







Keras 中长短期记忆模型的 5 步生命周期
原文:
machinelearningmastery.com/5-step-life-cycle-long-short-term-memory-models-keras/
使用 Keras 在 Python 中创建和评估深度学习神经网络非常容易,但您必须遵循严格的模型生命周期。
在这篇文章中,您将发现在 Keras 中创建,训练和评估长期短期记忆(LSTM)循环神经网络的分步生命周期,以及如何使用训练有素的模型做出预测。
阅读这篇文章后,你会知道:
- 如何在 Keras 中定义,编译,拟合和评估 LSTM。
- 如何为回归和分类序列预测问题选择标准默认值。
- 如何将它们联系起来,在 Keras 开发和运行您的第一个 LSTM 循环神经网络。
让我们开始吧。
- 2017 年 6 月更新:修复输入大小调整示例中的拼写错误。

Keras 长期短期记忆模型的 5 步生命周期
照片由 docmonstereyes 拍摄,保留一些权利。
概观
下面概述了我们将要研究的 Keras LSTM 模型生命周期中的 5 个步骤。
- 定义网络
- 编译网络
- 适合网络
- 评估网络
- 作出预测
环境
本教程假定您已安装 Python SciPy 环境。您可以在此示例中使用 Python 2 或 3。
本教程假设您安装了 TensorFlow 或 Theano 后端的 Keras v2.0 或更高版本。
本教程还假设您安装了 scikit-learn,Pandas,NumPy 和 Matplotlib。
接下来,让我们看看标准时间序列预测问题,我们可以将其用作此实验的上下文。
如果您在设置 Python 环境时需要帮助,请参阅以下帖子:
步骤 1.定义网络
第一步是定义您的网络。
神经网络在 Keras 中定义为层序列。这些层的容器是 Sequential 类。
第一步是创建 Sequential 类的实例。然后,您可以创建层并按照它们应连接的顺序添加它们。由存储器单元组成的 LSTM 复现层称为 LSTM()。通常跟随 LSTM 层并用于输出预测的完全连接层称为 Dense()。
例如,我们可以分两步完成:
model = Sequential()
model.add(LSTM(2))
model.add(Dense(1))
但是我们也可以通过创建一个层数组并将其传递给 Sequential 的构造函数来一步完成。
layers = [LSTM(2), Dense(1)]
model = Sequential(layers)
网络中的第一层必须定义预期的输入数量。输入必须是三维的,包括样本,时间步和特征。
- 样品。这些是数据中的行。
- 时间步。这些是过去对特征的观察,例如滞后变量。
- 功能。这些是数据中的列。
假设您的数据作为 NumPy 数组加载,您可以使用 NumPy 中的 reshape()函数将 2D 数据集转换为 3D 数据集。如果您希望列成为一个功能的时间步长,您可以使用:
data = data.reshape((data.shape[0], data.shape[1], 1))
如果您希望 2D 数据中的列成为具有一个时间步长的要素,则可以使用:
data = data.reshape((data.shape[0], 1, data.shape[1]))
您可以指定 input_shape 参数,该参数需要包含时间步数和要素数的元组。例如,如果我们有两个时间步长和一个特征用于单变量时间序列,每行有两个滞后观察值,则将指定如下:
model = Sequential()
model.add(LSTM(5, input_shape=(2,1)))
model.add(Dense(1))
可以通过将 LSTM 层添加到 Sequential 模型来栈式 LSTM 层。重要的是,在栈式 LSTM 层时,我们必须为每个输入输出一个序列而不是一个值,以便后续的 LSTM 层可以具有所需的 3D 输入。我们可以通过将 return_sequences 参数设置为 True 来完成此操作。例如:
model = Sequential()
model.add(LSTM(5, input_shape=(2,1), return_sequences=True))
model.add(LSTM(5))
model.add(Dense(1))
将 Sequential 模型视为一个管道,将原始数据输入到最后,预测从另一个输出。
这在 Keras 中是一个有用的容器,因为传统上与层相关的关注点也可以拆分并作为单独的层添加,清楚地显示它们在从输入到预测的数据转换中的作用。
例如,可以提取转换来自层中每个神经元的求和信号的激活函数,并将其作为称为激活的层状对象添加到 Sequential 中。
model = Sequential()
model.add(LSTM(5, input_shape=(2,1)))
model.add(Dense(1))
model.add(Activation('sigmoid'))
激活函数的选择对于输出层是最重要的,因为它将定义预测将采用的格式。
例如,下面是一些常见的预测性建模问题类型以及可以在输出层中使用的结构和标准激活函数:
- 回归:线性激活函数,或“线性”,以及与输出数量匹配的神经元数量。
- 二分类(2 类):Logistic 激活函数,或’sigmoid’,以及一个神经元输出层。
- 多分类(> 2 类):假设单热编码输出模式,Softmax 激活函数或’softmax’,以及每类值一个输出神经元。
第 2 步。编译网络
一旦我们定义了网络,我们就必须编译它。
编译是一个效率步骤。它将我们定义的简单层序列转换为高效的矩阵变换系列,其格式应在 GPU 或 CPU 上执行,具体取决于 Keras 的配置方式。
将编译视为网络的预计算步骤。定义模型后始终需要它。
编译需要指定许多参数,专门用于训练您的网络。具体地,用于训练网络的优化算法和用于评估由优化算法最小化的网络的损失函数。
例如,下面是编译定义模型并指定随机梯度下降(sgd)优化算法和均值误差(mean_squared_error)损失函数的情况,用于回归类型问题。
model.compile(optimizer='sgd', loss='mean_squared_error')
或者,可以在作为编译步骤的参数提供之前创建和配置优化程序。
algorithm = SGD(lr=0.1, momentum=0.3)
model.compile(optimizer=algorithm, loss='mean_squared_error')
预测性建模问题的类型对可以使用的损失函数的类型施加约束。
例如,下面是不同预测模型类型的一些标准损失函数:
- 回归:均值平方误差或’mean_squared_error’。
- 二分类(2 类):对数损失,也称为交叉熵或“binary_crossentropy”。
- 多分类(> 2 类):多类对数损失或’categorical_crossentropy’。
最常见的优化算法是随机梯度下降,但 Keras 还支持一套其他最先进的优化算法,这些算法在很少或没有配置的情况下都能很好地工作。
也许最常用的优化算法因为它们通常具有更好的表现:
- 随机梯度下降或’sgd’,需要调整学习速度和动量。
- ADAM 或’adam’,需要调整学习率。
- RMSprop 或’rmsprop’,需要调整学习率。
最后,除了损失函数之外,您还可以指定在拟合模型时收集的度量标准。通常,要收集的最有用的附加度量标准是分类问题的准确率。要收集的度量标准由数组中的名称指定。
例如:
model.compile(optimizer='sgd', loss='mean_squared_error', metrics=['accuracy'])
步骤 3.适合网络
一旦网络被编译,它就可以适合,这意味着在训练数据集上调整权重。
安装网络需要指定训练数据,包括输入模式矩阵 X 和匹配输出模式数组 y。
使用反向传播算法训练网络,并根据编译模型时指定的优化算法和损失函数进行优化。
反向传播算法要求网络训练指定数量的时期或暴露于训练数据集。
每个迭代可以被划分为称为批次的输入 - 输出模式对的组。这定义了在一个迭代内更新权重之前网络所接触的模式数。它也是一种效率优化,确保一次不会将太多输入模式加载到内存中。
拟合网络的最小例子如下:
history = model.fit(X, y, batch_size=10, epochs=100)
适合后,将返回历史对象,该对象提供训练期间模型表现的摘要。这包括损失和编译模型时指定的任何其他指标,记录每个迭代。
训练可能需要很长时间,从几秒到几小时到几天,具体取决于网络的大小和训练数据的大小。
默认情况下,每个迭代的命令行上都会显示一个进度条。这可能会给您带来太多噪音,或者可能会给您的环境带来问题,例如您使用的是交互式笔记本电脑或 IDE。
通过将详细参数设置为 2,可以减少每个时期显示的信息量。您可以通过将详细设置为 1 来关闭所有输出。例如:
history = model.fit(X, y, batch_size=10, epochs=100, verbose=0)
第 4 步。评估网络
一旦网络被训练,就可以对其进行评估。
可以在训练数据上评估网络,但是这不会提供作为预测模型的网络表现的有用指示,因为它之前已经看到了所有这些数据。
我们可以在测试期间看不到的单独数据集上评估网络的表现。这将提供对网络表现的估计,以便对未来看不见的数据做出预测。
该模型评估所有测试模式的损失,以及编译模型时指定的任何其他指标,如分类准确率。返回评估指标列表。
例如,对于使用精度度量编制的模型,我们可以在新数据集上对其进行评估,如下所示:
loss, accuracy = model.evaluate(X, y)
与拟合网络一样,提供详细输出以了解评估模型的进度。我们可以通过将 verbose 参数设置为 0 来关闭它。
loss, accuracy = model.evaluate(X, y, verbose=0)
第 5 步。做出预测
一旦我们对拟合模型的表现感到满意,我们就可以使用它来预测新数据。
这就像使用新输入模式数组调用模型上的 predict()函数一样简单。
For example:
predictions = model.predict(X)
预测将以网络输出层提供的格式返回。
在回归问题的情况下,这些预测可以是直接问题的格式,由线性激活函数提供。
对于二分类问题,预测可以是第一类的概率数组,其可以通过舍入转换为 1 或 0。
对于多分类问题,结果可以是概率数组的形式(假设单热编码输出变量),可能需要使用 argmax()NumPy 函数将其转换为单个类输出预测。
或者,对于分类问题,我们可以使用 predict_classes()函数,该函数会自动将 uncrisp 预测转换为清晰的整数类值。
predictions = model.predict_classes(X)
与拟合和评估网络一样,提供详细输出以给出模型预测的进度的概念。我们可以通过将 verbose 参数设置为 0 来关闭它。
predictions = model.predict(X, verbose=0)
端到端工作示例
让我们将所有这些与一个小例子结合起来。
这个例子将使用一个学习 10 个数字序列的简单问题。我们将向网络显示一个数字,例如 0.0,并期望它预测为 0.1。然后显示它 0.1 并期望它预测 0.2,依此类推到 0.9。
- 定义网络:我们将构建一个 LSTM 神经网络,在可见层有 1 个输入时间步长和 1 个输入特征,LSTM 隐藏层有 10 个存储单元,在完全连接的输出层有 1 个神经元线性(默认)激活功能。
- 编译网络:我们将使用具有默认配置和均方误差丢失函数的高效 ADAM 优化算法,因为它是一个回归问题。
- 适合网络:我们将使网络适合 1,000 个时期,并使用等于训练集中模式数量的批量大小。我们还将关闭所有详细输出。
- 评估网络。我们将在训练数据集上评估网络。通常,我们会在测试或验证集上评估模型。
- 制作预测。我们将对训练输入数据做出预测。同样,通常我们会对我们不知道正确答案的数据做出预测。
完整的代码清单如下。
# Example of LSTM to learn a sequence
from pandas import DataFrame
from pandas import concat
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
# create sequence
length = 10
sequence = [i/float(length) for i in range(length)]
print(sequence)
# create X/y pairs
df = DataFrame(sequence)
df = concat([df.shift(1), df], axis=1)
df.dropna(inplace=True)
# convert to LSTM friendly format
values = df.values
X, y = values[:, 0], values[:, 1]
X = X.reshape(len(X), 1, 1)
# 1\. define network
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1))
# 2\. compile network
model.compile(optimizer='adam', loss='mean_squared_error')
# 3\. fit network
history = model.fit(X, y, epochs=1000, batch_size=len(X), verbose=0)
# 4\. evaluate network
loss = model.evaluate(X, y, verbose=0)
print(loss)
# 5\. make predictions
predictions = model.predict(X, verbose=0)
print(predictions[:, 0])
运行此示例将生成以下输出,显示 10 个数字的原始输入序列,对整个序列做出预测时网络的均方误差损失以及每个输入模式的预测。
输出间隔开以便于阅读。
我们可以看到序列被很好地学习,特别是如果我们将预测舍入到第一个小数位。
[0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
4.54527471447e-05
[ 0.11612834 0.20493418 0.29793766 0.39445466 0.49376178 0.59512401
0.69782174 0.80117452 0.90455914]
进一步阅读
- 顺序模型的 Keras 文档。
- LSTM 层的 Keras 文档。
- Keras 优化算法文档。
- Keras 损失函数文档。
摘要
在这篇文章中,您使用 Keras 库发现了 LSTM 循环神经网络的 5 步生命周期。
具体来说,你学到了:
- 如何在 Keras 中为 LSTM 网络定义,编译,拟合,评估和预测。
- 如何为分类和回归问题选择激活函数和输出层配置。
- 如何在 Keras 开发和运行您的第一个 LSTM 模型。
您对 Keras 的 LSTM 型号有任何疑问,或者关于这篇文章?
