







今天给大家分享一个强大的算法模型,transformer
Transformer 算法是一种基于注意力机制(Attention Mechanism)的深度学习模型,最早由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。
与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)不同,Transformer 完全基于注意力机制,实现了更高的并行性和更好的长距离依赖建模能力。
Transformer 模型因其强大的性能和灵活性,广泛应用于自然语言处理(NLP)、计算机视觉等领域,并成为现代深度学习的重要基石。
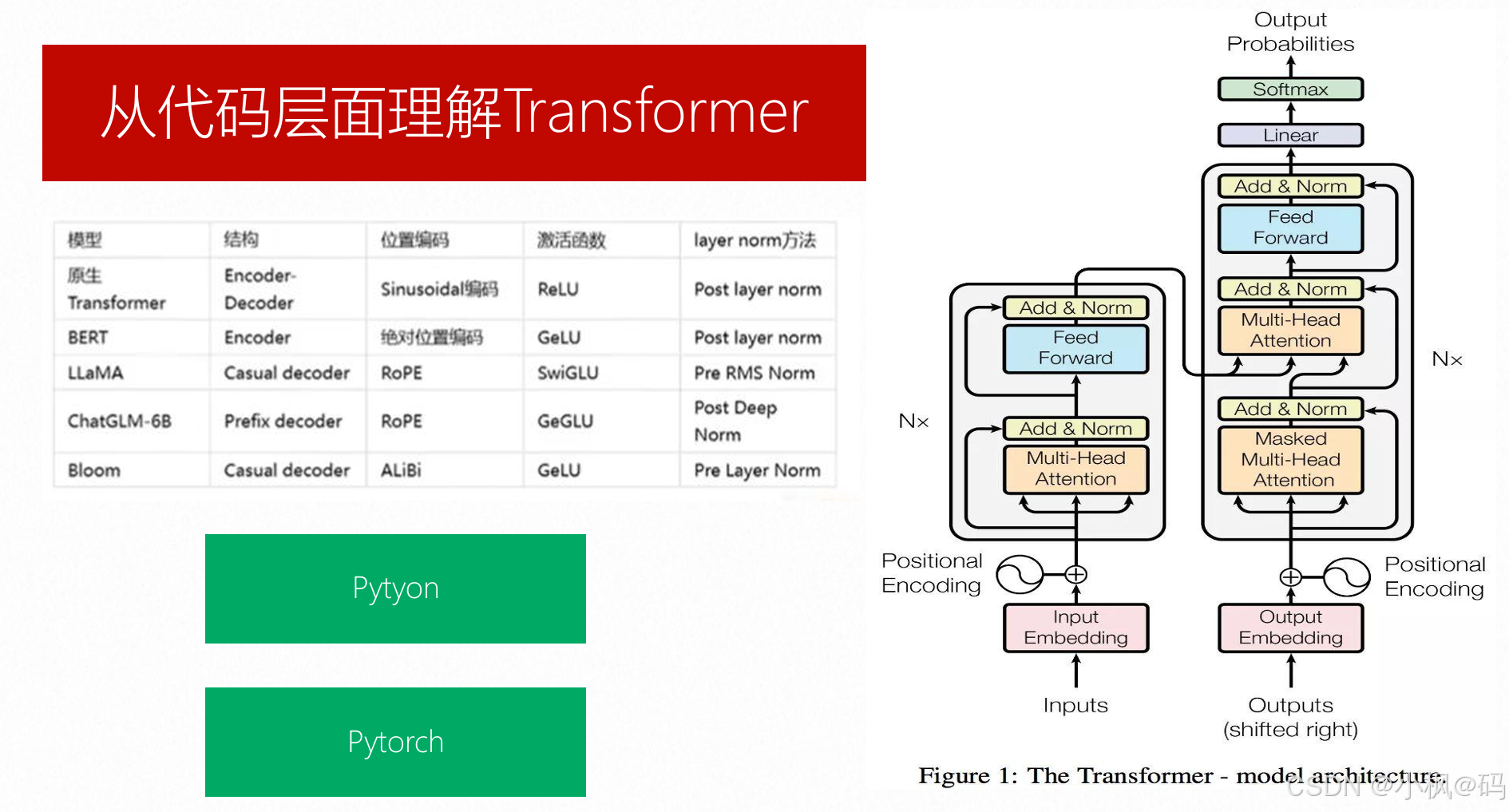
Transformer 模型的整体架构
Transformer 模型主要由编码器(Encoder)和解码器(Decoder)两部分组成,每部分由多个相同的层(Layer)堆叠而成。
编码器负责将输入序列转换为上下文相关的表示,解码器则基于编码器的输出生成目标序列。
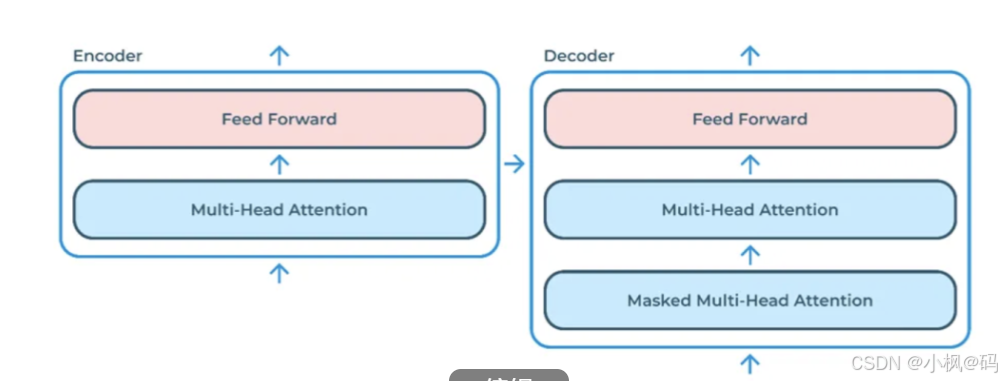
编码器
编码器由 N 个相同的编码器层组成,每个编码器层包括两个子层。
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈神经网络(Feed-Forward Network)
解码器
解码器同样由 N 个相同的解码器层组成,每个解码器层包括三个子层。
-
掩蔽多头自注意力机制(Masked Multi-Head Self-Attention)
-
