列表中,前六个特征与相应产品的年度支出相关,第七个特征显示了购买该产品的渠道,第八个特征显示了该地区:
FRESHMILKGROCERYFROZENDETERGENTS_PAPERDELICATESSENCHANNELREGION
首先下载数据集并将其读取为numpy数组:
from numpy import genfromtxt
wholesales_data = genfromtxt('Wholesale customers data.csv', delimiter=',', skip_header=1)
您可以快速查看数据。 这里是:
print(wholesales_data[:5])
[[2.0000e+00 3.0000e+00 1.2669e+04 9.6560e+03 7.5610e+03 2.1400e+02
2.6740e+03 1.3380e+03]
[2.0000e+00 3.0000e+00 7.0570e+03 9.8100e+03 9.5680e+03 1.7620e+03
3.2930e+03 1.7760e+03]
[2.0000e+00 3.0000e+00 6.3530e+03 8.8080e+03 7.6840e+03 2.4050e+03
3.5160e+03 7.8440e+03]
[1.0000e+00 3.0000e+00 1.3265e+04 1.1960e+03 4.2210e+03 6.4040e+03
5.0700e+02 1.7880e+03]
[2.0000e+00 3.0000e+00 2.2615e+04 5.4100e+03 7.1980e+03 3.9150e+03
1.7770e+03 5.1850e+03]]
选中shape将显示行数和变量数,如下所示:
wholesales_data.shape
## (440, 8)
该数据集具有440个记录,每个记录都有8个特征。
通过使用以下代码来规范化数据集是一个好主意:
wholesales_data_norm = wholesales_data / np.linalg.norm(wholesales_data)
print(wholesales_data_norm[:5])
[[ 1\. 0\. 0.30168043 1.06571214 0.32995207 -0.46657183
0.50678671 0.2638102 ]
[ 1\. 0\. -0.1048095 1.09293385 0.56599336 0.08392603
0.67567015 0.5740085 ]
[ 1\. 0\. -0.15580183 0.91581599 0.34441798 0.3125889
0.73651183 4.87145892]
[ 0\. 0\. 0.34485007 -0.42971408 -0.06286202 1.73470839
-0.08444172 0.58250708]
[ 1\. 0\. 1.02209184 0.3151708 0.28726 0.84957326
0.26205579 2.98831445]]
您可以使用以下代码将数据集读取到pandas.DataFrame中:
import pandas as pd
df = pd.DataFrame(wholesales_data_norm,
columns=['Channel',
'Region',
'Fresh',
'Milk',
'Grocery',
'Frozen',
'Detergents_Paper',
'Delicatessen'])
df.head(10)
让我们创建一个scatterplot矩阵以更仔细地查看数据集。 看一下代码:
fig = ff.create_scatterplotmatrix(df, diag='histogram', size=7, height=1200, width=1200)
plot(fig)