在评论中提出您的问题,我会尽力回答。
长短期记忆循环神经网络的注意事项
原文:
machinelearningmastery.com/attention-long-short-term-memory-recurrent-neural-networks/
编解码器架构很受欢迎,因为它已经在一系列领域中展示了最先进的结果。
该架构的局限性在于它将输入序列编码为固定长度的内部表示。这对可以合理学习的输入序列的长度施加了限制,并且导致非常长的输入序列的表现更差。
在这篇文章中,您将发现寻求克服此限制的循环神经网络的注意机制。
阅读这篇文章后,你会知道:
- 编码 - 解码器架构和固定长度内部表示的限制。
- 克服限制的注意机制允许网络在输出序列中的每个项目的输入序列中学习在哪里注意。
- 在诸如文本翻译,语音识别等领域中具有循环神经网络的注意机制的 5 种应用。
让我们开始吧。

长期记忆循环神经网络
的注意事项 Jonas Schleske 的照片,保留一些权利。
长序列的问题
编解码器循环神经网络是这样的架构,其中一组 LSTM 学习将输入序列编码成固定长度的内部表示,第二组 LSTM 读取内部表示并将其解码成输出序列。
这种架构已经在诸如文本翻译等困难的序列预测问题上展示了最先进的结果,并迅速成为主导方法。
例如,请参阅:
- 用神经网络进行序列学习的序列,2014
- 使用 RNN 编解码器进行统计机器翻译的学习短语表示,2014
编解码器架构仍然在广泛的问题上实现了出色的结果。然而,它受到所有输入序列被强制编码为固定长度内部向量的约束。
这被认为限制了这些网络的表现,特别是在考虑长输入序列时,例如文本翻译问题中的非常长的句子。
这种编解码器方法的潜在问题是神经网络需要能够将源句子的所有必要信息压缩成固定长度的向量。这可能使神经网络难以处理长句,特别是那些比训练语料库中的句子长的句子。
- Dzmitry Bahdanau 等,神经机器翻译通过联合学习调整和翻译,2015
序列中的注意事项
注意是将编解码器架构从固定长度内部表示中释放出来的想法。
这是通过保持来自编码器 LSTM 的中间输出来自输入序列的每个步骤并训练模型以学习选择性地关注这些输入并将它们与输出序列中的项目相关联来实现的。
换句话说,输出序列中的每个项都取决于输入序列中的选择项。
每次所提出的模型在翻译中生成单词时,它(软)搜索源语句中的一组位置,其中最相关的信息被集中。然后,模型基于与这些源位置和所有先前生成的目标词相关联的上下文向量来预测目标词。
…它将输入句子编码成一系列向量,并在解码翻译时自适应地选择这些向量的子集。这使得神经翻译模型不必将源句的所有信息(无论其长度)压缩成固定长度的向量。
— Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
这增加了模型的计算负担,但产生了更有针对性和更好表现的模型。
此外,该模型还能够显示在预测输出序列时如何关注输入序列。这有助于理解和诊断模型正在考虑的具体内容以及特定输入 - 输出对的程度。
所提出的方法提供了一种直观的方式来检查生成的翻译中的单词与源句中的单词之间的(软)对齐。这是通过可视化注释权重来完成的…每个图中矩阵的每一行都表示与注释相关的权重。由此我们看到源句中哪些位置在生成目标词时被认为更重要。
— Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
大图像问题
应用于计算机视觉问题的卷积神经网络也受到类似的限制,其中在非常大的图像上学习模型可能是困难的。
结果,可以对大图像进行一系列的瞥见,以在做出预测之前形成图像的近似印象。
人类感知的一个重要特性是人们不会倾向于一次完整地处理整个场景。相反,人们将注意力有选择地集中在视觉空间的某些部分上以在需要的时间和地点获取信息,并且随着时间的推移组合来自不同注视的信息以建立场景的内部表示,指导未来的眼睛运动和决策。
- 视觉注意的复发模型,2014
这些基于瞥见的修改也可能被视为关注,但在本文中未予考虑。
看文件。
- 视觉注意的复发模型,2014
- DRAW:用于图像生成的循环神经网络,2014
- 具有视觉注意力的多目标识别,2014
5 序列预测中的注意事项
本节提供了一些具体示例,说明如何将注意力用于具有循环神经网络的序列预测。
1.文本翻译中的注意力
上面提到的激励例子是文本翻译。
给定法语句子的输入序列,翻译并输出英语句子。注意用于注意输出序列中每个单词的输入序列中的特定单词。
我们通过在生成每个目标字时对模型(软)搜索一组输入字或由编码器计算的注释来扩展基本编解码器。这使得模型不必将整个源句子编码成固定长度的向量,并且还使模型仅关注与下一个目标词的生成相关的信息。
— Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015

法语与英语翻译的注意解释
摘自 Dzmitry Bahdanau 等人,通过联合学习对齐和翻译的神经机器翻译,2015
2.图像描述中的注意事项
与瞥见方法不同,基于序列的注意机制可以应用于计算机视觉问题,以帮助了解如何在输出序列(例如标题)时最好地使用卷积神经网络来关注图像。
给定图像的输入,输出图像的英文描述。注意用于将焦点集中在输出序列中每个单词的图像的不同部分。
我们提出了一种基于注意力的方法,它可以在三个基准数据集上提供最先进的表现…我们还展示了如何利用学习的注意力来为模型生成过程提供更多的可解释性,并证明学习的对齐与人类的直觉非常吻合。 。

输入图像输出图像的注意解释
取自显示,参与和告诉:神经图像标题生成与视觉注意,2016
3.蕴涵中的注意力
给出一个前提情景和关于英语情景的假设,输出前提是否矛盾,是否相关,或是否有假设。
例如:
- 前提:“_ 婚礼派对拍照 _”
- 假设:“_ 有人结婚 _”
注意用于将假设中的每个单词与前提中的单词相关联,反之亦然。
我们提出了一个基于 LSTM 的神经模型,它一次读取两个句子来确定蕴涵,而不是将每个句子独立地映射到语义空间。我们用神经逐字注意机制来扩展这个模型,以鼓励对词语和短语对的蕴涵进行推理。 …具有逐字神经注意力的扩展超越了这一强大的基准 LSTM 结果 2.6 个百分点,创造了一种新的最先进的准确率…
- 关于神经注意蕴涵的推理,2016 年
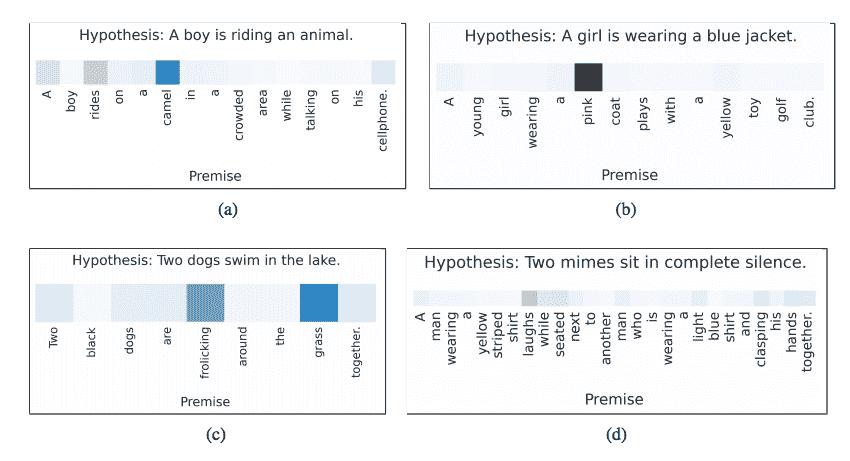
关于假设词的前提词的注意解释
摘自 2016 年神经注意蕴涵的推理
4.语音识别中的注意力
给定英语语音片段的输入序列,输出一系列音素。
注意用于将输出序列中的每个音素与输入序列中的特定音频帧相关联。
…基于混合注意机制的新颖的端到端可训练语音识别架构,其结合内容和位置信息以便选择输入序列中的下一个位置用于解码。所提出的模型的一个理想特性是它能够比它训练的那些更长时间地识别话语。
- 基于注意力的语音识别模型,2015。
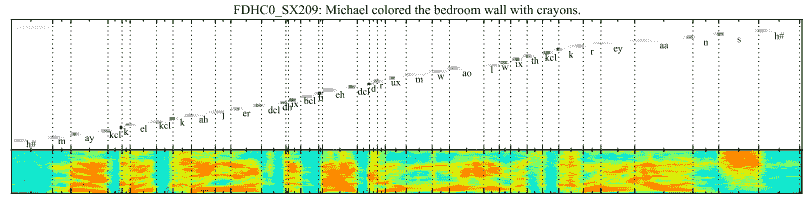
从基于注意力的语音识别模型中获取音频输入帧的输出音素位置的注意解释
,2015
5.文本摘要中的注意事项
给定英文文章的输入序列,输出一系列总结输入的英语单词。
注意用于将输出摘要中的每个单词与输入文档中的特定单词相关联。
基于神经机器翻译的最新发展,基于神经注意的抽象概括模型。我们将此概率模型与生成算法相结合,生成算法可生成准确的抽象摘要。
- 抽象句概括的神经注意模型,2015

输入文件中输入文字中词汇的注意解释
摘自抽象句概括的神经注意模型,2015。
进一步阅读
如果您想了解有关增加对 LSTM 的关注的更多信息,本节将提供其他资源。
在撰写本文时,Keras 并未提供开箱即用的注意事项,但很少有第三方实现。看到:
- 使用 Keras 进行问答的深度语言建模
- 注意模型可用!
- Keras 注意机制
- 注意和增强循环神经网络
- 如何在循环层(文本分类)之上添加注意
- 注意机制实现问题
- 实现简单的神经注意模型(用于填充输入)
- 注意层需要另一个 PR
- seq2seq 库
你知道在循环神经网络中有一些关注的好资源吗?
请在评论中告诉我。
摘要
在这篇文章中,您发现了 LSTM 循环神经网络的序列预测问题的注意机制。
具体来说,你学到了:
- 用于循环神经网络的编解码器架构使用固定长度的内部表示,其施加限制学习非常长的序列的约束。
- 该注意力通过允许网络学习在哪里注意输出序列中的每个项目的输入来克服编码 - 解码器架构中的限制。
- 该方法已用于不同类型的序列预测问题,包括文本翻译,语音识别等。
您对复发神经网络中的注意力有任何疑问吗?
