








1、引言
YOLOv11是YOLO系列的最新版本,建立在YOLOv1所奠定的基础上。在YOLO视觉2024(YV24)大会上发布,YOLOv11在实时物体检测技术方面实现了重大飞跃。这一新版本在架构和训练方法上都进行了大幅改进,推动了精度、速度和效率的边界。
YOLOv11的创新设计结合了先进的特征提取技术,允许捕捉更细微的细节,同时保持精简的参数计数。YOLOv11在保证检测效果的同时,处理速度上也取得了显著的提升,大大增强了实时性能。
2、YOLO模型的演变
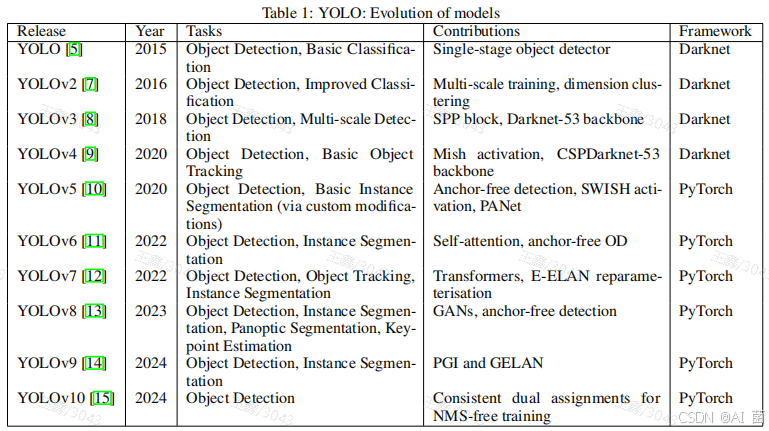
表1展示了YOLO模型从最初版本到最新版本的进展。每次迭代都带来了目标检测能力、计算效率和处理各种CV任务的通用性的显著改进。YOLO系列详细改进历程请见:YOLO系列算法精讲:从yolov1至yolov8的进阶之路
最新版本YOLO11在此基础上进一步提升了特征提取、效率和多任务处理能力。本文将深入探讨YOLO11的架构创新,包括其改进的主干和颈部结构,以及在目标检测、实例分割和姿态估计等各类计算机视觉任务中的表现。
3、YOLOv11模型架构
YOLO架构的核心由三个基本组件构成:
- 主干网络:作为主要特征提取器,利用卷积神经网络将原始图像数据转换为多尺度特征图
- 颈部组件:充当中间处理阶段,采用专门的层来聚合和增强不同尺度上的特征表示。
- 头部组件:作为预测机制,根据精炼后的特征图生成最终的对象定位和分类输出。
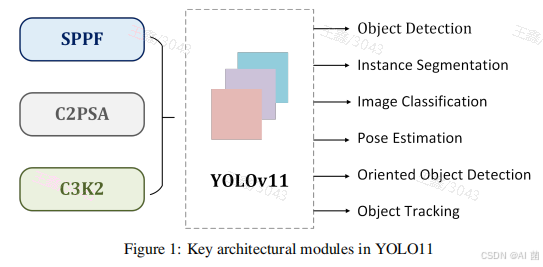
YOLO11 在 YOLOv8 的基础上,引入架构创新和参数优化,以实现如图所示的卓越检测性能。下面将详细介绍关键的架构修改:
3.1 主干网络
骨干网络是YOLO架构的关键组成部分,负责从输入图像中提取多尺度特征。该过程包括堆叠卷积层和专用模块,以生成不同分辨率的特征图。
1)卷积层
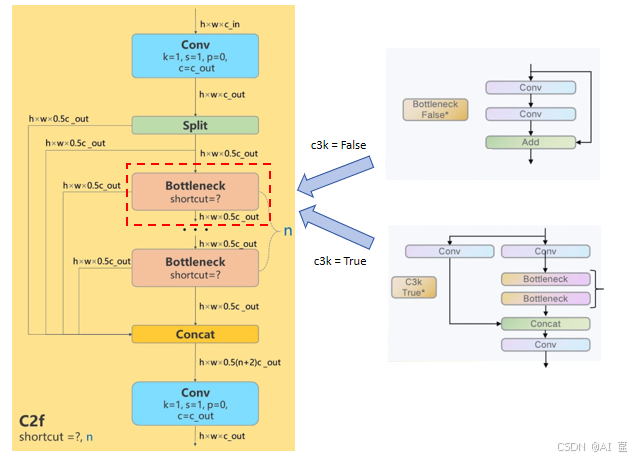
YOLOv11的一个重要改进是引入了C3k2模块,取代了之前版本中使用的C2f模块。C3k2模块是跨阶段部分(CSP)瓶颈的更高效的计算实现。它采用了两个较小的卷积,而不是像YOLOv8那样使用一个大的卷积。“k2”在C3k2中表示较小的内核尺寸,这有助于加快处理速度,同时保持性能。
2)SPPF and C2PSA
YOLO11保留了前一版本中的空间金字塔池化-快速(SPPF)模块,但在其后引入了一个新的跨阶段部分带空间注意力(C2PSA)模块,C2PSA 有助于增强特征图中的空间注意力。这种空间注意力机制使模型能够更有效地聚焦于图像中的重要区域。通过空间池化特征,C2PSA模块使YOLO11能够集中于特定的兴趣区域,从而可能提高对不同大小和位置的物体的检测精度。
3.2 颈部
颈部结合不同尺度的特征并将其传递到头部进行预测,该过程通常包括上采样和连接来自不同层级的特征图,使模型能够有效地捕捉多尺度信息。
1)C3k2 Block
YOLO11引入了一项重大变革,即用C3k2模块替换了颈部的C2f模块。C3k2模块设计得更快、更高效,从而提升了特征聚合过程的整体性能。经过上采样和拼接后,YOLO11的颈部采用了这一改进模块,从而实现了速度和性能的提升。
2)注意力机制
YOLO11的一个显著改进是通过C2PSA模块增加了对空间注意力的关注。这种注意力机制使模型能够集中于图像中的关键区域,从而可能实现更准确的检测,特别是对于较小或部分遮挡的对象。C2PSA的加入使得YOLO11与其前身YOLOv8区别开来,后者缺乏这一特定的注意力机制。
