








多时间尺度 3D 卷积神经网络的步态识别
论文题目:Gait Recognition with Multiple-Temporal-Scale 3D Convolutional Neural Network
paper是北京交通大学发表在MM上的工作
论文链接:链接
ABSTRACT
步态识别是最重要和最有效的生物识别技术之一,在长距离识别系统中具有显著优势。对于现有的步态识别方法,基于模板的方法可能会丢失时间信息,而基于序列的方法不能充分利用序列之间的时间关系。为了解决上述问题,作者提出了一种新的多时间尺度步态识别框架,该框架整合了多个时间尺度的信息,同时利用了帧和区间融合信息。此外,区间级表示由局部变换模块实现。具体来说,3D卷积神经网络(3D CNN)在小时间尺度和大时间尺度上都被应用以提取时空信息。此外,还开发了一种帧池化方法来解决 3D 网络和视频帧的输入不匹配问题,并设计了一种新的 3D 基本网络块来提高效率。实验表明,基于多时间尺度 3D CNN 的步态识别方法可以实现比 CASIA-B 数据集中sota方法更好的性能。所提出的方法在正常情况下获得了 96.7% 的 rank-1 准确率,在复杂场景下的平均准确率分别优于其他方法至少 5.8% 和 11.1%。
KEYWORDS
步态识别;时空特征;局部变换
1 INTRODUCTION
步态识别是一种典型的基于步行姿势的生物识别技术。与其他生物识别技术不同,步态识别不需要subject的配合,在远距离条件下很有用,可广泛应用于视频监控和安防系统等多个领域。然而,步态识别仍然是一项具有挑战性的任务,因为它的性能受到许多复杂因素的严重影响,包括服装、携带条件、跨视角等。
通常,根据识别模型的输入类型,现有的步态识别方法可以分为两种不同的类别,如图 1(a)(b) 所示。第一种称为基于模板的模型,它通常通过压缩时间轴上的步态信息来生成步态模板。该模型中的模板可以在特征提取之前或之后生成。对于特征提取前生成的模板,通常使用步态能量图像(GEI)来提取步态特征,它是利用时间轴上的均值统计函数生成的。例如,Shiraga 等人提出了基于 2D 卷积神经网络(CNN)的 GEINet,以从 GEI 中提取空间信息。虽然步态模板可能有利于整合不固定长度的步态序列信息,但它忽略了步态序列之间的时空信息。另一方面,在许多其他方法中,步态模板也有在特征提取后生成的。例如,Chao等人提出了一个基于二维卷积的新框架,名为GaitSet,通过构建与步态集合相对应的许多模板来保留周期中的空间信息,但每个步态集中的时间信息仍然丢失。
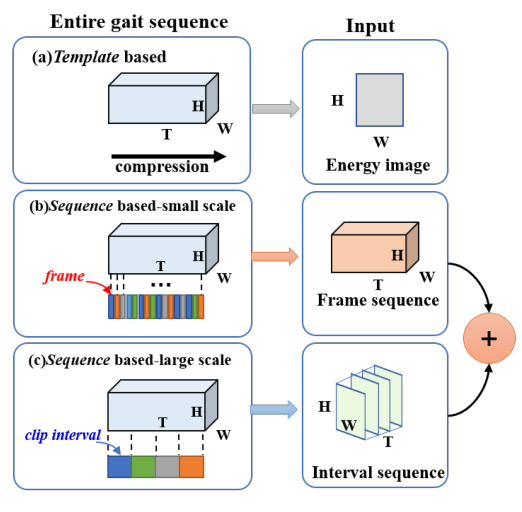
图1:步态识别不同层次的输入
与基于模板的识别方法不同,基于序列的步态识别方法使用3D CNN来提取整个步态序列的时空信息。然而,由于3D CNN需要固定长度的帧作为输入,并且聚焦于单个时间尺度,因此它不能灵活处理序列的不同长度,也不能充分表示步态。
为了解决当前步态识别方法的缺点,本文提出了一种基于多时间尺度 3D CNN 的步态识别框架,称为 MT3D。首先,作者提出了一种新的 3D CNN 模型,在序列级别具有两个不同的分支,如图 1(b)© 所示。对应于小时间尺度的第一个分支可以通过利用帧之间的关系来提取时空信息。第二个分支对应于大尺度,通过挖掘区间关系,将序列分割成片段得到。区间分支是通过局部变换实现的,可以更好地表示大规模的时间信息。通过结合这两个分支,可以整合小尺度和大尺度的时间信息。