







我们要进行一个模型的部署,通常我们需要考虑
1、硬件的配置分析
2、llama3模型介绍
3、Model Scope在线平台部署llama3
4、在自己电脑上部署调用Llama3
Llama3介绍
Llama3是Meta于2024年4月18日开源的LLM,目前开放了8B和 70B两个版本,两个版本均支持最大为8192个token的序列长度 ( GPT-4支持128K )
Llama3在Meta自制的两个24K GPU集群上进行预训练,使用15T 的训练数据,其中5%为非英文数据,故Llama3的中文能力稍弱, Meta认为Llama3是目前最强的开源大模型。
部署硬件分析
在本地对8B版本的Llama3进行部署测试,最低硬件配置为
1. **CPU**: Intel Core i7 或 AMD 等价(至少 4 个核心)
2. **GPU**: NVIDIA GeForce GTX 1060 或 AMD Radeon RX 580 (至少 6 GB VRAM) •
3. **内存**: 至少 16 GB 的 RAM
4. **操作系统**: Ubuntu 20.04 或更高版本,或者 Windows 10 或更高版本
部署环境
总之一句话,环境用最新的即可。
Llama3的部署环境对各个包的版本需求有些严格,需要注意,否 则会报各种错误,环境列表附在最后(去最上面的github里找也可, 我环境里可能有单纯部署之外用不到的包),其中最需要注意的是 transformers的版本,需要大于4.39.0 ( 我用的4.40.1 ),
因为Llama3比较新,老版本的transformers里没有Llama3的模型 和分词器,另外就是pytorch和cuda的版本,torch 2.1.0 + cu118, 主要是transformers对cuda版本有要求,部署过程中遇到的多数 错误都是包的版本问题。
