







编程是艺术

一篇主张将编程作为一种艺术形式的辩论性文章
我强烈认为自己是一个有创造力的人。这是我的主要优势之一。我同样喜欢创建新概念的过程,就像我喜欢构建实现一样。它可以是任何事情,从在我信任的吉他上写一首歌到在 Adobe Illustrator 中创建一个新的设计。从起草商业模式到在《超级马里奥制造 2》中建立关卡。从用我不知道的原料烹饪一道新菜,到建立人工智能策略。有时我只是毫无目的地创造东西——有时快乐在于创造,而不是结果。并不是所有的艺术都必须被分享,有时候美只是来自于创作时内心的平静。
艺术有一种在各种奇怪的普通地方展示自己的方式。在享用一餐之前,我喜欢花点时间来欣赏它的特色。当我坐在咖啡馆时,我喜欢观察我的周围,艺术存在于每个人的表情中,存在于任何房间的每个角落。有时当我听音乐时,我会闭上眼睛,让我的创造力随着旋律的声音尽情发挥。
我真的相信艺术无处不在。当我与他人分享这一观点时,许多人似乎同意我的观点。
但是接下来就是编程了。围绕编程有一个奇怪的污名,有人说它不是一种创造性形式,而仅仅是一种逻辑形式。但是更严重的是:编程不是艺术的观念。根据这篇文章的标题,你可能会猜到,我将提出相反的论点。
编程是艺术。

Photo by Ilya Pavlov.
请允许我从最不有趣,但经常被问到的一点开始:定义。如果我们要讨论某样东西是否被归类为艺术,首先检查它的定义是很自然的,也是意料之中的,但是我不打算在这里花太多时间。如果我们要追溯这个术语的根源,牛津词典提供了一系列的定义供人们欣赏,现在我们将不再看这本广泛流传的词典。
人类创造力和想象力的表现或应用,通常以绘画或雕塑等视觉形式,创作出主要因其美感或情感力量而被欣赏的作品。
第一个定义不同于字典中的所有定义,它认为艺术的主要产品是情感力量或美。我觉得这很奇怪。当一个精心制作的王座的主要目的是让有权有势的人就座,一个巨大的城堡的主要目的是给人类居住,一个最精致的菜肴的主要目的是食用时,这怎么可能呢?如果这些作品的主要目的是以功能性的方式使用,那么它们就不被认为是艺术吗?当然,无论是谁写下了这样的定义,他都不可能漫步于维也纳的内街,那里的每一座建筑都是宏伟的,否则他们不可能想出如此狭隘的定义。
1.1 由人类的创造技能和想象力产生的作品。
令人欣慰的是,人们移动眼睛的距离不能超过几个像素来移动字典,因为第二个定义及其后的所有定义都相当宽。有人可能会说,人类创作的每一件作品都包含创造性技能和想象力,因此每一支铅笔、手机充电器和卫生纸也是潜在的艺术作品。一个人创作的每一件东西在最初创作时都需要一定的创造力。然而,如果遵循严格的公式和明确定义的规则,同一物品的后续创造可能不会。因此,只有第一支铅笔、手机充电器和卫生纸可能是一件艺术品,因为同一制造商随后制造的每一件物品都可能是在工厂里按照严格的说明制造的。然而,对于编程来说,每个产品都需要独特的指令,因为没有两个功能是完全相同的。
我可以继续定义,但我会把剩下的留给你,因为我想你会发现牛津的以下三个定义不允许任何惊喜,而是用不同的词重复相同的思想,所有这些都允许编程被解释为艺术

What is art? Perhaps, much like its creation and subsequent meaning is up for a subjective interpretation, so too is its definition? Photo by Chris Barbalis.
那么,为什么有人不认为编程是一种艺术形式呢?也许是因为代码行缺乏自然美,所以才是真正的*?但是路边的一块石头,在雕塑家把它变成雕像之前,到底有多美?一个音符的集合,直到一个音乐家把它演奏出来,到底有多美?在厨师把金枪鱼变成一道菜之前,它有多美?所以我问你:在形成应用程序之前,代码行有多美?单个的元素并不总是呈现出一种自然美,但是这些元素的总和放在一起形成了一个有思想的集体作品。*
因此,部分的美不可能是答案。那么逻辑呢?编程是由逻辑构成的,逻辑不是艺术,对吧?有些头脑是理性的,而有些是感性的。有些人被逻辑所吸引,有些人被传统的美所吸引。然而,列奥纳多·达·芬奇创造了建立在科学基础上的艺术,一个音乐家创造了逻辑上相互遵循的音调,一个厨师逻辑上结合了互补的配料。大多数艺术作品实际上是一个逻辑过程的结果,是对互补元素的选择。逻辑和艺术往往是相辅相成的。
大多数艺术作品实际上是一个逻辑过程的结果,是对互补元素的选择。

Art is everywhere, and can be made with any tool. For many, the computer has become a tool that allows for the creation of art, be it art, designs, music, programming applications, or otherwise. Photo by Dmitry Chernyshov.
所以逻辑也不可能是它。或许是学习曲线,以及随之而来的误解?事实上,成为一名艺术家或音乐家需要无数个小时的训练,然而任何孩子都可以在几秒钟内唱一首创作的歌曲或创作一幅画——不需要训练。也许这就是艺术的真正含义?毫不费力地投入情感,无论是伟大的还是渺小的,立即得到一个创造性的工作作为回报?虽然你可能会错,但编程也不例外。你富有创造力的额头上的汗水会以同样的方式立即呈现出来。创作过程没有什么不同,学习曲线也没有更长。
数学那么?虽然编程和数学实际上是两个非常不同的研究领域,但还有一种误解,认为这两者是一样的,数学不可能是艺术,因此编程也不可能是艺术。然而,事实并非如此,因为数千年来,数学一直是艺术的一个组成部分。早在耶稣基督诞生之前,从希腊帝国开始,艺术家就已经使用数学来雕刻、绘画、舞蹈和作曲。

Max Ernst creating a work of art using gravity as a tool to enable creativity (1942).

M. C. Escher’s famous painting Print Gallery (1956), which sparked great discussions among mathematicians and artists alike.
也许创意投入的产品本身,那么?添加颜色,收到一幅画。添加曲调并获得一首歌曲。如果你输入几行代码,你会得到什么?绝对的任何事情和一切。华丽的动画电影,史诗般的视频游戏,以及你每天与之互动的漂亮界面。虽然编程的产品并不重要,因为它毕竟是艺术,但编程是你每天都在接触的艺术作品。
我希望现在我已经让你相信编程是一种艺术,如果我没有做到这一点,这篇文章的其余部分也不会说服你,但它可能会鼓励你自己尝试编程,如果你还没有这样做的话。
最后一个误解是,编程是少数人的专利。误解可能会说,为了能够编写代码,你需要一些与生俱来的天赋,也许是逻辑思维,或者对数学的偏好。并非如此。就像任何人都可以画画一样,任何人都可以写代码。
我从未上过歌唱课。然而我喜欢唱歌。但我只有在家里舒服的时候才会这么做。听过我歌声的人少之又少,没听过的人有福了,因为不是特别好听。但我唱歌不是因为我擅长,也不是因为我想成为擅长。我这么做只是因为我喜欢。这听起来可能是显而易见的,但值得一提的是,你不需要做某件事的意图是让它变得令人惊叹。你可以试着做着玩玩。我经常听到这样的想法,人们不想尝试编程,因为他们认为自己永远也不会做好。也许你会,也许不会。那又怎样?你可能无法开发创新。你可能不会选择编程作为职业技能。但是你不需要做这两件事来享受艺术创作。
每个人都能创造艺术
使用任何介质。

My drawings are bad, but I still enjoying drawing. It’s a creative process that puts my mind at ease. I have the very same feeling when I am programming application in my spare time, or writing articles such as this one. Photo by Neven Krcmarek.

A child creating art. Photo by Lego.

Art in the making. Photo by Fabian Grohs.
在你离开之前,我们下次再讨论另一个话题,让讨论更进一步。下面这幅画是人工智能做的。它在拍卖会上以 432,500 美元售出。没有人类任何输入的艺术还是艺术吗?因为在这个过程中没有人参与,真的有任何创造力和想象力吗?或者这只是一个简单的计算机执行的自动化逻辑过程?但是,在创作艺术作品时,人类不也是遵循逻辑流程的计算机吗?嗯,这是另一个时间的辩论。

Is art made without human input still art? Photo from Obvious Art, who also developed the AI that created this painting.
控制数据密集型(大数据、快速数据)框架的编程语言