在下面的评论中提出您的问题,我会尽力回答。
CNN 长短期记忆网络
原文:
machinelearningmastery.com/cnn-long-short-term-memory-networks/
使用示例 Python 代码轻松介绍 CNN LSTM 循环神经网络
。
具有空间结构的输入(如图像)无法使用标准 Vanilla LSTM 轻松建模。
CNN 长短期记忆网络或简称 CNN LSTM 是一种 LSTM 架构,专门用于具有空间输入的序列预测问题,如图像或视频。
在这篇文章中,您将发现用于序列预测的 CNN LSTM 架构。
完成这篇文章后,你会知道:
- 关于用于序列预测的 CNN LSTM 模型架构的开发。
- CNN LSTM 模型适合的问题类型的示例。
- 如何使用 Keras 在 Python 中实现 CNN LSTM 架构。
让我们开始吧。

卷积神经网络长短期记忆网络
摄影: Yair Aronshtam ,保留了一些权利。
CNN LSTM 架构
CNN LSTM 架构涉及使用卷积神经网络(CNN)层对输入数据进行特征提取以及 LSTM 以支持序列预测。
CNN LSTM 是针对视觉时间序列预测问题以及从图像序列(例如视频)生成文本描述的应用而开发的。具体来说,问题是:
- 活动识别:生成在一系列图像中演示的活动的文本描述。
- 图像说明:生成单个图像的文本描述。
- 视频说明:生成图像序列的文本描述。
[CNN LSTM]是一类在空间和时间上都很深的模型,并且可以灵活地应用于涉及顺序输入和输出的各种视觉任务
- 用于视觉识别和描述的长期循环卷积网络,2015。
这种架构最初被称为长期循环卷积网络或 LRCN 模型,尽管我们将使用更通用的名称“CNN LSTM”来指代在本课程中使用 CNN 作为前端的 LSTM。
该架构用于生成图像的文本描述的任务。关键是使用在具有挑战性的图像分类任务上预先训练的 CNN,该任务被重新用作字幕生成问题的特征提取器。
…使用 CNN 作为图像“编码器”是很自然的,首先将其预训练用于图像分类任务,并使用最后隐藏层作为生成句子的 RNN 解码器的输入
- Show and Tell:神经图像标题生成器,2015。
该架构还用于语音识别和自然语言处理问题,其中 CNN 用作音频和文本输入数据上的 LSTM 的特征提取器。
此架构适用于以下问题:
- 在其输入中具有空间结构,例如 2D 结构或图像中的像素或句子,段落或文档中的单词的一维结构。
- 在其输入中具有时间结构,诸如视频中的图像的顺序或文本中的单词,或者需要生成具有时间结构的输出,诸如文本描述中的单词。
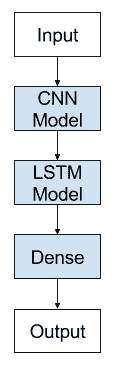
卷积神经网络长短期记忆网络架构
在 Keras 实现 CNN LSTM
我们可以定义一个在 Keras 联合训练的 CNN LSTM 模型。
可以通过在前端添加 CNN 层,然后在输出上添加具有 Dense 层的 LSTM 层来定义 CNN LSTM。
将此架构视为定义两个子模型是有帮助的:用于特征提取的 CNN 模型和用于跨时间步骤解释特征的 LSTM 模型。
让我们在一系列 2D 输入的背景下看一下这两个子模型,我们假设它们是图像。
CNN 模型
作为复习,我们可以定义一个 2D 卷积网络,它由 Conv2D 和 MaxPooling2D 层组成,这些层被排列成所需深度的栈。
Conv2D 将解释图像的快照(例如小方块),并且轮询层将合并或抽象解释。
例如,下面的片段期望读入具有 1 个通道(例如,黑色和白色)的 10×10 像素图像。 Conv2D 将以 2×2 快照读取图像,并输出一个新的 10×10 图像解释。 MaxPooling2D 将解释汇集为 2×2 块,将输出减少到 5×5 合并。 Flatten 层将采用单个 5×5 贴图并将其转换为 25 个元素的向量,准备用于处理其他层,例如用于输出预测的 Dense。
cnn = Sequential()
cnn.add(Conv2D(1, (2,2), activation='relu', padding='same', input_shape=(10,10,1)))
cnn.add(MaxPooling2D(pool_size=(2, 2)))
cnn.add(Flatten())
这对于图像分类和其他计算机视觉任务是有意义的。
LSTM 模型
上面的 CNN 模型仅能够处理单个图像,将其从输入像素变换为内部矩阵或向量表示。
我们需要跨多个图像重复此操作,并允许 LSTM 在输入图像的内部向量表示序列中使用 BPTT 建立内部状态和更新权重。
在使用现有的预训练模型(如 VGG)从图像中提取特征的情况下,可以固定 CNN。 CNN 可能未经过训练,我们可能希望通过将来自 LSTM 的错误反向传播到多个输入图像到 CNN 模型来训练它。
在这两种情况下,概念上存在单个 CNN 模型和一系列 LSTM 模型,每个时间步长一个。我们希望将 CNN 模型应用于每个输入图像,并将每个输入图像的输出作为单个时间步骤传递给 LSTM。
我们可以通过在 TimeDistributed 层中包装整个 CNN 输入模型(一层或多层)来实现这一点。该层实现了多次应用相同层的期望结果。在这种情况下,将其多次应用于多个输入时间步骤,并依次向 LSTM 模型提供一系列“图像解释”或“图像特征”以进行处理。
model.add(TimeDistributed(...))
model.add(LSTM(...))
model.add(Dense(...))
我们现在有模型的两个元素;让我们把它们放在一起。
CNN LSTM 模型
我们可以在 Keras 中定义 CNN LSTM 模型,首先定义一个或多个 CNN 层,将它们包装在 TimeDistributed 层中,然后定义 LSTM 和输出层。
我们有两种方法可以定义相同的模型,只是在品味上有所不同。
您可以首先定义 CNN 模型,然后通过将整个 CNN 层序列包装在 TimeDistributed 层中将其添加到 LSTM 模型,如下所示:
# define CNN model
cnn = Sequential()
cnn.add(Conv2D(...))
cnn.add(MaxPooling2D(...))
cnn.add(Flatten())
# define LSTM model
model = Sequential()
model.add(TimeDistributed(cnn, ...))
model.add(LSTM(..))
model.add(Dense(...))
另一种也许更容易阅读的方法是在将 CNN 模型中的每个层添加到主模型时,将其包装在 TimeDistributed 层中。
model = Sequential()
# define CNN model
model.add(TimeDistributed(Conv2D(...))
model.add(TimeDistributed(MaxPooling2D(...)))
model.add(TimeDistributed(Flatten()))
# define LSTM model
model.add(LSTM(...))
model.add(Dense(...))
第二种方法的好处是所有层都出现在模型摘要中,因此现在是首选。
您可以选择您喜欢的方法。
进一步阅读
如果您要深入了解,本节将提供有关该主题的更多资源。
CNN LSTM 论文
- 用于视觉识别和描述的长期循环卷积网络,2015。
- Show and Tell:神经图像标题生成器,2015。
- 卷积,长短期记忆,完全连接的深度神经网络,2015。
- 字符意识神经语言模型,2015。
- 卷积 LSTM 网络:用于降水预报的机器学习方法,2015。
Keras API
帖子
- 用于机器学习的卷积神经网络的速成课程
- 用 Keras 在 Python 中用 LSTM 循环神经网络进行序列分类
摘要
在这篇文章中,您发现了 CNN LSTM 模型架构。
具体来说,你学到了:
- 关于用于序列预测的 CNN LSTM 模型架构的开发。
- CNN LSTM 模型适合的问题类型的示例。
- 如何使用 Keras 在 Python 中实现 CNN LSTM 架构。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。
深度学习中的循环神经网络的速成课程
原文:
machinelearningmastery.com/crash-course-recurrent-neural-networks-deep-learning/
另一种类型的神经网络主导着困难的机器学习问题,涉及称为循环神经网络的输入序列。
循环神经网络具有连接,其具有循环,随时间向网络添加反馈和存储器。该存储器允许这种类型的网络学习和概括输入序列而不是单个模式。
一种称为长短期记忆网络的强大类型的循环神经网络在堆叠成深层配置时显示出特别有效,从语言翻译到自动字幕等各种各样的问题上实现了最先进的结果的图像和视频。
在这篇文章中,您将获得用于深度学习的循环神经网络的速成课程,获得足够的理解以开始在使用 Keras 的 Python 中使用 LSTM 网络。
阅读这篇文章后,你会知道:
- 通过循环神经网络解决的多层感知机的局限性。
- 必须解决的问题是使循环神经网络有用。
- 应用深度学习中使用的长短期记忆网络的细节。
让我们开始吧。

用于深度学习的循环神经网络的速成课程
Martin Fisch 的照片,保留一些权利。
支持神经网络中的序列
有一些问题类型是最好的框架,涉及序列作为输入或输出。
例如,考虑一个单变量的时间序列问题,例如股票随时间的价格。通过定义窗口大小(例如 5)并训练网络学习从固定大小的输入窗口进行短期预测,可以将该数据集构建为经典前馈多层感知机网络的预测问题。
这可行,但非常有限。输入窗口为问题增加了记忆,但仅限于固定数量的点,必须在充分了解问题的情况下进行选择。一个朴素的窗口无法捕捉可能与预测相关的分钟,小时和天的更广泛趋势。从一个预测到下一个预测,网络仅知道它所提供的特定输入。
单变量时间序列预测很重要,但还有更多有趣的问题涉及序列。
考虑以下需要将输入映射到输出的序列问题分类(取自 Andrej Karpathy)。
- 一对多:序列输出,用于图像字幕。
- 多对一:序列输入,用于情感分类。
- 多对多:序列输入和输出,用于机器翻译。
- 同步多对多:同步序列输入和输出,用于视频分类。
我们还可以看到输入到输出的一对一示例将是用于诸如图像分类的预测任务的经典前馈神经网络的示例。
对神经网络中的序列的支持是一类重要的问题,并且深度学习最近显示出令人印象深刻的结果。最先进的结果是使用一种专门为序列问题设计的网络,称为循环神经网络。
循环神经网络
循环神经网络或 RNN 是一种特殊类型的神经网络,专为序列问题而设计。
给定标准的前馈多层 Perceptron 网络,可以将循环神经网络视为向架构添加循环。例如,在给定层中,除了前进到下一层之外,每个神经元可以随后(侧向)传递其信号。网络的输出可以作为具有下一输入向量的网络的输入反馈。等等。
循环连接为网络添加状态或内存,并允许它从输入序列中学习更广泛的抽象。
利用流行的方法很好地建立了循环神经网络领域。为了使技术在实际问题上有效,需要解决两个主要问题,使网络变得有用。
- 如何使用反向传播训练网络。
- 如何在训练期间停止梯度消失和爆炸。
1.如何训练循环神经网络
用于训练前馈神经网络的主要技术是反向传播错误并更新网络权重。
由于循环或循环连接,反向传播在循环神经网络中发生故障。
这通过对后传播技术的改进来解决,该技术称为反向传播时间或 BPTT。
如上所述,不是在循环网络上执行反向传播,而是展开网络的结构,其中创建具有循环连接的神经元的副本。例如,具有与其自身连接的单个神经元(A-> A)可以表示为具有相同权重值的两个神经元(A-> B)。
这允许将循环神经网络的循环图转换为类似经典前馈神经网络的非循环图,并且可以应用反向传播。
2.如何在训练期间保持稳定的梯度
当反向传播用于非常深的神经网络和展开的循环神经网络时,为更新权重而计算的梯度可能变得不稳定。
它们可以变成非常大的数字,称为梯度爆炸或非常小的数字,称为消失梯度问题。反过来,这些大数字用于更新网络中的权重,使训练不稳定,网络不可靠。
通过使用整流器传递函数,这种问题在深层多层感知机网络中得到了缓解,甚至更加奇特但现在不那么流行的使用无监督预层训练的方法。
在循环神经网络架构中,使用称为长短期记忆网络的新型架构可以缓解这个问题,该架构允许训练深度复现网络。
长期短期记忆网络
长期短期记忆或 LSTM 网络是一种循环神经网络,使用反向传播时间训练并克服消失的梯度问题。
因此,它可以用于创建大型(堆叠)循环网络,这反过来可以用于解决机器学习中的困难序列问题并实现最先进的结果。
LSTM 网络具有连接到层中的存储块,而不是神经元。
块具有使其比经典神经元更聪明的组件和用于最近序列的存储器。块包含管理块状态和输出的门。单元对输入序列进行操作,并且单元内的每个门使用 S 形激活功能来控制它们是否被触发,使状态的改变和流过该单元的信息的添加成为条件。
存储器单元中有三种类型的门:
- 忘记门:有条件地决定从本机丢弃哪些信息。
- 输入门:有条件地决定输入中的哪些值来更新存储器状态。
- 输出门:根据输入和设备的内存有条件地决定输出内容。
每个单元就像一个小型状态机,其中单元的门具有在训练过程中学习的权重。
您可以看到如何从一层 LSTM 中获得复杂的学习和记忆,并且不难想象高阶抽象如何与多个这样的层分层。
资源
我们在这篇文章中介绍了很多内容。下面是一些资源,您可以使用这些资源深入了解用于深度学习的循环神经网络的主题。
有关了解 Recurrent Neural Networks 和 LSTM 的更多信息的资源。
- 维基百科上的循环神经网络
- 维基百科上的长短期记忆
- 反复神经网络的不合理效力作者:Andrej Karpathy
- 了解 LSTM 网络
- 深入研究循环神经网络
- 经常性网络和 LSTM 初学者指南
实现 LSTM 的热门教程。
LSTM 的主要来源。
- 长期记忆 [pdf],1997 年 Hochreiter 和 Schmidhuber 的论文
- 学会忘记:使用 LSTM 进行持续预测,2000 年 Schmidhuber 和 Cummins 加上遗忘门
- 关于训练循环神经网络的难度 [pdf],2013
人们跟随 LSTM 做了很多工作。
摘要
在这篇文章中,您发现了序列问题和可用于解决它们的循环神经网络。
具体来说,你学到了:
- 经典前馈神经网络的局限性以及循环神经网络如何克服这些问题。
- 训练复现神经网络的实际问题及其克服方法。
- 用于创建深度循环神经网络的长短期记忆网络。
您对深度循环神经网络,LSTM 或关于这篇文章有任何疑问吗?在评论中提出您的问题,我会尽力回答。
可变长度输入序列的数据准备
原文:
machinelearningmastery.com/data-preparation-variable-length-input-sequences-sequence-prediction/
深度学习库假设您的数据的向量化表示。
在可变长度序列预测问题的情况下,这需要转换您的数据,使得每个序列具有相同的长度。
此向量化允许代码有效地为您选择的深度学习算法批量执行矩阵运算。
在本教程中,您将发现可用于使用 Keras 在 Python 中为序列预测问题准备可变长度序列数据的技术。
完成本教程后,您将了解:
- 如何填充具有虚拟值的可变长度序列。
- 如何将可变长度序列填充到新的更长的期望长度。
- 如何将可变长度序列截断为更短的期望长度。
让我们开始吧。

用于序列预测的可变长度输入序列的数据准备
照片由 Adam Bautz ,保留一些权利。
概观
本节分为 3 部分;他们是:
- 受控序列问题
- 序列填充
- 序列截断
环境
本教程假定您已安装 Python SciPy 环境。您可以在此示例中使用 Python 2 或 3。
本教程假设您使用 TensorFlow(v1.1.0 +)或 Theano(v0.9 +)后端安装了 Keras(v2.0.4 +)。