您还可以通过运行以下命令来检查要素之间的相关性:
df.corr()
这将为您提供一个关联表,如下所示:
您还可以使用seaborn热图,如下所示:
import seaborn as sns; sns.set()
ax = sns.heatmap(df.corr(), annot=True)
Correlations between the features
您可以看到特征之间存在一些很强的相关性,例如Grocery和Detergents_Paper之间的相关性。
让我们使用以下代码绘制Grocery,Detergents_Paper和Milk三个特征:
## Creating data for the plotly
trace1 = go.Scatter3d(
# Extracting data based on label
x=df['Grocery'],
y=df['Detergents_Paper'],
z=df['Milk'],
mode='markers',
marker=dict(
size=12,
line=dict(
color='rgba(217, 217, 217, 0.14)',
width=0.5
),
opacity=0.8
)
)
## Layout settings
layout = go.Layout(
scene = dict(
xaxis = dict(
title= 'Grocery'),
yaxis = dict(
title= 'Detergents_Paper'),
zaxis = dict(
title= 'Milk'),),
)
data = [trace1]
fig = dict(data=data, layout=layout)
plot(fig)
现在,您将继续扩展已为更高维度实现的 K 均值算法。 首先,您可以从数据集中删除Channel和Region,如下所示:
df = df[[col for col in df.columns if col not in ['Channel', 'Region']]]
df.head(10)
在实现方面,您还可以使用np.linalg.norm来计算距离,这实际上取决于您使用哪种距离函数。 另一个替代方法是scipy.spatial中的distance.euclidean,如下所示:
def Kmeans_nD(X, n_clusters, random_seed=442):
# Randomly choose random indexes as cluster centers
rng = np.random.RandomState(random_seed)
i = rng.permutation(X.shape[0])[:n_clusters]
c_centers = X[i]
# Calculate distances between each point and cluster centers
deltas = np.array([[np.linalg.norm(i - c) for c in c_centers] for i in X])
# Get labels for each point
labels = deltas.argmin(1)
while True:
# Calculate mean of each cluster
new_c_centers = np.array([X[np.where(deltas.argmin(1) == i)[0]].mean(axis=0) for i in range(n_clusters)])
# Calculate distances again
deltas = np.array([[np.linalg.norm(i - c) for c in new_c_centers] for i in X])
# Get new labels for each point
labels = deltas.argmin(1)
