







文章目录
APPENDIX
A RELATION GRAPH
在图 3 中给出了一个关系图来描述卷积、depth-wise separable convolution(depth-wise convolution + 1 × 1 1 \times 1 1×1 convolution)、Vision Transformer、Local Vision Transformer 以及多层感知器(MLP)、Separable MLP 之间的关系在稀疏连接、权重共享和动态权重方面。表 7
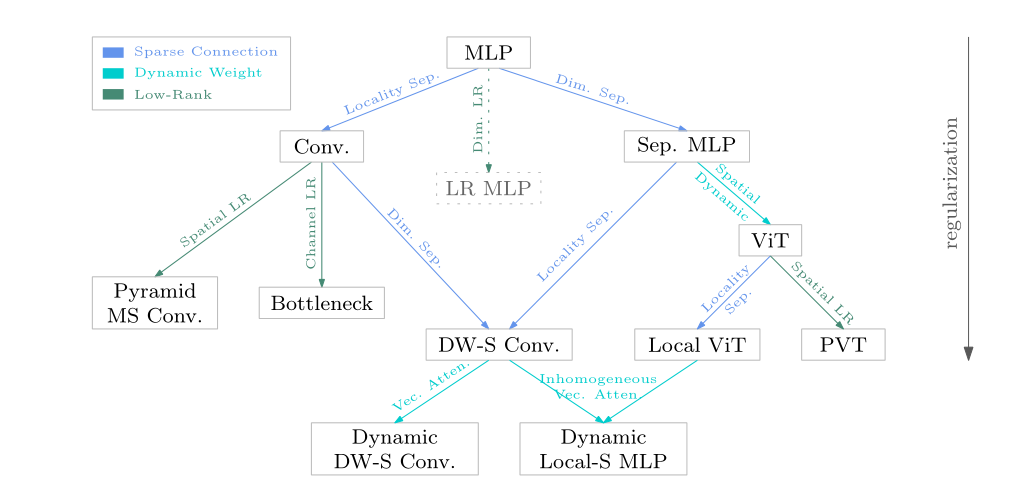
图 3:卷积 (Conv)、深度可分离卷积 (DW-S Conv)、Vision Transformer (ViT) 构建块、局部 ViT 构建块、Sep MLP(例如 MLP-Mixer 和 ResMLP)、动态深度的关系图在稀疏连通性和动态权重方面,可分离卷积(Dynamic DW-S Conv),以及动态局部可分离 MLP。 Dim = 包括空间和通道的维度,Sep = 可分离,LR = 低秩,MS Conv = 多尺度卷积,PVT = 金字塔视觉Transformer。
表 7:注意力、局部 MLP(局部注意力的非动态版本,注意力权重作为静态模型参数学习)、局部注意力、卷积、深度卷积(DW-Conv.)和动态变体( D-DW-Conv.),以及在稀疏连接、权重共享和动态权重模式方面的 MLP 和 MLP 变体。 Spatial-mixing MLP(channel-separable MLP)对应于token-mixer MLP。 ‡ 1 × 1 1\times 1 1×1转化率也称为逐点(空间可分离)MLP。 权重可能在每组通道内共享。有关连接模式的说明,请参阅图 1。
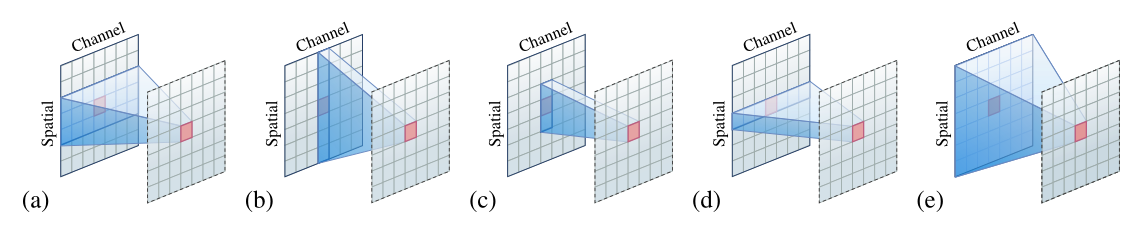
图 1:(a) 卷积、(b) 全局注意力和空间混合 MLP、© 局部注意力和深度卷积、(d) 逐点 MLP 或 1 × 1 1 \times 1 1×1卷积 (e) MLP(全连接层)。在空间维度上,为了清楚起见,使用一维来说明局部连接模式。
多层感知器 (MLP) 是一个全连接层:一层中的每个神经元(每个位置和每个通道的一个元素)都与前一层中的所有神经元相连。卷积和可分离 MLP 是 MLP 的稀疏版本。连接权重可以表示为张量(例如,3D 张量,空间的二维和通道的一维),并且张量的低秩近似可用于正则化 MLP。
卷积是一个局部连接层,通过将每个神经元连接到一个小的局部窗口中的神经元而形成,其权重在空间位置之间共享。 Depth-wise separable convolution是通过将卷积分解成两个分量形成的:一个是point-wise 1 × 1 1 \times 1 1×1卷积,将信息跨通道混合,另一个是depth-wise convolution,混合空间信息。卷积的其他变体,例如瓶颈、多尺度卷积或金字塔,可以被视为低秩变体。
可分离 MLP(例如 MLP-Mixer 和 ResMLP)将 3D 张量重塑为具有空间维度和通道维度的 2D 格式。可分离 MLP 由两个分别沿两个维度的稀疏 MLP 组成,它们是通过将输入神经元分成组而形成的。关于通道稀疏性,同一通道中的神经元组成一个组,对每组进行一次 MLP,MLP 参数在组间共享,形成第一个稀疏 MLP(空间/token混合)。通过将同一位置的神经元观察到一组来完成类似的过程,形成第二个稀疏 MLP(通道混合)。
Vision Transformer 是可分离 MLP 的动态版本。第一个稀疏 MLP(空间/token混合)中的权重是从每个实例动态预测的。 Local Vision Transformer 是 Vision Transformer 的空间稀疏版本:每个输出神经元都连接到局部窗口中的输入神经元。 PVT是 Vision Transformer 的金字塔(空间采样/低秩)变体。
深度可分离卷积也可以被视为可分离 MLP 的空间稀疏版本。在第一个稀疏 MLP(空间/token混合)中,每个输出神经元仅依赖于局部窗口中的输入神经元,形成深度卷积。此外,连接权重是跨空间位置共享的,而不是跨通道共享的。
B MATRIX FORM EXPLANATION
使用矩阵形式来解释各个层的稀疏连通性以及它们是如何通过修改 MLP 获得的。