本教程还假设您安装了 scikit-learn,Pandas,NumPy 和 Matplotlib。
如果您在设置 Python 环境时需要帮助,请参阅以下帖子:
受控序列问题
为了本教程的目的,我们可以设计一个简单的序列问题。
该问题被定义为整数序列。有三个序列,长度在 4 到 1 个步骤之间,如下所示:
1, 2, 3, 4
1, 2, 3
1
这些可以在 Python 中定义为列表列表,如下所示(可读性的间距):
sequences = [
[1, 2, 3, 4],
[1, 2, 3],
[1]
]
我们将使用这些序列作为本教程中探索序列填充的基础。
序列填充
Keras 深度学习库中的 pad_sequences()函数可用于填充可变长度序列。
默认填充值为 0.0,适用于大多数应用程序,但可以通过“value”参数指定首选值来更改。例如:
pad_sequences(..., value=99)
要应用于序列的开头或结尾的填充(称为前序列或后序列填充)可以通过“填充”参数指定,如下所示。
预序列填充
预序列填充是默认值(padding =‘pre’)
下面的示例演示了具有 0 值的预填充 3 输入序列。
from keras.preprocessing.sequence import pad_sequences
# define sequences
sequences = [
[1, 2, 3, 4],
[1, 2, 3],
[1]
]
# pad sequence
padded = pad_sequences(sequences)
print(padded)
运行该示例将打印 3 个预先填充零序列的序列。
[[1 2 3 4]
[0 1 2 3]
[0 0 0 1]
序列后填充
填充也可以应用于序列的末尾,这可能更适合于某些问题域。
可以通过将“padding”参数设置为“post”来指定序列后填充。
from keras.preprocessing.sequence import pad_sequences
# define sequences
sequences = [
[1, 2, 3, 4],
[1, 2, 3],
[1]
]
# pad sequence
padded = pad_sequences(sequences, padding='post')
print(padded)
运行该示例将打印相同的序列,并附加零值。
[[1 2 3 4]
[1 2 3 0]
[1 0 0 0]]
填充序列到长度
pad_sequences()函数还可用于将序列填充到可能比任何观察到的序列更长的优选长度。
这可以通过将“maxlen”参数指定为所需长度来完成。然后将对所有序列执行填充以获得所需的长度,如下所述。
from keras.preprocessing.sequence import pad_sequences
# define sequences
sequences = [
[1, 2, 3, 4],
[1, 2, 3],
[1]
]
# pad sequence
padded = pad_sequences(sequences, maxlen=5)
print(padded)
运行示例将每个序列填充到所需的 5 个步骤的长度,即使观察序列的最大长度仅为 4 个步骤。
[[0 1 2 3 4]
[0 0 1 2 3]
[0 0 0 0 1]]
序列截断
序列的长度也可以修剪到所需的长度。
可以使用“maxlen”参数将所需的序列长度指定为多个时间步长。
有两种方法可以截断序列:通过从序列的开头或末尾删除时间步长。
序列前截断
默认的截断方法是从序列的开头删除时间步。这称为序列前截断。
下面的示例将序列截断为所需的长度 2。
from keras.preprocessing.sequence import pad_sequences
# define sequences
sequences = [
[1, 2, 3, 4],
[1, 2, 3],
[1]
]
# truncate sequence
truncated= pad_sequences(sequences, maxlen=2)
print(truncated)
运行该示例将从第一个序列中删除前两个时间步,从第二个序列中删除第一个时间步,并填充最终序列。
[[3 4]
[2 3]
[0 1]]
序列后截断
也可以通过从序列末尾删除时间步长来修剪序列。
对于某些问题域,这种方法可能更合适。
可以通过将“截断”参数从默认的“pre”更改为“post”来配置序列后截断,如下所示:
from keras.preprocessing.sequence import pad_sequences
# define sequences
sequences = [
[1, 2, 3, 4],
[1, 2, 3],
[1]
]
# truncate sequence
truncated= pad_sequences(sequences, maxlen=2, truncating='post')
print(truncated)
运行该示例将从第一个序列中删除最后两个时间步,从第二个序列中删除最后一个时间步,然后再次填充最终序列。
[[1 2]
[1 2]
[0 1]]
摘要
在本教程中,您了解了如何准备可变长度序列数据以用于 Python 中的序列预测问题。
具体来说,你学到了:
- 如何填充具有虚拟值的可变长度序列。
- 如何将可变长度序列填充到新的所需长度。
- 如何将可变长度序列截断为新的所需长度。
您对准备可变长度序列有任何疑问吗?
在评论中提出您的问题,我会尽力回答。
如何用 Python 和 Keras 开发用于序列分类的双向 LSTM
原文:
machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/
双向 LSTM 是传统 LSTM 的扩展,可以提高序列分类问题的模型表现。
在输入序列的所有时间步长都可用的问题中,双向 LSTM 在输入序列上训练两个而不是一个 LSTM。输入序列中的第一个是原样,第二个是输入序列的反向副本。这可以为网络提供额外的上下文,从而更快,更全面地学习问题。
在本教程中,您将了解如何使用 Keras 深度学习库在 Python 中开发用于序列分类的双向 LSTM。
完成本教程后,您将了解:
- 如何开发一个小的人为和可配置的序列分类问题。
- 如何开发 LSTM 和双向 LSTM 用于序列分类。
- 如何比较双向 LSTM 中使用的合并模式的表现。
让我们开始吧。

如何使用 Keras 开发用于 Python 序列分类的双向 LSTM
照片由 Cristiano Medeiros Dalbem ,保留一些权利。
概观
本教程分为 6 个部分;他们是:
- 双向 LSTM
- 序列分类问题
- LSTM 用于序列分类
- 用于序列分类的双向 LSTM
- 将 LSTM 与双向 LSTM 进行比较
- 比较双向 LSTM 合并模式
环境
本教程假定您已安装 Python SciPy 环境。您可以在此示例中使用 Python 2 或 3。
本教程假设您使用 TensorFlow(v1.1.0 +)或 Theano(v0.9 +)后端安装了 Keras(v2.0.4 +)。
本教程还假设您安装了 scikit-learn,Pandas,NumPy 和 Matplotlib。
如果您在设置 Python 环境时需要帮助,请参阅以下帖子:
双向 LSTM
双向循环神经网络(RNN)的想法很简单。
它涉及复制网络中的第一个复现层,以便现在有两个并排的层,然后按原样提供输入序列作为第一层的输入,并将输入序列的反向副本提供给第二层。
为了克服常规 RNN 的局限性,我们提出了一种双向循环神经网络(BRNN),可以在特定时间范围的过去和未来使用所有可用的输入信息进行训练。
…
这个想法是将常规 RNN 的状态神经元分成负责正时间方向的部分(前向状态)和负时间方向的部分(后向状态)。
- Mike Schuster 和 Kuldip K. Paliwal,双向循环神经网络,1997
这种方法已被用于长期短期记忆(LSTM)循环神经网络的巨大效果。
最初在语音识别领域中使用双向提供序列是合理的,因为有证据表明整个话语的语境用于解释所说的内容而不是线性解释。
…依赖于对未来的了解似乎乍一看违反了因果关系。我们怎样才能将我们所听到的东西的理解基于尚未说过的东西?然而,人类听众正是这样做的。根据未来的背景,听起来,单词甚至整个句子最初都意味着没有任何意义。我们必须记住的是真正在线的任务之间的区别 - 在每次输入后需要输出 - 以及仅在某些输入段结束时需要输出的任务。
- Alex Graves 和 Jurgen Schmidhuber,具有双向 LSTM 和其他神经网络架构的 Framewise 音素分类,2005
双向 LSTM 的使用对于所有序列预测问题可能没有意义,但是对于那些适当的域,可以提供更好的结果。
我们发现双向网络比单向网络明显更有效…
— Alex Graves and Jurgen Schmidhuber, Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005
需要说明的是,输入序列中的时间步长仍然是一次处理一次,只是网络同时在两个方向上逐步通过输入序列。
Keras 中的双向 LSTM
Keras 通过双向层包装器支持双向 LSTM。
该包装器将循环层(例如第一个 LSTM 层)作为参数。
它还允许您指定合并模式,即在传递到下一层之前应如何组合前向和后向输出。选项是:
- ‘
sum’:输出加在一起。 - ‘
mul’:输出相乘。 - ‘
concat’:输出连接在一起(默认值),为下一层提供两倍的输出。 - ‘
ave’:输出的平均值。
默认模式是连接,这是双向 LSTM 研究中经常使用的方法。
序列分类问题
我们将定义一个简单的序列分类问题来探索双向 LSTM。
该问题被定义为 0 和 1 之间的随机值序列。该序列被作为问题的输入,每个时间步提供一个数字。
二进制标签(0 或 1)与每个输入相关联。输出值均为 0.一旦序列中输入值的累积和超过阈值,则输出值从 0 翻转为 1。
使用序列长度的 1/4 的阈值。
例如,下面是 10 个输入时间步长(X)的序列:
0.63144003 0.29414551 0.91587952 0.95189228 0.32195638 0.60742236 0.83895793 0.18023048 0.84762691 0.29165514
相应的分类输出(y)将是:
0 0 0 1 1 1 1 1 1 1
我们可以用 Python 实现它。
第一步是生成一系列随机值。我们可以使用随机模块中的 random()函数。
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(10)])
我们可以将阈值定义为输入序列长度的四分之一。
# calculate cut-off value to change class values
limit = 10/4.0
可以使用 cumsum()NumPy 函数计算输入序列的累积和。此函数返回一系列累积和值,例如:
pos1, pos1+pos2, pos1+pos2+pos3, ...
然后我们可以计算输出序列,确定每个累积和值是否超过阈值。
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
下面的函数名为 get_sequence(),将所有这些一起绘制,将序列的长度作为输入,并返回新问题案例的 X 和 y 分量。
from random import random
from numpy import array
from numpy import cumsum
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
return X, y
我们可以使用新的 10 个步骤序列测试此函数,如下所示:
X, y = get_sequence(10)
print(X)
print(y)
首先运行该示例打印生成的输入序列,然后输出匹配的输出序列。
[ 0.22228819 0.26882207 0.069623 0.91477783 0.02095862 0.71322527
0.90159654 0.65000306 0.88845226 0.4037031 ]
[0 0 0 0 0 0 1 1 1 1]
LSTM 用于序列分类
我们可以从为序列分类问题开发传统的 LSTM 开始。
首先,我们必须更新 get_sequence()函数以将输入和输出序列重新整形为 3 维以满足 LSTM 的期望。预期结构具有尺寸[样本,时间步长,特征]。分类问题具有 1 个样本(例如,一个序列),可配置的时间步长,以及每个时间步长一个特征。
分类问题具有 1 个样本(例如,一个序列),可配置的时间步长,以及每个时间步长一个特征。
因此,我们可以如下重塑序列。
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
更新后的 get_sequence()函数如下所示。
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
我们将序列定义为具有 10 个时间步长。
接下来,我们可以为问题定义 LSTM。输入层将有 10 个时间步长,1 个特征是一个片段,input_shape =(10,1)。
第一个隐藏层将具有 20 个存储器单元,输出层将是完全连接的层,每个时间步输出一个值。在输出上使用 sigmoid 激活函数来预测二进制值。
在输出层周围使用 TimeDistributed 包装层,以便在给定作为输入提供的完整序列的情况下,可以预测每个时间步长一个值。这要求 LSTM 隐藏层返回一系列值(每个时间步长一个)而不是整个输入序列的单个值。
最后,因为这是二分类问题,所以使用二进制日志丢失(Keras 中的 binary_crossentropy)。使用有效的 ADAM 优化算法来找到权重,并且计算每个时期的精度度量并报告。
# define LSTM
model = Sequential()
model.add(LSTM(20, input_shape=(10, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
LSTM 将接受 1000 个时期的训练。将在每个时期生成新的随机输入序列以使网络适合。这可以确保模型不记忆单个序列,而是可以推广解决方案以解决此问题的所有可能的随机输入序列。
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
一旦经过训练,网络将在另一个随机序列上进行评估。然后将预测与预期输出序列进行比较,以提供系统技能的具体示例。
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print('Expected:', y[0, i], 'Predicted', yhat[0, i])
下面列出了完整的示例。
from random import random
from numpy import array
from numpy import cumsum
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
# define problem properties
n_timesteps = 10
# define LSTM
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print('Expected:', y[0, i], 'Predicted', yhat[0, i])
运行该示例在每个时期的随机序列上打印日志丢失和分类准确率。
这清楚地表明了模型对序列分类问题的解决方案的概括性。
我们可以看到该模型表现良好,达到最终准确度,徘徊在 90%左右,准确率达到 100%。不完美,但对我们的目的有好处。
将新随机序列的预测与预期值进行比较,显示出具有单个错误的大多数正确结果。
...