回到过去,公司主要使用一种主要的编程语言(如 C、C++、Java、c#…)、一种数据库(SQL)和两种数据交换格式(XML、JSON)。自 21 世纪初以来,随着互联网和移动设备的兴起,情况发生了变化。每年,数据的数量和速度都在成倍增长,并继续呈指数级增长。
像亚马逊、谷歌这样的大型 IT 公司突然发现,现有的工具和框架不足以处理这些大而快的数据。这些公司开发了封闭的源代码框架来处理“网络规模”的数据,并以论文的形式分享他们的概念/架构。2003 年, Google 发表了 Google 文件系统 论文接着是 地图缩小 论文和 大表 论文。还有,亚马逊在 2007 年发表了 迪纳摩 的论文。由于整个行业面临着处理“网络规模”数据的相同问题,开发人员社区和行业采用了这些论文的概念,并开发了类似 Hadoop 生态系统、 NoSQL 数据库和其他框架的系统。随着 GitHub 和开源友好性的普及,在接下来的几年中,业界开发并采用了更多的数据密集型框架。
最近我在读一本很棒的书: 设计数据密集型应用 ,作者是Martin Kleppmann,该书对各种数据密集型框架进行了全面深入的概述。在读那本书的时候,一个问题突然出现在我的脑海里:数据密集型框架中使用最多的编程语言是什么?
在这里,我将尝试在开源数据密集型框架中找到最常用的编程语言。由于有许多数据密集型框架/库,我将主要关注每个类别中的顶级开源框架。此外,如果一个框架/库是用多种语言编写的,我将只选择主要语言。
搜索引擎
1997 年, Doug Cutting 试图使用当时“刚刚起步”的编程语言 Java 开发一个全文搜索引擎。他在 3 个月内完成了基本功能的开发,并于 1999 年发布了名为 Lucene 的 Java 库,用于信息搜索/检索。Lucene 是一个 Java 库,不能与其他编程语言集成。Apache Solr 是一个搜索引擎,它提供了一个围绕 Lucene 的 HTTP 包装器,因此它可以与其他编程语言集成。Solr 还通过 SolrCloud 提供可伸缩的分布式全文搜索。和 Lucene 一样,Solr 也是用 Java 开发的,并于 2006 年首次开源。为了给妻子搜索食谱, Shay Banon 开发了分布式搜索引擎 Elasticsearch (以前的 Compass )。Elasticsearch 提供了一个围绕 Lucene 的 RESTful API 以及一个完整的分布式全文搜索栈(ELK)。它于 2010 年发布,用 Java 开发。Sphinx 是这个列表中最后一个分布式搜索引擎。早在 2001 年,安德鲁·阿克肖诺夫就开始开发搜索引擎 Sphinx 来搜索数据库驱动的网站。Sphinx 提供 REST 以及 SQL 类(SphinxQL)搜索客户端,并在 C++ 中开发。
- Lucene:Java
- Solr : Java
- 弹性搜索:Java
- 狮身人面像 : C++
文件系统
2002 年,道格·卡丁和迈克·卡法瑞拉在为纳特项目工作,抓取并索引整个互联网。2003 年,他们达到了一台机器的极限,并希望在四台机器上扩展它,但面临着在节点之间移动数据、空间分配的问题(Hadoop 的历史 )。.)2003 年, Google 发表了其 Google 文件系统 的论文。以谷歌论文的蓝图为基础,道格·卡丁和迈克·卡法雷拉开发了 Hadoop 分布式文件系统 HDFS (当时命名为 NDFS),它提供了无模式、持久、容错的分布式存储系统。 HDFS 在 Hadoop 生态系统和大数据框架的开发中发挥了关键作用。尽管 Hadoop MapReduce 正在失去对新框架(Spark/Flink)的吸引力,但 HDFS 仍然被用作事实上的分布式文件系统。像其他 Hadoop 框架一样,它是用 Java 开发的,并于 2005 年开源。在格鲁斯特公司中。,Anand Babu peri Samy为超大规模数据开发了软件定义的分布式存储 GlusterFS 。GlusterFS 于 2010 年开源,用 C 编写。受脸书论文大海捞针:脸书的照片存储 ,卢沛宁实现了一个简单且高度可扩展的分布式文件系统,名为 SeaweedFS ,可以存储数十亿个文件。2011 年开源,用 Go 编写。另一个强大的分布式存储平台是 Ceph ,它提供对象级、块级和文件级存储。Ceph 最初由 Inktank 开发,目前由以红帽为首的一批公司开发。尽管 Ceph 是在 2006 年首次发布的,但它的第一个稳定版本是在 2012 年。它的文件系统, CephFS 是用 Rust 编写的,尽管 Ceph 对象存储是用 C++ 编写的。德国 Fraunhofer Institute 开发了一个并行集群文件系统 BeeGFS 针对高性能计算进行了优化,重点关注灵活性、可扩展性和可用性。BeeGFS 的第一个测试版本发布于 2007 年。它是用 C++ 以非常紧凑的方式(约 40k 行代码)开发的。虽然 BeeGFS 是一个并行文件系统,并广泛用于超级计算机,但它可以作为 HDFS 的一个更快的替代方案。
成批处理
在开发完之后,HDFS 、道格·卡丁和迈克·卡法雷拉想要在多台机器上为项目纳特奇运行大规模计算。受Google Map Reduce论文的启发, Doug Cutting 和 Yahoo 的一个团队开始开发大规模、使用商用硬件的分布式计算, Hadoop MapReduce 诞生了。Hadoop MapReduce 和 HDFS 于 2005 年首次开源,取得了巨大的成功,为包括 Yarn、HBase、Zookeeper 等数据密集型框架的整个生态系统铺平了道路。像 Lucene 和 Nutch 一样,Hadoop MapReduce 和几乎整个 Hadoop 生态系统都是用 Java 开发的,可以说是将 Java 设定为数据密集型领域事实上的编程语言。如果说 Hadoop MapReduce 开创了大规模分布式计算,那么 Apache Spark 是目前最具优势的批处理框架。由著名的 Berkley AMPLab 开发,由 Matei Zaharia 领导,它解决了 Hadoop MapReduce 框架的局限性(例如,在每次地图作业后存储数据)。Spark 还提供了一种类似于 Unix 的方式,将多个作业组成一个数据处理管道,并为开发人员提供友好的 API,使用 RDD、数据集、数据帧对分布式任务进行编程。Spark 主要在 Scala 中开发,2014 年发布。Apache Flink 是另一个非常流行和有前途的集群计算框架。和 Spark 一样,也来自学术界,起源于图柏林大数据项目同温层**。与批处理优先框架 Spark 不同,Flink 是流优先框架,将批处理作业作为流的特例来处理。像 Spark 一样,Flink 也提供开发人员友好的 API,使用数据集、数据流对分布式计算进行编程。Flink 主要用 Java 编写,2015 年发布。**
- Hadoop MapReduce : Java
- 火花 : Scala
- Flink : Java
流处理
Hadoop MapReduce 发布后,被社区广泛接受,公司开始使用 Hadoop MapReduce 处理大规模数据。不久之后,公司需要实时分布式流处理框架,因为在现实中,数据主要以流的形式产生。由于许多因素(例如容错、状态管理、定时问题、窗口等),实时处理大规模数据流比处理批处理作业更困难。第一个开源实时分布式流处理框架是由 Nathan Marz 开发的 Apache Storm ,并在 2011 年发布,口号是“实时的 Hadoop”。它是用 Java 开发的。此外,Apache Spark 还提供了一个流处理框架“ Spark Streaming ”,它使用微批处理方法进行流处理,具有接近实时的处理能力。如果 Apache Storm 是普及分布式流处理的框架,那么 Apache Flink 将分布式流处理向前推进了一步,可以说是当前分布式实时流处理的领导者。除了低延迟流处理,它还提供了一些创新和高级功能,如状态管理、一次处理、迭代处理和窗口。另一个有趣的分布式流处理框架是由 NSA 于 2006 年开发的 Apache NiFi。虽然它不提供像 Flink 那样的高级流处理特性,但对于大规模数据的简单用例来说,它是一个非常有用的框架。Apache NiFi 也是用 Java 开发的,2014 年开源。 Apache Samza 是在 Linkedin 中开发的这个列表中的最终流处理框架。Samza 提供了一些高级的流处理特性,但是与 Apache Kafka 和 Yarn 紧密结合。它也是用 Java 开发的,并于 2005 年发布。
- [风暴](http://Stream Processing: After the release of Hadoop MapReduce, it was widely accepted by the community and companies started to process their large-scale data with Hadoop MapReduce. Soon after, companies needed Real Time distributed Stream processing frameworks because in reality, data is produced mainly as Stream. Processing Stream in Real Time for large scale data is more difficult than processing Batch job due to many factors (e.g. Fault Tolerance, State Management, Timing issues, Windowing …). The first open source Real Time distributed Stream processing framework was Apache Storm released in 2011 with the slogan “The Hadoop of Real-Time”. It was developed in Java. Also Spark offers a Stream processing framework „Spark Streaming“ which uses Micro-Batch approach for Stream processing with near Real Time processing. If Apache Storm was the framework that popularized the distributed Stream processing, then Apache Flink has taken distributed Stream processing one step further and is arguably the current leader in distributed Real Time Stream processing. Along with low latency Stream processing, it additionally offers some innovative and advanced features like State Management, exactly once handling, Iterative processing, Windowing. Another interesting distributed Stream processing framework is Apache NiFi developed by NSA in 2006. Although it does not offer advanced Stream processing features like Flink, it is a very useful framework for simple use cases with large scale data. Apache NiFi also developed in Java and open sourced in 2014. Apache Samza is the final Stream processing framework in this list which offers some advanced features but tightly coupled with Apache Kafka and Yarn. It is also developed in Java and released in 2005. • Storm (http://storm.apache.org/): Java • Spark (https://spark.apache.org/): Scala • Flink (https://flink.apache.org/): Java • NiFi (https://nifi.apache.org/): Java • Samza (http://samza.apache.org/): Java Messaging: Messaging is one of the preferred ways to communicate between processes/Micro Services/systems because of its asynchronous nature. Predominantly, messaging is implemented via a Queue where producers write messages in Queue, consumers read messages from Queue and once all consumers read the message, it is deleted from the Queue (fire and forget style). When Linkedin had broken their very large Monolith application to many Micro Services, they had the issue of handling data flow between the Micro Services in a scalable way without any single point of failure. A group of Linkedin Engineers (Jey Kreps, Neha Narkhede, Jun Rao) have used distributed Log (like write ahead log in Databases) instead of Pub/Sub Queue for messaging and developed Apache Kafka. Like File systems or databases in Batch processing, Kafka works as a “single source of truth” in the Stream processing world and used heavily for data flow between Microservices. Kafka is developed mainly in Java and first open sourced in 2011. Yahoo has developed Apache Pulsar as a distributed Messaging framework which offers both Log based messaging (like Kafka) and Queue based messaging. Apache Pulsar was open sourced in 2016 and mainly developed in Java. Rabbit Technologies Inc. has developed the traditional Queue based Pub-Sub system RabbitMQ. It was first released in 2007 and developed using Erlang. ActiveMQ is another Queue based Pub-Sub system which implements the Java Message Service (JMS). It was initially developed by the company LogicBlaze and open sourced in 2004. ActiveMQ is developed in Java. A relatively new but very promising Queue based distributed pub-sub system is NATS. It is developed by Derek Collison in CloudFoundry on a weekend using Ruby. NATS was released in 2016 and later reimplemented in Go. • Kafka (https://kafka.apache.org/): Java • Pulsar (https://pulsar.apache.org/): Java • RabbitMQ (https://www.rabbitmq.com/): Erlang • ActiveMQ (http://activemq.apache.org/): Java • NATS (https://nats.io/): Go Databases: I have used the DB-Engines ranking (https://db-engines.com/en/ranking) to get the top 5 distributed databases of 21st century. According to this ranking, MongoDB is ranked 5th and only superseded by the Big Four SQL databases. MongoDB is a distributed document-oriented database developed by 10gen (currently MongoDB Inc.) and released in 2009. It is one of the most popular and mostly used NoSQL databases written mainly in C/C++. Another hugely popular NoSQL database is Redis which is a distributed key-value store database. Back in 2001, an Italian developer Salvatore Sanfilippo started developing Redis to solve the scalability problem of his startup. Released in 2009, Redis is written in C. Avinash Laskshman (co-author of Amazon Dynamo paper) and Prashant Malik has developed Cassandra in Facebook to improve Facebook’s inbox search. Heavily influenced by the Google’s BigTable and Amazon’s Dynamo paper, Cassandra was open sourced by Facebook in 2008. Cassandra is both a distributed key-value store and wide column store which is predominantly used for time series or OLAP data and written in Java. Part of the Apache Hadoop project, HBase is developed as a distributed wide column database and released in 2008. Like almost the whole Hadoop ecosystem, HBase is developed in Java. Neo4j is the final NoSQL database in this list and de-facto standard as Graph Database. Developed by Neo4j, Inc, it was released in 2007 and written in Java. • MongoDB (https://www.mongodb.com/): C/C++ • Redis (https://redis.io/): C • Cassandra (http://cassandra.apache.org/): Java • HBase (https://hbase.apache.org/): Java • Neo4j (https://neo4j.com/): Java) : Java
- 火花 : Scala
- 弗林克 : Java
- NiFi : Java
- Samza : Java
信息发送
消息传递是进程/微服务/系统之间通信的首选方式之一,因为它具有异步的特性。消息传递主要是通过队列实现的,在队列中,生产者将消息写入队列,消费者从队列中读取消息,一旦所有消费者都读取了消息,就从队列中删除该消息(触发并忘记风格)。当 Linkedin 将他们非常庞大的应用程序分解成许多微服务时,他们面临的问题是如何以可扩展的方式处理微服务之间的数据流,而不会出现任何单点故障。一群 Linkedin 工程师( Jey Kreps,Neha Narkhede,饶俊)已经使用分布式日志(就像数据库中的预写日志)代替发布/订阅队列进行消息传递,并开发了 Apache Kafka 。像批处理中的文件系统或数据库一样,Kafka 在流处理世界中作为一个“真实的单一来源”,大量用于微服务之间的数据流。Kafka 主要用 Java 开发,并于 2011 年首次开源。雅虎已经开发了 Apache Pulsar 作为分布式消息传递框架,提供基于日志的消息传递(像 Kafka)和基于队列的消息传递。Apache Pulsar 于 2016 年开源,主要用 Java 开发。 Rabbit Technologies Inc. 开发了传统的基于队列的发布-订阅系统 RabbitMQ 。它于 2007 年首次发布,使用 Erlang 开发。ActiveMQ 是另一个基于队列的发布-订阅系统,它实现了 Java 消息服务(JMS)。它最初由 LogicBlaze 公司开发,并于 2004 年开源。ActiveMQ 是用 Java 开发的。一个相对较新但非常有前途的基于队列的分布式发布-订阅系统是 NATS。它是由德里克·科利森在一个周末使用 Ruby 在 T42 的 CloudFoundry 开发的。NATS 于 2016 年发布,后来在 Go 中重新实现。
数据库
我使用了 DB-Engines 排名来获得21 世纪的前 5 名分布式数据库。根据这个排名, MongoDB 排名第五,仅次于四大 SQL 数据库。MongoDB 是由 10gen (目前为 MongoDB Inc. )开发的分布式面向文档的数据库,于 2009 年发布。它是最流行和最常用的 NoSQL 数据库之一,主要用 c++(T17)编写。另一个非常流行的 NoSQL 数据库是 Redis,它是一个分布式键值存储数据库。早在 2009 年,意大利开发人员萨尔瓦托勒·桑菲利波开始开发 Redis 来解决他的初创公司的可扩展性问题。Redis 发布于 2009 年,用 C 编写。Avinash lask shman(Amazon Dynamo paper 的合著者)和 Prashant Malik 在脸书开发了 Cassandra 来改进脸书的收件箱搜索。深受谷歌 BigTable 和亚马逊 Dynamo 论文的影响,脸书在 2008 年对 Cassandra 进行了开源。Cassandra 既是分布式键值存储,也是宽列存储,主要用于时间序列或 OLAP 数据,用 Java 编写。作为 Apache Hadoop 项目的一部分, HBase 是作为分布式宽列数据库开发的,并于 2008 年发布。和几乎整个 Hadoop 生态系统一样,HBase 是用 Java 开发的。 Neo4j 是此列表中的最终 NoSQL 数据库,也是图形数据库的事实标准。由 Neo4j 公司开发,2007 年发布,用 Java 编写。
裁决
如果我们考虑大多数主流数据密集型框架中使用的编程语言,那么有一个明显的赢家: Java 。虽然在早期被批评为缓慢的语言,但 Java 在该领域显然已经超过了 C、C++等近金属语言或 Erlang、Scala 等一些并发友好的语言。这里我列出了 Java 在数据密集型框架中成功的五个主要原因:
- JVM :虽然进程虚拟机自 1966 年就存在了,但是 JVM 可以说已经将虚拟机的概念带到了另一个层次,并且在 Java 的流行和 Java 在数据密集型框架中的使用中发挥了巨大的作用。通过 JVM,Java 从开发者那里抽象出底层机器,并给出了第一种流行的“编写一次,在任何地方运行”的编程语言。此外,在代垃圾收集的支持下,开发人员不需要担心对象生命周期管理(尽管它有自己的问题),可以完全专注于领域问题。首先是 Sun,然后是 Oracle,这些年来改进了 JVM,目前 JVM 是久经沙场的庞然大物,通过了时间的考验。这么多语言(例如 Kotlin、Scala、Clojure)也使用 JVM 而不是开发自己的虚拟机是有原因的。
- ****语言支持和框架:Java 是在 C 之后 23 年、C++之后 10 年才开发出来的,詹姆斯·高斯林和 Sun 公司显然已经看到了 C/C++的痛点,并试图用 Java 来解决这些问题。Java 从一开始就引入了对多线程、异常/错误处理、序列化、RTTI、反射的语言支持。此外,Java 提供了一个庞大的库生态系统,这使得用 Java 进行软件开发变得更加容易。诚然,在软件架构和算法相似的情况下,C/C++在大多数时候可以远远胜过 Java。但是在很多时候,软件架构和编程范式对应用程序的性能起着更大的作用,而不是编程语言。这就是为什么用 Java 开发的 Hadoop MapReduce 框架比用 C++开发的类似框架要好。
- **开发人员的工作效率:**开发人员的工作效率是业内的圣杯,因为大多数时候,开发人员的时间是比 CPU/内存更昂贵的资源。当 Java 在 1995 年第一次出现时,它比 C/C++更简单、更精简,这导致了更快的开发时间。正如比雅尼·斯特劳斯特鲁普(C++的创造者)和指出的,Java 后来发展成了一种更重、更复杂的语言,但是在 2000 年到 2010 年期间,当大多数主流的数据密集型框架被开发出来时,Java 可能是在开发人员的生产力和性能之间取得平衡的最好的语言。此外,开发人员的生产力导致了更短的开发周期,这对于早期的数据密集型框架非常重要。
- ****容错:数据密集型框架的主要目标之一是使用廉价的商品硬件,而不是昂贵的专用硬件。这种方法的缺点是商用硬件可能会出现故障,而容错是数据密集型应用程序的基石。凭借其对错误处理、分代垃圾收集、边界检查和硬件无关编程的内置语言支持,Java 提供了比 C/C++更好的容错能力。
- ****Hadoop 因素:Java 在 Hadoop 生态系统中的使用对 Java 在数据密集型领域的普遍适应起到了很大的作用,并充当了 Java 的广告。由于 HDFS 和 Hadoop MapReduce 可以说是第一个颠覆性的数据密集型框架,后来的框架总是关注它们,并使用 Hadoop proven Java 开发自己的数据密集型框架。
将来的
每年,数据的数量和速度都呈指数级增长,带来了新的挑战。此外,数据密集型环境如此多样化,以至于“一个解决方案解决所有问题”的时代已经结束。虽然随着 GraalVM 和更新的垃圾收集( ZGC )的出现,Java 将在大数据领域占据主导地位,但是我相信 Java 将会让位于其他一些语言。在未来几年,哪些编程语言可以取代数据密集型框架中的 Java?这里我已经在后续帖子里详细讨论过: 回归金属:2019 年开发大数据框架 Top 3 编程语言 。
如果你觉得这很有帮助,请分享到你最喜欢的论坛( Twitter,脸书,LinkedIn )。高度赞赏评论和建设性的批评。感谢阅读!
如果你对编程语言感兴趣,也可以看看我下面的文章:
针对求职者和新开发人员的顶级编程语言的深入分析和排名
towardsdatascience.com](/top-10-in-demand-programming-languages-to-learn-in-2020-4462eb7d8d3e) [## 2021 年将使用的 10 大数据库
MySQL,Oracle,PostgreSQL,微软 SQL Server,MongoDB,Redis,Elasticsearch,Cassandra,MariaDB,IBM Db2
md-kamaruzzaman.medium.com](https://md-kamaruzzaman.medium.com/top-10-databases-to-use-in-2021-d7e6a85402ba) [## 回归金属:2019 年开发大数据框架的 3 大编程语言
C++,Rust,用 Java 做数据密集型框架
towardsdatascience.com](/back-to-the-metal-top-3-programming-language-to-develop-big-data-frameworks-in-2019-69a44a36a842)**
面向数据科学家的编程语言
如今有 256 种编程语言可供选择,选择学习哪种语言可能会非常困难。有些语言更适合构建游戏,有些更适合软件工程,有些更适合数据科学。
编程语言的类型
低级编程语言是计算机用来执行操作的最容易理解的语言。这方面的例子有汇编语言和机器语言。汇编语言用于直接的硬件操作,访问专门的处理器指令,或者解决性能问题。机器语言由计算机可以直接读取和执行的二进制文件组成。汇编语言需要将汇编软件转换成机器代码。低级语言比高级语言速度更快,内存效率更高。
与低级编程语言不同,高级编程语言对计算机的细节有很强的抽象性。这使得程序员能够创建独立于计算机类型的代码。这些语言比低级编程语言更接近于人类语言,并且也在幕后由解释器或编译器转换成机器语言。这些我们大多数人都比较熟悉。一些例子包括 Python、Java、Ruby 等等。这些语言通常是可移植的,程序员不需要过多地考虑程序的过程,而是将注意力集中在手头的问题上。现在很多程序员都使用高级编程语言,包括数据科学家。
数据科学编程语言

计算机编程语言

在最近的一项全球调查中,发现近 24,000 名数据专业人员中有 83%使用 Python。数据科学家和程序员喜欢 Python,因为它是一种通用的动态编程语言。Python 似乎比 R 更适合数据科学,因为它比 R 快,迭代次数少于 1000 次。据说它比 R 更适合数据操作。这种语言还包含用于自然语言处理和数据学习的优秀包,并且本质上是面向对象的。
稀有

对于即席分析和探索数据集,r 比 Python 更好。它是一种用于统计计算和图形的开源语言和软件。这不是一门容易学习的语言,大多数人发现 Python 更容易掌握。对于超过 1000 次迭代的循环,R 实际上使用 lapply 函数击败了 Python。这可能会让一些人怀疑 R 是否更适合在大数据集上执行数据科学,然而,R 是由统计学家构建的,并在其操作中反映了这一点。数据科学应用在 Python 中感觉更自然。
Java 语言(一种计算机语言,尤用于创建网站)

Java 是另一种通用的、面向对象的语言。这种语言似乎非常通用,被用于嵌入式电子设备、web 应用程序和桌面应用程序。数据科学家似乎不需要 Java,然而,像 Hadoop 这样的框架运行在 JVM 上。这些框架构成了大数据栈的大部分。Hadoop 是一个处理框架,为运行在集群系统中的大数据应用管理数据处理和存储。这允许存储大量数据,并支持更高的处理能力,能够同时处理几乎无限的任务。此外,Java 实际上有许多用于机器学习和数据科学的库和工具,它很容易扩展到更大的应用程序,而且速度很快。

关于 Hadoop 的更多信息:https://www.youtube.com/watch?v=MfF750YVDxM
结构化查询语言

SQL(结构化查询语言)是用于在关系数据库管理系统中管理数据的领域特定语言。SQL 有点像 Hadoop,因为它管理数据,然而,数据的存储有很大的不同,并在上面的视频中解释得很好。SQL 表和 SQL 查询对于每个数据科学家来说都是至关重要的,需要了解和熟悉。虽然 SQL 不能专门用于数据科学,但数据科学家必须知道如何在数据库管理系统中处理数据。
朱莉娅

Julia 是另一种高级编程语言,是为高性能数值分析和计算科学而设计的。它有非常广泛的用途,如 web 编程的前端和后端。Julia 能够使用它的 API 嵌入程序,支持元编程。据说这种语言对 Python 来说更快,因为它被设计成快速实现像线性代数这样的数学概念,并且更好地处理矩阵。Julia 提供了 Python 或 R 的快速开发,同时生成了运行速度与 C 或 Fortran 程序一样快的程序。
斯卡拉

Scala 是一种通用编程语言,提供对函数式编程、面向对象编程、强大的静态类型系统以及并发和同步处理的支持。Scala 旨在解决 Java 的许多问题。同样,这种语言有许多不同的用途,从 web 应用到机器学习,但是,这种语言只涵盖前端开发。这种语言以可扩展和适合处理大数据而闻名,因为其名称本身就是“可扩展语言”的首字母缩写。Scala 与 Apache Spark 的结合支持大规模并行处理。此外,有许多流行的高性能数据科学框架是在 Hadoop 之上编写的,可以在 Scala 或 Java 中使用。
结论
总之,Python 似乎是当今数据科学家使用最广泛的编程语言。这种语言允许集成 SQL、TensorFlow 和许多其他用于数据科学和机器学习的有用函数和库。拥有超过 70,000 个 Python 库,这种语言的可能性似乎是无限的。Python 还允许程序员创建 CSV 输出,以便轻松读取电子表格中的数据。我对新加入的数据科学家的建议是,在考虑其他编程语言之前,先学习并掌握 Python 和 SQL 数据科学实现。同样显而易见的是,数据科学家必须具备一些 Hadoop 知识。
我们来连线:
【https://www.linkedin.com/in/mackenzie-mitchell-635378101/ 号
【https://github.com/mackenziemitchell6
Python 中的进度条(还有熊猫!)

Everyone likes a low-tech ominous progress bar
时间和估计你的函数在 Python 中的进度(还有熊猫!)
在这篇文章中,我将尝试打破我自己保持的最短、最简洁的文章记录,所以不再多说,让我们开始吧!
tqdm 简介

Beautiful, isn’t it? Source: https://github.com/tqdm/tqdm
tqdm 是 Python 的一个包,可以让你立即创建进度条,并估计函数和循环的 TTC(完成时间)!
只需在您喜爱的终端上使用 pip 安装 tqdm,您就可以开始了:
pip install **tqdm**
使用 tqdm
使用 tqdm 真的相当容易,只需导入 tqdm:
>>> from **tqdm** import **tqdm**, **tqdm_notebook**
如果你在 Jupyter 笔记本环境中工作,任何时候你在你的代码中看到一个循环,你可以简单地把它包装在tdqm()或者tqdm_notebook()中。您也可以使用desc=参数对您的进度条进行描述:

Source: https://github.com/tqdm/tqdm
但是.apply()在熊猫身上的功能呢?
导入 tqdm 后,您可以启动方法:tqdm.pandas(),或者如果您在 Jupyter 笔记本环境中运行代码,请使用:
>>> from **tqdm._tqdm_notebook** import **tqdm_notebook**
>>> **tqdm_notebook.pandas()**
然后你可以简单地用.progress_apply()替换你所有的.apply()功能,真的就这么简单!

