







一、直接说:“你好,TBB!”
线程构建模块(TBB)库在首次发布 10 年后,已经成为并行编程中使用最广泛的 C++ 库之一。虽然它保留了其核心理念和功能,但随着新的机遇和挑战的出现,它将继续扩展以应对这些机遇和挑战。
在这一章中,我们讨论了 TBB 的动机,提供了其主要组件的简要概述,描述了如何获得该库,然后直接跳到几个简单的例子。
为什么要线程化构建模块?
并行编程有着悠久的历史,可以追溯到 20 世纪 50 年代甚至更久。几十年来,科学家们一直在为超级计算机开发大规模并行模拟,企业也一直在为大型多处理器大型机开发企业应用程序。但是大约 10 年前,第一批用于台式机和笔记本电脑的多核芯片开始进入市场。这改变了游戏规则。
第一批多核台式机和笔记本电脑系统中的处理器数量很少——只有两个内核——但必须成为并行程序员的开发人员数量巨大。如果多核处理器成为主流,并行编程也必须成为主流,特别是对于关心性能的开发人员。
TBB 库于 2006 年 9 月首次发布,旨在应对主流并行编程的独特挑战。它现在的目标,也是 10 年前首次推出时的目标,是为开发人员提供一种简单而强大的方法来构建应用程序,随着具有不同架构和更多内核的新平台的推出,这些应用程序将继续扩展。随着主流处理器中的内核数量从 2006 年的两个增加到 2018 年的 64 个以上,这种“面向未来”的做法取得了成效!
为了实现这一目标,即让并行应用不受处理内核数量和能力变化的影响,TBB 背后的关键理念是让开发人员能够轻松地在其应用中表达并行性,同时限制他们对这种并行性到底层硬件的映射的控制。对于一些有经验的并行程序员来说,这种哲学似乎是违反直觉的。如果我们认为并行编程必须通过对系统的裸机编程,并手动调整和优化应用程序以挤出最后一点性能来不惜一切代价获得最高性能,那么 TBB 可能不适合我们。相反,TBB 库是为那些希望编写在今天的平台上获得高性能的应用程序,但又愿意牺牲一点性能来确保他们的应用程序在未来的系统上继续良好运行的开发人员准备的。
为了实现这一目标,TBB 中的接口让我们能够表达应用中的并行性,同时为库提供灵活性,以便它可以有效地将这种并行性映射到当前和未来的平台,并在运行时使其适应系统资源的动态变化。
性能:开销小,对 C++ 好处大
我们无意对性能损失小题大做,也不想否认这一点。对于以“Fortran”风格编写的简单 C++ 代码,具有单层平衡良好的并行循环,可能根本不需要 TBB 的动态特性。然而,这种编码风格的局限性是 TBB 存在的一个重要因素。TBB 旨在高效支持嵌套、并发和顺序的并行组合,并将这种并行动态映射到目标平台。使用像 TBB 这样的可组合库,开发人员可以通过组合包含并行性的组件和库来构建应用程序,而不用担心它们会相互干扰。重要的是,TBB 不要求我们限制我们表达的并行性来避免性能问题。对于使用 C++ 的大型复杂的应用程序,TBB 很容易推荐,没有免责声明。
TBB 库经过多年的发展,不仅适应了新的平台,也满足了开发人员的需求,他们希望对库在将并行性映射到硬件时所做的选择有更多的控制。虽然 TBB 1.0 为用户提供的性能控制非常少,但 TBB 2019 提供了相当多的性能控制——例如亲和力控制、工作隔离的构造、可用于将线程固定到内核的钩子等等。TBB 的开发人员努力设计这些控件,在不牺牲可组合性的情况下提供合适的控件级别。
该库提供的接口层次分明——TBB 提供了适合大多数程序员需求的高级模板,专注于常见案例。但它也提供了低级接口,因此我们可以深入研究,并根据需要为我们的特定应用创建定制的解决方案。TBB 拥有两个世界的精华。我们通常依靠库的默认选择来获得出色的性能,但是如果需要的话,我们可以深入研究细节。
在 TBB 和 C++ 中不断发展对并行性的支持
自从最初的 TBB 问世以来,TBB 库和 C++ 语言都有了很大的发展。2006 年的时候,C++ 还没有对并行编程的语言支持,包括标准模板库(STL)在内的很多库都不容易在并行程序中使用,因为它们不是线程安全的。
C++ 语言委员会一直忙于直接向该语言及其附带的标准模板库(STL)添加线程特性。图 1-1 显示了解决并行性的新的和计划中的 C++ 特性。
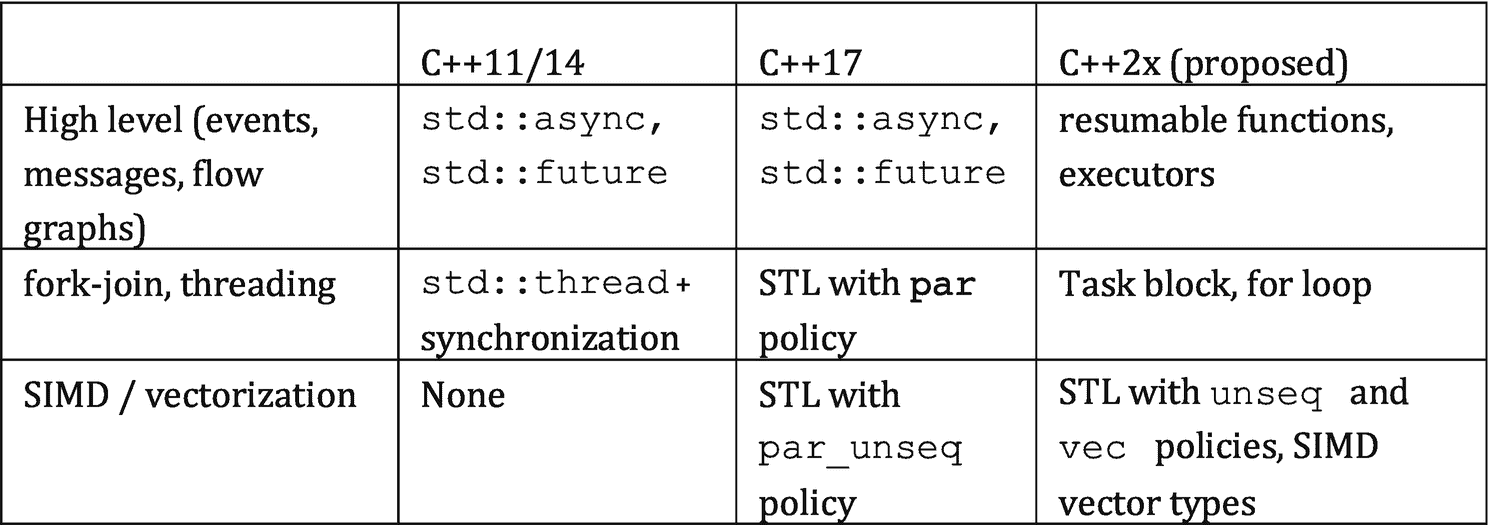
图 1-1。
C++ 标准中的特性以及一些建议的特性
尽管我们是 TBB 的忠实粉丝,但事实上我们更希望并行所需的所有基础支持都在 C++ 语言本身中。这将允许 TBB 利用一致的基础来构建更高级别的并行抽象。TBB 的最初版本必须解决缺乏 C++ 语言支持的问题,在这个领域,C++ 标准已经有了很大的发展,以填补 TBB 最初别无选择,只能用可移植锁和原子等功能来填补的基本空白。不幸的是,对于 C++ 开发人员来说,该标准仍然缺乏完全支持并行编程所需的特性。幸运的是,对于本书的读者来说,这意味着 TBB 对于 C++ 中有效的线程化仍然是重要的,并且很可能在未来许多年都是重要的。
理解这一点非常重要,我们并不是在抱怨 C++ 标准流程。向语言标准添加特性最好是非常小心地完成,并仔细检查。例如,C++11 标准委员会在内存模型上花费了巨大的精力。这对于并行编程的重要性对于每个基于该标准构建的库来说都是至关重要的。对于语言标准应该包括什么,应该支持什么,也有一些限制。我们相信 TBB 的任务分配系统和流程图系统不会直接成为语言标准的一部分。即使我们错了,这也不是短期内会发生的事情。
针对并行性的最新 C++ 新增功能
如图 1-1 所示,C++11 标准为线程引入了一些底层的、基本的构建模块,包括std::async、std::future和std::thread。它还引入了原子变量、互斥对象和条件变量。这些扩展要求程序员做大量的编码工作来建立更高层次的抽象——但是它们允许我们直接用 C++ 来表达基本的并行性。C++11 标准对于线程来说是一个明显的改进,但是它并没有为我们提供可以轻松编写可移植的、高效的并行代码的高级特性。它也没有为我们提供任务或底层的偷工减料任务调度程序。
C++17 标准引入了一些特性,这些特性将抽象级别提升到了这些低级构件之上,使我们更容易表达并行性,而不必担心每一个低级细节。正如我们在本书后面所讨论的,仍然有一些重要的限制,所以这些特性还没有足够的表达力或性能——在 C++ 标准方面还有很多工作要做。
这些 C++17 新增功能中最相关的是可以与标准模板库(STL)算法一起使用的执行策略。这些策略让我们选择算法是否可以安全地并行化、矢量化、并行化和矢量化,或者它是否需要保留其原始的有序语义。我们称支持这些策略的 STL 实现为并行 STL。
展望未来,未来的 C++ 标准可能会包含更多的并行特性,如可恢复函数、执行器、任务块、并行 for 循环、SIMD 向量类型和 STL 算法的附加执行策略。
线程构建模块(TBB)库
线程构建模块(TBB)库是一个 C++ 库,它有两个关键作用:(1)在 C++ 标准没有充分发展或新功能没有被所有编译器完全支持的情况下,它填补了支持并行性的基本空白;以及(2)它为并行性提供了更高级别的抽象,这超出了 C++ 语言标准可能包含的范围。TBB 包含许多功能,如图 1-2 所示。
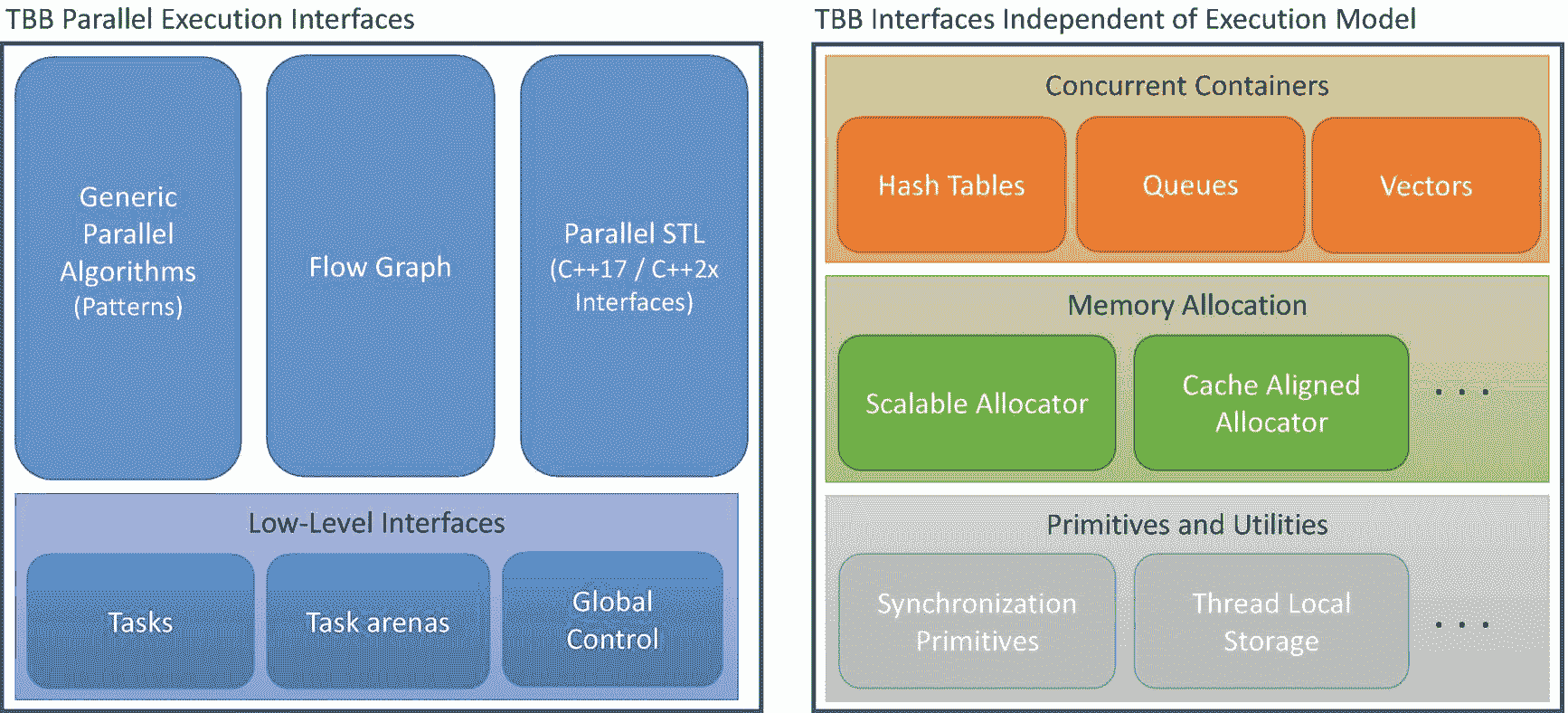
图 1-2。
TBB 图书馆的特色
这些特性可以分为两大类:表达并行计算的接口和独立于执行模型的接口。
并行执行接口
当我们使用 TBB 创建并行程序时,我们使用高级接口之一或直接通过任务来表达应用程序中的并行性。我们将在本书后面更详细地讨论任务,但是现在我们可以把 TBB 任务看作是一个轻量级对象,它定义了一个小的计算及其相关数据。作为 TBB 开发者,我们直接或间接地通过预先打包的 TBB 算法,使用任务来表达我们的应用,并且库为我们将这些任务调度到平台的硬件资源上。
值得注意的是,作为开发人员,我们可能想要表达不同种类的并行性。图 1-3 显示了并行应用中最常见的三个并行层。我们应该注意,一些应用程序可能包含所有三层,而其他应用程序可能只包含其中的一层或两层。TBB 最强大的一个方面是,它为这些不同的并行层提供了高级接口,允许我们使用同一个库来利用所有的层。
图 1-3 中所示的消息驱动层捕获并行性,这种并行性被构造为通过显式消息相互通信的相对较大的计算。这一层中的常见模式包括流图、数据流图和依赖图。在 TBB,这些模式通过流程图接口得到支持(在第三章中描述)。
图 1-3 所示的 fork-join 层支持这样的模式:串行计算分支成一组并行任务,然后仅当并行子计算完成时才继续。fork-join 模式的例子包括功能并行(任务并行)、并行循环、并行归约和流水线。TBB 用它的通用并行算法支持这些(在第二章中描述)。
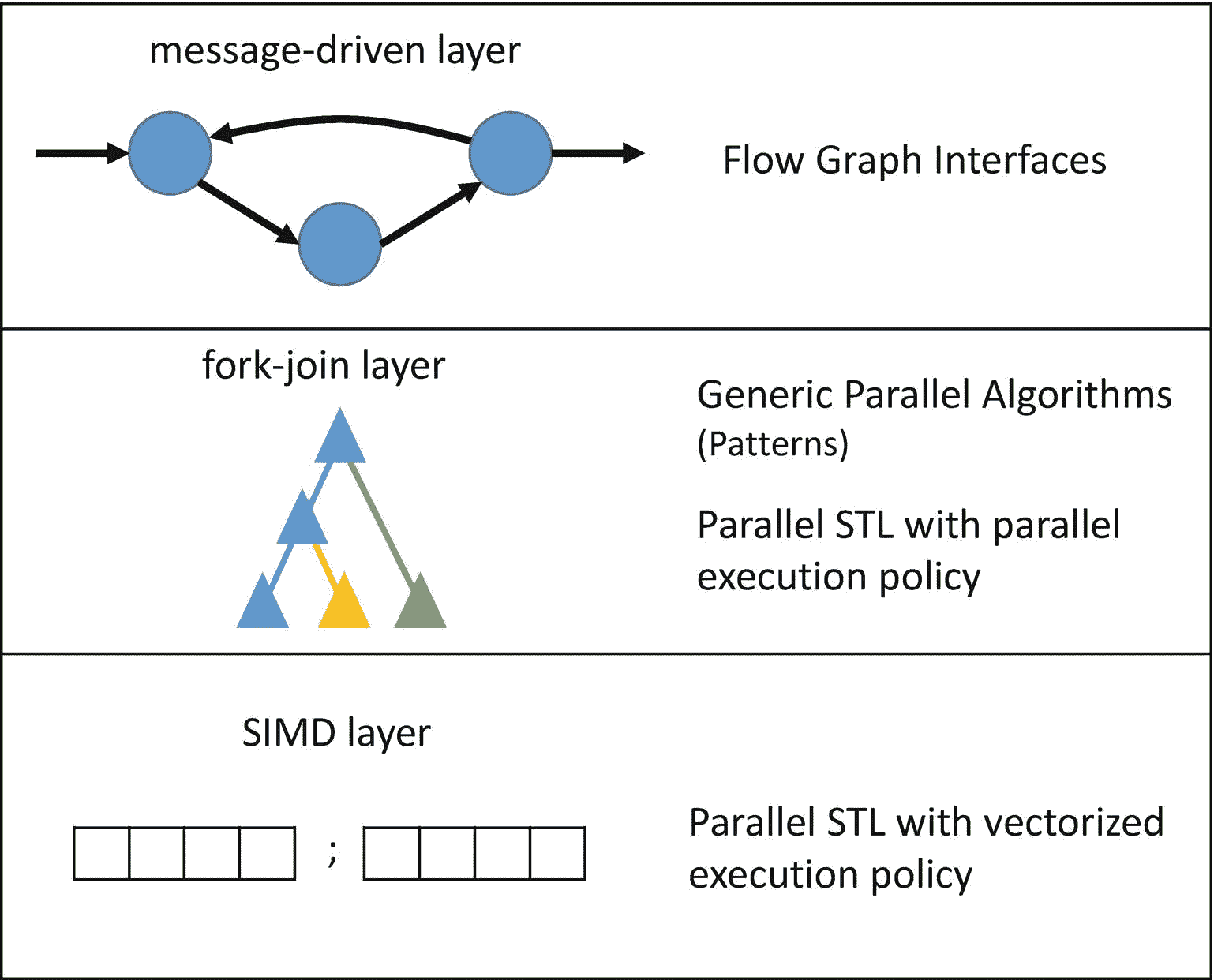
图 1-3。
应用中常见的三个并行层,以及它们如何映射到高级 TBB 并行执行接口
最后,在单指令多数据(SIMD)层,通过对多个数据元素同时应用相同的操作来利用数据并行性。这种类型的并行性通常使用矢量扩展来实现,如 AVX、AVX2 和 AVX-512,它们使用每个处理器内核中可用的矢量单元。所有的 TBB 发行版都有一个并行的 STL 实现(在第四章中描述),它提供了矢量实现,以及其他利用这些扩展的功能。
TBB 为许多常见的并行模式提供了高级接口,但是仍然存在没有高级接口匹配问题的情况。如果是这样的话,我们可以直接使用 TBB 任务来构建我们自己的算法。
TBB 并行执行接口的真正力量来自于将它们混合在一起的能力,这通常被称为“可组合性”我们可以创建在顶层具有流图的应用程序,该流图具有使用嵌套的通用并行算法的节点。反过来,这些嵌套的通用并行算法可以在其主体中使用并行 STL 算法。由于所有这些层所表达的并行性都暴露给了 TBB 库,所以这个库可以以高效且可组合的方式来调度相应的任务,从而充分利用平台的资源。
使 TBB 成为可组合的关键属性之一是它支持宽松的顺序语义。宽松的顺序语义意味着我们使用 TBB 任务表达的并行性实际上只是对库的一个暗示;不能保证任何任务实际上彼此并行执行。这为 TBB 图书馆提供了极大的灵活性,可以根据需要安排任务以提高性能。这种灵活性使该库能够在系统上提供可扩展的性能,无论它们是单核、八核还是 80 核。它还允许库适应平台上的动态负载;例如,如果一个内核超额完成工作,TBB 可以在其他内核上安排更多工作,甚至选择只使用一个内核来执行并行算法。我们将在第九章中详细描述为什么 TBB 被认为是一个可组合的库。
独立于执行模型的接口
与并行执行接口不同,图 1-2 中的第二大组特性完全独立于执行模型和 TBB 任务。这些特性在使用本机线程的应用程序(如pthreads或WinThreads)中与在使用 TBB 任务的应用程序中一样有用。
这些特性包括并发容器,这些容器为常见的数据结构(如哈希表、队列和向量)提供线程友好的接口。它们还包括内存分配的特性,如 TBB 可伸缩内存分配器和高速缓存对齐分配器(两者都在第七章中描述)。它们还包括低级功能,如同步原语和线程本地存储。
使用 TBB 的积木
作为开发人员,我们可以挑选 TBB 中对我们的应用程序有用的部分。例如,我们可以只使用可伸缩的内存分配器(在第七章中描述),其他什么都不用。或者,我们可以使用并发容器(在第六章中描述)和一些通用的并行算法(第二章)。当然,我们也可以选择全力以赴,构建一个结合了所有三个高级执行接口的应用程序,并利用 TBB 可伸缩内存分配器和并发容器,以及库中的许多其他功能。
让我们开始吧!
获取线程构建模块(TBB)库
在开始使用 TBB 之前,我们需要获得该库的副本。有几种方法可以做到这一点。在写这本书的时候,这些方法包括
-
点击
www.threadingbuildingblocks.org或https://software.intel.com/intel-tbb的链接,直接从英特尔获得 TBB 库的免费版本。有适用于 Windows、Linux 和 macOS 的预编译版本。最新的软件包包括 TBB 库和并行 STL 算法的实现,该算法使用 TBB 进行线程处理。 -
访问
https://github.com/intel/tbb获得 TBB 图书馆的免费开源版本。TBB 的开源版本绝不是该库的精简版;它包含商业支持版本的所有功能。您可以选择从源代码中检验和构建,也可以单击“发布”下载由英特尔构建和测试的版本。在 GitHub,预构建和测试版本可用于 Windows、Linux、macOS 和 Android。同样,TBB 预建版本的最新包包括 TBB 库和一个使用 TBB 线程的并行 STL 实现。如果你想要并行 STL 的源代码,你需要从https://github.com/intel/parallelstl单独下载。 -
您可以下载一份英特尔 Parallel Studio XE 工具套件
https://software.intel.com/intel-parallel-studio-xe。TBB 和使用 TBB 的并行 STL 目前包含在该工具套件的所有版本中,包括最小的 Composer 版本。如果您安装了最新版本的英特尔 C++ 编译器,那么您的系统中可能已经安装了 TBB。
我们让读者选择获得 TBB 的最合适的途径,并遵循相应站点上提供的安装软件包的说明。
获取示例的副本
本书中使用的所有代码示例都可以在 https://github.com/Apress/pro-TBB 获得。在这个库中,每个章节都有目录。许多源文件是根据它们出现的图来命名的,例如ch01/fig_1_04.cpp包含与本章中的图 1-4 匹配的代码。
写第一句“你好,TBB!”例子
图 1-4 提供了一个小例子,使用一个tbb::parallel_invoke来评估两个函数,一个打印Hello,另一个并行打印TBB!。这个例子很简单,不会从并行化中受益,但是我们可以使用它来确保我们已经正确地设置了使用 TBB 的环境。在图 1-4 中,我们包含了 tbb.h 头来访问 tbb 函数和类,它们都在名称空间 TBB 中。对parallel_invoke的调用向 TBB 库断言,传递给它的两个函数是相互独立的,在不同的内核或线程上以任何顺序并行执行都是安全的。在这些约束条件下,得到的输出可能首先包含Hello或TBB!。我们甚至可以看到,在输出的末尾,两个字符串和两个连续的换行符之间没有换行符,因为每个字符串及其std::endl的打印不是自动进行的。

图 1-4。
一个你好 TBB 的例子
图 1-5 提供了一个使用并行 STL std::for_each将一个函数并行应用到一个std::vector中的两个项目的例子。将一个pstl::execution::par策略传递给std::for_each断言,在不同的内核或线程上并行地将所提供的函数应用于解引用范围v.begin(), v.end()).中的每个迭代器的结果是安全的,就像图 [1-4 一样,运行该示例的输出可能会首先打印任一字符串。

图 1-5。
Hello 并行 STL 示例
在两个图 1-4 和 1-5 中,我们使用 C++ lambda 表达式来指定函数。当使用像 TBB 这样的库来指定作为任务执行的用户代码时,Lambda 表达式非常有用。为了帮助复习 C++ lambda 表达式,我们提供了一个标注框“C++ Lambda 表达式入门”,概述了这一重要的现代 C++ 特性。
C++ Lambda 表达式入门
对 lambda 表达式的支持是在 C++11 中引入的。它们用于创建匿名函数对象(尽管您可以将它们赋给命名变量),这些对象可以从封闭范围中捕获变量。C++ lambda 表达式的基本语法是
- 【捕获清单】[参数)->【ret】**
**在哪里
-
捕获列表是一个逗号分隔的捕获列表。我们通过在捕获列表中列出变量名来按值捕获变量。我们通过引用捕获一个变量,在它前面加上一个&符号,例如,
&v**。**我们可以使用this通过引用来捕获当前对象。也有默认:[=]用于通过值捕获主体中使用的所有自动变量,通过引用捕获当前对象,[&]用于通过引用捕获主体中使用的所有自动变量以及当前对象,[]什么都不捕获。 -
params是函数参数列表,就像命名函数一样。 -
ret是返回类型。如果未指定->ret,则从返回语句中推断出来。 -
body是函数体。
下一个例子展示了一个 C++ lambda 表达式,它通过值捕获一个变量i,通过引用捕获另一个变量j。它还有一个参数k0和另一个通过引用接收的参数l0:
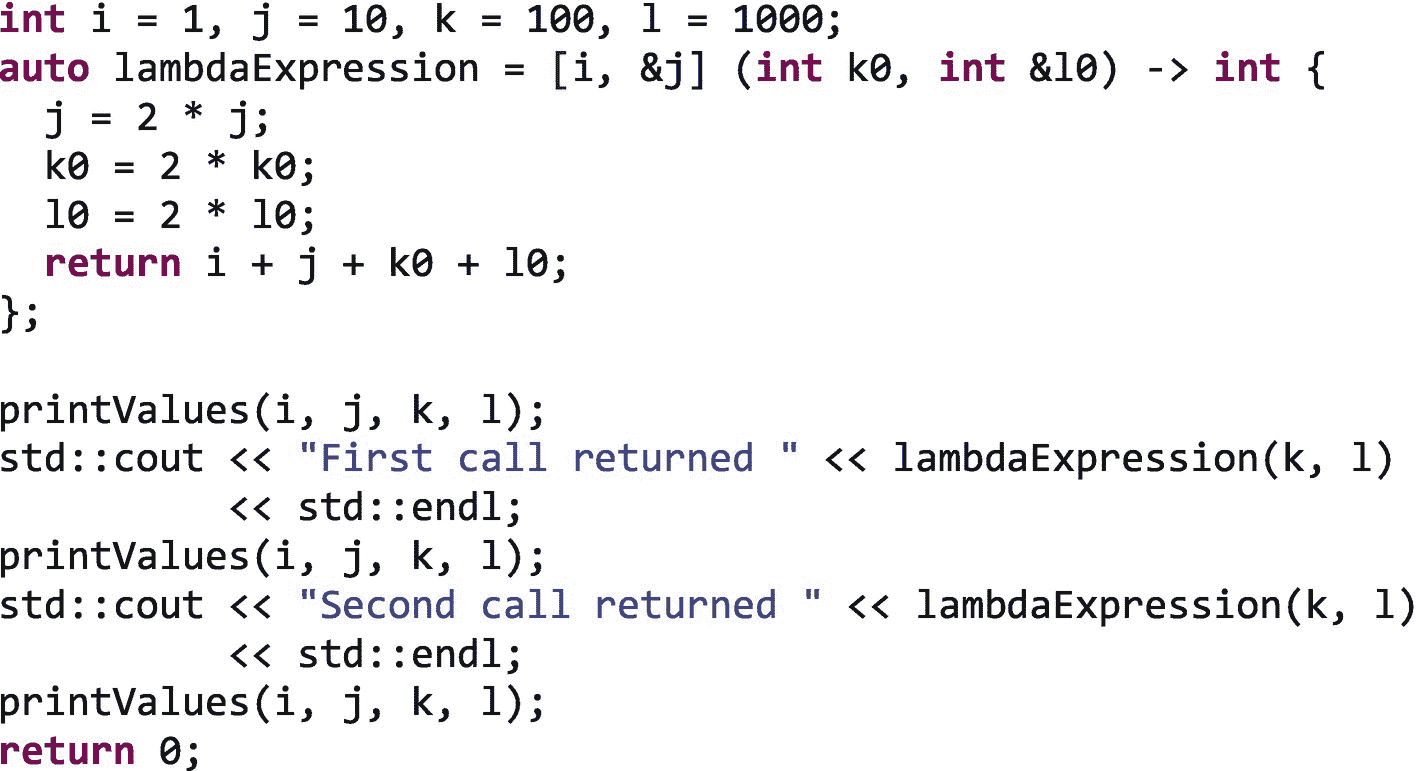
运行该示例将产生以下输出:
i == 1
j == 10
k == 100
l == 1000
First call returned 2221
i == 1
j == 20
k == 100
l == 2000
Second call returned 4241
i == 1
j == 40
k == 100
l == 4000
我们可以把 lambda 表达式看作一个函数对象的实例,但是编译器为我们创建了类定义。例如,我们在前面的例子中使用的 lambda 表达式类似于一个类的实例:

无论我们在哪里使用 C++ lambda 表达式,我们都可以用一个函数对象的实例来代替它,就像前面的例子一样。事实上,TBB 库早于 C++11 标准,它的所有接口都需要传入用户定义类的对象实例。C++ lambda 表达式通过消除每次使用 TBB 算法时定义一个类的额外步骤,简化了 TBB 的使用。
构建简单的示例
一旦我们编写了图 1-4 和 1-5 中的例子,我们需要从它们构建可执行文件。构建使用 TBB 的应用程序的指令依赖于操作系统和编译器。但是,一般来说,正确配置环境需要两个必要的步骤。
设置环境的步骤
-
我们必须通知编译器 TBB 头文件和库的位置。如果我们使用并行 STL 接口,我们还必须通知编译器并行 STL 头文件的位置。
-
我们必须配置我们的环境,以便应用程序可以在运行时定位 TBB 库。TBB 是作为动态链接库提供的,这意味着它不是直接嵌入到我们的应用程序中的;相反,应用程序在运行时定位并加载它。并行 STL 接口不需要自己的动态链接库,但是依赖于 TBB 库。
我们现在将简要讨论在 Windows 和 Linux 上完成这些步骤的一些最常见的方法。macOS 的指令类似于 Linux 的指令。TBB 库附带的文档中有更多的案例和更详细的说明。
使用 Microsoft Visual Studio 在 Windows 上构建
如果我们下载 TBB 的商业支持版本或英特尔 Parallel Studio XE 的版本,我们可以在安装时将 TBB 库与微软 Visual Studio 集成,然后从 Visual Studio 使用 TBB 就非常简单了。
创造一个“你好,TBB!”项目,我们在 Visual Studio 中照常创建一个项目,用图 1-4 或图 1-5 中包含的代码添加一个“.cpp文件,然后转到项目的属性页,遍历到配置属性➤英特尔性能库,将使用 TBB 改为是,如图 1-6 所示。这就完成了步骤 1。Visual Studio 现在会将 TBB 库链接到项目中,因为它具有指向头文件和库的正确路径。这也正确地设置了并行 STL 文件头的路径。
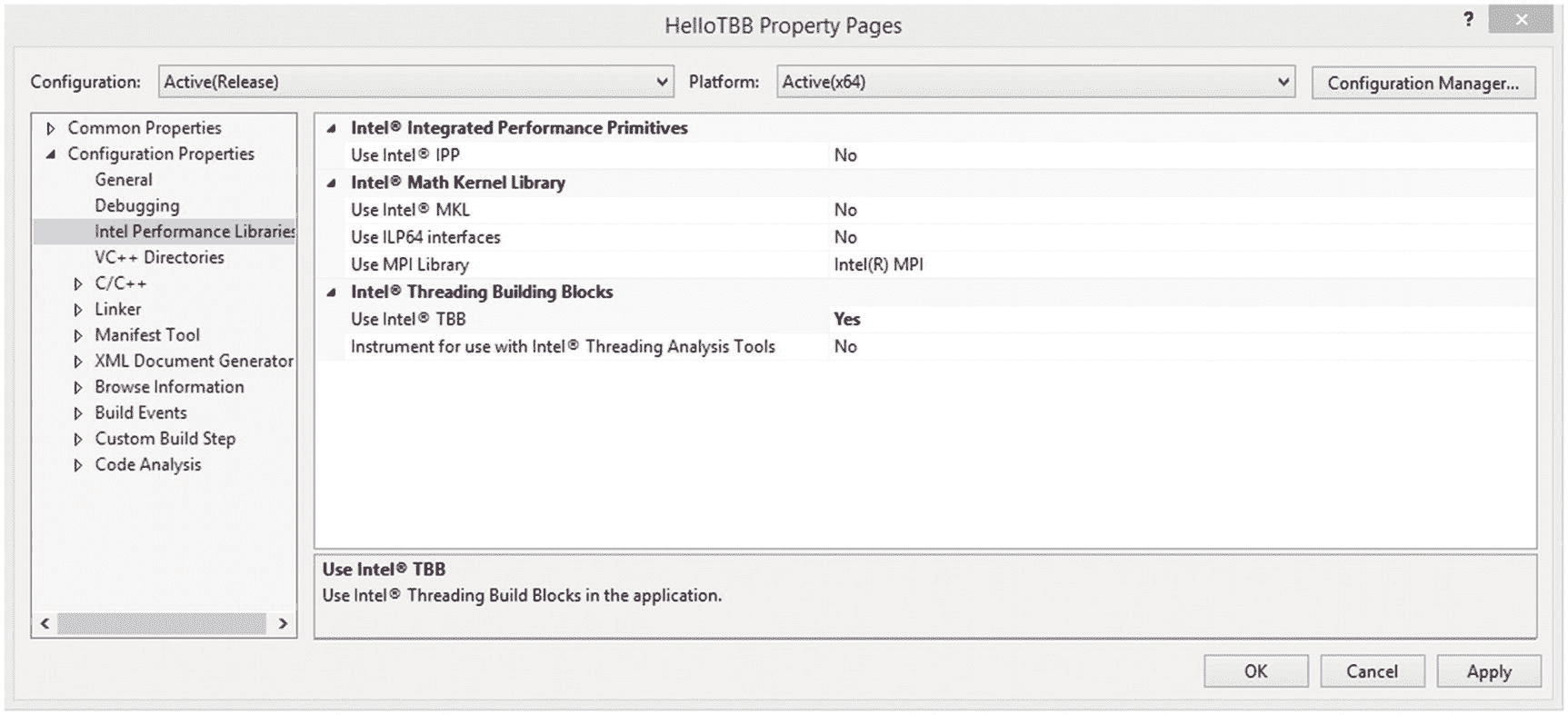
图 1-6。
在 Visual Studio 的项目属性页中设置使用***【TBB】***到 是
在 Windows 系统上,由应用程序可执行文件在运行时动态加载的 TBB 库是。dll"文件。为了完成设置环境的第 2 步,我们需要将这些文件的位置添加到 PATH 环境变量中。我们可以通过将路径添加到我们的用户或系统路径变量中来做到这一点。找到这些设置的一个地方是在 Windows 控制面板中,通过遍历系统和安全➤系统➤高级系统设置➤环境变量。关于“.dll”文件的确切位置,我们可以参考我们的 TBB 安装文档。
注意
对环境中 PATH 变量的更改只有在 Microsoft Visual Studio 重新启动后才会生效。
一旦我们输入了源代码,让使用 TBB 设置为是,并且在我们的 path 变量中有了 TBB 的路径.dll,我们就可以通过输入 Ctrl-F5 来构建和执行程序。
从终端构建在 Linux 平台上
使用英特尔编译器
使用英特尔 C++ 编译器时,编译过程得到了简化,因为 TBB 库包含在编译器中,它支持一个编译器标志–tbb,可以在编译过程中为我们正确设置包含和库路径。因此,要使用英特尔 C++ 编译器编译我们的示例,我们只需在编译行添加–tbb标志。
icpc –std=c++11 -tbb –o fig_1_04 fig_1_04.cpp
icpc –std=c++11 -tbb –o fig_1_05 fig_1_05.cpp
tbbvars和pstlvars脚本
如果我们不使用英特尔 C++ 编译器,我们可以使用 TBB 和并行 STL 发行版中包含的脚本来设置我们的环境。这些脚本修改了CPATH、LIBRARY_PATH和LD_LIBRARY_PATH环境变量,以包含构建和运行 TBB 和并行 STL 应用程序所需的目录。当编译器查找#include文件时,CPATH变量将额外的目录添加到编译器搜索的目录列表中。LIBRARY_PATH在编译时查找要链接的库时,将额外的目录添加到编译器搜索的目录列表中。并且LD_LIBRARY_PATH将额外的目录添加到可执行文件在运行时加载动态库时将搜索的目录列表中。
让我们假设我们的 TBB 安装的根目录是TBB_ROOT。TBB 库在${TBB_ROOT}/bin目录中附带了一组脚本,我们可以执行这些脚本来正确地设置环境。我们需要将我们的架构类型[ia32|intel64|mic]传递给这个脚本。我们还需要在编译时添加一个标志来启用 C++11 特性的使用,比如我们对 lambda 表达式的使用。
尽管所有最近的 TBB 库包中都包含了并行 STL 头文件,但我们需要额外的步骤来将它们添加到我们的环境中。就像 TBB 一样,并行 STL 在${PSTL_ROOT}/bin目录中附带了一组脚本。PSTL_ROOT目录通常是TBB_ROOT目录的兄弟。我们还需要传入我们的架构类型,并启用 C++11 特性来使用并行 STL。
在采用 64 位英特尔处理器的 Linux 平台上构建和执行图 1-4 中的示例的步骤如下
source ${TBB_ROOT}/bin/tbbvars.sh intel64 linux auto_tbbroot
g++ -std=c++11 -o fig_1_04 fig_1_04.cpp -ltbb
./fig_1_04
在采用 64 位英特尔处理器的 Linux 平台上构建和执行图 1-5 中的示例的步骤如下
source ${TBB_ROOT}/bin/tbbvars.sh intel64 linux auto_tbbroot
source ${PSTL_ROOT}/bin/pstlvars.sh intel64 auto_pstlroot
g++ -std=c++11 -o fig_1_05 fig_1_05.cpp -ltbb
./fig_1_05
注意
越来越多的 Linux 发行版包含了 TBB 库的副本。在这些平台上,GCC 编译器可能链接到平台版本的 TBB 库,而不是由tbbvars脚本添加到 LIBRARY_PATH 的 TBB 库版本。如果我们在使用 TBB 时发现链接问题,这可能就是问题所在。如果是这种情况,我们可以在编译器的命令行中添加一个显式的库路径,以选择特定版本的 TBB 库。
例如:
g++ -L${TBB_ROOT}/lib/intel64/gcc4.7 –ltbb ...
我们可以在g++命令行中添加–Wl,--verbose来生成一份报告,报告编译期间被链接的所有库,以帮助诊断这个问题。
虽然我们显示了g++的命令,但是除了使用的编译器名称之外,英特尔编译器(icpc)或 LLVM ( clang++)的命令行是相同的。
不使用tbbvars脚本或英特尔编译器手动设置变量
有时我们可能不想使用tbbvars脚本,要么是因为我们想确切地知道正在设置什么变量,要么是因为我们需要与构建系统集成。如果不适合您,请跳过这一部分,除非您真的很想手动操作。
既然您还在阅读本节,让我们看看如何在不使用tbbvars脚本的情况下在命令行上构建和执行。当用非英特尔编译器编译时,我们没有可用的–tbb标志,所以我们需要指定 TBB 头文件和共享库的路径。
如果我们的 TBB 安装的根目录是TBB_ROOT,,那么头文件在${TBB_ROOT}/include中,共享库文件存储在${TBB_ROOT}/lib/${ARCH}/${GCC_LIB_VERSION},中,其中ARCH是系统架构[ia32|intel64|mic],而GCC_LIB_VERSION是与您的 GCC 或 clang 安装兼容的 TBB 库的版本。
TBB 库版本之间的根本区别是它们依赖于 C++ 运行时库中的特性(例如libstdc++或libc++)。
通常,为了找到合适的 TBB 版本,我们可以在终端中执行命令gcc –version。然后,我们选择在${TBB_ROOT}/lib/${ARCH}中可用的最接近的 GCC 版本,该版本不比我们的 GCC 版本新(即使当我们使用 clang++ 时,这通常也是有效的)。但是由于不同机器的安装可能不同,并且我们可以选择编译器和 C++ 运行时的不同组合,这种简单的方法可能并不总是有效。如果没有,请参考 TBB 文档以获得更多指导。
例如,在安装了 GCC 5.4.0 的系统上,我们用
g++ -std=c++11 -o fig_1_04 fig_1_04.cpp \
–I ${TBB_ROOT}/include \
-L ${TBB_ROOT}/lib/intel64/gcc4.7 –ltbb
而在使用 clang++ 的时候,我们用的是同一个 TBB 版本:
clang++ -std=c++11 -o fig_1_04 fig_1_04.cpp \
-I ${TBB_ROOT}/include \
-L ${TBB_ROOT}/lib/intel64/gcc-4.7 –ltbb
为了编译图 1-5 中的例子,我们还需要添加并行 STL 包含目录的路径:
g++ -std=c++11 -o fig_1_05 fig_1_05.cpp \
–I ${TBB_ROOT}/include \
-I ${PSTL_ROOT}/include \
-L ${TBB_ROOT}/lib/intel64/gcc4.7 –ltbb
不管我们是用英特尔编译器、gcc 还是 clang++ 编译,我们都需要将 TBB 共享库位置添加到我们的LD_LIBRARY_PATH中,以便在应用程序运行时可以找到它。同样,假设我们的 TBB 安装的根目录是TBB_ROOT,,我们可以这样设置,例如,用
export LD_LIBRARY_PATH=${TBB_ROOT}/lib/${ARCH}/${GCC_LIB_VERSION}:${LD_LIBRARY_PATH}
一旦我们使用英特尔编译器、gcc 或 clang++ 编译了我们的应用,并根据需要设置了我们的LD_LIBRARY_PATH,我们就可以从命令行运行应用了:
./fig_1_04
这将产生类似于以下内容的输出
Hello
Parallel STL!
一个更完整的例子
前面几节提供了编写、构建和执行一个简单的 TBB 应用程序和一个简单的并行 STL 应用程序的步骤,每个应用程序都打印几行文本。在这一节中,我们编写了一个更大的示例,它使用图 1-2 中所示的所有三个高级执行接口,可以从并行执行中获益。我们不解释用于创建该示例的算法和特性的所有细节,而是使用该示例来查看可以用 TBB 表达的不同并行层。这个例子显然是人为的。用几个段落解释足够简单,但展示图 1-3 中描述的所有并行层又足够复杂。我们在这里创建的最终多级并行版本应该被视为一个语法演示,而不是如何编写一个最佳 TBB 应用程序的指南。在随后的章节中,我们将更详细地介绍本节中使用的所有特性,并就如何使用它们在更现实的应用中获得更好的性能提供指导。
从串行实现开始
让我们从图 1-7 所示的串行实现开始。本示例对图像矢量中的每个图像应用灰度校正和色调,并将每个结果写入一个文件。突出显示的函数fig_1_7包含一个 for 循环,通过对每幅图像执行applyGamma、applyTint和writeImage函数来处理矢量的元素。图 1-7 中也提供了这些功能的串行实现。图像表示和一些辅助功能的定义包含在ch01.h中。在 https://github.com/Apress/threading-building-blocks 可以找到这个头文件,以及这个例子的所有源代码。


