







塑造想象力:使用人工智能创建新的3D可打印物体
使用Midjourney和开源项目Shap-E、MVDream和threestudio将您的想法转化为有形的物品
文章目录

从文本提示中打印的3D物体,作者提供的图片
如果您一直在阅读我在Medium上的文章,那么您就知道我喜欢使用人工智能进行创造性的实验,并写下我的经验。我已经涵盖了图像生成、创意写作和音乐创作等领域。这是我第一次将研究扩展到了第三维度。我研究了使用商业和开源的人工智能工具来创建新的物理物体,并使用3D打印机将它们打印出来。在本文中,我将向您展示我使用各种商业和开源工具设计和打印四个不同的3D网格的步骤。您可以在附录的3D画廊中找到这四个物体。
概述
在接下来的几节中,我将为您介绍我使用不同的工具进行的四个实验,并展示结果。第一个实验使用了商业工具:Midjourney用于创建2D图像,以及一个名为3dMaker.ai的网站,用于提取3D网格,即包含用于在3D中显示和打印的几何形状的文件。第二个实验使用了OpenAI的开源AI模型Shape-E [1]。第三个实验使用了一个名为MVDream [2]的开源模型,第四个实验使用了MVDream和另一个名为threestudio [3]的开源项目的组合。
在所有情况下,我都是从一个文本提示开始,生成一个3D网格,然后使用开源桌面应用程序Blender来修改和清理3D网格。然后,我使用桌面上的“切片”应用程序Ultimaker Cura和PrusaSlicer来准备和预览3D网格,然后在当地图书馆中打印它们。如果您有兴趣打印这些物体,您可以在我的Thingiverse个人资料页面上查看它们。
在介绍完这四个示例之后,我将谈谈使用人工智能生成3D物体的社会影响和伦理问题。我将讨论各种服务和系统的所有权政策。最后,我将总结我从实验中学到的东西。
使用Midjourney和3dMaker.ai创建3D物体
对于我的第一个实验,我从Midjourney开始,这是一个根据文本提示创建图像的商业服务。有关该服务的更多信息,请查看我的之前的文章。
为了创建一个2D图像,我登录到我的Midjourney账户,并输入了以下提示:“一个简单的几何形状的3D打印雕塑,纯白色塑料,放在一个小的白色塑料基座上,灰色背景”。它创建了四个缩略图图像,如下所示。

Midjourney生成的3D物体的2D渲染图,作者提供的图片
所有四个图像都非常好。系统了解3D打印;所有形式都很有趣且可打印。我最喜欢左上角的“Figure 8”图像。然后,我使用Midjourney的放大功能创建了一个更大的图像。
使用Clipdrop去除背景
从2D图像创建3D网格的下一步是去除场景的背景。许多人工智能模型都可以做到这一点,但我发现了一个名为Clipdrop的免费服务,它可以很好地完成这项工作。Clipdrop是由stability.ai提供的,可以通过Web浏览器访问。

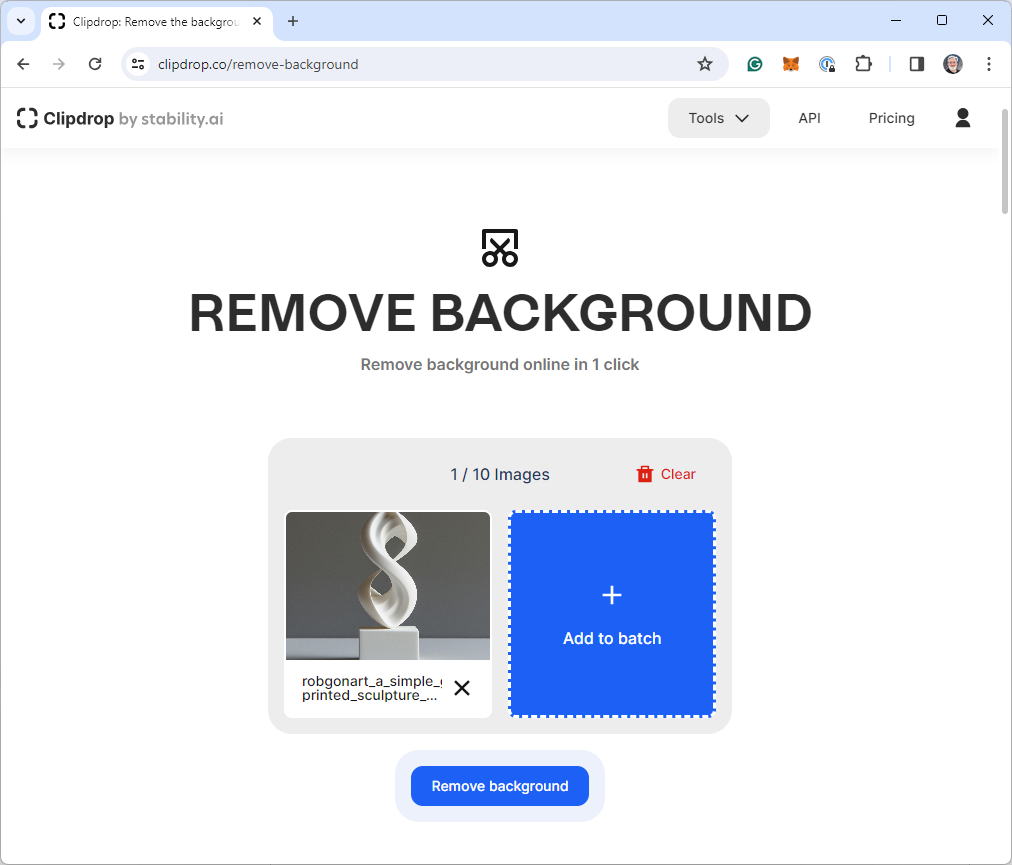
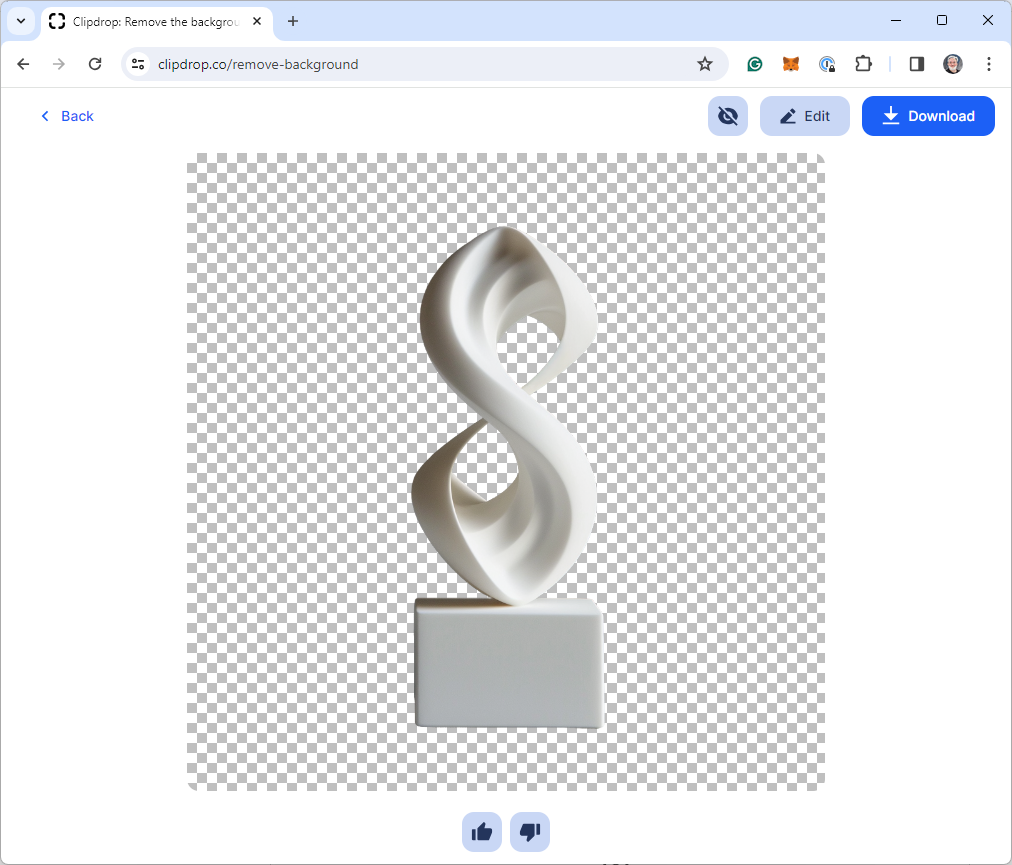
Midjourney的2D图像(左),Clipdrop用户界面(中),结果(右),作者提供的图片
从上面的图像序列中可以看出,Clipdrop非常容易使用。我进入网站,上传了我的源图像,然后点击“Remove background”按钮。系统很好地去除了背景,包括阴影,但保留了雕塑的所有细节。然后,我下载了生成的图像。
使用3dMaker.ai从2D图像创建3D网格
为了打印一个3D模型,我需要先将Midjourney创建的2D图像转换为3D网格。有几个开源模型可以做到这一点,但我发现了一个名为3dMaker.ai的商业服务,它可以很好地完成这项工作,但需要支付费用。

