







原文:Octopus Blog
八达通部署 1.1-八达通部署
今天我很高兴地宣布,Octopus Deploy1.1 版已经发布。自上一个 1.0 版本以来,已经做了很多改进,在这篇博客文章中,我想带您了解其中的一些改进。
计算机角色
这个版本中最大的变化是概念上的变化。以前,环境包含机器,步骤和变量指向这些机器。从 1.1 开始,一台机器将被标记为一个或多个“角色”,这些角色是步骤和变量所指向的。我在上一篇博客文章中详细描述了这一变化,因此我将使用这篇文章来了解该功能的工作原理。
编辑计算机时,现在可以输入角色列表:

您可以输入任何您喜欢的角色名称,您以前使用过的角色将使用自动完成(使用Select2控件)显示。角色可能是通用的(“web 服务器”),也可能是特定于您的应用程序的(“crm 批量导入器”)。
还要注意,上述机器属于两种不同的环境。以前,您必须复制一台机器,但现在可以轻松地在环境之间移动机器。
编辑步骤时,您现在将选择将接收包的角色:

但是,变量的作用域可以是角色或计算机:

这些变化带来了许多好处:
- 无需创建新版本即可添加或删除机器
- 机器可以在环境之间移动
- 现在可以更容易地将变量限定到一组计算机
自动触手注册也支持此功能——使用tentacle register-with时只需传递--role=my-role命令行参数。
项目组
本版本中引入的另一个新概念是“项目组”的概念。这为您的项目提供了一个嵌套级别,使它们能够更容易地分组和管理。
例如,在我的一个内部 Octopus Deploy 安装中,我有两个组-一个用于实际应用程序,另一个用于示例:

项目设置页面用于配置项目组:

项目菜单也将使用组显示项目:

项目组有一个名称和一个环境列表,该组中的项目可以部署到这些环境中:

在这里,您可以看到我的“真正的应用程序”项目组只被允许部署到两个环境中——登台和生产。另一方面,我的“示例应用程序”项目组只被允许部署到一个临时环境中。这将影响仪表板的布局,仪表板现在分为多个组:

以及哪些环境出现在组内项目的部署屏幕中:

在未来,项目组将变得更加重要,因为它们将成为设置保留策略和大多数权限的地方。目前,它们是驯服仪表板的好方法。
最喜欢的项目
我们还引入了“收藏夹”的概念,以控制哪些项目出现在下拉菜单中。这是针对每个用户的设置。您可以通过点按星形图标将项目标记为个人收藏:

如果您设置了任何喜爱的项目,则只有您的喜爱的项目会出现在菜单中(如果您没有选择任何喜爱的项目,则前 20 个项目会出现):

升级
支持角色的变化需要打破旧的数据模型,因此必须引入一些变化。在安装新的 Octopus 服务器之前,请确保进行备份(您可以在 Octopus 门户网站的配置下的存储选项卡中进行备份)。然后,安装新的 Octopus 服务器后,使用 Octopus 管理工具中服务器选项卡上的开始按钮。这将对您现有的项目进行一些更改,以启用角色支持。在这篇博客文章中,我写了更多关于将要做出的改变(我们选择了选项 3) 。
如您所见,1.1 是一个相当大的变化。我们要解决的下一个特性是让 Octopus 服务器和触须自己清理以节省磁盘空间,这个特性我们称之为“保留策略”,它可能会挂在项目组上。
请注意,由于版本中的许多变化,我们也发布了 Octo.exe 的新版本。
如果您对此升级有任何问题,请使用帮助台或跳到 Jabbr 。愉快的部署!
八达通 1.2 及保留政策-八达通部署
今天,我发布了Octopus Deploy 1.2,其中包括我上个月在博客上发布的保留策略功能,这也是我们Trello 板上投票最高的功能。在这篇文章中,我想演示该功能是如何工作的。
安装 1.2 之后,您将在配置区域下找到一个新选项卡,您可以在其中定义保留策略。

保留策略是在项目组级别设置的,这是 Octopus 1.1 中引入的功能。您可以在项目组设置对话框中选择项目组使用的保留策略:

请注意,有一个名为“永远保留所有内容”的默认保留策略。如果删除保留策略,项目组将恢复为此“保留所有内容”策略。
保留策略有三个不同的部分:

当您部署到环境时,Tentacle 选项将生效。在本例中,一旦我将一个包部署到给定的机器上 4 次,该包(.nupkg 及其提取到的目录)也将被删除。

八达通选项按计划运行,很像自动健康检查任务。您可以在“任务”页面上看到输出:

任务的输出会告诉您由于保留策略而删除了哪些发布:

当保留策略任务自动运行时,您也可以从保留策略页面手动运行它。您可能会发现,当您第一次升级到 1.2 时,您必须多次运行该任务,因为索引不会完全更新。
我希望你会发现这个新添加有用。
具有手动步骤、电子邮件步骤和 PowerShell 步骤的 Octopus 1.3-Octopus 部署
章鱼 1.3 刚刚发布。它包括许多错误修复,以及对最近发布的 RavenDB 2.0 的升级,感觉快得多。它还包括三种新类型的部署步骤:

Octopus 仍然面向使用 NuGet 包的应用程序的自动部署,但是这三个新的步骤类型提供了很大的灵活性。
运行 PowerShell 脚本
这种步骤类型允许您在给定角色的所有触角上运行 PowerShell 片段。

注意,该脚本可以引用任何 Octopus 定义的变量作为 PowerShell 变量。在部署过程中,您将在部署日志中看到输出:

发送电子邮件
这一步允许您发送电子邮件。您可以使用 Octopus 变量替换语法在您的电子邮件正文中引用 Octopus 变量。

SMTP 服务器设置在配置菜单下单独配置:

需要手动干预
虽然 Octopus 是一个自动化部署解决方案,但有些任务是无法自动化的。有时部署需要签署,无论是在开始还是结束。Octopus 中的手动步骤使这成为可能。我之前在博客中提到了我们的手动部署计划,现在这些计划已经实现了。

当遇到该步骤时,部署将暂停:

授权组中的用户将看到说明,然后可以决定部署是通过还是失败:

部署任务实际上是暂停的,同时等待手动步骤完成。这意味着您可以重启 Octopus 服务器,并在一周后批准这一步骤。

我希望这些新增加的东西对你有用!
Octopus 1.6 改进了直接下载和发布功能- Octopus Deploy
我们刚刚发布了 Octopus Deploy 1.6,你可以从下载页面获得。这个版本将是最后一个主要版本 1。x 发布;从现在开始,我们将把注意力集中在 Octopus Deploy 2.0 上。我会在 2.0 中发布更多的想法,但是现在让我们看看 1.6 中的新内容。
从触须直接下载软件包
我在博客上写了我们上个月的计划:
第二个变化是软件包步骤设置中的一个选项,让 Tentacles 直接下载软件包。八达通不是下载软件包,而是指示触手下载软件包。下载会在部署步骤运行之前发生(同样,这样我们就不用在部署步骤之间等待复制包),但是它们会直接到达 NuGet 服务器。
创建包步骤时,您可以通过从下面的单选按钮中进行选择来加入:

改进的发布创建屏幕
我们还对创建发布屏幕实施了一些计划中的更改。

代理服务系统
我们增加了 Octopus 和触手使用代理服务器的能力,包括使用基本和集成认证的代理。您可以在管理工具中指定代理服务器:

步进变量
以前,在包步骤中可以使用许多预定义的变量:
Octopus.Step.Name
Octopus.Step.Package.NuGetPackageId
Octopus.Step.Package.NuGetPackageVersion
然而,这些变量在电子邮件或手动步骤中是不可用的,因为没有包。如果您想发送一封包含上一步的 NuGet 版本号的电子邮件,这就会引起问题。
现在,您可以通过索引来访问变量:
Octopus.Step[0].Name
Octopus.Step[0].Package.NuGetPackageId
Octopus.Step[0].Package.NuGetPackageVersion
索引从 0 开始,并根据步骤的执行顺序进行编号。
1.6 还包括了许多其他的错误修正和改变,你可以在发布说明中读到更多关于的内容。愉快的部署!
实用 Kubernetes 部署的 10 大支柱- Octopus 部署
原文:https://octopus.com/blog/10-pillars-kubernetes-deployments
继实用部署的 10 大支柱之后,我写了一本关于实用部署的 10 大支柱 Kubernetes 和 Octopus Deploy的电子书。
这 10 个支柱反映了现代 DevOps 团队的需求,他们总是被要求在更短的时间内交付更多。通过理解每个支柱的价值,并学习实际的实现,DevOps 团队可以正面迎接这些挑战。
谁将从电子书中受益?
这本电子书是构建从 Octopus 到 Kubernetes 的可重复部署管道的全面指南。
它面向那些希望构建可随以下需求增长而扩展的部署管道的人:
- 参与部署的团队数量
- 正在部署的应用程序的数量
- 部署的频率
- 对代码更快到达客户手中的期望
您需要什么来开始
为了完成书中的练习,你需要:
- 库伯内特星团。这本书使用了一个托管在 Google Cloud 中的 Kubernetes 集群,但是除了依赖于 Google Cloud Kubernetes 集群公开的管理凭证的初始管理任务之外,任何 Kubernetes 集群都可以使用。
- 访问管理凭据。
- 章鱼的实例。如果你不是 Octopus 的用户,你可以注册一个免费试用来学习书中的例子。
本电子书假设您了解 pod、部署、服务、服务帐户、机密和配置图等概念。然而,书中创建的所有 Kubernetes 资源都提供了关于输入 Octopus 的值的详细说明,所以即使没有深入理解每个设置,也可以对部署过程有所了解。
愉快的部署!
数据库部署速度快 100 倍- Octopus 部署
在紧耦合系统中跳过不必要的模式比较

