







开始使用 GANs 的最佳资源
最后更新于 2019 年 7 月 12 日
生成对抗网络,或 GANs ,是一种用于生成性建模的深度学习技术。
GANs 是令人惊讶的真实感人脸生成背后的技术,以及令人印象深刻的图像转换任务,如照片着色、人脸去老化、超分辨率等。
开始使用 GANs 可能非常具有挑战性。这既是因为该领域非常年轻,从 2014 年第一篇论文开始,也是因为每个月都有大量关于该主题的论文和应用发表。
在这篇文章中,你将发现可以用来学习生成对抗网络的最佳资源。
看完这篇文章,你会知道:
- 什么是生成对抗网络,以及该技术的具体应用示例。
- 该技术的发明者提供了关于 GANs 的视频教程和讲座。
- 阅读列表包括最常阅读的关于 GANs 的论文和关于深度生成模型的书籍。
用我的新书Python 生成对抗网络启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。
概观
本教程分为五个部分;它们是:
- 什么是 GANs?
- GAN 应用
- GAN 视频演示
- GAN 论文阅读列表
- GAN 书籍
什么是生成对抗网络?
生成对抗网络是一种用于生成建模的神经网络体系结构。
生成性建模包括使用模型生成新的示例,这些示例似乎来自现有的样本分布,例如生成新的照片,这些照片通常与现有照片数据集相似,但又有所不同。
GAN 是使用两个神经网络模型训练的生成模型。一种模型被称为“T0”生成器或“T2”生成网络模型,它学习生成新的似是而非的样本。另一个模型称为“鉴别器”或“鉴别网络”,并学习将生成的示例与真实示例区分开来。
这两个模型是在竞赛或游戏(在博弈论意义上)中建立的,其中生成器模型试图欺骗鉴别器模型,并且鉴别器被提供真实和生成的例子的例子。
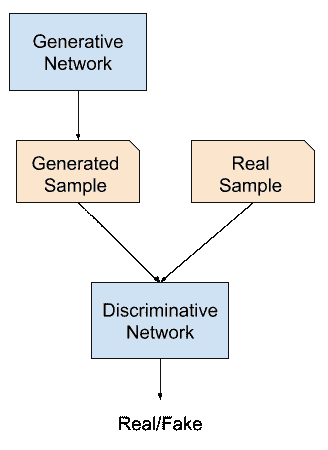
生成对抗网络综述
经过训练后,生成模型可以用于按需创建新的似是而非的样本。
生成对抗网络的应用
GANs 的大部分研究和应用都集中在计算机视觉领域。
其原因是,在过去的 5 到 7 年里,卷积神经网络(CNNs)等深度学习模型在计算机视觉领域取得了巨大的成功,例如在对象检测和人脸识别等具有挑战性的任务上取得了最先进的结果。
GAN 的典型例子是新的逼真照片的生成,最令人吃惊的是照片级逼真人脸的生成。

GAN 生成的真实感人脸示例。摘自《生成对抗网络的基于风格的生成器体系结构》。
还有很多“生成新实例”的问题,比如:
- 生成新的动漫角色。
- 生成新的徽标。
- 生成新的口袋妖怪。
- 生产新衣服。
GANs 可以用于令人惊讶的照片和视频图像处理任务。广义上,这被称为图像转换,例如:
- 把夏天的照片翻译成冬天。
- 把草图翻译成照片。
- 把白天的照片翻译成晚上的。
一些更具体的图像转换示例包括:
- 人脸照片的自动老化或去老化。
- 黑白照片的自动着色。
- 照片的自动分辨率增强。
- 自动风格转换(例如,将绘画风格应用于照片)。
- 自动图像修复(例如,填充图像的模糊部分)。
GANs 还可以用于生成图像或视频序列,并用于自动预测视频帧序列甚至幻觉场景等任务,用于训练强化学习模型。
除了图像处理之外,该技术通常还可以用于数据扩充,在训练模型时,可以生成全新的似是而非的样本作为输入。
有关 GANs 有趣应用的更多示例,请参见:
生成对抗网络的视频展示
观看视频演示是温和介绍 GANs、其工作原理和应用程序的好方法。
作为这项技术的发明者,伊恩·古德费勒(Ian Goodfellow)已经做了许多讲座和教程演示,这些都可以在 YouTube 上免费获得。伊恩是一个优秀的沟通者,他清晰地展示了这项技术。
我推荐在 NIPS(现在的neurops)看 Ian 的 2016 教程。
视频时长约两个小时,包括对 GANs、理论和应用的详细回顾,并在最后与观众进行问答。
我也强烈建议阅读附带的幻灯片和纸质版教程:
- NIPS 2016 教程:生成对抗网络,幻灯片,2016。
- NIPS 2016 教程:生成对抗网络,论文,2016。
如果你对理论较少的相同材料的更集中的演示(约 28 分钟)感兴趣,我推荐伊恩 2016 年的在线会议“AI With Best”的演示。
- 生成对抗网络,伊恩·古德费勒,AIWTB ,2016。
最近,伊恩在 2019 年给 AAAI 做了一个演讲,主题是对抗性机器学习,也涵盖了 GANs,这个演讲也非常值得推荐。
- 对抗性机器学习,伊恩·古德费勒,AAAI ,2019。
如果你正在寻找一个更学术的 GANs 演示,那么我会推荐斯坦福卷积神经网络课程中关于生成模型的讲座。
这堂课为 GANs 提供了一个有用的背景,也涵盖了变分自动编码器和像素神经网络的相关技术。
- 生成模型,用于视觉识别的卷积神经网络,2017。
生成对抗网络的论文阅读列表
GANs 是一个非常新的研究领域。
我试图将这份阅读清单与更广泛的 GAN 应用论文清单分开,重点是 GAN 模型的理论发展和训练。
伊恩·古德费勒等人在 2014 年发表了第一篇专门关于作为生成模型的遗传神经网络的论文,题为“生成对抗网络”
本文介绍了这种通用技术,并用一些简单的例子来说明它,这些例子包括从 MNIST(手写数字)、CIFAR-10(小照片)和人脸生成图像。
- 生成对抗网络,2014。
亚历克·拉德福德等人在 2015 年发表的题为“深度卷积生成对抗网络的无监督表示学习”的论文中提供了一个使用现代配置和卷积神经网络训练实践的更新版本的遗传神经网络,称为深度卷积生成对抗网络,或称之为离散余弦变换遗传神经网络。
这是一篇重要的论文,因为它展示了该技术的力量是如何通过生成逼真的房间和人脸等例子来释放的。
- 深度卷积生成对抗网络的无监督表示学习,2015。
在 DCGAN 论文发表之后,一系列的论文被写出来,为训练 GAN 模型的固有的不稳定过程提供了改进。也许这些论文中最重要的包括:
- 训练 GANs 的改进技术,2016。
- 基于能量的生成对抗网络,2016。
- InfoGAN:通过信息最大化生成对抗网络进行可解释表征学习,2016。
最近一些关于培训和评估 GANs 挑战的高质量论文包括:
- 水的输入 gan2017 年。
- 【GANs 生来平等吗?一项大型研究,2017 年。
- GAN 景观:损失、架构、规范化和标准化,2018 年。
除了这些论文之外,可以在 GANs 的维基百科页面上看到相关生成模型历史的高级概述。
有许多 GAN 调查论文可以帮助了解该领域的范围。少数几个选择包括:
- 生成对抗网络:概述,2017。
- 生成对抗网络:介绍与展望,2017
许多人试图为 GANs 整理阅读清单,考虑到该领域的新鲜感和新论文的速度,这非常具有挑战性。其他一些纸质阅读清单包括:
生成对抗网络
现代深度学习书籍中有一些关于 GANs 的内容。
也许最重要的起点是古德费勒等人编写的深度学习教科书。第二十章的标题是“深度生成模型”,它提供了一系列技术的有用总结,包括第 20.10.4 节中涵盖的 GANs。
- 第二十章。深度生成模型,深度学习,2016。
《Keras 深度学习框架》的作者 Francois Chollet 在他 2017 年出版的名为《用 Python 进行深度学习》的书中,提供了一章关于深度生成模型的内容具体来说,第 8.5 节标题为“生成对抗网络的介绍”,涵盖了 GANs 和如何在 Keras 训练 DCGAN。
- 第八章。生成式深度学习,Python 深度学习,2017。
在撰写本文时,在预计于今年晚些时候发行的作品中,还有两本关于生成建模深度学习的有趣书籍。它们是:
看到这些书涵盖的内容将是令人兴奋的。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
书
- 第二十章。深度生成模型,深度学习,2016。
- 第八章。生成式深度学习,Python 深度学习,2017。
- 生成性深度学习,2019
- GANs 在行动,2019 年。
报纸
- NIPS 2016 教程:生成对抗网络,2016。
- 生成对抗网络,2014。
- 深度卷积生成对抗网络的无监督表示学习,2015。
- 水的输入 gan2017 年。
- 【GANs 生来平等吗?一项大型研究,2017 年。
- GAN 景观:损失、架构、规范化和标准化,2018 年。
- 生成对抗网络:概述,2017。
- 生成对抗网络:介绍与展望,2017
录像
- 生成对抗网络,伊恩·古德费勒,NIPS ,2016。
- 生成对抗网络,伊恩·古德费勒,AIWTB ,2016。
- 对抗性机器学习,伊恩·古德费勒,AAAI ,2019。
- 生成模型,用于视觉识别的卷积神经网络,2017。
文章
摘要
在这篇文章中,你发现了可以用来学习生成对抗网络的最佳资源。
具体来说,您了解到:
- 什么是生成对抗网络,以及该技术的具体应用示例。
- 该技术的发明者提供了关于 GANs 的视频教程和讲座。
- 阅读列表包括最常阅读的关于 GANs 的论文和关于深度生成模型的书籍。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何在 Keras 中从头实现半监督 GAN(SGAN)
原文:https://machinelearningmastery.com/semi-supervised-generative-adversarial-network/
最后更新于 2020 年 9 月 1 日
半监督学习是在包含少量已标记示例和大量未标记示例的数据集中训练分类器的挑战性问题。
生成对抗网络(GAN)是一种有效利用大型未标记数据集,通过图像鉴别器模型训练图像生成器模型的体系结构。在某些情况下,鉴别器模型可以用作开发分类器模型的起点。
半监督的 GAN,或 SGAN,模型是 GAN 体系结构的扩展,包括同时训练监督鉴别器、非监督鉴别器和生成器模型。结果是一个监督分类模型和一个生成器模型,前者能很好地概括出看不见的例子,后者能从该领域输出看似合理的图像例子。
在本教程中,您将发现如何从零开始开发一个半监督生成式对抗网络。
完成本教程后,您将知道:
- 半监督遗传神经网络是遗传神经网络体系结构的扩展,用于训练分类器模型,同时利用标记和未标记的数据。
- 在用于半监督 GAN 的 Keras 中,至少有三种方法来实现监督和非监督鉴别器模型。
- 如何在 MNIST 上从零开始训练半监督的 GAN,并加载和使用训练好的分类器进行预测。
用我的新书Python 生成对抗网络启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

如何从零开始实现半监督生成对抗网络?
卡洛斯·约翰逊摄影,版权所有。
教程概述
本教程分为四个部分;它们是:
- 什么是半监督 GAN?
- 如何实现半监督鉴别器模型
- 如何为 MNIST 开发半监督式 GAN
- 如何加载和使用最终的 SGAN 分类器模型
什么是半监督 GAN?
半监督学习是指一个问题,其中需要一个预测模型,有标签的例子很少,无标签的例子很多。
最常见的例子是分类预测建模问题,其中可能有非常大的示例数据集,但只有一小部分具有目标标签。该模型必须从小的已标记示例集合中学习,并以某种方式利用较大的未标记示例数据集,以便在未来对新示例进行分类。
半监督网络,有时简称 SGAN,是生成对抗网络体系结构的扩展,用于解决半监督学习问题。
这项工作的主要目标之一是提高半监督学习的生成对抗网络的有效性(通过在额外的未标记例子上学习来提高监督任务的表现,在这种情况下是分类)。
——训练 GANs 的改进技术,2016 年。
传统 GAN 中的鉴别器被训练来预测给定图像是真实的(来自数据集)还是虚假的(生成的),从而允许它从未标记的图像中学习特征。然后,当为同一数据集开发分类器时,可以通过转移学习使用鉴别器作为起点,从而允许有监督的预测任务受益于无监督的神经网络训练。
在半监督 GAN 中,更新鉴别器模型来预测 K+1 个类,其中 K 是预测问题中的类数,并为新的“伪”类添加额外的类标签。它包括同时为无监督的 GAN 任务和有监督的分类任务直接训练鉴别器模型。
我们在输入属于 N 个类之一的数据集上训练生成模型 G 和鉴别器 D。在训练时,让 D 预测输入属于 N+1 个类中的哪一个,其中增加一个额外的类来对应 g 的输出
——生成对抗网络的半监督学习,2016。
因此,鉴别器以两种模式训练:监督和非监督模式。
- 无监督训练:在无监督模式下,对鉴别器进行和传统 GAN 一样的训练,来预测例子是真的还是假的。
- 监督训练:在监督模式下,训练鉴别器预测真实例子的类标签。
无监督模式下的训练允许模型从大的未标记数据集中学习有用的特征提取能力,而有监督模式下的训练允许模型使用提取的特征并应用类别标签。
结果是一个分类器模型,当在很少的标记例子上训练时,例如几十个、几百个或一千个,它可以在标准问题上获得最先进的结果,例如 MNIST 问题。此外,训练过程还可以导致生成器模型输出质量更好的图像。
例如,奥古斯都·奥达在他 2016 年发表的题为《带有生成对抗网络的半监督学习》的论文中,展示了当用 25 个、50 个、100 个和 1000 个标记的例子进行训练时,GAN 训练的分类器在 MNIST 手写数字识别任务上的表现如何与独立的 CNN 模型一样好或更好。
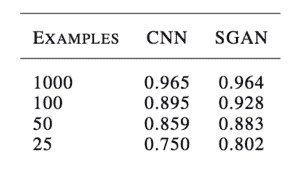
比较美国有线电视新闻网和 MNIST 国家地理通道分类准确度的结果表示例。
摘自:生成对抗网络的半监督学习
来自 OpenAI 的 Tim Salimans 等人在他们 2016 年发表的题为“训练 GANs 的改进技术”的论文中,使用半监督 GAN(包括 MNIST)在许多图像分类任务上取得了当时最先进的结果。

