










这段代码导入了Image模块,并使用Image模块的filename参数加载并显示了一张图片。
目录
# 导入Image模块
from IPython.display import Image
# 加载并显示图片
# 图片来源:https://unsplash.com/photos/iUfusOthmgQ
Image(filename='iUfusOthmgQ.jpg')
图片的来源是https://unsplash.com/photos/iUfusOthmgQ。
```python
# 导入绘图库matplotlib和数据可视化库seaborn
from matplotlib import pyplot as plt
import seaborn as sns
介绍 - 数据的规模很重要
越来越深入地涉足机器学习,我越来越确信,在数据预处理期间深入理解我们正在做什么对结果有很大影响。
数据转换是数据处理的基本步骤之一。标准化或归一化变量的主要原因是将特征带到相同的尺度上,使它们可比较。我们的数据集通常包含具有不同数量级、单位和范围的特征。使用原始尺度可能会给具有大范围的变量带来更多的权重,这是非常不可取的。
期望的结果:
- 数值特征被缩放到标准范围;
- 缩放过程允许算法给变量分配相等的权重。
- 标准化(或Z-score归一化)的结果是将特征重新缩放,以确保均值为0,标准差为1。标准化没有范围限制;
- 归一化(使用MinMaxScaler)的结果始终在[0,1]或[-1,1]的范围内,如果存在负值。
1.1 重要问题
缩放变量的过程中,我将尝试回答以下所有重要问题:
- StandardScaler是否真的假设高斯分布,以及这会带来什么后果?
- 对于非正态分布的变量,标准化是否有效?
- 标准化和归一化过程的缺点和常见误解是什么?
- 哪种技术更好?我应该进行归一化还是标准化?
- RobustScaler是否真的稳健,并且总是最佳选择?
1.2 特征缩放与不同的机器学习算法
特征缩放对于所有机器学习算法的影响不同。其中一些算法对特征缩放敏感,而其他算法则不敏感。
- 梯度下降算法
使用梯度下降作为优化技术的机器学习算法,如线性回归、逻辑回归、神经网络等,需要对数据进行缩放。
- 基于距离的算法
KNN、K-means和SVM等距离算法最受特征范围的影响。这是因为它们使用数据点之间的距离来确定它们的相似性。
- 基于树的算法对特征的缩放更具鲁棒性。
在执行**主成分分析(PCA)**时,缩放是至关重要的。PCA试图获取具有最大方差的特征,而高幅度特征的方差较高。这会使PCA偏向于高幅度特征。
1.3 在训练测试分离之前还是之后进行归一化/标准化?
我们永远不应忘记测试数据集代表着真实世界的数据。因此,在分割数据之后,始终要进行归一化或标准化。如果在分割之前进行标准化(即对整个数据集取均值和方差),将会将未来的信息引入训练解释变量(即均值和方差)。
1.4 是否有必要对目标值进行缩放?
在回归建模中,对目标值进行缩放是一个好主意。数据的缩放使模型更容易学习和理解问题。
“反过来,具有大范围值的目标变量可能导致大的误差梯度值,从而导致权重值发生剧烈变化,使学习过程不稳定。”
— 《神经网络模式识别》第298页,1995年。
1.5 在进行缩放之前,我们应该删除异常值吗?
包括异常值在数据驱动模型中可能存在风险。一个极端的、具有误导性的值的存在有可能改变模型所暗示的结论。因此,管理这种风险非常重要。
那么是删除还是不删除呢?
这取决于情况。特别是当数据集极度不平衡时,删除异常值可能是非常不可取的,因为这样做可能会丢失重要的数据。
在删除异常值之后,我们应该始终检查我们所做的事情。有时候我们肯定应该保留数据集中的异常值。
看一下这个笔记本:
通过删除异常值,我们在这种情况下丢失了大约40% 非常重要的数据! **我们不应该这样做! **
当数据平衡时,我们应考虑删除异常值。
请查看此笔记本以获取有关处理异常值的**更多信息**:异常值检测方法!
1.6 最佳实践
- 在特征具有差异很大的尺度时,通常不建议在机器学习模型上进行训练。
- 在缩放数据之前,考虑删除异常值,但在数据高度不平衡时要非常小心。
- 一些机器学习算法对特征缩放敏感(梯度下降、基于距离的算法),而其他算法则不敏感(基于树的算法)。
- 在拆分数据之后始终进行归一化或标准化(当然,您还需要对测试数据应用归一化/标准化)。
- StandardScaler、MinMaxScaler和RobustScaler不会影响数据分布(算法不强制要求正态分布)。
- 归一化对异常值处理不好(MinMax Scaler将数据缩小到给定范围内,这将影响算法为特征分配适当权重的能力)。
- 当上下边界在领域知识中非常明确时,可以使用MinMaxScaler。
- 标准化可以更好地处理异常值,并更好地促进特征的收敛(这对于梯度下降和基于距离的算法很重要)。
- StandardScaler对异常值也敏感(比MinMaxScaler更少,但仍然敏感)。均值和标准差受异常值的影响很大,因此距离(以标准差衡量)也受异常值的影响-算法将大部分数据缩放到一个小区间。
- RobustScaler的结果不会受到异常值的影响,其传播代表真实距离。
- RobustScaler有意排除某些数据可能会限制用于进行预测的总体信息量,从而降低结果的置信度。
- 在我看来,标准化非正态分布不会出现任何问题。
- 您始终可以将模型拟合到原始、归一化和标准化的数据上,并比较性能以获得最佳结果。
我通常更喜欢标准化而不是归一化。
如果满足以下条件,我会使用StandardScaler:
- 我决定删除异常值或数据集中不存在异常值;
- 当数据不是非常高度偏斜时。
在相反的情况下,我会使用RobustScaler,并且只在非常特殊的情况下使用MinMaxScaler。
设置
2.1 导入库
```python # 导入所需的库 import numpy as np import pandas as pd import seaborn as sns import plotly.express as px import tkinter from matplotlib import pyplot as plt from sklearn.model_selection import cross_val_score from collections import Counter # 这段代码没有需要添加的内容,只是导入了一些库供后续使用<a id="2.2"></a> ## <b>2.2 <span style='color:#E1B12D'>导入数据</span></b> ```python # 尝试从指定路径读取csv文件,如果路径不存在则捕获异常 try: raw_df = pd.read_csv('/kaggle/input/telco-customer-churn/WA_Fn-UseC_-Telco-Customer-Churn.csv') # 如果路径不存在,则从另一个路径读取csv文件 except: raw_df = pd.read_csv('telco.csv')2.3 数据集特征