问题:紧密耦合的系统
我经常被问到的一个问题是,一个服务器上的所有数据库是应该放在一个 repo/Octopus 部署项目中,还是应该放在不同的 repo/项目中。另一个相关的问题是数据库和应用程序是否应该进入同一个回购/项目。这些问题没有简单的答案。作为一名顾问,我以“视情况而定”开始我的回答。
接下来,我将询问他们是使用分布式源代码控制系统(git)还是集中式源代码控制系统(TFS、SVN 等)。).了解这一点很重要,这样我才能校准我的答案。Git 通常比一个巨大的整体更适合许多小的 repos,但是对于许多集中式源代码控制系统来说就不一样了。
然后我会问一个更重要的问题:“数据库/应用程序之间的耦合有多紧密?”如果他们要求澄清,我会问这样的问题:
- 数据库之间有多少依赖关系?你有建筑图吗?(我会做梦,不是吗?)
- 数据库可以独立构建吗,还是需要按照一定的顺序一起构建/部署?(我祈祷没有任何循环依赖!)
- 单个工作项可能需要对多个数据库进行更改吗?
- 一个数据库的错误更改会给另一个数据库带来问题吗?
- 如果一个数据库因几个版本而与另一个数据库不同步,会有什么后果?
- 当有人“部署数据库”时,他们通常是指单个数据库,还是可能需要将更改部署到多个数据库?
在理想的世界中,架构应该是松散耦合的。这将允许人们把数据库分割成单独的较小的回购,可以独立管理。粒度越大越好。虽然这可能会强加一些严格的体系结构规则并引入一些局部复杂性,但它将显著降低全局复杂性并降低每个部署的风险。这也可以大大减少与完成工作相关的技术和官僚挑战。
本质上,松散耦合的系统允许人们更加线性地扩展开发工作,而不是扩大开发工作,这将带来天文数字的、通常被低估的管理成本和挑战。扩大开发努力的尝试往往会陷入政治、延迟和问题的泥沼。阅读凤凰计划,大多数人会意识到他们已经为这一现象的经典案例研究工作。
人们可能会说,这很好,但对我没有帮助。我已经有一块巨石了。我没有构建它,也不能快速更改它。也许还有其他原因导致了紧密耦合的系统,这些原因太长或太复杂,无法在这里一一介绍。
在这种情况下,虽然我可能主张采取措施分离系统,但我承认这不太可能是一个快速或廉价的解决方案。与此同时,有效的源代码控制和部署很重要,即使它是一个整体。在这些情况下,最终可能会有巨大的源代码控制 repos 和部署项目,需要协调许多相关部分的部署。
症状:整体回购和部署项目
我有几个从事商业智能系统的客户。他们有多达十几个相互读取的数据库。第一个通常负责从各种来源加载原始源数据。这通常是高度规范化的,并针对存储和耐用性进行了优化。接下来是各种中间数据库,在这些数据库中,数据被逐渐清理和转换,直到最终出现在各种数据仓库和数据集市中,这些数据仓库和数据集市为分析进行了优化。
通常,数据库可以按一定的顺序部署。数据仓库从中间数据库读取数据,这些中间数据库从源数据库读取数据。因此,理论上,我们可以首先部署数据源,然后按顺序部署中间数据库,最后部署数据仓库。
然而,现实世界并不总是那么简单。出于各种原因,有一些依赖项不适合该模型,重构它们会非常困难。虽然我们通常可以按照指定的顺序进行部署,但是有些跨数据库的依赖关系有时意味着顺序需要改变,而 Octopus Deploy 项目不够智能,无法提前发现这一点。
一位客户使用了一点黑客手段来解决这个问题。他们部署的最后一步是Deploy Release步骤,如果任何数据库部署步骤由于依赖关系中断而失败,该步骤将重新运行部署。该过程可能会根据数据库的数量重新运行部署(最大重新运行次数由输出变量控制)。只要在每次迭代中至少有一个数据库被成功部署,Octopus 就会一直尝试,直到所有数据库都被部署,因此,如果数据库的部署有任何顺序,Octopus 最终都会找到。很丑但是很管用。
最大的实际问题是这需要多长时间。客户使用基于状态的部署流程。这意味着每次部署数据库时,数据库比较软件(Redgate 或 SSDT)都会执行完整的比较。对于每个数据库,这通常需要一两分钟的时间,但时间会有所不同。对于最大的数据库,可能需要 5 分钟以上。12 个数据库乘以 12 次尝试,通常可以累加起来。
但比那更糟。这个 BI 系统不是一个内部系统,而是我的客户向他们的客户销售的一项服务。他们为每个客户维护一个数据库实例。当他们部署到生产环境时,他们不只是部署一次,而是部署多次,而且通常是在严格的部署窗口内。如果部署时间太长,他们错过了机会,客户会不高兴的。一些客户是批量部署的,而另一些客户有自己独特的合同,需要更复杂、更不频繁的部署。较不频繁的部署会导致较大的部署,这很可能需要多次重新运行。
持续时间、风险和复杂性在多个轴上成倍增长。
团队也受到资源的限制。大量的处理工作被迫通过少数工人完成,这通常是瓶颈。这是一场完美的风暴。我提到过单片系统真的很可怕吗?
真正令人沮丧的是,虽然我们可能会进行数百次数据库比较,但绝大多数都是浪费时间,因为我们不知道实际上什么都没有改变。即使部署第一次成功,也可能只有一两个数据库被更新,但是所有的数据库都会按顺序进行比较。只需一两分钟的部署可能需要几个小时。
如何治疗这些症状
有一种观点认为,即使没有任何变化,进行比较仍然是有价值的。它保护你不受漂移的影响。通过强制每次都从源代码控制中重新部署所有数据库,它确保了源代码控制的真实性,并减少了由于生产中的意外变化而导致失败的机会。
总的来说,我同意这个原则,但是对于我的客户来说,进行所有这些比较的成本让他们不堪重负。如果在第一次尝试中就已经成功部署了数据库,那么在第二次或第三次尝试中重新部署数据库也是非常困难的。虽然重新部署所有数据库可能是有价值的,但是短时间的部署也是有价值的,所以最终,人们需要做出权衡。
我向我的客户建议,他们应该设计他们的部署过程,以便只在软件包编号增加时才部署数据库。这意味着两件事:
- 我们需要改变构建过程,以确保新的 NuGet 包只在 DB 模式实际发生变化时才被创建。(所有数据库都在一个 git 回购中。构建过程最初为每次提交构建并打包所有数据库,验证所有依赖关系。然而,这导致了非常长的构建时间(1 小时以上)。只构建已经更新的数据库并不像您想象的那样简单,因为由于依赖关系,当两个数据库同时更新时,它们需要以正确的顺序构建。我去年在我的个人博客上写了更多关于我们如何解决这个问题的内容:http://workingwithdevs . com/azure-devo PS-services-API-powershell-hosted-build-agents/。
- 我们需要改变我们的部署过程来识别当前的包是否已经被部署。这也比你想象的要难,我很感谢 Bob Walker 花时间与我讨论各种选项和陷阱。在这篇博文的剩余部分,我将重点关注这一部分。
起初,我低估了这项任务的复杂性。我打算用章鱼。触手. previous installation . package version系统变量确定之前部署的包。我可以编写一个简单的 PowerShell 脚本来比较以前的包号和当前的包号,如果它们相同,我可以跳过部署。
然而,这是有问题的。如果之前的部署失败了怎么办?如果已经将包部署到了触手上,但是后续的数据库模式比较步骤(从包中读取文件)还没有执行,该怎么办?如果我在池中的一个工人上运行任务会怎么样?如果我在一个动态工作者上运行这个会怎么样?在我意识到这一点之前,我进行了比我最初预期的更多的 API 调用,代码开始看起来复杂得令人恼火。
经过一番思考,我决定从基于迁移的部署工具那里借用一个技巧。我在每个目标数据库上创建了 __DeployLog 表。在每次部署之后,我都将包和版本号记录到该表中,同时记录时间戳、用户 ID、部署状态和任何错误消息。
由于以前部署的数据现在安全地存储在数据库本身上,所以可以用几个快速的 SQL 命令来完成所有长的数据库部署步骤,以验证当前版本中的包是否已经部署到目标数据库。这些额外的查询会稍微增加部署的总持续时间,但是每个跳过的部署都会显著减少总部署时间。因此,对于具有许多基于状态的数据库部署步骤的项目,最终结果可能是大大减少部署时间。对于我的客户来说,这将常规部署时间减少了大约 10 倍,并且由于重新运行问题,最具挑战性的部署减少了大约 100 倍。
结果是,团队可以多次尝试部署,中间有足够的时间来调查任何问题,而不是因为一次漫长的部署尝试而错过生产部署窗口。在开发和测试领域,生产力得到了巨大的提升。开发人员可以在测试服务器上运行部署,并在几分钟内看到结果,而不是几个小时。除了显著改善开发人员的反馈循环之外,它还显著减少了共享环境中的资源占用问题。
最重要的是,事实证明 __DeployLog 表很受内部和客户操作人员的欢迎,他们在数据库中有一个简洁可靠的审计日志。

代码
要在您自己的部署项目中做同样的事情,您需要在流程开始时使用类似这样的代码来读取 __DeployLog,以确定是否有必要部署数据库。您可以将它作为每个数据库的单独部署步骤运行,也可以将其添加到部署数据库的现有脚本的顶部。
注意,在脚本的顶部,有几个变量需要声明。这个任务留给了用户。如果可以的话,我推荐使用 Octopus 变量,而不是将值硬编码到脚本中。
还要注意最后一行:
Set-OctopusVariable -name "Deploy:$DLM_ServerInstance-$DLM_Database" -value $deployRequired
这段代码假设脚本作为一个独立于现有数据库部署步骤的部署步骤运行,并设置一个输出变量,该变量决定是否应该执行数据库部署步骤。
如果您将此作为一个单独的步骤运行,则不需要修改此代码。但是,如果您已经将代码复制到了现有数据库部署脚本的顶部,那么您会希望删除上面的行,而将数据库代码移动到如下所示的 if 语句中:
If ($deployRequired){
# put your existing db deploy code here
}
Else {
Write-Output “Skipping database deployment.”
}
假设您已经创建了一个单独的步骤来读取 __DeployLog,那么您现有的数据库部署步骤应该更新为使用下面的变量表达式作为运行条件。这会读取输出变量,并使用它来决定是否执行数据库部署:
#{if Octopus.Action[Read \__DeployLog].Output.Deploy:sql01-db== "True"}true#{/if}

记住用您自己的 SQL Server 实例和数据库名称替换“sql01”和“db”。
在您的数据库部署之后,您需要添加以下脚本来用包号和部署状态更新 __DeployLog。如果您只是将代码复制到数据库部署脚本中,那么您会希望将其包装到相同的 If 条件中。如果您将它作为一个单独的步骤运行,您将希望使用与上面相同的运行条件。除非实际执行了数据库部署,否则不希望更新 __DeployLog。
最后,为了使这一切尽可能简单,我刚刚向社区图书馆发布了几个 Octopus 部署步骤模板:

最终的过程可能如下所示:

现在,如果软件包编号自上次成功部署后没有更改,则不会重新部署:

处理潜在问题
我充分意识到这篇博文只是治标不治本。而且有副作用要注意。
数据库漂移可能会持续更长时间才被发现,这并不理想。也有可能一些依赖关系会被破坏,因为我们不会定期重建/部署所有的数据库。考虑在一些测试或试运行环境中运行完整的构建和端到端的部署和集成测试是有益的,也许是每晚一次,以确保没有遗漏任何依赖项。
还有不直观的问题。由于这是一种有点不寻常和复杂的处理部署的方式,所以维护这个过程会有更大的认知和操作成本。这增加了误解的可能性,从而可能导致问题。
然而,这里真正的问题是数据库与循环依赖紧密耦合。这是一个更难解决、更昂贵的问题,我不确定我能通过一篇博文解决这个问题。
话又说回来,我不相信任何一个读到这篇文章的人都有一个完美的系统。对我们大多数人来说,这是一种权衡、错误和“这在当时看来是个好主意”的过程。对于那些只是试图保持服务器运行,而没有支持或投资来“正常运行”的人,我向你们致敬,我希望这是有用的。
自 2010 年以来,Alex Yates 一直在帮助组织将 DevOps 原则应用于他们的数据。他最引以为豪的是帮助 Skyscanner 开发了一天 95 次部署的能力,并支持联合国项目服务办公室的发布流程。亚历克斯与除南极洲以外的各大洲的客户都有过合作——所以他渴望见到任何研究企鹅的人。
作为一名热心的社区成员,他共同组织了数据接力,是【www.SpeakingMentors.com】的创始人,并自 2017 年以来被公认为微软数据平台 MVP 。
Alex 是官方 Octopus Deploy 合作伙伴 DLM 顾问的创始人。他喜欢为那些希望通过改进 IT 和数据库交付实践来实现更好业务成果的客户提供指导、辅导、培训和咨询。
如果你想和亚历克斯一起工作,请发电子邮件:enquiries@dlmconsultants.com
基于角色的访问控制演示- Octopus 部署
这篇文章是我们 Kubernetes 培训系列的第 14 篇,为 DevOps 工程师提供了关于 Docker、Kubernetes 和 Octopus 的介绍。
此视频演示了如何创建一个 Octopus 目标,该目标使用服务帐户令牌向集群进行身份验证。
如果您还没有八达通帐户,您可以开始免费试用。
您可以使用下面的链接完成该系列。
示例代码
RBAC 资源公司
这是复合 YAML 文档,包含用于将服务帐户限制到单个名称空间的 RBAC 资源:
apiVersion: v1
kind: ServiceAccount
metadata:
name: octopub-deployer
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: octopub-deployer-role
rules:
- apiGroups: ["", "extensions", "apps", "networking.k8s.io"]
resources: ["deployments", "replicasets", "pods", "services", "ingresses", "secrets", "configmaps"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: [""]
resources: ["namespaces"]
verbs: ["get"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: octopub-deployer-rolebinding
subjects:
- kind: ServiceAccount
name: octopub-deployer
apiGroup: ""
roleRef:
kind: Role
name: octopub-deployer-role
apiGroup: ""
---
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: octopub-deployer-secret
annotations:
kubernetes.io/service-account.name: "octopub-deployer"
目标创建脚本
该脚本通过从当前 Kubernetes 上下文中提取密码和 Kubernetes URL 来创建新的 Octopus 令牌帐户和目标:
SERVER=$(kubectl config view -o json | jq -r '.clusters[0].cluster.server')
TOKEN=$(kubectl get secret octopub-deployer-secret -n octopub -o json | jq -r '.data.token' | base64 -d)
echo "##octopus[create-tokenaccount \
name=\"$(encode_servicemessagevalue "Octopub #{Octopus.Environment.Name}")\" \
token=\"$(encode_servicemessagevalue "${TOKEN}")\" \
updateIfExisting=\"$(encode_servicemessagevalue 'True')\"]"
echo "##octopus[create-kubernetestarget \
name=\"$(encode_servicemessagevalue "Octopub #{Octopus.Environment.Name}")\" \
octopusRoles=\"$(encode_servicemessagevalue 'Octopub')\" \
clusterUrl=\"$(encode_servicemessagevalue "${SERVER}")\" \
octopusAccountIdOrName=\"$(encode_servicemessagevalue "Octopub #{Octopus.Environment.Name}")\" \
namespace=\"$(encode_servicemessagevalue "octopub")\" \
octopusDefaultWorkerPoolIdOrName=\"$(encode_servicemessagevalue "Laptop")\" \
updateIfExisting=\"$(encode_servicemessagevalue 'True')\" \
skipTlsVerification=\"$(encode_servicemessagevalue 'True')\"]"
资源
了解更多信息
如果您想在 AWS 平台(如 EKS 和 ECS)上构建和部署容器化的应用程序,请尝试使用 Octopus Workflow Builder 。构建器使用 GitHub Actions 工作流构建的示例应用程序填充 GitHub 存储库,并使用示例部署项目配置托管的 Octopus 实例,这些项目展示了最佳实践,如漏洞扫描和基础架构代码(IaC)。
愉快的部署!
Octopus Deploy 2.0 已经发布!-章鱼部署
昨天,我们发货了 章鱼部署 2.0 。这是 Octopus 2.0 的正式、非测试版、公开、发布到网络的版本。呜哇!

Octopus 2.0 的开发工作始于去年 5 月。你能相信吗?我们并不只是添加一些功能和改变配色方案,而是着手开发一个真正的 2.0 版本。我们在制作 Octopus 1.0 的过程中学到了很多东西,我们想对产品的架构和一些核心概念做一些根本性的改变。
REST API
影响最大的变化是决定开发一个全面的 REST API。Octopus 1.0 的用户界面是在 ASP.NET MVC 中构建的。对于 2.0,我们删除了几乎所有的代码——控制器和视图——而是从头构建了一个 REST API。然后,我们使用 Angular JS 在该 API 之上构建了 UI。现在,你可以在 UI 中做的任何事情都可以通过 API 来完成。事实上,很长一段时间 2.0 代码根本没有 UI;我们构建了一套端到端运行的 API 测试,使用 REST API 执行 Octopus 的所有功能。
投票触角
另一个巨大的变化是章鱼和触须之间的通讯栈。在 1.0 版本中,我们使用 WCF——触须监听,章鱼连接。

在 2.0 中,我们现在支持触须在监听或轮询模式下。为了实现这一点,我们开发了一个基于消息和参与者的通信栈,在传输层使用 HTTP 和 SSL 来交换消息。对于与服务器网络的双向安全通信来说,这是一个非常强大的机制,我希望以后能更多地使用这个特性。
更轻松的 Windows 服务和 ASP.NET/IIS 部署
我们添加了一些新的约定和特性来处理 Windows 服务和 IIS/ASP。NET 应用程序部署。
加密的数据库和变量
章鱼数据库现在被加密了,我们也增加了对 T2 加密变量的支持。如果您将连接字符串或密码存储在变量中,现在可以用一种安全的方式来实现。
同时,我们也让在项目之间共享变量成为可能。
引导失败
当出现问题时,您现在可以选择重试或跳过失败的步骤,而不是简单地部署失败。
滚动部署
滚动部署让您能够在一台服务器上运行一系列步骤,然后在另一台服务器上开始执行步骤。这使得部署到停机时间有限的 web 服务器群这样的场景变得更加容易。