其次,为了实现提出的 MT3D 模型,作者提出了一个新的 BasicBlock3d (B3D) 模块,它可以更好、更有效地提取时空特征。具体来说,B3D 模块由两个分支组成:传统的 3D 卷积和低秩卷积。传统的3D卷积作为backbone可以从步态序列中提取时空特征,而低秩卷积作为分支可以增强backbone的特征表示。第三,作者引入了帧池化操作,可以使输入特征具有相同的长度,打破了 3D 网络输入要求的限制。因此,整个步态序列可以输入到所提出的框架中,以在测试阶段提取步态特征。最近,为了充分利用人体的信息,将人体水平分割成多个条带,然后用应用于行人重识别中的全局平均池化(GAP)和全局最大池化(GMP)操作。受上述操作成功的启发,本文采用相同的特征映射策略来尽可能地保留人类步态信息。
该方法的主要贡献总结如下。
-
本文提出了一种基于多时间尺度 3D CNN 的新型步态识别方法 MT3D,该方法同时采用 3D CNN 提取时空特征,并使用多时间尺度框架来整合小尺度和大尺度时间信息。具体而言,将BasicBlock3D模块作为基本的3D CNN块,使用局部变换模块来实现所提出的3D CNN模型的大尺度区间分支。
-
引入帧池化算法进行标准化。帧池化操作用于使输入序列具有相同的长度,从而使模型拟合不同长度的视频。对于特征映射,利用 GAP 和 GMP 操作生成多个水平特征分量,提高特征表示能力。
-
所提出的方法可以实现最佳性能,并且在公共数据集 CASIA-B 和 OUISIR 上优于大多数最先进的步态识别方法。MT3D在服装、携带等复杂条件下具有显著优势。
2 RELATED WORK
2.1 Gait Recognition
从时间信息层次来看,步态识别方法可以分为两类。一种是基于模板的方法,另一种是基于序列的方法。对于基于模板的方法,生成步态模板和构建网络至关重要。模板生成方法可以分为两类:一类是基于统计函数的时间池化,另一类是加权平均。Shiraga 等人使用均值的统计函数生成步态模板。Chao等人使用多个统计函数来整合时间信息。最后,他们选择 max 的统计函数来生成步态模板。Zhang等人引入长短期记忆(LSTM)单元作为注意力模块来学习每一帧的权重,加权平均将用于生成步态模板。模板可以在 CNN 之前和 CNN 之后生成。Shiraga 等人提出了基于2D卷积的GEINet,它在步态模板生成后提取空间特征,而Chao等人和Zhang等人在生成步态模板之前使用 2D CNN 提取帧级别的空间特征。然而,基于模板的方法在特征提取过程中不使用时间信息。对于基于序列的方法,3D CNN 可以从固定长度的步态序列中提取时空信息。然而,它面临着 3D 网络的输入与视频序列的不匹配问题。本文提出了一种新的3D CNN 框架,该框架遵循基于序列的多时间尺度模型,可以同时利用小时间尺度信息和大时间尺度信息。此外,还引入了一个帧池化模块来解决上述不匹配问题。
从特征表示的角度来看,步态识别方法可以分为三类。第一类基于多个摄像机捕获的 3D 步态数据构建人类 3D 模型进行表示。与单个相机捕获的 2D 步态数据相比,人体 3D 模型保留了更多的人体步态信息。虽然它具有很强的表示能力,但人体 3D 模型需要巨大的资源,这限制了它的应用。因此,现有的大部分步态识别方法都是基于二维步态数据来实现身份认证的。在这种情况下,主要考虑提高跨视角条件下的步态识别准确率。
第二类专注于解决视角变化的问题。这些方法要么提取具有较高专业知识的视角不变步态特征,要么构建视图变换模型(VTM)来归一化不同的视角。 Kusakunniran 等人提出了基于视角不变特征的步态识别框架对不同的视角进行归一化,可以通过域变换来实现。另一方面,Kusakunniran 等人利用截断奇异值分解(TSVD)技术构建视角变换模型,可以将gallery样本和probe样本的不同视角转换为相同的视角。