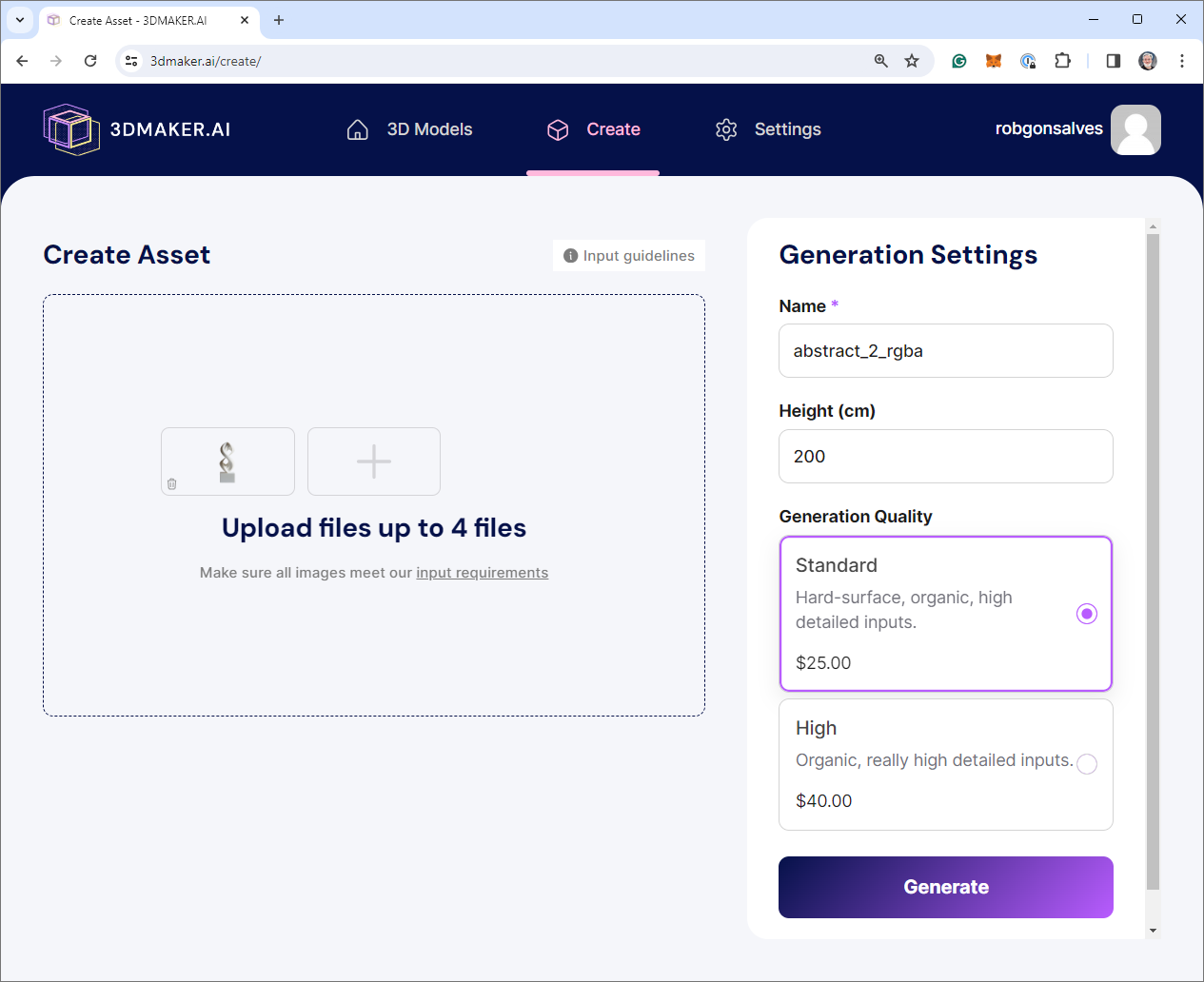

Clipdrop生成的图像(左),3dMaker .ai用户界面(中),生成的3D网格(右),作者提供的图片
为了创建3D网格,我访问了3dMaker.ai,创建了一个账户,并上传了去除背景的2D图像。创建3D网格有两个选择:标准质量(25美元)和高质量(40美元)。该网站表示,标准质量适用于硬表面、有机、高度详细的输入,而高质量适用于有机、非常高度详细的输入。我选择了标准质量,并点击了“Generate”按钮。结果大约需要30分钟,然后我以OBJ格式下载了模型,这是一种描述3D几何形状的常见格式。结果非常出色!它捕捉到了原始图像的细节,并忠实地构建了图像的背部。