图 1-7。
对图像矢量应用灰度校正和色调的示例的串行实现
applyGamma函数和applyTint函数在外部 for 循环中遍历图像的行,在内部 for 循环中遍历每行的元素。计算新的像素值并将其分配给输出图像。applyGamma功能应用伽马校正。applyTint功能将蓝色调应用于图像。这些函数接收并返回std::shared_ptr对象以简化内存管理;不熟悉std::shared_ptr的读者可以参考侧栏讨论“关于智能指针的说明”图 1-8 显示了通过示例代码输入的图像输出示例。
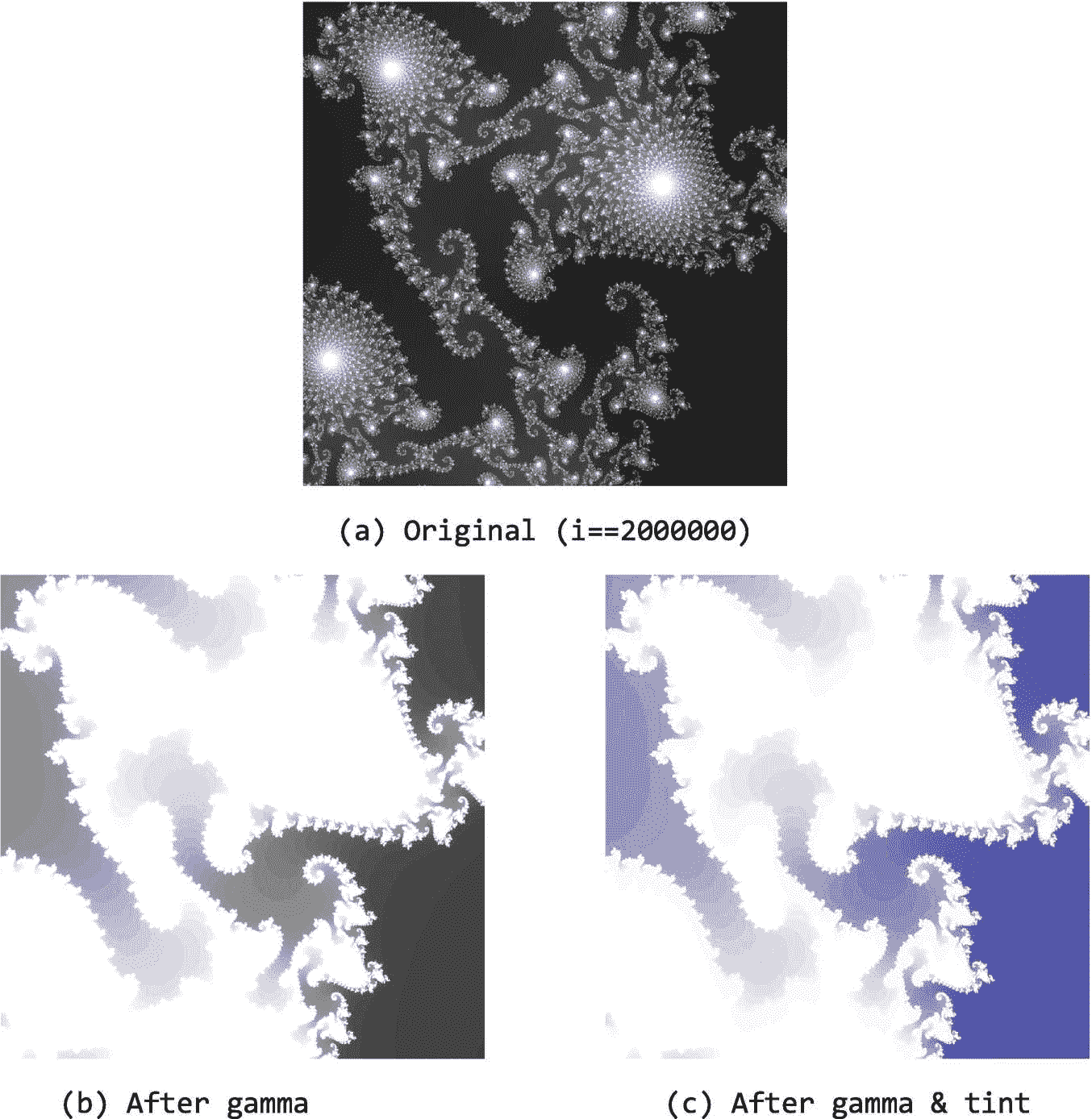
图 1-8。
示例输出:(a)由ch01::makeFractalImage(2000000)生成的原始图像,(b)经过伽马校正后的图像,以及©经过伽马校正和着色后的图像
关于智能指针的一个注释
C/C++ 编程中最具挑战性的部分之一是动态内存管理。当我们使用 new/delete 或 malloc/free 时,我们必须确保正确地匹配它们,以避免内存泄漏和双重释放。C++11 中引入了智能指针,包括unique_ptr、shared_ptr和weak_ptr,以提供自动的、异常安全的内存管理。例如,如果我们通过使用make_shared分配一个对象,我们会收到一个指向该对象的智能指针。当我们将这个共享指针分配给其他共享指针时,C++ 库会为我们处理引用计数。当没有通过任何智能指针对我们的对象进行未完成的引用时,对象将被自动释放。在本书的大多数例子中,包括图 1-7 ,我们使用智能指针而不是原始指针。使用智能指针,我们不必担心找到所有需要插入或删除的点——我们可以依靠智能指针做正确的事情。
使用流程图添加消息驱动层
使用自上而下的方法,我们可以用一个 TBB 流图来代替图 1-7 中函数fig_1_07的外部循环,该图通过一组过滤器来传输图像,如图 1-9 所示。我们承认,在这个特殊的例子中,这是我们最做作的选择。在这种情况下,我们可以很容易地使用外部并行循环;或者我们可以将 Gamma 和 Tint 循环嵌套合并在一起。但是出于演示的目的,我们选择用一个单独节点的图来表示,以展示 TBB 如何被用来表示消息驱动的并行性,这是图 1-3 中的顶级并行性。在第三章中,我们将了解更多关于 TBB 流图接口的知识,并发现这种高级的、消息驱动的执行接口的更多自然应用。

图 1-9。
有四个节点的数据流图:(1)获取或生成图像的节点,(2)应用灰度校正的节点,(3)应用色调的节点,以及(4)写出结果图像的节点
通过使用图 1-9 中的数据流图,我们可以将应用于不同图像的不同阶段流水线的执行重叠。例如,当第一个图像 img 0 在gamma节点完成时,结果被传递到tint节点,而新图像 img 1 进入gamma节点。同样,当这个下一步完成时,现在已经通过gamma和tint节点的 img 0 被发送到write节点。同时,img 1 被发送到tint节点,新的图像 img 2 在gamma节点开始处理。在每一步,过滤器的执行都是相互独立的,因此这些计算可以分布在不同的内核或线程上。图 1-10 显示了函数fig_1_7的循环,现在表示为 TBB 流程图。

图 1-10。
使用 TBB 流图代替外部 for 循环
正如我们将在第三章中看到的,构建和执行 TBB 流图需要几个步骤。首先,构建一个图形对象g。接下来,我们在数据流图中构建代表计算的节点。将图像传输到图的其余部分的节点是一个名为src的source_node。计算由名为gamma、tint和write的function_node对象执行。我们可以认为source_node是一个没有输入的节点,它继续发送数据,直到没有数据可发送。我们可以把function_node看作是接收输入并生成输出的函数的包装器。
创建节点后,我们使用边将它们相互连接起来。边表示节点之间的依赖关系或通信通道。因为,在图 1-10 的例子中,我们希望src节点发送初始图像到gamma节点,我们从src节点到gamma节点.做一条边,然后从gamma节点到tint节点做一条边。同样,我们制作一条从tint节点到write节点的边。一旦我们完成了图结构的构建,我们调用src.activate()来启动source_node并调用g.wait_for_all()来等待直到图完成。
当图 1-10 中的应用程序执行时,由src节点生成的每幅图像都将通过节点管道,如前所述。当一个图像被发送到gamma节点时,TBB 库创建并调度一个任务,将gamma节点的主体应用到图像上。当该处理完成时,输出被馈送到tint节点。同样,TBB 将创建并调度一个任务,在gamma节点的输出上执行tint节点的主体。最后,当处理完成时,tint节点的输出被发送到write节点。同样,一个任务被创建并被调度来执行节点的主体,在本例中是将图像写入文件。每次执行完src节点并返回true时,都会产生一个新的任务来再次执行src节点的主体。只有在src节点停止生成新图像并且它已经生成的所有图像已经在写入节点中完成处理之后,wait_for_all调用才会返回。
使用parallel_for添加分叉连接层
现在,让我们把注意力转向applyGamma和applyTint函数的实现。在图 1-11 中,我们用对tbb::parallel_for的调用替换了串行实现中的外部i循环。我们使用一个parallel_for通用并行算法来并行执行不同的行。一个parallel_for创建的任务可以在一个平台上的多个处理器内核间扩展。该模式是图 1-3 中分叉连接层的一个例子,在第二章中有更详细的描述。

图 1-11。
添加parallel_for以并行应用跨行的伽马校正和色调
使用并行 STL 转换添加 SIMD 层
我们可以通过调用并行 STL 函数transform.来替换内部j循环,从而进一步优化我们的两个计算内核。transform算法将函数应用于输入范围内的每个元素,并将结果存储到输出范围内。transform的参数是(1)执行策略,(2 和 3)元素的输入范围,(4)输出范围的开始,以及(5)应用于输入范围中的每个元素并且其结果存储到输出元素的 lambda 表达式。
在图 1-12 中,我们使用unseq执行策略来告诉编译器使用 SIMD 版本的转换函数。并行 STL 功能在第四章中有更详细的描述。

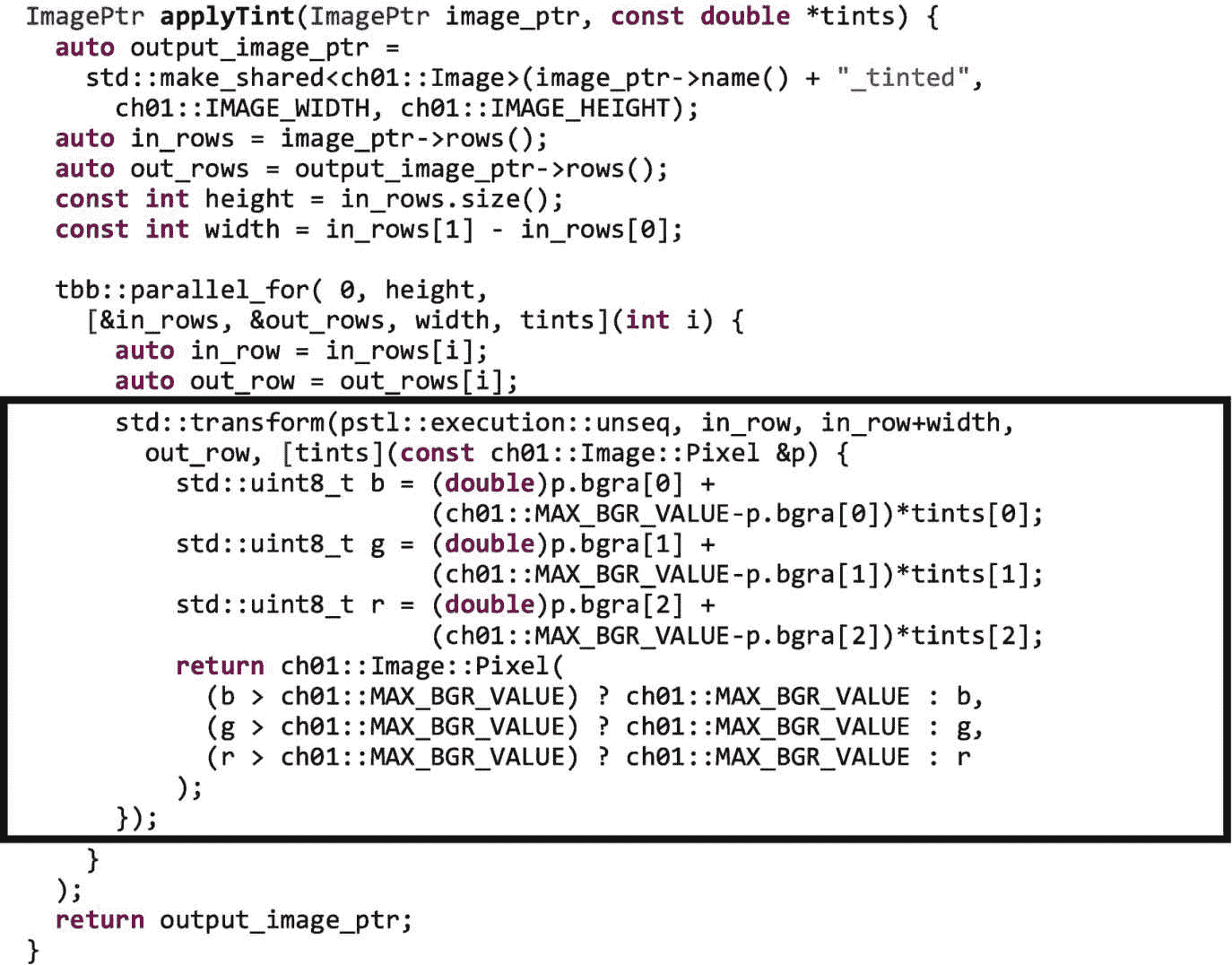
图 1-12。
使用std::transform将 SIMD 并行添加到内部循环中
在图 1-12 中,每个Image::Pixel对象包含一个具有四个单字节元素的数组,代表该像素的蓝色、绿色、红色和 alpha 值。通过使用unseq执行策略,一个向量化的循环被用来跨元素行应用函数。这种级别的并行化对应于图 1-3 中的 SIMD 层,并利用 CPU 内核中的矢量单元来执行代码,但不会将计算分散到不同的内核中。
注意
将执行策略传递给并行 STL 算法并不能保证并行执行。库选择比所要求的更严格的执行策略是合法的。因此,检查使用执行策略的影响非常重要——尤其是依赖编译器实现的执行策略!
虽然我们在图 1-7 到图 1-12 中创建的例子有点做作,但它们展示了 TBB 库的并行执行接口的广度和力量。使用单个库,我们表达了消息驱动、fork-join 和 SIMD 并行,将它们组合成一个应用程序。
摘要
在这一章中,我们首先解释了为什么像 TBB 这样的图书馆在今天比 10 年前首次推出时更有意义。然后,我们简要地看了一下库中的主要特性,包括并行执行接口和独立于执行接口的其他特性。我们看到,高级执行接口映射到许多并行应用程序中常见的消息驱动、fork-join 和 SIMD 层。然后,我们讨论了如何获得 TBB 的副本,并通过编写、编译和执行非常简单的示例来验证我们的环境设置是否正确。我们通过构建一个使用所有三个高级执行接口的更完整的例子来结束这一章。
我们现在准备在接下来的几章中介绍并行编程的关键支持:通用并行算法(第二章)、流程图(第三章)、并行 STL(第四章)、同步(第五章)、并发容器(第六章)和可伸缩内存分配(第七章)。

开放存取本章根据知识共享署名-非商业-非专用 4.0 国际许可协议(http://Creative Commons . org/licenses/by-NC-nd/4.0/)的条款进行许可,该协议允许以任何媒体或格式进行任何非商业使用、共享、分发和复制,只要您适当注明原作者和来源,提供知识共享许可协议的链接,并指出您是否修改了许可材料。根据本许可证,您无权共享从本章或其部分内容派生的改编材料。
本章中的图像或其他第三方材料包含在本章的知识共享许可中,除非在材料的信用额度中另有说明。如果材料不包括在本章的知识共享许可中,并且您的预期使用不被法律法规允许或超出了允许的使用范围,您将需要直接从版权所有者处获得许可。**
二、通用并行算法
调度并行循环的最佳方法是什么?我们如何并行处理不支持随机访问迭代器的数据结构?向看起来像管道的应用程序添加并行性的最佳方式是什么?如果 TBB 图书馆只提供任务和任务调度程序,我们将需要自己回答这些问题。幸运的是,我们不需要费力地阅读许多关于这些主题的硕士和博士论文。TBB 图书馆的开发人员已经为我们做了这些肮脏的工作!它们以模板函数和模板类的形式提供了解决这些问题的最佳方法,这是一组被称为 TBB 通用并行算法的功能。这些算法捕获了许多处理模式,这些模式是多线程编程的基石。
注意
TBB 库的开发者历史上一直使用通用并行算法来描述这组特性。所谓的算法,并不是指像矩阵乘法、LU 分解这样的特定计算,甚至是像std::find这样的东西,而是指常见的执行模式。这本书的一些评论家认为,这些特征因此被更准确地称为模式而不是算法。然而,为了与 TBB 图书馆多年来一直使用的术语保持一致,我们在本书中将这些特性称为通用并行算法。
无论何时应用这些预先写好的算法,我们都应该优先使用它们,而不是编写我们自己的实现。TBB 的开发者已经花了数年时间来测试和改进他们的性能!当然,TBB 库中包含的算法集并没有详尽地涵盖所有可能的场景,但是如果其中一个确实符合我们的处理模式,我们应该使用它。TBB 提供的算法捕获了应用程序中大多数可扩展的并行性。在第八章中,我们将讨论并行编程的设计模式,例如马特森、桑德斯和马辛吉(Addison-Wesley) 的《并行编程的模式》中描述的那些模式,以及我们如何使用 TBB 通用并行算法来实现它们。
如图 2-1 所示,所有的 TBB 通用算法都是从一个执行线程开始的。当线程遇到并行算法时,它会将与该算法相关的工作分散到多个线程中。当所有的工作都完成后,执行会合并到一起,并在最初的单线程上继续执行。
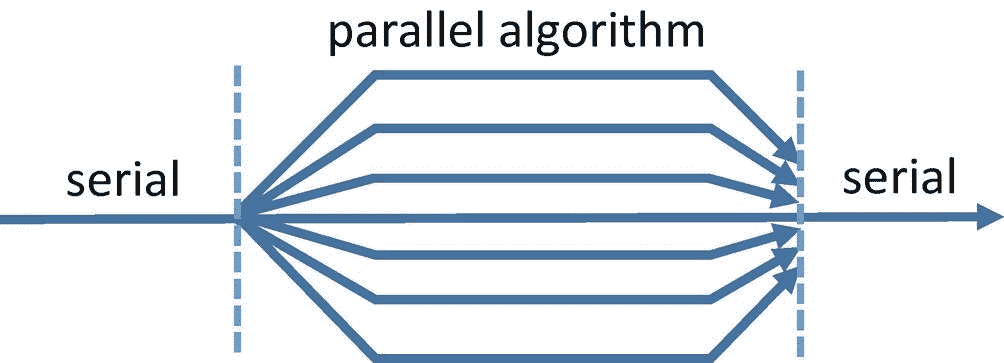
图 2-1。
TBB 并行算法的分叉连接性质
TBB 算法提供了一个强大但相对容易应用的并行模型,因为它们通常可以增量地添加,并且具有所考虑的代码的相当局部的视图。我们可以寻找程序最耗时的区域,添加 TBB 并行算法来加速该区域,然后寻找下一个最耗时的区域,在那里添加并行性,等等。
但是必须明白,TBB 算法并不能保证并行执行!相反,它们只通知库允许并行执行。如果我们从 TBB 的角度来看图 2-1 ,这意味着所有的工作线程都可以参与执行部分计算,只有一部分线程可以参与,或者只有主线程可以参与。像 TBB 那样假设并行性是可选的程序和库被称为具有宽松的顺序语义。
**如果仅使用单线程执行并行程序不会改变程序的语义,则该程序具有顺序语义。正如我们将在本书中多次提到的,由于舍入问题和其他不精确的原因,程序的顺序和并行执行的结果可能并不总是完全匹配。我们通过使用术语*宽松序列语义来承认这些潜在的、无意义的差异。*虽然 TBB 和 OpenMP API 等模型提供了宽松的顺序语义,但 MPI 等其他模型让我们可以编写具有循环关系的应用,这些关系需要并行执行。正如在第一章中介绍的以及在第九章中更详细描述的,TBB 宽松的顺序语义是它对于编写可组合应用有用的一个重要部分。现在,我们应该记住,本章描述的任何算法都会将工作分散到一个或多个线程上,但不一定是系统中所有可用的线程。
线程构建模块 2019 发行版中可用的算法集如图 2-2 中的表格所示。它们都在名称空间 tbb 中,并且在包含 tbb.h 头文件时可用。本章介绍了粗体算法的基础知识,其他算法将在后面的章节中介绍。我们还提供了一个侧栏Lambda expressions–vs-user-defined classes,解释了虽然我们在本书的示例中几乎只使用 Lambda 表达式将代码传递给 TBB 算法,但是如果需要的话,这些参数几乎总是可以被用户定义的函数对象替换。
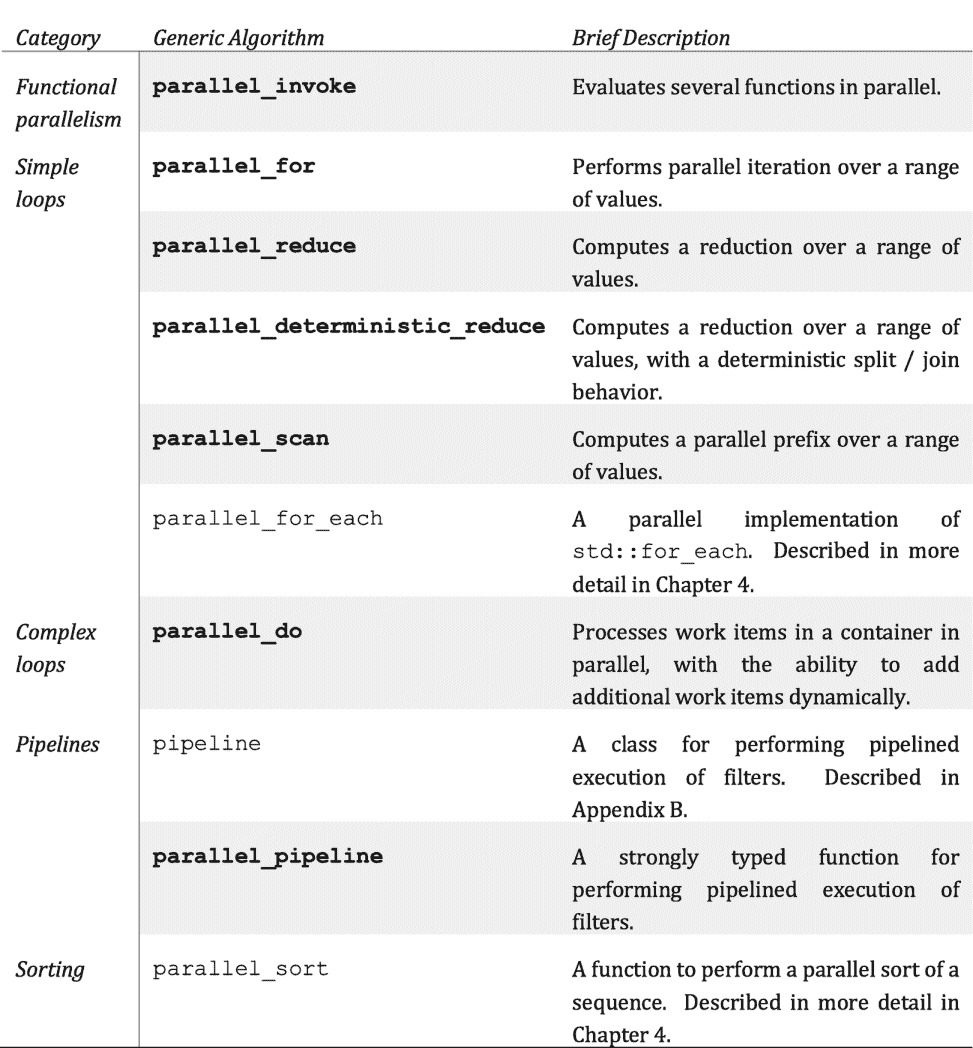
图 2-2。
线程构建模块库中的通用算法。本章将更详细地介绍粗体算法。
Lambda 表达式–vs .用户定义的类
由于 TBB 的第一版早于将 lambda 表达式引入语言的 C++11 标准,TBB 泛型算法不需要使用 lambda 表达式。有时,我们可以对 lambda 表达式或函数对象(仿函数)使用相同的接口。在其他情况下,一个算法有两组接口:一组更适合 lambda 表达式,另一组更适合用户定义的对象。
例如,代替

我们可以使用用户定义的类并编写

通常,选择使用 lambda 表达式还是用户定义的对象只是个人喜好的问题。
功能/任务并行性
也许 TBB 库提供的最简单的算法是parallel_invoke,这个函数允许我们并行执行少至两个函数,或者我们希望指定的任意多个函数:
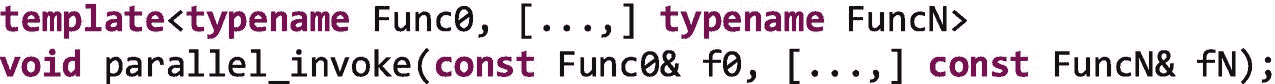
这个概念的模式名是map——我们将在第八章中详细讨论模式。这种算法/模式所表达的独立性使得它可以很好地扩展,当我们可以应用它时,它是首选的并行方式。我们还将看到parallel_for,因为循环体必须是独立的,可以用于类似的效果。
对parallel_invoke可用接口的完整描述可以在附录 b 中找到。如果我们有一组需要调用的函数,并且并行执行调用是安全的,那么我们使用parallel_invoke。例如,我们可以对两个向量v1和v2进行排序,方法是在每个向量上依次调用一个serialQuicksort:
serialQuicksort(serial_v1.begin(), serial_v1.end());
serialQuicksort(serial_v2.begin(), serial_v2.end());
或者,由于这些调用彼此独立,我们可以使用一个parallel_invoke来允许 TBB 库创建可以由不同工作线程并行执行的任务,以重叠这两个调用,如图 2-3 所示。
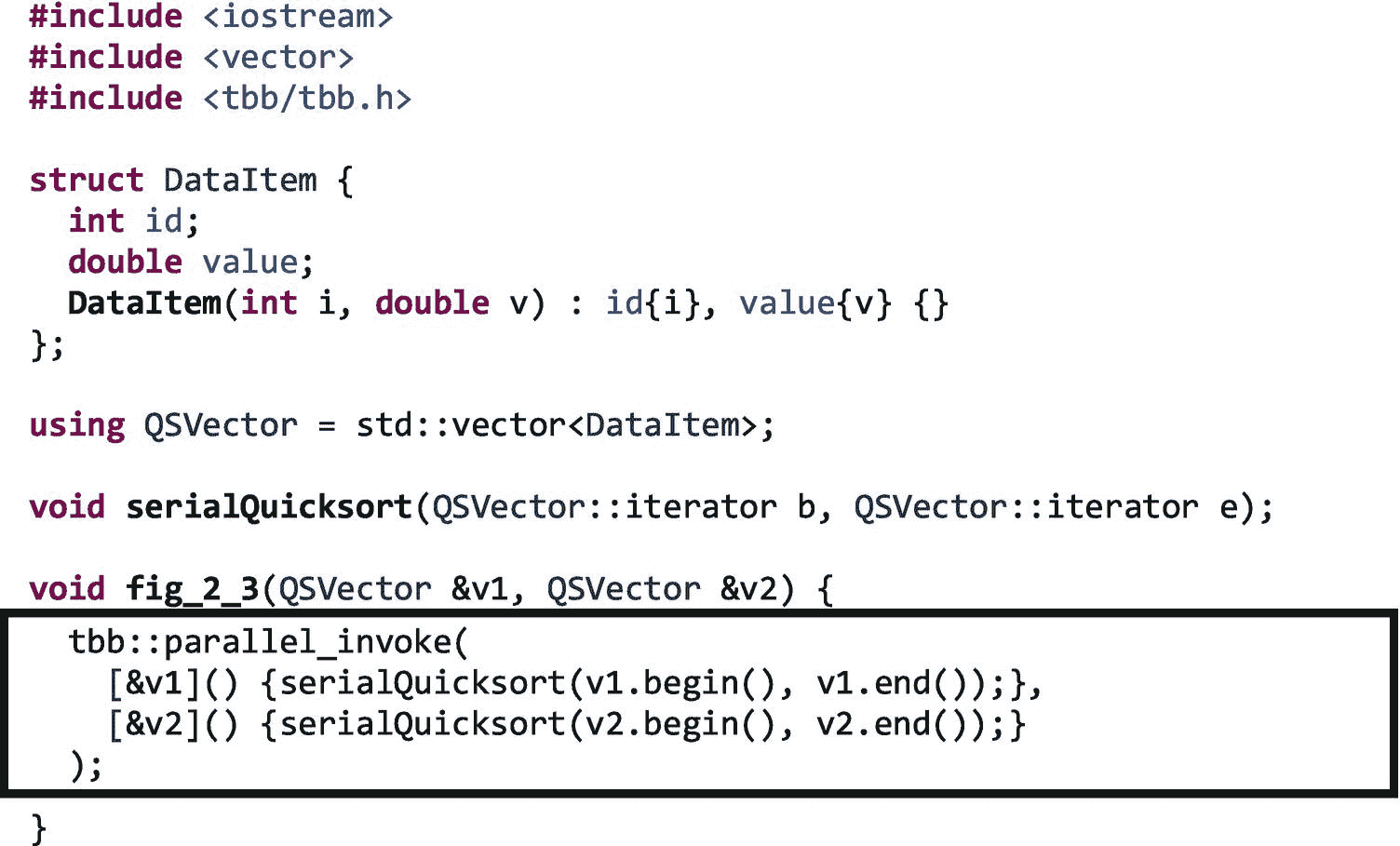
图 2-3。
使用parallel_invoke并行执行两个serialQuicksort调用
如果对serialQuicksort的两次调用执行的时间大致相同,并且没有资源限制,那么这种并行实现可以用顺序地一个接一个调用函数所需时间的一半来完成。
注意
作为开发人员,我们只有在函数可以安全地并行执行时,才负责并行调用函数。也就是说,TBB 将 而不是 自动识别依赖性,并应用同步、私有化或其他并行化策略来确保代码安全。当我们使用parallel_invoke或本章中讨论的任何并行算法时,这就是我们的责任。
使用parallel_invoke很简单,但是对parallel_invoke的一次调用不太具有可伸缩性。一个可扩展的算法可以有效地利用可用的额外内核和硬件资源。
一种算法显示出强伸缩性如果随着额外内核的增加,解决一个固定大小的问题所需的时间减少。例如,当两个内核可用时,表现出良好的强扩展性的算法完成给定数据集的处理的速度可能比顺序算法快两倍,但是当 100 个内核可用时,完成相同数据集的处理的速度比顺序算法快 100 倍。
如果随着更多处理器的增加,每个处理器用相同的时间解决固定数据集大小的问题,算法显示弱伸缩*。例如,表现出良好弱伸缩性的算法在使用两个处理器的固定时间段内能够处理两倍于其顺序版本的数据,而在使用 100 个处理器的相同固定时间段内能够处理 100 倍于其顺序版本的数据。*
使用一个parallel_invoke来并行执行两个排序将不会显示强或弱的伸缩,因为该算法最多可以使用两个处理器。如果我们有 100 个处理器可用,其中 98 个将会闲置,因为我们没有给它们任何事情做。我们应该开发可扩展的应用程序,而不是像我们的示例那样编写代码,这样我们就可以实现一次并行,而无需在每次包含更多内核的新架构可用时都重新实施。
幸运的是,TBB 可以有效地处理嵌套并行(在第九章中有详细描述),因此我们可以通过在递归分治算法中使用parallel_invoke来创建可伸缩的并行(这种模式我们将在第八章中讨论)。TBB 还包括其他通用并行算法,这将在本章后面介绍,这些算法针对的是已经证明对实现可扩展并行性有效的模式,比如循环。
一个稍微复杂一点的例子:Quicksort 的并行实现
递归分治算法的一个众所周知的例子是快速排序,如图 2-4 所示。Quicksort 的工作原理是递归地将一个数组放在枢轴值周围,将小于或等于枢轴值的值放在数组的左分区,将大于枢轴值的值放在数组的右分区。当递归到达基数为 1 的数组时,整个数组已经被排序。
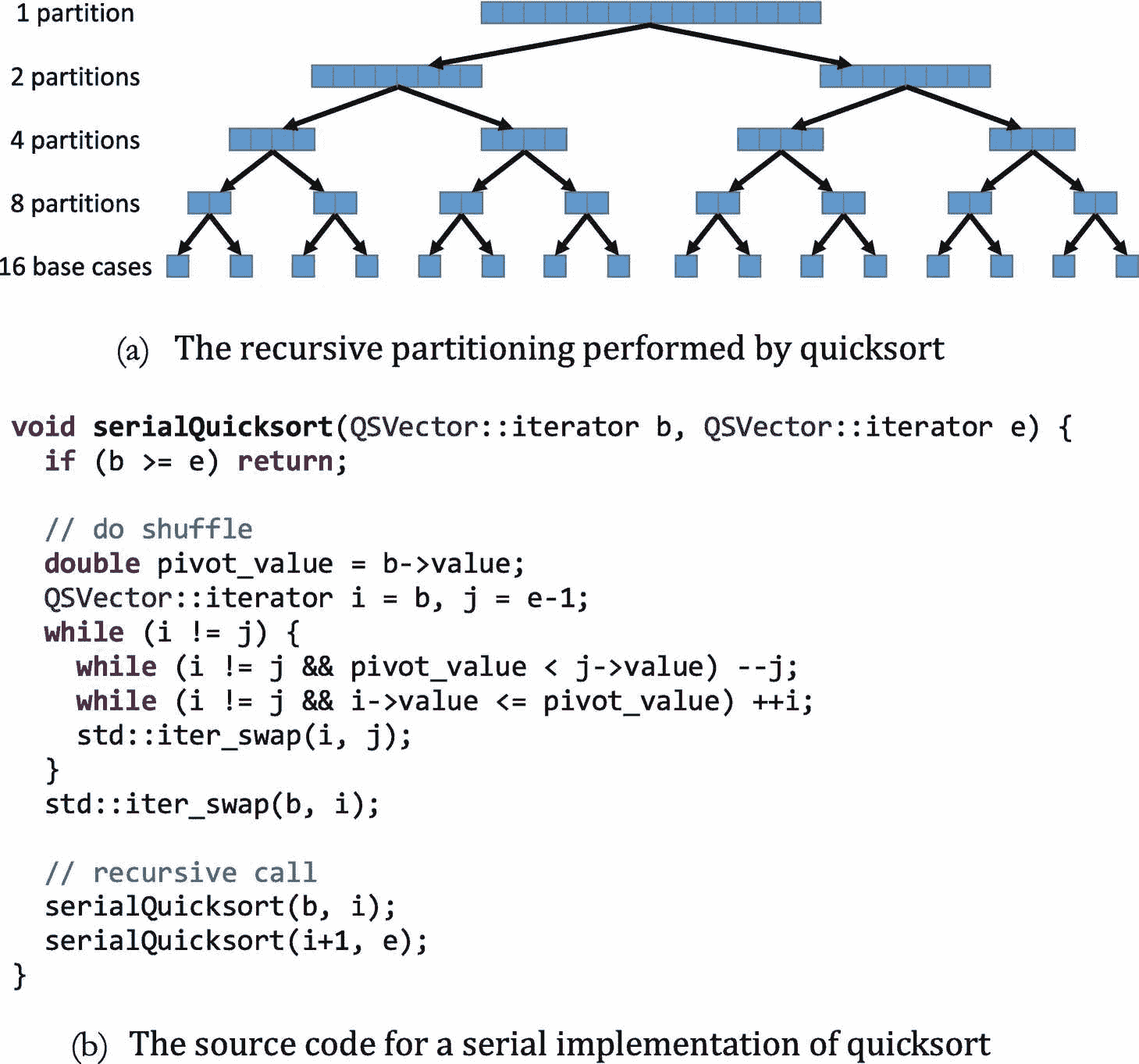
图 2-4。
快速排序的串行实现
我们可以开发一个 quicksort 的并行实现,如图 2-5 所示,用一个parallel_invoke代替两个对serialQuicksort的递归调用。除了使用parallel_invoke,我们还引入了一个截止值。在最初的串行快速排序中,我们一直向下递归划分到单个元素的数组。
注意
生成和调度 TBB 任务并不是免费的——经验法则是,任务应该至少执行 1 微秒或 10,000 个处理器周期,以减少与任务创建和调度相关的开销。在第十六章中,我们提供了实验来更详细地证明这一经验法则。
为了在我们的并行实现中限制开销,我们只递归调用parallel_invoke直到我们降到 100 个元素以下,然后直接调用serialQuicksort来代替。

图 2-5。
使用parallel_invoke并行实现快速排序
您可能会注意到 quicksort 的并行实现有一个很大的局限性 shuffle 是完全串行完成的。在顶层,这意味着在任何并行工作开始之前,我们有一个在单线程上完成的O(n)操作。这可能会限制加速。我们让那些有兴趣的人来看看已知的并行分区实现如何解决这个限制(参见本章末尾的“更多信息”一节)。
循环:parallel_for、parallel_reduce和parallel_scan
对于许多应用程序来说,执行时间主要由循环时间决定。有几种 TBB 算法可以表达并行循环,让我们可以快速地为应用程序中的重要循环添加可扩展的并行性。图 2-2 中标记为“简单循环”的算法是那些迭代空间的开始和结束可以通过循环开始的时间容易地确定的算法。
例如,我们知道在下面的循环中将有正好 N 次迭代,所以我们将其归类为简单循环:
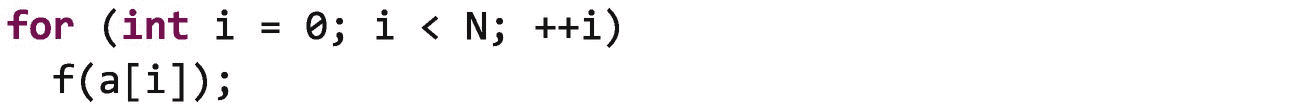
TBB 所有的简单循环算法都基于两个重要的概念,一个范围和一个主体。范围代表一组可递归分割的值。对于循环,范围通常是迭代空间中的索引或者迭代器在遍历容器时将采用的值。主体是我们应用于范围内每个值的函数;在 TBB 中,主体通常作为 C++ lambda 表达式提供,但也可以作为函数对象提供(参见 Lambda 表达式–vs-用户定义的类 )。
parallel_for:对范围内的每个元素应用主体
让我们从一个小的串行for循环开始,它在每次迭代中将函数应用于数组的一个元素:
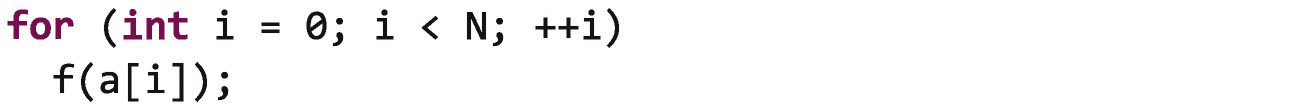
我们可以通过使用parallel_for来创建这个循环的并行版本:

对parallel_for可用接口的完整描述可以在附录 b 中找到。在小示例循环中,范围是半开区间[0, N),步长是 1,主体是f(a[i])。我们可以这样表达,如图 2-6 所示。

图 2-6。
使用parallel_for创建并行回路
当 TBB 执行一个parallel_for的时候,这个范围被分成几个迭代块。与主体配对的每个块成为一个任务,该任务被调度到参与执行算法的一个线程上。TBB 库为我们处理任务的调度,所以我们需要做的就是使用parallel_for函数来表示循环的迭代应该并行执行。在后面的章节中,我们将讨论如何调整 TBB 并行循环的行为。现在,让我们假设对于可用内核的范围大小和数量,TBB 生成了大量的任务。在大多数情况下,这是一个很好的假设。
理解这一点很重要,通过使用parallel_for,我们断言以任何顺序并行执行循环迭代是安全的。TBB 库没有检查并行执行一个parallel_for(或者实际上任何通用算法)的迭代是否会产生与串行执行算法相同的结果——当我们选择使用并行算法时,确保这一点是我们作为开发人员的工作。在第五章中,我们讨论了 TBB 的同步机制,它可以用来让一些不安全的代码变得安全。在第六章中,我们将讨论提供线程安全数据结构的并发容器,这些数据结构有时也能帮助我们使代码线程安全。但最终,我们需要确保当我们使用并行算法时,读写访问模式的任何潜在变化都不会改变结果的有效性。我们还需要确保在并行代码中只使用线程安全的库和函数。
例如,下面的循环作为parallel_for执行是 而不是 安全的,因为每次迭代依赖于前一次迭代的结果。改变这个循环的执行顺序将改变数组a的元素中存储的最终值:
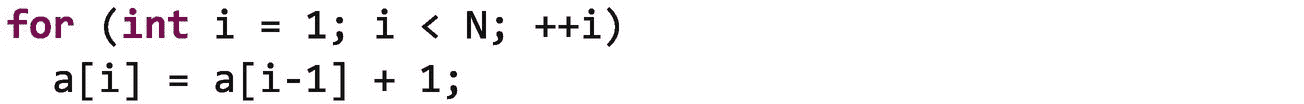
想象一下如果数组a={1,0,0,0,...,0}。顺序执行此循环后,它将保持{1,2,3,4,...,N}。但是如果循环执行顺序错误,结果将会不同。在寻找可以安全并行执行的循环时,一个心理练习是问自己,如果循环迭代一次全部执行,或者随机执行,或者逆序执行,结果是否相同。在这种情况下,如果a={1,0,0,0,...,0}和循环的迭代以相反的顺序执行,当循环完成时a将保持{1,2,1,1,...,1}。显然,执行顺序对这个循环很重要!
数据依赖分析的正式描述超出了本书的范围,但可以在许多编译器和并行编程书籍中找到,包括迈克尔·沃尔夫(Pearson)的高性能并行计算编译器和艾伦和肯尼迪(Morgan Kaufmann)的现代架构优化编译器。英特尔 Parallel Studio XE 中的 Intel Inspector 等工具也可用于查找和调试线程错误,包括使用 TBB 的应用中的线程错误。
稍微复杂一点的例子:并行矩阵乘法
图 2-7 显示了为MxM矩阵计算C = AB的矩阵乘法循环嵌套的非优化串行实现。我们在这里使用这个内核是为了进行演示——如果您需要在实际应用中使用矩阵乘法,并且不认为自己是优化专家——使用数学库中的高度优化的实现几乎肯定会更好,这些实现实现了基本线性代数子程序(BLAS ),如英特尔数学内核库(MKL)、BLIS 或 ATLAS。矩阵乘法在这里是一个很好的例子,因为它是一个小内核,执行一个我们都很熟悉的基本操作。有了这些免责声明,让我们继续看图 2-7 。

图 2-7。
矩阵乘法的非优化实现
我们可以通过使用如图 2-8 所示的parallel_for快速实现图 2-7 中矩阵乘法的并行版本。在这个实现中,我们使外部的i循环并行。外部i循环的迭代执行封闭的j和k循环,因此,除非M非常小,否则将有足够的工作超过 1 微秒的经验法则。如果可能的话,最好使外部循环并行,以保持较低的开销。

图 2-8。
矩阵乘法的简单实现
图 2-8 中的代码很快为我们提供了一个矩阵乘法的基本并行版本。虽然这是一个正确的并行实现,但由于它遍历数组的方式,它将会大大降低性能。在第十六章中,我们将讨论parallel_for中可以用来调优性能的高级特性。
parallel_reduce:跨Range计算单个结果
在应用程序中发现的另一个非常常见的模式是归约,通常被称为“归约模式”或“映射归约”,因为它往往与映射模式一起使用(参见第八章中关于模式术语的更多信息)。
归约从值的集合中计算出单个值。示例应用包括计算总和、最小值或最大值。
让我们考虑一个寻找数组中最大值的循环:
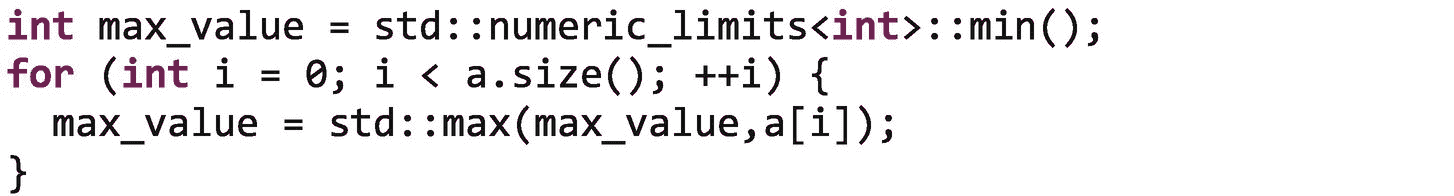
从一组值中计算最大值是一种关联操作;也就是说,对值组执行此操作,然后按顺序组合这些部分结果是合法的。计算最大值也是可交换的,所以我们甚至不需要以任何特定的顺序组合部分结果。
对于执行关联运算的循环,TBB 提供了函数parallel_reduce:
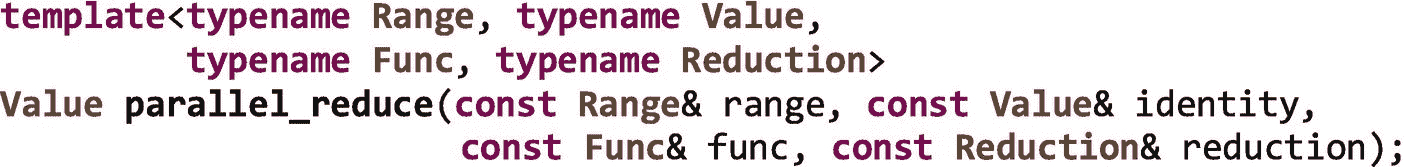
附录 b 中提供了对parallel_reduce接口的完整描述。
许多常见的数学运算是相关的,例如加法、乘法、计算最大值和计算最小值。一些操作在理论上是关联的,但是在实际系统中由于数值表示的限制而不是关联的。我们应该意识到依赖结合性对于并行性的影响(参见 结合性和浮点类型 )。
结合性和浮点类型
在计算机算术中,精确地表示实数并不总是可行的。相反,浮点类型如float, double,和long double用作近似值。这些近似的结果是,适用于实数运算的数学属性不一定适用于浮点运算。例如,虽然加法在实数上是结合的和可交换的,但在浮点数上却不是这样。
例如,如果我们计算N个真实值的总和,每个值都等于 1.0,我们会期望结果是N。
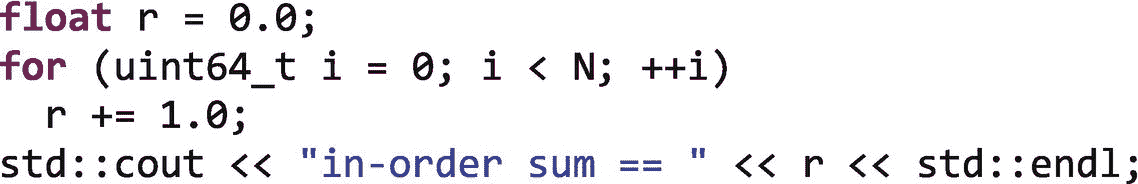
但是在float表示中有有限数量的有效数字,因此并不是所有的整数值都能被精确地表示。例如,如果我们用N == 10e6(1000 万)运行这个循环,我们将得到10000000的输出。但是如果我们用N == 20e 6 执行这个循环,我们会得到16777216的输出。变量 r 根本不能表示16777217,因为标准的float表示法有 24 位尾数(有效数),而16777217需要 25 位。当我们添加1.0时,结果向下舍入到16777216,并且1.0的每个后续加法也向下舍入到16777216。平心而论,在每一步,16777216的结果都是对16777217的很好的近似。正是这些舍入误差的累积,使得最终的结果如此糟糕。
如果我们将这个和分成两个循环,并组合部分结果,我们在两种情况下都会得到正确的答案:

为什么呢?因为r可以表示更大的数字,只是不总是精确的。tmp1和tmp2中的值具有相似的数量级,因此相加影响表示中可用的有效数字,我们得到的结果是 2000 万的良好近似值。这个例子是结合性如何改变使用浮点数的计算结果的一个极端例子。
这个讨论的要点是,当我们使用一个parallel_reduce时,它使用结合性来并行计算和组合部分结果。因此,在使用浮点数时,与串行实现相比,我们可能会得到不同的结果。事实上,根据参与线程的数量,parallel_reduce的实现可能会选择创建不同数量的部分结果。因此,在并行实现中,即使是相同的输入,我们也可能得到不同的结果。
在我们惊慌失措并得出永远不应该使用parallel_reduce的结论之前,我们应该记住,使用浮点数的实现通常会产生一个近似值。相同的输入得到不同的结果并不一定意味着至少有一个结果是错误的。这仅仅意味着对于两次不同的运行,舍入误差不同地累积。作为开发人员,我们有责任决定这些差异对应用程序是否重要。
如果我们想确保我们至少在相同输入数据的每次运行中得到相同的结果,我们可以选择使用第十六章中描述的parallel_deterministic_reduce。这种确定性实现总是创建相同数量的部分结果,并针对相同的输入以相同的顺序组合它们,因此每次运行的近似值都是相同的。
与所有简单的循环算法一样,要使用 TBB parallel_reduce,我们需要提供范围(range)和主体(func)。但是我们还需要提供一个标识值(identity)和一个归约体(reduction)。
为了给一个parallel_reduce创建并行性,TBB 库将range分成块,并创建将func应用于每个块的任务。在第十六章中,我们将讨论如何使用分区器来控制创建的块的大小,但是现在,我们可以假设 TBB 创建了适当大小的块来最小化开销和平衡负载。每个执行func的任务以一个用identity初始化的值init开始,然后计算并返回其块的部分结果。TBB 库通过调用reduction函数组合这些部分结果,为整个循环创建一个单一的最终结果。
identity参数是一个值,当使用正在并行化的操作将其他值与其组合时,该值保持不变。众所周知,关于加法(加法恒等式)的恒等式元素是“0”(自x + 0 = x),关于乘法(乘法恒等式)的恒等式元素是“1”(自x * 1 = x)。reduction函数获取两个部分结果并将它们组合起来。
图 2-9 显示了如何应用func和reduction函数从 16 个元素的数组中计算最大值,如果范围被分成四个块。在这个例子中,func对数组元素应用的关联运算是 max(),单位元素是- ∞,因为max(x,- ∞ )=x。在 C++ 中,我们可以用std::max作为运算,用std::numeric_limits<int>::min()作为- ∞的程序化表示。
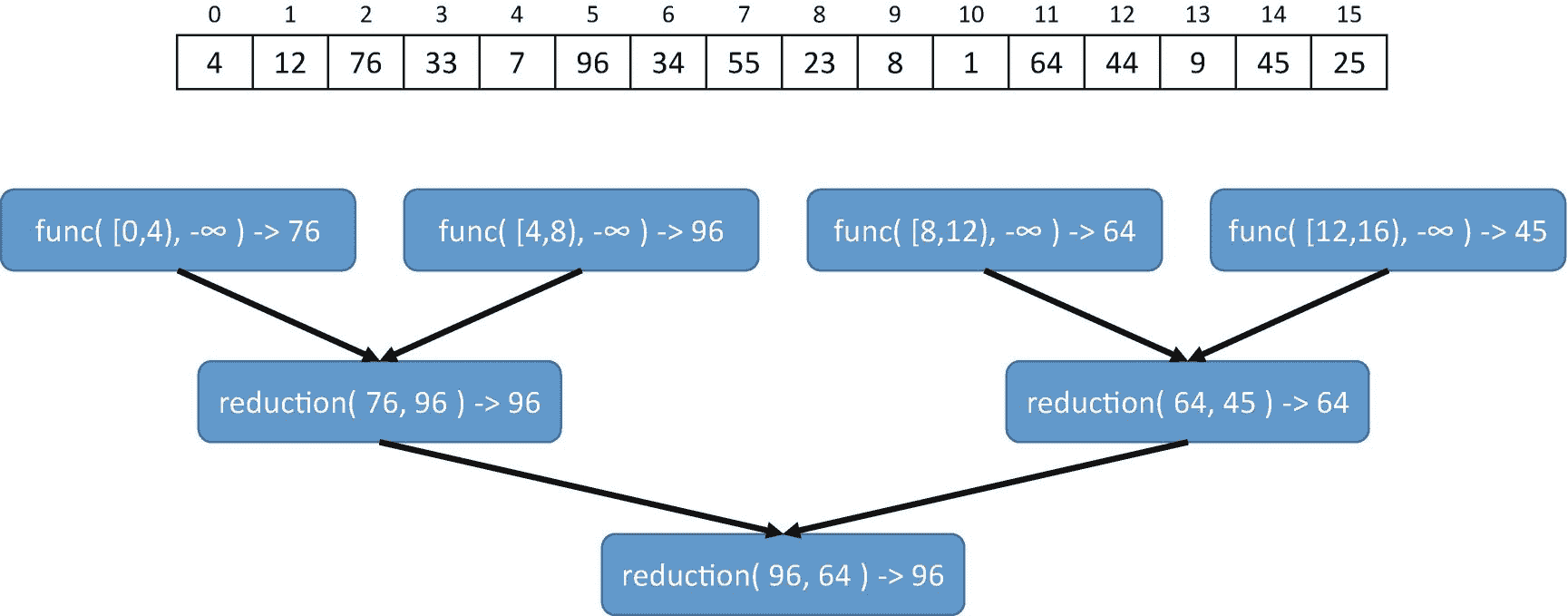
图 2-9。
如何调用func和reduction函数来计算最大值
我们可以用图 2-10 所示的parallel_reduce来表达我们简单的最大值循环。

图 2-10。
使用parallel_reduce计算最大值
您可能会注意到,在图 2-10 中,我们为范围使用了一个blocked_range对象,而不是像使用parallel_for那样只提供范围的开始和结束。parallel_for算法提供了一个简化的语法,这是parallel_reduce所没有的。对于parallel_reduce,我们必须直接传递一个 Range 对象,但幸运的是我们可以使用库提供的预定义范围之一,其中包括blocked_range、blocked_range2d和blocked_range3d等等。这些其他范围对象将在第十六章中详细描述,它们的完整接口在附录 b 中提供。
图 2-10 中使用的blocked_range代表一个 1D 迭代空间。为了构造一个,我们提供开始和结束值。在主体中,我们使用它的begin()和end()函数来获取主体执行所分配的值块的起始值和结束值,然后遍历该子范围。在图 2-8 中,范围中的每个单独的值都被发送到parallel_for主体,因此不需要i循环来迭代范围。在图 2-10 中,主体接收到一个代表迭代块的blocked_range对象,因此我们仍然有一个i循环来迭代分配给它的整个块。
稍微复杂一点的例子:用数值积分计算π
图 2-11 显示了通过数值积分计算π的方法。使用勾股定理计算每个矩形的高度。单位圆一个象限的面积在循环中计算,乘以 4 得到圆的总面积,等于π。

图 2-11。
用矩形积分法进行连续π计算
图 2-11 中的代码计算所有矩形的面积之和,这是一个归约操作。要使用 TBB parallel_reduce,我们需要识别range、body、identity值和reduction函数。本例中,range为0, num_intervals),body与图 [2-11 中的i回路相似。因为我们正在执行求和操作,所以identity值为0.0。而需要组合部分结果的reduction主体将返回两个值的和。使用 TBB parallel_reduce的并行实现如图 2-12 所示。

图 2-12。
使用tbb:实现圆周率:parallel_reduce
和parallel_for一样,有一些高级特性和选项可以和parallel_reduce一起使用来调整性能和管理舍入误差(参见结合性和浮点类型)。这些高级选项将在第十六章中介绍。
parallel_scan:具有中间值的缩减
应用程序中一种不太常见但仍然重要的模式是扫描(有时称为前缀)。扫描类似于归约,但它不仅从值的集合中计算单个值,还计算范围内每个元素的中间结果(前缀)。一个例子是值x0, x1, ... xN的运行总和。结果包括运行总和中的各个值,y0, y1... yN,以及最终总和y N 。
-
y0= x0 -
y1= x0+ xT5 -
. . . -
yN= x0+ x1+ ... + xN
根据向量v计算累计和的串行循环如下:

从表面上看,扫描看起来像一个串行算法。每个前缀取决于所有先前迭代中计算的结果。虽然看起来令人惊讶,但是这种看似串行的算法也有高效的并行实现。TBB parallel_scan算法实现了高效的并行扫描。它的接口要求我们提供一个range、一个identity value、一个scan body和一个combine body:

range、identity value、combine body类似于parallel_reduce的range、identity value、reduction body。和其他简单的循环算法一样,range被 TBB 库分成块,TBB 任务被创建来将主体(scan)应用到这些块。附录 b 中提供了parallel_scan接口的完整描述。
parallel_scan的不同之处在于scan主体可以在同一个迭代块上执行多次——首先是在预扫描模式下,然后是在最终扫描模式下。
在最终扫描模式中,主体被传递一个精确的前缀结果,该结果是紧接在其子范围之前的迭代的结果。使用这个value,主体计算并存储其子范围中每个迭代的前缀,并返回其子范围中最后一个元素的准确前缀。
然而,当在预扫描模式下执行扫描主体时,它接收一个起始前缀值,该值不是其给定范围之前的元素的最终值。就像parallel_reduce一样,parallel_scan依赖于结合性。在预扫描模式下,起始前缀值可能代表它前面的子范围,但不是它前面的完整范围。使用这个值,它返回其子范围中最后一个元素的前缀(还不是最终的)。返回值表示起始前缀及其子范围的部分结果。通过使用这些预扫描和最终扫描模式,可以在扫描算法中利用有用的并行性。
这是如何工作的?
让我们再来看一下运行总和的例子,并考虑用三个模块A、B和C来计算它。在一个连续的实现中,我们计算A,然后B,然后C的所有前缀(按顺序完成三个步骤)。我们可以用并行扫描做得更好,如图 2-13 所示。
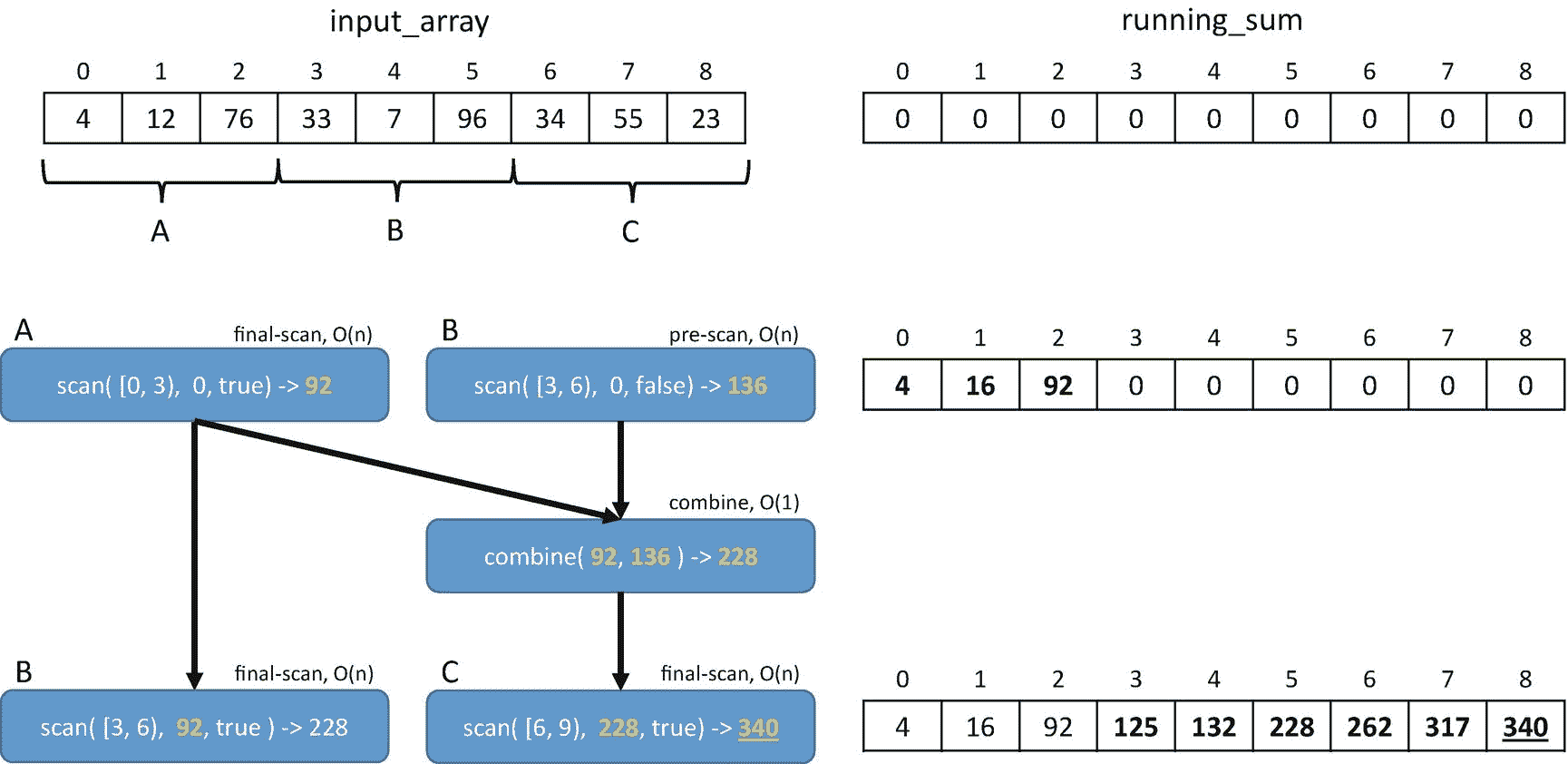
图 2-13。
并行执行扫描以计算总和
首先,我们在最终扫描模式下计算A的扫描,因为它是第一组值,所以如果它被传递一个初始值identity,它的前缀值将是准确的。在我们启动A的同时,我们以预扫描模式启动B。一旦这两次扫描完成,我们现在可以计算出B和C的准确起始前缀。向B提供来自A ( 92)的最终结果,向C提供A的最终扫描结果与B ( 92+136 = 228)的预扫描结果的组合。
组合操作需要恒定的时间,因此比扫描操作便宜得多。不像顺序实现采用三个大步骤一个接一个地应用,并行实现并行执行A的最终扫描和B的预扫描,然后执行恒定时间合并步骤,然后最终并行计算B和C的最终扫描。如果我们至少有两个内核,并且N足够大,那么使用三个块的并行前缀和可以在顺序实现的大约三分之二的时间内计算出来。并且parallel_prefix当然可以使用三个以上的块来执行,以利用更多的内核。
图 2-14 显示了使用 TBB parallel_scan的简单部分和示例的实现。range是区间1, N),identity value是0,combine函数返回其两个参数之和。scan body返回其子范围内所有值的部分和,加到它接收的初始sum上。然而,只有当它的is_final_scan参数为true时,它才会将前缀结果分配给running_sum数组。
![…/img/466505_1_En_2_Fig14_HTML.png
图 2-14。
使用parallel_scan实现运行总和
稍微复杂一点的例子:视线
图 2-15 显示了一个视线问题的串行实现,该问题类似于 Guy E. Blelloch(麻省理工学院出版社)的数据并行计算矢量模型中描述的问题。给定观察点的高度和距观察点固定间隔的点的高度,视线代码确定从观察点可见的点。如图 2-15 所示,如果一个点与视点altitude[0]之间的任意一点具有较大的ѳ.角,则该点不可见串行实现执行扫描以计算给定点和观察点之间所有点的最大ѳ值。如果给定点的ѳ值大于这个最大角度,那么它就是一个可见点;否则,它不可见。

图 2-15。
视线示例
图 2-16 显示了使用 TBB parallel_scan的视线示例的并行实现。当算法完成时,is_visible数组将包含每个点的可见性(true或false)。需要注意的是,图 2-16 中的代码需要计算每个点的最大角度,以确定该点的可见性,但最终输出的是每个点的可见性,而不是每个点的最大角度。因为max_angle是需要的,但不是最终结果,它在pre-scan和final-scan模式下都被计算,但is_visible值仅在final-scan执行期间为每个点存储。

图 2-16。
使用parallel_scan实现视线
煮熟为止:parallel_do 和 parallel_pipeline
对于某些应用程序,简单的循环可以让我们全面了解有用的并行性。但是对于其他的,我们需要在循环中表达并行性,在循环开始之前不能完全计算范围。例如,考虑一个 while 循环:
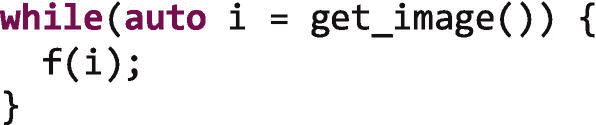
这个循环一直读取图像,直到没有更多的图像可以读取。每幅图像被读取后,由函数f进行处理。我们不能使用parallel_for,因为我们不知道将会有多少图像,因此不能提供一个范围。
一个更微妙的情况是,我们有一个不提供随机访问迭代器的容器:
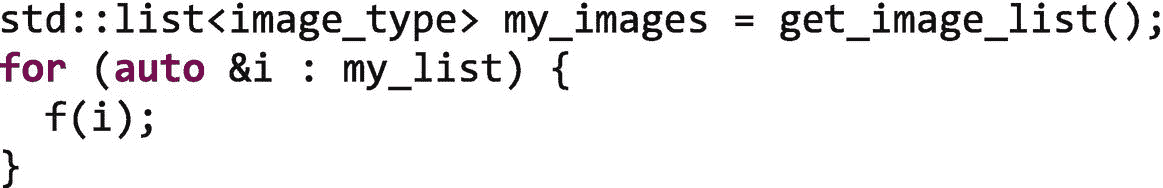
注意
在 C++ 中,迭代器是一个对象,它指向一个元素范围中的一个元素,并定义提供遍历该范围中的元素的能力的操作符。迭代器有不同的类别,包括正向、双向和随机访问迭代器。随机访问迭代器可以在常量时间内指向范围内的任何元素。
因为一个std::list不支持对其元素的随机访问,我们可以获得范围my_images.begin()和my_images.end(),的定界符,但是如果不依次遍历列表,我们就不能到达这两个点之间的元素。因此,TBB 库不能快速地(在恒定的时间内)创建迭代块来作为任务分发,因为它不能快速地指向这些块的开始和结束点。
为了处理这样的复杂循环,TBB 库提供了两个通用算法:parallel_do和parallel_pipeline。
parallel_do:应用一个身体,直到没有更多的项目了
TBB parallel_do将主体应用于工作项目,直到不再有项目需要处理。一些工作项目可以在循环开始时预先提供,其他的可以在主体执行处理其他项目时添加。
parallel_do函数有两个接口,一个接受第一个和最后一个迭代器,另一个接受容器。附录 b 中提供了对parallel_do接口的完整描述。在本节中,我们将查看接收容器的版本:

作为一个简单的例子,让我们从一个std::pair<int, bool>元素的std::list开始,每个元素包含一个随机整数value和false。对于每个元素,我们将计算int value是否是质数;如果是,我们将true存储到bool value。我们将假设我们被给定了填充容器并确定一个数是否是质数的函数。串行实现如下:

我们可以使用 TBB parallel_do创建这个循环的并行实现,如图 2-17 所示。

图 2-17。
使用parallel_do实现质数循环
TBB parallel_do算法将安全地顺序遍历容器,同时创建任务将主体应用于每个元素。因为必须顺序遍历容器,所以parallel_do不像parallel_for那样可伸缩,但是只要主体相对较大(> 100,000 个时钟周期),遍历开销与主体在元素上的并行执行相比可以忽略不计。
除了处理不提供随机访问的容器之外,parallel_do还允许我们从主体执行中添加额外的工作项。如果主体正在并行执行,并且它们添加了新的项目,那么这些项目也可以并行生成,从而避免了parallel_do的顺序任务生成限制。
图 2-18 提供了一个计算值是否是质数的串行实现,但是这些值存储在一个树中而不是一个列表中。

图 2-18。
检查元素树中的质数
我们可以使用如图 2-19 所示的parallel_do,来创建这个树版本的并行实现。为了突出显示提供工作项的不同方式,在这个实现中,我们使用了一个保存单个值树的容器。parallel_do只从一个工作项开始,但是在每个主体执行中添加了两个项,一个处理左子树,另一个处理右子树。我们使用parallel_do_feeder.add方法向迭代空间添加新的工作项。类parallel_do_feeder由 TBB 库定义,并作为第二个参数传递给主体。
随着主体遍历树的各个级别,可用工作项的数量呈指数增长。在图 2-19 中,我们甚至在检查当前元素是否为质数之前就通过feeder添加了新的项目,以便其他任务尽可能快地产生。

图 2-19。
使用 TBB 检查元素树中的质数parallel_do

我们应该注意到,我们考虑的parallel_do的两种用法有可能因为不同的原因而伸缩。第一个实现没有图 2-17 中的进给器,如果每个主体执行都有足够的工作来减少顺序遍历列表的开销,那么它可以表现出良好的性能。在第二个实现中,使用图 2-19 中的 feeder,我们只从一个工作项目开始,但是随着主体执行和添加新项目,可用工作项目的数量会快速增长。
一个稍微复杂一点的例子:正向替换
正向代换是求解一组方程Ax = b的方法,其中A是一个nxn下三角矩阵。作为矩阵来看,这组方程看起来像
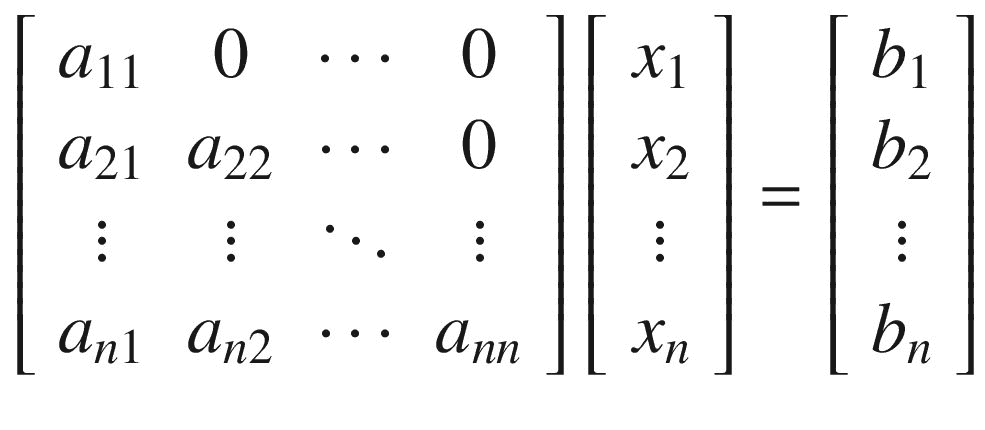
并且可以一次解决一行:
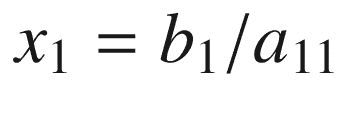
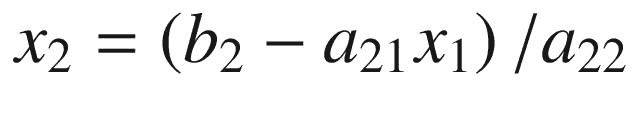
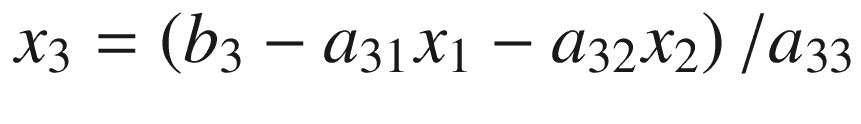
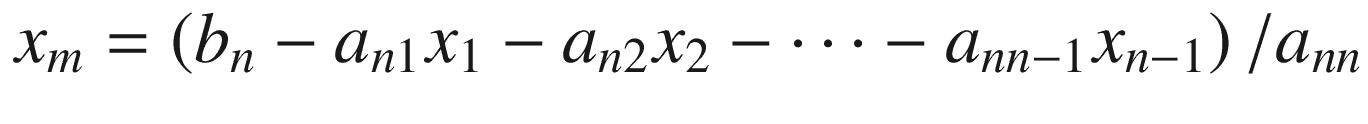
该算法直接实现的串行代码如图 2-20 所示。在串行代码中,b 被破坏性地更新以存储每行的总和。

图 2-20。
向前替换的直接实现的串行代码。编写该实现是为了使算法清晰明了,而不是为了获得最佳性能。
图 2-21(a) 显示了图 2-20 中i,j循环嵌套体迭代之间的依赖关系。内部j循环的每次迭代(如图中的行所示)执行到b[i]的归约,并且还依赖于在i循环的早期迭代中编写的x的所有元素。我们可以使用parallel_reduce来并行化内部的j循环,但是在i循环的早期迭代中可能没有足够的工作来实现这一点。图 2-21(a) 中的虚线显示了在这个循环嵌套中还有另外一种寻找并行性的方法,那就是对角穿过迭代空间。我们可以通过使用parallel_do来利用这种并行性,仅在满足依赖关系时添加迭代,类似于我们在图 2-19 中发现新的树元素时添加它们的方式。
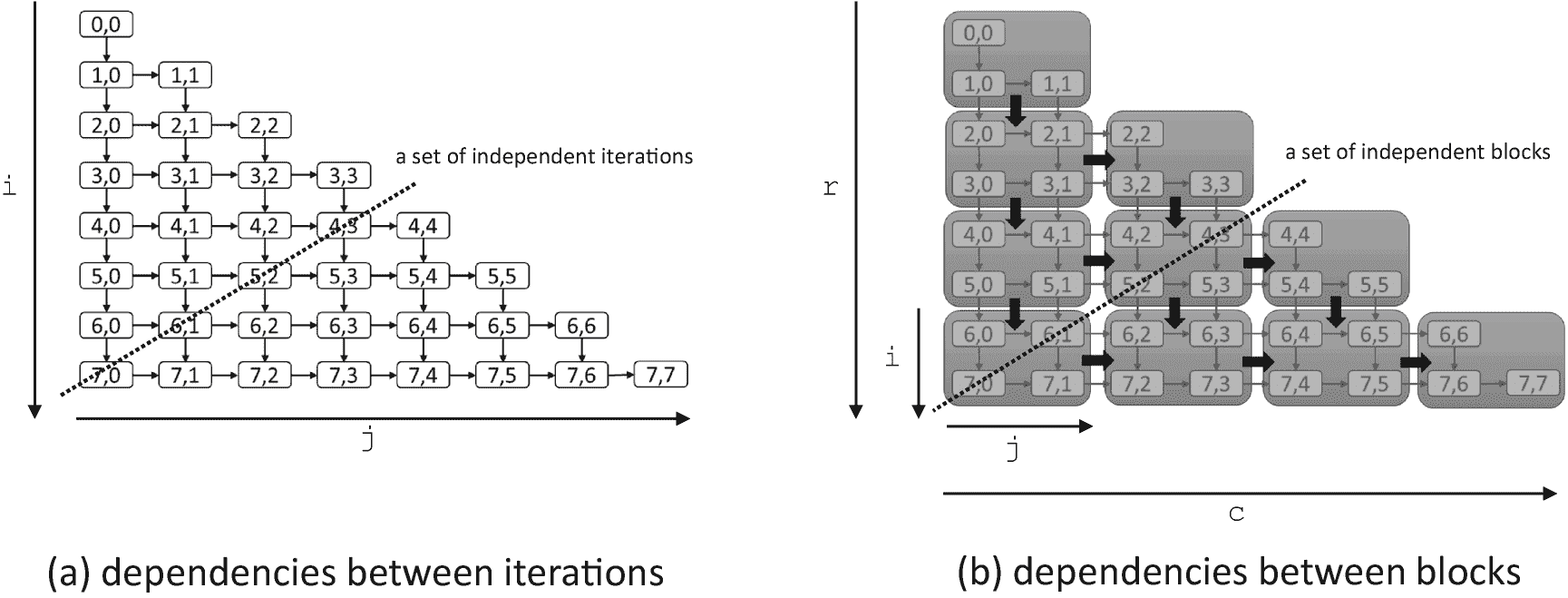
图 2-21。
8 × 8 小矩阵正向代换中的依赖性。在(a)中,显示了迭代之间的依赖性。在(b)中,迭代被分组为块以减少调度开销。在(a)和(b)中,每个块都必须等待它上面的邻居和它左边的邻居完成,然后才能安全执行。
如果我们分别表示每个迭代的并行性,我们将创建太小而不能克服调度开销的任务,因为每个任务将只是一些浮点操作。相反,我们可以修改循环嵌套来创建迭代块,如图 2-21(b) 所示。依赖模式保持不变,但是我们将能够把这些更大的迭代块作为任务来调度。串行代码的封锁版本如图 2-22 所示。

图 2-22。
向前替换的串行实现的阻塞版本
使用parallel_do的并行实现如图 2-23 所示。这里,我们使用parallel_do的接口,它允许我们指定开始和结束迭代器,而不是整个容器。你可以在附录 b 中看到这个接口的细节。
与图 2-19 中的质数树示例不同,我们不想简单地将每个相邻的块发送到馈送器。相反,我们初始化一个计数器数组,ref_count,来保存在每个块被允许开始执行之前必须完成的块数。原子变量将在第五章中详细讨论。对于我们这里的目的,我们可以把这些看作是我们可以安全地并行修改的变量;特别是,递减是以线程安全的方式完成的。我们初始化计数器,使左上角的元素没有依赖关系,第一列和对角线上的块有一个依赖关系,所有其他的有两个依赖关系。这些计数与图 2-21 所示的每个模块的前任数量相匹配。

图 2-23。
使用parallel_do实现正向替换
在图 2-23 中对parallel_do的调用中,我们最初只提供了左上角的块&top_left, &top_left+1)。但是在每个主体执行中,底部的if-语句会递减依赖于刚刚处理的块的块的原子计数器。如果计数器达到零,则该块满足其所有依赖性,并被提供给馈送器。
和前面的质数例子一样,这个例子展示了使用parallel_do:的应用程序的特点。并行性受到顺序访问容器的需求或动态查找工作项目并将其提供给算法的需求的限制。
parallel_pipeline:通过一系列过滤器流式传输项目
TBB 用于处理复杂循环的第二个通用并行算法是parallel_pipeline。管道是一系列线性的过滤器,当项通过它们时,它们会对其进行转换。管道通常用于处理流入应用程序的数据,如视频或音频帧或金融数据。在第 [3 章中,我们将讨论流图接口,它让我们可以构建更复杂的图形,包括进出滤波器的扇入和扇出。
图 2-24 显示了一个小的示例循环,它读入字符数组,通过将所有小写字符转换为大写字符以及将所有大写字符转换为小写字符来转换字符,然后将结果按顺序写入输出文件。