将其他 GAN 模型的分类准确率与 MNIST 的 SGAN 进行比较的结果表示例。
摘自:训练 GANs 的改进技术
如何实现半监督鉴别器模型
有许多方法可以实现半监督 GAN 的鉴别器模型。
在本节中,我们将回顾三种候选方法。
传统鉴别器模型
考虑标准 GAN 模型的鉴别器模型。
它必须以一幅图像作为输入,并预测它是真的还是假的。更具体地说,它预测输入图像是真实的可能性。输出层使用 sigmoid 激活函数预测[0,1]中的概率值,模型通常使用二元交叉熵损失函数进行优化。
例如,我们可以定义一个简单的鉴别器模型,它以 28×28 像素的灰度图像作为输入,并预测图像真实的概率。我们可以使用最佳实践并使用卷积层对图像进行下采样,卷积层具有 2×2 步长和泄漏 ReLU 激活函数。
下面的 define_discriminator() 函数实现了这一点,并定义了我们的标准鉴别器模型。
# example of defining the discriminator model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Flatten
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
# define the standalone discriminator model
def define_discriminator(in_shape=(28,28,1)):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# output layer
d_out_layer = Dense(1, activation='sigmoid')(fe)
# define and compile discriminator model
d_model = Model(in_image, d_out_layer)
d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
return d_model
# create model
model = define_discriminator()
# plot the model
plot_model(model, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True)
运行该示例创建了鉴别器模型的图,清楚地显示了输入图像的 28x28x1 形状和单个概率值的预测。
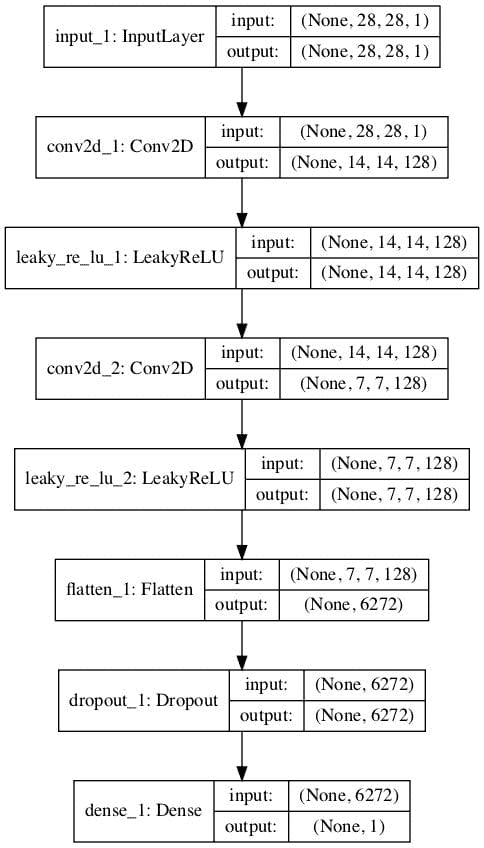
标准 GAN 鉴别器模型图
具有共享权重的独立鉴别器模型
从标准的 GAN 鉴别器模型开始,我们可以更新它来创建两个共享特征提取权重的模型。
具体来说,我们可以定义一个分类器模型来预测输入图像是真的还是假的,以及定义第二个分类器模型来预测给定模型的类别。
- 二分类器模型。预测图像是真的还是假的,输出层中的 sigmoid 激活函数,并使用二进制交叉熵损失函数进行优化。
- 多类分类器模型。预测图像的类别,输出层中的 softmax 激活函数,并使用分类交叉熵损失函数进行优化。
两种模型具有不同的输出层,但共享所有的要素提取层。这意味着对其中一个分类器模型的更新将影响两个模型。
下面的示例首先创建具有二进制输出的传统鉴别器模型,然后重新使用特征提取层,并创建一个新的多类预测模型,在本例中有 10 个类。
# example of defining semi-supervised discriminator model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Flatten
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
# define the standalone supervised and unsupervised discriminator models
def define_discriminator(in_shape=(28,28,1), n_classes=10):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# unsupervised output
d_out_layer = Dense(1, activation='sigmoid')(fe)
# define and compile unsupervised discriminator model
d_model = Model(in_image, d_out_layer)
d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
# supervised output
c_out_layer = Dense(n_classes, activation='softmax')(fe)
# define and compile supervised discriminator model
c_model = Model(in_image, c_out_layer)
c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
return d_model, c_model
# create model
d_model, c_model = define_discriminator()
# plot the model
plot_model(d_model, to_file='discriminator1_plot.png', show_shapes=True, show_layer_names=True)
plot_model(c_model, to_file='discriminator2_plot.png', show_shapes=True, show_layer_names=True)
运行该示例会创建和绘制两个模型。
第一个模型的图和之前一样。
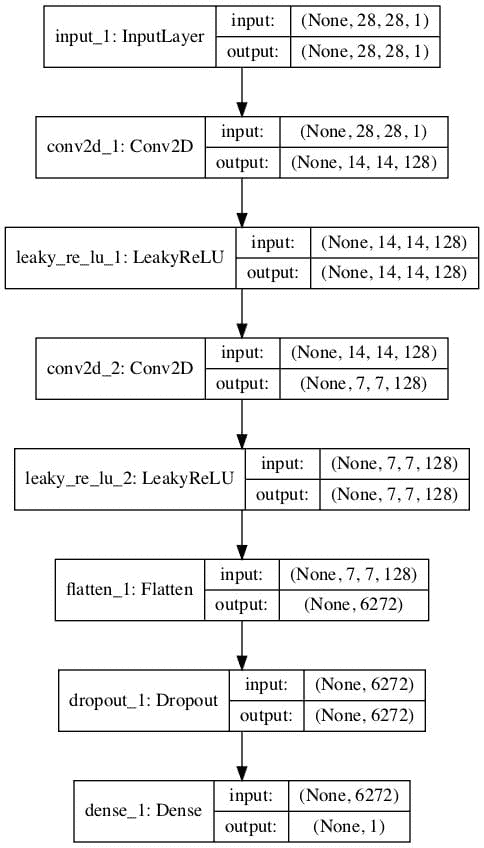
无监督二进制分类 GAN 鉴别器模型的绘制
第二个模型的图显示了相同的预期输入形状和相同的特征提取层,以及新的 10 类分类输出层。
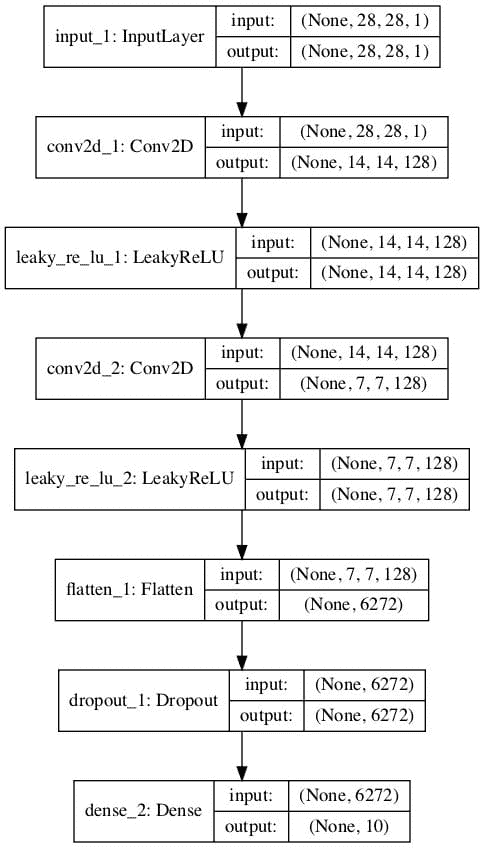
一种有监督的多类分类 GAN 鉴别器模型的绘制
多输出单鉴别器模型
实现半监督鉴别器模型的另一种方法是使用具有多个输出层的单一模型。
具体来说,这是一个单一模型,一个输出层用于无监督任务,一个输出层用于有监督任务。
这就像有监督和无监督任务的独立模型,因为它们都共享相同的特征提取层,除了在这种情况下,每个输入图像总是有两个输出预测,特别是真实/虚假预测和监督类预测。
这种方法的一个问题是,当更新模型时,没有标记和生成的图像,没有监督类标签。在这种情况下,这些图像必须具有来自监督输出的“未知的”或“假的”的输出标签。这意味着监督输出层需要一个额外的类标签。
**下面的例子实现了半监督 GAN 架构中鉴别器模型的多输出单模型方法。
我们可以看到,模型由两个输出层定义,监督任务的输出层由 n _ classes 定义。在这种情况下为 11,为额外的“未知”类标签腾出空间。
我们还可以看到,模型被编译为两个损失函数,模型的每个输出层一个。
# example of defining semi-supervised discriminator model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Flatten
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
# define the standalone supervised and unsupervised discriminator models
def define_discriminator(in_shape=(28,28,1), n_classes=10):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# unsupervised output
d_out_layer = Dense(1, activation='sigmoid')(fe)
# supervised output
c_out_layer = Dense(n_classes + 1, activation='softmax')(fe)
# define and compile supervised discriminator model
model = Model(in_image, [d_out_layer, c_out_layer])
model.compile(loss=['binary_crossentropy', 'sparse_categorical_crossentropy'], optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
return model
# create model
model = define_discriminator()
# plot the model
plot_model(model, to_file='multioutput_discriminator_plot.png', show_shapes=True, show_layer_names=True)
运行该示例会创建并绘制单个多输出模型。
该图清楚地显示了共享层以及单独的无监督和有监督输出层。
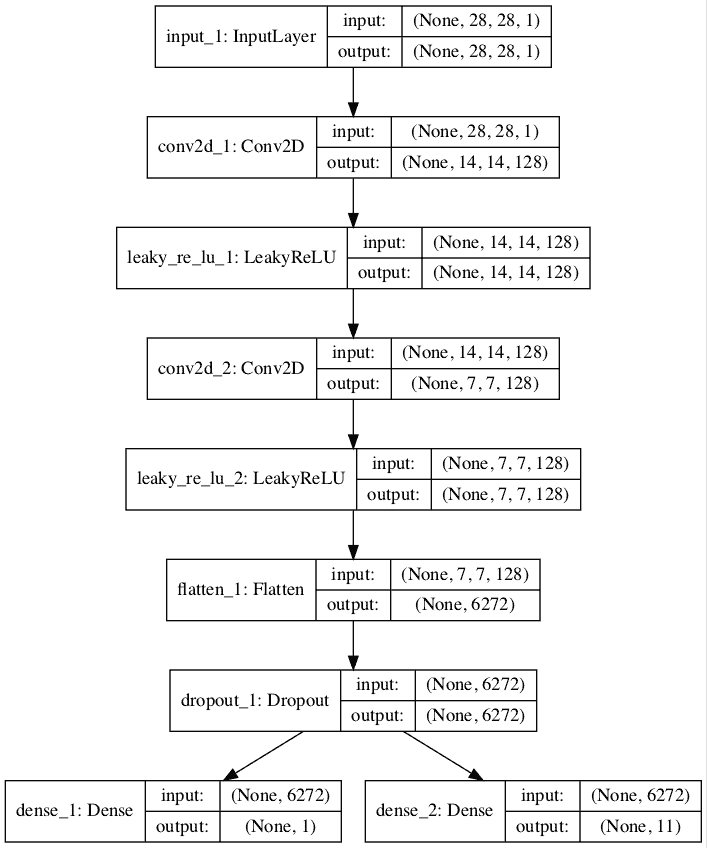
具有无监督和有监督输出层的半监督 GAN 鉴别器模型图
具有共享权重的堆叠鉴别器模型
最后一种方法非常类似于前面的两种方法,包括创建单独的逻辑无监督模型和有监督模型,但试图重用一个模型的输出层作为另一个模型的输入。
该方法基于 OpenAI 的 Tim Salimans 等人在 2016 年的论文中对半监督模型的定义,该论文题为“训练 GANs 的改进技术
在这篇论文中,他们描述了一个有效的实现,首先用 K 个输出类和一个 softmax 激活函数创建监督模型。然后定义无监督模型,该模型在 softmax 激活之前获取有监督模型的输出,然后计算指数输出的归一化和。
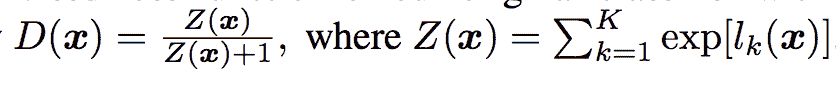
SGAN 中无监督鉴别器模型的输出函数示例。
摘自:训练 GANs 的改进技术
为了更清楚地说明这一点,我们可以在 NumPy 中实现这个激活函数,并通过它运行一些示例激活,看看会发生什么。
下面列出了完整的示例。
# example of custom activation function
import numpy as np
# custom activation function
def custom_activation(output):
logexpsum = np.sum(np.exp(output))
result = logexpsum / (logexpsum + 1.0)
return result
# all -10s
output = np.asarray([-10.0, -10.0, -10.0])
print(custom_activation(output))
# all -1s
output = np.asarray([-1.0, -1.0, -1.0])
print(custom_activation(output))
# all 0s
output = np.asarray([0.0, 0.0, 0.0])
print(custom_activation(output))
# all 1s
output = np.asarray([1.0, 1.0, 1.0])
print(custom_activation(output))
# all 10s
output = np.asarray([10.0, 10.0, 10.0])
print(custom_activation(output))
请记住,在 softmax 激活函数之前,无监督模型的输出将是节点的直接激活。它们将是小的正值或负值,但不会标准化,因为这将由 softmax 激活来执行。
自定义激活函数将输出一个介于 0.0 和 1.0 之间的值。
对于小激活或负激活,输出接近 0.0 的值,对于正激活或大激活,输出接近 1.0 的值。当我们运行示例时,我们可以看到这一点。
0.00013618124143106674
0.5246331135813284
0.75
0.890768227426964
0.9999848669190928
这意味着鼓励模型为真实示例输出强类预测,为虚假示例输出小类预测或低激活。这是一个聪明的技巧,允许在两个模型中重用监督模型的相同输出节点。
激活功能几乎可以直接通过 Keras 后端实现,并从 Lambda 层调用,例如,将自定义功能应用于层输入的层。
下面列出了完整的示例。首先,用软最大激活和分类交叉熵损失函数定义监督模型。在 softmax 激活之前,无监督模型被堆叠在有监督模型的输出层之上,节点的激活通过 Lambda 层传递给我们的自定义激活函数。
不需要 sigmoid 激活函数,因为我们已经标准化了激活。如前所述,使用二元交叉熵损失拟合无监督模型。
# example of defining semi-supervised discriminator model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers import Activation
from keras.layers import Lambda
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
from keras import backend
# custom activation function
def custom_activation(output):
logexpsum = backend.sum(backend.exp(output), axis=-1, keepdims=True)
result = logexpsum / (logexpsum + 1.0)
return result
# define the standalone supervised and unsupervised discriminator models
def define_discriminator(in_shape=(28,28,1), n_classes=10):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# output layer nodes
fe = Dense(n_classes)(fe)
# supervised output
c_out_layer = Activation('softmax')(fe)
# define and compile supervised discriminator model
c_model = Model(in_image, c_out_layer)
c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
# unsupervised output
d_out_layer = Lambda(custom_activation)(fe)
# define and compile unsupervised discriminator model
d_model = Model(in_image, d_out_layer)
d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
return d_model, c_model
# create model
d_model, c_model = define_discriminator()
# plot the model
plot_model(d_model, to_file='stacked_discriminator1_plot.png', show_shapes=True, show_layer_names=True)
plot_model(c_model, to_file='stacked_discriminator2_plot.png', show_shapes=True, show_layer_names=True)
运行该示例会创建并绘制两个模型,这两个模型看起来与第一个示例中的两个模型非常相似。
无监督鉴别器模型的堆叠版本:
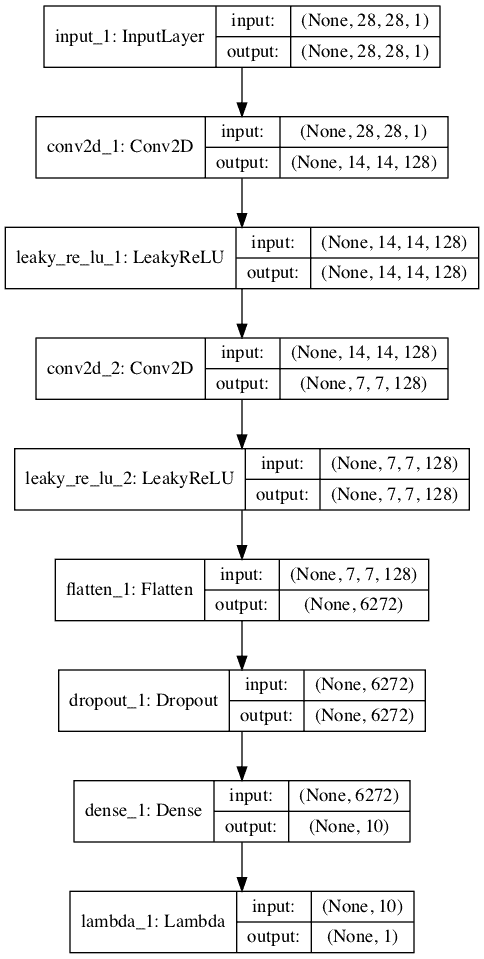
半监督 GAN 无监督鉴别器模型的堆叠图
监督鉴别器模型的堆叠版本:
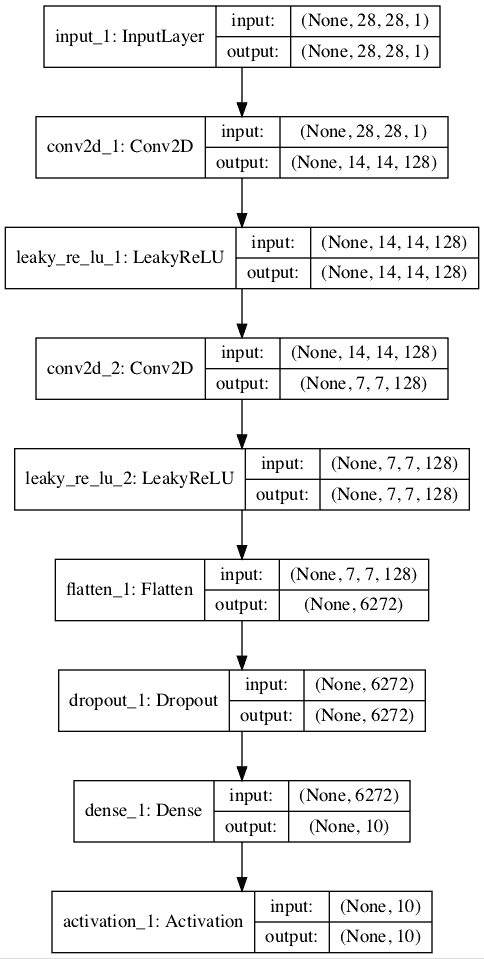
半监督 GAN 监督鉴别器模型的堆叠图
现在我们已经看到了如何在半监督 GAN 中实现鉴别器模型,我们可以为图像生成和半监督分类开发一个完整的例子。
如何为 MNIST 开发半监督式 GAN
在本节中,我们将为 MNIST 手写数字数据集开发半监督 GAN 模型。
数据集对于数字 0-9 有 10 个类,因此分类器模型将有 10 个输出节点。该模型将适合包含 60,000 个示例的训练数据集。训练数据集中只有 100 个图像将与标签一起使用,10 个类别中各有 10 个。
我们将从定义模型开始。
我们将使用堆叠鉴别器模型,正如上一节所定义的那样。
接下来,我们可以定义生成器模型。在这种情况下,生成器模型将把潜在空间中的一个点作为输入,并将使用转置卷积层来输出 28×28 灰度图像。下面的 define_generator() 函数实现了这一点,并返回定义的生成器模型。
# define the standalone generator model
def define_generator(latent_dim):
# image generator input
in_lat = Input(shape=(latent_dim,))
# foundation for 7x7 image
n_nodes = 128 * 7 * 7
gen = Dense(n_nodes)(in_lat)
gen = LeakyReLU(alpha=0.2)(gen)
gen = Reshape((7, 7, 128))(gen)
# upsample to 14x14
gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen)
gen = LeakyReLU(alpha=0.2)(gen)
# upsample to 28x28
gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen)
gen = LeakyReLU(alpha=0.2)(gen)
# output
out_layer = Conv2D(1, (7,7), activation='tanh', padding='same')(gen)
# define model
model = Model(in_lat, out_layer)
return model
生成器模型将通过无监督鉴别器模型进行拟合。
我们将使用复合模型架构,当在 Keras 中实现时,该架构通常用于训练生成器模型。具体来说,在生成器模型的输出被直接传递给无监督鉴别器模型,并且鉴别器的权重被标记为不可训练的情况下,使用权重共享。
下面的 define_gan() 函数实现了这一点,将已经定义的生成器和鉴别器模型作为输入,并返回用于训练生成器模型权重的复合模型。
# define the combined generator and discriminator model, for updating the generator
def define_gan(g_model, d_model):
# make weights in the discriminator not trainable
d_model.trainable = False
# connect image output from generator as input to discriminator
gan_output = d_model(g_model.output)
# define gan model as taking noise and outputting a classification
model = Model(g_model.input, gan_output)
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt)
return model
我们可以加载训练数据集并将像素缩放到范围[-1,1]以匹配生成器模型的输出值。
# load the images
def load_real_samples():
# load dataset
(trainX, trainy), (_, _) = load_data()
# expand to 3d, e.g. add channels
X = expand_dims(trainX, axis=-1)
# convert from ints to floats
X = X.astype('float32')
# scale from [0,255] to [-1,1]
X = (X - 127.5) / 127.5
print(X.shape, trainy.shape)
return [X, trainy]
我们还可以定义一个函数来选择训练数据集的一个子集,在该子集中我们保留标签并训练鉴别器模型的监督版本。
下面的*select _ supervised _ samples()*函数实现了这一点,并小心地确保示例的选择是随机的,并且类是平衡的。标记示例的数量被参数化并设置为 100,这意味着 10 个类中的每一个都将有 10 个随机选择的示例。
# select a supervised subset of the dataset, ensures classes are balanced
def select_supervised_samples(dataset, n_samples=100, n_classes=10):
X, y = dataset
X_list, y_list = list(), list()
n_per_class = int(n_samples / n_classes)
for i in range(n_classes):
# get all images for this class
X_with_class = X[y == i]
# choose random instances
ix = randint(0, len(X_with_class), n_per_class)
# add to list
[X_list.append(X_with_class[j]) for j in ix]
[y_list.append(i) for j in ix]
return asarray(X_list), asarray(y_list)
接下来,我们可以定义一个函数来检索一批真实的训练示例。
选择图像和标签的样本,并进行替换。这个相同的函数可以用来从标记和未标记的数据集中检索示例,稍后当我们训练模型时。在“无标签数据集的情况下,我们将忽略标签。
# select real samples
def generate_real_samples(dataset, n_samples):
# split into images and labels
images, labels = dataset
# choose random instances
ix = randint(0, images.shape[0], n_samples)
# select images and labels
X, labels = images[ix], labels[ix]
# generate class labels
y = ones((n_samples, 1))
return [X, labels], y
接下来,我们可以定义函数来帮助使用生成器模型生成图像。
首先,generate _ 潜伏 _points() 函数会在潜伏空间中创建一批有价值的随机点,这些随机点可以作为生成图像的输入。 generate_fake_samples() 函数将调用该函数来生成一批有价值的图像,这些图像可以在训练期间被馈送到无监督鉴别器模型或复合 GAN 模型。
# generate points in latent space as input for the generator
def generate_latent_points(latent_dim, n_samples):
# generate points in the latent space
z_input = randn(latent_dim * n_samples)
# reshape into a batch of inputs for the network
z_input = z_input.reshape(n_samples, latent_dim)
return z_input
# use the generator to generate n fake examples, with class labels
def generate_fake_samples(generator, latent_dim, n_samples):
# generate points in latent space
z_input = generate_latent_points(latent_dim, n_samples)
# predict outputs
images = generator.predict(z_input)
# create class labels
y = zeros((n_samples, 1))
return images, y
接下来,当我们想要评估模型的表现时,我们可以定义一个要调用的函数。
该功能将使用发电机模型的当前状态生成并绘制 100 幅图像。该图像图可用于主观评估发电机模型的表现。
然后在整个训练数据集上评估监督鉴别器模型,并报告分类准确率。最后,生成器模型和监督鉴别器模型被保存到文件中,以供以后使用。
下面的*summary _ performance()*函数实现了这一点,可以定期调用,比如每个训练时期的结束。可以在运行结束时查看结果,以选择分类器甚至生成器模型。
# generate samples and save as a plot and save the model
def summarize_performance(step, g_model, c_model, latent_dim, dataset, n_samples=100):
# prepare fake examples
X, _ = generate_fake_samples(g_model, latent_dim, n_samples)
# scale from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot images
for i in range(100):
# define subplot
pyplot.subplot(10, 10, 1 + i)
# turn off axis
pyplot.axis('off')
# plot raw pixel data
pyplot.imshow(X[i, :, :, 0], cmap='gray_r')
# save plot to file
filename1 = 'generated_plot_%04d.png' % (step+1)
pyplot.savefig(filename1)
pyplot.close()
# evaluate the classifier model
X, y = dataset
_, acc = c_model.evaluate(X, y, verbose=0)
print('Classifier Accuracy: %.3f%%' % (acc * 100))
# save the generator model
filename2 = 'g_model_%04d.h5' % (step+1)
g_model.save(filename2)
# save the classifier model
filename3 = 'c_model_%04d.h5' % (step+1)
c_model.save(filename3)
print('>Saved: %s, %s, and %s' % (filename1, filename2, filename3))
接下来,我们可以定义一个函数来训练模型。定义的模型和加载的训练数据集作为参数提供,训练时期的数量和批处理大小用默认值参数化,在本例中是 20 个时期和 100 个批处理大小。
发现所选择的模型配置快速过度训练数据集,因此训练时期的数量相对较少。将纪元增加到 100 个或更多会产生质量更高的图像,但分类器模型的质量较低。平衡这两个问题可能是一个有趣的扩展。
首先,选择训练数据集的标记子集,并计算训练步骤的数量。
训练过程几乎与普通 GAN 模型的训练相同,只是增加了用标记的例子更新监督模型。
通过更新模型的单个周期包括首先用标记的例子更新有监督的鉴别器模型,然后用未标记的真实和生成的例子更新无监督的鉴别器模型。最后,通过复合模型更新发电机模型。
鉴别器模型的共享权重用 1.5 批样本更新,而生成器模型的权重每次迭代用一批样本更新。改变这一点,使每个模型更新相同的量,可能会改善模型训练过程。
# train the generator and discriminator
def train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=20, n_batch=100):
# select supervised dataset
X_sup, y_sup = select_supervised_samples(dataset)
print(X_sup.shape, y_sup.shape)
# calculate the number of batches per training epoch
bat_per_epo = int(dataset[0].shape[0] / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# calculate the size of half a batch of samples
half_batch = int(n_batch / 2)
print('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' % (n_epochs, n_batch, half_batch, bat_per_epo, n_steps))
# manually enumerate epochs
for i in range(n_steps):
# update supervised discriminator (c)
[Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch)
c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real)
# update unsupervised discriminator (d)
[X_real, _], y_real = generate_real_samples(dataset, half_batch)
d_loss1 = d_model.train_on_batch(X_real, y_real)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
d_loss2 = d_model.train_on_batch(X_fake, y_fake)
# update generator (g)
X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1))
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# summarize loss on this batch
print('>%d, c[%.3f,%.0f], d[%.3f,%.3f], g[%.3f]' % (i+1, c_loss, c_acc*100, d_loss1, d_loss2, g_loss))
# evaluate the model performance every so often
if (i+1) % (bat_per_epo * 1) == 0:
summarize_performance(i, g_model, c_model, latent_dim, dataset)
最后,我们可以定义模型并调用函数来训练和保存模型。
# size of the latent space
latent_dim = 100
# create the discriminator models
d_model, c_model = define_discriminator()
# create the generator
g_model = define_generator(latent_dim)
# create the gan
gan_model = define_gan(g_model, d_model)
# load image data
dataset = load_real_samples()
# train model
train(g_model, d_model, c_model, gan_model, dataset, latent_dim)
将所有这些结合在一起,下面列出了在 MNIST 手写数字图像分类任务上训练半监督 GAN 的完整示例。
# example of semi-supervised gan for mnist
from numpy import expand_dims
from numpy import zeros
from numpy import ones
from numpy import asarray
from numpy.random import randn
from numpy.random import randint
from keras.datasets.mnist import load_data
from keras.optimizers import Adam
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers import Flatten
from keras.layers import Conv2D
from keras.layers import Conv2DTranspose
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Lambda
from keras.layers import Activation
from matplotlib import pyplot
from keras import backend
# custom activation function
def custom_activation(output):
logexpsum = backend.sum(backend.exp(output), axis=-1, keepdims=True)
result = logexpsum / (logexpsum + 1.0)
return result
# define the standalone supervised and unsupervised discriminator models
def define_discriminator(in_shape=(28,28,1), n_classes=10):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# output layer nodes
fe = Dense(n_classes)(fe)
# supervised output
c_out_layer = Activation('softmax')(fe)
# define and compile supervised discriminator model
c_model = Model(in_image, c_out_layer)
c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
# unsupervised output
d_out_layer = Lambda(custom_activation)(fe)
# define and compile unsupervised discriminator model
d_model = Model(in_image, d_out_layer)
d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
return d_model, c_model
# define the standalone generator model
def define_generator(latent_dim):
# image generator input
in_lat = Input(shape=(latent_dim,))
# foundation for 7x7 image
n_nodes = 128 * 7 * 7
gen = Dense(n_nodes)(in_lat)
gen = LeakyReLU(alpha=0.2)(gen)
gen = Reshape((7, 7, 128))(gen)
# upsample to 14x14
gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen)
gen = LeakyReLU(alpha=0.2)(gen)
# upsample to 28x28
gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen)
gen = LeakyReLU(alpha=0.2)(gen)
# output
out_layer = Conv2D(1, (7,7), activation='tanh', padding='same')(gen)
# define model
model = Model(in_lat, out_layer)
return model
# define the combined generator and discriminator model, for updating the generator
def define_gan(g_model, d_model):
# make weights in the discriminator not trainable
d_model.trainable = False
# connect image output from generator as input to discriminator
gan_output = d_model(g_model.output)
# define gan model as taking noise and outputting a classification
model = Model(g_model.input, gan_output)
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt)
return model
# load the images
def load_real_samples():
# load dataset
(trainX, trainy), (_, _) = load_data()
# expand to 3d, e.g. add channels
X = expand_dims(trainX, axis=-1)
# convert from ints to floats
X = X.astype('float32')
# scale from [0,255] to [-1,1]
X = (X - 127.5) / 127.5
print(X.shape, trainy.shape)
return [X, trainy]
# select a supervised subset of the dataset, ensures classes are balanced
def select_supervised_samples(dataset, n_samples=100, n_classes=10):
X, y = dataset
X_list, y_list = list(), list()
n_per_class = int(n_samples / n_classes)
for i in range(n_classes):
# get all images for this class
X_with_class = X[y == i]
# choose random instances
ix = randint(0, len(X_with_class), n_per_class)
# add to list
[X_list.append(X_with_class[j]) for j in ix]
[y_list.append(i) for j in ix]
return asarray(X_list), asarray(y_list)
# select real samples
def generate_real_samples(dataset, n_samples):
# split into images and labels
images, labels = dataset
# choose random instances
ix = randint(0, images.shape[0], n_samples)
# select images and labels
X, labels = images[ix], labels[ix]
# generate class labels
y = ones((n_samples, 1))
return [X, labels], y
# generate points in latent space as input for the generator
def generate_latent_points(latent_dim, n_samples):
# generate points in the latent space
z_input = randn(latent_dim * n_samples)
# reshape into a batch of inputs for the network
z_input = z_input.reshape(n_samples, latent_dim)
return z_input
# use the generator to generate n fake examples, with class labels
def generate_fake_samples(generator, latent_dim, n_samples):
# generate points in latent space
z_input = generate_latent_points(latent_dim, n_samples)
# predict outputs
images = generator.predict(z_input)
# create class labels
y = zeros((n_samples, 1))
return images, y
# generate samples and save as a plot and save the model
def summarize_performance(step, g_model, c_model, latent_dim, dataset, n_samples=100):
# prepare fake examples
X, _ = generate_fake_samples(g_model, latent_dim, n_samples)
# scale from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot images
for i in range(100):
# define subplot
pyplot.subplot(10, 10, 1 + i)
# turn off axis
pyplot.axis('off')
# plot raw pixel data
pyplot.imshow(X[i, :, :, 0], cmap='gray_r')
# save plot to file
filename1 = 'generated_plot_%04d.png' % (step+1)
pyplot.savefig(filename1)
pyplot.close()
# evaluate the classifier model
X, y = dataset
_, acc = c_model.evaluate(X, y, verbose=0)
print('Classifier Accuracy: %.3f%%' % (acc * 100))
# save the generator model
filename2 = 'g_model_%04d.h5' % (step+1)
g_model.save(filename2)
# save the classifier model
filename3 = 'c_model_%04d.h5' % (step+1)
c_model.save(filename3)
print('>Saved: %s, %s, and %s' % (filename1, filename2, filename3))
# train the generator and discriminator
def train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=20, n_batch=100):
# select supervised dataset
X_sup, y_sup = select_supervised_samples(dataset)
print(X_sup.shape, y_sup.shape)
# calculate the number of batches per training epoch
bat_per_epo = int(dataset[0].shape[0] / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# calculate the size of half a batch of samples
half_batch = int(n_batch / 2)
print('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' % (n_epochs, n_batch, half_batch, bat_per_epo, n_steps))
# manually enumerate epochs
for i in range(n_steps):
# update supervised discriminator (c)
[Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch)
c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real)
# update unsupervised discriminator (d)
[X_real, _], y_real = generate_real_samples(dataset, half_batch)
d_loss1 = d_model.train_on_batch(X_real, y_real)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
d_loss2 = d_model.train_on_batch(X_fake, y_fake)
# update generator (g)
X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1))
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# summarize loss on this batch
print('>%d, c[%.3f,%.0f], d[%.3f,%.3f], g[%.3f]' % (i+1, c_loss, c_acc*100, d_loss1, d_loss2, g_loss))
# evaluate the model performance every so often
if (i+1) % (bat_per_epo * 1) == 0:
summarize_performance(i, g_model, c_model, latent_dim, dataset)
# size of the latent space
latent_dim = 100
# create the discriminator models
d_model, c_model = define_discriminator()
# create the generator
g_model = define_generator(latent_dim)
# create the gan
gan_model = define_gan(g_model, d_model)
# load image data
dataset = load_real_samples()
# train model
train(g_model, d_model, c_model, gan_model, dataset, latent_dim)
该示例可以在带有中央处理器或图形处理器硬件的工作站上运行,尽管建议使用图形处理器来加快执行速度。
注:考虑到算法或评估程序的随机性,或数值准确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
在运行开始时,总结了训练数据集的大小,以及监督子集,从而确认了我们的配置。
每个模型的表现在每次更新结束时进行总结,包括有监督鉴别器模型的损失和准确性( c )、无监督鉴别器模型在真实和生成示例上的损失( d )以及通过复合模型更新的生成器模型的损失( g )。
监督模型的损失将缩小到接近于零的小值,并且准确率将达到 100%,这将在整个运行期间保持不变。如果无监督鉴别器和发生器保持平衡,它们的损失在整个运行过程中应保持在适当的值。
(60000, 28, 28, 1) (60000,)
(100, 28, 28, 1) (100,)
n_epochs=20, n_batch=100, 1/2=50, b/e=600, steps=12000
>1, c[2.305,6], d[0.096,2.399], g[0.095]
>2, c[2.298,18], d[0.089,2.399], g[0.095]
>3, c[2.308,10], d[0.084,2.401], g[0.095]
>4, c[2.304,8], d[0.080,2.404], g[0.095]
>5, c[2.254,18], d[0.077,2.407], g[0.095]
...
在每个训练时期结束时,在每 600 次训练更新之后,在整个训练数据集上评估监督分类模型。此时,对该模型的表现进行了总结,表明其快速获得了良好的技能。
这是令人惊讶的,因为该模型只在每个类的 10 个有标签的例子上训练。
Classifier Accuracy: 85.543%
Classifier Accuracy: 91.487%
Classifier Accuracy: 92.628%
Classifier Accuracy: 94.017%
Classifier Accuracy: 94.252%
Classifier Accuracy: 93.828%
Classifier Accuracy: 94.122%
Classifier Accuracy: 93.597%
Classifier Accuracy: 95.283%
Classifier Accuracy: 95.287%
Classifier Accuracy: 95.263%
Classifier Accuracy: 95.432%
Classifier Accuracy: 95.270%
Classifier Accuracy: 95.212%
Classifier Accuracy: 94.803%
Classifier Accuracy: 94.640%
Classifier Accuracy: 93.622%
Classifier Accuracy: 91.870%
Classifier Accuracy: 92.525%
Classifier Accuracy: 92.180%
模型也在每个训练时期结束时保存,并且生成的图像图也被创建。
给定相对少量的训练时期,所生成的图像的质量是好的。

