







用于注释和协作的新冠肺炎放射数据集(胸部 x 光和 CT)(第 1 部分)
迫切需要诊断工具来识别新冠肺炎。在疫情爆发的最初阶段,包括美国在内的所有国家都面临一个主要问题——缺乏诊断工具和适当的检测。为了能够构建诊断工具,数据科学家正在争先恐后地获取任何可用的少量数据。
鉴于对抗新冠肺炎疫情需要诊断工具,TrainingData.io 正在提供一个预先加载了开源数据集的免费协作工作空间。这个协作工作区允许数据科学家和放射学家共享训练数据的注释,这些数据用于训练新冠肺炎的机器学习模型。此数据集植入了以下数据集:
- GitHub covid-chestx ray-dataset(150 个 CT+x 射线病例)
- GitHub UCSD-AI4H/COVID-CT(169 例 CT,288 幅图像)
- SIIM.org(60 例 CT)
任何人都可以通过点击这个链接来创建和下载注释

机器学习的新冠肺炎训练数据
**用于研究的开源数据集:**我们邀请医院、诊所、研究人员、放射科医生上传更多去识别成像数据,尤其是 CT 扫描。目的是从受影响最严重的地方,如韩国、新加坡、意大利、法国、西班牙和美国,获得不同的数据集。这种对开源社区的贡献将帮助独立研究人员更快地构建诊断工具。本案涉及的产品使用将完全免费。我们的目的是在遵守所有许可法的同时,帮助全球抗击新冠肺炎病毒。
如何创建和下载新冠肺炎数据集的注记?
从这里开始:https://app.trainingdata.io/v1/td/login

https://www.trainingdata.io
**使用 NVIDIA Clara train SDK 构建 ML 模型:**training data . io 的团队拥有在 NVIDIA Clara 上使用 U-Net 构建细分模型的专业知识。我们愿意为社区提供构建开源模型的服务。这是一个在 NVIDIA Clara train SDK 中使用 2D U-Net 模型检测椎体的样本模型。
NVIDIA Clara 中使用 U-Net 检测椎体的样本分割模型
**联系人:**更多信息请联系我们: info@trainingdata.io
**当前状态:**工作区有来自 319 个不同患者的 429 个不同图像,369 个 ct 图像,60 个 x 光图像。
**如何下载数据集?😗*只能从 TrainingData.io 下载由 community 创建的注释(遮罩),数据集的原始图像不能从我们的网站下载。要下载原始图像,请访问各自的来源。
**成本:**不考虑免费使用的限制,使用我们的产品在这个新冠肺炎数据集上工作将是零成本。
本系列第二部分: 使用 NVIDIA Clara on TrainingData 自动检测胸部 CT 中的新冠肺炎感染. io
使用机器学习分析新冠肺炎对公司收益的影响

图片由 Unsplash 的 Bud Helisson 提供
“我们选择的镜头改变了我们看待事物的方式”——德威特·琼斯
注来自《走向数据科学》的编辑: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
数据可用性的增加,更高的计算能力,以及易于实现的人工智能框架的可用性,开启了从大衰退到现在的人工智能复兴时代。这让我们有能力以 2008 年无法做到的方式分析新冠肺炎后的衰退。
本文通过研究新冠肺炎事件后公司收益的变化来研究新冠肺炎事件的影响。具体来说,它使用机器学习来预测纳斯达克上市公司 2010 财年第二季度收益同比下降超过 10%背后的关键因素。
本文使用来自财务报表分析和机器学习的概念来获得见解。我首先介绍我的方法和发现,然后深入研究建模。这更像是一个分析的框架,而不是一项获得具体见解的研究。喝杯咖啡,坐下来享受吧!
内容
- 摘要
- 关键驱动因素+精选深度挖掘
- 公司建模示例:Salesforce
- 模拟深潜
- 进一步的背景阅读
- 总结想法
1。总结
我比较了 2010 财年第二季度和 2019 财年第二季度的公司财务报表数据,以了解从 2019 财年第二季度到 2010 财年第二季度,净收入是否下降了 10%以上,这可能是由新冠肺炎造成的。我开发了一个基于 lightgbm 的机器学习模型,用包括 2019 财年财务在内的几个输入来预测产出(>净收入下降 10%)。
机器学习模型提供了对宏观和微观趋势进行建模的能力,这是一种识别关键影响维度的强大工具。它还可以用来分析哪些因素对公司收益下降的影响最大
该模型使用 yahooquery 从雅虎财经获取数据,并使用 T2 SHAP 对 ML 模型进行分析。除了提供 ML + SHAP 分析的发现外,我还尽可能对结果提供直观的解释。
**2。**关键驱动因素+精选深度挖掘
K

*2010 财年第二季度和 2020 财年 Q2 净收入下降 10%的主要预测指标。*图片作者。
S 行业深潜:行业对收益下降有很大影响。下图(Y 轴表示新冠肺炎影响,X 轴表示行业)中,分析的公司是单独的数据点,有力地说明了能源和消费周期是受影响最大的行业,而消费防御、技术和公用事业是受影响最小的行业。


*行业(和全职员工)对>2019 财年第二季度至 2020 财年 Q2 净收入下降 10%的影响。*图片作者。
直觉:新冠肺炎导致能源公司需求方面的冲击(简单地说,加油的人少了)导致收入减少,因此石油公司出现亏损。在消费品公司中,防御性消费品公司(销售主食和日常用品的公司)保持不变,因为对其产品的需求相对缺乏弹性,而周期性消费品公司(销售冲动和便利商品的公司)的收益大幅下降。需求的无弹性也解释了对公用事业公司的低影响。由于 WFH 的增加,数字化的加速推进等,科技也相对未受影响。
**附加观察:**观察 3 区(消费者防御)塔顶的一组红点——这可能是可口可乐、百事可乐等公司的影响。大量全职员工表示Q2 季度质量下降
C 点的颜色=关键次要因素的影响程度,即总收入)。

*资本支出对收入比率(和总收入)的影响>2019 财年第二季度和 2020 财年 Q2 净收入下降 10%。*图片作者。
直觉:新冠肺炎抑制了财政收入。公司本可以迅速采取行动在一定程度上控制运营支出,但是,前几年较高的资本支出(在以后几年创造潜在收入的成本)将意味着较高的损益折旧和较低的净收入。此外,观察顶部的红点,可以推断出具有较大绝对资本支出(不仅仅是资本支出与收入的比率)的公司受影响最大。
P **/E 比率深度挖掘:**收益下降> 10%的可能性较高的公司,其 P/E(市盈率,也就是市值与净收入的比率)比其他公司低。

*市值与净收入比率对>2019 财年第二季度至 2020 财年 Q2 净收入下降 10%的影响。*图片作者。
**直觉:**市场先生永远是对的。股票的弹性反映在其价格溢价中,即收益质量较高的公司(包括在不利的市场条件下保持不变的潜力)将比质量较低的公司定价更高。从收益角度来看,市场认为更好的股票平均来说更好地经受住了新冠肺炎风暴。
3。公司建模示例:Salesforce
Salesforce 有了一个精彩的 Q2FY20 。净收入从 9100 万美元增长至 26 亿美元。该模型正确预测这是一只收益下降> 10%概率非常小的股票。它进一步给出了关键的积极贡献因素及其影响的大小——事实上,这只具有高市盈率的科技股从总收入范围等维度做出了显著的积极贡献(蓝色)远远超过了消极贡献(红色)。

Salesforce 的公司影响建模结果。图片作者。
4.模拟深潜
(如果你对细节不太感兴趣,可以跳过这一部分)

我的模特工作流程。图片作者。
- 我选择特征/输入时谨记两个关键原则:(1)包括具有高水平数据可用性的字段(较少 NaNs 等)。)和
(2)避免多重共线性:例如,毛利=收入— COGS,因此不能选择所有三个,只选择最多两个等。 - 该模型的 AUC(模型质量的量度)为> . 65
- 如果你想看的话,我的作品在的 Kaggle 上。任何反馈都非常受欢迎。我的 Kaggle 笔记本也有一些更有潜在意义的快照,可以用来产生更多的见解。
5.进一步的背景阅读
关于财务报表分析…
这个 Investopedia 链接是财务报表分析 101 的良好起点。如果你想对财务报表中的关键术语有一个完整的解释,美世资本的这个资源是个不错的选择。
关于机器学习…
从商业角度来看,麦肯锡的这个页面是我见过的最好的资源之一。如果你想更专业一点,杰森·梅耶斯的精彩幻灯片非常适合你。
6。结论性想法
我们研究了一个分析新冠肺炎对公司收益影响的框架。我们深入研究了行业、资本支出和市盈率如何影响收益下降。下面使用 SHAP 的可视化很好地总结了我们的分析。

*2010 财年第二季度和 2020 财年第二季度之间>净收入下降 10%的关键预测指标的更精细视图,包括方向性影响。*图片作者。
可以利用该框架来分析宏观收益趋势,如上面的深入分析,或者执行微观分析,如上面的 Salesforce 示例。这种分析从更深的角度揭示了新冠肺炎危机对经济的影响。
后记:
- 对于金融类股,我在 9 月中旬左右从雅虎财经(Yahoo Finance)获取了数据快照。根据拍摄数据的时间,结果可能会有所不同。
- 这不是一个投资假设,也不应被视为投资建议。
- 本文表达的观点是我的个人观点。我们随时欢迎您的反馈。
学分:
斯科特·伦德伯格负责精彩的 SHAP 框架【https://shap.readthedocs.io/en/latest/T2
道格·格思里负责 yahooquery 我用来收集数据https://pypi.org/project/yahooquery/
比利时的新冠肺炎
应用 R 分析比利时新型新冠肺炎冠状病毒

马库斯·斯皮斯克拍摄的照片
介绍
新型新冠肺炎冠状病毒仍在几个国家快速传播,而且似乎不会很快停止,因为许多国家尚未达到高峰。
自其开始扩张以来,世界各地的大量科学家一直在从不同的角度和使用不同的技术分析这种冠状病毒,希望找到一种治疗方法,以阻止其扩张并限制其对公民的影响。
冠状病毒的顶级资源
与此同时,流行病学家、统计学家和数据科学家正在努力更好地了解病毒的传播,以帮助政府和卫生机构做出最佳决策。这导致了大量关于该病毒的在线资源的发布,我收集并整理了一篇文章,涵盖了关于冠状病毒的顶级资源。本文收集了我有机会发现的最好的资源,并对每个资源进行了简要总结。它包括闪亮的应用程序、仪表盘、R 包、博客帖子和数据集。
发布这个集合导致许多读者提交他们的作品,这使得文章更加完整,对任何有兴趣从定量角度分析病毒的人来说更有见地。感谢每一个贡献和帮助我收集和总结这些关于新冠肺炎的资源的人!
鉴于我的专业领域,我无法从医学角度帮助对抗病毒。然而,我仍然想尽我所能做出贡献。从更好地了解这种疾病到将科学家和医生聚集在一起,建立更大、更有影响力的东西,我真诚地希望这个收藏能在一定程度上帮助抗击疫情。
你自己国家的冠状病毒仪表板
除了收到来自世界各地的分析、博客帖子、R 代码和闪亮的应用程序,我意识到许多人都在试图为自己的国家创建一个跟踪冠状病毒传播的仪表板。因此,除了收集顶级 R 资源之外,我还发表了一篇文章,详细介绍了创建特定于某个国家的仪表板的步骤。在这篇文章和一个关于比利时的示例中,查看如何创建这样的仪表板。
该代码已在 GitHub 上发布,并且是开源的,因此每个人都可以复制它并根据自己的国家进行调整。仪表板有意保持简单,这样任何对 R 有最低限度了解的人都可以很容易地复制它,高级用户可以根据他们的需要增强它。
文章的动机、限制和结构
通过查看和整理许多关于新冠肺炎的 R 资源,我有幸阅读了许多关于疾病爆发、不同卫生措施的影响、病例数量预测、疫情长度预测、医院能力等的精彩分析。
此外,我必须承认,一些国家,如中国、韩国、意大利、西班牙、英国和德国受到了很多关注,正如对这些国家所做的分析数量所示。然而,据我所知,在本文发表之日,我不知道有任何针对比利时冠状病毒传播的分析。本文旨在填补这一空白。
在我的统计学博士论文中,我的主要研究兴趣是应用于癌症患者的生存分析(更多信息在我的个人网站的研究部分)。我不是流行病学家,也不具备通过流行病学模型模拟疾病爆发的广博知识。
我通常只写我认为自己熟悉的东西,主要是统计学及其在 R 的应用。在写这篇文章的时候,我很好奇比利时在这种病毒传播方面的立场,我想在 R(对我来说是新的)中研究这种数据,看看会有什么结果。
为了满足我的好奇心,虽然我不是专家,但在这篇文章中,我将复制更多知识渊博的人所做的分析,并将它们应用于我的国家,即比利时。从我到目前为止读到的所有分析中,我决定重复 Tim Churches 和 Holger K. von Jouanne-Diedrich 教授所做的分析。这篇文章是根据他们的文章组合而成的,在这里可以找到这里和这里。他们都对如何模拟冠状病毒的爆发进行了非常翔实的分析,并显示了它的传染性。他们的文章也让我了解了这个话题,尤其是最常见的流行病学模型。我强烈建议感兴趣的读者也阅读他们的最近的文章,以获得更深入的分析和对新冠肺炎疫情传播的更深入的理解。
其他更复杂的分析也是可能的,甚至是更好的,但是我把这个留给这个领域的专家。还要注意,下面的分析只考虑了截至本文发表之日的数据,因此默认情况下,这些结果不应被视为当前的发现。
在文章的剩余部分,我们首先介绍将用于分析比利时冠状病毒爆发的模型。我们还简要讨论并展示了如何计算一个重要的流行病学措施,繁殖数。然后,我们使用我们的模型来分析在没有公共卫生干预的情况下疾病的爆发。最后,我们总结了更先进的工具和技术,可以用来进一步模拟比利时的新冠肺炎。
比利时冠状病毒分析
经典的流行病学模型:SIR 模型
在深入实际应用之前,我们首先介绍将要使用的模型。
有许多流行病学模型,但我们将使用最常见的一个,即先生模型*。先生模型可以被复杂化,以纳入病毒爆发的更多特性,但在本文中,我们保持其最简单的版本。Tim Churches 对这个模型的解释以及如何使用 R 来拟合它是如此的好,我将在这里复制它,并做一些小的修改。*
传染病爆发的爵士模型背后的基本思想是,有三组(也称为区间)个体:
- S :健康但易患病者(即有被污染的风险)。在疫情开始的时候, S 是整个种群,因为没有人对病毒免疫。
- 我:有传染性的(因此,被感染的)人
- R :已经康复的个人,即曾经受到污染但已经康复或死亡的人。它们不再具有传染性。
随着病毒在人群中的传播,这些群体会随着时间而演变:
- S 减少当个体被污染并转移到传染组 I
- 随着人们康复或死亡,他们从受感染的群体进入康复的群体
为了对疫情的动态进行建模,我们需要三个微分方程来描述每组的变化率,参数如下:
- β,感染率,它控制着 S 和 I 之间的转换
- γ,去除率或回收率,其控制在 I 和 R 之间的转换
形式上,这给出了:

第一个等式(等式。1)声明易感个体的数量( S )随着新感染个体的数量而减少,其中新感染病例是感染率(β)乘以与感染个体( S )有过接触的易感个体数量( I )的结果。
第二个等式(等式。2)说明感染个体数( I )随着新感染个体数(βIS)的增加而增加,减去之前感染的已痊愈者(即γI,即去除率γ乘以感染个体数 I )。
最后,最后一个等式(Eq。3)说明恢复的组随着具有传染性并且恢复或死亡的个体数量的增加而增加(γI)。
流行病的发展过程如下:
- 在疾病爆发前,S 等于整个人口,因为没有人有抗体。
- 在疫情开始时,一旦第一个人被感染, S 减 1, I 也增加 1。
- 这个第一个被感染的个体会感染(在恢复或死亡之前)其他易感的个体。
- 这种动态还在继续,最近被感染的人在康复之前又会感染其他易感人群。
视觉上,我们有:

SIR 模型。来源:凯佐佐木。
在将 SIR 模型拟合到数据之前,第一步是将这些微分方程表示为相对于时间 t 的 R 函数。
*SIR <- function(time, state, parameters) {
par <- as.list(c(state, parameters))
with(par, {
dS <- -beta * I * S / N
dI <- beta * I * S / N - gamma * I
dR <- gamma * I
list(c(dS, dI, dR))
})
}*
用 SIR 模型拟合比利时数据
为了使模型符合数据,我们需要两样东西:
- 这些微分方程的解算器
- 为我们的两个未知参数β和γ寻找最佳值的优化器
来自{deSolve} R 包的函数ode()(针对常微分方程)使得求解方程组变得容易,并且为了找到我们希望估计的参数的最佳值,我们可以使用 base R 中内置的optim()函数
具体来说,我们需要做的是最小化 I(t) 之间的平方差之和,这是在时间 t 时感染室 I 中的人数,以及我们的模型预测的相应病例数。这个量被称为残差平方和( RSS ):

为了拟合比利时发病率数据的模型,我们需要一个初始未感染人群的数值 N 。据维基百科统计,2019 年 11 月比利时人口为 11515793 人。因此,我们将使用 N = 11515793 作为初始未感染人群。
接下来,我们需要用比利时从 2 月 4 日(我们的每日发病率数据开始时)到 3 月 30 日(本文发布时的最后可用日期)的每日累积发病率创建一个向量。然后,我们将把根据这些数据拟合的 SIR 模型预测的发病率与 2 月 4 日以来的实际发病率进行比较。我们还需要初始化 N 、 S 、 I 和 R 的值。请注意,比利时的每日累积发病率摘自 Rami Krispin 开发的[{coronavirus}](https://www.statsandr.com/blog/top-r-resources-on-covid-19-coronavirus/#coronavirus) R 包。
*# devtools::install_github("RamiKrispin/coronavirus")
library(coronavirus)
data(coronavirus)`%>%` <- magrittr::`%>%`# extract the cumulative incidence
df <- coronavirus %>%
dplyr::filter(country == "Belgium") %>%
dplyr::group_by(date, type) %>%
dplyr::summarise(total = sum(cases, na.rm = TRUE)) %>%
tidyr::pivot_wider(
names_from = type,
values_from = total
) %>%
dplyr::arrange(date) %>%
dplyr::ungroup() %>%
dplyr::mutate(active = confirmed - death - recovered) %>%
dplyr::mutate(
confirmed_cum = cumsum(confirmed),
death_cum = cumsum(death),
recovered_cum = cumsum(recovered),
active_cum = cumsum(active)
)# put the daily cumulative incidence numbers for Belgium from
# Feb 4 to March 30 into a vector called Infected
library(lubridate)
Infected <- subset(df, date >= ymd("2020-02-04") & date <= ymd("2020-03-30"))$active_cum# Create an incrementing Day vector the same length as our
# cases vector
Day <- 1:(length(Infected))# now specify initial values for N, S, I and R
N <- 11515793
init <- c(
S = N - Infected[1],
I = Infected[1],
R = 0
)*
注意,需要的是当前感染人数(累计感染人数减去移除人数,即痊愈或死亡人数)。然而,被找回的人数很难获得,并且可能由于漏报偏差而被低估。我因此考虑了 累计 感染人数,这在这里可能不是一个问题,因为在分析时恢复的病例数可以忽略不计。
然后我们需要定义一个函数来计算 RSS ,给定一组β和γ的值。
*# define a function to calculate the residual sum of squares
# (RSS), passing in parameters beta and gamma that are to be
# optimised for the best fit to the incidence data
RSS <- function(parameters) {
names(parameters) <- c("beta", "gamma")
out <- ode(y = init, times = Day, func = SIR, parms = parameters)
fit <- out[, 3]
sum((Infected - fit)^2)
}*
最后,我们可以找到β和γ的值,使观察到的累积发病率(在比利时观察到的)和预测的累积发病率(通过我们的模型预测的)之间的残差平方和最小,从而使 SIR 模型符合我们的数据。我们还需要检查我们的模型是否已经收敛,如下面显示的消息所示:
*# now find the values of beta and gamma that give the
# smallest RSS, which represents the best fit to the data.
# Start with values of 0.5 for each, and constrain them to
# the interval 0 to 1.0# install.packages("deSolve")
library(deSolve)Opt <- optim(c(0.5, 0.5),
RSS,
method = "L-BFGS-B",
lower = c(0, 0),
upper = c(1, 1)
)# check for convergence
Opt$message## [1] "CONVERGENCE: REL_REDUCTION_OF_F <= FACTR*EPSMCH"*
确认收敛。请注意,对于初始值或约束条件的不同选择,您可能会发现不同的估计值。这证明拟合过程是不稳定的。这里有一个潜在的解决方案用于更好的装配过程。
现在我们可以检查β和γ的拟合值:
*Opt_par <- setNames(Opt$par, c("beta", "gamma"))
Opt_par## beta gamma
## 0.5841185 0.4158816*
记住,β控制着 S 和 I 之间的转换(即易感和传染),γ控制着 I 和 R 之间的转换(即传染和痊愈)。然而,这些值并不意味着很多,但我们使用它们来获得我们的 SIR 模型的每个隔间中截至 3 月 30 日用于拟合模型的拟合人数,并将这些拟合值与观察到的(真实)数据进行比较。
*sir_start_date <- "2020-02-04"# time in days for predictions
t <- 1:as.integer(ymd("2020-03-31") - ymd(sir_start_date))# get the fitted values from our SIR model
fitted_cumulative_incidence <- data.frame(ode(
y = init, times = t,
func = SIR, parms = Opt_par
))# add a Date column and the observed incidence data
library(dplyr)
fitted_cumulative_incidence <- fitted_cumulative_incidence %>%
mutate(
Date = ymd(sir_start_date) + days(t - 1),
Country = "Belgium",
cumulative_incident_cases = Infected
)# plot the data
library(ggplot2)
fitted_cumulative_incidence %>%
ggplot(aes(x = Date)) +
geom_line(aes(y = I), colour = "red") +
geom_point(aes(y = cumulative_incident_cases), colour = "blue") +
labs(
y = "Cumulative incidence",
title = "COVID-19 fitted vs observed cumulative incidence, Belgium",
subtitle = "(Red = fitted incidence from SIR model, blue = observed incidence)"
) +
theme_minimal()*

