







 本文详细分析了稀疏专家混合模型(MoE)中的SwitchTransformer,一种在大型语言模型中实现显著性能提升的技术。通过硬路由机制,SwitchTransformer在保持计算复杂度不变的同时,大幅提升了模型的扩展性和训练速度。
本文详细分析了稀疏专家混合模型(MoE)中的SwitchTransformer,一种在大型语言模型中实现显著性能提升的技术。通过硬路由机制,SwitchTransformer在保持计算复杂度不变的同时,大幅提升了模型的扩展性和训练速度。
稀疏专家混合模型的崛起:Switch Transformer
深入探讨为当今行业中最强大的LLM铺平道路的技术

使用Dall-E生成的图片
稀疏专家混合模型(MoE)已成为最新一代LLM(大型语言模型)的关键技术,如OpenAI的GPT-4、Mistral AI的Mixtral-8x7等。简而言之,稀疏MoE是一种非常强大的技术,因为理论上它允许我们以O(1)的计算复杂度扩展任何模型的容量!
然而,通常情况下,魔鬼在细节中,要使稀疏MoE正常工作,需要准确把握这些细节。
在本文中,我们将深入研究稀疏MoE领域的一个关键贡献,即Switch Transformer(Fedus et al 2022),它首次展示了这种技术可以实现令人印象深刻的扩展性能,训练Transformer模型的速度提高了7倍。我们将涵盖以下内容:
- 硬路由:仅对每个标记执行单个专家的有利扩展性质,
- Switch Transformer架构:MoE如何适应Transformer架构的更广泛背景,
- 标记路由动态:如何使用容量因子在计算效率和建模准确性之间进行权衡,以及
- 实证结果:Switch Transformer的令人印象深刻的扩展性能。
让我们开始吧。
硬路由
作为提醒,MoE的关键思想是使用专家E(x)的线性组合来对给定输入x建模输出y,每个专家的权重由门控G(x)控制,
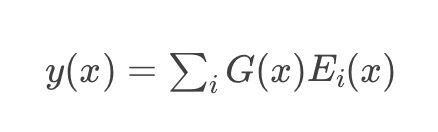
其中门控是输入x与可学习权重矩阵W相乘的softmax:

在训练MoE模型时,学习目标是双重的:
- 专家将学习将给定的输入处理成最佳输出(即预测),
- 门控将学习通过学习矩阵W将正确的训练样本分配给正确的专家。
这种最初的MoE公式可以追溯到30多年前Geoffrey Hinton在90年代的原始工作,如今被称为软路由。之所以称为“软路由”,是因为即使不同的专家可能具有非常不同的权重(其中一些几乎不可察觉),我们仍然将所有专家的输出组合在最终结果中,无论他们的贡献有多小。
相比之下,在硬路由中,我们仅对由门控确定的最合适的单个专家进行前向传递,即我们近似执行