第三类对应于基于深度学习的方法。虽然它没有明确地对变化的视角进行建模,但基于深度学习的步态识别可以通过使用 2D 或 3D 卷积实现跨视角步态识别的出色性能。最近,各种深度神经网络已被应用于提取更稳健的步态特征。例如,Wu等人和 Shiraga 等人提出了基于CNN的步态识别框架来学习跨视角步态特征。He等人基于生成对抗网络 (GAN) 学习特定于视角的特征表示。Chao等人提出了 GaitSet算法,该算法使用 CNN 来提取无序步态集合中的帧级和集合级特征。然而,这些方法大多只提取单个模板级别或序列级别的 CNN 特征,忽略了时间信息。
2.2 3D CNN and Triplet Loss
3D CNN 已广泛应用于计算机视觉领域,并在各种应用中取得了巨大成功,例如动作识别。由于 3D CNN 可以同时提取空间和时间信息,因此可以大大提高表示能力。但是,仅使用 3D 卷积构建的 3D CNN 可能无法获得良好的性能。一方面,堆叠 3D 卷积块可能会在训练期间造成巨大的资源消耗。另一方面,过多的卷积块也会造成参数冗余。因此,许多现有方法通过将 3D 参数矩阵分解为低秩矩阵来提高性能。Tran等人引入了一个新的时空卷积块,名为 R(2+1)D。 R(2+1)D 结构可以通过将 3D 参数矩阵分解为 1D 和 2D 参数矩阵来提高性能。Qiu等人提出了 Pseudo-3D (P3D) 的网络结构,以减少模型的参数并提取更鲁棒的 3D 特征。尽管可以提取鲁棒的时空特征,但这些结构可能会导致信息丢失。本文通过结合 3D 卷积和低秩矩阵来构建 3D 网络的基本 3D 结构。以低秩结构为分支将增强 3D 卷积的能力。
作为一种生物识别技术,步态识别旨在最大化类间距离和最小化类内距离,以获得更好的识别性能。受已成功用于行人重新识别的三元组损失的启发,还选择三元组损失作为损失函数来训练本文提出的 MT3D。
3 METHOD
所提出的步态识别方法的概述如图2所示。首先提取视频中每一帧的轮廓,然后将整个轮廓序列作为输入,输入MT3D模型。模型的输出是每个样本对应的步态特征。 MT3D模型是该方法的核心,它包括一个双分支结构和几个关键组件,如BasicBlock3D、局部变换模块、帧池化等。
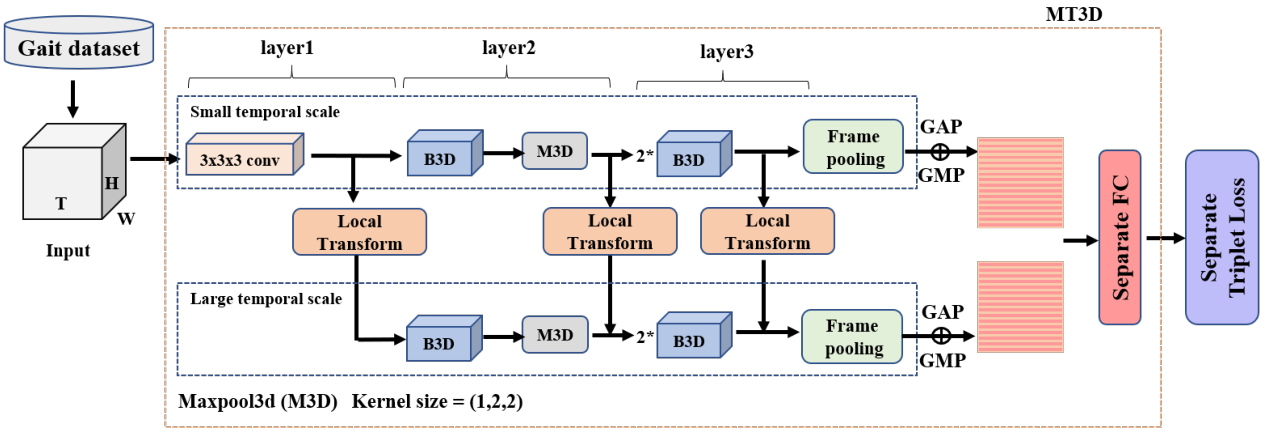
图 2:提出的 MT3D 方法概述
3.1 MT3D Framework
为了更好地利用步态序列的空间和时间信息,提出了一种新的 3D CNN 模型 MT3D,用于步态识别。首先,在序列级别构建两个分支,即小时间尺度的分支和大时间尺度的分支来构建 MT3D 结构。双分支结构的完整过程如图2所示,该结构具有以下两个优点。1.双分支结构可以充分利用不同时间尺度上的时间信息。传统的 3D CNN 模型从固定大小的剪辑中提取时空特征,而 2D CNN 模型仅提取空间特征。本文引入了帧池化操作来消除固定大小输入的限制。因此,构建了基于不同时间尺度的 3D CNN 模型,以提高特征表示能力。小时间尺度的分支可以通过利用整个序列之间的帧关系来学习更具判别性的时空特征,而大时间尺度的分支可以在序列的每个分割区间中提取更鲁棒的局部时空特征。2.这两个分支都可以通过卷积和池化等典型操作轻松实现。注意,这两个分支的结构是相似的。因此,可以将小时间尺度分支的信息多次融合到大时间尺度分支中,提高特征表示能力。