从上图中我们可以看到,不幸的是,观察到的确诊病例数遵循了我们的模型所预期的确诊病例数。这两种趋势重叠的事实表明,疫情在比利时明显处于指数增长阶段。需要更多的数据来观察这一趋势是否会在长期内得到证实。
下图与上图相似,除了 y 轴是在对数标尺上测量的。这种图被称为半对数图,或者更准确地说是对数线性图,因为只有 y 轴以对数标度进行变换。转换对数标度的优势在于,就观察到的和预期的确诊病例数之间的差异而言,它更容易阅读,并且它还显示了观察到的确诊病例数如何不同于指数趋势。
*fitted_cumulative_incidence %>%
ggplot(aes(x = Date)) +
geom_line(aes(y = I), colour = "red") +
geom_point(aes(y = cumulative_incident_cases), colour = "blue") +
labs(
y = "Cumulative incidence",
title = "COVID-19 fitted vs observed cumulative incidence, Belgium",
subtitle = "(Red = fitted incidence from SIR model, blue = observed incidence)"
) +
theme_minimal() +
scale_y_log10(labels = scales::comma)*

该图表明,在疫情开始时至 3 月 12 日,确诊病例数低于指数阶段的预期值。特别是,从 2 月 4 日至 2 月 29 日,确诊病例数保持不变,为 1 例。从 3 月 13 日到 3 月 30 日,确诊病例数量以接近指数的速度持续增加。
我们还注意到 3 月 12 日和 3 月 13 日之间有一个小的跳跃,这可能表明数据收集中的错误,或者测试/筛选方法的变化。
再现数 R0
我们的 SIR 模型看起来与在比利时观察到的累积发病率数据非常吻合,因此我们现在可以使用我们的拟合模型来计算基本生殖数 R0,也称为基本生殖率,它与β和γ密切相关。 2
繁殖数给出了每个感染者感染的平均易感人数。换句话说,繁殖数指的是每一个患病人数中被感染的健康人数。当 R0 > 1 时,疾病开始在人群中传播,但如果 R0 < 1. Usually, the larger the value of R0, the harder it is to control the epidemic and the higher the probability of a pandemic.
Formally, we have:

We can compute it in R:
*Opt_par## beta gamma
## 0.5841185 0.4158816R0 <- as.numeric(Opt_par[1] / Opt_par[2])
R0## [1] 1.404531*
An R0 of 1.4 is below values found by others for COVID-19 and the R0 for SARS and MERS, which are similar diseases also caused by coronavirus. Furthermore, in the literature, it has been estimated that the reproduction number for COVID-19 is approximately 2.7 (with β close to 0.54 and γ close to 0.2). Our reproduction number being lower is mainly due to the fact that the number of confirmed cases stayed constant and equal to 1 at the beginning of the pandemic.
A R0 of 1.4 means that, on average in Belgium, 1.4 persons are infected for each infected person.
For simple models, the proportion of the population that needs to be effectively immunized to prevent sustained spread of the disease, known as the “herd immunity threshold”, has to be larger than 1−1/R0 (Fine, Eames, and Heymann 2011).
The reproduction number of 1.4 we just calculated suggests that, given the formula 1-(1 / 1.4), 28.8% of the population should be immunized to stop the spread of the infection. With a population in Belgium of approximately 11.5 million, this translates into roughly 3.3 million people.
Using our model to analyze the outbreak if there was no intervention
It is instructive to use our model fitted to the first 56 days of available data on confirmed cases in Belgium, to see what would happen if the outbreak were left to run its course, without public health intervention.
*# time in days for predictions
t <- 1:120# get the fitted values from our SIR model
fitted_cumulative_incidence <- data.frame(ode(
y = init, times = t,
func = SIR, parms = Opt_par
))# add a Date column and join the observed incidence data
fitted_cumulative_incidence <- fitted_cumulative_incidence %>%
mutate(
Date = ymd(sir_start_date) + days(t - 1),
Country = "Belgium",
cumulative_incident_cases = I
)# plot the data
fitted_cumulative_incidence %>%
ggplot(aes(x = Date)) +
geom_line(aes(y = I), colour = "red") +
geom_line(aes(y = S), colour = "black") +
geom_line(aes(y = R), colour = "green") +
geom_point(aes(y = c(Infected, rep(NA, length(t) - length(Infected)))),
colour = "blue"
) +
scale_y_continuous(labels = scales::comma) +
labs(y = "Persons", title = "COVID-19 fitted vs observed cumulative incidence, Belgium") +
scale_colour_manual(name = "", values = c(
red = "red", black = "black",
green = "green", blue = "blue"
), labels = c(
"Susceptible",
"Recovered", "Observed incidence", "Infectious"
)) +
theme_minimal()*

The same graph in log scale for the y 轴没有传播,并带有一个可读性更好的图例:
*# plot the data
fitted_cumulative_incidence %>%
ggplot(aes(x = Date)) +
geom_line(aes(y = I, colour = "red")) +
geom_line(aes(y = S, colour = "black")) +
geom_line(aes(y = R, colour = "green")) +
geom_point(aes(y = c(Infected, rep(NA, length(t) - length(Infected))), colour = "blue")) +
scale_y_log10(labels = scales::comma) +
labs(
y = "Persons",
title = "COVID-19 fitted vs observed cumulative incidence, Belgium"
) +
scale_colour_manual(
name = "",
values = c(red = "red", black = "black", green = "green", blue = "blue"),
labels = c("Susceptible", "Observed incidence", "Recovered", "Infectious")
) +
theme_minimal()*

更多汇总统计数据
其他有趣的统计数据可以从我们模型的拟合中计算出来。例如:
- 疫情顶峰的日期
- 重症病例的数量
- 需要特别护理的人数
- 死亡人数
*fit <- fitted_cumulative_incidence# peak of pandemic
fit[fit$I == max(fit$I), c("Date", "I")]## Date I
## 89 2020-05-02 531000.4# severe cases
max_infected <- max(fit$I)
max_infected / 5## [1] 106200.1# cases with need for intensive care
max_infected * 0.06## [1] 31860.03# deaths with supposed 4.5% fatality rate
max_infected * 0.045## [1] 23895.02*
鉴于这些预测,在完全相同的环境下,如果没有任何干预措施来限制疫情的传播,比利时的峰值预计将在 5 月初达到。届时将有大约 530,000 人受到感染,这意味着大约 106,000 个严重病例,大约 32,000 人需要重症监护(鉴于比利时有大约 2000 个重症监护病房,卫生部门将完全不堪重负),以及多达 24,000 人死亡(假设死亡率为 4.5%,如本来源所述)。
至此,我们明白比利时为什么要采取如此严格的遏制措施和规定了!
请注意,这些预测应该非常谨慎。一方面,如上所述,它们是基于相当不切实际的假设(例如,没有公共卫生干预、固定的再生数 R0 等。).利用{projections}包,更高级的预测是可能的,等等(见部分了解更多关于这个问题的信息)。另一方面,我们仍然必须小心谨慎,严格遵循公共卫生干预措施,因为以前的大流行,如西班牙和猪流感,已经表明,令人难以置信的高数字不是不可能的!
本文的目的是用一个简单的流行病学模型来说明这种分析是如何进行的。这些是我们的简单模型产生的数字,我们希望它们是错误的,因为生命的代价是巨大的。
其他注意事项
如前所述, SIR 模型和上面所做的分析相当简单,可能无法真实反映现实。在接下来的章节中,我们将重点介绍五项改进措施,以加强这些分析,并更好地了解冠状病毒在比利时的传播情况。
查明率
在之前的分析和图表中,假设确诊病例数代表所有具有传染性的病例。这与现实相去甚远,因为在官方数字中,只有一部分病例得到筛查、检测和统计。这一比例被称为查明率。
在疾病爆发过程中,确诊率可能会发生变化,特别是如果检测和筛查工作增加,或者如果检测方法发生变化。这种变化的确定率可以通过对发生情况使用加权函数而容易地结合到模型中。
在他的第一篇文章中,Tim Churches 证明了 20%的固定确诊率对于没有干预的模型化疾病爆发没有什么影响,除了它发生得更快一点。
更复杂的模型
更复杂的模型也可以用来更好地反映现实生活中的传播过程。例如,疾病爆发的另一个经典模型是 SEIR 模型。这种扩展模式类似于 SIR 模式,其中 S 代表Sus 可接受, R 代表 R ecovered,但感染者分为两个车厢:
- E 为 E 暴露/感染但无症状
- I 为 I 感染并出现症状
这些模型属于假设固定转换率的连续时间动态模型。还有其他随机模型,允许根据个人属性、社交网络等改变转换率。
使用对数线性模型模拟流行病轨迹
如上所述,当以对数线性图(对数标度上的 y 轴和没有变换的 x 轴)显示时,爆发的初始指数阶段看起来(有些)是线性的。这表明我们可以使用以下形式的简单对数线性模型来模拟流行病的增长和衰退:
log(y) = rt + b
其中 y 为发病率, r 为增长率, t 为自特定时间点(通常为疫情开始)起的天数, b 为截距。在这种情况下,两个对数线性模型,一个是高峰前的生长期,一个是高峰后的衰退期,被拟合到流行病(发病率)曲线。
您经常在新闻中听到的翻倍和减半时间估计值可以从这些对数线性模型中估计出来。此外,这些对数线性模型还可以用于流行病轨迹,以估计流行病增长和衰退阶段的再生数 R0。
R 中的{incidence}包是 R 流行病联盟(RECON) 流行病建模和控制包套件的一部分,使得这种模型的拟合非常方便。
估计有效再生数 Re 的变化
在我们的模型中,我们设置了一个再生数 R0,并保持不变。然而,逐日估算当前的有效再生数 Re 将是有用的,以便跟踪公共卫生干预的有效性,并可能预测发病率曲线何时开始下降。
R 中的{EpiEstim}包可用于估计 Re,并允许考虑除本地传播外来自其他地理区域的人类传播(柯里等人,2013;汤普森等 2019)。
更复杂的预测
除了基于简单 SIR 模型的天真预测之外,更先进和复杂的预测也是可能的,特别是利用{projections}软件包。该软件包使用关于每日发病率、序列间隔和繁殖数的数据来模拟可能的流行轨迹和预测未来发病率。
结论
本文首先(I)描述了可用作背景材料的关于冠状病毒疫情的几个 R 资源(即集合和仪表板),以及(ii)本文背后的动机。然后,我们详细介绍了最常见的流行病学模型,即 SIR 模型,然后将其实际应用于比利时发病率数据。
这导致了在比利时对拟合的和观察的累积发病率的直观比较。这表明,就确诊病例数量而言,新冠肺炎疫情在比利时明显处于指数增长阶段。
然后,我们解释了什么是繁殖数,以及如何在 r 中计算繁殖数。最后,我们的模型用于分析在完全没有公共卫生干预的情况下冠状病毒的爆发。
在这种(可能过于)简单的情况下,比利时新冠肺炎的峰值预计将在 2020 年 5 月初达到,感染人数约为 530,000 人,死亡人数约为 24,000 人。这些非常危言耸听的天真预测凸显了政府采取限制性公共卫生行动的重要性,以及公民采取这些卫生行动以减缓病毒在比利时的传播(或至少减缓到足以让卫生保健系统应对它)的紧迫性。
在这篇文章的结尾,我们描述了五个可以用来进一步分析疾病爆发的改进。
请注意,这篇文章已经在 UCLouvain 进行了演讲。
感谢阅读。我希望这篇文章让你对新冠肺炎冠状病毒在比利时的传播有了很好的了解。请随意使用这篇文章作为分析这种疾病在你自己国家爆发的起点。
对于感兴趣的读者,另请参阅:
和往常一样,如果您有与本文主题相关的问题或建议,请将其添加为评论,以便其他读者可以从讨论中受益。
相关文章:
- 关于新型新冠肺炎冠状病毒的前 25 个 R 资源
- 如何创建针对贵国的简单冠状病毒仪表板
- 如何在 R 中一次对多个变量进行 t 检验或方差分析,并以更好的方式传达结果
- 如何手动执行单样本 t 检验,并对一个平均值进行 R:检验
参考
柯里,安妮,尼尔·M·费格森,克利斯朵夫·弗雷泽和西蒙·柯西梅兹。2013."一个新的框架和软件来估计流行病期间随时间变化的繁殖数."美国流行病学杂志 178 卷 9 期。牛津大学出版社:1505-12。
好的,保罗,肯·伊姆斯和大卫·海曼。2011.“《群体免疫》:粗略指南。”临床传染病 52 (7)。牛津大学出版社:911–16。
Thompson,RN,JE·斯托克温,RD van Gaalen,JA Polonsky,ZN Kamvar,PA Demarsh,E Dahlqwist 等,2019 年。"改进传染病爆发期间随时间变化的繁殖数的推断."流行病 29。爱思唯尔:100356。
- 如果您专门针对比利时进行了一些分析,我可以将这些分析包含在我的文章中,报道关于冠状病毒的顶级 R 资源,请随时在评论中或通过联系我让我知道。 ↩
- 如果你需要更深入的理解,请参见詹姆斯·霍兰德·琼斯关于复制号的更详细的注释。 ↩
原载于 2020 年 3 月 31 日 https://statsandr.com。**
编者注: 迈向数据科学 是一份以数据科学和机器学习研究为主的中型刊物。我们不是健康专家或流行病学家,本文的观点不应被解释为专业建议。想了解更多关于疫情冠状病毒的信息,可以点击 这里 。
新冠肺炎在比利时:结束了吗?
比利时新冠肺炎引起的住院率和新增确诊病例数的变化。
介绍
注 1:本文写于 2020 年 5 月 22 日,不经常更新。因此,比利时新冠肺炎的现状可能与下文所述不同。更多剧情更新请看我的 推特 简介。
注 2:这是与 尼可·斯佩布鲁克 教授 凯瑟琳·里纳德 教授 西蒙·德利库尔 和 天使罗萨斯-阿吉雷 的联合作品。
比利时最近开始解除最初为遏制新冠肺炎病毒蔓延而实施的封锁措施。在比利时当局做出这一决定后,我们分析了迄今为止形势的演变。
与我在之前的一篇文章中使用 SIR 模型分析了比利时冠状病毒的爆发相反,在这篇文章中,我们关注的是:
- 住院人数
- 医院里的病人
- 重症监护中的病人
- 新确诊病例
在省和国家一级。
数据来自科学杂志,所有的图都是用[{ggplot2}](https://www.statsandr.com/blog/graphics-in-r-with-ggplot2/) 软件包创建的。
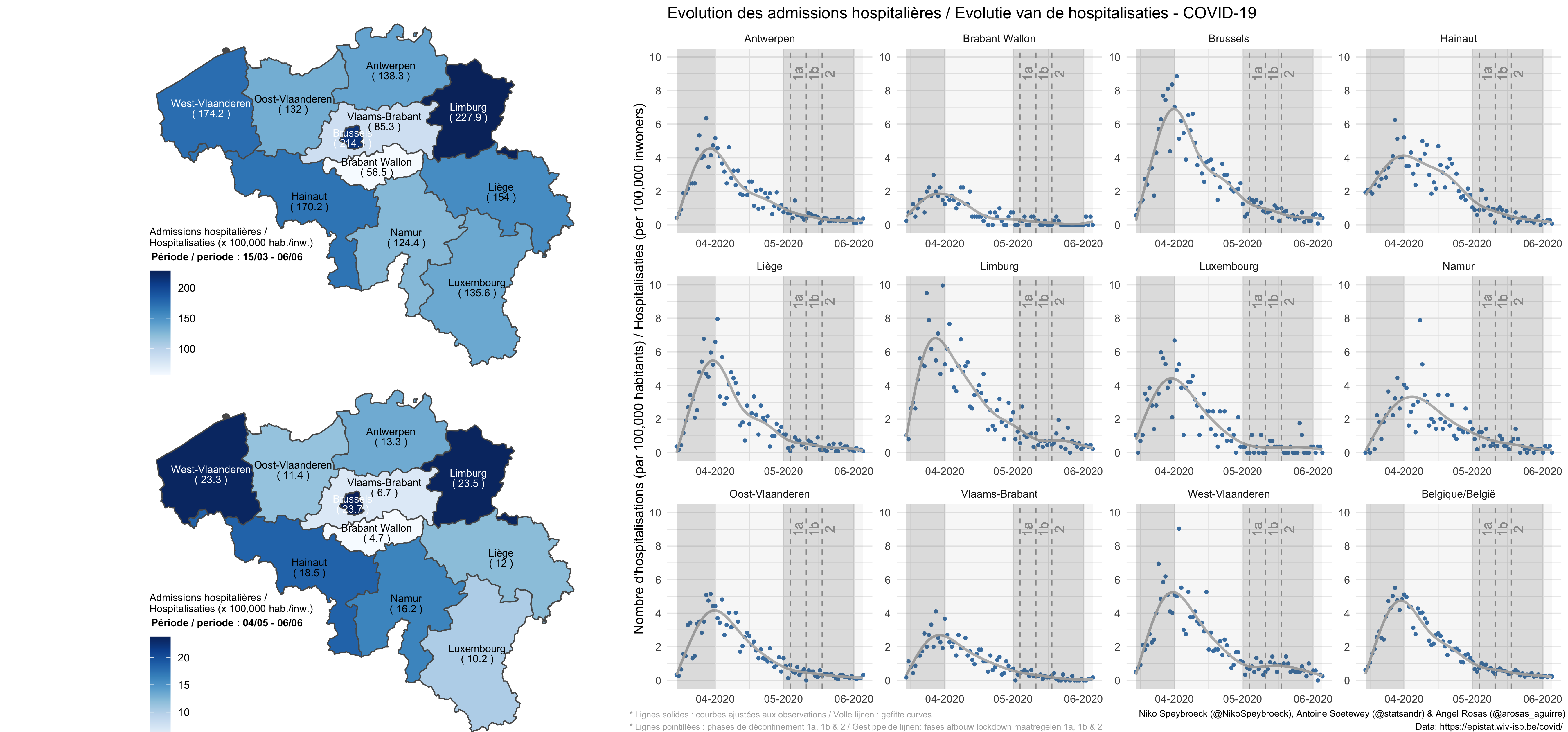
新入院人数
全部的

新冠肺炎比利时医院
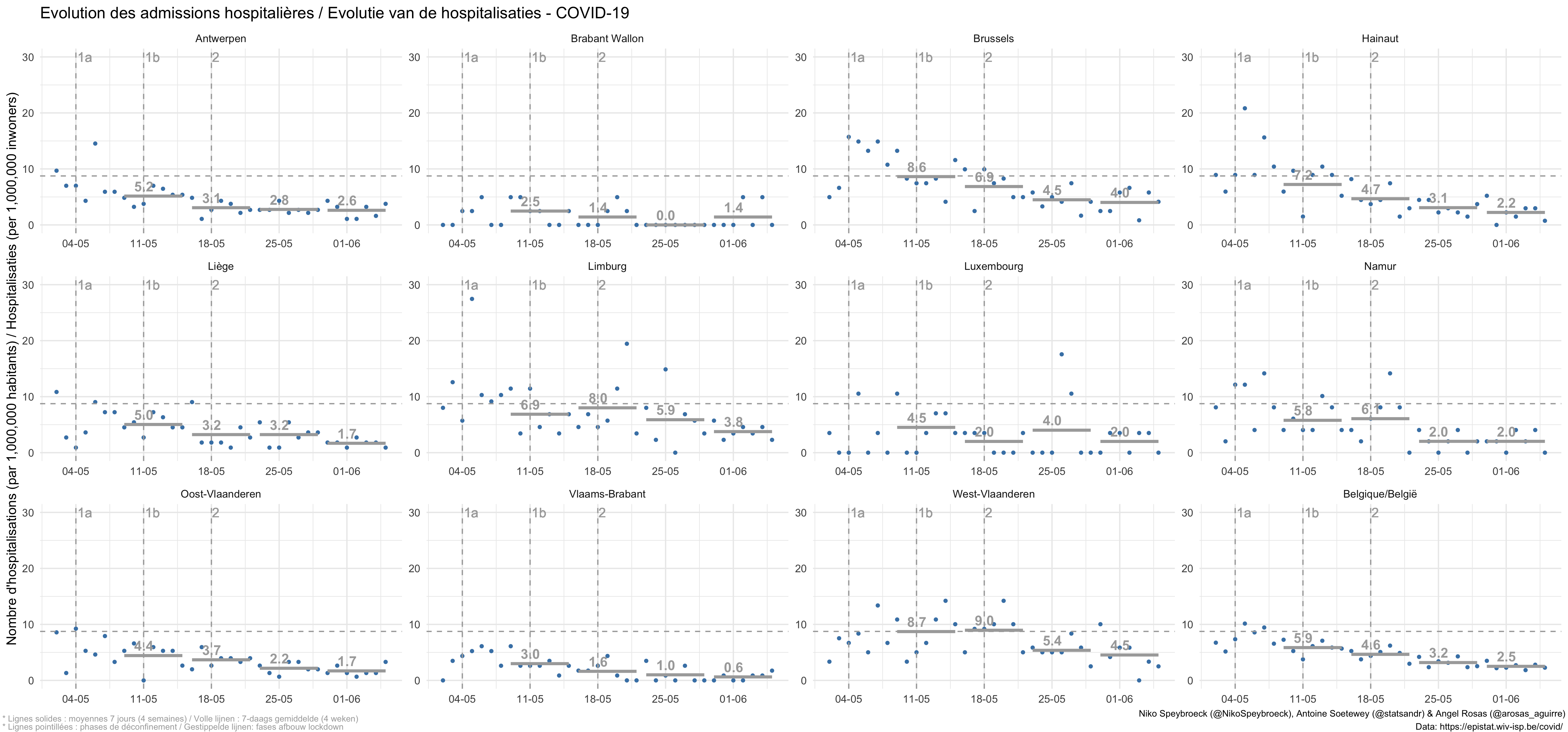
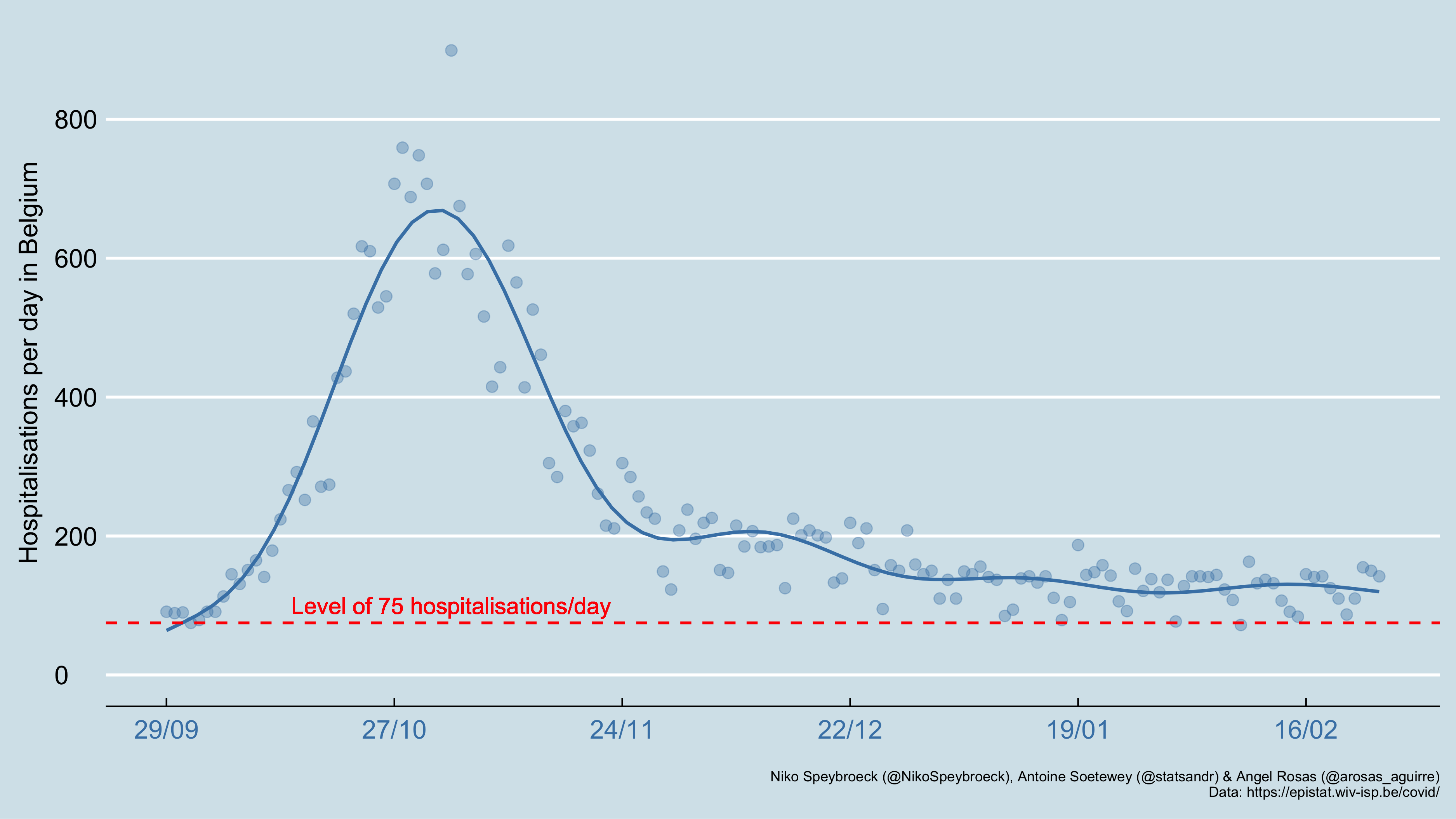
从上图可以看出,住院率在所有省份都呈下降趋势(比利时也是如此)。
2020 年 10 月 27 日更新:

比利时的住院治疗
布拉班特的详细情况:

按周期

2020 年 3 月至 10 月比利时的每日 COVID19 住院情况
2020 年 11 月 16 日更新:

比利时期间每天的 COVID19 住院情况
下载图。
在第一波中,林堡省每百万居民平均住院人数最高。在第二次浪潮中,列日和海瑙特努力争取最高税率。除了两个例外(安特卫普和林堡),上个月的情况比 3-4 月更糟糕。在三个省(海瑙特、那慕尔和列日),这一数字增加了一倍多。
在 2020 年 6 月 14 日至 7 月 15 日期间,比利时的 COVID19 住院人数降至非常低的相对水平,但我们未能保持这一水平。既然住院人数不再增加,我们希望随着年底的临近,颜色会再亮一点。
放大

比利时新冠肺炎医院

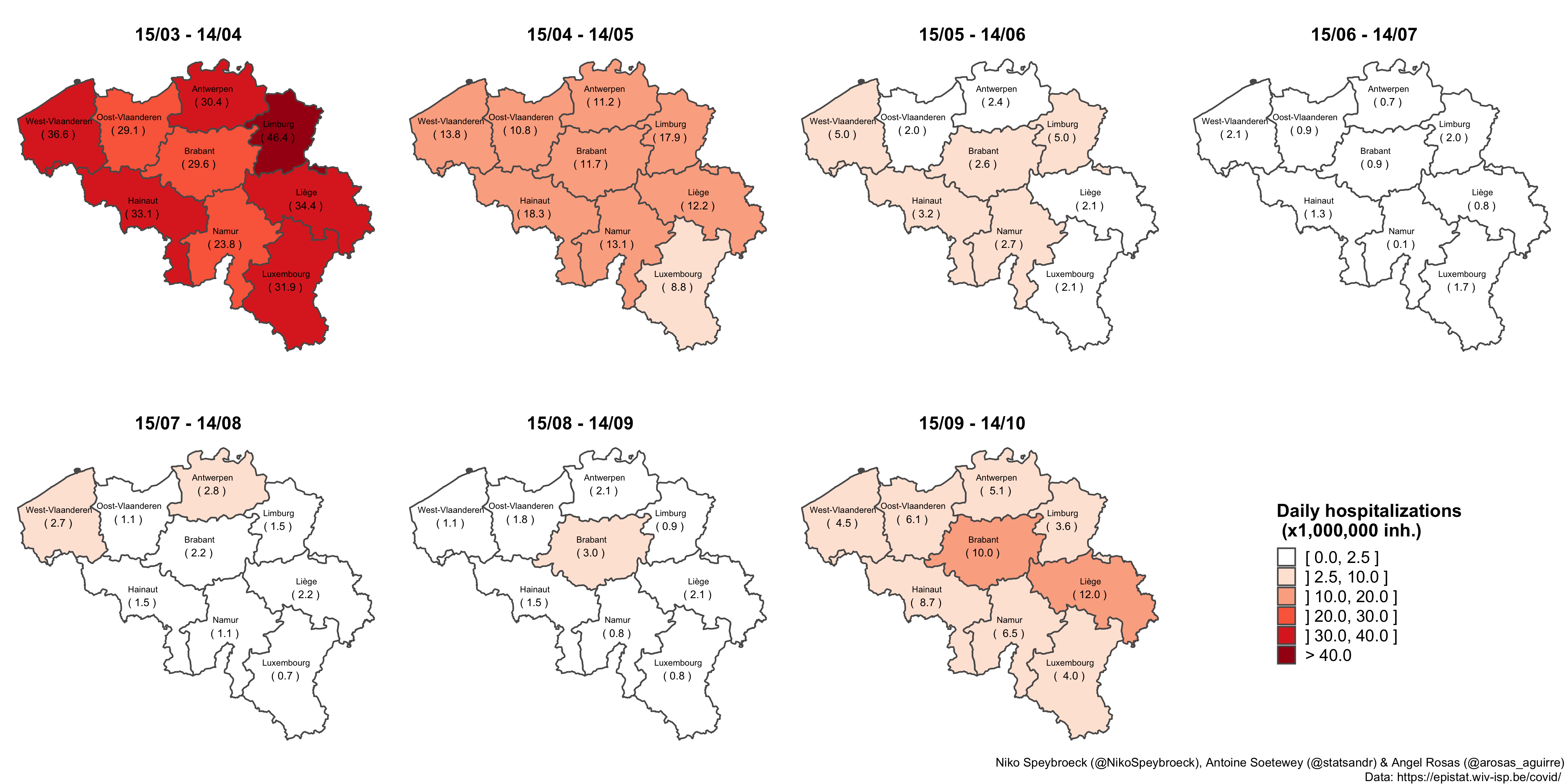
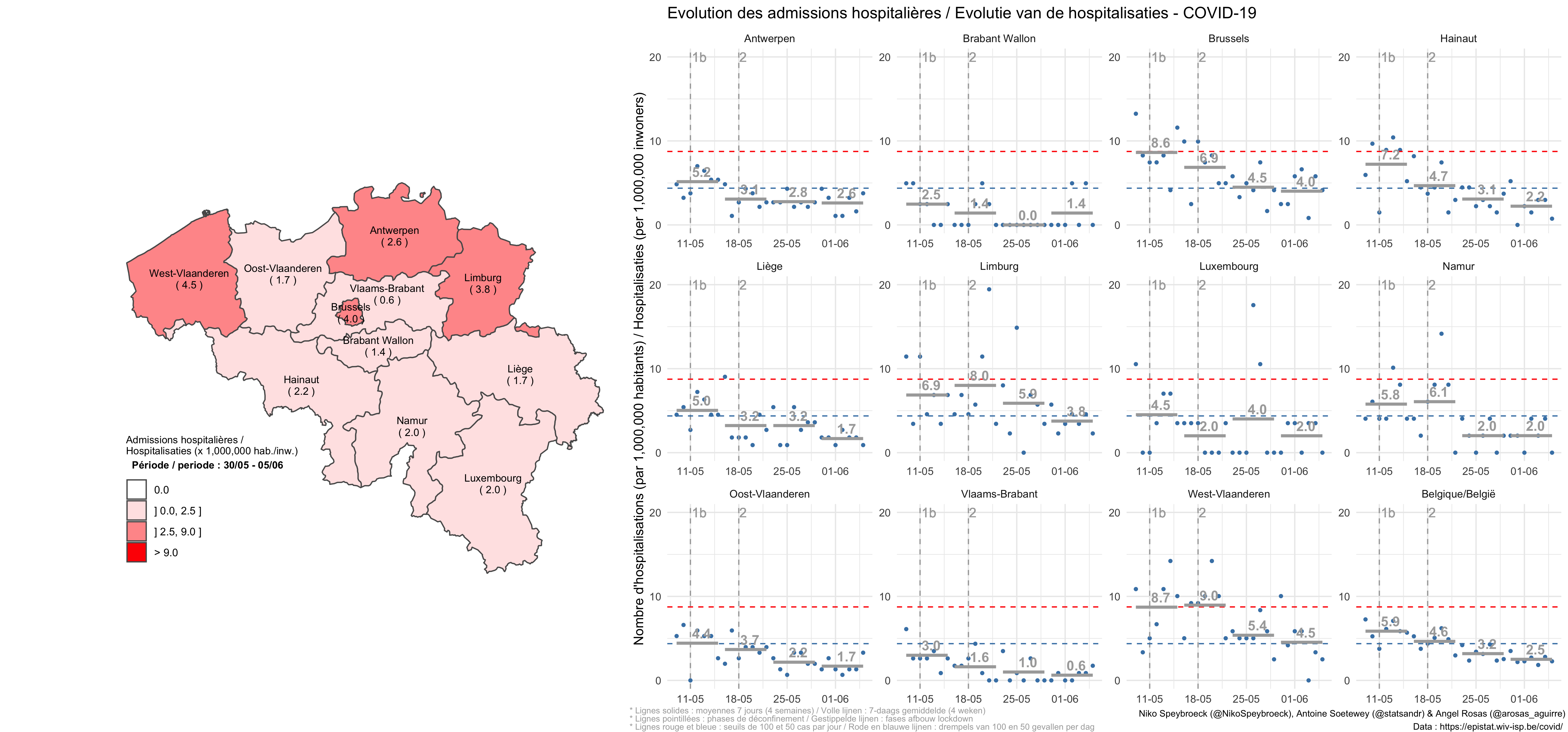
2021 年 2 月 26 日更新:
比利时正在讨论是否要放松限制。2021 年 2 月 26 日,比利时当局将开会、讨论、辩论并做出决定。新冠肺炎住院治疗的当前水平和趋势可以为他们提供指导:

仍然没有强有力的证据表明比利时的新冠肺炎住院曲线下降。第一波(灰色-日期和曲线)和第二波(蓝色-日期和曲线)之间的比较需要谨慎,但表明当前的住院水平并不像一些人希望的那样低:

放大显示了第一波和第二波省级新冠肺炎水平的更多信息:

这表明,在比利时大多数省份,第二次浪潮导致的住院人数比第一次更多,尽管第一次致命浪潮发出了警告。这也说明了一个事实,即比利时目前的每日住院率仍然高于第一波结束时的水平。
简而言之,坏消息是接触人数和通过接触传播的风险的组合似乎(目前)还不足以导致住院人数大幅减少。然而(简而言之),今天的好消息是人群中已经有了一些免疫力,疫苗接种可能会大大增加这种免疫力。这有助于向下推动曲线。让我们不要失去希望。
医院里的病人
以下是比利时医院病人数量的变化情况:

比利时医院中的 COVID19 患者
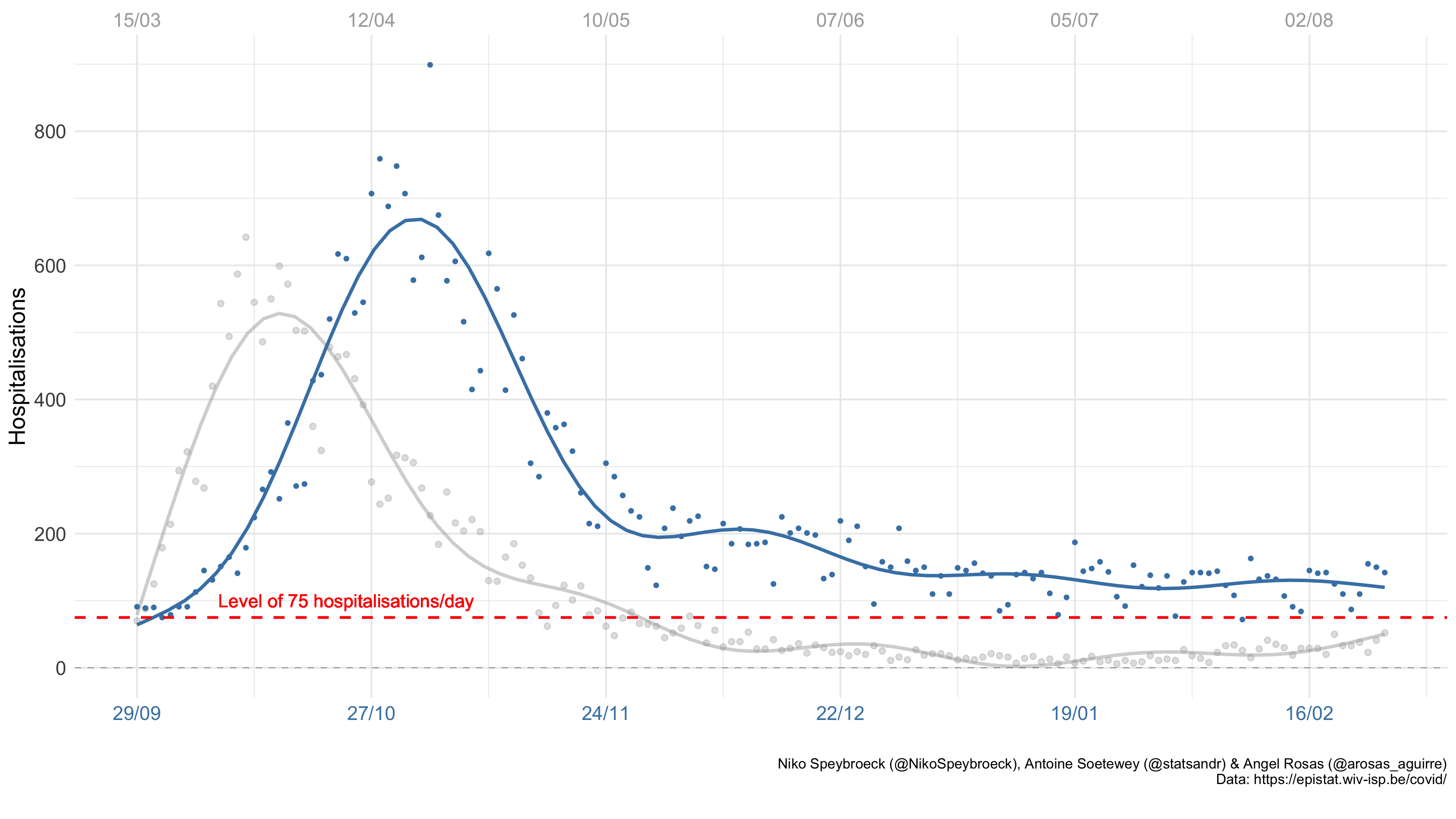
我们看到,截至 2020 年 10 月 28 日,比利时医院的 COVID19 患者数量达到第一波高峰。因此,尽管与第一波相比,第二波患者在医院停留的时间较短,但医院仍然越来越拥挤。
因此,如果未来几周医院中的患者数量遵循同样的路径,医院将很快变得过于拥挤,并且将无法接收新患者,因为其最大容量将很快达到(如果这还不是情况……)。
重症监护中的病人
根据短期预测和 99%的置信区间,比利时重症监护中 COVID19 患者的演变如下:

比利时重症监护病房中 COVID19 患者的演变
下载图。
短期预测表明,如果传播速度没有减慢,可能会发生什么。这种放缓是积极的消息。
这些地图显示了各省重症监护患者的总数(如果有比利时人口的话)。顶部的地图显示 3 月至 4 月的最高水平,底部的地图显示当前水平。该图显示了 COVID19 导致的高重症监护使用率。在比利时大多数省份,今天的数字仍然高于 3 月至 4 月的峰值。
观察结果与其他初步迹象一致,如 COVID19 住院趋势(目前相对不稳定),表明传播正在放缓:

下载图。
确诊病例
请注意,报告的新增确诊病例数可能被低估。这一数字不包括未诊断(无症状或症状很少)或未检测的病例。因此,应极其谨慎地解释带有病例数的数字。
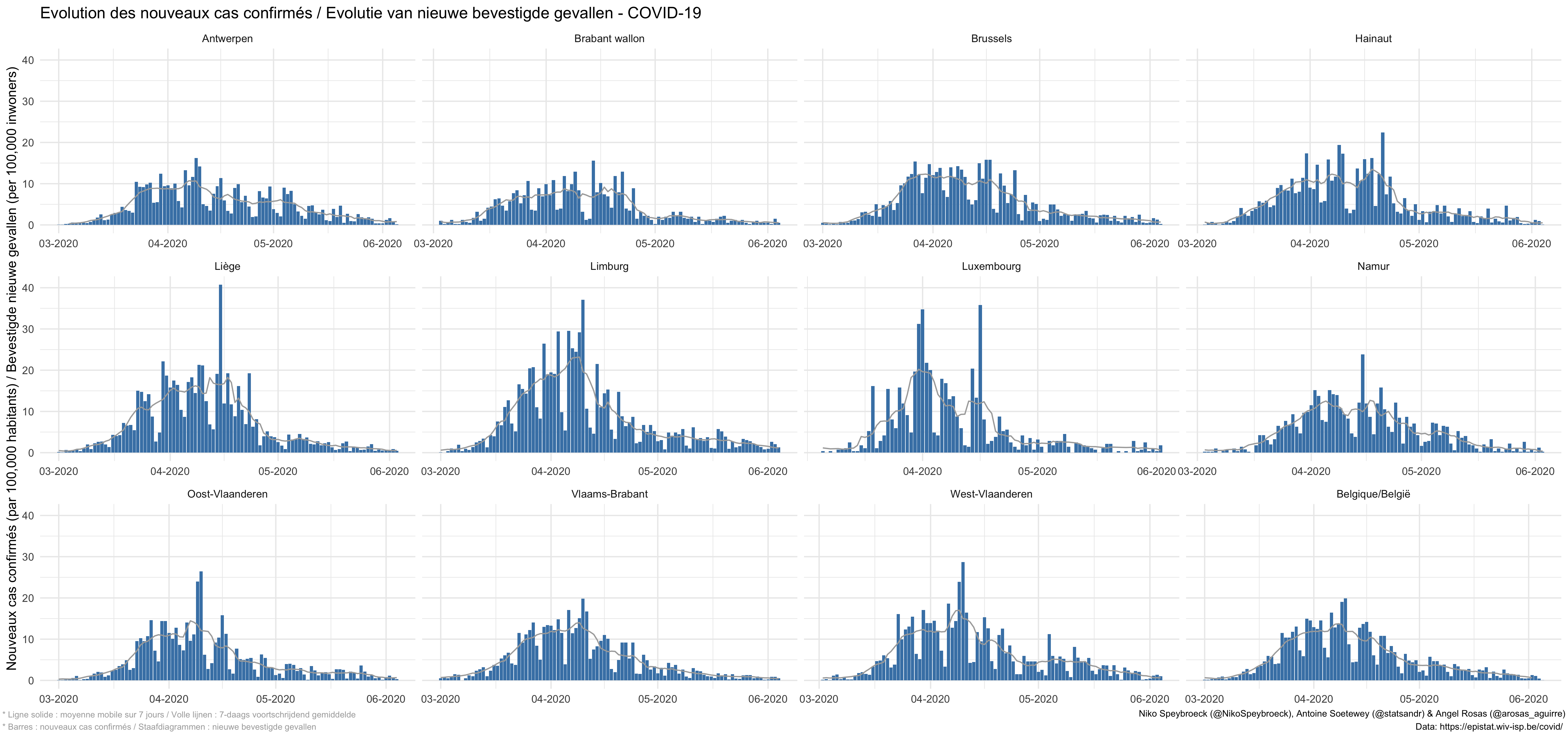
按省份