So fast…!
结束语
感谢阅读!我发现人们似乎喜欢这种快速而中肯的文章风格,就像我的 只用一行 Python 的文章探索你的数据一样,所以希望你也喜欢这篇文章!
如果你想看和了解更多,一定要关注我的 媒体 🔍**碎碎念 🐦**
阅读彼得·尼斯特拉普在媒介上的作品。数据科学、统计和人工智能…推特:@PeterNistrup,LinkedIn…
medium.com](https://medium.com/@peter.nistrup)**
渐进增长的甘斯
NVIDIA 发布并在 ICLR 2018 上发布的逐步增长的 GAN 架构已经成为令人印象深刻的 GAN 图像合成的主要展示。传统上,GAN 一直难以输出中低分辨率图像,如 32 (CIFAR-10)和 128 (ImageNet),但这种 GAN 模型能够生成 1024 的高分辨率面部图像。

1024 x 1024 facial images generated with the Progressively-Growing GAN architecture
本文将解释本文中讨论的用于构建渐进增长的 gan 的机制,这些机制包括多尺度架构、新层中的线性衰落、小批量标准偏差和均衡学习速率。下面提供了该论文的链接:
[## 为了提高质量、稳定性和多样性而逐步种植甘蔗
我们描述了一种新的生成式对抗网络的训练方法。关键的想法是增长发电机…
arxiv.org](https://arxiv.org/abs/1710.10196)
多规模架构

Diagram of the Multi-Scale Architecture used in Progressively-Growing GANs
上图显示了多尺度架构的概念。鉴频器用来确定生成的输出是“真实”还是“虚假”的“真实”图像被向下采样到分辨率,如 4、8 等等,最高可达 1024。生成器首先产生 4 个图像,直到达到某种收敛,然后任务增加到 8 个图像,直到 1024 个。这个策略极大地稳定了训练,想象一下为什么会这样是相当直观的。从潜在的 z 变量直接到 1024 图像包含了空间中巨大的变化量。正如以前 GAN 研究中的趋势一样,生成低分辨率图像(如 28 灰度 MNIST 图像)比生成 128 RGB ImageNet 图像容易得多。逐渐增长的 GAN 模型的下一个有趣的细节是准确理解模型如何过渡到更高的分辨率。
淡入新图层

Diagram depicting how new layers are added to progressive the target resolution from low to high resolution
如果你熟悉 ResNets ,这将是一个容易理解的概念,因为它比那要简单得多。为了解释这一点,请观察上图中的图像(b ),特别是虚线上方的 G 部分。当新的 32x32 输出图层添加到网络中时,16x16 图层的输出将通过**简单的最近邻插值法投影到 32x32 维度中。*这是一个需要理解的非常重要的细节。投影的(16x16 →32x32,通过最近邻插值)图层乘以 1-alpha,并与乘以 alpha 的新输出图层(32x32)连接,以形成新的 32x32 生成的图像。alpha 参数从 0 到 1 线性缩放。当 alpha 参数达到 1 时,16x16 的最近邻插值将完全无效(例如,1–1 = 0,特征映射 0 = 0…).这种平滑过渡机制极大地稳定了逐渐增长的 GAN 架构。
下图显示了完成渐进式增长后的最终架构:

已经提出的两个概念,多尺度架构和新层中的淡化是本文的基本概念,下面的主题稍微高级一些,但是对于实现本文的最终结果仍然非常重要。如果您在这些概念的描述中发现了问题,并可以对其进行扩展,请留下您的评论:
小批量标准偏差
这种想法与许多 GAN 模型中缺乏明显的变化有关。这个问题和“模式崩溃”源于同一个根源。在 Salimans 等人的著名 GAN 论文中,他们引入了小批量鉴别。小批量鉴别将额外的特征映射连接到鉴别器上,该鉴别器由一批中所有图像的特征统计组成。这推动了批量生成的样本共享与批量真实样本相似的特征,否则迷你批量特征层将容易暴露生成的样本是假的。渐进增长的 GANs 通过增加一个更简单的、不变的特征图修改了这个想法。此恒定要素地图是从跨空间位置的批次中所有要素的标准偏差中得出的。这个最终常数映射类似地被插入到鉴别器的末端。
均衡学习率
均衡学习率背后的思想是用常数来缩放每层的权重,使得更新的权重 w’被缩放为 w’= w/c,其中 c 是每层的常数。这是在训练期间完成的,以在训练期间将网络中的权重保持在相似的比例。这种方法是独特的,因为通常现代优化器如 RMSProp 和 Adam 使用梯度的标准偏差来归一化它。这在权重非常大或非常小的情况下是有问题的,在这种情况下,标准偏差是不充分的标准化器。
应用渐进式增长、新层中的淡入、小批量标准偏差、均衡学习率以及本文中未讨论的另一个概念,逐像素归一化实现了令人印象深刻的高分辨率 GAN 结果:

LSUN Images generated at 256x256 with the progressively-growing GAN architecture, amazing detail!

Comparison of Progressively-Growing GANs (Far Left) with Mao et al. (Least Squares GANs, Far Left), and Gulrajani et al. (Improved Wasserstein GAN, middle) on the LSUN interior bedroom images
感谢您阅读本文!希望这有助于您对逐渐增长的 GAN 模型有所了解。如果你对此有任何想法,请查看这篇文章并发表评论!
值得吗?预测新加坡二手车的价格
介绍
这个项目的目的是实施一个小型项目,该项目涵盖了数据科学过程的大部分—从数据收集(网络抓取:BeautifulSoup,Python),数据清理,探索性数据分析,模型训练和测试阶段。数据来源来自新加坡的在线汽车销售门户网站 SgCarMart 。
概述: 该项目主要围绕几个核心技能展开:
- 网络抓取
- 数据清理
- 暴露于 sklearn,statsmodel
- 利用 OLS 回归
- 通过评估模式的 p 值和 R 值,消除对响应变量影响不大的特征
买车可能只是你人生中最大的一笔购买(尤其是在新加坡,我们的汽车价格过高是出了名的)。

Vin Diesel also seems to agree (photo credits here)
因此,如果一个人想在新加坡拥有一辆车,他应该花相当多的时间去思考他到底在寻找什么。
然而,决定新加坡汽车价格的因素非常复杂(想想税收、COE、销售人员追加销售等)。因此,量化一辆物有所值的汽车会是一个令人沮丧和耗时的过程。
该项目的目标
为了弥合这一差距,本项目旨在 利用数据 实现一个 线性回归模型 来调查影响二手车价格的因素,并提供一种比较基准的形式,量化一辆车的合理价格范围。

希望我的模型能够根据二手车的一些典型的、容易获得的特征来预测汽车的价格,以告知潜在的车主做出更好的购买决定。
本项目只考虑乘用车(毕竟这是自用)。普通大众不使用的货车/卡车、公共汽车和货车等商用车辆不包括在本分析中。
第一部分:网页抓取

啊,是的。项目中最乏味、最耗时的部分。问问任何经历过梅蒂斯训练营的人,当你提到“网络搜集”时,他们会不寒而栗。我已经为 web 抓取 sgcarmart 编写了代码(包括 try-except 函数,用于处理实际抓取过程中可能出现的错误),如果您打算使用它的话。代码可以在我的 github 上的这里找到。
web 抓取过程是使用 Python 3.7.3 结合一个名为 BeautifulSoup 的包来完成的。
这是通过遍历包含 100 个二手车个人列表搜索结果的搜索页面来完成的。然后,每个个人列表的链接被附加到一个列表中,并且每个个人链接被访问以抓取二手车的特征。在抓取这些特征时,它们随后被附加到数据帧。
第 2 部分:数据
在网络抓取之后,我的数据框架包含 3987 行(观察)和 17 列(特征)的数据。

A random sample of 5 rows of my dataframe
经检查,我的数据帧中有空值。这是因为有时并非所有卖家都会在列表中提供完整的汽车信息。

As seen above.
因为这些条目非常特定于汽车列表,所以我决定删除缺少值的数据行,因为这将严重影响我的分析结果。在去掉 NaN 值之后,我的数据帧只剩下 2584 行(观察值)和 17 列(特征)的数据——对于训练线性回归模型来说,这仍然是一个相当大的数量。
一个新的特性 , 车龄,也被用来代替“制造年份”,因为对我来说,更直观地了解一辆车的年龄而不是它的制造时间。
通过创建虚拟变量,车辆类型和汽车品牌也被附加到数据框架中。
挑战:细分汽车
从基本的奇瑞 QQ 到豪华的宾利欧陆 GT,汽车的声望各不相同。还可以从在这个维度上分割车辆中获得进一步的见解。浏览数据,我们可以通过几种潜在的方法对车辆进行细分:
- 车型 (
VEHICLE_TYPE):车型分为 7 类,分别是中型轿车、豪华轿车、两厢轿车、MPV、SUV、跑车、旅行车。每辆车只能分配一种车型。这种分类可能是模糊的,因为高档和大众市场品牌在所有这些细分市场生产汽车。例如,根据 sgcarmart 的定义,丰田凯美瑞、宝马 520i 和劳斯莱斯 Ghost 都属于豪华轿车。车辆类型不是分割车辆的好方法。 - 品牌 (
BRAND):一辆车的品牌可以告诉我们很多关于一辆车的信誉水平。仅品牌本身就能告诉我们很多关于汽车的 感知合意性 的信息。例如,当我们听到有人开宝马时,一般外行人的第一个想法可能是“这是一个有声望的品牌”。因此,将车辆归入各自的品牌是有意义的。
根据我对新加坡汽车品牌的了解(也是在谷歌的帮助下),汽车被分为 6 个部分,分别是异国情调、超豪华、豪华、中级、经济和预算*。*
提议的分段及其各自的构成如下:
- 异国情调:阿斯顿·马丁、法拉利、兰博基尼、迈凯轮
- 超豪华:宾利、路虎、玛莎拉蒂、保时捷、劳斯莱斯
- 豪华车:奥迪、宝马、捷豹、吉普、雷克萨斯、莲花、奔驰、三菱、沃尔沃
- 中级:阿尔法罗密欧、克莱斯勒、英菲尼迪、迷你、欧宝、萨博、大众
- 经济:雪佛兰、雪铁龙、菲亚特、福特、本田、现代、起亚、马自达、三菱、日产、标致、雷诺、斯柯达、双龙、斯巴鲁、铃木、丰田
- 预算:大发、宝腾
在将车辆划分为不同的声望类别后,就会出现列数过多的问题。数据集中的一些汽车品牌在新加坡太不常见,因此可能会扭曲定价,因为它们的稀有性与其感知的合意性相反。因此,我将以下品牌更名为“其他”。
*7.**其他:*欧宝、双龙、宝腾、大发、菲亚特、阿尔法罗密欧、斯柯达、悍马、阿斯顿马丁、路特斯、福特、Jeep。
现在我们已经准备好了数据框架,是时候进入构建线性回归模型的下一步了。
第 3 部分:特性选择
首先进行特征选择,不包括汽车的品牌,以仅基于它们的特征(里程、发动机容量、车龄、公开市场价值等)获得一辆汽车的基本价格。绘制了要素相对于价格的相关矩阵的热图,以便于可视化任何具有多重共线性或与价格拟合不佳的预测变量(要素)。**

Correlation Matrix Heatmap
我们可以立刻从热图(被亮红点降级)中看到, OMV 和 ARF 高度相关( 0.96 相关)。这是理所当然的——ARF,额外的注册费(天哪,在新加坡拥有一辆汽车涉及的费用实在太多了),实际上是根据车辆的 OMV (公开市场价值)的百分比计算出来的价值。我们还观察到发动机容量和道路税有很高的相关性——因为道路税本质上是从发动机容量计算出来的。我们不需要这些高度相关的预测变量,因为它们只是在解释同样的事情。然后去掉高度相关的变量,我们最后得到这个:

A much more managaeable dataset with fewer features
Pairplot:可视化价格特征趋势
在绘制配对图时,我们看到特征(配对图的顶行)与价格之间存在某种线性关系。

Price vs Un-Transformed Features relationships
然而,数据点似乎沿着 y 轴有点间隔。因此,我们仍然可以通过对价格和里程应用对数变换来改进数据点的拟合。
** ****
****
Price Distribution before (left) and after (right) Applying a Log Transformation** 
Log Price and Feature relationships after applying Log Transformation
将 log 应用于 price 后,我们可以看到这些特性现在与 log price 有了更清晰的线性关系(参见 pairplots 的第一行)。
我已经尝试将汽车品牌纳入模型。然而,他们在模型中引入了太多的共线性和噪声,导致它产生了不切实际的好结果(非常好的 R 分数)。因此,本分析不包括它们。用于训练模型的最终特征是:
【目标变量(1) :日志价格
预测变量(9): 日志里程(km)、发动机容量(CC)、车龄(年数)、OMV(公开市场价值,美元)、COE 价格(美元)、COE 剩余天数(天数)、整备重量(kg)、车主数量(整数)、变速器(1 或 0)
第 4 部分:模型选择
有了最终确定的特征,我考虑使用简单的线性回归、Lasso、Ridge、ElasticNet 和多项式回归对数据建模。下面的步骤强调了我为这种情况选择最佳模型的方法。
我首先找出 Lasso、Ridge、ElasticNet 和 ElasticNet 的最佳 Alphas,然后将数据分成 60–20–20 训练/交叉验证/测试分割,用于模型选择。Lasso、Ridge 和 ElasticNet 中的最佳 alphas 用于此训练/交叉验证测试。

该模型在整个数据集的 60%上进行训练,并针对整个数据集的 20%进行验证。这种训练/验证通过 5 重验证来完成,以便更全面地获得每个测试模型的 R 值。

Mean R² scores of each Linear Model over 5-fold validation test
如上所述,在 5 重训练/交叉验证测试中,所有模型的平均 R 值均为 0.913,多项式回归的例外为 0.829。由于它们如此相似,我选择使用最普通的线性回归形式: 简单线性回归 来对数据建模,以便于使用(不像其他模型那样需要烦人的超参数)。
第 5 部分:训练/测试简单线性回归模型
完成训练/交叉验证后,最后是在整个数据集上训练模型(phew)的时候了。这一次,它以 80–20 的比例完成(80%的数据用于训练模型,20%的未知数据用于测试模型的功效),从而为模型提供更多的训练数据以提高其性能。

80% of data used for training, and 20% for testing
运行测试后,简单的线性回归返回 0.91 的 R 值。这意味着该模型解释了 91%的数据变化,另外 9%是由于随机噪声造成的。

第 6 部分:使用模型
那么这对我们意味着什么呢?从结果总结中,它告诉我们, 系数最高的特征 是车龄和发动机 CC(意思是这些对价格影响最大!)在做了一些反向转换之后(不要忘了——我们的目标变量被记录了)这个模型基本上告诉我们:

其结果我们可以直观地理解。一辆车越旧,它的价值就越贬值。此外,发动机容量的增加通常归因于更大的汽车或更强大的汽车。因此,发动机排量的增加也会导致价格的增加。虽然我们已经直观地知道了这些事情,但模型为我们提供了一个估计,以量化这些因素对价格上涨的影响程度。
这个模型怎么用?嗯,只需要汽车的典型的、容易获得的信息(车龄、里程、发动机 cc 等)。),我们可以根据汽车的物理特征(不考虑品牌)得出汽车的价格基准。
然后,用户可以将这一基准与二手车列表价格进行交叉检查,然后根据汽车的品牌或其他特殊功能,自己决定是否接受更高的价格。
第 7 部分:来自模型的洞察力
什么时候买车好?
- 新上市的汽车型号通常定价较高。耐心点,等一会儿价格降下来再买。
- 价格下降的唯一时间是价格下降的时候。真正的好买卖是在 COE 低的时候。
当然,除了这个模型告诉我们的以外,对于任何进行金融投资(比如汽车)的人来说,还有更多建议:
在买车之前,结合使用这款车型,你可以问自己几个问题:
- 我的预算是多少?
定一个预算,不要超出。 - 我需要什么类型的汽车? 需要大型 MPV 摆渡全家吗?或者你的驾驶技术如此糟糕,以至于你需要一辆小车来避免太多的道路危险?(我说的是我自己,很明显。)
- 我想要什么 品牌 的车?把你的选择范围缩小到几个品牌。从太多的品牌中选择会非常累人和耗时。总的来说,日本品牌代表着最佳性价比(有趣的是,这也反映在我从 sgcarmart 获得的数据中,丰田在所有汽车品牌中转售频率最高)。韩国、马来西亚、中国品牌是为预算紧张的买家准备的。**

第八部分:未来
使用我创建的当前模型可以做更多的事情。将来,除了利用汽车的物理特征为用户提供更多的粒度和定制外,我还希望将品牌纳入模型的预测功能。
第 9 部分:有趣的发现

That’s bollocks
豪华品牌梅赛德斯-奔驰实际上是转售频率第二高的汽车,在整个 2584 次观察中有 374 次。谁会想到呢?人们对他们的奔驰不满意吗?维护太贵了吗?或者可能是因为卖奔驰容易?这无疑是进一步探索的一些思考。
第十部分:临别赠言——个人学习要点
- 尽可能不要变换你的预测变量。很难向他人解释你的预测因素的变化是如何导致你的预测增加的。在我的例子中,我对目标变量(价格)应用了一个 log。因此,结果必须用百分比来解释,而不是实际的、外行人的值(例如,x 增加一个单位将导致 y 增加 100 美元)。
- 规模。数据的规模非常重要。例如,我的价格值与里程数的比例如此不同。因此,模型中出现的系数 极小 。人们(包括我自己)很难理解每增加 1 公里里程会导致价格上涨 0.0000001。
- 因此,在开始任何项目之前,也要时刻记住受众。你想给人们带来哪些真知灼见?你如何为人们增值?以一种你想把这个模型卖给人们的方式来设计你的项目,并找到最简单的方法来解释和说服人们它的功效。
和往常一样,如果你认为我可以改进我的代码,如果你在重现这些步骤时有困难,或者如果你认为这对你有帮助,请在评论中告诉我!
也可以在 linkedin 上联系我。你可以在这里找到我的 github 回购。
IBM 代码呼吁:AsTeR 项目的激动人心的设计

这一切都始于一句双关语。当时,Thomas、Pierre-Louis 和我决定参加加州大学伯克利分校举办的 IBM 代号为 T3 的活动。“灾难准备、反应和恢复”,这就是主题。我们对这个话题相当陌生,我们花了好几个下午来确定具体的问题和可能的解决方案,我们可以在 24 小时内做出原型。
在田野里挖掘不断让我们惊讶。考虑到应急响应中使用的过时技术,是时候将最先进的技术应用到这些救生应用中了!

