







 本文详细介绍如何使用YoloV5模型进行图像数据的采集、标记与处理,涵盖模型训练、转化及集成到安卓应用的全过程。特别关注轻量级模型的选择与集成,适用于手机摄像头实时检测。
本文详细介绍如何使用YoloV5模型进行图像数据的采集、标记与处理,涵盖模型训练、转化及集成到安卓应用的全过程。特别关注轻量级模型的选择与集成,适用于手机摄像头实时检测。
前言
最近接到一个项目,希望使用手机摄像头对图像数据进行采集,并使用训练好的模型对图像数据进行检测,主要任务包括:
- 寻找一个轻量的检测模型,以方便集成到安卓应用中
- 使用自己的检测数据集对模型进行训练
- 探索模型集成到安卓应用中的方式
由于需要轻量模型,这里很自然的想到最近比较热的yolov5s模型。兔丁哥由于刚刚接触深度学习,比较喜欢简单容易上手的pytorch,而yolov5正好有pytorch版。但众所周知的是,pytorch在集成上并不如tensorflow方便高效,这也导致了pytorch在工业界不如tensorflow,这次项目让我对这一块深有体会。接下来我会从数据采集和处理,模型训练,模型导出,安卓集成等方面来介绍这个项目,由于内容比较多,将分成三篇文章对该项目进行讲解,分别是:
- 【Yolov5】训练自己的yolov5模型并集成到安卓应用中【上】——模型训练
- 【Yolov5】训练自己的yolov5模型并集成到安卓应用中【中】——模型转化
- 【Yolov5】训练自己的yolov5模型并集成到安卓应用中【下】——模型集成
数据采集和处理
采集
由于项目中的数据集包括一些涉密数据,因此本文以检测车辆为例来介绍项目。
首先使用自己的摄像设备到大街上,停车场上采集数据(当然也可以爬取或使用网上的公开数据集),这里就直接下载汽车数据集了,展示如下:

标记
这里使用labelImg来对图像进行标记,官方文档对安装和使用进行了详细的说明,本文在Windows + Anaconda中使用,因此安装过程如下:
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
# or
# python labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
打开后展示如下界面:
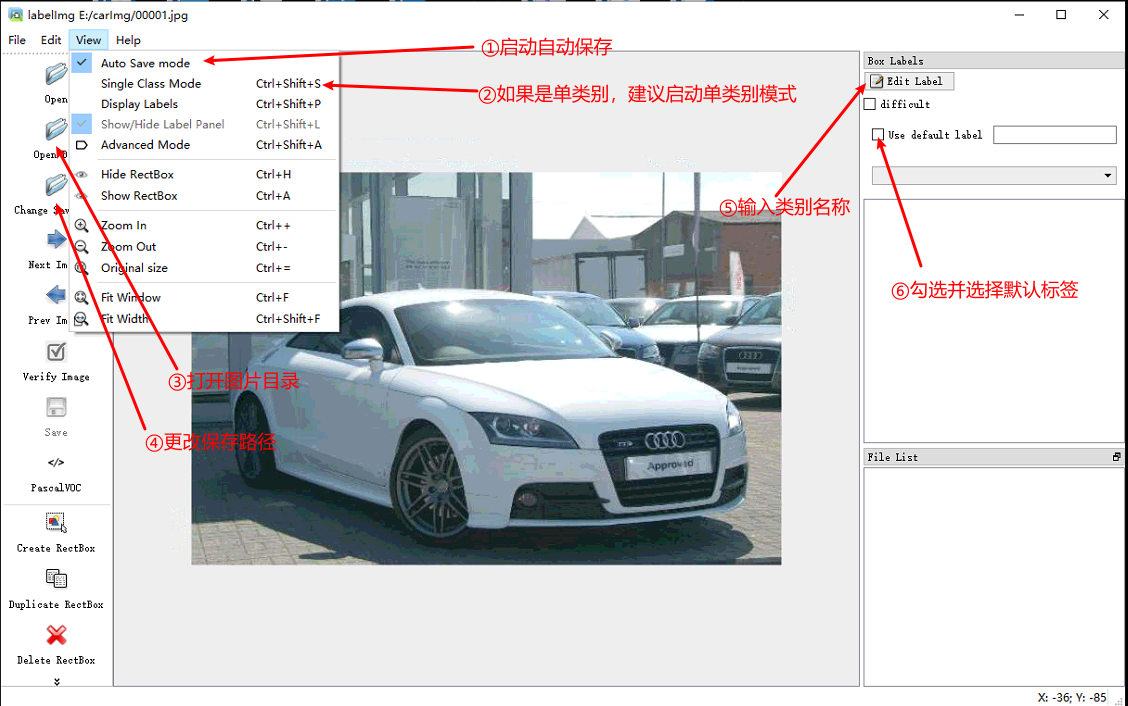
按照图片中的指示设置后,可以左手按w启动标记,右手鼠标画框标记,左手按d保存并切换至下一张图片。
标记是个大工程,突然来了灵感,能不能在这种标记软件上集成现成的或者想训练的模型,边标记边训练,边训练边由模型标记下一张图片,然后手工调整模型标记结果,再训练,再模型标记,再调整……随着训练的进行,准确率的提高,将极大减少调整过程,这样不仅提高了标记速度,在标记完成后模型也训练好了,一举两得。先记下灵感,以后有能力了再和小伙伴慢慢实现。
处理
标记完成后,会生成xml文件如下所示:
<annotation>
<folder>tagImage</folder>
<filename>00001.jpg</filename>
<path>E:\tagImage\00001.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>33</width>
<height>33</height>
<depth>1</depth>
</size>
<segmented>0</segmented>
<object>
<name>CAR</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>3</xmin>
<ymin>3</ymin>
<xmax>30</xmax>
<ymax>30</ymax>
</bndbox>
</object>
</annotation>
为了能在yolov5中训练,还需要对标记结果进行处理,假设图片存储在images目录中,XML存储在tagXml,这里使用python类的形式对数据进行了处理,处理过程包括:
- 检测是否存在漏标记的异常数据
- 读取XML,并完成坐标转化
- 将转化的坐标写入标记文件txt中
- 拆分训练集和测试集
- 保存处理结果到文件中
首先先导入必要的包
import os
import sys
import random
import xml.etree.ElementTree as ET
import matplotlib.image as mp
读取XML文件
ReadXML类用于读取xml文件,并提取图片尺寸信息及图片中的标记(方框及类别)。由于图片中的标记可能存在多个,所以返回的是list。
class ReadXML():
def __init__(self, filename):
self.filename = filename
with open(self.filename,'rb') as xmlfile:
tree = ET.parse(xmlfile)
root = tree.getroot()
size = root.find('size')
self.imageSize = ( int(size.find('width').text), int(size.find('height').text) )