图 2-24。
一个系列案例变化的例子
操作必须在每个缓冲区上按顺序进行,但是我们可以重叠应用于不同缓冲区的不同过滤器的执行。图 2-25(a) 将此示例显示为一个流水线,其中“写缓冲区”在buffer i 上运行,而并行的“处理”过滤器在buffer i+1 上运行,“获取缓冲区”过滤器在buffer i+2 中读取。
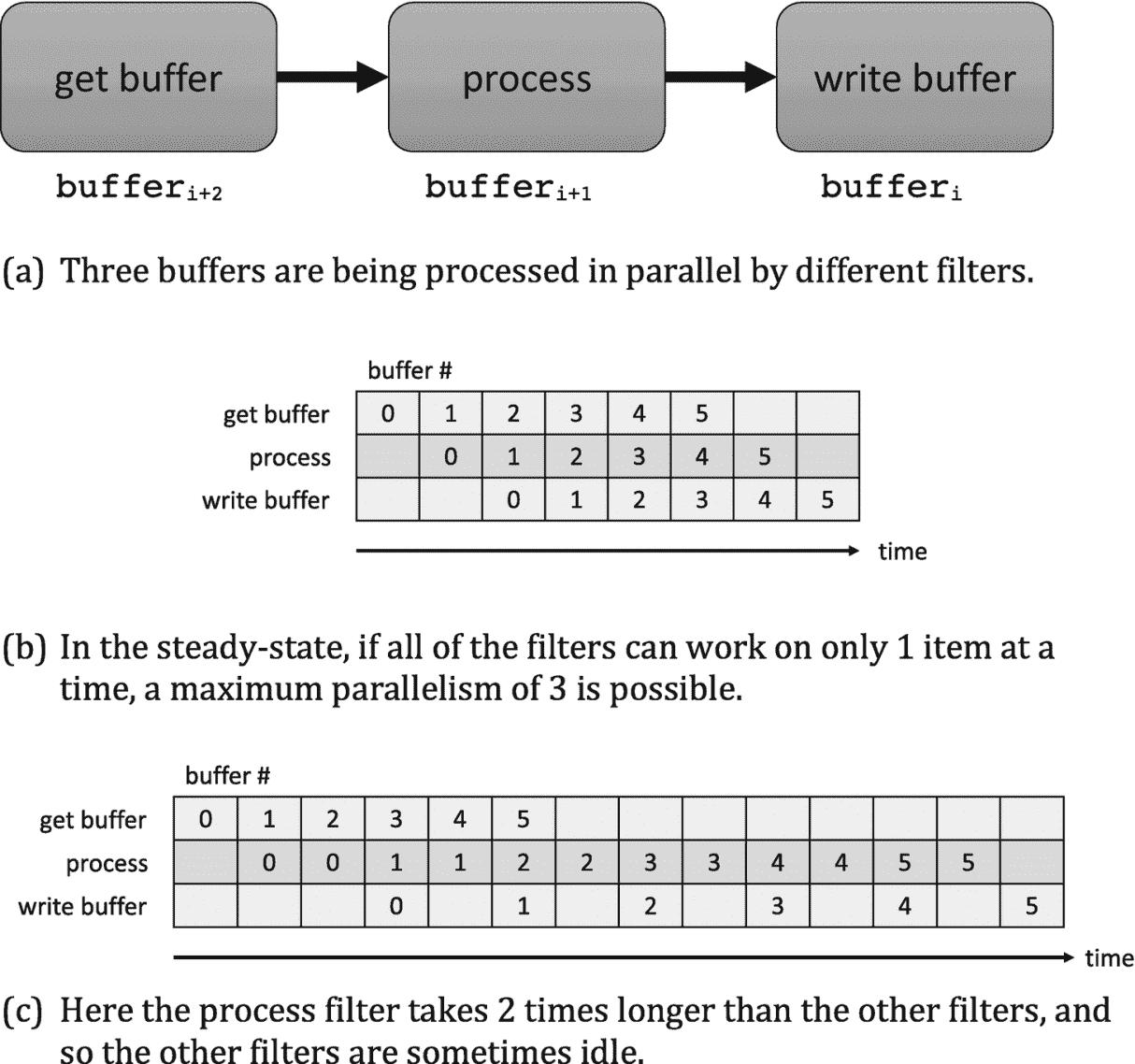
图 2-25。
使用管道的案例更改示例
如图 2-25(b) 所示,在稳定状态下,每个过滤器都很忙,它们的执行是重叠的。然而,如图 2-25© 所示,不平衡滤波器会降低加速比。串行滤波器流水线的性能受到最慢串行级的限制。
TBB 库支持串行和并行过滤器。并行过滤器可以并行应用于不同的项目,以增加过滤器的吞吐量。图 2-26(a) 显示了“案例变化”的例子,中间/过程过滤器在两个项目上并行执行。图 2-26(b) 说明了如果中间的过滤器在任何给定的项目上花费的时间是其他过滤器的两倍,那么给这个过滤器分配两个线程将允许它匹配其他过滤器的吞吐量。
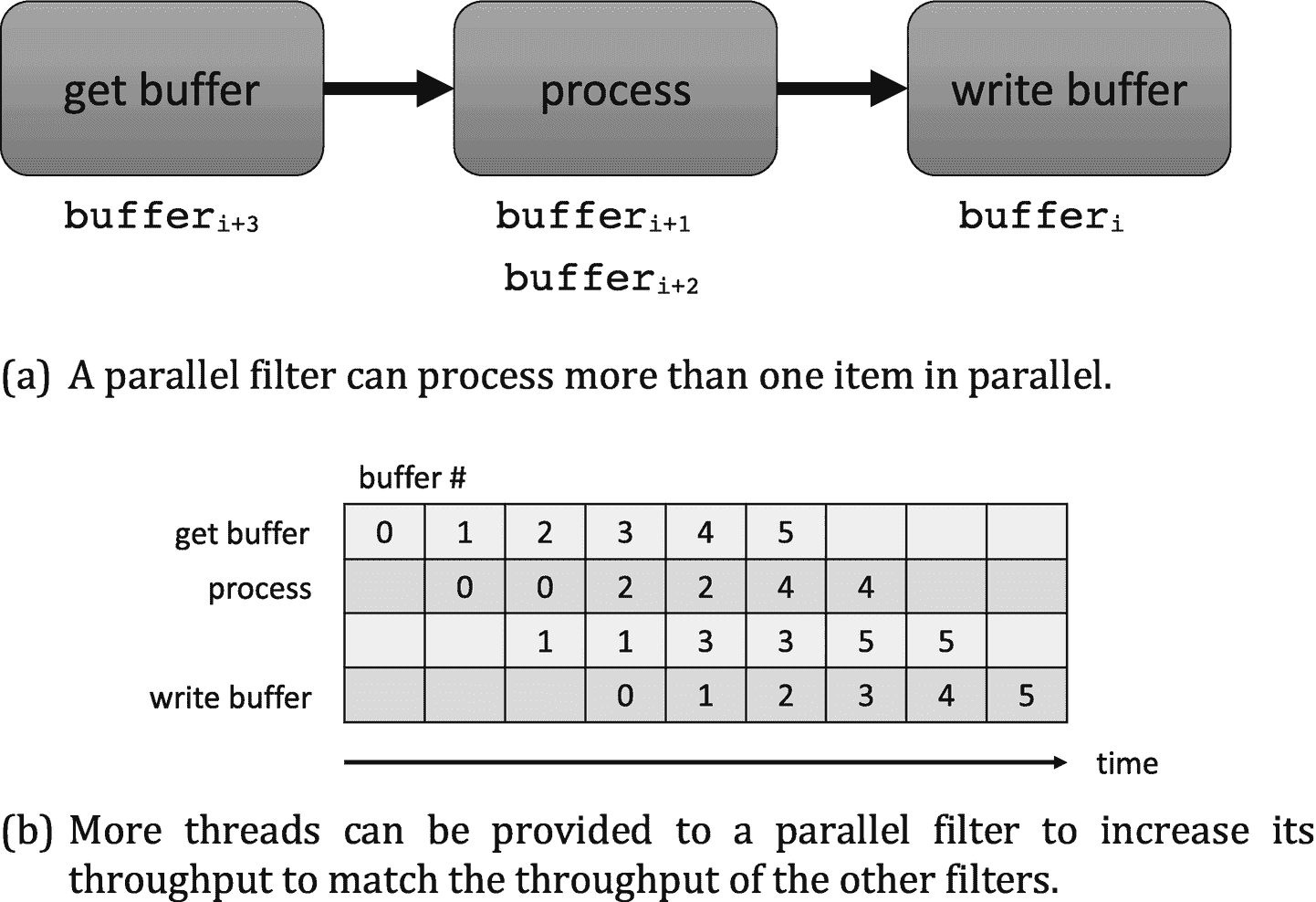
图 2-26。
使用具有并行过滤器的管道的情况变化示例。通过使用并行过滤器的两个副本,流水线最大化了吞吐量。
附录 b 中提供了对parallel_pipeline接口的完整描述。我们在本节中使用的parallel_pipeline接口如下所示:
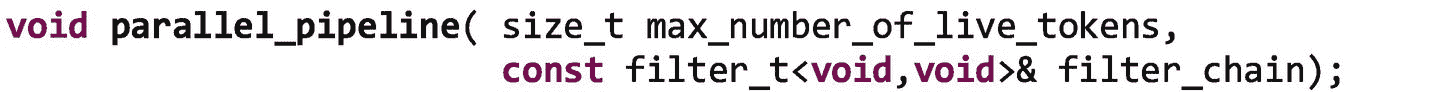
第一个参数max_number_of_live_tokens是在任何给定时间允许流经管道的最大项目数。该值对于限制资源消耗是必要的。例如,考虑简单的三个过滤器管道。如果中间的滤波器是一个串行滤波器,并且它比获得新缓冲器的滤波器花费的时间长 1000 倍呢?第一个过滤器可能会分配 1000 个缓冲区,仅用于在第二个过滤器之前对它们进行排队,从而浪费大量内存。
parallel_pipeline的第二个参数是filter_chain,这是一系列通过串联使用make_filter函数创建的过滤器而创建的过滤器:

模板参数 T 和 U 指定过滤器的输入和输出类型。模式参数可以是serial_in_order、serial_out_of_order或 parallel。f 参数是过滤器的主体。图 2-27 显示了使用 TBB parallel_pipeline实现案例变更示例。附录 b 中提供了对parallel_pipeline接口的更完整描述。
我们可以注意到,第一个过滤器,因为它的输入类型是void,接收类型为tbb::flow_control.的特殊参数。当管道中的第一个过滤器不再生成新项目时,我们使用该参数来发出信号。比如图 2-27 中的第一个过滤器,当getCaseString()返回的指针为null时,我们调用stop()。

图 2-27。
使用具有并行中间过滤器的管道的情况变化示例
在该实现中,使用serial_in_order模式创建第一个和最后一个过滤器。这指定了两个过滤器一次只能对一个项目运行,并且最后一个过滤器应该按照第一个过滤器生成项目的顺序执行项目。一个serial_out_of_order过滤器被允许以任何顺序执行项目。中间的过滤器通过parallel作为它的模式,允许它并行执行不同的项目。parallel_pipeline支持的模式在附录 b 中有更详细的描述。
一个稍微复杂一点的例子:创建 3D 立体图像
图 2-28 显示了一个更复杂的管道示例。while 循环读入帧数,然后为每一帧读取左右图像,给左图像添加红色,给右图像添加蓝色。然后,它将生成的两幅图像合并成一幅红-青 3D 立体图像。

图 2-28。
红青色 3D 立体样本应用程序
与简单的 case change 示例类似,我们也有一系列通过一组过滤器的输入。我们识别重要的函数,并将它们转换成管道过滤器:getNextFrameNumber、getLeftImage、getRightImage、increasePNGChannel(到左图)、increasePNGChannel(到右图)、mergePNGImages和right.write()。图 2-29 显示了绘制成管道的示例。increasePNGChannel滤镜应用两次,第一次在左图像上,然后在右图像上。

图 2-29。
作为流水线的 3D 立体采样应用
使用 TBB parallel_pipeline的并行实现如图 2-30 所示。

图 2-30。
使用parallel_pipeline实现的立体 3D 示例
TBB parallel_pipeline函数对管道滤波器进行线性化。当来自第一级的输入流过管道时,过滤器被一个接一个地应用。这实际上是对这个例子的限制。在mergeImageBuffers滤波器之前,左右图像的处理是独立的,但是由于parallel_pipeline的接口,滤波器必须线性化。即便如此,只有读入图像的过滤器是串行过滤器,因此,如果执行时间由后面的并行阶段支配,则该实现仍然是可伸缩的。
在第三章中,我们介绍了 TBB 流图,它将允许我们更直接地表达受益于滤波器非线性执行的应用。
摘要
本章提供了 TBB 库提供的通用并行算法的基本概述,包括捕获功能并行、简单和复杂循环以及流水线并行的模式。这些预先打包的算法(模式)提供了经过充分测试和调整的实现,可以逐步应用到应用程序中以提高性能。
本章显示的代码提供了一些小例子,展示了如何使用这些算法。在本书的第二部分(从第九章开始),我们将讨论如何以可组合的方式组合这些算法,并使用可用于优化局部性、最小化开销和添加优先级的库特性来调优应用程序,从而充分利用 TBB。本书的第二部分还讨论了在使用 TBB 通用并行算法时如何处理异常处理和取消。
我们将在下一章继续,看看 TBB 的另一个高级特征,流程图。
更多信息
这里有一些我们推荐的与本章相关的额外阅读材料。
-
我们讨论了并行编程的设计模式,以及它们与 TBB 通用并行算法的关系。设计模式的集合可以在
Timothy Mattson,Beverly Sanders 和 Berna Massingill,并行编程的模式(第一版。),2004 年,艾迪森-卫斯理专业。
-
在讨论 quicksort 的并行实现时,我们注意到分区仍然是一个串行瓶颈。讨论并行分区实现的文章包括
页(page 的缩写)Heidelberger,A. Norton 和 J. T. Robinson,“使用取加的并行快速排序”,1990 年 1 月,IEEE 计算机汇刊第 39 卷第 1 期第 133-138 页。
页(page 的缩写)齐加斯和张艺谋。快速排序的简单快速并行实现及其在 SUN enterprise 10000 上的性能评估。在第 11 届欧洲并行、分布式和基于网络的处理研讨会上(PDP 2003),第 372–381 页,2003 年。
-
您可以在许多编译器或并行编程书籍中了解更多关于数据依赖分析的知识,包括
Michael Joseph Wolfe,面向并行计算的高性能编译器, 1995,Addison-Wesley Longman 出版公司,波士顿,MA,美国。
肯尼迪和约翰·R·艾伦,现代体系结构的优化编译器, 2001,摩根考夫曼出版公司,旧金山,加利福尼亚州,美国。
-
当我们讨论矩阵乘法时,我们注意到除非我们是优化专家,否则我们通常更喜欢使用线性代数内核的预打包实现。
这种包包括
www.netlib.org/blas/中的基本线性代数子程序(BLAS)英特尔数学内核库(英特尔 MKL)位于
https://software.intel.com/mkl自动调谐线性代数软件(图集)发现
http://math-atlas.sourceforge.net/FLAME 项目研究和开发密集线性代数库。他们的 BLIS 软件框架可以用来创建高性能的 BLAS 库。火焰项目可以在
www.cs.utexas.edu/~flame找到。 -
本章中的视线示例是根据中提供的说明使用并行扫描实现的
数据并行计算的向量模型,Guy E. Blelloch(麻省理工学院出版社)。
图 2-28a 、 2-29 和 3-7 中使用的照片由 Elena Adams 拍摄,经 Halide 项目教程 http://halide-lang.org 许可使用。
[外链图片转存中…(img-YKoqTELA-1722837544013)]
开放存取本章根据知识共享署名-非商业-非专用 4.0 国际许可协议(http://Creative Commons . org/licenses/by-NC-nd/4.0/)的条款进行许可,该协议允许以任何媒体或格式进行任何非商业使用、共享、分发和复制,只要您适当注明原作者和来源,提供知识共享许可协议的链接,并指出您是否修改了许可材料。根据本许可证,您无权共享从本章或其部分内容派生的改编材料。
本章中的图像或其他第三方材料包含在本章的知识共享许可中,除非在材料的信用额度中另有说明。如果材料不包括在本章的知识共享许可中,并且您的预期使用不被法律法规允许或超出了允许的使用范围,您将需要直接从版权所有者处获得许可。**
三、流程图
在第二章中,我们介绍了一组匹配我们在应用中经常遇到的模式的算法。那些太棒了!我们应该尽可能地使用它们。不幸的是,并不是所有的应用程序都适合这些盒子;它们可能会很乱。当事情开始变得混乱时,我们会变成控制狂,试图对每件事都进行微观管理,或者只是决定“随波逐流”,对事情的发展做出反应。TBB 让我们选择任何一条道路。
在第十章中,我们讨论了如何直接使用任务来创建我们自己的算法。任务既有高级接口,也有低级接口,所以如果我们直接使用任务,如果我们真的想成为控制狂,我们可以选择。
然而,在本章中,我们将关注线程构建模块流程图界面。第二章中的大多数算法都是面向那些我们预先有大量数据,并且需要创建任务来分割和并行处理这些数据的应用程序的。流程图适用于在数据可用时做出反应的应用程序,或者具有比简单结构所能表达的更复杂的依赖性的应用程序。流图接口已经成功地用于广泛的领域,包括图像处理、人工智能、金融服务、医疗保健和游戏。
流图接口让我们表达包含并行性的程序,这些并行性可以用图来表达。在许多情况下,这些应用程序通过一组过滤器或计算来传输数据流。我们称这些数据流图为。图形还可以表达操作之间的前后关系,允许我们表达不能用并行循环或管道容易表达的依赖结构。一些线性代数计算,例如乔莱斯基分解,有高效的并行实现,通过跟踪较小操作的依赖性来避免重量级的同步点。我们称表达这些前后关系的图为依赖图。
在第二章中,我们介绍了两种通用的并行算法,像流程图一样,不需要提前知道所有的数据,parallel_do和parallel_pipeline。这些算法在应用时非常有效;然而,这两种算法都有流图所没有的限制。一个parallel_do只有一个单一的体函数,当它可用时应用于每个输入项。A parallel_pipeline在输入项流经管道时对其应用一系列线性过滤器。在第二章的最后,我们看了一个 3D 立体示例,它比一系列线性滤镜具有更多的并行性。流程图 API 让我们表达比parallel_do或parallel_pipeline更复杂的结构。
在这一章中,我们首先讨论基于图的并行性为什么重要,然后讨论 TBB 流图 API 的基础知识。之后,我们探索两种主要类型的流图的例子:数据流图和依赖图。
为什么要用图来表示并行?
用计算图表示的应用程序公开了可以在运行时有效地用来并行调度其计算的信息。我们可以看看图 3-1(a) 中的代码作为例子。
图 3-1。
可以表示为数据流图的应用程序
在图 3-1(a) 中 while 循环的每次迭代中,一幅图像被读取,然后通过一系列过滤器:f1、f2、f3 和 f4。我们可以绘制这些过滤器之间的数据流,如图 3-1(b) 所示。在此图中,用于传递从每个函数返回的数据的变量被替换为从生成值的节点到消费值的节点的边。
现在,让我们假设图 3-1(b) 中的图表捕获了这些功能之间共享的所有数据。如果是这样,我们(以及像 TBB 这样的库)可以推断出很多关于并行执行什么是合法的,如图 3-2 所示。
图 3-2 显示了从我们的小例子的数据流图表示中可以推断出的并行类型。在图中,我们通过图表传输四个图像。因为节点 f2 和 f3 之间没有边,所以它们可以并行执行。在相同的数据上并行执行两个不同的功能是功能并行(任务并行)的一个例子。如果我们假设这些函数是无副作用的,也就是说,它们不更新全局状态,只从它们的传入消息中读取和写入它们的传出消息,那么我们也可以在图中重叠不同消息的处理,利用流水线并行。最后,如果函数是线程安全的,也就是说,我们可以在不同的输入上并行执行每个函数,那么我们也可以选择在同一节点中重叠两个不同映像的执行,以利用数据并行性。
图 3-2。
从图表中可以推断出的并行度的种类
当我们使用 TBB 流图接口将我们的应用表示为图形时,我们向库提供了利用这些不同种类的并行性所需的信息,因此它可以将我们的计算映射到平台硬件以提高性能。
TBB 流程图界面的基础
TBB 流图的类和函数在flow_graph.h中定义,并包含在tbb::flow名称空间中。包罗万象的tbb.h也包括flow_graph.h,所以如果我们使用那个头,我们不需要包括任何其他东西。
为了使用流图,我们首先创建一个图对象。然后我们创建节点来对流经图的消息执行操作,比如应用用户计算、连接、分离、缓冲或重新排序消息。我们用边来表示这些节点之间的消息通道或依赖关系。最后,在我们从图对象、节点对象和边组装了一个图之后,我们将消息输入到图中。消息可以是基本类型、对象或指向对象的指针。如果我们想等待处理完成,我们可以使用 graph 对象作为句柄。
图 3-3 显示了一个小例子,它执行了使用 TBB 流图所需的五个步骤。在本节中,我们将更详细地讨论这些步骤。

图 3-3。
具有两个节点的示例流程图
步骤 1:创建图形对象
创建流图的第一步是构造一个图形对象。在流程图界面中,图对象用于调用整个图的操作,例如等待与图的执行相关的所有任务完成,重置图中所有节点的状态,以及取消图中所有节点的执行。当构建一个图时,每个节点恰好属于一个图,并且在同一个图中的节点之间形成边。一旦我们构建了图,那么我们需要构建实现图的计算的节点。
步骤 2:制作节点
TBB 流图接口定义了一组丰富的节点类型(图 3-4 ),大致可以分为三组:功能节点类型、控制流节点类型(包括连接节点类型)和缓冲节点类型。在附录 b 的“流图:节点”一节中可以找到对 graph 类提供的接口和所有节点类型提供的接口的详细回顾。我们并不期望您现在就详细阅读这些表,而是希望您知道在本章和后续章节中使用节点类型时可以引用它们。
图 3-4。
流程图节点类型(参见章节 3 、 17 、 18 、19;附录 B)中的接口细节
像所有的函数节点一样,function_node将 lambda 表达式作为其参数之一。我们在功能节点中使用这些主体参数来提供我们想要应用于传入消息的代码。在图 3-3 中,我们定义了第一个节点来接收一个int值,打印该值,然后将其转换为一个std::string,,返回转换后的值。该节点复制如下:

节点通常通过边相互连接,但是我们也可以显式地向节点发送消息。例如,我们可以通过调用try_put向my_first_node发送消息:
my_first_node.try_put(10);
这导致 TBB 库产生一个任务来执行int消息 10 上的my_first_node主体,产生如下输出
first node received: 10
与我们提供主体参数的功能节点不同,控制流节点类型执行预定义的操作,这些操作在消息流经图时连接、拆分或定向消息。例如,我们可以创建一个join_node,它将来自多个输入端口的输入连接在一起,通过提供元组类型、连接策略和对图形对象的引用来创建一个类型为std::tuple<int, std::string, double>的输出:
这个join_node、j,有三个输入端口和一个输出端口。输入端口 0 将接受类型为int的消息。输入端口 1 将接受类型为std::string的消息。输入端口 2 将接受double类型的消息。将有一个单一的输出端口来广播std::tuple<int, std::string, double>.类型的消息
一个join_node可以有四个连接策略之一:queueing、reserving, key_matching和tag_matching。对于queueing、key_matching和tag_matching策略,join_node在消息到达其每个输入端口时对其进行缓冲。queueing策略将传入的消息存储在每个端口的队列中,使用先进先出的方法将消息加入到一个元组中。key_matching和tag_matching策略将传入的消息存储在每个端口的映射中,并根据匹配的键或标签连接消息。
预留join_node根本不缓冲传入的消息。相反,它跟踪前面的缓冲区的状态——当它认为每个输入端口都有可用的消息时,它会尝试为每个输入端口保留一个项目。当保留被保持时,保留防止任何其他节点消费该项目。只有当join_node能够成功地为每个输入端口获取一个元素的预留时,它才消费这些消息;否则,它释放所有的预留并将消息留在前面的缓冲区中。如果一个预留join_node未能预留所有的输入,它稍后再试。我们将在第十七章中看到这种预留策略的使用案例。
缓冲节点输入缓冲消息。由于功能节点function_node和multifunction_node,在其输入端包含缓冲器,而source_node在其输出端包含缓冲器,因此缓冲节点在有限的情况下使用——通常与预留节点join_node一起使用(参见第十七章)。
步骤 3:添加边缘
在我们构建了一个图形对象和节点之后,我们使用make_edge调用来设置消息通道或依赖关系:
make_edge(predecessor_node, successor_node);
如果一个节点有多个输入端口或输出端口,我们使用input_port和output_port功能模板来选择端口:
make_edge(output_port<0>(predecessor_node),
input_port<1>(successor_node));
在图 3-3 中,我们在简单的双节点图中的my_first_node和my_second_node之间做了一条边。图 3-5 显示了一个稍微复杂一点的流程图,有四个节点。

图 3-5。
具有四个节点的示例流程图
图 3-5 中的前两个节点生成结果,这些结果通过排队join_node、my_join_node连接在一起成为一个元组。当边缘被制作到join_node的输入端口时,我们需要指定端口号:
make_edge(my_node, tbb::flow::input_port<0>(my_join_node));
make_edge(my_other_node, tbb::flow::input_port<1>(my_join_node));
join_node的输出,即std::tuple<std::string, double>,被发送到my_final_node。当只有一个端口时,我们不需要指定端口号:
make_edge(my_join_node, my_final_node);
第四步:开始绘制图表
创建和使用 TBB 流图的第四步是开始执行图。消息进入图有两种主要方式:( 1)通过一个显式的try_put到一个节点,或者(2)作为一个source_node的输出。在图 3-3 和图 3-5 中,我们在节点上调用try_put来开始消息流入图中。
默认情况下,在活动状态下构建一个source_node。每当形成传出边缘时,它立即开始跨边缘发送消息。不幸的是,我们认为这很容易出错,所以我们总是在非活动状态下构造源节点,也就是说,将 false 作为is_active参数传递。为了在我们的图被完全构建后让消息流动,我们在所有不活动的节点上调用activate()函数
图 3-6 展示了如何使用source_node代替串行回路向图形提供信息。在图 3-6(a) 中,一个循环在一个节点my_node上重复调用try_put,向其发送消息。在图 3-6(b) 中,a source_node用于相同的目的。
source_node的返回值就像串行循环中的布尔条件一样使用——如果为真,则执行循环体的另一次执行;否则,循环停止。由于source_node的返回值用于表示布尔条件,所以它通过更新提供给其主体的参数来返回其输出值。在图 3-6(b) 中,source_node取代了图 3-6(a) 中的计数回路。

图 3-6。
在(a)中,循环将int值0, 1和2发送到节点my_node。在(b)中,a source_node将int值0, 1和2发送到节点my_node。
使用source_node而不是循环的主要优点是它响应图中的其他节点。在第十七章中,我们将讨论如何使用source_node和预留join_node或limiter_node来控制允许多少消息进入一个图。如果我们使用一个简单的循环,我们可以用输入来淹没我们的图,如果节点跟不上,迫使节点缓冲许多消息。
步骤 5:等待图形完成执行
一旦我们使用try_put或source_node将消息发送到图表中,我们就通过调用图表对象上的wait_for_all()来等待图表的执行完成。我们可以在图 3-3 、图 3-5 和图 3-6 中看到这些呼叫。
如果我们构建并执行图 3-3 中的图形,我们会看到如下输出
first node received: 10
second node received: 10
如果我们构建并执行图 3-5 中的图表,我们会看到如下输出
other received: received: 21
final: 1 and 2
图 3-5 的输出看起来有点混乱,确实如此。前两个功能节点并行执行,都流向std::cout。在我们的输出中,我们看到两个输出混杂在一起,因为我们打破了我们在本章早些时候讨论基于图的并行性时所做的假设——我们的节点不是没有副作用的!这两个节点并行执行,并且都影响全局std::cout对象.的状态。在本例中,这是可以的,因为输出只是为了通过图形显示消息的进度。但这是需要记住的重要一点。
图 3-5 中的最后一个function_node只有当来自前面函数节点的两个值被join_node连接在一起并传递给它时才会执行。因此,这个最终节点自己执行,因此它将预期的最终输出流式传输到std::cout:“final:1 和 2”。
数据流图的一个更复杂的例子
在第二章中,我们介绍了一个将红-青 3D 立体效果应用于左右图像对的例子。在第二章中,我们用一个 TBB parallel_pipeline对这个例子进行了并行化,但这样做意味着我们通过线性化流水线阶段在桌面上留下了一些并行性。输出示例如图 3-7 所示。

图 3-7。
左图像和右图像用于生成红-青立体图像。原始照片由埃琳娜·亚当斯拍摄。
图 3-8 显示了图 2-28 所示串行代码中的数据和控制依赖关系。数据依赖关系显示为实线,控制依赖关系显示为虚线。从这个图中,我们可以看到对getLeftImage和increasePNGChannel的调用并不依赖于对getRightImage和increasePNGChannel的调用。因此,这两个系列的调用可以彼此并行进行。我们还可以看到,mergePNGImages无法继续,直到左右图像上的increasePNGChannel都已完成。最后,write必须等到对mergePNGImages的调用结束。
与第二章不同,在第二章中,我们使用线性管道,使用 TBB 流图,我们现在可以更准确地表达依赖性。为此,我们需要首先理解应用程序中保持正确执行的约束。例如,while 循环的每次迭代直到前一次迭代完成后才开始,但这可能只是使用串行 while 循环的副作用。我们需要确定哪些约束是真正必要的。
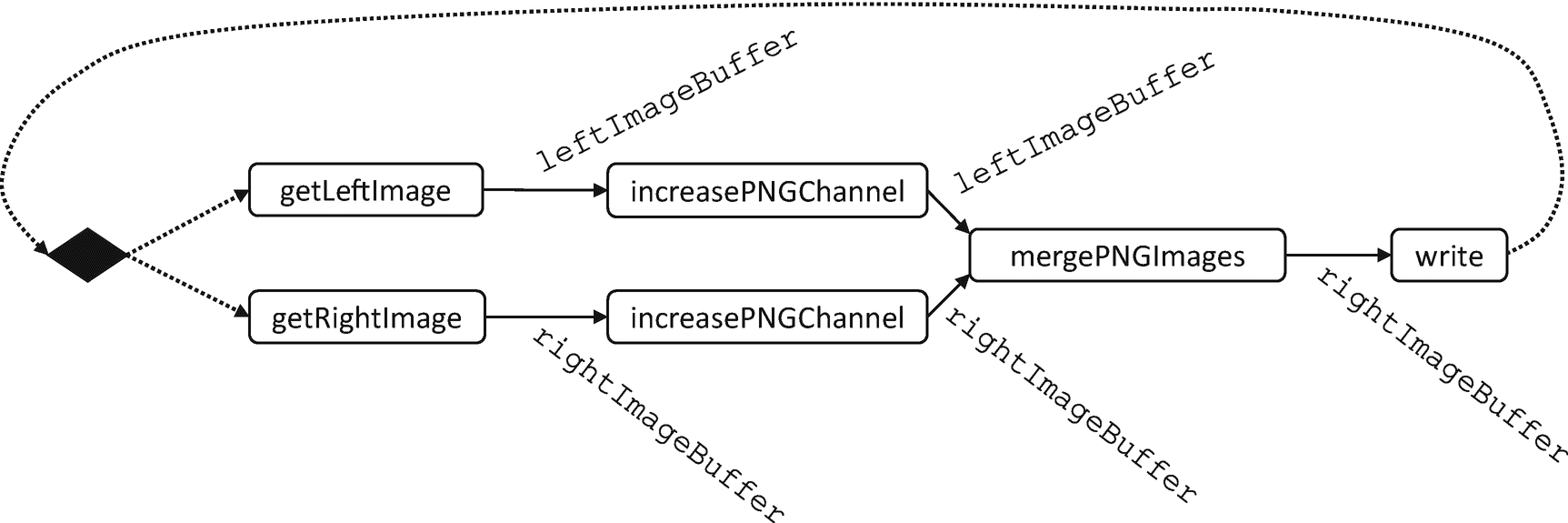
图 3-8。
图 2-28 中代码示例的控制和数据依赖,其中实线代表数据依赖,虚线代表控制依赖
在这个例子中,让我们假设图像代表从文件或照相机中按顺序读取的帧。由于图像必须按顺序读取,我们不能同时多次调用getLeftImage或getRightImage;这些是串行操作。然而,我们可以将对getLeftImage的调用与对getRightImage的调用重叠,因为这些函数不会相互干扰。除了这些约束,我们将假设increasePNGChannel、mergePNGImages和write在不同的输入上并行执行是安全的(它们都是无副作用和线程安全的)。因此,while 循环的迭代不能完全并行执行,但是只要保留这里确定的约束,我们就可以在迭代内部和迭代之间利用一些并行性。
将示例实现为 TBB 流程图
现在,让我们逐步完成实现我们的立体 3D 样本的 TBB 流图的构造。我们将要创建的流程图的结构如图 3-9 所示。这个图看起来与图 3-8 不同,因为现在节点代表 TBB 流图节点对象,边代表 TBB 流图边。
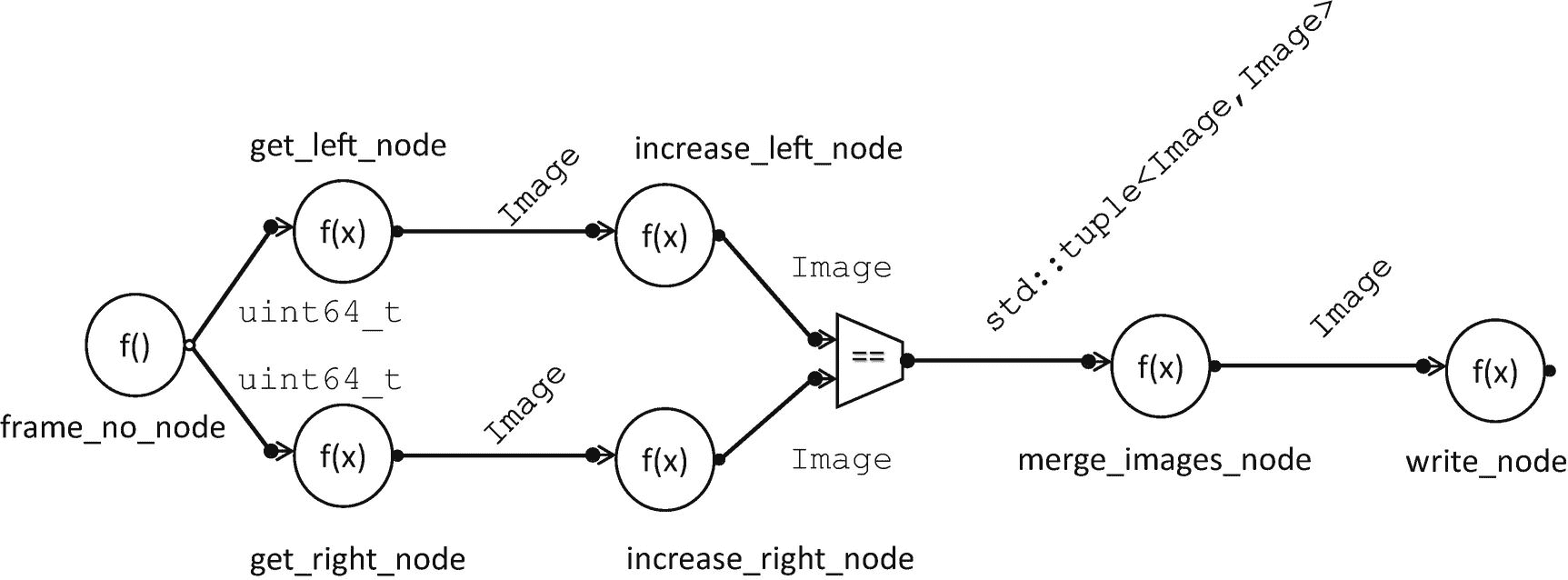
图 3-9。
表示图 2-28 中调用的图表。圆圈封装了图 2-28 中的功能。边缘代表中间值。梯形表示将消息连接成二元组的节点。
图 3-10 显示了使用 TBB 流程图接口实现的立体 3D 示例。方框中概述了五个基本步骤。首先,我们创建一个图形对象。接下来,我们创建八个节点,包括一个source_node、几个function_node实例和一个join_node。然后,我们使用对make_edge的调用来连接节点。在创建边之后,我们激活源节点。最后,我们等待图形完成。
在图 3-9 的图表中,我们看到frame_no_node是图表的输入源,在图 3-10 中,该节点使用source_node实现。只要一个source_node的主体继续返回true,运行时库就会继续衍生出新的任务来执行它的主体,进而调用getNextFrameNumber()。
正如我们前面提到的,getLeftImage和getRightImage函数必须串行执行。在图 3-10 的代码中,我们通过将这些节点的并发约束设置为flow::serial来将该约束传达给运行时库。对于这些节点,我们使用类function_node。你可以在附录 b 中看到更多关于function_node的细节。如果一个节点用flow::serial声明,运行时库将不会产生下一个任务来执行它的主体,直到任何未完成的主体任务完成。

图 3-10。
作为 TBB 血流图的立体 3D 例子
相比之下,increase_left_node和increase_rigt_node对象是用flow::unlimited.的并发约束构造的,无论何时有消息到达,运行时库都会立即生成一个任务来执行这些节点的主体。
在图 3-9 中,我们看到merge_images_node函数需要一个右图像和一个左图像。在最初的串行代码中,我们确保图像来自同一帧,因为 while 循环一次只对一帧进行操作。然而,在我们的流程图版本中,多个帧可以通过流程图流水线化,因此可以同时进行。因此,我们需要确保只合并对应于同一帧的左右图像。
为了给我们的merge_images_node提供一对匹配的左右图像,我们用tag_matching策略创建了join_images_node。你可以在附录 b 中了解join_node及其不同的策略。在图 3-10 中,join_images_node被构造为具有两个输入端口,并基于匹配其frameNumber成员变量创建一个Image对象元组。对构造器的调用现在包括两个 lambda 表达式,用于从两个输入端口上的传入消息中获取标记值。merge_images_node接受一个元组并生成一个合并的图像。
图 3-10 中创建的最后一个节点是write_node。接收Image对象并调用write将每个传入缓冲区存储到输出文件的是一个flow::unlimited function_node。
一旦构建完成,节点通过调用make_edge相互连接,创建如图 3-9 所示的拓扑。我们应该注意,只有一个输入或输出的节点不需要指定端口。然而,对于像join_images_node这样有多个输入端口的节点,端口访问器函数用于将特定的端口传递给make_edge调用。
最后,在图 3-10 中,frame_no_node被激活,调用wait_for_all来等待图形完成执行。
了解数据流图的性能
值得注意的是,与其他一些数据流框架不同,TBB 流图中的节点不是作为线程实现的。相反,当消息到达节点并且并发限制允许时,TBB 任务被反应性地产生。一旦任务产生,它们就被调度到 TBB 工作线程上,使用与 TBB 通用算法相同的工作窃取方法(参见第九章了解工作窃取调度器的详细信息)。
有三个主要因素会限制 TBB 流图的性能:(1)串行节点,(2)工作线程的数量,以及(3)并行执行 TBB 任务的开销。
让我们考虑如何将我们的 3D 立体图形映射到 TBB 任务,以及如何执行这些任务。节点frame_no_node、get_left_node和get_right_node是flow::serial节点。剩下的节点是flow::unlimited。
串行节点会导致工作线程空闲,因为它们限制了任务的可用性。在我们的立体 3D 示例中,按顺序读取图像。一旦每个图像被读取,图像的处理可以立即开始,并且可以与系统中的任何其他工作重叠。因此,这三个串行节点是我们图中限制任务可用性的节点。如果读取这些图像的时间支配了其余的处理,我们将看到很少的加速。然而,如果处理时间比读取图像的时间长得多,我们可能会看到明显的加速。
如果图像读取不是我们的限制因素,那么性能就会受到工作线程数量和并行执行开销的限制。当我们使用流程图时,我们在可能在不同工作线程上执行的节点之间传递数据,同样,在处理器内核上也是如此。我们还重叠不同功能的执行。跨线程传递数据和在不同线程上同时执行函数都会影响内存和缓存行为。我们将在本书的第二部分更详细地讨论局部性和开销优化。
依赖图的特例
TBB 流图接口支持数据流和依赖图。数据流图中的边是数据在节点之间传递的通道。我们在本章前面构建的立体 3D 示例是数据流图的一个示例—Image对象在图中从一个节点到另一个节点的边上通过。
依赖图中的边表示正确执行必须满足的前后关系。在依赖图中,数据通过共享内存从一个节点传递到另一个节点,而不是通过边上的消息直接传递。图 3-11 显示了制作花生酱和果冻三明治的依赖关系图;边传达了一个节点直到其所有的完成后才能开始。
**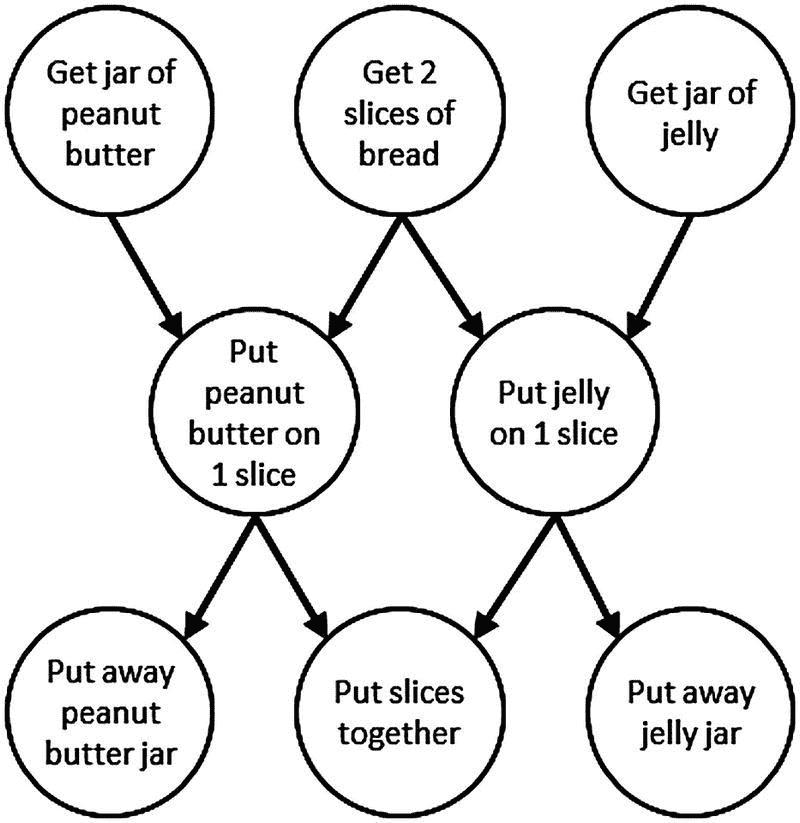
图 3-11。
制作花生酱和果冻三明治的依赖图。这里的边代表前后关系。
为了使用 TBB 流图类来表达依赖图,我们使用类continue_node作为节点并传递类型continue_msg的消息。function_node和continue_node的主要区别在于它们对信息的反应。你可以在附录 b 中看到continue_node的细节
当一个function_node接收到一个消息时,它将它的主体应用于该消息——要么立即产生一个任务,要么缓冲该消息直到合法产生一个任务来应用主体。相比之下,continue_node计算它接收的消息数量。当它接收到的消息数等于它拥有的前辈的数量时,它产生一个任务来执行它的主体,然后重置它的消息接收计数。例如,如果我们使用continue_nodes来实现图 3-11 ,那么“将切片放在一起”节点将在每次接收到两个continue_msg对象时执行,因为它在图中有两个前置对象。
对象对消息进行计数,并且不跟踪每个单独的前任已经发送的消息。例如,如果一个节点有两个前置节点,它将在收到两个消息后执行,而不管消息来自哪里。这使得这些节点的开销更低,但也要求依赖图是非循环的。此外,虽然依赖图可以重复执行直到完成,但是将continue_msg对象流入依赖图是不安全的。在这两种情况下,当存在循环或者如果我们将项目流式传输到依赖图中,简单的计数机制意味着节点可能会错误地触发,因为当它真正需要等待来自不同后继者的输入时,它会对从相同后继者接收的消息进行计数。
实现依赖图
使用依赖图的步骤与使用数据流图的步骤相同;我们创建一个图形对象,制作节点,添加边,并将消息输入图形。主要的区别是只使用了continue_node和broadcast_node类,图必须是非循环的,并且我们必须在每次向图中输入消息时等待图执行完成。
现在,让我们构建一个示例依赖图。对于我们的例子,让我们使用一个 TBB parallel_do来实现我们在第二章中实现的同一个正向替换例子。你可以参考那一章中串行例子的详细描述。
图 3-12 再现了该示例的串行平铺实现。