Epoch 1/1
0s - loss: 0.2039 - acc: 0.9000
Epoch 1/1
0s - loss: 0.2985 - acc: 0.9000
Epoch 1/1
0s - loss: 0.1219 - acc: 1.0000
Epoch 1/1
0s - loss: 0.2031 - acc: 0.9000
Epoch 1/1
0s - loss: 0.1698 - acc: 0.9000
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
用于序列分类的双向 LSTM
现在我们知道如何为序列分类问题开发 LSTM,我们可以扩展该示例来演示双向 LSTM。
我们可以通过使用双向层包装 LSTM 隐藏层来完成此操作,如下所示:
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1)))
这将创建隐藏层的两个副本,一个适合输入序列,一个适合输入序列的反向副本。默认情况下,将连接这些 LSTM 的输出值。
这意味着,而不是 TimeDistributed 层接收 10 个时间段的 20 个输出,它现在将接收 10 个时间段的 40(20 个单位+ 20 个单位)输出。
The complete example is listed below.
from random import random
from numpy import array
from numpy import cumsum
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import Bidirectional
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
# define problem properties
n_timesteps = 10
# define LSTM
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1)))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print('Expected:', y[0, i], 'Predicted', yhat[0, i])
运行该示例,我们看到与前一个示例中类似的输出。
双向 LSTM 的使用具有允许 LSTM 更快地学习问题的效果。
通过在运行结束时查看模型的技能,而不是模型的技能,这一点并不明显。
...
Epoch 1/1
0s - loss: 0.0967 - acc: 0.9000
Epoch 1/1
0s - loss: 0.0865 - acc: 1.0000
Epoch 1/1
0s - loss: 0.0905 - acc: 0.9000
Epoch 1/1
0s - loss: 0.2460 - acc: 0.9000
Epoch 1/1
0s - loss: 0.1458 - acc: 0.9000
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
将 LSTM 与双向 LSTM 进行比较
在此示例中,我们将在模型正在训练期间比较传统 LSTM 与双向 LSTM 的表现。
我们将调整实验,以便模型仅训练 250 个时期。这样我们就可以清楚地了解每个模型的学习方式以及学习行为与双向 LSTM 的不同之处。
我们将比较三种不同的模型;特别:
- LSTM(原样)
- 具有反向输入序列的 LSTM(例如,您可以通过将 LSTM 层的“go_backwards”参数设置为“True”来执行此操作)
- 双向 LSTM
这种比较将有助于表明双向 LSTM 实际上可以添加的东西不仅仅是简单地反转输入序列。
我们将定义一个函数来创建和返回带有前向或后向输入序列的 LSTM,如下所示:
def get_lstm_model(n_timesteps, backwards):
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
我们可以为双向 LSTM 开发类似的函数,其中可以将合并模式指定为参数。可以通过将合并模式设置为值’concat’来指定串联的默认值。
def get_bi_lstm_model(n_timesteps, mode):
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
最后,我们定义一个函数来拟合模型并检索和存储每个训练时期的损失,然后在模型拟合后返回收集的损失值的列表。这样我们就可以绘制每个模型配置的日志丢失图并进行比较。
def train_model(model, n_timesteps):
loss = list()
for _ in range(250):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0)
loss.append(hist.history['loss'][0])
return loss
综合这些,下面列出了完整的例子。
首先,创建并拟合传统的 LSTM 并绘制对数损失值。使用具有反向输入序列的 LSTM 重复此操作,最后使用具有级联合并的 LSTM 重复此操作。
from random import random
from numpy import array
from numpy import cumsum
from matplotlib import pyplot
from pandas import DataFrame
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
from keras.layers import Bidirectional
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
def get_lstm_model(n_timesteps, backwards):
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
def get_bi_lstm_model(n_timesteps, mode):
model = Sequential()
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
def train_model(model, n_timesteps):
loss = list()
for _ in range(250):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0)
loss.append(hist.history['loss'][0])
return loss
n_timesteps = 10
results = DataFrame()
# lstm forwards
model = get_lstm_model(n_timesteps, False)
results['lstm_forw'] = train_model(model, n_timesteps)
# lstm backwards
model = get_lstm_model(n_timesteps, True)
results['lstm_back'] = train_model(model, n_timesteps)
# bidirectional concat
model = get_bi_lstm_model(n_timesteps, 'concat')
results['bilstm_con'] = train_model(model, n_timesteps)
# line plot of results
results.plot()
pyplot.show()
运行该示例会创建一个线图。
您的具体情节可能会有所不同,但会显示相同的趋势。
我们可以看到 LSTM 前向(蓝色)和 LSTM 后向(橙色)在 250 个训练时期内显示出类似的对数丢失。
我们可以看到双向 LSTM 日志丢失是不同的(绿色),更快地下降到更低的值并且通常保持低于其他两个配置。

LSTM,反向 LSTM 和双向 LSTM 的对数损失线图
比较双向 LSTM 合并模式
有 4 种不同的合并模式可用于组合双向 LSTM 层的结果。
它们是串联(默认),乘法,平均和总和。
我们可以通过更新上一节中的示例来比较不同合并模式的行为,如下所示:
n_timesteps = 10
results = DataFrame()
# sum merge
model = get_bi_lstm_model(n_timesteps, 'sum')
results['bilstm_sum'] = train_model(model, n_timesteps)
# mul merge
model = get_bi_lstm_model(n_timesteps, 'mul')
results['bilstm_mul'] = train_model(model, n_timesteps)
# avg merge
model = get_bi_lstm_model(n_timesteps, 'ave')
results['bilstm_ave'] = train_model(model, n_timesteps)
# concat merge
model = get_bi_lstm_model(n_timesteps, 'concat')
results['bilstm_con'] = train_model(model, n_timesteps)
# line plot of results
results.plot()
pyplot.show()
运行该示例将创建比较每个合并模式的日志丢失的线图。
您的具体情节可能有所不同,但会显示相同的行为趋势。
不同的合并模式会导致不同的模型表现,这将根据您的特定序列预测问题而变化。
在这种情况下,我们可以看到,总和(蓝色)和串联(红色)合并模式可能会带来更好的表现,或至少更低的日志丢失。

线图用于比较双向 LSTM 的合并模式
摘要
在本教程中,您了解了如何使用 Keras 在 Python 中开发用于序列分类的双向 LSTM。
具体来说,你学到了:
- 如何开发一个人为的序列分类问题。
- 如何开发 LSTM 和双向 LSTM 用于序列分类。
- 如何比较双向 LSTM 的合并模式以进行序列分类。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。
如何在 Keras 中开发用于序列到序列预测的编解码器模型
原文:
machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
编解码器模型提供了使用循环神经网络来解决具有挑战性的序列到序列预测问题(例如机器翻译)的模式。
可以在 Keras Python 深度学习库中开发编解码器模型,并且在 Keras 博客上描述了使用该模型开发的神经机器翻译系统的示例,其中示例代码与 Keras 项目一起分发。
这个例子可以为您自己的序列到序列预测问题提供编解码器 LSTM 模型的基础。
在本教程中,您将了解如何使用 Keras 为序列到序列预测问题开发复杂的编解码器循环神经网络。
完成本教程后,您将了解:
- 如何在 Keras 中正确定义复杂的编解码器模型以进行序列到序列预测。
- 如何定义可用于评估编解码器 LSTM 模型的人为但可扩展的序列到序列预测问题。
- 如何在 Keras 中应用编解码器 LSTM 模型来解决可伸缩的整数序列到序列预测问题。
让我们开始吧。

如何开发 Keras 序列到序列预测的编解码器模型
照片由BjörnGroß,保留一些权利。
教程概述
本教程分为 3 个部分;他们是:
- Keras 中的编解码器模型
- 可扩展的序列到序列问题
- 用于序列预测的编解码器 LSTM
Python 环境
本教程假定您已安装 Python SciPy 环境。您可以在本教程中使用 Python 2 或 3。
您必须安装带有 TensorFlow 或 Theano 后端的 Keras(2.0 或更高版本)。
本教程还假设您安装了 scikit-learn,Pandas,NumPy 和 Matplotlib。
如果您需要有关环境的帮助,请参阅此帖子:
Keras 中的编解码器模型
编解码器模型是一种组织序列到序列预测问题的循环神经网络的方法。
它最初是为机器翻译问题而开发的,尽管它已经证明在相关的序列到序列预测问题上是成功的,例如文本摘要和问题回答。
该方法涉及两个循环神经网络,一个用于编码源序列,称为编码器,第二个用于将编码的源序列解码为目标序列,称为解码器。
Keras 深度学习 Python 库提供了一个如何实现机器翻译的编解码器模型的例子( lstm_seq2seq.py ),由库创建者在帖子中描述:“十分钟的介绍在 Keras 中进行序列到序列学习。“
有关此型号的详细分类,请参阅帖子:
有关使用 return_state 的更多信息,可能是您的新手,请参阅帖子:
有关 Keras Functional API 入门的更多帮助,请参阅帖子:
使用该示例中的代码作为起点,我们可以开发一个通用函数来定义编解码器循环神经网络。下面是这个名为 define_models() 的函数。
# returns train, inference_encoder and inference_decoder models
def define_models(n_input, n_output, n_units):
# define training encoder
encoder_inputs = Input(shape=(None, n_input))
encoder = LSTM(n_units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
# define training decoder
decoder_inputs = Input(shape=(None, n_output))
decoder_lstm = LSTM(n_units, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(n_output, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# define inference encoder
encoder_model = Model(encoder_inputs, encoder_states)
# define inference decoder
decoder_state_input_h = Input(shape=(n_units,))
decoder_state_input_c = Input(shape=(n_units,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
# return all models
return model, encoder_model, decoder_model
该函数有 3 个参数,如下所示:
- n_input :输入序列的基数,例如每个时间步长的要素,单词或字符数。
- n_output :输出序列的基数,例如每个时间步长的要素,单词或字符数。
- n_units :在编码器和解码器模型中创建的单元数,例如 128 或 256。
然后该函数创建并返回 3 个模型,如下所示:
- train :在给定源,目标和移位目标序列的情况下可以训练的模型。
- inference_encoder :在对新源序列做出预测时使用的编码器模型。
- inference_decoder 解码器模型在对新源序列做出预测时使用。
在给定源序列和目标序列的情况下训练模型,其中模型将源序列和移位版本的目标序列作为输入并预测整个目标序列。
例如,一个源序列可以是[1,2,3]和靶序列[4,5,6]。训练期间模型的输入和输出将是:
Input1: ['1', '2', '3']
Input2: ['_', '4', '5']
Output: ['4', '5', '6']
当为新源序列生成目标序列时,该模型旨在被递归地调用。
对源序列进行编码,并且使用诸如“_”的“序列开始”字符一次一个元素地生成目标序列以开始该过程。因此,在上述情况下,在训练期间会出现以下输入输出对:
t, Input1, Input2, Output
1, ['1', '2', '3'], '_', '4'
2, ['1', '2', '3'], '4', '5'
3, ['1', '2', '3'], '5', '6'
在这里,您可以看到如何使用模型的递归使用来构建输出序列。
在预测期间,inference_encoder模型用于编码输入序列,其返回用于初始化inference_decoder模型的状态。从那时起,inference_decoder模型用于逐步生成预测。
在训练模型以生成给定源序列的目标序列之后,可以使用下面名为 predict_sequence() 的函数。
# generate target given source sequence
def predict_sequence(infenc, infdec, source, n_steps, cardinality):
# encode
state = infenc.predict(source)
# start of sequence input
target_seq = array([0.0 for _ in range(cardinality)]).reshape(1, 1, cardinality)
# collect predictions
output = list()
for t in range(n_steps):
# predict next char
yhat, h, c = infdec.predict([target_seq] + state)
# store prediction
output.append(yhat[0,0,:])
# update state
state = [h, c]
# update target sequence
target_seq = yhat
return array(output)
该函数有 5 个参数如下:
- infenc :在对新源序列做出预测时使用的编码器模型。
- infdec :在对新源序列做出预测时使用解码器模型。
- source :编码的源序列。
- n_steps :目标序列中的时间步数。
- 基数:输出序列的基数,例如每个时间步的要素,单词或字符的数量。
然后该函数返回包含目标序列的列表。
可扩展的序列到序列问题
在本节中,我们定义了一个人为的,可扩展的序列到序列预测问题。
源序列是一系列随机生成的整数值,例如[20,36,40,10,34,28],目标序列是输入序列的反向预定义子集,例如前 3 个元素以相反的顺序[40,36,20]。
源序列的长度是可配置的;输入和输出序列的基数以及目标序列的长度也是如此。
我们将使用 6 个元素的源序列,基数为 50,以及 3 个元素的目标序列。
下面是一些更具体的例子。
Source, Target
[13, 28, 18, 7, 9, 5] [18, 28, 13]
[29, 44, 38, 15, 26, 22] [38, 44, 29]
[27, 40, 31, 29, 32, 1] [31, 40, 27]
...