self.objs = []
for obj in root.iter("object"):
cls = obj.find('name').text
if cls not in classes:
continue
classID = classes.index(cls)
bndbox = obj.find('bndbox')
boxCoor = ( float(bndbox.find('xmin').text), float(bndbox.find('xmax').text), float(bndbox.find('ymin').text), float(bndbox.find('ymax').text) )
self.objs.append({'classID': classID, 'boxCoor' : boxCoor})
def getImageSize(self):
return self.imageSize
def getObjs(self):
return self.objs
坐标转化
XML标记文件中的方框信息取的是左上角的坐标(x1,y1),和右小角的坐标(x2, y2),而yolov5需要的坐标表示形式为方框中心点坐标与原图片的占比(x, y)和方框的宽度w和高度h与原图片的占比,convert函数实现了此功能:
def convert(imageSize, boxCoor):
x = (boxCoor[0] + boxCoor[1]) / 2.0 / imageSize[0]
y = (boxCoor[2] + boxCoor[3]) / 2.0 / imageSize[1]
w = (boxCoor[1] - boxCoor[0]) * 1.0 / imageSize[0]
h = (boxCoor[3] - boxCoor[2]) * 1.0 / imageSize[1]
return x, y, w, h
检测异常数据
DataSet类用来对数据集进行处理,其中getOutliers用来检测异常数据,getDatas返回正确的数据集(即既有图片又有XML标签文件的数据):
class DataSet():
def __init__(self, imagePath, xmlPath):
self.train, self.val, self.text = None, None, None
self.imagePath = imagePath
self.xmlPath = xmlPath
imageFiles = os.listdir(self.imagePath)
self.imageData = [name.split(".")[0] for name in imageFiles if name.endswith("jpg") or name.endswith("jpeg")]
xmlFiles = os.listdir(self.xmlPath)
self.xmlData = [name.split(".")[0] for name in xmlFiles if name.endswith("xml")]
self.dataSet = [data for data in self.imageData if data in self.xmlData]
def getDatas(self):
return self.dataSet
def getOutliers(self):
return {"NoXML":[data for data in self.imageData if data not in self.xmlData], "NoImage": [data for data in self.xmlData if data not in self.imageData]}
# ......省略部分内容......
生成txt标记文件
DataSet类的writeAnnotationsToFile函数在调用convert进行坐标转化后,将生成可供yolov5训练的txt标记文件
class DataSet():
# ......省略部分内容......
def writeAnnotationsToFile(self, pathname):
pbar = ProgressBar(50)
total = len(self.dataSet)
count = 0
for data in self.dataSet:
xml = ReadXML(os.path.join(self.xmlPath, data + '.xml'))
with open(os.path.join(pathname, data + '.txt'), 'w') as annFile:
imageSize = xml.getImageSize()
objs = xml.getObjs()
for obj in objs:
x, y, w, h = convert(imageSize, obj['boxCoor'])
cid = obj['classID']
annFile.write(str(cid) + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + " \n")
count += 1
pbar.log(count/total, data + '.xml')