图 3-12。
用于直接实现正向替换的串行阻塞代码。编写该实现是为了使算法清晰明了,而不是为了获得最佳性能。
在第二章中,我们讨论了本例中操作之间的依赖关系,并注意到,如图 3-13 所示,在计算的对角线上可以看到一个并行波前。当使用parallel_do时,我们创建了一个原子计数器的 2D 阵列,并且必须手动跟踪每个块何时可以被安全地提供给parallel_do算法来执行。虽然有效,但这很麻烦且容易出错。
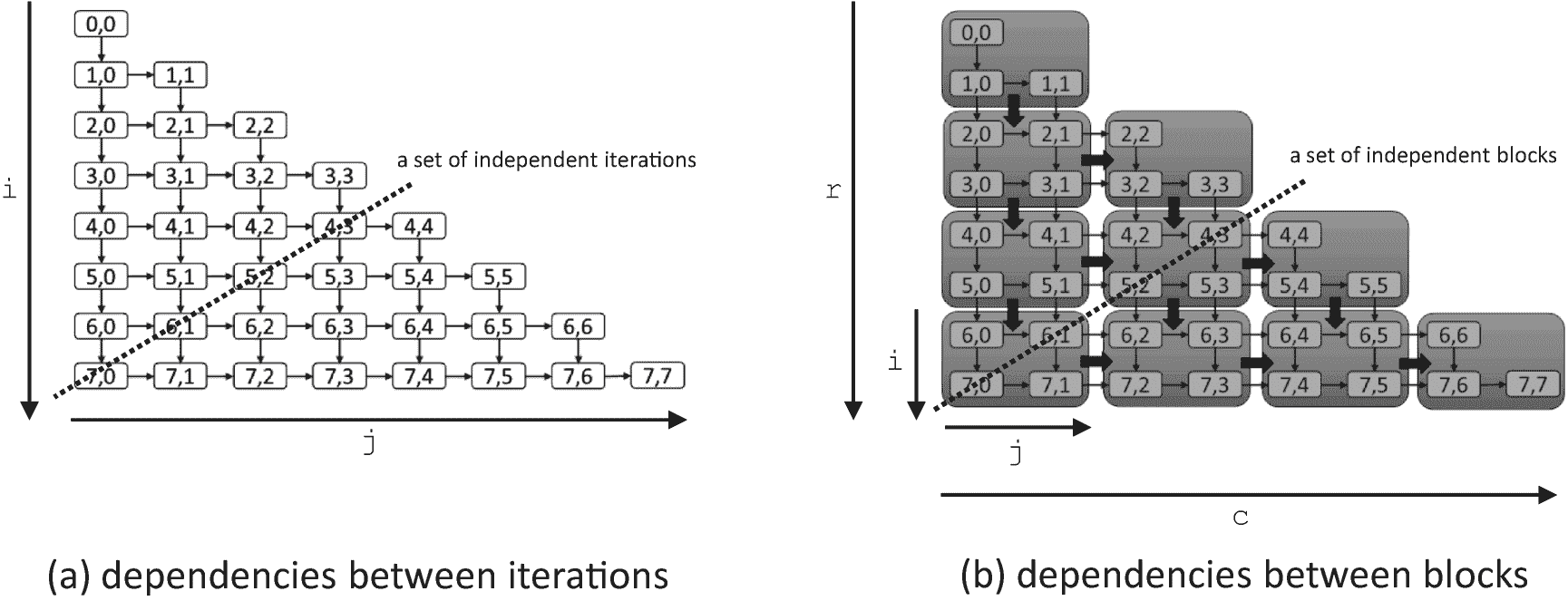
图 3-13。
8 × 8 小矩阵正向代换中的依赖性。在(a)中,显示了迭代之间的依赖性。在(b)中,迭代被分组为块以减少调度开销。在(a)和(b)中,每个节点都必须等待它上面的邻居和它左边的邻居完成,然后才能执行。
在第二章的中,我们注意到在这个例子中我们也可以使用一个parallel_reduce来表达并行性。我们可以在图 3-14 中看到这样的实现。

图 3-14。
使用parallel_reduce进行正向并行替换
然而,正如我们在图 3-15 中看到的,主线程必须等待每个parallel_reduce完成,然后才能继续下一个。行之间的这种同步增加了不必要的同步点。例如,一旦块 1,0 完成,立即开始处理 2,0 是安全的,但是我们必须等到 fork-join parallel_reduce算法完成,直到我们移动到那一行。
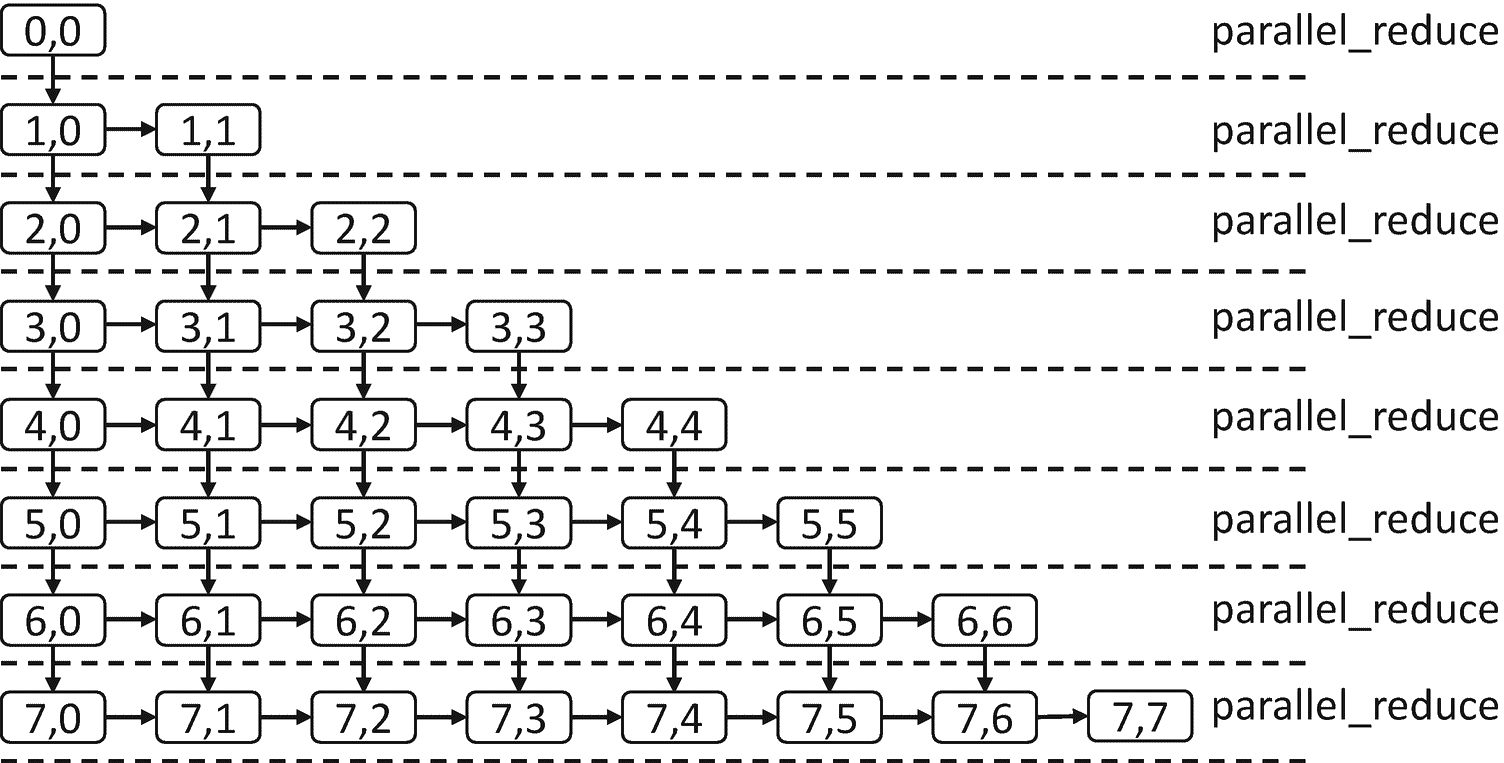
图 3-15。
主线程必须等待每个parallel_reduce完成,然后才能移动到下一个parallel_reduce,引入同步点
使用依赖图,我们简单地直接表达依赖关系,并允许 TBB 库发现和利用图中可用的并行性。我们不必像第二章中的parallel_do版本那样明确地维护计数或跟踪完成,我们也不会像图 3-14 那样引入不必要的同步点。
图 3-16 显示了该示例的依赖图版本。我们使用一个std::vector nodes来保存一组continue_node对象,每个节点代表一个迭代块。为了创建图形,我们遵循常见的模式:(1)创建图形对象,(2)创建节点,(3)添加边,(4)向图形中输入消息,以及(5)等待图形完成。然而,我们现在使用循环嵌套创建图结构,如图 3-16 所示。函数createNode为每个块创建一个新的continue_node对象,函数addEdges将节点连接到必须等待其完成的邻居。
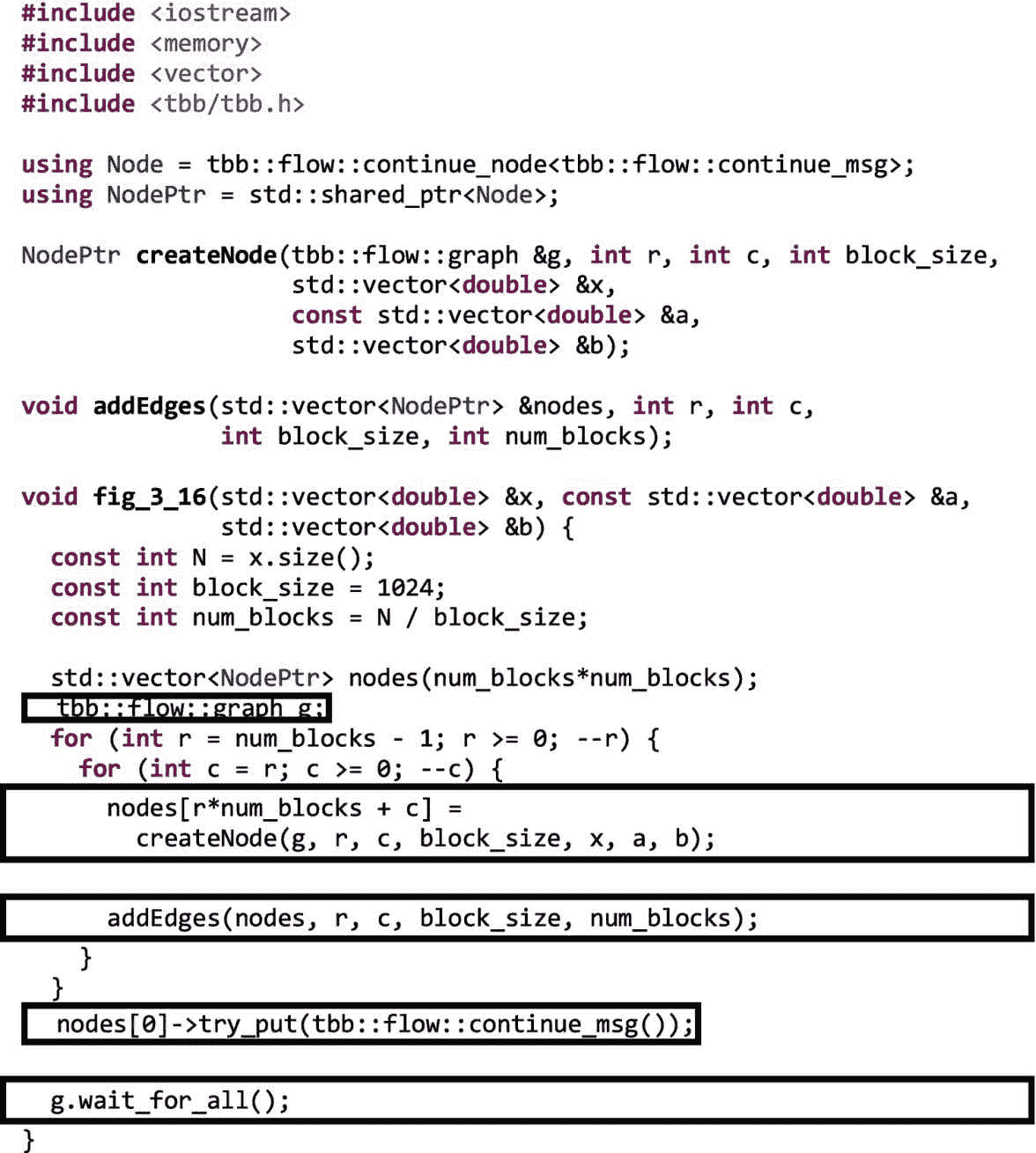
图 3-16。
正向替换示例的依赖图实现
在图 3-17 中,我们展示了createNode.的实现。

图 3-17。
createNode功能实现
在createNode中创建的continue_node对象使用一个 lambda 表达式,该表达式封装了图 3-12 中所示的前向替换的阻塞版本的两个内部循环。由于没有数据通过依赖图的边传递,每个节点需要的数据通过共享内存使用 lambda 表达式捕获的指针来访问。在图 3-17 中,节点通过值捕获整数r、c、N和block_size,以及对向量x、a和b的引用。
在图 3-18 中,函数addEdges使用make_edge调用将每个节点连接到它的右下邻居,因为它们必须等待新节点完成后才能执行。当图 3-16 中的循环嵌套完成后,一个类似于图 3-13 中的依赖图就被构建好了。

图 3-18。
addEdges功能实现
如图 3-16 所示,一旦构建了完整的图,我们通过向左上角的节点发送一个continue_msg来开始它。任何没有前置任务的continue_node都会在收到消息时执行。向左上角的节点发送消息会启动依赖图。同样,我们使用g.wait_for_all()来等待图形执行完毕。
评估依赖图的可伸缩性
适用于数据流图的相同性能限制也适用于依赖图。然而,因为依赖图必须是非循环的,所以更容易估计它们的可伸缩性上限。在本讨论中,我们使用由麻省理工学院 Cilk 项目引入的符号(参见,例如, Blumofe,Joerg,Kuszmaul,Leiserson,Randall 和 Zhou,“Cilk:一个高效的多线程运行时系统”,并行编程的原理和实践,1995 )。
我们用 T 1 表示执行图中所有节点的时间之和;1 表示如果我们只有一个执行线程,这是执行图形所花费的时间。我们将沿着关键(最长)路径执行节点的时间表示为 T ∞ ,因为这是最小可能的执行时间,即使我们有无限数量的线程可用。通过依赖图中的并行性可实现的最大加速是 T 1 /T ∞ 。在 P 个处理器的平台上执行时,执行时间绝不能小于 T 1 /P 和 T ∞ 中的最大值。
例如,为了简单起见,让我们假设图 3-13(a) 中的每个节点花费相同的时间来执行。我们将这个时间称为t n 。图中有 36 个节点(行数*列数),所以T1= 36tn。从0,0到7,7的最长路径包含 15 个节点(行数+列数–1),因此对于此图T= 15tn。即使我们有无限数量的处理器,关键路径上的节点也必须按顺序执行,不能重叠。因此,我们对于这个小 8 × 8 图的最大加速是36tn/15tn= 2.4。然而,如果我们有一个更大的方程组要解,让我们假设一个512×512矩阵,沿着关键路径将有512×512=131,328节点和512+512-1=1023节点,对于131,328/1023 ≈ 128的最大加速。
如果可能,如果您正在考虑实现串行应用程序的依赖图版本,那么分析您的串行代码、收集每个潜在节点的时间并估计关键路径长度是一个很好的实践。然后,您可以使用前面描述的简单计算来估计可实现的加速上限。
TBB 流图的高级主题
TBB 流图有一组丰富的节点和接口,我们在这一章才刚刚开始触及这个表面。在第十七章中,我们更深入地研究 API 来回答一些重要的问题,包括
-
我们如何在流程图中控制资源的使用?
-
我们什么时候需要使用缓冲?
-
有需要避免的反模式吗?
-
有没有有效的模式可以模仿?
此外,流程图支持异步和异构的能力,我们将在第 18 和 19 章中探讨。
摘要
在这一章中,我们学习了让我们开发数据流和依赖图的tbb::flow namespace中的类和函数。我们首先讨论了为什么用图来表达并行性是有用的。然后,我们学习了 TBB 流图界面的基础知识,包括界面中可用的不同节点类别的简要概述。接下来,我们一步一步地构建了一个小型数据流图,该图将 3D 立体效果应用于左右图像集。之后,我们讨论了如何将这些节点映射到 TBB 任务,以及流图的性能限制是什么。接下来,我们看了依赖图,这是数据流图的一个特例,其中边传递依赖消息而不是数据消息。我们还构建了一个向前替换的例子作为依赖图,并讨论了如何估计它的最大加速比。最后,我们提到了一些重要的高级主题,这些主题将在本书的后面部分讨论。
图 2-28a 、 2-29 和 3-7 中使用的照片由 Elena Adams 拍摄,经 Halide 项目教程 http://halide-lang.org 许可使用。
[外链图片转存中…(img-7pP6Rrqm-1722837544016)]
开放存取本章根据知识共享署名-非商业-非专用 4.0 国际许可协议(http://Creative Commons . org/licenses/by-NC-nd/4.0/)的条款进行许可,该协议允许以任何媒体或格式进行任何非商业使用、共享、分发和复制,只要您适当注明原作者和来源,提供知识共享许可协议的链接,并指出您是否修改了许可材料。根据本许可证,您无权共享从本章或其部分内容派生的改编材料。
本章中的图像或其他第三方材料包含在该章的知识共享许可中,除非该材料的信用额度中另有说明。如果材料未包含在本章的知识共享许可中,并且您的预期用途不被法定法规允许或超出了允许的用途,您将需要直接从版权所有者处获得许可。**
四、TBB 和 C++ 标准模板库的并行算法
为了有效地使用线程构建模块(TBB)库,了解它如何支持和扩充 C++ 标准是很重要的。在本章中,我们讨论了 TBB 与标准 C++ 关系的三个方面:
-
TBB 库经常包含 C++ 标准中新增的与并行性相关的特性。在 TBB 中包含这样的特性可以让开发人员在它们被广泛应用于所有编译器之前就可以提前使用它们。在这种情况下,所有预构建的 TBB 发行版现在都包含了英特尔对 C++ 标准模板库(STL)并行算法的实现。这些实现使用 TBB 任务来实现多线程,使用 SIMD 指令来实现向量化。本章主要讨论并行 STL。
-
TBB 库还提供了一些 C++ 标准中没有的特性,但是让开发人员更容易表达并行性。通用并行算法和流程图就是这样的例子。在这一章中,我们将讨论 TBB 中包含的自定义迭代器,它拓宽了并行 STL 算法的应用范围。
-
最后,我们在本章中注意到,对 C++ 标准的一些补充可能会取代对某些 TBB 特性的需求。然而,我们也注意到,在可预见的未来,TBB 的价值可能不会被 C++ 标准所包含。例如,TBB 提供的将持续受益的特性包括它的工作窃取任务调度器、线程安全容器、流图 API 和可伸缩内存分配器。
C++ STL 库属于这本书吗?
关于 C++ 标准模板库的一章真的属于一本关于 TBB 的书吗?是的,确实如此!TBB 是一个并行的 C++ 库,它不存在于真空中。我们需要理解它与 C++ 标准的关系。
我们在本章中讨论的执行策略在某些方面类似于第二章中介绍的 TBB 并行算法,因为它们让我们表达了并行执行算法是安全的——但是它们 没有 规定确切的实现细节。如果我们想在一个应用程序中混合 TBB 算法和并行 STL 算法,并且仍然拥有高效、可组合的并行性(参见第九章),我们可以从使用 TBB 作为并行执行引擎的并行 STL 实现中获益!因此,当我们在本章中讨论并行执行策略时,我们将关注基于 TBB 的实现。当我们使用一个底层使用 TBB 的并行 STL 时,并行 STL 就变成了我们在代码中使用 TBB 任务的另一个途径。
回到第一章中的图 1-3 ,我们注意到许多应用都有多级并行可用,包括最适合在矢量单元上执行的单指令多数据(SIMD)层。正如图 4-1 中所示二项式期权应用的性能结果所示,利用这种级别的并行性至关重要。向量并行在单独使用时只能提高很小一部分性能;它受到向量宽度的限制。然而,图 4-1 提醒我们,不应该忽视同时使用任务并行和向量并行的倍增效应。
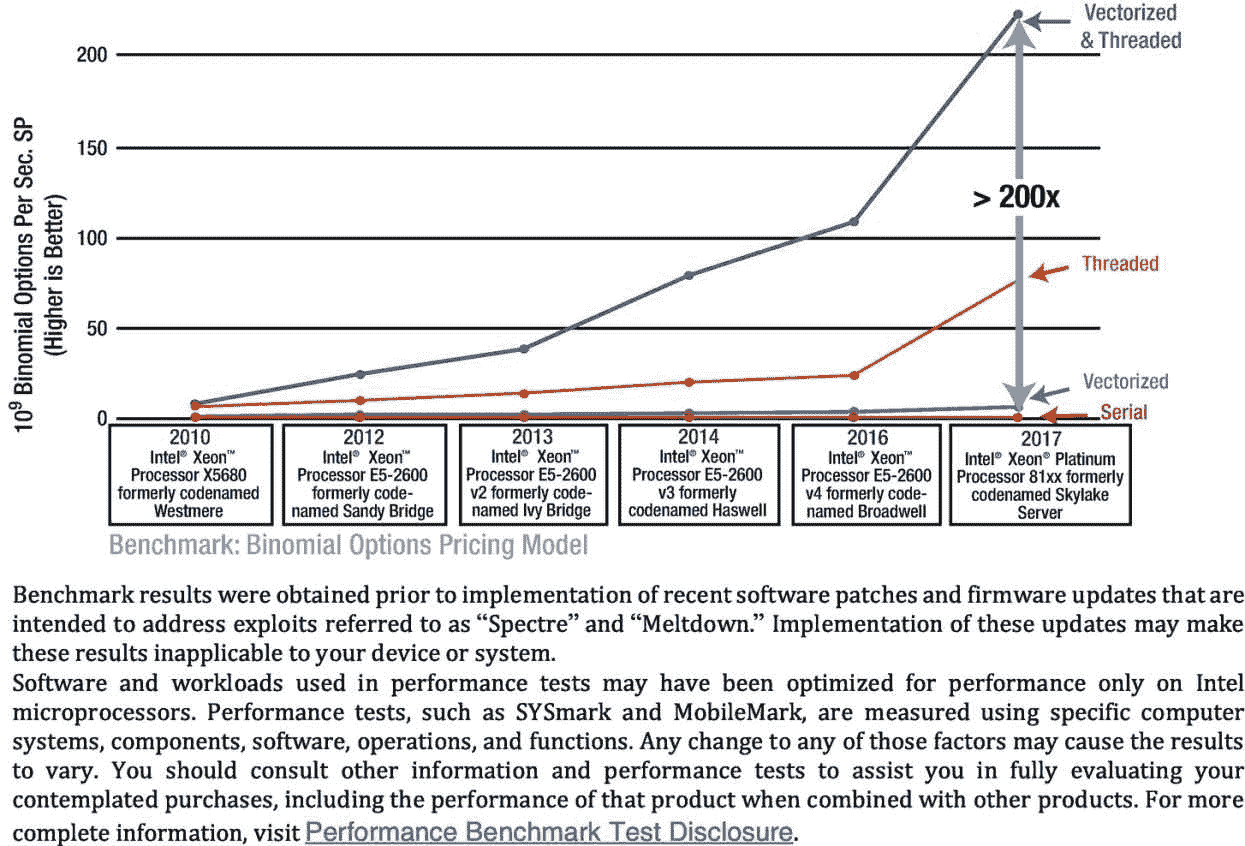
图 4-1
二项式期权定价应用程序在串行、矢量化、线程化以及矢量化和线程化执行时的性能
在第一章中,我们实现了一个示例,该示例使用顶级 TBB 流图形层来引入线程,在图形节点中嵌套通用 TBB 并行算法来获得更多线程,然后嵌套 STL 算法,该算法在并行算法体中使用矢量策略来引入矢量化。当我们将 TBB 与并行 STL 及其执行策略相结合时,我们不仅获得了可组合的消息传递和 fork-join 层,还获得了对 SIMD 层的访问。
正是由于这些原因,STL 库中的执行策略是我们探索 TBB 的重要部分!
TBB 和 C++ 标准
开发 TBB 的团队是 C++ 语言本身支持线程的强烈支持者。事实上,TBB 经常包括模仿 C++ 中标准化的并行特性,以允许开发人员在主流编译器广泛支持这些接口之前迁移到这些接口。这方面的例子是std::thread。TBB 的开发人员认识到了std::thread的重要性,因此在它在所有 C++ 标准库中可用之前,就为开发人员提供了一个可移植的实现,将该特性直接注入到了std名称空间中。今天,TBB 对std::thread的实现简单地包括了平台对std::thread的实现(如果有的话),并且只有当平台的标准 C++ 库不包括实现时才回退到它自己的实现。对于其他现在标准的 C++ 特性,如原子变量、互斥对象和std::condition_variable,也有类似的情况。
并行 STL 执行策略模拟
为了帮助思考并行 STL 库提供的不同执行策略,我们可以想象一条多线高速公路,如图 4-2 所示。与大多数类比一样,这并不完美,但它可以帮助我们看到不同政策的好处。
我们可以将多车道高速公路中的每条车道视为一个执行线程,将每个人视为一个要完成的操作(例如,这个人需要从 A 点到 B 点),将每辆汽车视为一个处理器内核,将汽车中的每个座位视为(向量)寄存器中的一个元素。在串行执行中,我们只使用高速公路的一条车道(单线程),每个人都有自己的车(我们没有使用矢量单元)。无论人们是否在同一条路线上行驶,他们都各自开着自己的车,在同一条车道上行驶。
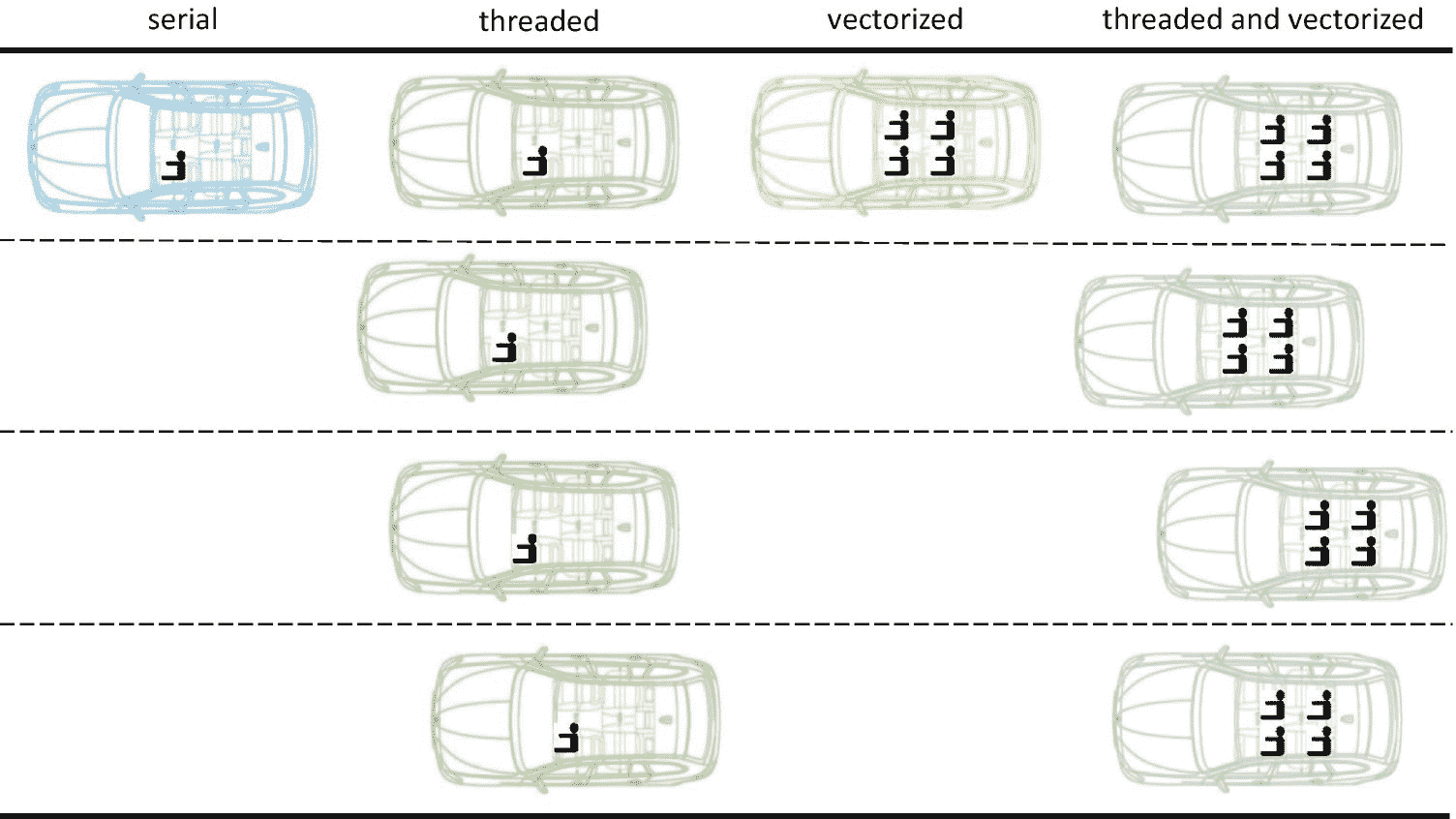
图 4-2
并行 STL 中执行策略的多线高速公路模拟
在一个线程执行中,我们使用了不止一条高速公路车道(即不止一个执行线程)。现在,我们在单位时间内完成了更多的任务,但是仍然不允许拼车。如果几个人从同一个起点出发,前往同一个目的地,他们各自开自己的车。我们正在更有效地利用高速公路,但我们的汽车(核心)正在被低效使用。
一个矢量化执行就像拼车。如果几个人需要走完全相同的路线,他们共用一辆车。许多现代处理器支持向量指令,例如英特尔处理器中的 SSE 和 AVX。如果我们不使用向量指令,我们就没有充分利用我们的处理器。这些内核中的矢量单元可以同时对多段数据应用相同的操作。向量寄存器中的数据就像人们共用一辆汽车,他们走完全相同的路线。
最后,线程化和矢量化的执行就像使用高速公路上的所有车道(所有内核)以及拼车(使用每个内核中的矢量单元)。
使用std:和:for_each的简单例子
现在我们已经对执行策略有了一个大致的概念,但是在我们进入所有血淋淋的细节之前,让我们从对 vector v中的所有元素应用一个函数void f(float &e)开始,如图 4-3(a) 所示。使用 C++ STL 库中的算法之一std::for_each,我们也可以做同样的事情,如图 4-3(b) 。就像基于范围的for,for_each从v.begin()迭代到v.end(),并对向量中的每一项调用 lambda 表达式。这是for_each的默认顺序行为。
然而,使用并行 STL,我们可以通知库,为了利用并行性,可以放松这些语义,或者如图 4-3© 所示,我们可以让库明确知道我们需要序列语义。使用英特尔的并行 STL 时,我们需要在代码中包含算法和执行策略头,例如:

在 C++17 中,省略执行策略或者传入sequenced_policy对象seq,会导致相同的默认执行行为:它看起来就好像lambda 表达式按顺序在 vector 中的每一项上被调用。我们说“好像”是因为硬件和编译器被允许并行化算法,但前提是这样做对符合标准的程序是不可见的。
并行 STL 的强大之处来自于放松了这种顺序约束的其他执行策略。我们说,通过使用unsequenced_policy对象unseq,操作可以从一个执行的单线程中重叠或矢量化,如图 4-3(d) 所示。然后,该库可以在单线程中重叠操作,例如,通过使用 SSE 或 AVX 等单指令多数据(SIMD)扩展来矢量化执行。图 4-4 显示了这种行为,使用并排的方框来表示这些操作使用矢量单位同时执行。unseq执行政策允许“拼车”
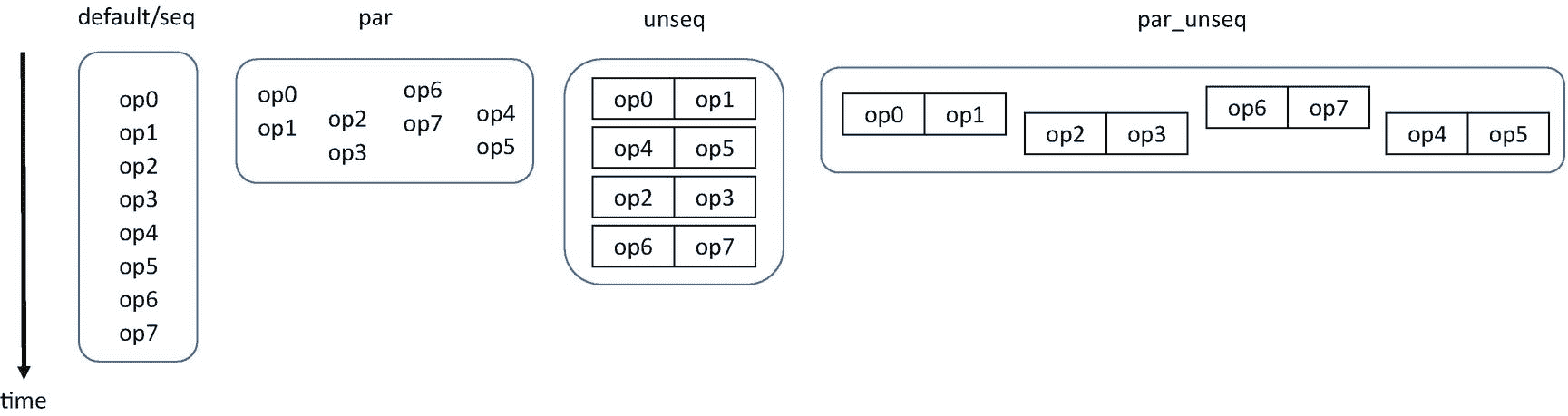
图 4-4
使用不同的执行策略应用操作

图 4-3
用std::for_each实现的简单循环,使用各种并行 STL 执行策略
在图 4-3(e) 中,我们告诉库,使用parallel_policy对象、par的多线程执行,在 vector 中的所有元素上执行这个函数是安全的。如图 4-4 所示,par策略允许操作分布在不同的执行线程上,但是,在每个线程内,操作不会重叠(即,它们不会被矢量化)。回想一下我们的多车道高速公路的例子,我们现在使用高速公路上的所有车道,但还没有拼车。
最后,在图 4-3(f) 中,parallel_unsequenced_policy对象,par_unseq用于传达 lambda 表达式对元素的应用既可以并行化也可以矢量化。在图 4-4 中,par_unseq的执行使用了多个执行线程和在每个线程内重叠操作。我们现在充分利用了平台中的所有内核,并通过利用每个内核的向量单元来有效地利用每个内核。
在实践中,我们在使用执行策略时必须小心。就像一般的 TBB 并行算法一样,当我们使用执行策略来放松 STL 算法的执行顺序时,我们向库声明这种放松是合法且有利可图的。图书馆不检查我们是正确的。同样,该库也不能保证使用某种执行策略不会降低性能。
图 4-3 中需要注意的另一点是,STL 算法本身在名称空间std中,但是由英特尔的并行 STL 提供的执行策略在名称空间pstl::execution中。如果您有一个完全兼容的 C++17 编译器,那么如果您在std::execution名称空间中使用标准执行策略,将会选择其他可能不使用 TBB 的实现。
并行 STL 实现中提供了哪些算法?
C++ 标准模板库(STL)主要包括应用于序列的操作。有一些异常值,如std::min和std::max,可以应用于值,但在大多数情况下,算法,如std::for_each、std::find, std::transform, std::copy,和std::sort,应用于项目序列。当我们想要在支持迭代器的容器上操作时,这种对序列的关注是很方便的,但是如果我们想要表达一些不能在容器上操作的东西,这就有点麻烦了。在这一章的后面,我们会看到有时我们可以“跳出框框思考”,使用自定义迭代器使一些算法的行为更像一般的循环。
解释每个 STL 算法做什么超出了本章和本书的范围。有很多关于 C++ 标准模板库以及如何使用它的书籍,包括 Nicolai Josuttis(Addison-Wesley Professional)的《C++ 标准库:教程和参考》。在本章中,我们只关注在 C++17 中首次引入的执行策略对这些算法意味着什么,以及它们如何与 TBB 一起使用。
C++ 标准中规定的大多数 STL 算法在 C++17 中都有接受执行策略的重载。此外,增加了一些新算法,因为它们在并行程序中特别有用,或者因为委员会希望避免语义上的变化。我们可以通过查看标准本身或在类似 http://en.cppreference.com/w/cpp/algorithm 的网站上找到支持执行策略的算法。
如何获得和使用一个使用 TBB 的并行 STL 副本
“获取线程构建模块(TBB)库”一节中的第一章提供了下载和安装英特尔并行 STL 的详细说明如果你下载并安装了 TBB 2018 update 5 或更高版本的预建副本,无论是通过英特尔获得的商业许可副本还是从 GitHub 下载的开源二进制分发,那么你也会获得英特尔的并行 STL。并行 STL 附带了所有预构建的 TBB 包。
但是,如果您想从 GitHub 获得的源代码构建 TBB 库,那么您需要从 GitHub 单独下载并行 STL 源代码,因为这两个库的源代码分别保存在不同的库 https://github.com/intel/tbb 和 https://github.com/intel/parallelstl 中。
正如我们已经看到的,并行 STL 支持几种不同的执行策略,有些支持并行执行,有些支持矢量化执行,有些两者都支持。英特尔的并行 STL 支持 TBB 并行和使用 OpenMP 4.0 SIMD 结构的矢量化。为了充分利用英特尔的并行 STL,你必须拥有一个支持 C++11 和 OpenMP 4.0 SIMD 结构的 C++ 编译器——当然你还需要 TBB。我们强烈建议使用任何版本的英特尔 Parallel Studio XE 2018 或更高版本附带的英特尔编译器。这些编译器不仅包括 TBB 库并支持 OpenMP 4.0 SIMD 结构,还包括专门用于提高某些 C++ STL 算法在使用unseq或par_unseq执行策略时的性能的优化。
要构建一个在命令行使用并行 STL 的应用程序,我们需要为编译和链接设置环境变量。如果我们安装了英特尔 Parallel Studio XE,我们可以通过调用套件级环境脚本(如compilervars.{sh|csh|bat})来实现。如果我们刚刚安装了并行 STL,那么我们可以通过在<pstl_install_dir>/{linux|mac|windows}/pstl/bin.中运行pstlvars.{sh|csh|bat}来设置环境变量,额外的说明在第一章中提供。
英特尔并行 STL 中的算法
英特尔的并行 STL 还不支持每个 STL 算法的所有执行策略。可以在 https://software.intel.com/en-us/get-started-with-pstl 找到该库提供的算法以及每个算法支持的策略的最新列表。
图 4-5 显示了本书撰写时所支持的算法和执行策略。

