







网页抓取基础知识——硒和美丽的汤应用于搜索营地可用性

[Image[1] (Image courtesy: https://pixabay.com)]
对于数据科学领域的人来说,网络搜集是一项重要的基本数据收集技能。它对于收集项目和兴趣的小信息也非常有用。并不是你分析的每一个数据集都能以一种方便的格式获得,而且,如果你想做有趣和独特的分析,那么通过搜集自己编译一个数据集是做新颖和有见地的工作的一个很好的方法。
在这篇文章中,我将介绍 Python 中抓取的一些基础知识,并提供创建一个抓取器的示例代码,该抓取器将收集关于即将到来的营地预留空缺的信息。我选择这个特别的例子,是因为我想解决自己在加州营地保留地导航的问题,还因为除了促进技术素养,帮助人们走出户外享受自然对我个人来说也很有意义。
让我们开始吧——如果你从头到尾都遵循了这篇教程和文章,你应该掌握了从网络上收集易于访问的数据并用于你自己的项目的所有技能。更具体地说,您将能够:
- 了解如何导航 HTML 源代码以找到您想要捕获的信息
- 使用 Beautiful Soup 从网站收集并解析 HTML 代码
- 使用 Selenium 和 ChromeDriver 自动导航到站点,在文本框中填充信息,单击所需的下拉菜单和输入,并为多个网站地址、变量和输入返回这样做的响应
- 了解如何使用 Requests、ChromeDriver、BeautifulSoup 和 Selenium 进行网页抓取的基础知识
- 使用 Pandas 解析 HTML 表,使用 datetime 转换日期
一些背景和基础知识:
Web 抓取就是从互联网上自动收集和解析数据。这些数据可以构成数据科学项目的基础,用于比较各种产品或服务,用于研究或其他商业用途。
Python 中有许多对 web 抓取有用的库,一些主要的有:请求、美汤、硒和刺儿头。本教程将只涵盖前三个,但我会鼓励你自己去看看 Scrapy。
我们将使用 Requests 向网站发送请求信息,使用 Beautiful Soup 提取和解析 HTML 组件,使用 Selenium 选择和导航网站中非静态的、需要单击或从下拉菜单中选择的组件。
如果你不熟悉 HTML——超文本标记语言,也称为 web 编码语言——你可能想尝试一下 W3schools 基础教程,然而对于这个例子来说,你只需要熟悉一些标题的基本标签<标题>、表格<表格>以及行< tr >和数据单元格< td >、项目列表< li >和链接【就足够了
网络抓取示例——营地预订信息教程

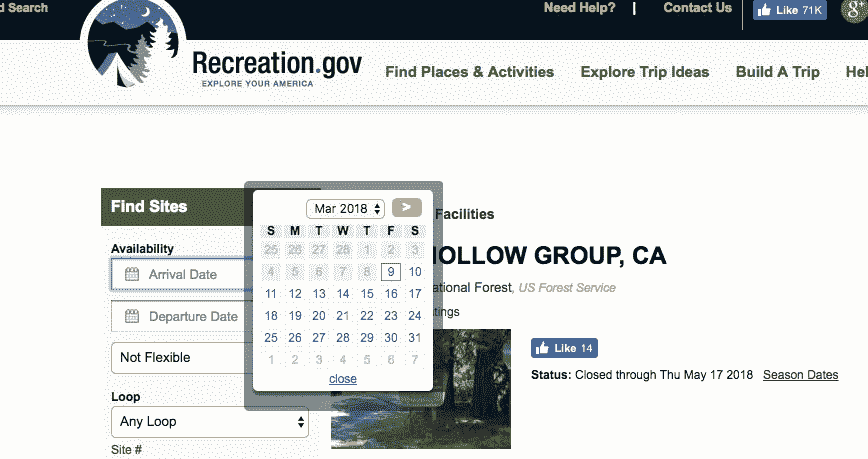
[Image[2] — Recreation.gov search bar (Image courtesy: https://recreation.gov)]
我们将要浏览和收集信息的网站是www.recreation.gov,特别是他们的页面,用于预订阿斯彭·霍洛群营地。
让我们首先导入这项工作所需的库,并定义要导航到的 url:
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from random import randint
import datetime
import os
import time
import pandas as pdurl = '[https://www.recreation.gov/camping/aspen-hollow-group/r/campgroundDetails.do?contractCode=NRSO&parkId=71546'](https://www.recreation.gov/camping/aspen-hollow-group/r/campgroundDetails.do?contractCode=NRSO&parkId=71546')
我对查找与我当前日期相关的预订感兴趣,所以我将使用 datetime 库来管理它。下面的代码存储今天的。现在时间戳为当前时间,时间戳的一部分为今天的日期,格式为网站可以读取的格式。
current_time = datetime.datetime.now()
current_time.strftime("%m/%d/%Y")
我可以定义我想在露营地呆多少个晚上,从现在开始我想看多远,以及我想查看多少个周末的预订,以便开始为这些日期收集信息:
nights_stay = 2
weeks_from_now_to_look = 13
how_many_weeks_to_check = 4
在查看了预订网站如何格式化输入日期后,我将检查以确保我的格式化方式看起来是正确的:
for week in range(0, how_many_weeks_to_check):
start_date = current_time + datetime.timedelta(days=week*7) + datetime.timedelta(days=weeks_from_now_to_look*7)
end_date = start_date + datetime.timedelta(days=nights_stay)
print(start_date.strftime("%a %b %d %Y") + ' to ' + end_date.strftime("%a %b %d %Y"))
这给了我一个看起来正确的输出—我看到的是:
Sat Jun 02 2018 to Mon Jun 04 2018
Sat Jun 09 2018 to Mon Jun 11 2018
Sat Jun 16 2018 to Mon Jun 18 2018
Sat Jun 23 2018 to Mon Jun 25 2018
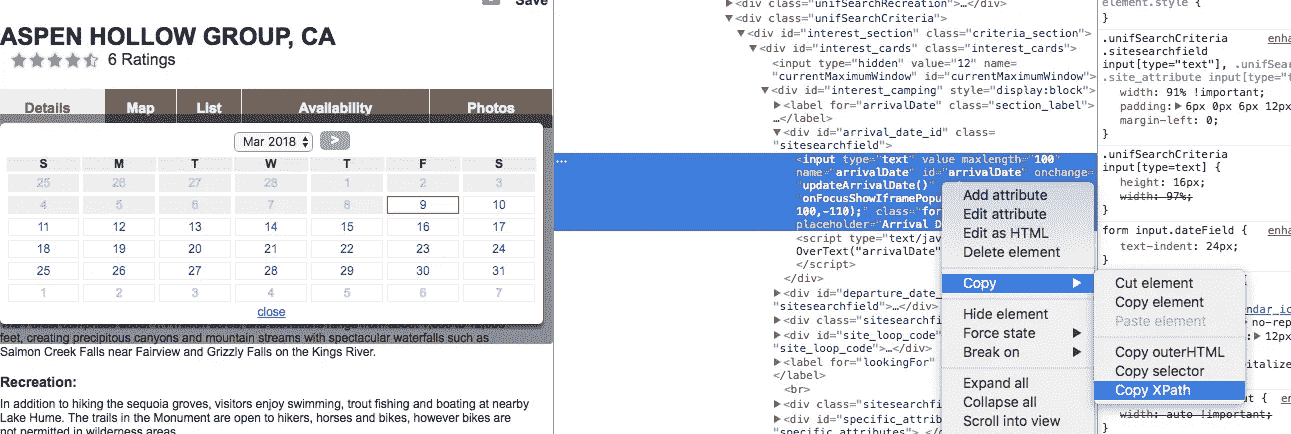
为了选择网站的元素并解析出将返回我想要的信息的源代码,我将通过右键单击并选择“inspect”来选择网站的元素,这将允许我查看页面的 HTML 源代码,并将自动突出显示我单击的元素。
[Image[3] — Inspecting source code (Image courtesy: https://recreation.gov)]
从那里,我可以右键单击与我感兴趣的元素相关的代码,并复制 xpath,这样我就可以在我的抓取代码中使用它作为导航输入。
[Image[4] — Coping element XPath (Image courtesy: https://recreation.gov)]
我将这样做来查找到达日期、离开日期和输出信息摘要的类路径的 xpath,以便我可以使用 chromedriver 来根据路径查找和选择这些元素。
下面的代码通过访问网站,在开始和结束日期字段中选择和输入信息,然后将它得到的汇总信息存储到我命名为camping_availability_dictionary的字典中来实现这一点。请注意,我在这段代码中包含了一个介于 3 和 6 之间的随机整数秒的时间延迟,这样,如果您运行这个示例,您将能够看到 chromedriver 启动、导航、输入您的开始和结束日期,以及点击。我通过类名找到站点摘要数据,并将其存储到一个列表中,然后获取该列表的文本并保存到我初始化的字典中。该字典使用文本格式的搜索开始和结束日期作为关键字,并将搜索的摘要数据存储为其值。
chromedriver = "/Applications/chromedriver"
os.environ["webdriver.chrome.driver"] = chromedriverdriver = webdriver.Chrome(chromedriver)time_delay = randint(3,6)
camping_availability_dictionary={}for week in range(0,how_many_weeks_to_check):
driver.get(url)
time.sleep(time_delay)
start_date = current_time + datetime.timedelta(days=week*7) + datetime.timedelta(days=weeks_from_now_to_look*7)
end_date = start_date + datetime.timedelta(days=nights_stay)
selectElem=driver.find_element_by_xpath('//*[[@id](http://twitter.com/id)="arrivalDate"]')
selectElem.clear()
selectElem.send_keys(start_date.strftime("%a %b %d %Y"))
time.sleep(time_delay)
selectElem.submit()
time.sleep(time_delay)
selectElem=driver.find_element_by_xpath('//*[[@id](http://twitter.com/id)="departureDate"]')
selectElem.clear()
selectElem.send_keys(end_date.strftime("%a %b %d %Y"))
time.sleep(time_delay)
selectElem.submit()
time.sleep(time_delay)
site_data = driver.find_elements_by_class_name('searchSummary')
time.sleep(time_delay)
property_data = []for i in site_data:
if len(i.text) != 0:
property_data.append(i.text)
camping_availability_dictionary[start_date.strftime("%a %b %d %Y") + ' to ' + end_date.strftime("%a %b %d %Y")] = property_data
time.sleep(time_delay)
现在,如果我查看一下camping_availability_dictionary存储了什么,它有以下键和值:
{'Sat Jun 02 2018 to Mon Jun 04 2018': ['1 site(s) available out of 1 site(s)\nALL (1)\nGROUP STANDARD NONELECTRIC (1)'],
'Sat Jun 09 2018 to Mon Jun 11 2018': ['0 site(s) available out of 1 site(s)\nALL (0)\nGROUP STANDARD NONELECTRIC (0)'],
'Sat Jun 16 2018 to Mon Jun 18 2018': ['0 site(s) available out of 1 site(s)\nALL (0)\nGROUP STANDARD NONELECTRIC (0)'],
'Sat Jun 23 2018 to Mon Jun 25 2018': ['0 site(s) available out of 1 site(s)\nALL (0)\nGROUP STANDARD NONELECTRIC (0)']}
这对于了解这个站点的可用性来说已经足够了,但是让我们使用其他的图书馆来整理信息,并把一些露营地服务打印出来。
我们将导入我们的请求库,通过 html 文本从我们的 url 和页面请求信息,并定义我们的汤配方:
import requestsresponse = requests.get(url)
page = response.text
soup = BeautifulSoup(page,"lxml")
如果我们要打印出刚刚通过调用print(soup.prettify())得到的页面信息,我们会看到页面的 HTML 代码的格式化版本,比如:
<!DOCTYPE html>
<html lang="en" xml:lang="en" xmlns:fb="http://www.facebook.com/2008/fbml" xmlns:og="http://opengraphprotocol.org/schema/">
<head>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<script type="text/javascript">
window.name="ra";
var _brandName_ = "NRSO";
</script>
<script type="text/javascript">
// Instructions: please embed this snippet directly into every page in your website template.
// For optimal performance, this must be embedded directly into the template, not referenced
// as an external file.
通过滚动该文本,我们可以看到我们可能想要获取
‘Facility Details — ASPEN HOLLOW GROUP, CA — Recreation.gov’
进一步查看代码,我们可以看到我们想要的内容表,并使用基于类名的 find:
print(soup.find_all(class_='contable'))
退货:
[<table class="contable" id="contenttable" name="contenttable">
<thead>
<tr style="display:none;">
<th id="th1">th1</th></tr></thead>
<tbody>
<tr>
<td class="td1" colspan="2">Within Facility</td></tr>
<tr>
<td class="td2"><ul class="detail"><li>Bike Rentals</li><li>Boat Rentals</li><li>Campfire Rings</li><li>Drinking Water</li><li>Food storage lockers</li></ul></td>
<td class="td2"><ul class="detail"><li>General Store</li><li>Laundry Facilities</li><li>Potable Water</li><li>Vault Toilets</li></ul></td></tr>
<tr class="brline">
<td class="td1" colspan="2">Within 10 Miles</td></tr>
<tr>
<td class="td2"><ul class="detail"><li>Canoeing</li><li>Fishing</li><li>Kayaking</li></ul></td>
<td class="td2"><ul class="detail"><li>Swimming</li><li>Wireless Internet</li></ul></td></tr></tbody></table>]
现在我们只想获取该文本,让我们使用table_body = soup.find_all(class='contable')将它分配给一个变量,并获取该列表的第一个元素,以便对信息进行一些格式化。
作为最终输出,我们希望打印出营地信息和可用性,以及设施内和设施附近的内容摘要:
print(campsite_info.get_text()+"\n")
print("Campsite availability: \n")
for key in camping_availability_dictionary:
full_string = str(camping_availability_dictionary[key])
parsed_string = " - " + full_string.split(" out of")[0][2::] + ", type: " + full_string.split("ALL")[1][6:-5]
print(key, parsed_string)
print("\n")rows = table_body[0].find_all('tr')
for row in rows:
columns = row.find_all('td')
for column in columns:
string = column.get_text()
if string == 'Within Facility':
print("Items Within Facility: \n")
if string == 'Within 10 Miles':
print("\nItems Within 10 Miles: \n")
else:
items = column.find_all('li')
for item in items:
words = item.get_text()
print(words)
上面给出了我们的最终输出:
Facility Details - ASPEN HOLLOW GROUP, CA - Recreation.gov
Campsite availability:
Sat Jun 02 2018 to Mon Jun 04 2018 - 1 site(s) available, type: GROUP STANDARD NONELECTRIC
Sat Jun 09 2018 to Mon Jun 11 2018 - 0 site(s) available, type: GROUP STANDARD NONELECTRIC
Sat Jun 16 2018 to Mon Jun 18 2018 - 0 site(s) available, type: GROUP STANDARD NONELECTRIC
Sat Jun 23 2018 to Mon Jun 25 2018 - 0 site(s) available, type: GROUP STANDARD NONELECTRIC
Items Within Facility:
Bike Rentals
Boat Rentals
Campfire Rings
Drinking Water
Food storage lockers
General Store
Laundry Facilities
Potable Water
Vault Toilets
Items Within 10 Miles:
Canoeing
Fishing
Kayaking
Swimming
Wireless Internet
现在你可以去预定那个网站了——露营快乐!
参考链接:
用 Python 对 HTML 表格进行 Web 抓取
Pokemon Database Website
首先,我们将尝试抓取在线口袋妖怪数据库(http://pokemondb.net/pokedex/all)。
检查 HTML
在前进之前,我们需要了解我们希望抓取的网站的结构。这可以通过点击 来完成,右击我们想要刮的元素,然后点击“检查” *。*出于我们的目的,我们将检查表格的元素,如下所示:
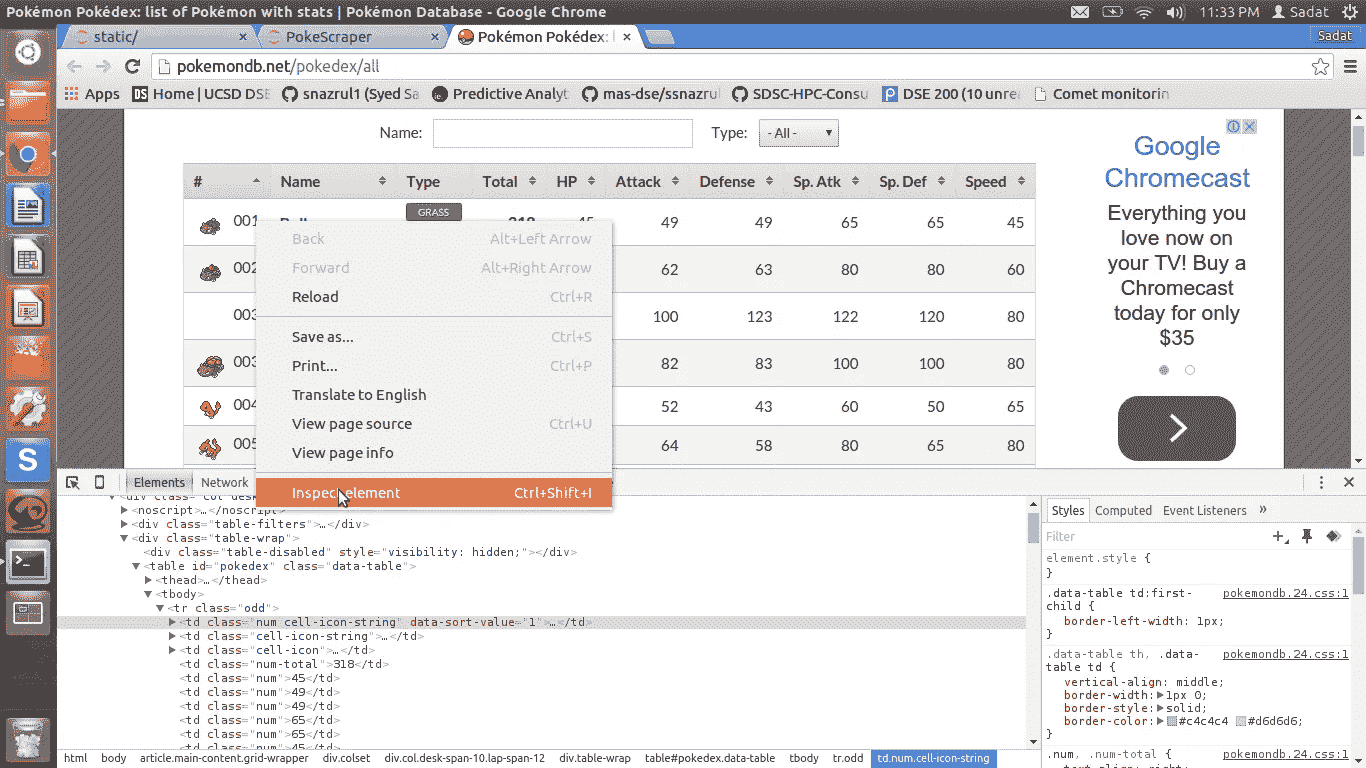
Inspecting cell of HTML Table
根据 HTML 代码,数据存储在 < tr >之后…< /tr > 。这是行信息。每一行都有一个对应的 < td >…/或单元格数据信息。
导入库
我们需要请求来获取网站的 HTML 内容,需要lxml.html来解析相关字段。最后,我们将把数据存储在熊猫数据帧上。
**import** **requests**
**import** **lxml.html** **as** **lh**
**import** **pandas** **as** **pd**
刮掉表格单元格
下面的代码允许我们获得 HTML 表的 Pokemon 统计数据。
url='http://pokemondb.net/pokedex/all'*#Create a handle, page, to handle the contents of the website*
page = requests.get(url)*#Store the contents of the website under doc*
doc = lh.fromstring(page.content)*#Parse data that are stored between <tr>..</tr> of HTML*
tr_elements = doc.xpath('//tr')
为了进行健全性检查,请确保所有行都具有相同的宽度。如果没有,我们得到的可能不仅仅是桌子。
*#Check the length of the first 12 rows*
[len(T) **for** T **in** tr_elements[:12]]
输出:【10,10,10,10,10,10,10,10,10,10,10,10】
看起来我们所有的行正好有 10 列。这意味着在 tr_elements 上收集的所有数据都来自这个表。
解析表格标题
接下来,让我们将第一行解析为标题。
tr_elements = doc.xpath('//tr')*#Create empty list*
col=[]
i=0*#For each row, store each first element (header) and an empty list*
**for** t **in** tr_elements[0]:
i+=1
name=t.text_content()
**print** '**%d**:"**%s**"'%(i,name)
col.append((name,[]))
输出:
1:“#”
2:“名”
3:“型”
4:“总”
5:“HP”
6:“攻”
7:“防”
8:“Sp。Atk"
9:“Sp。Def”
10:“速度”
创建熊猫数据框架
每个头都和一个空列表一起被附加到一个元组中。
*#Since out first row is the header, data is stored on the second row onwards*
**for** j **in** range(1,len(tr_elements)):
*#T is our j'th row*
T=tr_elements[j]
*#If row is not of size 10, the //tr data is not from our table*
**if** len(T)!=10:
**break**
*#i is the index of our column*
i=0
*#Iterate through each element of the row*
**for** t **in** T.iterchildren():
data=t.text_content()
*#Check if row is empty*
**if** i>0:
*#Convert any numerical value to integers*
**try**:
data=int(data)
**except**:
**pass**
*#Append the data to the empty list of the i'th column*
col[i][1].append(data)
*#Increment i for the next column*
i+=1
为了确保万无一失,让我们检查一下每列的长度。理想情况下,它们应该都相同。
[len(C) **for** (title,C) **in** col]
输出:【800,800,800,800,800,800,800,800,800,800】
完美!这表明我们的 10 列中的每一列正好有 800 个值。
现在,我们准备创建数据帧:
Dict={title:column **for** (title,column) **in** col}
df=pd.DataFrame(Dict)
查看数据框中的前 5 个单元格:
df.head()
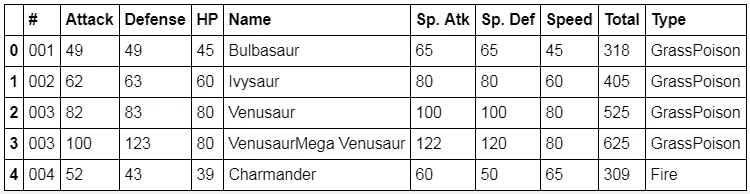
你有它!现在你有了一个包含所有需要信息的熊猫数据框架!
附加说明
本教程是 3 部分系列的子集:
该系列包括:
- 抓取口袋妖怪网站
- 数据分析
- 构建 GUI Pokedex
网页抓取 Indeed.com
在这个项目中,我想展示我通过网络抓取获取自己数据的能力。该项目的主要目标是确定一名数据科学家在不同大都市地区的工资。由于大多数公司不公布 Indeed.com 的工资,我使用自然语言处理来确定一个职位发布的工资是高于还是低于基于职位的工资中位数。任何网络抓取项目的第一步是确保服务条款允许你挖掘他们的数据。在阅读服务条款后,我发现网络抓取确实是允许的,所以我继续我的项目。