比利时新增确诊新冠肺炎病例
按年龄组和性别
静态
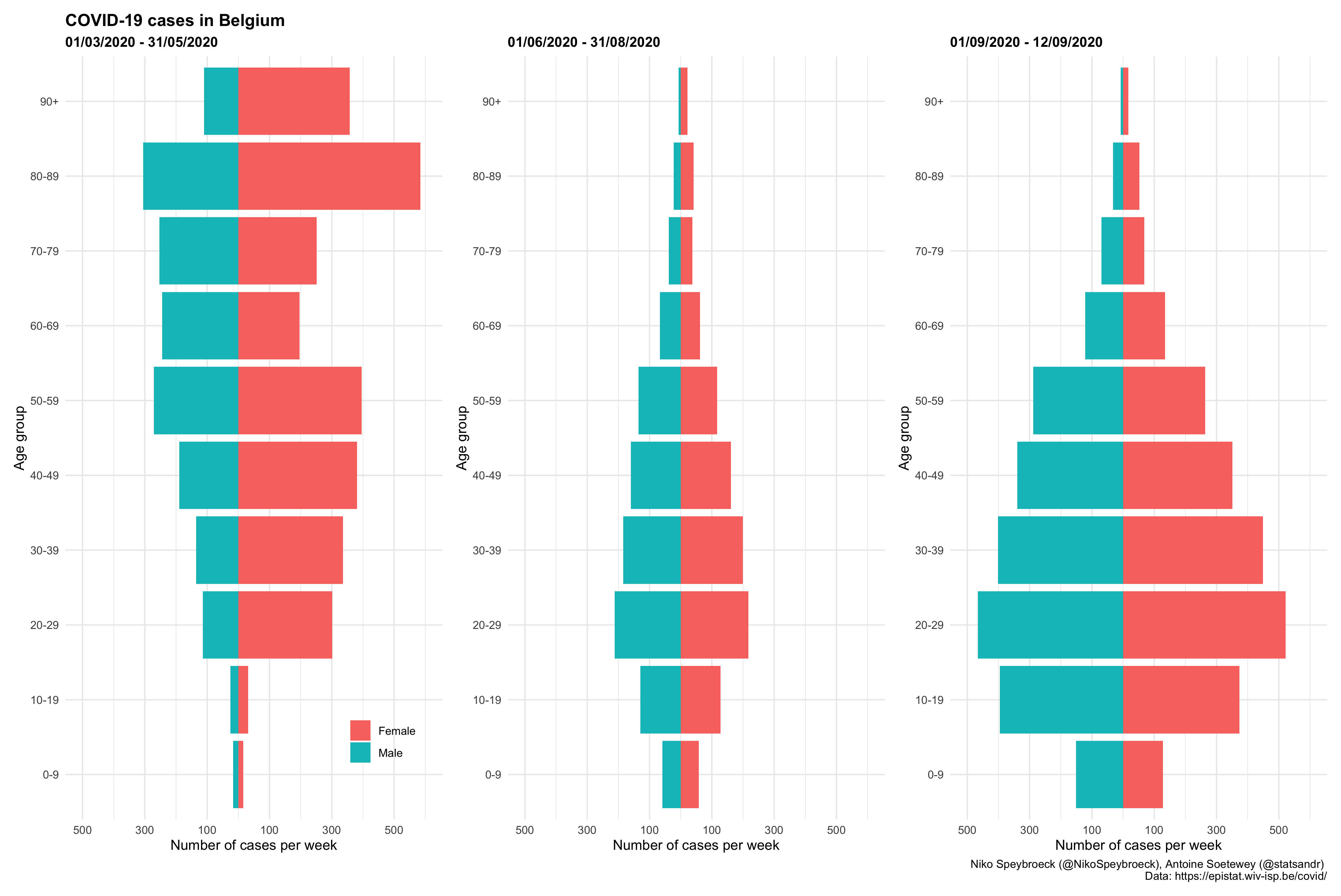
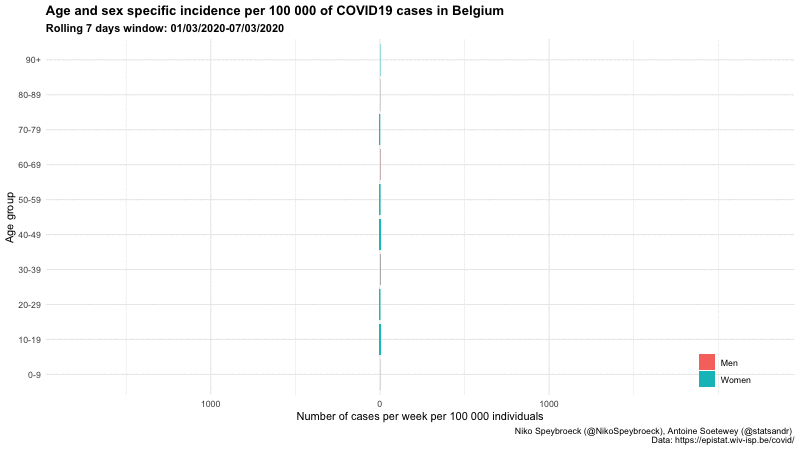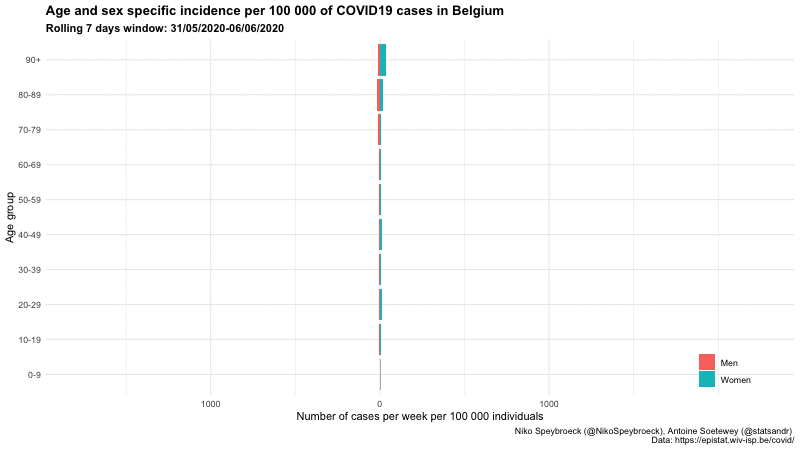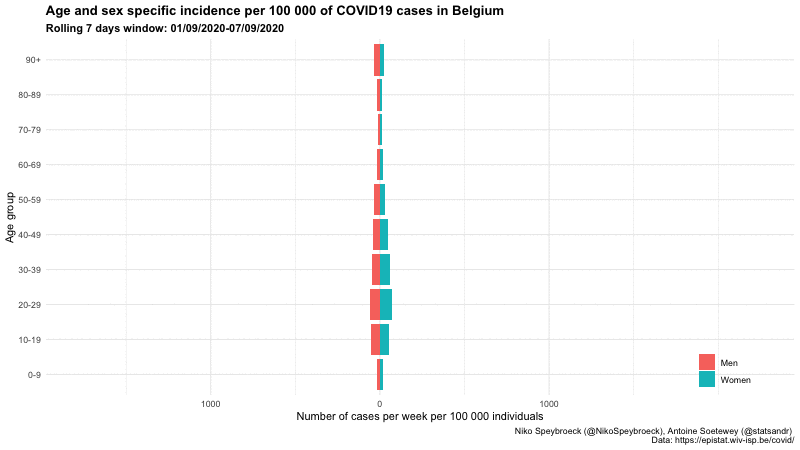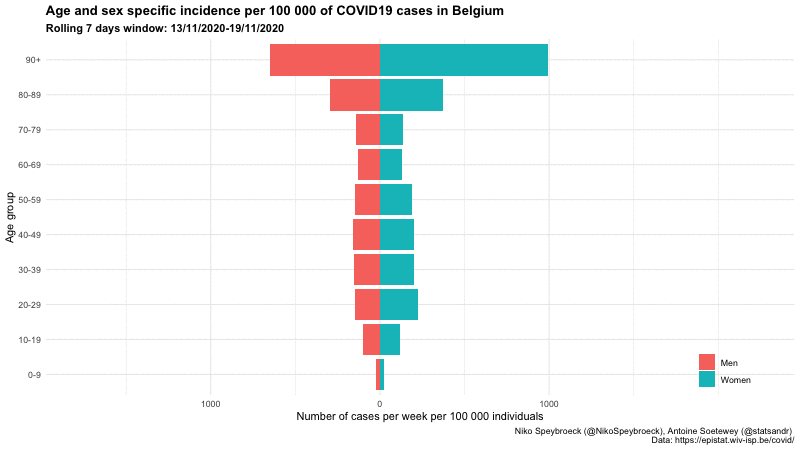
下面是比利时三个不同时期按年龄组和性别分列的病例数的另一个图表:

比利时按年龄组和性别分列的新冠肺炎病例
这一形象化显示了报告病例年龄而不仅仅是总数的重要性。
此外,我们看到,9 月初按年龄组划分的每周病例分布与暑假期间相似,但每周病例数更高。然而,9 月初按年龄组划分的每周病例分布与“第一波”(2020 年 3 月 1 日至 2020 年 5 月 31 日期间)不同。在第一阶段,大多数病例是老年人,而在 9 月初,大多数病例是年轻人。观察冬季不同年龄组的病例分布如何演变将是很有意思的。
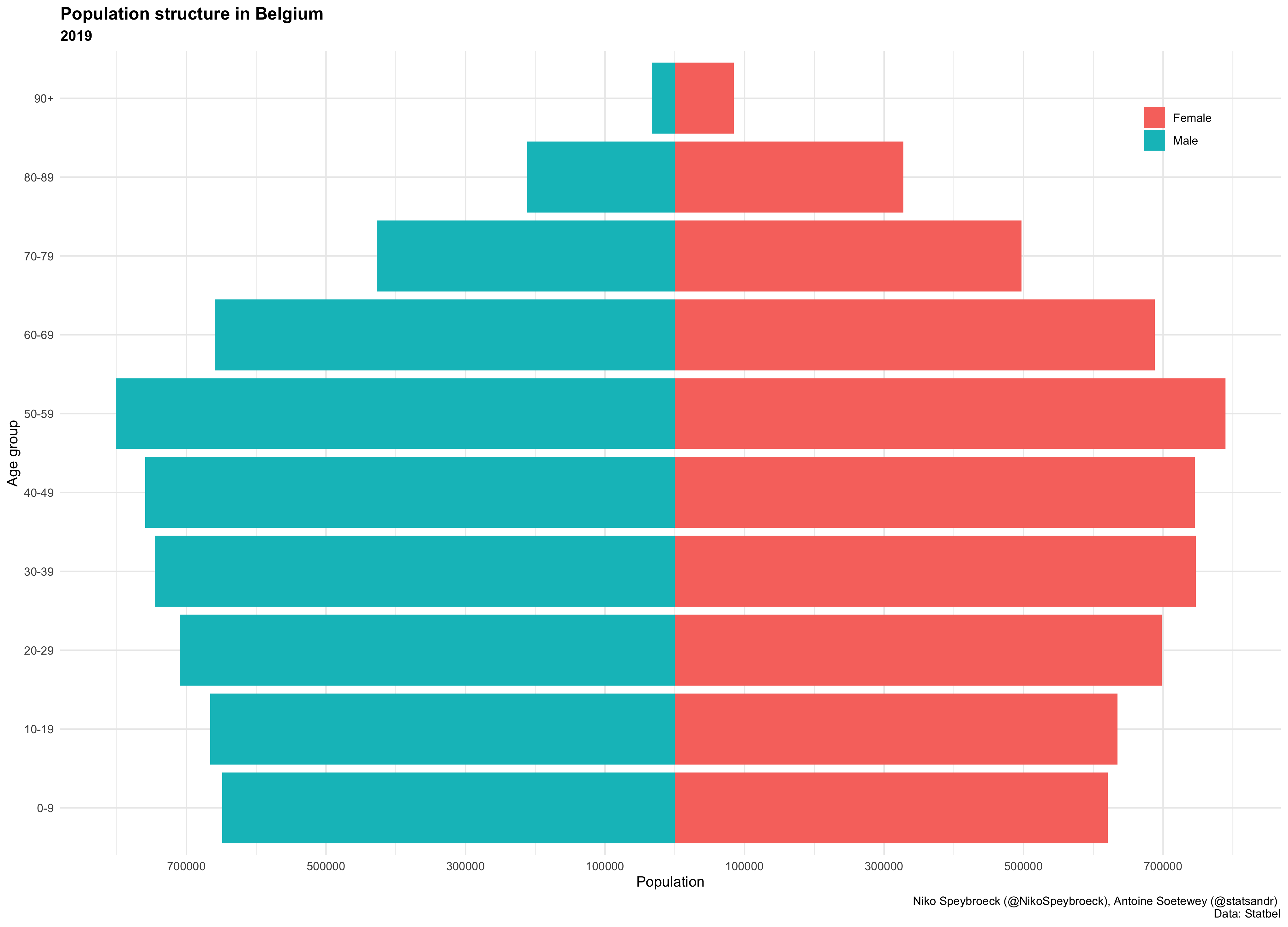
上述数字可能与比利时人口结构有关:

比利时人口结构(2019 年)
动态的
此外,还可以动态查看这些信息:

比利时按年龄组和性别划分的新冠肺炎病例-动态版本
随着第二波的更新:

比利时每 100,00 0 例 COVID19 病例的年龄和性别特异性发病率—动态版本
按年龄组、性别和省份

感谢阅读。我们希望这些数字将朝着正确的方向发展。与此同时,请注意安全!
如果你想进一步了解新冠肺炎疫情的发展,有两个选择:
- 不时访问博客,并且
- 加入 Twitter 并关注我们: statsandr ,NikoSpeybroeck&arosas _ agui rre
和往常一样,如果您有与本文主题相关的问题或建议,请将其添加为评论,以便其他读者可以从讨论中受益。
相关文章
原载于 2020 年 5 月 22 日 https://statsandr.com。
编者注: 走向数据科学 是一份以数据科学和机器学习研究为主的中型刊物。我们不是健康专家,这篇文章的观点不应被解释为专业建议。
欧洲足球联赛中的新冠肺炎

欧洲五大足球国家的职业足球运动员如何感染新冠肺炎病毒
失望之余,当我最喜欢的球队利物浦输给马德里竞技时,我感到一股愤怒在我的血管中流淌。这意味着利物浦足球俱乐部将不再参加本赛季余下的欧洲冠军联赛。此外,这导致了我们持续三个赛季的不败本垒打的结束。
这也标志着一个重要事件的开始,欧洲足球的暂时终结。随着冠状病毒疫情开始像野火一样在全球蔓延,大多数欧洲足球联赛开始关闭并无限期推迟任何体育赛事。因此,接下来的两到三个月将不会有足球比赛。
对我来说,这是一种可怕的方式,因为那次痛苦的损失。欧洲各地的足球俱乐部开始进行多种测试,以了解他们的球员和工作人员是否感染了新冠肺炎病毒。当他们测试他们的球员和工作人员时,他们在网上报告了测试结果,关于谁得到了它以及下一步是什么。
看到许多足球专业人士(工作人员和球员)感染了新冠肺炎,以及它是如何在欧洲传播的,这促使我进行研究,以找出新冠肺炎如何影响五大足球国家(英、西、意、德、法)的欧洲联赛。我不得不阅读多篇文章来找出谁感染了新冠肺炎。
一篇非常有用的文章可以在这里找到。它提供了大量的信息,包括名字,球队,年龄,联赛,在球队中的角色和状态。我决定将所有这些细节一行一行地插入到谷歌的电子表格中。
在记录了 86 个病例后,我遇到了一个障碍,因为我阅读的所有其他文章都没有提供任何关于感染该病毒的人口统计数据的细节。标题是“经过又一轮检测,X 人的新冠肺炎病毒检测呈阳性”我开始绘制图表,显示新冠肺炎如何影响不同的联赛。我创建的图表可以在下面看到。
感染新冠肺炎的职业足球运动员的平均年龄

欧洲五大足球国家的地图,突出显示了感染新冠肺炎的职业足球运动员的平均年龄
在德国,足球专业人士感染新冠肺炎的平均年龄是 23.5 岁,是最少的。第二少的是法国,25.5 分。意大利居中,得分为 27.5。联合王国的平均年龄为 35.8 岁。最高的是西班牙,为 36.33。
各联盟的案件数量

一个条形图,显示了整个联盟的案件数量
在五个主要足球国家中,西班牙西甲记录的案件数量最高,为 32 起。排在第二位的是意甲联赛,记录了 19 起。英超联赛以 17 枚位列第三。德甲以 7 枚位列第四。前三名是法国排名前两名的联赛,分别是法甲和法乙。两者都记录了一个病例。右上角的图例显示了联盟的位置。
基于新冠肺炎案例的团队排名

根据新冠肺炎案例对团队进行排名的水平条形图
阿拉维斯受到重创,因为其组织的 15 名成员感染了新冠肺炎病毒。同样在西班牙的西班牙人受到重创,有 11 人被诊断患有新冠肺炎。第三是意大利的桑普多利亚,记录了 8 例。巴伦西亚和伯恩茅斯排名第四,共有 5 起案件。
结论
在这个项目中,我利用 Tableau 创建了一个地图,显示了各个国家感染新冠肺炎病毒的足球专业人士的平均年龄。我还构建了一个条形图来显示不同联盟中记录了多少个案例。最后,我使用了一个水平条形图,根据感染冠状病毒的人数对各个团队进行排名。
结合这三个图表,我能够构建一个交互式仪表板,并通过 Tableau Public 部署它。这个交互式仪表盘可以在这里查看。
感谢您的阅读。
您可能还会对以下内容感兴趣:
印度的新冠肺炎
新冠肺炎教对印度影响的详细统计分析。

马库斯·温克勒在 Unsplash 上的照片
新冠肺炎是一种由冠状病毒引起的传染病,生物学上称为严重急性呼吸综合征冠状病毒 2 型(新型冠状病毒)。这种疾病于 2019 年 12 月在中国湖北省省会武汉首次被发现,此后蔓延到世界各地。当我写这篇文章时,IST 时间 2020 年 4 月 28 日 00:55,根据谷歌的数据,全世界有 300 万确诊病例,并导致 208,000 人死亡。
在这篇文章中,我将看看印度的现状。我们将看看受疫情影响最严重的地区,以及该国的人数是如何稳步攀升的
首先,我们将导入我将在分析中使用的必要库。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns%matplotlib inline
%matplotlib notebook
接下来,我们将从我获取信息的地方导入不同的数据表。
covid19_df = pd.read_csv("./datasets/covid_19_india.csv")
individuals_df = pd.read_csv("./datasets/IndividualDetails.csv")excel_file = pd.ExcelFile("./datasets/Indian States Population and Area.xlsx")
indian_states_df = excel_file.parse('Sheet1')
在这个分析中,我使用了三个不同的数据来源。我要感谢 Sudalai Rajkumar 和他的合作者,我从 Kaggle 下载了前两个文件。最后一个数据集是我从 uidai 网站和维基百科上收集的州级 Aadhaar 饱和度数据。
你可以从我的 GitHub 库下载数据集,我在文章末尾附上了链接,或者你也可以从 Kaggle 下载。如果你在网上使用它们,记得给出到期的学分!
让我们看看来自 Kaggle 的 COVID 19 数据集的前几条记录。

covid19_df.head()

covid19_df.tail()
因此,我们可以看到,该数据集提供了该国特定州每天发现的病例数记录。在进一步的检查中,我们发现这个数据集包含 1350 个条目和 9 个特征。这些数据包含了一些重要的数据,比如某个州某一天的确诊人数、死亡人数和治愈人数。确诊病例进一步细分为印度国民和外国人。这个数据集中的细节层次是我最喜欢的!

covid19_df.shape

covid19_df.isna().sum()
在这里,我们看到这个数据集中没有丢失的值,这使我的工作更容易。现在让我们看一下每个州的最新记录,了解一下我们目前的情况。从最后一组记录中,我们可以看到我们拥有截至 2020 年 4 月 25 日的数据。
covid19_df_latest = covid19_df[covid19_df['Date']=="25/04/20"]
covid19_df_latest.head()

covid19_df_latest['Confirmed'].sum()

因此,现在我们已经根据每个州的最新数据筛选了 1318 条记录的数据集。通过检查这些数据,我们看到截至 2020 年 4 月 25 日,印度共有 24,893 例病例。
治国人物
covid19_df_latest = covid19_df_latest.sort_values(by=['Confirmed'], ascending = False)
plt.figure(figsize=(12,8), dpi=80)
plt.bar(covid19_df_latest['State/UnionTerritory'][:5], covid19_df_latest['Confirmed'][:5],
align='center',color='lightgrey')
plt.ylabel('Number of Confirmed Cases', size = 12)
plt.title('States with maximum confirmed cases', size = 16)
plt.show()

显示确诊新冠肺炎阳性病例最多的州的条形图。
在检查上面的可视化,我们看到,马哈拉施特拉邦有最多的案件检查到目前为止。马哈拉施特拉邦接近 7000 例,在我上传这个笔记本的时候可能已经超过了这个数字。根据我们掌握的数据,马哈拉施特拉邦的情况如此严重,以至于印度没有任何其他邦超过这一标准的一半。古吉拉特邦和德里即将达到 3000 例,而拉贾斯坦邦和中央邦只有 2000 多例。
covid19_df_latest['Deaths'].sum()

根据数据集中的数据,印度各邦已有 779 人死亡。我们现在将了解哪些州的死亡人数最多。
covid19_df_latest = covid19_df_latest.sort_values(by=['Deaths'], ascending = False)
plt.figure(figsize=(12,8), dpi=80)
plt.bar(covid19_df_latest['State/UnionTerritory'][:5], covid19_df_latest['Deaths'][:5], align='center',color='lightgrey')
plt.ylabel('Number of Deaths', size = 12)
plt.title('States with maximum deaths', size = 16)
plt.show()

条形图显示了因新冠肺炎死亡人数最多的州。
毫不奇怪,上图中出现的五个状态中的四个也出现在这张图中。马哈拉施特拉邦目前几乎占了印度因新冠肺炎死亡人数的一半。排名第二的古吉拉特邦也没有达到一半。中央邦即将达到三位数,德里和安得拉邦紧随其后。
接下来,我想看看印度各邦每个确诊病例的死亡人数,以便更好地了解可用的医疗设施。
covid19_df_latest['Deaths/Confirmed Cases'] = (covid19_df_latest['Confirmed']/covid19_df_latest['Deaths']).round(2)
covid19_df_latest['Deaths/Confirmed Cases'] = [np.nan if x == float("inf") else x for x in covid19_df_latest['Deaths/Confirmed Cases']]
covid19_df_latest = covid19_df_latest.sort_values(by=['Deaths/Confirmed Cases'], ascending=True, na_position='last')
covid19_df_latest.iloc[:10]

因此,在创建了这个新的衡量标准,并根据这个数字对各州进行排序之后,我来看看这方面最差的十个州。我们看到,在梅加拉亚邦、恰尔肯德邦和阿萨姆邦等一些邦,病例和死亡人数目前都很低,情况似乎得到了控制。但是像旁遮普邦、卡纳塔克邦等其他邦看起来也受到了这种情况的影响。我们将西孟加拉邦排除在整个等式之外,因为该邦已经出现了关于错误发布数字的消息。中央邦、古吉拉特邦和马哈拉施特拉邦也榜上有名。
然而,这些统计数据并不总是提供清晰的画面。印度是一个人口结构多变的国家,没有两个邦是相同的。也许将这些数字等同于一个州的估计人口可能会对整个情况有更好的了解。
每 1000 万例
indian_states_df.head()