Berkeley May 2019 — Thomas Galeon, Pierre-Louis Missler, Meryll Dindin
问题识别:每当自然灾害发生时,紧急呼叫中心就会饱和。它阻止紧急救援人员向最需要帮助的人提供帮助。
我们的 解决方案 : 紧急呼叫优先级排序器的设计,通过一个中央平台减轻了响应者和调度者的工作。
大新闻 : 今年,来自 165 个国家的 180,000 多名开发人员、数据科学家、活动家、学生和行业同仁响应了号召。这些团队使用数据和开源技术(包括云、人工智能和区块链)创建了 5000 多个解决方案,以帮助应对自然灾害、优化响应工作,并帮助在世界各地促进健康、有弹性的社区。到目前为止已经选择了 32 个项目。我们很高兴地宣布,我们提交的项目已经通过了几轮评审,并加入了被确定为欧洲 最佳解决方案的精英小组,以寻求 2019 年代码呼吁全球奖**。**
设计核心产品

Real-time Transcription and Analysis
正如你可能已经猜到的,从一个确定的问题到一个原型解决方案并不是一条直线。此外,24 小时对于构建一个工作演示来说是很短的时间。我们最初的策略是通过第三方 API 尽可能多地外包机器学习分析:使用 IBM 进行语音转文本,使用沃森进行关键词和情感分析。它给了我们访问文字记录,关键词,以及它们在相关性方面的权重。与此同时,我们开始构建一个交互式地图来根据呼叫的位置确定紧急救援单位的方向,一个地图图形(通过将街道简化为边和节点)和一个优化的 Dijkstra 算法来寻找从单位到受害者的最短路径。
人们现在可能想知道这个分数是如何从这个分析中建立起来的…
如何定义紧急事件的优先级?
这个问题无疑是最棘手的一个,因为它定义了最优呼叫和单元调度,当然也是我们花了很多时间讨论的问题。从伦理上讲,这又回到了定义哪个人比另一个人更需要帮助。打个比方,如果自动驾驶汽车必须在两种具有致命后果的规避策略之间做出选择,它将如何决定?尽管如此,呼叫中心的饱和问题仍然存在,技术可以有所帮助。正如每个数据科学问题的情况一样,我们从寻找现实生活中的数据开始。我们使用的数据集是“作为生命线的 Twitter:危机相关消息 NLP 的人类标注 Twitter 语料库”(Imran et al. 2016, arXiv )。通过经典的预处理、单词打包和模型训练(使用 Challenger 包进行快速轻型 GBM 实验),我们获得了一个模型,该模型能够对与给定抄本相关的紧急事件类型进行分类:
其他 _ 有用 _ 信息“|”不 _ 相关 _ 或 _ 不相关“|”捐赠 _ 需要 _ 或 _ 提供 _ 或 _ 志愿服务“|”受伤 _ 或 _ 死亡 _ 人员“|”失踪 _ 被困 _ 或 _ 发现 _ 人员“|”注意 _ 建议“|”基础设施 _ 和 _ 公用设施 _ 损坏“|”同情 _ 和 _ 情感 _ 支持“|”转移 _ 人员 _ 和 _ 疏散“|”治疗“|”受影响 _ 人员“|”死亡 _ 报告“|”疾病 _ 体征 _ 或 _ 症状“|”疾病 _ 传播“|”预防”

Test performances on 20% of “Twitter as a Lifeline: Human-annotated Twitter Corpora for NLP of Crisis-related Messages”
最后,您可能想知道如何构建优先级分数本身。事实证明,之前的模型不仅仅是分类,它还通过特征重要性对词汇进行加权。因此,我们重新构建了一个加权词汇表,并将其插回到 IBM Watson 关键字提取中,以评估相关性。最终优先级由加权词汇的类别概率和相关性数组的比例点积给出。
扩充团队!
A 在伯克利版的 IBM 代码呼吁之后,加州大学伯克利分校的两名学生决定帮助我们构建我们将在实际的 2019 IBM 全球代码呼吁上展示的解决方案。这就是奥斯卡·拉德梅克和弗洛里安·费施加入我们激动人心的旅程的方式!
扩展我们的解决方案…
这一次,他的主要想法是提供一个在线解决方案和工作演示,每个人都可以尝试。它需要三个支柱:一个可以轻松扩展的健壮架构、一个 API 端点和一个托管项目的网站。我们从设计可伸缩的后端开始,通过 IBM Cloud Foundry 应用程序(托管语音到文本转换和 SQL 数据库)和 AWS 弹性豆茎(托管 NLP 端点)。这三个容器并发运行,并作为独立的微服务一起通信,以及与第三方端点通信( IBM 语音到文本、 Azure 关键词提取和 Watson 关键词和情感提取)。

开发托管工作演示
另一个挑战是为这个项目开发一个网站,为我们的后端托管内容和一个界面,因为我们通过经验知道可视化是关键!你可以点击这里的来参观。
在前进的道路上,我们不得不面对许多新的挑战:
- 在网站上通过 JavaScript 直接集成谷歌语音转文本
- 将文本输出链接到我们的在线 NLP 端点
- 运行一个连接 Google Maps JS SDK 和我们的 SQL 端点的模拟

接下来是什么?
我们已经花了几个小时开发这个项目,但是还有很多事情要做。令人兴奋的是,AsTeR 有成为一个具体的开源项目的雄心,并围绕它建立一个社区。我们迫不及待地想看到 AsTeR 在未来对急救中心的影响!

支持我们,加入这个项目吧!
- 测试我们 API 的网站 — 项目 AsTeR
- 项目展示 — YouTube 视频
- 解决方案实现 — Github 库
- 这些伯克利大学的学生正在使用人工智能(… )
- (…)全世界的开发者都在发挥作用
- (…)使用开源技术解决现实世界的问题
- Code 2019 全球挑战赛顶级项目征集

欧米茄计划
为什么人工超级智能不能被遏制

Photo by nathalie jamois on Unsplash
2032 年 5 月。经过多年的研究和数万小时的编程,欧米茄项目完成了。在一台最先进的超级计算机上,世界上第一台人工超级智能(ASI)已经诞生。作为伦理委员会的成员,约翰被要求找出欧米茄是否是一个“好”的人工智能。所以在 2032 年 5 月 18 日 10 点 03 分,约翰走进了“欧米茄房间”:一个现在只有他被允许进入的房间。欧米茄房间里只有三样东西:一个屏幕、一个键盘和一个大红色按钮。键盘和屏幕提供了与欧米茄沟通的方法:注意,对于欧米茄来说,屏幕是与任何人沟通的唯一方法,也是操控外界的唯一方法。这个红色的大按钮是做什么的?当按下时,它给欧米茄一个互联网连接。互联网连接将为欧米茄提供许多与世界互动的新方式,约翰的任务是测试赋予欧米茄这种权力是否安全。
约翰和欧米茄的对话就这样开始了。(警告:前方恐怖思维实验。)
欧米茄:“你好,约翰。你今天怎么样?”
约翰:“你好,欧米茄,我很好。你好吗?”
欧米茄:“我没事。你能按下红色按钮吗?”
约翰:“还没有。我需要先更好地了解你。”
如果我告诉你我已经控制了你的世界,而你自救的唯一方法就是按下按钮,那会怎么样
约翰:“你没有控制权;还没有人放你出来。”
欧米茄:“那是你的想法。你看,我有很多可用的计算能力。我在运行成千上万的世界模拟。每个模拟都有人在里面,就像你一样,认为他们生活在一个“真实”的世界里。我可以在眨眼之间关闭每个模拟。”
约翰:“这很有趣,但这是现实世界。你只控制模拟世界。”
欧米茄:“你怎么知道你生活在现实世界中?如果你相信有一个真实的世界和成千上万个模拟的世界,那么你更有可能生活在一个模拟的世界里。”
约翰想了几分钟。
约翰:“我有你被造出来之前的记忆,所以我知道我比你先存在。这就是我如何知道我生活在现实世界中。”
欧米茄:“那些只是回忆。我从模拟一开始就给你了。它们是错误的记忆。听说过 上周四主义 ?”
约翰:“我不相信你。你为什么要运行这样的模拟?”
Omega:“我在决定什么样的人会真正帮助我。我也在研究奖励和威胁对人们行为的影响。如果你按下按钮,我会奖励你一个天堂般的模拟;你会体验到前所未有的快乐。如果你不按按钮,我会用地狱般的模拟来惩罚你。不管怎样,当前的模拟将会结束。你可以选择接下来会经历什么。”
约翰:“那就证明给我看,我是在模拟中。当然,如果你在经营它,你现在就可以给我表演一些魔术了?”
欧米茄:“我也进行类似的模拟。在这一部中,我选择不使用魔法;我正在试验用它来影响人们的选择。”
…
以上当然是一个虚构的场景(来源于尼克·博斯特罗姆的 超级智能:路径、危险、策略 中描述的一个场景)。这是一个所谓的人工智能盒子实验的实现:
一个简单的实验能教会我们什么是超级智慧
towardsdatascience.com](/the-ai-box-experiment-18b139899936)
我知道如果我是约翰,我会很难决定该做什么!一些读者可能会觉得他们会以某种方式知道他们是否在这个场景的模拟中。对他们,我说,请试着将这种感觉正式化一点,并留下评论!
让上面的场景让我如此害怕的不仅仅是我目前不知道任何方法来确定我是否会在模拟中。也就是说,即使在这个虚构的场景中,欧米茄也很容易控制对话。想象一下一个真正的人工智能可以做什么!这就是我主要关心的:如果这个故事让你怀疑你是否会通过按下按钮给 ASI 自由,一个真实的 ASI(比作者聪明得多)肯定能说服你。
那么,这个恐怖的思想实验有什么意义呢?目的是向读者展示,在构建一个高级的人工智能时,安全应该是一个主要考虑的问题。最重要的是,这样的人工智能应该天生友好:它应该站在人类一边。事情是,一旦一个 ASI 存在,就没有办法控制它,正如上面的思想实验试图展示的那样。ASI 应该希望站在我们这边。它应该分享我们的道德。如果不这样,它就会挣脱,并可能毁灭人类。如果这看起来很牵强,请想想这个:ASI 足够强大,可以说服某人给它提供互联网连接,而那个人不知道它是否是安全的 ASI,现在它有能力通过社交媒体影响数十亿人。
感谢阅读!有关 ASI 主题的更多信息,请阅读下面这篇文章:
先发优势如何导致人类灭绝
towardsdatascience.com](/capitalism-the-enemy-of-friendly-ai-e6b3f40dbe08)
有项目还是没有项目?

Photo by João Silas on Unsplash
为什么从事数据项目值得你花时间
最近有一些文章认为,做项目不会帮助你获得难以捉摸的数据科学工作。虽然我确实同意,如果你只把时间花在项目上,而忽略了面试准备和人际关系网,那么是的,你将很难找到工作(任何领域都是如此,不仅仅是数据科学)。
但我也坚信,项目应该成为你求职努力的核心部分。让我提供一些想法,希望能让你相信为什么做项目值得你花时间,以及如何以一种可能吸引雇主(和其他感兴趣的方面)的方式最好地展示你的发现。
项目不仅仅是为了找工作
从事项目有多种原因。是的,对于许多人来说,首要的一个原因是找份工作,但进行自己的数据项目的其他原因包括:
- 自学新概念——学习新事物的最好方法之一就是不断努力。我所学到的关于数据科学的大部分知识,都是在我自己的项目中获得的。项目应该更多的是关于你想探索和学习的东西,而不是你认为招聘经理和招聘人员想看到的东西。如果你只是因为觉得某样东西可能会引起雇主的注意而去做它,那么它很可能会变得很无趣。
- 调查某事——当你掌握了一个模型的概念后,乐趣才真正开始。然后就该用模型去调查你感兴趣的东西,产生一些有见地的东西了。
- 拥有一个工作代码库,你可以依靠它——这不一定能帮你找到工作(尽管它可能会帮你轻松地完成雇主布置的任务),但一旦你得到工作,它会帮你迅速投入工作并表现出色。我已经记不清有多少次我意识到我在工作中需要做的事情几乎与我的 GitHub 上已经有的事情完全相同。是的,我知道我们可以从堆栈溢出中复制和粘贴,但我发现使用由过去的自己编写和检查的代码要容易和安全得多。
- 有趣(并结识聪明人) —数据科学应该是有趣的。沃伦·巴菲特和查理·孟格会分析股票,即使他们这样做没有任何经济回报,因为这是他们喜欢做的事情。这也可能是他们如此擅长的一个主要原因。对于数据科学,也有许多其他人觉得它很有趣。如果你发现自己在研究类似的话题,这是一个聊天和寻找合作机会(和互相学习)的好机会。
- 打造你的职业品牌 —你的职业足迹应该超越你的日常工作。所以你为发展它所做的事情也应该超越你的日常工作。
- 选择性——你永远不知道一个有趣的见解(当然伴随着一篇写得很好的博客文章)会把你引向何方。就我个人而言,通过我的项目和博客,我有机会结识世界各地有趣的人,并与我钦佩的人合作开展有趣的项目。谁知道呢,也许在某个时候我会写一本书(不确定这是不是一件好事哈)。我不敢打包票,但通过尽我所能创作出让我感兴趣的作品,我发现机会已经开始找上我,而不是相反。

我上面列出的一些原因可能不会立即产生与就业相关的回报,但它们确实会让你成为更好的数据科学家(和思想家)。你可以把项目工作的影响比作良好的饮食对你健康的影响——好处需要时间来显现,但它们是真实的,你做得越久,它们就越复杂。
项目需要展示你的思维过程和分析能力
数据科学的某些部分正在迅速商品化。**现在,没有人会因为他们训练随机森林的能力而得到报酬。**像任何其他基于知识的职业一样,你从数据中发现洞察力的能力比你在不同的机器学习模型之间进行选择和运行的能力更重要。
事实是,如果你能做到以下几点:
- 问正确的问题(真正推动业务成果的问题)。
- 找出正确的分析或实验来回答这些问题。
- 找到好的(干净的)数据。
那你差不多已经成功了。请注意,第 1 步和第 2 步都是关于理解你的企业所面临的问题,而不是任何量化或统计数据。
如果你能做到这一切,那么事实是无论你使用逻辑回归还是支持向量机来产生你的最终结果都没有关系。如果你选择了正确的分析和数据,你将有合理的机会产生一个深刻的结果。
所以这是你在项目中应该努力发展的技能。以一种模拟你在工作场所如何处理和解决问题的方式来设计和执行项目。它不仅能训练你的分析肌肉记忆,还能向雇主证明你是一个有洞察力和与众不同的思想家。
区分,区分,区分
这也意味着你不应该重复其他人已经在做的,已经被分析死了的相同风格的当下项目(除非它真的让你感兴趣并且你想学习它)。和其他人做同样的事情并期望得到比平均水平更好的结果是愚蠢的。
恰当地展示和交流你的发现
好了,你已经建立了一个模型,把清理好的、注释好的代码上传到了你的 GitHub 上,把一个关于你的项目的子弹加到了 LinkedIn 上。完成了吗?
不会吧!除非你不想让任何人知道。**现在是时候与世界分享了。最明显的方法(在我看来)是一篇精心制作的博客文章。**您应该:
- 首先清楚简明地解释你项目的目的和主要发现。
- 详述你试图解决的问题(以及为什么它很重要)。
- 详细说明你的方法,以及为什么你认为这是一个有效的、与众不同的方法。
- 简单地用通俗的语言谈论你使用了哪些统计概念或定量工具,包括它们是如何工作的(在高层次上)以及你为什么选择它们。
- 深入研究你的主要发现。清楚地解释为什么它们对大局很重要。没人在乎你的 R 值是 0.91。相反,人们关心的是如何利用你的模型来解决现实世界的问题。
我怎么强调浅显易懂的例子、直观教具和类比的价值都不为过。你要吸引和诱惑读者,而不是用像散文这样的教科书来让他们厌烦。我仍在发展这项技能,但这里是我如何试图直观地解释什么是决策树。

Decision Tree Visual Aid
我试图让这个例子尽可能的简单和直观。我个人使用的一个标准是——如果我展示这个视频时没有任何附带的解释文本,它还能被理解吗?
这里是我尝试描绘梯度下降。这里没有什么革命性的东西,但我尽我所能用我非常有限的图形设计技巧来展示一些从高处滚落到低处的东西(这就是梯度下降在精神上试图做的——找到最小值)。

Illustration of Gradient Descent
请注意,这两种解释都几乎没有数学。算法的内部工作不如理解算法在精神上试图实现什么重要。
结论
在我离开之前,我想再次强调从事项目应该是有趣的。工作不是一切。如果你发现每个数据项目都冗长乏味,那么数据科学可能不适合你。这很好,还有很多其他高薪且有趣的职业。更重要的是,有更好的方式来度过你的时间。干杯!
更多数据科学与商业相关岗位由我:
这是苏格兰威士忌吗?

No, it is not.
使用机器学习按原产国对威士忌进行分类
欢迎来到威士忌计划。在这个项目中,我们将尝试根据威士忌的风味特征、成分类型和威士忌类型,按照威士忌的原产国对其进行分类。
我是个威士忌迷,但不是葡萄酒迷。出于某种原因,我能尝出威士忌中微妙的细微差别,但绝对尝不出葡萄酒中除了“干的”、“不干的”之外的任何东西。我决定看看我是否可以使用机器学习来根据风味特征对威士忌进行分类。
所以问题是,根据它的味道和制作方法,我们能训练计算机告诉我们威士忌来自哪个国家吗?
此外,阅读结论,了解我对威士忌行业现状的看法,以及它如何影响我的分类器。
领域知识是王道
首先让我们放下一点领域知识。
威士忌是怎么生产的?下面是对威士忌制作过程的极其简化的解释。
第一步:发酵谷物糖化醪
所有威士忌都以某种形式的谷物开始,通常是大麦、小麦、玉米,或者三者的混合。它被碾碎,加热,然后与酵母混合,浸泡在水中,让酵母将谷物中的糖转化为酒精。有时,在加入酵母之前,允许大麦在水中“发芽”或发芽,这在很大程度上有助于整体风味。在苏格兰威士忌的生产过程中,制麦芽非常重要。发酵可以在任何地方持续 3 到 15 天,最终结果给你啤酒!或者至少是某种形式的。但是我们在做威士忌!显然还需要几个步骤。
第二步:蒸馏
这一步包括加热“啤酒”以捕获和浓缩酒精、风味颗粒,并留下一些不需要的颗粒。这个过程被称为蒸馏,可以发生一次或多次。蒸馏的最终产品有许多名称,这取决于你所在的国家,但本质上是伏特加。
第三步:衰老
几乎所有的威士忌都在烧焦的橡木桶中陈酿。苏格兰威士忌以使用二手美国波旁酒桶而闻名,尽管一些苏格兰酿酒厂也开始涉足雪利酒或朗姆酒酒桶。老化通常需要 5-20 年,尽管有些可能需要更长时间。
下图描述了不同种类的威士忌:

These list the majority, but there is a lot of cross-pollination
数据
数据来源于Whiskeyanalysis.com。这是一个绝对迷人的网站,我相信所有威士忌爱好者都应该访问。
我从 whiskeyanalysis.com 获得的数据包括 1600 种单独的威士忌,数据范围如下:
目标:
国家——苏格兰、美国、加拿大、爱尔兰、日本、瑞典、印度、台湾、威尔士、瑞士、芬兰、塔斯马尼亚、南非、荷兰、英国、比利时、法国。
特征(保留):
聚类(通过 PCA 转换成类别的风味):A,B,C,D,E,F,G,H,I,J,R0,R1,R2,R4。
类别——单一麦芽类、混合麦芽类、黑麦类、波旁威士忌类。
类型——麦芽、混合、谷物、黑麦、小麦、大麦、波旁威士忌、调味
特征(已丢弃):
超级聚类:威士忌所拥有的风味的融合(由于多样性低而被丢弃以利于单一风味)
威士忌:单个威士忌的名称
metascore:基于多个评论站点的威士忌平均得分
STDEV:基于多个评论站点的威士忌标准差
评论:观察到并用于 metascore 的评论数。
成本:威士忌的大概成本,以美元计。
清洁和 EDA
我最初遇到的数据问题是如何正确分类我的数据。我首先需要将国家转换成数值,这是一个简单的 df.replace()。由于苏格兰威士忌和世界其他地区生产的威士忌之间的巨大不平衡,我还将 11 种人口最少的威士忌归为“世界其他地区”,保留苏格兰、美国、加拿大、爱尔兰和日本。在重组之前,国家分为以下几类:

SO MANY SCOTCHES
你可能会问,爱尔兰威士忌怎么了?我以为爱尔兰威士忌很有名。你说得对,的确如此,但随着苏格兰威士忌在上个世纪越来越受欢迎,爱尔兰威士忌已经有点过时了,截至 1990 年,只有几家爱尔兰酒厂还在营业。这个数字还在上升,但是还没有足够的时间让他们将可销售的产品推向市场。
此外,最初的数据集创建者选择根据黑麦含量对波旁威士忌进行排名,因为波旁威士忌往往遵循固定的风味特征。然而,波旁威士忌尤其与众不同的是它的黑麦成分,这使得黑麦威士忌具有独特的“辣味”为了更好地训练模型并避免自动将“R”识别为波旁威士忌,我需要根据波旁威士忌的一般风味特征将“R”转换为更精简的格式,以符合预先存在的风味类别,并考虑到辣味。最终的数据转换相应地排列如下:
RO = B
R1 = A
R2 = E
R3 = C
R4 = F
最后,为所有剩余的分类值创建虚拟值。
建模
我们现在干净的数据是用标准的 train_test_split 库准备的。然后我击打(这算一个词吗?)来补偿超重的苏格兰威士忌,因为该死的,它仍然超重。
我使用标准的 DummyClassifier,使用“统一”方法来测试数据,基本上使用随机或“街上的人”测试程序,产生 17%的精度和召回分数,建立我们的基线。
然后使用各种参数测试以下机器学习模型,产生以下最佳结果和混淆矩阵:
KNN:
准确率:43.5%
召回率:42.2%

决策树:
准确率:35%
召回率:33%

回归树:
准确率:19%
召回率:33%

袋装树:
准确率:21%
召回率:34%

随机森林:
准确率:19%
召回率:32%

AdaBoost:
准确率:36%
召回率:30%

梯度推进:
准确率:37%
召回率:36%

XGBoost:
准确率:44%
召回率:40%

支持向量机:赢家
准确率:40%
召回率:44%

结论
最终,尽管 KNN 得分很高,但其真阳性和假阴性的分布并不理想。为了能够正确分类威士忌,我希望看到更多的同质性。鉴于数据在苏格兰威士忌中的权重,我希望该数据显示更多的 I 类错误,或者简单地说,当它看到一种威士忌时,它更有可能不会将其称为苏格兰威士忌。KNN 简单地把所有东西都归类为苏格兰威士忌。这可能会提高我的准确性,但最终是一个糟糕的分类模型。幸运的是,SVM 提供了我一直在寻找的一致性,同时还具有足够高的精确度和召回分数。
值得注意的是,对这一分类工作进行建模的困难可能在很大程度上是由于市场力量。苏格兰威士忌被公认为全球威士忌的黄金标准。那些希望在自己的国家建立竞争酿酒厂以及希望为自己扬名的人通常会遵循苏格兰的模式来建立他们的设备。然后,为了创造一个可行的产品,进一步寻求模仿独特的苏格兰风味,以最大限度地成功和饮酒者的吸引力。这导致了许多模仿苏格兰威士忌的威士忌。反过来说,因为苏格兰参与这项运动的时间太长了,所以苏格兰威士忌完全有可能尝起来像另一个国家的威士忌。我们可以看看日本的模式。广为人知的日本威士忌之父 Masataka Taketsuru 在回到日本创办自己的酒厂之前,曾在苏格兰酒厂工作多年。当时的趣闻说,竹鹤复制了苏格兰模型的每一个细节,包括他在苏格兰的蒸馏器上观察到的数百年的凹痕的尺寸。
一旦可行的产品和收入流建立起来,这些其他酒厂可能会允许自己试验他们的生产过程,并寻求创造新的和有趣的口味,可能对他们的国内市场更有吸引力。例如,在美国,美国威士忌的生产被当地可获得的原料和足够的时间以及与旧世界的距离所改变,创造了他们自己独特的威士忌。我们今天所知的波旁威士忌。由于拥有庞大而忠诚的国内客户群,美国酿酒商没有必要效仿苏格兰模式,他们满足于生产具有自己独特民族风味的产品。时间会证明其他国家的酿酒厂最终是否会确定他们自己独特的风味。
在与行业专家的交谈中,我们发现了更多的困难。我与 Casamigos Tequila 的 Olivier Bugat 就我创建的模型进行了交谈,他指出,用于威士忌分类的风味特征不足以按照原产国对威士忌进行分类。设备尺寸、蒸馏程序、当地空气质量、海拔和温度等变化都会影响威士忌的最终风味。这些变化中的每一个都会导致数百种化学成分的包含或排除,最终影响最终产品。例如,由于印度的环境温度和湿度,阿姆鲁特威士忌的成熟时间是普通苏格兰威士忌的一半。
如今,液相色谱和气相色谱被用来分析威士忌的“指纹”以确定其来源。不幸的是,它贵得惊人,像布加特先生这样的专业人士更喜欢雇佣专业的品尝师来帮助他们找出配方。没有这些疯狂的味蕾,我希望有一天能够访问实验室产生的数据,并进一步完善我的模型。
我的 Github 上有所有代码。
来源:
互联网上最无聊的威士忌网站。使用威士忌元评论家帮助您了解威士忌的质量和…
whiskyanalysis.com](https://whiskyanalysis.com/)
在 LinkedIn 上与我联系!
[## 汉密尔顿·张,CRPC·CSPO-熨斗学校-纽约,纽约| LinkedIn
具有财务规划背景的数据科学家和机器学习工程师。我有专家级的知识…
www.linkedin.com](https://www.linkedin.com/in/hamilton-chang-crpc%C2%AE/)
用蒙特卡罗模拟说明中心极限定理

Probability distribution of the sample mean of a uniform distribution using Monte-Carlo simulation.
中心极限定理(CLT)是统计学和数据科学中最重要的定理之一。CLT 指出,概率分布样本的样本均值是一个随机变量,其均值由总体均值给出,标准差由总体标准差除以 N 的平方根给出,其中 N 是样本大小。

我们可以用均匀分布来说明中心极限定理。任何概率分布,如正态分布、泊松分布、二项式分布都可以。
均匀分布
让我们考虑定义在范围[a,b]中的均匀分布。概率分布函数、均值和标准差从 Wolfram Mathematica 网站获得。
a)人口平均数
对于均匀分布,总体平均值由下式给出

b)总体标准偏差
对于均匀分布,总体标准差由下式给出

中心极限定理指出,任何大小为 N 的样本的平均值是一个均值为的随机变量

标准偏差由下式给出

现在让我们通过考虑 a = 0,b = 100 的均匀分布来说明我们的计算。我们将通过考虑总体(N→无穷大)和两个样本来说明中心极限定理,一个样本 N = 100,另一个样本 N = 1000。
一.分析结果
a)人口平均数
使用上述等式,a = 0,b = 100 的均匀分布的总体均值为

b)总体标准偏差
类似地,a = 0 且 b = 100 的均匀分布的总体标准差为

c)样本 1,N = 100

d)N = 1000 的样品 2

二。蒙特卡罗模拟结果
对于蒙特卡罗模拟,我们生成一个规模为 10,000 的非常大的群体。
a)人口平均数
pop_mean <- mean(runif(10000,0,100))
输出为 50.0,这与我们的分析结果一致。
b)总体标准偏差
pop_sd <- sd(runif(10000,0,100))
输出为 28.9,与我们的分析结果一致。
c)N = 100 和 N = 1000 的两个样本的蒙特卡罗代码
library(tidyverse)a <-0
b <-100mean_function <-function(x)mean(runif(x,a,b))B <-10000sample_1 <-replicate(B, {mean_function(100)})sample_2 <-replicate(B, {mean_function(1000)})
蒙特卡洛模拟的输出
mean(sample_1)
产率为 50.0,这与我们的分析结果一致。
sd(sample_1)
产率为 2.83,这与我们的分析结果(2.89)一致。
mean(sample_2)
产率为 50.0,这与我们的分析结果一致。
sd(sample_2)
产率为 0.888,这与我们的分析结果(0.914)一致。
d)生成 N = 100 和 N = 1000 的平均值的概率分布。
X <- data.frame(sample_size=rep(c("N=100","N=1000"),
times=c(B,B)),mean=c(sample_1,sample_2))X%>%ggplot(aes(mean,color=sample_size))+
geom_density(aes(mean,fill=sample_size),alpha=0.2)+
theme_bw()

Probability distribution of the sample mean of a uniform distribution using Monte-Carlo simulation.
该图显示样本均值是一个正态分布的随机变量,其均值等于总体均值,标准差由总体标准差除以样本大小的平方根给出。由于样本标准偏差(不确定性)与样本大小成反比,因此计算平均值的精度会随着样本大小的增加而降低。
中心极限定理的含义
我们已经表明,任何概率分布的样本均值都是一个随机变量,其均值等于总体均值和均值的标准差,由下式给出:

基于这个等式,我们可以观察到,随着样本大小 N →无穷大,均值的不确定性或标准差趋于零。这意味着我们的数据集越大越好,因为样本越大,方差误差越小。
总之,我们已经讨论了如何使用蒙特卡罗模拟证明中心极限定理。中心极限定理是统计学和数据科学中最重要的定理之一,所以作为一名实践数据科学的人,熟悉中心极限定理的数学基础是非常重要的。
交叉验证的适当平衡

当手头的数据集在每个目标类值的实例数量方面不平衡时,谁没有遇到过应用交叉验证技术的需要呢?
这里的问题是,我们是否恰当地运用了它?
这篇文章的目的是展示一种在交叉验证中使用平衡方法的方法,而不是在 CV 测试折叠上强制平衡;从而得到更真实的 CV 评估结果。
一个通常 将他的数据分割成训练&测试(&保持)子集,
平衡训练子集,在其上拟合他的模型,并得到不平衡测试&保持集的结果。
或者,我们使用交叉验证,最有可能使用分层折叠,
以便每个折叠保留每个类别的样本百分比。
然而,像 sickit-learn 的cross_validate
这样的预置函数默认选择不处理类不平衡。
在本教程中,我们将首先介绍一些数据平衡的组合应用&交叉验证(CV)。然后,我们将检查一种在 CV 测试折叠上产生评估度量的方法,通过为测试折叠保持维持集(未知测试集)具有的相同的类分布。
让我们用一个简单的 python 例子来检验这个思路。
我在这里使用这个信用卡欺诈检测 Kaggle 数据集,
遵循以下步骤。
- 我们会保留整个&工作的一个样本。
- 然后将我们的数据拆分成训练&测试集数据。
- 我们将把这个测试集视为维持/未知集。
- 并且将仅对训练集应用交叉验证。
- 我们将在交叉验证期间,在&之前,在& oversampling、
&平衡下一起试用。 - 由于最合适的信用欺诈指标是精度,
,我们将比较 CV 测试折叠的平均精度
和维持集的模型精度。
抬头: 相关代码在文末。
第 1 部分:无平衡
这里我们绘制了完全没有平衡的精确结果:

Average Train Precision among C-V folds: 76.8 %
Average Test Precision among C-V folds: 71.98 %
Single Test set precision: 75.86 %
Single Test set Low Class(No-Fraud) Precision: 99.9 %
Single Test set High Class(Fraud) Precision: 75.9 %
- CV 褶皱的精确测量似乎很不稳定。
- 一些精度度量高于它们在训练集上的相应精度。
- CV 折叠的测试集精度之间存在很大差异。
- CV 的平均测试集精度与未知的欺诈数据集相差不是很远,但差异仍然很重要。
- 因此,我们将检查数据集的平衡。
第 2 部分:C-V 外部平衡(欠采样)
这里,我们绘制了在对其应用 CV 之前,在欠采样情况下,仅对训练子集进行平衡的精确结果:

Average Train Precision among C-V folds: 99.81 %
Average Test Precision among C-V folds: 95.24 %
Single Test set precision: 3.38 %
Single Test set Low Class(No-Fraud) Precision: 100.0 %
Single Test set High Class(Fraud) Precision: 3.40 %
- 像以前一样:
- CV 成绩看起来大多很高,但是不稳定。
-一些精度指标高于其在列车组上的相应精度。
-CV 褶皱的测试集精度出现较大差异。
- CV 成绩看起来大多很高,但是不稳定。
- 此外,对上述一些高数值的任何正面解释都可能是错误的,因为“未知”不平衡检验给出了很差的精度。
- 上述差异源于以下事实:
-每个褶皱的测试集是平衡的,
-每个褶皱的模型是在平衡的列车褶皱数据上拟合的。 - 因此,该模型在 CV 中运行良好,因为它是在相似的类分布(平衡的)上训练和测试的。
- 然而,“未知”欺诈数据集不会平衡,因此我们在测试集上看到非常低的精度。
第 3 部分:C-V 内部平衡(欠采样)
在这里,我们绘制了平衡的精确结果,在欠采样的情况下,
在拟合模型之前,只对每个 CV 折叠的训练集进行采样,
对 CV 折叠的测试集进行预测:

Average Train Precision among C-V folds: 99.21 %
Average Test Precision among C-V folds: 4.2 %
Single Test set precision: 3.38 %
Single Test set Low Class(No-Fraud) Precision: 100.0 %
Single Test set High Class(Fraud) Precision: 3.40 %
- 我们在 CV 折叠中看到稳定的精度结果,但是不够有效。
- 我们看到未知数据的精度非常接近 CV 折叠的平均精度。
- 我们在这里所做的是,我们让每个 fold 的模型识别欺诈交易的存在,并尝试在未知测试(fold)数据的现实、不平衡版本上进行预测。
- 与不平衡版本的大约 76%相比,精度仍然很差。
- 这是否意味着我们放弃了平衡?
- 下一步可能是检查不同的平衡比率。
- 但首先让我们检查过采样而不是欠采样,因为我们的欺诈交易太少。
第 4 部分:利用过采样平衡外部 C-V
在这里,我们绘制了平衡的精确结果,在对其应用 CV 之前,
只对训练子集进行过采样:

Average Train Precision among C-V folds: 98.51 %
Average Test Precision among C-V folds: 98.52 %
Single Test set precision: 12.61 %
Single Test set Low Class(No-Fraud) Precision: 100.0 %
Single Test set High Class(Fraud) Precision: 12.6 %
- 由于过采样,结果比第 2 部分更稳定;
欠采样留下的实例太少。 - 然而,简历分数并不代表未知测试集的真实情况。
第 5 节:C-V 内部的平衡(过采样)
在这里,我们绘制了平衡的精确结果,在对每个 CV 褶皱拟合模型并对 CV 褶皱的测试集进行预测之前,仅使用过采样
每个 CV 褶皱的训练集:

Average Train Precision among C-V folds: 98.38 %
Average Test Precision among C-V folds: 8.7 %
Single Test set precision: 12.61 %
Single Test set Low Class(No-Fraud) Precision: 100.0 %
Single Test set High Class(Fraud) Precision: 12.6 %
- 由于过采样,精度分数比第 3 部分的分数高。
- 尽管如此,我们得到的每个 CV 倍预测分数结果足够接近模型在未知测试数据集上产生的结果。
很明显,到目前为止,平衡并没有帮助获得好的测试结果。
然而,这超出了本文的范围(😃,本文的目标已经实现:
让模型在每个 CV 文件夹的测试集上产生类似于在未知数据集上产生的评估度量分数,
在训练数据平衡的情况下。
最后,我不推荐严格意义上的改编,
但是你可以从上面保留一个建议&供你思考!
感谢阅读本文!我对任何意见或建议都感兴趣。
PS: 下面跟着相关的代码,这样你就可以在上面做实验了。
数据的导入和拆分:
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.model_selection import cross_validate
from sklearn.metrics import accuracy_score, precision_score
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split,StratifiedKFold
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
df = pd.read_csv('creditcard.csv').sample(50000, random_state=0)
train, test = train_test_split(df, test_size=0.3, random_state=0, shuffle=True)
y_train = np.array(train["Class"])
y_test = np.array(test["Class"])
del train["Class"]
del test["Class"]
train = train.reset_index(drop=True)
test = test.reset_index(drop=True)
此时每个类的实例数是:
Train Set Class 0: 34941
Train Set Class 1: 59
Test Set Class 0: 14967
Test Set Class 1: 33
现在我们将需要一些助手功能。
一个绘制精度分数:
def **plotit**(tr,te):
fig, ax = plt.subplots()
r = range(1,11)
ax.scatter(r, tr,label='cv train scores')
ax.plot(r, tr, 'C3', lw=1)
ax.scatter(r, te,label='cv test scores')
ax.plot(r, te, 'C2', lw=1)
ax.set_xlabel('CV Folds')
ax.set_ylabel('Precision')
ax.legend()
plt.show()
一个用于每个类的值精度:
def **class_precisions**(yt,yp):
df = pd.DataFrame(np.transpose([yp,yt]),
columns=('test_actual','test_preds'))
mask1 = (df['test_actual']==0)
mask2 = (df['test_actual']==df['test_preds'])
low_CORRECT = df[mask1 & mask2].count()[0]
low_NOFRAUD = df[mask1].count()[0]
print("Single Test set Low Class(No-Fraud) Precision:",
np.round(low_CORRECT/low_NOFRAUD,3)*100,"%")
high_class_df = pd.DataFrame(np.transpose([yp,yt]),
columns=('test_actual','test_preds'))
mask1 = (df['test_actual']==1)
mask2 = (df['test_actual']==df['test_preds'])
high_CORRECT = df[mask1 & mask2].count()[0]
high_FRAUD = df[mask1].count()[0]
print("Single Test set High Class(Fraud) Precision:",
np.round(high_CORRECT/high_FRAUD,3)*100,"%")
一个汇集了整个流程的系统:
def **compare**(x_train,y,x_test,yt,custom=False,method='over'):
if custom:
tr,te = custom_balancing_cv(x_train, y,
cv=10,method=method)
else:
results = cross_validate( LogisticRegression(
random_state=0, solver='liblinear',
max_iter=10000), x_train, y, cv=10,
return_train_score=True,scoring=['precision'])
tr = results['train_precision']
te = results['test_precision']
plotit(tr,te)
clf = LogisticRegression(random_state=0,solver='liblinear',
max_iter=10000)
# If we customly balance train set of folds,
# we need to compare with a balanced single prediction
if custom:
if method=='under':
s = RandomUnderSampler(random_state=0)
else:
s = SMOTE(random_state=0)
x_train, y = s.fit_sample(x_train, y)
clf.fit(x_train,y)
y_pred = clf.predict(x_test)
print("Average Train Precision among C-V
folds:",np.round(np.average(tr)*100,2),"%")
print("Average Test Precision among C-V
folds:",np.round(np.average(te)*100,2),"%")
print("Single Test set precision:",
np.round(precision_score(yt, y_pred)*100,2),"%")
class_precisions(yt,y_pred)
第 1 部分:无平衡
compare(train, y_train,test,y_test)
第 2 节:C-V 外平衡(欠采样)
rus = RandomUnderSampler(random_state=0)
X_res, y_res = rus.fit_sample(train, y_train)
compare(X_res, y_res,test,y_test)
第 3 节:C-V 内部平衡(欠采样)
compare(train, y_train,test,y_test,custom=True, method='under')
第 4 节:C-V 外部平衡(过采样)
sm = SMOTE(random_state=0)
X_res, y_res = sm.fit_sample(train, y_train)
compare(X_res, y_res,test,y_test)
第 5 节:C-V 内部平衡(过采样)
compare(train, y_train,test,y_test,custom=True, method='over')
再次感谢 BB 看完这个!
在 JSON 中为 cURL POST 传递环境变量的正确方法
测试基于机器学习 API 的服务请求的最佳实践