MLP。术语MLP,即多层感知器,在任何前馈神经网络中都使用得很模糊,有时使用得很松散。采用其中一种常见的定义,并使用它来指代全连接层。讨论基于一个全连接的层,可以很容易地推广到两个或更多全连接的层。除非线性单位和其他单位外,一个主要组成部分是线性变换:
y
=
W
x
(
9
)
\mathbf{y}=\mathbf{W} \mathbf{x} \quad(9)
y=Wx(9)
其中
x
\mathbf{x}
x表示输入神经元,
y
\mathbf{y}
y表示输出神经元,
W
\mathbf{W}
W表示连接权重,例如
W
∈
R
N
C
×
N
C
\mathbf{W} \in \mathbb{R}^{N C \times N C}
W∈RNC×NC,其中
N
N
N是位置数,
C
C
C是通道数。
卷积。考虑单通道的1D情况(2D情况类似),连接权重矩阵
W
∈
R
N
×
N
\mathbf{W} \in \mathbb{R}^{N \times N}
W∈RN×N为以下稀疏形式,也称为Toeplitz矩阵(以窗口大小3为例):
W
=
[
a
2
a
3
0
0
⋯
0
a
1
a
1
a
2
a
3
0
⋯
0
0
⋮
⋮
⋮
⋮
⋱
⋮
⋮
a
3
0
0
0
⋯
a
1
a
2
]
(
10
)
\mathbf{W}=\left[\begin{array}{ccccccc} a_{2} & a_{3} & 0 & 0 & \cdots & 0 & a_{1} \\ a_{1} & a_{2} & a_{3} & 0 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ a_{3} & 0 & 0 & 0 & \cdots & a_{1} & a_{2} \end{array}\right] \quad (10)
W=⎣⎢⎢⎢⎡a2a1⋮a3a3a2⋮00a3⋮000⋮0⋯⋯⋱⋯00⋮a1a10⋮a2⎦⎥⎥⎥⎤(10)
对于
C
C
C通道的情况,按通道将输入组织成一个向量通道:
[
x
1
⊤
x
2
⊤
…
x
C
⊤
]
⊤
\left[\begin{array}{llll}\mathbf{x}_{1}^{\top} & \mathbf{x}_{2}^{\top} & \ldots & \mathbf{x}_{C}^{\top}\end{array}\right]^{\top}
[x1⊤x2⊤…xC⊤]⊤,因此对于
c
o
c_{o}
co输出通道,逐通道连接权重矩阵
W
c
o
=
[
W
c
o
1
W
c
o
2
…
W
c
o
C
]
\mathbf{W}_{c_{o}}=\left[\mathbf{W}_{c_{o} 1} \mathbf{W}_{c_{o} 2} \ldots \mathbf{W}_{c_{o} C}\right]
Wco=[Wco1Wco2…WcoC](
W
c
o
i
\mathbf{W}_{c_{o} i}
Wcoi的形式与上式相同)。整个表格可以写成
[
y
1
y
2
⋮
y
C
]
=
[
W
1
W
2
⋮
W
C
]
[
x
1
x
2
⋮
x
C
]
\left[\begin{array}{c} \mathbf{y}_{1} \\ \mathbf{y}_{2} \\ \vdots \\ \mathbf{y}_{C} \end{array}\right]=\left[\begin{array}{c} \mathbf{W}_{1} \\ \mathbf{W}_{2} \\ \vdots \\ \mathbf{W}_{C} \end{array}\right]\left[\begin{array}{c} \mathbf{x}_{1} \\ \mathbf{x}_{2} \\ \vdots \\ \mathbf{x}_{C} \end{array}\right]
⎣⎢⎢⎢⎡y1y2⋮yC⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡W1W2⋮WC⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡x1x2⋮xC⎦⎥⎥⎥⎤
Sep. MLP 。 Sep. MLP,例如 ResMLP 和 MLP-Mixer,由两种块稀疏矩阵组成:一种用于通道混合,另一种用于空间混合。在输入按通道组织的情况下(每个通道中的神经元形成一个组),
x
=
[
x
1
⊤
x
2
⊤
⋯
x
C
⊤
]
⊤
\mathbf{x}=\left[\mathbf{x}_{1}^{\top} \mathbf{x}_{2}^{\top} \quad \cdots \quad \mathbf{x}_{C}^{\top}\right]^{\top}