新的安全模式
我们重新审视了我们的权限模型,并试图构建一个同样安全,但更有用的东西。团队是一个新概念,它允许您指定一组用户及其权限,范围是环境和/或项目。
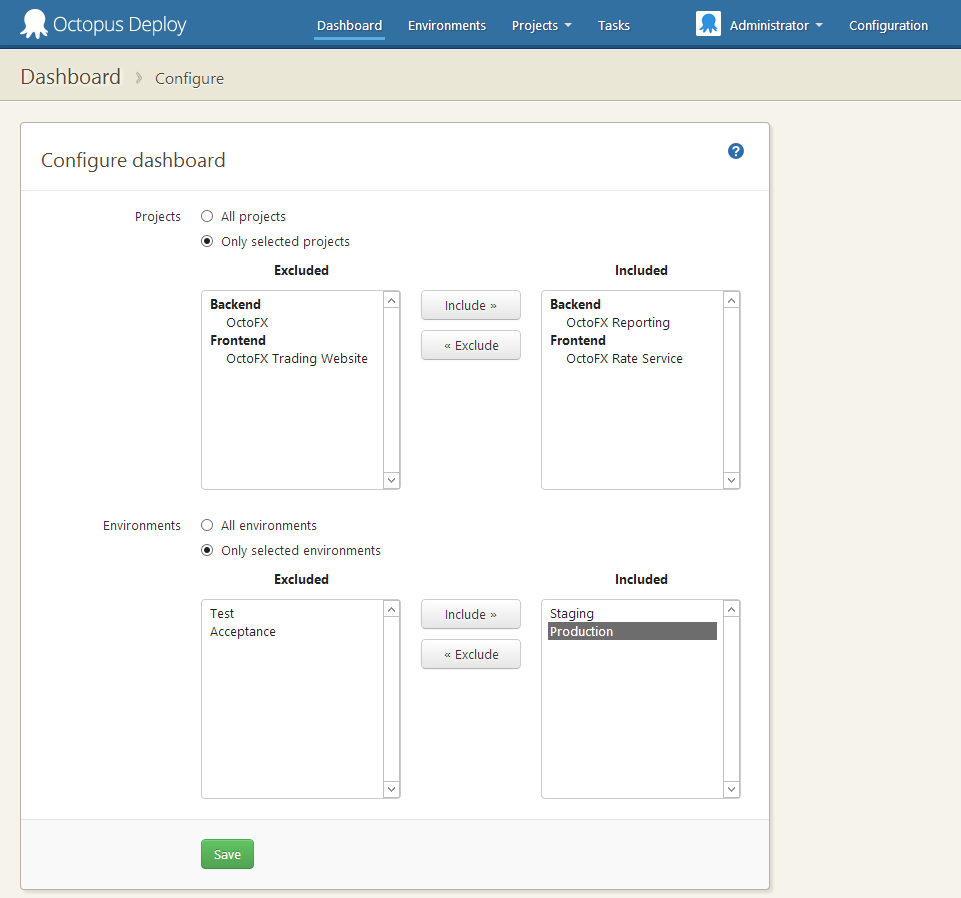
可配置仪表板
是的,您现在终于可以更改显示在仪表板上的内容。
失败步骤,以及在包下载之前运行的步骤
我们对管理部署步骤的方式进行了一些大的改变。现在,您可以在下载软件包之前运行 PowerShell 和手动步骤(例如,如果您需要建立 VPN),或者指定仅在失败时运行的步骤(例如,发送电子邮件)。
变量编辑器改进
在 1.0 中,一个变量一次只能作用于一个环境、机器、角色或步骤。现在,变量可以同时作用于多个级别。这大大减少了所需变量的数量。我们还对 UX 做了一些改进,比如一次编辑多个变量,一次删除多个变量,以及一系列其他的 UI 更改。

摘要
因为有太多的东西被改变了,我们也做了很多其他的改进。安装程序改头换面了,发布创建页面有了一些新特性,我们在项目列表页面添加了图表来显示活动,还有很多其他的东西。
如果你目前使用的是 1.6,你绝对应该升级。我希望你喜欢使用章鱼 2.0 就像我们喜欢构建它一样!
Octopus 2.1 的新特性- Octopus 部署
今天我们发布了章鱼部署 2.1 的预览版。Octopus 2.0 仅在一周前发布,在那一周,我认为我们已经做了很多。让我们看看 2.1 有什么新功能。
内置的 NuGet 存储库
Octopus 现在附带了一个内置的 NuGet 存储库,你可以将应用程序包推送到这个存储库。这个知识库是基于优秀的 NuGet。Lucene ,使它成为比使用文件共享更快的选择。该存储库是只写的;你可以使用 NuGet.exe推送 NuGet 包给它,但是你不能像标准的 NuGet feed 一样查询它。

当然,您可以继续使用其他外部 NuGet 包存储库;当你正在设置一个 Octopus 服务器,并且没有你想要使用的现有存储库时,这个存储库只是提供了一个很好的缺省值。
详细审计
为了提高责任性和透明度,审计日志现在在查看文档更改时会显示不同的更改内容。例如,这里我们可以看到是 Bob 将测试环境重命名为 Staging。淘气的鲍勃!

(有趣的是,自从 Octopus 2.0 发布以来,我们实际上一直在捕捉这些信息,但直到现在我们还没有一个 UI 来显示活动细节)
变量编辑器改进
我们有很多人要求这样做:你现在可以在变量编辑器中排序和过滤变量。

作为客人登录
有时你可能希望允许人们在没有用户帐户的情况下登录 Octopus。我们引入了作为访客登录的功能。

当然,默认情况下**是禁用的。**您可以从 Octopus Manager 中启用它:

来宾用户始终是只读的。您可以通过为他们分配角色来限制他们可以查看的环境和项目。
多实例管理
你知道吗,你可以在一台机器上运行多个 Octopus 服务器和触手,每个都有自己的数据库、配置、Windows 服务等等。以前只能通过命令行管理这些实例,但现在我们可以直接从 Octopus 和触手管理器管理实例。

其他变化
2.1 还包括许多小的 bug 修复和微小的增强,比如克隆项目的能力。阅读完整的发行说明看看还有什么变化。愉快的部署!
Octopus 2.2 的新特性- Octopus 部署
我们刚刚发布了章鱼部署 2.2 的预发布版本。这个版本包含了许多错误修复和小的增强,以及一些新的功能。
脚本控制台
对于管理员来说,2.2 引入了一个新的脚本控制台,它可以用来使用 PowerShell 执行特定的管理任务。这使得在多台机器上运行 PowerShell 代码片段变得容易,并且可以在一个地方查看结果。

当脚本运行时,所有服务器的所有输出都显示在任务输出中:

以这种方式运行的脚本也会出现在审核日志中,您可以随时查看运行的脚本。我认为这是使用远程桌面或 PowerShell Remoting 来远程执行任务的一个很好的替代方法。
在 Octopus 中定义部署脚本
大多数时候,当您需要在 Octopus 中执行自定义操作时,您可以使用嵌入在 NuGet 包中的 PowerShell 脚本来执行它们。我们还支持将 PowerShell 脚本作为独立步骤运行的能力。
但是有时您需要在包部署期间运行一个脚本(这样您就有了所有可用的变量),但是不需要将它们嵌入到 NuGet 包中。现在,您可以使用包装步骤中的新功能来实现这一点:

启用该特性后,您的部署脚本现在可以在 Octopus UI 中编辑,而不是在 NuGet 包中编辑:

注意,通常我们仍然建议将定制的部署逻辑放在 NuGet 包中;这个特性实际上只适用于少数不可能实现这一点的场景。
全屏 PowerShell 编辑
在上面的屏幕截图中,您可能已经注意到,脚本编辑控件现在显示了一个按钮,使 PowerShell 编辑器全屏显示。不再编辑微小的文本区域!
IIS 绑定可以是…束缚
另一个变化是,当使用自动 IIS 站点创建功能时,您现在可以在为站点定义的 HTTP/HTTPS 绑定上绑定字段。

错误修复
相当多的小错误和改进也在这个版本中出现了——详情请查看版本说明。愉快的部署!
Octopus 2.3 的新特性- Octopus 部署
我们刚刚发布了一个预发布的章鱼部署 2.3 。自从 2.0 发布以来,我们已经习惯了,每隔几周就发布新的版本。如果你看看我们的发布历史,你可以看到我们上一次发布是在两周前,章鱼 2.2 。
以下是 2.3 的亮点。我想你会同意我们在这么短的时间内一直很忙!
部署时提示变量
有时,在对部署进行排队时,您需要向 Octopus 提供额外的信息。提示变量允许您定义变量以及标签和帮助文本,其值将由用户在创建部署时提供。

当您单击提示链接时,您将能够配置提示的详细信息:

在部署时,提示将出现在“创建部署”页面上。如果您为变量提供了默认值,这将是文本框中的默认值:

请注意,提示变量可以像其他变量一样确定作用域;因此,您可以对一个环境使用固定值,对生产部署使用提示值。提示变量也可以标记为敏感,在这种情况下,将出现一个密码框。
提示变量可以像任何其他变量一样在脚本和配置中使用:

敏感的提示变量会像其他变量一样被屏蔽。

部署到特定机器
有时,您可能会向环境中添加一台新机器,并且您需要向该机器重新部署一个版本,但是不希望影响环境中的其他机器。在 Octopus 2.3 中,您现在可以选择要部署到的特定机器:

任务输出“有趣”模式
当任务正在运行时,您必须连续单击“Expand All”才能在添加新的日志节点时看到输出(与按顺序记录输出的构建服务器不同,Octopus 并行执行许多事情,因此日志输出是分层的,多个节点同时生成日志消息)。
我们现在已经使“全部展开/错误/无”链接“有粘性”——如果您全部展开,并且添加了新节点,它们也会自动展开。我们还创建了一个新模式,称为有趣模式,它可以自动扩展正在运行或已经失败的节点。这是默认的模式,它带来了很好的体验——当您查看任务输出时,您会自动看到您可能最感兴趣的内容。

审核日志过滤
审计日志现在可以按人员、项目或日期范围过滤:

包 ID 和源中的自定义表达式
这个更容易用图片解释。现在,您可以像这样定义部署过程中的步骤:

像这样的变量:

这仍然有效:

这也是:

这使得某些工作流变得更加容易,比如针对不同的环境使用不同的提要,但是我稍后会在博客中对此进行介绍。
为什么我的部署在排队?
有时,当您执行部署时,您的部署可能处于“排队”状态。原因通常是因为另一个部署当前正在为该环境/项目组合运行,但是很难找出原因。
为了有所帮助,我们现在显示了当前任务在执行之前正在等待的任务列表:

基于模板的文件转换
尼克已经在博客上介绍了这个功能。我觉得挺酷的!
消除器
在以前版本的 Octopus 中,正在运行的任务上的 Cancel 按钮更多的是一个建议,而不是命令。例如,假设我有这样一个脚本:
Write-Output "Sleeping for 1 second..."
Start-Sleep 1000
Write-Output "Done!"
哎呀!默认情况下,假设我指的是秒,而不是毫秒。现在我将永远等待我的部署完成。啊!
在以前的版本中,点击任务上的取消不会有帮助——在取消其余的动作之前,触手仍然会等待脚本完成。但是在 Octopus 2.3 中,我们现在将终止正在运行的 PowerShell 进程:

这是一个更好的体验,因为这意味着当你有一个挂起的任务时,现在取消实际上是有效的。另一方面,你在使用它的时候必须更加小心一点!
更好的任务输出和仪表板性能
仪表板和任务输出页面得到了很多关注。以前,任务输出会冻结在几百行输出中,当您有许多项目/环境时,仪表板会间歇性地冻结。这两个问题现在都得到了解决,他们应该感觉更快了!
我们还解决了此版本中的一些其他已知错误和其他性能问题。检查一下,如果遇到任何问题,请告诉我。愉快的部署!
Octopus 2.4 的新特性- Octopus 部署
我刚刚在一个预发布版本的章鱼部署 2.4 上按下按钮。这次发行比宾虚还大!我们上一次主要发布是在大约两个月前,它显示:我们关闭了 GitHub 中的 79 个问题,并添加了一堆大的新功能。它是如此之大,以至于我们将做一个关于 2.4 中新特性的免费网络研讨会。希望你能成功!
以下是此版本中新增内容的简要概述。
库标签
2.4 中最显著的变化是我们增加了一个新的顶级区域,叫做库:

以前,NuGet feed 设置和库变量集位于 Configuration 选项卡下,仅供管理员使用。由于我们增加了许多新的特性,这些特性将在项目间共享,我们决定是时候为这些设置提供一个专用的地方了。
更好的内置 NuGet 存储库管理
库下面有许多选项卡,默认是内置的 NuGet 存储库。

您可以单击任何包来查看版本列表:

您可以选择包来删除它们,或者单击某个版本来查看详细信息:

您甚至可以直接从 UI 上传软件包,这在部署一次性实用程序时非常有用:

作为保留策略的一部分,内置存储库中的软件包现在会自动清理。当相应的发行版被删除时,不再被任何发行版使用的软件包将被自动从磁盘中删除。
步骤模板
这个功能在我看来是 2.4 中最酷的功能。步骤模板允许您创建可以跨项目使用的可重用步骤。这个功能实际上是来自体育解决方案的大卫·桑苏姆的一个拉式请求,我们喜欢这个概念。非常感谢大卫和运动解决方案!
它是这样工作的。“步骤模板”选项卡是您的模板所在的位置:

添加模板时,您可以选择使用任何内置步骤类型。对于这个例子,我将使用一个 PowerShell 脚本:

为您的模板命名和描述,以便其他人知道它的用途:

我的脚本将停止一个 Windows 服务,所以我希望使用我的步骤模板的人告诉我他们想要停止哪个服务。我通过定义参数来做到这一点:

定义了参数后,我现在可以定义如何运行我的步骤模板,并利用这些参数:

这是激动人心的部分。当定义任何项目的部署过程时,我可以使用我的步骤模板**,就好像它是一个内置步骤**:

使用步骤模板时,我定义的参数可以编辑,并且可以绑定到变量:

我认为这个特性将会开启大量的可能性,围绕着能够创建可重用的脚本块或其他步骤。我们将在未来为人们建立一个共享他们的 step 模板的地方,所以请关注这个空间!😃
脚本模块
如果您的所有部署都遵循相似的模式,那么创建一组可重用的 PowerShell 函数在它们之间使用是很有诱惑力的。在过去,虽然这是可能的,但从来没有一个非常好的方法能够轻松地使用共享这些功能。
现在在 Octopus 2.4 中,您可以使用脚本模块来定义一组 PowerShell 函数——本质上是一个.psm1文件:

然后,您可以将脚本模块作为项目部署过程的一部分:

现在,无论何时在该项目中运行 PowerShell,该模块都是可用的。这意味着您可以从脚本步骤或者在您的Deploy.ps1和相关文件中引用该模块。在运行期间,Octopus 将确保模块在触手上并被加载;没有额外的工作要做:
团队中的 Active directory 组
用户之声的第三高投票建议现在已经完成——你可以将 Octopus 中的团队链接到活动目录组:

我们需要你的帮助来测试这一点,因为即使在最好的情况下,活动目录集成也是棘手的。如果你正在使用 AD,并且可以为我们试用 2.4.1 以确保群组成员工作,我们将非常感谢。
自定义角色
在 Octopus 2.0 中,我们通过创建一些高级角色极大地简化了权限系统。然而,一些客户需要修改这些内置角色的能力,或者定义新的角色。在 2.4 中,您现在可以定义自己的。
可以在团队页面中找到角色:

在那里,您可以添加自定义角色,或修改内置角色的权限:

集成 Windows 身份验证
如果您使用的是 Active Directory 身份验证,用户现在可以选择使用集成的 windows 身份验证质询登录,而不是直接键入密码:

当然,如果您有时需要以不同的用户身份登录,或者由于某种原因这不起作用,您可以继续以旧的方式登录。
保留有限数量的备份
Henrik 在他工作的第一天就实现了这一点。现在,您可以告诉 Octopus 应该保留 Octopus 数据库的多少个备份:

可定制的版本号策略
当您创建一个版本时,Octopus 试图通过增加以前的版本号来为您生成一个版本号。现在,您可以通过编辑项目设置来更好地控制这种行为。您可以告诉 Octopus 使发布号与特定 NuGet 包的号相匹配:

或者,您可以使用如下语法自行指定格式:

项目徽标
有时,在像 Octopus 这样的应用程序中,搞清楚自己的确切位置可能会令人困惑。在 2.4 中,我们增加了为每个项目上传自定义徽标的功能。导航您的项目时,此徽标将出现在左上角:

您可以从设置页面更改徽标:

试试吧,告诉我们你的想法!
现在这个版本的 Octopus 是一个预发布版本,虽然它修复了大量的问题,但它总是有可能引入一些问题。由于有这么多的变化,我们真的很希望你下载它,并采取了一个旋转。我认为新功能使它成为一个相当引人注目的升级!
Octopus 2.5 的新特性- Octopus 部署
作为预发布版本提供的 Octopus Deploy 2.5 已经上架(可以这么说)。关闭不到 50 个 GitHub 问题,让我们看看引擎盖下是什么。
计划部署
您是那些不得不在深夜起床运行部署的系统管理员之一吗?这是你的特色。现在,您可以躺在床上,等待计划的部署为您运行。

如您所见,您现在可以计划部署运行的时间。

提交时,“任务”页面会显示部署已排队以及何时运行。

您还可以在项目仪表板上查看排队部署。
有组织的任务页面,包括过滤
以前在任务页面上很难找到已经运行的特定任务,只是按日期提供所有任务的列表。但不是现在。现在,您可以选择环境、项目或活动类型,并过滤列表。它在页面顶部列出一个组中的所有活动任务,下面是可过滤和可搜索的已完成任务列表。

Octo.exe 现在显示出进步
现在,当使用 Octo.exe 进行部署时,您可以传递--progress参数,这会将部署输出到控制台。

步骤模板更新
第一个步骤模板发生了变化:现在您可以查看步骤模板的使用位置,以及它在项目中是否是最新的。

我们还更新了步骤模板变量。它们现在允许自定义字段类型和类型化参数。

部署不再试图过时的触角
以前,如果触手没有与 Octopus 服务器匹配的版本,部署将继续。已通过停止部署并给出错误消息纠正了此问题。

突破性变化!
在这个版本中有两个突破性的变化值得注意。
重大变化:内部 NuGet 存储库不再被监视
那些使用内置 NuGet 存储库的人,我们不再监视文件夹的变化,因为这导致了一些锁定问题。如果您使用 API 或 nuget.exe 将文件推送到存储库,这种变化应该不会影响您。如果你使用 XCOPY,它会有效果。使用外部馈送将是唯一的选择。不过,我们会在每次重启八达通服务器服务时刷新存储库索引。
重大变化:部署中使用的所有机器都需要唯一的 SQUID
如果部署检测到两台或多台机器具有相同的 SQUID,部署将停止,直到重复的机器从机器目标中删除。
现在就去看看吧!
我们已经更新了章鱼现场演示使用 2.5!所以去看看吧!
Octopus Deploy 2.6 的新特性- Octopus Deploy
Octopus Deploy 2.6 现已发布!喜欢边缘生活的可以下载 Octopus Deploy 2.6 预发布。当这个版本包含如此多的新功能时,谁不想生活在边缘呢?以下是亮点:
- 控制推广和自动化部署的生命周期
- 从 NuGet push 自动创建发布
- 并行运行步骤
- 高达 5 倍的包上传速度
- 跳过脱机计算机
生活过程
这个标题只是没有足够的宣传这个功能。想象一下,气球弹出,小号手吹号,五彩纸屑炮弄得到处都是。
好吧,我会停止,但我喜欢这个功能!

生命周期允许您指定和控制部署到环境的进度。您不仅能够订购部署环境,还可以:
- 当环境符合部署条件时,将环境设置为自动部署
- 检查您的工作流程,确保在继续之前已经部署了 N QA 环境
- 将多个环境归入一个阶段
- 一次部署到多个环境
是的,一次部署到多个环境!
生命周期由阶段和保留策略组成。先说阶段。
生命周期阶段

一个生命周期可以由许多阶段组成。一个阶段可以由许多环境组成。每个阶段都允许您向其中添加环境。您可以控制每个阶段,以确保在下一个阶段有资格部署之前,已经发布了 N 个环境。

当选择将哪个环境添加到阶段时,您可以选择是手动发布还是自动发布。如果它们被设置为自动发布,当它们到达部署链的阶段时,它们将开始部署。
生命周期和保留政策
生命周期有自己的保留策略。每个阶段都有一个总体的保留策略。但是,您可以为每个阶段覆盖它。

这意味着对于一周有 1300 个版本的开发,您可以设置一个非常严格的保留策略来删除除最后 3 个版本之外的所有版本。但是对于生产来说,你可以永远保留一切。或者在中间的某个地方,如果你的需求不是那么极端的话
生命周期和项目
生命周期通过进程屏幕分配给项目。

您可能会注意到,您的项目概览屏幕有一点大修。

它现在将显示您的最新版本,它们在每个环境中的位置,并提供任何部署或升级按钮。它让您可以一目了然地看到最新和以前的部署。持续绿色表示您最近的部署,中度褪色绿色表示您以前的部署,浅褪色绿色表示所有其他部署。
生命周期、发布、部署和促销

发布页面现在为您提供了一个图形树,显示了当前部署的位置、阶段和正在部署的内容。你可能会注意到这里的一些事情。部署/升级按钮变得更智能了。它知道链条中的下一步是什么。它还允许您部署到已经部署到的任何环境中。

现在,只需点击一个按钮,就可以发布到多个环境中。没错。

或者你可以使用这个选择框,并选择它们!

当您完成部署后,promote 按钮会知道下一步是什么,并为您提供升级到下一个环境的选项。

部署屏幕也变得简单了一些。更容易找到“立即部署”按钮。但是不要担心,所有的东西在高级下都是可用的,如果你愿意,你可以告诉它记住一直显示高级设置。
生命周期和阻止部署
如果您有一个坏的发布,它刚刚对您的 QA 服务器做了一些坏的事情(tm ),那么您可能想要阻止这个发布进一步向下发布,直到问题被解决。现在,您可以阻止部署。

第 1 步阻止部署的原因。

在您的发布屏幕上,您可以看到“升级”按钮已经消失,并且您的生命周期部署树对于那些它不能升级到的环境有一个红色图标。

现在,您还会在概览中看到一个警告标记,而不会再看到该版本的促销按钮。事实上,所有的推广按钮都不见了。此时,您只能部署到已经部署到的环境中。问题解决后解除阻止将授予您部署该版本的完全权限。
生命周期和自动发布创建
是的,还有更多!

在 project process 屏幕上,您可以定义一个包的名称,当它被推送到或上传到内部存储库时,将自动为您创建一个版本。

如果您在生命周期设置中有第一个要自动部署的环境,这意味着您可以将一个 NuGet 包推送到内部存储库,让它自动创建一个发布并部署它!我们在看你们 TFS 的用户!
正如你所看到的,生命周期是 Octopus 的许多领域都有的功能,这是一个很大的功能,我们对此非常自豪。我们借此机会尝试在 UserVoice 中听取您的反馈和建议,以增加更多价值。我们真的希望你和我们一样喜欢它!
并行运行步骤
2.6 中的另一个特性允许您设置多个并行运行的项目步骤。

您可以选择一个项目步骤,使其与前一个步骤并行运行。

流程页面已更新,以显示这些组合在一起的步骤。如果它们运行在同一台机器上,它们仍然会排队,除非你配置项目允许多个步骤并行运行
保留策略已经改变
如上所述,保留策略已经进入了生命周期。您将不再在“配置”下找到“保留策略”选项卡。它们也不能再为项目组设置。剩下的工作就是为内部包存储库设置保留策略。

这已经被移到包所在的位置,在库->包下。
包上传流
在 2.6 版本中,当 Octopus 下载一个包,然后发送给 Tentacles 时,它现在将通过流媒体来完成。我们看到速度提高了 5 倍。这也将减少一些内存开销,在保存之前,触手使用这些内存来存储包块。
SNI 支持
除了修复 SSL 绑定的一些问题,我们还增加了 SNI 支持。

跳过脱机计算机
目前,当在非常大的环境中进行部署时,离线机器可能会妨碍您的工作。我们现在可以继续部署,但跳过离线机器。

我们现在在部署屏幕上显示离线计算机(显示为红色)。这将允许您返回并检查机器的连接。或者您可以使用“忽略脱机计算机”功能。

这将自动列出除脱机计算机之外的所有计算机。
这就结束了 2.6 中的新特性之旅。我们只提到了这个版本中的主要特性,但是也有一些小的改动和错误修复,所以请查看发行说明以了解这些小项目的更多细节。我们希望你和我们一样对生命周期感到兴奋!
立即下载 Octopus Deploy 2.6 预发布版!
2022 年开发运营状况加速报告- Octopus 部署
每年在 Octopus Deploy,我们都期待发布加速发展状态报告。来自 Google Cloud 和 DORA 的这份报告是一份学术严谨的长期研究成果,提供了实现软件交付高性能所需的实践和能力的重要见解。
从这份报告中,我们已经了解了什么样的技术和文化技术的结合推动了软件交付和组织层面的性能。从 33,000 多份调查反馈中分析了这些能力和关系。
今年我们比往年更加兴奋,因为 Octopus 赞助了 2022 年 9 月 28 日发布的 2022 年加速发展状况报告。
背景
DevOps 加速状态报告已经运行了 8 年,跟踪预测高软件交付性能和组织性能的特定实践。该报告建立了实践、能力、文化和重要成果之间的联系,目标是能够谈论与高绩效团队和组织相关的内容。
DevOps 功能协同工作效果最佳,放大了积极效果,增加了文化和组织效益。
2021 年,主要观点包括:
- 文化如何减轻倦怠
- 云的采用是性能的驱动因素
- 软件供应链安全如何影响性能
- 文档如何提高安全性、可靠性和云的使用
DORA 指标是报告中出现的实用工具之一。第五个指标是 2021 年增加的可靠性。
Octopus Deploy 2022.3+ 包含 DevOps Insights,可根据前 4 项 DORA 指标显示数据,从而更好地了解贵公司的 DevOps 绩效。我们的 DevOps Insights 报告帮助您确定 DevOps 绩效的结果,并查看您可以改进的地方。
2022 年的新见解
与往常一样,最新的加速开发运维状态报告包含新的见解,您将在今年的报告中发现几处变化。
头条新闻之一是,安全实践的最大预测因素之一是文化,而不是技术。如果一个组织有一种高度信任/低责备的文化,它更有可能采用适当的安全实践。这些实践提高了软件交付和操作性能,并减少了倦怠。
Google Cloud DORA 研究主管 Claire Peters 表示:“今年的 Accelerate State of DevOps 报告深入研究了安全性,发现组织的应用程序开发安全实践的最大预测因素是文化,而不是技术。“每个组织都将安全放在首位,我们发现,具有高度信任和注重绩效的低责备文化的团队更有可能成功采用有效的安全实践。比以往任何时候都更明显的是,组织文化和现代开发流程是希望改善其安全状况的组织的最佳起点。”
此外,还有以下见解:
- 可靠性在性能中的作用
- 云技术的采用率
- 对受访者进行聚类的新分类
谢谢你
我们在今年的一些新闻简报中邀请您参与开发运维加速状态调查。感谢每一个回复并分享自己经历的人。
你可以在这里阅读完整报告。查看 DevOps 工程师手册以了解更多关于 DevOps 指标的信息。
愉快的部署!
在 Octopus 3.0 中,我们将从 RavenDB 切换到 SQL Server - Octopus Deploy
Octopus 的早期测试版本使用带有实体框架的 SQL Server。2012 年,就在 1.0 之前,我改用了 RavenDB,写了一篇关于我们如何使用嵌入式版本 RavenDB 的博文。
两年多来,我们一直在基于 RavenDB 进行开发。在此期间,我们安装了超过 10,000 台 Octopus,这意味着我们负责将 RavenDB 投入生产超过 10,000 次。由于大多数客户没有内部的 Raven 专家,所以当 Raven 出现问题时,我们是第一(唯一)支持线。我们不只是在踢轮胎或“看着”乌鸦,我们把农场押在它身上。
对于 Octopus 3.0,我们将停止使用 RavenDB,而使用 SQL Server。可以理解,许多人对“为什么”感兴趣。开始了。
第一,好的
RavenDB 有很好的开发经验。与 SQL + EF 或 NHibernate 相比,使用 RavenDB 可以极快地进行迭代,并且它通常“工作正常”。如果我在一个紧张的期限内构建一个最小可行的产品,RavenDB 将是我的首选数据库。我们在 6 个月的时间里重写了 Octopus 1.6 和 2.0 之间的几乎所有内容,我不认为我们可以在 SQL + EF 上这么快地迭代。
坏事
我们通过电子邮件/论坛处理大部分支持,但当出现大问题时,我们会将其升级为 Skype/GoToMeeting 电话,以便帮助客户。通常是在早上很早的时候,或者晚上很晚的时候,所以最小化做这些事情的需求对我们的理智是至关重要的。
我们大多数支持电话的原因是什么?不幸的是,它要么是 Raven,要么是我们在使用 Raven 时犯的一个错误。而且用 Raven 的时候真的很容易出错。这些问题通常分为两类:索引/数据损坏问题,或 API/使用问题。
最重要的是,数据库需要坚如磐石,性能可靠。Raven 的底层使用 ESENT,我们通常不会丢失 Raven 事务方面的任何数据。但是指数是基于 Lucene.NET 的,这是一个不同的故事。已经损坏并需要重建的索引是如此常见,以至于我们为 1.6 版写了一篇博文解释人们如何能够重置他们的索引。我们把这篇博文发给了很多人,所以在 2.0 中我们在 UI 中为他们构建了一个完整的功能。