3D Maker AI创建的网格背面的三个视图,作者提供的图片
令人惊讶的是,3D Maker AI仅根据正面视图的一个图像就创建了雕塑的背面细节。您可以在本文后面看到该服务的另一个输出示例。
3D打印服务和当地图书馆
这个实验的最后一步是打印3D网格。我没有自己的3D打印机,但令我惊喜的是,波士顿地区的许多公共图书馆提供免费或低成本的3D打印服务。居民可以使用这些打印机制作有用的物品,如手机壳和曲奇切割器,以及小型装饰物。
图书馆提供不同类型的访问方式。有些图书馆在“创客空间”中配备了3D打印机,这是一种协作工作空间,居民可以在其中聚集起来创造、发明和学习。其他图书馆则提供在线打印服务,居民可以上传3D网格进行打印。图书馆的服务也有所不同,如最大打印尺寸和打印材料颜色的选择。
打印3D物体
为了打印3D网格,我首先需要准备一个文件。3D打印的标准文件格式是STL,但3dMaker.ai不支持导出该格式。因此,我使用了一个名为Blender的开源桌面应用程序进行读取OBJ文件并将其导出为STL。然后,我启动了一个名为PrusaSlicer的切片应用程序,并导入了STL文件以预览打印效果。
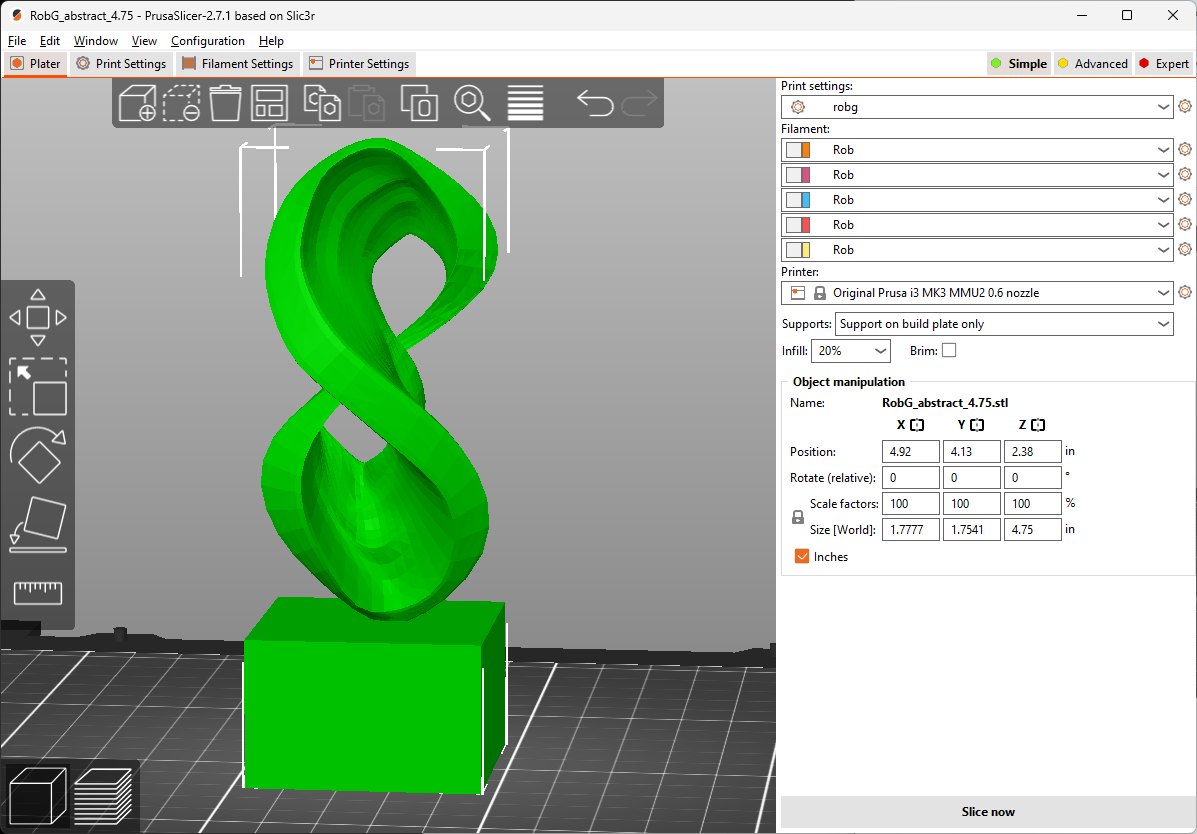

PrusaSlicer的用户界面(左),以及Waltham公共图书馆的Prusa 3D打印机(右),作者提供的图片
我在Waltham公共图书馆的创客空间使用了深灰色的丝线进行打印。在3D打印中,丝线是熔融沉积建模(FDM)打印机的热塑性原料。它以卷筒的形式提供,材料各异,通过打印机的喷嘴熔化和挤出,逐层构建物体。居民可以自由使用Waltham图书馆的3D打印机打印物体。我使用他们的Prusa MK3S打印机和0.6mm的喷嘴打印了上面的样品。
我还使用白色丝线在Woburn公共图书馆使用他们的在线表单进行打印。他们允许打印高度达到11英寸,但由于打印时间的原因,我将我的打印高度设置为6.5英寸。他们不接受打印时间超过10小时的任务。与其他图书馆不同,Woburn图书馆会收取打印材料的费用。但他们会发放每月5美元的信用额。在使用信用后,我的总费用为3.63美元。这是两个打印件。