3.3 头部
YOLOv11的头部负责生成最终的物体检测和分类预测结果。它处理从颈部传递过来的特征图,最终输出图像中物体的边界框和类别标签。
1)C3k2 Block
在头部部分,YOLOv11利用多个C3k2模块高效地处理和优化特征图。C3k2模块分布在头部的几条路径中,用于在不同深度处理多尺度特征。C3k2模块根据c3k参数的值表现出灵活性。
- 当c3k = False时,C3k2模块的行为类似于C2f模块,利用标准的瓶颈结构。
- 当c3k = True时,瓶颈结构被C3模块取代,允许进行更深入和更复杂的特征提取。
C3k2模块的主要特征:
- 更快的处理:使用两个较小的卷积相比单个大的卷积减少了计算开销,从而加快了特征提取。
- 参数效率:C3k2是CSP瓶颈的一个更紧凑的版本,使得架构在可训练参数数量方面更加高效。
2)CBS Blocks
YOLOv11的头部在C3k2块之后包含几个CBS层(卷积-批量标准化-Silu激活函数),这些层通过以下方式进一步细化特征图:
- 提取相关特征以实现精确的目标检测。
- 通过批量归一化稳定和标准化数据流。
- 利用Sigmoid线性单元(SiLU)激活函数进行非线性处理,提高模型性能。
3.4 最终卷积层和检测层
每个检测分支以一组Conv2D层结束,该层将特征减少到用于边界框坐标和类别预测的所需输出数量。最终的Detect层整合这些预测,其中包括:
- 用于定位图像中对象的边界框坐标。
- 表示目标存在的置信度分数。
- 用于确定检测到的目标类别的类别分数。
4、模型效果对比
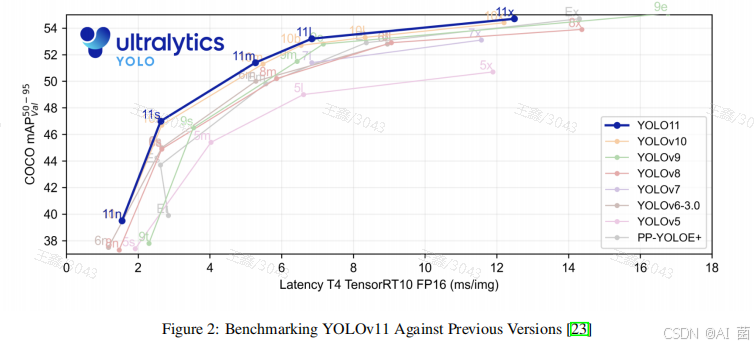
图2所示的性能对比图表揭示了几个关键见解。YOLOv11变体(11n、11s、11m和11x)形成了独特的性能前沿,每个模型在其各自的延迟点上都达到了更高的COCO mAP50−95分数。值得注意的是:
- YOLOv11x在13 ms耗时达到了约54.5%的mAP50−95,超越了所有之前的YOLO版本。
- 其中间变体(特别是YOLOv11m),通过显著减少处理时间,实现了与前几代大型模型相当的精度,表现出卓越的效率。
- 在低耗时区域(2-6 ms)中,YOLOv11的性能有了显著提升。在此区域内,YOLOv11保持了较高的精度(大约47%mAP50−95),同时运行速度与之前精度较低的模型相当。
5、总结
YOLOv11全文总结如下:
- 结构上的创新:引入了如C3k2模块、SPPF和C2PSA等新元素,增强了其特征提取和处理能力。这些改进使得模型能够更好地分析和解释复杂的视觉信息,在各种场景中可能提高检测精度。
- 增强了注意力机制:集成了复杂的空域注意力机制,特别是C2PSA组件。使模型能够更有效地聚焦图像中的关键区域,增强了其检测和分析物体的能力。改进的注意力能力对于识别复杂或部分遮挡的物体尤为有利,解决了物体检测任务中常见的难题。
- 多功能模型:YOLO11的多功能性超越了物体检测,包括实例分割、图像分类、姿态估计和定向物体检测等任务。这种多方面的方法使YOLO11成为解决各种CV挑战的全面解决方案。
- 效率和可扩展性:YOLO11推出了从纳米级到超大型的一系列模型尺寸,满足了各种应用需求。这种可扩展性使得它能够在从资源受限的边缘设备到高性能计算环境的各种场景中部署。特别是纳米级版本,在速度和效率方面相比前代产品有了显著提升,非常适合实时应用。


















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











