






简介
文章主要对比了包括 VideoLLaMA 2 、CogVLM2-video 、MiniCPM-V、llava-video模型
目前主流的多模态视觉问答大模型,大部分采用视觉编码器、大语言模型、图像到文本特征的投影模块
目录
1. VideoLLaMA 2
1.1 网络结构

该部分最主要的为一个STCconnector
主要过程:
- 输入的连续图像帧进入视觉编码器中进行视觉编码
- 后进入STC connector 该部分由空间卷积(ResNet) -> 时间空间的下采样(3D卷积) -> 空间卷积(ResNet)->进行flatten操作 -> 后进入几层全连接层(Priojection W)
- 组后进入Pre-trained Large Lanuage Model(可自主选择不同的大语言模型进行拼接)
1.2 STC connector具体的架构
其中:STC connector的伪代码如下图所示:

2. MiniCPM-V 2.6
2.1 模型的主要架构

2.2 Model部分
(1)引入了一种自适应视觉编码方法,来源于 LLAVA-UHD 方法。
(2)通过分割图像、调整分辨率及压缩视觉 token 来达到高效编码的目的。
但是在实际使用的过程中,虽然模型的准确率在同量级的视觉问答大模型中,但是在推理的速度上相比还是存在较大的差距
- Image Partition(图像分割)
-
输入分辨率与预训练分辨率:
- 输入图像分辨率为 ( W I , H I ) (W_I, H_I) (WI,HI),模型的预训练分辨率为 ( W v , H v ) (W_v, H_v) (Wv,Hv)。
- 通过以下公式计算理想的切片数量:
N = W I × H I W v × H v N = \frac{W_I \times H_I}{W_v \times H_v} N=Wv×HvWI×HI
这里 N N N 是切片数量。
-
选择分割方案:
- 将图像切分为 m m m行和 n n n 列的矩形网格,满足 m × n = N m \times n = N m×n=N。
- 用以下目标函数
S
(
m
,
n
)
S(m, n)
S(m,n) 评估每种分割方案:
S ( m , n ) = − ( log W I / m W v + log H I / n H v ) S(m, n) = - \left( \log \frac{W_I / m}{W_v} + \log \frac{H_I / n}{H_v} \right) S(m,n)=−(logWvWI/m+logHvHI/n)- 该目标函数衡量切片的宽高比与预训练分辨率的偏差,越小越好。
-
最优分割方案选择
- 选择目标函数值
S
(
m
,
n
)
S(m, n)
S(m,n)最大的方案:
( m ∗ , n ∗ ) = argmax ( m , n ) ∈ C N S ( m , n ) (m^*, n^*) = \text{argmax}_{(m, n) \in C_N} S(m, n) (m∗,n∗)=argmax(m,n)∈CNS(m,n) - C N C_N CN是所有可能的 m , n m, n m,n组合集合。
- 选择目标函数值
S
(
m
,
n
)
S(m, n)
S(m,n)最大的方案:
-
实际约束
- 为减少复杂度,限制切片数量 N ≤ 10 N \leq 10 N≤10。
- 当 N N N 是质数时,允许引入更多的分割选项,如 ( N − 1 ) (N-1) (N−1) 和 ( 1 , N + 1 ) (1, N+1) (1,N+1)。
- 目标是在高分辨率(如 1344 × 1344 1344 \times 1344 1344×1344)下兼顾效率和细节。
- Slice Encoding(切片编码)
在图像被分割后,每个切片需要适配模型的输入分辨率。
-
调整切片大小
- 每个切片被调整为与 ViT 预训练分辨率 ( W v , H v ) (W_v, H_v) (Wv,Hv)相匹配。
- 调整大小时保留切片的宽高比,从而尽量减少失真。
-
位置编码调整
- ViT 的预训练位置编码是 1D 的,需要对 2D 图像重新插值:
- 原始位置编码 P 1 ∈ R q × q P_1 \in \mathbb{R}^{q \times q} P1∈Rq×q被插值为 2D 形式 P 2 ∈ R q 2 × q 2 P_2 \in \mathbb{R}^{q^2 \times q^2} P2∈Rq2×q2,以适配切片大小。
- 保留全局信息:
- 额外加入整幅图像的缩略图作为全局信息的补充。
- Token Compression(令牌压缩)
在编码切片后,每个切片会生成大量的视觉 token,这部分讨论了如何压缩这些 token。
- 问题
- 高分辨率图像会生成过多的视觉 token。
- 例如,10 个切片每个生成 1024 个 token,总计 10,240 个 token,这会导致计算负担。
- 压缩方法
- 使用一个跨层注意力(cross-attention)模块对 token 进行压缩。
- 每个切片的 token 从 1024 压缩到 64,总计 640 个 token。
- 在 MiniCPM-Llama-v2 的框架下,这种压缩方法在性能与效率之间取得了平衡。
- Spatial Schema(空间模式)
为帮助模型理解切片之间的空间关系,引入了空间标记。- 位置标记:每个切片前后加上特殊 token:
<slice>标记切片的开始,<slice_end>标记切片的结束。行与行之间用特殊 token"n"分隔。 - 全局信息 将图像整体位置编码加入输入中,帮助模型理解图像切片的全局位置关系。