每一行代表一个客户,每一列包含在列元数据中描述的客户属性。
数据集包括以下信息:
- 最近一个月内离开的客户 - 列名为Churn。
- 每个客户注册的服务 - 电话、多线路、互联网、在线安全、在线备份、设备保护、技术支持以及流媒体电视和电影。
- 客户账户信息 - 他们成为客户的时间、合同、付款方式、无纸化账单、每月费用和总费用。
- 关于客户的人口统计信息 - 性别、年龄范围以及是否有伴侣和受抚养人。
数据集中没有缺失值。
# 定义颜色调色板,用于绘制图表 palette = ['#008080','#FF6347', '#E50000', '#D2691E']3 | 数据预处理
我们不需要一个customerID列,所以我将删除它。
# 从原始数据框中删除'customerID'列,并将结果赋值给df变量 df = raw_df.drop('customerID', axis=1)3.1 处理TotalCharges中的缺失值
# 将df数据框中的'TotalCharges'列转换为浮点型数据类型在尝试执行上面的代码时发生了错误:无法将字符串转换为浮点数:‘’。
要转换的字符串不能包含任何字符或符号。错误发生是由于将值错误地初始化为字符串变量。
我们可能在’TotalCharges’列中有空字符串,但由于它们被定义为字符串,它们没有显示为Null值。
# 计算每个'TotalCharges'元素的单词数量 step1 = [len(i.split()) for i in df['TotalCharges']] # 找出'TotalCharges'元素长度不等于1的索引值 step2 = [i for i in range(len(step1)) if step1[i] != 1] # 打印'TotalCharges'中空字符串的条目数量 print('空字符串的条目数量:', len(step2))Number of entries with empty string: 11我们可以尝试通过建立一个模型来填补缺失值,或者使用一些在这种情况下经常使用的值,比如平均值、中位数或众数来填充它们,但是由于空字符串的数量非常低(11个),所以直接从数据集中删除相应的行可能更简单(也可能更好)。
# 通过使用.drop()方法删除在'Total_charges'列中没有值的行 df = df.drop(step2, axis=0).reset_index(drop=True)# 将'TotalCharges'列的数据类型转换为float类型 df['TotalCharges'] = df['TotalCharges'].astype(float)3.2 处理重复值
# 打印训练数据集中重复值的数量 print('Number of duplicated values in training dataset: ', df.duplicated().sum())Number of duplicated values in training dataset: 22# 删除数据框中的重复行 df.drop_duplicates(inplace=True) # 输出提示信息,表示重复值已经成功删除 print("Duplicated values dropped succesfully") # 输出100个"*",用于分隔不同的输出信息 print("*" * 100)Duplicated values dropped succesfully ****************************************************************************************************3.3 创建数字和分类列表
# 将数据集的列名存储在列表中 columns = list(df.columns) # 创建空列表,用于存储分类变量和数值变量的列名 categoric_columns = [] numeric_columns = [] # 遍历数据集的每一列 for i in columns: # 如果该列的唯一值数量大于6,则将其视为数值变量 if len(df[i].unique()) > 6: numeric_columns.append(i) # 否则将其视为分类变量 else: categoric_columns.append(i) # 由于最后一个分类变量是目标变量,所以将其从列表中移除 categoric_columns = categoric_columns[:-1] # 排除目标变量 'Churn'3.4 特征缩放
# 导入所需的库 from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler # 创建标准缩放函数 def Standard_Scaler (df, col_names): # 选择需要缩放的特征列 features = df[col_names] # 创建StandardScaler对象并拟合特征数据 scaler = StandardScaler().fit(features.values) # 对特征数据进行缩放 features = scaler.transform(features.values) # 将缩放后的特征数据更新到原始数据框中 df[col_names] = features # 返回缩放后的数据框 return df # 创建最小-最大缩放函数 def MinMax_Scaler (df, col_names): # 选择需要缩放的特征列 features = df[col_names] # 创建MinMaxScaler对象并拟合特征数据 scaler = MinMaxScaler().fit(features.values) # 对特征数据进行缩放 features = scaler.transform(features.values) # 将缩放后的特征数据更新到原始数据框中 df[col_names] = features # 返回缩放后的数据框 return df # 创建鲁棒缩放函数 def Robust_Scaler (df, col_names): # 选择需要缩放的特征列 features = df[col_names] # 创建RobustScaler对象并拟合特征数据 scaler = RobustScaler().fit(features.values) # 对特征数据进行缩放 features = scaler.transform(features.values) # 将缩放后的特征数据更新到原始数据框中 df[col_names] = features # 返回缩放后的数据框 return df重要的是要记住,fit方法用于计算数据集中每个特征的均值和方差。