8400 次更新后半监督 GAN 生成的手写数字图。
如何加载和使用最终的 SGAN 分类器模型
既然我们已经训练了生成器和鉴别器模型,我们就可以使用它们了。
在半监督 GAN 的情况下,我们对生成器模型不太感兴趣,而对监督模型更感兴趣。
查看特定运行的结果,我们可以选择已知在测试数据集上具有良好表现的特定保存模型。在这种情况下,模型在 12 个训练时期或 7,200 次更新后保存,在训练数据集上的分类准确率约为 95.432%。
我们可以通过 load_model() Keras 函数直接加载模型。
...
# load the model
model = load_model('c_model_7200.h5')
一旦加载,我们可以在整个训练数据集上再次评估它以确认发现,然后在保持测试数据集上评估它。
回想一下,特征提取层期望输入图像的像素值缩放到范围[-1,1],因此,这必须在将任何图像提供给模型之前执行。
下面列出了加载保存的半监督分类器模型并在完整的 MNIST 数据集中对其进行评估的完整示例。
# example of loading the classifier model and generating images
from numpy import expand_dims
from keras.models import load_model
from keras.datasets.mnist import load_data
# load the model
model = load_model('c_model_7200.h5')
# load the dataset
(trainX, trainy), (testX, testy) = load_data()
# expand to 3d, e.g. add channels
trainX = expand_dims(trainX, axis=-1)
testX = expand_dims(testX, axis=-1)
# convert from ints to floats
trainX = trainX.astype('float32')
testX = testX.astype('float32')
# scale from [0,255] to [-1,1]
trainX = (trainX - 127.5) / 127.5
testX = (testX - 127.5) / 127.5
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
print('Train Accuracy: %.3f%%' % (train_acc * 100))
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Test Accuracy: %.3f%%' % (test_acc * 100))
运行该示例会加载模型,并在 MNIST 数据集上对其进行评估。
注:考虑到算法或评估程序的随机性,或数值准确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
我们可以看到,在这种情况下,模型在训练数据集上达到了 95.432%的预期表现,证实我们已经加载了正确的模型。
我们还可以看到,在保持测试数据集上的准确率同样好,或者略好,大约为 95.920%。这表明所学习的分类器具有良好的泛化能力。
Train Accuracy: 95.432%
Test Accuracy: 95.920%
我们已经通过 GAN 架构成功地演示了半监督分类器模型拟合的训练和评估。
扩展ˌ扩张
本节列出了一些您可能希望探索的扩展教程的想法。
- 独立分类器。将一个独立的分类器模型直接安装在标记的数据集上,并将表现与 SGAN 模型进行比较。
- 标注示例数量。重复更多或更少的标记示例,并比较模型的表现
- 模型调整。调整鉴别器和生成器模型的表现,以进一步提升监督模型的表现,使其更接近最先进的结果。
如果你探索这些扩展,我很想知道。
在下面的评论中发表你的发现。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
报纸
- 生成对抗网络的半监督学习,2016。
- 训练 GANs 的改进技术,2016。
- 分类生成对抗网络的无监督和半监督学习,2015。
- 带 GANs 的半监督学习:改进推理的流形不变性,2017。
- 带 GANs 的半监督学习:重温流形正则化,2018。
应用程序接口
- 硬数据集接口。
- Keras 顺序模型 API
- Keras 卷积层应用编程接口
- 如何“冻结”Keras 层?
- MatplotLib API
- NumPy 随机采样(numpy.random) API
- NumPy 数组操作例程
文章
- 与 GANs 的半监督学习,2018。
- 生成对抗网络半监督学习(GANs) ,2017。
项目
摘要
在本教程中,您发现了如何从零开始开发半监督生成式对抗网络。
具体来说,您了解到:
- 半监督遗传神经网络是遗传神经网络体系结构的扩展,用于训练分类器模型,同时利用标记和未标记的数据。
- 在用于半监督 GAN 的 Keras 中,至少有三种方法来实现监督和非监督鉴别器模型。
- 如何在 MNIST 上从零开始训练半监督的 GAN,并加载和使用训练好的分类器进行预测。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。**
生成对抗网络模型之旅
原文:https://machinelearningmastery.com/tour-of-generative-adversarial-network-models/
最后更新于 2019 年 7 月 12 日
生成对抗网络,或称 GANs,是已经获得广泛成功的深度学习架构生成模型。
关于 GANs 的论文有几千篇,命名的-GANs 有几百篇,也就是定义了名字的模型,通常包括“ GAN ”,比如 DCGAN,而不是方法的一个小的扩展。考虑到 GAN 文献的巨大规模和模型的数量,知道 GAN 模型应该关注什么至少是令人困惑和沮丧的。
在这篇文章中,你将发现生成对抗网络模型,你需要知道这些模型才能在这个领域建立有用和有效的基础。
看完这篇文章,你会知道:
- 为研究领域提供基础的基础 GAN 模型。
- GAN 扩展模型建立在可行的基础上,并为更高级的模型开辟了道路。
- 先进的 GAN 模型,推动了架构的极限,并取得了令人印象深刻的结果。
用我的新书Python 生成对抗网络启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