- 位置标记:每个切片前后加上特殊 token:
2.3 训练过程
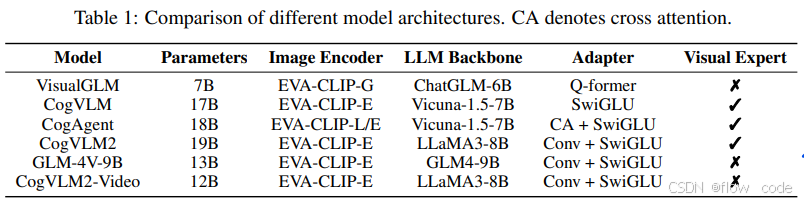
3. CogVLM2
3.1 简介
1. 增强视觉-语言融合
视觉-语言融合是视觉语言模型(VLM)训练中的一个关键议题。在2023年5月发布的VisualGLM中,研究团队采用Qformer作为唯一可训练的参数,以对齐图像和语言空间。为了在保持语言性能的前提下实现更深层次的视觉-语言对齐,该团队设计了视觉专家架构,并将其应用于CogVLM和CogVLM2(2023年10月)。为进一步促进多模态融合,他们正在积极探索文本和图像数据的混合视觉-语言训练,例如GLM-4V-9B(2024年6月)。
2. 更高分辨率的输入与高效架构
在对高分辨率图像进行理解(如细粒度图像识别和文档解析)时,通常会面临内存和计算成本过高的问题。为了解决这一挑战,研究团队在CogAgent(2023年12月)中提出了高效的高分辨率跨模块设计,使通用领域VLM的输入分辨率首次提升至1120×1120。此外,在CogVLM2、GLM-4V和CogVLM2-Video(2024年5月)的训练过程中,团队研究了后降采样方法,并发现通过2×2卷积操作降采样图像编码器的输出特征,几乎不会导致性能下降,同时有效缩短了图像序列长度。
3. 更广泛的模态和应用
随着VLM在视觉理解方面能力的不断提升,研究团队正在致力于拓展其应用场景和模态。例如,在CogVLM-grounding(2023年10月)中引入视觉定位功能,在CogAgent(2023年12月)中引入了GUI智能体功能,并计划在2024年7月发布面向视频理解的应用。
在CogVLM2-video版本中相比图像版本,其图像采样的分辨率降低。
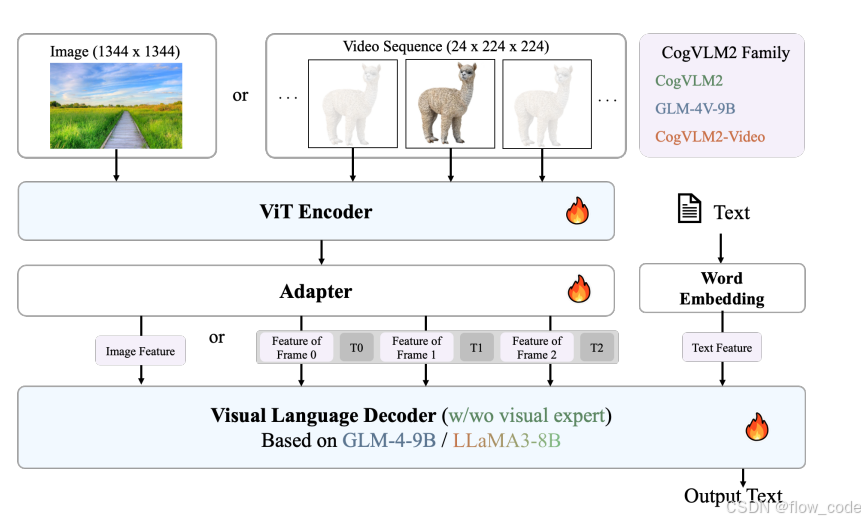
3.2 训练方法
3.2.1 数据的准备
-
Iterative Refinement 首先,初始模型在公开数据集上进行训练,然后用于重新标注一批新数据。对模型生成的注释进行细致的人工校正,以确保其准确性。修正后的数据随后将用于反复完善和增强未来版本的模型。这种迭代过程促进了训练数据的质量,从而提高模型的性能。
-
Synthetic Data Generation:大规模图像-文本数据集通常侧重于对真实图像的粗粒度自然语言描述,从而导致数据分散。例如,它们通常缺乏中文文本识别和图形用户界面图像理解的数据。为了使模型具备更多样化的基本视觉能力,我们通过根据特定规则合成数据或利用高级方法生成高质量图像-文本调色板来创建部分数据集。
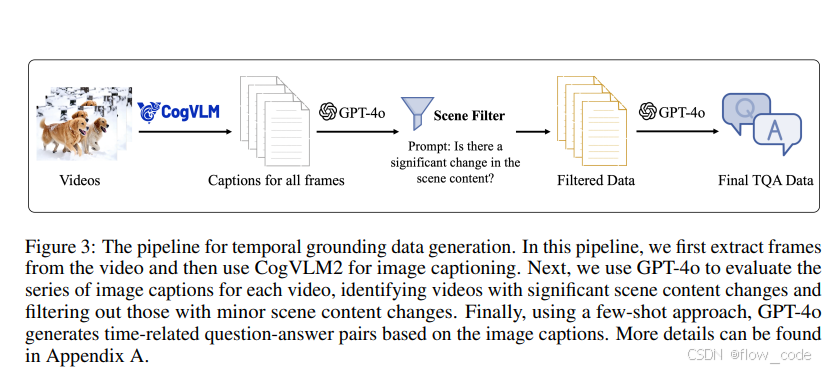