在Waltham公共图书馆打印的最终Figure 8打印件(左)和在Woburn公共图书馆打印的打印件(右),作者提供的图片
这两个打印件都非常出色!在Waltham打印的那个只有4.75英寸高,但显示了原始Midjourny图像的许多细节。由于在相对较小的比例下打印,您可以看到一些分层痕迹。Waltham的免费打印服务仅限于创建高达8小时的物体。在Woburn打印的那个在6.5英寸高时看起来更好,分层痕迹较少。但是,物体表面上有一些深色痕迹。
使用Shape-E创建3D物体
对于我的下一个实验,我使用了OpenAI的开源AI模型Shape-E [1],它可以根据文本提示创建3D网格。Shap-E的名称是对他们的DALL-E AI模型的一个变种,该模型可以根据文本提示创建2D图像。以下是他们论文中的一些示例图像。

Shap-E 模型
2023年5月,OpenAI发布了一款名为 Shap-E 的文本到3D模型。该系统旨在通过生成隐式函数的参数来创建3D网格,从而实现详细的3D可视化渲染。他们采用了两步训练过程,首先将3D资源映射到参数,然后使用条件扩散模型对结果进行优化。这种方法可以高效地根据文本提示生成各种各样的3D模型。每个样本在GPU上生成大约需要13秒[1]。OpenAI在GitHub上以MIT开源许可证发布了训练模型的源代码和权重。
该系统使用了三个AI模型,详见OpenAI的模型卡片。
**transmitter**- 用于将编码器输出转换为隐式神经表示的编码器和相应的投影层。**decoder**-transmitter的最终投影层组件。与transmitter相比,这是一个较小的检查点,因为它不包括用于编码3D资源的参数。这是将扩散输出转换为隐式神经表示所需的最小模型。**text300M**- 文本条件下的潜在扩散模型。
还有一个图像条件下的潜在扩散模型,但我在这个项目中没有使用。
在Python中运行 Shap-E
我使用了Google Colab来根据提示创建一个3D网格。以下是显示我如何初始化系统的Python代码。
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
xm = load_model('transmitter', device=device)
model = load_model('text300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
该代码下载了三个模型:编码器、解码器和文本扩散模型。如果有GPU,则将所有模型加载到GPU上。
使用 Shap-E 创建3D对象
我使用以下代码将文本提示发送到 Shap-E 以生成3D形状的潜在参数。
from shap_e.diffusion.sample import sample_latents
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images
import numpy as np
import random
prompt = "a dolphin"
seed = 0
batch_size = 1
guidance_scale = 15
render_mode = 'nerf'
size = 512
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
latents = sample_latents(
batch_size=batch_size, model=model, diffusion=diffusion,
guidance_scale=guidance_scale, model_kwargs=dict(texts=[prompt] * batch_size),
progress=True, clip_denoised=True, use_fp16=True, use_karras=True,
karras_steps = 64, sigma_min=1e-3, sigma_max=160, s_churn=0)
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
您可以看到我如何使用文本提示“a dolphin”使用 Shap-E 来采样潜在参数。我将随机种子初始化为0,这将始终生成相同的网格。将随机种子更改为1、2或任何其他整数将创建不同的网格变体。这是生成的图像。

“a dolphin”的 Shap-E 渲染,图片由作者提供
这个网格相当简单,有很多空白空间。但它确实看起来像一只海豚。以下是导出3D网格的代码。
from shap_e.util.notebooks import decode_latent_mesh
for i, latent in enumerate(latents):
t = decode_latent_mesh(xm, latent).tri_mesh()
with open(f'example_mesh_{i}.ply', 'wb') as f:
t.write_ply(f)
这段代码使用潜在参数生成了另一种用于3D对象的文件格式,称为PLY。以下是在Blender中显示的网格。

Blender中的海豚网格,图片由作者提供
它仍然看起来像一只海豚,但是网格有一些问题。您可以看到物体的身体上有分层的步骤,鳍似乎被切成了水平切片。此外,网格没有底座以便作为打印对象展示。为了解决分层问题,我在Blender中使用了位移修饰器,然后使用平滑修饰器来增加形状的厚度并使其更加平滑。为了创建底座,我使用了提示“a cylindrical pedestal in the style of an ocean wave”重新运行了Shap-E,并导出了网格。然后我在Blender中将两个对象定位并连接在一起。这是修改后的网格。

在Blender中清理的带底座的海豚网格,图片由作者提供
您可以看到我如何平滑了海豚的两侧并修复了鳍。Shap-E在渲染底座方面做得很好,只需要在Blender中添加一个细长的圆柱体,以帮助整个物体平放在表面上。接下来,我将模型保存为STL文件。
打印3D物体
由于海豚下方有很多空白空间,切片应用程序添加了临时支撑柱以使上层能够打印。您可以在下面的图像中看到这些支撑柱。
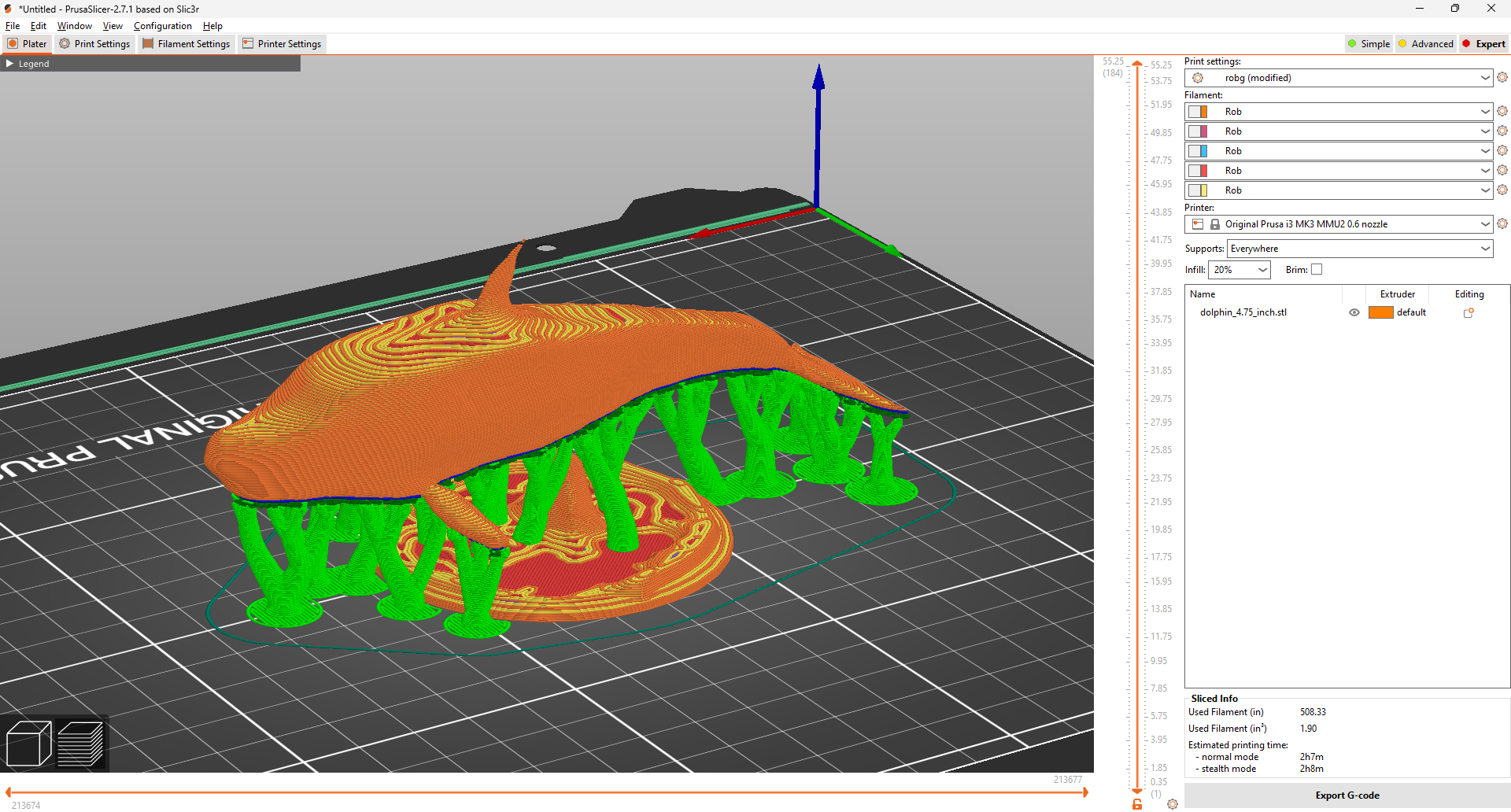