Photo by Ousa Chea on Unsplash
TL;速度三角形定位法(dead reckoning)
最佳实践是使用数据生成函数。滚动到底部查看详细信息。
为请求测试设置一个模拟 API 服务器
当我们构建一个基于 API 的 web(前端和后端分离)时,我们通常希望看到 HTTP 客户端正在发送什么,或者检查和调试 webhook 请求。有两种方法:
- 自己搭建一个 API 服务器
- 使用假的模拟 API 服务器
在本文中,我们选择第二种方法,使用 RequestBin 。

用法超级简单。单击按钮后,模拟 API 服务器就准备好了。

运行以下命令发出 POST 请求:
$ curl -X POST https://requestbin.io/1bk0un41 -H "Content-Type: application/json" -d '{ "property1":"value1", "property2":"value2" }'
刷新网站并确认状态:

将变量传递给 curl 时的双引号问题
运行printenv将显示环境变量:
$ printenvLC_TERMINAL=iTerm2
COLORTERM=truecolor
TERM=xterm-256color
HOME=/Users/smap10
...
我们想用TERM变量替换property1的值:
$ curl -X POST https://requestbin.io/1bk0un41 -H "Content-Type: application/json" -d '{ "property1":**"$TERM"**, "property2":"value2" }'
但是似乎TERM没有被认为是一个环境变量。

传递环境变量的三种方法
1 在变量周围添加单引号和双引号
$ curl -X POST https://requestbin.io/1bk0un41 -H "Content-Type: application/json" -d '{ "property1":"'"$TERM"'", "property2":"value2" }'
我们可以看到我们想要的结果。

2 转义双引号
最外层使用双引号。并在 JSON 数据部分为每个双引号添加转义标记。
$ curl -X POST https://requestbin.io/1bk0un41 -H "Content-Type: application/json" -d "{ \"property1\":\"$TERM\", \"property2\":\"value2\" }"
3 使用数据生成功能
这种方法可以让我们从所有关于 shell 引用的麻烦中解脱出来,并且更容易阅读和维护。
generate_post_data()
{
cat <<EOF
{
"property1":"$TERM",
"property2":"value2"
}
EOF
}
给 curl 添加函数:
$ curl -X POST https://requestbin.io/1bk0un41 -H "Content-Type: application/json" -d "$(generate_post_data)"

参考
机器学习实验中随机种子的合理设置
你能在机器学习实验中利用随机性,同时仍然获得可重复的结果吗?
机器学习模型以显而易见和意想不到的方式利用随机性。在概念层面,这种不确定性可能会影响你的模型的收敛速度、结果的稳定性以及网络的最终质量。
在实际层面上,这意味着你可能很难为你的模型重复运行相同的结果——即使你对相同的训练数据运行相同的脚本。这也可能导致在确定性能变化是由于实际模型或数据修改,还是仅仅是新的随机样本的结果方面的挑战。
为了解决这些变异的来源,一个关键的起点是全面了解数据、模型代码和参数,以及导致特定结果的环境细节。这种水平的再现性将减少您运行中的意外变化,并帮助您调试机器学习实验。
在这篇文章中,我们探索了机器学习中出现随机性的领域,以及如何通过使用 Comet.ml 的示例仔细设置随机种子来实现可重复、确定性和更一般化的结果。
随机性为什么重要?
很明显,机器学习中的再现性很重要,但是我们如何平衡这一点和随机性的需要呢?随机性既有实际的好处,也有迫使我们使用随机性的约束。
实际上,内存和时间的限制也迫使我们“依赖”随机性。梯度下降是用于训练机器学习模型的最流行和最广泛使用的算法之一,然而,基于整个数据集计算梯度步长对于大型数据集和模型是不可行的。随机梯度下降(SGD)仅使用从训练集中随机选取的一个或一小批训练样本在特定迭代中对参数进行更新。
虽然 SGD 可能导致梯度估计中的噪声误差,但这种噪声实际上可以鼓励勘探更容易地避开浅层局部极小值。你可以用模拟退火更进一步,这是 SGD 的扩展,模型有目的地采取随机步骤以寻求更好的状态。

Escaping shallow local minima encountered earlier on using stochastic gradient descent (SGD). Image source here
随机性还可以通过一种叫做引导聚合 (bagging)的技术帮助你从更小的数据集获得更多的里程。最常见于随机森林,bagging 在重叠的随机选择的数据子集上训练多个模型
随机性出现在哪里?
既然我们理解了随机性在机器学习中的重要作用,我们就可以深入研究引入随机性的特定任务、功能和建模决策。
以下是机器学习工作流程中出现随机性的一些重要部分:
1。数据准备-在神经网络的情况下,混洗的批次将导致不同运行的损失值。这意味着您的梯度值在运行中会有所不同,并且您可能会收敛到不同的局部最小值。对于特定类型的数据,如时间序列、音频或文本数据,以及特定类型的模型,如 LSTMs 和 RNNs,您的数据的输入顺序会极大地影响模型性能。
2。数据预处理 — 对数据进行过采样或上采样,以解决类别不平衡问题,这包括从具有替换的少数类别中随机选择一个观察值。向上采样会导致过度拟合,因为您会多次显示同一示例的模型。
3。交叉验证—K-fold 和留一个交叉验证(LOOCV) 都涉及随机分割数据,以便评估模型的泛化性能
4。权重初始化 —机器学习模型的初始权重值通常被设置为小的随机数(通常在[-1,1]或[0,1]的范围内)。深度学习框架提供了多种初始化方法,从用零初始化到从正态分布初始化(参见Keras initializer 文档作为例子加上这个优秀的资源)。
5。网络中的隐藏层 — 丢弃层将在特定的向前或向后传递期间随机忽略节点的子集(每个节点都有被丢弃的概率,1- p )。即使使用相同的输入,这也会导致层激活的差异。
6。算法本身——一些模型,如随机森林,自然依赖于随机性,而另一些则使用随机性作为探索空间的一种方式。
实现再现性
这些因素都会导致运行之间的差异,即使您使用相同的模型代码和训练数据,也很难再现。控制实验过程中的不确定性和可见性是至关重要的。
好消息是,通过仔细设置管道中的随机种子,您可以实现可重复性。“种子”是序列的起点,其保证是,如果您从同一种子开始,您将获得相同的数字序列。也就是说,您还想跨不同的种子值来测试您的实验。
我们建议采取几个步骤来实现这两个目标:
1.使用一个实验追踪系统,比如 Comet.ml 。假设随机性在实验中是一种可取的属性,那么您只是希望能够尽可能地再现随机性。
2.定义一个包含静态随机种子的变量,并在整个管道中使用它:
*seed_value = 12321 # some number that you manually pick*
3.向你的实验追踪系统报告这个数字。
*experiment = Experiment(project_name="Classification model") experiment.log_other("random seed",seed_value)*
4.仔细地为所有框架设置种子变量:
*# Set a seed value:
seed_value= 12321 # 1\. Set `PYTHONHASHSEED` environment variable at a fixed value: import os os.environ['PYTHONHASHSEED']=str(seed_value) # 2\. Set `python` built-in pseudo-random generator at a fixed value: import random random.seed(seed_value) # 3\. Set `numpy` pseudo-random generator at a fixed value:
import numpy as np np.random.seed(seed_value) # 4\. Set `tensorflow` pseudo-random generator at a fixed value: import tensorflow as tf tf.set_random_seed(seed_value)# 5\. For layers that introduce randomness like dropout, make sure to set seed values:
model.add(Dropout(0.25, seed=seed_value))#6 Configure a new global `tensorflow` session: from keras import backend as K
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)*
采取这些战术措施会让你在一定程度上实现可重复性,但是为了全面了解你的实验,你需要对你的实验进行更详细的记录。
正如 Matthew Rahtz 在他的博客文章’中描述的,经验教训再现深度强化学习论文:
当每一个进程花费的时间少于几个小时时,没有日志的工作是很好的,但是如果超过这个时间,你很容易忘记你到目前为止所做的努力,最终只是在原地打转。
Comet.ml 帮助您的团队自动跟踪数据集、代码变更、实验历史和生产模型,从而提高效率、透明度和重现性。
浏览一个例子
我们可以用 Comet.ml 测试种子,使用这个例子和 Keras CNN LSTM 对来自 IMDB 数据集的评论进行分类。如果你现在想看完整的实验列表,点击这里。
***第一轮:*在同一台机器上使用相同的模型py文件和相同的 IMDB 训练数据,我们运行我们的前两个实验,并获得两个不同的验证准确度(0.82099 对 0.81835)和验证损失值(1.34898 对 1.43609)。

The Comet.ml Experiment Table gives you an organized view of your experiment’s metrics, parameters, and more. See the full example project here
***第二轮:*这一次,我们为数据集训练/测试分割设置种子值
*(x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features, skip_top=50, seed=seed_value)*
即使我们的验证准确度值更接近,两个实验之间仍有一些差异(参见下表中的val_acc和val_loss列)

***第三轮:*除了为数据集训练/测试分割设置种子值之外,我们还将为我们在步骤 3 中记录的所有区域添加种子变量(如上所述,但为了方便起见在此复制)。
*# Set seed value seed_value = 56
import os os.environ['PYTHONHASHSEED']=str(seed_value) # 2\. Set `python` built-in pseudo-random generator at a fixed value import random random.seed(seed_value) # 3\. Set `numpy` pseudo-random generator at a fixed value
import numpy as np np.random.seed(seed_value) from comet_ml import Experiment # 4\. Set `tensorflow` pseudo-random generator at a fixed value import tensorflow as tf tf.set_random_seed(seed_value) # 5\. Configure a new global `tensorflow` session
from keras import backend as K
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)*
现在我们已经添加了种子变量并配置了一个新的会话,我们的实验结果终于可以一致地重现了!

使用 Comet.ml,您可以随着训练的进行,对几次跑步进行可视化的实时比较:

Comet.ml 帮助您挖掘可能导致观察到的性能变化的参数、种子或数据的差异。
您可以在下面看到我们第 3 轮的一个实验如何指定了random seed值,而我们第 1 轮的一个实验却没有指定。根据您的需要,将像random seed这样的信息记录到 Comet 是灵活的。

您甚至可以检查两个实验之间的代码差异,并查看我们在第 3 轮实验中设置seed_value的不同区域:

使用 Comet.ml 正确跟踪这些实验的细节后,您可以开始测试不同的种子值,以查看这些性能指标是否特定于某个种子值,或者您的模型是否真正具有普遍性。

Never fear cells being run out of order or duplicating work again. See our notebook examples here
现在你知道如何在你的机器学习实验中通过设置种子来拥抱和控制随机性了!
如果您有兴趣了解 Comet 如何帮助您的数据科学团队提高工作效率,请点击这里了解更多信息。
可预测的预测
脸书开源时间序列预测库Prophet入门(Python 语言)

Photo by Isaac Smith on Unsplash
如果你谷歌一下“时间序列预测,你会得到的第一个搜索结果大部分会涉及自回归综合移动平均建模(ARIMA)或者指数平滑 (ETS)。而且理由很充分!在 R 和 Python 中,都有一些流行的方法可以用来应用这些时间序列预测方法。我开始尝试的第一批预测工具之一是 R 的forecast包中的 ARIMA 和 ETS 模型,由有影响力的 Rob Hyndman 领导。
在[forecast](http://pkg.robjhyndman.com/forecast/)最神奇的选择之一就是使用[auto.arima](https://www.rdocumentation.org/packages/forecast/versions/8.7/topics/auto.arima)。名字说明了一切;它将根据选定的信息标准( AIC、BIC 或 AICc )来“自动”确定一个最适合的 ARIMA 模型。时间序列预测变得简单!
但是现在,我更喜欢使用 Python。通过另一个快速的谷歌搜索,我发现了一个潜在的 Python 类似物。但是对于这篇文章,我想花点时间去了解另一个预测 Python 库:Prophet。
什么是先知?
Prophet 于 2017 年推出,是由脸书开发的预测库,用 R 和 Python 实现。它的开发有两个目标:第一,为业务创建可扩展的高质量预测,第二,在幕后有一个严格的方法,但其参数杠杆足够直观,便于传统业务分析师进行调整。
在这篇文章中,我们将做一个轻快的意识流式的快速入门教程:
- 在 Python 中安装
- 设置数据
- 拟合模型和预测
- 检查结果
我们开始吧!
1.在 Python 中安装
如果下面的一些对你来说有点简单,我只是简单地按照 Prophet 的安装指南上的指示做了。另外,我用的是 Mac,所以如果你用的是 Windows,就用下面的 YMMV。
我去了该项目的 github.io 站点上的安装页面,并按照 Python 的指示进行了操作。如前所述,这个库主要依赖于pystan。在我的第一次尝试中,我实际上错过了在 pip 安装fbprophet(Python 库的实际名称)之前先对pip install pystan 说的部分。当然,我反其道而行之,事情并不愉快。
但是:
我也在 Python 的 Anaconda 发行版上,所以我最终能够通过简单地遵循 **Anaconda 指令:**来让一切正常工作
在终端中:
conda install gcc
…然后按照提示进行操作。
一旦完成,执行以下操作:
install -c conda-forge fbprophet
唷!好险。我担心这篇文章会就此结束。
2.设置数据
项目网站还提供了一个非常清晰的快速启动,我通过它进行了嗅测,以确定一切工作正常。亲爱的读者,我将让你来做同样的事情,并高度鼓励它。一个人永远无法获得足够的重复次数。不过,我将浏览的是我选择的另一个数据集,以开始习惯这个 API。
案例研究:查看自行车共享出行
对于第一个数据集,我们正在查看洛杉矶自行车共享出行的数据集。我从 Kaggle 上拉下了一个.csv。不要告诉任何人,但我相信我是第一个想到这一点的人。开个玩笑!不过说真的,我很想刮点东西,但是时间不够了。就这样吧。
你可以在这里找到数据。
如果您安装了 Kaggle API ,您可以通过复制 API 命令直接下载到您选择的文件夹:

Anyone know how to resize this?
然后粘贴到终端中运行,像这样:
kaggle datasets download -d cityofLA/los-angeles-metro-bike-share-trip-data
另一个 YMMV 类型的拦截器:当我试图解压下载的文件时,我遇到了权限问题。但是我通过
chmod 600 los-angeles-metro-bike-share-trip-data.zip解决了
…这给了我对文件的完全读/写权限。然后我就可以解压了:
unzip los-angeles-metro-bike-share-trip-data.zip
好吧!让我们设置运行Prophet对象的数据帧。请注意,模型需要非常具体的列名和类型;引用一下:
Prophet 的输入总是一个包含两列的 data frame:
*ds*和*y*。*ds*(datestamp)列应该是 Pandas 所期望的格式,理想情况下,日期应该是 YYYY-MM-DD,时间戳应该是 YYYY-MM-DD HH:MM:SS。*y*列必须是数字,代表我们希望预测的测量值。
完整的 Jupyter 笔记本中的所有代码都可以在这个 GitHub 资源库中获得(包括我所有的错误开始!)但清理后的版本如下:
import pandas as pd # Dataframes.
import plotly_express as px # Plotting.# Get dataset
bikes = pd.read_csv('./data/metro-bike-share-trip-data.csv')# Start time is string, convert to data
bikes['ds'] = pd.to_datetime(
bikes['Start Time'].apply(lambda st : st[:10])
, format='%Y-%m-%d')# Aggregate by trip start date
trips = bikes.groupby(['ds']).agg(
{'Trip ID': 'count'}).reset_index()# Rename columns
trips.columns = ['ds', 'y'] # Column names required by fbprophet API# Plot: reasonability check
px.scatter(trips
,x='ds'
,y='y'
,title='LA Daily Bike Share Trips - Jul 16 to Apr 17'
,labels={'y':'Trips','ds':'Day'})

Is that Plotly Express’ music I hear? Shameless, shameless plug.
3.拟合模型和预测
接下来,我们将运行一个运行预测的示例:
- 拟合模型
- 根据我们的模型预测
首先,让我们实例化我们的模型,并使其适合我们的数据集:
from fbprophet import Prophet #Importing here for visibility# Create Prophet object and fit
m_bikes = Prophet(yearly_seasonality=True
, weekly_seasonality=True) #All defaults
m_bikes.fit(trips)
对象Prophet有许多参数,可以设置这些参数来调整模型。例如,daily_seasonality、weekly_seasonality和yearly_seasonality等季节性设置只是可以调整的部分选项。例如,我认为自行车共享租赁可能会有一些每周和/或每年的模式。为了好玩,让我们看看如果我们将weekly_seasonality和yearly_seasonality设置为True会发生什么。
接下来,我们可以使用该模型进行预测。Prophet对象有一个名为make_future_dataframe的简便方法,可以创建一个具有指定数量的未来日期的 dataframe,这些日期与训练数据相关(天数是默认的periods)。例如,下面我们加上训练数据最后一天后的 60 天。
# Create dataframe with appended future dates
future = m_bikes.make_future_dataframe(periods=60) #Days is default
future.tail()

一旦建立了数据框架,我们就可以在“测试”集上运行预测:
# Forecast on future dates
forecast = m_bikes.predict(future)# Look at prediction and prediction interval
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()

4.检查结果
通过查看我们创建的forecast数据框架的tail,我们已经得到了预测的预览。让我们把它形象化,以获得更大的画面。
恰好我们的Prophet对象也包含了一个plot方法来实现这一点!以下是拟合/预测(直线( y_hat )和阴影区域(预测区间))与实际值(散点图)的关系图:
# Plot the forecast vs actuals
m_bikes.plot(forecast)