3.2.2 后训练设置总结
-
图像监督微调
- 方法:采用两阶段的监督微调(SFT)训练:
- 第一阶段:
- 使用所有视觉问答(VQA)数据集和30万条对齐语料来提升模型的基础能力。
- 参数设置:学习率为1e-5,批量大小为2340,训练3000次迭代。
- 第二阶段:
- 选取部分VQA数据集和5万条偏好对齐数据来优化输出风格。
- 参数设置:学习率为原参数的十分之一,批量大小减少至1150,训练750步。
- 第一阶段:
- 方法:采用两阶段的监督微调(SFT)训练:
-
视频监督微调
-
基础模型:基于预训练的224×224版本CogVLM2图像理解模型。
-
方法:分为两个阶段:
- 指令调优阶段:
- 使用详细标注数据和公开问答数据进行训练,提升整体视频理解能力。
- 学习率:4e-6,使用了33万条视频样本。
- 时间定位调优阶段:
- 在TQA数据集上训练,学习率为1e-6。
- 训练耗时约8小时,使用8个NVIDIA A100节点的集群。
- 指令调优阶段:
-
发布模型:
- “cogvlm2-video-llama3-base”:在指令调优阶段完成训练,适用于一般视频理解任务。
- “cogvlm2-video-llama3-chat”:在TQA数据集上进一步微调,具备时间定位能力。
-
重点总结
- 图像训练:两阶段的SFT方法提高了图像理解能力及输出风格的适配性。
- 视频训练:分阶段训练增强了视频理解和时间定位能力,并发布了两种针对不同应用的模型。
3.3 效果
CogVLM2家族:CogVLM2、CogVLM2-video、GLM-4V-9B、GLM-4V-Plus
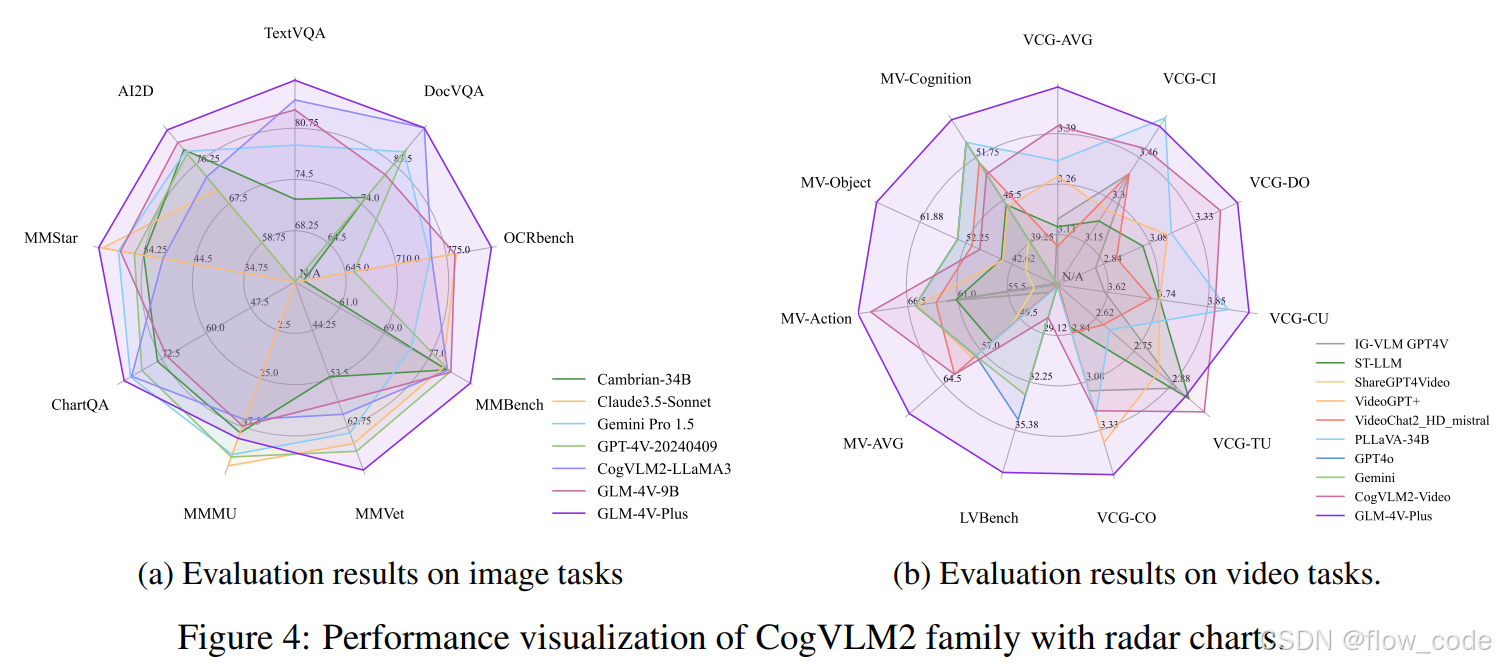
图4:CogVLM2家族性能的雷达图可视化。
(a) 图像任务评估结果
(b) 视频任务评估结果
在本节中,我们对CogVLM2家族进行评估,包括CogVLM2、CogVLM2-Video、GLM-4V-9B。在GLM-4V-9B和CogVLM2-Video的训练方案基础上,我们进一步预训练了GLM-4V-Plus,这是功能强大的内部视觉语言模型,能够进行图像和视频理解,且可在智谱MaaS平台上使用⁴。我们对CogVLM2家族进行了全面评估,涵盖了各种图像和视频理解任务,展示了其在不同视觉领域的能力。
3.3.1 图像任务评估
我们在多个图像任务上评估模型性能,并与广泛使用的大规模视觉语言模型进行对比,这些模型包括开源和专有的不同版本。详细列出了在表4中。为了全面评估我们的模型,我们选择了以下任务:
- OCR理解:TextVQA [72]、DocVQA [63]、OCRBench [46]、VCR [92]
- 图表和图形理解:ChartQA [59]、AI2D [27]