我选择了纽约、芝加哥、旧金山、奥斯汀、西雅图、洛杉矶、费城、亚特兰大、达拉斯、匹兹堡、波特兰、凤凰城、丹佛、休斯顿、迈阿密、夏洛特,当然还有 DC 的华盛顿。通过观察大范围的城市,我可以看到全国各地的工资差异。这个项目将来的一个可能扩展是遍历所有 50 个州的列表,看看它们在全国范围内有什么不同。
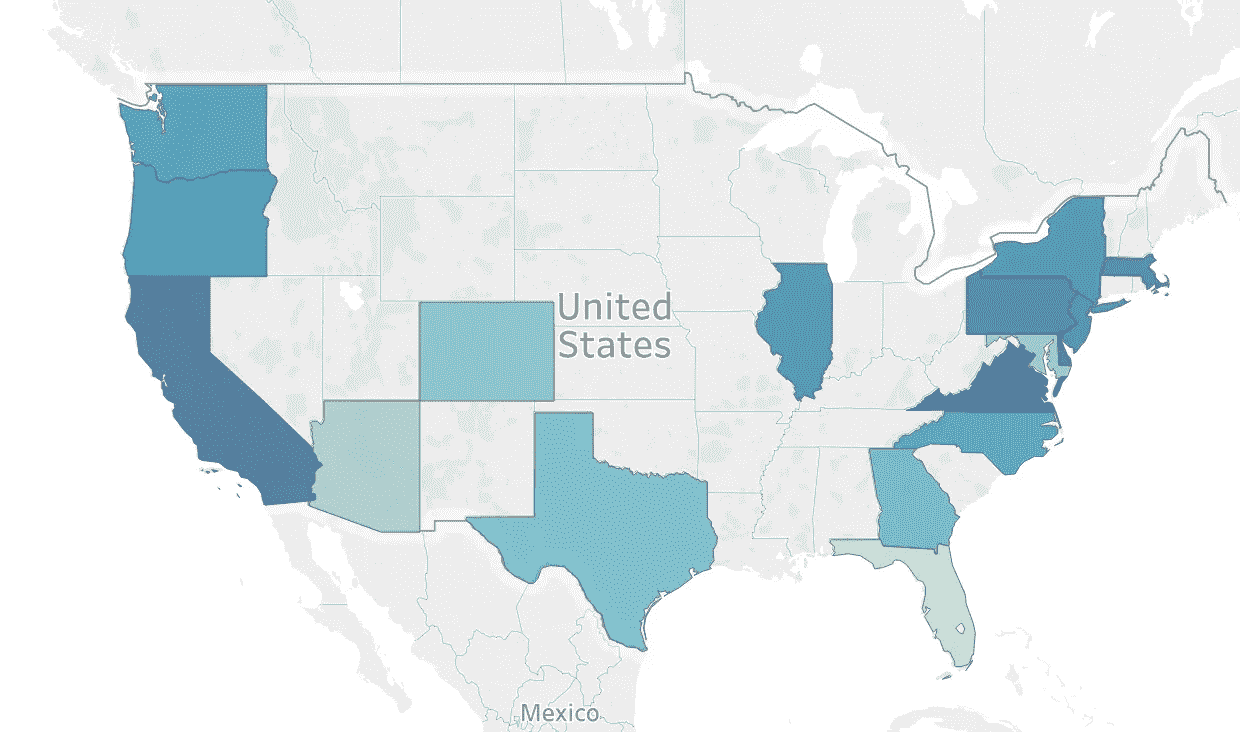

一些简单的直观分析告诉我,成为数据科学家的一些最佳地点是加利福尼亚、弗吉尼亚和纽约。这张地图有点误导,因为虽然弗吉尼亚的平均工资很高,但那里只有三份带薪的工作。大部分年薪的招聘职位都在纽约、加州和伊利诺伊州。我们可以看到,这些地区的工资仍然相对较高,并有助于使工资中位数超过 10 万美元。
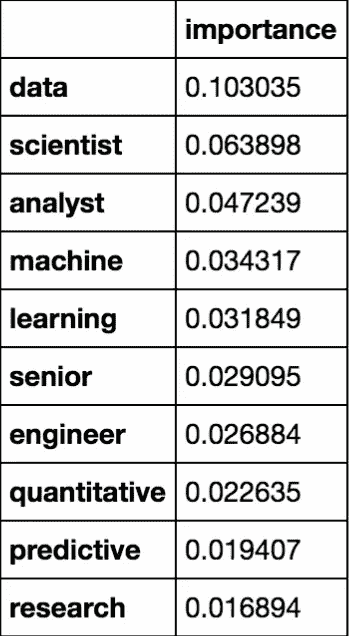
我使用了一个计数矢量器,并确定在决定工资是高于还是低于中位数时,最重要的词或“特征”是数据、科学家、分析师等。需要注意的一点是,这些数字没有给我们任何关于这是正相关还是负相关的见解。例如,我发现头衔中有分析师的工作比头衔中有科学家的工作更有可能显示出低于中位数的工资。这个项目的另一个可能的扩展是改变我使用的 n _ grams 的数量,因为数据可能会出现在大多数职位中,如果我们有数据科学家、数据分析师等,这可能更能说明问题。作为自己的特色。
这个项目向我展示了网络抓取的重要性,以利用互联网上已经存在的东西来创建有意义的数据分析。在您了解了模型的基本假设之后,创建模型并不困难。数据科学家的许多工作是确定使用哪种模型,如何获取数据,以及如何将数据处理成完成分析所需的任何形式。
我将收集各种市场中数据科学工作的薪资信息。然后使用位置、标题…
nbviewer.jupyter.org](http://nbviewer.jupyter.org/github/rowandl/portfolio/blob/master/Webscraping%20Indeed.com/Webscraping%20Indeed.ipynb)
Web 抓取、正则表达式和数据可视化:全部用 Python 完成

一个学习三种无价数据科学技能的小型真实项目
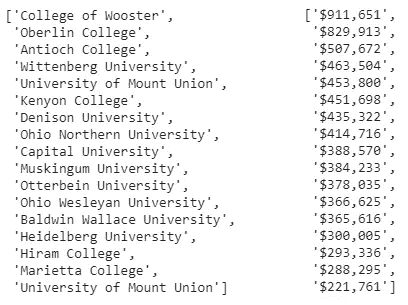
与大多数有趣的项目一样,这个项目以一个简单的问题开始,这个问题被半认真地问了一遍:我为我的大学校长的五分钟时间支付多少学费?在与我们学校的校长( CWRU )进行了一次偶然而愉快的讨论后,我想知道我的谈话到底花了我多少钱。
我的搜索导致了这篇文章,它和我的校长的薪水一起,有一张显示俄亥俄州私立大学校长薪水的表格:
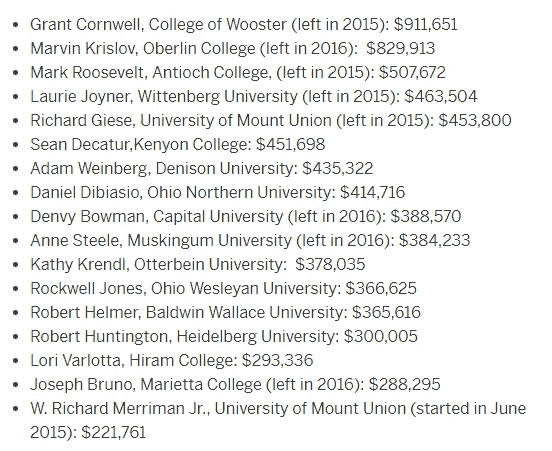
虽然我可以为我的总统找到答案(剧透一下,是 48 美元/五分钟),并且感到满意,但我想利用这张桌子进一步推广这个想法。我一直在寻找机会练习 Python 中的网页抓取和正则表达式,并认为这是一个很棒的短期项目。
尽管在 Excel 中手动输入数据几乎肯定会更快,但我不会有宝贵的机会来练习一些技能!数据科学是关于使用各种工具解决问题的,web 抓取和正则表达式是我需要努力的两个领域(更不用说制作图表总是很有趣)。结果是一个非常短但完整的项目,展示了我们如何将这三种技术结合起来解决数据科学问题。
这个项目的完整代码可以在谷歌联合实验室的 Jupyter 笔记本上获得(这是我正在尝试的一项新服务,你可以在云端分享和合作 Jupyter 笔记本。感觉是未来!)要编辑笔记本,在 Colaboratory 中打开它,选择文件>在驱动器中保存一份副本,然后您可以进行任何更改并运行笔记本。
网页抓取
虽然课堂和教科书中使用的大多数数据看起来都是现成的,格式简洁,但实际上,世界并没有这么美好。获取数据通常意味着弄脏我们的手,在这种情况下,从网上提取(也称为抓取)数据。Python 有很好的工具来完成这项工作,即用于从网页中检索内容的requests库,以及用于提取相关信息的bs4 (BeautifulSoup)。
这两个库通常以下列方式一起使用:首先,我们向网站发出 GET 请求。然后,我们从返回的内容中创建一个漂亮的 Soup 对象,并使用几种方法解析它。
# requests for fetching html of website
import requests# Make the GET request to a url
r = requests.get('[http://www.cleveland.com/metro/index.ssf/2017/12/case_western_reserve_university_president_barbara_snyders_base_salary_and_bonus_pay_tops_among_private_colleges_in_ohio.html'](http://www.cleveland.com/metro/index.ssf/2017/12/case_western_reserve_university_president_barbara_snyders_base_salary_and_bonus_pay_tops_among_private_colleges_in_ohio.html'))# Extract the content
c = r.contentfrom bs4 import BeautifulSoup# Create a soup object
soup = BeautifulSoup(c)
由此产生的汤对象相当吓人:

我们的数据就在那里的某个地方,但我们需要提取它。为了从汤里选择我们的桌子,我们需要找到正确的 CSS 选择器。一种方法是访问网页并检查元素。在这种情况下,我们也可以只查看 soup,并看到我们的表驻留在带有属性class = "entry-content"的<div> HTML 标签下。使用这些信息和我们的 soup 对象的.find方法,我们可以提取文章的主要内容。
# Find the element on the webpage
main_content = soup.find('div', attrs = {'class': 'entry-content'})
这将返回另一个不够具体的 soup 对象。要选择表格,我们需要找到<ul>标签(见上图)。我们还想只处理表中的文本,所以我们使用了 soup 的.text属性。
# Extract the relevant information as text
content = main_content.find('ul').text

我们现在有了字符串形式的表的确切文本,但显然它对我们没有多大用处!为了提取文本字符串的特定部分,我们需要使用正则表达式。这篇文章我没有篇幅(也没有经验!)来完整解释正则表达式,所以这里我只做一个简单的概述,并展示结果。我自己也还在学习,我发现变得更好的唯一方法就是练习。请随意查看本笔记本进行一些练习,并查看 Python re 文档开始(文档通常很枯燥,但非常有用)。
正则表达式
正则表达式的基本思想是我们定义一个模式(“正则表达式”或“regex”),我们希望在一个文本字符串中进行匹配,然后在字符串中搜索以返回匹配。其中一些模式看起来非常奇怪,因为它们既包含我们想要匹配的内容,也包含改变模式解释方式的特殊字符。正则表达式在解析字符串信息时总是出现,并且是至少在基础水平上学习的重要工具!
我们需要从文本表中提取 3 条信息:
- 总统的名字
- 学院的名称
- 薪水
首先是名字。在这个正则表达式中,我利用了这样一个事实,即每个名字都位于一行的开头,以逗号结尾。下面的代码创建一个正则表达式模式,然后在字符串中搜索以找到该模式的所有匹配项:
# Create a pattern to match names
name_pattern = re.compile(r'^([A-Z]{1}.+?)(?:,)', flags = re.M)# Find all occurrences of the pattern
names = name_pattern.findall(content)