# If there's no change in centers, exit
if np.array_equal(c_centers, new_c_centers):
break
c_centers = new_c_centers
return c_centers, labels
Grocery和Detergents_Paper将用于聚类,并且k将设置为3。 通常,应使用外观检查或弯头方法确定k,如下所示:
centers, labels = Kmeans_nD(df[['Grocery', 'Detergents_Paper']].values, 3)
现在,您可以使用以下命令在数据集中再添加一列:
df['labels'] = labels
您可以使用以下代码来首先可视化结果,以查看结果是否有意义:
## Creating data for the plotly
trace1 = go.Scatter(
# Extracting data based on label
x=df[df['labels'] == 0]['Grocery'],
y=df[df['labels'] == 0]['Detergents_Paper'],
mode='markers',
name='clust_1',
marker=dict(
size=12,
line=dict(
color='rgba(217, 217, 217, 0.14)',
width=0.5
),
opacity=0.8
)
)
trace2 = go.Scatter(
# Extracting data based on label
x=df[df['labels'] == 1]['Grocery'],
y=df[df['labels'] == 1]['Detergents_Paper'],
mode='markers',
name='clust_2',
marker=dict(
color='rgb(#3742fa)',
size=12,
symbol='circle',
line=dict(
color='rgb(204, 204, 204)',
width=1
),
opacity=0.9
)
)
trace3 = go.Scatter(
# Extracting data based on label
x=df[df['labels'] == 2]['Grocery'],
y=df[df['labels'] == 2]['Detergents_Paper'],
mode='markers',
name='clust_3',
marker=dict(
color='rgb(#ff4757)',
size=12,
symbol='circle',
line=dict(
color='rgb(104, 74, 114)',
width=1
),
opacity=0.9
)
)
data = [trace1, trace2, trace3]
## Layout settings
layout = go.Layout(
scene = dict(
xaxis = dict(
title= 'Grocery'),
yaxis = dict(title= 'Detergents_Paper'),
)
)
fig = go.Figure(data=data, layout=layout)
plot(fig)
Plotting the clusters
乍一看,集群看起来很合理,并将最终取决于领域知识支持的解释。
您可以使用以下代码轻松查看每个集群每个特征的平均支出:
df.groupby('labels').mean()
从这个简单的集群中可以看出,第三集群在Milk,Grocery和Detergents_Paper上的支出最高。 第二个集群的支出较低,第一个集群倾向于Milk,Grocery和Detergents_Paper,因此k=2也可以使用。
总结
在本章中,您学习了无监督学习的基础知识,并使用 K 均值算法进行聚类。