当我说我们从未丢失过交易数据时,这并不完全正确。在 RavenDB 中添加一个导致大问题的索引真的很容易。拿着这个:
Map = processes => from process in processes
from step in process.Steps
select {...}
Reduce = results => from result in results
group result by ....
你可以写这个索引,它对你来说很好,你把它投入生产。然后,您发现一个客户有 10,000 个流程文档,每个文档有 40 个步骤。
虽然 Raven 使用 Lucene 进行索引,但它也将索引记录写入 ESENT。我不知道内部的情况,但是 Raven ESENT 数据库内部有各种各样的表,有些是用来临时写这些 map/reduce 记录的。对于每个被索引的条目,它将向这些表中写入大量的记录。因此,我们从一个客户那里得到一个支持问题:他们启动 Octopus,他们的数据库文件以每秒几十或几百 MB 的速度增长,直到填满磁盘。数据库文件变得太大,他们无法修复。他们所能做的就是从备份中恢复。当我们最终获得这些巨大数据文件中的一个副本,并使用 ESENT 的一些 UI 工具对其进行研究时,这些表包含了数百万条记录,仅 10,000 个文档。
RavenDB 团队意识到这是一个问题,因为在 3.0 中他们增加了一个新功能。如果地图操作产生的输出记录超过 15 条,则该文档不会被索引。
我是说,再读一遍那一段。你写一些代码,测试它,它在开发中运行良好。你把它放到生产环境中,它对每个人都很好。然后你接到一个客户的电话:我刚刚添加了一个新流程,它没有出现在列表中。只有在许多电子邮件和支持电话之后,你才意识到这是因为 Raven 认为 15 是可以的,16 是不行的,并且该项目没有被索引。你没有阅读文档是你的错!
“默认安全”是所以生产中痛苦
Raven 有一个“默认安全”的哲学,但是 API 使得编写“安全”的代码变得如此容易,以至于在生产中中断。例如:
session.Query<Project>().ToList();
把它投入生产,你会得到一个支持电话:“我刚刚添加了我的第 129 个项目,但它没有出现在屏幕上”。为了避免可怕的“无界结果集”问题,Raven 限制了任何查询返回的项数。感谢不是这个:
DeleteExcept(session.Query<Project>().Where(p => !p.KeepForever).ToList())
无界的结果集当然不好。但是,在开发和生产中工作的代码,直到当记录数量改变时,它突然表现出不同的行为,就更糟糕了。如果 RavenDB 相信防止无限的结果集,他们根本就不应该让那个查询运行——当我在没有调用.Take()的情况下做任何查询时抛出一个异常。让它成为开发问题,而不是生产问题。
在一个会话中,您只能执行 30 个查询。结果集是有界的*。每个被映射的项目只有 15 个映射结果。当你和 Raven 一起工作时,每次和 RavenDB 互动时,都要记住这些限制,否则你会后悔的。*
这些限制被清楚地记录下来,但是你会忘记它们。只有当生产中发生了奇怪的事情,你去寻找时,你才会意识到它们。尽管有两年使用 Raven 的生产经验,这些意见仍然咬着我们。看到像这样的帖子出现在网站上让我很沮丧,这些帖子提倡的解决方案如果有人尝试,将会积极地打破生产。
结论
RavenDB 非常适合开发。也许我们正在经历的问题是我们的错。所有的数据库都有它们的缺点,也许这是另一边的草总是更绿的例子。切换到 SQL Server 可能看起来像是一种倒退,并且可能会使开发更加困难,但是在这一点上,我确实觉得我们在生产中使用 SQL Server 会有更少的问题。它已经存在了很长一段时间,其中的陷阱至少是众所周知和可以预见的。
关于我们为什么要离开 RavenDB 已经说得够多了。下周我将分享一些关于我们计划如何在 Octopus 3.0 中使用 SQL Server 的细节。
(*)您可以通过指定要返回的无限项来禁用无限结果集保护,如果您知道在哪里关闭它的话。但是您仍然必须在每次编写查询时显式调用.Take(int.MaxValue)。
创建 Kubernetes pods、复制集和部署- Octopus 部署
原文:https://octopus.com/blog/k8s-training/4-creating-kubernetes-resources
这篇文章是我们 Kubernetes 培训系列的第四篇,为 DevOps 工程师提供了关于 Docker、Kubernetes 和 Octopus 的介绍。
此视频演示了 Kubernetes pods、副本集和部署,并展示了每种部署的示例。
如果您还没有八达通帐户,您可以开始免费试用。
您可以使用下面的链接完成该系列。
资源
样品舱 YAML
apiVersion: v1
kind: Pod
metadata:
name: underwater
spec:
containers:
- name: webapp
image: octopussamples/underwater-app
ports:
- containerPort: 80
样本复制集 YAML
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: webapp
spec:
replicas: 3
selector:
matchLabels:
tier: webapp
template:
metadata:
labels:
tier: webapp
spec:
containers:
- name: webapp
image: octopussamples/underwater-app
ports:
- containerPort: 80
示例部署 YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
spec:
replicas: 3
selector:
matchLabels:
tier: webapp
template:
metadata:
labels:
tier: webapp
spec:
containers:
- name: webapp
image: octopussamples/underwater-app
ports:
- containerPort: 80
了解更多信息
如果您希望在 AWS 平台(如 EKS 和 ECS)上构建和部署容器化的应用程序,那么 Octopus Workflow Builder 将用 GitHub Actions 工作流构建的示例应用程序填充 GitHub 存储库,并用示例部署项目配置托管的 Octopus 实例,这些项目展示了最佳实践,如漏洞扫描和基础设施代码(IaC)。
愉快的部署!
Selenium 系列:样本 web 页面——Octopus Deploy
原文:https://octopus.com/blog/selenium/5-a-sample-web-page/a-sample-web-page
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
既然我们已经有了用于编写 WebDriver 测试的框架的基础,是时候开始与网页交互了。
为了展示 WebDriver 的强大功能,我们将首先创建一个简单的 web 页面,其中包含常见的表单元素,以及其他常见的 HTML 元素,如 images 和 div。
完整的网页如下所示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>A sample web site</title>
<style>
form > * {
display: block;
}
</style>
<script>
/*
Print a message to the page
*/
function interactionMessage(message) {
document.getElementById('message').textContent = message;
}
/*
Create a new element on the page after 5 seconds
*/
setTimeout(function() {
var newDiv = document.createElement("div");
newDiv.setAttribute("id", "newdiv_element");
newDiv.textContent = "I am a newly created div";
document.body.appendChild(newDiv);
document.getElementById("div3_element").style.display = "";
}, 5000);
</script>
</head>
<body>
<div id="message"></div>
<form id="form_element" onsubmit="interactionMessage('Form Submitted'); return false">
<button name="button_element" id="button_element" type="button" onclick="interactionMessage('Button Clicked')">Form Button</button>
<input name="text_element" id="text_element" type="text" oninput="interactionMessage('Text Input Changed')">
<select name="select_element" id="select_element" onchange="interactionMessage('Select Changed')">
<optgroup label="Group 1">
<option id="option1.1_element">Option 1.1</option>
</optgroup>
<optgroup label="Group 2">
<option id="option2.1_element">Option 2.1</option>
<option id="option2.2_element">Option 2.2</option>
</optgroup>
<optgroup label="Group 3" disabled>
<option id="option3.1_element">Option 3.1</option>
<option id="option3.2_element">Option 3.2</option>
<option id="option3.3_element">Option 3.3</option>
</optgroup>
</select>
<textarea name="textarea_element" id="textarea_element" name="textarea" rows="10" cols="50"
oninput="interactionMessage('Text Area Changed')"></textarea>
<div><input name="radio_group" id="radio1_element" type="radio" name="color" value="blue"
onchange="interactionMessage('Radio Button Changed')"> Blue
</div>
<div><input name="radio_group" id="radio2_element" type="radio" name="color" value="green"
onchange="interactionMessage('Radio Button Changed')"> Green
</div>
<div><input name="radio_group" id="radio3_element" type="radio" name="color" value="red"
onchange="interactionMessage('Radio Button Changed')"> Red
</div>
<div><input name="checkbox1_element" id="checkbox1_element" type="checkbox" name="vehicle" value="Bike"
onchange="interactionMessage('Checkbox Changed')"> I have a bike
</div>
<div><input name="checkbox2_element" id="checkbox2_element" type="checkbox" name="vehicle" value="Car" checked
onchange="interactionMessage('Checkbox Changed')"> I have a car
</div>
<input id="submit_element" type="submit">
</form>
<img id="image_element" src="java.png" width="128" height="128" onclick="interactionMessage('Image Clicked')">
<div id="div_element" onclick="interactionMessage('Div Clicked')">I am a div</div>
<div id="div2_element" onclick="interactionMessage('Div 2 Clicked')">I am a div too</div>
<div id="div3_element" style="display: none" onclick="interactionMessage('Div 3 Clicked')">I am a hidden div</div>
</body>
</html>
让我们来看看这个网页的一些有趣的方面。
我们有一个名为interactionMessage()的 JavaScript 函数,它在页面上显示一些文本。我们将通过 WebDriver 与之交互的 HTML 元素将使用像onclick、onchange或oninput这样的事件将消息打印到页面上。然后,我们可以验证该消息的存在,以确保 WebDriver 确实如我们所期望的那样与元素进行了交互。
function interactionMessage(message) {
document.getElementById('message').textContent = message;
}
第二个 JavaScript 函数使用setTimeout()函数等待 5 秒钟,然后向页面追加一个新的<div>元素。它还重置了 ID 为div3_element的 div 的样式,这将具有显示隐藏元素的效果。
在以后的文章中,我们将使用这两种对网页的动态更新来演示如何使用隐式和显式等待:
setTimeout(function() {
var newDiv = document.createElement("div");
newDiv.setAttribute("id", "newdiv_element");
newDiv.textContent = "I am a newly created div";
document.body.appendChild(newDiv);
document.getElementById("div3_element").style.display = "";
}, 5000);
我们有一个<form>元素,它将保存一组常见的 HTML 表单元素,如按钮、文本框、单选按钮等。当表单提交时,onsubmit事件调用interactionMessage()方法显示一条消息。通过返回false阻止表单在提交时尝试重新加载页面:
<form id="form_element" onsubmit="interactionMessage('Form Submitted'); return false">
表单内部是文本框、文本区域、按钮、单选按钮、复选框和选择元素的集合。像父元素<form>一样,大多数子元素调用interactionMessage()方法来响应事件:
<button name="button_element" id="button_element" type="button" onclick="interactionMessage('Button Clicked')">Form Button</button>
<input name="text_element" id="text_element" type="text" oninput="interactionMessage('Text Input Changed')">
<select name="select_element" id="select_element" onchange="interactionMessage('Select Changed')">
<optgroup label="Group 1">
<option id="option1.1_element">Option 1.1</option>
</optgroup>
<optgroup label="Group 2">
<option id="option2.1_element">Option 2.1</option>
<option id="option2.2_element">Option 2.2</option>
</optgroup>
<optgroup label="Group 3" disabled>
<option id="option3.1_element">Option 3.1</option>
<option id="option3.2_element">Option 3.2</option>
<option id="option3.3_element">Option 3.3</option>
</optgroup>
</select>
<textarea name="textarea_element" id="textarea_element" name="textarea" rows="10" cols="50"
oninput="interactionMessage('Text Area Changed')"></textarea>
<div><input name="radio_group" id="radio1_element" type="radio" name="color" value="blue"
onchange="interactionMessage('Radio Button Changed')"> Blue
</div>
<div><input name="radio_group" id="radio2_element" type="radio" name="color" value="green"
onchange="interactionMessage('Radio Button Changed')"> Green
</div>
<div><input name="radio_group" id="radio3_element" type="radio" name="color" value="red"
onchange="interactionMessage('Radio Button Changed')"> Red
</div>
<div><input name="checkbox1_element" id="checkbox1_element" type="checkbox" name="vehicle" value="Bike"
onchange="interactionMessage('Checkbox Changed')"> I have a bike
</div>
<div><input name="checkbox2_element" id="checkbox2_element" type="checkbox" name="vehicle" value="Car" checked
onchange="interactionMessage('Checkbox Changed')"> I have a car
</div>
<input id="submit_element" type="submit">
在<form>之外,我们有一些 image 和 div 元素:
<img id="image_element" src="java.png" width="128" height="128" onclick="interactionMessage('Image Clicked')">
<div id="div_element" onclick="interactionMessage('Div Clicked')">I am a div</div>
<div id="div2_element" onclick="interactionMessage('Div 2 Clicked')">I am a div too</div>
最后一个 div 元素的display样式设置为none,实际上在页面上隐藏了它。这个元素将在 5 秒钟后由setTimeout()方法调用的 JavaScript 显示:
<div id="div3_element" style="display: none" onclick="interactionMessage('Div 3 Clicked')">I am a hidden div</div>
最终结果是这样的。