现在让我们真正使用你收集的数据集。该数据集提供了截至 2019 年每个州分配的 Aadhaar 卡的数量以及每个州每平方公里的面积等细节。每个州分配的 Aadhaar 卡的数量是一个很好的衡量或估计每个州人口数字的方法。我决定使用这个数字,因为印度政府的官方人口普查是在 2011 年进行的,差距太大,不能使用。我还决定不采用基于以往人口普查预测的各种人口预测数字。
我们现在将从主新冠肺炎数据集中删除一些要素,因为这些细节对我的分析没有太大帮助。我们还会将分配的 Aadhaar 卡的数量列重命名为人口,并放弃面积功能,因为我决定不使用它,因为最近印度各邦和 UTs 进行了更新。
covid19_df_latest = covid19_df_latest.drop(['Sno','Date','Time','ConfirmedIndianNational','ConfirmedForeignNational'], axis = 1)
covid19_df_latest.shape

indian_states_df = indian_states_df[['State', 'Aadhaar assigned as of 2019']]
indian_states_df.columns = ['State/UnionTerritory', 'Population']
indian_states_df.head()

我们现在将人口数据集与主数据集合并,并创建一个名为“每 1000 万病例数”的新要素,以获得更多关于哪些病例受新冠肺炎危机影响更大的信息。我觉得这个新措施现在是一个更加冷静的措施,因为它考虑到了不同州之间存在的人口差异。
covid19_df_latest = pd.merge(covid19_df_latest, indian_states_df, on="State/UnionTerritory")
covid19_df_latest['Cases/10million'] = (covid19_df_latest['Confirmed']/covid19_df_latest['Population'])*10000000
covid19_df_latest.head()

covid19_df_latest.fillna(0, inplace=True)
covid19_df_latest.sort_values(by='Cases/10million', ascending=False)

错过了大约 5 个州,因为我不能把它们放在一张图片里!对不起,读者们!
df = covid19_df_latest[(covid19_df_latest['Confirmed']>=1000) | (covid19_df_latest['Cases/10million']>=200)]
plt.figure(figsize=(12,8), dpi=80)
plt.scatter(covid19_df_latest['Confirmed'], covid19_df_latest['Cases/10million'], alpha=0.5)
plt.xlabel('Number of confirmed Cases', size=12)
plt.ylabel('Number of cases per 10 million people', size=12)
plt.scatter(df['Confirmed'], df['Cases/10million'], color="red")for i in range(df.shape[0]):
plt.annotate(df['State/UnionTerritory'].tolist()[i], xy=(df['Confirmed'].tolist()[i], df['Cases/10million'].tolist()[i]),
xytext = (df['Confirmed'].tolist()[i]+1.0, df['Cases/10million'].tolist()[i]+12.0), size=11)plt.tight_layout()
plt.title('Visualization to display the variation in COVID 19 figures in different Indian states', size=16)
plt.show()

散点图显示了印度不同邦之间新冠肺炎数字的变化。
因此,从图表和视觉效果来看,我们意识到,即使我们把邦人口考虑在内,马哈拉施特拉邦、古吉拉特邦、德里、拉贾斯坦邦和中央邦确实受到了严重影响。除了这些邦,还有其他邦和中央直辖区,如泰米尔纳德邦、北方邦、安得拉邦、泰伦加纳、昌迪加尔和拉达克。然而,拉达克的情况看起来不错,在 20 例确诊病例中,有 14 例已经康复。昌迪加尔也是如此,28 例确诊病例中有 15 例已经康复。
现在我们已经有了每个状态的六个重要特征,我们可以看看这些特征是如何相互关联的,并从中得出一些见解。
plt.figure(figsize = (12,8))
sns.heatmap(covid19_df_latest.corr(), annot=True)

显示不同功能之间相互关系的热图。
我们注意到,一些指标,如确诊、治愈、死亡和每 1000 万人病例数,是非常相关的,我们并不急于去认识其中的原因。
个人数据
接下来,我们来看一下现有的个案数据。在对该数据集进行初步检查时,我们发现该数据集中有大量缺失数据,我们在继续分析时必须考虑这些数据。

individuals_df.isna().sum()individuals_df.iloc[0]

2020 年 1 月 30 日,印度发现首例新冠肺炎病例。这是在喀拉拉邦的特里斯苏尔市发现的。该人有在武汉的旅行史。

individuals_grouped_district = individuals_df.groupby('detected_district')
individuals_grouped_district = individuals_grouped_district['id']
individuals_grouped_district.columns = ['count']
individuals_grouped_district.count().sort_values(ascending=False).head()
接下来,我决定根据发现病例的地区对个人数据进行分组。在做这件事的时候,我必须格外小心,因为这一栏中有一些丢失的数据。从现有数据来看,孟买是全国受灾最严重的地区。它有 2000 多个病例,其次是艾哈迈达巴德。浦那是马哈拉施特拉邦的另一个区,也在这个名单中。所有这些地区都属于我们在前面的图表中看到的州。
individuals_grouped_gender = individuals_df.groupby('gender')
individuals_grouped_gender = pd.DataFrame(individuals_grouped_gender.size().reset_index(name = "count"))
individuals_grouped_gender.head()plt.figure(figsize=(10,6), dpi=80)
barlist = plt.bar(individuals_grouped_gender['gender'], individuals_grouped_gender['count'], align = 'center', color='grey', alpha=0.3)
barlist[1].set_color('r')
plt.ylabel('Count', size=12)
plt.title('Count on the basis of gender', size=16)
plt.show()

基于性别的新冠肺炎案例分布。
继续我们的分析,我想看看病例数是如何根据性别分布的。我们看到在这个分布中没有宇称。从数据来看,在印度,这种病毒对男性的影响似乎大于女性。这也得到不同新闻机构的证实。挖一下谷歌!
印度病例数的进展
在本节中,我们将了解印度的病例数是如何增加的。之后,我们将检查这条曲线,并找出与州级曲线的相似之处。
为了做这个分析,我必须稍微修改一下数据集。我根据诊断数据特征对数据进行了分组,这样我就有了全印度每天检测到的病例数。接下来,我对这个特性进行了累加,并将其添加到一个新的列中。
individuals_grouped_date = individuals_df.groupby('diagnosed_date')
individuals_grouped_date = pd.DataFrame(individuals_grouped_date.size().reset_index(name = "count"))
individuals_grouped_date[['Day','Month','Year']] = individuals_grouped_date.diagnosed_date.apply(
lambda x: pd.Series(str(x).split("/")))
individuals_grouped_date.sort_values(by=['Year','Month','Day'], inplace = True, ascending = True)
individuals_grouped_date.reset_index(inplace = True)
individuals_grouped_date['Cumulative Count'] = individuals_grouped_date['count'].cumsum()
individuals_grouped_date = individuals_grouped_date.drop(['index', 'Day', 'Month', 'Year'], axis = 1)
individuals_grouped_date.head()

individuals_grouped_date.tail()

该数据集包含截至 4 月 20 日的数据。当天,印度共有 18032 例确诊病例。我们注意到数据集包含 1 月 30 日的数据,但不包含中间的数据,因为在此期间没有检测到病例。为了保持连续性,我决定假设 2020 年 3 月 2 日为第一天,因为我们有从那以后每天的数据。
individuals_grouped_date = individuals_grouped_date.iloc[3:]
individuals_grouped_date.reset_index(inplace = True)
individuals_grouped_date.columns = ['Day Number', 'diagnosed_date', 'count', 'Cumulative Count']
individuals_grouped_date['Day Number'] = individuals_grouped_date['Day Number'] - 2
individuals_grouped_dateplt.figure(figsize=(12,8), dpi=80)
plt.plot(individuals_grouped_date['Day Number'], individuals_grouped_date['Cumulative Count'], color="grey", alpha = 0.5)
plt.xlabel('Number of Days', size = 12)
plt.ylabel('Number of Cases', size = 12)
plt.title('How the case count increased in India', size=16)
plt.show()

印度新冠肺炎阳性病例的进展。
在上面的曲线中,我们看到上升或多或少是稳定的,直到第 20 天。在 20-30 之间的区间,曲线稍微倾斜。这种倾斜逐渐增加,在 30 天后,我们看到一个稳定而陡峭的斜坡,没有变平的迹象。这些都是不祥的迹象。
在接下来的几个代码元素中,我准备并处理数据集,根据不同的状态对数据进行分组。在接下来的分析中,我使用了以下五种状态:
- 马哈拉施特拉邦
- 喀拉拉邦
- 德里
- 拉贾斯坦邦
- 古吉拉特邦
covid19_maharashtra = covid19_df[covid19_df['State/UnionTerritory'] == "Maharashtra"]
covid19_maharashtra.head()
covid19_maharashtra.reset_index(inplace = True)
covid19_maharashtra = covid19_maharashtra.drop(['index', 'Sno', 'Time', 'ConfirmedIndianNational', 'ConfirmedForeignNational','Cured'], axis = 1)
covid19_maharashtra.reset_index(inplace = True)
covid19_maharashtra.columns = ['Day Count', 'Date', 'State/UnionTerritory', 'Deaths', 'Confirmed']
covid19_maharashtra['Day Count'] = covid19_maharashtra['Day Count'] + 8
missing_values = pd.DataFrame({"Day Count": [x for x in range(1,8)],
"Date": ["0"+str(x)+"/03/20" for x in range(2,9)],
"State/UnionTerritory": ["Maharashtra"]*7,
"Deaths": [0]*7,
"Confirmed": [0]*7})
covid19_maharashtra = covid19_maharashtra.append(missing_values, ignore_index = True)
covid19_maharashtra = covid19_maharashtra.sort_values(by="Day Count", ascending = True)
covid19_maharashtra.reset_index(drop=True, inplace=True)
print(covid19_maharashtra.shape)
covid19_maharashtra.head()

covid19_kerala = covid19_df[covid19_df['State/UnionTerritory'] == "Kerala"]
covid19_kerala = covid19_kerala.iloc[32:]
covid19_kerala.reset_index(inplace = True)
covid19_kerala = covid19_kerala.drop(['index','Sno', 'Time', 'ConfirmedIndianNational', 'ConfirmedForeignNational','Cured'], axis = 1)
covid19_kerala.reset_index(inplace = True)
covid19_kerala.columns = ['Day Count', 'Date', 'State/UnionTerritory', 'Deaths', 'Confirmed']
covid19_kerala['Day Count'] = covid19_kerala['Day Count'] + 1
print(covid19_kerala.shape)
covid19_kerala.head()

covid19_delhi = covid19_df[covid19_df[‘State/UnionTerritory’] == “Delhi”]
covid19_delhi.reset_index(inplace = True)
covid19_delhi = covid19_delhi.drop([‘index’,’Sno’, ‘Time’, ‘ConfirmedIndianNational’, ‘ConfirmedForeignNational’,’Cured’], axis = 1)
covid19_delhi.reset_index(inplace = True)
covid19_delhi.columns = [‘Day Count’, ‘Date’, ‘State/UnionTerritory’, ‘Deaths’, ‘Confirmed’]
covid19_delhi[‘Day Count’] = covid19_delhi[‘Day Count’] + 1
print(covid19_delhi.shape)
covid19_delhi.head()

covid19_rajasthan = covid19_df[covid19_df['State/UnionTerritory'] == "Rajasthan"]
covid19_rajasthan.reset_index(inplace = True)
covid19_rajasthan = covid19_rajasthan.drop(['index','Sno', 'Time', 'ConfirmedIndianNational', 'ConfirmedForeignNational','Cured'], axis = 1)
covid19_rajasthan.reset_index(inplace = True)
covid19_rajasthan.columns = ['Day Count', 'Date', 'State/UnionTerritory', 'Deaths', 'Confirmed']
covid19_rajasthan['Day Count'] = covid19_rajasthan['Day Count'] + 2
missing_values = pd.DataFrame({"Day Count": [1],
"Date": ["02/03/20"],
"State/UnionTerritory": ["Rajasthan"],
"Deaths": [0],
"Confirmed": [0]})
covid19_rajasthan = covid19_rajasthan.append(missing_values, ignore_index = True)
covid19_rajasthan = covid19_rajasthan.sort_values(by="Day Count", ascending = True)
covid19_rajasthan.reset_index(drop=True, inplace=True)
print(covid19_rajasthan.shape)
covid19_rajasthan.head()

covid19_gujarat = covid19_df[covid19_df['State/UnionTerritory'] == "Gujarat"]
covid19_gujarat.reset_index(inplace = True)
covid19_gujarat = covid19_gujarat.drop(['index','Sno', 'Time', 'ConfirmedIndianNational', 'ConfirmedForeignNational','Cured'], axis = 1)
covid19_gujarat.reset_index(inplace = True)
covid19_gujarat.columns = ['Day Count', 'Date', 'State/UnionTerritory', 'Deaths', 'Confirmed']
covid19_gujarat['Day Count'] = covid19_gujarat['Day Count'] + 19
missing_values = pd.DataFrame({"Day Count": [x for x in range(1,19)],
"Date": [("0" + str(x) if x < 10 else str(x))+"/03/20" for x in range(2,20)],
"State/UnionTerritory": ["Gujarat"]*18,
"Deaths": [0]*18,
"Confirmed": [0]*18})
covid19_gujarat = covid19_gujarat.append(missing_values, ignore_index = True)
covid19_gujarat = covid19_gujarat.sort_values(by="Day Count", ascending = True)
covid19_gujarat.reset_index(drop=True, inplace=True)
print(covid19_gujarat.shape)
covid19_gujarat.head()

所有五个州都有 55 个记录,包含 5 个特征。每个记录代表一天。在这个分析中,为了保持一致,我也决定将 2020 年 3 月 2 日作为第一天。
现在让我们来看看可视化。
plt.figure(figsize=(12,8), dpi=80)
plt.plot(covid19_kerala['Day Count'], covid19_kerala['Confirmed'])
plt.plot(covid19_maharashtra['Day Count'], covid19_maharashtra['Confirmed'])
plt.plot(covid19_delhi['Day Count'], covid19_delhi['Confirmed'])
plt.plot(covid19_rajasthan['Day Count'], covid19_rajasthan['Confirmed'])
plt.plot(covid19_gujarat['Day Count'], covid19_gujarat['Confirmed'])
plt.legend(['Kerala', 'Maharashtra', 'Delhi', 'Rajasthan', 'Gujarat'], loc='upper left')
plt.xlabel('Day Count', size=12)
plt.ylabel('Confirmed Cases Count', size=12)
plt.title('Which states are flattening the curve ?', size = 16)
plt.show()

印度一些邦新冠肺炎病例的进展。
我们看到几乎所有的曲线都遵循着整个国家的曲线。唯一的例外是喀拉拉邦。与其他曲线一样,喀拉拉邦的曲线在 20-30 天内逐渐倾斜。但喀拉拉邦成功做到的是,它没有让曲线进一步倾斜,而是设法让曲线变平。因此,国家已经能够控制局势。
马哈拉施特拉邦的形势看起来确实非常严峻。这条曲线非常陡峭,没有减速的迹象。与其他地区相比,古吉拉特曲线在较晚的时间间隔变陡。它一直保持在控制状态,直到第 30 天,40 天后病情恶化。
作为一个整体,我们防止这场迫在眉睫的危机的唯一方法是拉平曲线。所有邦政府都需要遵循喀拉拉模式。这是唯一一个设法使曲线变平的国家,因此,大多数事情都做对了。是时候我们遵循喀拉拉模式了。
卡格尔邮报:https://www.kaggle.com/pritamguha31/covid-19-in-india
Github 链接:【https://github.com/PritamGuha31/COVID-19-Analysis
意大利的新冠肺炎感染。数学模型和预测
logistic 和指数模型在意大利新冠肺炎病毒感染中的比较。

Viktor Forgacs 在 Unsplash 上拍摄的照片
这些天来,世界正在与一个新的敌人作战,这就是新冠肺炎病毒。
自从在中国首次出现以来,这种病毒在世界上迅速传播。不幸的是,意大利正在记录欧洲新冠肺炎感染人数最高。我们是西方世界面对这个新敌人的第一个国家,我们每天都在与这种病毒的所有经济和社会影响作斗争。
在本文中,我将向您展示 Python 中感染增长的简单数学分析和两个模型,以更好地理解感染的演变。
数据收集
每天,意大利民事保护部门都会刷新累计感染人数数据。此数据在 GitHub 上公开为公开数据:https://raw . githubusercontent . com/PCM-DPC/新冠肺炎/master/dati-andamento-Nazionale/DPC-covid 19-ita-andamento-Nazionale . CSV
我的目标是创建到目前为止的总感染人数的时间序列的模型**(即实际感染人数加上已经感染的人数)。这些模型都有参数,将通过曲线拟合来估算。**
用 Python 来做吧。
首先,让我们导入一些库。
import pandas as pd
import numpy as np
from datetime import datetime,timedelta
from sklearn.metrics import mean_squared_error
from scipy.optimize import curve_fit
from scipy.optimize import fsolve
import matplotlib.pyplot as plt
%matplotlib inline
现在,我们来看看原始数据。
url = "https://raw.githubusercontent.com/pcm-dpc/COVID-19/master/dati-andamento-nazionale/dpc-covid19-ita-andamento-nazionale.csv"df = pd.read_csv(url)

我们需要的列是“totale_casi ”,它包含迄今为止的累计感染人数。
这是一切开始的原始数据。现在,让我们为我们的分析准备它。
数据准备
首先,我们需要将日期转换成数字。我们将从 1 月 1 日开始休假。
df = df.loc[:,['data','totale_casi']]FMT = '%Y-%m-%d %H:%M:%S'date = df['data']df['data'] = date.map(lambda x : (datetime.strptime(x, FMT) - datetime.strptime("2020-01-01 00:00:00", FMT)).days )

我们现在可以分析我将参加考试的两个模型,它们是逻辑函数和指数函数。
每个模型有三个参数,这些参数将通过对历史数据的曲线拟合计算来估计。
逻辑模型
逻辑斯蒂模型被广泛用于描述人口的增长。感染可以被描述为病原体的增长,因此逻辑模型似乎合理。
这个公式在数据科学家中非常有名,因为它被用在逻辑回归分类器中,并作为神经网络的激活函数。
逻辑函数最通用的表达式是:

在这个公式中,我们有变量 x 即时间和三个参数: a,b,c 。
- a 指感染速度
- b 是发生感染最多的一天
- c 是感染结束时记录的感染者总数
在高时间值时,感染人数越来越接近和 c ,在这一点上我们可以说感染已经结束。该函数在 b 处还有一个拐点,即一阶导数开始降低的点(即感染开始变得不那么具有攻击性并降低的峰值)。
我们用 python 来定义吧。
def logistic_model(x,a,b,c):
return c/(1+np.exp(-(x-b)/a))
我们可以使用 scipy 库的 curve_fit 函数,从原始数据开始估计参数值和误差。
x = list(df.iloc[:,0])
y = list(df.iloc[:,1])fit = curve_fit(logistic_model,x,y,p0=[2,100,20000])
以下是这些值:
- 答 : 3.54
- b : 68.00
- c : 15968.38
该函数也返回协方差矩阵,其对角线值是参数的方差。取它们的平方根,我们可以计算出标准误差。
errors = [np.sqrt(fit[1][i][i]) for i in [0,1,2]]
- a 的标准误差:0.24
- b 的标准误差:1.53
- c 的标准误差:4174.69
这些数字给了我们许多有用的见解。
感染结束时的预期感染人数为 15968+/- 4174。
感染高峰预计在 2020 年 3 月 9 日左右。
预期感染结束时间可以计算为累计感染人数等于到四舍五入到最接近整数的 c 参数的那一天。
我们可以使用 scipy 的 fsolve 函数来数值求解定义感染结束日的方程的根。
sol = int(fsolve(lambda x : logistic_model(x,a,b,c) - int(c),b))
时间是 2020 年 4 月 15 日。
指数模型
逻辑模型描述的是 ain 感染增长将在未来停止,而指数模型描述的是不可阻挡的感染增长。例如,如果一个病人每天感染 2 个病人,1 天后我们会有 2 个感染,2 天后 4 个,3 天后 8 个,依此类推。
最普通的指数函数是:

变量 x 是时间,我们还有参数 a,b,c 。然而,其含义不同于逻辑函数参数。
让我们在 Python 中定义函数,并执行用于逻辑增长的相同曲线拟合过程。
def exponential_model(x,a,b,c):
return a*np.exp(b*(x-c))exp_fit = curve_fit(exponential_model,x,y,p0=[1,1,1])
参数及其标准误差为:
- 一个 : 0.0019 +/- 64.6796
- b : 0.2278 +/- 0.0073
- c : 0.50 +/- 144254.77
情节
我们现在有了可视化结果的所有必要数据。
pred_x = list(range(max(x),sol))
plt.rcParams['figure.figsize'] = [7, 7]plt.rc('font', size=14)# Real data
plt.scatter(x,y,label="Real data",color="red")# Predicted logistic curve
plt.plot(x+pred_x, [logistic_model(i,fit[0][0],fit[0][1],fit[0][2]) for i in x+pred_x], label="Logistic model" )# Predicted exponential curve
plt.plot(x+pred_x, [exponential_model(i,exp_fit[0][0],exp_fit[0][1],exp_fit[0][2]) for i in x+pred_x], label="Exponential model" )plt.legend()
plt.xlabel("Days since 1 January 2020")
plt.ylabel("Total number of infected people")
plt.ylim((min(y)*0.9,c*1.1))plt.show()

两条理论曲线似乎都非常接近实验趋势。哪个做得更好?再来看看残差。
残差分析
残差是每个实验点和相应理论点之间的差。我们可以分析两个模型的残差,以验证最佳拟合曲线。在一级近似中,理论和实验数据之间的均方差越低,越符合。
y_pred_logistic = [logistic_model(i,fit[0][0],fit[0][1],fit[0][2]) for i in x]y_pred_exp = [exponential_model(i,exp_fit[0][0], exp_fit[0][1], exp_fit[0][2]) for i in x]mean_squared_error(y,y_pred_logistic)
mean_squared_error(y,y_pred_exp)
Logistic 模型均方误差:8254.07
指数模型均方误差:16219.82
哪个型号合适?
残差分析似乎指向逻辑模型。很有可能是因为感染应该在未来的某一天结束;即使每个人都会被感染,他们也会发展出适当的免疫防御来避免二次感染。只要病毒不会变异太多(比如流感病毒),就没错。
但是有一点还是让我担心。自从感染开始,我每天都在拟合逻辑曲线,每天我都得到不同的参数值。末感染人数增加,最大感染日往往是当天或次日(这个参数上兼容 1 天的标准误)。这就是为什么我认为,尽管逻辑模型似乎是最合理的一个,但曲线的形状很可能会由于像新感染热点**、政府控制感染的行动等外部影响而改变**。
这就是为什么我认为这个模型的预测只有在几周内,也就是感染高峰期过后,才会开始变得有用。
编者按:【towardsdatascience.com】是一家以数据科学和机器学习研究为主的中型刊物。我们不是健康专家或流行病学家。想了解更多关于疫情冠状病毒的信息,可以点击 这里 。
新冠肺炎-按美国州和县列出的所有案例的交互式 Power BI 地图
疫情对全国的影响的局部视图