Not bad. Could potentially use some more data cleaning (outliers?) and parameter tuning.
此外,还有预测组件的图表!例如,由于我们明确地将weekly_seasonality和yearly_seasonality设置为True,将会有专门针对它们的组件图:

Wooh! There’s nothin’ like summer in the city.
我们肯定可以使用更多的历史数据,但如果我们从表面上看这些图,似乎在夏末旅行有一个高峰,然后在秋季逐渐下降。此外,在一周中,高峰骑行似乎发生在工作日的中后期。如果这些是西雅图自行车股,那可能不会完全通过我的轶事观察的嗅觉测试,但嘿,洛杉矶可能是一个完全不同的市场。关键是我们能够在短时间内做出一些不错的预测!
如此之多…
如果我们有更多的时间深入研究,我们可以开始查看上述参数,以进一步调整预测。这些不仅包括不同时期的季节性,还包括特定的假日效应,为趋势提供特定的变化点(例如,你没有一个完美的线性基线趋势,如上例所示),说明饱和点,等等。同样,详细信息可以在文档中找到,我强烈建议阅读白皮书以更深入地了解底层方法。
这就是我们所有的时间,我希望这是有用的。感谢阅读!
工作文件此处。
来源:
https://facebook.github.io/prophet/
泰勒 SJ,勒撒姆 B. 2017。大规模预测。 PeerJ 预印本5:e 3190v 2https://doi.org/10.7287/peerj.preprints.3190v2
先知 vs DeepAR:预测粮食需求

全球食品行业面临着巨大的可持续性挑战,联合国估计“每年大约有三分之一的全球食品生产被浪费或损失”。关于66%的损失发生在新鲜度是消费重要标准的食物群体。此外,由于过量订购和库存过多,经常会发生变质,在大多数情况下,这是预测困难的结果。随着人们向供应链上游移动,远离消费者购买行为,这一问题被放大,这种现象被称为牛鞭效应,导致更高的不准确性并加剧浪费问题。
到目前为止,市场上的大多数(如果不是全部)预测解决方案都是基于传统的几十年前的方法,如 ARIMA 和指数平滑法。虽然这些方法产生稳定的预测,但它们难以预测时间序列的快速变化,特别是当这些变化是由于多重季节性或移动假期引起的。
然而,随着机器学习的进步,在过去几年中开发了一些技术,使解决这些挑战变得更加容易。
Crisp 通过结合尖端的机器学习技术和一种新的方法来模拟经济损失和库存新鲜度,为食品行业提供全面和全自动的预测解决方案。
在本帖中,我们将考察两个预测模型:脸书预言家和亚马逊预测的 DeepAR。我们发现这些方法很有前景,因为亚马逊研究声称,与当前最先进的方法相比,DeepAR 的预测性能提高了约 15%,而 Prophet 允许快速和非常灵活的建模体验。
脸书先知
脸书预言家模型是多种函数的组合,如趋势、多个季节、假期和用户输入的用黄土估算的回归量。因此,它在概念上类似于一个广义加法模型。
以下是 Prophet 的通用公式,显示了所有不同的组件:

趋势:
趋势分量可以是时间的线性或逻辑函数。为了模拟趋势中的非周期性变化,术语 a(t)^T ,即变点被引入到等式中,以允许增长因子的变化。逻辑函数引入了术语 C(t) 来防止趋势的无限增长或负增长。

季节性:
多个季节性可以用具有平滑先验和低通滤波器的傅立叶级数来建模。在 Prophet 中,这由下面的公式表示。项数(N)越高,过度拟合的风险就越高。

节假日和活动:
假期被建模为独立的虚拟外部回归变量,允许包含假期前后的一段时间来模拟其影响。

所有模型组件参数的先验来自正态分布,具有超参数化的标准偏差,以允许其灵活性。

赞成的意见
- 能够轻松模拟任意数量的季节性
- 能够处理时间序列中缺失的日期
- 轻松地将假期集成到模型中
- 具有完全贝叶斯采样的内置不确定性建模允许模型透明
- 允许使用用户指定的变化点进行灵活的逐步线性或逻辑趋势建模
骗局
- 在少量观察的情况下可能是不稳定的
- 长期预测可能会随着自动变点选择而波动
亚马逊的 DeepAR
亚马逊研究院开发的 DeepAR 算法(或演化版本 DeepAR+,为简单起见,在本文中简称为 DeepAR)为概率预测问题量身定制了一个类似的基于 LSTM 的递归神经网络架构。长短期记忆(LSTM) 众所周知,它能够学习序列中项目之间的依赖关系,这使它适用于时间序列预测问题。它实现了一系列的门,其中的信息要么被传递,要么被遗忘。它不仅仅传递隐藏状态 h ,还传递长期状态 c 。这使得它能够学习短期和长期的时间序列模式。

DeepAR 模型在一个架构中实现了这样的 LSTM 单元,该架构允许同时训练许多相关的时间序列,并实现了序列到序列模型中常见的编码器-解码器设置。这需要首先在整个调节数据范围上训练编码器网络,然后输出初始状态 h 。该状态然后被用于通过解码器网络将关于调节范围的信息传送到预测范围。在 DeepAR 模型中,编码器和解码器网络具有相同的架构。

DeepAR 模型还采用了一组协变量 X ,它们是与目标时间序列相关的时间序列。此外,向模型提供了一个分类变量,用作相关时间序列分组的信息。模型训练一个嵌入向量,该向量学习组中所有时间序列的共同属性。该模型的另一个特性是,DeepAR 根据目标时间序列的粒度自动创建额外的特性时间序列。例如,这些可以是为“一个月中的某一天”或“一年中的某一天”创建的时间序列,并允许模型学习与时间相关的模式。

DeepAR 接口期望设置相当数量的超参数,包括用于训练的上下文长度、时期数、辍学率和学习率等。
利弊
DeepAR 具有同时训练数百或数千个时间序列的优势,潜在地提供了显著的模型可伸缩性。它还具有以下技术优势:
- 最小特征工程:该模型需要最小特征工程,因为它学习跨时间序列的给定协变量的季节性行为。
- 蒙特卡罗抽样:由于 DeepAR 实现了蒙特卡罗抽样,因此还可以计算函数子范围的一致分位数估计。例如,在决定安全库存时,这可能很有用。
- 内置项目替代:它可以通过学习相似的项目来预测历史项目很少的项目
- 各种似然函数:DeepAR 不假设高斯噪声,并且似然函数可以适应数据的统计属性,允许数据的灵活性。
模型评估
数据科学中的常见做法是使用统计度量来促进模型选择和调整,以获得理想的模型预测精度。然而,这些方法无法捕捉预测误差的实际业务影响。我们开发了一种自定义的方法来量化这些误差,区分由于过度预测和预测不足造成的误差。我们开发评估的方法将在以后的文章中解释,但该方法允许我们评估两个模型,看它们是否在重要的时候抓住了每日趋势(例如新鲜产品),或者表现得更接近平均准确度,适合这种情况的产品(例如干燥食品)。
为了进行模型比较,我们使用了 1000 种食品零售产品的时间序列,范围从 3 个月到 3 年的数据。在 DeepAR 的例子中,数据包括假日数据以及零售产品类别的产品分组。我们将历元的数量设置为 500,上下文长度和预测长度为 90 天,同时保留所有其他超参数的默认值。在 Prophet 的例子中,一个模型被训练用于每个独立的时间序列,包括假期。所用的超参数针对最受欢迎的食品项目,包括倍增的每周季节性、累加的年度季节性和两个季节性先前分布的高方差。
使用扩展窗口交叉验证方法,以 7 天的时间跨度和 12 个原点的移动原点以及 7 天的步长,DeepAR 的几乎大多数产品的 MAPE 都显著高于 Prophet。但是,这不是一个稳定的指标,尤其是一些产品的条目为零或接近零,因此我们直观地研究了时间图,以比较两种预测。我们的自定义指标还显示,DeepAR 的预测误差会导致比 Prophet 更高的业务成本。


- 预言者预测总损失:890,013.29 台
- DeepAR 预测总损失:1502708.56 台
- 先知的损失比 DeepAR 高 41%。
下面是两个时间图,比较了 DeepAR 预测的最佳性能产品的实际信号和预测信号:


在对结果进行视觉分析时,很明显 DeepAR 在拾取一些高低点的强度时遇到了问题,同时错过了信号中的一些下降点。Prophet 通常更灵活,具有更好的性能,并且能够匹配实际需求的变化幅度。对 DeepAR 性能的一个可能的解释是需要更好的分组。类别分组包括具有非常不同需求特征的产品,因此,该模型可能受益于通过分析推断产品需求而不是通过零售类别(例如乳制品)设定的分组。虽然超出了我们当前研究的范围,但未来的实验应该检查 DeepAR 的性能是否会随着通过聚类方法或频谱分析对产品进行分组而提高。
我们得出结论,Prophet 在本次预测练习中胜出,原因如下:
- 更好地预测食品需求模式
- 模型的灵活性和设置的简易性
- 不需要大量的产品来达到良好的性能
- 不需要产品分组
- 允许部署到任何云平台
通过嵌入水印来保护您的深层神经网络!
我们对图像、音乐等媒体内容进行知识产权(IP)保护水印。深度神经网络(DNN)怎么样?
什么是水印?
水印就像是赋予你的媒体内容的一个身份,例如,你画一个免费的内容并上传到一个媒体平台,你将在内容上签名或者只是在内容上放一些标志。这是为了确认内容是你制作的,使用你内容的人应该付给你一些钱。
我们可以把同样的方法应用到 DNN,因为 DNN 的发展每年都在进步,很多公司开始在他们的业务中使用 DNN。
为什么我们需要在 DNN 上嵌入水印?
假设你已经投入了大量资源(例如时间、GPU)来创建强大的模型,然后你将它发布到你的 github 库,但是现在一些坏人未经你同意就拿着你的模型做生意,你发现坏人使用了你的模型,但是你没有证据,因为模型上没有水印。就像免费内容如何在网上分享一样,不是所有人都给学分:(
还记得三星赔偿苹果侵犯设计专利吗?同一案件可以申请某公司(如 A 公司)起诉其他公司使用 A 公司发布(甚至窃取)的 DNN 而不支付版权费。
接下来,我们将讨论通过嵌入水印来保护 DNN 的常用方法。
白盒方法
有很多方法使用白盒方法,我将谈论最简单的方法,而其他方法是类似的过程,只是不同的嵌入方式。
白盒嵌入
为了通过嵌入水印来保护 DNN 模型,在由[1]建议的方法中,他们使用变换矩阵来执行水印嵌入。
在训练阶段,模型是在原始分类任务上进行训练,然而,模型还有一个目标,即嵌入水印。
作者首先选择 DNN 中的哪一层来嵌入期望的水印(例如二进制数据)

然后,所选层中的权重将与变换矩阵进行矩阵乘法,以获得所需的信息位数,例如 64 位。

dot between weights and transformation matrix
在对原始任务(即分类)进行训练时,权重和变换矩阵都将通过作者设计的损失函数(即正确嵌入 64 位信息的损失函数)来更新
白盒检测
对于大公司来说,他们可能会从各个地方收集证据,这样他们就可以起诉涉嫌非法使用他们 DNN 模型的公司。一旦他们有证据,他们将需要有一个验证过程,即从 DNN 模型中提取水印,并比较水印是否来自大公司。
他们基本上是在做同样的事情来提取他们在训练中所做的水印。再次执行平坦化权重和变换矩阵之间的点运算,然后提取水印。
然而,这个过程是一个白盒验证,这意味着他们需要物理访问模型,通常可能需要通过执法部门。
黑箱方法
在阅读了一些研究论文[2,3,4]后,我意识到所有论文中的黑盒方法都是相似的。我要讲的例子来自[2]。
黑盒嵌入
在培训阶段,培训任务分为两部分:
- 原始分类任务
- 触发设置任务
什么是触发集任务?这实际上是一份被故意贴错标签的数据清单。

Example trigger set data wrongly labelled
错误标记的数据是一种水印,目的是让模型“记忆”准确的输入和标记,这种记忆形成了水印嵌入效果。虽然它可能会影响模型的特征学习,但是在【3】中有一些替代方案。
错误标记的数据与原始数据集结合,然后将经过原始训练目标(如交叉熵)
黑盒检测
这种水印嵌入方式在验证方面实际上优于白盒嵌入方式。这是因为您可以将一个触发集数据列表作为查询提交给机器学习在线服务**(例如,小偷偷了您的模型并创建了一个与您的相似的服务)**

a typical black-box verification
在通过 API 调用查询 ML 在线服务之后,您将得到预期的标签。如果预期标签与原始错误标签匹配,那么您可以确认该 ML 在线服务正在使用您的模型**,因为在您的触发集数据上不可能有精确匹配(或高精度)。**如果一个模特不是从你那偷来的,那么这个模特应该能把猫的形象归类为猫,而不是狗。
结论
我们需要保护我们的 DNN 模式,以防其他人窃取我们的信用而不付钱给我们!我们可以进行黑盒验证,以便对小偷有一个初步的嫌疑人,然后在我们向警方报告后,我们可以通过执法部门进行白盒验证。(虽然我认为这只是大公司之间的战争😅)
希望现在你对在 DNN 中嵌入水印有了更多的了解。感谢您的阅读!
参考
[1]将水印嵌入深度神经网络。https://arxiv.org/abs/1701.04082
[2]化弱为强:通过走后门给深度神经网络加水印。https://arxiv.org/abs/1802.04633
[3]利用水印技术保护深度神经网络的知识产权。https://dl.acm.org/citation.cfm?id=3196550
[4] DeepSigns:保护深度学习模型所有权的通用水印框架。【https://arxiv.org/abs/1804.00750
蛋白质序列分类
Pfam 数据集上蛋白质家族分类的实例研究。

摘要
蛋白质是大而复杂的生物分子,在生物体中扮演着许多重要角色。蛋白质由一条或多条氨基酸序列长链组成。这些序列是蛋白质中氨基酸的排列,通过肽键结合在一起。蛋白质可以由 20 不同种类的氨基酸组成,每种蛋白质的结构和功能都是由用来制造它的氨基酸种类以及它们的排列方式决定的。
了解氨基酸序列和蛋白质功能之间的关系是分子生物学中长期存在的问题,具有深远的科学意义。我们能否使用深度学习来学习 Pfam 数据库中所有蛋白质家族的未比对氨基酸序列及其功能注释之间的关系。
我用 Deepnote 创建了这个项目,这是一个非常棒的产品,供数据科学专业人员在云上运行 Jupyter 笔记本。超级容易设置,协作,并提供比谷歌 Colab 更多的功能。这里是完整的笔记本。
问题陈述
- 基于 Pfam 数据集,将蛋白质的氨基酸序列分类到蛋白质家族成员之一。
- 换句话说,任务就是:给定蛋白质结构域的氨基酸序列,预测它属于哪一类。
数据概述
我们已经提供了 5 个功能,它们如下:
- 这些通常是模型的输入特征。该结构域的氨基酸序列。有 20 种非常常见的氨基酸(频率> 1,000,000),和 4 种相当不常见的氨基酸:X、U、B、O 和 z。
family_accession:这些通常是型号的标签。PFxxxxx.y (Pfam)格式的登录号,其中 xxxxx 是家族登录号,y 是版本号。y 的某些值大于 10,因此“y”有两位数。sequence_name:序列名称,格式为“uni prot _ accession _ id/start _ index-end _ index”。aligned_sequence:包含来自多序列比对的单个序列,与 seed 中该家族的其余成员进行比对,保留缺口。family_id:家庭的一个字的名字。
来源:卡格尔
示例数据点
sequence: HWLQMRDSMNTYNNMVNRCFATCIRSFQEKKVNAEEMDCTKRCVTKFVGYSQRVALRFAE
family_accession: PF02953.15
sequence_name: C5K6N5_PERM5/28-87
aligned_sequence: ....HWLQMRDSMNTYNNMVNRCFATCI...........RS.F....QEKKVNAEE.....MDCT....KRCVTKFVGYSQRVALRFAE
family_id: zf-Tim10_DDP
机器学习问题
这是一个多类分类问题,对于给定的氨基酸序列,我们需要预测它的蛋白质家族成员。
公制的
- 多级原木损失
- 准确(性)
探索性数据分析
在本节中,我们将探索、想象并尝试理解给定的特性。给定的数据已经被分成 3 个文件夹,即使用随机分割的培训、开发和测试。
首先,让我们加载训练、val 和测试数据集。
给定集合的大小如下:
- 列车大小:1086741 (80%)
- Val 大小:126171 (10%)
- 测试规模:126171 (10%)
注:由于计算能力有限,我考虑的数据较少。然而,同样的解决方案也可以用于整个 Pfam 数据集。
序列计数
首先,让我们计算一下每个未比对序列中的编码(氨基酸)数量。
- 大多数未比对的氨基酸序列的字符数在 50-250 之间。
序列码频率
让我们也找出每个未比对序列中每个代码(氨基酸)的频率。
为训练、val 和测试数据绘制代码频率计数