生成对抗网络模型和扩展之旅
图片由 Tomek Niedzwiedz 提供,保留部分权利。
概观
本教程分为三个部分;它们是:
- 基础
- 生成对抗网络
- 深度卷积生成对抗网络
- 扩展ˌ扩张
- 条件生成对抗网络
- 信息最大化生成对抗网络
- 辅助分类器生成对抗网络
- 堆叠生成对抗网络
- 上下文编码器
- Pix2Pix
- 先进的
- Wasserstein 生成对抗网络
- 循环一致生成对抗网络
- 渐进增长的生成对抗网络
- 基于风格的生成对抗网络
- 大型生成对抗网络
基础生成对抗网络
本节总结了大多数(如果不是全部的话)其他 GAN 所基于的基础 GAN 模型。
生成对抗网络
伊恩·古德费勒等人在 2014 年发表的题为“生成对抗网络”的论文中描述了生成对抗网络体系结构和该方法的首次经验演示
该论文简洁地描述了该体系结构,包括一个生成器模型和一个鉴别器模型,该生成器模型将潜在空间中的点作为输入并生成图像,该鉴别器模型将图像分类为真实(来自数据集)或虚假(由生成器输出)。
我们提出了一个通过对抗过程估计生成模型的新框架,其中我们同时训练两个模型:捕获数据分布的生成模型 G 和估计样本来自训练数据而不是 G 的概率的判别模型 D。G 的训练过程是最大化 D 出错的概率。
——生成对抗网络,2014。
这些模型由完全连接的层(MLPs)组成,生成器中的 ReLU 激活和鉴别器中的 maxout 激活,并应用于标准图像数据集,如 MNIST 和 CIFAR-10。
我们将对抗网络训练为一系列数据集,包括 MNIST、多伦多人脸数据库(TFD)和 CIFAR-10。发生器网络混合使用整流器线性激活和 sigmoid 激活,而鉴别器网络使用 maxout 激活。在训练鉴别器网络时使用了 Dropout。
——生成对抗网络,2014。
深度卷积生成对抗网络
深度卷积生成对抗网络,简称 DCGAN,是 GAN 体系结构的扩展,用于将深度卷积神经网络用于生成器和鉴别器模型,以及模型和训练的配置,导致生成器模型的稳定训练。
我们引入了一类称为深度卷积生成对抗网络(DCGANs)的 CNNs,它们具有一定的体系结构约束,并证明了它们是无监督学习的强候选。
——深度卷积生成对抗网络的无监督表示学习,2015。
DCGAN 很重要,因为它提出了在实践中有效开发高质量发电机模型所需的模型约束。这种架构反过来为大量 GAN 扩展和应用的快速发展提供了基础。
我们提出并评估了卷积神经网络体系结构拓扑上的一组约束,这些约束使它们在大多数环境下训练都很稳定。
——深度卷积生成对抗网络的无监督表示学习,2015。
生成对抗网络扩展
本节总结了命名的 GAN 模型,这些模型为 GAN 模型体系结构或训练过程提供了一些更常见或广泛使用的离散扩展。
条件生成对抗网络
条件生成对抗网络,简称 cGAN,是 GAN 体系结构的扩展,它利用图像之外的信息作为生成器和鉴别器模型的输入。例如,如果类标签可用,它们可以用作输入。
如果生成器和鉴别器都以某些额外信息为条件,那么生成对抗网可以扩展到条件模型。y 可以是任何类型的辅助信息,例如类标签或来自其他模态的数据。我们可以通过将 y 作为附加输入层输入鉴别器和发生器来执行调节。
——条件生成对抗网,2014。
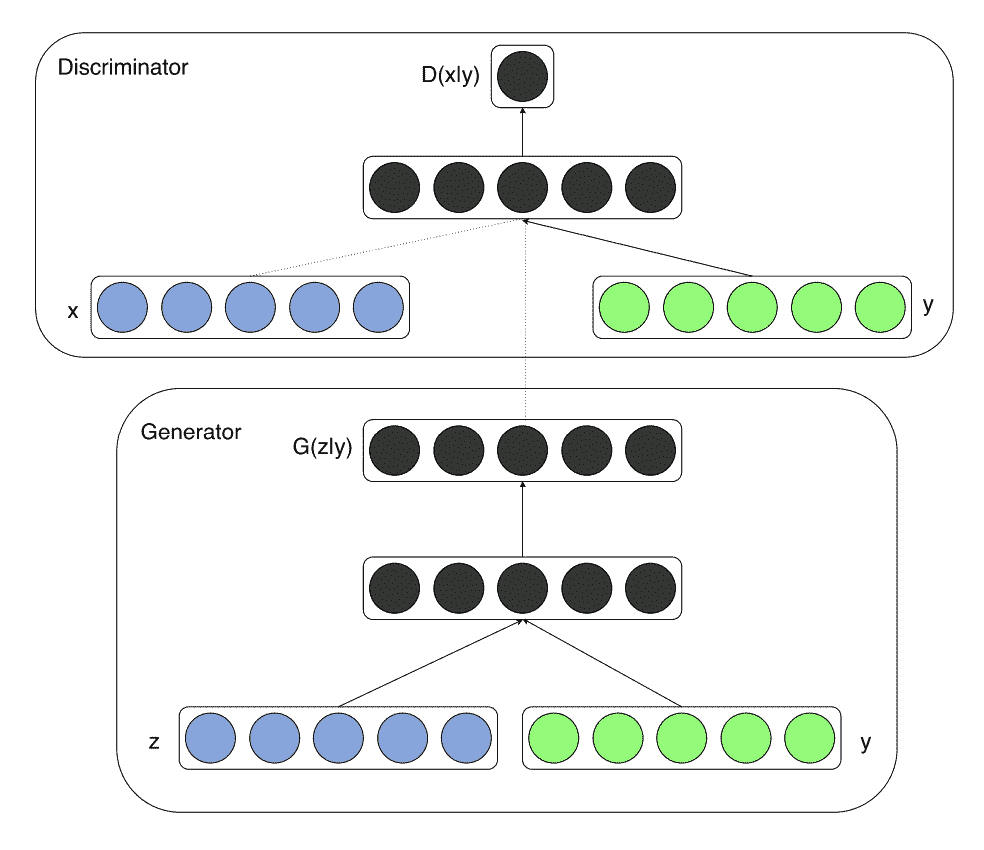
条件生成对抗网络模型架构示例。
摘自:条件生成对抗网。
信息最大化生成对抗网络
信息生成对抗网络,简称 InfoGAN,是 GAN 的扩展,它试图为生成器构建输入或潜在空间。具体来说,目标是为潜在空间中的变量添加特定的语义含义。
…,当从 MNIST 数据集生成图像时,如果模型自动选择分配一个离散的随机变量来表示手指的数字标识(0-9),并选择有两个额外的连续变量来表示手指的角度和手指笔画的粗细,这将是理想的。
——InfoGAN:通过信息最大化生成对抗网进行可解释表征学习,2016。
这是通过将潜在空间中的点分成噪声和潜在代码来实现的。潜在代码随后被用于调节或控制生成的图像中的特定语义属性。
……我们建议将输入噪声向量分解为两部分,而不是使用单一的非结构化噪声向量:(i) z,它被视为不可压缩噪声的来源;(ii) c,我们称之为潜在代码,目标是数据分布的显著结构化语义特征
——InfoGAN:通过信息最大化生成对抗网进行可解释表征学习,2016。

使用潜在代码改变生成的手写数字特征的示例。
摘自:InfoGAN:信息最大化生成对抗网的可解释表征学习。
辅助分类器生成对抗网络
辅助分类器生成对抗网络(AC-GAN)是 GAN 的扩展,它既像 cGAN 一样将生成器更改为类条件,又为经过训练以重建类标签的鉴别器添加附加或辅助模型。
…我们引入了一个模型,它结合了利用辅助信息的两种策略。也就是说,下面提出的模型是类条件的,但是带有一个辅助解码器,其任务是重构类标签。
——辅助分类器条件图像合成 GANs ,2016。
这种体系结构意味着鉴别器既预测给定类别标签的图像的可能性,也预测给定图像的类别标签的可能性。
鉴别器给出了源上的概率分布和类标签上的概率分布,P(S | X),P(C | X) = D(X)。
——辅助分类器条件图像合成 GANs ,2016。
堆叠生成对抗网络
堆叠生成对抗网络,或称堆叠网络,是遗传神经网络的扩展,使用条件遗传神经网络模型的分层堆叠从文本生成图像。
……我们提出堆叠生成对抗网络(StackGAN)来生成以文本描述为条件的 256×256 的照片真实感图像。
——stack gan:使用堆叠生成对抗网络的文本到照片真实感图像合成,2016 年。
该架构由一系列基于文本和图像的 GAN 模型组成。第一级发生器(第一级 GAN)以文本为条件,产生低分辨率图像。第二级发生器(第二级 GAN)以文本和第一级输出的低分辨率图像为条件,输出高分辨率图像。
低分辨率图像首先由我们的第一阶段 GAN 生成。在我们的第一阶段 GAN 的顶部,我们堆叠第二阶段 GAN,以根据第一阶段结果和文本描述生成逼真的高分辨率(例如,256×256)图像。通过再次调节阶段一的结果和文本,阶段二的 GAN 学会捕捉被阶段一的 GAN 省略的文本信息,并为对象绘制更多的细节
——stack gan:使用堆叠生成对抗网络的文本到照片真实感图像合成,2016 年。
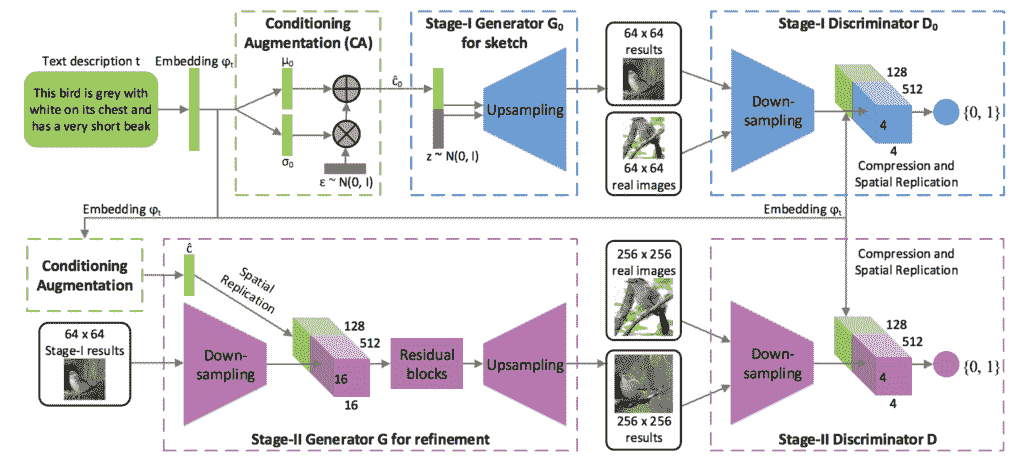
用于文本到图像生成的堆叠生成对抗网络的体系结构示例。
摄自:StackGAN:使用堆叠生成对抗网络的文本到照片真实感图像合成。
上下文编码器
上下文编码器模型是用于条件图像生成的编码器-解码器模型,使用为 GANs 设计的对抗方法进行训练。虽然在论文中没有将其称为 GAN 模型,但它具有许多 GAN 特性。
通过与自动编码器的类比,我们提出了上下文编码器——一种卷积神经网络,它被训练来生成以周围环境为条件的任意图像区域的内容。
——上下文编码器:通过修复进行特征学习,2016。
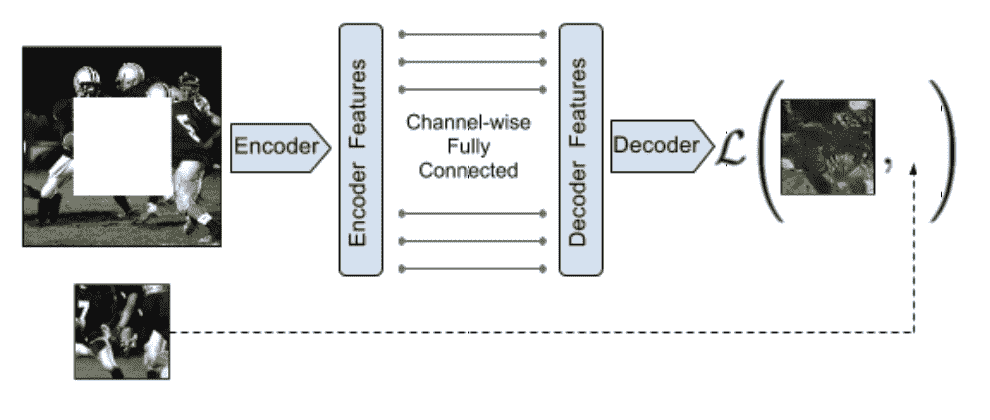
上下文编码器编码器-解码器模型架构示例。
摘自:上下文编码器:通过修复进行特征学习
用联合损失训练该模型,该联合损失结合了发生器和鉴别器模型的对抗损失和计算预测和预期输出图像之间的向量范数距离的重建损失。
当训练上下文编码器时,我们已经试验了标准像素级重建损失,以及重建加对抗损失。后者产生更清晰的结果,因为它可以更好地处理输出中的多种模式。
——上下文编码器:通过修复进行特征学习,2016。
Pix2Pix
pix2pix 模型是用于图像条件图像生成的 GAN 的扩展,称为任务图像到图像转换。生成器模型采用 U-Net 模型架构,鉴别器模型采用 PatchGAN 模型架构。
我们的方法在生成器和鉴别器的几个架构选择上也不同于先前的工作。与以往的工作不同,对于我们的生成器,我们使用了基于“U-Net”的体系结构,对于我们的鉴别器,我们使用了卷积的“PatchGAN”分类器,它只在图像块的尺度上惩罚结构。
——条件对抗网络下的图像到图像转换,2016。
生成器模型的损失被更新,以包括到目标输出图像的矢量距离。
鉴别器的工作保持不变,但是生成器的任务不仅是愚弄鉴别器,而且是在 L2 意义上接近地面真实输出。我们还探索了这个选项,使用 L1 距离而不是 L2,因为 L1 鼓励减少模糊。
——条件对抗网络下的图像到图像转换,2016。
高级生成对抗网络
本节列出了最近在先前的 GAN 扩展的基础上导致令人惊讶或印象深刻的结果的 GAN 模型。
这些模型主要集中在允许生成大的真实感图像的开发上。
Wasserstein 生成对抗网络
Wasserstein 生成对抗网络,简称 WGAN,是 GAN 的一个扩展,它改变训练过程来更新鉴别器模型,现在被称为批评家,每次迭代比生成器模型多很多倍。

