






信息时代,最不缺的是学习资源,最缺的是系统的学习资源。——于我心有戚戚焉
常有粉丝留言问我,有没有系统的、可供小白、初学者快速上手时间序列预测的学习资源——教材书籍、视频直播、或者论文都行。
我去请教了一位大佬,YY。YY大佬在TOP餐饮集团、消费品集团主持过数据科学项目,长期担任人员经理、负责新人培训,在初学者快速上手入门这块很有发言权。
大佬YY
本科:中科大少年班
研究生:柏林工业大学&皇家理工学院数学和计算机双硕
国内TOP餐饮集团数据科学项目负责人
全球TOP消费品集团数据科学项目负责人

YY给我列了一张paper list,涵盖教材和综述、机器学习算法用于时序预测、RNN用于时序预测、CNN用于时序预测、GNN用于时序预测、Transformer用于时序预测、传统统计学与深度学习结合、多层级时序预测、时序领域数据增强方法以及具体领域的时序预测案例等,计有20篇论文,是小白、初学者快速上手入门时序领域的最佳途径之一。
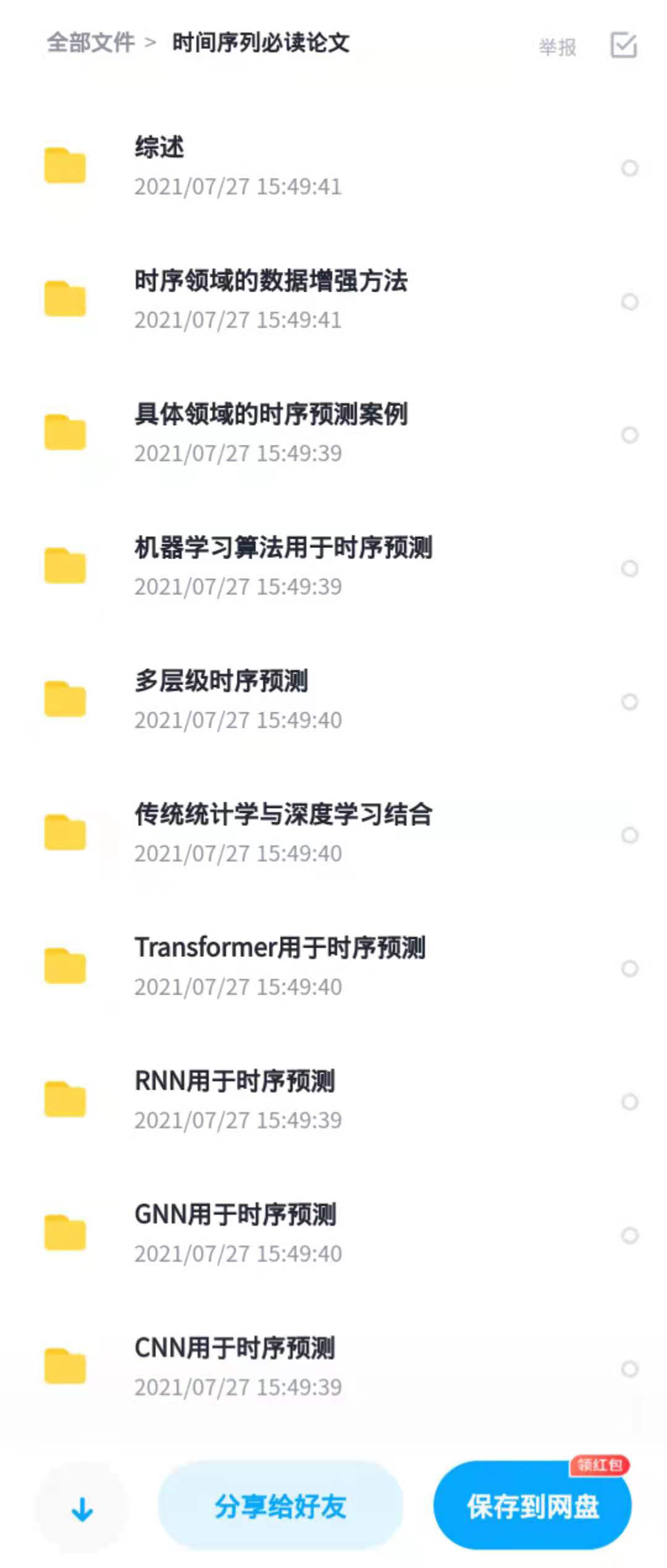
需要paper list 文档的朋友,加我微信索取。
扫码回复“时序”领取paper list 文档
????