就像我说的,这个模式非常复杂,但是它确实是我们想要的!不要担心模式的细节,只需要考虑大致的过程:首先定义一个模式,然后搜索一个字符串来找到模式。
我们对大学和薪水重复这个过程:
# Make school patttern and extract schools
school_pattern = re.compile(r'(?:,|,\s)([A-Z]{1}.*?)(?:\s\(|:|,)')
schools = school_pattern.findall(content)# Pattern to match the salaries
salary_pattern = re.compile(r'\$.+')
salaries = salary_pattern.findall(content)
不幸的是,薪水的格式是任何计算机都无法理解的数字。幸运的是,这给了我们一个练习使用 Python 列表理解将字符串 salaries 转换成数字的机会。下面的代码说明了如何使用字符串切片、split和join,所有这些都在一个列表理解中,以获得我们想要的结果:
# Messy salaries
salaries = ['$876,001', '$543,903', '$2453,896']# Convert salaries to numbers in a list comprehension
[int(''.join(s[1:].split(','))) for s in salaries] **[876001, 543903, 2453896]**
我们将这种转换应用到我们的工资中,最终得到我们想要的所有信息。让我们把一切都放进一个pandas数据框架。此时,我手动插入了我的大学(CWRU)的信息,因为它不在主表中。重要的是要知道什么时候手工做事情比编写复杂的程序更有效(尽管整篇文章有点违背这一点!).
Subset of Dataframe
形象化
这个项目是数据科学的象征,因为大部分时间都花在了收集和格式化数据上。然而,现在我们有了一个干净的数据集,我们可以画一些图了!我们可以使用matplotlib和seaborn来可视化数据。
如果我们不太关心美观,我们可以使用内置的数据帧绘图方法来快速显示结果:
# Make a horizontal bar chart
df.plot(kind='barh', x = 'President', y = 'salary')
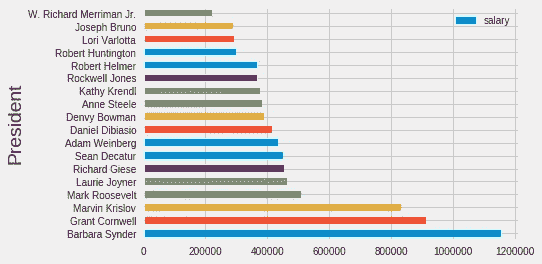
Default plot using dataframe plotting method
为了得到更好的情节,我们必须做一些工作。像正则表达式一样,用 Python 绘制代码可能有点复杂,需要一些实践来适应。大多数情况下,我通过在 Stack Overflow 等网站上寻找答案或者阅读官方文档来学习。
经过一点工作,我们得到了下面的情节(详情见笔记本):
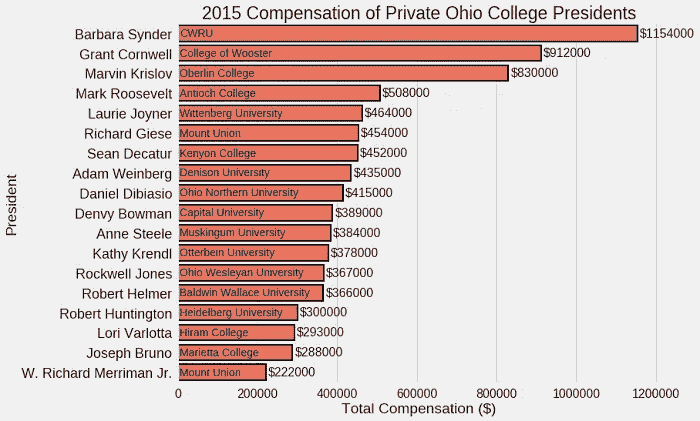
Better Plot using seaborn
好多了,但是这还是没有回答我原来的问题!为了显示学生为他们校长的 5 分钟时间支付了多少钱,我们可以将工资转换成美元/5 分钟,假设每年工作 2000 小时。

Final Figure
这不一定是值得出版的情节,但这是结束一个小项目的好方法。
结论
学习技能最有效的方法是实践。虽然整个项目可以通过手动将值插入 Excel 来完成,但我喜欢从长计议,思考在这里学到的技能如何在未来有所帮助。学习的过程比最终结果更重要,在这个项目中,我们能够看到如何将 3 项关键技能用于数据科学:
- Web 抓取:检索在线数据
- 正则表达式:解析我们的数据以提取信息
- 可视化:展示我们所有的辛勤工作
现在,走出去,开始你自己的项目,记住:不一定要改变世界才有价值。
我欢迎反馈和讨论,可以通过 Twitter @koehrsen_will 联系。
从维基百科上抓取最棒的视频游戏列表
嗨,欢迎来到我的博客。
博客和数据科学(以及两者的结合)是我生活中相对较新的尝试,但伟大的事情往往来自卑微的开始。
在我学习 python 及其相关库的短暂时间里,我已经被自己学到的东西震惊了。为了努力工作并展示我不断发展的技能,我希望我的每一篇博文都可以作为我不断进步的标志。
撇开序言不谈,让我们进入这篇文章的实质内容。
作为对自己的最初挑战,我想尝试使用 python 进行 web 抓取,从网页中提取数据,并以一种允许进一步检查和可视化的方式对其进行格式化。维基百科似乎非常适合这项任务,因为它非常容易访问,并且包含大量有趣的数据。
作为一个终生的电子游戏迷,我认为看看这个被认为是有史以来最好的电子游戏列表会很有趣。我正在研究的表格根据“有史以来最好的游戏”名单中的提及次数对视频游戏进行排序。
该表列出了 1978 年至 2013 年间发布的 100 款不同游戏,结构如下:
宝宝的第一次刮网
接近网络抓取时,我发现这个来自分析网站 Vidhya 的指南非常有价值。我鼓励任何第一次接触网络搜索的人使用这个资源来收集他们的方位。
在 python 中,我使用了两个 python 库:Urllib2 和 BeautifulSoup。
Urllib2 帮助 python 获取 URL,而 BeautifulSoup 使用 HTML 和 XML 文件从网页中提取信息。
随着分析 Vidhya 指南的编码,我能够利用以下代码检索网页的 HTML 数据:
#import library to query webpage of interest
import urllib2#specifying page of interest
wiki = “[https://en.wikipedia.org/wiki/List_of_video_games_considered_the_best](https://en.wikipedia.org/wiki/List_of_video_games_considered_the_best)"#save the HTML of the site within the page variable
page = urllib2.urlopen(wiki)#import library to parse HTML from page
from bs4 import BeautifulSoup#parse data from "page" and save to new variable "soup"
soup = BeautifulSoup(page)
该指南提供了一些额外的演示,说明如何检查 HTML 的结构,以及如何使用各种 HTML 标签从“soup”文件中返回感兴趣的信息。出于本文的目的,我不会深入讨论这个问题,但它有助于更好地理解如何阅读上述步骤的 HTML 输出。
为了从感兴趣的页面中提取适当的表数据,我需要确定表“class”。在 Chrome 浏览器中,我通过(右键单击-> inspect)检查了我感兴趣的表,并确定该表属于“wikitable sortable”类型。页面本身特别将其标注为“wikitable sortable jquery-table sorter”,但是,soup 文件只将其识别为“wiki table sortable”在对这个次要组件进行故障排除之后,我能够以下面的方式提取表信息:
#pinpointing the location of the table and its contents
first_table = soup.find(“table”, class_ = “wikitable sortable”)#creating lists for each of the columns I know to be in my table.
A=[]
B=[]
C=[]
D=[]
E=[]
F=[]#utilizing HTML tags for rows <tr> and elements <td> to iterate through each row of data and append data elements to their appropriate lists:for row in first_table.findAll(“tr”):
cells = row.findAll(‘td’)
if len(cells)==6: #Only extract table body not heading
A.append(cells[0].find(text=True))
B.append(cells[1].find(text=True))
C.append(cells[2].find(text=True))
D.append(cells[3].find(text=True))
E.append(cells[4].find(text=True))
F.append(cells[5].find(text=True))
当我检查输出时,我注意到数据是 unicode 格式的,这使得对其执行操作变得更加复杂。由于堆栈溢出,我利用列表理解将所有值从 unicode 转换为简单的 python 字符串值:
#convert all values from unicode to string
A = [x.encode(‘UTF8’) for x in A]
B = [x.encode(‘UTF8’) for x in B]
C = [x.encode(‘UTF8’) for x in C]
D = [x.encode(‘UTF8’) for x in D]
E = [x.encode(‘UTF8’) for x in E]
F = [x.encode(‘UTF8’) for x in F]
最后,我导入了 pandas,并将每个数据列表连接到一个数据框架中。这样做的时候,我指定了出现在维基百科页面上的列名:
#import pandas to convert list to data frame
import pandas as pd
df=pd.DataFrame(A,columns=[‘Year’])
df[‘Game’]=B
df[‘Genre’]=C
df[‘Lists’]=D
df[‘Original Platform’]=E
df[‘References’]=F
万岁。打印 dataframe 得到了以下输出。我没有拿出所有的参考信息,但这在我的后续检查中不需要。
要了解我是如何用 Tableau Public 可视化这些数据的,请查看我的另一篇博文。感谢阅读!
R 中的网页抓取教程
几天前,数据学校的凯文·马卡姆发表了一篇很好的教程,讲述了使用 16 行 Python 代码进行网络抓取的方法。
[## 网络抓取总统的 16 行 Python 谎言
注意:本教程以 Jupyter 笔记本的形式提供,谎言的数据集以 CSV 文件的形式提供,两者都…
www.dataschool.io](http://www.dataschool.io/python-web-scraping-of-president-trumps-lies/)
教程很简单,制作精良。我强烈建议你看一看。事实上,这样的教程激励我复制结果,但这次使用 r。在 Kevin 的允许下,我将使用与他的博客帖子相似的布局。此外,我将使用同一个网站发表一篇名为特朗普的谎言的观点文章。这将有助于对这两种方法进行比较。
检查纽约时报的文章
为了更好地描述我们将要学习的文章,我鼓励你看看 Kevin 的教程。总之,我们感兴趣的数据由一个谎言记录组成,每个谎言包含 4 个部分:
- 谎言的日期
- 谎言本身
- 解释为什么这是一个谎言
- 支持解释的文章的 URL(嵌入在文本中)

The data that we want to extract from the web page.
将网页读入 R
要将网页读入 R,我们可以使用 R 大师 Hadley Wickham 制作的包。这个包的灵感来自于像 Beautiful Soup 这样的库,使得从 html 网页中抓取数据变得容易。要使用的第一个重要函数是read_html(),它返回一个包含关于网页的所有信息的 XML 文档。
收集所有的记录
正如 Kevin 的教程中所解释的那样,每条记录在 HTML 代码中具有以下结构:
<span class="short-desc"><strong> DATE </strong> LIE <span class="short-truth"><a href="URL"> EXPLANATION </a></span></span>
因此,要收集所有的谎言,我们需要识别所有属于class="short-desc"的<span>标签。将帮助我们这样做的功能是html_nodes()。这个函数需要我们已经阅读过的 XML 文档和我们想要选择的节点。对于后者,我们鼓励使用 SelectorGadget ,这是一个开源工具,可以轻松地生成和发现 CSS 选择器。使用这样一个工具,我们发现所有的谎言都可以通过使用选择器".short-desc"来选择。
这将返回一个包含 116 个 XML 节点的列表,其中包含了网页中 116 个谎言的信息。
请注意,我使用的是 magritter包中的%>%管道操作符,它可以帮助将复杂的操作表达为由简单、容易理解的部分组成的优雅管道。
提取日期
让我们从简单的开始,专注于从第一个谎言中提取所有必要的细节。然后,我们可以很容易地将这种方法推广到其他领域。请记住,单个记录的一般结构是:
<span class="short-desc"><strong> **DATE** </strong> **LIE** <span class="short-truth"><a href="**URL**"> **EXPLANATION** </a></span></span>
注意,日期嵌入在<strong>标签中。要选择它,我们可以使用选择器"strong"使用html_nodes()功能。
然后我们需要使用html_text()函数只提取文本,trim 参数被激活来修剪前导和尾随空格。最后,我们利用 stringr 包将年份添加到提取的日期中。
提取谎言
为了选择 lie,我们需要使用 xml2 包中的xml_contents()函数(这个包是 rvest 包所需要的,所以没有必要加载它)。该函数返回一个包含属于first_result的节点的列表。
我们感兴趣的是谎言,它是第二个节点的文本。
请注意,谎言周围多了一对引号(“…”)。为了去掉它们,我们只需使用 stringr 包中的str_sub()函数来选择谎言。
提取解释
希望现在不要太复杂,我们只需要选择属于class=".short-truth"的<span>标签中的文本就可以提取解释。这将把文本连同左括号和右括号一起提取出来,但是我们可以很容易地去掉它们。
正在提取 URL
最后,要获取 URL,请注意这是<a>标签中的一个属性。我们简单地用html_nodes()函数选择这个节点,然后用html_attr()函数选择href属性。
构建数据集
我们找到了提取第一条记录的 4 个部分的方法。我们可以使用 for 循环将这个过程扩展到所有其他地方。最后,我们想要一个有 116 行(每条记录一行)和 4 列(保存日期、谎言、解释和 URL)的数据框。一种方法是创建一个空数据框,并在处理每个新记录时简单地添加一个新行。但是,这被认为不是一个好的做法。正如这里建议的,我们将为每条记录创建一个单独的数据帧,并将它们全部存储在一个列表中。一旦我们有了 116 个数据帧,我们将使用 dplyr 包中的bind_rows()函数将它们绑定在一起。这就创建了我们想要的数据集。
注意,日期列被认为是一个字符向量。如果把它作为日期时间向量就更好了。为此,我们可以使用 lubridate 包并使用mdy()函数(月-日-年)进行转换。
将数据集导出到 CSV 文件
如果想导出数据集,可以使用 R 默认自带的write.csv()函数,或者使用 readr 包中的write_csv()函数,这比第一个函数快两倍,也更方便。
类似地,要检索数据集,可以使用默认函数read.csv()或 readr 包中的read_csv()函数。
摘要
本教程的完整代码如下所示:
我还想提一下,stringr、dplyr、lubridate 和 readr 包都是 tidyverse 家族的一部分。这是一个 R 包的集合,它们被设计成一起工作来使数据分析过程更容易。事实上,你也可以使用流行的 purrr 包来避免 for 循环。但是,这需要创建一个函数,将每个记录映射到一个数据框。关于如何进行网络抓取的另一个例子,请看迪安·阿塔利写的这篇很棒的博客文章。
希望你觉得这个教程有用。它的目的不是展示哪种编程语言更好,而是向 Python 和 R 学习,以及增加您的编程技能和工具来处理更多样化的问题。
使用 Selenium-Python 进行 Web 抓取
如何在 Python 中使用 Selenium 浏览网站的多个页面并收集大量数据

Shhh! Be Cautious Web Scraping Could be Troublesome!!!
在我们深入探讨本文的主题之前,让我们先了解一下什么是网络抓取,它有什么用处。
- 什么是网络抓取?
网络抓取是一种使用模拟人类网上冲浪的软件从互联网上自动提取信息的技术。
2.网络抓取有什么用?
网络抓取帮助我们提取大量关于客户、产品、人员、股票市场等的数据。使用传统的数据收集方法通常很难获得大规模的此类信息。我们可以利用从电子商务门户网站、社交媒体渠道等网站收集的数据来了解客户行为和情绪、购买模式以及品牌属性关联,这些对于任何企业都是至关重要的洞察。
现在让我们把手弄脏吧!!
既然我们已经定义了抓取的目的,那就让我们深入研究如何真正做有趣的事情吧!在此之前,下面是一些关于软件包安装的内务操作说明。
a. Python 版本:我们将会使用 Python 3.0,但是也可以通过稍微的调整来使用 Python 2.0。我们将使用 jupyter 笔记本,所以你不需要任何命令行知识。
b. Selenium 包:您可以使用以下命令安装 Selenium 包
!pip install selenium
c. Chrome 驱动:请从这里安装最新版本的 Chrome 驱动。
请注意,你需要在你的机器上安装谷歌浏览器来完成这个插图。
当抓取一个网站时,首要的事情是理解网站的结构。我们将刮Edmunds.com,汽车论坛。这个网站帮助人们做出购车决定。人们可以在论坛上发布他们对不同汽车的评论(非常类似于在亚马逊上发布评论)。我们将讨论入门级豪华车品牌。
我们将从不同用户的多个页面收集约 5000 条评论。我们将收集用户 id、评论日期和评论,并将其导出到 csv 文件中,以供进一步分析。
让我们开始编写我们的刮刀!
我们将首先在笔记本中导入重要的包—
#Importing packages
from selenium import webdriver
import pandas as pd
现在让我们创建一个新的谷歌浏览器实例。这将有助于我们的程序在谷歌浏览器中打开一个网址。
driver = webdriver.Chrome('Path in your computer where you have installed chromedriver')
现在让我们访问谷歌浏览器,打开我们的网站。顺便说一句,chrome 知道你是通过一个自动化软件来访问它的!
driver.get('[https://forums.edmunds.com/discussion/2864/general/x/entry-level-luxury-performance-sedans/p702'](https://forums.edmunds.com/discussion/2864/general/x/entry-level-luxury-performance-sedans/p702'))