- 特定主题问答:MMMU [88]
- 常规问答:MMVet [87]、MMBench [45]、MMStar [11] 和 MME [85]
与同等参数规模的开源模型相比,CogVLM2和GLM-4V-9B在大多数任务上取得了先进的性能,甚至超越了更大规模的模型,如Mini-Gemini 34B、LLaVA-NeXT-110B,以及专有模型如QwenVL-Plus、Claude3-Opus、Gemini 1.5 Pro和GPT-4v-20231106在多个基准上的表现。
3.3.2 视频任务评估
CogVLM2-Video在多个视频问答任务上达到了先进水平。表5展示了CogVLM2-Video在以下基准上的表现:
- MVBench [35]
- VideoChatGPT-Bench [54]
- LVBench [77]
其中,MV- 指的是 MVBench 的任务*,VCG- 指的是 VideoChatGPT-Bench 的任务*。更多关于MVBench的详细信息请参考附录C。
4. Llava-Video
4.1 简介
主要贡献在于:
- 使用一种专门为视频指令跟随创建了一个高质量的合成数据集LLaVA-Video-178k
- 一种新的多模态的视频大模型架构LLaVA-Video
4.2 数据集的构建
构建此类数据集的关键因素是:在视频内容及其语言标注方面确保丰富性和多样性。
- 对现有的基准进行了全面调查,涵盖了各种公开的视频字幕和问答数据集,并从中确定了10个独特的视频来源,这些来源贡献了超过40个视频-语言基准。从这些来源中,我们选择了具有显著时间动态的视频;
- 为保持标注的多样性,建立了一个能够生成任意长度视频的详细字幕的流程;
- 定义了16种问题类型,指导GPT-4o生成问答对,以评估视频语言模型的感知和推理能力。
发现不同数据集的特点:不同的数据集侧重于不同的视频理解任务:如AGQA侧重于时空关系;STAR侧重于情境推理;
- 视频描述流程:
不同的时间粒度逐步总结视频信息。每个层级的描述如下:
- 一级描述(Level-1 Description):
- 频率:每10秒生成一次。
- 内容:描述当前10秒片段的事件。该描述基于当前片段的帧和历史上下文,包括所有尚未被总结到二级>描述中的一级描述,以及最近的二级描述。
- 特点:提供细粒度的事件描述,适合记录短时间内的视频动态。
- 二级描述(Level-2 Description):
- 频率:每30秒生成一次。
- 内容:总结到当前时间点为止的整个视频内容。该描述基于最近30秒内的三个一级描述和最新的二级描>述。
- 特点:提供中等粒度的总结,适合对较长时间段的内容进行归纳。
- 三级描述(Level-3 Description):
- 频率:在视频结束时生成。
- 内容:总结整个视频的内容。该描述基于尚未被总结的一级描述,