有许多聚类算法显示不同的行为。 当涉及到无监督学习算法时,可视化是关键,并且您已经看到了几种不同的方式来可视化和检查数据集。
在下一章中,您将学习 NumPy 常用的其他库,例如 SciPy,Pandas 和 scikit-learn。 这些都是从业者工具包中的重要库,它们相互补充。 您会发现自己将这些库与 NumPy 一起使用,因为每个库都会使某些任务变得更容易。 因此,重要的是要了解有关 Python 数据科学堆栈的更多信息。

















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
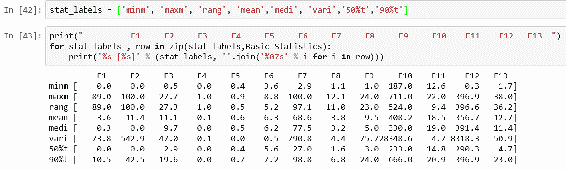{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
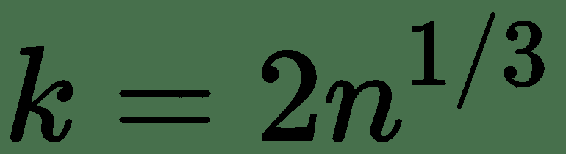{kind=link}
{kind=link}
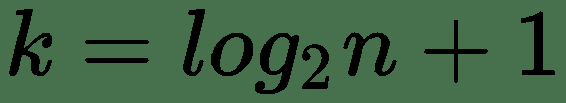{kind=link}
{kind=link}
{kind=link}
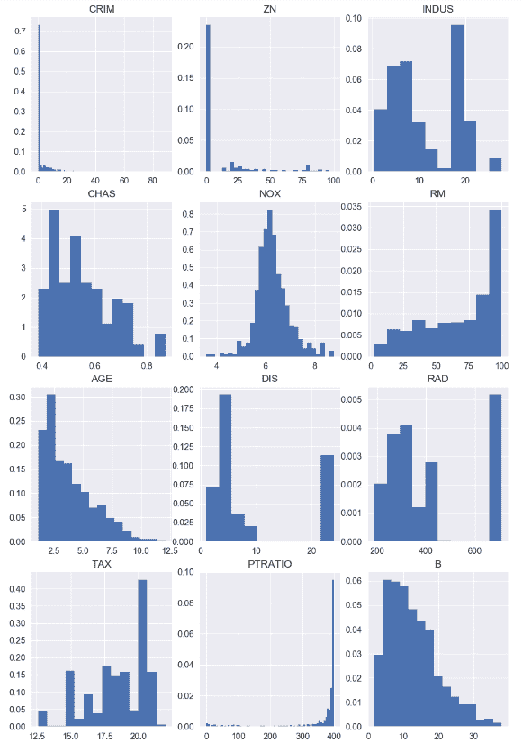{kind=link}
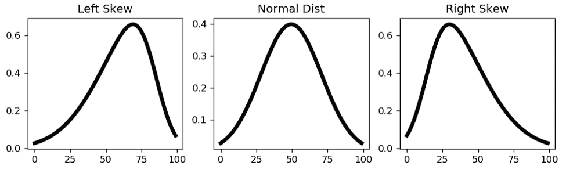{kind=link}
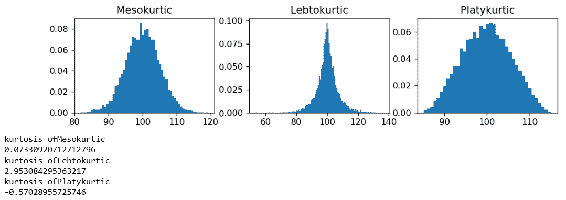{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
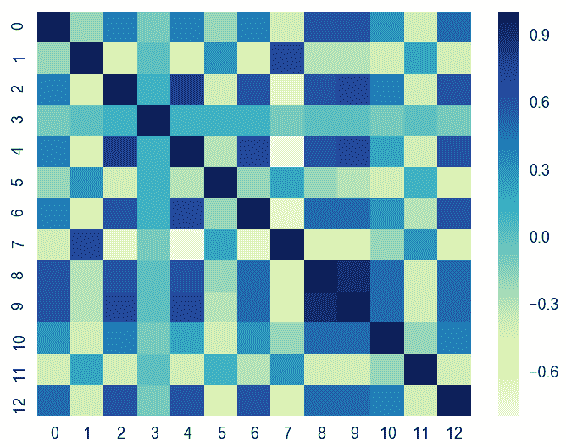{kind=link}
{kind=link}
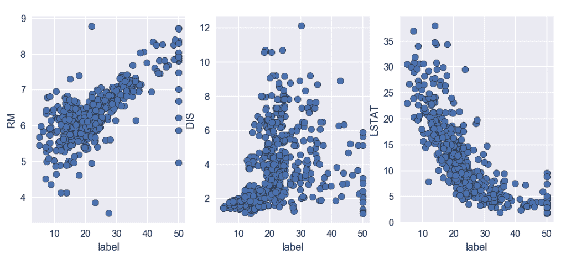{kind=link}
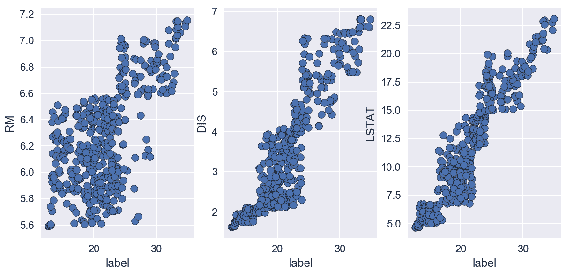{kind=link}
{kind=link}
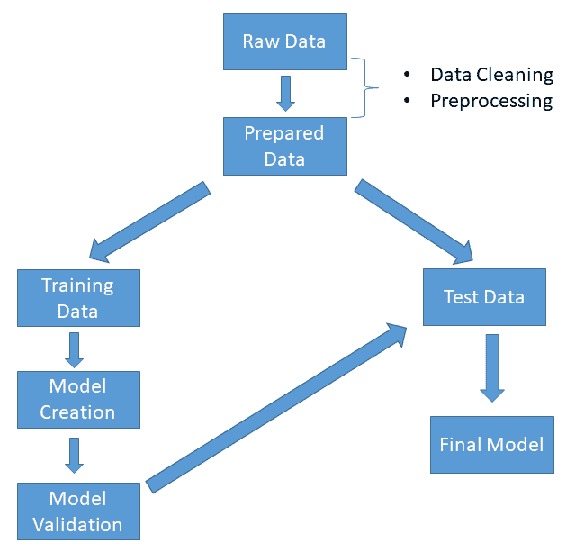{kind=link}
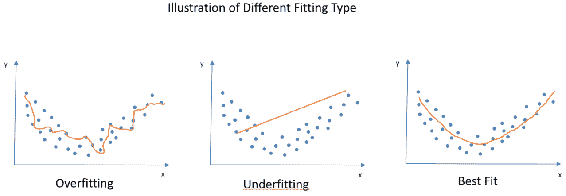{kind=link}
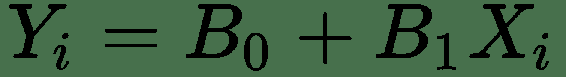{kind=link}
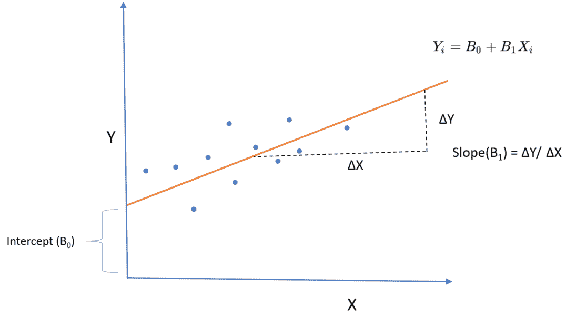{kind=link}
{kind=link}
{kind=link}
{kind=link}
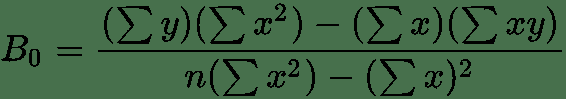{kind=link}
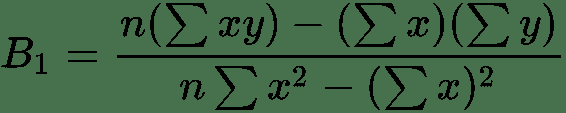{kind=link}
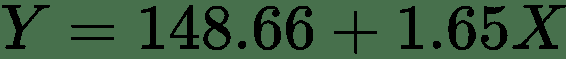{kind=link}
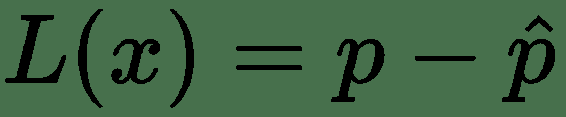{kind=link}
{kind=link}
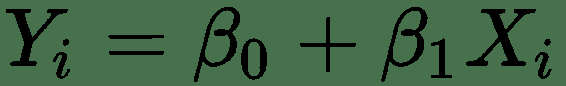{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
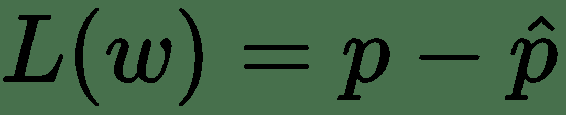{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
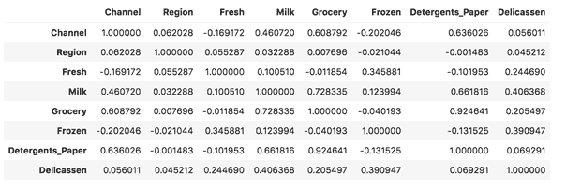{kind=link}
{kind=link}
{kind=link}
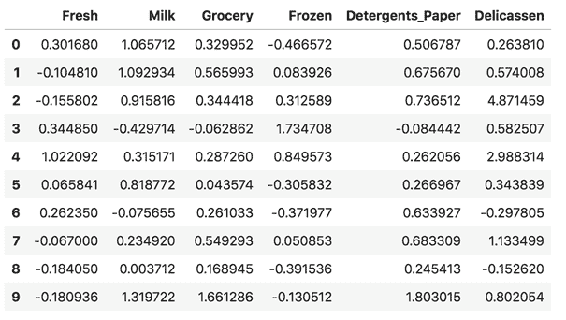{kind=link}
{kind=link}
{kind=link}