为了在 Java 测试中使用这个页面,我们需要将它保存在src/test/resources目录中。这是找到资源文件的标准 Maven 目录。
这个目录还不存在,所以我们通过右击测试目录并选择新➜目录来创建它。

输入名称 resources,然后单击OK按钮。

正如我们已经多次看到的,在 Maven 项目中创建一个具有特殊意义的目录并不会自动更新 IntelliJ 项目。我们可以在下面的截图中看到,resources目录现在已经存在,但是在我们的项目中它看起来像一个普通的目录。

要更新 IntelliJ 项目,打开Maven Projects工具窗口并点击Reimport All Maven Projects按钮。

目录的图标被更新,以反映这样一个事实,即它将保存像我们的示例 web 页面这样的文件。

一旦配置了resources文件夹,将 HTML 代码保存到一个名为form.html的文件中。

我们现在已经完成了拼图的两个重要部分。首先,我们已经有了框架的雏形,它将允许我们创建灵活的AutomatedBrowser对象,通过这些对象我们可以与网页进行交互。第二,我们有一个样例 web 页面,其中包含了我们在编写 WebDriver 测试时可能会遇到的大多数元素。现在是时候写一些真正的 WebDriver 测试了。
让我们在类FormTest中创建一个测试方法formTestByID(),它将打开浏览器,打开我们的测试网页,然后再次关闭浏览器:
package com.octopus;
import org.junit.Test;
import java.net.URISyntaxException;
public class FormTest {
private static final AutomatedBrowserFactory AUTOMATED_BROWSER_FACTORY = new AutomatedBrowserFactory();
@Test
public void formTestByID() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
} finally {
automatedBrowser.destroy();
}
}
}
注意,我们可以通过调用FormTest.class.getResource()来访问样本 HTML 文件。因为我们将这个文件保存在标准目录src/test/resources下,Maven(以及通过扩展 IntelliJ)允许我们通过 Java 代码访问这个文件。以下代码返回样本 HTML 文件的完整 URL:
FormTest.class.getResource("/form.html").toURI().toString()
现在让我们手动打开同一个网页。IntelliJ 为本地托管网页提供了便利的服务。当 HTML 文件在编辑器中打开时,可以通过单击屏幕右上角的快捷方式来访问它。

点击 Chrome 浏览器图标会打开 Chrome 到一个类似http://localhost:63342/web driver training/form . html?_ ijt = 2r 0 gmmveunmkptr 759 pintjfe 5。这是一种快速简单的方法来查看我们的样本网页。
IntelliJ 生成的 URL 不是我们通过调用FormTest.class.getResource()得到的 URL。使用 IntelliJ 来托管 web 页面只是为了方便我们作为最终用户,但是我们在测试中不使用这个 URL。事实上,我们不能使用这个 URL,因为最后的查询字符串是随机生成的,会阻止任何其他用户或进程访问 IntelliJ 托管的页面。
我们要测试的第一件事是使用 WebDriver 点击页面顶部的按钮。
要与按钮交互,我们需要知道它的 ID。我们知道这个按钮的 ID 是button_element,因为我们编写了 HTML。但是,并不总是能够访问您将要测试的 web 应用程序的源代码。因此,我们将假设我们无法访问 HTML 源代码,而是使用 Chrome 提供的工具来查找这些信息。
在 Chrome 中加载页面后,右键单击按钮元素并单击Inspect选项。

这将打开 Chrome 的开发者工具,并高亮显示Elements标签中的按钮 HTML 元素。
当 JavaScript 调用添加、删除和更改元素时,显示在开发工具Elements选项卡中的 HTML 元素会实时更新。这意味着您将经常从开发人员工具中获得比仅仅查看 HTML 源代码更多的信息。
您可以通过右击显示I am a newly created div的文本并选择Inspect选项来亲自查看。这将显示作为setTimeout()方法调用的结果而创建的<div>元素。您将不会在 HTML 源代码中看到那个<div>元素,因为它是在运行时动态生成的。

回到<button>元素,我们可以看到 ID 属性确实是button_element。

既然我们知道了想要与之交互的元素的 ID,我们就可以开始构建我们的测试了。我们首先调用clickElementWithId(),传入我们想要点击的元素的 ID:
@Test
public void formTestByID() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("button_element");
} finally {
automatedBrowser.destroy();
}
}
接下来,在WebDriverDecorator类中,我们需要添加一个clickElementWithId()方法的实现:
@Override
public void clickElementWithId(final String id) {
webDriver.findElement(By.id(id)).click();
}
当您将这段代码粘贴到WebDriverDecorator类中时,ItelliJ 将以红色显示By类。这是因为我们没有导入包含By类的包。
要解决这个问题,请将鼠标光标放在红色文本上,然后单击 ALT + Enter。这将显示一个带有Import class选项的上下文菜单。

IntelliJ 通常很擅长根据类的上下文来决定导入哪个包,在这种情况下,它会将import org.openqa.selenium.By;语句添加到类的顶部。

clickElementWithId()方法做了三件重要的事情。
首先,它通过调用By.id(id)找到我们希望与之交互的元素。By类用于查找网页中的元素,并提供一系列方法来执行搜索。因为我们通过 ID 搜索元素,所以我们称之为By.id()。
其次,我们调用 web 驱动程序类上的findElement()方法来查找元素。
第三,我们获取由findElement()返回的元素并调用click()方法来模拟终端用户点击该元素。
定义如何用By类搜索元素,用findElement()方法找到元素,并调用类似click()的方法来模拟一个动作,这个过程是我们在构建测试框架时要反复重复的。
但是我们如何确定 WebDriver 真的点击了按钮呢?如果您回头看一下form.html页面的源代码,您会看到<button>元素具有属性onclick="interactionMessage('Button Clicked')"。这意味着当点击按钮时,用'Button Clicked'调用interactionMessage()方法,这又会在页面上显示文本Button Clicked。
然后,我们可以从保存消息Button Clicked的元素中提取文本,并验证它是否表达了我们期望它表达的内容。
为此,我们调用getTextFromElementWithId()方法,传入包含我们希望返回的文本的元素的 ID,在我们的例子中是保存我们希望验证的消息文本的<div>元素的 ID。然后,我们使用 JUnit 提供的assertEquals()来验证这个方法调用的结果:
@Test
public void formTestByID() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("button_element");
assertEquals("Button Clicked", automatedBrowser.getTextFromElementWithId("message"));
} finally {
automatedBrowser.destroy();
}
}
然后,getTextFromElementWithId()方法需要在WebDriverDecorator类中实现。
注意,getTextFromElementWithId()方法遵循与clickElementWithId()相同的模式。事实上,唯一的区别是我们在结果元素上调用了getText(),而不是click():
@Override
public String getTextFromElementWithId(final String id) {
return webDriver.findElement(By.id(id)).getText();
}
这样,我们就成功地用 WebDriver 点击了一个元素,并验证了页面的响应符合我们的预期。
让我们继续用文本填充文本框和文本区域,并验证这些字段上的事件处理程序将预期的消息打印到页面上:
automatedBrowser.populateElementWithId("text_element", "test text");
assertEquals("Text Input Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.populateElementWithId("textarea_element", "test text");
assertEquals("Text Area Changed", automatedBrowser.getTextFromElementWithId("message"));
然后,populateElementWithId()方法需要在WebDriverDecorator类中实现。在这种情况下,我们对返回的元素使用sendKeys()方法来填充文本:
@Override
public void populateElementWithId(String id, String text) {
webDriver.findElement(By.id(id)).sendKeys(text);
}
接下来,我们将从下拉列表中选择一个选项:
automatedBrowser.selectOptionByTextFromSelectWithId("Option 2.1", "select_element");
assertEquals("Select Changed", automatedBrowser.getTextFromElementWithId("message"));
selectOptionByTextFromSelectWithId()方法与我们之前看到的模式略有不同。
findElement()方法返回WebElement接口的一个实例。WebElement接口反过来通过如下方法公开了一些常见的动作:
click()sendKeys()clear()submit()getText()
您可以通过查看 Javadoc API 文档获得这些方法的完整列表。
值得注意的是,这个动作列表中没有从下拉列表中选择选项的功能。为了与一个<select>元素交互,我们需要创建一个Select类的实例,它的构造函数接受由findElement()返回的WebElement。然后我们可以使用selectByVisibleText()方法,该方法选择带有相应文本的选项:
@Override
public void selectOptionByTextFromSelectWithId(String optionText, String selectId) {
new Select(webDriver.findElement(By.id(selectId))).selectByVisibleText(optionText);
}
点击单选按钮和复选框的方法与我们点击按钮的方法相同:
automatedBrowser.clickElementWithId("radio3_element");
assertEquals("Radio Button Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.clickElementWithId("checkbox2_element");
assertEquals("Checkbox Changed", automatedBrowser.getTextFromElementWithId("message"));
我们不局限于与表单元素交互。clickElementWithId()方法同样适用于图像和普通旧 div 等元素:
automatedBrowser.clickElementWithId("image_element");
assertEquals("Image Clicked", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.clickElementWithId("div_element");
assertEquals("Div Clicked", automatedBrowser.getTextFromElementWithId("message"));
通过formTestByID()测试,我们已经成功地点击、检查、输入和选择了一个实时的交互式网页的选项,并验证了结果。简而言之,这就是编写 WebDrivers 测试的全部内容。然而,我们并不总是能够根据 ID 属性来定位元素。在这些情况下,WebDriver 提供了许多其他方法来定位 web 页面中的元素,接下来我们将讨论这些方法。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
Actors vs. RPC:为 Octopus 3.0 构建新的(旧的)传输层- Octopus Deploy
在 Octopus 1.0 中,我们使用 WCF 在 Octopus 服务器和触手之间进行通信。当 Octopus 服务器需要告诉触手做一些事情时,比如运行 PowerShell 脚本,它看起来像这样:
var client = clientBroker.Create<IJobService>("http://some-machine");
var ticket = client.RunScript("Write-Host 'Hello'; Start-Sleep -s 100; Write-Host 'Bye'");
do
{
var status = client.GetJobStatus(ticket);
log.Append(status.Log);
Thread.Sleep(4000);
if (IsCancelled())
{
client.Cancel(ticket);
}
} while (status.State == JobStatus.InProgress);
log.Append("Script run complete");
这种 RPC 风格的编程工作得很好,但是它有一个限制:这意味着触手必须始终是 TCP 侦听器,而 Octopus 必须始终是 TCP 客户端。
在设计 Octopus 2.0 的时候,当时最大的特性要求是能够拥有轮询触角;实际上,颠倒了 TCP 客户机/服务器关系。