模型下载
国内访问最多的就是 ModelScope,魔塔社区
选择 Llama-3.2-1B-Instruct 1b模型。
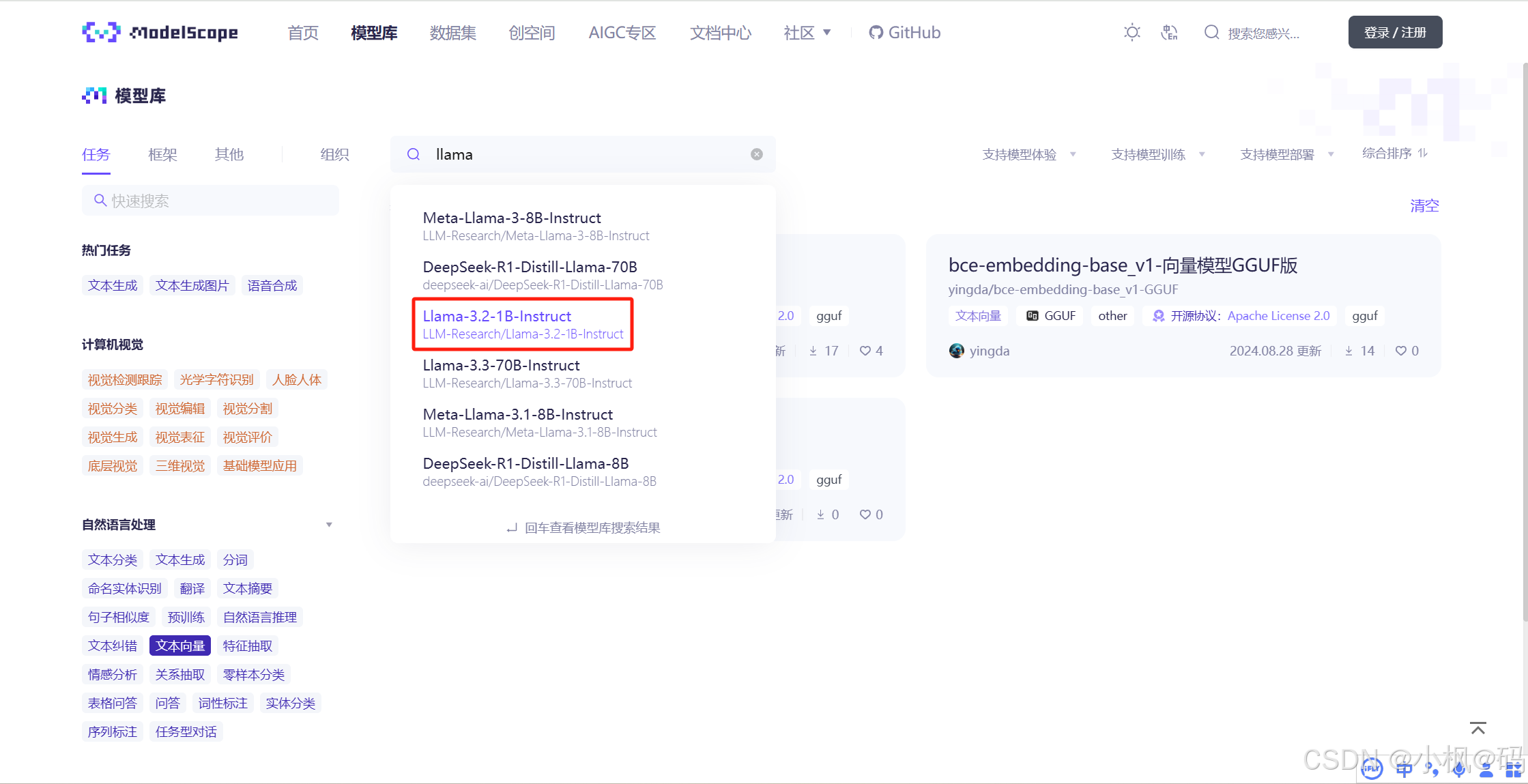
推荐使用SDK的方式来进行下载
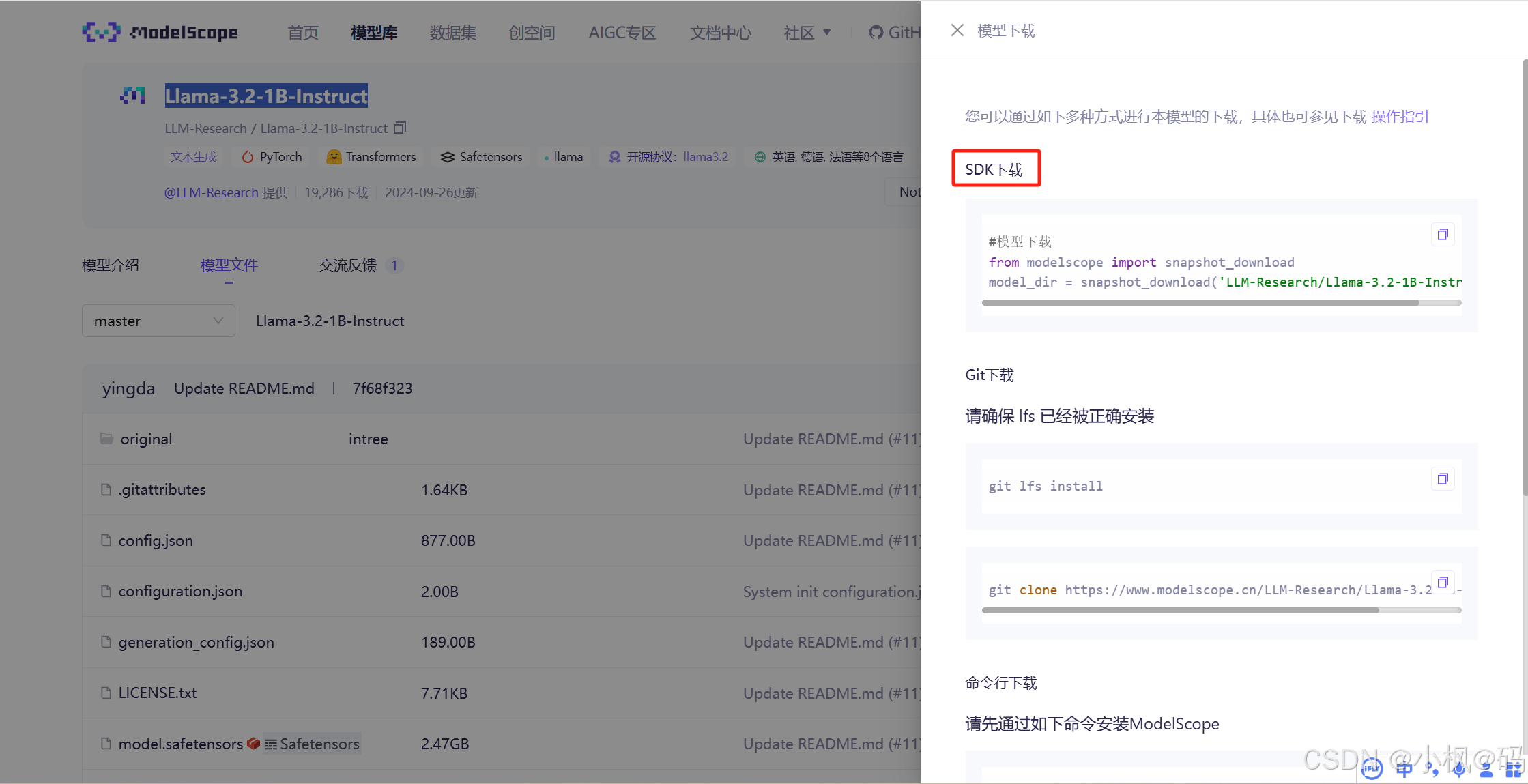
首先需要安装modelscope的平台
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