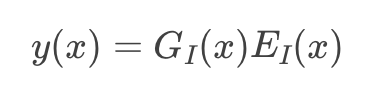
其中i是使G最大化的索引。
这种方法的动机是在一定程度上牺牲建模准确性以换取大量的计算成本节省:如果一个专家的权重为0.01,那么对该专家进行前向传递真的值得吗?
顺便说一下,硬路由实际上是top-k路由的特例,最初由Shazeer等人(2017)提出,其中k=1。虽然Shazeer等人假设在实践中使用k=1可能效果不好,因为这会严重限制通过专家传递的梯度,但Switch Transformer证明了相反的结果。
(需要注意的是,“门控”和“路由器”这两个术语通常可以互换使用,在稀疏MoE的上下文中,它们实际上是指同一件事。)
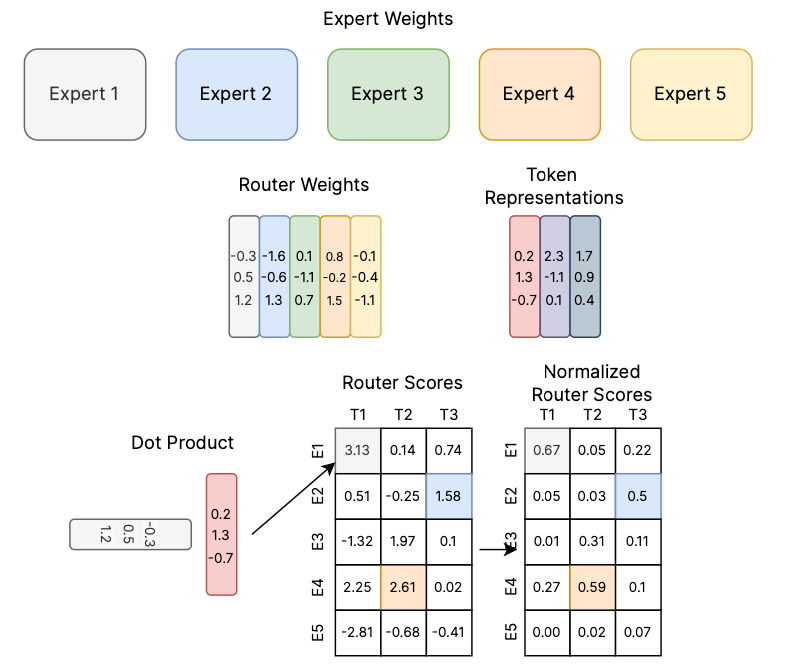
具有5个专家和3个标记的硬路由示例,每个标记具有3维嵌入。在这里,路由器将标记1分配给专家1,将标记2分配给专家4,将标记3分配给专家2。图片来自Fedus et al 2022。
Switch Transformer架构
在常规(密集)Transformer块中,我们在自注意层之上堆叠了一个前馈神经网络(FFN)层,并在它们之间使用残差连接。从高层次上看,自注意层选择模型关注的输入,FFN层处理该输入并将输出传递到下一个块,依此类推。例如,BERT-Large是一个堆叠了24个这样的Transformer块的Transformer模型。
下面是这个密集Transformer块的可视化表示:
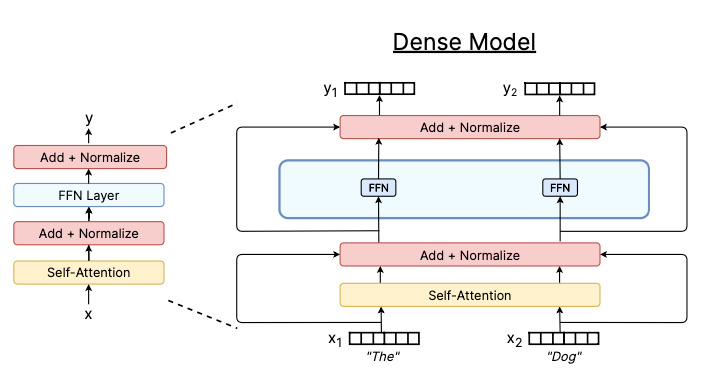
密集Transformer块。图片来源:Fedus et al 2022.
在Switch Transformer中,我们用多个FFN“专家”替换了单个FFN模块,并使用硬路由将标记分配给专家,如下所示:
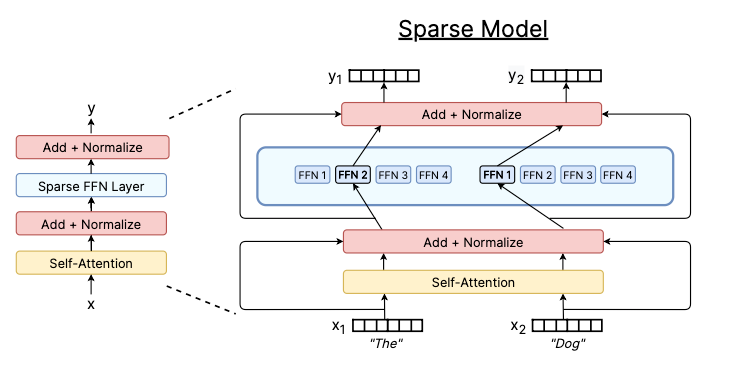
Switch Transformer中的稀疏Transformer块。图片来源:Fedus et al 2022.
最重要的是,这两种架构具有相同的计算复杂度,但后者的建模容量(即神经元数量)实际上是前者的4倍!这仅仅得益于稀疏MoE的硬路由:虽然我们现在有了4个FFN而不是一个,但在任何给定的标记中,只有一个FFN将处于活动状态。
标记路由动态和容量因子
到目前为止,我们只考虑了路由器如何在专家之间分配标记,但没有考虑这些专家实际上位于何处。在实践中,我们通常将专家分布在多台机器上,这是一种被称为专家并行的模型并行化形式。
专家并行具有一个重要的物理限制:我们不能将更多的标记路由到专家上,超过其机器内存允许的范围!