transform方法使用相应的均值和方差来转换所有特征。在我们的情况下(这个笔记本),我们在不分割的情况下转换整个数据集,但是当我们执行训练-测试分割时,我们必须记住fit和transform是用于训练和测试集的转换。# 将给定的列名赋值给变量col_names,这些列名是数值型的列 col_names = numeric_columns # 复制数据框df,得到一个新的数据框df_ss df_ss = df.copy() # 对数据框df_ss中的指定列进行标准化处理,使用Standard_Scaler函数 # 标准化是将数据按照均值为0,标准差为1的方式进行转换,使得数据具有相同的尺度 # 标准化可以消除不同变量之间的量纲差异,使得不同变量之间可以进行比较和分析 df_ss = Standard_Scaler(df_ss, col_names)# 复制数据框df并命名为df_mm df_mm = df.copy() # 使用MinMaxScaler对df_mm中的指定列进行归一化处理 df_mm = MinMax_Scaler(df_mm, col_names)# 复制数据框df并命名为df_rs df_rs = df.copy() # 使用Robust_Scaler函数对df_rs中的指定列进行缩放处理 df_rs = Robust_Scaler(df_rs, col_names)不同的缩放器和常见误解
4.1 MinMaxScaler 归一化
- MinMaxScaler公式:
x ′ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x' = \frac {x − min(x)}{max(x)-min(x)} x′=max(x)−min(x)x−min(x)
这种技术用于重新缩放具有0到1之间分布值的特征。对于每个特征,最小值被转换为0,最大值被转换为1。
在许多来源中,我们可以读到当数据没有高斯分布时使用归一化,而当数据具有高斯分布时使用标准化。就个人而言,我对这个想法持怀疑态度。
# 导入必要的库 # 无需增加import语句 # 创建一个大小为(20,7)的图形 fig = plt.figure(figsize = (20,7)) # 在图形中创建一个1行2列的子图,当前选中第1个子图 plt.subplot(1,2,1) # 在当前选中的子图中绘制散点图,x轴为"TotalCharges",y轴为"tenure",颜色为"#008080",点的大小为9 ax = sns.scatterplot(data=df, x= "TotalCharges", y="tenure",color='#008080', s=9) # 设置当前选中的子图的标题为"Before scaling" ax.set(title = "Before scaling") # 在图形中创建一个1行2列的子图,当前选中第2个子图 plt.subplot(1,2,2) # 在当前选中的子图中绘制散点图,x轴为"TotalCharges",y轴为"tenure",颜色为"#FF6347",点的大小为9 ax = sns.scatterplot(data=df_mm, x= "TotalCharges", y="tenure",color='#FF6347', s=9) # 设置当前选中的子图的标题为"After scaling (MinMaxScaler)" ax.set(title = "After scaling (MinMaxScaler)") # 调整子图的布局,使它们更紧凑 plt.tight_layout() # 显示图形 plt.show()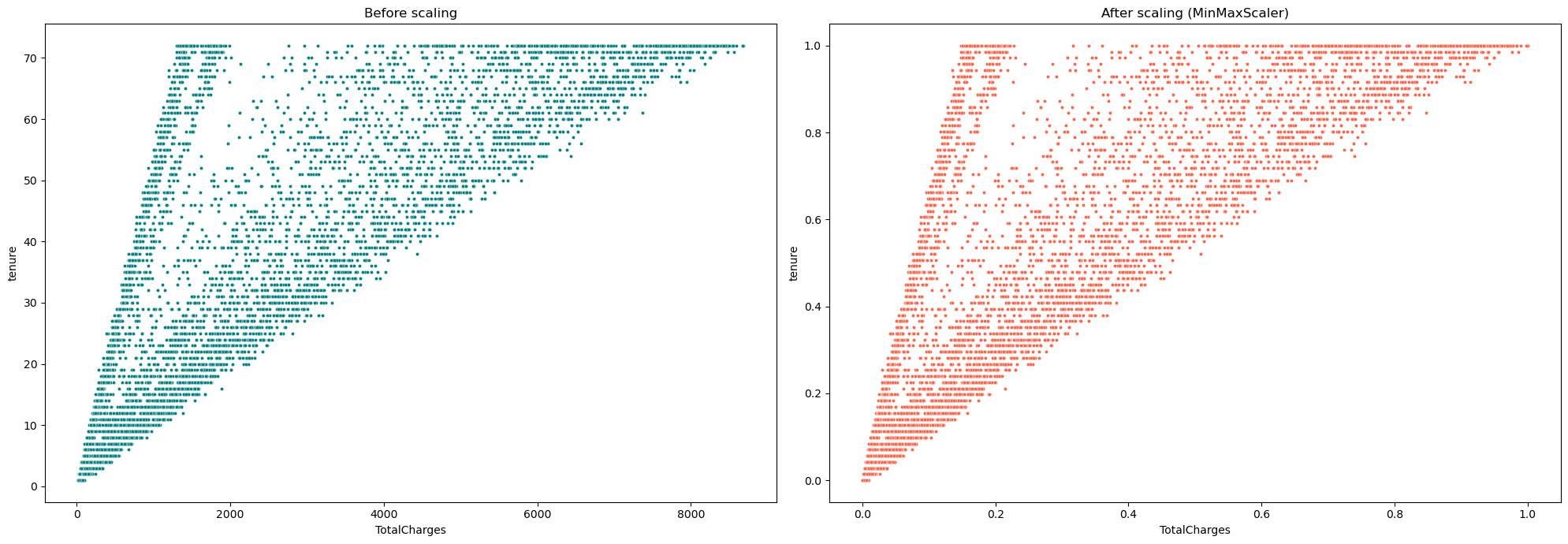
# 创建一个图形对象 fig = plt.figure(figsize=(20, 9)) # 在图形对象中创建一个2x2的子图,并选择第1个子图 plt.subplot(2, 2, 1) # 使用sns.kdeplot绘制核密度估计图,x轴为df["tenure"],颜色为'#008080',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df["tenure"], color='#008080', fill=True, alpha=0.7, linewidth=0) # 设置子图标题 ax.set(title="缩放前") # 设置x轴标签 ax.set_xlabel('使用期限') # 在图形对象中选择第2个子图 plt.subplot(2, 2, 2) # 使用sns.kdeplot绘制核密度估计图,x轴为df_mm["tenure"],颜色为'#FF6347',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df_mm["tenure"], color='#FF6347', fill=True, alpha=0.7, linewidth=0) # 设置子图标题 ax.set(title="缩放后 (MinMaxScaler)") # 设置x轴标签 ax.set_xlabel('使用期限') # 在图形对象中选择第3个子图 plt.subplot(2, 2, 3) # 使用sns.kdeplot绘制核密度估计图,x轴为df["TotalCharges"],颜色为'#008080',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df["TotalCharges"], color='#008080', fill=True, alpha=0.7, linewidth=0) # 设置x轴标签 ax.set_xlabel('总费用') # 在图形对象中选择第4个子图 plt.subplot(2, 2, 4) # 使用sns.kdeplot绘制核密度估计图,x轴为df_mm["TotalCharges"],颜色为'#FF6347',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df_mm["TotalCharges"], color='#FF6347', fill=True, alpha=0.7, linewidth=0) # 设置x轴标签 ax.set_xlabel('总费用') # 调整子图布局 plt.tight_layout() # 显示图形 plt.show()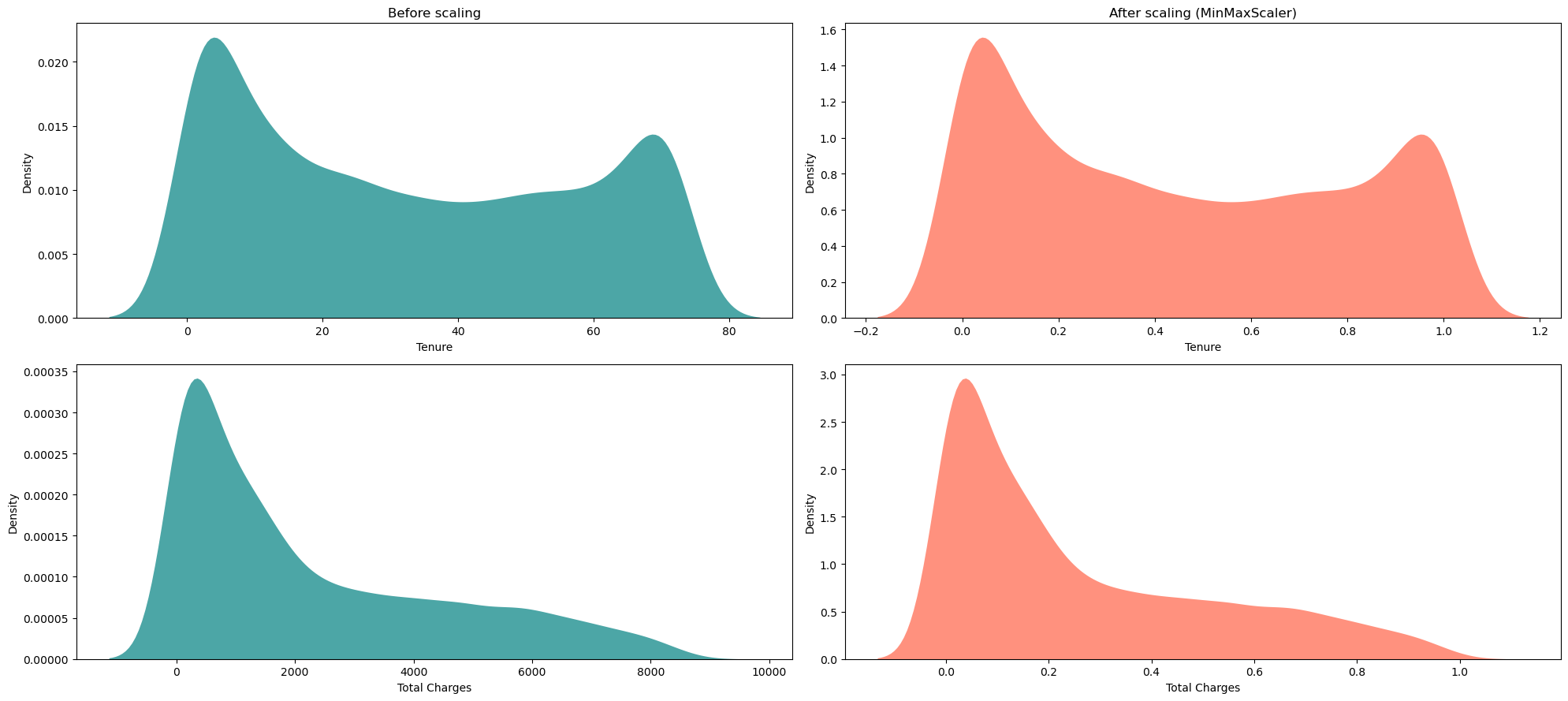
从上面的图表中,我们可以理解到经过MinMaxScaler处理后,分布仍然保持不变,但是尺度已经发生了改变(正如预期的那样)。