进入python命令行
#模型下载
from modelscope import snapshot_download
# 这是下载到服务器
model_dir = snapshot_download('LLM-Research/Llama-3.2-1B-Instruct',cache_dir="/root/data/")
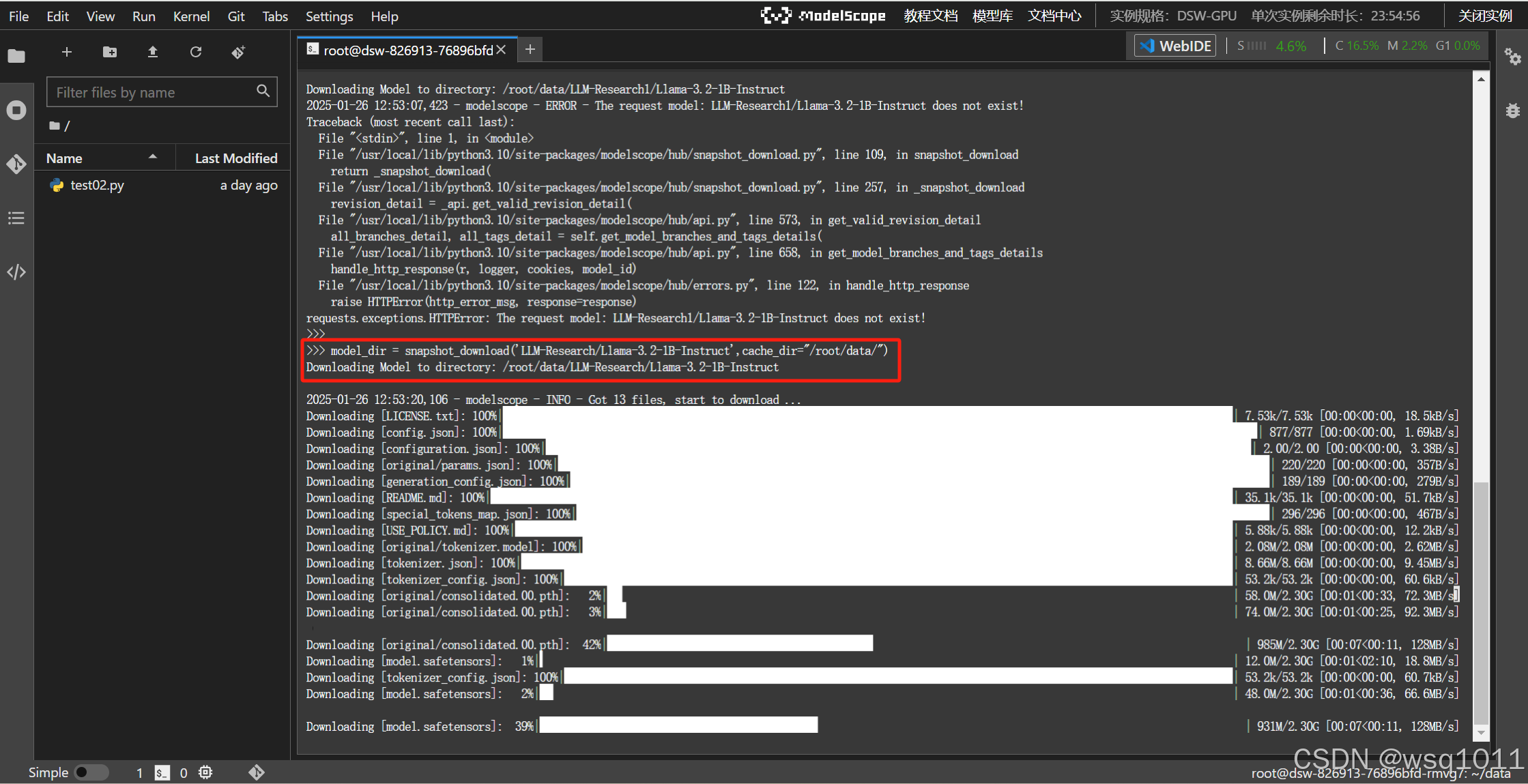
模型整体的大小权重在模型的配置文件中可以看到。
在魔塔社区服务器上下载
