









无需归一化的Transformer
paper是FAIR发布在CVPR 2025的工作
paper title:Transformers without Normalization
Code:地址
Abstract
归一化层在现代神经网络中无处不在,并长期被认为是必不可少的。本研究表明,不使用归一化的Transformer可以通过一种极其简单的技术达到甚至超过标准性能。我们提出了Dynamic Tanh(DyT),这是一种逐元素的操作 DyT ( x ) = tanh ( α x ) \operatorname{DyT}(\boldsymbol{x})=\tanh (\alpha \boldsymbol{x}) DyT(x)=tanh(αx),可以直接替代Transformer中的归一化层。DyT的灵感来自于一个观察:Transformer中的层归一化通常会产生类似tanh的、 S S S形的输入输出映射。通过引入DyT,去归一化的Transformer在大多数情况下甚至无需调参,就能达到或超过使用归一化的模型的性能。我们在多种任务中验证了DyT的有效性,涵盖了从识别到生成、从监督到自监督学习、从计算机视觉到语言建模等多个场景。这些发现挑战了“归一化层在现代神经网络中不可或缺”的传统认知,并为理解深度网络中归一化的作用提供了新的视角。
1 Introduction
在过去的十年里,归一化层已经牢牢确立了其在现代神经网络中的核心地位。这一切可以追溯到 2015 年批归一化(Batch Normalization)的发明(Ioffe 和 Szegedy,2015),它显著加快并改善了视觉识别模型的收敛速度,并在随后几年迅速获得了广泛应用。从那时起,已经提出了许多归一化层的变种,面向不同的网络结构或领域(Ba 等,2016;Ulyanov 等,2016;Wu 和 He,2018;Zhang 和 Sennrich,2019)。如今,几乎所有现代神经网络都使用归一化层,其中层归一化(Layer Normalization,简称 LN)(Ba 等,2016)尤为流行,尤其是在主导性的 Transformer 架构中(Vaswani 等,2017;Dosovitskiy 等,2020)。
归一化层被广泛采用的原因主要是其在优化方面带来的经验性优势(Santurkar 等,2018;Bjorck 等,2018)。除了能够获得更好的结果外,它们还能加速并稳定收敛。随着神经网络变得越来越宽、越来越深,这种需求变得愈加关键(Brock 等,2021a;Huang 等,2023)。因此,归一化层被广泛认为是训练深度网络所必需的,甚至是不可或缺的。这种观念也从侧面体现在一个事实中:近年来,许多新颖的网络结构尝试替代注意力层或卷积层(Tolstikhin 等,2021;Gu 和 Dao,2023;Sun 等,2024;Feng 等,2024),但几乎总是保留了归一化层。
本文通过在 Transformer 中引入一种简单的归一化层替代方案,挑战了这一主流认知。
我们的探索始于这样一个观察:LN 层将输入映射为具有类似
tanh
\tanh
tanh 的 S 型曲线的输出,即对输入激活进行缩放,同时压制极端值。受到这一观察的启发,我们提出了一种称为 Dynamic Tanh(DyT)的逐元素操作,其定义如下:
$
\operatorname{DyT}(x) = \tanh(\alpha x)
$
其中
α
\alpha
α 是一个可学习参数。该操作旨在通过学习合适的缩放因子
α
\alpha
α 并利用有界的
tanh
\tanh
tanh 函数压缩极端值,从而模拟 LN 的行为。值得注意的是,与归一化层不同,它无需计算激活统计量即可实现这两个效果。