-视频问答
除了详细的视频描述外,我们的数据集还包含多种为复杂交互设计的问答对。这种设置提升了视频理解模型处理现实场景查询的能力。主要包含:当前问题类型的任务说明。
4.3 模型
视觉编码器部分使用SigLIP编码器,最重要的创新点Llava-Video SlowFast:
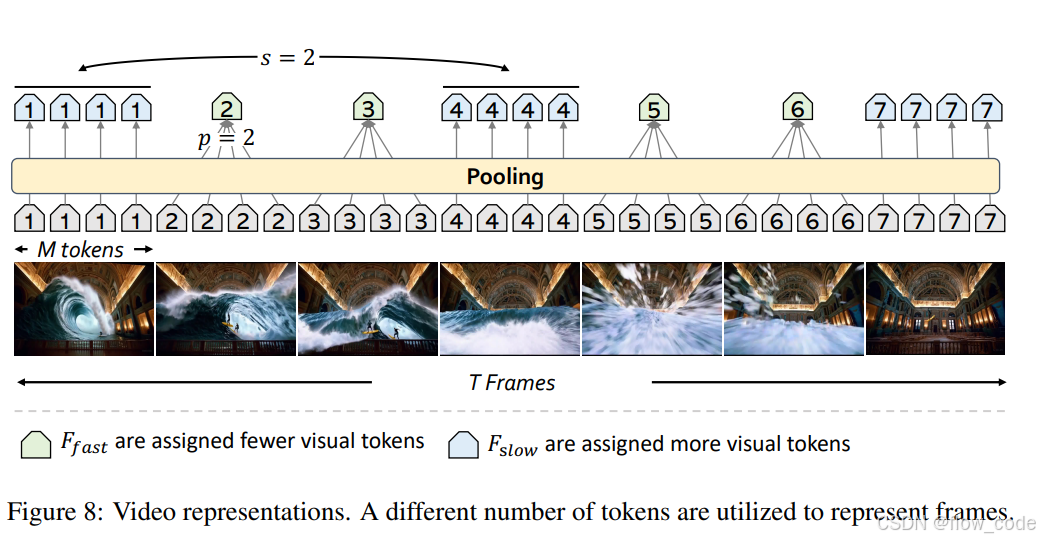
图8 展示了视频表示。不同数量的标记用于表示视频帧。
- f_fast(快速帧)分配较少的视觉标记。
- f_slow(慢速帧)分配较多的视觉标记。
在 LLaVA-Video SlowFast 模型中,将帧分为两组,基于一个采样率 s。每隔 s 帧选取一帧作为 慢速帧组(slow frame group),其余帧归为 快速帧组(fast frame group)。特殊情况 s = 1 时,仅生成一个组,这时SlowFast表示退化为原始简单表示。
对于每个组,我们使用PyTorch函数 avg_pool2d() 应用不同的池化率:
- p × p 池化用于慢速帧。
- 2p × 2p 池化用于快速帧。
参数化视频表示
我们将视频表示参数化为:
V = (T, M, s, p)。
标记总数计算公式:
#
t
o
k
e
n
s
=
⌈
T
s
⌉
×
⌈
M
p
2
⌉
+
(
T
−
⌈
T
s
⌉
)
×
⌈
M
p
2
⌉
\#tokens = \left\lceil \frac{T}{s} \right\rceil \times \left\lceil \frac{M}{p^2} \right\rceil + (T - \left\lceil \frac{T}{s} \right\rceil) \times \left\lceil \frac{M}{p^2} \right\rceil
#tokens=⌈sT⌉×⌈p2M⌉+(T−⌈sT⌉)×⌈p2M⌉
4.4 效果
以下是以第三人称进行的描述:
5 结论
本研究引入了LLaVA-Video-178K数据集,这是一个专为视频-语言指令跟随任务设计的高质量合成数据集。该数据集因其在较长且未剪辑的视频中具有密集的帧采样率而受到重视,涵盖了字幕生成、开放式问答和多项选择问答等多样化任务。研究人员通过在LLaVA-Video-178K与现有视觉指令调优数据的联合训练下,开发了一类新的模型家族LLaVA-Video。该模型家族在设计时充分考虑了视频表示,以便有效利用GPU资源,从而在训练过程中纳入更多帧。
实验结果表明,该合成数据集具有显著的效果,LLaVA-Video模型在多种视频基准任务上均取得了优异的性能。


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