x=[x1⊤x2⊤⋯xC⊤]⊤,连接权重矩阵为块稀疏形式:
W
=
[
W
c
0
⋯
0
0
0
W
c
⋯
0
0
⋮
⋮
⋱
⋮
⋮
0
0
⋯
0
W
c
]
\mathbf{W}=\left[\begin{array}{ccccc} \mathbf{W}_{c} & \mathbf{0} & \cdots & \mathbf{0} & \mathbf{0} \\ \mathbf{0} & \mathbf{W}_{c} & \cdots & \mathbf{0} & \mathbf{0} \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ \mathbf{0} & \mathbf{0} & \cdots & \mathbf{0} & \mathbf{W}_{c} \end{array}\right]
W=⎣⎢⎢⎢⎡Wc0⋮00Wc⋮0⋯⋯⋱⋯00⋮000⋮Wc⎦⎥⎥⎥⎤
其中块矩阵
W
c
∈
R
N
×
N
\mathbf{W}_{c} \in \mathbb{R}^{N \times N}
Wc∈RN×N在所有通道之间共享,并且可以修改共享模式以在每组通道内共享权重。
输入可以逐个位置重塑(每个位置的神经元形成一个组):
x
=
[
x
1
⊤
x
2
⊤
⋯
x
C
⊤
]
⊤
\mathbf{x}=\left[\mathbf{x}_{1}^{\top} \mathbf{x}_{2}^{\top} \quad \cdots \quad \mathbf{x}_{C}^{\top}\right]^{\top}
x=[x1⊤x2⊤⋯xC⊤]⊤,类似地,可以用块稀疏形式表示另外一个连接权重矩阵(它本质上是一个
1
×
1
1 \times 1
1×1卷积,
W
p
∈
R
C
×
C
\mathbf{W}_{p} \in \mathbb{R}^{C \times C}
Wp∈RC×C):
W
′
=
[
W
p
0
⋯
0
0
0
W
p
⋯
0
0
⋮
⋮
⋱
⋮
⋮
0
0
⋯
0
W
p
]
\mathbf{W}^{\prime}=\left[\begin{array}{ccccc} \mathbf{W}_{p} & \mathbf{0} & \cdots & \mathbf{0} & \mathbf{0} \\ \mathbf{0} & \mathbf{W}_{p} & \cdots & \mathbf{0} & \mathbf{0} \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ \mathbf{0} & \mathbf{0} & \cdots & \mathbf{0} & \mathbf{W}_{p} \end{array}\right]
W′=⎣⎢⎢⎢⎡Wp0⋮00Wp⋮0⋯⋯⋱⋯00⋮000⋮Wp⎦⎥⎥⎥⎤
在交错组卷积中研究了块稀疏性的形式,而没有在组之间共享权重。
Sep. MLP也可以看成是用Kronecker克积来逼近连接矩阵,
W
x
=
vec
(
A
mat
(
x
)
B
)
\mathbf{W} \mathbf{x}=\operatorname{vec}(\mathbf{A} \operatorname{mat}(\mathbf{x}) \mathbf{B})
Wx=vec(Amat(x)B)
这里, W = B ⊤ ⊗ A = W c ⊤ ⊗ W p \mathbf{W}=\mathbf{B}^{\top} \otimes \mathbf{A}=\mathbf{W}_{c}^{\top} \otimes \mathbf{W}_{p} W=B⊤⊗A=Wc⊤⊗Wp。 ⊗ \otimes ⊗是Kronecker乘积算子。mat ( x ) (\mathbf{x}) (x)将向量 x \mathbf{x} x重塑为 2D 矩阵形式,而vec ( x ) (\mathbf{x}) (x)将 2D 矩阵重塑为向量形式。在 Sep. MLP 中,2D 矩阵mat ( x ) ∈ R C × N (\mathbf{x}) \in \mathbb{R}^{C \times N} (x)∈RC×N被组织成每一行对应一个通道,每一列对应一个空间位置。 CCNet和interlaced self-attention使用 Kronecker 积来逼近空间连接:前者沿 x 和 y 轴以 2D 矩阵形式重塑向量,而后者通过窗口重塑矢量窗口。