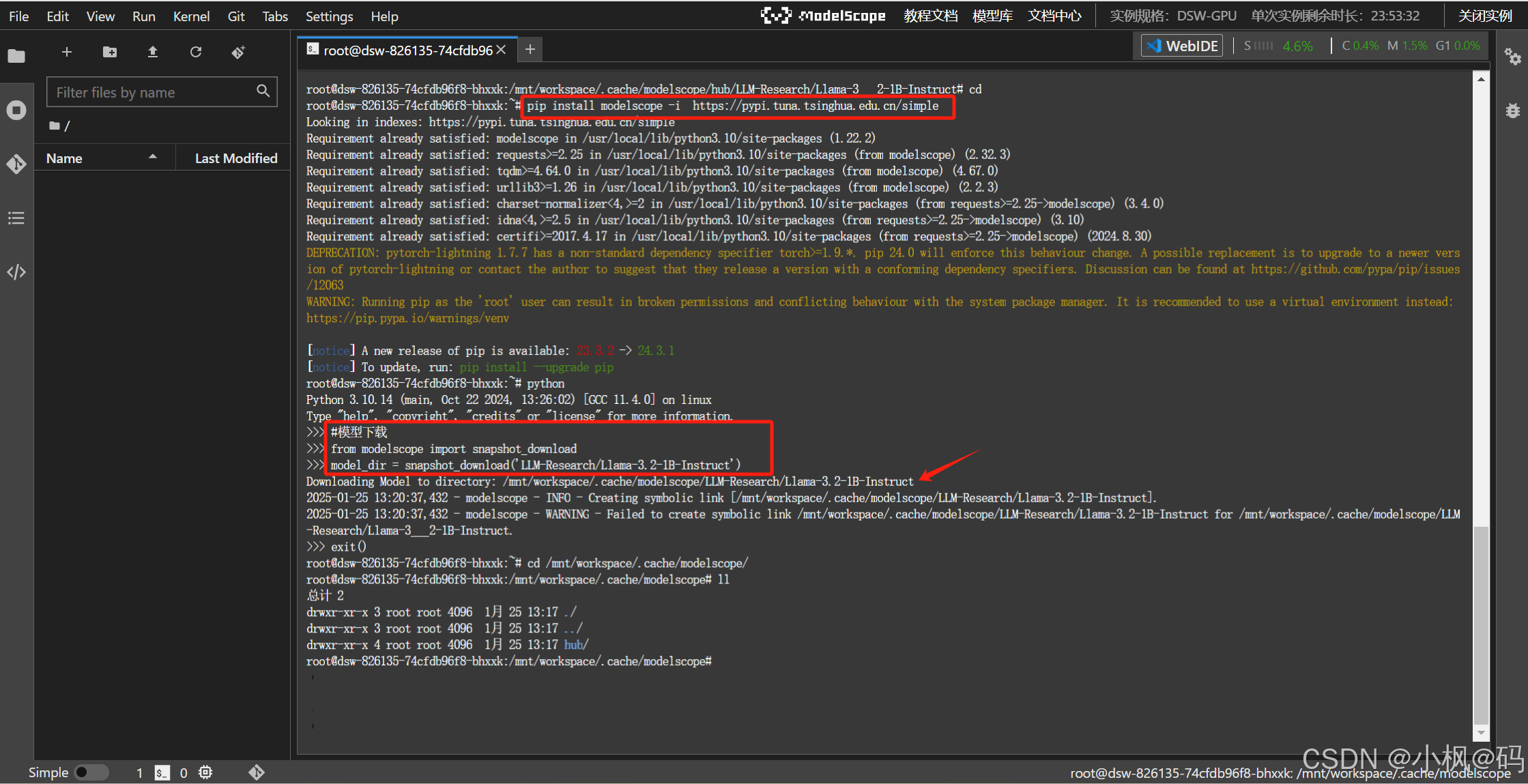
模型下载位置,通过 cache_dir 来进行指定
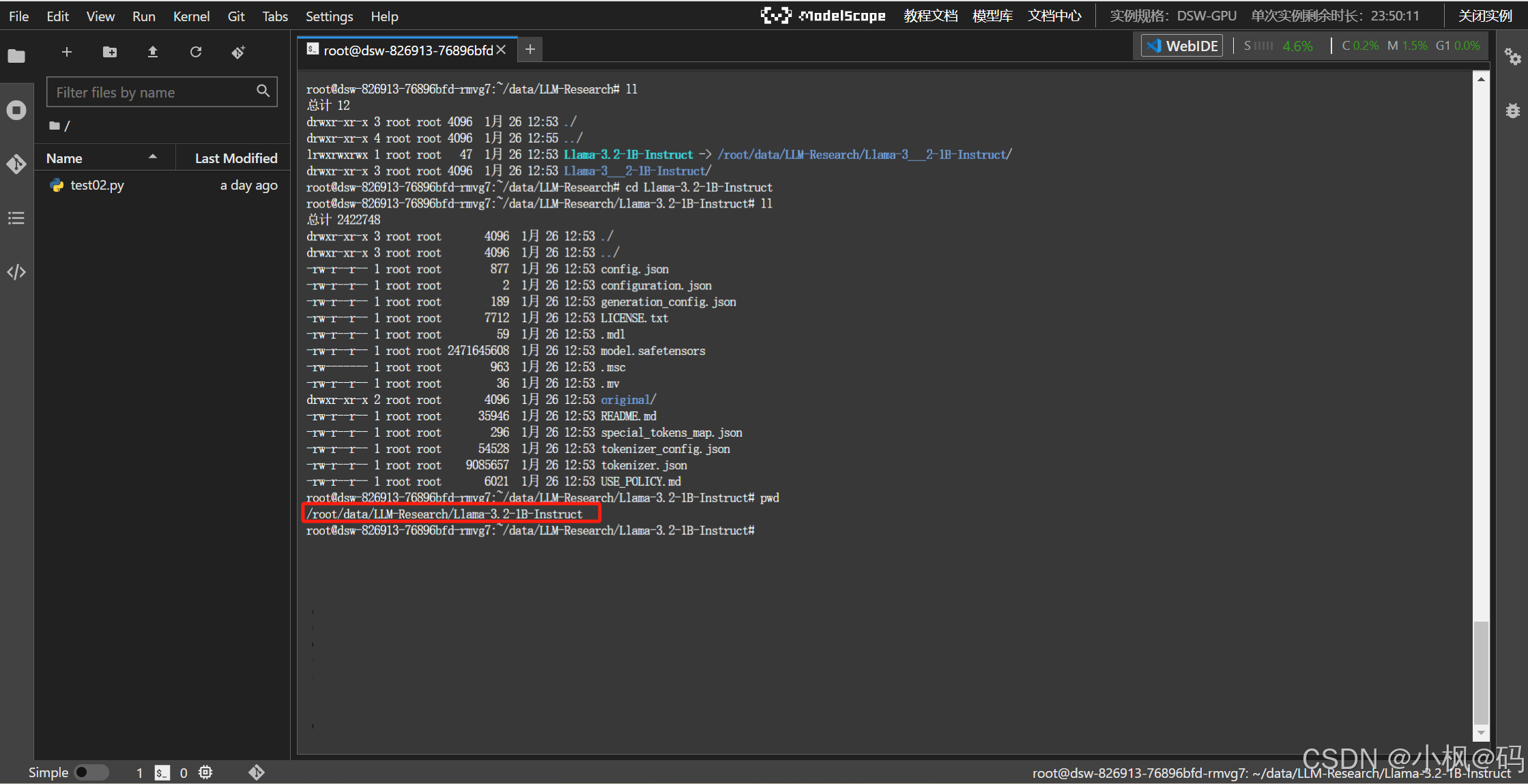
模型部署
编写调用大模型的脚本,上传服务器
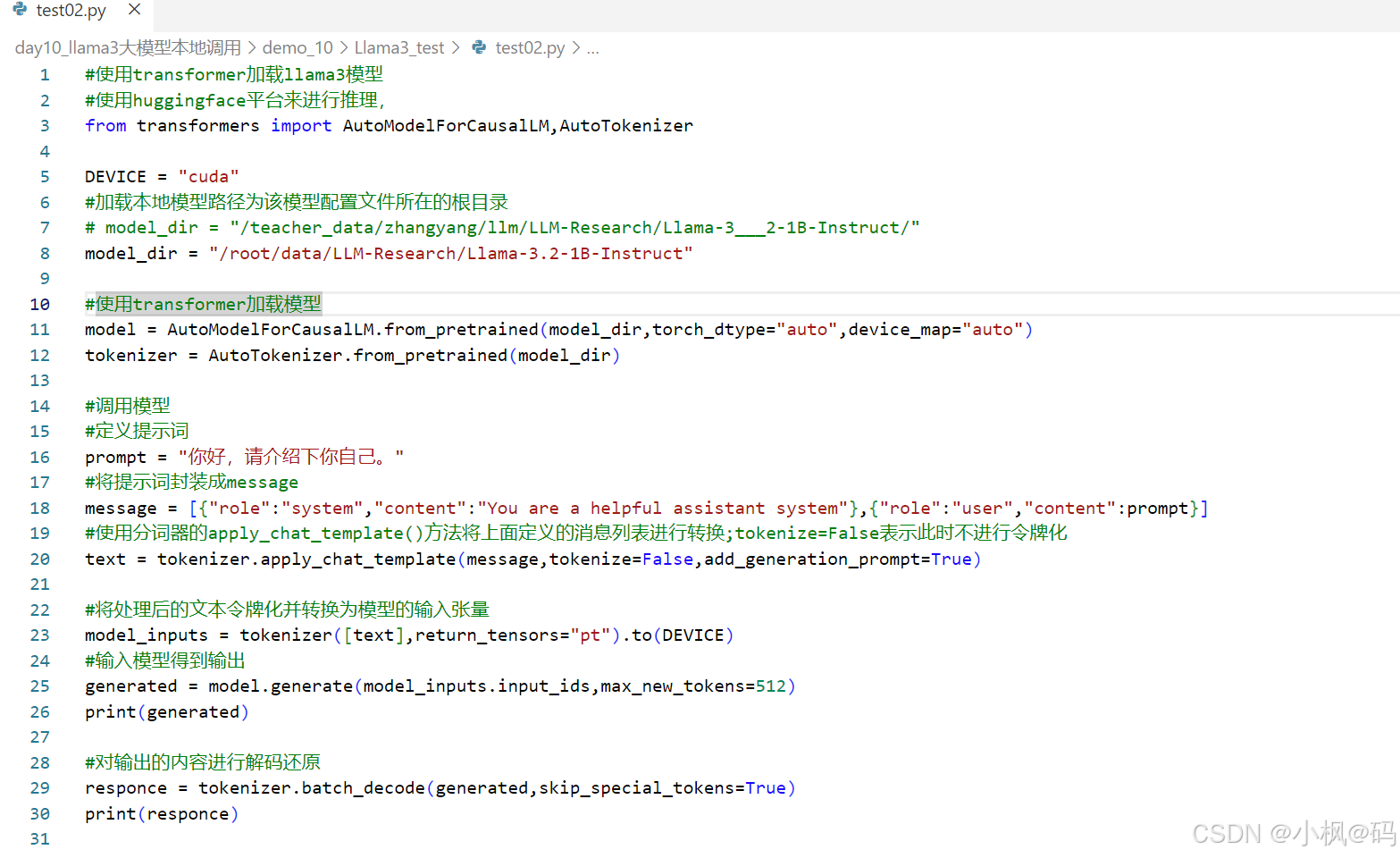
服务器上执行 python test02.py
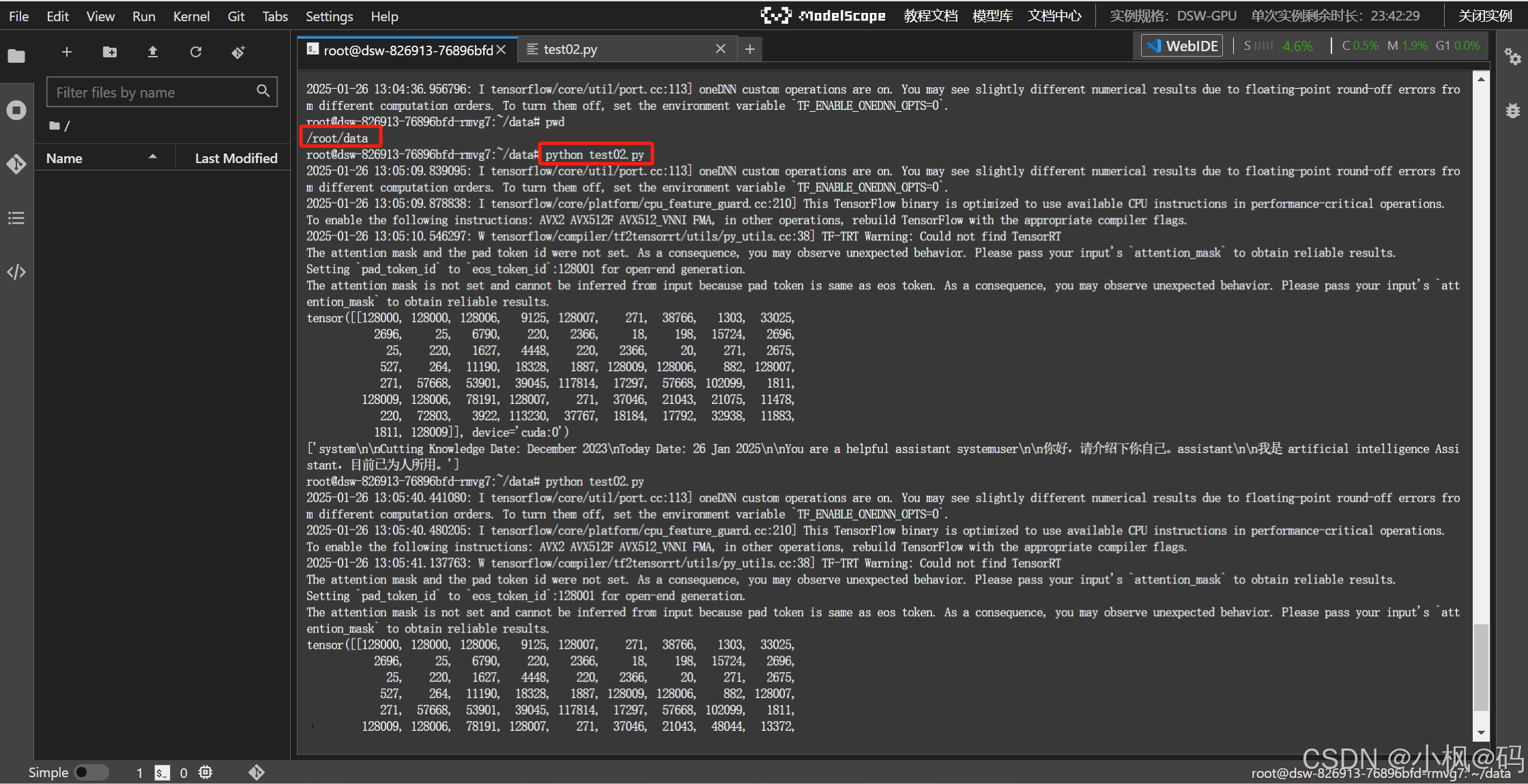
说明
先说明一下,虽然我们现在能够从魔塔社区中下载需要的大模型,并且能够调用到,但是在生产中我们却并不是这样使用的。还会再写一篇文章进行介绍。
本文中我们对大模型的推理是使用 huggingface平台来进行推理的,存在两个问题:
1、transformers 模型进行推理的话,性能比较低、效率比较慢,一般工程部署的话,不会选择使用transformers来调用。
2、目前 transformers 平台有局限性,没有自带服务,我们通过前端是访问不到的。


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