4.1.1 MinMax Scaler - 何时使用?
MinMaxScaler
MinMaxScaler可以在领域知识中上下边界已知的情况下使用。一个常见的应用是图像处理,其中像素强度必须被归一化到特定的范围内(例如,RGB颜色范围的0到255)。
4.2 StandardScaler标准化
- StandardScaler公式:
x ′ = x − μ σ x' = \frac {x-μ}{σ} x′=σx−μ
μ - 均值
σ - 标准差
在互联网上的许多地方,你可以读到StandardScaler假设数据服从高斯分布。我们通常从这个陈述中得出结论,当数据不服从正态分布时,我们不应该利用StandardScaler。在我看来,这是不正确的。当数据服从正态分布时,StandardScaler会提供最佳结果 - 这是事实,但同样的陈述也适用于MinMax Scaler。这并不意味着我们不能对非正态数据进行标准化。让我们来看一下图表。
# 创建一个大小为20x7的图形对象 fig = plt.figure(figsize=(20, 7)) # 在图形对象中创建一个1行2列的子图,并选择第一个子图 plt.subplot(1, 2, 1) # 在子图中创建一个散点图,x轴为"TotalCharges",y轴为"tenure",颜色为"#008080",点的大小为9 ax = sns.scatterplot(data=df, x="TotalCharges", y="tenure", color='#008080', s=9) # 设置子图的标题为"Before scaling" # 在图形对象中创建一个1行2列的子图,并选择第二个子图 plt.subplot(1, 2, 2) # 在子图中创建一个散点图,x轴为"TotalCharges",y轴为"tenure",颜色为"#FF6347",点的大小为9 ax = sns.scatterplot(data=df_ss, x="TotalCharges", y="tenure", color='#FF6347', s=9) # 设置子图的标题为"After scaling (StandardScaler)" # 调整子图的布局,使得子图之间的间距合适 plt.tight_layout() # 显示图形对象 plt.show()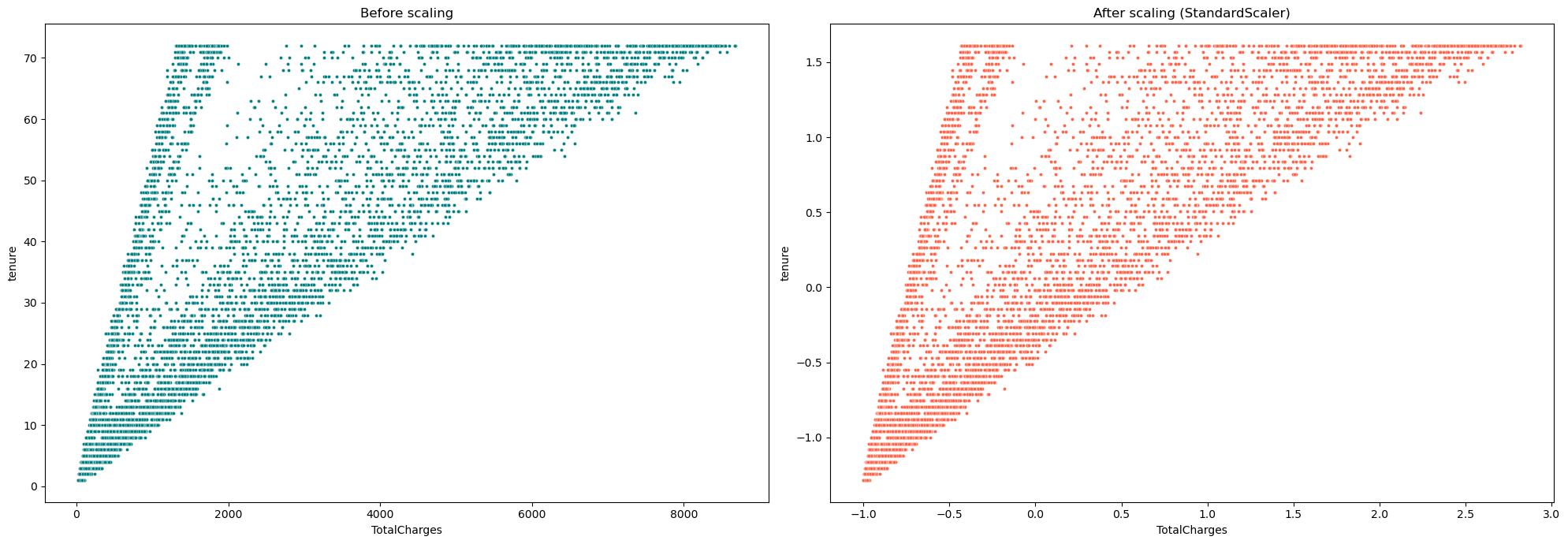
# 绘制四个子图的密度图 # 创建一个大小为20x9的图像对象 fig = plt.figure(figsize = (20,9)) # 在第一个子图中绘制df["tenure"]的密度图 plt.subplot(2,2,1) ax = sns.kdeplot(df["tenure"], color='#008080', fill= True, alpha=.7, linewidth=0) ax.set(title = "Before scaling") # 设置子图标题为"Before scaling" ax.set_xlabel('Tenure') # 设置x轴标签为"Tenure" # 在第二个子图中绘制df_ss["tenure"]的密度图 plt.subplot(2,2,2) ax = sns.kdeplot(df_ss["tenure"], color='#FF6347', fill= True, alpha=.7, linewidth=0) ax.set(title = "After scaling (StandardScaler)") # 设置子图标题为"After scaling (StandardScaler)" ax.set_xlabel('Tenure') # 设置x轴标签为"Tenure" # 在第三个子图中绘制df["TotalCharges"]的密度图 plt.subplot(2,2,3) ax = sns.kdeplot(df["TotalCharges"], color='#008080', fill= True, alpha=.7, linewidth=0) ax.set_xlabel('Total Charges') # 设置x轴标签为"Total Charges" # 在第四个子图中绘制df_ss["TotalCharges"]的密度图 plt.subplot(2,2,4) ax = sns.kdeplot(df_ss["TotalCharges"], color='#FF6347', fill= True, alpha=.7, linewidth=0) ax.set_xlabel('Total Charges') # 设置x轴标签为"Total Charges" # 调整子图的布局,使其紧凑显示 plt.tight_layout() # 显示图像 plt.show()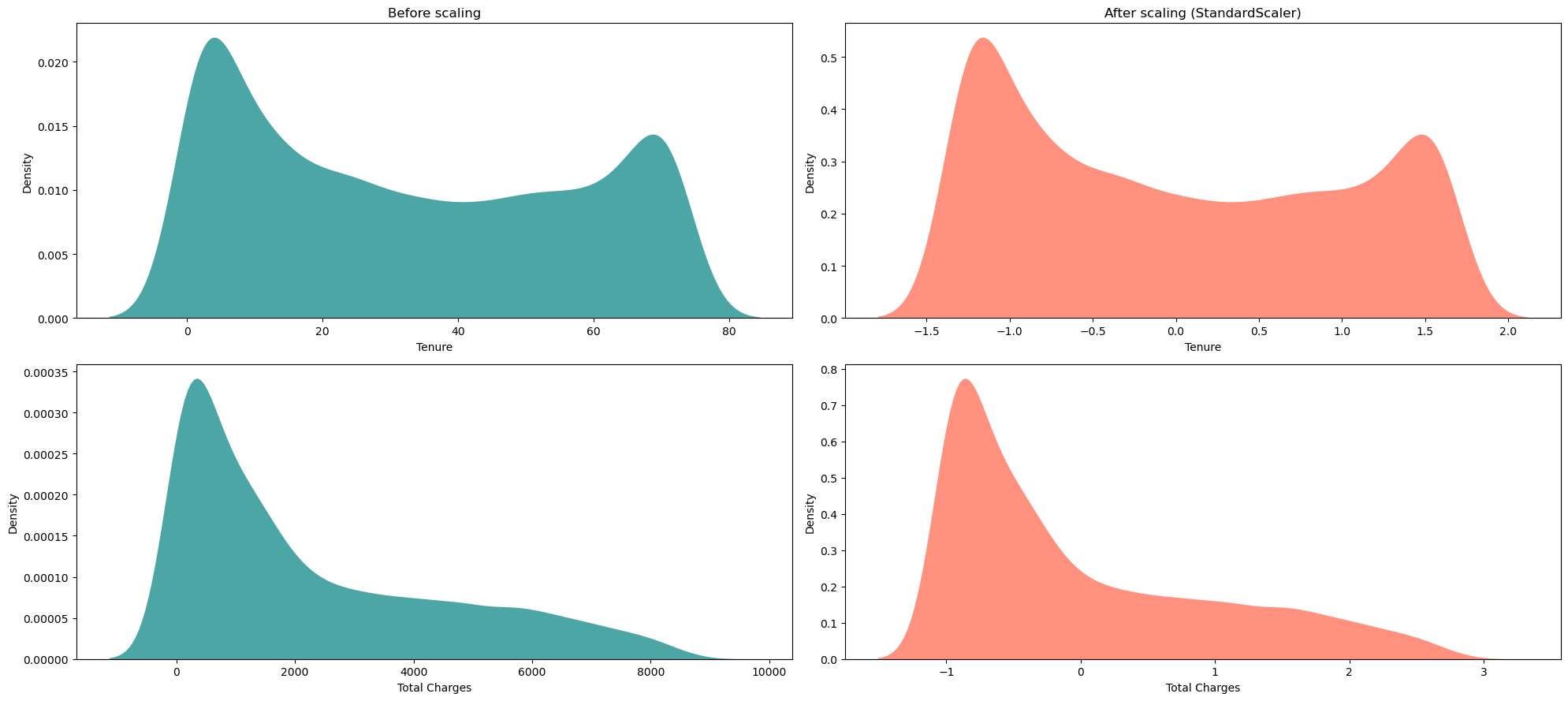
从上面的散点图和KDE图中,我们可以看到在应用StandardScaler之后,数据分布保持不变。只有尺度发生了变化。无论数据是否服从正态分布。
4.3 非正态分布的变量是否可以进行标准化?
再次强调一下:StandardScaler不会影响数据分布。如果你认为它会改变数据的分布,那你需要摆脱这个概念。需要记住的是,StandardScaler只是对数据中的特征进行标准化,它不会强制要求一个正态分布。
- 在我看来,对非正态分布进行标准化不会出现任何问题。换句话说,如果在标准化之前特征不符合正态分布,那么在标准化之后也不会符合(分布仍然完全相同,只是尺度发生了变化)。因此,在非正态分布上进行标准化是有效的。
- 标准化也不会对变量的分布(正态分布或其他分布)做任何假设。
- 可以放心地对变量进行标准化(如果需要),不用担心分布问题!
- 但是当数据高度倾斜或存在显著的异常值时要小心(稍后讨论的主题)!