使用 DyT 非常简单,如图 1 所示:我们直接将视觉和语言 Transformer 中原有的归一化层替换为 DyT。我们通过实验证明,在各种设置下,使用 DyT 的模型可以稳定训练,并获得与原始归一化版本相当甚至更好的最终性能。它通常不需要对原始架构的训练超参数进行调整。我们的工作挑战了“归一化层在现代神经网络中不可或缺”的传统观念,并提供了对归一化层性质的实证理解。此外,初步的测量结果表明 DyT 在训练和推理速度上具有优势,使其成为面向效率设计的网络结构中的一个有力候选方案。
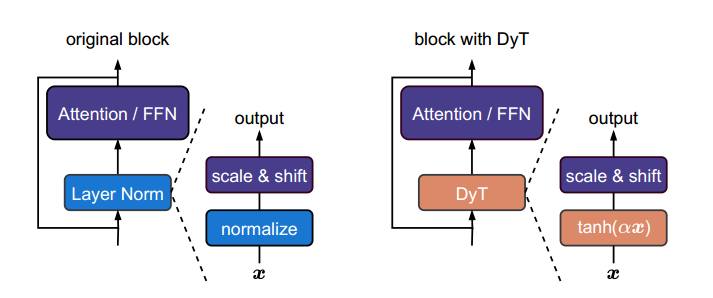
图 1 左图:原始的 Transformer 模块。 右图:我们提出的 Dynamic Tanh(DyT)模块。
DyT 是对常用层归一化(Layer Norm,Ba 等,2016)(某些情况下为 RMSNorm(Zhang 和 Sennrich,2019))层的直接替代。
使用 DyT 的 Transformer 在性能上可与使用归一化层的版本持平甚至更优。
2 Background: Normalization Layers
我们从回顾归一化层开始。大多数归一化层具有一个共同的公式。给定输入 x \boldsymbol{x} x,其形状为 ( B , T , C ) (B, T, C) (B,T,C),其中 B B B 是 batch 大小, T T T 是 token 数量, C C C 是每个 token 的嵌入维度,输出通常计算如下:
normalization ( x ) = γ ∗ ( x − μ σ 2 + ϵ ) + β \operatorname{normalization}(\boldsymbol{x})=\gamma *\left(\frac{\boldsymbol{x}-\boldsymbol{\mu}}{\sqrt{\boldsymbol{\sigma}^2+\epsilon}}\right)+\boldsymbol{\beta} normalization(x)=γ∗(σ2+ϵx−μ)+β
其中 ϵ \epsilon ϵ 是一个很小的常数, γ \boldsymbol{\gamma} γ 和 β \boldsymbol{\beta} β 是形状为 ( C , ) (C,) (C,) 的可学习向量参数。它们是“缩放”和“平移”的仿射参数,允许输出位于任意范围内。 μ \boldsymbol{\mu} μ 和 σ 2 \boldsymbol{\sigma}^2 σ2 分别表示输入的均值和方差。不同方法的主要区别在于这两个统计量的计算方式。这使得 μ \boldsymbol{\mu} μ 和 σ 2 \boldsymbol{\sigma}^2 σ2 具有不同的维度,并在计算中应用了广播机制。
Batch normalization(BN)(Ioffe 和 Szegedy,2015)是第一个现代归一化层,主要用于卷积网络模型(Szegedy 等,2016;He 等,2016;Xie 等,2017)。它的引入是深度学习架构设计中的一个重要里程碑。BN 在 batch 和 token 维度上计算均值和方差,具体如下: μ k = 1 B T ∑ i , j x i j k \mu_k=\frac{1}{B T} \sum_{i, j} x_{i j k} μk=BT1∑i,jxijk, σ k 2 = 1 B T ∑ i , j ( x i j k − μ k ) 2 \sigma_k^2=\frac{1}{B T} \sum_{i, j}\left(x_{i j k}-\mu_k\right)^2 σk2=BT1∑i,j(xijk−μk)2。