视觉Transformer (ViT)。矩阵形式类似于 Sep. MLP 。不同之处在于矩阵 W c \mathbf{W}_{c} Wc是从每个图像实例中预测的。 ViT 中的权重预测方式有一个好处:处理任意数量的输入神经元。
深度可分离卷积。有两个基本组成部分:深度卷积和
1
×
1
1 \times 1
1×1卷积,与 Sep. MLP 中的通道混合 MLP 相同。深度卷积可以写成矩阵形式:
[
y
1
y
2
⋮
y
C
]
=
[
W
11
0
⋯
0
0
W
22
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
W
C
C
]
[
x
1
x
2
⋮
x
C
]
,
\left[\begin{array}{c} \mathbf{y}_{1} \\ \mathbf{y}_{2} \\ \vdots \\ \mathbf{y}_{C} \end{array}\right]=\left[\begin{array}{cccc} \mathbf{W}_{11} & \mathbf{0} & \cdots & \mathbf{0} \\ \mathbf{0} & \mathbf{W}_{22} & \cdots & \mathbf{0} \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{0} & \mathbf{0} & \cdots & \mathbf{W}_{C C} \end{array}\right]\left[\begin{array}{c} \mathbf{x}_{1} \\ \mathbf{x}_{2} \\ \vdots \\ \mathbf{x}_{C} \end{array}\right],
⎣⎢⎢⎢⎡y1y2⋮yC⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡W110⋮00W22⋮0⋯⋯⋱⋯00⋮WCC⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡x1x2⋮xC⎦⎥⎥⎥⎤,
其中
W
c
c
\mathbf{W}_{c c}
Wcc的形式与公式 10 相同。
局部 ViT。在非重叠窗口分区的情况下,局部 ViT 只是简单地在每个窗口上单独重复 ViT,线性投影应用于键、值和查询,在窗口之间共享。在重叠的情况下,形式有点复杂,但直觉是一样的。极端情况下,分区与卷积相同,形式如下:
[
y
1
y
2
⋮
y
C
]
=
[
W
d
0
⋯
0
0
W
d
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
W
d
]
[
x
1
x
2
⋮
x
C
]
,
\left[\begin{array}{c} \mathbf{y}_{1} \\ \mathbf{y}_{2} \\ \vdots \\ \mathbf{y}_{C} \end{array}\right]=\left[\begin{array}{cccc} \mathbf{W}^{d} & \mathbf{0} & \cdots & \mathbf{0} \\ \mathbf{0} & \mathbf{W}^{d} & \cdots & \mathbf{0} \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{0} & \mathbf{0} & \cdots & \mathbf{W}^{d} \end{array}\right]\left[\begin{array}{c} \mathbf{x}_{1} \\ \mathbf{x}_{2} \\ \vdots \\ \mathbf{x}_{C} \end{array}\right],
⎣⎢⎢⎢⎡y1y2⋮yC⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡Wd0⋮00Wd⋮0⋯⋯⋱⋯00⋮Wd⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡x1x2⋮xC⎦⎥⎥⎥⎤,
其中动态权重矩阵
W
d
\mathbf{W}^{d}
Wd如下所示:
W
d
=
[
a
12
a
13
0
0
⋯
0
a
11
a
21
a
22
a
23
0
⋯
0
0
⋮
⋮
⋮
⋮
⋱
⋮
⋮
a
N
3
0
0
0
⋯
a
N
1
a
N
2
]
.