Web page opened from python notebook
哇哈哈!我们刚刚从 python 笔记本中打开了一个 url。
那么,我们的网页看起来怎么样?
我们将检查网页上的 3 个项目(用户 id、日期和评论),并了解如何提取它们。
- 用户 id :检查用户 id,我们可以看到高亮显示的文本代表用户 id 的 XML 代码。
XML path for user id
userid 的 XML 路径(XPath)如下所示。这里有一件有趣的事情需要注意,XML 路径包含一个评论 id,它唯一地表示网站上的每个评论。这将非常有帮助,因为我们试图递归抓取多个评论。
//*[[@id](http://twitter.com/id)=”Comment_5561090"]/div/div[2]/div[1]/span[1]/a[2]
如果我们看到图中的 XPath,我们会发现它包含用户 id‘dino 001’。
我们如何提取 XPath 中的值?
Selenium 有一个函数叫做“ find_elements_by_xpath ”。我们将把 XPath 传递给这个函数,并获得一个 selenium 元素。一旦有了元素,我们就可以使用’ text '函数提取 XPath 中的文本。在我们的例子中,文本基本上是用户 id ('dino001 ')。
userid_element = driver.find_elements_by_xpath('//*[[@id](http://twitter.com/id)="Comment_5561090"]/div/div[2]/div[1]/span[1]/a[2]')[0]
userid = userid_element.text
2.评论日期:类似于用户 id,我们现在将检查发表评论的日期。

XML path for comment date
让我们看看注释日期的 XPath。再次注意 XPath 中惟一的注释 id。
//*[[@id](http://twitter.com/id)="Comment_5561090"]/div/div[2]/div[2]/span[1]/a/time
那么,我们如何从上面的 XPath 中提取 date 呢?
我们将再次使用函数“find_elements_by_xpath”来获取 selenium 元素。现在,如果我们仔细观察图片中突出显示的文本,我们会看到日期存储在“title”属性中。我们可以使用函数“get_attribute”来访问属性中的值。我们将在这个函数中传递标记名,以获取其中的值。
user_date = driver.find_elements_by_xpath('//*[[@id](http://twitter.com/id)="Comment_5561090"]/div/div[2]/div[2]/span[1]/a/time')[0]date = user_date.get_attribute('title')
3.评论:最后,我们来探讨一下如何提取每个用户的评论。
XML Path for user comments
下面是用户评论的 XPath
//*[[@id](http://twitter.com/id)="Comment_5561090"]/div/div[3]/div/div[1]
同样,我们的 XPath 中有注释 id。与 userid 类似,我们将从上面的 XPath 中提取注释
user_message = driver.find_elements_by_xpath('//*[[@id](http://twitter.com/id)="Comment_5561090"]/div/div[3]/div/div[1]')[0]comment = user_message.text
我们刚刚学习了如何从网页中抓取不同的元素。现在如何递归提取 5000 个用户的这些项?
如上所述,我们将使用注释 id,注释 id 对于提取不同用户数据的注释是唯一的。如果我们看到整个注释块的 XPath,我们会看到它有一个与之关联的注释 id。
//*[[@id](http://twitter.com/id)="Comment_5561090"]

XML Path for entire comment block
下面的代码片段将帮助我们提取特定网页上的所有评论 id。我们将再次对上述 xpath 使用函数’ find_elements_by_xpath ,并从’ id 属性中提取 id。
ids = driver.find_elements_by_xpath("//*[contains([@id](http://twitter.com/id),'Comment_')]")
comment_ids = []
for i in ids:
comment_ids.append(i.get_attribute('id'))
上面的代码给出了一个特定网页上所有评论 id 的列表。
如何将所有这些整合在一起?
现在,我们将把目前为止看到的所有东西放入一个大代码中,这将递归地帮助我们提取 5000 条评论。我们可以通过遍历在前面的代码中找到的所有评论 id 来提取特定网页上每个用户的用户 id、日期和评论。
下面是从特定网页中提取所有评论的代码片段。
Scrapper To Scrape All Comments from a Web Page
最后,如果你检查我们的网址有页码,从 702 开始。因此,我们可以通过简单地改变 url 中的页码来递归地转到前面的页面,以提取更多的评论,直到我们获得所需数量的评论。
这个过程需要一些时间,取决于你的计算机的计算能力。所以,冷静下来,喝杯咖啡,和你的朋友和家人聊聊天,让硒发挥它的作用吧!
总结:我们学习了如何在 Python 中使用 Selenium 抓取网站并获得大量数据。您可以进行多种非结构化数据分析,并发现有趣的趋势、观点等。利用这些数据。如果有人有兴趣看完整的代码,这里是我的 Github 的链接。
让我知道这是否有帮助。享受刮擦,但要小心!
如果你喜欢读这篇文章,我会推荐你读另一篇关于使用 Reddit API 和 Google BigQuery 抓取 Reddit 数据的文章,作者是德克萨斯大学奥斯汀分校的一位同学(Akhilesh naraparetdy)。
[## 使用 Python 和 Google BigQuery 抓取 Reddit 数据
访问 Reddit API 和 Google Bigquery 的用户友好方法
towardsdatascience.com](/scrape-reddit-data-using-python-and-google-bigquery-44180b579892)
周末项目:从卫星图像中探测太阳能电池板

我花了很多时间处理卫星图像或衍生产品,主要是与土壤科学相关的项目。你可以看看我以前的一篇文章,我用多任务卷积神经网络和环境信息来预测土壤有机碳含量:
使用上下文空间信息的数字土壤制图。从点信息生成土壤图的多任务 CNN
towardsdatascience.com](/deep-learning-and-soil-science-part-2-129e0cb4be94)
这个周末,我想探索另一个领域,我认为这将是一个好主意,试图从卫星图像检测太阳能电池板。目前我住在澳大利亚,利用太阳能的潜力是巨大的。政府坚持推动使用煤来生产能源,所以我认为任何强调可再生能源的个人努力都是重要的。
目标
这是一个周末项目,所以我的想法是在短时间内实现一些东西,并希望得到一些下降的结果。结果并不完美,但这是良好的第一步。
整个过程包括:
- 生成数据集
- 训练卷积神经网络(CNN)
- 尝试用模型做一些有趣的事情
资料组
我确信有可能找到一个好的数据集来实现这一点,但目标之一是从头生成一个数据集。CNN 非常强大,但是没有数据,你做不了什么。
为了生成对应于太阳能电池板位置的多边形,我使用了谷歌地球引擎。我花了大约 1.5 个小时在 1 公里的范围内划分太阳能电池板,结果总共 124 个多边形(没有我预期的那么多)。

Creating polygons
下一步是在这些多边形内生成 1800 个随机点,并提取以这些位置为中心的图像。那些是阳性样品(有太阳能电池板)。对于负样本(没有太阳能电池板),我生成了 1800 个不与多边形相交的随机点(加上一个缓冲区,以确保电池板不在图像中)。

Examples of positive samples (top) and negative samples (bottom)
模型
我能想到几种检测太阳能电池板的方法。我们可以尝试分割图像,使用遮罩,预测多边形的顶点。我不想花几个小时训练这个模型,所以我选择了一个相对简单的完全卷积神经网络来预测一个像素成为太阳能电池板一部分的概率。几个 conv-马克斯普尔序列,最初几层中的一些空间退学者,以及接近结尾时更多的退学者。我使用的一个小技巧(我在一次会议上从谷歌的某人那里学到的)是计算 RGB 图像的相对亮度,并将其用作上下文。我对 RGB 图像进行了裁剪(没有调整大小),并将其与亮度图像合并(在使用一些卷积减少亮度图像的大小之后)。

People has been asking about this “trick”. Just make sure that the shape of the cropped RGB is equal to the RelLum after the convolutions. The number of convolutions will depend on the shape of the original image and how much you crop it (not resize it).
在训练 100 个时期的模型之前,我使用 Kera 的ImageDataGenerator对图像应用了一些数据增强(垂直和水平翻转,80-120%亮度范围)。用 GPU 在桌面上运行训练只需要几分钟。
结果
考虑到我花在生成数据集和训练模型上的时间,我对结果印象深刻。该模型对训练集和验证集的准确率分别达到了 95%和 92%。
输出的几个例子:
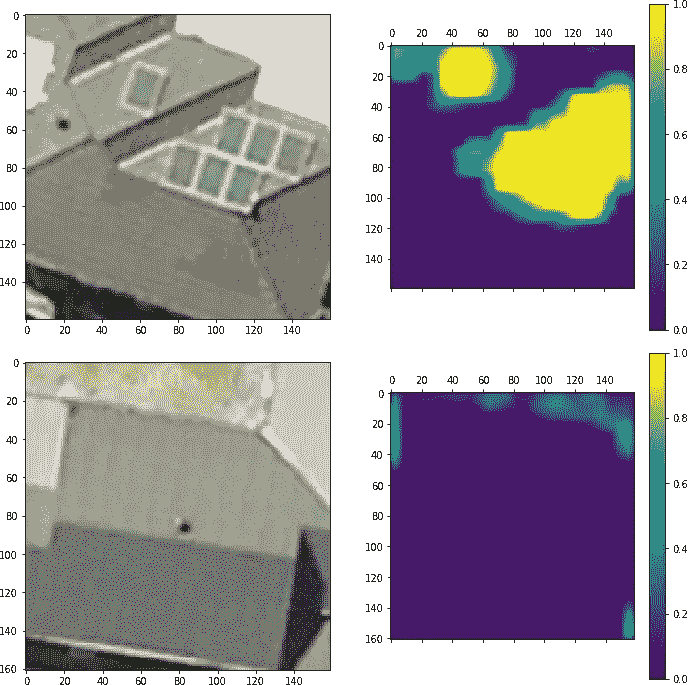
High probabilities in an image with solar panels (top) and low probability in image without panels.
总的来说,结果是好的。有些地方模型会混淆,比如汽车挡风玻璃,房屋边缘,电缆。在实践中这不是一个大问题,因为在这些区域的概率通常低于 0.8,所以在适当的阈值下,误差是最小的。通过这个模型的第一次迭代,我可以预测一个大的区域,并手动选择负样本来进一步改进模型。
使用私有 API 进行预测
我决定使用 Flask 编写一个小的 tile 服务器,而不是运行 Jupyter 笔记本并使用它来预测新图像。大概我会写一篇关于这个的文章,但总的来说逻辑是:
- 给定 API 的视口,前端向 API 请求图块。
- API 从官方切片服务器(卫星视图)检索切片。
- API 使用图块进行预测。
- API 使用用户定义的模型、阈值和不透明度生成覆盖图(原始图像+概率)。
- 前端显示瓷砖。
由于这种方法,我可以探索任何领域,并迅速得到预测。

Frontend displaying tiles predicted “on-the-fly”. Showing probabilities > 95%. Still some errors, but probably easy to correct with more negative samples.
最后的话
这是一个有趣的项目,结果比我预期的好得多。我可能会尝试改进模型,使其达到生产水平。API 肯定是我想继续改进的东西,因为我需要这样的东西已经有一段时间了。如果有人知道替代方案,请告诉我。
我希望你喜欢这篇文章。我想我会坚持太阳能主题,并尝试生成一个辐射模型来估计一所房子安装太阳能电池板的潜力。
数据科学每周 Python 摘要(7 月第一周)
大家好!我正在开始一个新的系列,我将谈论和测试一些谈论 Python 和 R 的库、代码或博客,以及它们在机器学习、深度学习和数据科学中的应用。第一份出版物是关于 Python 的。

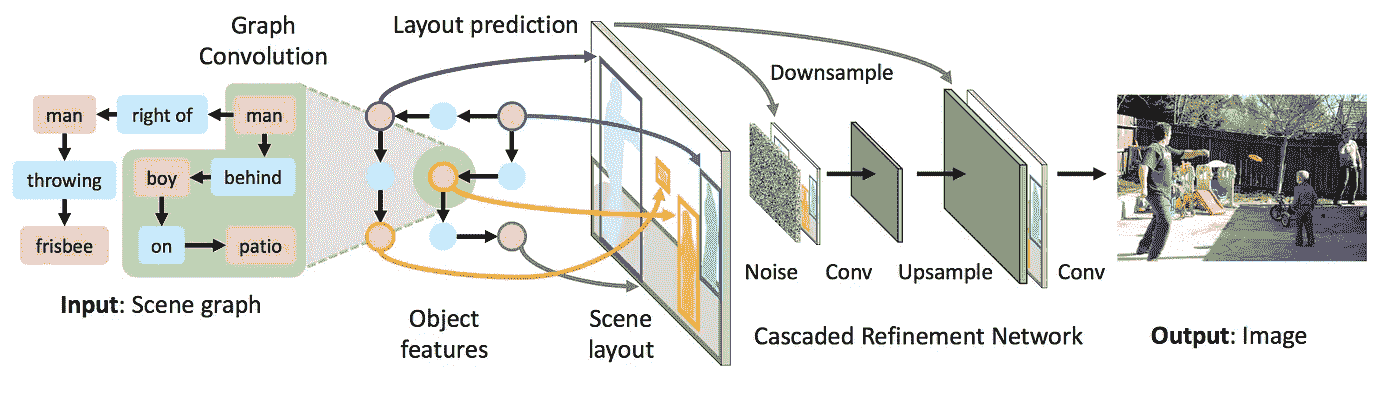
1。sg2im —从场景图生成图像
https://github.com/google/sg2im
这个伟大的开源代码将允许您使用图形卷积来处理输入图形,通过预测对象的边界框和分段遮罩来计算场景布局,并使用级联优化网络将布局转换为图像。
该论文可在此处找到:
[## [1804.01622]从场景图生成图像
摘要:要真正理解视觉世界,我们的模型不仅要能识别图像,还要能生成…
arxiv.org](https://arxiv.org/abs/1804.01622)
那么这段代码是做什么的呢?它实现了一个端到端的神经网络模型,输入一个场景图,输出一个图像。场景图是视觉场景的结构化表示,其中节点表示场景中的对象,边表示对象之间的关系。
用 图形卷积 网络 处理输入的场景图形,该网络沿着边缘传递信息以计算所有对象的嵌入向量。这些向量用于预测所有对象的边界框和分割遮罩,它们被组合以形成粗略的 场景布局 。该布局被传递到 级联细化网络 ,该网络以递增的空间比例生成输出图像。该模型针对一对 鉴别器网络 进行对抗性训练,以确保输出图像看起来逼真。
如何运行和测试代码?
首先克隆代码
git clone https://github.com/google/sg2im.git
原始代码是在 Ubuntu 16.04 上用 Python 3.5 和 PyTorch 0.4 开发和测试的。我在我的 Mac 上测试,没有问题:)
我建议您在虚拟环境中尝试一下。您可以设置虚拟环境来运行代码,如下所示:
python3 -m venv env # Create a virtual environment
source env/bin/activate # Activate virtual environment
pip install -r requirements.txt # Install dependencies
echo $PWD > env/lib/python3.5/site-packages/sg2im.pth # Add current directory to python path
# Work for a while ...
deactivate # Exit virtual environment
你需要安装 python-venv 来完成这个。哦,顺便说一句,我需要改变一些脚本,这是我用的:
python3 -m venv --without-pip env # Added the --without-pip
source env/bin/activate # Activate virtual environment
pip install -r requirements.txt # Install dependencies
echo $PWD > env/lib/python3.6/site-packages/sg2im.pth # Add current directory to python path
# Work for a while ...
deactivate # Exit virtual environment
哦!也因为某些原因,我需要从 requirements.txt 中删除**pkg-resources=0.0.0** 。这似乎是一个错误:
[## pip 冻结命令输出中的“pkg-resources==0.0.0”是什么
本网站使用 cookies 来提供我们的服务,并向您显示相关的广告和工作列表。通过使用我们的网站,您…
stackoverflow.com](https://stackoverflow.com/questions/39577984/what-is-pkg-resources-0-0-0-in-output-of-pip-freeze-command/39638060)
我已经创建了问题和 PR:)
要运行预先训练好的模型,您需要通过运行脚本bash scripts/download_models.sh来下载它们。这将下载以下型号,并需要大约 355 MB 的磁盘空间:
sg2im-models/coco64.pt:在 COCO-Stuff 数据集上训练生成 64 x 64 的图像。该模型用于从论文中生成图 5 中的 COCO 图像。

https://arxiv.org/pdf/1804.01622.pdf
sg2im-models/vg64.pt:经过训练可以在可视基因组数据集上生成 64 x 64 的图像。该模型用于从论文中生成图 5 中的可视基因组图像。

https://arxiv.org/pdf/1804.01622.pdf
sg2im-models/vg128.pt:经过训练,可以在可视基因组数据集上生成 128 x 128 的图像。这个模型被用来从纸上生成图 6 中的图像。

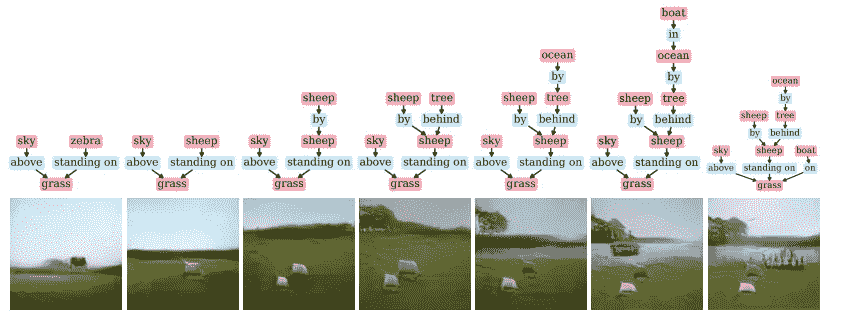
您可以使用脚本scripts/run_model.py使用简单的人类可读的 JSON 格式在新的场景图上轻松运行任何预训练的模型。
要重现上面的绵羊图像,你必须运行:
python scripts/run_model.py \
--checkpoint sg2im-models/vg128.pt \
--scene_graphs scene_graphs/figure_6_sheep.json \
--output_dir outputs
您将获得:







我们来看看 figure_6_sheep.json:
[
{
"objects": ["sky", "grass", "zebra"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1]
]
},
{
"objects": ["sky", "grass", "sheep"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1]
]
},
{
"objects": ["sky", "grass", "sheep", "sheep"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1],
[3, "by", 2]
]
},
{
"objects": ["sky", "grass", "sheep", "sheep", "tree"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1],
[3, "by", 2],
[4, "behind", 2]
]
},
{
"objects": ["sky", "grass", "sheep", "sheep", "tree", "ocean"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1],
[3, "by", 2],
[4, "behind", 2],
[5, "by", 4]
]
},
{
"objects": ["sky", "grass", "sheep", "sheep", "tree", "ocean", "boat"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1],
[3, "by", 2],
[4, "behind", 2],
[5, "by", 4],
[6, "in", 5]
]
},
{
"objects": ["sky", "grass", "sheep", "sheep", "tree", "ocean", "boat"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1],
[3, "by", 2],
[4, "behind", 2],
[5, "by", 4],
[6, "on", 1]
]
}
]
让我们来分析第一个:
{
"objects": ["sky", "grass", "zebra"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1]
]
}
因此,我们有天空、草地和斑马,其中天空[0]在草地[1]上方,斑马[2]站在草地[1]上。

First image from figure_6_sheep.json
让我们创建一个新的来测试代码:
[{
"objects": ["sky", "grass", "dog", "cat", "tree", "ocean", "boat"],
"relationships": [
[0, "above", 1],
[2, "standing on", 1],
[3, "by", 2],
[4, "behind", 2],
[5, "by", 4],
[6, "on", 1]
]
}]
跑步:
python scripts/run_model.py \
--checkpoint sg2im-models/vg128.pt \
--scene_graphs scene_graphs/figure_blog.json \
--output_dir outputs
我有:

有点奇怪,但很有趣:)。
2。算法 / Python —所有算法都用 Python 实现。嗯“所有”
所有算法都用 Python 实现
github.com](https://github.com/TheAlgorithms/Python)
编程是数据科学中的一项必备技能,在这个伟大的资源库中,我们将看到几个重要算法的全 Python 代码实现。
这些仅用于演示目的。出于性能原因,Python 标准库中有许多更好的实现。
例如,你会发现机器学习代码,神经网络,动态编程,排序,哈希等等。例如,这是用 Numpy 在 Python 中从头开始的 K-means:
3。mlens — ML-Ensemble —高性能集成学习

高性能集成学习
github.com](https://github.com/flennerhag/mlens)
ML-Ensemble 将 Scikit-learn 高级 API 与低级计算图框架相结合,以尽可能少的代码行构建内存高效、最大化并行化的集成网络。
只要基础学习者是线程安全的,ML-Ensemble 就可以依靠内存映射多处理实现内存中立的基于进程的并发。有关教程和完整文档,请访问项目网站。
通过 PyPI 安装
ML-Ensemble 在 PyPI 上可用。与一起安装
pip install mlens
简单示例(iris 义务示例):
**import** numpy **as** np
**from** pandas **import** DataFrame
**from** sklearn.metrics **import** accuracy_score
**from** sklearn.datasets **import** load_iris
seed **=** 2017
np**.**random**.**seed(seed)
data **=** load_iris()
idx **=** np**.**random**.**permutation(150)
X **=** data**.**data[idx]
y **=** data**.**target[idx]**from** mlens.ensemble **import** SuperLearner
**from** sklearn.linear_model **import** LogisticRegression
**from** sklearn.ensemble **import** RandomForestClassifier
**from** sklearn.svm **import** SVC
*# --- Build ---*
*# Passing a scoring function will create cv scores during fitting*
*# the scorer should be a simple function accepting to vectors and returning a scalar*
ensemble **=** SuperLearner(scorer**=**accuracy_score, random_state**=**seed, verbose**=**2)
*# Build the first layer*
ensemble**.**add([RandomForestClassifier(random_state**=**seed), SVC()])
*# Attach the final meta estimator*
ensemble**.**add_meta(LogisticRegression())
*# --- Use ---*
*# Fit ensemble*
ensemble**.**fit(X[:75], y[:75])
*# Predict*
preds **=** ensemble**.**predict(X[75:])
您将获得:
Fitting 2 layers
Processing layer**-**1 done **|** 00:00:00
Processing layer**-**2 done **|** 00:00:00
Fit complete **|** 00:00:00
Predicting 2 layers
Processing layer**-**1 done **|** 00:00:00
Processing layer**-**2 done **|** 00:00:00
Predict complete **|** 00:00:00
要检查层中估计器的性能,请调用data属性。属性可以包装在一个[**pandas.DataFrame**](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html#pandas.DataFrame)中,但是以表格格式打印出来。
**print**("Fit data:\n%r" **%** ensemble**.**data)
我们看到:
Fit data:
score**-**m score**-**s ft**-**m ft**-**s pt**-**m pt**-**s
layer**-**1 randomforestclassifier 0.84 0.06 0.05 0.00 0.00 0.00
layer**-**1 svc 0.89 0.05 0.01 0.01 0.00 0.00
还不错。让我们来看看整体表现如何:
Prediction score: 0.960
他们这里有很棒的教程:
[## 入门- mlens 0.2.1 文档
编辑描述
ml-ensemble.com](http://ml-ensemble.com/info/tutorials/start.html)
今天就到这里了:)。很快你会得到更多的信息,也可以用 R 发帖。如果您想了解最新信息,请订阅以下内容:
感谢你阅读这篇文章。希望你在这里发现了一些有趣的东西:)
如果你有任何问题,请在推特上关注我
Favio Vázquez 的最新推文(@FavioVaz)。数据科学家。物理学家和计算工程师。我有一个…
twitter.com](https://twitter.com/faviovaz)
还有 LinkedIn。
[## Favio Vázquez —首席数据科学家— OXXO | LinkedIn
查看 Favio Vázquez 在世界上最大的职业社区 LinkedIn 上的个人资料。Favio 有 15 个工作职位列在…
linkedin.com](http://linkedin.com/in/faviovazquez/)
那里见:)
数据科学每周文摘(7 月第一周)
大家好!在这个新系列中,我将讨论并测试一些关于 R 及其在机器学习、深度学习和数据科学中的应用的库、代码或博客。你可以在这里阅读的 Python 版本。

1。调色板 —单个 R 包中大多数调色板的集合

https://github.com/EmilHvitfeldt/paletteer
数据可视化在数据科学中至关重要。是我们向企业解释我们的发现的途径,它还帮助我们理解我们正在分析的数据,将几周的工作压缩成一幅画面。
r 是一种很好的可视化语言。这个伟大的软件包 paletteer 的目标是使用一个公共接口成为 R 中调色板的综合集合。把它想象成“调色板的脱字符号”。
这个包还没有在 CRAN 上,但是如果你想要开发版本,那么直接从 GitHub 安装:
# install.packages("devtools")
devtools::install_github("EmilHvitfeldt/paletteer")
调色板
调色板分为两组;离散和连续。对于离散调色板,您可以在固定宽度调色板和动态调色板之间进行选择。两者中最常见的是固定宽度调色板,它具有固定的颜色数量,当所需的颜色数量变化时,该数量不会改变,如下调色板所示:

另一方面,我们有动态调色板,其中调色板的颜色取决于您需要的颜色数量,如cartography包中的green.pal调色板:
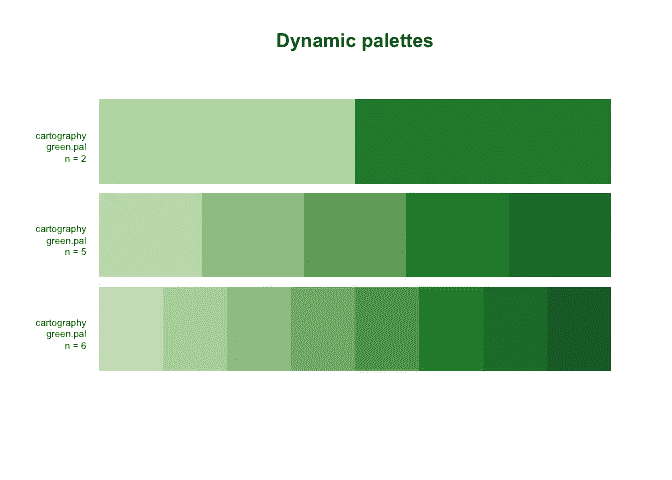
最后,我们有连续调色板,它可以根据您的需要提供任意多种颜色,以实现颜色的平滑过渡:

该包包括来自 28 个不同包的 958 个包,有关这些包的信息可以在以下数据框中找到:palettes_c_names、palettes_d_names和palettes_dynamic_names。
该套件还包括使用相同标准接口的ggplot2秤
library(ggplot2)ggplot(iris, aes(Sepal.Length, Sepal.Width, color = Species)) +
geom_point() +
scale_color_paletteer_d(nord, aurora)
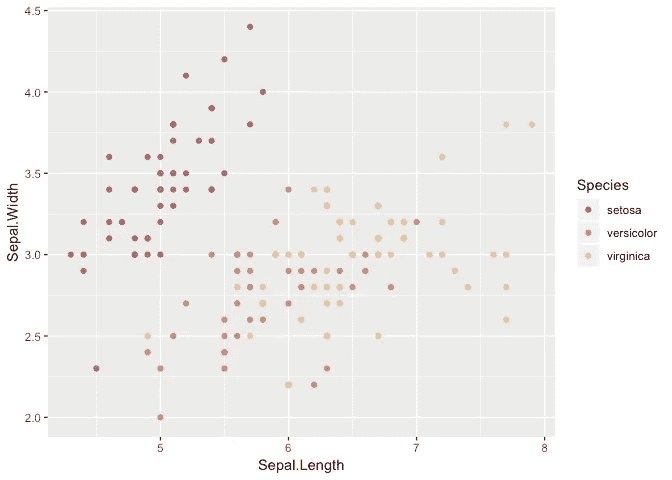
非常容易和有用。记得访问 GitHub repo:
调色板-在一个 R 包中收集了大多数调色板
github.com](https://github.com/EmilHvitfeldt/paletteer)
并启动它;).
2。DALEX —描述性的机器学习解释