在卷积网络中流行的其他归一化层,如 group normalization(Wu 和 He,2018)和 instance normalization(Ulyanov 等,2016),最初是为目标检测和图像风格化等特定任务提出的。它们遵循相同的总体公式,但在统计量计算所涉及的轴和范围上有所不同。
Layer normalization(LN)(Ba 等,2016)和 root mean square normalization(RMSNorm)(Zhang 和 Sennrich,2019)是 Transformer 架构中最主要的两种归一化方法。LN 为每个样本中的每个 token 独立计算统计量,其中 μ i j = 1 C ∑ k x i j k \mu_{i j}=\frac{1}{C} \sum_k x_{i j k} μij=C1∑kxijk, σ i j 2 = 1 C ∑ k ( x i j k − μ i j ) 2 \sigma_{i j}^2=\frac{1}{C} \sum_k\left(x_{i j k}-\mu_{i j}\right)^2 σij2=C1∑k(xijk−μij)2。
RMSNorm(Zhang 和 Sennrich,2019)通过移除均值中心化步骤简化了 LN,其归一化方式为 μ i j = 0 \mu_{i j}=0 μij=0, σ i j 2 = 1 C ∑ k x i j k 2 \sigma_{i j}^2=\frac{1}{C} \sum_k x_{i j k}^2 σij2=C1∑kxijk2。
如今,大多数现代神经网络由于 LN 的简洁性和普适性而采用了 LN。近期,RMSNorm 越来越受到欢迎,特别是在语言模型中,如 T5(Raffel 等,2020)、LLaMA(Touvron 等,2023a,b;Dubey 等,2024)、Mistral(Jiang 等,2023)、Qwen(Bai 等,2023;Yang 等,2024)、InternLM(Zhang 等,2024;Cai 等,2024)以及 DeepSeek(Liu 等,2024;Guo 等,2025)。
我们在本工作中研究的 Transformers 均使用 LN,除了 LLaMA 使用的是 RMSNorm。
3 What Do Normalization Layers Do?
分析设置。我们首先通过实证研究归一化层在训练后网络中的行为。在本次分析中,我们使用了三个模型:一个在 ImageNet-1K(Deng et al., 2009)上训练的 Vision Transformer 模型(ViT-B)(Dosovitskiy et al., 2020),一个在 LibriSpeech(Panayotov et al., 2015)上训练的 wav2vec 2.0 Large Transformer 模型(Baevski et al., 2020),以及一个在 ImageNet-1K 上训练的 Diffusion Transformer(DiT-XL)(Peebles 和 Xie, 2023)。在这三个模型中,LN 都被应用在每一个 Transformer 块中以及最终线性投影层之前。
对于这三个训练好的网络,我们从数据集中采样一个 mini-batch,并前向传播通过整个网络。
随后,我们测量归一化层的输入和输出张量,即归一化操作前后的张量(不包括可学习的仿射变换)。由于 LN 保持输入张量的维度不变,我们可以在输入和输出之间建立一一对应关系,从而直接可视化它们的映射关系。我们将这种映射绘制在图2中。