Wasserstein 生成对抗网络的算法。
取自:Wasserstein GAN。
批评器被更新以输出实值(线性激活),而不是具有 sigmoid 激活的二进制预测,并且批评器和生成器模型都使用“Wasserstein 损失来训练,该损失是来自批评器的实值和预测值的乘积的平均值,设计用于提供对更新模型有用的线性梯度。
鉴别器学习辨别真假非常快,而且不出所料,没有提供可靠的梯度信息。然而,批评家不能饱和,并且收敛到一个线性函数,该函数在任何地方都给出非常干净的梯度。我们限制权重的事实限制了函数在空间的不同部分至多线性的可能增长,迫使最优批评家具有这种行为。
——2017 年一根筋。
此外,批评模型的权重被剪裁以保持较小,例如[-0.01 的边界框。0.01].
为了使参数 W 位于一个紧凑的空间中,我们可以做一些简单的事情,即在每次梯度更新后将权重固定在一个固定的框中(比如 W =[0.01,0.01]l)。
——2017 年一根筋。
循环一致生成对抗网络
循环一致生成对抗网络,简称 CycleGAN,是 GAN 的扩展,用于在没有成对图像数据的情况下进行图像到图像的翻译。这意味着目标图像的例子并不像条件 GANs 那样是必需的,例如 Pix2Pix。
…对于许多任务,配对的训练数据将不可用。我们提出了一种在没有配对例子的情况下学习将图像从源域 X 翻译到目标域 Y 的方法。
——使用循环一致对抗网络的不成对图像到图像转换,2017。
他们的方法寻求“周期一致性”,使得从一个域到另一个域的图像转换是可逆的,这意味着它形成了一个一致的翻译周期。
……我们利用了翻译应该“循环一致”的特性,也就是说,如果我们把一个句子从英语翻译成法语,然后再把它从法语翻译回英语,我们就应该回到原来的句子
——使用循环一致对抗网络的不成对图像到图像转换,2017。
这是通过拥有两个生成器模型来实现的:一个用于将 X 转换为 Y,另一个用于重构给定的 Y。
……我们的模型包括两个映射 G : X -> Y 和 F : Y -> X,此外,我们引入了两个对抗性判别器 DX 和 DY,其中 DX 旨在区分图像{x}和翻译图像{ F(Y)};同样,DY 旨在区分{y}和{G(x)}。
——使用循环一致对抗网络的不成对图像到图像转换,2017。
渐进增长的生成对抗网络
渐进增长的生成对抗网络,简称渐进 GAN,是对 GAN 模型的架构和训练的改变,包括在训练过程中逐步增加模型深度。
关键思想是逐步增长生成器和鉴别器:从低分辨率开始,我们添加新的层,随着训练的进行,这些层对越来越精细的细节进行建模。这既加快了训练速度,又极大地稳定了训练,使我们能够生成前所未有质量的图像…
——为提高质量、稳定性和变化性而进行的肝的渐进式增长,2017 年。
这是通过在训练期间保持生成器和鉴别器在深度上对称并逐步添加层来实现的,很像深度神经网络早期开发中的贪婪逐层预训练技术,只是先前层中的权重没有冻结。
我们使用的生成器和鉴别器网络是彼此的镜像,并且总是同步增长。两个网络中的所有现有层在整个训练过程中都是可训练的。当新层添加到网络中时,我们会平滑地淡入它们…
——为提高质量、稳定性和变化性而进行的肝的渐进式增长,2017 年。
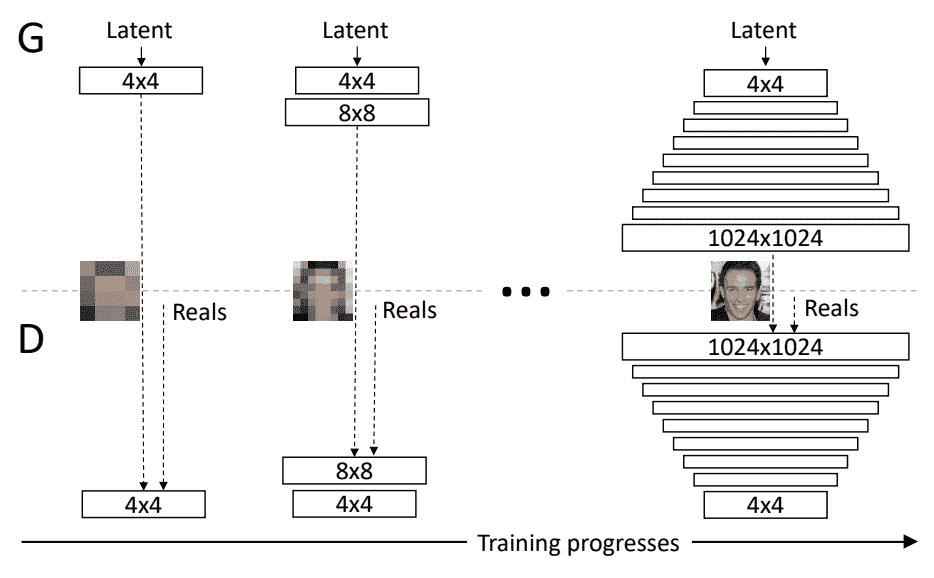
训练过程中生成对抗网络逐渐发展的例子。
取自:为提高质量、稳定性和变异而进行的肝的渐进式增长。
大型生成对抗网络
大型生成对抗网络,简称 BigGAN,是一种展示如何通过扩展现有的类条件 GAN 模型来创建高质量输出图像的方法。
我们证明,与现有技术相比,GANs 从扩展中受益匪浅,训练模型的参数是现有技术的 2 到 4 倍,批量是现有技术的 8 倍
——高保真自然图像合成的大规模 GAN 训练,2018。
模型架构是基于一系列 GAN 模型和扩展的最佳实践的集合。通过系统的实验实现了进一步的改进。
使用“截断技巧”,其中在生成时从截断的高斯潜在空间采样点,这不同于训练时的未截断分布。
值得注意的是,我们最好的结果来自于使用与训练中不同的潜在采样分布。采用用 z∞N(0,1)训练的模型并从截断的法线采样 z(其中落在范围之外的值被重新采样以落在该范围之内)立即提供了提升
——高保真自然图像合成的大规模 GAN 训练,2018。
基于风格的生成对抗网络
基于样式的生成对抗网络,简称 StyleGAN,是生成器的扩展,它允许潜在代码在模型的不同点用作输入,以控制生成图像的特征。
…我们重新设计了生成器架构,以展示控制图像合成过程的新颖方法。我们的生成器从学习的常量输入开始,并基于潜在代码调整每个卷积层的图像“样式”,从而直接控制不同比例下图像特征的强度。
——一种基于风格的生成对抗网络生成器架构,2018 年。
代替将潜在空间中的点作为输入,该点在被提供作为发生器模型中的多个点的输入之前通过深度嵌入网络被馈送。此外,噪声也随着嵌入网络的输出而增加。
传统上,潜在代码是通过输入层提供给生成器的[……]我们从这个设计出发,完全省略了输入层,而是从一个已知的常数开始。给定输入潜在空间 Z 中的潜在代码 Z,非线性映射网络 f : Z -> W 首先产生 w ∈ W。
——一种基于风格的生成对抗网络生成器架构,2018 年。
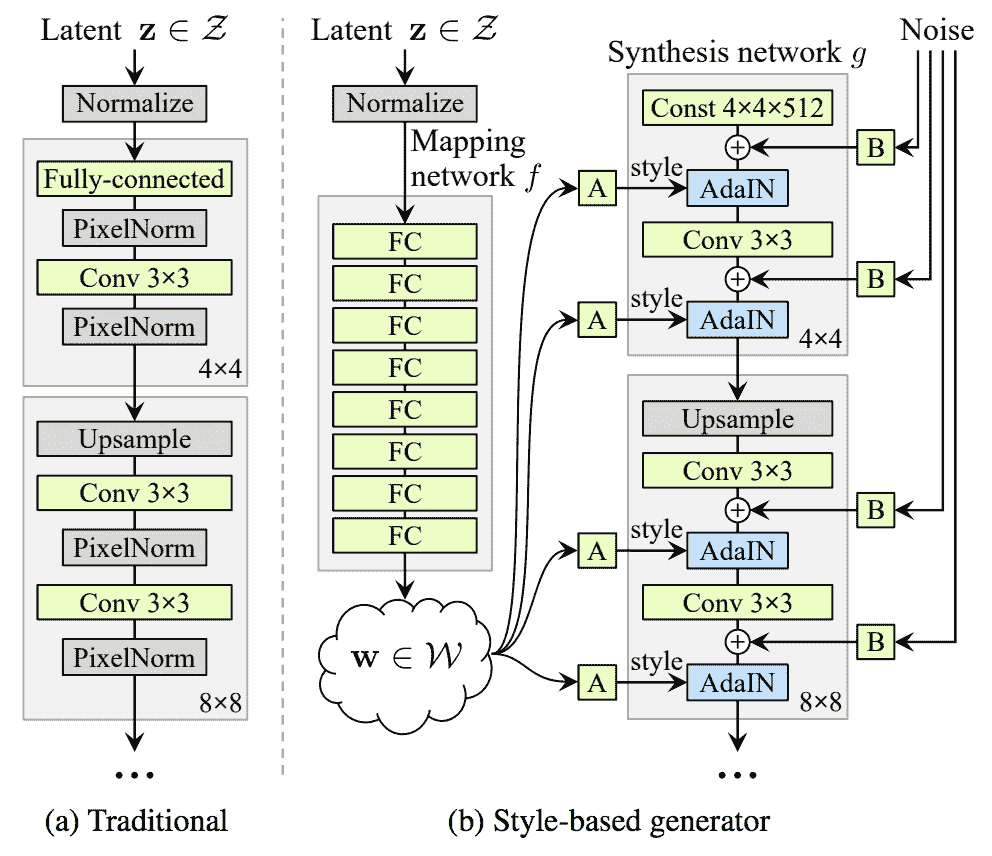
传统生成器体系结构与基于样式的生成器模型体系结构的比较示例。
摘自:生成对抗网络的基于风格的生成器架构。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
基础论文
- 生成对抗网络,2014。
- 深度卷积生成对抗网络的无监督表示学习,2015。
扩展文件
- 条件生成对抗网,2014。
- InfoGAN:通过信息最大化生成对抗网络进行可解释表征学习,2016。
- 辅助分类器的条件图像合成 GANs ,2016。
- StackGAN:使用堆叠生成对抗网络的文本到照片真实感图像合成,2016。
- 上下文编码器:通过修复进行特征学习,2016。
- 条件对抗网络下的图像到图像转换,2016。
高级论文
- 水的输入 gan2017 年。
- 使用循环一致对抗网络的不成对图像到图像转换,2017。
- 为改善质量、稳定性和变异而进行的肝的渐进式增长,2017 年。
- 一种基于风格的生成对抗网络生成器架构,2018。
- 高保真自然图像合成的大规模 GAN 训练,2018。
文章
摘要
在这篇文章中,你发现了生成对抗网络模型,你需要知道这些模型才能在这个领域建立有用和有效的基础
具体来说,您了解到:
- 为研究领域提供基础的基础 GAN 模型。
- GAN 扩展模型建立在可行的基础上,并为更高级的模型开辟了道路。
- 先进的 GAN 模型,推动了架构的极限,并取得了令人印象深刻的结果。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何在 Keras 中使用 UpSampling2D 和 Conv2D 转置层
最后更新于 2019 年 7 月 12 日
生成对抗网络是一种用于训练生成模型的体系结构,例如用于生成图像的深度卷积神经网络。
GAN 架构由一个生成器和一个鉴别器模型组成。生成器负责创建新的输出,如图像,这些输出很可能来自原始数据集。生成器模型通常使用深度卷积神经网络和结果专用层来实现,结果专用层学习填充图像中的特征,而不是从输入图像中提取特征。
可以在生成器模型中使用的两种常见类型的层是简单地将输入的维度加倍的上采样层(upsample layer,UpSampling2D)和执行反卷积运算的转置卷积层(Conv2DTranspose)。
在本教程中,您将发现如何在生成图像时使用创成式对抗网络中的增强 2D 和转换 2D 置换层。
完成本教程后,您将知道:
- GAN 架构中的生成模型需要对输入数据进行上采样,以生成输出图像。
- 上采样层是一个没有权重的简单层,它将使输入的维度加倍,并且可以在传统卷积层之后的生成模型中使用。
- 转置卷积层是一个反向卷积层,它将对输入进行上采样,并学习如何在模型训练过程中填充细节。
用我的新书Python 生成对抗网络启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