\mathbf{W}^{d}=\left[\begin{array}{ccccccc} a_{12} & a_{13} & 0 & 0 & \cdots & 0 & a_{11} \\ a_{21} & a_{22} & a_{23} & 0 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ a_{N 3} & 0 & 0 & 0 & \cdots & a_{N 1} & a_{N 2} \end{array}\right] .
Wd=⎣⎢⎢⎢⎡a12a21⋮aN3a13a22⋮00a23⋮000⋮0⋯⋯⋱⋯00⋮aN1a110⋮aN2⎦⎥⎥⎥⎤.
低秩 MLP 。低秩 MLP 使用两个低秩矩阵的乘积来逼近等式 9 中的连接权重矩阵
W
∈
R
D
o
×
D
i
\mathbf{W} \in \mathbb{R}^{D_{o} \times D_{i}}
W∈RDo×Di:
W
←
W
D
o
r
W
r
D
i
,
\mathbf{W} \leftarrow \mathbf{W}_{D_{o} r} \mathbf{W}_{r D_{i}},
W←WDorWrDi,
其中
r
r
r是一个小于
D
i
D_{i}
Di和
D
o
D_{o}
Do的数。
金字塔。金字塔网络中的下采样过程可视为空间低秩: W ( ∈ R N C × N C ) → W ′ ( ∈ R N ′ C × N ′ C ) \mathbf{W}\left(\in \mathbb{R}^{N C \times N C}\right) \rightarrow \mathbf{W}^{\prime}\left(\in \mathbb{R}^{N^{\prime} C \times N^{\prime} C}\right) W(∈RNC×NC)→W′(∈RN′C×N′C),其中在分辨率降低的情况下 N ′ N^{\prime} N′等于 N 4 \frac{N}{4} 4N乘以 1 2 \frac{1}{2} 21。如果输入和输出通道的数量不同,则变为 W ( ∈ R N C ′ × N C ) → W ′ ( ∈ R N ′ C ′ × N ′ C ) \mathbf{W}\left(\in \mathbb{R}^{N C^{\prime} \times N C}\right) \rightarrow \mathbf{W}^{\prime}\left(\in \mathbb{R}^{N^{\prime} C^{\prime} \times N^{\prime} C}\right) W(∈RNC′×NC)→W′(∈RN′C′×N′C)。
多尺度并行卷积。 HRNet中使用的多尺度并行卷积也可以看作是空间低秩。考虑四个尺度的情况,多尺度并行卷积可以形成如下:
W
→
[
W
1
∈
R
N
C
1
W
2
∈
R
N
C
2
W
3
∈
R
N
C
3
W
4
∈
R
N
C
4
]
→
[
W
1
′
∈
R
N
C
1
W
2
′
∈
R
N
4
C
2
W
3
′
∈
R
N
16
C
3
W
4
′
∈
R
N
64
C
4
]
,
\mathbf{W} \rightarrow\left[\begin{array}{l} \mathbf{W}_{1} \in \mathbb{R}^{N C_{1}} \\ \mathbf{W}_{2} \in \mathbb{R}^{N C_{2}} \\ \mathbf{W}_{3} \in \mathbb{R}^{N C_{3}} \\ \mathbf{W}_{4} \in \mathbb{R}^{N C_{4}} \end{array}\right] \rightarrow\left[\begin{array}{c} \mathbf{W}_{1}^{\prime} \in \mathbb{R}^{N C_{1}} \\ \mathbf{W}_{2}^{\prime} \in \mathbb{R}^{\frac{N}{4} C_{2}} \\ \mathbf{W}_{3}^{\prime} \in \mathbb{R}^{\frac{N}{16} C_{3}} \\ \mathbf{W}_{4}^{\prime} \in \mathbb{R}^{\frac{N}{64} C_{4}} \end{array}\right],
W→⎣⎢⎢⎡W1∈RNC1W2∈RNC2W3∈RNC3W4∈RNC4⎦⎥⎥⎤→⎣⎢⎢⎡W1′∈RNC1W2′∈R4NC2W3′∈R16NC3W4′∈R64NC4⎦⎥⎥⎤,
其中
C
1
,
C
2
,
C
3
C_{1}, C_{2}, C_{3}
C1,C2,C3和
C
4
C_{4}
C4是四种分辨率的通道数。
C LOCAL ATTENTION VS CONVOLUTION: DYNAMIC WEIGHTS