具有 tanh 形状映射的 LayerNorm。对于这三个模型,在较早的 LN 层(图2的第1列)中,我们发现输入-输出关系大体是线性的,在 x − y x-y x−y 图中近似一条直线。然而,在更深的 LN 层中,我们观察到更有趣的现象。
一个显著的观察结果是,深层的许多曲线形状非常类似于完整或部分的 S S S 形曲线,这正是 tanh 函数的形状(见图3)。人们可能预期 LN 层只是对输入张量执行线性变换,因为减去均值再除以标准差是线性操作。LN 是按 token 独立归一化的,因此它确实线性地变换每个 token 的激活。然而,由于每个 token 的均值和标准差不同,对所有激活值而言,其线性关系整体上并不成立。尽管如此,我们仍然惊讶地发现,该非线性变换竟如此类似于一个缩放的 tanh 函数。
对于这样的 S S S 形曲线,我们注意到中间部分( x x x 接近 0 的点)仍然主要是线性形状。大多数点(约 99 % 99\% 99%)位于这个线性区间内。然而,仍然有不少点落在这个区间之外,我们称这些点具有“极值”,例如在 ViT 模型中 x > 50 x > 50 x>50 或 x < − 50 x < -50 x<−50 的值。归一化层对这些极值的主要作用是将它们压缩(squash)为较不极端的值,从而更符合大多数点的分布。这就是归一化层不能被简单仿射变换替代的原因之一。我们假设,这种对极值的非线性、非均衡压缩效应正是归一化层重要且不可或缺的根本原因。
Ni 等人(2024)的最新研究也强调了 LN 层引入的强非线性特性,并展示了这种非线性如何增强模型的表达能力。此外,这种压缩行为与生物神经元对大输入的饱和特性相似,这一现象最早约在一个世纪前被观察到(Adrian, 1926;Adrian 和 Zotterman, 1926a,b)。
按 token 和通道的归一化。LN 层是如何同时对每个 token 执行线性变换,又以非线性方式压缩极值的?为了理解这一点,我们将数据分别按 token 和通道进行分组,并可视化这些点。如图4所示,我们取图2中 ViT 模型的第二和第三个子图,选取部分点以便于展示。在左边两个图中,我们用不同颜色标示每个 token 的激活值。可以观察到,来自同一 token 的所有点确实构成了一条直线。然而,由于每个 token 的方差不同,其直线的斜率也不同。输入 x x x 范围较小的 token 通常具有较小的方差,归一化层会用较小的标准差对其除法,从而产生更大的斜率。所有 token 的集合共同形成了一条类似 tanh 函数的 S S S 形曲线。
在右边两个图中,我们用相同颜色表示每个通道的激活值。我们发现,不同通道的输入范围差异很大,只有少数几个通道(如红色、绿色和粉色)展示了明显的极值。这些就是被归一化层压缩最严重的通道。
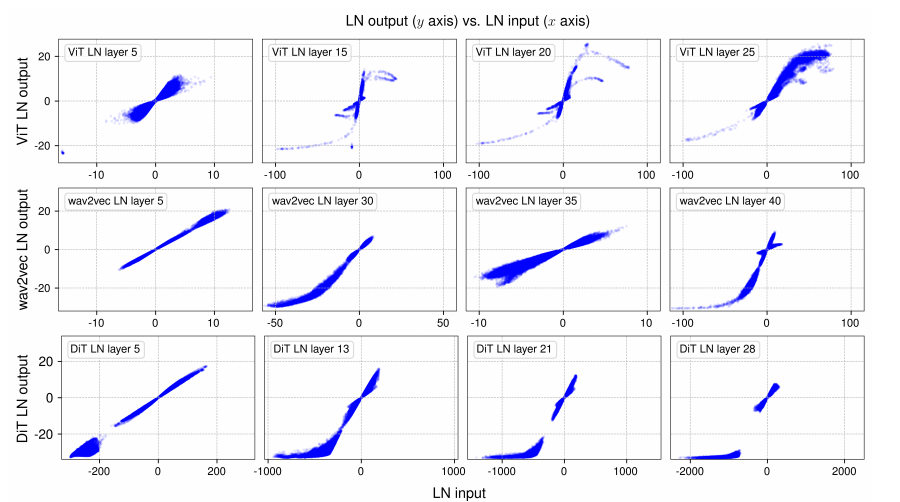
图2 Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(一种语音 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中所选的层归一化(LN)层的输出与输入关系图。我们对每个模型采样一个 mini-batch,并绘制其中四个 LN 层的输入 / 输出值。输出是在 LN 中仿射变换之前的结果。这些 S S S 形曲线与 tanh 函数的形状高度相似(参见图3)。而前层中更线性的形状也可以通过 tanh 曲线的中心部分来近似。这启发我们提出了 Dynamic Tanh(DyT)作为替代方法,并引入可学习的缩放因子 α \alpha α 来适应 x x x 轴上的不同尺度。