在上面的例子中,这意味着 Octopus 服务器需要以某种方式将一个命令排队让触手运行脚本,当触手轮询 Octopus 要做的任务时,它会找到这个命令并处理它。从概念上讲,它的意思大概是这样的:
var runScriptCommand = new RunScriptCommand("Write-Host....");
messageQueue.For("MachineA").Enqueue(runScriptCommand);
使用消息将 TCP 客户机/服务器关系从代码中分离出来——我们将能够用 Octopus 编写代码来编排触角,而不需要大量的if/else条件来使它根据触角是监听还是轮询而不同地工作。由于轮询触角要求我们对消息进行排队以便稍后获取,我们也可以将它们用于监听触角。
围绕构建基于消息和队列的分布式系统有大量的知识,所以一旦我们决定我们需要消息队列,那些模式和实践就成为我们思考的中心。我们在消息传递方面的大部分经验来自类似 NServiceBus 和类似的框架,我们已经多次将其付诸实践。
按照预期使用消息确实使编排代码变得更加复杂,我们的编排代码开始类似于 NServiceBus sagas :
void Handle(BeginScriptRun message)
{
Send("MachineA", new RunScriptCommand("Write-Host ...."));
}
void Handle(JobStartedMessage message)
{
State.Ticket = message.Ticket;
}
void Handle(CancelMessage message)
{
Send("MachineA", new CancelCommand(State.Ticket));
}
void Handle(ScriptOutputLogged message)
{
log.Append(message.Log);
}
void Handle(ScriptCompletedMessage message)
{
log.Append("Script run complete");
Complete();
}
脱离请求/响应 RPC 范式而使用消息传递似乎带来了许多好处:
- 它可以更好地处理真正长时间运行的任务,因为您没有等待响应的线程被阻塞
- 服务器正常运行时间是分离的——如果触手最初是离线的,但最终恢复在线,那么本例中运行的脚本可以完成
- 它允许我们支持轮询和监听触角,因为我们的应用程序代码可以编写成与底层传输无关
随着时间的推移,我们的 NServiceBus 传奇类演变成了一个演员框架,类似于 Akka (尽管这是在Akka.NET开始之前大约六个月)。我们从 Akka 借用了一些概念,比如监督树,这使得错误处理变得更容易忍受。
这已经生产了 12 个月了。虽然它基本上运行良好,但我已经开始注意到这种面向参与者/消息的方法的许多缺点:
- actors 的单线程特性非常好,使并发变得很容易。然而,有时您确实需要某种互斥,但最终您不得不使用一些难看的消息传递方法来实现它。
- 遵循代码并对其进行推理要困难得多。在 Visual Studio 中,查找哪个参与者处理哪个消息始终是一个两步导航过程。
- 崩溃转储和堆栈跟踪变得几乎毫无用处。
- 管理演员的寿命真的很难。上面例子末尾的那个调用很重要,因为它告诉我们什么时候可以清理这个 actor。很容易忘记调用这些函数(我是否也应该在取消消息处理程序中调用它?)
- 错误处理同样令人讨厌。例如,在第一个代码示例中,如果远程机器出现故障,异常就会冒泡,或者用
try/catch来处理。在第二个例子中,捕捉和处理这些错误是一个显式的步骤。 - 向新开发人员教授这种编程风格要困难得多
当我查看 Octopus 1.6 中的编排代码时,它真的很容易推理和遵循。也许它不能很好地扩展,也许有太多的地方我们明确地处理线程或锁。但是堆栈跟踪是可读的,我可以很容易地浏览它。当阅读 2.0 中的部署编排代码时,我必须真正集中注意力。
事实证明,我提到的“服务器正常运行时间被分离”的好处对我们来说也不是很有用。如果触须离线,我们可能需要一些自动重试,比如 30 秒或几分钟。除此之外,我们真的不需要消息排队。如果我们在部署过程中,有一台机器离线,我们需要做出决定:要么跳过它,要么部署失败。我们不会等 6 个小时。这通常在消息传递框架中通过给予消息非常短的生存时间来处理,但是这仍然使异常处理过程变得复杂。
actors 的主要好处是,与直接使用线程/锁定原语相比,您可以用更简单的代码获得更好的并发性。然而,当我查看 Octopus 1.0 编排代码时,我们使用的原语如此之少,以至于 actor 方法变得不那么简洁。这表明我们的问题域并不真正适合演员。虽然我们可能无法避免在某种级别上使用消息来处理轮询/监听配置,但请求/响应语义似乎更合适。
那么,我们为章鱼 3.0 做些什么呢?我们将回归到与章鱼 1.0 风格非常相似的东西。不同之处在于,虽然从编码的角度来看,我们将使用请求/响应,但在这些代理之下,我们仍然允许轮询或监听触角:
- 如果触手正在监听,我们将打开一个
TcpClient并连接。 - 如果触手正在轮询,我们将把响应放入队列,并在等待句柄上等待。当请求被拾取并且响应可用时,等待句柄将完成。
您可以将这看作是两层:传输层,其中任何一方都可以是TcpClient/TcpListener,以及位于顶层的逻辑请求/响应层。
我们新的通信栈将是开源的(并将建立在我不久前写的大比目鱼的基础上),随着它的发展,我会发布更多的细节。
2019.5 活动目录突破性变化- Octopus 部署
我们在 2019.5 版本中宣布 Active Directory 有一个突破性的变化,我想写一篇博客来帮助人们了解这对您的组织、infosec 团队以及最重要的 Octopus 管理员意味着什么,您可以在 Github 上看到这个问题。
背景和问题
在大多数组织中,他们使用最小特权原则。这意味着技术人员拥有一个标准用户作为活动目录域的一部分,用于他们的日常工作,如编写文档、阅读电子邮件和浏览网页。他们还可以访问他们在日常技术工作中使用的特权帐户,这些工作可能包括部署、开发、重置用户密码和访问敏感系统。
在 2019.5.0 版本之前,Octopus 将用户邮件视为一把钥匙,并期望它们是唯一的。这导致了 Active Directory 的问题,在 Active Directory 中没有这样的限制,当多个用户拥有相同的电子邮件地址时,Octopus 会认为他们是同一用户。他们是同一个人,但不是活动目录意义上的同一用户。没有其他身份验证提供者以这种方式工作,但为了防止 Active Directory 以这种方式使用时出现问题,我们需要放弃唯一性约束,并假设同一个人可以使用与一个电子邮件地址关联的不同用户帐户。
Active Directory 登录检查也需要更改,以支持检测重复项,并且仍然检测用户是否在 AD 中被修改,而不是新用户首次登录。这是 Active Directory 管理员挑选用户并将他们转移到另一个 OU 或为他们分配所有新 upn 或 SamAccountNames 的场景。我们在过去有几个客户这样做了,失去了对他们的 Octopus 实例的所有访问,因为用户突然看起来都不一样了,我们把他们当作新用户。
这次修复又影响了谁?
我们对此问题的解决方案是确保这些帐户不会根据电子邮件地址进行匹配和合并。这是为了确保如果一个叫罗伯特的用户。Jones 有一个指定的活动目录用户 Work\Robert。琼斯和一个名为“工作\管理-RJ”的管理帐户都有 Robert.Jones@Work.com 的电子邮件地址,但这两个帐户与同一个八达通帐户不匹配。
如果只有管理员帐户可以访问八达通,那么你不会受到影响。
如果您使用的用户帐户不共享电子邮件地址,则您不会受到影响。
如果您在非管理帐户和管理员帐户之间共享电子邮件帐户,那么您会受到影响,我们建议您进行概念验证升级,并测试管理员帐户在升级后是否具有所需的访问权限。
如果您之前在两个用户上使用了相同的电子邮件地址,那么您现在可以拥有独立的帐户,不会基于电子邮件地址进行匹配和合并。
如果你是在事后读到这篇文章的,并且你在一次升级的证明后不小心把自己锁在了 Octopus 之外,我们有办法在我们的文档中获得一个管理帐户。这将允许你访问你的八达通实例,但如果你卡住了,然后与支持取得联系。
结论
我们相信这是我们客户解决这一特殊问题的正确方法,但如果您有任何问题,请联系支持。
Selenium 系列:添加 BrowserMob 代理- Octopus Deploy
原文:https://octopus.com/blog/selenium/11-adding-the-browsermob-proxy/adding-the-browsermob-proxy
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
在这篇文章中,我们将添加对 BrowserMob 代理的支持,这是一个免费的开源 Java 代理服务器。然后,我们将使用 BrowserMob 保存一个包含测试期间所有网络请求的报告,并截取一些网络请求。
为了利用 BrowserMob 库,我们需要将它作为一个依赖项添加到 Maven pom.xml文件中:
<project
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- ... -->
<properties>
<!-- ... -->
<browsermob.version>2.1.5</browsermob.version>
</properties>
<dependencies>
<!-- ... -->
<dependency>
<groupId>net.lightbody.bmp</groupId>
<artifactId>browsermob-core</artifactId>
<version>${browsermob.version}</version>
</dependency>
</dependencies>
</project>
BrowserMob 代理的一个实例将被一个名为BrowserMobDecorator的新装饰器创建和销毁:
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import net.lightbody.bmp.BrowserMobProxy;
import net.lightbody.bmp.BrowserMobProxyServer;
import org.openqa.selenium.Proxy;
import org.openqa.selenium.remote.CapabilityType;
import org.openqa.selenium.remote.DesiredCapabilities;
public class BrowserMobDecorator extends AutomatedBrowserBase {
private BrowserMobProxy proxy;
public BrowserMobDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
}
@Override
public DesiredCapabilities getDesiredCapabilities() {
proxy = new BrowserMobProxyServer();
proxy.start(0);
final DesiredCapabilities desiredCapabilities =
getAutomatedBrowser().getDesiredCapabilities();
final Proxy seleniumProxy = new Proxy();
final String proxyStr = "localhost:" + proxy.getPort();
seleniumProxy.setHttpProxy(proxyStr);
seleniumProxy.setSslProxy(proxyStr);
desiredCapabilities.setCapability(CapabilityType.PROXY, seleniumProxy);
return desiredCapabilities;
}
@Override
public void destroy() {
getAutomatedBrowser().destroy();
if (proxy != null) {
proxy.stop();
}
}
}
让我们来分解这个类中的代码。
在getDesiredCapabilities()方法中,我们创建了一个BrowserMobProxyServer类的实例,并调用它的start()方法。通过将0传递给start()方法,我们可以在任何可用的端口上公开代理:
proxy = new BrowserMobProxyServer();
proxy.start(0);
WebDriver 代理配置信息保存在Proxy类的实例中:
final Proxy seleniumProxy = new Proxy();
然后,我们需要构建一个表示代理网络地址的字符串。因为代理将在本地运行,所以主机名将始终是localhost。
代理暴露的端口可以在每次测试运行时改变,因为我们用0调用了start()方法,表明 BrowserMob 代理应该使用一个可用的端口。我们可以通过调用proxy上的getPort()方法来获取被占用的端口。
这两个字符串组合在一起形成一个类似于localhost:57470的字符串:
final String proxyStr = "localhost:" + proxy.getPort();
然后我们配置Proxy对象将 HTTP 和 HTTPS 流量定向到本地代理:
seleniumProxy.setHttpProxy(proxyStr);
seleniumProxy.setSslProxy(proxyStr);
接下来,我们得到一个DesiredCapabilities对象的副本。如果您还记得上一篇文章,该对象用于配置可应用于任何由 WebDriver 启动的浏览器的设置:
final DesiredCapabilities desiredCapabilities =
getAutomatedBrowser().getDesiredCapabilities();
然后用Proxy实例配置DesiredCapabilities实例。
在之前的文章中,我们注意到DesiredCapabilities类本质上是一个键/值存储。现在你可以在实践中看到这一点,因为我们根据CapabilityType.PROXY值保存了Proxy实例。
CapabilityType.PROXY是设置为proxy的字符串常量,该值被所有浏览器识别为包含代理配置设置:
desiredCapabilities.setCapability(CapabilityType.PROXY, seleniumProxy);
然后返回DesiredCapabilities实例,以便其他 decorators 可以添加到它,或者使用它来构建浏览器驱动程序:
return desiredCapabilities;
更新AutomatedBrowserFactory类以创建BrowserMobDecorator类的新实例:
private AutomatedBrowser getChromeBrowser(final boolean headless) {
return new ChromeDecorator(headless,
new ImplicitWaitDecorator(10,
new BrowserMobDecorator(
new WebDriverDecorator()
)
)
);
}
private AutomatedBrowser getFirefoxBrowser(final boolean headless) {
return new FirefoxDecorator(headless,
new ImplicitWaitDecorator(10,
new BrowserMobDecorator(
new WebDriverDecorator()
)
)
);
}
private AutomatedBrowser getChromeBrowserNoImplicitWait() {
return new ChromeDecorator(
new BrowserMobDecorator(
new WebDriverDecorator()
)
);
}
private AutomatedBrowser getFirefoxBrowserNoImplicitWait() {
return new FirefoxDecorator(
new BrowserMobDecorator(
new WebDriverDecorator()
)
);
}
现在我们的AutomatedBrowserFactory正在配置浏览器将流量传递给 BrowserMob 代理的实例。这不会改变测试的运行方式;代理被设计成对最终用户基本不可见,因此我们的测试将像以前一样运行。然而,如果我们愿意的话,我们现在有办法监控和拦截网络请求。
我们可以通过在测试运行后保持浏览器窗口打开来确认 BrowserMob 代理正在被创建。Firefox 特别容易看到代理设置,所以在下面的测试方法中,我们通过注释掉对finally块中automatedBrowser.destroy()的调用,在测试完成后让浏览器窗口保持打开:
@Test
public void formTestByIDFirefox() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Firefox");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("button_element");
assertEquals("Button Clicked", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.populateElementWithId("text_element", "test text");
assertEquals("Text Input Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.populateElementWithId("textarea_element", "test text");
assertEquals("Text Area Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.selectOptionByTextFromSelectWithId("Option 2.1", "select_element");
assertEquals("Select Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.clickElementWithId("radio3_element");
assertEquals("Radio Button Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.clickElementWithId("checkbox2_element");
assertEquals("Checkbox Changed", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.clickElementWithId("image_element");
assertEquals("Image Clicked", automatedBrowser.getTextFromElementWithId("message"));
automatedBrowser.clickElementWithId("div_element");
assertEquals("Div Clicked", automatedBrowser.getTextFromElementWithId("message"));
} finally {
//automatedBrowser.destroy();
}
}
测试完成后,它启动的 Firefox 浏览器仍会显示。然后从菜单中,我们可以选择Preferences选项。

在首选项页面的底部是Network Proxy部分。点击Settings...按钮。

这里我们可以看到我们在代码中定义的代理设置。这是对我们的代理已经通过 WebDriver 配置的确认。

配置代理服务器使我们能够观察测试过程中的网络请求并与之交互,这是单独使用 WebDriver 无法做到的。下一步是公开对我们有用的 BrowserMob 代理的特性。但是在我们这样做之前,我们将看一看在配置代理时可能出现的常见错误配置,并了解如何调试显示的错误。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
替代 Kubernetes 仪表板-八达通部署
原文:https://octopus.com/blog/alternative-kubernetes-dashboards

最初有*Kubernetes 仪表板。对于任何想要监控 Kubernetes 集群的人来说,这个仪表板都是默认选项,但是多年来,已经开发出了许多值得研究的替代方案。*
*在这篇博客中,我们将看看这些替代 Kubernetes 仪表板。
Kubernetes 星团样本
对于这篇文章,我在本地运行 minikube,用 Istio 提供的 Bookinfo 应用程序填充。
K8Dash
K8Dash 是管理 Kubernetes 集群最简单的方法。
K8Dash 有一个干净、现代的界面,使用过 Kubernetes 官方仪表盘的人应该都很熟悉。K8Dash 的卖点是界面会自动更新,不需要手动刷新页面来查看集群的当前状态。
使用以下命令可以轻松完成安装:
kubectl apply -f https://raw.githubusercontent.com/herbrandson/k8dash/master/kubernetes-k8dash.yaml
kubectl port-forward service/k8dash 9999:80 -n kube-system


星状的
可视化 Kubernetes 应用程序
Konstellate 与其说是一个 Kubernetes 仪表板,不如说是一个创建、链接和可视化 Kubernetes 资源的工具。
主画布允许您添加新的 Kubernetes 资源,如部署、服务和入口。动态用户界面允许您构建这些资源的 YAML 描述,通过相关描述公开可用的子属性。


然后可以连接两个相关的实体,Konstellate 显示将它们链接在一起的相关属性。

 【
【如果说手工编辑 YAML 有什么挑战的话,那就是我总是在谷歌上搜索准确的房产名称和它们之间的关系。上下文感知的 Konstellate 编辑器是探索给定实体的各种可用属性的好方法。
一个杀手级的特性是能够可视化现有集群中的资源,但是这个特性还没有实现。
Konstellate 是从源代码构建的,并没有提供我所能看到的任何预构建的 Docker 映像或二进制文件。您所需要的只是 Clojure 和一个构建并运行应用程序的命令,但下载所有依赖项可能需要几分钟时间。GitHub 页面链接到一个演示,但是当我尝试的时候它关闭了。
总的来说,这是一个非常酷的应用程序,绝对是一个值得关注的项目。
库伯纳特
与高级的 Kubernetes Dashboard 不同,Kubernator 提供了对集群中所有对象的低级控制和清晰的视图,并具有创建新对象、编辑和解决冲突的能力。
Kubernator 是一个功能强大的 YAML 编辑器,直接链接到 Kubernetes 集群。导航树显示了类似文件系统的集群视图,而编辑器提供了选项卡、键盘快捷键和差异视图等功能。