编码器-解码器注意力机制(Encoder-Decoder Attention)
-
前馈神经网络(Feed-Forward Network)
每个子层后均采用残差连接(Residual Connection)和层归一化(Layer Normalization),以促进梯度传播和模型稳定性。
核心组件
1.输入嵌入
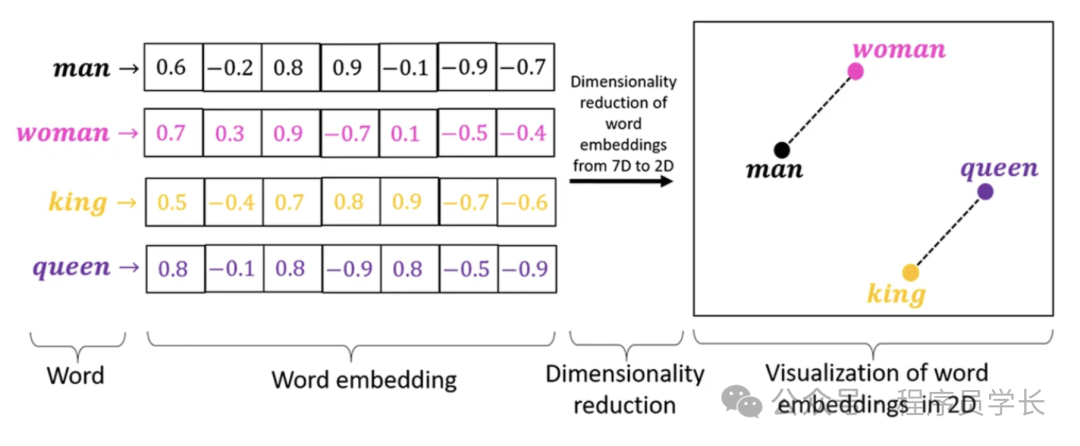
输入嵌入将离散的输入词汇(如单词、子词或字符)映射到连续的高维向量空间。
这些向量表示捕捉了词汇之间的语义和语法关系,是 Transformer 处理序列数据的基础。
数学表示
对于输入序列中的每个词汇 ,输入嵌入层通过查找嵌入矩阵 将其转换为一个 维的向量,其中 V 是词汇表大小, 是模型的维度。
import torch
import torch.nn as nn
vocab_size = 10000 # 词汇表大小
embedding_dim = 512 # 嵌入维度
sequence_length = 20 # 输入序列长度
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
input_tokens = torch.randint(0, vocab_size, (sequence_length,)) # 模拟输入序列
embedded_input = embedding_layer(input_tokens)
print(embedded_input.shape) # 输出: torch.Size([20, 512])
2.位置编码
由于 Transformer 架构不具备处理序列顺序的内在机制(如 RNN 中的时间步),因此需要通过位置编码为输入序列添加位置信息。