TL;DR 链接到仪表板此处
我和我妻子谈到美国各县是如何在新闻中单独报道新冠肺炎病例的。有很多地图追踪器用于世界和美国的州级报告,但没有多少地图在县一级整理。
她将此视为一项挑战,并在一个晚上就构建了这个惊人的公开可用的 Power BI 交互式仪表盘!
支持仪表板的 API 和数据:
最初,我们将这个令人敬畏的 GitHub API 归功于 GitHub 用户JKSenthil:【https://github.com/JKSenthil/coronavirus-county-api】
,他构建了这个基于 python 的 API,从https://coronavirus.1point3acres.com/en抓取数据
但是,当 1point3acres 更改他们的 html UI 数据格式时,我们遇到了一些问题,这破坏了 API。我最终克隆了 API,并对其进行了编辑,使其起死回生(这占用了我周日的大部分时间)。但是,嘿,一个星期天花在帮助妻子上是值得的。😃
API 分叉和调整:
API 使用 Selenium WebDriver,它运行一个无头 Chrome 来抓取 web URL,并将 API 数据作为 JSON 返回。API 是用 python 编写的,运行在通过 gunicorn 提供服务的 Flask 上,部署并托管在 Heroku 上。我遇到了一些问题:
问题# 1:API 中断是因为 scraper 失败。这源于源 UI 格式的变化。我可以通过调整抓取逻辑来解决这个问题。
问题#2: Heroku 的自由等级意味着我必须限制 gunicorn 的工人数量为 1。这对于应用程序来说不是问题,因为它是唯一请求数据的 API 用户。这些请求每隔几个小时才会刷新一次仪表板。
问题# 3:API 需要一段时间来响应,因为抓取器必须遍历美国所有 3200 多个县来抓取数据。我不得不将 gunicorn 的超时值提高到比默认值更长。
结束语:
总的来说,这是一次很酷的经历,特别是使用 Python 和 Heroku 主机。
我相信这张公共地图也揭示了有趣的县级统计数据和空间分布。随着美国新冠肺炎病例的增加,这一点尤其重要。在#隔离期间,帮助我的妻子做一个数据科学项目也很有趣!
如果您对该主题有任何想法或对仪表盘或所用工具有任何疑问,请通过 LinkedIn 与我联系
这里是交互式仪表盘的链接,它每 24 小时更新一次:新冠肺炎美国仪表盘
新冠肺炎正在改变我们的生活方式,而人工智能正在努力跟上
根据过去行为训练的机器学习模型很难猜测我们的下一步行动

在 Unsplash 上 engin akyurt 拍摄的照片
本周,亚马逊建议我买一加仑的洗手液,谷歌的地理位置记录告诉我总共去过零个地方,YouTube 认为我可能会喜欢看更多的面具制作 DIY 和面包烘焙教程。
显然,自从疫情开始以来,我们的日常生活已经发生了变化。对我们中的许多人来说,我们买什么,去哪里,做什么都和以前有很大的不同。
在国际卫生危机期间,这些变化是意料之中的。然而,对于根据正常人类行为训练的人工智能系统来说,我们的新行动对它们的算法来说是一个相当大的冲击,它们正在努力跟上。
人工智能是一个包含很多东西的宽泛术语,但在这种情况下,我们谈论的是机器学习。这些算法使用大量数据来找到一种模式,并对接下来会发生什么做出有根据的猜测。对于亚马逊来说,这个猜测就是你想买的东西。对于 YouTube 来说,就是你想看的。
无论我们是否意识到这一点,我们的生活已经深深扎根于机器学习模型。除了在线商店和流媒体应用,它们还用于欺诈检测、安全、营销等领域。
但是这些模型只能脱离给它们的数据。当他们遇到一个与他们从中学到的数据相差太大的场景时,他们很难猜到你要做什么。
当新冠肺炎开始影响我们的日常生活时,机器学习算法开始遇到一些问题。
据《麻省理工技术评论》报道,一家公司的预测算法被一次不寻常的批量订单打破。当算法告诉他们重新进货的商品不再与客户购买的商品匹配时,他们注意到了这一点。
类似的用户激增给一家在线流媒体公司使用的推荐算法带来了问题。他们发现用户数据的涌入降低了推荐的准确性。
对于一家信用欺诈检测公司来说,引起警惕的不是如何购买了多少,而是购买了什么。他们发现,人们突然开始购买园艺设备和电动工具,他们的算法通常会将其记录为欺诈性支出。
在这种情况下,公司的工程师们有先见之明,为消费习惯的改变做出了调整。
当发生重大变化时,像这样的修改对于保持机器学习算法的工作是必不可少的。你不能简单地训练自动化系统,然后走开。为了跟上时代,他们需要监督、调整,甚至可能需要一些再培训。
例如,亚马逊调整了他们的算法,以解释他们在购买中看到的变化。
它们通常会为使用其仓库的卖家带来流量,但当疫情开始,人们开始更多地在网上购物时,仓库变得不堪重负。通过调整他们的算法,他们能够让订单更均匀地分配给卖家。
另一家使用机器学习来编写广告电子邮件的公司也对他们的算法进行了一些修改。他们的系统选择最好的短语来使用,但在当前全球疫情的情况下,该公司认为最好避免某些短语,如“病毒式传播”
展望未来,随着我们的生活在疫情期间和之后继续进化,负责维护机器学习模型的计算机科学团队将需要继续做出这些改变。这样,我们正在经历的新世界将会在算法的行为中得到反映。
这也适用于新的机器学习模型的开发,这些模型是为了响应疫情而创建的。
随着新冠肺炎病毒带来的种种不确定性,科学家们一直在开发预测该病毒未来的算法。
在5 月 19 日发表的一项研究中,西奈山医院的研究人员将胸部 CT 扫描和患者数据与机器学习模型相结合,以诊断新冠肺炎患者。他们发现,在某些情况下,他们的算法在确定哪个病人感染了病毒方面甚至比高级胸科放射科医生还要好。
其他医院迫切希望了解哪些病人会病情危急,甚至已经开始使用尚未验证的算法。
机器学习也被用于预测病毒的传播,并确定隔离和社会距离等缓解措施的效果。
伦斯勒理工学院的研究人员将这些努力集中在单个城市。他们指出,较小的城市更难建模,因为训练算法的数据较少。在这些情况下,他们需要做出调整以做出准确的预测。
就像影响我们日常生活其他方面的算法一样,随着我们对病毒的了解越来越多,并适应新常态,这些模型也必须更新。
AI 的目的是让我们的生活更简单。机器学习模型在许多不同的行业中以许多不同的方式做到这一点。但是,随着这种相互联系,我们有必要共同成长。否则,他们就有被落下的危险。
新冠肺炎和机器学习
一种潜在的机器学习方法,可以帮助控制新冠肺炎
成功提交:【https://innovate.mygov.in/covid19/】

注: 注:我的方法将侧重于解决印度(我的祖国)在评估新冠肺炎的影响时所面临的挑战。但是下面的方法很容易推广,因为其他受影响的国家也面临着与印度类似的挑战。
此外,我通过考虑从高感染和受打击最严重的国家(如意大利、西班牙、英国、美国)以及在控制新冠肺炎疫情方面非常成功的国家(如韩国)获得的经验,制定了这个 ML 方法;中国-武汉,澳大利亚,阿联酋!
目录?
- 解决控制印度新冠肺炎病毒传播和死亡人数的主要问题/挑战&其他国家?
- 我提出的想法/解决方案
- ML 问题公式化&解决上述挑战的解决方案
- 一种潜在的 ML 方法/解决方案
- 这是长久之计吗?
1: 解决印度控制新冠肺炎病毒传播和死亡人数的主要问题/挑战&其他国家?
—问题是:
缺乏专注的测试!!!
1.1:为什么测试很重要
- 测试让受感染的人知道他们被感染了。这可以帮助他们接受所需的护理,也可以帮助他们采取措施降低感染他人的概率。不知道自己被感染的人可能不会呆在家里,从而有感染他人的风险。
- 测试对于适当应对疫情也至关重要。它让我们了解疾病的传播,并采取循证措施减缓疾病的传播。
- 不幸的是,在许多国家,包括印度和世界各地,新冠肺炎检测的能力仍然很低。由于这个原因,我们仍然没有很好地了解疫情的传播。
新冠肺炎考试如何进行: 这里
1.2:那么,测试阈值应该是多少呢?
为了找到这一点,我们需要理解可视化。我还在下面附上了整个 ipython 笔记本的链接。
数据来源:https://ourworldindata.org/

百万分之 2 Y 轴条形图
- 像 中、汉、韩、澳 这样的国家在拉平新冠肺炎传播曲线方面一直很繁荣,因为他们根据每百万人口增加了每百万人口的检测。
显然,从上面的可视化中,我们可以得出结论,为了控制新冠肺炎传播,(test _ per _ million≥population _ per _ million * 100)意味着 100 万人口需要至少 100 个测试容量。
像印度、美国、英国、西班牙和意大利这样的国家还没有达到上述检测标准,并且仍然在与新冠肺炎疫情做斗争,甚至还在与每百万人口检测做斗争。
1.3:对印度&其他国家来说,增加每百万人的检测数量有哪些挑战?还有为什么需要倍数?
- 印度&其他受影响的国家卫生资源有限。印度每万人拥有 8 名医生,而意大利和韩国分别为 41 名和 71 名。
- 疾病的早期(最初 1-3 天)病毒载量太低,无法检测。这会导致假阴性,因此需要多次测试/个体,最终导致每百万人的测试应至少大于或等于每百万人口的 100 倍,这一点我们可以从其他成功国家的数据中学习。
- 测试是一个手动过程,导致 处理&人为错误 。
为什么我们没有足够的新冠肺炎测试(详细): 这里
2:我提出的想法/解决方案
所以,如果问题是缺乏集中测试!!!那么新冠肺炎疫情的解决方案就是:
“测试测试测试&然后检疫”
但是,我已经提到,增加检测数量的挑战不是微不足道的,特别是当印度和其他国家,甚至美国、英国、意大利和伊朗,也有最少的卫生资源和同样的问题。
在计算机科学中,有一句流行的话:“最好的解决方案是最简单的!”。我们需要在很短的时间内增加每百万测试的数量,这里我提出了我对这个问题的想法/解决方案:
我们应该使用基于优先级的自动化测试系统(PbATS) 使用 ML/AI 来区分测试的优先级。这有助于确定测试的优先级,并有助于确定提供有限医疗服务的优先级。
使用 PbATS,我们将根据他们的输入对人群进行分类。为此,假设我们将人口分为以下三类:
***类别 1(自我隔离)😗它们要么未受影响,要么仍未显示系统,但已受影响(假阴性)。它主要包含了未受影响的&一些假阴性病例。因此,他们需要定期接受 PbATS,直到特定的持续时间。
***类别 2(测试优先级)😗该类别包含一些假阴性,但开始显示症状,因此需要手动测试
第 3 类 (医疗保健服务-优先):这一类由极有可能感染新冠肺炎病毒的人组成,因此,他们应该被严格隔离,并得到优先的医院服务。

PbATS 工作流程
注: 这种 PbATS 机制将是一种 AI/ML 方法,我们根据过去所有新冠肺炎患者的历史数据对这三个类别进行分类。众所周知,“所有的机器学习模型都是错误的,只有一些是有用的”——考虑到这一点,我的解决方案包含对类别 1 和类别 3 的多次尝试,因为类别 2 已经有了手动测试。
此外,在领域专家/新冠肺炎专家的帮助下,可以准确确定类别数量和周期。
3:解决上述挑战的 ML 问题公式和解决方案
现在,为了让上述解决方案发挥作用,我们需要鲁棒的 PbATS。现在,我将展示一种使用机器学习技术构建这种 PbATS 的潜在方法。
ML 问题公式化: 我们需要根据那里、特征(年龄、性别)、症状、过往旅行史对人群进行分类。
***解决方案工作流程:*一旦该 PbATS 准备就绪,每个人都需要通过数字方式或通过志愿者填写他们的详细信息(以最大限度地减少错误),然后医生可以轻松确定测试/医疗保健服务的优先级,并选择要隔离的人。这有助于医生和政府用最少的卫生资源阻止新冠肺炎。
最终,这种 PbATS 机制将间接帮助政府&医疗服务提供者增加test _ per _ million根据 人口 _per_million 阻止新冠肺炎传播所需的。
4:潜在的 ML 方法/解决方案
4.1:数据? 对于这一点,我已经取了数据,刮了数据(使用文本挖掘技术),并把它们串联起来。数据来源如下:
- https://ourworldindata.org/coronavirus
- https://www.kaggle.com/tags/covid19
- https://www . who . int/docs/default-source/corona virus/situation-reports/2020 03 23-sit rep-63-covid-19 . pdf?sfvrsn=d97cb6dd_2
下面是原始数据的样子:

原始数据样本
4.2:数据清理后:

数据清理
4.3:然后,我做了一些特色工程如下:
- 将年龄范围(60-65)转换为平均值(62.5)
- 增加了 日期 _ 过去 _ 发病 _ 症状(dpos) 这是天数 b/w 日期 _ 确认的差异&日期 _ 发病 _ 症状
- 基于 travel _ history _ dates&travel _ history _ locations 之间的操作,增加了**travel _ history(th)**标志
- 最后,将来自整个数据点的所有特征合并为一个 主症状/混合症状 。我这样做的原因稍后会更明显
4.4:最终数据集:

最终数据集
4.5:主症状上的自然语言处理
然后,我执行了所有标准的 NLP 技术来矢量化主症状。我用过BoW+W2V(word 2 vec-gensim)。我使用 W2V 是因为我需要根据*关系(不是相似性&计数)*对症状进行聚类,这有助于聚类过程。
我使用了 BoW,而不是 TF-IDF ,因为我们的数据集没有很多罕见的、出现的、需要更多重要性的单词。
4.6: ML 聚类:
**最后,我用****k means++**做了聚类(最通用)。我们使用肘方法得到的聚类数也是 3(巧合的是),但是也可以使用更多的 领域知识 来改变它!
4.7:结果/词云:

基于 3 个聚类的主症状,dpos:过去发病天数-症状,th:旅行史
最终类别: 从上面主症的词云可以看出,我们可以大致将易发人群归类为:
第 3 类(医疗保健服务-优先):【年龄在 30-75 岁之间】+【发热、咳嗽、呼吸道感染、流鼻涕、喉咙痛、肺炎、头痛、胸闷(主要有dpos>4*)+[th-1经常旅行记录】*
第 2 类(测试优先):【年龄在 0-75 岁之间】+【发热、咳嗽、不适、肺炎、僵硬、关节、肌肉酸痛以及dpo 在 1-3 之间* ] + [ th-0/1 活动或不活动的旅行记录】*
第 1 类(自我隔离):【年龄在 0-75 岁之间】+【发热、咳嗽、虚弱、腹泻、头晕、寒战,dpos 在 1-3 之间】+[th-0大部分无旅行史,也有一些有旅行史】
学问: 我们可以看到,症状模式取决于 年龄, 主要以新冠肺炎为例,而变得严重的有dpos我的努力只是为了检测这些模式,以便优先使用 PbATS 进行测试。**
Jupyter 笔记本
类似实现:此处
5:这是永久的解决方案吗?
根本没有! 上述解决方案仅通过有限的医疗服务帮助印度和其他国家阻止新冠肺炎的传播。因此有助于遏制 Sars-CoV-2。
这种永久性的解决方案是 疫苗 ,需要数周甚至数月才能准备好。通过使用现有病毒疫苗(Sars-1,西班牙流感)等的组合找到疫苗,这种缺口也可以使用 ML/AI 容易地发现。,使用 ML/AI 技术。
最后,是的,上述方法解决了医疗资源有限的问题。尽管如此,像印度和其他国家需要每百万人口中至少有 30%-40%的医疗资源(床位/呼吸机)用于第三类。
这个博客是我对在印度盛行的新冠肺炎 esp 战斗的一点微薄贡献。报送:https://innovate.mygov.in/covid19/
差不多就是这样!【bbhopalw@gmail.com】接:
PS:
- 关于数据集的请求——我已经把用 nodeJS 编写的 数据集& Web 抓取代码都开源了,可以在我的 GitHub 上获得。
- 关于 合作 ,请直接发邮件给我。
- 这是博客原文。读者可能会在其他数据科学 简讯(upGrad,DS news) 中找到这一点(再版!).

再版—时事通讯
连接 🤝 :
- 邮箱:bbhopalw @ Gmail
- Linkedin:www.linkedin.com/in/bbhoaplw
延伸阅读✍️*😗****
大数据&云工程博客:
后端工程&软件工程博客:
基于新冠肺炎机器学习的普通实验室检查快速诊断
塔尔西斯·苏扎博士、古斯塔沃·文泽尔·塞纳托医学博士和赫利·苏扎医学博士
来自巴西 5644 名患者的证据

摘要
- 新冠肺炎病例的突然快速增长正在使全球卫生系统不堪重负。快速、准确和早期检测新型冠状病毒对控制病毒传播至关重要。然而,基于 RT-PCR 分析的传统新型冠状病毒检测可能成本高、耗时长且普遍不可用,使得检测每个病例成为不切实际的努力。
- 我们提出了一种基于机器学习的方法,使用通常可用的实验室测试数据来快速检测新冠肺炎病例。
- 我们分析了巴西圣保罗的以色列阿尔伯特爱因斯坦医院的 5644 名患者样本,其中 558 名患者的新型冠状病毒检测呈阳性。考虑到原始样本数据的⅓的保留测试组,所提出的模型呈现出 92% (AUC)的总体高性能。
- 我们观察到,有新冠肺炎症状且鼻病毒、肠病毒、B 型流感和 Inf 检测呈阴性的患者。2009 年甲型 H1N1 流感,白细胞和血小板水平较低,更有可能检测出新型冠状病毒阳性。
- 我们提出了一个基于不同场景的参数模型,这些场景是作为目标敏感度水平或医院有能力优先处理的潜在阳性病例总数的函数给出的。
- 在 25%的患者被认为是新型冠状病毒阳性的情况下,所提出的模型显示出分别超过 84%和 96%的灵敏度和特异性,因此被证明是一种有用的快速优先化工具。
介绍
背景
世界卫生组织(世卫组织)在 3 月 11 日将由新型冠状病毒引起的新冠肺炎定性为疫情,而病例数量的指数级增长有可能使世界各地的卫生系统不堪重负,对 ICU 床位的需求远远超过现有能力,意大利的一些地区就是突出的例子。

巴西于 2 月 26 日记录了第一例新型冠状病毒,病毒传播从仅输入病例发展到当地并最终社区传播非常迅速,联邦政府于 3 月 20 日宣布全国社区传播。
截至 2020 年 3 月 27 日,圣保罗州记录了 1223 例新冠肺炎确诊病例,68 例相关死亡,而截至 3 月 23 日,拥有约 1200 万人口和以色列阿尔伯特·爱因斯坦医院所在地的圣保罗州有 477 例确诊病例和 30 例相关死亡。该州和圣保罗县都决定建立隔离和社会距离措施,这将至少持续到 4 月初,以努力减缓病毒的传播。
动机和目标
这项工作的目标是根据通常收集的实验室检查结果预测疑似病例中的确诊新冠肺炎病例。我们考虑以下研究问题:
根据在急诊室就诊期间通常为疑似新冠肺炎病例收集的实验室检测结果,是否有可能预测 SARS-Cov-2 的检测结果(阳性/阴性)?
这项工作的一个动机是,在卫生系统不堪重负的情况下,对新型冠状病毒的检测进行测试可能会受到限制,测试每个病例是不切实际的,考虑到测试结果需要 48 小时到一整周的时间,即使只测试一个目标亚群,测试也可能会被推迟。
贡献
我们提出了一个简单的模型来快速预测感染新型冠状病毒病毒风险最高的患者,使他们能够得到优先考虑,并有可能采取隔离措施和相关的医疗程序。我们的贡献有三个方面:
- 新型冠状病毒的快速高准确度测试:提议的模型仅基于通常可获得的实验室测试数据,其表现出 92%的 AUC 和大于 85%的灵敏度水平以及大于 85%的合理特异性水平的高性能
- 可解释性:变量的重要性和与结果变量的条件依赖性很容易从模型中提取出来,其解释可以指导医疗决策
- 灵活性:根据目标敏感度水平、医院能力和疾病流行程度,模型构建可灵活适应不同的政策情景
资料组
该数据集包含在巴西圣保罗的以色列阿尔伯特爱因斯坦医院就诊的患者的匿名数据,这些患者在就诊期间收集了样本以进行新型冠状病毒 RT-PCR 和其他实验室测试。

巴西圣保罗的阿尔伯特·爱因斯坦医院收集并提供了该数据集。
所有数据都按照最佳国际惯例和建议进行了匿名处理。所有的临床数据被标准化为平均值为零和单位标准差。
该数据集包含 109 个变量(预测因子),一个患者 ID 和一个目标结果变量,该变量指示患者是否对 SARS-Cov-2 检测为阳性/阴性。有 5644 个样本可用,其中有 558 个阳性病例,占数据集的 10%。
数据准备
首先,我们执行一些基本的数据清理程序:
- 通过删除特殊字符、空格和符号,使变量名在语法上有效
- 将表示缺失数据的字符串转换为 NA ,即以下值:“no realization do”和“not_done”
- 将字符串分类值转换为因子
- 将变量尿…pH 转换为数值,因为它在输入数据中包含字符串和数值的混合
我们的结果变量被命名为 SARS。Cov.2.exam.result ,它是一个二元变量,表示患者对 SARS-COV2 病毒的检测是阳性还是阴性。我们将此变量转换为 S A R S 。 C o v . 2. e x a m . r e s u l t = 1 SARS。Cov.2.exam.result = 1 SARS。Cov.2.exam.result=1,如果患者检测为阳性,则为 S A R S 。 C o v . 2. e x a m . r e s u l t = 0 SARS。Cov.2.exam.result = 0 SARS。Cov.2.exam.result=0,否则。
如下所示,大多数变量都有很高的缺失值百分比(NA)。这里的问题是,在我们提出的预测建模中,当数据被分成交叉验证/自举子样本时,这些预测器可能成为零方差预测器。