图 4-5
截至 2019 年 1 月,英特尔并行 STL 中支持执行策略的算法。以后可能会支持其他算法和策略。更新见 https://software.intel.com/en-us/get-started-with-pstl 。
图 4-6 显示了英特尔并行 STL 所支持的政策,包括那些属于 C++17 标准的政策,以及那些被提议纳入未来标准的政策。C++17 策略允许我们选择顺序执行(seq)、使用 TBB 的并行执行(par)或使用也是矢量化的 TBB 的并行执行(par_unseq)。unsequenced ( unseq)策略让我们选择一个仅矢量化的实现。
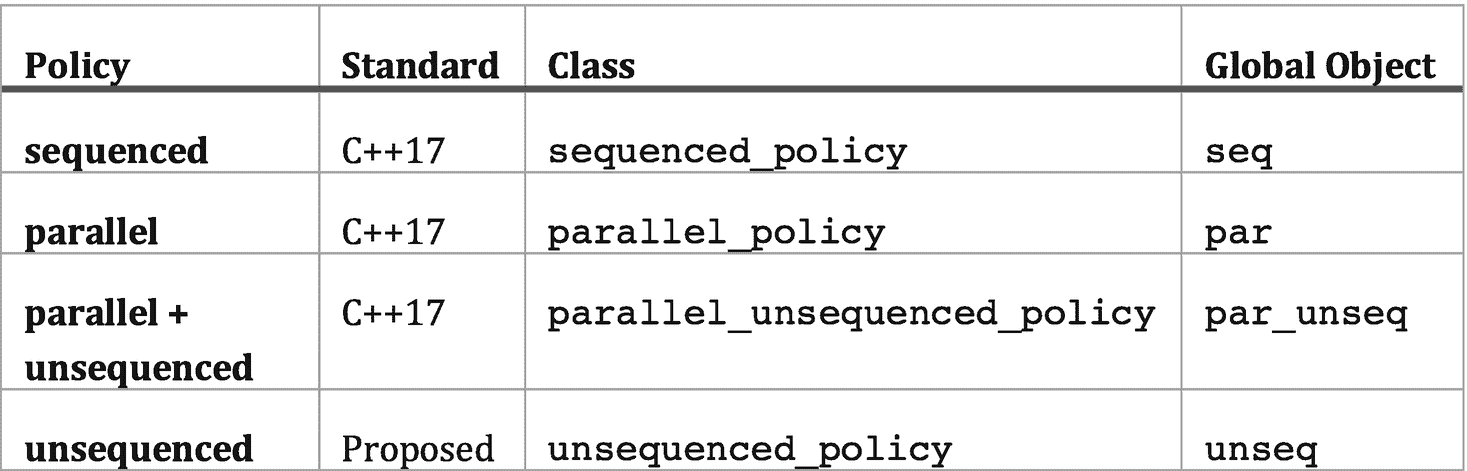
图 4-6
英特尔并行 STL 支持的执行策略
用定制迭代器捕获更多用例
在本章的前面,我们介绍了std::for_each的一个简单用法,并展示了不同的执行策略如何与它一起使用。我们用图 4-3(f) 中的par_unseq的简单例子看起来像

乍一看,for_each算法似乎相当有限,它访问序列中的元素,并对每个元素应用一元函数。当以这种预期的方式在容器上使用时,它实际上在适用性上受到限制。例如,它不接受像 TBB parallel_for这样的范围。
然而,C++ 是一种强大的语言,我们可以创造性地使用 STL 算法来扩展它们的适用性。正如我们在第二章中所讨论的,迭代器是一个对象,它指向一个元素范围中的一个元素,并定义提供遍历该范围中的元素的能力的操作符。迭代器有不同的类别,包括正向、双向和随机访问迭代器。许多标准 C++ 容器提供了返回迭代器的begin和end函数,让我们遍历容器的元素。将 STL 算法应用于更多用例的一种常见方式是使用定制的迭代器。这些类实现迭代器接口,但不包含在 C++ 标准模板库中。
TBB 库中包含了三个常用的自定义迭代器来帮助使用 STL 算法。这些迭代器类型在图 4-7 中有描述,并且可以在iterators.h头文件中或者通过全包tbb.h头文件获得。

图 4-7
TBB 提供的自定义迭代器类
例如,我们可以将自定义迭代器传递给std::for_each,使其更像一个普通的for循环。让我们考虑图 4-8(a) 所示的简单循环。对于范围[0,n)中的每个i,该循环将a[i]+b[i]*b[i]写回a[i]。

图 4-8
使用定制迭代器的std::for_each
在图 4-8(b) 中,counting_iterator类用于创建类似范围的东西。传递给for_eachλ表达式的参数将是从0到n-1的整数值。尽管for_each仍然只在单个序列上迭代,我们使用这些值作为两个向量a和b的索引。
在图 4-8© 中,zip_iterator类用于同时迭代a和b向量。TBB 库提供了一个make_zip_iterator函数来简化迭代器的构造:

在图 4-8© 中,我们仍然在对for_each的调用中只使用了一个序列。但是现在,传递给 lambda 表达式的参数是对float的引用的std::tuple,每个向量一个。
最后,在图 4-8(d) 中,我们添加了transform_iterator类的用法。我们首先使用zip_iterator类将来自向量a和b的两个序列合并成一个序列,就像我们在图 4-8© 中所做的那样。但是,我们也创建了一个 lambda 表达式,并将其赋值给square_b。lambda 表达式将用于转换对float的引用的std::tuple,这些引用是通过解引用zip_iterator.获得的。我们将此 lambda 表达式传递给对make_tranform_iterator函数的调用:

当图 4-8(d) 中的transform_iterator对象被解引用时,它们从底层zip_iterator接收一个元素,对元组的第二个元素求平方,并创建一个新的std::tuple,它包含对来自a的float和来自b的平方值的引用。传递给for_each lambda 表达式的参数包含一个已经平方的值,因此该函数不需要计算b[i]*b[i].
因为像图 4-7 中那样的自定义迭代器非常有用,它们不仅可以在 TBB 库中获得,还可以通过其他库获得,比如 Boost C++ 库( www.boost.org )和 Thrust ( https://thrust.github.io/doc/group__fancyiterator.html )。它们目前不能直接在 C++ 标准模板库中获得。
重点介绍一些最有用的算法
准备工作结束后,我们现在可以更深入地讨论并行 STL 提供的更有用的通用算法,包括for_each、transform、reduce和transform_reduce。当我们讨论每种算法时,我们指出了 TBB 通用算法中的相似之处。与 TBB 特定的接口相比,并行 STL 接口的优势在于并行 STL 是 C++ 标准的一部分。并行 STL 接口的缺点是,与一般的 TBB 算法相比,它们的表达能力和可调性较差。当我们在本节中讨论算法时,我们会指出其中的一些缺点。
std: :for_each,std: :for_each_n
在这一章中我们已经谈了很多关于for_each的内容。除了for_each,并行 STL 还提供了一个for_each_n算法,只访问第一个n元素。算法for_each和for_each_n都有几个接口;接受执行策略的如下:

结合定制迭代器,for_each可以非常有表现力,正如我们在图 4-8 中所展示的。例如,我们可以从第二章中提取简单的矩阵乘法示例,并使用counting_iterator类在图 4-9 中重新实现它。

图 4-9
使用std::for_each和tbb::counting_iterator创建矩阵乘法的并行版本
如果我们使用一个底层使用 TBB 的 STL,比如英特尔的并行 STL,par策略是使用tbb::parallel_for实现的,因此对于这样一个简单的例子来说,std::for_each和tbb::parallel_for的性能将是相似的。
这当然引出了一个问题。如果std::for_each使用一个tbb::parallel_for来实现它的par策略,但是它是一个标准接口,并且也给我们访问其他策略的权限,难道我们不应该总是使用std::for_each而不是tbb::parallel_for吗?
不幸的是,不是所有的代码都像这个例子一样简单。如果我们对有效的线程实现感兴趣,通常直接使用tbb::parallel_for会更好。即使对于这个矩阵乘法的例子,正如我们在第二章中提到的,我们的简单实现也不是最佳的。在本书的第二部分,我们讨论了 TBB 中可用的重要优化钩子,我们可以用它们来调优我们的代码。我们将在第十六章中看到这些钩子会带来显著的性能提升。不幸的是,当我们使用并行 STL 算法时,这些高级特性中的大部分都无法应用。标准的 C++ 接口根本不允许它们。
当我们使用一个并行 STL 算法并选择一个标准策略如par, unseq或par_unseq时,我们得到实现决定给我们的任何东西。有人提议在 C++ 中增加一些东西,比如 executors,将来可能会解决这个问题。但目前,我们对 STL 算法几乎没有控制权。当使用 TBB 遗传算法时,比如parallel_for,我们可以使用本书第二部分描述的丰富的优化特性,比如划分器、不同类型的阻塞范围、粒度、相似性提示、优先级、隔离特性等等。
对于一些简单的情况,一个标准的 C++ 并行 STL 算法可能和它的 TBB 版本一样好,但是在更现实的场景中,TBB 为我们提供了获得我们想要的性能所需的灵活性和控制。
std: :transform
并行 STL 中另一个有用的算法是transform。它对一个序列中的元素应用一元运算,对两个输入序列中的元素应用二元运算,并将结果写入单个输出序列中的元素。支持并行执行策略的两个接口如下:

在图 4-8 中,我们使用for_each和自定义迭代器从两个向量中读取并写回一个输出向量,在每次迭代中计算a[i] = a[i] + b[i]*b[i]。正如我们在图 4-10 中看到的,这是std::transform的一个很好的候选。因为transform有一个支持两个输入序列和一个输出序列的接口,这与我们的例子非常匹配。

图 4-10
使用std::transform将两个向量相加
与std::for_each一样,当以典型方式使用时,该算法的适用性受到限制,因为最多有两个输入序列,只有一个输出序列。如果我们有一个写不止一个输出数组或容器的循环,用一个单独的 transform 调用来表达它是不方便的。当然,这是可能的——几乎任何东西都在 C++ 中——但是它需要使用自定义迭代器,比如zip_iterator,以及一些非常难看的代码来访问许多容器。
std: :reduce
我们在第二章讨论tbb::parallel_reduce时讨论了缩减。并行 STL 算法reduce对一个序列的元素进行约简。然而与tbb::parallel_reduce不同的是,它只提供了一个归约操作。在下一节中,我们将讨论transform_reduce,它更像tbb::parallel_reduce,因为它同时提供了转换操作和归约操作。支持并行执行策略的std::reduce的两个接口如下:

reduce算法使用binary_op和恒等值init执行序列元素的广义求和。在第一个界面中,binary_op不是输入参数,默认使用std::plus<>。广义和意味着元素可以按任意顺序分组和重新排列的归约——因此该算法假设运算是结合的和交换的。正因为如此,我们可能会遇到我们在第二章的边栏中讨论过的浮点舍入问题。
如果我们想对向量中的元素求和,我们可以使用std::reduce和任何执行策略,如图 4-11 所示。

图 4-11
使用std::reduce对向量的柠檬求和四次
标准::转换 _ 减少
如前一节所述,transform_reduce类似于tbb::parallel_reduce,因为它提供了变换操作和归约操作。但是,与大多数 STL 算法一样,它一次只能应用于一个或两个输入序列:

我们可以用std::transform_reduce实现的一个重要且常见的内核是内积。这种用法非常普遍,以至于有一个接口在默认情况下使用std::plus<>和std::multiplies<>进行两种操作:

两个向量a和b的内积的串行码如图 4-12(a) 所示。我们可以使用一个std::transform_reduce,并为这两个操作提供我们自己的 lambda 表达式,如图 4-12(b) 所示。或者,如图 4-12© 所示,我们可以依赖默认操作。

图 4-12
使用std::transform_reduce计算内积
同样,与其他并行 STL 算法一样,如果我们稍微跳出框框思考,我们可以使用自定义迭代器,比如counting_iterator,使用这种算法来处理不仅仅是容器中的元素。例如,我们可以拿我们在第二章中用tbb::parallel_reduce实现的圆周率的计算例子,用一个std::transform_reduce来实现,如图 4-13 所示。

图 4-13
使用std::transform_reduce计算圆周率
使用类似于std::transform_reduce的并行 STL 算法而不是tbb::parallel_reduce带有和我们描述的其他算法一样的优点和缺点。它使用一个标准化的接口,因此具有更好的可移植性。然而,它不允许我们使用本书第二部分中描述的优化特性来优化它的性能。
对执行策略的深入探究
并行 STL 中的执行策略让我们在 STL 算法的执行过程中交流我们想要应用于操作排序的约束。标准策略集不是凭空而来的,它捕捉了执行高效并行/线程或 SIMD/矢量化代码所需的宽松约束。
如果您乐意将sequenced_policy理解为顺序执行、parallel_policy理解为并行执行、unsequenced_policy理解为向量化执行、parallel_unsequenced_policy理解为并行和向量化执行,那么您可以跳过本节的其余部分。然而,如果你想理解这些政策所隐含的微妙之处,请继续阅读我们深入探讨的细节。
sequenced_policy
sequenced_policy意味着一个算法的执行看起来好像 (1)该算法使用的所有元素访问函数都在调用该算法的线程上被调用,以及(2)元素访问函数的调用不是交错的(即,它们在一个给定的线程内相对于彼此被排序)。元素访问函数是在访问元素的算法期间调用的任何函数,例如迭代器中的函数、比较或交换函数,以及应用于元素的任何其他用户提供的函数。如前所述,我们说“好像”是因为硬件和编译器被允许违反这些规则,但前提是这样做对符合标准的程序是不可见的。
需要注意的一点是,许多 STL 算法并没有指定操作以任何特定的顺序应用,即使是在有序的情况下。例如,虽然std::for_each指定了序列的元素在有序的情况下按顺序访问,但是std::transform没有。std::transform访问一个序列中的所有元素,但不是以任何特定的顺序。除非另有说明,有序执行意味着元素访问函数的调用在调用线程中是不确定有序的 ??。如果两个函数调用是“不确定顺序的”,这意味着其中一个函数调用在另一个函数调用开始执行之前执行完毕——但是哪个函数调用先执行并不重要。结果是,库可能无法交叉执行这两个函数的操作,例如,阻止了 SIMD 操作的使用。
“好像”规则有时会导致意想不到的性能结果。例如,sequenced_policy执行可能和unsequenced_policy执行得一样好,因为编译器对两者都进行了矢量化。如果得到令人困惑的结果,您可能需要检查编译器的优化报告,看看应用了哪些优化。
并行政策
parallel_policy允许在调用线程中或从库创建的其他线程中调用元素访问函数,以帮助并行执行。然而,来自同一线程内的任何调用都是相对于彼此排序的,也就是说,同一线程上的访问函数的执行不能交错。
当我们使用英特尔的并行 STL 库时,parallel_policy是使用 TBB 通用算法和任务实现的。执行操作的线程是主线程和 TBB 工作线程。
unsequenced_policy
unsequenced_policy断言所有的元素访问函数都必须从调用线程中调用。然而,在调用线程中,这些函数的执行可以交错进行。顺序约束的这种放松是重要的,因为它允许库将不同函数调用中的操作聚集到单个 SIMD 指令中,或者重叠操作。
SIMD 并行可以用通过汇编代码、编译器内部函数或编译器编译指令引入的向量指令来实现。在英特尔的并行 STL 实现中,该库使用 OpenMP SIMD 编译指令。
因为元素访问函数的执行可以在单个线程中交错进行,所以在其中使用互斥对象是不安全的(互斥对象在第五章中有更详细的描述)。例如,想象一下,在执行任何匹配的解锁操作之前,交错来自不同函数的几个锁定操作。
并行未排序策略
正如我们在了解了前面的策略后所猜测的那样,parallel_unsequenced_policy以两种方式削弱了执行约束:(1)元素访问函数可以由调用线程或其他创建来帮助并行执行的线程调用,以及(2)每个线程内的函数执行可以是交错的。
我们应该使用哪种执行策略?
当我们选择一个执行策略时,我们首先必须确保它不会将约束放松到算法计算的值是错误的程度。
例如,我们可以使用一个std::for_each来计算一个向量a的a[i] = a[i] + a[i-1],但是代码依赖于for_each的排序顺序(与其他一些不确定排序的算法不同,它将运算符应用于按顺序排列的项目):

该示例将最后一个值存储到变量previous_value中,该值是由 lambda 表达式通过引用捕获的。只有当我们在单个执行线程中按顺序执行操作时,这个示例才起作用。使用除了seq之外的任何策略对象都会产生不正确的结果。
但是让我们假设我们做了尽职调查,并且我们知道哪些策略对于我们的操作和我们使用的 STL 算法是合法的。我们如何在sequenced_policy执行、unsequenced_policy执行、parallel_policy执行或parallel_unsequenced_policy执行之间做出选择?
不幸的是,没有简单的答案。但是我们可以使用一些指导方针:
-
只有当算法有足够的工作量从并行执行中获益时,我们才应该使用线程执行。我们将在本书第二部分的第十六章讨论何时使用任务的经验法则。这些规则在这里也适用。并行执行会有一些开销,如果工作量不够大,我们只会增加开销而不会提高性能。
-
矢量化的开销较低,因此可以有效地用于小型内部循环。当简单算法无法从线程化中获益时,它们可能会从矢量化中获益。
-
不过,矢量化也会有开销。要在处理器中使用向量寄存器,必须将数据打包在一起。如果我们的数据在内存中不是连续的,或者我们不能以单位步长访问它,编译器可能必须生成额外的指令来将数据收集到向量寄存器中。在这种情况下,矢量化循环的性能可能会比顺序循环差。您应该阅读编译器矢量化报告,并查看运行时配置文件,以确保添加矢量化不会使事情变得更糟。
-
因为我们可以使用并行 STL 轻松地切换策略,所以最好的选择可能是分析您的代码,看看哪种策略最适合您的平台。
引入 SIMD 并行的其他方法
除了使用 C++ STL 中的并行算法,还有几种方法可以将 SIMD 并行引入到应用程序中。最简单也是最受欢迎的方法是尽可能使用优化的特定领域或数学内核库。例如,英特尔数学内核库(英特尔 MKL)提供了许多数学函数的高度优化实现,如 BLAS、LAPACK 和 FFTW 中的那些。这些函数在有利可图的情况下利用了线程和矢量化——因此,如果我们使用这些函数,我们可以免费获得线程和矢量化。免费的好!英特尔 MLK 支持基于 TBB 的多项功能执行,因此,如果我们使用这些 TBB 版本,它们将与我们基于 TBB 的并行技术完美结合。
当然,我们可能需要实现任何预打包库中都没有的算法。在这种情况下,有三种添加向量指令的通用方法:(1)内联汇编代码,(2) simd内部函数,以及(3)基于编译器的向量化。
我们可以使用内联汇编代码将特定的汇编指令,包括向量指令,直接注入到我们的应用程序中。这是一种依赖于编译器和处理器的低级方法,因此可移植性最差,也最容易出错。但是,它确实给了我们对所使用的指令的完全控制权(不管是好是坏)。我们使用这种方法作为最后的手段!
唯一稍微好一点的方法是使用 SIMD 内部函数。大多数编译器都提供了一组内部函数,让我们无需借助内联汇编代码就能注入特定于平台的指令。但是,除了使注入指令变得更容易之外,最终结果仍然是依赖于编译器和平台的,并且容易出错。我们通常也避免这种方法。
最后一种方法是依靠基于编译器的矢量化。在一个极端,这可能意味着完全自动化的向量化,其中我们打开正确的编译器标志,让编译器做它的事情,并希望最好的。如果成功了,那太好了!我们免费获得了矢量化的好处。记住,免费是个好东西。然而,有时我们需要给编译器一些指导,以便它能够(或将会)向量化我们的循环。有一些特定于编译器的方法来提供指导,如英特尔编译器的#pragma ivdep and #pragma vector always和一些标准化方法,如使用 OpenMP simd编译指令。与通过内联汇编代码或编译器内部函数将特定于平台的指令直接插入到我们的代码中相比,全自动和用户指导的编译器矢量化要容易得多。事实上,即使是英特尔的并行 STL 库也使用 OpenMP simd编译指令以可移植的方式为unseq和parallel_unseq策略支持矢量化。
我们在本章末尾的“更多信息”一节中提供了一些链接,以了解有关添加矢量指令的选项的更多信息。
摘要
在这一章中,我们提供了并行 STL 的概述,它支持哪些算法和执行策略,以及如何获得一个使用线程构建块作为其执行引擎的副本。然后,我们讨论了 TBB 提供的自定义迭代器类,它们增加了 STL 算法的适用性。我们继续强调了一些最有用的和通用的并行编程算法:std::for_each、std::transform、std::reduce和std::transform_reduce。我们展示了我们在第二章中实现的一些示例也可以用这些算法来实现。但是我们也警告过,STL 算法的表达能力仍然不如 TBB,我们在本书第二部分讨论的重要性能挂钩不能用于并行 STL。虽然并行 STL 对于一些简单的情况是有用的,但是它目前的局限性使得我们不愿意将它广泛地推荐给线程。也就是说,TBB 任务并不是通向 SIMD 并行的道路。英特尔的并行 STL 提供的unseq和parallel_unseq策略,包含在所有最近的 TBB 发行版中,增强了 TBB 提供的线程,支持轻松矢量化。
更多信息
Vladimir Polin 和 Mikhail Dvorskiy,“并行 STL:提升 C++ STL 代码的性能:C++ 和向并行化的演进”,《并行宇宙》杂志,英特尔公司,第 28 期,第 5-18 页,2017 年。
阿列克谢·莫斯卡列夫和安德烈·费多罗夫,《并行 STL 入门》, https://software.intel.com/en-us/get-started-with-pstl ,2018 年 3 月 29 日。
Pablo Halpern,Arch D Robison,Robert 杰瓦,Clark Nelson,Jen Maurer,《向量与波前政策》,编程语言 C++ (WG21),P0076r3, http://open-std.org/JTC1/SC22/WG21/docs/papers/2016/p0076r3.pdf ,2016 年 7 月 7 日。
英特尔 64 和 IA-32 架构软件开发人员手册: https://software.intel.com/en-us/articles/intel-sdm 。
英特尔内部函数指南: https://software.intel.com/sites/landingpage/IntrinsicsGuide/ 。
[外链图片转存中…(img-QnnfIyCR-1722837544020)]
开放存取本章根据知识共享署名-非商业-非专用 4.0 国际许可协议(http://Creative Commons . org/licenses/by-NC-nd/4.0/)的条款进行许可,该协议允许以任何媒体或格式进行任何非商业使用、共享、分发和复制,只要您适当注明原作者和来源,提供知识共享许可协议的链接,并指出您是否修改了许可材料。根据本许可证,您无权共享从本章或其部分内容派生的改编材料。
本章中的图像或其他第三方材料包含在本章的知识共享许可中,除非在材料的信用额度中另有说明。如果材料不包括在本章的知识共享许可中,并且您的预期使用不被法律法规允许或超出了允许的使用范围,您将需要直接从版权所有者处获得许可。
五、同步:为什么以及如何避免同步
让我们先强调这一点:如果您不需要使用本章中描述的同步特性,那就更好了。在这里,我们讨论同步机制和实现互斥的替代方案。“同步”和“排除”对于关心性能的并行程序员来说,应该有相当负面的内涵。这些是我们想要避免的操作,因为它们耗费时间,并且在某些情况下,耗费处理器资源和能量。如果我们可以重新思考我们的数据结构和算法,使其既不需要同步也不需要互斥,这是非常好的!不幸的是,在许多情况下,避免同步操作是不可能的,如果这是你今天的情况,请继续阅读!我们从这一章中得到的另外一个信息是,仔细地重新思考我们的算法通常可以得到一个不滥用同步的更干净的实现。我们通过并行化一个简单的代码来说明这种重新思考算法的过程,首先采用一种天真的方法,即求助于互斥体,将其发展为利用原子操作,然后通过私有化和简化技术进一步减少线程之间的同步。在后者中,我们展示了如何利用线程本地存储(TLS)来避免高度竞争的互斥开销。在本章中,我们假设您在某种程度上熟悉“锁”、“共享可变状态”、“互斥”、“线程安全”、“数据竞争”以及其他与同步相关的问题。如果没有,在本书的序言中会有一个温和的介绍。
一个运行的例子:图像的直方图
让我们从一个简单的例子开始,这个例子可以用不同种类的互斥(mutex)对象、原子或者甚至通过完全避免大多数同步操作来实现。我们将描述所有这些可能的实现及其优缺点,并使用它们来说明互斥、锁、原子变量和线程本地存储的使用。
有不同种类的直方图,但图像直方图可能是使用最广泛的,尤其是在图像和视频设备以及图像处理工具中。例如,在几乎所有的照片编辑应用程序中,我们可以很容易地找到一个调色板来显示我们任何一张照片的直方图,如图 5-1 所示。
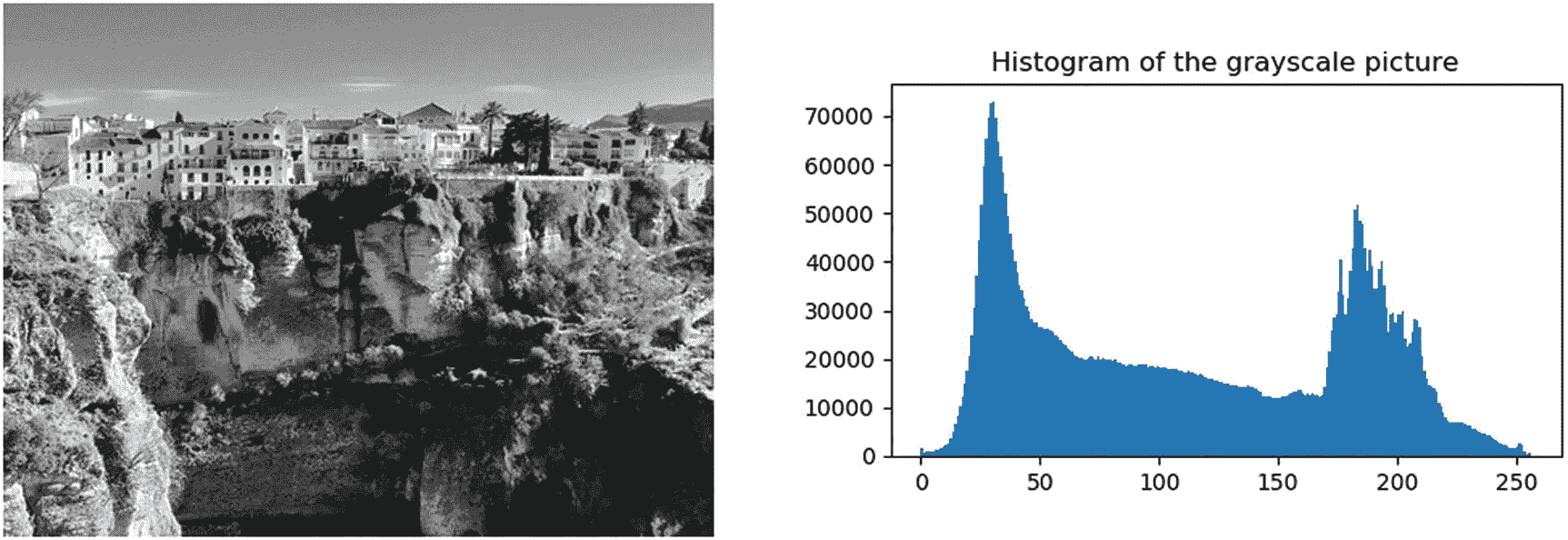
图 5-1。
灰度图片(Ronda,Málaga)及其相应的图像直方图
为了简单起见,我们将假设灰度图像。在这种情况下,直方图用每个可能的亮度值(x 轴)表示像素数(y 轴)。如果图像像素被表示为字节,那么只有 256 个色调或亮度值是可能的,0 是最暗的色调,255 是最亮的色调。在图 5-1 中,我们可以看到图片中最常见的色调是暗色调:在 5 兆像素中,超过 7 万个具有色调 30,正如我们在 x=30 附近的尖峰处看到的。摄影师和图像专业人员依靠直方图来帮助快速查看像素色调分布,并识别图像信息是否隐藏在图片的任何黑色或饱和区域。
在图 5-2 中,我们展示了 4×4 图像的直方图计算,其中像素只能有从 0 到 7 的八种不同色调。二维图像通常被表示为一维向量,其按照行主顺序存储 16 个像素。因为只有八个不同的音调,所以直方图只需要八个元素,索引从 0 到 7。直方图矢量的元素有时被称为“面元”,我们在其中“分类”,然后对每个色调的像素进行计数。图 5-2 显示了与特定图像相对应的直方图hist。我们看到存储在一号箱中的“4”是用色调 1 对图像中的四个像素进行计数的结果。因此,在遍历图像时更新面元值的基本操作是hist[<tone>]++。
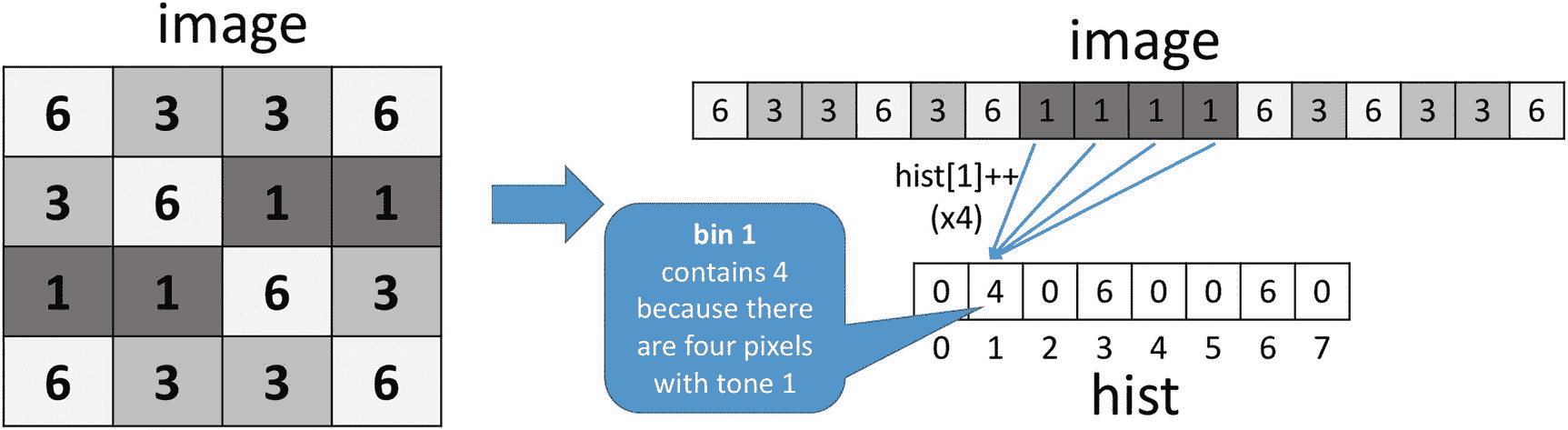
图 5-2。
从具有 16 个像素的图像计算直方图 hist(图像的每个值对应于像素色调)
从算法的角度来看,直方图被表示为一个整数数组,其中有足够的元素来说明所有可能的色调级别。假设图像是字节数组,现在有 256 种可能的音调;因此,直方图需要 256 个元素或仓。图 5-3 显示了计算此类图像直方图的顺序代码。

图 5-3。
带有图像直方图计算的顺序实现的代码清单。相关陈述在方框中突出显示。
如果您已经理解了前面代码清单中的所有内容,那么您可能希望跳过本节的其余部分。这段代码首先声明大小为n的向量image(比如说一百万个百万像素的图像),在初始化随机数生成器之后,它用类型为uint8_t的范围【0,255】内的随机数填充图像向量。为此,我们使用一个Mersenne_twister_engine、mte,它生成均匀分布在[0, num_bins)范围内的随机数,并将它们插入到image向量中。接下来,用num_bins位置构造hist向量(默认情况下初始化为零)。注意,我们声明了一个空向量image,我们后来为它保留了n整数,而不是构造image(n)。这样我们就避免了先遍历向量用零初始化,然后再插入随机数。
实际的直方图计算可以使用更传统的方法用 C 编写:
for (int i = 0; i < N; ++i) hist[image[i]]++;
其在直方图矢量的每个仓中计数每个色调值的像素数量。然而,在图 5-3 的例子中,我们想向你展示一个 C++ 的替代方案,它使用 STL for_each算法,对 C++ 程序员来说可能更自然。使用for_each STL 方法,图像向量的每个实际元素(类型为uint8_t的色调)被传递给 lambda 表达式,该表达式增加与色调相关的 bin。为了方便起见,我们依靠tbb::tick_count类来计算直方图计算中所需的秒数。成员函数now和seconds是不言自明的,所以我们在这里不包括进一步的解释。
不安全的并行实现
第一次尝试将直方图计算并行化是使用图 5-4 所示的tbb: :parallel_for。

图 5-4。
代码清单用并行实现图像直方图计算
**为了能够比较图 5-3 的顺序执行产生的直方图和并行执行的结果,我们声明一个新的直方图向量hist_p。接下来,这里疯狂的想法是并行遍历所有像素…为什么不呢?不是独立像素吗?为此,我们依靠第二章中提到的parallel_for模板,让不同的线程遍历迭代空间的不同块,从而读取图像的不同块。然而,这是行不通的:图 5-4 最后的向量hist和hist_p(是的,hist!=hist_p在 C++ 中做对了),的比较,揭示了这两个向量是不同的:
c++ -std=c++11 -O2 -o fig_5_4 fig_5_4.cpp -ltbb
./fig_5_4
Serial: 0.606273, Parallel: 6.71982, Speed-up: 0.0902216
Parallel computation failed!!
问题出现了,因为在并行实现中,不同的线程可能同时增加相同的共享 bin。换句话说,我们的代码不是线程安全的(或不安全的)。更正式的说法是,我们的并行不安全代码表现出“未定义的行为”,这也意味着我们的代码是不正确的。在图 5-5 中,我们假设有两个线程 A 和 B 在内核 0 和 1 上运行,每个线程处理一半的像素。由于分配给线程 A 的图像块中有一个亮度为 1 的像素,它将执行hist_p[1]++。线程 B 也读取一个亮度相同的像素,也会执行hist_p[1]++。如果两个增量在时间上一致,一个在内核 0 上执行,另一个在内核 1 上执行,那么我们很可能会错过一个增量。
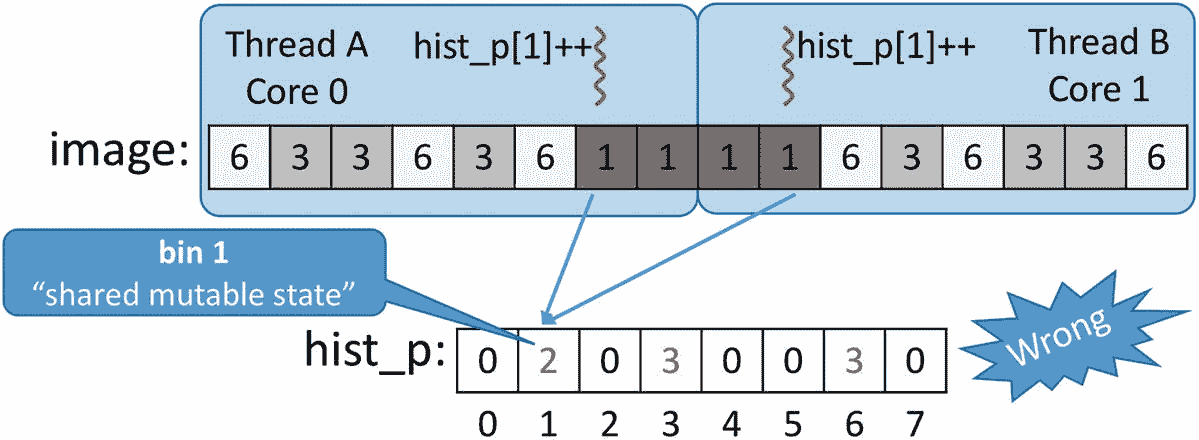
图 5-5。
共享直方图向量的不安全并行更新
这是因为递增操作不是原子的(或不可分的),相反,它通常由三个汇编级操作组成:将变量从内存加载到寄存器,递增寄存器,并将寄存器存储回内存。 1 用一个更正式的行话来说,这种操作被称为读-修改-写或 RMW 操作。对一个共享变量进行并发写入在形式上被称为共享可变状态。在图 5-6 中,我们展示了对应于 C++ 指令hist_p[1]++的一个可能的机器指令序列。

图 5-6。
共享变量或共享可变状态的不安全更新
如果在执行这两个增量时,我们已经发现一个具有亮度1, hist_p[1]的先前像素包含值 1。该值可以由两个线程读取并存储在私有寄存器中,这将最终在该 bin 中写入两个而不是三个,这是到目前为止已经遇到的亮度为 1 的像素的正确数量。这个例子在某种程度上过于简单,没有考虑缓存和缓存一致性,但是可以帮助我们说明数据竞争问题。前言中有一个更详细的例子(见图 P-15 和 P-16)。
我们可能会认为这一系列不幸的事件不太可能发生,或者即使发生了,在运行并行版本的算法时,略有不同的结果也是可以接受的。奖励不是更快的执行吗?不完全是这样:正如我们在上一页看到的,我们的不安全并行实现比顺序实现慢 10 倍左右(在四核处理器上运行四个线程,并且n等于 10 亿像素)。罪魁祸首是前言中介绍的缓存一致性协议(参见前言中的“缓存的局部性和报复”一节)。在串行执行中,直方图向量可能会完全缓存在运行代码的内核的 L1 缓存中。因为有一百万个像素,所以直方图向量中会有一百万个增量,其中大部分以缓存速度提供。
注意
在大多数英特尔处理器上,一条高速缓存线可以容纳 16 个整数(64 字节)。如果向量充分对齐,具有 256 个整数的直方图向量将只需要 16 个高速缓存行。因此,在 16 次缓存未命中之后(或者如果使用预取,则更少),所有直方图仓都被缓存,并且每个仓都仅在大约三个周期内被访问(这是非常快的速度!)在串行实现中(假设有足够大的 L1 高速缓存,并且直方图高速缓存行从不被其他数据驱逐)。
另一方面,在并行实现中,所有线程将争用每个内核私有缓存中的缓存箱,但是当一个线程在一个内核的一个缓存箱中写入时,缓存一致性协议会使适合所有其他内核中相应缓存行的 16 个缓存箱无效。这种无效导致对无效的高速缓存行的后续访问花费比非常期望的 L1 访问时间多一个数量级的时间。这种乒乓相互无效的净效应是并行实现的线程最终增加未缓存的容器,而串行实现的单个线程几乎总是增加缓存的容器。再次记住,一百万像素的图像需要一百万个直方图矢量增量,所以我们希望创建一个尽可能快的增量实现。在直方图计算的这种并行实现中,我们发现了假共享(例如,当线程 A 递增hist_p[0]而线程 B 递增hist_p[15]时,因为两个库都在同一高速缓存行中)和真共享(当线程 A 和 B 都递增hist_p[i]))。我们将在随后的章节中讨论真假共享。
第一个安全的并行实现:粗粒度锁定
让我们首先解决并行访问共享数据结构的问题。我们需要一种机制,当一个不同的线程已经在写入同一个变量时,它可以防止其他线程读取和写入共享变量。用更通俗的话来说,我们想要一个单独的人可以进入的试衣间,看看衣服如何合身,然后离开试衣间,等待下一个排队的人。图 5-7 显示试衣间上的一扇关闭的门排斥其他人。在并行编程中,试衣间的门被称为互斥体,当一个人进入试衣间时,他通过关门和锁门来获取并持有互斥体的锁,当这个人离开时,他们通过让门打开和解锁来释放锁。用更正式的术语来说,互斥体是一个用于在受保护的代码区域的执行中提供互斥的对象。这个需要互斥保护的代码区域通常被称为“关键部分”试衣间的例子也说明了竞争的概念,一种资源(试衣间)同时被多人使用的状态,如图 5-7© 所示。由于试衣间一次只能由一个人使用,所以试衣间的使用是“连续的”类似地,受互斥保护的任何东西都会降低程序的性能,首先是因为管理互斥对象带来的额外开销,其次也是更重要的是因为它会引发争用和序列化。我们希望尽可能减少同步的一个关键原因是避免争用和串行化,这反过来限制了并行程序的可伸缩性。
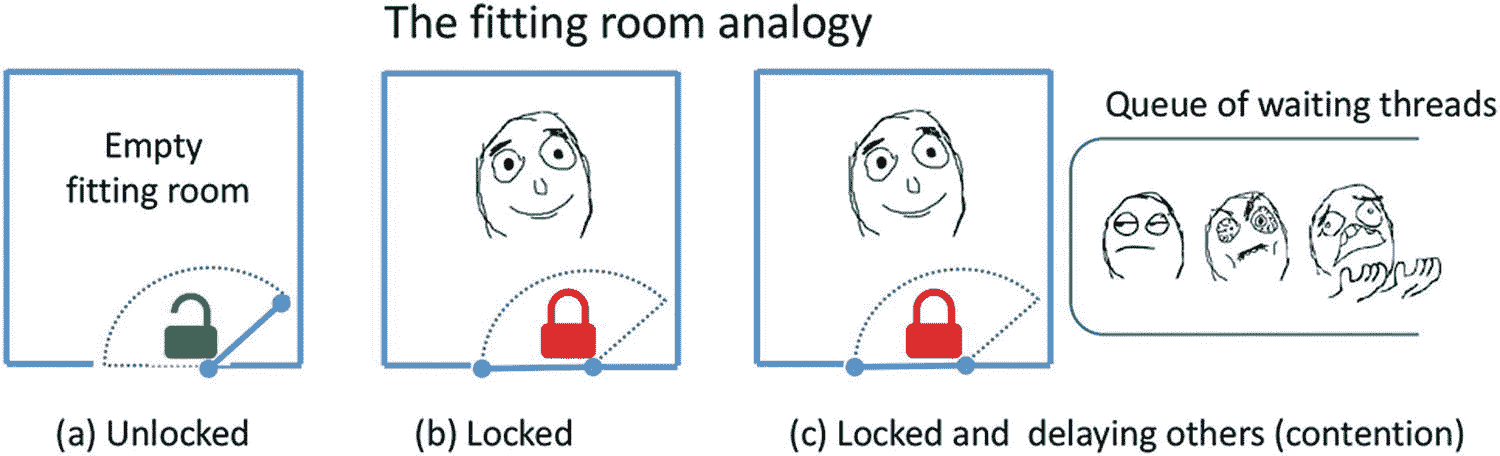
图 5-7。
关上试衣间的门会将其他人拒之门外
在这一节中,我们将重点介绍 TBB 互斥类和相关的同步机制。虽然 TBB 早于 C++11,但值得注意的是 C++11 确实标准化了对互斥类的支持,尽管它不像 TBB 库中的那些那样可定制。在 TBB,最简单的互斥体是在包含了tbb/spin_mutex.h或包罗万象的tbb.h头文件之后可以使用的spin_mutex。有了这个新工具,我们可以实现图像直方图计算的安全并行版本,如图 5-8 所示。
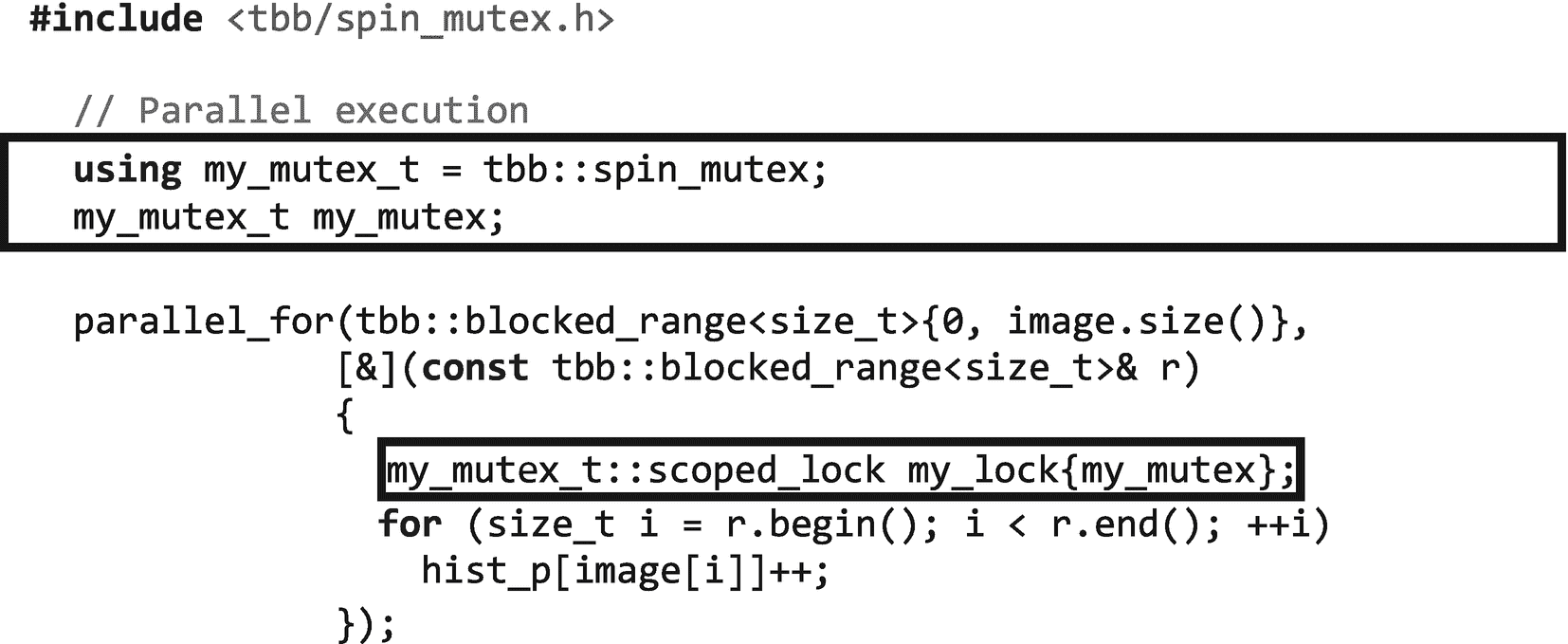
图 5-8。
使用粗粒度锁定的图像直方图计算的第一个安全并行实现的代码清单
在my_mutex上获得锁的对象my_lock,当它被创建时,自动解锁(或释放)对象析构函数中的锁,当离开对象范围时调用这个析构函数。因此,建议用额外的大括号{}将受保护的区域括起来,以保持锁的生存期尽可能短,以便其他等待的线程可以尽快轮到它们。
注意
如果在图 5-8 的代码中,我们忘记给锁对象命名,例如:
// was my_lock{my_mutex} my_mutex_t::scoped_lock {my_mutex};
代码编译时没有警告,但是scoped_lock的范围在分号处结束。没有对象的名字(my_lock),我们正在构造一个scoped_lock类的匿名/未命名对象,它的生命周期在分号处结束,因为没有一个命名对象比定义更长。这是没有用的,临界区是不是互斥保护。
图 5-9 中给出了一个更明确但不推荐的替代方案,即编写图 5-8 的代码。