https://github.com/pbiecek/DALEX
解释机器学习模型并不总是容易的,但对于一些商业应用来说却非常重要。有一些很棒的库可以帮助我们完成这项任务,例如:
本地可解释的模型不可知解释(原始 Python 包的 R 端口)
github.com](https://github.com/thomasp85/lime)
顺便说一句,有时候一个简单的 ggplot 可视化可以帮助你解释一个模型。关于这方面的更多信息,请看马修·梅奥的这篇精彩文章:
一篇关于机器学习解释的文章早在三月份就出现在 O’Reilly 的博客上,作者是 Patrick Hall,Wen…
www.kdnuggets.com](https://www.kdnuggets.com/2017/11/interpreting-machine-learning-models-overview.html)
在许多应用中,我们需要知道、理解或证明输入变量是如何在模型中使用的,以及它们对最终模型预测有什么影响。DALEX是一套帮助理解复杂模型如何工作的工具。
要从 CRAN 安装,只需运行:
install.packages("DALEX")
他们有关于如何将 DALEX 用于不同 ML 包的惊人文档:
- 如何使用带有脱字符号的 DALEX】
- 如何配合 mlr 使用 DALEX】
- 如何与 H2O 一起使用 DALEX】
- 如何在 xgboost 包中使用 DALEX】
- 如何使用 DALEX 进行教学?第一部分
- 如何使用 DALEX 进行教学?第二部分
- 分解 vs 石灰 vs 沙普利
伟大的备忘单:
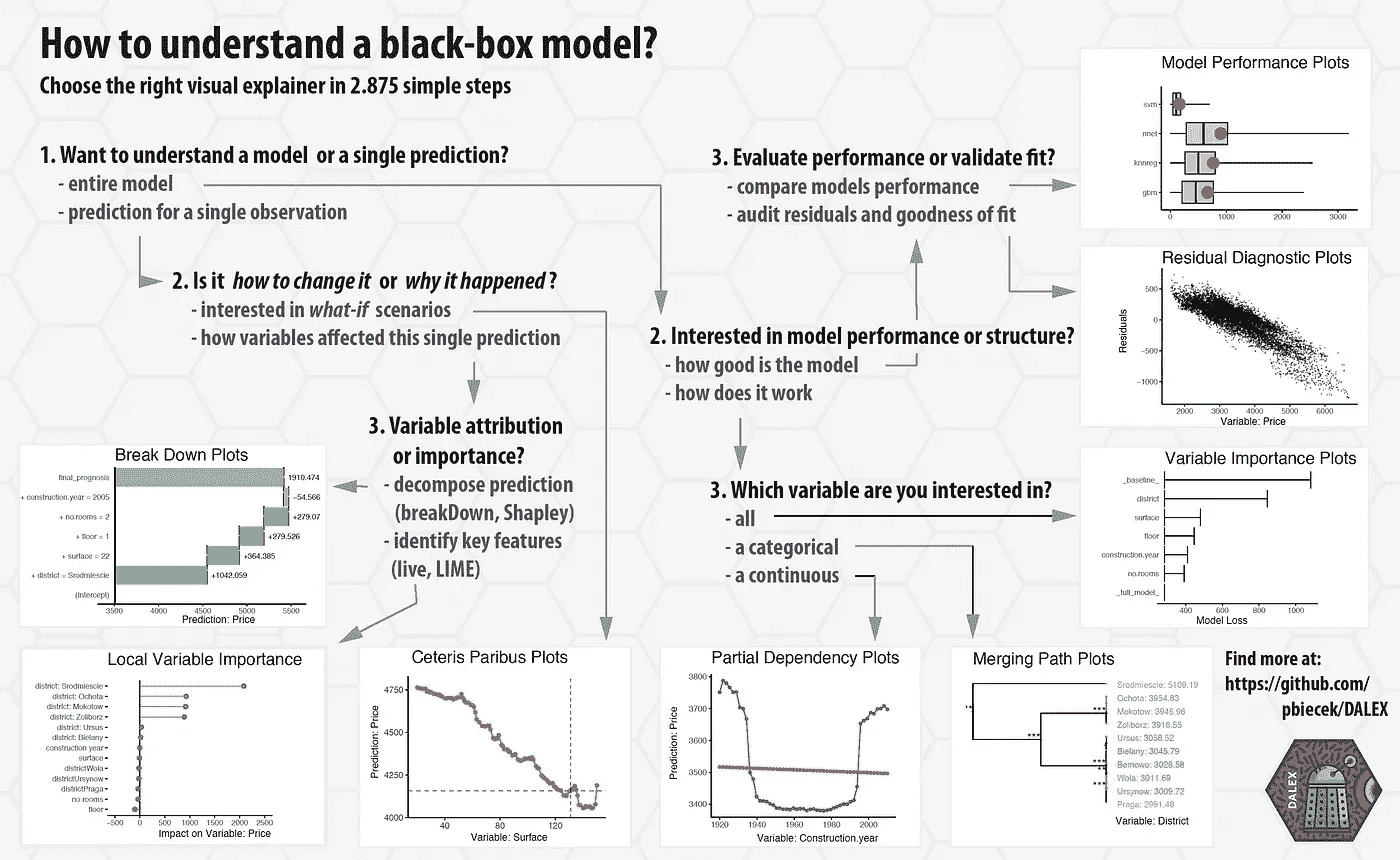
https://github.com/pbiecek/DALEX
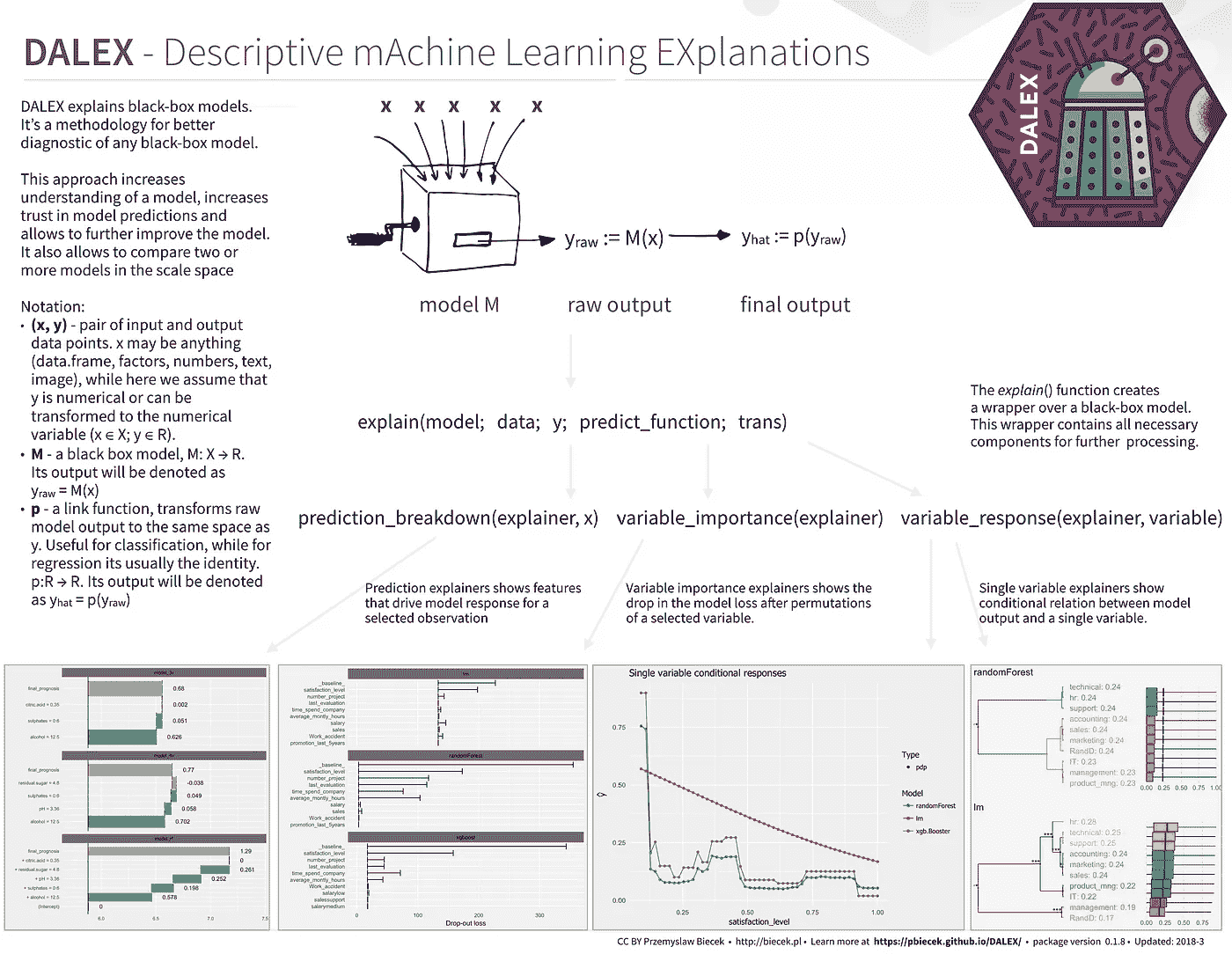
https://github.com/pbiecek/DALEX
一个交互式笔记本,您可以在其中了解有关该产品包的更多信息:
[## 粘合剂(测试版)
编辑描述
mybinder.org](https://mybinder.org/v2/gh/pbiecek/DALEX_docs/master?filepath=jupyter-notebooks%2FDALEX.ipynb)
最后是一个书籍风格的文档,其中讨论了 DALEX、机器学习和可解释性:
[## DALEX:描述性机器学习解释
不要相信黑箱模型。除非它能自我解释。
pbiecek.github.io](https://pbiecek.github.io/DALEX_docs/)
在原始存储库中签出它:
DALEX -描述性机器学习解释
github.com](https://github.com/pbiecek/DALEX)
而且记得启动它:)。
modelDown —生成一个包含预测模型的 HTML 摘要的网站
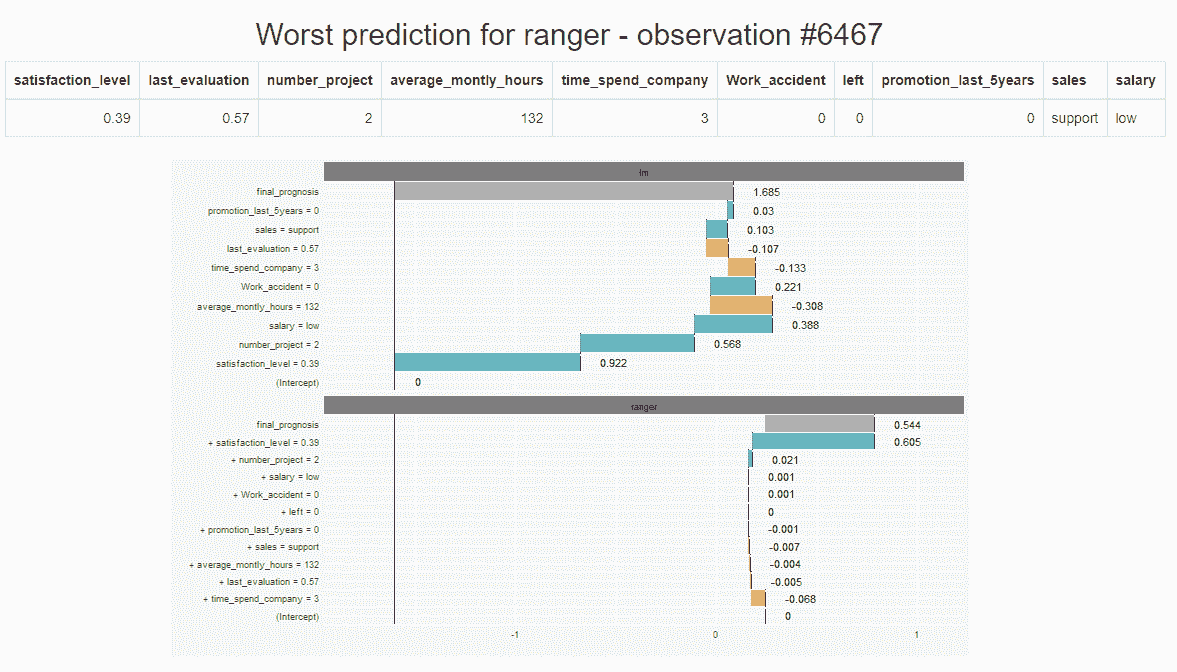
modelDown生成一个包含预测模型 HTML 摘要的网站。Is 使用 DALEX (见上文)解释器来计算和绘制给定模型如何表现的概要。我们可以看到预测分数是如何精确计算的(预测分解),每个变量对预测的贡献有多大(变量响应),哪些变量对给定模型最重要(变量重要性),以及模型的表现如何(模型性能)。
您现在可以从 GitHub 安装它:
devtools::install_github("MI2DataLab/modelDown")
当您成功地安装了这个包之后,您需要为您的模型创建 DALEX 解释器。下面是一个简单的例子(来自作者):
*# assuming you have two models: glm_model and ranger_model for HR_data*
explainer_glm <- DALEX::explain(glm_model, data=HR_data, y=HR_data$left)
explainer_ranger <- DALEX::explain(ranger_model, data=HR_data, y=HR_data$left)
接下来,将所有创建的解释器传递给函数modelDown。例如:
modelDown::modelDown(explainer_ranger, explainer_glm)
就是这样!现在,您应该已经用默认选项生成了 html 页面。
您将看到如下页面:
索引页
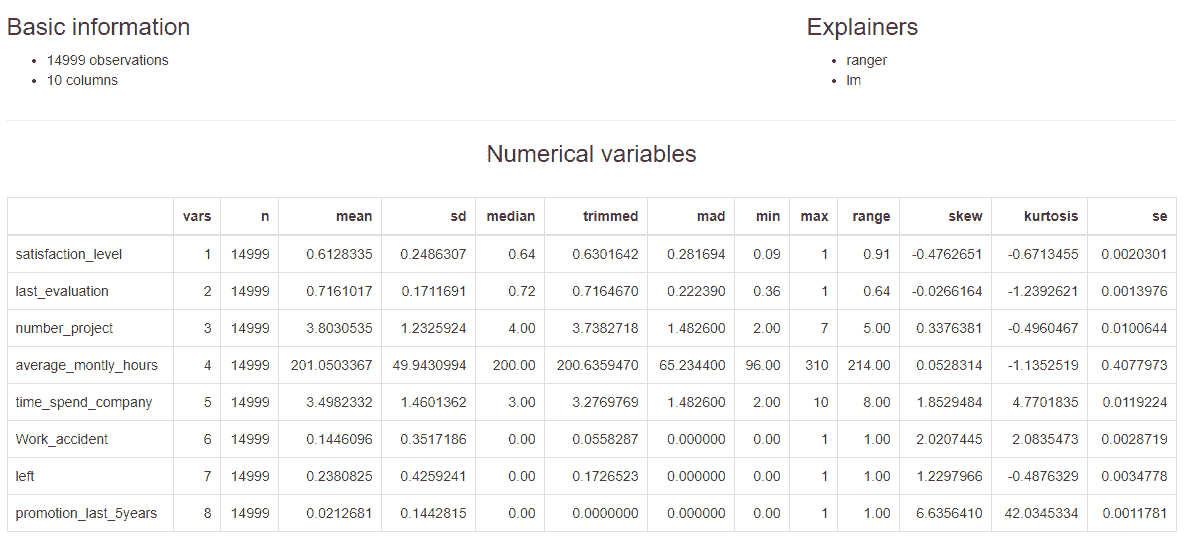
索引页提供了 explainers 中提供的数据的基本信息。您还可以看到作为参数给出的所有解释器的类型。此外,数字变量的汇总统计数据也是可用的。对于分类变量,表中列出了因子水平的频率。
模型性能
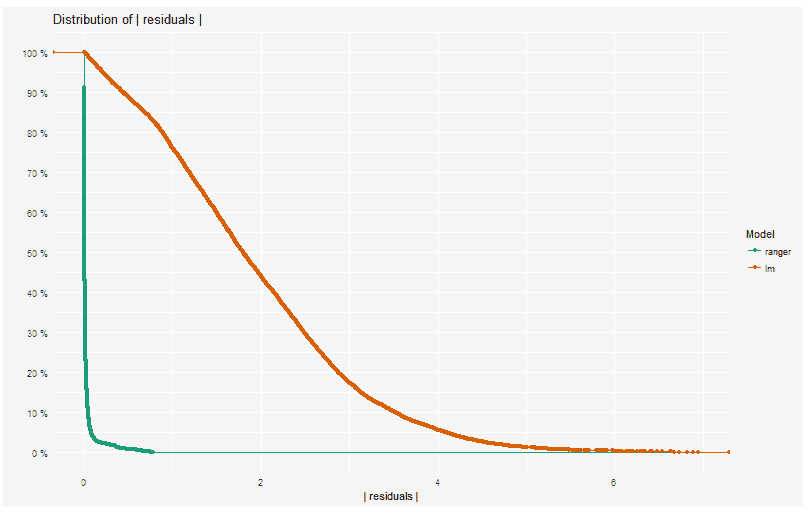
模块显示功能model_performance的结果。
可变重要性
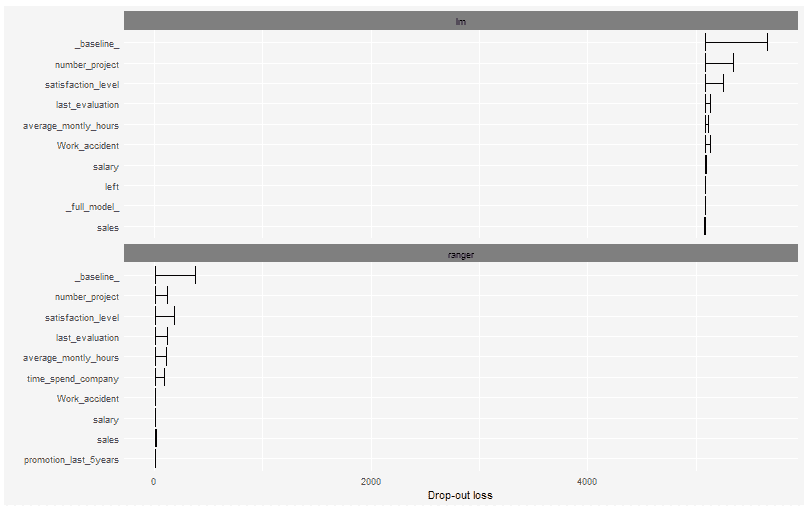
函数variable_importance的输出以图表的形式呈现。
还有更多。下面是一个用这个包生成的页面的实例:
https://mi2datalab.github.io/modelDown_example/
今天就到这里了:)。很快你会得到更多的信息,也可以用 R 发帖。如果您想了解最新信息,请订阅以下内容:
感谢你阅读这篇文章。希望你在这里发现了一些有趣的东西:)
如果你有任何问题,请在推特上关注我
Favio Vázquez 的最新推文(@FavioVaz)。数据科学家。物理学家和计算工程师。我有一个…
twitter.com](https://twitter.com/faviovaz)
还有 LinkedIn。
[## Favio Vázquez —首席数据科学家— OXXO | LinkedIn
查看 Favio Vázquez 在世界上最大的职业社区 LinkedIn 上的个人资料。Favio 有 15 个工作职位列在…
linkedin.com](http://linkedin.com/in/faviovazquez/)
那里见:)
每周精选—2017 年 10 月 13 日

怎样才能成为小公司的优秀数据科学家
由 Shanif Dhanani — 7 分钟阅读。
数据科学是每个人都在谈论的领域之一,但很少有人知道如何“正确地”做学校现在才开始了解如何教授它。就数据科学而言,每个公司都有自己的招聘实践(见鬼,有些根本没有)。
计算机视觉及其为何如此困难
大卫·阿默兰——5 分钟阅读。
最难理解的是最基本的东西。我们生活在一个视觉世界。我们看到东西,立即明白它们是什么,以及我们可以用它们做什么。我们不仅可以识别它们,还可以了解它们的特殊属性和它们所属的类别。
权力的游戏单词嵌入,R+L = J 吗?—第 1 部分
通过 JC 泰斯图德 — 7 分钟读取。
在我的第一篇关于文本生成的文章之后,我决定学习并撰写关于单词嵌入的文章。单词嵌入是 2013 年(现在是史前时代)的热门新事物。现在,让我们将这一数据科学突破应用于一些愚蠢的事情!
2017 年大数据趋势点燃
由 Mac Fowler — 4 分钟读取。
我有幸参加了在密歇根州大急流城举行的大数据点燃 2017 大会。为期三天的会议以“指数智能时代”为主题,并为我提供了一个机会,让我后退一步,更广泛地了解大数据和分析市场。
时尚品牌利用人工智能实现个性化的五种方式
由克拉克博伊德 — 9 分钟阅读。
很少有行业不受正在进行的人工智能革命的影响。在大量开源技术的推动下,各种品牌都在挖掘人工智能和机器学习的潜力,以理解大数据。
人工智能能帮你找到爱情吗:了解婚介行业
由 Shamli Prakash — 5 分钟阅读。
我认为我这一代人是极其幸运的一代,他们处在由技术革命推动的世界巨变的尖端。
在数据科学社区敢于与众不同
通过 Jerica Copeny — 4 分钟阅读。
如果您想提高对某个问题的认识或倡导一项重要的事业,将数据科学作为您的工具,该怎么办?作为一名数据科学家,这种想法可能会让你非常兴奋:让问题变得明朗,用数据让故事变得生动。
对算法公平性讨论的温和介绍
按 Gal Yona — 10 分钟读取。
近年来,机器学习算法已经兴起:在打破了几乎所有可以想象的计算机视觉相关任务的基准之后,机器学习算法现在一直在我们的家里和口袋里。
- 与我们的团队实时聊天
- 写给走向数据科学的
- 订阅我们的官方简讯(新)
- 成为 Patreon
每周精选
亲爱的读者和投稿人:
感谢您继续支持数据科学。本周,我们扩展了每月数据科学初级读本的主题,向您展示了本周的一些最佳人工智能帖子。
我们非常高兴地欢迎伊内斯·特谢拉、阿伦·南比亚尔、钟楚红、萨米·阿梅加维和达希·奥尔连多加入我们的编辑团队。我们很高兴为我们的贡献者提供这种支持,我们希望作家将充分利用他们的才华。
与麦迪逊关于机器学习的坦诚对话 5 月
由瑞安·路易——阅读:8 分钟。
欢迎来到坦诚的机器学习对话。我是 Ryan Louie,我采访了机器学习从业者,了解他们职业背后的思考。
Wolfram 暑期学校 Reddit 的计算思维
到瑞典人怀特——读数:8 分钟。
大约在去年的这个时候,我在想这个夏天该做些什么。在研究生院度过了一个相当糟糕的学期,但我终于完成了路易斯安那州立大学社会学博士项目的核心课程。
前馈网络的反向传播
由酱油猫——读数:7 分钟。
为了训练网络,使用特定的误差函数来测量模型性能。目标是通过更新相应的模型参数来最小化误差(成本)。为了知道在哪个方向和多大程度上更新参数,必须计算它们相对于误差函数的导数。这就是反向传播的用途。
自动驾驶汽车跟踪行人
由 Priya DWI vedi——阅读:5 分钟。
自动驾驶汽车在行驶时需要周围的世界地图。它必须能够连续跟踪路上的行人、汽车、自行车和其他移动物体。在这篇文章中,我将通过一种称为扩展卡尔曼滤波器的技术进行讨论,谷歌自动驾驶汽车正在使用这种技术来跟踪道路上的移动物体。
每周精选—2017 年 10 月 20 日