我们鼓励您探索更大,更复杂的变体。在下面的评论中发布您的发现。
让我们首先定义一个函数来生成一系列随机整数。
我们将使用 0 的值作为填充或序列字符的开头,因此它是保留的,我们不能在源序列中使用它。为实现此目的,我们将为配置的基数添加 1,以确保单热编码足够大(例如,值 1 映射到索引 1 中的’1’值)。
例如:
n_features = 50 + 1
我们可以使用randint()python 函数生成 1 到 1 范围内的随机整数 - 减去问题基数的大小。下面的 generate_sequence() 生成一系列随机整数。
# generate a sequence of random integers
def generate_sequence(length, n_unique):
return [randint(1, n_unique-1) for _ in range(length)]
接下来,我们需要在给定源序列的情况下创建相应的输出序列。
为了简单起见,我们将选择源序列的前 n 个元素作为目标序列并反转它们。
# define target sequence
target = source[:n_out]
target.reverse()
我们还需要一个版本的输出序列向前移动一个步骤,我们可以将其用作到目前为止生成的模拟目标,包括第一个时间步骤中序列值的开始。我们可以直接从目标序列创建它。
# create padded input target sequence
target_in = [0] + target[:-1]
现在已经定义了所有序列,我们可以对它们进行一次热编码,即将它们转换成二进制向量序列。我们可以使用内置 to_categorical() 函数的 Keras 来实现这一点。
我们可以将所有这些放入名为 get_dataset() 的函数中,该函数将生成特定数量的序列,我们可以使用它来训练模型。
# prepare data for the LSTM
def get_dataset(n_in, n_out, cardinality, n_samples):
X1, X2, y = list(), list(), list()
for _ in range(n_samples):
# generate source sequence
source = generate_sequence(n_in, cardinality)
# define target sequence
target = source[:n_out]
target.reverse()
# create padded input target sequence
target_in = [0] + target[:-1]
# encode
src_encoded = to_categorical([source], num_classes=cardinality)
tar_encoded = to_categorical([target], num_classes=cardinality)
tar2_encoded = to_categorical([target_in], num_classes=cardinality)
# store
X1.append(src_encoded)
X2.append(tar2_encoded)
y.append(tar_encoded)
return array(X1), array(X2), array(y)
最后,我们需要能够解码单热门的编码序列,使其再次可读。
这对于打印所生成的靶序列以及容易地比较完整预测的靶序列是否与预期的靶序列匹配是必需的。 one_hot_decode() 函数将解码编码序列。
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
我们可以将所有这些结合在一起并测试这些功能。
下面列出了一个完整的工作示例。
from random import randint
from numpy import array
from numpy import argmax
from keras.utils import to_categorical
# generate a sequence of random integers
def generate_sequence(length, n_unique):
return [randint(1, n_unique-1) for _ in range(length)]
# prepare data for the LSTM
def get_dataset(n_in, n_out, cardinality, n_samples):
X1, X2, y = list(), list(), list()
for _ in range(n_samples):
# generate source sequence
source = generate_sequence(n_in, cardinality)
# define target sequence
target = source[:n_out]
target.reverse()
# create padded input target sequence
target_in = [0] + target[:-1]
# encode
src_encoded = to_categorical([source], num_classes=cardinality)
tar_encoded = to_categorical([target], num_classes=cardinality)
tar2_encoded = to_categorical([target_in], num_classes=cardinality)
# store
X1.append(src_encoded)
X2.append(tar2_encoded)
y.append(tar_encoded)
return array(X1), array(X2), array(y)
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
# configure problem
n_features = 50 + 1
n_steps_in = 6
n_steps_out = 3
# generate a single source and target sequence
X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 1)
print(X1.shape, X2.shape, y.shape)
print('X1=%s, X2=%s, y=%s' % (one_hot_decode(X1[0]), one_hot_decode(X2[0]), one_hot_decode(y[0])))
首先运行示例打印生成的数据集的形状,确保训练模型所需的 3D 形状符合我们的期望。
然后将生成的序列解码并打印到屏幕,证明源和目标序列的准备符合我们的意图并且解码操作正在起作用。
(1, 6, 51) (1, 3, 51) (1, 3, 51)
X1=[32, 16, 12, 34, 25, 24], X2=[0, 12, 16], y=[12, 16, 32]
我们现在准备为这个序列到序列预测问题开发一个模型。
用于序列预测的编解码器 LSTM
在本节中,我们将第一部分中开发的编解码器 LSTM 模型应用于第二部分中开发的序列到序列预测问题。
第一步是配置问题。
# configure problem
n_features = 50 + 1
n_steps_in = 6
n_steps_out = 3
接下来,我们必须定义模型并编译训练模型。
# define model
train, infenc, infdec = define_models(n_features, n_features, 128)
train.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
接下来,我们可以生成 100,000 个示例的训练数据集并训练模型。
# generate training dataset
X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 100000)
print(X1.shape,X2.shape,y.shape)
# train model
train.fit([X1, X2], y, epochs=1)
一旦模型被训练,我们就可以对其进行评估。我们将通过对 100 个源序列做出预测并计算正确预测的目标序列的数量来实现此目的。我们将在解码序列上使用 numpy array_equal() 函数来检查是否相等。
# evaluate LSTM
total, correct = 100, 0
for _ in range(total):
X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 1)
target = predict_sequence(infenc, infdec, X1, n_steps_out, n_features)
if array_equal(one_hot_decode(y[0]), one_hot_decode(target)):
correct += 1
print('Accuracy: %.2f%%' % (float(correct)/float(total)*100.0))
最后,我们将生成一些预测并打印解码的源,目标和预测的目标序列,以了解模型是否按预期工作。
将所有这些元素放在一起,下面列出了完整的代码示例。
from random import randint
from numpy import array
from numpy import argmax
from numpy import array_equal
from keras.utils import to_categorical
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from keras.layers import Dense
# generate a sequence of random integers
def generate_sequence(length, n_unique):
return [randint(1, n_unique-1) for _ in range(length)]
# prepare data for the LSTM
def get_dataset(n_in, n_out, cardinality, n_samples):
X1, X2, y = list(), list(), list()
for _ in range(n_samples):
# generate source sequence
source = generate_sequence(n_in, cardinality)
# define padded target sequence
target = source[:n_out]
target.reverse()
# create padded input target sequence
target_in = [0] + target[:-1]
# encode
src_encoded = to_categorical([source], num_classes=cardinality)
tar_encoded = to_categorical([target], num_classes=cardinality)
tar2_encoded = to_categorical([target_in], num_classes=cardinality)
# store
X1.append(src_encoded)
X2.append(tar2_encoded)
y.append(tar_encoded)
return array(X1), array(X2), array(y)
# returns train, inference_encoder and inference_decoder models
def define_models(n_input, n_output, n_units):
# define training encoder
encoder_inputs = Input(shape=(None, n_input))
encoder = LSTM(n_units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
# define training decoder
decoder_inputs = Input(shape=(None, n_output))
decoder_lstm = LSTM(n_units, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(n_output, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# define inference encoder
encoder_model = Model(encoder_inputs, encoder_states)
# define inference decoder
decoder_state_input_h = Input(shape=(n_units,))
decoder_state_input_c = Input(shape=(n_units,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
# return all models
return model, encoder_model, decoder_model
# generate target given source sequence
def predict_sequence(infenc, infdec, source, n_steps, cardinality):
# encode
state = infenc.predict(source)
# start of sequence input
target_seq = array([0.0 for _ in range(cardinality)]).reshape(1, 1, cardinality)
# collect predictions
output = list()
for t in range(n_steps):
# predict next char
yhat, h, c = infdec.predict([target_seq] + state)
# store prediction
output.append(yhat[0,0,:])
# update state
state = [h, c]
# update target sequence
target_seq = yhat
return array(output)
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
# configure problem
n_features = 50 + 1
n_steps_in = 6
n_steps_out = 3
# define model
train, infenc, infdec = define_models(n_features, n_features, 128)
train.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
# generate training dataset
X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 100000)
print(X1.shape,X2.shape,y.shape)
# train model
train.fit([X1, X2], y, epochs=1)
# evaluate LSTM
total, correct = 100, 0
for _ in range(total):
X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 1)
target = predict_sequence(infenc, infdec, X1, n_steps_out, n_features)
if array_equal(one_hot_decode(y[0]), one_hot_decode(target)):
correct += 1
print('Accuracy: %.2f%%' % (float(correct)/float(total)*100.0))
# spot check some examples
for _ in range(10):
X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 1)
target = predict_sequence(infenc, infdec, X1, n_steps_out, n_features)
print('X=%s y=%s, yhat=%s' % (one_hot_decode(X1[0]), one_hot_decode(y[0]), one_hot_decode(target)))
首先运行该示例将打印准备好的数据集的形状。
(100000, 6, 51) (100000, 3, 51) (100000, 3, 51)
接下来,该模型是合适的。您应该看到一个进度条,并且在现代多核 CPU 上运行应该不到一分钟。
100000/100000 [==============================] - 50s - loss: 0.6344 - acc: 0.7968
接下来,评估模型并打印精度。我们可以看到该模型在新随机生成的示例上实现了 100%的准确率。
Accuracy: 100.00%
最后,生成 10 个新示例并预测目标序列。同样,我们可以看到模型在每种情况下正确地预测输出序列,并且期望值与源序列的反向前 3 个元素匹配。
X=[22, 17, 23, 5, 29, 11] y=[23, 17, 22], yhat=[23, 17, 22]
X=[28, 2, 46, 12, 21, 6] y=[46, 2, 28], yhat=[46, 2, 28]
X=[12, 20, 45, 28, 18, 42] y=[45, 20, 12], yhat=[45, 20, 12]
X=[3, 43, 45, 4, 33, 27] y=[45, 43, 3], yhat=[45, 43, 3]
X=[34, 50, 21, 20, 11, 6] y=[21, 50, 34], yhat=[21, 50, 34]
X=[47, 42, 14, 2, 31, 6] y=[14, 42, 47], yhat=[14, 42, 47]
X=[20, 24, 34, 31, 37, 25] y=[34, 24, 20], yhat=[34, 24, 20]
X=[4, 35, 15, 14, 47, 33] y=[15, 35, 4], yhat=[15, 35, 4]
X=[20, 28, 21, 39, 5, 25] y=[21, 28, 20], yhat=[21, 28, 20]
X=[50, 38, 17, 25, 31, 48] y=[17, 38, 50], yhat=[17, 38, 50]
您现在有一个编解码器 LSTM 模型的模板,您可以将其应用于您自己的序列到序列预测问题。
进一步阅读
如果您希望深入了解,本节将提供有关该主题的更多资源。
相关文章
- 如何使用 Anaconda 设置用于机器学习和深度学习的 Python 环境
- 如何定义 Keras 神经机器翻译的编解码器序列到序列模型
- 了解 Keras 中 LSTM 的返回序列和返回状态之间的差异
- 如何使用 Keras 功能 API 进行深度学习
Keras 资源
摘要
在本教程中,您了解了如何使用 Keras 为序列到序列预测问题开发编解码器循环神经网络。
具体来说,你学到了:
- 如何在 Keras 中正确定义复杂的编解码器模型以进行序列到序列预测。
- 如何定义可用于评估编解码器 LSTM 模型的人为但可扩展的序列到序列预测问题。
- 如何在 Keras 中应用编解码器 LSTM 模型来解决可伸缩的整数序列到序列预测问题。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。
如何诊断 LSTM 模型的过拟合和欠拟合
原文:
machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/
可能很难确定您的长短期记忆模型是否在您的序列预测问题上表现良好。
您可能获得了良好的模型技能分数,但重要的是要知道您的模型是否适合您的数据,或者它是不合适还是过度适应,并且可以使用不同的配置做得更好。
在本教程中,您将了解如何诊断 LSTM 模型在序列预测问题上的拟合程度。
完成本教程后,您将了解:
- 如何收集和绘制 LSTM 模型的训练历史。
- 如何诊断身体不适,身体健康和过度模特。
- 如何通过平均多个模型运行来开发更强大的诊断。
让我们开始吧。
教程概述
本教程分为 6 个部分;他们是:
- 在 Keras 训练历史
- 诊断图
- Underfit 示例
- 合适的例子
- 适合例子
- 多次运行示例
1.在 Keras 训练历史
通过查看模型的表现,您可以了解很多关于模型行为的信息。
通过调用 fit() 函数来训练 LSTM 模型。此函数返回一个名为 _ 历史记录 _ 的变量,该变量包含损失的跟踪以及在编译模型期间指定的任何其他指标。这些分数记录在每个时代的末尾。
...
history = model.fit(...)