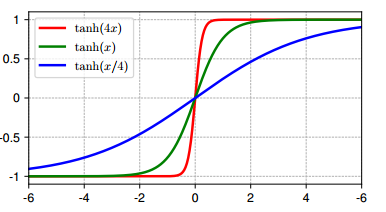
图3 tanh ( α x ) \tanh (\alpha x) tanh(αx) 在三个不同的 α \alpha α 值下的曲线。
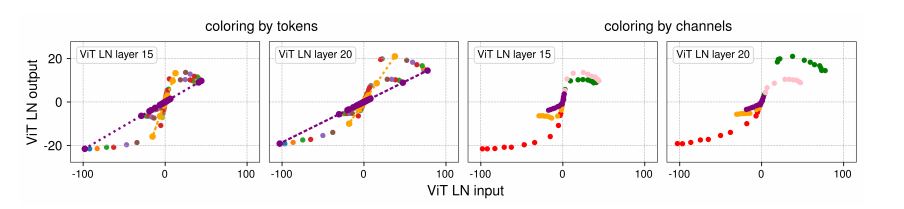
图4 两个LN层的输出与输入对比,张量元素按不同的channel和token维度上色。输入张量的形状为(samples, tokens, channels),可视化时为相同token分配相同颜色(左两图),为相同channel分配相同颜色(右两图)。
左两图:代表同一token的点(同一颜色)在不同的channel上形成直线,因为LN在每个token上是按channel线性变换的。有趣的是,当所有token的直线共同绘制时,整体呈现出非线性的tanh形状曲线。
右两图:每个channel的输入在 x x x轴上覆盖的范围不同,共同构成整体的tanh形状曲线的不同部分。某些channel(如红色、绿色、粉色)具有更极端的 x x x值,这些值被LN压缩(squash)掉。
4 Dynamic Tanh (DyT)
受到归一化层输出形状与缩放tanh函数曲线形状相似性的启发,我们提出了Dynamic Tanh(DyT),作为归一化层的可直接替换方案。给定输入张量 x \boldsymbol{x} x,DyT层定义如下:
DyT ( x ) = γ ∗ tanh ( α x ) + β \operatorname{DyT}(\boldsymbol{x})=\gamma * \tanh (\alpha \boldsymbol{x})+\boldsymbol{\beta} DyT(x)=γ∗tanh(αx)+β
其中, α \alpha α是可学习的标量参数,用于根据输入范围对输入进行缩放,适配不同的 x x x尺度(见图2)。这也是我们将该操作命名为“Dynamic” Tanh的原因。 γ \boldsymbol{\gamma} γ和 β \boldsymbol{\beta} β是可学习的、逐通道的向量参数,与所有归一化层中使用的相同——它们允许输出重新缩放到任意范围。有时这两个参数被视作单独的仿射层;但在我们的设定中,它们是DyT层的一部分,就像归一化层通常也包含这两个参数一样。DyT的Pytorch伪代码见算法1。
将DyT层集成到已有架构中非常简单:一个DyT层替代一个归一化层(参见图1)。这适用于注意力模块、前馈模块(FFN)中的归一化层以及最终输出前的归一化层。虽然DyT可能看起来像是一种激活函数,但本研究仅用于替代归一化层,不会更改原始架构中的任何激活函数(如GELU或ReLU)。网络的其他部分也保持不变。我们还观察到,原始架构中使用的超参数无需特别调整,DyT即可取得良好表现。
关于缩放参数的说明:我们始终将 γ \boldsymbol{\gamma} γ初始化为全1向量, β \boldsymbol{\beta} β初始化为全0向量,方式与归一化层相同。对于缩放器参数 α \alpha α,默认初始化为0.5通常足够,除了在LLM训练中。关于 α \alpha α初始化的详细分析见第7节。除非特别说明,后续实验中 α \alpha α均初始化为0.5。
备注:DyT不是一种新的归一化层,因为它在前向传播过程中对张量的每个输入元素独立操作,不涉及统计量或其他聚合操作。然而,它仍保留了归一化层在非线性方式压缩极值的效果,同时在输入中心区域近似保持线性变换。



















 6006
6006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