其次,介绍了几个关键组件来实现所提出的 MT3D 模型。为了构建大时间尺度分支,提出了局部变换操作,小尺度分支的信息可以自动整合到大尺度子模块中。为了更好地提取步态序列特征,将传统的 3D 卷积和 P3D 的低秩结构相结合,构建了一个新的基本 3D 模块,称为 BasicBlock3D。由于传统的 3D CNN 在训练和测试期间需要固定长度的帧作为输入,因此引入了帧池化操作来打破这一限制。
第三,本文关注特定的特征映射和损失函数,以提高特征表示能力。对于特征映射,引入 GAP 和 GMP 操作来实现步态特征映射,可以保留更多的步态信息。另一方面,选择三元组损失函数来训练提出的框架,它可以更好地衡量样本的多样性。
3.2 Local Transform
本文MT3D 的小时间尺度分支将提取整个序列的连续帧之间的时空特征。因此,该分支倾向于关注连续帧之间的强关系,而忽略局部时间间隔之间的关系。为了利用局部时间间隔之间的关系并提取步态剪辑的特征,设计了局部变换模块来聚合每个局部剪辑中的信息。给定一个序列
X
~
=
{
X
1
,
X
2
,
…
,
X
N
}
\tilde{X}=\left\{X_{1}, X_{2}, \ldots, X_{N}\right\}
X~={X1,X2,…,XN},
N
N
N是整个步态序列轮廓的长度,局部剪辑由下式生成
C
i
=
F
(
X
(
i
−
1
)
×
s
+
1
,
X
(
i
−
1
)
×
s
+
2
,
…
,
X
(
i
−
1
)
×
s
+
s
)
i
=
1
,
2
…
,
⌊
N
s
⌋
\begin{array}{r} C_{i}=F\left(X_{(i-1) \times s+1}, X_{(i-1) \times s+2}, \ldots, X_{(i-1) \times s+s}\right) \\ i=1,2 \ldots,\left\lfloor\frac{N}{s}\right\rfloor \end{array}
Ci=F(X(i−1)×s+1,X(i−1)×s+2,…,X(i−1)×s+s)i=1,2…,⌊sN⌋
其中
C
i
C_{i}
Ci定义为第
i
i
i个剪辑,
s
s
s是剪辑索引的移动步幅。同时,
s
s
s被定义为局部时间间隔内的帧长度。
F
(
⋅
)
F(\cdot)
F(⋅)表示用于融合局部剪辑中的帧信息的聚合操作,可以通过max或mean操作实现如下
F
(
⋅
)
=
α
Max
s
×
1
×
1
(
⋅
)
+
β
Mean
s
×
1
×
1
(
⋅
)
F(\cdot)=\alpha \operatorname{Max}^{s \times 1 \times 1}(\cdot)+\beta \operatorname{Mean}^{s \times 1 \times 1}(\cdot)
F(⋅)=αMaxs×1×1(⋅)+βMeans×1×1(⋅)
其中
α
\alpha
α和
β
\beta
β为 0 或 1。它也可以通过核大小
(
s
,
1
,
1
)
(s, 1,1)
(s,1,1)和步长为
(
s
,
1
,
1
)
(s, 1,1)
(s,1,1)的卷积来实现,如下式所示
F
(
⋅
)
=
c
s
×
1
×
1
(
⋅
)
F(\cdot)=c^{s \times 1 \times 1}(\cdot)
F(⋅)=cs×1×1(⋅)
通过局部变换模块,多个时间尺度分支被集成到一个可以端到端训练的统一框架中。
3.3 BasicBlock3D