PrusaSlicer的用户界面(左)和带支撑的3D打印(右),图片由作者提供
我还在Waltham公共图书馆的创客空间打印了这个模型。我使用了他们的Prusa MK3S打印机进行打印。这是最终的作品。

最终的海豚3D打印,图片由作者提供
这个打印效果也很好。由于打印尺寸较小,只有5英寸宽,因此可以看到打印过程中的分层线条。此外,顶部的背鳍非常薄,需要更好地定义。
使用 MVDream 创建3D对象
在我的下一个实验中,我使用了一个名为MVDream的开源项目,其中MV代表“多视图”。它是一种稳定扩散文本到图像模型的变体,可以根据文本提示创建3D对象的多个2D视图。作者在论文中描述了该模型[2]。
我们介绍了MVDream,一种多视图扩散模型,能够从给定的文本提示生成一致的多视图图像。通过从2D和3D数据中学习,多视图扩散模型可以实现2D扩散模型的泛化能力和3D渲染的一致性。我们证明了这种多视图先验可以作为一种通用的3D先验,对3D表示不加偏见。它可以通过分数蒸馏采样应用于3D生成,显著增强现有2D提升方法的一致性和稳定性。— Yichun Shi等人[2]
请注意,机器学习中的“先验”是指模型在接收到任何特定输入之前具有的知识。MVDream的多视图扩散模型充当了一种对特定3D表示不加偏见的3D先验。这意味着它可以生成类似3D的图像,而不受任何特定3D数据格式的限制,使其能够根据文本提示从各个角度生成多样化的3D表示。以下是使用MVDream生成的一些示例对象。

使用MVDream根据文本提示生成的图像的四个视图,图片由Yichun Shi等人提供
这些图像展示了MVDream从文本提示中创建多视图3D对象的能力,展示了不同角度的一致且详细的渲染。例如,宇航员骑在马上和雕刻的鹰等示例展示了该模型在准确生成多样化的3D图像方面的实际应用。
我在Google Colab中使用以下Python代码运行了MVDream。
from mvdream.camera_utils import get_camera
from IPython.display import display
prompt = """a 3d-printed Cubist-styled sculpture of a male bust,
in light-gray plastic, on a simple light-gray pedestal,
dark-gray background"""
num_views = 4
seed = 12
set_seed(seed)
img = t2i(model, prompt=prompt, uc=uc, sampler=sampler, step=100, scale=10,
batch_size=num_views, ddim_eta=0.0, device=device, camera=camera,
num_frames=num_views, image_size=256, seed=seed)
images = np.concatenate(img, 1)
pil_image = Image.fromarray(images, 'RGB')
display(pil_image)
该代码展示了我如何使用MVDream从文本提示中生成3D对象的多个2D视图。我指定了要生成的对象的期望属性(一个立体主义风格的男性半身雕塑),并配置了模型以生成四个不同的视图。然后,它处理这些视图以创建一个将它们并排组合在一起的单个图像,并使用IPython的display函数显示。您可以在这里看到结果。

MVDream为立体头部生成的输出视图,图片由作者提供
这些图像显示了一个3D打印的立体主义风格的男性半身雕塑的四个角度,每个视图与其他视图一致,突出了该模型准确解释和可视化文本提示的能力。雕塑的纹理表明与3D打印类似的颗粒度,而放置在底座上使其具有展示的外观。
使用四个2D图像创建3D网格的3dMaker.ai
我再次使用了3D Maker AI服务,从这四个图像中生成了一个3D网格。以下是在Blender中渲染的网格的四个视图。