以窗口大小为 2 K + 1 2 K+1 2K+1的一维情况为例来说明动态权重预测方式。令 { x i − K , … , x i , … , x i + k } \left\{\mathbf{x}_{i-K}, \ldots, \mathbf{x}_{i}, \ldots, \mathbf{x}_{i+k}\right\} {xi−K,…,xi,…,xi+k}对应于第 i i i个窗口中的 ( 2 K + 1 ) (2 K+1) (2K+1)个位置, { w i − K , … , w i , … , w i + K } \left\{w_{i-K}, \ldots, w_{i}, \ldots, w_{i+K}\right\} {wi−K,…,wi,…,wi+K}是更新第 i i i个(中心)位置表示的相应动态权重。可以很容易地扩展到每个位置的多个权重,例如 M-head attention 和更新其他位置的表示。
非均匀动态卷积。仅使用单个线性投影的情况来说明非均匀动态卷积。将讨论的属性对于更线性的投影是相似的。动态权重预测如下:
[
w
i
−
K
⋮
w
i
⋮
w
i
+
K
]
=
Θ
x
i
=
[
θ
−
K
⊤
⋮
θ
0
⊤
⋮
θ
K
⊤
]
x
i
\left[\begin{array}{c} w_{i-K} \\ \vdots \\ w_{i} \\ \vdots \\ w_{i+K} \end{array}\right]=\Theta \mathbf{x}_{i}=\left[\begin{array}{c} \theta_{-K}^{\top} \\ \vdots \\ \theta_{0}^{\top} \\ \vdots \\ \theta_{K}^{\top} \end{array}\right] \mathbf{x}_{i}
⎣⎢⎢⎢⎢⎢⎢⎡wi−K⋮wi⋮wi+K⎦⎥⎥⎥⎥⎥⎥⎤=Θxi=⎣⎢⎢⎢⎢⎢⎢⎡θ−K⊤⋮θ0⊤⋮θK⊤⎦⎥⎥⎥⎥⎥⎥⎤xi
可以看出,动态卷积通过不同位置的不同参数来学习每个位置的权重,例如 θ k \theta_{k} θk对应 w i + k w_{i+k} wi+k。它将窗口中的位置视为向量形式,保持空间顺序信息。
点积注意力。单头情况下的点积注意力机制预测权重如下:
[
w
i
−
K
⋮
w
i
⋮
w
i
+
K
]
=
[
(
x
i
−
K
)
⊤
⋮
(
x
i
)
⊤
⋮
(
x
i
+
K
)
⊤
]
P
k
⊤
P
q
x
i
\left[\begin{array}{c} w_{i-K} \\ \vdots \\ w_{i} \\ \vdots \\ w_{i+K} \end{array}\right]=\left[\begin{array}{c} \left(\mathbf{x}_{i-K}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i+K}\right)^{\top} \end{array}\right] \mathbf{P}_{k}^{\top} \mathbf{P}_{q} \mathbf{x}_{i}
⎣⎢⎢⎢⎢⎢⎢⎡wi−K⋮wi⋮wi+K⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡(xi−K)⊤⋮(xi)⊤⋮(xi+K)⊤⎦⎥⎥⎥⎥⎥⎥⎥⎤Pk⊤Pqxi
点积注意力对所有位置使用相同的参数
P
k
⊤
P
q
\mathbf{P}_{k}^{\top} \mathbf{P}_{q}
Pk⊤Pq。权重取决于同一位置的特征,例如,
w
i
−
k
w_{i-k}
wi−k对应于
x
i
−
k
\mathbf{x}_{i-k}
xi−k。它在某种意义上将窗口中的位置视为一种集合形式,丢失了空间顺序信息。
重写如下:
Θ
d
=
[
(
x
i
−
K
)
⊤
⋮
(
x
i
)
⊤
⋮
(
x
i
+
K
)
⊤
]
P
k
⊤
P
\Theta_{d}=\left[\begin{array}{c} \left(\mathbf{x}_{i-K}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i+K}\right)^{\top} \end{array}\right] \mathbf{P}_{k}^{\top} \mathbf{P}
Θd=⎣⎢⎢⎢⎢⎢⎢⎢⎡(xi−K)⊤⋮(xi)⊤⋮(xi+K)⊤⎦⎥⎥⎥⎥⎥⎥⎥⎤Pk⊤P
从中可以看到参数
Θ
d
\Theta_{d}
Θd是动态预测的。换句话说,点积注意力可以看作是一个两级的动态方案。
相对位置嵌入等效于添加保留空间顺序信息的静态权重:
[
w
i
−
K
⋮
w
i
⋮
w
i
+
K
]
=
Θ
d
x
i
+
[
β
−
K
⋮
β
0
⋮
β
K
]
(
23
)
\left[\begin{array}{c} w_{i-K} \\ \vdots \\ w_{i} \\ \vdots \\ w_{i+K} \end{array}\right]=\Theta_{d} \mathbf{x}_{i}+\left[\begin{array}{c} \beta_{-K} \\ \vdots \\ \beta_{0} \\ \vdots \\ \beta_{K} \end{array}\right]\quad(23)