除了编辑原始 YAML,Kubernator 还将可视化基于角色的访问控制(RBAC)资源,显示用户、组、服务帐户、角色和集群角色之间的关系。

安装速度很快,Docker 映像可以随时部署到现有的 Kubernetes 集群中:
kubectl create ns kubernator
kubectl -n kubernator run --image=smpio/kubernator --port=80 kubernator
kubectl -n kubernator expose deploy kubernator
kubectl proxy
接下来,只需在浏览器中打开服务代理 URL 。
Kubernetes 运营视图
多个 K8s 集群的只读系统控制面板
你有没有想过像电影里的超级极客一样管理你的 Kubernetes 集群?那 KOV 就是你的了。
基于 WebGL,KOV 将你的 Kubernetes 仪表盘可视化为一系列嵌套的盒子,显示集群、节点和单元。附加的图表直接嵌套在这些元素中,工具提示提供了附加的细节。可视化效果可以缩放和平移,以深入查看各个窗格。

KOV 是一个只读仪表板,因此您不能使用它来管理集群或设置警报。
然而,我用 KOV 来演示 Kubernetes 集群如何在添加和删除 pod 和节点时工作,人们说这种特殊的可视化是他们第一次理解 Kubernetes 是什么。
KOV 提供了一组 YAML 文件,可以作为一个组部署到现有集群中,从而简化了安装:
kubectl apply -f deploy
kubectl port-forward service/kube-ops-view 8080:80
库布里克斯
针对单个 Kubernetes 集群的可视化工具/故障排除工具
Kubricks 是一个桌面应用程序,它将 Kubernetes 集群可视化,并允许您从节点级别深入到流量视图,反映 kube-proxy 通过服务将传入请求定向到不同 pods 的方式。
我的 minikube 集群只有一个节点,看起来没什么意思:

单击节点会显示部署到该节点的单元:

这是 Kubricks 的交通视图:

我不得不承认,我很难理解库布里克斯向我展示了什么。要查看流量图中各点之间的连接,我必须缩小到标签难以阅读的位置,节点视图似乎缺少一些窗格。
macOS 和 Linux 的下载安装很容易。
八分仪
一个基于 web 的、高度可扩展的平台,供开发人员更好地理解 Kubernetes 集群的复杂性。
Octant 是一个本地安装的应用程序,它公开了一个基于 web 的仪表板。Octant 有一个直观的界面,用于导航、检查和编辑 Kubernetes 资源,并能够可视化相关资源。它还有明暗模式。



我特别喜欢直接从接口配置端口转发的能力。


使用 Brew 和 Chocolatey 提供的包,以及针对 Linux 编译的 RPM 和 DEB 包,安装非常容易。
编织范围
Docker & Kubernetes 的监控、可视化和管理
Weave Scope 提供了 Kubernetes 节点、pod 和容器的可视化,显示了有关内存和 CPU 使用的详细信息。
【T8

更令人感兴趣的是 Weave Scope 捕捉吊舱如何相互通信的能力。这种洞察力是我在这里测试的其他仪表板所没有的。

但是,Weave 范围是非常面向过程的,忽略了静态资源,如配置映射、机密等。
安装很简单,只需一个 YAML 文件就可以直接部署到 Kubernetes 集群中。
kubectl apply -f "https://cloud.weave.works/k8s/scope.yaml?k8s-version=$(kubectl version | base64 | tr -d '\n')"
kubectl port-forward -n weave "$(kubectl get -n weave pod --selector=weave-scope-component=app -o jsonpath='{.items..metadata.name}')" 4040
结论
如果官方的 Kubernetes 仪表板不能满足您的需求,有大量高质量、免费和开源的替代品可供选择。总的来说,我对这些仪表板的安装简单印象深刻,很明显,他们的设计中投入了大量的工作,大多数都提供了至少一个令人信服的更换理由。*
为 CloudFormation - Octopus Deploy 创建 AMI 映射
AWS 提供的许多服务都是针对个别地区的,亚马逊机器图像(AMIs)只是其中一个例子。虽然通用 AMI 发布到所有地区,但每个地区的 AMI ID 都是唯一的。
这在编写 CloudFormation 脚本时提出了一个挑战,因为传递给 EC2 资源的 AMI ID 是特定于区域的,这使得您的模板也是特定于区域的。
Mappings 可以用来编写通用的 CloudFormation 模板,允许 AMI IDs 映射到一个区域,并在部署模板时进行查找。不幸的是,AMI IDs 经常变化,并且没有简单的映射引用包含在您的模板中。
在本文中,您将了解如何使用最新的区域 AMI IDs 生成最新的映射,以便包含在您的 CloudFormation 模板中。
先决条件
脚本需要jq。jq 下载页面包含为主要 Linux 发行版安装工具的说明。
查找脚本
下面的 Bash 脚本在 YAML 构建了一个云结构图:
#!/usr/bin/env bash
echo "Mappings:"
echo " RegionMap:"
regions=$(aws ec2 describe-regions --output text --query 'Regions[*].RegionName')
for region in $regions; do
(
echo " $region:"
AMI=$(aws ec2 describe-images --region $region --filters Name=is-public,Values=true Name=name,Values="$1*" Name=architecture,Values=x86_64 | jq -r '.Images |= sort_by(.CreationDate) | .Images | reverse | .[0].ImageId')
echo " ami: $AMI"
)
done
将脚本保存到类似于amimap.sh的文件中,然后使用命令将该文件标记为可执行文件:
chmod +x amimap.sh
调用该脚本时,AMI 名称(或 AMI 名称的开头)作为第一个参数:
./amimap.sh amzn2-ami-kernel-5.10
输出如下所示:
$ ./amimap.sh amzn2-ami-kernel-5.10-hvm
Mappings:
RegionMap:
eu-north-1:
ami: ami-06bfd6343550d4a29
ap-south-1:
ami: ami-052cef05d01020f1d
eu-west-3:
ami: ami-0d3c032f5934e1b41
eu-west-2:
ami: ami-0d37e07bd4ff37148
eu-west-1:
ami: ami-04dd4500af104442f
ap-northeast-3:
ami: ami-0f1ffb565070e6947
ap-northeast-2:
ami: ami-0eb14fe5735c13eb5
ap-northeast-1:
ami: ami-0218d08a1f9dac831
sa-east-1:
ami: ami-0056d4296b1120bc3
ca-central-1:
ami: ami-0bae7412735610274
ap-southeast-1:
ami: ami-0dc5785603ad4ff54
ap-southeast-2:
ami: ami-0bd2230cfb28832f7
eu-central-1:
ami: ami-05d34d340fb1d89e5
us-east-1:
ami: ami-0ed9277fb7eb570c9
us-east-2:
ami: ami-002068ed284fb165b
us-west-1:
ami: ami-03af6a70ccd8cb578
us-west-2:
ami: ami-00f7e5c52c0f43726
在云形成中使用映射
以下 CloudFormation 模板演示了如何使用脚本生成的映射:
Mappings:
RegionMap:
eu-north-1:
ami: ami-06bfd6343550d4a29
ap-south-1:
ami: ami-052cef05d01020f1d
eu-west-3:
ami: ami-0d3c032f5934e1b41
eu-west-2:
ami: ami-0d37e07bd4ff37148
eu-west-1:
ami: ami-04dd4500af104442f
ap-northeast-3:
ami: ami-0f1ffb565070e6947
ap-northeast-2:
ami: ami-0eb14fe5735c13eb5
ap-northeast-1:
ami: ami-0218d08a1f9dac831
sa-east-1:
ami: ami-0056d4296b1120bc3
ca-central-1:
ami: ami-0bae7412735610274
ap-southeast-1:
ami: ami-0dc5785603ad4ff54
ap-southeast-2:
ami: ami-0bd2230cfb28832f7
eu-central-1:
ami: ami-05d34d340fb1d89e5
us-east-1:
ami: ami-0ed9277fb7eb570c9
us-east-2:
ami: ami-002068ed284fb165b
us-west-1:
ami: ami-03af6a70ccd8cb578
us-west-2:
ami: ami-00f7e5c52c0f43726
Resources:
myEC2Instance:
Type: "AWS::EC2::Instance"
Properties:
ImageId: !FindInMap
- RegionMap
- !Ref 'AWS::Region'
- ami
InstanceType: m1.small
查找 AMI 名称
您会从上面的命令中注意到,AMI 名称必须作为参数传递。然而,AWS 控制台通常会显示 AMI 描述,这对用户更友好。那么,如何从 AMI ID 或描述中找到名字呢?
一个简单的解决方案是在 EC2 控制台中打开图像链接。这允许通过其 ID 或描述来搜索公共 AMI,然后 AMI 详细信息页面显示 AMI 名称:

使用参数存储
允许 CloudFormation 模板自动引用最新的 Amazon AMIs 的另一个选项是查询 AWS Systems Manager 参数存储。博客使用 AWS 系统管理器参数存储查询最新的 Amazon Linux AMI id演示了如何使用如下所示的模板引用最新的 Amazon Windows 和 Linux AMI:
Parameters:
LatestAmiId:
Type: 'AWS::SSM::Parameter::Value<AWS::EC2::Image::Id>'
Default: '/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2'
Resources:
Instance:
Type: 'AWS::EC2::Instance'
Properties:
ImageId: !Ref LatestAmiId
结论
用最新的 AMI IDs 保持您的 CloudFormation 模板的更新是一个持续的挑战。因为每个地区都有唯一的 AMI IDs,所以情况更加复杂。
在本文中,您了解了如何使用区域 AMI IDs 生成最新的映射,以便复制并粘贴到您的 CloudFormation 模板中。
查看我们的关于云形成模板的其他帖子。
阅读我们的 Runbooks 系列的其余部分。
愉快的部署!
章鱼圣诞颂歌-章鱼展开
2022 年即将结束。当章鱼团队的大部分人准备休息时(不要担心,如果你需要,我们仍然可以提供帮助),我们想喘口气,反思一下。
因此,*‘进来吧,进来吧,更好地了解我们’*当我们与过去、现在和未来的部署幽灵一起旅行。
我们保证他们比拜访史克鲁奇的人要好得多。
过去的部署
在我们看 2022 年的章鱼之前,让我们花点时间看看 2021 年我们从哪里停下来的。
2021 年对章鱼来说是巨大的一年,有很多里程碑。我们:
- 我们的团队从 77 人发展到 179 人
- 宣布来自 Insight Partners 的项投资
- 我们的收入增长了 60%
- 通过了我们的第一次财务审计
- 在早期访问预览版中推出了新功能,如配置为代码和 Amazon ECS 支持
- 在布里斯班南岸开设了我们的新办公室。随便看看!
部署完毕
2022 年对章鱼来说也是非凡的一年。下面我们来探讨一些值得注意的亮点。
我们如何改进章鱼
2022 年,我们推出了一系列新功能,为您的部署节省时间和精力。此外,我们为您使用的服务创建了更多集成。
我们开发了易于使用的工具,帮助您构建部署管道。
我们的主页有了新的外观
虽然我们仍在进行调整,还会有更多的改进,但我们更新了 octopus.com。
它不仅看起来很棒(如果我们自己这么说的话),它更好地解释了 Octopus Deploy 解决的问题以及它如何帮助您更快地交付软件。
我们宣布了我们的第一笔收购
在二月份,我们收购了 Dist——一个云容器和工件存储服务。
此次收购有助于我们更好地完善 Octopus 的云功能和支持。
由于我们的 ISO 27001 认证,八达通比以往任何时候都更安全
Octopus 一直非常重视安全性,但我们知道我们的客户不能只相信我们的话。我们的信任团队 2022 年的目标是获得 ISO 27001 认证,这是信息安全管理领域最著名的标准。
为此,我们的团队:
- 设置许多新的安全审计和审查功能
- 更新了我们的安全政策和培训
- 确保我们的文档在开发生命周期的每一步都与我们的行动相匹配
辛勤的工作在 2022 年末得到了回报,我们成功通过了审核,并获得了 ISO 27001 官方认证。我们希望这一认证能让您安心。
证书将很快在我们的网站上下载,但我们的旅程并没有就此结束。我们的目标是在 2023 年增加我们的安全资格,所以敬请关注新的发展。
我们发布了 DevOps 工程师手册
DevOps 可能会令人困惑,因此我们创建了 DevOps 工程师手册来帮助其他人了解其流程和理念。
首先,我们非常关注我们的专业主题——连续交付——但是手册将会扩展和发展。
另外,如果你正在寻找 DevOps 书籍推荐,请查看我们的互动阅读列表。
我们有一个创纪录的季度
我们将在高潮中结束 2022 年!第四季度是完成业务的创纪录季度。
我们期待以此为基础,帮助更多的组织更快、更可靠地交付软件。
2022 年统计
最后,这里有一些关于章鱼一年的有趣数据(在我写这篇文章的时候):
- 我们的客户完成了超过 36,479,186 次部署
- 我们有超过 9080 个新的试验
- 我们的团队增加了 61 人,达到 240 人
- 我们的博客有 673,058 次浏览量——如何在 Docker 上安装 Jenkins是我们最受欢迎的帖子,有 33,392 次浏览量
- Octopus 服务器进行了以下代码更改:
- 更改了 18,062 个文件
- 增加了 649,364 行
- 删除 361,422 行
- 修改了 63,987 行
即将进行部署
我们一直在努力改进 Octopus,那么我们的未来会怎样呢?目前,我们正致力于:
- 动态环境支持——轻松提供测试新功能分支、集成等的基础设施。
- Octopus Runbooks 的 Config as 代码——在您的 Git 存储库中查看和管理您的 runbook 流程,就像您已经可以使用您的部署流程一样。
- Octopus CLI vNext -我们正在添加新的功能,比如一个易于使用的交互模式。
关注我们的路线图了解关于这些特性的更多信息,并发现即将推出的其他产品。
各位,部署愉快!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}