3D Maker AI为立体头部生成的输出视图,图片由作者提供

减少多边形后的 PrusaSlicer 输出视图,作者提供的图片
虽然不太明显,但你可以看到这个头部比上面显示的版本有更多明显的角形三角形。我做出了这个艺术选择,使作品看起来更具立体派风格。
打印 3D 模型
我在 Watertown Free Public Library 的 Hatch Makerspace 上打印了这个网格。他们使用了不同的切片软件,Unitmaker Cura,但打印机是一样的,都是 Prusa i3 MK3。我使用了连接到构建板上的树状支撑物,这样可以最大程度地减少成品上的附着点。
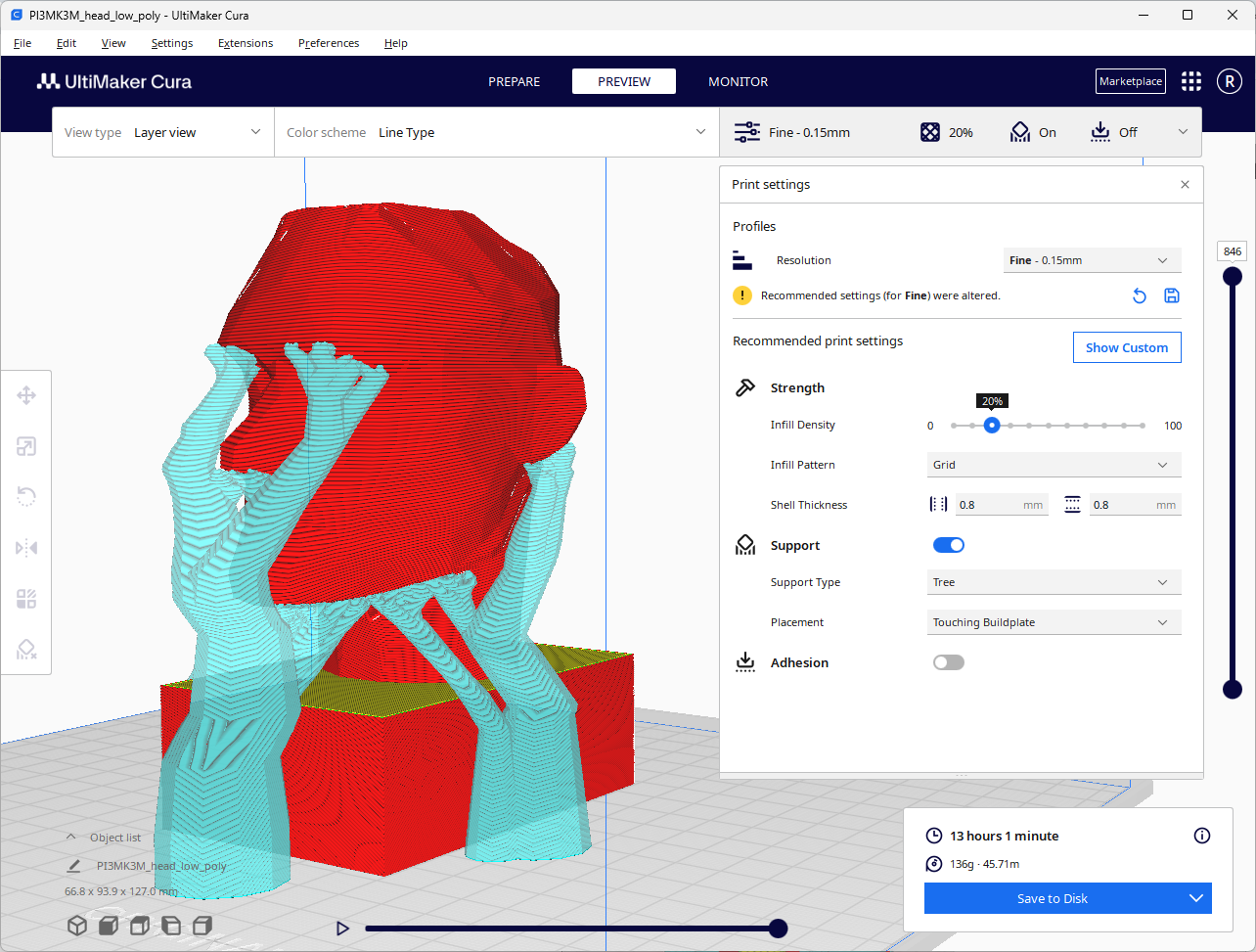


Cura 切片软件的用户界面(左),Hatch Makerspace 的 Prusa 3D 打印机(中),带支撑物的 3D 打印(右),作者提供的图片
这些树状支撑物在这个 3D 作品上看起来特别可怕。然而,软件需要一种支撑方式来支撑正在构建的眉毛的悬挑部分。由于附着点很少,所以很容易去除这些支撑物。这是最终的作品。

最终的立体派头像 3D 打印品,作者提供的图片
这个打印效果很好。这个 3D 打印的头部通过其角形和多面体表面呈现了立体派风格。以统一的蓝色铸造,这个雕塑强调了几何形状而不是细节,尖锐的平面定义了脸部的轮廓。它放在一个简单的底座上。
使用 threestudio 和 MVDream 创建 3D 对象
MVDream 模型很适合根据文本提示渲染 3D 对象的多个视图,但它不会生成 3D 网格。这就是 threestudio 的用武之地。threestudio 是一个开源项目,提供了一个模块化框架,允许用户尝试各种文本到 3D 和图像到 3D 的组件,包括 MVDream。以下是作者在论文中的介绍。
我们介绍了 threestudio,这是一个开源、统一且模块化的框架,专门用于 3D 内容生成。该框架将基于扩散的 2D 图像生成模型扩展到 3D 生成引导,同时结合文本和图像等条件。我们描述了 threestudio 中每个组件的模块化架构和设计。此外,我们在 threestudio 中重新实现了用于 3D 生成的最先进方法,并对它们的设计选择进行了全面比较。这个多功能的框架有潜力使研究人员和开发人员深入探索 3D 生成的前沿技术,并具备促进 3D 生成之外的进一步应用的能力 — Ying-Tian Liu 等 [3]
下面是论文中显示主要组件的流程图。
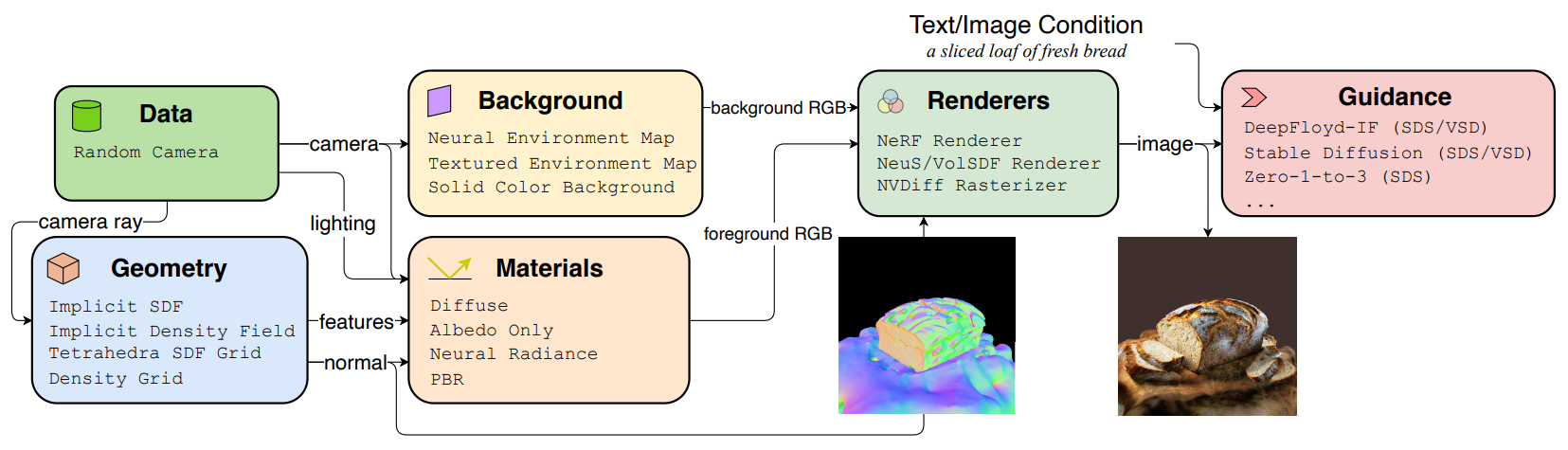
threestudio 中文本/图像条件下的 3D 生成流程,图片由 Ying-Tian Liu 等 提供
threestudio 用于使用 AI 从文本或图像生成 3D 内容的流程包括几个关键组件。该过程从为优化生成随机相机参数开始,包括外部和内部属性以及光照条件。几何形状通过隐式有符号距离函数(SDF)、隐式密度场等表示来定义 3D 对象或场景。材料确定了对象在特定条件下的外观,采用了漫反射和基于物理的渲染(PBR)类型。背景创建选项包括神经环境贴图、纹理贴图或纯色。渲染由各种光栅化器处理,考虑几何形状和材料以生成最终图像。扩散模型(如 DeepFloyd-IF 和 Stable Diffusion)的指导使用文本或图像输入来引导优化过程,以生成所需的 3D 内容。这种结构化方法允许从文本或视觉输入模块化生成 3D 表示 [3]。
使用 threestudio 和 MVDream 创建 3D 对象
我在 Google Colab 上使用 threestudio 和 MVDream 运行了这个模型,但该模型需要具有超过 16GB VRAM 的 GPU。因此,它只能在 Colab Pro 订阅中运行,以访问 A100 GPU。
在安装了 threestudio 和 MVDream 扩展之后,我使用以下代码从文本提示中创建了一个 3D 对象。
prompt = """a 3d-printed abstract sculpture with geometric shapes,
in light-gray plastic, on a simple pedestal"""
!python launch.py --config custom/threestudio-mvdream/configs/mvdream-sd21.yaml \
--train --gpu 0 system.prompt_processor.prompt="$prompt" seed=42
我定义了提示并运行了 launch.py 脚本,指示使用配置文件使用 MVDream。操作是“train”系统,这意味着它运行一个优化循环,创建一个基于文本提示定义 3D 几何的检查点文件。我将种子设置为 42,以始终获得相同的输出。更改种子号将创建不同的变体。运行该脚本大约需要 40 分钟。
从训练好的检查点创建 3D 网格
在运行训练优化过程中,系统会渲染显示正在形成的形状的图像状态。下面是从提示“a 3d-printed abstract sculpture with geometric shapes,
in light-gray plastic, on a simple pedestal”生成的结果 3D 对象的图像。