⎣⎢⎢⎢⎢⎢⎢⎡wi−K⋮wi⋮wi+K⎦⎥⎥⎥⎥⎥⎥⎤=Θdxi+⎣⎢⎢⎢⎢⎢⎢⎡β−K⋮β0⋮βK⎦⎥⎥⎥⎥⎥⎥⎤(23)
一个简单的变体是静态
Θ
\Theta
Θ和动态
Θ
d
\Theta_{d}
Θd的组合:
[
w
i
−
K
⋮
w
i
⋮
w
i
+
K
]
=
(
Θ
d
+
Θ
)
\left[\begin{array}{c} w_{i-K} \\ \vdots \\ w_{i} \\ \vdots \\ w_{i+K} \end{array}\right]=\left(\Theta_{d}+\Theta\right)
⎣⎢⎢⎢⎢⎢⎢⎡wi−K⋮wi⋮wi+K⎦⎥⎥⎥⎥⎥⎥⎤=(Θd+Θ)
卷积注意力。引入了卷积注意力框架,使其享受动态卷积和点积注意力的好处:保持空间顺序信息和两级动态权重预测。
卷积后注意力机制左乘一个矩阵(内核大小为 3):
Θ
d
=
[
a
2
a
3
0
0
⋯
0
a
1
a
1
a
2
a
3
0
⋯
0
0
⋮
⋮
⋮
⋮
⋱
⋮
⋮
a
3
0
0
0
⋯
a
1
a
2
]
[
(
x
i
−
K
)
⊤
⋮
(
x
i
)
⊤
⋮
(
x
i
+
K
)
⊤
]
P
k
⊤
P
q
\Theta_{d}=\left[\begin{array}{ccccccc} a_{2} & a_{3} & 0 & 0 & \cdots & 0 & a_{1} \\ a_{1} & a_{2} & a_{3} & 0 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ a_{3} & 0 & 0 & 0 & \cdots & a_{1} & a_{2} \end{array}\right]\left[\begin{array}{c} \left(\mathbf{x}_{i-K}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i+K}\right)^{\top} \end{array}\right] \mathbf{P}_{k}^{\top} \mathbf{P}_{q}
Θd=⎣⎢⎢⎢⎡a2a1⋮a3a3a2⋮00a3⋮000⋮0⋯⋯⋱⋯00⋮a1a10⋮a2⎦⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎡(xi−K)⊤⋮(xi)⊤⋮(xi+K)⊤⎦⎥⎥⎥⎥⎥⎥⎥⎤Pk⊤Pq
这可以看作是相对位置嵌入的一种变体(公式 23)。在左矩阵是对角矩阵的简化情况下,它可以看作是相对位置嵌入的乘积版本(公式 23 是一个加法版本)。
可以执行卷积核大小为 3,跨通道共享核权重(不共享权重也可以),然后进行点积注意力。这称为预卷积注意:对表示进行卷积。这两个过程可以写成如下(省略卷积后面的BN和ReLU),
[
w
i
−
K
⋮
w
i
⋮
w
i
+
K
]
=
[
a
1
a
2
a
3
⋯
0
0
0
0
a
1
a
1
⋯
0
0
0
⋮
⋮
⋮
⋱
⋮
⋮
⋮
0
0
0
⋯
a
2
a
3
0
0
0
0
⋯
a
1
a
2
a
3
]
[
(
x
i
−
K
−
1
)
⊤
(
x
i
−
K
)
⊤
⋮
(
x
i
)
⊤
⋮
(
x
i
+
K
)
⊤
(
x
i
+
K
+
1
)
⊤
]
P
k
⊤
P
q
[
x
i
−
1
x
i
x
i
+
1
]
[
a
2
a
3
]
\left[\begin{array}{c} w_{i-K} \\ \vdots \\ w_{i} \\ \vdots \\ w_{i+K} \end{array}\right]=\left[\begin{array}{ccccccc} a_{1} & a_{2} & a_{3} & \cdots & 0 & 0 & 0 \\ 0 & a_{1} & a_{1} & \cdots & 0 & 0 & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & \cdots & a_{2} & a_{3} & 0 \\ 0 & 0 & 0 & \cdots & a_{1} & a_{2} & a_{3} \end{array}\right]\left[\begin{array}{c} \left(\mathbf{x}_{i-K-1}\right)^{\top} \\ \left(\mathbf{x}_{i-K}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i}\right)^{\top} \\ \vdots \\ \left(\mathbf{x}_{i+K}\right)^{\top} \\ \left(\mathbf{x}_{i+K+1}\right)^{\top} \end{array}\right] \mathbf{P}_{k}^{\top} \mathbf{P}_{q}\left[\mathbf{x}_{i-1} \quad \mathbf{x}_{i} \quad \mathbf{x}_{i+1}\right]\left[\begin{array}{c} a_{2} \\ a_{3} \end{array}\right]