最近,许多著名的块,例如ResBlock和DenseBlock被提出并作为基本单元通过堆叠生成深度神经网络。但是,如果堆叠策略直接与 3D 卷积模块配合,当通道数增加时可能会带来巨大的计算成本。此外,由于参数冗余,堆叠 3D 块可能无法实现高效的性能。受低秩结构成功的启发,本文提出了一种新的 3D 卷积模块,它由两个分支组成,称为 BasicBlock3D(B3D)。一方面,以传统的3D卷积为主干提取时空特征。另一方面,使用低秩结构作为分支,进一步提高主干的表示能力。 3D 卷积模块的概述如图 3 所示,其中 BasicBlock3D 模块旨在通过结合传统的 3D 卷积和低秩结构来学习更具判别性、稳定的时空特征。假设 X i ∈ R C i × T × H × W X_{i} \in \mathbb{R}^{C_{i} \times T \times H \times W} Xi∈RCi×T×H×W和 X i + 1 ∈ R C i + 1 × T × H × W X_{i+1} \in \mathbb{R}^{C_{i+1} \times T \times H \times W} Xi+1∈RCi+1×T×H×W是第 i i i层和第 i + 1 i+1 i+1层的输出, 其中 C i C_{i} Ci和 C i + 1 C_{i+1} Ci+1是通道数, T T T是步态序列的长度, ( H , W ) (\mathrm{H}, \mathrm{W}) (H,W)是图片大小。
首先,利用传统的 3D 卷积来构建 BasicBlock3D 的truck。传统 3D 卷积中
i
i
i层和第
i
+
1
i+1
i+1层之间的特征映射表示为:
X
i
+
1
=
c
3
×
3
×
3
(
X
i
)
X_{i+1} = c^{3 \times 3 \times 3}(X_{i})
Xi+1=c3×3×3(Xi)
其中
c
3
×
3
×
3
c^{3 \times 3 \times 3}
c3×3×3被定义为核大小为
(
3
,
3
,
3
)
(3,3,3)
(3,3,3)的卷积层。与 2D 卷积相比,传统的 3D 卷积可以同时提取空间和时间特征。然而,基于 3D 卷积构建的 3D 网络,由于参数冗余和表示能力弱,可能无法达到高性能。
其次,为了更有效和更好地利用时空,引入了低秩结构来实现 BasicBlock3D 的分支。因此,我们主要采用两种不同的低秩结构,即 P3D-A 结构和 P3D-B 结构 。P3D模型被视为BasicBlock3D的一个分支,它使用低秩矩阵代替全参数矩阵来学习更鲁棒的时空特征,有效缓解参数冗余。它带来了更多的非线性,可以表示更复杂的功能,更容易优化。图 3(b)© 显示了 P3D 模型的两种不同实现。此外,
X
i
X_{i}
Xi和
X
i
+
1
X_{i+1}
Xi+1层的特征映射设计如下:
X
i
+
1
=
c
1
×
1
×
1
(
(
c
3
×
1
×
1
(
c
1
×
3
×
3
(
X
i
)
)
)
(
5
)
X
i
+
1
=
c
1
×
1
×
1
(
(
c
1
×
3
×
3
(
X
i
)
+
c
3
×
1
×
1
(
X
i
)
)
(
6
)
\begin{gathered} X_{i+1}=c^{1 \times 1 \times 1}\left(\left(c^{3 \times 1 \times 1}\left(c^{1 \times 3 \times 3}\left(X_{i}\right)\right)\right)\right.(5) \\ X_{i+1}=c^{1 \times 1 \times 1}\left(\left(c^{1 \times 3 \times 3}\left(X_{i}\right)+c^{3 \times 1 \times 1}\left(X_{i}\right)\right)\right.(6) \end{gathered}