# ......省略部分内容......
拆分数据集
DataSet类的splitSet函数用于拆分数据集,其中trainval_per表示训练和验证集占整体数据集的比例,剩余的为测试集,train_per为训练集占训练和验证集的比例,可以根据情况自行调整。__writeSetToFile用于将拆分的数据集写入文件中,方便查看,并且可以指定是否需要后缀名,及是否需要图片路径。
class DataSet():
# ......省略部分内容......
def splitSet(self, trainval_per = 0.8, train_per = 0.8):
total = len(self.dataSet)
trainval_total = int(trainval_per * total)
train_total = int(train_per * trainval_total)
trainval_temp = random.sample(self.dataSet, trainval_total)
train_temp = random.sample(trainval_temp, train_total)
self.trainval = [data for data in self.dataSet if data in trainval_temp]
self.train = [data for data in self.trainval if data in train_temp]
self.val = [data for data in self.trainval if data not in self.train]
self.text = [data for data in self.dataSet if data not in self.trainval]
return self.train, self.val, self.text
# 省略各种get方法
def __writeSetToFile(self, datas, filename, suffix = False, path = False):
with open(filename, 'w') as outfile:
if path:
for data in datas:
if os.path.exists(os.path.join(self.imagePath, data + ".jpg")):
outfile.write(self.imagePath + '/' + data + ".jpg\n")
elif os.path.exists(os.path.join(self.imagePath, data + ".jpeg")):
outfile.write(self.imagePath + '/' + data + ".jpeg\n")
elif suffix:
for data in datas:
if os.path.exists(os.path.join(self.imagePath, data + ".jpg")):
outfile.write(data + ".jpg\n")
elif os.path.exists(os.path.join(self.imagePath, data + ".jpeg")):
outfile.write( data + ".jpeg\n")
else:
for data in datas:
outfile.write(data + '\n')
def writeTrainToFile(self, filename, suffix = False, path = False):
self.__writeSetToFile(self.train, filename, suffix, path)
def writeValToFile(self, filename, suffix = False, path = False):
self.__writeSetToFile(self.val, filename, suffix, path)
def writeTrainValToFile(self, filename, suffix = False, path = False):
self.__writeSetToFile(self.trainval, filename, suffix, path)
def writeTextToFile(self, filename, suffix = False, path = False):
self.__writeSetToFile(self.text, filename, suffix, path)
def writeAllToFile(self, filename, suffix = False, path = False):
self.__writeSetToFile(self.dataSet, filename, suffix, path)
def writeSetToFile(self, pathname, suffix = False, path = False):
self.writeAllToFile(os.path.join(pathname, 'all.txt'), suffix, path)
self.writeTextToFile(os.path.join(pathname, 'test.txt'), suffix, path)
self.writeValToFile(os.path.join(pathname, 'val.txt'), suffix, path)
self.writeTrainToFile(os.path.join(pathname, 'train.txt'), suffix, path)
self.writeTrainValToFile(os.path.join(pathname, 'trainval.txt'), suffix, path)
处理入口
之后调用上诉函数对数据集进行处理。
if __name__ == "__main__":
datas = DataSet("E:/data/images","E:/data/tagXml")
print(datas.getOutliers())
train, val, text = datas.splitSet(0.8, 0.8)
# print(len(train), len(val), len(text))
datas.writeSetToFile("E:/data", True, True)
datas.writeAnnotationsToFile("E:/data/labels")
注意:建议将图片存放在images目录中,生成的txt标记存放在labels目录中,因为yolov5在训练使并不需要指定标签目录,只需指定图片目录即可,yolov5将在图片的当前目录下寻找同名的txt标记文件,或将路径中的images简单替换为labels目录,并在其目录下寻找同名txt标记文件。
模型训练
下载yolov5,并用自己喜欢IDE打开yolov5目录,将上诉images文件夹、labels文件夹、以及生成的训练集train.txt、验证集val.txt、测试集test.txt放在data目录下。兔丁哥对VSCode情有独钟,其文件目录如下所示:

安装依赖包
官方给的安装依赖包的方式是pip install -qr yolov5/requirements.txt,但我对conda情有独钟,打开requirements.txt文件,看到官方也提供了conda安装依赖包的方式
# Conda commands (in place of pip) ---------------------------------------------
# conda update -yn base -c defaults conda
# conda install -yc anaconda numpy opencv matplotlib tqdm pillow ipython
# conda install -yc conda-forge scikit-image pycocotools tensorboard
# conda install -yc spyder-ide spyder-line-profiler
# conda install -yc pytorch pytorch torchvision
# conda install -yc conda-forge protobuf numpy && pip install onnx==1.6.0 # https://github.com/onnx/onnx#linux-and-macos
其实只需安装几个重要的包即可:numpy, opencv, matplotlib, tqdm, pillow, ipython, scikit-image, tensorboard, pytorch, torchvision, protobuf。
更改配置文件
在data目录下新建一个car.yaml文件,参照coco.yaml写入自己的数据集目录,及类别信息,如下所示:
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: data\\train.txt
val: data\\val.txt
test: data\\test.txt
# number of classes
nc: 1
# class names
names: ['car']
打开models/yolov5s.yaml,更改nc为自己的类别数,如下:
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# ......省略后面其他内容......