⎣⎢⎢⎢⎢⎢⎢⎡wi−K⋮wi⋮wi+K⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎡a10⋮00a2a1⋮00a3a1⋮00⋯⋯⋱⋯⋯00⋮a2a100⋮a3a200⋮0a3⎦⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡(xi−K−1)⊤(xi−K)⊤⋮(xi)⊤⋮(xi+K)⊤(xi+K+1)⊤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤Pk⊤Pq[xi−1xixi+1][a2a3]
它可以推广到使用普通卷积:
[
w
i
−
K
⋮
w
i
⋮
w
i
+
K
]
=
C
′
[
x
i
−
K
−
1
x
i
−
K
−
1
⋯
x
i
−
K
−
1
x
i
−
K
x
i
−
K
⋯
x
i
−
K
⋮
⋮
⋱
⋮
x
i
x
i
⋯
x
i
⋮
⋮
⋱
⋮
x
i
+
K
x
i
+
K
⋯
x
i
+
K
x
i
+
K
+
1
x
i
+
K
+
1
⋯
x
i
+
K
+
1
]
P
q
C
3
[
x
i
−
1
x
i
x
i
+
1
]
\left[\begin{array}{c} w_{i-K} \\ \vdots \\ w_{i} \\ \vdots \\ w_{i+K} \end{array}\right]=\mathbf{C}^{\prime}\left[\begin{array}{cccc} \mathbf{x}_{i-K-1} & \mathbf{x}_{i-K-1} & \cdots & \mathbf{x}_{i-K-1} \\ \mathbf{x}_{i-K} & \mathbf{x}_{i-K} & \cdots & \mathbf{x}_{i-K} \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{x}_{i} & \mathbf{x}_{i} & \cdots & \mathbf{x}_{i} \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{x}_{i+K} & \mathbf{x}_{i+K} & \cdots & \mathbf{x}_{i+K} \\ \mathbf{x}_{i+K+1} & \mathbf{x}_{i+K+1} & \cdots & \mathbf{x}_{i+K+1} \end{array}\right] \mathbf{P}_{q} \mathbf{C}_{3}\left[\begin{array}{c} \mathbf{x}_{i-1} \\ \mathbf{x}_{i} \\ \mathbf{x}_{i+1} \end{array}\right]
⎣⎢⎢⎢⎢⎢⎢⎡wi−K⋮wi⋮wi+K⎦⎥⎥⎥⎥⎥⎥⎤=C′⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡xi−K−1xi−K⋮xi⋮xi+Kxi+K+1xi−K−1xi−K⋮xi⋮xi+Kxi+K+1⋯⋯⋱⋯⋱⋯⋯xi−K−1xi−K⋮xi⋮xi+Kxi+K+1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤PqC3⎣⎡xi−1xixi+1⎦⎤
这里,
C
′
\mathbf{C}^{\prime}
C′是一个
(
2
K
+
1
)
(2 K+1)
(2K+1)行矩阵,可以很容易地从卷积核
C
3
\mathbf{C}_{3}
C3推导出来。
(
2
K
+
1
)
(2 K+1)
(2K+1)个权重
{
w
i
−
1
,
w
i
,
w
i
+
1
}
\left\{w_{i-1}, w_{i}, w_{i+1}\right\}
{wi−1,wi,wi+1}分别对应于
C
\mathbf{C}
C中的
(
2
K
+
1
)
(2 K+1)
(2K+1)行。这意味着这三个位置是有区别的,每个窗口中的相同位置对应于同一行。这解释了为什么在采用卷积时不需要位置嵌入。使用不同的对
(
W
q
,
W
k
)
\left(\mathbf{W}_{q}, \mathbf{W}_{k}\right)
(Wq,Wk)会导致每个位置有更多的权重,例如,M 对对应于 M-head attention。


















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