除了paper list 打牢理论基础外,快速上手时间序列预测,更多需要项目实战的积累。时间序列预测与具体业务场景的结合非常紧密。预测对象、颗粒度、前置期、准确性指标等对于构建模型最关键的因素往往并非一目了然,只有通过对不同场景的需求进行深入分析才能找到合适解决方案。
这里我给大家推荐几个实战项目。涵盖金融、IT、新零售、供应链等当今最热的领域????
项目1
基于企业现金流预测的投资决策
项目意义:
企业经营者需要做现金流预测,以决定运营、投资、融资规划是否需要调整,保持现金收支平衡和偿债能力。
在本项目中,大家需要对不同现金池中的流入、流出现金做出预测,并且基于预测结果给出短期、中期和长期的投资决策建议。
重要知识点:
拆解业务需求、Prophet时间序列预测算法
技术方法还可以复用到的场景:
客流预测、水位预测、交通流量预测、用电量预测
项目2
AIOps实时异常检测和根因分析
项目意义:
在对互联网Web服务的运维过程中,首要需求通常是对监控的各种关键性能指标(KPI)进行异常检测,而后则需要对检测出的异常信息进行分析定位,以便尽快做进一步的修复止损等操作。由于Web服务直接影响生意,因此异常检测和根因分析需要做到实时响应。
在本场景中,大家需要搭建一个实时的异常检测和根因分析系统。当关键服务的KPI被检测到异常时,需要尽快定位到是组件最可能是根因
重要知识点:
无监督异常检测算法:基于时序预测的算法、基于时序拆解的算法、基于机器学习的算法
根因分析算法:基于决策树、基于关联规则
如何搭建实时模型服务
技术方法还可以用到的场景:
零件异常检测、水位异常检测
项目3
新零售销量预测与动态定价
项目意义:
动态定价这在日常生活中非常常见,比如购买机票、预订酒店客房、叫出租车服务和甚至到菜场买菜,所要付的费用其实并不是一成不变的,而是根据市场需求在调整。动态定价模型允许根据需求调整产品或服务的定价,以增加收益。
在本场景中,大家为某新零售便利店搭建需求预测模型,并且需要模拟商品在不同价格下的销量,从而帮助企业决定商品定价,达到收益的最大化。
重要知识点:
价格敏感度概念
时间序列预测算法:单层级预测、多层级预测、传统统计学算法融合深度学习算法
技术方法还可以用到的场景:
航班定价、电影定价
项目4
供应链需求预测和计划
项目意义:
企业供应链本质就是需要回答3W1Q的问题,即就是Where(哪里)、When(什么时候)、What(需要什么)、Quantity(需求数量)。敏捷的供应链系统离不开两个核心模块:需求预测和计划。前者用以回答市场的需求量和需求的不确定性;后者是结合需求预测、业务限制和业务目标,实现供应链的最优化。
在本场景中,大家需要搭建商品销量预测和商品补货计划系统。其中商品销量预测既包含有历史销售数据的商品,也包含没有历史数据的新品。补货计划需要涵盖区域大仓和销售终端。
重要知识点:
供应链重要概念:需求预测、多级补货、前置期、安全库存、欠品率、库存周转天数
时间序列预测算法:单层级预测、多层级预测、新品预测
运筹学算法:装箱问题、整数规划
技术方法还可以用到的场景:
人员排班计划、生产排程计划
以上4个项目全部由YY大佬指导完成。缺少项目实战经验、想积累实战项目的朋友,可以跟着YY大佬学习。感兴趣的朋友,扫下方二维码添加我。
扫码回复“时序”即可
????


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