-
4.4 RobustScaler标准化
- RobustScaler公式:
x ′ = x − m e d i a n ( x ) I Q R x' = \frac {x − median(x)}{IQR} x′=IQRx−median(x)
IQR - 描述了从最低到最高排序的值的中间50%(IQR = Q3 - Q1)。
缩放后的值的中位数和IQR将分别设置为0和1。
中位数四分位数图

不同的方法来标准化输入变量在存在异常值的情况下是忽略它们对均值和标准差的计算,然后使用计算出的值来缩放变量。
与先前的缩放器不同,RobustScaler的居中和缩放统计数据基于百分位数,因此不受少数非常大的边缘异常值的影响。因此,转换后的特征值的范围比先前的缩放器更大,更重要的是,它们大致相似。
转换后的变量不会因为异常值而偏斜,并且异常值仍然与其他值具有相同的相对关系。
- StandardScaler使用均值和标准差。RobustScaler使用中位数和四分位距(IQR)。
- 异常值可以显著改变均值,但不会影响中位数。这是因为中位数不依赖于列表中的每个值。
# 创建一个图形对象fig,设置图形大小为20x7 fig = plt.figure(figsize=(20, 7)) # 在图形对象fig中创建一个子图,位置为1行2列的第1个位置 plt.subplot(1, 2, 1) # 创建一个散点图,数据为df,x轴为"TotalCharges",y轴为"tenure",颜色为'#008080',点的大小为9 ax = sns.scatterplot(data=df, x="TotalCharges", y="tenure", color='#008080', s=9) # 设置子图的标题为"Before scaling" ax.set(title="Before scaling") # 在图形对象fig中创建一个子图,位置为1行2列的第2个位置 plt.subplot(1, 2, 2) # 创建一个散点图,数据为df_rs,x轴为"TotalCharges",y轴为"tenure",颜色为'#FF6347',点的大小为9 ax = sns.scatterplot(data=df_rs, x="TotalCharges", y="tenure", color='#FF6347', s=9) # 设置子图的标题为"After scaling (RobustScaler)" ax.set(title="After scaling (RobustScaler)") # 调整子图的布局,使其紧凑显示 plt.tight_layout() # 显示图形对象fig plt.show()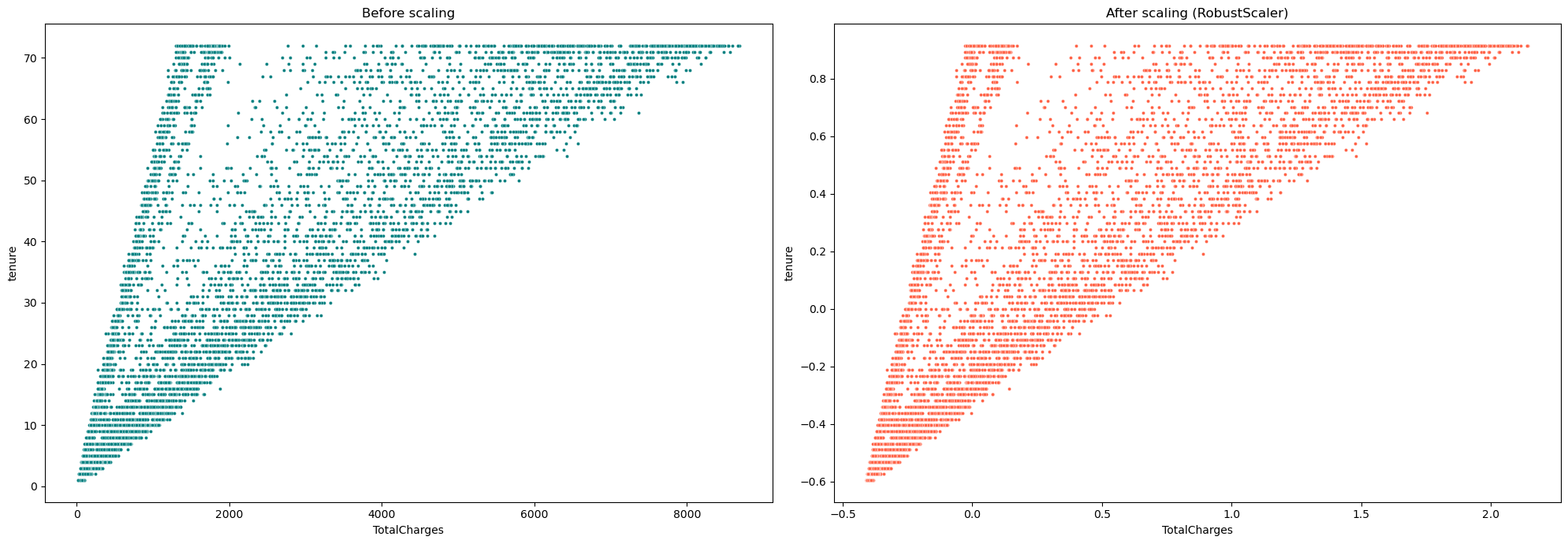
# 绘制四个子图的图表 # 创建一个大小为20x9的图表 fig = plt.figure(figsize=(20, 9)) # 第一个子图 plt.subplot(2, 2, 1) # 使用sns.kdeplot函数绘制核密度估计图,并设置颜色为'#008080',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df["tenure"], color='#008080', fill=True, alpha=0.7, linewidth=0) # 设置子图标题为"Before scaling" ax.set(title="Before scaling") # 设置x轴标签为'Tenure' ax.set_xlabel('Tenure') # 第二个子图 plt.subplot(2, 2, 2) # 使用sns.kdeplot函数绘制核密度估计图,并设置颜色为'#FF6347',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df_rs["tenure"], color='#FF6347', fill=True, alpha=0.7, linewidth=0) # 设置子图标题为"After scaling (RobustScaler)" ax.set(title="After scaling (RobustScaler)") # 设置x轴标签为'Tenure' ax.set_xlabel('Tenure') # 第三个子图 plt.subplot(2, 2, 3) # 使用sns.kdeplot函数绘制核密度估计图,并设置颜色为'#008080',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df["TotalCharges"], color='#008080', fill=True, alpha=0.7, linewidth=0) # 设置x轴标签为'Total Charges' ax.set_xlabel('Total Charges') # 第四个子图 plt.subplot(2, 2, 4) # 使用sns.kdeplot函数绘制核密度估计图,并设置颜色为'#FF6347',填充为True,透明度为0.7,线宽为0 ax = sns.kdeplot(df_rs["TotalCharges"], color='#FF6347', fill=True, alpha=0.7, linewidth=0) # 设置x轴标签为'Total Charges' ax.set_xlabel('Total Charges') # 调整子图的布局 plt.tight_layout() # 显示图表 plt.show()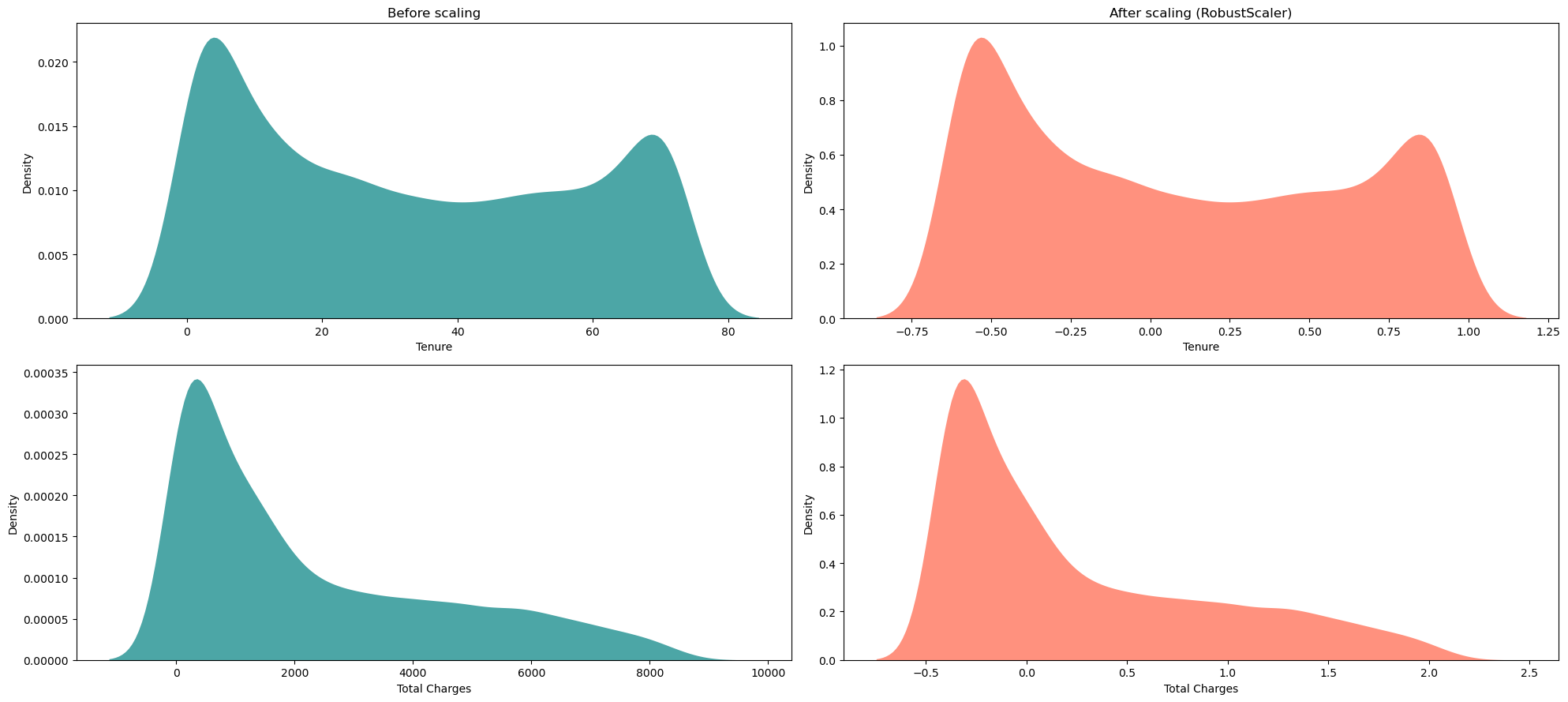
再次强调 - 经过RobustScaler处理后的分布保持不变,异常值仍然存在!