Join us as an Editorial Associate of Towards Data Science
庆祝迈向数据科学一周年
由钟楚红 — 3 分钟读完。
迈向数据科学始于一年前的 2016 年 10 月 21 日。我们现在已经成长为一个在 Medium 上拥有超过 30,000 名粉丝的社区,并在脸书、 Twitter 、 LinkedIn 和 Instagram 上开展业务。
为什么 OpenMined 成为开源项目的榜样
由 Awa 孙茵 — 3 分钟读完。
这不是我第一次写关于 OpenMined 的开源项目。
机器学习工程师新手犯的 6 大错误
克里斯托弗档案员 — 5 分钟阅读。
在机器学习中,有许多方法来构建产品或解决方案,每种方法都有不同的假设。很多时候,如何导航和识别哪些假设是合理的并不明显。
利用 Python 中的客户细分找到您的最佳客户
由苏珊李 — 5 分钟读完。
当谈到找出谁是你的最佳客户时,古老的 RFM 矩阵原理再次发挥作用。RFM 代表近期、频率和货币。
为机器学习和深度学习学习数学
由 Aneesha Bakharia — 3 分钟阅读。
虽然我在攻读工程学位时确实学了很多数学,但当我想进入机器学习领域时,我已经忘记了大部分。毕业后,我从未真正需要过任何数学。
从网络开发到计算机视觉和地理
由伦纳德·博格多诺夫 — 7 分钟读完。
在过去的四年里,我一直有一个想法,那就是我要创办一家公司。潜在的感觉是,我想做一些我能热情地承担全部责任的事情。
- 与我们的团队实时聊天
- 为走向数据科学而写作
- 订阅我们的官方简讯(新)
- 成为 Patreon
每周精选—2017 年 10 月 27 日

Join us as an Editorial Associate of Towards Data Science
为什么医院需要更好的数据科学
由Sanjeev agr awal—6 分钟阅读。
可以说,航空公司比医院在运营上更复杂,资产更密集,监管更严格,但迄今为止,在保持低成本并获得可观利润的同时,表现最好的航空公司比大多数医院做得更好。
教一个变分自动编码器(VAE)画 MNIST 字符
由菲利克斯莫尔 — 4 分钟读取。
自动编码器是一种神经网络,可用于学习输入数据的有效编码。给定一些输入,网络首先应用一系列变换,将输入数据映射到低维空间。
利用文本挖掘改进 Airbnb 收益预测
通过 Joaee 咀嚼 — 11 分钟阅读。
Airbnb 是一个受欢迎的家庭共享平台,让世界各地的人们分享他们独特的住宿。对于潜在的主人来说,这可能是一个有利可图的选择,因为他们有空的度假屋、多余的房间甚至是多余的床。
吴恩达深度学习专业化— 21 条经验教训
Ryan Shrott — 10 分钟阅读。
我最近完成了吴恩达在 Coursera 上的新深度学习课程的所有可用材料(截至 2017 年 10 月 25 日)。该专业目前有 3 门课程。
人工智能应用:数据科学遇上采购
由 Shamli Prakash — 4 分钟阅读。
采购职能是组织中最重要的职能之一,但往往不被人们所重视。不知何故,它很少拥有与营销、金融或科技等更时髦的同行相关的浮华和魅力。
一个气泡图,对比 10 个数据可视化工具
由苏珊李 — 7 分钟读完。
对于任何想学习数据分析和可视化的人来说,网上不乏“最佳工具”文章,告诉你该选择什么。我不会尝试创建一个列表,因为有太多的工具可以列举。
使用深度学习的狗品种分类:实践方法
通过 Kirill Panarin — 8 分钟读取。
几天前,我注意到由 Kaggle 主办的犬种鉴定挑战赛。我们的目标是建立一个模型,能够通过“观察”狗的图像来进行狗的品种分类。
每周精选

克拉姆甘笔记
由亚瑟·格雷顿 — 8 分钟阅读。
下面的讨论与最近的论文有关:“克莱姆距离作为有偏瓦瑟斯坦梯度的解决方案”
数据科学复兴
通过罗布·托马斯 — 7 分钟读取。
“如果人们知道我是多么努力才掌握这门技能,那就一点也不美妙了。”——米开朗基罗。
甘戈:用甘戈创造艺术
肯尼·琼斯——13 分钟阅读。
这里介绍的工作是 Kenny Jones 和 Derrick Bonafilia(都是威廉姆斯学院 2017 级)在 Andrea Danyluk 教授的指导下进行了一个学期的独立研究的结果。
Z 分数的惊人寿命
由此生 — 5 分钟读完。
1730 年 6 月 6 日星期二的深夜,亚伯拉罕·德莫佛跌跌撞撞地从考文特花园的一家咖啡馆里走了出来,由于喝了太多的杜松子酒,又上了几个小时的课,还在赌博,他还有点晕头转向。
用 Tensorflow 和 OpenCV 构建实时物体识别 App
通过 Dat Tran — 4 分钟读取。
在本文中,我将介绍如何使用 Python 3(具体来说是 3.5)中的tensor flow(TF)新的对象检测 API 和 OpenCV 轻松构建自己的实时对象识别应用程序。
如何不按人气排序
由华雷斯博奇 — 8 分钟读取。
问题:你是一个 web 程序员。你有用户。你的用户阅读你网站上的内容,但不评价他们。您想要制作一个用户可能想要点击的流行内容列表。你需要某种“分数”来排序。
每周精选
亲爱的读者和投稿人:
本周,春天来了,我们对深度学习、统计学和数据科学应用的理解也来了,这要感谢我们知识渊博的作家。我们很高兴向您展示我们每周精选的关于数据科学的文章。
我们的使命一直是为您带来关于数据科学哲学、理论和应用的有趣、有用的文章。我们希望提供高质量、可信的信息,让我们的读者能够从中学习,并展示我们的作者能够创作出的最佳作品。
三月给 TDS 带来了一些大的变化。我们非常自豪,目前我们每天收到多达 10 份投稿,现在已经有超过 70 名投稿者。
现在是提高标准的时候了。
我们正在寻找我们社区的成员来帮助我们向读者提供优秀的文章,并通过编辑协助帮助我们崭露头角的作家发展他们的声音。
加入我们,成为《走向数据科学》的编辑助理。
我们期待着在接下来的一周阅读您的意见,我们希望欢迎一些编辑助理加入 TDS 团队!
神经网络架构
由尤金尼奥·库勒切罗——阅读:14 分钟
深度神经网络和深度学习是强大和流行的算法。他们的成功很大程度上在于神经网络架构的精心设计。
LSTM 举例使用 Tensorflow
作者:罗威尔·阿蒂恩萨
在深度学习中,递归神经网络(RNN)是一个神经网络家族,擅长从序列数据中学习。已经找到实际应用的一类 RNN 是长短期记忆(LSTM ),因为它对长期依赖的问题是稳健的。
数据解释中的萤火虫、热手和其他(所谓的)谬误。
作者:亨利·金——阅读:4 分钟
很久以前,当我第一次学习认知心理学时,我被分配到了关于所谓“热手谬误”的著名论文。要点很简单:人们不擅长评估概率。
根除癌症的机器
作者奥利弗·米切尔——阅读:6 分钟
本周在奥斯汀举行的 SxSw 互动大会上,前副总统乔·拜登(Joe Biden)向所有创新者发出挑战,要求他们有更远大的想法。拜登的癌症登月任务组于去年 1 月成立,汇集了 20 个政府机构和 70 多家私营公司,目标只有一个——“消除我们所知的癌症。”
特征工程:宁滨的贝叶斯方法
作者:Andrew Greatorex —阅读:5 分钟
任何数据科学难题中最关键的一块,或许也是最不迷人的一块:特征工程。这可能是漫长而令人沮丧的,但如果做得不好,它可能会给随后的任何建模或分析带来灾难。
蒙特卡罗分析与模拟
由阿纳尔多·冈兹——阅读:8 分钟
蒙特卡罗方法是解决非常困难的概率问题的简单方法。这篇课文是对这门学科的一个非常简单的、说教式的介绍,融合了历史、数学和神话。
我叫伊尼戈·蒙托亚。一个与语音识别应用共情的案例。
卢西恩·利塔(Lucian Lita)—阅读:6 分钟
你好。我的名字叫蒙古朋友。叹气。靛蓝拉托亚。Grrrr。伊尼戈蒙托亚。有时候,在使用语音识别应用程序时,你需要竭尽全力保持冷静。对我们许多人来说,名字是最糟糕的压力源。
用爬山搜索算法解决幻灯片难题
由拉胡尔察觉 —读数:3 分钟
爬山搜索算法是局部搜索和优化技术中最简单的算法之一。Miroslav Kubat 在《机器学习导论》一书中是这样定义的。
区块链 VS 人工智能
鲍里斯·拉夫罗夫(Boris Lavrov)——阅读:12 分钟
在当今的科技世界中,有两大趋势是你不能错过的。首先是人工智能(AI)技术的复兴:计算机视觉、自然语言处理和生成、机器翻译以及大规模数据集的处理和分析的进步。
每周精选

车辆检测与跟踪
由伊万·卡萨科夫 — 7 分钟阅读。
在我的实现中,我使用了深度学习方法来进行图像识别。具体来说,我利用卷积神经网络(CNN)的非凡能力来识别图像。
纽约时报新闻数据集的主题建模
由 Moorissa Tjokro — 4 分钟读取。
我们生活在一个不断收集数据流的世界。因此,从收集的信息中寻找见解会变得非常乏味和耗时。主题建模是作为组织、搜索和理解大量文本信息的工具而设计的。
2017 年 GPU 技术大会(GTC)上人工智能(AI)、虚拟和增强现实(VR 和 AR)对医学成像的影响
通过erinjeri—10 分钟读取。
今年的 GTC 组织了一场医疗保健追踪,致力于人工智能和健康技术之间的应用。许多研讨会专注于使用 Nvidia 硬件、图形处理单元(GPU)应用机器学习算法来预测早期癌症检测的开始,许多会议分析解剖结构中的其他癌症肿瘤,如肺、乳腺和大脑。
如何增长数据
由艾德·怀尔德-詹姆斯 — 5 分钟阅读。
数字化和人工智能的双重浪潮已经高涨到任何企业都无法忽视的地步。它已经从幕后成为价值和创新的驱动力。难怪最近一期《经济学人》宣称“世界上最有价值的资源不再是石油,而是数据”。
我的赛博克隆:数字化的自己
由Sampreeti Bhattacharyya—4 分钟阅读。
一年前,我开始将这个项目作为个人夜间爱好来研究(https://TechCrunch . com/2016/01/09/virtual-reality-and-a-parallel-universe-of-cyber clones/Ross FinmanBenjamin Reinhardt)。并不是说我在攻读博士学位、创业、指导学生和抱怨生活之间没有任何事情可做。
犯错是算法:算法的易错性和经济组织
由 juan.mateos-garcia — 5 分钟阅读。
深入挖掘当今一些最大的技术争议,你可能会发现一种算法失灵了。
每周精选
亲爱的读者和投稿人:
是时候对我们最喜欢的关于数据科学的文章进行每周综述了。本周,我们遇到了文化冲突,因为人工智能帖子揭示了分析的技术方面,而我们更具商业头脑的贡献者阐明了表现大数据的实用性。
我们总是渴望听到新的观点,为什么不加入到关于数据科学的对话中来呢?看看我们的作家网页,了解如何提交您的文章!
我们要感谢我们的作家提供了这些精彩的贡献,它们都值得一读,但这里有一些我们最喜欢的开始你:
数据丰富的人越来越富有——人工智能的现状(第一部分)和(第二部分)
由弗雷德里克·阿南德——阅读:8 分 17 秒
你可能没有错过这些天关于人工智能(AI)和机器学习的讨论。在一个两部分的博客中,我们看看什么是人工智能,以及它的影响,然后探索人工智能在北欧的状态。
为什么重叠置信区间对统计显著性毫无意义
作者:Prasanna Parasurama——阅读:4 分钟
重叠的置信区间/误差线对统计显著性没有任何意义。然而,许多人错误地推断缺乏统计学意义。很可能是因为相反——非重叠置信区间——意味着统计显著性。我犯了这个错误。
利用人性和大数据解决问题
瑞安·莫里森——阅读:3 分钟
想象一下,如果你能让十几个、一百个、一千个甚至上万个人一起工作来发现模式,会有什么样的成就。你可能会有令人难以置信的新发现,发现以前从未了解的事物,或者发现以前从未见过的事物。
灭绝和濒危语言的数据可视化
由明成 —阅读:3 分钟
我们的项目展示了世界各地灭绝和濒危语言的分布。数据集是从《卫报》发布的 Kaggle 上下载的。它总共包括 14 个变量(即列),但我们只选择了 5 个变量在这个项目中进行可视化:语言的名称、经度、纬度、濒危程度(脆弱、绝对脆弱、严重脆弱、严重濒危或灭绝),以及说话者的数量。
成为机器学习极客
到莫莉莎·乔克罗——读数:4 分钟
我认为家是任何你可以自由做自己的地方。最快乐的时候,最原始的你。当我开始阅读我的机器学习教材时,我差不多就是这样。尽管我很开心(也很书呆子气),但我还是疯狂地阅读了这本书,即使是在地铁上或吃着一碗拉面的时候。
每周精选
ResNet 及其变体概述
由冯文森 — 11 分钟阅读。
在 AlexNet [1]在 LSVRC2012 分类大赛上取得辉煌胜利之后,deep Residual Network [2]可以说是过去几年中计算机视觉/深度学习社区中最具开创性的工作。
我对当今优秀数据科学家的两点看法?
通过 Dat Tran — 6 分钟读取。
我的父母最近问我,我为了重新生活做些什么。过去,这并不容易解释,因为数据科学不是一个定义明确的领域。甚至当我在埃森哲开始我的第一份工作时,我几乎不知道我到底在做什么。当然有一些定义,比如:
用机器学习预测逻辑的歌词
由汉斯·卡明 — 9 分钟读完。
这个实现的关键是创建一个二元模型 马尔可夫链来表示英语。更具体地说,我们的链将是一个 dictionary 对象,其中每个键都是一个惟一的元组,由一个单词及其后面的单词组成。
构建贝叶斯深度学习分类器
由凯尔·多尔曼 — 19 分钟读完。
在这篇博客文章中,我将教你如何使用 Keras 和 tensorflow 来训练贝叶斯深度学习分类器。
使用 TensorFlow 进行基因组变异调用的简单卷积神经网络
由杰森钦 — 10 分钟阅读。
毫无疑问,使用深度神经网络的最新进展的快速发展已经改变了我们可以解决从图像识别到基因组学的各种问题的方式。
最佳书架:用 D3.js 改编真实世界对象的数据可视化
到谭永金 — 8 分钟读完。
当你听到“数据可视化”时,第一个想到的视觉形式是什么?条形图还是折线图?一些更奇特的东西,比如热图或者定向网络?
这是玉米卷吗?自定义视觉的机器学习实验
通过 Elisha Terada — 5 分钟阅读。
想知道如何获得机器学习(ML)吗?那么,现在你可以通过云端提供的机器学习服务,称为功能即服务(FaaS)。
黄画的蒙特利尔:神经风格网络
由 Gabriel Tseng — 6 分钟读取。
最近,CNN(卷积神经网络)的一个非常酷的应用是设计神经网络;这些包括分离一个图像的风格,另一个图像的内容,并把它们结合起来。
机器学习在让 EHR 物有所值中的作用
伦纳德·达沃利奥博士——5 分钟阅读。
华尔街日报发表的一篇名为“关掉电脑,倾听病人的声音”的专栏文章将一个关键的医疗保健问题推到了全国讨论的前沿
深度神经网络能作曲吗?
由贾斯汀·斯韦利亚托 — 9 分钟阅读。
当我去年九月开始读研时,我想尽快投入到深度学习的热潮中。
关于神经网络和深度学习
由 Pranjal Srivastava — 19 分钟阅读。
现代计算机的数字运算和数据处理能力令人惊叹。但是,如果我告诉你,与人脑相比,这些都不算什么呢?
释放流程挖掘的价值
托马斯·菲拉雷(Thomas Filaire)—10 分钟阅读。
本文的目的是向读者介绍流程挖掘,这是一种创新的分析方法以客观和详尽的方式了解任何流程。
每周精选
亲爱的读者和投稿人:
我们欢迎你来参加我们的第一次每周综述。感谢我们的作家们精彩的一周精彩的文章。从如何构建数据科学就绪硬件的技术教程,到对人工智能未来的哲学思考,我们阅读了您的提交内容。
向加入我们 slack 频道的贡献者致意!我们在作者页面上为潜在贡献者添加了一些资源,请阅读。我们还提供一些提示,帮助您为下一期简讯选择每周精选的特色文章。我们期待您的回复。
在这里,我们选择了几个突出的职位,值得一读,如果你错过了他们……我们希望你会发现他们像我们一样丰富和愉快!
神经网络能解决任何问题吗?
作者布伦丹·福特纳——阅读:6 分钟
在你深度学习之旅的某个时候,你可能会遇到通用逼近定理:“一个单层的前馈网络足以表示任何函数,但该层可能大得不可行,可能无法正确学习和推广”。
语音识别:懒狗入门
卢西恩·利塔 —阅读:8 分钟
我和一个好朋友最近在吃饭时聊起了语音识别应用。没错,我们就是那些人。隔着一张桌子,刻板的极客们对技术、创业和变革变得兴致勃勃。你可以走进几乎任何一家硅谷咖啡店,买一杯超定制的拿铁咖啡,仅仅五分钟后,你就可以成为风险投资或移动开发领域的迷你专家——或者至少感觉自己是专家。
卡尔曼滤波器:直觉和离散情况推导
作者:Vivek Yadav——阅读:6 分钟
在这篇文章中,我们将回顾离散卡尔曼滤波器的推导过程。我们将首先建立由离散动态控制的系统的方程,然后表达近似系统,计算误差协方差并计算最小化误差协方差的更新规则。由于经由卡尔曼滤波的估计涉及连续的测量和状态传播,所以在离散实现的情况下它们更容易理解。
我们时代的新闻
由卢克·阿姆布鲁斯特——阅读:18 分钟
假新闻是 2016 年美国总统大选后这些天非常热门的话题。脸书和谷歌正在用自己的行动来减少假新闻的传播,包括降低搜索结果的排名和收回广告资金。自动标记假新闻而不彻底交叉检查声明的技术挑战——目前只有人类才能完成这项任务——是防止假新闻传播的严重障碍。
推荐古腾堡计划的书籍
劳拉·普罗韦尔——阅读:7 分钟
为年轻读者选择他们喜欢阅读的书籍对父母和教育工作者来说是一个挑战。我的解决方案是建立一个推荐引擎,既考虑阅读水平,也考虑最近阅读的书籍的主题,并返回下一步阅读的建议。
每周精选