因此,我们去除了有太多缺失数据点(> = 95%)的变量。我们还去除了实验室数据中过于稀疏的样本,我们选择保留至少有 10 个变量和数据点的阴性样本。这样做是为了避免过拟合的情况,在过拟合的情况下,少数样本(稀疏但正的)可能会对预测模型产生不适当的影响。
删除了以下变量:
[1] "Serum.Glucose" [2] "Mycoplasma.pneumoniae" [3] "Alanine.transaminase" [4] "Aspartate.transaminase" [5] "Gamma.glutamyltransferase." [6] "Total.Bilirubin" [7] "Direct.Bilirubin" [8] "Indirect.Bilirubin" [9] "Alkaline.phosphatase" [10] "Ionized.calcium." [11] "Magnesium" [12] "pCO2..venous.blood.gas.analysis." [13] "Hb.saturation..venous.blood.gas.analysis." [14] "Base.excess..venous.blood.gas.analysis." [15] "pO2..venous.blood.gas.analysis." [16] "Fio2..venous.blood.gas.analysis." [17] "Total.CO2..venous.blood.gas.analysis." [18] "pH..venous.blood.gas.analysis." [19] "HCO3..venous.blood.gas.analysis." [20] "Rods.." [21] "Segmented" [22] "Promyelocytes" [23] "Metamyelocytes" [24] "Myelocytes" [25] "Myeloblasts" [26] "Urine...Esterase" [27] "Urine...Aspect" [28] "Urine...pH" [29] "Urine...Hemoglobin" [30] "Urine...Bile.pigments" [31] "Urine...Ketone.Bodies" [32] "Urine...Nitrite" [33] "Urine...Density" [34] "Urine...Urobilinogen" [35] "Urine...Protein" [36] "Urine...Sugar" [37] "Urine...Leukocytes" [38] "Urine...Crystals" [39] "Urine...Red.blood.cells" [40] "Urine...Hyaline.cylinders" [41] "Urine...Granular.cylinders" [42] "Urine...Yeasts" [43] "Urine...Color" [44] "Partial.thromboplastin.time..PTT.." [45] "Relationship..Patient.Normal." [46] "International.normalized.ratio..INR." [47] "Lactic.Dehydrogenase" [48] "Prothrombin.time..PT...Activity" [49] "Vitamin.B12" [50] "Creatine.phosphokinase..CPK.." [51] "Ferritin" [52] "Arterial.Lactic.Acid" [53] "Lipase.dosage" [54] "D.Dimer" [55] "Albumin" [56] "Hb.saturation..arterial.blood.gases." [57] "pCO2..arterial.blood.gas.analysis." [58] "Base.excess..arterial.blood.gas.analysis." [59] "pH..arterial.blood.gas.analysis." [60] "Total.CO2..arterial.blood.gas.analysis." [61] "HCO3..arterial.blood.gas.analysis." [62] "pO2..arterial.blood.gas.analysis." [63] "Arteiral.Fio2" [64] "Phosphor" [65] "ctO2..arterial.blood.gas.analysis."
其余的变量如下:
[1] "Patient.age.quantile" [2] "SARS.Cov.2.exam.result" [3] "Patient.addmited.to.regular.ward..1.yes..0.no." [4] "Patient.addmited.to.semi.intensive.unit..1.yes..0.no." [5] "Patient.addmited.to.intensive.care.unit..1.yes..0.no." [6] "Hematocrit" [7] "Hemoglobin" [8] "Platelets" [9] "Mean.platelet.volume" [10] "Red.blood.Cells" [11] "Lymphocytes" [12] "Mean.corpuscular.hemoglobin.concentration..MCHC." [13] "Leukocytes" [14] "Basophils" [15] "Mean.corpuscular.hemoglobin..MCH." [16] "Eosinophils" [17] "Mean.corpuscular.volume..MCV." [18] "Monocytes" [19] "Red.blood.cell.distribution.width..RDW." [20] "Respiratory.Syncytial.Virus" [21] "Influenza.A" [22] "Influenza.B" [23] "Parainfluenza.1" [24] "CoronavirusNL63" [25] "Rhinovirus.Enterovirus" [26] "Coronavirus.HKU1" [27] "Parainfluenza.3" [28] "Chlamydophila.pneumoniae" [29] "Adenovirus" [30] "Parainfluenza.4" [31] "Coronavirus229E" [32] "CoronavirusOC43" [33] "Inf.A.H1N1.2009" [34] "Bordetella.pertussis" [35] "Metapneumovirus" [36] "Parainfluenza.2" [37] "Neutrophils" [38] "Urea" [39] "Proteina.C.reativa.mg.dL" [40] "Creatinine" [41] "Potassium" [42] "Sodium" [43] "Influenza.B..rapid.test" [44] "Influenza.A..rapid.test" [45] "Strepto.A"
预测分析
模特培训
为了预测患者感染 SARS-Cov2 病毒的可能性,我们将数据集随机分为训练和测试测试,训练与测试的分割比为 2/3。我们分解数据集,使得结果变量也遵循训练集和测试集之间的相同分割比。
我们使用剩余的数据集变量作为预测器来训练 GBM 模型。我们还定义了一个袋分数,它定义了随机选择的训练集观察值的分数,以提出扩展中的下一棵树。这将随机性引入模型拟合,并减少过度拟合。
模型可解释性
我们通过观察变量的相对重要性以及它们相对于结果变量的条件依赖概率来评估模型的可解释性。模型解释是重要的,因为它们可以用来改善医疗决策和指导政策制定的倡议。
模型返回的前 10 个最重要的变量如下所示。重要性度量是标准化的,它们基于变量被选择用于树分裂的次数,由作为每个分裂的结果的模型的改进来加权,并在所有树上平均。

我们分析了下面 5 个最重要变量的条件概率图,其中 x 轴代表预测值,y 轴代表感染的可能性(数字是归一化的)。我们观察到以下情况:
- 当鼻病毒。肠病毒,流感。b 或 Inf。甲型 H1N1.2009 未被检测到,患者更有可能检测出 SARS-COV2 阳性
- 白细胞或血小板低的患者更有可能检测出 SARS-COV2 阳性





作为严重新冠肺炎病例的主要指标,一个被广泛讨论的变量是年龄。因此,我们分析变量 age_quantile 和之前讨论的前 5 个最重要的变量之间的二元关系。我们观察到,当与研究的其他前 5 个变量结合时,患者的年龄分位数可以增加 SARS-COV2 感染的可能性。





预测
我们将训练好的模型应用于 668 名患者的测试数据集。我们观察到该模型表现非常好,AUC 为 92%。然而,模型的特异性和敏感性的确定依赖于可能性阈值的定义,以确定在疑似病例中被认为可能是阳性新冠肺炎病例的患者。

下面我们可以看到阈值的选择如何影响模型的灵敏度和特异性(使用训练集的样本内分析)。具有高灵敏度的模型在那些真正的阳性患者中找到阳性患者方面取得了良好的结果。然而,预测为阳性的患者数量可能过高,并影响模型的特异性。此外,如果这个数字太高,医院可能没有足够的资源来为所有被分配了阳性标签的患者应用必要的程序。因此,理想的模型是平衡良好的模型,即,具有高灵敏度但不会给患者过多分配阳性标记的模型。

为了确定选择哪种可能性以及如何确定哪些患者更有可能被感染,我们讨论了与不同的医院、城市、州或国家特定政策相关的不同场景。对于每个场景,我们将从训练集中选择阈值,该阈值优化由场景中的策略驱动的给定目标函数。
场景 1:资源的高可用性
在场景 1 中,我们假设医院具有高可用性的资源。这样,模型就可以放松,高估阳性病例的数量。因此,我们的目标函数是使灵敏度最大化。
我们使用训练数据来选择最大化模型灵敏度的阈值。然后,我们将这个阈值应用于测试集中的预测概率。该过程返回 1.6%的概率阈值,并且该模型呈现 95%的高灵敏度值,如预期的那样。然而,高召回率是以特异性为代价的,特异性呈现 34%的低值。此外,测试集中约 74%的患者被标记为阳性,因此该模型作为优先化工具的使用有限。
场景 2:资源有限
在场景 2 中,我们假设环境资源有限,因此,如果我们能够获得一个平衡的模型,那么降低模型的敏感度是可以接受的。为此,我们选择最大化定义为 m a x ( 灵敏度 + 特异性 ) max(灵敏度+特异性) max(灵敏度+特异性)的约登 J 统计量作为目标函数。
下面,我们可以看到阈值对相应的约登 J 统计值的影响(样本内分析)。我们观察到,过低或过高的阈值会导致模型中的次优平衡。
在对测试集进行预测后,我们将从训练集中选择一个阈值,该阈值最大化约登 J 统计量,以实现良好平衡的模型。我们观察到,与场景 1 的 95%相比,场景 2 下的模型现在提供了 84%的灵敏度。然而,它返回 96%的特异性,同时保持 92%的高 AUC(因为阈值的选择不影响 AUC),因此提供了预期的更好平衡的模型。此外,现在该模型仅将 26%的测试集分配给阳性标签,显示出作为潜在的患者优先化工具是有用的。

场景 3:有限的资源,不同的政策
在情景 3 中,我们假设不同的医院可能对敏感度的可接受值有不同的政策,或有不同的能力检测优先患者,以及有不同的流行水平。因此,我们通过提出一个具有成本函数的参数模型来概括场景 1 和 2 下研究的模型,该成本函数允许医生根据目标策略以及作为输入参数的输入流行度,与假阳性分类相比,高估或低估假阴性分类。
我们的目标函数是
m a x ( 灵敏度 + r ∗ s p e c i f i c ) max(灵敏度+r * specific) max(灵敏度+r∗specific),
在哪里
r = 1 —流行率 / 成本 ∗ 流行率 r = 1 —流行率/成本*流行率 r=1—流行率/成本∗流行率
并且 r r r是假阴性分类的相对成本(与假阳性分类相比)。不同的国家和地区可能有不同的流行率,而不同的医院可能有不同的政策来定义 c o s t cost cost参数。
我们的研究结果表明,在标记为阳性的患者百分比数($num . positive . pct $)低于 30%的情况下,可以提供特异性和敏感性均大于 85%的实用模型,因此可以作为相关的优先化工具。此外,该模型被参数化,以允许容易地微调,从而针对目标敏感度、患病率或要优先考虑的患者的最大数量进行调整。


实际应用
在实践中,使用建议模型的卫生工作者/医院将为最低可接受敏感度水平或要优先考虑的患者目标数量定义政策,并指定当前流行率。这些参数将作为模型的输入,以确定可能检测为阳性的优先患者。然后,该模型将输出新型冠状病毒感染、可能性测量和准确性的二元指标。该模型的输出可用作优先化的工具,并支持进一步的医疗决策过程。输入参数和医院的政策可以根据卫生系统的状况定期更新。然后,该模型将被重新训练,并纳入新的可用数据。
结论
在这项工作中,我们通过分析来自以色列阿尔伯特·爱因斯坦医院的 5644 名患者(其中 558 名患者的新型冠状病毒病毒检测呈阳性)的样本,表明可以根据通常为疑似新冠肺炎病例收集的实验室检测结果来预测新型冠状病毒的检测结果。
根据目标政策/方案,所提出的模型具有 92%的 AUC 和大于 85%的敏感性/特异性水平的实际应用。该模型具有较高的可解释性,进一步显示了鼻病毒、肠病毒、B 型流感和 Inf 检测阴性的新冠肺炎症状患者。2009 年甲型 H1N1 流感,白细胞和血小板水平较低,更有可能检测出新型冠状病毒阳性。
我们还研究了如何根据不同的场景来调整模型的性能,这些场景被定义为目标敏感度的函数或医院对大量患者进行优先排序的政策。我们发现,如果医院愿意考虑选择 75%的患者进行检测,特异性水平可以达到 98%以上。然而,我们表明,在患者优先级别约为 25%的情况下,可以实现良好平衡的模型(特异性和敏感性均大于 85%),因此证明这是一个相关的优先程序。模型的性能平衡可定义为考虑患病率、患者优先级别或目标敏感度级别的医院特定政策的函数。
我们采用了一种简约的建模方法,并构建了一个简单有效且透明的基线模型。我们承认,由于研究中的几个限制因素,应该谨慎对待这些发现,这些限制因素包括:(1)数据样本数量少;㈡不平衡的数据集;(iii)预测值的高度稀疏性。此外,该数据集具有潜在偏见,即在本研究中研究的特定医院的普通实验室检测中存在病毒筛查,这可能在巴西或世界范围内的许多其他医疗机构中不可用。
进一步的研究应该通过考虑生命体征和体检记录来解决变量的稀疏性。鉴于这种疾病的概况,来自 x 射线和断层扫描的图像研究可以提供严重病例的早期检测,预测是否需要 ICU 病床。
数据和代码可用性声明
这项工作报告了由巴西圣保罗的以色列阿尔伯特爱因斯坦医院创建的 Kaggle 数据集诊断新冠肺炎及其临床谱的结果。
完整代码可在 https://github.com/souzatharsis/covid-19-ML-Lab-Test获得
用 Python 在 5 分钟内创建新冠肺炎地图动画
数据可视化
用 Python 和 Plotly 制作新冠肺炎地图动画

马特·拉默斯在 Unsplash 上拍摄的照片
在抗击新冠肺炎的战斗中,GIS 技术在很多方面都发挥了重要作用,包括数据整合、疫情信息的地理空间可视化、确诊病例的空间追踪、区域传播预测等等。这些为政府部门抗击新冠肺炎疫情提供了支持信息。[1]为了解决这个问题,JHU 提供了一个用 ESRI ArcGIS operation dashboard 创建的漂亮的仪表盘:

CSSE 在 JHU 的 新冠肺炎仪表盘(2020 年 5 月 29 日截图)
仪表板提供了累计确诊病例总数、活跃病例、发病率、病死率、检测率和住院率的非常好的概览。但是,在地图上可视化数据随时间变化的功能丢失了!
本文将向您介绍一种使用 JHU·新冠肺炎数据集创建可视化新冠肺炎随时间扩展的动态地图的简单方法。
我们开始吧!
步骤 1:准备 Python 库
我们将在本文中使用的 Python 库主要是 Pandas、PyCountry 和 Plotly Express。你们中的大多数人可能已经知道 Plotly 库,但是如果不知道,你可以在这篇文章中查看它的所有特性。
**$ pip install pandas
$ pip install pycountry
$ pip install plotly**
步骤 2:加载数据集
我们将在这里使用的数据集是 JHU·CSSE·新冠肺炎数据集。你可以从 CSSE Github repo 下载或获取它的最新更新版本。您可以查看这篇文章,了解如何使用 PythonGit 在您的 Python 项目中随时间自动更新数据源。在本文中,我们将只关注**time_series_covid19_confirmed_global.csv** 数据集。

来自 JHU CSSE 的时间序列 _ covid 19 _ confirmed _ global . CSV
然后,您可以使用以下命令轻松地将数据加载到 dataframe
**import pandas as pd
df_confirm =** **pd.read_csv('path_to_file')**

****时间序列 _ covid19 _ 已确认 _ 全局数据集
步骤 3:清理数据集
为了使用 Plotly Express 动态可视化时间序列数据集,您需要满足以下数据框架要求。
- ****将数据集聚合到国家级别。
- 获取每个国家在ISO 3166–1中定义的三个字母的国家代码;例如,
AFG代表阿富汗。你可以使用 PyCountry 来做到这一点。 - 将数据集转换为长格式,其中日期值在单个列中表示。您可以轻松完成此操作,首先将数据集加载到 Pandas 数据帧中,然后在 Pandas 中使用 melt 。
您可以使用此 Python 脚本执行以下步骤:
总体而言,最终的干净数据帧如下图所示:

****已清理的时间序列 _ covid19 _ 已确认 _ 全局数据集
步骤 4:使用 Plotly Express 创建地图动画
数据集准备就绪后,您可以使用 Plotly Express 轻松创建地图动画。例如,您可以使用下面的脚本从步骤 3 的数据帧创建一个动画 choropleth 图,您也可以根据自己的喜好调整每个参数。
使用 Plotly Express 从 time _ series _ covid 19 _ confirmed _ global 数据集创建动画 choropleth 的 Python 脚本

使用 Plotly Express 从时间序列 _ covid19 _ 已确认 _ 全局数据集制作的动画 choropleth】
差不多就是这样!简单对吗?
下一步是什么?
此示例可视化了已确认的新冠肺炎病例数据集,但您也可以尝试将此方法应用于可视化新冠肺炎死亡病例和康复病例数据集。
关于用 plotly 绘制动画 choropleth 地图的更多信息,查看完整文档这里。如果你想改变色阶,你可以简单地从这里选择内置色阶。应用更好的颜色符号规则。尝试创建其他类型的地图,如散点图或热图,通过查看 Plotly 地图库这里。
或者,您可以通过本文查看如何在 Kepler.gl 中可视化新冠肺炎数据,这是一个用于动态数据可视化的地理空间分析工具。
结论
本文将向您介绍如何使用 Plotly Express 以简单的方式准备数据集和创建地图动画。我希望你喜欢这篇文章,并发现它对你的日常工作或项目有用。如果您有任何问题或意见,请随时给我留言。
关于我&查看我所有的博客内容:链接
安全健康和健康**!💪**
感谢您的阅读。📚
参考
[1]周,陈,苏,李,李,马,蒋,李,阎,李,易,胡,杨,肖,(2020)。新冠肺炎:大数据对 GIS 的挑战。地理和可持续性,1(1),77–87。https://doi.org/10.1016/j.geosus.2020.03.005
使用 ELK 构建新冠肺炎地图
变更数据
使用 elasticsearch 创建您自己的自定义新冠肺炎地图

新冠肺炎麋鹿地图,可在https://covid 19 Map . uah . es/app/dashboards #/view/478 e9 b 90-71e 1-11ea-8d D8-e 1599462 e 413|图片由作者提供
可能你们大多数人都熟悉约翰·霍普金斯大学(JHU)的地图代表新冠肺炎疫情的现状。

约翰·霍普金斯大学(JHU)地图的图像(约翰·霍普金斯大学)
这张地图是使用 ArcGIS 技术开发的,在很多情况下,这已经成为开发疫情地图的事实上的标准,例如世卫组织政府的地图。
在看到这个之后,我想用麋鹿创建我自己的地图;几天后,在一个朋友的帮助下,一切都运转起来了。根据我的经验,我决定写你如何也能轻松做到这一点。这一系列的文章将集中在如何使用 ELK 栈创建你自己的自定义地图。
为什么选择 Elasticsearch?
第一个要回答的问题是为什么是麋鹿?而不是使用 ArcGIS 技术。Elasticsearch 是开源的,每个人都可以轻松部署一个正在运行的集群。此外,Elasticsearch 使用 Kibana 进行了漂亮的展示,并且还提供了地图,因此它拥有我们构建令人难以置信的新冠肺炎地图所需的一切。我真的很喜欢麋鹿栈,所以我决定尝试一下。
我在一个月 10 美元的数字海洋 VPS 中运行了 ELK stack,显然没有冗余和大量空间,但我们会发现我们不需要大量空间来存储数据。
基于这一点,我们的成本将只是运行 ELK 的基础设施,但一个小的 VPS 可以运行一个小的集群。我没有很多闲钱,所以我总是试图将成本保持在最低水平。我已经运行了 ELK stack,每月 10 美元数字海洋 VPS ,显然没有冗余和大量空间,但我们会发现我们不需要大量空间来存储数据。另一种选择是使用弹性云。

我当前部署的弹性云|图片作者
弹性云是运行 ELK 集群最简单的方式,并提供许多有用的功能。例如,ELK 的一个问题是频繁更新新功能的数量。在 Elastic Cloud 中,更新集群就像按下控制面板中的一个按钮一样简单。此外,最小的部署成本低于每月 20 美元。就我而言,我停止使用弹性云是因为它的易用性和易于管理。我完全推荐这个选项,不要忘记你有 14 天的试用期。
新冠肺炎数据来源
同意 ELK 堆栈的惊人之处后,我们可以开始考虑如何在 ELK 中插入新冠肺炎数据。首先,我们为地图确定一个可靠和更新的数据源。我们需要每天检索和插入新数据来更新我们的地图。
约翰霍普金斯大学(JHU) 在 GitHub 上发布他们的数据。它们都是 CSV 格式,可以很容易地使用。新冠肺炎意大利数据也发生了类似的事情。这种格式可以很容易地被解析和插入,但是有几个问题。在解析这些数据的过程中,我遇到了几个问题。第一个是数据更新过程,例如,JHU 并不总是更新数据最快的。这很正常,他们需要等待新数据的发布,并将其纳入数据集中。您将看到意大利知识库更新更加频繁。
如果你计划运行一个更新的地图,最好的选择是不要使用那些 Github 库。
最好的选择是使用新冠肺炎 API。我们有几个选择,但我决定使用新冠肺炎叙事 API。
另一个问题是文件结构的变化。有时 CSV 结构已经改变,然后您需要再次解析这些文件,可以重命名列或者改变顺序。因此,如果你计划运行一个更新的地图,最好的选择是不要使用 Github 库。
为了避免这些问题,最好的选择是使用新冠肺炎 API。我们有几个选项,但我决定使用新冠肺炎叙事 API 。
要检索 2020 年 9 月 3 日的新冠肺炎数据,我们只需向 https://api.covid19tracking.narrativa.com/api/2020–09–03 的发出请求。在执行该请求后,我们将获得一个 JSON 响应,避免前面提到的所有问题。叙事瓦已经从几个官方数据来源检查和下载新冠肺炎信息:

新冠肺炎叙事 API |图片由作者提供
使用这个 API,我们可以检索我们需要的所有数据。从世界数据到国家和地区数据。API 的完整文档可以在这里找到。到了这一步,我们可以开始在 Elasticsearch 中消费和插入数据。
在松紧带内插入新冠肺炎
为了使用来自 API 的数据,我们可以使用 Logstash。Logstash 是在插入 Elasticsearch 之前收集、解析和转换信息的标准工具。此外,Logstash 已经为普通日志发布了许多预配置配置。
但是也有其他的可能性,比如 Python。我真的很喜欢 Python 语法和编程,所以当我从一个 API 消费时,我通常会结束构建一个脚本来消费数据并插入到 Elasticsearch 中。就像我说的,你可以用 Logstash 来做这件事,但是我觉得用 Python 编程更舒服。
所以还是从代码开始吧!!首先,我们需要从疫情开始到今天的所有数据。此外,我们希望将这些数据按日期分开,以便从不同的时间段过滤或创建可视化效果。使用 Python 请求和 datetime,我们可以轻松地迭代抛出所有日期并检索所有数据。我个人更喜欢的请求而不是的 urrlib ,我觉得它简单优雅得多。
使用 Python 请求和 datetime,我们可以轻松地迭代抛出所有日期并检索所有数据。
import requests
from datetime import datetime, date, timedeltastart_date = date(2020, 3, 1)
end_date = date(2020, 4, 9)
delta = timedelta(days=1)while start_date <= end_date:
day = start_date.strftime("%Y-%m-%d")
print ("Downloading " + day)
url = "https://api.covid19tracking.narrativa.com/api/" + day
r = requests.get(url)
data = r.json()
start_date += delta
获得每个日期的数据后,我们可以将它插入到 Elasticsearch 中,但在此之前,有必要对数据进行一些格式化。我们将在一个弹性地图中表示与国家相关的数据。为了将数据与每个国家相关联,elasticsearch 需要识别国家/地区的名称。叙事 API 为我们提供了英语、意大利语和西班牙语的名称,但有些国家的名称可能会有问题。因此,发明了 ISO 3166-1α-2(iso 2)和 ISO 3166-1α-3(iso 3)。使用这种命名法,我们可以很容易地识别每个国家的名字,不会出错。Python 有一个包 countryinfo 可以帮助我们将国家名称翻译成 iso3 格式。
Python 有一个包 countryinfo 可以帮助我们将国家名称翻译成 iso3 格式。
你需要比较人群的感染率,或者使用统计学指标,而不是绝对数字。这个主题在我完全推荐的 ArcGis 帖子中有详细介绍。
from countryinfo import CountryInfofor day in data['dates']:
for country in data['dates'][day]['countries']:
try:
country_info = CountryInfo(country)
country_iso_3 = country_info.iso(3)
population = country_info.population()
except Exception as e:
print("Error with " + country)
country_iso_3 = country
population = None
infection_rate=0
print(e)
另外,如果你检查了代码,可能大多数人都会看到一个人口值。不幸的是,Elasticsearch 现在不包括每个国家的人口数值,他们正在做那个。为了代表性地绘制新冠肺炎疫情,有必要获得每个国家的人口值,仅具有数量的热图是不具有代表性的。你需要比较感染率和人口数量,或者使用统计指标,而不是绝对数字。我强烈推荐的一篇 ArcGis 帖子中详细介绍了这个主题。
获得每个国家受感染人数代表性指标的一个简单方法是使用感染率。感染率代表人群感染的概率或风险。

感染率公式|作者图片
再次使用 Python,我们可以很容易地计算出这个数字。不幸的是,Python countryinfo 不包括所有国家的人口,因此我控制了这个例外。大多数国家都得到支持,但我发现了一些错误,如巴哈马群岛、Cabo 和其他一些国家。
def getInfectionRate(confirmed, population):
infectionRate = 100 * (confirmed / population)
return float(infectionRate)if population != None:
try:
infection_rate=getInfectionRate(data['dates'][day]['countries'][country]['today_confirmed'], population)
print(infection_rate)
except:
infection_rate=0
我用日期时间格式日期替换了时间戳。这样,Elasticsearch 将自动检测日期格式,而您将忘记创建 Kibana 索引。
完成所有这些修改后,我们只需要将这些数据插入到 Elasticsearch 中。在插入数据之前,我倾向于创建一个包含所有数据的自定义字典。我添加了以前的数据,人口,国家 iso3 名称,感染率,并用日期时间格式日期替换了时间戳。这样,Elasticsearch 将自动检测日期格式,而您将忘记创建 Kibana 索引。
def save_elasticsearch_es(index, result_data):
es = Elasticsearch(hosts="") #Your auth info
es.indices.create(
index=index,
ignore=400 # ignore 400 already exists code
)
id_case = str(result_data['timestamp'].strftime("%d-%m-%Y")) + \
'-'+result_data['name']
es.update(index=index, id=id_case, body {'doc':result_data,'doc_as_upsert':True}) result_data = data['dates'][day]['countries'][country]
del result_data['regions']
result_data['timestamp'] = result_data.pop('date')result_data.update(
timestamp=datetime.strptime(day, "%Y-%m-%d"),
country_iso_3=country_iso_3,
population=population,
infection_rate=infection_rate,
)save_elasticsearch_es('covid-19-live-global',result_data)
完整的脚本可以在 GitHub 上找到,只要记得在运行脚本之前添加你的 elasticsearch 主机,并安装所有的依赖项。
使用 Kibana 创建新冠肺炎可视化
Kibana 将自动识别时间戳字段作为时间过滤器,你只需要选择它。
运行该脚本后,将在 elasticsearch 中创建一个索引,您可以从 Kibana 配置它。Kibana 将自动识别时间戳字段作为时间过滤器,你只需要选择它。

基巴纳指数模式|图片由作者提供
数据表可视化
我们可以做的最简单的可视化之一是一个简单的表格,显示新冠肺炎病例最多的国家。

基巴纳表格显示新冠肺炎病例数最多的国家|图片由作者提供
为了创建这个可视化,我们需要一个数据表可视化。第一列可以是确诊病例的总数,使用 today_confirmed 上的简单 max 聚合,我们可以获得该数字。

Kibana 中的确诊病例总数配置|作者提供的图片
另一个有趣的指标可能是过去 48 小时内的最后确诊病例。人们可能会认为 24 小时的数字可能更有意义,但许多国家花了更多的时间来报告它们的病例,有了 48 小时的窗口,你将能够代表更多的结果。为了在 Kibana 中执行这种表示,我们需要一个 Sum Bucket 聚合。使用这种聚合,我们可以使用过去 48 小时的日期范围,现在-2d,然后再次使用最大聚合获得确诊病例数。

基巴纳最近 48 小时确诊病例配置|图片由作者提供
有了我们的聚合之后,我们唯一需要做的事情就是使用国家名称来拆分行。选择“按名称.关键字分割”将会这样做。此外,我会建议设置一个大小限制,我们将看到最重要的数字。在我的仪表板中,25 个降序数字似乎就足够了,但是您可以根据自己的喜好调整这个数字。

按国家名称拆分行|按作者拆分图片
新冠肺炎疫情地图可视化
我们能创造的最不可思议的可视化或者至少是最受欢迎的是一张显示新冠肺炎疫情演变的地图。Kibana 提供了几个创建地图的选项,在本例中,我们将选择 choropleth 选项。使用此选项,我们可以选择一个单词国家层,并选择 ISO 3166–1 alpha-3 作为格式,请记住我们是如何将它包含在脚本中的。统计源将是我们的索引名,包含 ISO 3166-1 alpha-3 的字段将是我们的连接字段,在我们的例子中是 country_iso_3。
还有,要意识到这一点!!,如果添加图层后地图仍然是黑色的,请检查您的基巴纳日期过滤器,并将最近 15 分钟选择器更改为最近 1 年。我花了很多时间思考我做错了什么,问题出在基巴纳时间选择器上。

Kibana 地图 choropleth 配置以在作者的地图|图像中创建一个图层
添加这一层后,我们还没有完成,所有国家都呈现相同的数据。我们需要选择 infection_rate 变量作为度量,以便根据其值绘制颜色,然后选择“按值填充颜色”,并再次选择 infection_rate。此外,我们可以在图层样式下的几个调色板中选择,我更喜欢红色调的那个。到达这一点,地图上应该有一些颜色。还有,要意识到这一点!!,如果添加图层后地图仍然是黑色的,请检查您的基巴纳日期过滤器,并将最近 15 分钟选择器更改为最近 1 年。我花了很多时间思考我做错了什么,问题出在基巴纳时间选择器上。

基巴纳地图 choropleth 图层配置|图片由作者提供
选择这些选项后,您应该能够看到如下内容:

基巴纳地图创作|作者图片
结论
希望通过本文提供的代码和示例,您能够创建自己的自定义地图和可视化。在这篇文章中有很多可能的基巴纳可视化,我只提出了一些想法。我的建议是尽可能多地尝试 Kibana 可视化。Kibana 是一个不可思议的工具,只需点击几下,你就可以创建以你的国家、地区或大陆为中心的图表。
新冠肺炎开源仪表板
作为数据科学家,我们必须尽最大努力从数据角度接近当前的新冠肺炎疫情。因此,我使用开源工具创建了一个仪表板来跟踪和可视化新冠肺炎的传播。
几周来,新冠肺炎疫情一直是一个不可回避的话题。媒体用新感染名人的突发新闻淹没了我们,几个国家的病例和死亡人数呈指数增长。如今,人们在社交媒体上无法谈论其他任何事情,卫生纸囤积者的视频在网上疯传。
公司没有错过这一趋势。在过去的几天里,我的 Twitter 和 LinkedIn 上充斥着各种公司,展示他们的技术有多棒,以及他们如何无私地利用它来支持政府机构、医疗保健机构等。不要误解我,我认为公司愿意提供帮助是很棒的;在当前的危机中,向任何需要帮助的公共机构提供援助的每一家公司都值得称赞!然而,如果这些贡献中的每一个都必须在营销方面得到充分利用,它们会留下一种陈腐的味道。
此外,最受欢迎的仪表盘使用了鼓励制造恐慌的黑红配色方案,就像各种新闻页面都有令人震惊的标题一样。可视化的确很重要,作为数据科学家,我们应该很好地意识到这一点,正如这篇文章所概述的。我知道使用开源技术,如 R Shiny 或 Python Dash ,可以创建一个不那么危言耸听的仪表板,与最流行的新冠肺炎仪表板不相上下。我就是这么做的!你可以在这里找到我创建的 R 闪亮仪表盘。
数据
用于所有可视化的数据由约翰·霍普金斯大学系统科学与工程中心(JHU·CSSE)提供,他们在 Github 公共页面上分享了他们的数据。约翰霍普金斯 CSSE 汇总了主要来源的数据,如世界卫生组织、国家和地区公共卫生机构。这些数据免费提供,并且每天更新。
仪表板中使用的人口数据来源于 世界银行公开数据 。这些数据只需要做一些小的修改就可以适应约翰霍普金斯大学 CSSE 新冠肺炎分校的数据。数据集中没有的“国家”人口(大部分是岛屿实体)是用来自维基百科的数据手动添加的。世界银行有一个庞大的数据库,涵盖从性别统计到投资流动的各种主题。这个存储库是高度可访问的,要么直接使用他们的 API,要么使用大多数通用编程语言中可用的各种第三方 API 之一。这为我们提供了在仪表板中集成各种有趣的数据集的机会,这些数据集目前不包括在“主流”选项中。你可以在这里找到更多关于开发者的信息。
新冠肺炎仪表板——开源版
仪表板分为几个部分,可在浏览器窗口的左上角选择。
仪表板的总览部分显示了新冠肺炎疫情最重要的关键数字和可视化效果,例如世界地图和国家列表,以及它们各自的确诊、治愈、死亡和活跃病例数。包括一个带有简单滑块的延时功能,以了解疫情的发展。

新冠肺炎仪表板-概览部分
“绘图”部分包含可视化新冠肺炎·疫情级数的几个有趣方面的绘图。这些额外信息包括一些问题,如案件的全球演变;新案件;以及两个允许在不同国家之间进行比较的图表。用户能够手动选择她或他感兴趣的国家。大多数图都有复选框,y 轴可以切换到对数刻度,特定国家的图可以按人口进行标准化。默认情况下,在特定国家图中选择确诊病例最多的五个国家。

新冠肺炎仪表板—绘图部分(用红色标记:国家选择)
仪表板上的“关于”部分描述了动机、数据来源以及关于发展和贡献的其他信息。
考虑
请注意,这个数据不能想当然。关于新冠肺炎案件的数字有很多不确定性。我避免计算死亡率和类似的数字,因为它们相对模糊,如几个来源所述[1][2]。各国的检测制度差异很大,因此很难在各国之间进行直接比较。
技术
仪表板是使用 R shiny 开发的,它让你只用 R 代码就能构建和托管交互式 web 应用。对于 IDE,我使用的是 IntelliJ 社区版,其中有一个 R 插件,可以让你像在最流行的 R IDE 中一样有效地编写 R 代码;r 工作室。我使用的其他库有:
- Shinydashboard :提供了很多预先配置好的仪表盘元素,可以相对容易的集成。
- Tidyverse :为数据争论和处理而设计的 R 包的集合,它们共享底层的设计哲学、语法和数据结构。
- 传单 :围绕最流行的用于交互式地图的开源 JavaScript 库的包装器库。
- Plotly :一个绘图库,允许你创建多种颜色和形状的交互式绘图。
- WBstats :一个包,只需要一行代码就可以访问和下载世界银行的数据。
仪表板目前托管在 shinyapps.io 上,它有一个免费使用计划,允许您访问 shinyapps.io 云上的一些有限资源。由于资源非常有限,我需要评估更换另一家服务器/云提供商是否有意义。尽管如此,shinyapps.io 是一种发布 R 应用程序的快捷方式。
为什么要开源?
那么为什么创建一个开源版本的仪表板很重要呢?
- 开源是免费的,每个人都可以使用。
- 如果你创造了一些开源的东西,并向其他人展示你的代码,错误将会很快被发现并修复。
- 使用群体智能来改进你的产品,或者获得解决某些问题的其他想法。
- 迅速从各方面获得反馈,这样你就可以提高技能,学习新事物。
Github 的创始人 Tom Preston-Werner 大约十年前写了一篇关于为什么我们应该(几乎)开源所有东西的伟大文章,他的观点今天仍然适用!
捐助
这个项目的想法是创建一个使用免费工具的开源仪表板。我希望这个仪表板有助于为全球疫情提供更多的见解。如果你对如何改进仪表板有任何想法,或者对新的情节或这方面的任何事情,请贡献。你可以在 Github 上找到所有代码。如果你有问题,需要帮助或类似的事情,请给我留言。我很乐意帮忙!
编者按: 走向数据科学 是一份以数据科学和机器学习研究为主的中型刊物。我们不是健康专家或流行病学家,本文的观点不应被解释为专业建议。想了解更多关于疫情冠状病毒的信息,可以点击 这里 。
更新:
上周末,我创建了一个专门针对瑞士的仪表盘。如果您想为您所在的国家制作一个特定的仪表板,请派生存储库并添加您所在国家的数据。如果您有任何问题或需要一些输入,请随时给我留言!
来源
- https://www . medical news today . com/articles/why-are-新冠肺炎-死亡率-如此难以计算-专家权衡
- https://time.com/5798168/coronavirus-mortality-rate/
数据
感谢迷离情骇、艾弗和托马斯的校对!
[## Christoph schnenberger-数据科学家-苏黎世集团| LinkedIn
在我的童年,我小心翼翼地将乐高积木分类、组织并组装成新的东西。今天…
www.linkedin.com](https://www.linkedin.com/in/cschonenberger/)
基于机器学习算法的新冠肺炎疫情预测

新冠肺炎灾难性的爆发给社会带来了威胁
传输的早期预测可以适应采取所需的响应
编者按: 《走向数据科学》是一份以研究数据科学和机器学习为主的中型刊物。我们不是健康专家或流行病学家,本文的观点不应被解释为专业的健康建议。然而,本文将关注如何使用机器学习来预测疫情的传播。
介绍
我们的社会正处于一个难以置信的时代,人们试图在基础设施、金融、商业、制造业和其他一些资源方面与这种威胁生命的状况进行斗争。人工智能(AI)研究人员加强了他们在开发数学范式方面的熟练程度,以便使用全国范围内的分布式数据调查这一疫情。本文旨在通过使用来自 Johns Hopkins 仪表板的实时数据,将机器学习模型与全国范围内新冠肺炎的预期可达性预测同时应用。

Erik Mclean 在 Unsplash 上拍摄的照片
传输阶段
冠状病毒传播分为四个阶段。第一阶段始于记录的前往或来自受影响国家或城市的人的病例,而在第二阶段,病例在与来自受影响国家的人有过接触的家庭、朋友和团体中按区域报告。因此,受影响的人是可以识别的。接下来,第三阶段导致严重的情况,因为感染者变得不可检测,并且在既没有任何旅行记录也没有与受感染者有联系的个体中变平。这种情况迫使全国立即封锁,以减少个人之间的社会接触,以衡量病毒的移动。最后,第四阶段在传播转变为地方病和不可控时开始。中国是第一个感受到新冠肺炎传播第四阶段的国家,而大多数发达国家现在都处于传播的这一阶段,与中国相比,承受着更多的流行病和损失。
机器学习算法在疫情调查和预测中发挥着重要作用。此外,机器学习技术有助于揭示流行模式。因此,可能会立即准备应对措施,以防止病毒的传播( Kalipe,Gautham & Behera,2018;辛格,辛格&巴蒂亚,2018 )。此外,通过使用来自 Johns Hopkins 仪表板的实时数据,利用机器学习模型来识别集体行为以及新冠肺炎在整个社会的预期传播预测。
资料组
从约翰霍普金斯大学的官方知识库中检索到的数据集。这些数据由每日案例报告和每日时间序列汇总表组成。在这项研究中,我们选择了 CSV 格式的时间序列汇总表,其中有三个表用于新冠肺炎的确诊、死亡和康复病例,有六个属性。例如,省/州、国家/地区、上次更新、已确认、死亡和已恢复的病例。CSV 数据可在 Github⁴ 仓库中获得。
预测和分析
冠状病毒的传播将社会置于社会生活丧失的边缘。此外,调查未来的传输增长并预测传输的未来事件也至关重要。在并发中,基于机器学习选择最先进的数学模型用于预测病毒传播的计算过程,例如:
- 支持向量 Regression⁵ (SVR)
- 多项式 Regression⁶ (PR)
- 深度学习回归模型
它还涉及:
- 人工神经 Network⁷ (安)
- 递归神经 Networks⁸ (RNN)使用长短期 Memory⁹ (LSTM)细胞。
使用 python 库执行机器学习和深度学习策略,以广泛预测确诊、恢复和死亡病例的总数。这种预测将允许根据传播增长做出具体决定,例如延长封锁期,执行卫生计划,以及提供日常支持和供应。
回归分析
回归分析是机器学习算法的一部分。它是领先的机器学习算法。想象一下由任意两个变量 X 和 Y 组合而成的直线方程,可以用代数方法表示为:

其中 b 声明 y 轴上的截距,a 称为直线的斜率。这里, a 和 b 也称为回归分析的参数。这些参数应该通过适当的学习方法来学习。
回归分析包含一组机器学习方法,使我们能够根据一个或多个预测变量(X)的值来预测连续的结果变量(Y)。它假装结果和预测变量之间存在持续的联系。
相关系数
相关系数被解释为两个变量之间线性关系的强度。卡尔·皮尔逊强调,相关系数是两个变量之间线性相关的权重或程度。他还生成了一个被称为相关系数的公式。两个随机变量 X 和 Y 之间的相关系数,通常由这些变量之间线性相关性的数值度量表示,定义为:

其中, i = 1,2,3,4,…N ,是输入输出变量的集合。下面给出了一些预测:
- 如果相关系数的值等于零,则表明输入变量 X 和输出变量 y 之间没有相关性。
- 如果相关系数的值等于正 1,则表明输入变量和输出变量之间有很强的关系。换句话说,如果输入变量增加,那么输出变量也会增加。
- 如果相关系数的值等于负,则表明输入变量增加,然后输出变量也减少,以此类推。
那些线性相关性很小或没有线性相关性的变量可能具有很强的非线性关系。另一方面,在拟合模型之前估计线性相关性是识别具有简单关系的变量的一种有价值的方法。在这项拟议的研究中,我们测量了全国范围内 COVID-2019 确诊病例的日期和数量之间的相关系数。
用 Python 编码


注意:完整的源代码可以在本文末尾获得
结论
我们的环境处于新冠肺炎病毒的控制之下。本文旨在通过来自 Johns Hopkins 的数据集使用机器学习模型进行疫情分析。总之,在预测新冠肺炎传输时,多项式回归(PR)方法比其他方法产生了最小的均方根误差(RMSE)。然而,如果传播模仿 PR 模型的预测趋势,那么它将导致大量的生命损失,因为它呈现了全球传播的不可思议的增长。正如中国所认为的,新冠肺炎病例的增加可以通过减少感染者中敏感个体的数量来降低。这种新常态可以通过变得不合群和支持有控制的锁定规则来获得。
**References**#1 [Predicting Malarial Outbreak using Machine Learning and Deep Learning Approach: A Review and Analysis](https://ieeexplore.ieee.org/document/8724266)#2 [Sentiment analysis using machine learning techniques to predict outbreaks and epidemics](https://www.researchgate.net/publication/332819639_Sentiment_analysis_using_machine_learning_techniques_to_predict_outbreaks_and_epidemics)#3 [Johns Hopkins University](https://coronavirus.jhu.edu/)#4 [Johns Hopkins University: COVID-19 Data Repository](https://github.com/CSSEGISandData/COVID-19)#5 [Support Vector Regression](https://www.researchgate.net/publication/340883347_Detection_of_coronavirus_Disease_COVID-19_based_on_Deep_Features_and_Support_Vector_Machine)#6 [Polynomial Regression](https://www.researchgate.net/publication/341109515_Application_of_Hierarchical_Polynomial_Regression_Models_to_Predict_Transmission_of_COVID-19_at_Global_Level)#7 [Artificial Neural Network](https://www.researchgate.net/publication/340538849_Novel_Coronavirus_Forecasting_Model_using_Nonlinear_Autoregressive_Artificial_Neural_Network)#8 [Recurrent Neural Networks](https://www.researchgate.net/publication/341474954_How_well_can_we_forecast_the_COVID-19_pandemic_with_curve_fitting_and_recurrent_neural_networks)#9 [Long Short-Term Memory](https://www.researchgate.net/publication/340255782_Application_of_Long_Short-Term_Memory_LSTM_Neural_Network_for_COVID-19_cases_Forecasting_in_Algeria)***Disclaimer*** *This is for education and information purposes only, additional research in the machine learning algorithm needed to give the exact amount of prediction data from the real-time dataset. The source code of the experiment can be access* [***here on GitHub***](https://github.com/wiekiang/covid-predict-analyst)*.*

















 9808
9808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}