异常值(和高度偏斜的数据)
Min-max归一化有一个显著的缺陷:它不能很好地处理偏斜数据和异常值。例如,如果您有99个值在0到40之间,而一个值为100,则这99个值都将被转换为0到0.4之间的值!因此,如果您的特征(列)中有异常值,归一化数据将使大部分数据缩放到一个小区间。标准化对异常值更具有鲁棒性。
- MinMax Scaler将数据缩小到给定范围内,这将影响算法为特征分配充分权重的能力。结果看起来是有效的 - 看起来我们所有的特征都具有相同的比例,但实际上,由于异常值的存在,变换后的比例对它们来说并不相等!
还要考虑到:根据scikit-learn文档,“StandardScaler和MinMaxScaler都对异常值非常敏感”。
但是RobustScaler要好得多:
重要的是要记住,MinMAxScaler、StandardScaler和RobustScaler不会从数据集中删除异常值。我们可以说,标准化对异常值比归一化更具鲁棒性(尤其是使用RobustScaler),这是因为我们刚刚看到的缩放过程。换句话说,在标准化和归一化之后,异常值仍然会保留在数据集中。# 导入必要的库 # 画布大小为20*9 fig = plt.figure(figsize = (20,9)) # 在画布中添加子图,2行3列,第1个子图 plt.subplot(2,3,1) # 绘制df_ss中"tenure"列的直方图,颜色为'#008080',分为72个区间 ax = sns.histplot(df_ss["tenure"], color='#008080', bins=72) # 设置子图标题为"Standarization (StandardScaler)" ax.set(title = "Standarization (StandardScaler)") # 设置x轴标签为"Tenure" ax.set_xlabel('Tenure') # 在画布中添加子图,2行3列,第2个子图 plt.subplot(2,3,2) # 绘制df_mm中"tenure"列的直方图,颜色为'#FF6347',分为72个区间 ax = sns.histplot(df_mm["tenure"], color='#FF6347', bins=72) # 设置子图标题为"Normalization (MinMaxScaler)" ax.set(title = "Normalization (MinMaxScaler)") # 设置x轴标签为"Tenure" ax.set_xlabel('Tenure') # 在画布中添加子图,2行3列,第3个子图 plt.subplot(2,3,3) # 绘制df_rs中"tenure"列的直方图,颜色为'#FBDD7E',分为72个区间 ax = sns.histplot(df_rs["tenure"], color='#FBDD7E', bins=72) # 设置子图标题为"Standardization (RobustScaler)" ax.set(title = "Standardization (RobustScaler)") # 设置x轴标签为"Tenure" ax.set_xlabel('Tenure') # 在画布中添加子图,2行3列,第4个子图 plt.subplot(2,3,4) # 绘制df_ss中"TotalCharges"列的直方图,颜色为'#008080',分为72个区间 ax = sns.histplot(df_ss["TotalCharges"], color='#008080', bins=72) # 设置x轴标签为"Total Charges" ax.set_xlabel('Total Charges') # 在画布中添加子图,2行3列,第5个子图 plt.subplot(2,3,5) # 绘制df_mm中"TotalCharges"列的直方图,颜色为'#FF6347',分为72个区间 ax = sns.histplot(df_mm["TotalCharges"], color='#FF6347', bins=72) # 设置x轴标签为"Total Charges" ax.set_xlabel('Total Charges') # 在画布中添加子图,2行3列,第6个子图 plt.subplot(2,3,6) # 绘制df_rs中"TotalCharges"列的直方图,颜色为'#FBDD7E',分为72个区间 ax = sns.histplot(df_rs["TotalCharges"], color='#FBDD7E', bins=72) # 设置x轴标签为"Total Charges" ax.set_xlabel('Total Charges') # 调整子图之间的间距 plt.tight_layout() # 显示画布 plt.show()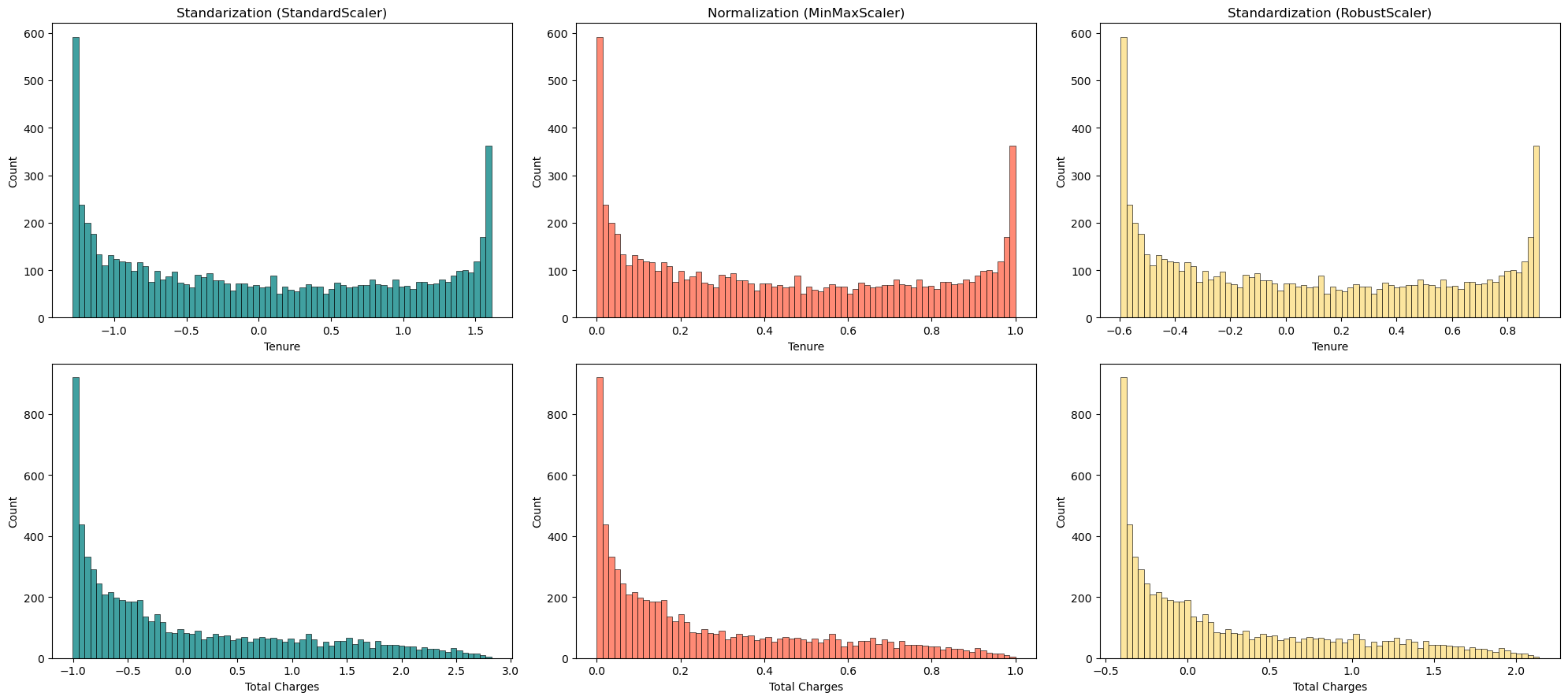
- 在对特征进行缩放后,我们可以看到使用MinMaxScaler和StandardScaler得到的结果不同!'TotalCharges’变量高度倾斜,在标准化后得到了合适的尺度表示。
- 当我们比较’Tenure’和’TotalCharges’时,可以看到它们的尺度差异,但在归一化(MinMax scaler)之后,差异消失了 - 两个变量都分布在0和1之间。这是重要的,但并不理想!
- 特别注意的是,由于每个特征的值具有不同的数量级,标准化后每个特征的转换数据的分布也不同!这可能也是有问题的,但相比使用MinMaxScaler进行强制转换,这更加真实。
- 在聚类分析中,标准化可能特别重要,以便基于距离度量比较特征之间的相似性。另一个例子是主成分分析(PCA),在这里我们通常更喜欢使用标准化而不是最小-最大缩放,因为我们对最大化方差的成分感兴趣。
当数据平衡时,我们应考虑删除异常值。
请查看此笔记本以获取有关处理异常值的**更多信息**:异常值检测方法!