Xi+1=c1×1×1((c3×1×1(c1×3×3(Xi)))(5)Xi+1=c1×1×1((c1×3×3(Xi)+c3×1×1(Xi))(6)
其中式5对应于P3D-A的结构,而式6对应于P3D-B的结构。与传统的 3D 卷积不同,P3D 模型可以通过使用核大小(1×1×1)的卷积来调整通道数来减少参数冗余。此外,P3D-A 和 P3D-B 的不同结构探索了空间和时间卷积的不同组合。
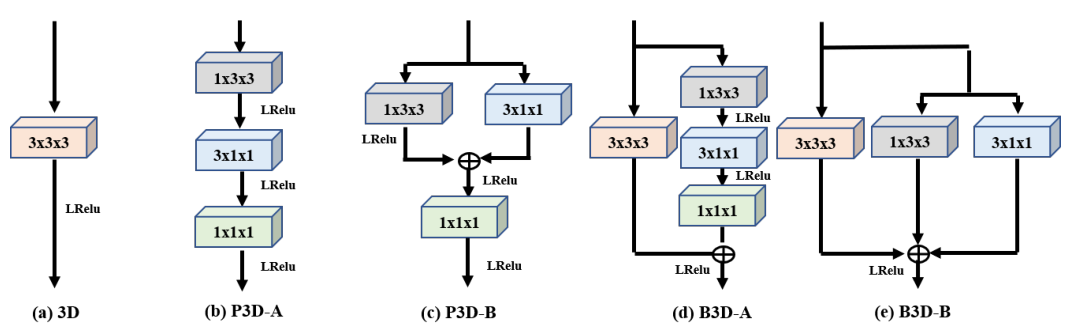
图 3:3D 卷积模块概述
最后,通过结合传统3D卷积的truck和P3D结构的分支来实现BasicBlock3D,如图3(d)(e)所示。分别选择 P3D-A 和 P3D-B 的低秩结构作为分支来增强 3D 卷积,对应的 BasicBlock3D 模型分别表示为 B3D-A 和 B3D-B。具体来说,我们去掉了 B3D-B 结构中核大小为(1×1×1)的卷积模块,可以进一步减少内存消耗。 B3D-A 和 B3D-B 的结构表示为
X
i
+
1
=
c
3
×
3
×
3
(
X
i
)
+
c
1
×
1
×
1
(
(
c
3
×
1
×
1
(
c
1
×
3
×
3
(
X
i
)
)
)
X
i
+
1
=
c
3
×
3
×
3
(
X
i
)
+
c
1
×
3
×
3
(
X
i
)
+
c
3
×
1
×
1
(
X
i
)
\begin{gathered} X_{i+1}=c^{3 \times 3 \times 3}\left(X_{i}\right)+c^{1 \times 1 \times 1}\left(\left(c^{3 \times 1 \times 1}\left(c^{1 \times 3 \times 3}\left(X_{i}\right)\right)\right)\right. \\ X_{i+1}=c^{3 \times 3 \times 3}\left(X_{i}\right)+c^{1 \times 3 \times 3}\left(X_{i}\right)+c^{3 \times 1 \times 1}\left(X_{i}\right) \end{gathered}
Xi+1=c3×3×3(Xi)+c1×1×1((c3×1×1(c1×3×3(Xi)))Xi+1=c3×3×3(Xi)+c1×3×3(Xi)+c3×1×1(Xi)
BasicBlock3D 块可以吸收传统 3D 卷积和 P3D 结构的优点,可以更好地平衡内存假设和信息完整性。
3.4 Frame Pooling and Feature Mapping
由于 3D 网络通常需要固定大小的输入,而视频的长度可能不同,因此使用帧池化来解决不匹配问题。帧池化可以通过一些统计函数来实现。假设
X
in
∈
X_{\text {in }} \in
Xin ∈
R
C
i
n
×
T
i
n
×
H
i
n
×
W
i
n
\mathbb{R}^{C_{i n} \times T_{i n} \times H_{i n} \times W_{i n}}
RCin×Tin×Hin×Win是第3层的输出,其中
C
i
n
C_{i n}
Cin是输入通道数,
T
in
T_{\text {in }}
Tin 是步态特征序列的长度,