例如,如果编译模型以优化对数损失(binary_crossentropy)并测量每个时期的准确度,则将计算对数损失和准确度并记录在每个训练时期的历史记录中。
通过调用 fit() 返回的历史对象中的键访问每个分数。默认情况下,在拟合模型时优化的损失称为“_ 损失 _”,精度称为“acc”。
...
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, Y, epochs=100)
print(history.history['loss'])
print(history.history['acc'])
Keras 还允许您在拟合模型时指定单独的验证数据集,也可以使用相同的损失和指标进行评估。
这可以通过在 fit() 上设置validation_split参数来使用一部分训练数据作为验证数据集来完成。
...
history = model.fit(X, Y, epochs=100, validation_split=0.33)
这也可以通过设置validation_data参数并传递 X 和 y 数据集的元组来完成。
...
history = model.fit(X, Y, epochs=100, validation_data=(valX, valY))
在验证数据集上评估的度量标准使用相同的名称进行键控,并带有“val_”前缀。
...
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, Y, epochs=100, validation_split=0.33)
print(history.history['loss'])
print(history.history['acc'])
print(history.history['val_loss'])
print(history.history['val_acc'])
2.诊断图
LSTM 模型的训练历史记录可用于诊断模型的行为。
您可以使用 Matplotlib 库绘制模型的表现。例如,您可以如下绘制训练损失与测试损失的关系:
from matplotlib import pyplot
...
history = model.fit(X, Y, epochs=100, validation_data=(valX, valY))
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
创建和查看这些图可以帮助您了解可能的新配置,以便从模型中获得更好的表现。
接下来,我们将看一些例子。我们将考虑训练上的模型技能和最小化损失的验证集。您可以使用对您的问题有意义的任何指标。
3.适合的例子
欠适应模型被证明在训练数据集上表现良好而在测试数据集上表现不佳。
这可以从训练损失低于验证损失的图中诊断出来,并且验证损失具有表明可以进一步改进的趋势。
下面提供了一个下装 LSTM 模型的小例子。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=100, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
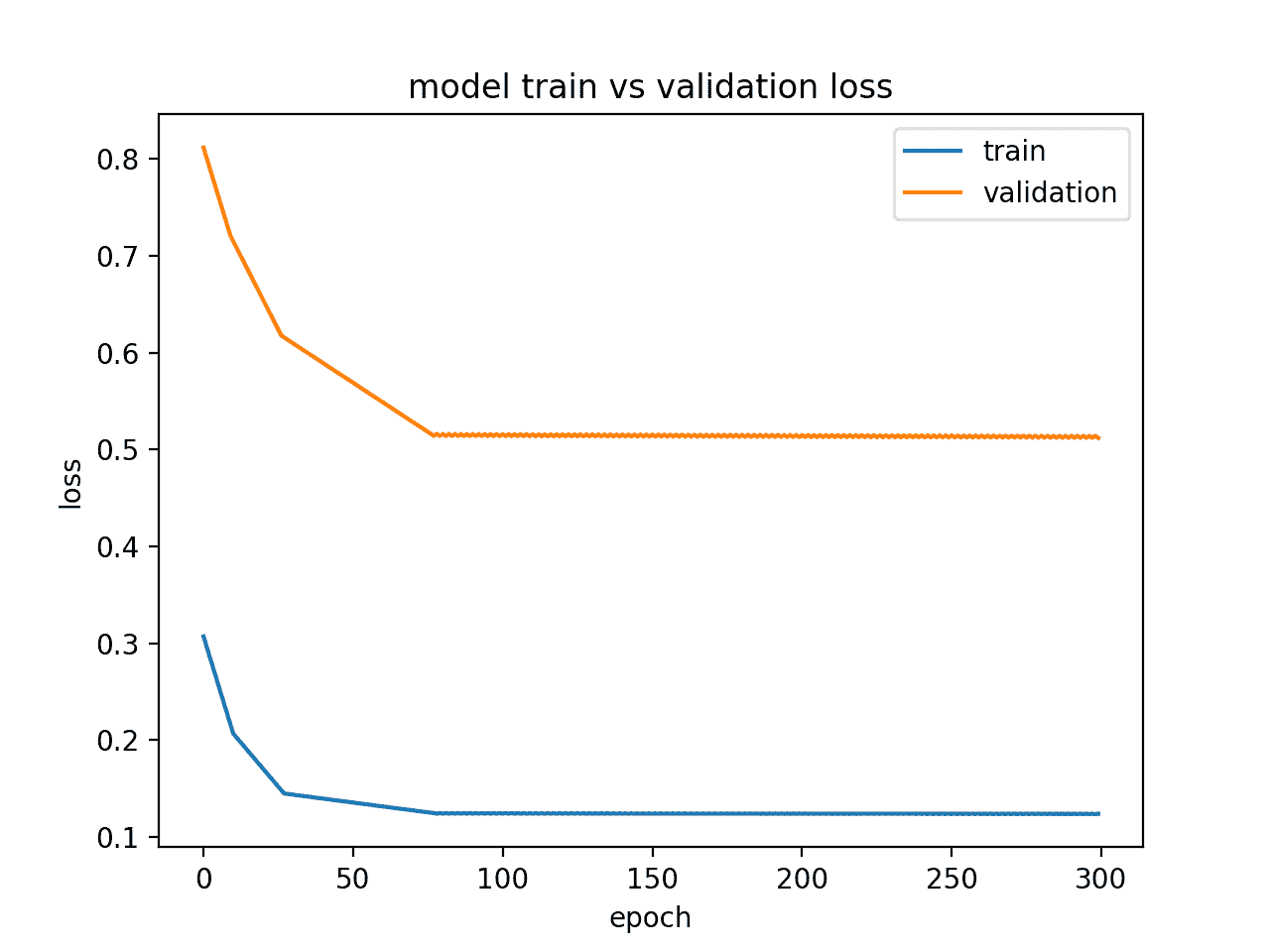
运行此示例会生成训练和验证损失图,显示欠装模型的特征。在这种情况下,可以通过增加训练时期的数量来改善表现。
在这种情况下,可以通过增加训练时期的数量来改善表现。
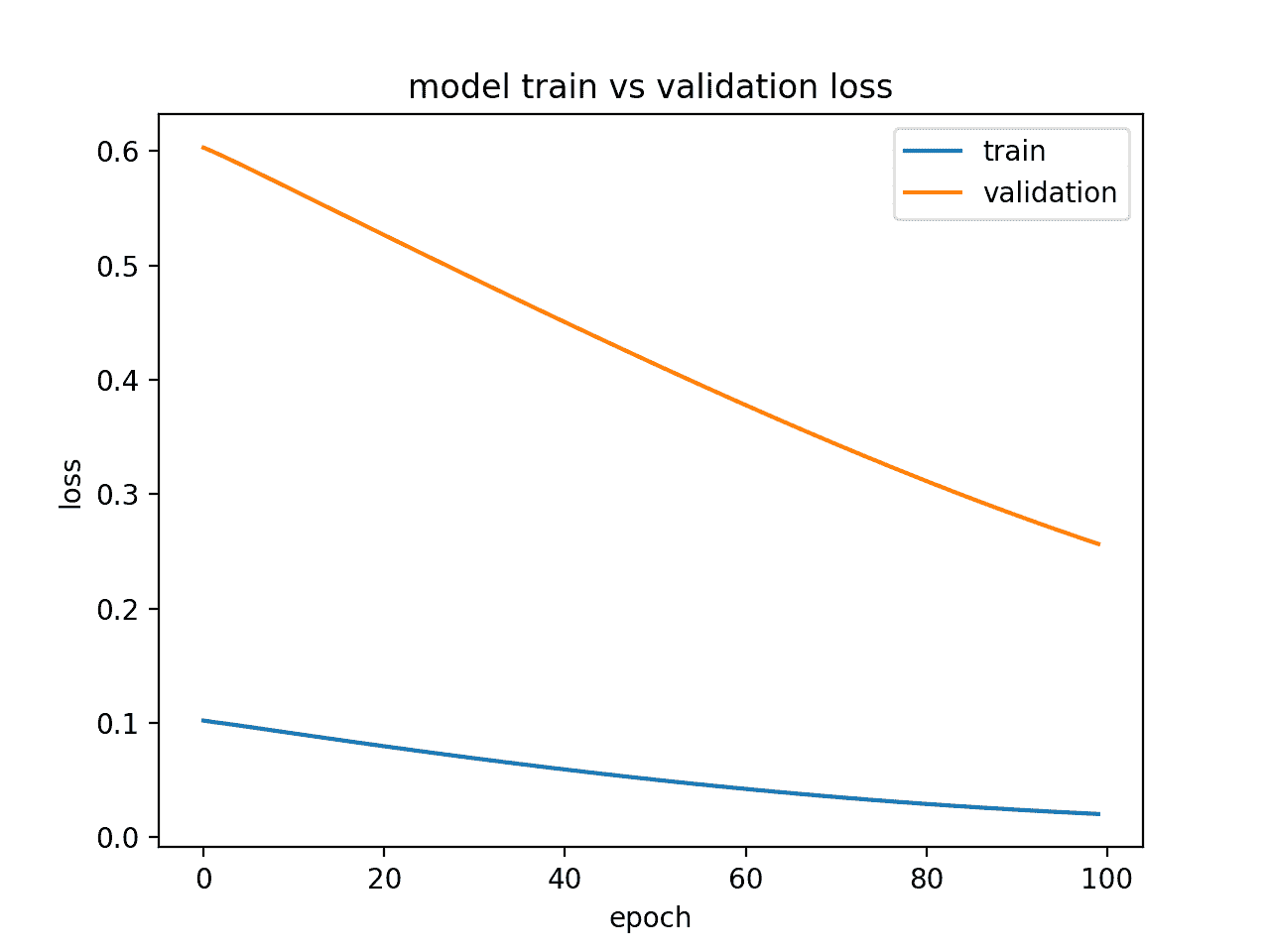
显示一个适合模型的诊断线剧情
或者,如果训练集上的表现优于验证集并且表现已经趋于平稳,则模型可能不合适。以下是一个例子
以下是具有不足的存储器单元的欠装模型的示例。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(1, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mae', optimizer='sgd')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行此示例显示了看似欠配置的欠装模型的特征。
在这种情况下,可以通过增加模型的容量来改善表现,例如隐藏层中的存储器单元的数量或隐藏层的数量。
通过状态显示适合模型的诊断线图
4.合适的例子
一个很好的拟合是模型的表现在训练和验证集上都很好。
这可以从训练和验证损失减少并在同一点附近稳定的图中诊断出来。