下载Yolov5权重文件
虽然训练的时候会自动下载,但由于是外网数据,下载极其缓慢,因此可以使用一切下载工具到tutorial.ipynb中提到的Google Drive进行下载,并存放在models目录下,本文下载的是yolov5s.pt文件。
模型训练
虽然tutorial.ipynb中使用如下命令对模型进行训练:
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --nosave --cache
但我更喜欢直接在train.py文件中进行修改,在文件末尾找到主入口if __name__ == '__main__':,修改如下:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='models/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path') # 存储模型结构的配置文件
parser.add_argument('--data', type=str, default='data/car.yaml', help='data.yaml path') # 存储训练、测试数据的文件
parser.add_argument('--hyp', type=str, default='', help='hyperparameters path, i.e. data/hyp.scratch.yaml')
parser.add_argument('--epochs', type=int, default=30) # 指的就是训练过程中整个数据集将被迭代多少次
parser.add_argument('--batch-size', type=int, default=5, help='total batch size for all GPUs') # 一次看完多少张图片才进行权重更新,梯度下降的mini-batch,
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes') # 输入图片宽高
parser.add_argument('--rect', action='store_true', help='rectangular training') # 进行矩形训练
parser.add_argument('--resume', nargs='?', const='get_last', default=False,
help='resume from given path/last.pt, or most recent run if blank') # 恢复最近保存的模型开始训练
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') # 仅保存最终checkpoint
parser.add_argument('--notest', action='store_true', help='only test final epoch') # 仅测试最后的epoch
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters') # 进化超参数
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket') # gsutil bucket
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training') # 缓存图像以加快训练速度
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied') # 重命名results.txt to results_name.txt
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # cuda device, i.e. 0 or 0,1,2,3 or cpu
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') # 多尺度训练,img-size +/- 50%
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset') # 单类别的训练集
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer') # 使用adam优化
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--logdir', type=str, default='runs/', help='logging directory')
这里主要修改了
| 参数 | default值 | 备注 |
|---|---|---|
| –weights | models/yolov5s.pt | 权重文件 |
| –cfg | models/yolov5s.yaml | 存储模型结构的配置文件 |
| –data | data/car.yaml | 存储训练、测试数据的文件 |
| –epochs | 30 | 训练过程中整个数据集的迭代次数 |
| –batch-size | 5 | 处理多少张图片后再进行权重更新 |
| –img-size | [640, 640] | 输入图片的宽和高 |
--epochs、--batch-size、--img-size可能需要根据自己电脑的配置来缩小,否则可能造成训练时间过长,显存溢出的问题。如果提示显存溢出,缩小--batch-size的值即可。
之后便可以在控制台输入以下命令进行训练了:
python train.py
在训练过程中,还可以输入以下命令打开tensorboard可视化训练过程
tensorboard --logdir runs
根据提示在浏览器上打开http://localhost:6006/即可查看,如下图所示:

模型检测
模型训练好后将在runs目录下生成训练过程和结果文件,其中runs\exp0\weights中存放着模型训练好的权重文件,此时就可以使用该权重文件进行检测。将需要检测的图片存放在data/tests/中,打开detect.py文件,在文件末尾找到主入口if __name__ == '__main__':,修改如下:
| 参数 | default值 | 备注 |
|---|---|---|
| –weights | runs\exp0\weights\best.pt | 权重文件 |
| –source | data/test | 存储需要检测的图片 |
| –output | data/output | 存储检测的结果 |
| –img-size | 640 | 输入图片的宽和高 |
然后在控制台输入以下命令进行检测了:
python detect.py
之后就可以在data/output目录下查看检测的结果了。
总结
通过这次项目,感觉Yolov5的检测能力还是挺强的,准确度和速度都比较高,而且官方文档从训练到检测都写得很清楚,想训练自己的模型是非常容易的。由于兔丁哥并没有真正使用车辆数据再跑一次模型,因此文中图片较少,但主要的细节都已经记录下来,如有问题,欢迎留言讨论。接下来我将使用TorchScrip对模型进行转化,敬请期待。。。


















 2398
2398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