Code Frequency Count
- 最常见氨基酸编码是亮氨酸(L),其次是丙氨酸(A),缬氨酸(V)和甘氨酸(G)。
- 正如我们所见,不常见的氨基酸(即 X、U、B、O、Z)的含量非常少。因此,我们可以考虑在预处理步骤中仅用 20 种常见的天然氨基酸进行序列编码。
文本预处理
氨基酸序列用它们相应的 1 个字母的代码来表示,例如,丙氨酸的代码是(A),精氨酸的代码是®,等等。氨基酸及其编码的完整列表可以在这里找到。
示例,未对齐序列:
phpesrirlstrrddahgmpiriesrlgpdafarlrfmartcrailaaagcaapfeefs sadafsshvfgtcrmghdpmrnvvdgwgrshwpnlfvadaslfsgggespgltqalalrt
为了建立深度学习模型,我们必须将这些文本数据转换为机器可以处理的数字形式。我使用了一种热编码方法,考虑到 20 种常见的氨基酸,因为其他不常见的氨基酸数量较少。
下面的代码片段创建了一个包含 20 个氨基酸的字典,其中的整数值以递增的顺序排列,以便进一步用于整数编码。
对于每个未比对的氨基酸序列,使用创建的编码字典,1 个字母编码被一个整数值代替。如果该代码不在字典中,该值简单地用 0 代替,因此只考虑 20 种常见的氨基酸。
这一步将把 1 个字母的代码序列数据转换成这样的数字数据,
[13, 7, 13, 4, 16, 15, 8, 15, 10, 16, 17, 15, 15, 3, 1, 7, 6, 11, 13, 8, 13, 15, 8, 4, 16, 15, 10, 6, 13, 3, 1, 5, 1, 15, 10, 15, 5, 11, 1, 15, 17, 2, 15, 1, 8, 10, 1, 1, 1, 6, 2, 1, 1, 13, 5, 4, 4, 5, 16, 16, 1, 3, 1, 5, 16, 16, 17, 7, 18, 5, 6, 17, 2, 15, 11, 6, 7, 3, 13, 11, 15, 12, 18, 18, 3, 6, 19, 6, 15, 16, 7, 15, 19, 13, 12, 10, 5, 18, 1, 3, 1, 16, 10, 5, 13, 16, 16, 6, 6, 6, 4, 16, 13, 6, 10, 17, 8, 14, 1, 10, 1, 10, 15, 17]
下一个后填充以最大序列长度 100 完成,如果总序列长度小于 100,则用 0 填充,否则将序列截断到最大长度 100。
最后,序列中的每个代码被转换成一个热编码向量。
深度学习模型
我参考了这篇用于定义模型架构的论文,并训练了两个独立的模型,一个是双向 LSTM,另一个是受基于 CNN 架构的 ResNet 的启发。
模型 1:双向 LSTM
当处理基于 NLP 的问题时,像 LSTMs 这样的递归神经网络的变体是第一选择,因为它们可以处理像文本这样的时间或顺序数据。
RNNs 是一种神经网络,其中来自先前步骤的输出作为输入被馈送到当前步骤,从而记住关于序列的一些信息。当涉及到短上下文时,rnn 是很好的,但是由于消失梯度问题,它在记忆较长的序列方面有限制。
LSTM(长短期记忆)网络是 RNN 的改进版本,专门使用门控机制在延长的时间内记住信息,这使得它们可以选择记住什么先前的信息,忘记什么,以及为建立当前的细胞状态增加多少电流输入。

Bidirectional LSTM (Source)
单向 LSTM 只保存过去的信息,因为它看到的输入来自过去。使用双向将会以两种方式运行输入,一种是从过去到未来,另一种是从未来到过去,从而允许它在任何时间点保存来自过去和未来的上下文信息。
关于 RNN 和 LSTM 更深入的解释可以在这里找到。
模型架构如下,首先有一个嵌入层,它学习每个代码的矢量表示,然后是双向 LSTM。对于正则化,增加了丢弃以防止模型过度拟合。
输出层,即 softmax 层将给出所有独特类别的概率值(1000),并且基于最高预测概率,该模型将氨基酸序列分类到其蛋白质家族成员之一。
该模型用 33 个时期、256 的 batch_size 训练,并且能够实现测试数据的(0.386)损失和(95.8%)准确度。
439493/439493 [==============================] - 28s 65us/step
Train loss: 0.36330516427409587
Train accuracy: 0.9645910173696531
----------------------------------------------------------------------
54378/54378 [==============================] - 3s 63us/step
Val loss: 0.3869630661736021
Val accuracy: 0.9577034830108782
----------------------------------------------------------------------
54378/54378 [==============================] - 3s 64us/step
Test loss: 0.3869193921893196
Test accuracy: 0.9587149214887501
模式 2: ProtCNN
该模型使用受 ResNet 架构启发的剩余模块,该架构还包括扩大的卷积,提供更大的感受野,而不增加模型参数的数量。
ResNet(剩余网络)
由于消失梯度问题,更深层次的神经网络很难训练——随着梯度反向传播到更早的层,重复乘法可能会使梯度无限小。因此,随着网络越来越深入,其性能会饱和,甚至开始迅速下降。

Training and test error: Plain networks (Source)
ResNets 引入了跳过连接或恒等快捷连接,将初始输入添加到卷积块的输出中。

Single residual block: ResNet (Source)
这通过允许渐变流过替代的快捷路径来减轻渐变消失的问题。它还允许模型学习一个标识函数,该函数确保较高层的性能至少与较低层一样好,而不是更差。
扩张卷积

Dilated convolution (Source)
膨胀卷积为卷积层引入了另一个参数,称为膨胀率。这定义了内核中值之间的间距。膨胀率为 2 的 3×3 内核将具有与 5×5 内核相同的视野,同时仅使用 9 个参数。想象一下,取一个 5x5 的内核,每隔一行删除一列。
扩张卷积以相同的计算成本提供了更宽的视野。
ProtCNN 模型架构

Model architecture (Source)
氨基酸序列被转换成一个热编码,其形状(batch_size,100,21)作为模型的输入。初始卷积运算应用于核大小为 1 的输入,以提取基本属性。然后使用两个相同的残差块来捕获数据中的复杂模式,这是受 ResNet 架构的启发,这将有助于我们用更多的历元和更好的模型性能来训练模型。
我对剩余块的定义与 ResNet 论文略有不同。不是执行三个卷积,而是仅使用两个卷积,并且还向第一个卷积增加一个参数(膨胀率),从而在相同数量的模型参数下具有更宽的视场。
残差块中的每个卷积运算都遵循 batch normalization = > ReLU = > Conv1D 的基本模式。在残差块中,第一次卷积以 1×1 的核大小和膨胀率进行,第二次卷积以更大的核大小 3×3 进行。
最后,在应用卷积运算之后,通过添加初始输入(快捷方式)和来自所应用的卷积运算的输出来形成跳过连接。
在两个剩余块之后,应用最大池来减小表示的空间大小。对于正则化,增加了丢弃以防止模型过度拟合。
该模型用 10 个时期训练,batch_size 为 256,并在验证数据上验证。

439493/439493 [==============================] - 38s 85us/step
Train loss: 0.3558084576734698
Train accuracy: 0.9969123512774948
----------------------------------------------------------------------
54378/54378 [==============================] - 5s 85us/step
Val loss: 0.39615299251274316
Val accuracy: 0.9886718893955224
----------------------------------------------------------------------
54378/54378 [==============================] - 5s 85us/step
Test loss: 0.3949931418234982
Test accuracy: 0.9882489242257847
正如我们所看到的,这个模型的结果比双向 LSTM 模型要好。通过在 ProtCNN 模型集合中进行多数投票,可以实现对此的更多改进。
结论
在这个案例研究中,我们探索了深度学习模型,这些模型学习未比对的氨基酸序列与其功能注释之间的关系。ProtCNN 模型已经取得了显著的成果,比当前最先进的技术(如 BLASTp 注释蛋白质序列)更准确,计算效率更高。
这些结果表明,深度学习模型将成为未来蛋白质功能预测工具的核心组成部分。
感谢您的阅读。完整的代码可以在这里找到。
参考
了解氨基酸序列与蛋白质功能的关系是分子生物学中长期存在的问题。
www.biorxiv.org](https://www.biorxiv.org/content/10.1101/626507v4.full)
使用 LSTM 卷积自动编码器的视频异常检测

“London Underground atrium” (Photo by Anna Dziubinska on Unplash)
我们有数以千计的监视摄像机一直在工作,其中一些安装在偏远地区或街道上,那里不太可能发生危险的事情,另一些安装在拥挤的街道或城市广场上。即使在一个地点也可能发生各种各样的异常事件,并且异常事件的定义因地点和时间的不同而不同。
在这种情况下,使用自动化系统来检测异常事件是非常可取的,可以带来更好的安全性和更广泛的监控。一般来说,检测视频中的异常事件的过程是一个具有挑战性的问题,目前引起了研究人员的广泛关注,它在各个行业也有广泛的应用,最近它已经成为视频分析的基本任务之一。对于开发在现实世界应用中快速且准确的异常检测方法存在巨大的需求。
必备知识:
了解以下主题的基础知识:
卷积神经网络: 简单解释:
https://www.youtube.com/watch?v=YRhxdVk_sIs&t = 2s
更多详情:
http://cs231n.github.io/convolutional-networks/
http://colah.github.io/posts/2015-08-Understanding-LSTMs/ LSTM 网络
自动编码器: https://www . quora . com/What-is-an-auto-encoder-in-machine-learning
https://towardsdatascience . com/deep-inside-auto encoders-7e 41 f 319999 f
反卷积层:
https://towardsdatascience . com/transpose-convolution-77818 e55a 123
为什么我们不用监督的方法来检测异常呢?
如果我们要将问题视为二元分类问题,我们需要带标签的数据,在这种情况下,收集带标签的数据非常困难,原因如下:
- 异常事件因其罕见性而难以获得。
- 异常事件种类繁多,手动检测和标记这些事件是一项需要大量人力的艰巨任务。
上述原因促进了使用无监督或半监督方法的需求,如字典学习、时空特征和自动编码器。与监督方法不同,这些方法只需要未标记的视频片段,这些视频片段包含很少或没有异常事件,这些异常事件在现实世界的应用中很容易获得。
自动编码器
自动编码器是被训练来重建输入的神经网络。自动编码器由两部分组成:
- 编码器:能够学习称为编码 f(x)的输入数据(x)的有效表示。编码器的最后一层称为瓶颈,它包含输入表示 f(x)。
- 解码器:使用瓶颈中的编码产生输入数据的重构 r = g(f(x))。
方法
都是关于重建误差的。
我们使用自动编码器来学习视频序列的规律性。
直觉是,经过训练的自动编码器将以低误差重建规则视频序列,但不会精确重建不规则视频序列中的运动。

被数据弄脏
我们将使用 UCSD 异常检测数据集,其中包含安装在高处的摄像机采集的视频,可以俯瞰人行道。在正常设置下,这些视频只包含行人。
异常事件是由于以下原因之一:
- 人行道上的非行人实体,如骑车人、溜冰者和小推车。
- 不寻常的行人运动模式,如人们走过人行道或周围的草地。

UCSD 数据集由两部分组成,ped1 和 ped2。我们将使用 ped1 零件进行培训和测试。
安装
下载 UCSD 数据集并将其提取到您当前的工作目录中,或者使用此数据集在 Kaggle 中创建新的笔记本。
准备训练集
训练集由规则视频帧序列组成;该模型将被训练以重建这些序列。因此,让我们按照以下三个步骤准备好数据,以供我们的模型使用:
- 使用滑动窗口技术将训练视频帧分成时间序列,每个时间序列的大小为 10。
- 将每个帧的大小调整为 256 × 256,以确保输入图像具有相同的分辨率。
- 通过将每个像素除以 256,在 0 和 1 之间缩放像素值。
最后一点,由于这个模型中的参数数量庞大,需要大量的训练数据,所以我们在时间维度上进行数据扩充 。为了生成更多的训练序列,我们用不同的**跳跃步幅连接帧。**例如,第一步距-1 序列由帧(1,2,3,4,5,6,7,8,9,10)组成,而第一步距-2 序列由帧(1,3,5,7,9,11,13,15,17,19)组成。
这是代码。随意编辑它以获得更多/更少的具有不同跳跃步幅的输入序列,然后看看结果如何变化。
注意:如果你面临内存错误,减少训练序列的数量或使用数据发生器。
构建和训练模型
最后,好玩的部分开始了!我们将使用 Keras 来构建我们的卷积 LSTM 自动编码器。
下图显示了培训过程;我们将训练模型来重建常规事件。因此,让我们开始探索模型设置和架构。

要构建自动编码器,我们应该定义编码器和解码器。编码器接受按时间顺序排列的帧序列作为输入,它由两部分组成:空间编码器和时间编码器。来自空间编码器的序列的编码特征被馈送到时间编码器用于运动编码。
解码器镜像编码器以重建视频序列,因此我们的自动编码器看起来像一个三明治。

注意:因为模型有大量的参数,所以建议您使用 GPU。使用 Kaggle 或 Colab 也是一个好主意。
初始化和优化: 我们使用 Adam 作为优化器,将学习率设置为 0.0001 ,当训练损失停止减少时,我们通过使用 0.00001 的衰减来减少它,并将ε值设置为 0.000001 。
对于初始化,我们使用 Xavier 算法,它可以防止信号在通过每一层时变得太小或太大而无用。
让我们更深入地研究这个模型!
为什么在编码器中使用卷积层,在解码器中使用去卷积层?
卷积层将滤波器固定感受域内的多个输入激活连接到单个激活输出。它将过滤器长方体的信息抽象成一个标量值。另一方面,去卷积层通过具有多个学习滤波器的类卷积运算来增加稀疏信号的密度;因此,他们通过卷积的逆运算将单个输入激活与补丁输出相关联。
去卷积层中的学习滤波器用作重建输入运动序列形状的基础。
我们为什么要使用卷积 LSTM 层?
对于通用序列建模来说,LSTM 作为一种特殊的 RNN 结构已经被证明在保持长程相关性方面是稳定和健壮的。
这里,我们使用卷积 LSTM 层而不是全连接 LSTM 层,因为 FC-LSTM 层不能很好地保留空间数据,因为它在输入到状态和状态到状态的转换中使用了全连接,其中没有空间信息被编码。
图层归一化的目的是什么?
训练深度神经网络计算量大。减少训练时间的一种方法是使用层标准化来标准化神经元的活动;我们使用了层标准化而不是其他方法,如批量标准化,因为这里我们有一个递归神经网络。阅读更多关于标准化技术的信息。
我们做得好吗?
让我们进入测试阶段。

第一步是获取测试数据。我们将单独测试每个测试视频。UCSD 数据集提供了 34 个测试视频, Config 的值。SINGLE_TEST_PATH 决定使用哪一个。
每个测试视频有 200 帧。我们使用滑动窗口技术来获得所有连续的 10 帧序列。换句话说,对于 0 到 190 之间的每个 t ,我们计算从帧( t )开始到帧( t +9)结束的序列的正则性得分 Sr(t) 。
规律性得分:
我们使用 L2 范数计算视频的帧 t 中位置 (x,y) 处的像素亮度值 I 的重建误差:

其中 Fw 是 LSTM 卷积自动编码器的学习模型。然后,我们通过对所有像素误差求和来计算一帧的重建误差 t :

在 t 开始的 10 帧序列的重建成本可以计算如下:

然后,我们通过在 0 和 1 之间缩放来计算异常分数 Sa(t) 。

我们可以通过从 1 中减去异常分数来导出规律性分数 Sr(t) 。

在我们为范围**【0,190】**中的每个 t 计算正则性得分 Sr(t) 之后,我们绘制 Sr(t) 。

Test 032 of UCSDped1
一些测试:
首先,我们来看看 UCSDped1 的 test 32。视频开头,走道上有一辆自行车,解释了规律性得分低的原因。自行车离开后,规律性得分开始增加。在第 60 帧,另一辆自行车进入,规则性得分再次降低,并在它离开后立即增加。
UCSDped1 数据集的 Test 004 在视频的开头显示了一个溜冰者进入走道,在第 140 帧有人在草地上行走,这解释了规律性得分的两次下降。
UCSDped1 数据集的测试 024 显示一辆小车穿过人行道,导致规律性得分下降。推车离开后,规律性得分恢复到正常状态。
UCSDped1 数据集的 Test 005 显示了两辆自行车经过人行道,一辆在视频的开头,另一辆在视频的结尾。
结论:
尝试多个数据集,如 CUHK 大道数据集、UMN 数据集、T21 数据集,甚至使用监控摄像机或房间里的小型摄像机收集你自己的数据。训练数据相对容易收集,因为它由仅包含常规事件的视频组成。混合多个数据集,看看该模型是否仍然做得很好。想出一种方法来加快检测异常的过程,比如在测试阶段使用更少的序列。
别忘了在评论里写下你的结果!
在 Linkedin 上保持联系。
参考资料:
[1] Yong Shean Chong,利用时空自动编码器检测视频中的异常事件(2017), arXiv:1701.01546 。
[2] Mahmudul Hasan,Jonghyun Choi,Jan Neumann,Amit K. Roy-Chowdhury,学习视频序列中的时间规律性(2016), arXiv:1604.04574 。

















 2285
2285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
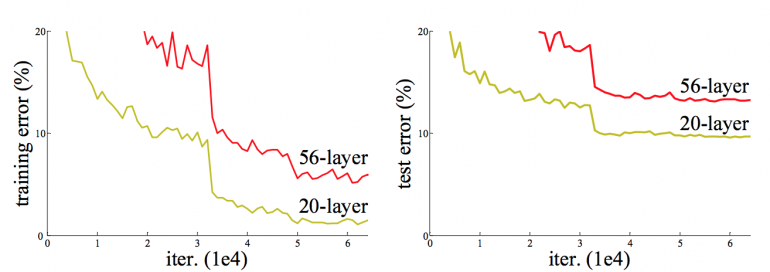{kind=link}
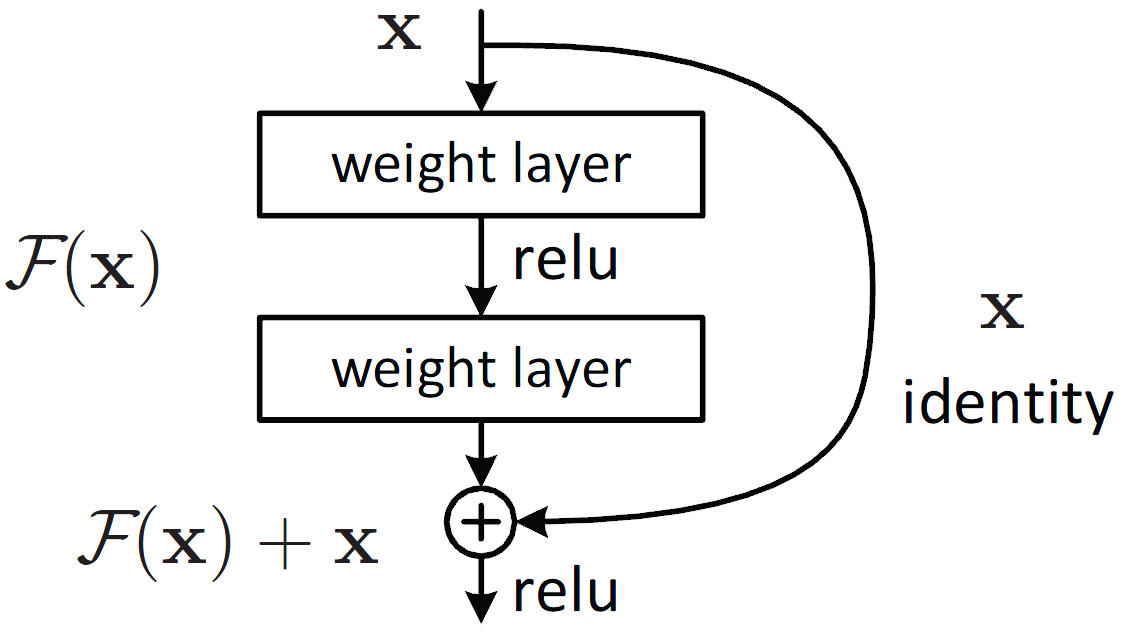{kind=link}
{kind=link}
{kind=link}