生成对抗网络的上采样和转置卷积层简介
图片由 BLM 内华达提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 需要在 GANs 中进行上采样
- 如何使用上采样层
- 如何使用转置卷积层
生成对抗网络中的上采样需求
生成对抗网络是一种用于训练生成模型的神经网络体系结构。
该体系结构由一个生成器和一个鉴别器模型组成,这两个模型都实现为一个深度卷积神经网络。鉴别器负责将图像分类为真实的(来自域)或虚假的(生成的)。生成器负责从问题域生成新的似是而非的例子。
生成器通过从潜在空间中选取一个随机点作为输入,并以一次拍摄的方式输出完整的图像来工作。
用于图像分类和相关任务的传统卷积神经网络将使用池化层对输入图像进行下采样。例如,平均池层或最大池层将在每个维度上将卷积图的特征图减少一半,从而产生四分之一输入面积的输出。
卷积层本身也通过对输入图像或特征图应用每个滤波器来执行一种形式的下采样;生成的激活是一个输出特征图,由于边界效应,它变小了。通常填充用来抵消这种效果。
GAN 中的生成器模型需要传统卷积层中池层的反向操作。它需要一个层来从粗糙的显著特征转换成更密集和详细的输出。
一个简单版本的非冷却或相反的池化层被称为上采样层。它通过重复输入的行和列来工作。
一种更复杂的方法是执行反向卷积运算,最初称为反卷积,这是不正确的,但更常见的是称为分数卷积层或转置卷积层。
这两个层都可以在 GAN 上使用,以执行所需的上采样操作,将小输入转换为大图像输出。
在接下来的部分中,我们将仔细研究每一个,并对它们如何工作形成直觉,以便我们可以在 GAN 模型中有效地使用它们。
如何使用放大的二维层
也许对输入进行上采样的最简单方法是每一行和每一列加倍。
例如,形状为 2×2 的输入图像将输出为 4×4。
1, 2
Input = (3, 4)
1, 1, 2, 2
Output = (1, 1, 2, 2)
3, 3, 4, 4
3, 3, 4, 4
使用上放大二维层的工作示例
Keras 深度学习库在一个名为upsmampling 2d的层中提供了这种能力。
它可以被添加到卷积神经网络,并在输出中重复作为输入提供的行和列。例如:
...
# define model
model = Sequential()
model.add(UpSampling2D())
我们可以用一个简单的人为例子来演示这个层的行为。
首先,我们可以定义一个 2×2 像素的人为输入图像。我们可以为每个像素使用特定的值,这样在上采样后,我们就可以确切地看到操作对输入的影响。
...
# define input data
X = asarray([[1, 2],
[3, 4]])
# show input data for context
print(X)
一旦定义了图像,我们必须添加一个通道维度(例如灰度)和一个样本维度(例如我们有 1 个样本),这样我们就可以将其作为输入传递给模型。
...
# reshape input data into one sample a sample with a channel
X = X.reshape((1, 2, 2, 1))
我们现在可以定义我们的模型了。
该模型只有上采样 2D 层,直接以 2×2 灰度图像作为输入,输出上采样操作的结果。
...
# define model
model = Sequential()
model.add(UpSampling2D(input_shape=(2, 2, 1)))
# summarize the model
model.summary()
然后,我们可以使用该模型进行预测,即对提供的输入图像进行上采样。
...
# make a prediction with the model
yhat = model.predict(X)
输出将像输入一样有四个维度,因此,我们可以将其转换回 2×2 数组,以便于查看结果。
...
# reshape output to remove channel to make printing easier
yhat = yhat.reshape((4, 4))
# summarize output
print(yhat)
将所有这些结合在一起,下面提供了在 Keras 中使用upsmampling 2d层的完整示例。
# example of using the upsampling layer
from numpy import asarray
from keras.models import Sequential
from keras.layers import UpSampling2D
# define input data
X = asarray([[1, 2],
[3, 4]])
# show input data for context
print(X)
# reshape input data into one sample a sample with a channel
X = X.reshape((1, 2, 2, 1))
# define model
model = Sequential()
model.add(UpSampling2D(input_shape=(2, 2, 1)))
# summarize the model
model.summary()
# make a prediction with the model
yhat = model.predict(X)
# reshape output to remove channel to make printing easier
yhat = yhat.reshape((4, 4))
# summarize output
print(yhat)
运行该示例首先创建并总结我们的 2×2 输入数据。
接下来,对模型进行总结。我们可以看到,它将输出我们所期望的 4×4 结果,重要的是,该层没有参数或模型权重。这是因为它没有学到任何东西;这只是投入的两倍。
最后,该模型用于对我们的输入进行上采样,如我们所料,导致我们的输入数据的每一行和每一列都翻倍。
[[1 2]
[3 4]]
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
up_sampling2d_1 (UpSampling2 (None, 4, 4, 1) 0
=================================================================
Total params: 0
Trainable params: 0
Non-trainable params: 0
_________________________________________________________________
[[1\. 1\. 2\. 2.]
[1\. 1\. 2\. 2.]
[3\. 3\. 4\. 4.]
[3\. 3\. 4\. 4.]]
默认情况下,向上放大 2D 将使每个输入尺寸加倍。这是由设置为元组(2,2)的“大小参数定义的。
您可能希望在每个维度上使用不同的因子,例如宽度的两倍和高度的三倍。这可以通过将“大小参数设置为(2,3)来实现。将该操作应用于 2×2 图像的结果将是 4×6 输出图像(例如 2×2 和 2×3)。例如:
...
# example of using different scale factors for each dimension
model.add(UpSampling2D(size=(2, 3)))
此外,默认情况下,upsmampling 2d层将使用最近邻算法来填充新的行和列。这具有简单地将行和列加倍的效果,如所述,并且由设置为最接近的“插值参数指定。
或者,可以使用利用多个周围点的双线性插值方法。这可以通过将“插值参数设置为“双线性来指定。例如:
...
# example of using bilinear interpolation when upsampling
model.add(UpSampling2D(interpolation='bilinear'))
带有上放大 2D 层的简单生成器模型
upsmamping 2d层简单有效,虽然不执行任何学习。
它不能在向上采样操作中填充有用的细节。为了在 GAN 中有用,每个upsmampling 2d层后面必须跟有一个 Conv2D 层,该层将学习解释加倍的输入,并被训练将其转化为有意义的细节。
我们可以用一个例子来证明。
在这种情况下,我们的小 GAN 生成器模型必须生成一个 10×10 的图像,并从潜在空间中获取一个 100 元素的向量作为输入。
首先,可以使用一个密集的完全连接层来解释输入向量,并创建足够数量的激活(输出),这些激活可以被重塑为我们输出图像的低分辨率版本,在本例中,是 5×5 图像的 128 个版本。
...
# define model
model = Sequential()
# define input shape, output enough activations for for 128 5x5 image
model.add(Dense(128 * 5 * 5, input_dim=100))
# reshape vector of activations into 128 feature maps with 5x5
model.add(Reshape((5, 5, 128)))
接下来,可以将 5×5 的要素图上采样为 10×10 的要素图。
...
# double input from 128 5x5 to 1 10x10 feature map
model.add(UpSampling2D())
最后,上采样的要素图可以由一个 Conv2D 层解释并填充有用的细节。
Conv2D 有一个单一的功能图作为输出,以创建我们需要的单一图像。
...
# fill in detail in the upsampled feature maps
model.add(Conv2D(1, (3,3), padding='same'))
将这些联系在一起,完整的示例如下所示。
# example of using upsampling in a simple generator model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers import UpSampling2D
from keras.layers import Conv2D
# define model
model = Sequential()
# define input shape, output enough activations for for 128 5x5 image
model.add(Dense(128 * 5 * 5, input_dim=100))
# reshape vector of activations into 128 feature maps with 5x5
model.add(Reshape((5, 5, 128)))
# double input from 128 5x5 to 1 10x10 feature map
model.add(UpSampling2D())
# fill in detail in the upsampled feature maps and output a single image
model.add(Conv2D(1, (3,3), padding='same'))
# summarize model
model.summary()
运行该示例会创建模型并总结每个层的输出形状。
我们可以看到密集层输出 3200 次激活,然后这些激活被重新整形为 128 个形状为 5×5 的特征图。
通过上放大 2D 层,宽度和高度增加了一倍,达到 10×10,从而生成面积增加了四倍的要素地图。
最后,Conv2D 处理这些特征图并添加细节,输出单个 10×10 图像。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 3200) 323200
_________________________________________________________________
reshape_1 (Reshape) (None, 5, 5, 128) 0
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 10, 10, 128) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 10, 10, 1) 1153
=================================================================
Total params: 324,353
Trainable params: 324,353
Non-trainable params: 0
_________________________________________________________________
如何使用转换 2 置换层
conv2d 转置或转置卷积层比简单的上采样层更复杂。
一个简单的方法是,它既执行上采样操作,又解释粗输入数据,以便在上采样时填充细节。它就像一个层,将upsmampling 2d和 Conv2D 层组合成一个层。这是一个粗略的理解,但却是一个实际的出发点。
对转置卷积的需求通常源于使用与正常卷积方向相反的变换的期望,即从具有某个卷积输出形状的事物到具有其输入形状的事物,同时保持与所述卷积兼容的连通性模式
——深度学习卷积算法指南,2016 年。
事实上,转置卷积层执行反卷积运算。
具体来说,卷积层的前向和后向通路是反向的。
一种说法是,内核定义了一个卷积,但是它是直接卷积还是转置卷积取决于向前和向后传递的计算方式。
——深度学习卷积算法指南,2016 年。
它有时被称为反卷积或反卷积层,使用这些层的模型可以被称为反卷积网络或反卷积集。
一个解卷积网络可以被认为是一个 convnet 模型,它使用相同的组件(过滤、池化),但方向相反,所以与其将像素映射到特征,不如反过来做。
——可视化和理解卷积网络,2013。
将该操作称为反褶积在技术上是不正确的,因为反褶积是该层不执行的特定数学操作。
事实上,传统的卷积层在技术上并不执行卷积运算,而是执行互相关。
人们通常所指的反卷积层首次出现在泽勒的论文中,作为反卷积网络的一部分,但没有具体的名称。[……]它也有许多名称,包括(但不限于)子像素或分数卷积层、转置卷积层、逆卷积层、上卷积层或后卷积层。
——反卷积层和卷积层一样吗?,2016 年。
这是一个非常灵活的层,尽管我们将重点关注它在对输入图像进行上采样的生成模型中的使用。
转置卷积层很像普通卷积层。它要求您指定过滤器的数量和每个过滤器的内核大小。这一层的关键是步幅。
典型地,卷积层的步距是(1×1),也就是说,对于从左到右的每次读取,滤波器沿着一个像素水平移动,然后对于下一行读取向下移动一个像素。正常卷积层上 2×2 的步长具有对输入进行下采样的效果,很像池化层。事实上,在鉴别器模型中,可以使用 2×2 步长来代替池化层。
转置卷积层类似于逆卷积层。因此,你会直觉地认为 2×2 的步幅会对输入进行上采样,而不是下采样,这正是发生的情况。
跨步是指传统卷积层中滤波器扫描输入的方式。而在转置卷积层中,步幅指的是特征图中输出的布局方式。
这种效果可以通过使用分数输入步幅(f)的普通卷积层来实现,例如步幅为 f=1/2。反转时,输出步幅设置为该分数的分子,例如 f=2。
从某种意义上说,用 f 因子进行上采样是用 1/f 的分数输入步长进行卷积。只要 f 是整数,自然的上采样方式就是用 f 的输出步长进行反向卷积(有时称为反卷积)
——语义分割的全卷积网络,2014。
使用普通卷积层可以实现这种效果的一种方式是在输入数据中插入 0.0 值的新行和新列。
最后要注意的是,总是可以用直接卷积来模拟转置卷积。缺点是它通常需要向输入中添加许多列和行的零…
——深度学习卷积算法指南,2016 年。
让我们用一个例子来具体说明。
考虑大小为 2×2 的输入图像,如下所示:
1, 2
Input = (3, 4)
假设单个滤波器具有 1×1 内核和模型权重,在输出时不会导致输入发生变化(例如,模型权重为 1.0,偏差为 0.0),输出步长为 1×1 的转置卷积运算将按原样再现输出:
1, 2
Output = (3, 4)
输出步长为(2,2)时,1×1 卷积需要在输入图像中插入额外的行和列,以便可以执行读取操作。因此,输入如下所示:
1, 0, 2, 0
Input = (0, 0, 0, 0)
3, 0, 4, 0
0, 0, 0, 0
然后,模型可以使用(2,2)的输出步幅读取该输入,并将输出 4×4 的图像,在这种情况下没有变化,因为我们的模型权重不受设计影响:
1, 0, 2, 0
Output = (0, 0, 0, 0)
3, 0, 4, 0
0, 0, 0, 0
使用 con v2 置换层的工作示例
Keras 通过 con v2 转置层提供转置卷积功能。
可以直接添加到您的模型中;例如:
...
# define model
model = Sequential()
model.add(Conv2DTranspose(...))
我们可以用一个简单的人为例子来演示这个层的行为。
首先,我们可以定义一个 2×2 像素的人为输入图像,就像我们在上一节中所做的那样。我们可以为每个像素使用特定的值,以便在转置卷积运算之后,我们可以确切地看到运算对输入有什么影响。
...
# define input data
X = asarray([[1, 2],
[3, 4]])
# show input data for context
print(X)
一旦定义了图像,我们必须添加一个通道维度(例如灰度)和一个样本维度(例如我们有 1 个样本),这样我们就可以将其作为输入传递给模型。
...
# reshape input data into one sample a sample with a channel
X = X.reshape((1, 2, 2, 1))
我们现在可以定义我们的模型了。
模型只有conv2d 转置层,直接以 2×2 灰度图像作为输入,输出运算结果。
con v2 转置两个上采样并执行卷积。因此,我们必须指定过滤器的数量和过滤器的大小,就像我们为 Conv2D 层所做的那样。此外,我们必须指定(2,2)的步距,因为上采样是通过输入卷积的步距行为实现的。
指定步幅为(2,2)具有分隔输入的效果。具体来说,插入 0.0 值的行和列以实现期望的步幅。
在本例中,我们将使用一个滤波器,其内核为 1×1,步长为 2×2,因此 2×2 的输入图像被上采样到 4×4。
...
# define model
model = Sequential()
model.add(Conv2DTranspose(1, (1,1), strides=(2,2), input_shape=(2, 2, 1)))
# summarize the model
model.summary()
为了弄清楚conv2d 转置层在做什么,我们将把单个过滤器中的单个权重固定为 1.0 的值,并使用 0.0 的偏差值。
这些权重以及内核大小(1,1)意味着输入中的值将乘以 1 并按原样输出,通过 2×2 的步长添加的新行和新列中的 0 值将输出为 0(例如,在每种情况下为 1 * 0)。
...
# define weights that they do nothing
weights = [asarray([[[[1]]]]), asarray([0])]
# store the weights in the model
model.set_weights(weights)
然后,我们可以使用该模型进行预测,即对提供的输入图像进行上采样。
...
# make a prediction with the model
yhat = model.predict(X)
输出将像输入一样有四个维度,因此,我们可以将其转换回 2×2 数组,以便于查看结果。
...
# reshape output to remove channel to make printing easier
yhat = yhat.reshape((4, 4))
# summarize output
print(yhat)
将所有这些结合在一起,下面提供了在 Keras 中使用conv2d 转置层的完整示例。
# example of using the transpose convolutional layer
from numpy import asarray
from keras.models import Sequential
from keras.layers import Conv2DTranspose
# define input data
X = asarray([[1, 2],
[3, 4]])
# show input data for context
print(X)
# reshape input data into one sample a sample with a channel
X = X.reshape((1, 2, 2, 1))
# define model
model = Sequential()
model.add(Conv2DTranspose(1, (1,1), strides=(2,2), input_shape=(2, 2, 1)))
# summarize the model
model.summary()
# define weights that they do nothing
weights = [asarray([[[[1]]]]), asarray([0])]
# store the weights in the model
model.set_weights(weights)
# make a prediction with the model
yhat = model.predict(X)
# reshape output to remove channel to make printing easier
yhat = yhat.reshape((4, 4))
# summarize output
print(yhat)
运行该示例首先创建并总结我们的 2×2 输入数据。
接下来,对模型进行总结。我们可以看到,它将输出我们期望的 4×4 的结果,重要的是,第二层参数或模型权重。一个用于单个 1×1 滤波器,一个用于偏置。与上采样 2D 层不同的是,conv2d 转置将在训练期间学习,并将尝试填充细节作为上采样过程的一部分。
最后,该模型用于对我们的输入进行上采样。我们可以看到,包含实值作为输入的单元格的计算导致实值作为输出(例如 1×1、1×2 等)。).我们可以看到,在以 2×2 的步幅插入新行和新列的情况下,它们的 0.0 值乘以单个 1×1 过滤器中的 1.0 值会在输出中产生 0 值。
[[1 2]
[3 4]]
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_transpose_1 (Conv2DTr (None, 4, 4, 1) 2
=================================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
_________________________________________________________________
[[1\. 0\. 2\. 0.]
[0\. 0\. 0\. 0.]
[3\. 0\. 4\. 0.]
[0\. 0\. 0\. 0.]]
记住:这是一个人为的例子,我们人为地指定了模型权重,这样我们就可以看到转置卷积运算的效果。
实际上,我们将使用大量的过滤器(例如 64 或 128 个),更大的内核(例如 3×3、5×5 等)。),该层将使用随机权重进行初始化,该权重将学习如何在训练过程中有效地对细节进行上采样。
事实上,您可能会想象不同大小的内核会导致不同大小的输出,超过输入的宽度和高度的两倍。在这种情况下,层的“填充参数可以设置为“相同,以强制输出具有所需的(双倍)输出形状;例如:
...
# example of using padding to ensure that the output is only doubled
model.add(Conv2DTranspose(1, (3,3), strides=(2,2), padding='same', input_shape=(2, 2, 1)))
带有 Model 转置层的简单生成器模型
conv2d 转置比upsmampling 2d层更复杂,但在 GAN 模型中使用时也很有效,尤其是发电机模型。
这两种方法都可以使用,尽管首选 Conv2DTranspose 层,这可能是因为更简单的生成器模型和可能更好的结果,尽管众所周知 GAN 的表现和技能很难量化。
我们可以用另一个简单的例子来演示在生成器模型中使用conv2d 转置层。
在这种情况下,我们的小 GAN 生成器模型必须生成一个 10×10 的图像,并从潜在空间中获取一个 100 元素的向量作为输入,就像前面的upsmamping 2d示例一样。
首先,可以使用一个密集的完全连接层来解释输入向量,并创建足够数量的激活(输出),这些激活可以被重塑为我们输出图像的低分辨率版本,在本例中,是 5×5 图像的 128 个版本。
...
# define model
model = Sequential()
# define input shape, output enough activations for for 128 5x5 image
model.add(Dense(128 * 5 * 5, input_dim=100))
# reshape vector of activations into 128 feature maps with 5x5
model.add(Reshape((5, 5, 128)))
接下来,可以将 5×5 的要素图上采样为 10×10 的要素图。
我们将对单个过滤器使用 3×3 的内核大小,这将导致输出要素图中的宽度和高度略大于两倍(11×11)。
因此,我们将“填充”设置为“相同”,以确保输出尺寸按要求为 10×10。
...
# double input from 128 5x5 to 1 10x10 feature map
model.add(Conv2DTranspose(1, (3,3), strides=(2,2), padding='same'))
将这些联系在一起,完整的示例如下所示。
# example of using transpose conv in a simple generator model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers import Conv2DTranspose
from keras.layers import Conv2D
# define model
model = Sequential()
# define input shape, output enough activations for for 128 5x5 image
model.add(Dense(128 * 5 * 5, input_dim=100))
# reshape vector of activations into 128 feature maps with 5x5
model.add(Reshape((5, 5, 128)))
# double input from 128 5x5 to 1 10x10 feature map
model.add(Conv2DTranspose(1, (3,3), strides=(2,2), padding='same'))
# summarize model
model.summary()
运行该示例会创建模型并总结每个层的输出形状。
我们可以看到密集层输出 3200 次激活,然后这些激活被重新整形为 128 个形状为 5×5 的特征图。
conv2d 转置层将宽度和高度增加了一倍,达到 10×10,从而形成面积增加了四倍的单一要素地图。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 3200) 323200
_________________________________________________________________
reshape_1 (Reshape) (None, 5, 5, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 10, 10, 1) 1153
=================================================================
Total params: 324,353
Trainable params: 324,353
Non-trainable params: 0
_________________________________________________________________
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
报纸
- 深度学习卷积算法指南,2016。
- 去进化网络,2010。
- 反卷积层和卷积层一样吗?,2016 年。
- 可视化和理解卷积网络,2013。
- 语义分割的全卷积网络,2014。
应用程序接口
文章
摘要
在本教程中,您发现了在生成图像时,如何在创成式对抗网络中使用 UpSampling2D 和 conv2d 转置层。
具体来说,您了解到:
- GAN 架构中的生成模型需要对输入数据进行上采样,以生成输出图像。
- 上采样层是一个没有权重的简单层,它将使输入的维度加倍,并且可以在传统卷积层之后的生成模型中使用。
- 转置卷积层是一个反向卷积层,它将对输入进行上采样,并学习如何在模型训练过程中填充细节。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
生成对抗网络(GANs)的温和介绍
原文:https://machinelearningmastery.com/what-are-generative-adversarial-networks-gans/
最后更新于 2019 年 7 月 19 日
生成对抗网络,简称 GANs,是一种使用深度学习方法(如卷积神经网络)进行生成建模的方法。
生成性建模是机器学习中的一项无监督学习任务,它涉及自动发现和学习输入数据中的规律或模式,使得该模型可以用来生成或输出新的示例,这些示例似乎是从原始数据集中提取的。
GANs 是一种训练生成模型的聪明方法,它通过两个子模型将问题框架化为有监督的学习问题:生成器模型,我们训练它来生成新的示例,以及鉴别器模型,它试图将示例分类为真实的(来自域)或虚假的(生成的)。这两个模型在一个零和博弈中一起训练,对抗性的,直到鉴别器模型被愚弄了大约一半的时间,这意味着生成器模型正在生成似是而非的例子。
GANs 是一个令人兴奋且快速变化的领域,在生成跨一系列问题领域的真实示例的能力方面实现了生成模型的承诺,最显著的是在图像到图像的翻译任务中,例如将夏天的照片翻译成冬天的照片或白天到晚上的照片,以及生成甚至人类都无法分辨的对象、场景和人的真实感照片是假的。
在这篇文章中,你会发现一个温和的关于生成对抗网络的介绍。
看完这篇文章,你会知道:
- GANs 的上下文,包括监督学习和非监督学习,以及区分建模和生成建模。
- GANs 是一种通过将无监督问题视为有监督问题并同时使用生成模型和判别模型来自动训练生成模型的体系结构。
- GANs 为复杂的特定领域数据扩充提供了一条途径,并为需要生成性解决方案的问题提供了解决方案,例如图像到图像的翻译。
用我的新书Python 生成对抗网络启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