使用 threestudio 和 MVDream 创建的抽象雕塑,作者提供的图片
哇,这太酷了!threestudio 系统使用 MVDream 进行引导,生成了一个在底座上摆放着三个堆叠的三角形形状的雕塑。表面的纹理似乎有些风化。
打印 3D 对象
该过程的下一步是导出定义形状的 3D 网格。以下是我用于此步骤的命令。
!python launch.py --config "$save_dir/../configs/parsed.yaml" --export \
--gpu 0 resume="$save_dir/../ckpts/last.ckpt" \
system.exporter_type=mesh-exporter \
system.geometry.isosurface_method=mc-cpu \
system.geometry.isosurface_resolution=256 \
system.exporter.save_texture=False system.exporter.fmt=obj
这个 Python 脚本使用先前生成的检查点文件运行导出命令。我告诉它使用网格导出器。“MC” 方法是用于渲染的“marching cubes”方法,它产生更高分辨率的网格以获得更详细的模型。我还指示只想要 OBJ 文件,而不是纹理贴图,以加快处理速度。运行这一步大约需要 81 秒。下面是在 Blender 中渲染的结果 3D 网格。


抽象雕塑的 3D 网格(左),在 Blender 中清理后的样子(右),作者提供的图片
它看起来像上面的渲染结果,但更加凹凸不平,并且底部有一些多余的材料。我在 Blender 中清理了网格,去除了大部分底座,并添加了一个锥形立方体作为替代。
打印 3D 模型
我在 Watertown 的 Hatch Makerspace 使用他们的 Prusa i3 MK3 打印了这个网格。我使用了连接到网格下部的普通支撑物。
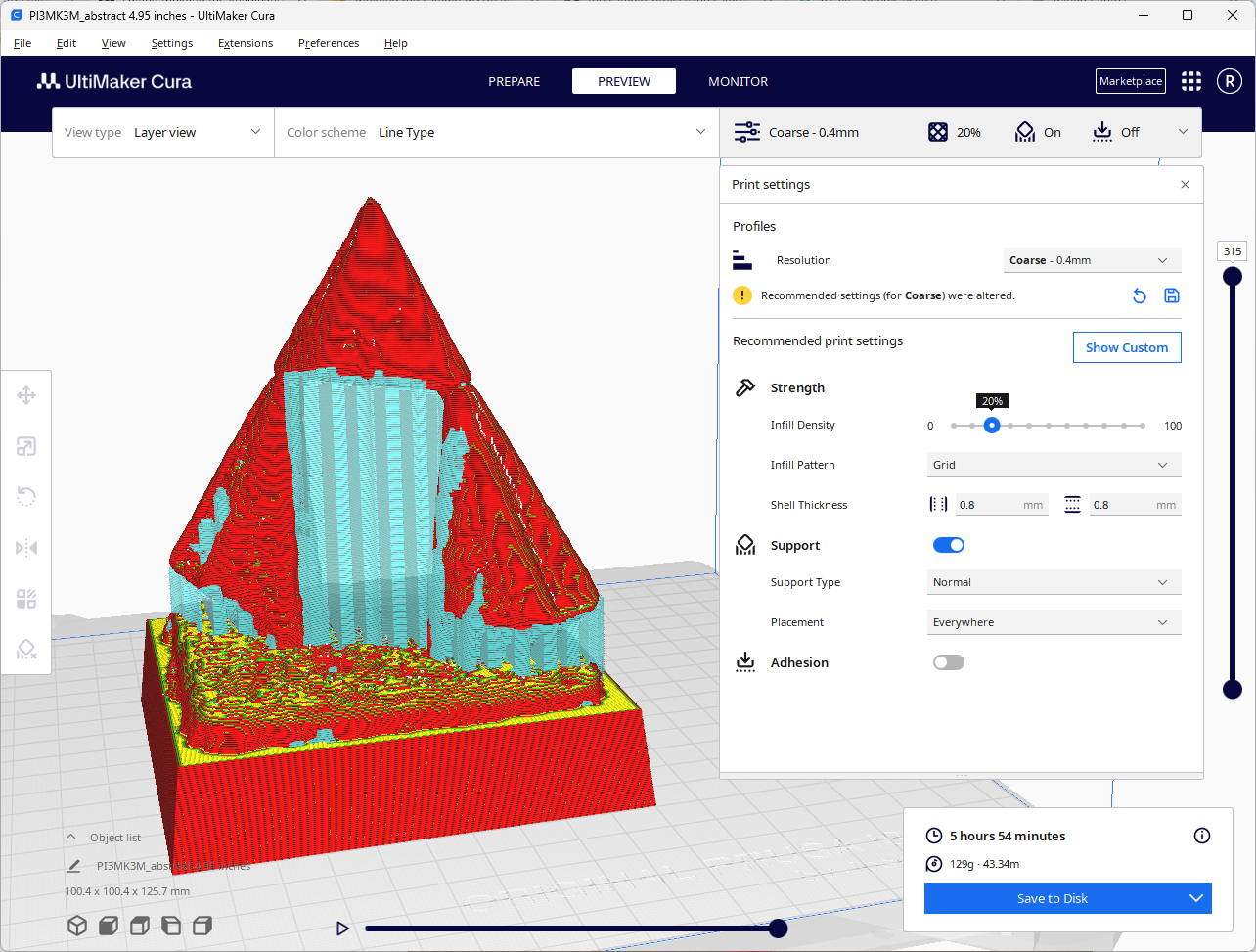