亲爱的读者和投稿人:
我们希望您喜欢本周选择的新文章:
从名字中深度学习性别——LSTM 递归神经网络
由迪帕克巴布公关 — 4 分钟阅读。
深度学习神经网络已经在与视觉、语音和文本相关的问题上显示出有希望的结果,并取得了不同程度的成功。我在这里试着看一个文本问题,我们试着从人名中预测性别。
英国皇家学会关于机器学习的报告(2017 年 4 月)
由朱利安哈里斯 — 10 分钟阅读。
英国皇家学会发起了一项(128 页!)关于机器学习的报告。我仔细阅读了它,并做了一些笔记,其中有一些有用的不同或以有用的方式传达的东西,其他人可能会觉得有用。在这里和那里,我链接了我发现的其他作品,并添加了一些观察。
纽约租赁市场分析| ka ggle 排名前 15%的网站!
通过Shubhankar Srivastava—9 分钟读取。
这是我第一次认真参与 Kaggle 竞赛的文档记录——租赁店租赁咨询。两个半月, 146 个 git 提交了和 87 个提交了之后,我站在了排行榜的前 15% 之内——这是一个我引以为豪的位置!
我参加 Kaggle 数据科学碗 2017(肺癌检测)的经历
由阿希什·沙阿 — 4 分钟读完。
我参加了 Kaggle 一年一度的数据科学碗(DSB) 2017 ,很想和大家分享我激动人心的经历。首先,我想强调一下我对这场比赛的技术方法。
数据和心理健康:2016 年 OSMI 调查
由绒毛哺乳动物 — 16 分钟读取。
大家好!首先,我要感谢我的朋友们,CMU 社区和媒体对我的上一篇文章提供了周到的反馈。分享的故事和关于这篇文章的对话非常感人,我真的很高兴这篇文章为 CMU 精神健康的讨论做出了贡献。
每周精选

神经形态和深度神经网络
由Eugenio culrciello—6 分钟阅读。
用于计算神经网络的神经形态或标准数字:哪个更好?这个问题很难回答。标准的数字神经网络是我们在深度学习中看到的那种,它们取得了所有的成功。他们使用 64 位或更低的数字值进行计算,所有这些都在标准数字硬件中。
提高机器学习模型的准确性
通过 Prashant Gupta — 8 分钟读取。
厌倦了机器学习模型的低准确率吗?助推是来帮忙的。 *Boosting 是一种流行的机器学习算法,可以提高你的模型的准确性,*就像赛车手使用 nitrous boost 来提高他们的汽车速度一样。
Tensorflow RMSD:使用 Tensorflow 做它没有被设计去做的事情
斯坦福大学潘德实验室(Matthew p . Harrigan)——8 分钟阅读。
深度学习彻底改变了图像和语音处理,让你可以把边缘变成猫。在我们的实验室里,我们将这些技术应用于小分子药物研发。
我的 Spotify 音乐很无聊吗?涉及音乐、数据和机器学习的分析
胡安·德·迪奥斯·桑托斯 10 分钟阅读。
几天前,我一边听着 Spotify 保存的歌曲,一边和一个朋友聊天。唱了几首歌后,她打断了谈话告诉我:“你的音乐品味很有趣……你的播放列表里有很多综艺、器乐歌曲,其中一些是无聊”。
上周的数据故事、数据集和可视化综述
本杰明·库利 — 8 分钟阅读。
每个星期,我都会剪辑、保存和收藏大量我在网上找到的关于用数据讲述故事的很酷的东西。以下是 5 月 22 日这一周吸引我眼球的内容。在典型的时事通讯中,我会包含一堆链接供你点击,保存起来以后再看(没关系,我们都这样做)。
生成模型和 gan
由 Anish Singh Walia — 4 分钟阅读。
简单地说,它们是一类无监督的机器学习模型,用于生成一些数据。它使用观测值的联合概率分布。
Stock2Vec —从 ML 到 P/E
由乔恩·佩尔 — 3 分钟读完。
Word2Vec 是一个简单却惊人强大的算法。
它构建单词向量来表示单词含义。它仅仅通过周围的单词来学习这些意思。然后你可以使用这些单词向量作为输入,让机器学习算法执行得更好并找到有趣的抽象。
为大家揭秘人工智能
由 Namit Chaturvedi — 8 分钟阅读。
每个计算机程序的核心都有一个数学函数在起作用。这可能像计算未偿还贷款的利息一样简单,也可能像自动驾驶飞机一样复杂。人工智能,或 AI ,是一个计算机程序的通称,其核心数学功能已经(几乎)自动创建;而机器学习,或 ML ,指的是提供创造人工智能方式的一系列技术。
每周精选

为什么预测是智慧的本质
由彼得·斯威尼 — 10 分钟读完。
机器学习和智能都植根于预测,这是巧合吗?当我们的技术体现了智能的本质时,我们是否正在接近一个重要的转折点?或者这是误解历史长河中的又一篇章?如果这确实是本质,在一个由许多组件组成的系统中,是什么让预测凌驾于其他之上?
用无监督学习重新定义篮球位置
埃文·贝克——8 分钟阅读。
NBA 总决赛结束了。最后一瓶香槟已经被倒空,五彩纸屑开始沉降。既然金州勇士队已经完成了在篮球界释放他们超凡脱俗的统治地位,我认为这将是结束一个以硬木为重点的机器学习项目的好时机。
具有 Sigmoid 函数的多层神经网络—菜鸟深度学习 1 和 2 。
由那华康 — 21 又 15 分钟读完。
上次,我们介绍了深度学习领域,并检查了一个简单的神经网络——感知器……或恐龙……好吧,说真的,单层感知器。我们还研究了感知器网络如何处理我们输入的输入数据并返回输出。
带张量流的拾波线发电机
由安德鲁·皮尔诺 — 5 分钟阅读。
几个月前我看到一篇文章,说有人创造了一个搭讪生成器。由于我刚刚开始进入深度学习的世界,我一直在考虑一些有趣的项目,这些项目至少可以在我学习的时候为我提供娱乐。一个可怕的搭讪发电机听起来像魔术。
人们利用机器学习赚钱的 6 种方式
由亚伦爱戴 — 5 分钟阅读。
机器学习绝对是非常酷的,很像虚拟现实或者你键盘上的触控条。但是酷和有用是有很大区别的。对我来说,如果能解决问题、节省时间或金钱,那就是有用的。通常,这三件事是有联系的,并且与一个更宏大的想法有关;投资回报。
关于谨慎选择优化算法
通过米歇尔·格林 — 6 分钟读取。
为什么模拟很重要?首先,我们需要它,因为许多现象(我甚至可以说是所有有趣的现象)无法用一个封闭的数学表达式来封装,而这基本上是你可以用笔和纸或数学软件来完成的。
介绍 PDPbox
通过酱汁猫 — 6 分钟读取。
PDPbox 是用 Python 编写的部分依赖绘图工具箱。目标是可视化某些特征对任何监督学习算法的模型预测的影响。(现在支持所有 scikit-learn 算法)
序列对序列模型:介绍和概念
通过 Manish Chablani — 3 分钟读取。
我们使用嵌入,所以我们必须首先编译一个“词汇表”列表,包含我们希望我们的模型能够使用或读取的所有单词。模型输入必须是包含序列中单词 id 的张量。
生成性对抗网络-历史和概述
由 Kiran Sudhir — 12 分钟阅读。
最近,生成模型越来越受欢迎。特别是由 Ian Goodfellow 等人提出的一个相对较新的模型,称为生成对抗网络或 GANs。
每周精选

如何用 TensorFlow 的物体检测器 API 训练自己的物体检测器
由 Dat Tran — 8 分钟读取。
这是关于“用 Tensorflow 和 OpenCV 构建一个实时物体识别应用程序”的后续帖子,在这里我专注于训练我自己的类。
人工智能和机器学习对交易和投资的影响
迈克尔·哈里斯 — 8 分钟阅读。
以下是我几个月前在欧洲做的一次演讲的节选,当时我是一名受邀演讲者,面对的是一群低调但高净值的投资者和交易者。
神经网络和 3D 程序内容生成的未来
通过Sam Snider-hold—8 分钟读取。
作为全球制作机构 MediaMonks 的一名创意技术专家,人们总是问我关于人工智能、人工智能、神经网络等方面的问题。它们是什么?他们能做什么?我们如何使用它们?
我们如何教会一台机器自己编程?—整洁的学习。
通过 Murat Vurucu — 5 分钟读取。
在这篇文章中,我将尝试解释一种叫做通过扩充拓扑进化神经网络(NEAT)的机器学习方法。
甘斯·恩罗斯
通过 Naresh Nagabushan — 10 分钟读取。
想象有一天,我们有了一个神经网络,它可以看电影并生成自己的电影,或者听歌并创作新的电影。
机器学习的基本模型——概述
由 gk_ — 10 分钟读完。
如今软件中最常见的“机器学习”形式是算法,可以从中学习并对数据做出预测。
CM1K 神经网络芯片实验
由诺亚发楞 — 11 分钟阅读。
2017 年 3 月,我获得了麻省理工学院沙盒项目的资助,利用 CM1K 神经网络芯片来开发一款产品。
基于模型强化学习的随机输入贝叶斯神经网络
由何塞·米格尔·埃尔南德斯·洛巴托 — 9 分钟读完。
关键贡献在于我们的模型:具有随机输入的贝叶斯神经网络,其输入层包含输入特征和随机变量,这些变量通过网络向前传播,并在输出层转换为任意噪声信号。
数据科学简化版:假设检验
由帕拉德普梅农 — 7 分钟阅读。
假设检验的应用在数据科学中占主导地位。对其进行简化和解构势在必行。就像犯罪小说故事一样,基于数据的假设检验将我们从一个新奇的建议引向一个有效的命题。
用机器学习预测逻辑的歌词
由汉斯·卡明——9 分钟读完。
从中学开始,当我第一次听到他的歌曲“我所做的一切”时,逻辑就对我的生活产生了显著的影响。
每周精选

深度学习的函数式编程
由 Joyce Xu — 11 min 阅读。
在我开始在 ThinkTopic 的最新工作之前,“函数式编程”和“机器学习”的概念完全属于两个不同的世界。一个是随着世界转向简单性、可组合性和不变性以维护复杂的扩展应用程序,编程范式越来越流行;另一个是教计算机自动完成涂鸦和制作音乐的工具。重叠在哪里?
face 2 face——模仿德国总理面部表情的 Pix2Pix 演示
通过 Dat Tran — 7 分钟读取。
受吉恩·科岗研讨会的启发,我制作了自己的 face2face 演示,可以在 2017 年德国总理发表新年致辞时将我的网络摄像头图像转换成她的图像。它还不完美,因为这个模型还有一个问题,例如,学习德国国旗的位置。
keras:R 中的深度学习
Karlijn Willems — 22 分钟阅读。
正如你现在所知道的,机器学习是计算机科学(CS)中的一个子领域。深度学习是机器学习的一个子领域,它是一套受大脑结构和功能启发的算法,通常被称为人工神经网络(ANN)。
我有数据。我需要洞察力。我从哪里开始?
由罗摩罗摩克里希南 — 5 分钟阅读。
这个问题经常出现。这通常是刚接触数据科学的数据科学家、分析师和管理人员会问的问题。他们的老板面临着压力,要求他们展示花在收集、存储和组织数据的系统上的所有资金的投资回报率(更不用说花在数据科学家身上的钱了)。
《贝叶斯可加回归树》论文摘要
到 Zak Jost — 4 分钟读取。
本文开发了一种贝叶斯方法来集成树。对于一篇学术论文来说,它非常具有可读性,如果你觉得这个主题有趣,我建议你花时间去读一读。
用降维技术降维
由埃利奥尔·科恩 — 13 分钟读完。
在这篇文章中,我将尽我所能去揭开三种降维技术的神秘面纱;主成分分析,t-SNE 和自动编码器。我这样做的主要动机是,这些方法大多被视为黑盒,因此有时会被误用。
每周精选

你现在能听到我说话吗?远场语音
由陆杰瑞 — 9 分钟读完。
在我之前的帖子中,我提出了一个案例,成功的人工智能公司将通过围绕数据创造网络效应或开发专有算法,在“计算语音”价值链中开发一条护城河
应用深度学习—第 1 部分:人工神经网络
由 Arden Dertat — 23 分钟阅读。
欢迎来到应用深度学习教程系列。我们将从人工神经网络(ANN)开始,特别是前馈神经网络,对几种深度学习技术进行详细分析。
如何成为数据科学家(第 1/3 部分)
通过实验 — 17 分钟读取。
我是专门从事数据科学领域的招聘人员。产生这个项目的想法是因为我最常被问到的一个问题是:“我如何获得数据科学家的职位?”
人工智能和经济不平等的加剧
由阿比纳夫·苏里 — 16 分钟读出。
几个世纪以来,技术在美国劳动力市场中发挥了关键作用,使工人能够以更高效的方式完成日常任务。
我在 TensorFlow 中学到了什么
通过 Malo Marrec — 7 分钟读取。
当我刚开始在 Good AI Lab 实习时,我的任务是制作一个基本的自动驾驶汽车演示。我既兴奋又沮丧。
最新热门话题:机器学习是种族歧视
由马特布雷姆斯 — 6 分钟阅读。
机器学习和人工智能是两个时髦词,它们在最近几年获得了大量关注。
遗传编程应用于人工智能启发式优化
Ryan Shrott — 6 分钟阅读。
我对遗传编程的兴趣始于 2015 年研究迭代最后通牒游戏。最近,我一直在使用遗传算法来优化工作中风险管理系统的参数。
每周精选

用于物体检测的深度学习:综述
由 Joyce Xu — 11 min 阅读。
随着自动驾驶汽车、智能视频监控、面部检测和各种人数统计应用的兴起,对快速准确的物体检测系统的需求不断增加。
离群点检测技术概述
到塞尔吉奥·桑托约 — 9 分钟读完。
异常值是偏离其他数据观察值的极端值,它们可能表明测量值的可变性、实验误差或新奇性。换句话说,异常值是偏离样本总体模式的观察值。
数据科学评估 ico
由 Debajyoti (Deb)射线 — 4 分钟读取。
我最喜欢的一句话是约翰·梅纳德·凯恩斯(John Maynard Keynes)的名言:“市场保持非理性的时间,可以超过你保持偿付能力的时间”。投资者可以在动荡的加密货币市场中赚(或赔)很多钱,并将他们的成功归功于技能。

《走向数据科学》是一份独立的出版物。为了保持我们的开放和编辑自由,我们要求我们的支持者承诺一小笔捐款来帮助我们竞选。非常感谢!
面试的 SQL 总结
通过Vijini mallawatarachchi—7 分钟读取。
SQL 或结构化查询语言是一种用于管理关系数据库管理系统(RDBMS) 中数据的语言。在本文中,我将带您了解每个程序员都应该知道的常用 SQL 命令。
如何编写分布式 TensorFlow 代码—以 TensorPort 为例
由马洛马雷克 — 9 分钟阅读。
当我第一次对这个话题感兴趣时,我对可用的好资源的稀缺感到惊讶。有 TensorFlow 文档和教程,但就系统的复杂性而言,它出奇的薄,我经常发现自己在阅读 TensorFlow 实现本身。
事件驱动架构模式
由阿努拉达·维克拉马拉奇——3 分钟读完。
这是用于开发高度可伸缩系统的最常见的分布式异步架构。该体系结构由单一用途的事件处理组件组成,这些组件监听事件并异步处理它们。
ConvNets 系列。空间变压器网络
由 Kirill Danilyuk — 11 分钟阅读。
空间转换器是不同模块集合中的另一个乐高积木。它通过应用可学习的仿射变换然后进行插值来消除图像的空间不变性。
神经网络:你的大脑像电脑吗?
由 Shamli Prakash — 5 分钟阅读。
大约三年前,当我怀儿子的时候,一个朋友送给我一本丽莎·艾略特的《里面发生了什么事?》。。对我来说,这是一个非常受欢迎的偏离,因为所有的育儿书籍都坚持告诉我,我的生活将变成一个充满不眠之夜、疲惫不堪和普遍缺乏理智的生活地狱。
交易策略开发的验证方法
迈克尔·哈里斯——6 分钟阅读。
有几种方法可以用来验证交易策略,但每种方法都有优点和缺点。在本文中,我们讨论四种验证方法。
人工智能时代的数据质量
由乔治·克拉萨达吉斯 — 9 分钟阅读。
作为数据挖掘决策支持系统的总监,我已经交付了 80 多个数据密集型项目,包括多个行业和知名企业的数据仓库、数据集成、商业智能、内容性能和预测模型。在大多数情况下,数据质量被证明是一个关键的成功因素。

















 2647
2647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