下面的小例子演示了一个非常合适的 LSTM 模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=800, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行该示例将创建一个显示训练和验证丢失会议的线图。
理想情况下,如果可能的话,我们希望看到这样的模型表现,尽管这对于大量数据的挑战性问题可能是不可能的。
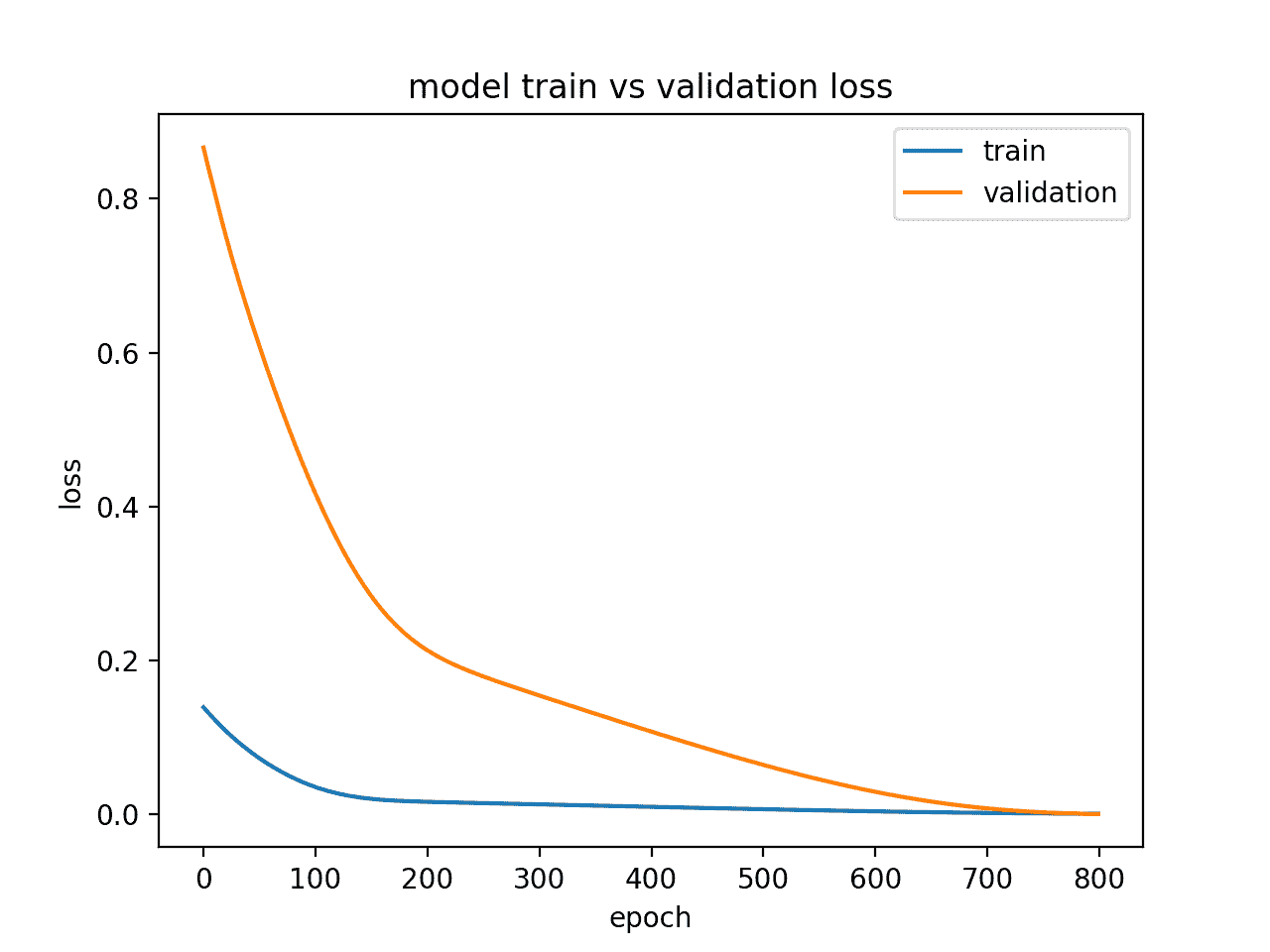
显示适合模型的诊断线图
5.过度配合示例
过拟合模型是训练组上的表现良好并且持续改进的模型,而验证组上的表现改善到某一点然后开始降级。
这可以从训练损失向下倾斜并且验证损失向下倾斜,到达拐点并且再次开始向上倾斜的图中诊断出来。
下面的示例演示了一个过拟合的 LSTM 模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=1200, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'][500:])
pyplot.plot(history.history['val_loss'][500:])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行此示例会创建一个图表,显示过拟合模型的验证丢失中的特征拐点。
这可能是太多训练时期的标志。
在这种情况下,模型训练可以在拐点处停止。或者,可以增加训练示例的数量。
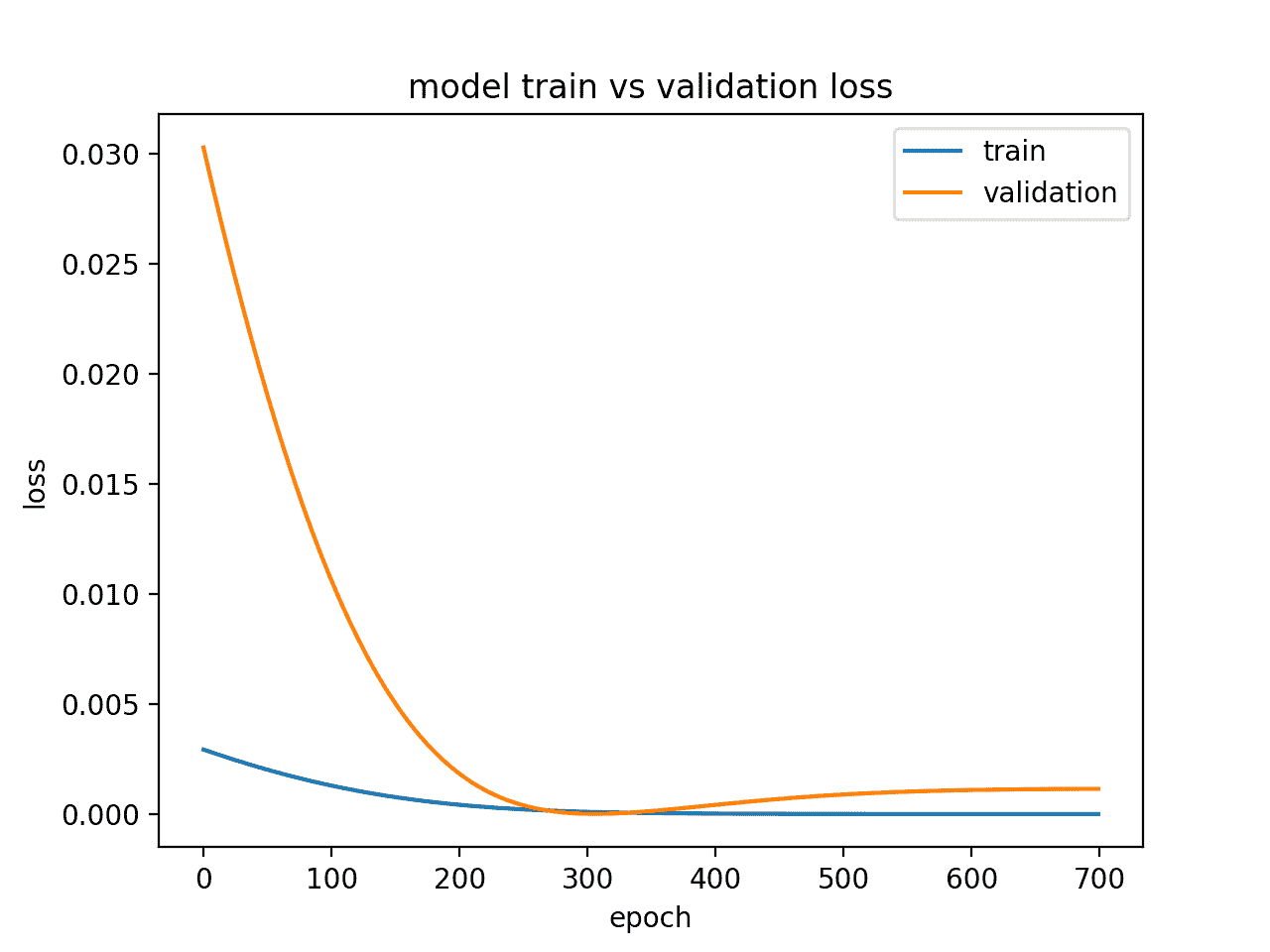
显示适合模型的诊断线剧情
6.多次运行示例
LSTM 是随机的,这意味着每次运行都会获得不同的诊断图。
多次重复诊断运行(例如 5,10 或 30)可能很有用。然后可以绘制来自每次运行的训练和验证轨迹,以更加稳健地了解模型随时间的行为。
下面的示例在绘制每次运行的训练跟踪和验证损失之前多次运行相同的实验。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
from pandas import DataFrame
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# collect data across multiple repeats
train = DataFrame()
val = DataFrame()
for i in range(5):
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
X,y = get_train()
valX, valY = get_val()
# fit model
history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False)
# story history
train[str(i)] = history.history['loss']
val[str(i)] = history.history['val_loss']
# plot train and validation loss across multiple runs
pyplot.plot(train, color='blue', label='train')
pyplot.plot(val, color='orange', label='validation')
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.show()
在得到的图中,我们可以看到欠拟合的总体趋势在 5 次运行中保持不变,并且可能增加训练时期的数量。
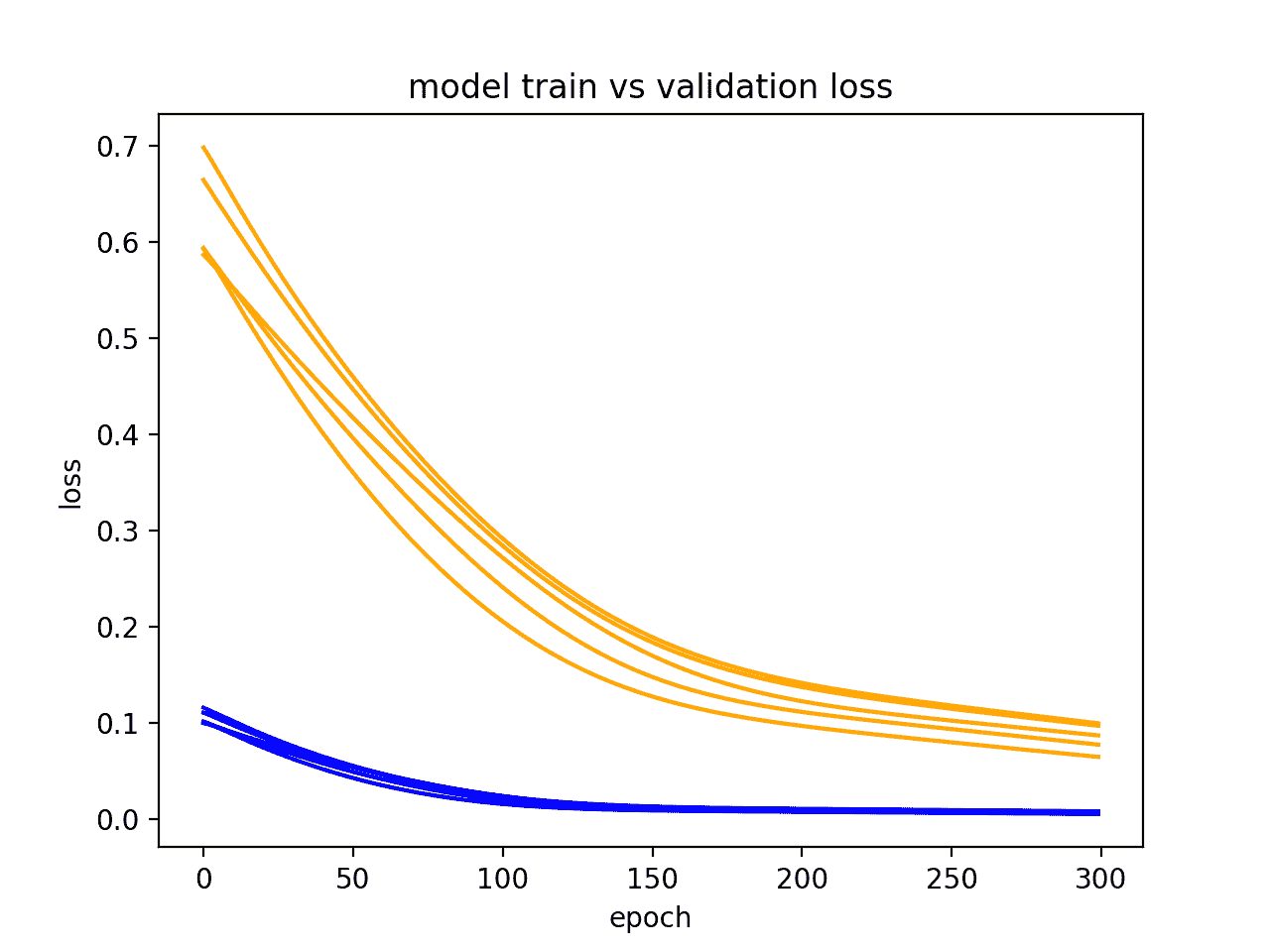
诊断线图显示模型的多个运行
进一步阅读
如果您要深入了解,本节将提供有关该主题的更多资源。
摘要
在本教程中,您了解了如何诊断 LSTM 模型在序列预测问题上的拟合。
具体来说,你学到了:
- 如何收集和绘制 LSTM 模型的训练历史。
- 如何诊断身体不适,身体健康和过度模特。
- 如何通过平均多个模型运行来开发更强大的诊断。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。

















 4122
4122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