(
H
i
n
,
W
i
n
)
\left(H_{i n}, W_{i n}\right)
(Hin,Win)是每一帧图像的大小.帧池化可以表述为:
X
out
=
α
Max
T
in
×
1
×
1
(
X
in
)
+
β
Mean
T
in
×
1
×
1
(
X
in
)
X_{\text {out }}=\alpha \operatorname{Max}^{T_{\text {in }} \times 1 \times 1}\left(X_{\text {in }}\right)+\beta \operatorname{Mean}^{T_{\text {in }} \times 1 \times 1}\left(X_{\text {in }}\right)
Xout =αMaxTin ×1×1(Xin )+βMeanTin ×1×1(Xin )
其中
α
\alpha
α和
β
\beta
β 可以是0或者1
X
out
∈
R
C
in
×
1
×
H
in
×
W
in
X_{\text {out }} \in \mathbb{R}^{C_{\text {in }} \times 1 \times H_{\text {in }} \times W_{\text {in }}}
Xout ∈RCin ×1×Hin ×Win 是帧池化的输出。
通过帧池化操作,可以得到大小固定的特征图
X
out
X_{\text {out }}
Xout 。为了使特征表示更具区分性,我们将特征图
X
out
X_{\text {out }}
Xout 划分为水平轴上的多个条带。然后,将在每个水平特征条中应用 GAP 和 GMP 操作以生成相应的水平分量。特征映射实现如下:
Y
=
Separate
f
c
(
Max
1
×
1
×
W
i
n
(
X
o
u
t
)
+
A
v
g
1
×
1
×
W
i
n
(
X
o
u
t
)
)
Y=\text { Separate }_{f c}\left(\operatorname{Max}^{1 \times 1 \times W_{i n}}\left(X_{o u t}\right)+A v g^{1 \times 1 \times W_{i n}}\left(X_{o u t}\right)\right)
Y= Separate fc(Max1×1×Win(Xout)+Avg1×1×Win(Xout))
其中
Separate
\text{Separate}
Separate
f
c
_{f c}
fc 多个独立的全连接层, 可以进一步整合通道信息。
A
v
g
1
×
1
×
W
i
n
A v g^{1 \times 1 \times W_{i n}}
Avg1×1×Win和
M
a
x
1
×
1
×
W
i
n
M a x^{1 \times 1 \times W_{i n}}
Max1×1×Win 分别代表GAP和GMP。
Y
∈
R
C
out
×
1
×
H
i
n
×
1
Y \in \mathbb{R}^{C_{\text {out }} \times 1 \times H_{i n} \times 1}
Y∈RCout ×1×Hin×1 是特征映射的输出。
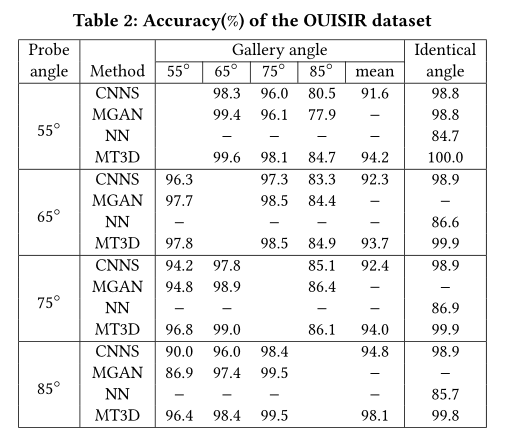
Experimental Result


















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