Cura 切片软件的用户界面(左),Hatch Makerspace 的 Prusa 3D 打印机(中),带支撑物的 3D 打印(右),作者提供的图片
上面的图片显示了我在 Cura 切片软件中使用的设置、正在进行的构建以及在我去除支撑物之前的成品。下面是成品的照片。

完成的 3D 打印几何雕塑,作者提供的图片
这个打印效果也很好。表面的纹理非常凹凸不平,你可以看到一些支撑物的残留。但总体上看起来不错。如果我再次打印它,我会只使用连接到构建板上的树状支撑物。
现在我已经向你展示了如何使用 AI 创建四个 3D 对象,接下来我将讨论两个重要的方面:使用 AI 生成的 3D 对象的社会影响以及我使用的系统的所有权利。
3D 对象生成系统的社会影响
MVDream 的社会影响
MVDream 的创建者在他们的论文中讨论了该模型的社会影响。
本文提出的多视角扩散模型旨在促进游戏和媒体行业广泛需求的3D生成任务。我们注意到,它也有可能被第三方进行微调,用于生成暴力和性内容。基于稳定扩散模型[4],它可能会继承偏见和限制,从而生成不需要的结果。因此,我们认为使用我们的方法合成的图像或模型应该经过仔细检查,并被标记为合成的。这样的生成模型也有可能通过自动化来取代创意工作者。话虽如此,这些工具也可能促进创意产业的增长和提高可访问性。— Yichun Shi 等 [2]
在探索文本到3D模型的社会影响时,我们必须谨慎权衡利用人工智能创新潜力和应对伴随其崛起而带来的伦理、文化和经济影响之间的平衡。
3D对象生成系统的所有权
所有权是媒体生成的重要方面,需要对每个工具的服务条款进行彻底审查,以了解授予创作者的权利。
Midjourney 用户的所有权
Midjourney 最近修改了其关于使用其服务生成的图像所有权的政策。该公司过去要求用户付费订阅才能拥有他们创建的图像。但对于个人用户,这一政策已经放宽。这是他们的更新政策。
您在使用服务时创建的所有资源(Assets)在适用法律允许的最大范围内归您所有。但也有一些例外:
- 您的所有权受本协议和任何第三方权利所施加的义务限制。
- 如果您是年收入超过100万美元的公司或任何该类公司的雇员,您必须订阅“Pro”或“Mega”计划才能拥有您的资源。
- 如果您放大了其他人的图像,则这些图像仍由原始创作者拥有。— Midjourney
因此,个人用户将拥有他们创建的图像。但如果您在一家年收入超过100万美元的公司工作,您必须支付每月60美元才能拥有您的图像。有关定价的详细信息在这里。
3dMaker.AI 用户的所有权
在使用 3dMaker.AI 时,所有权非常简单。该网站上的常见问题解答(FAQ)中写道:“从 3dMaker.AI 生成的模型完全属于您。”您不需要律师来解释这个!😊
总结
在我的项目中,我尝试使用商业和开源的人工智能工具将想法转化为可3D打印的对象。从使用 Midjourney 生成2D图像,然后使用 3dMaker.ai 将其转换为3D模型,我探索了从数字构思到物理创作的创作过程。开源模型如 Shape-E、MVDream 和 threestudio 进一步扩展了可能性,允许直接进行文本到3D的转换。
该过程涉及在 Blender 中对生成的模型进行优化,为打印做准备,然后使用当地图书馆的3D打印机将其实体化。这个过程展示了人工智能和3D打印技术的技术进步,并强调了考虑这些新兴工具的社会影响和了解所有权的重要性。
在创建和打印3D对象的过程中,该项目突显了创新和可访问性在该领域的融合,引发了对在创意过程中使用人工智能的伦理和实际影响的思考。
源代码
我在GitHub上发布了该项目的源代码。我还在Sketchfab和Thingiverse上发布了3D设计。我将代码和设计发布在知识共享署名-相同方式共享许可下。

知识共享署名-相同方式共享
致谢
我感谢 Jennifer Lim 对本文进行审查并提供反馈。我还要感谢 Waltham 公共图书馆 Makerspace、Watertown 免费公共图书馆的 Hatch Makerspace 和 Woburn 公共图书馆的工作人员,他们在打印本文中的物体时提供了帮助。
参考文献
[1] Heewoo Jun 和 Alex Nicho, Shap·E: Generating Conditional 3D Implicit Functions (2023)
[2] Yichun Shi 等,MVDream: Multi-view Diffusion for 3D Generation(2023)
[3] Ying-Tian Liu 等,threestudio: a modular framework for diffusion-guided 3D generation (2023)
[4] Rombach 等,High-Resolution Image Synthesis with Latent Diffusion Models (2022)


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