图 5-9
一种不鼓励的获取互斥锁的方法
C++ 专家们更喜欢图 5-8 中的另一种方案,即所谓的“资源获取即初始化”,RAII,因为它让我们不必记得释放锁。更重要的是,使用 RAII 版本,锁对象析构函数(锁在这里被释放)也会在出现异常的情况下被调用,这样我们就可以避免由于异常而获得锁。如果在图 5-9 的版本中,在调用my_lock.release()成员函数之前抛出了一个异常,那么无论如何锁也会被释放,因为析构函数被调用,在那里锁被释放。如果一个锁离开了它的作用域,但是之前已经用release()成员函数释放了,那么析构函数什么也不做。
回到我们的代码图 5-8 ,你可能想知道,“但是等等,我们不是用粗粒度锁序列化了并行代码吗?”是的,你是对的!正如我们在图 5-10 中看到的,每个想要处理其图像块的线程首先试图获取互斥锁,但只有一个会成功,其余的会不耐烦地等待锁被释放。直到持有锁的线程释放它,不同的线程才能执行受保护的代码。因此,parallel_for最终被串行执行!好消息是,现在直方图柱没有并发增量,结果最终是正确的。耶!
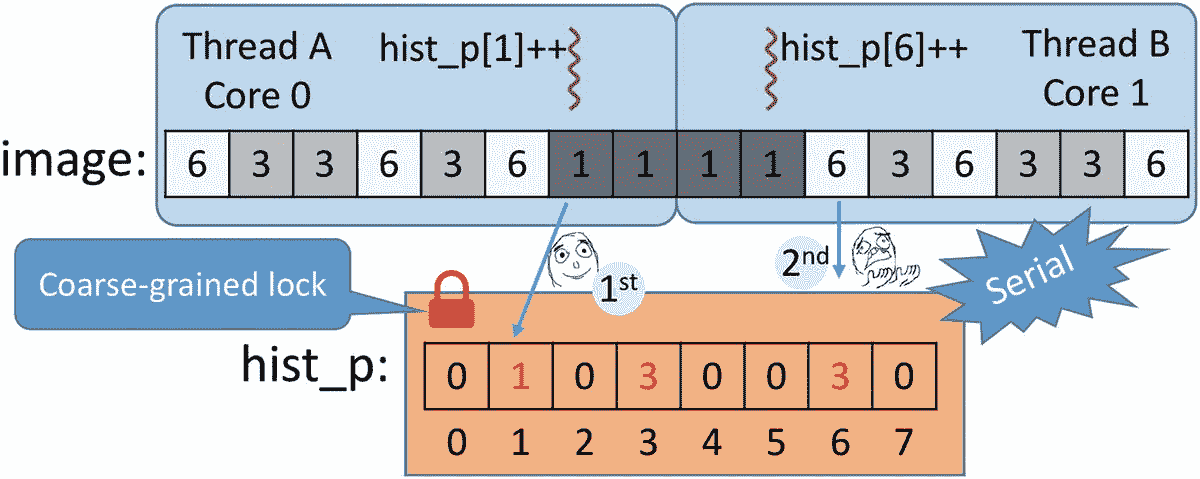
图 5-10
线程 A 持有粗粒度锁以增加库号 1,而线程 B 等待,因为整个直方图向量被锁定
实际上,如果我们编译并运行我们的新版本,我们得到的是比顺序执行稍微慢一点的并行执行:
c++ -std=c++11 -O2 -o fig_5_8 fig_5_8.cpp -ltbb
./fig_5_8
Serial: 0.61068, Parallel: 0.611667, Speed-up: 0.99838
这种方法被称为粗粒度锁定,因为我们保护的是粗粒度数据结构(实际上是整个数据结构——在本例中是直方图向量)。我们可以将向量划分成几个部分,并用它自己的锁来保护每个部分。这样,我们将增加并发级别(访问不同部分的不同线程可以并行进行),但是我们将增加代码的复杂性和每个互斥对象所需的内存。
有一句话要提醒你!图 5-11 展示了并行编程新手的一个常见错误。
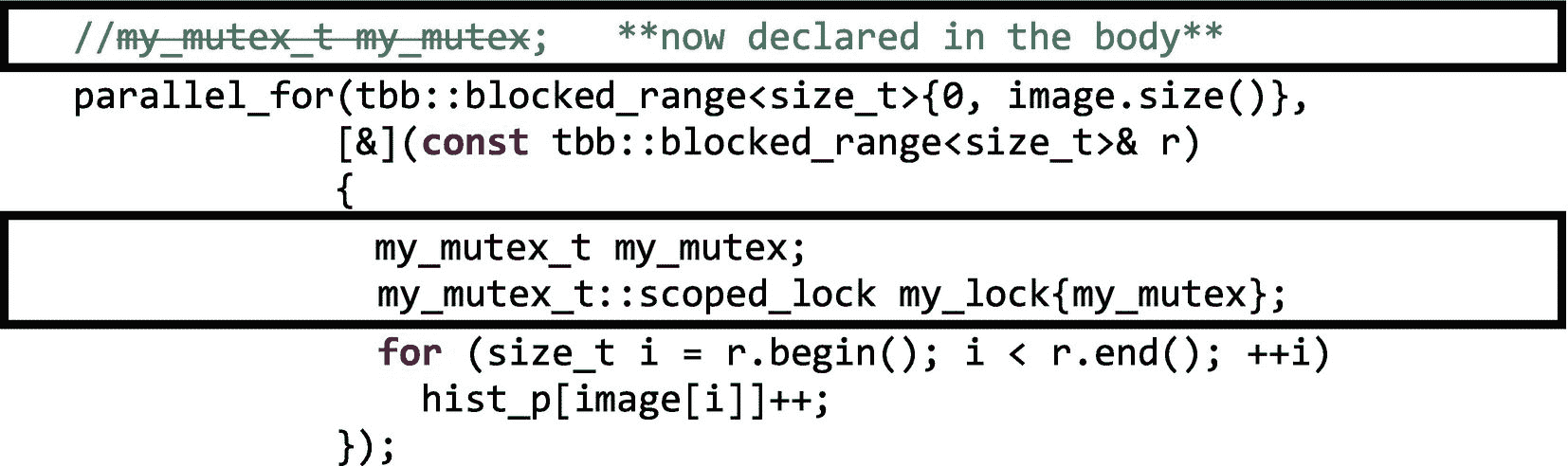
图 5-11
并行编程新手常犯的错误
这段代码编译时既没有错误也没有警告,那么它有什么问题呢?回到试衣间的例子,我们的目的是避免几个人同时进入试衣间。前面的代码中,my_mutex被定义在并行段内部,每个任务会有一个互斥对象,每个都锁定自己的互斥体,并不妨碍对临界段的并发访问。正如我们在图 5-12 中看到的,新手代码本质上为每个人进入同一个试衣间提供了一个单独的门!这不是我们想要的!解决方案是声明my_mutex一次(就像我们在图 5-8 中所做的那样),这样所有的通道都必须通过同一个门进入试衣间。
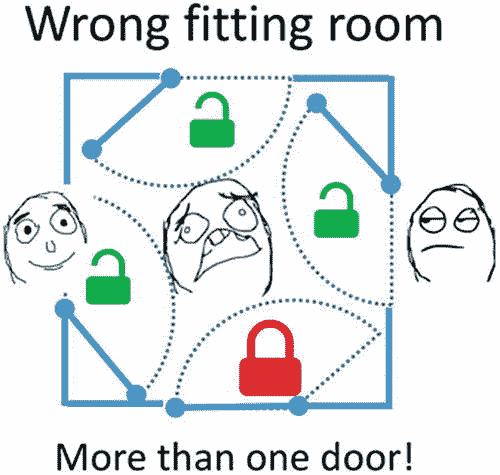
图 5-12
有不止一扇门的试衣间
在讨论细粒度锁定替代方案之前,让我们讨论两个值得评论的方面。首先,图 5-8 的“并行化然后串行化”代码的执行时间大于串行实现所需的时间。这是由于“先并行后序列化”的开销,也是由于缓存的利用率较低。当然,没有假共享也没有真共享,因为在我们的序列化实现中根本没有“共享”!还是有?在串行实现中,只有一个线程访问缓存的直方图向量。在粗粒度实现中,当一个线程处理其图像块时,它会将直方图缓存在线程运行的内核的缓存中。当队列中的下一个线程最终可以处理自己的块时,它可能需要在不同的缓存中缓存直方图(如果该线程运行在不同的内核上)。线程仍然共享直方图向量,与串行实现相比,使用建议的实现可能会出现更多的缓存未命中。
我们要提到的第二个方面是通过选择图 5-13 中显示的一种可能的互斥体类型来配置互斥体行为的可能性。因此,建议使用
using my_mutex_t = <mutex_flavor>
或者等效的 C-ish 替代物
typedef <mutex_flavor> my_mutex_t;
然后使用my_mutex_t前进。这样,我们可以很容易地在一个程序行中改变互斥体的风格,并通过实验很容易地评估哪种风格最适合我们。可能需要包含不同的头文件,如图 5-13 所示,或者使用全包tbb.h .
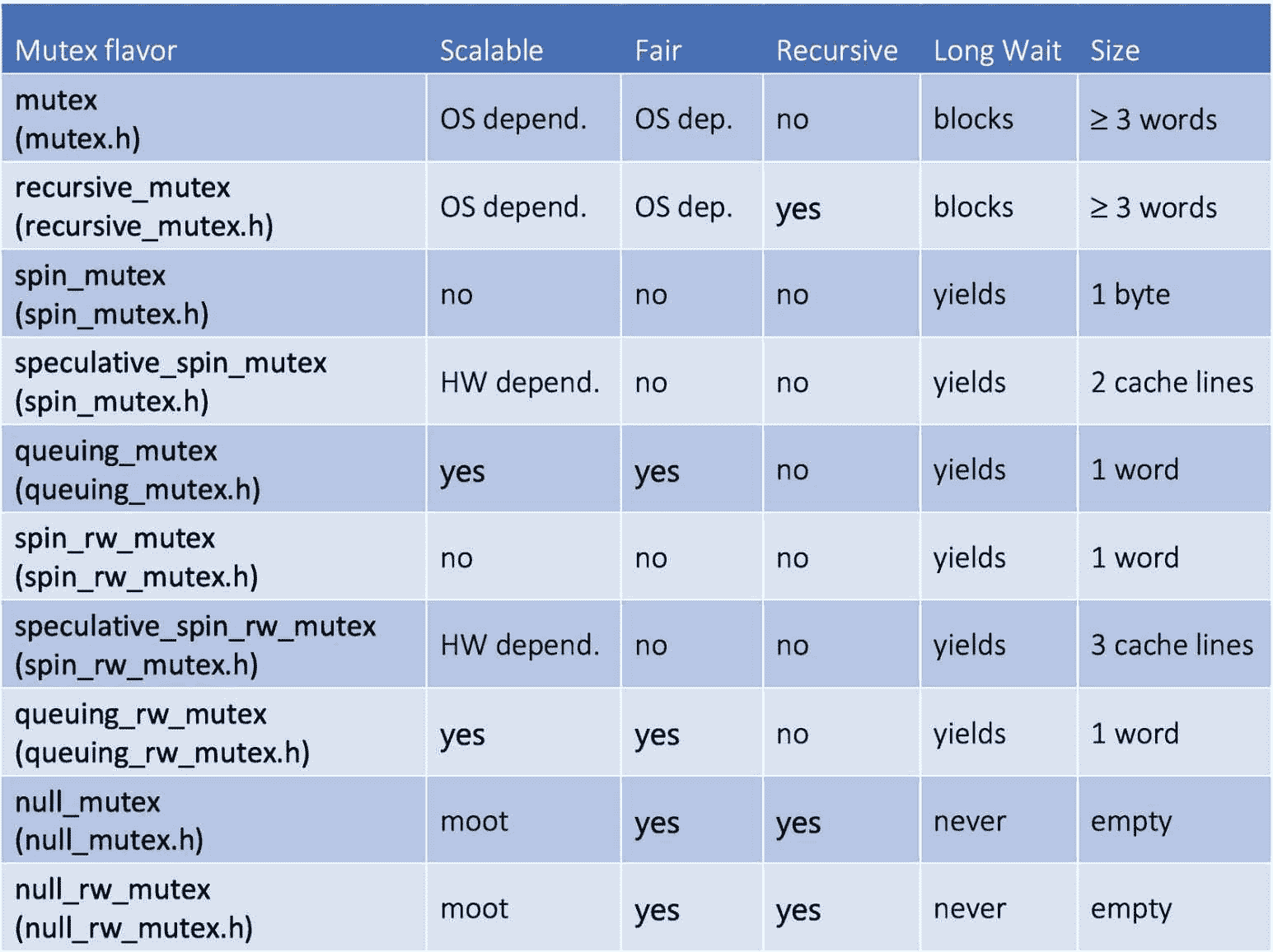
图 5-13
不同的互斥风格及其属性
互斥口味
为了理解互斥体的不同风格,我们必须首先描述我们用来对它们进行分类的属性:
-
可扩展互斥体在等待时不会消耗过多的内核周期和内存带宽。动机是等待线程应该避免消耗其他非等待线程可能需要的硬件资源。
-
公平的互斥体使用 FIFO 策略让线程轮流执行。
-
递归互斥锁允许已经持有一个互斥锁的线程可以获得同一个互斥锁的另一个锁。重新思考您的代码以避免互斥是很好的,这样做以避免递归互斥几乎是必须的!那么,TBB 为什么提供它们呢?在某些情况下,递归互斥是不可避免的。当我们不想被打扰或没有时间重新思考更有效的解决方案时,它们也可能会派上用场。
在图 5-13 的表格中,我们还包括了互斥对象的大小和线程的行为,如果它必须等待很长时间才能锁定互斥对象的话。关于最后一点,当一个线程正在等待轮到它的时候,它可以忙-等待、阻塞或放弃。阻塞的线程将被更改为阻塞状态,这样线程所需的唯一资源就是保持其睡眠状态的内存。当线程最终获得锁时,它会醒来并返回到就绪状态,此时所有就绪的线程都在等待下一轮。OS 调度程序将时间片分配给在就绪状态队列中等待的就绪线程。在等待轮到它持有锁时让步的线程被保持在就绪状态。当线程到达就绪状态队列的顶部时,它被分派运行,但是如果互斥体仍然被其他线程锁定,它再次释放它的时间片(它没有其他事情可做!)并返回就绪状态队列。
注意
请注意,在此过程中可能涉及两个队列:(I)由操作系统调度程序管理的就绪状态队列,其中就绪线程正在等待(不一定按 FIFO 顺序)被分派到空闲内核并成为运行线程,以及(ii)由操作系统或用户空间中的互斥体库管理的互斥体队列,其中线程等待轮到它们获取排队互斥体上的锁。
如果内核没有被超额订阅(在这个内核中只有一个线程在运行),由于互斥体仍然被锁定而退出的线程将是就绪状态队列中唯一的线程,并被立即调度。在这种情况下,让步机制实际上相当于忙等待。
既然我们已经理解了可以表征互斥体实现的不同属性,让我们深入研究 TBB 提供的特定互斥体风格。
mutex和recursive_mutex是围绕操作系统提供的互斥机制的 TBB 包装器。我们不使用“本地”互斥体,而是使用 TBB 包装器,因为它们为其他 TBB 互斥体添加了异常安全和相同的接口。这些互斥锁会阻塞长时间等待,因此它们浪费的周期较少,但是当互斥锁可用时,它们会占用更多的空间,并且具有更长的响应时间。
spin_mutex相反,从不屏蔽。它在用户空间中旋转 busy-waiting,同时等待持有互斥锁。等待线程将在多次尝试获取循环后放弃,但如果内核没有超额预订,该线程将继续浪费内核的周期和功率。另一方面,一旦互斥体被释放,获取它的响应时间是最快的(不需要醒来并等待被调度运行)。这个互斥锁是不公平的,所以不管一个线程已经等待了多长时间,如果一个更快的线程第一个发现互斥锁被解锁,它就可以超过它并获得锁。在这种情况下,自由竞争占了上风,在极端情况下,弱线程可能会饿死,永远得不到锁。尽管如此,在轻度争用的情况下,这是推荐的互斥风格,因为它可能是最快的。
queueing_mutex是spin_mutex的可扩展和公平版本。它仍然在旋转,在用户空间中忙着等待,但是等待互斥体的线程将按照 FIFO 的顺序获得锁,所以饥饿是不可能的。
speculative_spin_mutex构建在某些处理器中可用的硬件事务内存(HTM)之上。HTM 的哲学是乐观!HTM 让所有线程同时进入临界区,希望不会有共享内存冲突!但是如果有呢?在这种情况下,硬件检测到冲突并回滚其中一个冲突线程的执行,该线程必须重试临界区的执行。在图 5-8 所示的粗粒度实现中,我们可以添加下面这行代码:
using my_mutex_t = speculative_spin_mutex;
然后,穿过图像的parallel_for再次变得并行。现在,所有线程都被允许进入临界区(为图像的给定块更新直方图的仓),但只有在更新其中一个仓时存在实际冲突的情况下,其中一个冲突线程才必须重试执行。为了有效地工作,受保护的临界区必须足够小,以使冲突和重试很少发生,这与图 5-8 中的代码不同。
spin_rw_mutex , queueing_rw_mutex ,和speculative_spin_rw_mutex是前面提到的各种风味的读者-作者互斥对应。这些实现允许多个读取器同时读取一个共享变量。锁对象构造器有第二个参数,一个布尔值,如果我们只在临界区内读(不写),我们将它设置为 false:
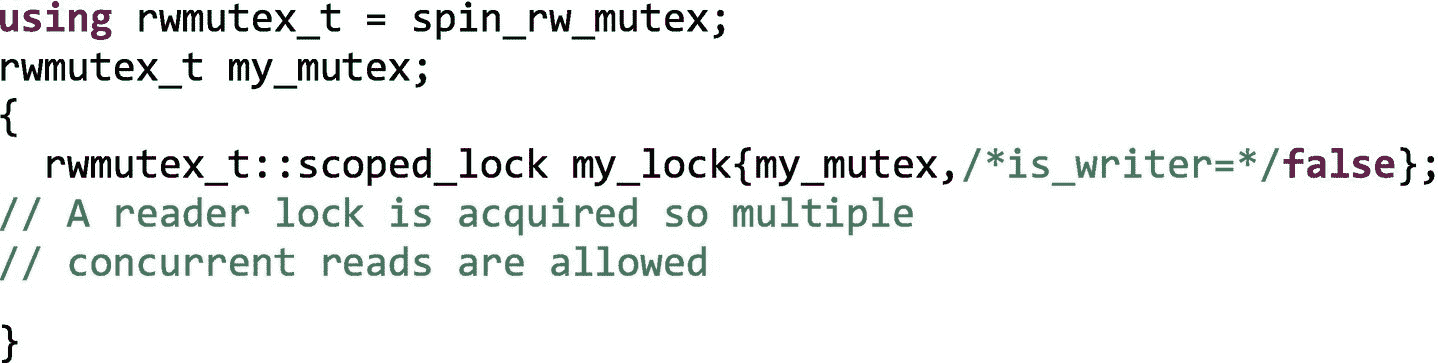
如果出于某种原因,必须将一个读线程锁升级为写线程锁,TBB 提供了一个upgrade_to_writer()成员函数,可以按如下方式使用:
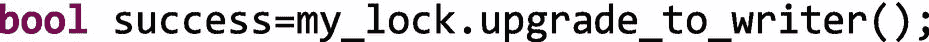
如果my_lock在没有释放锁的情况下成功升级为写线程锁,则返回 true,否则返回 false。
最后,我们有null_mutex和null_rw_mutex,它们只是不做任何事情的虚拟对象。那么,有什么意义呢?如果我们将一个互斥对象传递给一个可能需要也可能不需要真正互斥体的函数模板,我们会发现这些互斥体很有用。如果函数并不真的需要互斥体,只需传递伪类型即可。
第二个安全的并行实现:细粒度锁定
既然我们已经对不同种类的互斥体有了很多了解,让我们考虑一下图 5-8 中粗粒度锁的另一种实现。一种替代方法是为直方图的每个库声明一个互斥体,这样我们就不用用一个锁来锁定整个数据结构,而是只保护我们实际上正在增加的单个内存位置。为此,我们需要一个互斥体的载体fine_m,如图 5-14 所示。
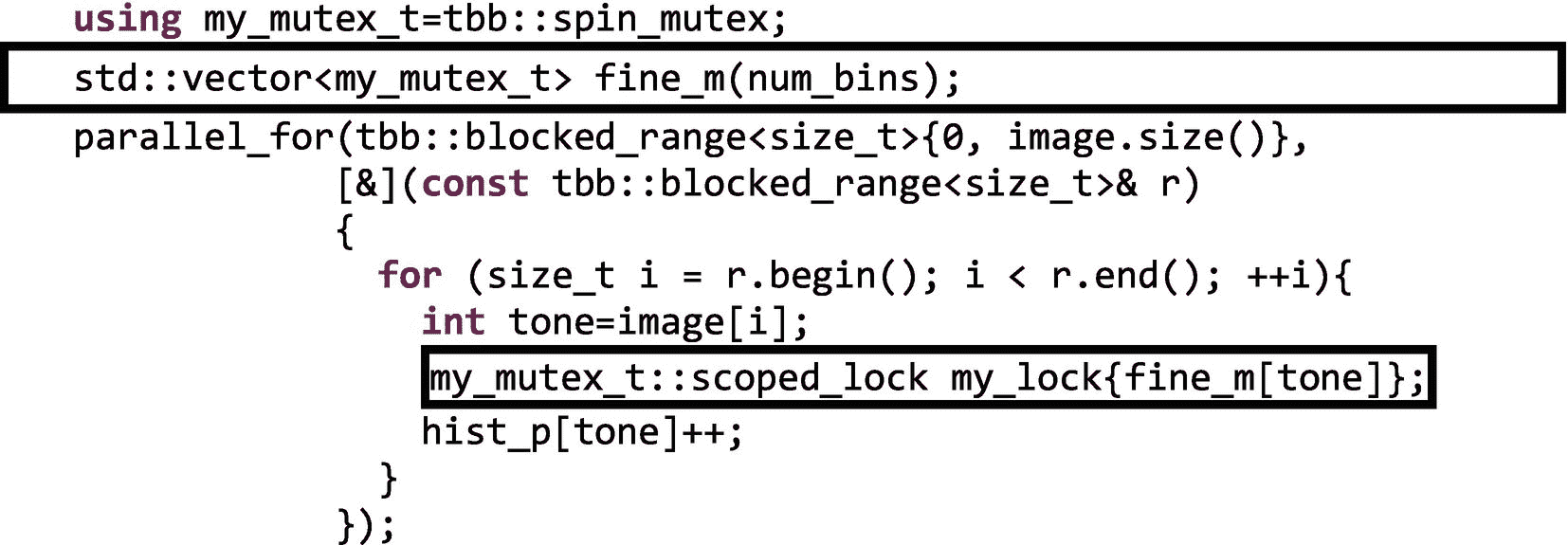
图 5-14
使用细粒度锁定的图像直方图计算的第二个安全并行实现的代码清单
正如我们在parallel_for中使用的 lambda 中看到的,当一个线程需要增加容器hist_p[tone]时,它将获得fine_m[tone]上的锁,防止其他线程接触同一个容器。基本上“你可以更新其他的媒体夹,但不能更新这个特定的媒体夹。”这如图 5-15 所示,其中线程 A 和线程 B 并行更新直方图向量的不同仓。
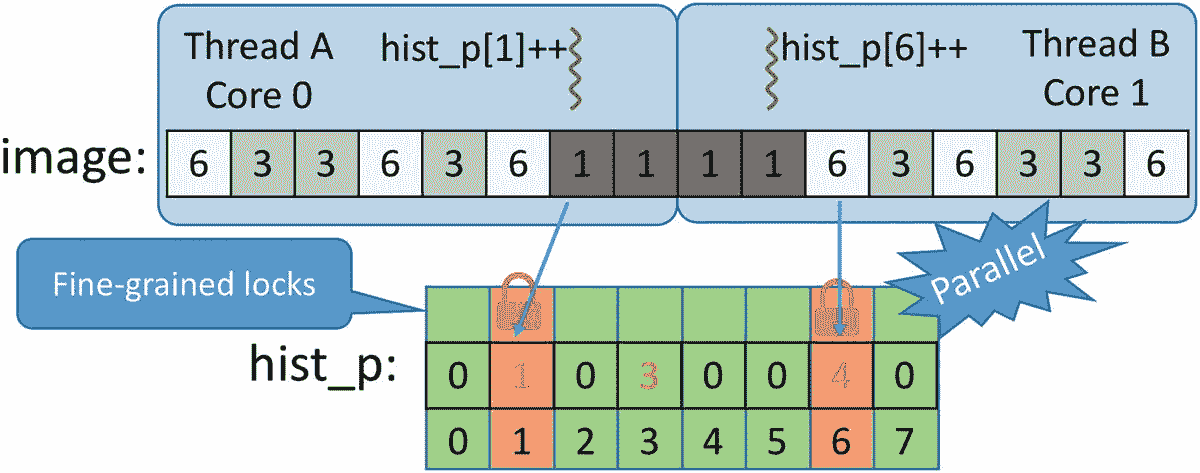
图 5-15
由于细粒度的锁定,我们可以利用更多的并行性
然而,从性能的角度来看,这种替代方案并不是真正的最佳方案(实际上,它是迄今为止最慢的替代方案):
c++ -std=c++11 -O2 -o fig_5_14 fig_5_14.cpp -ltbb
./fig_5_14
Serial: 0.59297, Parallel: 26.9251, Speed-up: 0.0220229
现在我们不仅需要直方图数组,还需要相同长度的互斥对象数组。这意味着更大的内存需求,此外,更多的数据将被缓存,并将遭受假共享和真共享。倒霉!
除了锁固有的开销之外,锁还是另外两个问题的根源:护送和死锁。让我们先来看看“护送”这个名字来自于所有线程以第一个线程的较低速度一个接一个地护航的心理图像。我们需要一个例子来更好地说明这种情况,如图 5-16 所示。假设我们有线程 1、2、3 和 4 在同一个内核上执行相同的代码,其中有一个关键部分受到自旋互斥体 a 的保护,如果这些线程在不同的时间持有锁,它们会愉快地运行而不会发生争用(情况 1)。但是可能发生的情况是,线程 1 在释放锁之前用完了它的时间片,这将发送一个到就绪状态队列的末尾(情况 2)。
图 5-16
超额订阅情况下的护送(一个内核运行四个线程,所有线程都需要相同的互斥 A)
线程 2、3 和 4 现在将获得它们对应的时间片,但是它们不能获得锁,因为 1 仍然是所有者(情况 3)。这意味着 2,3,4 现在可以让行或旋转,但无论如何,他们都卡在一档大卡车后面。当再次调度 1 时,它将释放锁 A(情况 4)。现在 2 号、3 号和 4 号都准备好争夺锁了,只有一个成功了,其他的都在等待。这种情况经常发生,尤其是如果线程 2、3 和 4 需要更多的时间片来运行它们受保护的临界区。此外,线程 2、3 和 4 现在被不经意地协调了,它们都在代码的同一个区域运行,这导致了互斥体上更高的争用概率!请注意,当内核超额预订时(如本例所示,四个线程竞争运行在一个内核上),护送尤为严重,这也强化了我们避免超额预订的建议。
锁带来的另一个众所周知的问题是“死锁”图 5-17(a) 显示了一个噩梦般的场景,在这个场景中,即使有可用的资源(没有车可以使用的空行),也没有人能够取得进展。这是现实生活中的僵局,但是把这种形象从你的头脑中去掉(如果你可以的话!)并回到我们的并行编程虚拟世界。如果我们有一组 N 个线程,它们持有一个锁,并且还在等待获取该组中任何其他线程已经持有的锁,那么我们的 N 个线程就被死锁了。图 5-17(b) 给出了一个只有两个线程的例子:线程 1 持有互斥体 A 的锁,并等待获取互斥体 B 的锁,但是线程 2 已经持有互斥体 B 的锁,并等待获取互斥体 A 的锁。很明显,没有线程会继续前进,永远注定在一个致命的拥抱中!如果线程已经拥有一个互斥体,我们可以通过不要求获取不同的互斥体来避免这种不幸的情况。或者至少让所有线程总是以相同的顺序获取锁。
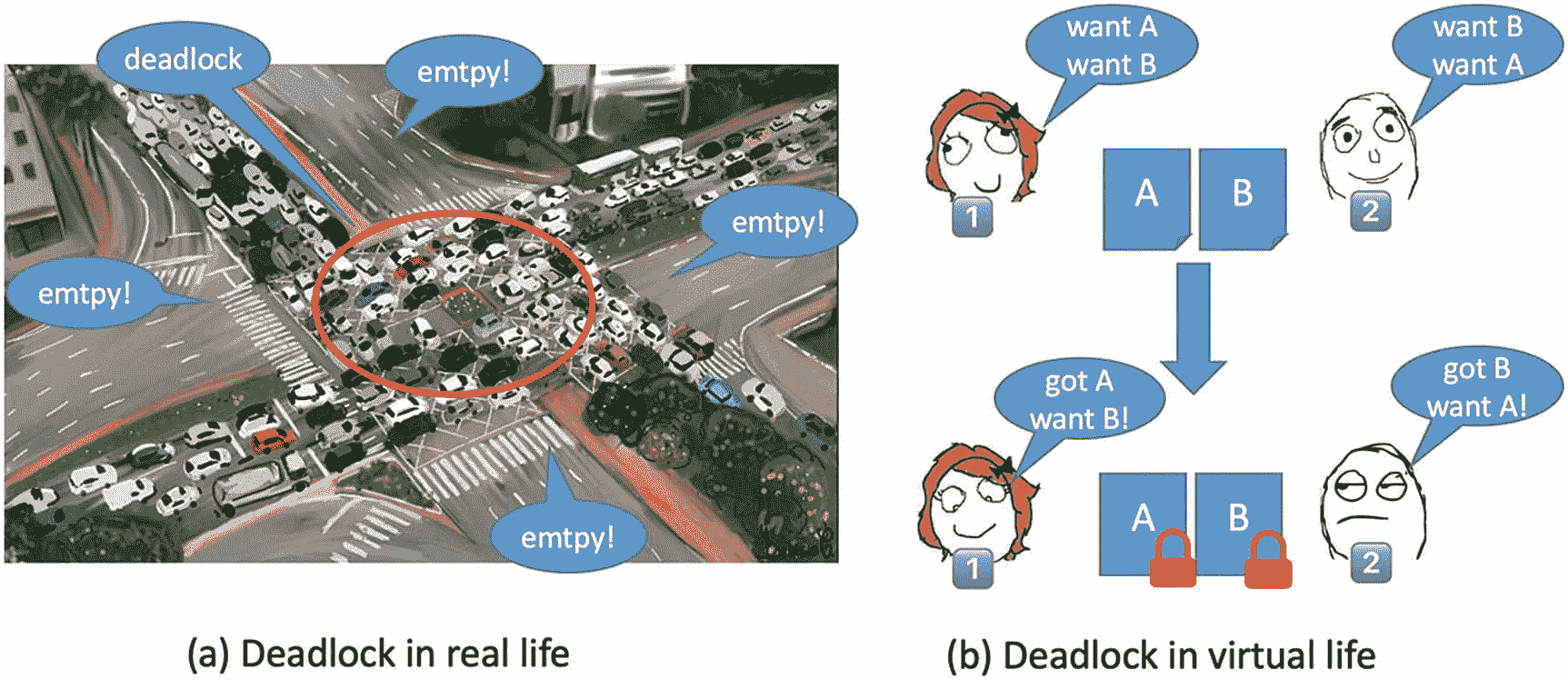
图 5-17
死锁情况
如果一个已经持有锁的线程调用了一个也获得了不同锁的函数,我们可能会无意中引发死锁。如果我们不知道函数做什么,建议避免在持有锁的情况下调用函数(通常建议不要在持有锁的情况下调用其他人的代码)。或者,我们应该仔细检查后续函数调用链不会导致死锁。啊!我们也可以尽可能避免锁!
虽然护送和死锁并没有真正影响我们的直方图实现,但它们应该有助于让我们相信锁带来的问题往往比它们解决的问题更多,并且它们不是获得高并行性能的最佳选择。只有当争用的可能性很低并且执行临界区的时间很短时,锁才是可以容忍的选择。在这些情况下,一个基本的spin_lock或speculative_spin_lock可以产生一些加速。但是在任何其他情况下,lock based算法的可伸缩性都会受到严重损害,最好的建议是跳出框框,设计一个完全不需要互斥的新实现。但是,我们能否在不依赖于几个互斥对象的情况下获得细粒度的同步,从而避免相应的开销和潜在问题呢?
第三种安全的并行实现:原子
幸运的是,在许多情况下,我们可以借助一种更便宜的机制来摆脱互斥锁和锁。我们可以使用原子变量来执行原子操作。如图 5-6 所示,递增操作不是原子操作,而是可以分成三个更小的操作(加载、递增和存储)。但是,如果我们声明一个原子变量并执行以下操作:

原子变量的增量是原子操作。这意味着任何其他访问 counter 值的线程都将“看到”该操作,就好像递增是在一个单独的步骤中完成的一样(不是三个较小的操作,而是一个单独的步骤)。也就是说,任何其他“眼尖”的线程要么观察到操作完成,要么观察不到,但它永远不会观察到增量完成一半。
原子操作不会遭受护送或死锁 2 并且比互斥选择更快。然而,并不是所有的操作都可以自动执行,那些可以自动执行的操作也不适用于所有的数据类型。更准确地说,当T是整数、枚举或指针数据类型时,atomic<T>支持原子操作。图 5-18 中列出了此类atomic<T>变量x支持的原子操作。
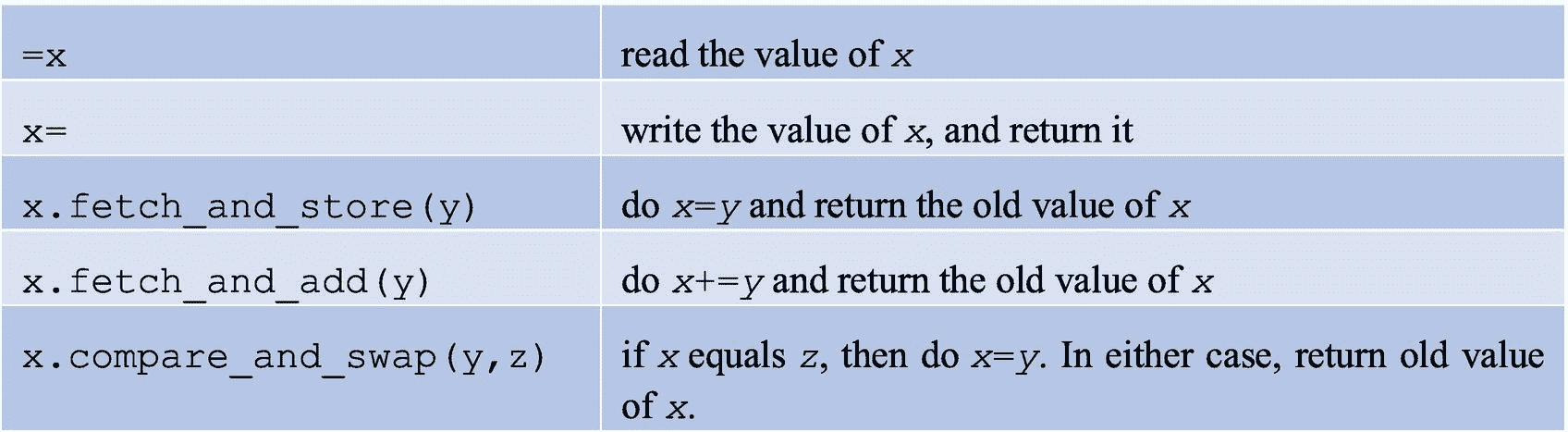
图 5-18
原子变量的基本运算
通过这五个操作,可以实现大量的派生操作。比如x++、x--、x+=...、x-=...都来源于x.fetch_and_add()。
注意
正如我们在前面的章节中已经提到的,从 C++11 开始,C++ 也包含了线程和同步特性。在这些特性被 C++ 标准接受之前,TBB 就包含了它们。尽管从 C++11 开始,std::mutex和std::atomic以及其他的都可用,TBB 仍然在它的tbb::mutex和tbb::atomic classes中提供了一些重叠的功能,主要是为了与以前开发的基于 TBB 的应用程序兼容。我们可以在同一个代码中毫无问题地使用这两种风格,并且由我们来决定在给定的情况下哪一种更好。关于std::atomic,一些额外的性能,w.r.t. tbb::atomic,如果用于在“弱有序”架构上开发无锁算法和数据结构(如 ARM 或 PowerPC 相比之下,英特尔 CPU 具有强有序内存模型)。在本章的最后一节“更多信息”中,我们推荐进一步阅读与内存一致性和 C++ 并发模型相关的内容,在这些内容中,这个主题得到了充分的阐述。对于我们这里的目的,可以说fetch_and_store、fetch_and_add和compare_and_swap默认遵循顺序一致性(C++ 术语中的memory_order_seq_cst),这可以防止一些无序的执行,因此花费了少量的额外时间。考虑到这一点,TBB 还提供了释放和获取语义:在原子读取中默认获取(...=x);并在原子写中默认释放(x=...)。所需的语义也可以使用模板参数来指定,例如,x.fetch_and_add<release>只强制执行释放内存顺序。在 C++11 中,还允许其他更宽松的内存顺序(memory_order_relaxed 和 memory_order_consume ),在特定的情况下和架构中,可以允许读写顺序有更大的自由度,并挤压少量的额外性能。如果我们想要更接近金属以获得最终的性能,即使知道额外的编码和调试负担,那么 C++11 较低级别的特性就在那里,然而我们可以将它们与 TBB 提供的较高级别的抽象相结合。
另一个基于原子的有用的习惯用法是已经在图 2-23 (第二章)给出的波前例子中使用的。将原子整数refCount初始化为“y ”,几个线程执行这段代码:
将导致只有第 y 个线程执行进入“body”的前一行。
在这五个基本操作中,compare_and_swap (CAS)可以被认为是所有原子读-修改-写,RMW 操作之母。这是因为所有原子 RMW 操作都可以在 CAS 操作之上实现。
注意
万一您需要保护一个小的临界区,并且您已经确信无论如何都要避开锁,那么让我们稍微研究一下 CAS 操作的细节。假设我们的代码需要将一个共享的整数变量v乘以 3(不要问我们为什么!我们有我们的理由!).我们的目标是一个无锁的解决方案,尽管我们知道乘法不包括在原子操作中。这就是 CAS 的用武之地。第一件事是将v声明为原子变量:
tbb::atomic<uint_32_t> v;
所以现在我们可以调用v.compare_and_swap(new_v, old_v),而在原子层面上调用
这是,当且仅当v等于old_v时,我们可以用新值更新v。无论如何,我们返回ov(在“==”比较中使用的共享v)。现在,实现我们的“乘以 3”原子乘法的技巧是编写被称为 CAS 循环的代码:

我们的新fetch_and_triple是线程安全的(可以被几个线程同时安全地调用),即使它被调用时传递相同的共享原子变量。这个函数基本上是一个 do-while 循环,在这个循环中,我们首先拍摄共享变量的快照(如果其他线程已经设法修改了它,这是稍后进行比较的关键)。然后,原子地,如果没有其他线程改变了 v (v==old_v),我们就更新它(v=old_v*3)并返回v。因为在这种情况下v == old_v(同样:没有其他线程改变v),我们离开 do-while 循环并从函数返回,共享的v成功更新。
不过拍快照之后,有可能其他线程更新 v。在这种情况下,v!=old_v,这意味着(I)我们不更新v,以及(ii)我们停留在 do-while 循环中,希望幸运女神下次会对我们微笑(当在我们拍摄快照和我们成功更新v之间的过渡期间,没有其他贪婪的线程敢碰我们的v。图 5-19 说明了线程 1 或线程 2 如何更新 v。有可能其中一个线程不得不重试一次或多次(例如线程 2 在最初准备写 27 时却写了 81 ),但是在设计良好的场景中这应该没什么大不了。
这种策略的两个警告是(I)它的伸缩性很差,以及(ii)它可能遭受“ABA 问题”(在第 201 页的第六章中有关于经典 ABA 问题的背景)。关于第一个,考虑竞争相同原子的 P 个线程,只有一个线程成功进行 P-1 次重试,然后另一个线程成功进行 P-2 次重试,然后 P-3 次重试,等等,导致二次工作。这个问题可以借助于“指数后退”策略来改善,该策略成倍地降低连续重试的速率以减少争用。另一方面,当在中间时间(在我们拍摄快照的时刻和我们成功更新v)的时刻之间),一个不同的线程将v从值A改变为值B并变回值A时,就会发生 ABA 问题。我们的 CAS 循环可以在没有注意到中间线程的情况下成功,这可能是有问题的。如果您在开发中需要求助于 CAS 循环,请仔细检查您是否理解这个问题及其后果。
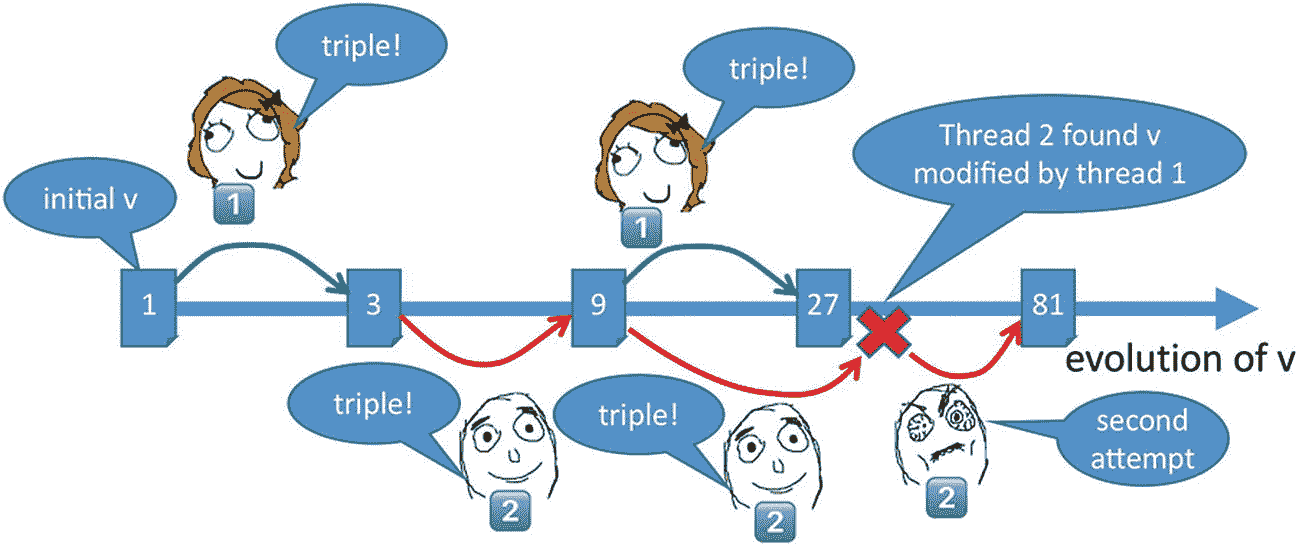
图 5-19
两个线程同时调用我们在 CAS 循环上实现的fetch_and_triple原子函数
但是现在是时候回到我们运行的例子了。直方图计算的重新实现现在可以借助原子来表达,如图 5-20 所示。
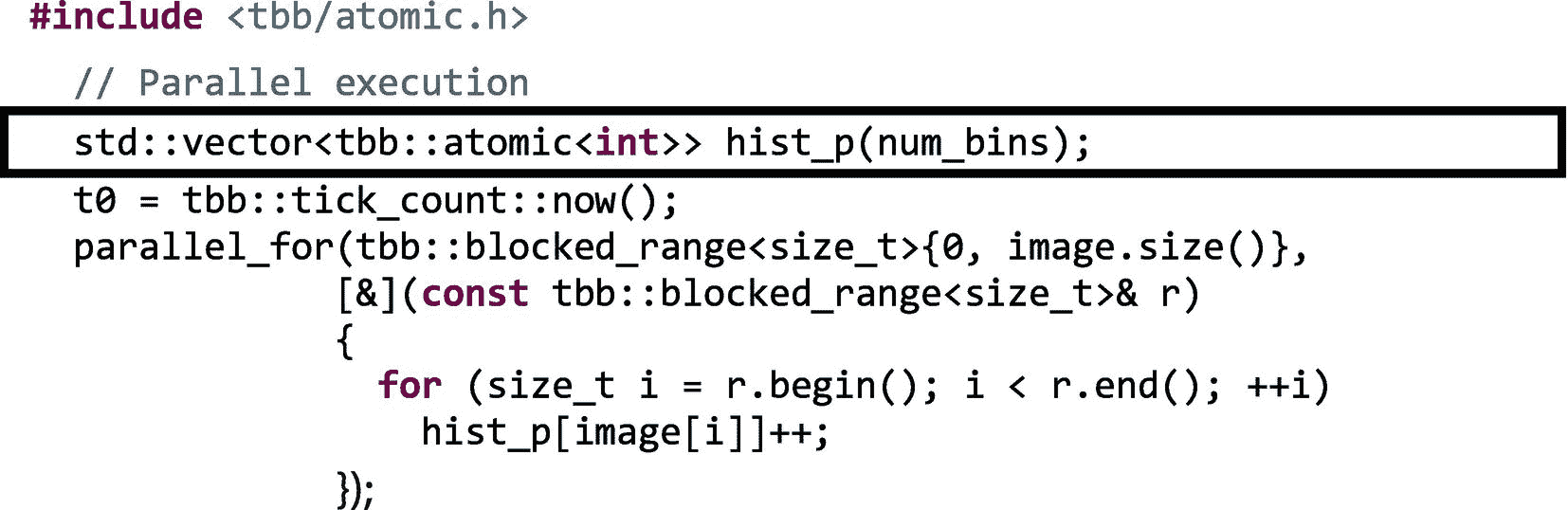
图 5-20
使用原子变量的图像直方图计算的第三种安全并行实现的代码清单
在这个实现中,我们去掉了互斥对象和锁,并声明了向量,使得每个 bin 都是一个tbb::atomic<int>(默认情况下初始化为0)。然后,在 lambda 中,并行增加容器是安全的。最终结果是,我们获得了直方图向量的并行增量,就像细粒度锁定策略一样,但是在互斥体管理和互斥体存储方面的成本更低。
然而,就性能而言,以前的实现仍然太慢:
c++ -std=c++11 -O2 -o fig_5_20 fig_5_20.cpp -ltbb
./fig_5_20
Serial: 0.614786, Parallel: 7.90455, Speed-up: 0.0710006
除了原子增量开销之外,伪共享和真共享是我们还没有解决的问题。在第七章中,通过利用对齐的分配器和填充技术来解决假共享问题。错误共享是妨碍并行性能的常见障碍,所以我们强烈建议您阅读第七章中推荐的避免错误共享的技术。
太好了,假设我们已经修复了假分享的问题,那么真分享的呢?两个不同的线程最终将增加同一个容器,这将从一个高速缓存乒乓到另一个。我们需要一个更好的主意来解决这个问题!
更好的并行实施:私有化和削减
直方图缩减带来的真正问题是,只有一个共享向量来保存所有线程都渴望增加的 256 个容器。到目前为止,我们已经看到了几种功能相当的实现,比如粗粒度的、细粒度的和基于原子的实现,但是如果我们还考虑性能和能量等非功能性指标,这些实现都不完全令人满意。
避免共享的常见解决方案是将其私有化。并行编程在这方面没有什么不同。如果我们给每个线程一个直方图的私有副本,每个线程都会愉快地使用它的副本,将其缓存在线程正在运行的内核的私有缓存中,因此以缓存速度递增所有的容器(在理想情况下)。不再有假共享,也没有真共享,也没有什么,因为直方图矢量不再被共享。
好吧,但是…每个线程最终都会看到直方图的一部分,因为每个线程只访问了整个图像的一些像素。没问题,现在是这个实现的缩减部分发挥作用的时候了。计算直方图的私有部分版本后的最后一步是减少所有线程的所有贡献,以获得完整的直方图向量。这部分仍然有一些同步,因为一些线程必须等待其他尚未完成本地/私有计算的线程,但是在一般情况下,这种解决方案最终比前面描述的其他实现要便宜得多。图 5-21 展示了直方图示例的私有化和缩减技术。
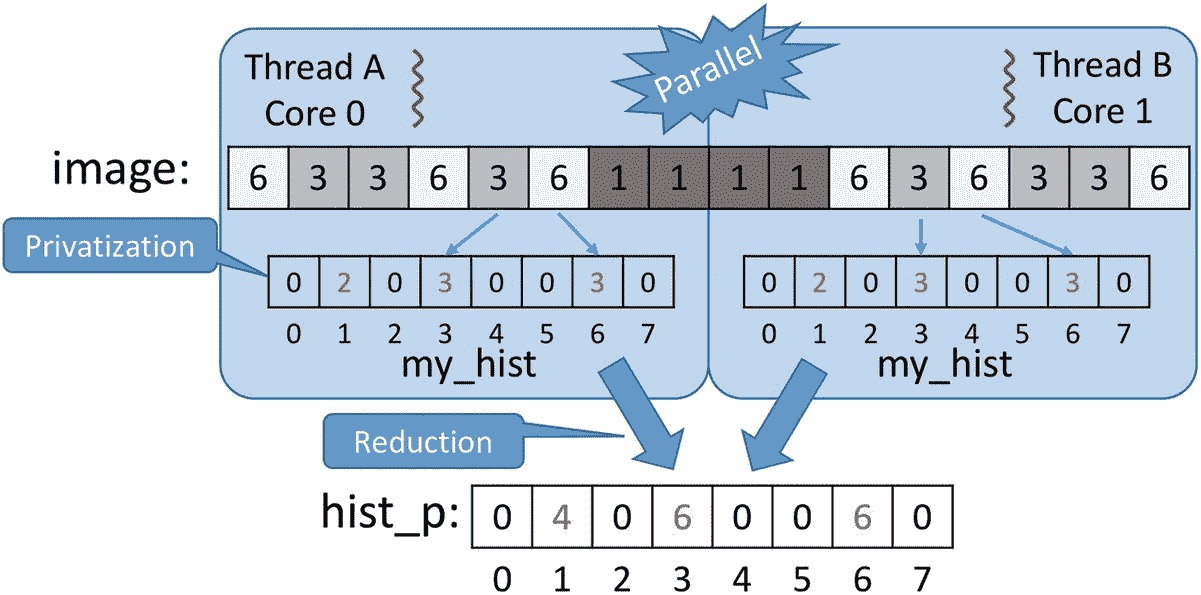
图 5-21
每个线程计算其局部直方图my_hist,该直方图稍后在第二步中被减少。
TBB 提供了几个备选方案来完成私有化和归约操作,一些基于线程本地存储(TLS ),另一个基于归约模板,更加用户友好。让我们先来看看 TLS 版本的直方图计算。
线程本地存储
在这里,线程本地存储指的是每个线程都有一个私有的数据副本。使用 TLS,我们可以减少对线程间共享可变状态的访问,还可以利用局部性,因为每个私有副本可以(有时是部分地)存储在线程运行的内核的本地缓存中。当然,副本会占用空间,所以不能过度使用。
TBB 的一个重要方面是我们不知道在任何给定的时间有多少线程正在被使用。即使我们运行在 32 核系统上,并且我们使用parallel_for进行 32 次迭代,我们也不能假设会有 32 个线程处于活动状态。这是使我们的代码可组合的一个关键因素,这意味着即使它在一个并行程序中被调用,或者如果它调用一个并行运行的库,它也将工作(更多细节见第九章)。因此,我们不知道需要多少数据的线程本地副本,即使在我们的 32 次迭代的parallel_for的例子中。TBB 线程本地存储的模板类在这里给出了一个抽象的方法,让 TBB 分配、操作和组合正确数量的副本,而不用我们担心有多少副本。这让我们能够创建可伸缩、可组合和可移植的应用程序。
TBB 为线程本地存储提供了两个模板类。两者都为每个线程提供对本地元素的访问,并按需创建元素(延迟)。它们的预期使用模式不同:
-
ETS 类提供了线程本地存储,就像一个 STL 容器,每个线程一个元素。容器允许使用通常的 STL 迭代习惯来迭代元素。任何线程都可以遍历所有本地副本,看到其他线程的本地数据。
-
类
combinable提供线程本地存储,用于保存每个线程的子计算,这些子计算稍后将被简化为单个结果。每个线程只能看到它的本地数据,或者在调用 combine 后,只能看到合并后的数据。
可枚举线程特定
首先,让我们看看如何通过enumerable_thread_specific类实现我们的并行直方图计算。在图 5-22 中,我们看到并行处理输入图像的不同块并让每个线程写入直方图向量的私有副本所需的代码。
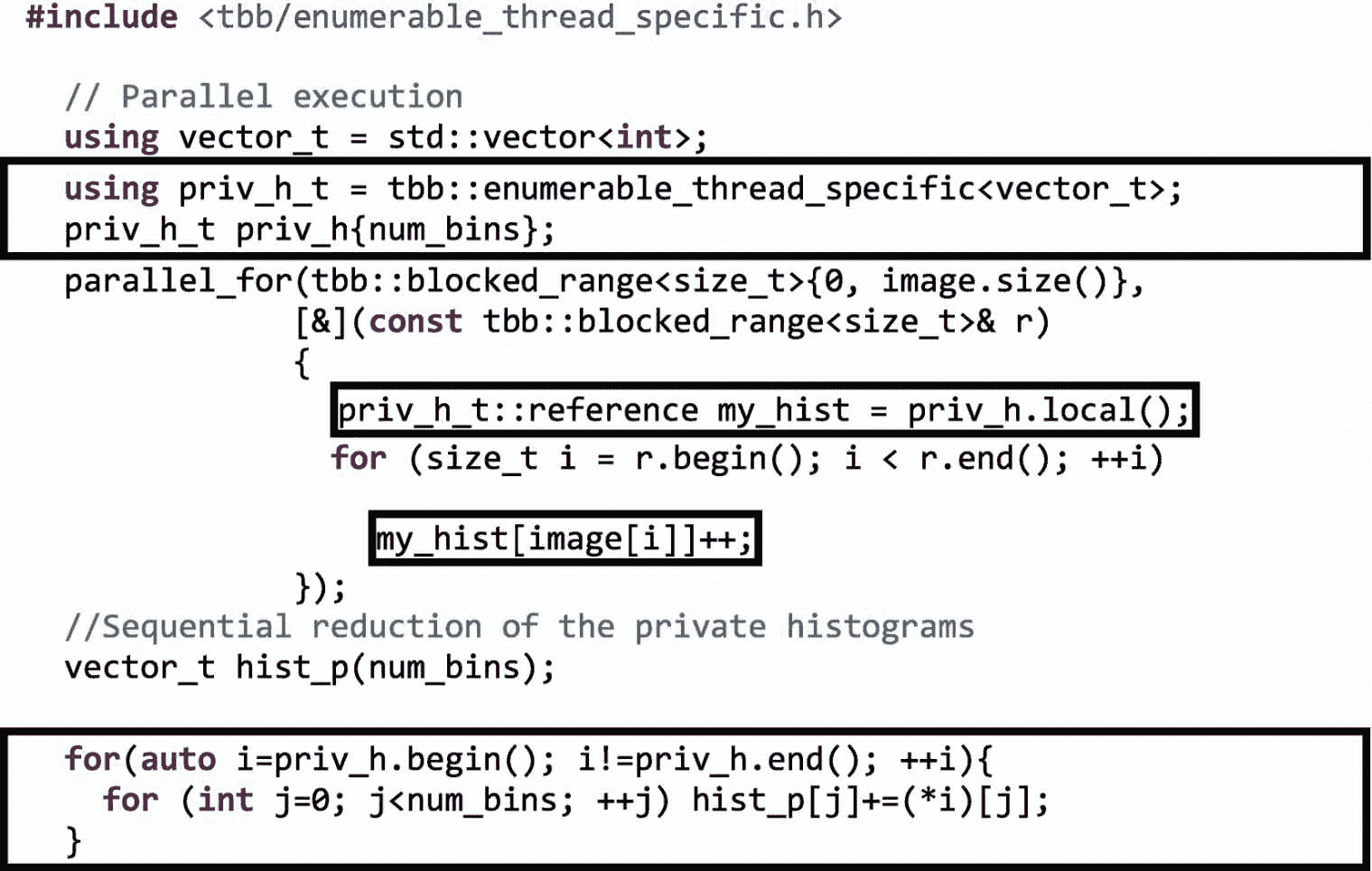
图 5-22
使用类enumerable_thread_specific对私有副本进行并行直方图计算
我们首先声明一个类型为vector<int>.的enumerable_thread_specific对象priv_h,构造器指出向量大小为num_bins整数。然后,在parallel_for,内部,不确定数量的线程将处理迭代空间的块,对于每个块,将执行parallel_for的主体(在我们的例子中是 lambda)。负责给定块的线程调用my_hist = priv_h.local(),其工作方式如下。如果这是这个线程第一次调用local()成员函数,就会为这个线程创建一个新的私有向量。如果相反,它不是第一次,向量已经被创建,我们只需要重用它。在这两种情况下,对私有向量的引用被返回并分配给my_hist,,它在parallel_for中被用来更新给定块的直方图计数。这样,处理不同块的线程将为第一个块创建私有直方图,并在后续块中重用它。很整洁,对吧?
在parallel_for结束时,我们以未确定数量的私有直方图结束,这些直方图需要被组合以计算最终直方图hist_p,累积所有的部分结果。但是,如果我们甚至不知道私有直方图的数量,我们如何进行这种简化呢?幸运的是,enumerable_thread_specific不仅为T类型的元素提供线程本地存储,还可以像 STL 容器一样从头到尾迭代。这在图 5-22 的末尾执行,其中变量i(类型priv_h_t::const_iterator)顺序遍历不同的私有直方图,嵌套循环j负责在hist_p上累积所有的箱计数。
如果我们更想炫耀我们出色的 C++ 编程技能,我们可以利用priv_h是另一个 STL 容器的事实,编写如图 5-23 所示的简化。

图 5-23
实现缩减的更时尚的方式
由于归约操作非常频繁,enumerable_thread_specific还提供了两个额外的成员函数来实现归约:图 5-24 中的combine_each()和combine().,我们在一个完全等同于图 5-23 的代码片段中演示了如何使用成员函数combine_each。

图 5-24
使用combine_each()实现还原
成员函数combine_each()有这样的原型:

正如我们在图 5-24 中看到的,Func f作为一个 lambda 提供,其中 STL transform算法负责将私有直方图累积到hist_p中。通常,成员函数combine_each为enumerate_thread_specific对象中的每个元素调用一元仿函数。这个带有签名void(T)或void(const T&)的组合函数通常将私有副本减少到一个全局变量中。
备选成员函数combine()确实返回类型为T的值,并且具有以下原型:

在图 5-25 中,二元函子f应该具有签名T(T,T)或T(const T&,const T&).,我们显示了使用T(T,T)签名的归约实现,对于每对私有向量,计算向量与向量a的加法,并将其返回以进行可能的进一步归约。combine()成员函数负责访问直方图的所有本地副本,以返回一个指向最终hist_p.的指针

图 5-25
使用combine()实现相同的缩减
而并行性能呢?
c++ -std=c++11 -O2 -o fig_5_22 fig_5_22.cpp -ltbb
./fig_5_22
Serial: 0.668987, Parallel: 0.164948, Speed-up: 4.05574
现在我们正在谈话!请记住,我们在四核机器上运行这些实验,因此 4.05 的加速比实际上有点超线性(由于四核的 L1 缓存的聚合)。图 5-23 、 5-24 和 5-25 中所示的三个等效缩减是顺序执行的,因此如果要缩减的私有副本的数量很大(比如说 64 个线程正在计算直方图)或者缩减操作是计算密集型的(例如,私有直方图有 1024 个仓),则仍有性能改进的空间。我们也将解决这个问题,但首先我们想讨论实现线程本地存储的第二种选择。
可组合的
一个combinable<T>对象为每个线程提供了自己的本地实例,类型为T,,用于在并行计算期间保存线程本地值。与之前描述的 ETS 类相反,一个可组合的对象不能像我们在图 5-22 和 5-23 中使用priv_h那样被迭代。然而,combine_each()和combine()成员函数是可用的,因为这个combinable类是在 TBB 提供的,其唯一目的是实现本地数据存储的减少。
在图 5-26 中,我们再次重新实现了并行直方图计算,现在依赖于可组合的类。
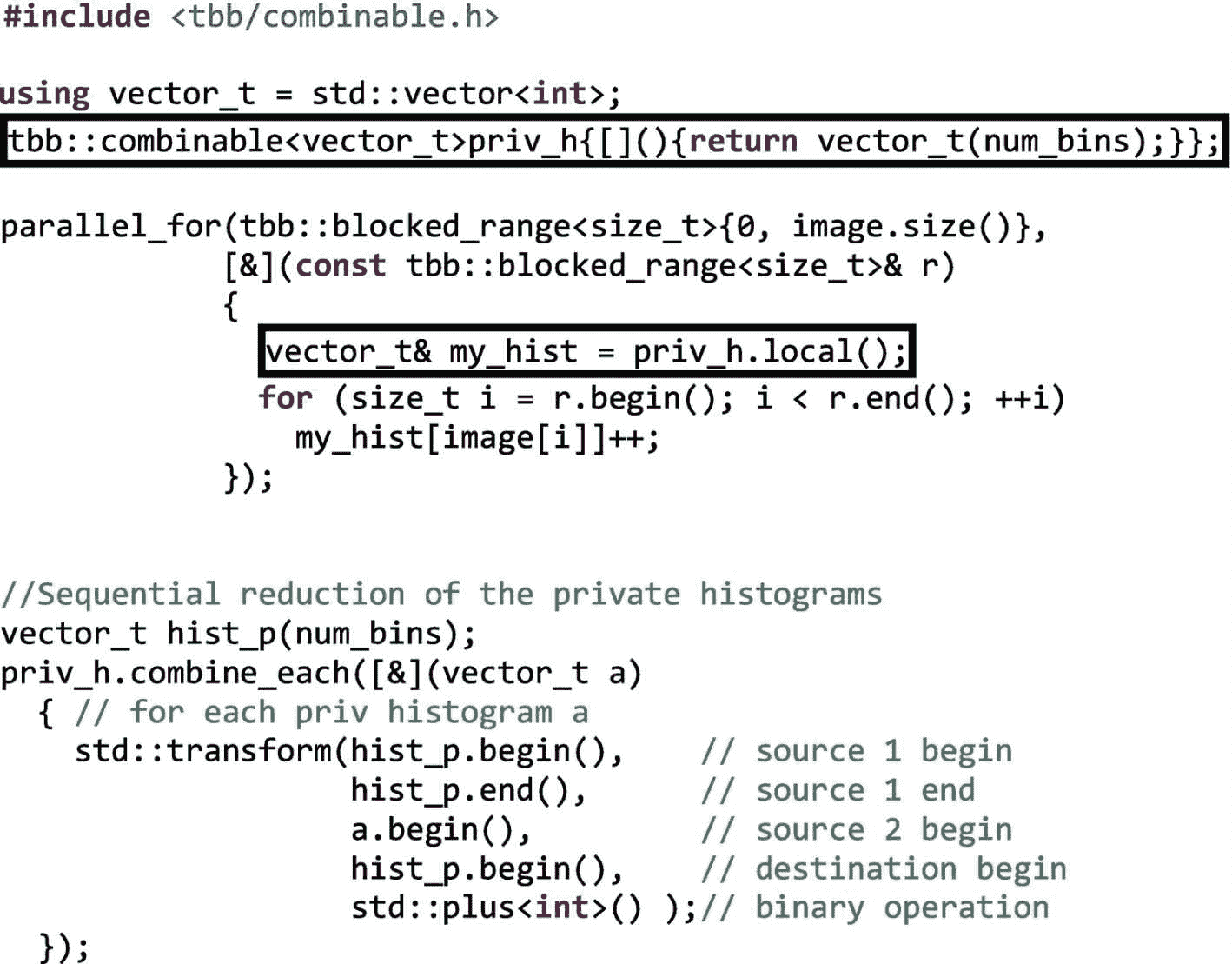
图 5-26
用combinable对象重新实现直方图计算
在这种情况下,priv_h是一个可组合的对象,其中构造器提供了一个 lambda,该函数将在每次调用priv_h.local()时被调用。在这种情况下,这个 lambda 只是创建了一个num_bins整数的空向量。更新每线程私有直方图的parallel_for与图 5-22 所示的 ETS 替代方案的实现非常相似,除了my_hist只是对整数向量的引用。正如我们所说,现在我们不能像在图 5-22 中那样手工迭代私有直方图,但是为了弥补这一点,成员函数combine_each()和combine()的工作方式与我们在图 5-24 和 5-25 中看到的 ETS 类的等价成员函数非常相似。请注意,这种缩减仍然是按顺序执行的,因此仅当要缩减的对象数量和/或缩减两个对象的时间很小时才适用。
ETS 和可组合类具有附加的成员函数和高级用途,详见附录 b。
最简单的并行实现:归约模板
正如我们在第二章中提到的,TBB 已经有了一个高级并行算法来轻松实现一个parallel_reduce。那么,如果我们要实现私有直方图的并行归约,为什么不仅仅依靠这个parallel_reduce模板呢?在图 5-27 中,我们看到了如何使用这个模板来编码一个高效的并行直方图计算。
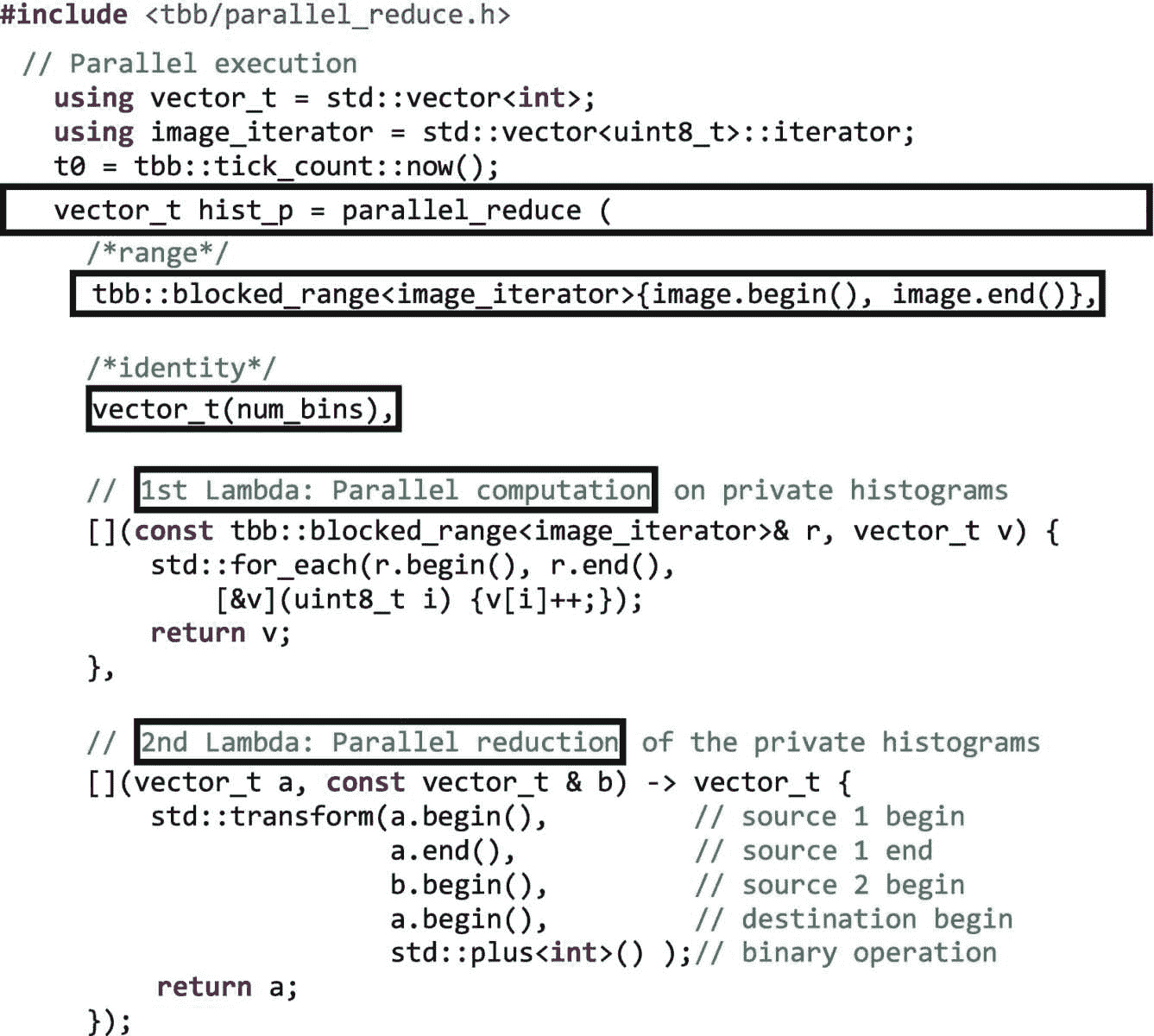
图 5-27
使用私有化和简化的图像直方图计算的更好的并行实现的代码清单
parallel_reduce的第一个参数是迭代的范围,它将被自动划分成块并分配给线程。有些过分简化了实际发生的事情,线程将获得一个用归约操作的标识值初始化的私有直方图,在本例中是初始化为 0 的面元向量。第一个 lambda 负责局部直方图的私有和本地计算,该局部直方图是通过仅访问图像的一些块而产生的。最后,第二个 lambda 实现了归约操作,在这种情况下可以表示为

这正是std: :transform STL 算法正在做的事情。执行时间与使用 ETS 获得的时间相似,并且可以组合:
c++ -std=c++11 -O2 -o fig_5_27 fig_5_27.cpp -ltbb
./fig_5_27
Serial: 0.594347, Parallel: 0.148108, Speed-up: 4.01293
为了更清楚地说明我们迄今为止讨论的直方图的不同实现的实际含义,我们在图 5-28 中收集了在我们的四核处理器上获得的所有加速。更准确地说,处理器是 2.6 GHz 的酷睿 i7-6700HQ (Skylake 架构,第六代),6 MB 三级高速缓存和 16 GB RAM。

图 5-28
英特尔酷睿 i7-6700HQ (Skylake)上不同直方图实施的加速
我们清楚地识别出三种不同的行为。四核的不安全、细粒度锁定和原子解决方案比顺序解决方案慢得多(慢得多意味着慢了不止一个数量级!).正如我们所说的,由于锁和假共享/真共享而导致的频繁同步是一个真正的问题,直方图仓在一个缓存和另一个缓存之间来回移动会导致非常令人失望的加速。细粒度的解决方案是最差的,因为直方图向量和互斥向量都有假共享和真共享。作为同类解决方案中的一个代表,粗粒度解决方案只是比顺序解决方案稍差一些。请记住,这只是一个“并行化然后序列化”的版本,其中粗粒度锁迫使线程一个接一个地进入临界区。粗粒度版本的小性能下降实际上是测量并行化和互斥管理的开销,但是我们现在没有假共享或真共享。最后,私有化+减支解决方案(TLS 和parallel_reduction)领先群雄。它们的伸缩性很好,甚至比线性更好,因为parallel_reduction由于树状缩减而有点慢,在这个问题上没有回报。核的数量很少,减少所需的时间(增加到 256 个int向量)可以忽略不计。对于这个小问题,用 TLS 类实现的顺序缩减已经足够好了。
概述我们的选择
为了支持我们提出的所有不同的备选方案,实现一个简单的算法,如直方图计算算法,让我们回顾并详细说明每个备选方案的优缺点。图 5-29 展示了我们的一些选项,使用八个线程进行 800 个数字的简单矢量加法。相应的顺序代码将类似于
正如在《善、恶、丑》中一样,这一章的“角色”是“错误的、顽强的、桂冠的、核心的、本地的和明智的”:
图 5-29
用八个线程对 800 个数求和时避免争用:(A)原子的:用原子操作 s 保护全局和,(B)局部的:使用enumerable_thread_specific,©明智的:使用parallel_reduce。
-
错误的:我们可以让八个线程并行递增一个全局计数器
sum_g,而无需任何进一步的考虑、思考或悔恨!最有可能的是,sum_g最终会不正确,缓存一致性协议也会破坏性能。你已经被警告了。
-
Hardy:如果我们使用粗粒度锁定,我们会得到正确的结果,但通常我们也会序列化代码,除非互斥体实现了 HTM(就像投机风格那样)。这是保护临界区最简单的方法,但不是最有效的方法。对于我们的 vector sum 示例,我们将通过保护每个 vector chunk 累积来说明粗粒度锁定,从而获得一个粗粒度临界区。

-
Laurel:细粒度锁实现起来更费力,通常需要更多内存来存储保护数据结构细粒度部分的不同互斥体。不过,令人欣慰的是线程间的并发性增加了。我们可能想要评估不同的互斥体风格,以便在产品代码中选择最好的一个。对于矢量和,我们没有一个可以分区的数据结构,这样每个部分都可以被独立保护。让我们考虑一个细粒度的实现,在下面的实现中,我们有一个较轻的临界区(在这种情况下,与粗粒度的实现一样串行,但是线程在更细粒度上竞争锁)。

-
在某些情况下,原子变量可以帮助我们。例如,当共享的可变状态可以存储在整型中,并且所需的操作足够简单时。这比细粒度的锁定方法成本更低,并发级别也不相上下。向量和示例(见图 5-29(A) )如下,在这种情况下,与前两种方法一样连续,并且全局变量与细粒度情况下一样高度竞争。

-
本地:我们并不总是能够提出一个实现,将共享可变状态的本地副本私有化来扭转局面。但在这种情况下,线程本地存储 TLS 可以通过
enumerate_thread_specific、ETS 或combinable类来实现。即使协作线程的数量未知,并且提供了方便的减少方法,它们也能工作。这些类提供了足够的灵活性,可以在不同的场景中使用,并且当单个迭代空间的缩减不够时,可以满足我们的需要。为了计算矢量和,我们在下面给出一个替代方案,其中私有部分和priv_s随后被顺序累加,如图 5-29(B) 所示。
-
明智之举:当我们的计算符合归约模式时,强烈建议依赖
parallel_reduction模板,而不是使用 TBB 线程本地存储特性手工编码私有化和归约。下面的代码可能看起来比前一个更复杂,但是聪明的软件架构师设计了巧妙的技巧来完全优化这个常见的归约操作。例如,在这种情况下,归约操作遵循一种类似树的方法,复杂性为O(log n)而不是O(n),如图 5-29© 所示。利用图书馆放在你手中的东西,而不是重新发明轮子。这无疑是最适合大量内核和成本高昂的缩减操作的方法。
与直方图计算一样,我们还在我们的酷睿 i7 四核架构上评估了大小为 10 9 的矢量加法的不同实现的性能,如图 5-30 所示。现在计算更加精细了(只是增加了一个变量),10 个 9 个锁定-解锁操作或原子增量的相对影响更大了,这可以从加速中看出(更确切地说是减速!)的原子(核)和细粒度(劳雷尔)实现。粗粒度(Hardy)实现现在比直方图情况下受到的冲击稍大。TLS(本地)方法仅比顺序代码快 1.86 倍。unsafe(missed)现在比 sequential 快 3.37 倍,现在的赢家是parallel_reduction (Wise)实现,它为四个内核提供了 3.53 倍的加速。

图 5-30
在英特尔酷睿 i7-6700HQ (Skylake)上,针对 N=10 9 的向量加法的不同实现的加速
你可能想知道为什么我们经历了所有这些不同的选择,最终推荐了最后一个。如果parallel_reduce解决方案是最佳方案,我们为什么不直接采用它呢?不幸的是,并行生活是艰难的,并不是所有的并行化问题都可以通过简单的简化来解决。在这一章中,我们将为您提供利用同步机制的设备,如果它们真的是必要的话,同时也展示了重新思考算法和数据结构的好处。
摘要
当我们需要安全地访问共享数据时,TBB 库提供了不同风格的互斥体和原子变量来帮助我们同步线程。该库还提供线程本地存储、TLS、类(如 ETS 和combinable)和算法(如parallel_reduction),帮助我们避免同步的需要。在本章中,我们经历了并行图像直方图计算的史诗般的旅程。对于这个正在运行的示例,我们看到不同的并行实现从一个不正确的实现开始,然后遍历不同的同步备选方案,如粗粒度锁定、细粒度锁定和原子,最后得到一些根本不使用锁的备选实现。在途中,我们在一些值得注意的地方停了下来,介绍了允许我们描述互斥体的特性、TBB 库中可用的不同种类的互斥体,以及依赖互斥体实现我们的算法时通常会出现的常见问题。现在,在旅程的最后,这一章带给我们的启示是显而易见的:除非性能不是您的目标,否则不要使用锁!
更多信息
以下是我们推荐的一些与本章相关的额外阅读材料:
-
C++ 并发在行动,安东尼·威廉姆斯,曼宁出版社,第二版,2018 年。
-
《内存一致性和缓存一致性入门》, Daniel J. Sorin、Mark D. Hill 和 David A. Wood,Morgan & Claypool 出版社,2011 年。
马拉加朗达的照片,如图 5-1 ,作者拉斐尔·阿森约拍摄,经许可使用。
第五章中显示的迷因数字是经 365psd.com 许可使用的“33 个矢量迷因面”
图 5-17 中的交通堵塞由 Denisa-Adreea Constantinescu 在马拉加大学攻读博士学位时绘制,经允许使用。
[外链图片转存中…(img-TGwgjfzE-1722837544027)]
开放存取本章根据知识共享署名-非商业-非专用 4.0 国际许可协议(http://Creative Commons . org/licenses/by-NC-nd/4.0/)的条款进行许可,该协议允许以任何媒体或格式进行任何非商业使用、共享、分发和复制,只要您适当注明原作者和来源,提供知识共享许可协议的链接,并指出您是否修改了许可材料。根据本许可证,您无权共享从本章或其部分内容派生的改编材料。
本章中的图像或其他第三方材料包含在该章的知识共享许可中,除非该材料的信用额度中另有说明。如果材料未包含在本章的知识共享许可中,并且您的预期用途不被法定法规允许或超出了允许的用途,您将需要直接从版权所有者处获得许可。
由于 von Neumman 架构的本质,计算逻辑与数据存储是分离的,因此数据必须移动到可以计算的地方,然后再计算,最后再移回存储。
2
原子操作不能嵌套,所以它们不会引起死锁。
**

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