生成对抗网络的温和介绍
图片由巴尼·莫斯提供,保留部分权利。
概观
本教程分为三个部分;它们是:
- 什么是生成模型?
- 什么是生成对抗网络?
- 为什么是生成对抗网络?
什么是生成模型?
在这一节中,我们将回顾生成模型的思想,跨越有监督和无监督的学习范例以及有区别的和生成的建模。
监督学习与非监督学习
典型的机器学习问题包括使用模型进行预测,例如预测建模。
这需要一个用于训练模型的训练数据集,该数据集由多个称为样本的示例组成,每个示例都有输入变量( X )和输出类标签( y )。模型是通过显示输入的例子,让它预测输出,并修正模型使输出更像预期的输出来训练的。
在预测或监督学习方法中,目标是学习从输入 x 到输出 y 的映射,给定一组标记的输入输出对…
—第 2 页,机器学习:概率视角,2012。
模型的这种修正通常被称为监督形式的学习,或监督学习。
监督学习的例子
监督学习问题的例子包括分类和回归,监督学习算法的例子包括逻辑回归和随机森林。
还有一种学习范式,模型只给定输入变量( X ),问题没有任何输出变量( y )。
通过提取或总结输入数据中的模式来构建模型。模型没有修正,因为模型没有预测任何东西。
机器学习的第二种主要类型是描述性或无监督学习方法。这里我们只得到输入,目标是在数据中找到“有趣的模式”。[……]这是一个定义不太明确的问题,因为我们没有被告知要寻找哪种模式,也没有明显的误差度量来使用(不像监督学习,在监督学习中,我们可以将给定 x 的 y 预测与观察值进行比较)。
—第 2 页,机器学习:概率视角,2012。
这种缺乏纠正通常被称为无监督的学习形式,或无监督学习。
无监督学习的例子
无监督学习问题的例子包括聚类和生成建模,无监督学习算法的例子是 K 均值和生成对抗网络。
区别建模与生成建模
在监督学习中,我们可能有兴趣开发一个模型来预测给定输入变量示例的类标签。
这种预测建模任务称为分类。
分类在传统上也被称为鉴别建模。
……我们使用训练数据找到一个判别函数 f(x),它将每个 x 直接映射到一个类标签上,从而将推理和决策阶段结合成一个单一的学习问题。
—第 44 页,模式识别与机器学习,2006。
这是因为模型必须跨类区分输入变量的例子;它必须选择或决定一个给定的例子属于哪一类。
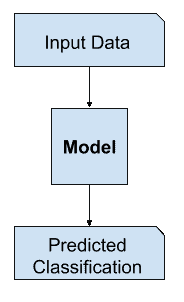
判别建模示例
或者,总结输入变量分布的无监督模型可以用于在输入分布中创建或生成新的示例。
因此,这些类型的模型被称为生成模型。
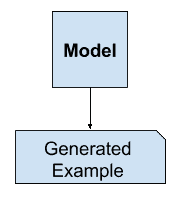
生成建模示例
例如,单个变量可能具有已知的数据分布,如高斯分布,或钟形。生成模型可能能够充分总结这种数据分布,然后用于生成似乎适合输入变量分布的新变量。
对输入和输出的分布进行显式或隐式建模的方法称为生成模型,因为通过对它们进行采样,可以在输入空间中生成合成数据点。
—第 43 页,模式识别与机器学习,2006。
事实上,一个真正好的生成模型可能能够生成新的例子,这些例子不仅看似合理,而且与问题领域的真实例子没有区别。
生成模型的例子
朴素贝叶斯是生成模型的一个例子,它更经常被用作判别模型。
例如,朴素贝叶斯通过总结每个输入变量和输出类的概率分布来工作。当进行预测时,为每个变量计算每个可能结果的概率,组合独立概率,并预测最可能的结果。反向使用时,可以对每个变量的概率分布进行采样,以生成新的似是而非(独立)的特征值。
生成模型的其他例子包括潜在狄利克雷分配(LDA)和高斯混合模型(GMM)。
深度学习方法可以用作生成模型。两个流行的例子包括受限玻尔兹曼机器(RBM)和深度信念网络(DBN)。
深度学习生成建模算法的两个现代例子包括变分自动编码器(VAE)和生成对抗网络(GAN)。
什么是生成对抗网络?
生成对抗网络是一种基于深度学习的生成模式。
更一般地说,GANs 是一种用于训练生成模型的模型架构,在这种架构中使用深度学习模型是最常见的。
2014 年,伊恩·古德费勒等人在题为“T2 生成对抗网络”的论文中首次描述了 GAN 架构
后来,亚历克·拉德福德等人在 2015 年发表的题为“利用深度卷积生成对抗网络的无监督表示学习”的论文中正式提出了一种称为深度卷积生成对抗网络(DCGAN)的标准化方法,该方法导致了更稳定的模型。
今天的大多数 GANs 至少是松散地基于 DCGAN 架构的…
——NIPS 2016 教程:生成对抗网络,2016。
GAN 模型架构包括两个子模型:用于生成新示例的生成器模型和用于分类生成的示例是来自域的真实示例还是生成器模型生成的虚假示例的鉴别器模型。
- 发电机。用于从问题域生成新的似是而非的示例的模型。
- 鉴别器。用于将示例分类为真实(来自域)或虚假(生成)的模型。
生成对抗网络是基于一个博弈论的场景,在这个场景中,生成网络必须与对手竞争。发生器网络直接产生样本。它的对手鉴别器网络试图区分从训练数据提取的样本和从生成器提取的样本。
—第 699 页,深度学习,2016。
发电机模型
生成器模型以固定长度的随机向量作为输入,并在域中生成样本。
该向量是从高斯分布中随机抽取的,该向量用于生成过程的种子。训练后,这个多维向量空间中的点将对应问题域中的点,形成数据分布的压缩表示。
这个向量空间被称为潜在空间,或者由潜在变量组成的向量空间。潜在变量,或者说隐藏变量,是那些对一个领域很重要但不能直接观察到的变量。
潜变量是我们不能直接观察的随机变量。
—第 67 页,深度学习,2016。
我们通常将潜在变量或潜在空间称为数据分布的投影或压缩。也就是说,潜在空间提供了观察到的原始数据(例如输入数据分布)的压缩或高级概念。在 GANs 的情况下,生成器模型将意义应用于所选潜在空间中的点,使得从潜在空间中提取的新点可以作为输入提供给生成器模型,并用于生成新的和不同的输出示例。
机器学习模型可以学习图像、音乐和故事的统计潜在空间,然后它们可以从这个空间中采样,创建新的艺术品,其特征类似于模型在其训练数据中看到的特征。
—第 270 页,Python 深度学习,2017。
经过训练后,生成器模型被保留并用于生成新的样本。
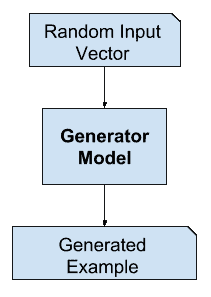
GAN 发生器模型示例
鉴别器模型
鉴别器模型以域中的一个例子作为输入(真实的或生成的),并预测真实的或虚假的二进制类标签(生成的)。
真实的例子来自训练数据集。生成的示例由生成器模型输出。
鉴别器是一个正常的(并且很好理解的)分类模型。
在训练过程之后,鉴别器模型被丢弃,因为我们对生成器感兴趣。
有时,生成器可以重新调整用途,因为它已经学会从问题领域的示例中有效地提取特征。一些或所有特征提取层可以在使用相同或相似输入数据的迁移学习应用中使用。
我们建议,建立良好图像表示的一种方法是训练生成对抗网络(GANs),然后重用部分生成器和鉴别器网络作为监督任务的特征提取器
——深度卷积生成对抗网络的无监督表示学习,2015。
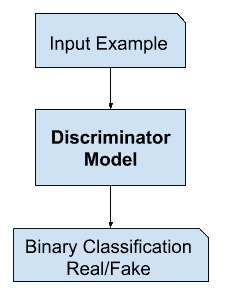
GAN 鉴别器模型示例
作为两人游戏的游戏
生成模型是一个无监督的学习问题,正如我们在前面的章节中所讨论的,尽管 GAN 体系结构的一个聪明的特性是生成模型的训练被构造成一个有监督的学习问题。
生成器和鉴别器这两个模型是一起训练的。生成器生成一批样本,这些样本以及来自该域的真实示例被提供给鉴别器,并被分类为真实或虚假。
然后更新鉴别器,以便在下一轮中更好地鉴别真假样本,重要的是,生成器根据生成的样本欺骗鉴别器的程度进行更新。
我们可以把生成器想象成一个伪造者,试图制造假币,把鉴别器想象成警察,试图允许合法货币,抓住假币。为了在这个游戏中取得成功,伪造者必须学会制造与真金白银无法区分的货币,生成器网络必须学会创建从与训练数据相同的分布中提取的样本。
——NIPS 2016 教程:生成对抗网络,2016。
这样,两个模型就在相互竞争,在博弈论意义上是对抗性的,在玩一个零和游戏。
因为 GAN 框架自然可以用博弈论的工具来分析,所以我们称 GAN 为“对抗性的”。
——NIPS 2016 教程:生成对抗网络,2016。
在这种情况下,零和意味着当鉴别器成功地识别真实和虚假样本时,它会得到奖励或者不需要改变模型参数,而生成器会因为模型参数的大量更新而受到惩罚。
或者,当生成器欺骗鉴别器时,它得到奖励,或者不需要改变模型参数,但是鉴别器受到惩罚,并且它的模型参数被更新。
在极限情况下,生成器每次都从输入域生成完美的副本,而鉴别器无法分辨两者之间的区别,并且在每种情况下都会预测“不确定”(例如,50%是真的还是假的)。这只是一个理想化案例的例子;我们不需要到达这一点就能得到一个有用的发电机模型。
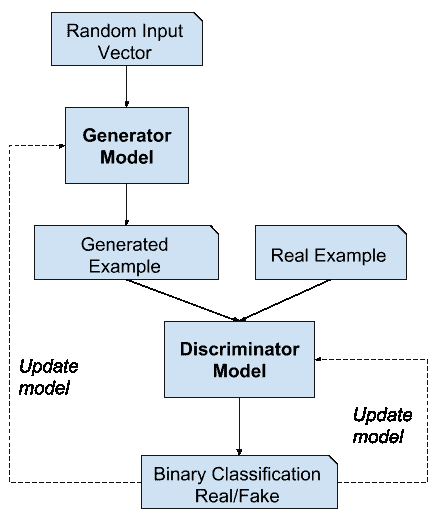
生成对抗网络模型架构示例
[训练]驱动鉴别器尝试学习正确地将样本分类为真或假。同时,生成器试图欺骗分类器相信它的样本是真实的。收敛时,发生器的样本与真实数据无法区分,鉴别器处处输出 1/2。然后可以丢弃该鉴别器。
—第 700 页,深度学习,2016。
遗传神经网络和卷积神经网络
神经网络通常处理图像数据,并使用卷积神经网络作为生成器和鉴别器模型。
其原因可能是因为该技术的第一次描述是在计算机视觉领域,并使用了 CNN 和图像数据,还因为近年来在更广泛地使用 CNN 来实现一系列计算机视觉任务(如对象检测和人脸识别)的最新成果方面取得了显著进展。
对图像数据建模意味着潜在空间(生成器的输入)提供了用于训练模型的一组图像或照片的压缩表示。这也意味着生成器生成新的图像或照片,提供模型的开发人员或用户可以轻松查看和评估的输出。
可能正是这一超越其他因素的事实,即直观评估生成输出质量的能力,导致了计算机视觉应用对 CNN 的关注,以及与其他基于深度学习或其他方式的生成模型相比,CNN 能力的巨大飞跃。
条件 gan
GAN 的一个重要扩展是用于有条件地产生输出。
生成模型可以被训练以从输入域生成新的例子,其中输入,来自潜在空间的随机向量,被提供有(由)一些附加输入。
额外的输入可以是类别值,例如在生成人的照片时是男性或女性,或者在生成手写数字图像时是数字。
如果生成器和鉴别器都以某些额外信息为条件,那么生成对抗网可以扩展到条件模型。y 可以是任何类型的辅助信息,例如类标签或来自其他模态的数据。我们可以通过将 y 作为额外的输入层输入鉴别器和发生器来进行调节。
——条件生成对抗网,2014。
鉴别器也是有条件的,这意味着它既有真实或虚假的输入图像,也有额外的输入。在分类标签类型条件输入的情况下,鉴别器将期望输入是该类的,反过来教导生成器生成该类的示例,以便欺骗鉴别器。
以这种方式,条件 GAN 可以用于从给定类型的域生成示例。
更进一步,GAN 模型可以基于来自域的示例,例如图像。这允许 GANs 的应用,如文本到图像的翻译,或图像到图像的翻译。这允许 GANs 的一些更令人印象深刻的应用,例如风格转换、照片彩色化、将照片从夏天转换成冬天或从白天转换成夜晚等等。
在用于图像到图像转换的条件 GANs 的情况下,例如将白天转换为夜晚,鉴别器被提供真实的和生成的夜间照片的例子以及(以)真实的白天照片作为输入。生成器提供了来自潜在空间的随机向量以及(根据条件)真实的白天照片作为输入。
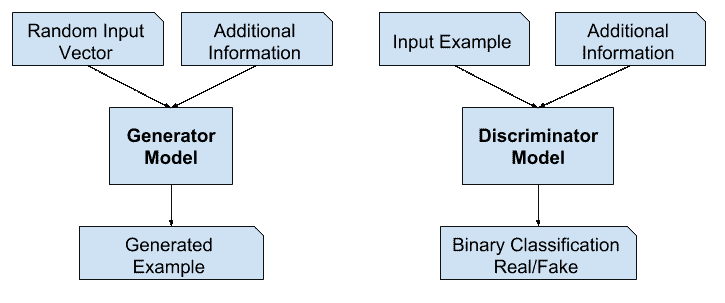
条件生成对抗网络模型架构示例
为什么是生成对抗网络?
在计算机视觉等领域使用深度学习方法的许多重大进步之一是一种称为数据扩充的技术。
数据扩充导致更好的模型表现,既增加了模型技能,又提供了规则效果,减少了泛化误差。它通过从训练模型的输入问题域中创建新的、人工的但看似合理的例子来工作。
在图像数据的情况下,这些技术是基本的,包括裁剪、翻转、缩放和训练数据集中现有图像的其他简单变换。
成功的生成性建模为数据扩充提供了一种替代的、潜在的更特定领域的方法。事实上,数据扩充是生成建模的简化版本,尽管很少这样描述。
…用潜在的(未观察到的)数据扩大样本。这被称为数据扩充。[……]在其他问题中,潜在数据是本应观察到但却缺失的实际数据。
—第 276 页,统计学习的要素,2016。
在复杂领域或数据量有限的领域中,生成式建模为建模提供了更多训练的途径。在深度强化学习等领域,GANs 在这个用例中看到了很多成功。
有许多研究原因可以解释为什么 GANs 有趣、重要,需要进一步研究。伊恩·古德费勒在他 2016 年的会议主题演讲和相关技术报告中概述了其中的一些内容,该报告题为“ NIPS 2016 教程:生成对抗网络”
在这些原因中,他强调了 GANs 对高维数据建模、处理缺失数据的成功能力,以及 GANs 提供多模态输出或多个可信答案的能力。
也许 GANs 最引人注目的应用是针对需要生成新示例的任务的条件 GANs。在这里,古德费勒指出了三个主要的例子:
- 图像超分辨率。生成输入图像的高分辨率版本的能力。
- 创造艺术。伟大的新的和艺术的图像,素描,绘画的能力,等等。
- 图像到图像的转换。跨域翻译照片的能力,例如白天到晚上,夏天到冬天,等等。
也许 GANs 被广泛研究、开发和使用的最令人信服的原因是因为它们的成功。GANs 已经能够生成如此逼真的照片,以至于人类无法分辨它们是真实生活中不存在的对象、场景和人。
对他们的能力和成功来说,惊人并不是一个足够的形容词。