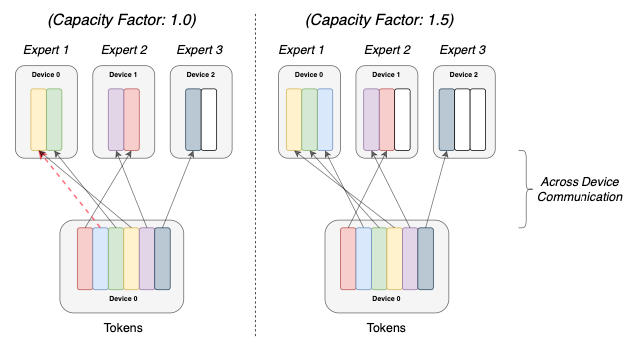
标记路由动态作为容量因子的函数。在因子为1的情况下,我们必须丢弃一个标记(红色箭头)。在因子为1.5的情况下,我们必须添加过多的填充(白色矩形)。来自Fedus et al 2022
在这种情况下,我们将专家容量定义为
容量 = f x T/E
其中T是标记数,E是专家总数,f是一个自由超参数,我们称之为容量因子。(如果我们使用k>1的top-k路由,那么我们还会在等式的右边添加一个k的因子 - 但是,由于我们在这里考虑的是使用硬路由的Switch Transformer,我们将使用k=1。)
例如,对于T=6,E=3和f=1,我们允许路由器将最多2个标记发送到每个专家,如上图左侧的面板所示。如果我们发送更多,我们将需要丢弃额外的标记,如果我们发送更少,我们将需要填充专家的输入以确保一致性 - 毕竟,可以在GPU上运行的计算图必须是静态的,不能是动态的。
因此,容量因子f引入了一个权衡:如果太大,我们会通过过多的填充浪费计算资源(这些是上图中的白色矩形)。如果太小,我们会因为丢弃标记而牺牲模型性能(如上图中的红色箭头所示)。
在Switch Transformer论文中,作者发现较低的容量因子可以获得更好的性能,例如在100k步之后,将f从2.0降低到1.0将对数困惑度从-1.554提高到-1.561。这表明,与浪费计算资源相比,我们通过丢弃标记所付出的代价并不那么严重。或者更简单地说:最好优化资源利用,即使牺牲标记丢弃的代价。
Switch Transformer的扩展性能
最重要的是,Switch Transformer可以通过增加专家数量而以近似恒定的计算复杂度进行扩展。这是因为更多的专家不会导致更多的专家前向传递 - 多亏了硬路由 - 并且当添加更多的专家时,门控需要执行的额外计算与整个模型架构相比是微不足道的,特别是与计算密集的Transformer块相比。
下图显示了通过用128个稀疏专家替换单个FFN模块,作者能够达到与T5语言模型相同的性能,但速度提高了7倍!所有这些模型都在相同的机器上进行训练,即32个TPUv3核心,每个训练样本的FLOPs相等。
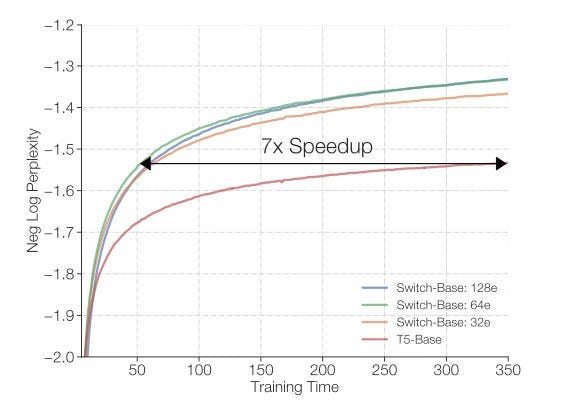
Switch Transformer通过硬路由实现了7倍的加速,同时保持恒定的计算复杂度。
乍一看,这看起来像是魔术。在相同的FLOPs下,如何能够以更快的速度达到目的地?这就好像一辆汽车以相同的速度行驶,却以7倍的速度到达目的地!
答案是,再次,Switch Transformer利用了稀疏性,特别是稀疏MoE。虽然我们通过增加更多的专家增加了建模容量,但由于硬路由,我们保持了FLOPs的恒定 - 也就是说,在每个训练迭代中,我们实际上并不执行所有的专家,而只执行最适合的专家。
总结
让我们回顾一下:
- 稀疏MoE是一项开创性的技术,因为它允许我们以约O(1)的计算复杂度扩展建模容量,并实现了Google的Switch Transformer、OpenAI的GPT-4、Mistral AI的Mixtral-8x7b等突破性进展。
- Switch Transformer 将 T5 Transformer 中的 FFN 层替换为使用硬路由的稀疏 MoE 层。
- 容量因子决定了每个专家允许处理多少个标记,是在权衡标记丢弃和机器利用率之间进行交换的杠杆。实验证明,即使牺牲标记丢弃,最大化机器利用率也是要优化的正确选择。
- 由于其有利的扩展特性,Switch Transformer 在训练速度上相较于 T5(密集)Transformer 模型实现了 7 倍的加速。
虽然 Switch Transformer 在大型语言模型中取得了突破,但我相信我们才刚刚开始看到它对行业的完整影响。稀疏 MoE 所带来的强大扩展特性有潜力在各个领域的应用中带来深刻的建模改进,而不仅仅局限于大型语言模型。这是机器学习中令人兴奋的时刻!


















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