另一个例子(和比较)
让我们创建一个新的数据集:从均值为5,标准差为8的正态分布中随机选取60个点。
# 生成一个包含60个随机数的数组,这些随机数是从均值为5,标准差为8的正态分布中随机采样得到的 data = np.random.normal(5, 8, 60) # 使用生成的随机数创建一个新的DataFrame,列名为"Data" new_df = pd.DataFrame({"Data":data})# 对new_df进行描述性统计分析 new_df.describe()Data count 60.000000 mean 5.111554 std 7.147523 min -9.469605 25% -0.032164 50% 5.455549 75% 10.437635 max 19.015909 # 创建一个大小为20x6的图形对象 fig = plt.figure(figsize=(20, 6)) # 使用seaborn库的histplot函数绘制直方图,并设置颜色为'#008080',显示核密度估计,使用60个箱子 ax = sns.histplot(new_df, color='#008080', kde=True, bins=60) # 设置图形的标题为"Dataframe without outliers" ax.set(title="Dataframe without outliers") # 隐藏图例 ax.legend([], [], frameon=False) # 在图形中绘制红色虚线,表示数据的中位数 ax.axvline(new_df['Data'].median(), color='red', ls='--', lw=2) # 在图形中绘制蓝色虚线,表示数据的平均值 ax.axvline(new_df['Data'].mean(), color='blue', ls='--', lw=2) # 显示图形 plt.show()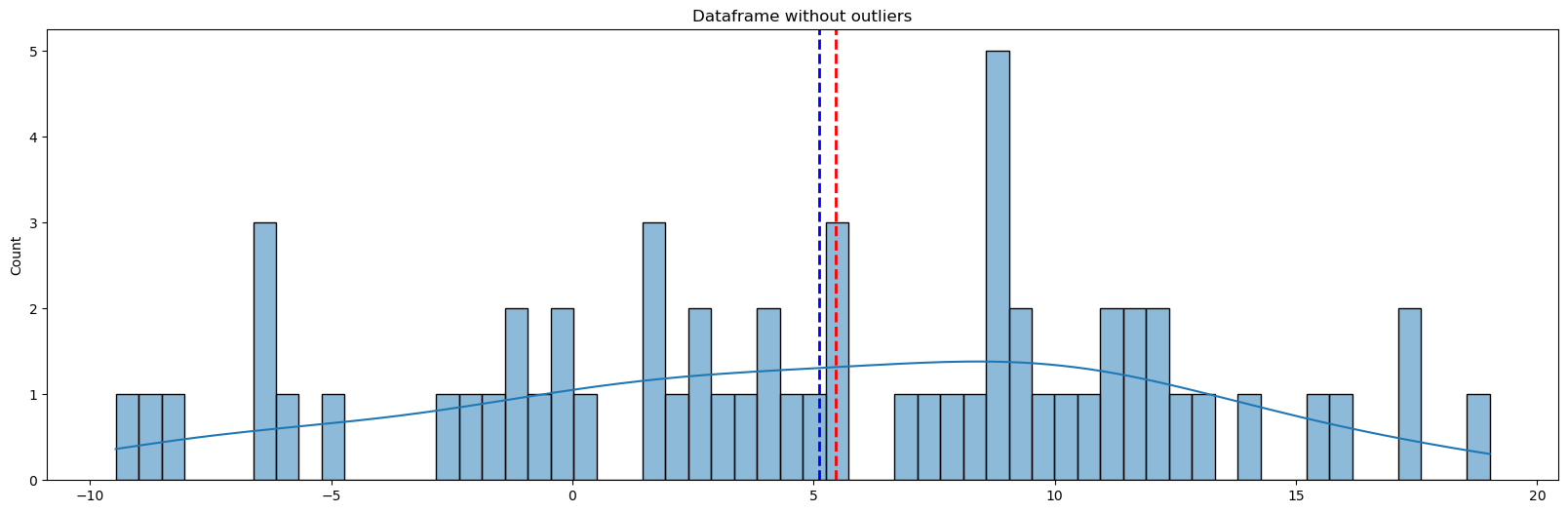
现在我们向输入列表中添加一些异常值。
# 生成5个在200到150之间的随机数作为异常值 outliers = np.random.uniform(200, 150, 5) # 将新的数据和异常值合并成一个DataFrame out_df = pd.DataFrame({"Data": np.append(new_df, outliers)})# 对out_df进行描述性统计分析Data count 65.000000 mean 18.348918 std 46.898096 min -9.469605 25% 0.145328 50% 6.739644 75% 11.683939 max 194.849317 异常值导致均值显著增加!然而,中位数只增加了一小部分。
# 创建一个大小为20x6的图形对象 fig = plt.figure(figsize=(20, 6)) # 使用seaborn库的histplot函数绘制直方图,并设置颜色为'#008080',显示核密度估计,将数据分成60个箱子 ax = sns.histplot(out_df, color='#008080', kde=True, bins=60) # 设置图形的标题为"Dataframe with outliers" ax.set(title="Dataframe with outliers") # 隐藏图例 ax.legend([], [], frameon=False) # 在直方图上绘制红色虚线,表示数据的中位数 ax.axvline(out_df['Data'].median(), color='red', ls='--', lw=2) # 在直方图上绘制蓝色虚线,表示数据的平均值 ax.axvline(out_df['Data'].mean(), color='blue', ls='--', lw=2) # 显示图形 plt.show()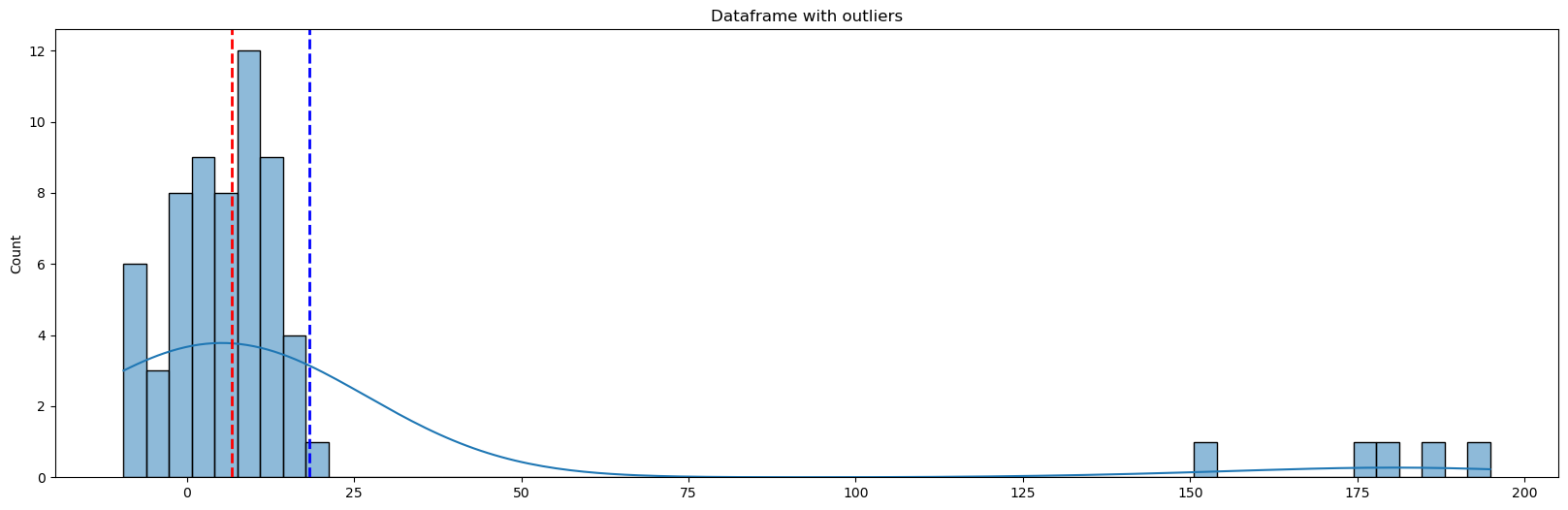
# 获取out_df的列名 col_names = out_df.columns # 复制out_df,生成三个新的DataFrame df_robust = out_df.copy() df_stand = out_df.copy() df_norm = out_df.copy() # 对三个新的DataFrame进行不同的缩放处理 df_robust = Robust_Scaler(df_robust, col_names) # 使用RobustScaler进行缩放 df_stand = Standard_Scaler(df_stand, col_names) # 使用StandardScaler进行缩放 df_norm = MinMax_Scaler(df_norm, col_names) # 使用MinMaxScaler进行缩放 # 复制new_df,生成三个新的DataFrame df_robust2 = new_df.copy() df_stand2 = new_df.copy() df_norm2 = new_df.copy() # 对三个新的DataFrame进行不同的缩放处理 df_robust2 = Robust_Scaler(df_robust2, col_names) # 使用RobustScaler进行缩放 df_stand2 = Standard_Scaler(df_stand2, col_names) # 使用StandardScaler进行缩放 df_norm2 = MinMax_Scaler(df_norm2, col_names) # 使用MinMaxScaler进行缩放# 绘制多个子图 # 创建一个大小为20x10的图形对象 fig = plt.figure(figsize=(20, 10)) # 第一个子图 plt.subplot(2, 3, 1) # 创建一个2行3列的子图矩阵,并选择第1个子图 ax = sns.histplot(df_stand2["Data"], color='#008080', fill=True, alpha=.7, kde=True) # 绘制直方图 ax.set(title="StandardScaler") # 设置子图标题 ax.set_xlabel(' ') # 设置x轴标签为空格 # 第二个子图 plt.subplot(2, 3, 2) # 创建一个2行3列的子图矩阵,并选择第2个子图 ax = sns.histplot(df_norm2["Data"], color='#FF6347', fill=True, alpha=.7, kde=True) # 绘制直方图 ax.set(title="MinMaxScaler") # 设置子图标题 ax.set_xlabel(' ') # 设置x轴标签为空格 # 第三个子图 plt.subplot(2, 3, 3) # 创建一个2行3列的子图矩阵,并选择第3个子图 ax = sns.histplot(df_robust2["Data"], color='#FBDD7E', fill=True, alpha=.7, kde=True) # 绘制直方图 ax.set(title="RobustScaler") # 设置子图标题 ax.set_xlabel(' ') # 设置x轴标签为空格 # 第四个子图 plt.subplot(2, 3, 4) # 创建一个2行3列的子图矩阵,并选择第4个子图 ax = sns.histplot(df_stand["Data"], color='#008080', fill=True, alpha=.7, kde=True) # 绘制直方图 ax.set(title="StandardScaler") # 设置子图标题 ax.set_xlabel(' ') # 设置x轴标签为空格 # 第五个子图 plt.subplot(2, 3, 5) # 创建一个2行3列的子图矩阵,并选择第5个子图 ax = sns.histplot(df_norm["Data"], color='#FF6347', fill=True, alpha=.7, kde=True) # 绘制直方图 ax.set(title="MinMaxScaler") # 设置子图标题 ax.set_xlabel(' ') # 设置x轴标签为空格 # 第六个子图 plt.subplot(2, 3, 6) # 创建一个2行3列的子图矩阵,并选择第6个子图 ax = sns.histplot(df_robust["Data"], color='#FBDD7E', fill=True, alpha=.7, kde=True) # 绘制直方图 ax.set(title="RobustScaler") # 设置子图标题 ax.set_xlabel(' ') # 设置x轴标签为空格 # 调整子图布局 plt.tight_layout() # 显示图形 plt.show()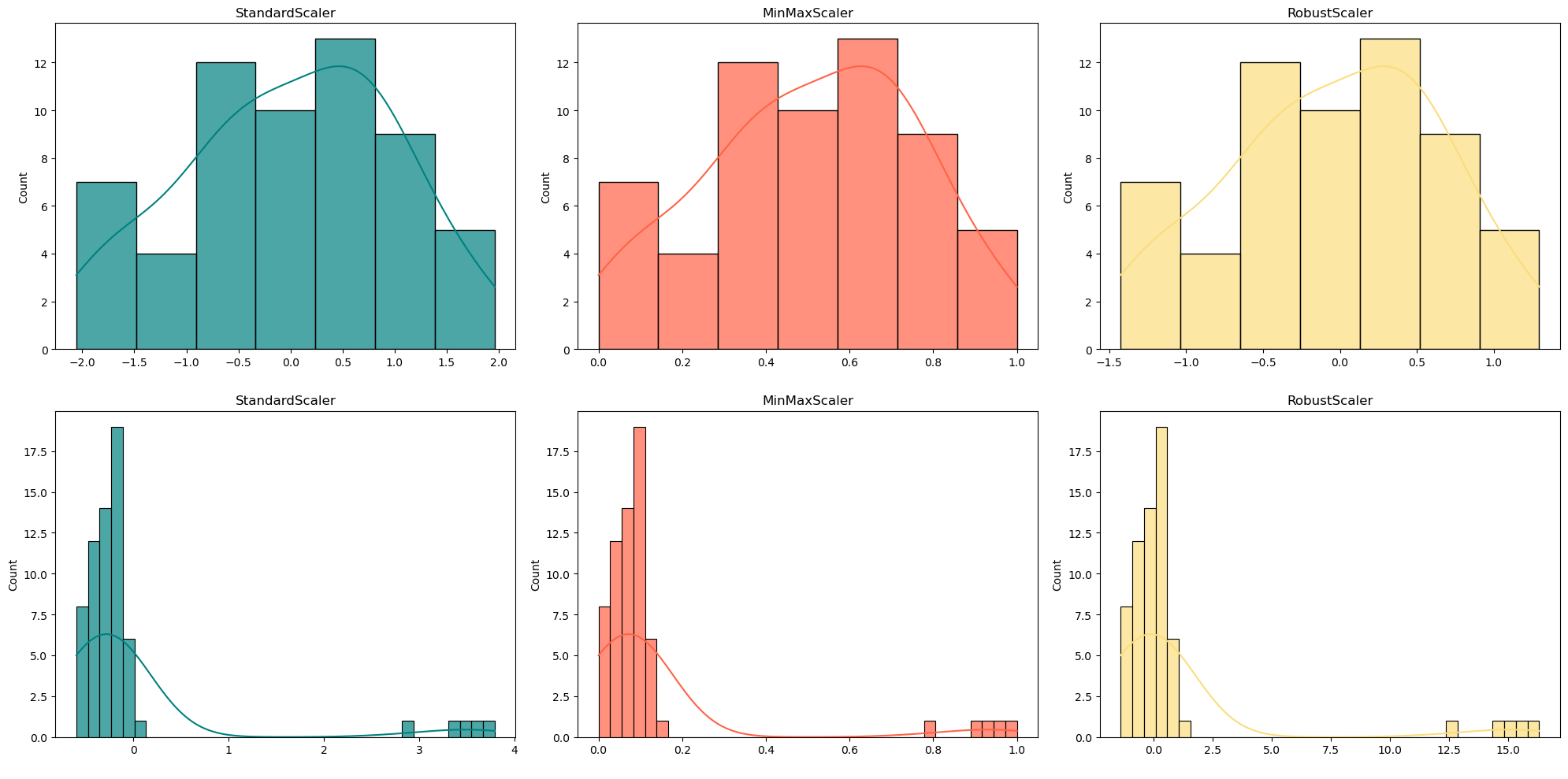 RobustScaler生成的值范围比StandardScaler要大得多。这是可以预料的。但是等一下 - 我们不是期望转换后的特征范围也大致相似吗?
RobustScaler生成的值范围比StandardScaler要大得多。这是可以预料的。但是等一下 - 我们不是期望转换后的特征范围也大致相似吗?我们可以看到,在比较有和没有异常值的缩放数据时,存在显著差异。使用StandardScaler时,差异要小得多。那么到底哪个缩放器是最好的呢?
- 在这里需要强调的是,RobustScaler的结果不会受到异常值的影响,其展示的是真实的距离。尽管乍一看不像,但它与非缩放数据更一致。
-
请记住,StandardScaler对异常值也很敏感(比MinMaxScaler敏感度低,但仍然敏感)。均值和标准差受异常值的影响很大。因此,距离(以标准差衡量)也会受到异常值的影响。
-
经过鲁棒缩放后,值的分布范围更大,但只有少数值具有较大的距离(异常值),而其他值则更接近。这是现实情况,算法不会被这种情况误导。相反,它应该工作得更好。
6.1 是否总是更好地使用RobustScaler?
当分析数据时,考虑从中提取的信息量非常重要。像四分位距(IQR)这样的健壮度量是设计用来专注于数据的特定子集,同时忽略可能不可靠的值。然而,这种有意排除某些数据的做法可能会限制用于预测的总体信息量,从而导致结果的置信度降低。
- 如果:
- 我决定删除异常值或数据集中不存在异常值
- 数据不是非常偏斜
我会利用StandardScaler。
在相反的情况下,我会使用RobustScaler。


















 9068
9068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