从 2014 年到 2017 年全球网络能力发展的例子。摘自《人工智能的恶意使用:预测、预防和缓解》,2018 年。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
邮件
书
- 第二十章。深度生成模型,深度学习,2016。
- 第八章。生成式深度学习,Python 深度学习,2017。
- 机器学习:概率视角,2012。
- 模式识别与机器学习,2006。
- 统计学习的要素,2016。
报纸
- 生成对抗网络,2014。
- 深度卷积生成对抗网络的无监督表示学习,2015。
- NIPS 2016 教程:生成对抗网络,2016。
- 条件生成对抗网,2014。
- 人工智能的恶意使用:预测、预防和缓解,2018。
文章
摘要
在这篇文章中,你发现了对生成对抗网络的温和介绍。
具体来说,您了解到:
- GANs 的上下文,包括监督学习和非监督学习,以及区分建模和生成建模。
- GANs 是一种通过将无监督问题视为有监督问题并同时使用生成模型和判别模型来自动训练生成模型的体系结构。
- GANs 为复杂的特定领域数据扩充提供了一条途径,并为需要生成性解决方案的问题提供了解决方案,例如图像到图像的翻译。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
CycleGAN 图像转换的温和介绍
最后更新于 2019 年 8 月 17 日
图像到图像的转换包括生成特定修改的给定图像的新合成版本,例如将夏季景观转换为冬季景观。
为图像到图像的转换训练模型通常需要大量成对的例子。这些数据集可能很难准备,也很昂贵,在某些情况下是不可能的,比如早已去世的艺术家的绘画照片。
CycleGAN 是一种在没有成对例子的情况下自动训练图像到图像转换模型的技术。使用来自源域和目标域的不需要以任何方式相关的图像集合,以无监督的方式训练模型。
这种简单的技术非常强大,在一系列应用领域取得了令人印象深刻的视觉效果,最显著的是将马的照片翻译成斑马,反之亦然。
在这篇文章中,你将发现用于不成对图像到图像转换的 CycleGAN 技术。
看完这篇文章,你会知道:
- 图像到图像的转换涉及对图像的受控修改,并且需要准备复杂或有时不存在的成对图像的大数据集。
- CycleGAN 是一种通过 GAN 架构使用来自两个不同领域的不成对图像集合来训练无监督图像转换模型的技术。
- CycleGAN 已经在一系列应用中进行了演示,包括季节转换、对象变形、风格转换以及从绘画中生成照片。
用我的新书Python 生成对抗网络启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

崔西·哈特曼拍摄的《自行车入门》图片,版权所有。
概观
本教程分为五个部分;它们是:
- 图像到图像转换的问题
- 基于 CycleGAN 的不成对图像到图像转换
- 什么是 CycleGAN 模型架构
- 仙客来的应用
- CycleGAN 的实现技巧
图像到图像转换的问题
图像到图像的转换是一项图像合成任务,需要生成一个新的图像,该图像是对给定图像的受控修改。
图像到图像的转换是一类视觉和图形问题,其目标是使用对齐图像对的训练集来学习输入图像和输出图像之间的映射。
——使用循环一致对抗网络的不成对图像到图像转换,2017。
图像到图像转换的例子包括:
- 将夏季景观转换为冬季景观(或相反)。
- 把画翻译成照片(或相反)。
- 把马翻译成斑马(或者相反)。
传统上,训练图像到图像的转换模型需要一个由成对例子组成的数据集。也就是说,输入图像 X(例如夏季风景)和具有期望修改的相同图像的许多示例的大数据集可以用作预期输出图像 Y(例如冬季风景)。
对成对训练数据集的要求是一个限制。这些数据集具有挑战性,并且制作成本高,例如不同条件下不同场景的照片。
在许多情况下,数据集根本不存在,例如名画和它们各自的照片。
然而,获得成对的训练数据可能是困难和昂贵的。[……]为艺术风格化等图形任务获取输入输出对可能更加困难,因为所需的输出非常复杂,通常需要艺术创作。对于许多任务,像对象变形(例如斑马马),期望的输出甚至没有被很好地定义。
——使用循环一致对抗网络的不成对图像到图像转换,2017。
因此,需要用于训练不需要成对示例的图像到图像转换系统的技术。具体而言,可以使用任何两个不相关图像的集合,并且从每个集合中提取一般特征并在图像转换过程中使用。
例如,能够以不相关的场景和位置作为第一位置拍摄大量的夏季风景照片和大量的冬季风景照片,并且能够将特定的照片从一组翻译到另一组。
这被称为不成对的图像到图像的翻译问题。
基于 CycleGAN 的不成对图像到图像转换
CycleGAN 是一种成功的不成对图像到图像的翻译方法。
CycleGAN 是一种使用生成对抗网络(GAN)模型架构来训练图像到图像转换模型的方法。
[……]我们提出了一种方法,可以学习[捕获]一个图像集合的特殊特征,并弄清楚如何将这些特征转化为另一个图像集合,所有这些都是在没有任何配对训练示例的情况下进行的。
——使用循环一致对抗网络的不成对图像到图像转换,2017。
GAN 体系结构是一种训练图像合成模型的方法,该模型由两个模型组成:生成器模型和鉴别器模型。生成器从潜在空间中获取一个点作为输入,并从域中生成新的似是而非的图像,鉴别器将图像作为输入,并预测它是真实的(来自数据集)还是虚假的(生成的)。这两个模型都是在游戏中训练的,因此生成器被更新以更好地欺骗鉴别器,鉴别器被更新以更好地检测生成的图像。
CycleGAN 是 GAN 架构的扩展,它涉及两个生成器模型和两个鉴别器模型的同时训练。
一个生成器将来自第一域的图像作为输入并输出第二域的图像,另一个生成器将来自第二域的图像作为输入并生成第一域的图像。然后使用鉴别器模型来确定生成的图像有多可信,并相应地更新生成器模型。
仅仅这个扩展可能就足以在每个域中生成看似合理的图像,但是不足以生成输入图像的翻译。
……仅仅是对抗损失不能保证学习的函数能够将单个输入 xi 映射到期望的输出 yi
——使用循环一致对抗网络的不成对图像到图像转换,2017。
CycleGAN 对称为周期一致性的体系结构进行了额外的扩展。这是由第一发生器输出的图像可以用作第二发生器的输入并且第二发生器的输出应该与原始图像匹配的想法。反之亦然:第二个发生器的输出可以作为第一个发生器的输入,结果应该与第二个发生器的输入相匹配。
循环一致性是机器翻译中的一个概念,从英语翻译成法语的短语应该从法语翻译回英语,并与原始短语相同。相反的过程也应该如此。
……我们利用了翻译应该“循环一致”的特性,也就是说,如果我们把一个句子从英语翻译成法语,然后再把它从法语翻译回英语,我们就应该回到原来的句子
——使用循环一致对抗网络的不成对图像到图像转换,2017。
CycleGAN 通过增加额外的损耗来测量第二个生成器生成的输出和原始图像之间的差异,从而提高了循环的一致性,反之亦然。这作为生成器模型的正则化,引导新领域中的图像生成过程朝向图像转换。
什么是 CycleGAN 模型架构
乍一看,CycleGAN 的架构似乎很复杂。
让我们花点时间浏览一下所有涉及的模型及其输入和输出。
考虑一下我们对从夏天到冬天和从冬天到夏天的图像转换感兴趣的问题。
我们有两组照片,它们不成对,意味着它们是不同时间不同地点的照片;我们在冬天和夏天没有完全相同的场景。
- 收藏 1 :夏日风景照片。
- 收藏 2 :冬季风景照。
我们将开发一个由两个 GAN 组成的架构,每个 GAN 都有一个鉴别器和一个生成器模型,这意味着架构中总共有四个模型。
第一个 GAN 将生成冬天的照片给夏天的照片,第二个 GAN 将生成夏天的照片给冬天的照片。
- GAN 1 :将夏天(合集 1)的照片翻译成冬天(合集 2)。
- GAN 2 :将冬季(集合 2)的照片翻译成夏季(集合 1)。
每个 GAN 都有一个条件发生器模型,它将合成给定输入图像的图像。每个 GAN 都有一个鉴别器模型来预测生成的图像来自目标图像集合的可能性。GAN 的鉴别器和发生器模型像标准 GAN 模型一样在正常对抗损失下训练。
我们可以将 GAN 1 的发生器和鉴别器模型总结如下:
- 发电机型号 1:
- 输入:拍夏天的照片(收藏 1)。
- 输出:生成冬天的照片(集合 2)。
- 鉴别器型号 1 :
- 输入:采集 2 号采集的冬季照片,发电机型号 1 输出。
- 输出:图像的可能性来自集合 2。
同样,我们可以将 GAN 2 中的生成器和鉴别器模型总结如下:
- 发电机型号 2 :
- 输入:拍摄冬天的照片(收藏 2)。
- 输出:生成夏天的照片(集合 1)。
- 鉴别器型号 2 :
- 输入:采集 1 号集合的夏天照片,发电机型号 2 输出。
- 输出:图像的可能性来自集合 1。
到目前为止,这些模型足以在目标域中生成似是而非的图像,但不是输入图像的翻译。
每个 GANs 也使用周期一致性损失进行更新。这是为了鼓励目标域中的合成图像是输入图像的翻译。
循环一致性损失将输入照片与生成的照片进行比较,并计算两者之间的差值,例如使用 L1 范数或像素值的绝对差值总和。
有两种方法可以计算循环一致性损失,并用于在每次训练迭代中更新生成器模型。
第一 GAN (GAN 1)将拍摄夏季景观的图像,生成冬季景观的图像,该图像作为输入提供给第二 GAN (GAN 2),第二 GAN(GAN 2)又将生成夏季景观的图像。循环一致性损失计算输入到 GAN 1 的图像和 GAN 2 输出的图像之间的差异,并且相应地更新生成器模型以减少图像中的差异。
这是周期一致性损失的正向循环。对于从发电机 2 到发电机 1 的反向循环一致性损失,以及将冬季的原始照片与生成的冬季照片进行比较,同样的过程是反向相关的。
- 正向循环一致性损失:
- 将夏季照片(收藏 1)输入到 GAN 1
- GAN 1 的冬季输出照片
- 从 GAN 1 到 GAN 2 的冬季输入照片
- 从 GAN 2 输出夏天的照片
- 将夏季照片(集合 1)与 GAN 2 中的夏季照片进行比较
- 反向循环一致性损失:
- 将冬季照片(收藏 2)输入到 GAN 2
- 从 GAN 2 输出夏天的照片
- 从 GAN 2 到 GAN 1 的夏季输入照片
- GAN 1 的冬季输出照片
- 将冬季照片(集合 2)与 GAN 1 中的冬季照片进行比较
仙客来的应用
CycleGAN 方法有许多令人印象深刻的应用。
在本节中,我们将回顾其中的五个应用程序,以了解该技术的功能。
风格转移
风格转移是指从一个领域(通常是绘画)学习艺术风格,并将艺术风格应用到另一个领域,如照片。
通过将莫奈、T2、梵高、T4、塞尚和浮世绘的艺术风格运用到风景照片中,展示了循环感。

从著名画家到风景照片风格转换的例子。
摘自:使用循环一致对抗网络的不成对图像到图像转换。
对象变形
对象变形是指对象从一类对象(如狗)转变为另一类对象(如猫)。
CycleGAN 演示了将马的照片转化为斑马,反之亦然:将斑马的照片转化为马。这种变形很有意义,因为马和斑马除了颜色不同之外,在大小和结构上都很相似。

从马到斑马和斑马到马的对象变形的例子。
摘自:使用循环一致对抗网络的不成对图像到图像转换。
CycleGAN 还演示了如何将苹果的照片翻译成橙子,以及相反的情况:将橙子的照片翻译成苹果。
同样,这种变形是有意义的,因为橘子和苹果都有相同的结构和大小。

从苹果到橘子和橘子到苹果的对象变形的例子。
摘自:使用循环一致对抗网络的不成对图像到图像转换。
季节转换
季节转换是指将在一个季节(如夏天)拍摄的照片翻译成另一个季节(如冬天)。
CycleGAN 演示了如何将冬季风景的照片转换为夏季风景,以及将夏季风景转换为冬季风景。

从冬季到夏季和从夏季到冬季的季节转换示例
摘自:使用周期一致对抗网络的不成对图像到图像转换。
从绘画中产生照片
顾名思义,从绘画中生成照片是给定一幅画的真实感图像的合成,通常由著名艺术家或著名场景绘制。
在将莫奈的许多画作翻译成看似合理的照片时,展示了循环。

将莫奈的画翻译成真实感场景的例子。
摘自:使用循环一致对抗网络的不成对图像到图像转换。
照片增强
照片增强是指以某种方式改善原始图像的变换。
CycleGAN 通过提高花卉特写照片的景深(例如,产生宏观效果)来增强照片效果。

照片增强示例提高花卉照片的景深。
摘自:使用循环一致对抗网络的不成对图像到图像转换。
CycleGAN 的实现技巧
CycleGAN 论文提供了许多关于如何在实践中实现该技术的技术细节。
发电机网络实现基于贾斯廷·约翰逊在 2016 年题为“实时风格转换和超分辨率的感知损失”的论文中描述的风格转换方法
生成器模型从使用深度卷积 GAN 的生成器的最佳实践开始,深度卷积 GAN 是使用多个残差块(例如来自 ResNet )实现的。
鉴别器模型使用 PatchGAN,正如 Phillip Isola 等人在 2016 年发表的题为“利用条件对抗网络的 T2 图像到图像转换”的论文中所描述的
这个鉴别器试图分类图像中的每个 NxN 补丁是真的还是假的。我们在图像上运行这个鉴别器卷积,平均所有响应,以提供 d 的最终输出。
——条件对抗网络下的图像到图像转换,2016。
在鉴别器模型中使用面片来将输入图像的 70×70 重叠面片分类为属于该域或已经生成。然后将鉴别器输出作为每个补丁的预测平均值。
对抗损失是使用最小二乘损失函数实现的,如毛旭东等人 2016 年的论文《T2 最小二乘生成对抗网络》中所述
[……]我们提出了最小二乘生成对抗网络,它采用最小二乘损失函数作为鉴别器。这个想法简单而强大:最小二乘损失函数能够将假样本移向决策边界,因为最小二乘损失函数惩罚了位于决策边界正确一侧很远的样本。
——最小二乘生成对抗网络,2016。
此外,50 个生成图像的缓冲区用于更新鉴别器模型,而不是新生成的图像,如 Ashish Shrivastava 的 2016 年论文《通过对抗性训练从模拟和无监督图像中学习》中所述
[……]我们引入了一种方法,通过使用精细图像的历史来更新鉴别器,而不仅仅是当前迷你批次中的图像,从而提高对抗训练的稳定性。
——通过对抗性训练从模拟和无监督图像中学习,2016。
用随机梯度下降的亚当版本和 100 个时期的小学习率训练模型,然后再用学习率衰减的 100 个时期。在每个图像之后更新模型,例如批量大小为 1。
论文附录中提供了该技术所基于的每个数据集的其他特定模型细节。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
报纸
- 使用循环一致对抗网络的不成对图像到图像转换,2017。
- 实时风格转移和超分辨率的感知损失,2016。
- 条件对抗网络下的图像到图像转换,2016。
- 最小二乘生成对抗性网络,2016。
- 通过对抗性训练从模拟和无监督图像中学习,2016。
文章
摘要
在这篇文章中,您发现了用于不成对图像到图像转换的 CycleGAN 技术。
具体来说,您了解到:
- 图像到图像的转换涉及对图像的受控修改,并且需要准备复杂或有时不存在的成对图像的大数据集。
- CycleGAN 是一种通过 GAN 架构使用来自两个不同领域的不成对图像集合来训练无监督图像转换模型的技术。
- CycleGAN 已在一系列应用中得到演示,包括季节转换、对象变形、风格转换以及从绘画中生成照片。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