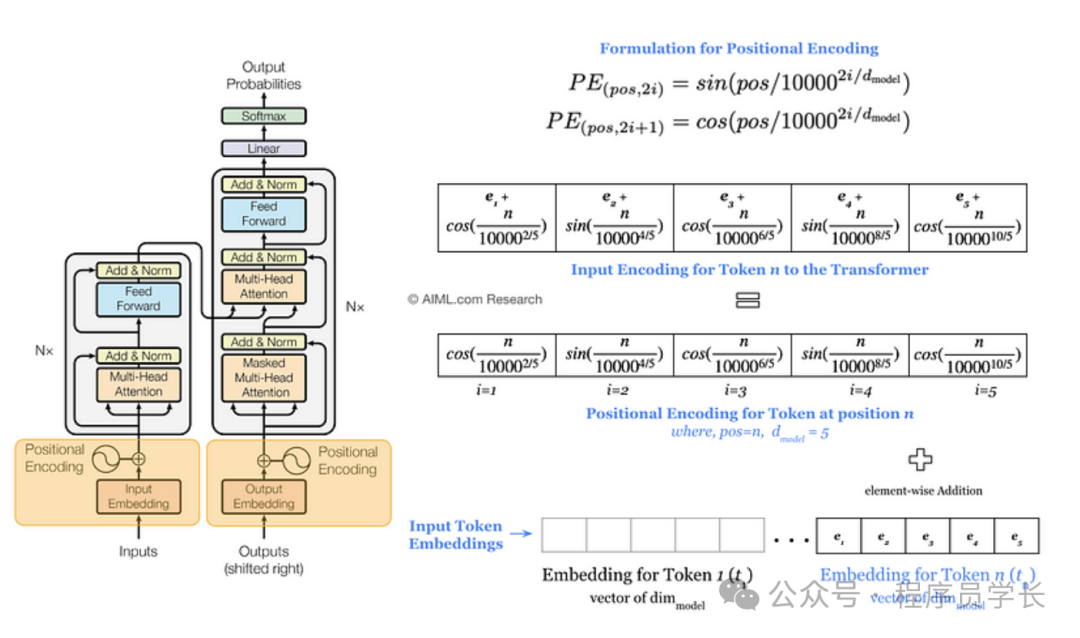
位置编码通常采用固定的正弦和余弦函数,以确保不同位置的编码具有唯一性和可区分性。
其中:
-
是位置索引
-
是嵌入维度索引
-
是嵌入维度
import numpy as np
def positional_encoding(seq_len, d_model):
pos = np.arange(seq_len)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angles = pos / np.power(10000, (2 * (i // 2)) / d_model)
pos_encoding = np.zeros((seq_len, d_model))
pos_encoding[:, 0::2] = np.sin(angles[:, 0::2])
pos_encoding[:, 1::2] = np.cos(angles[:, 1::2])
return torch.tensor(pos_encoding, dtype=torch.float32)
positional_encodings = positional_encoding(20, 512)
print(positional_encodings.shape) # 输出: torch.Size([20, 512])
3.自注意力机制
自注意力机制是 Transformer 的核心,允许模型在处理每个词时,动态地关注序列中其他相关词,从而捕捉长距离依赖关系和上下文信息。
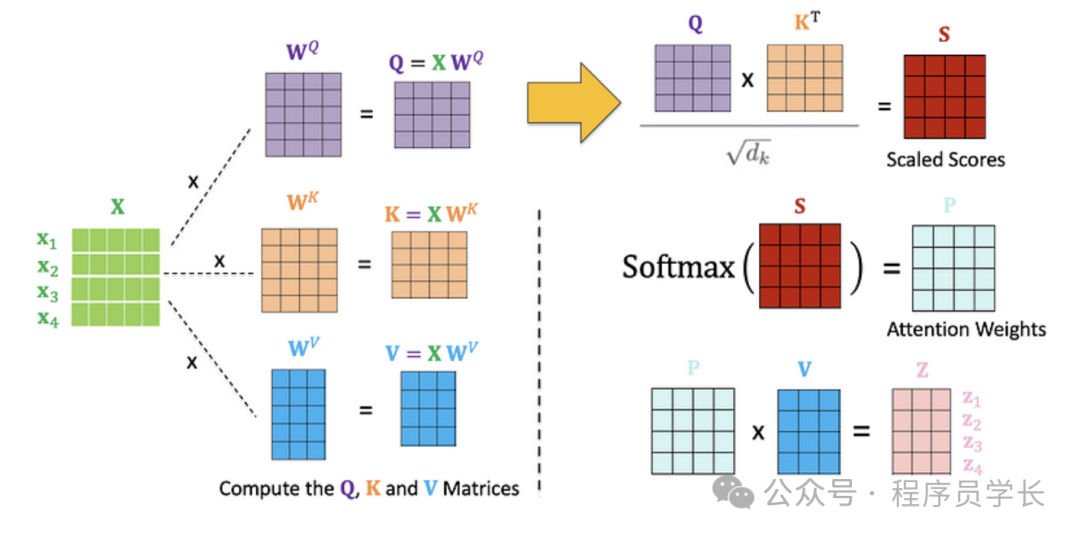
自注意力的计算过程包括以下步骤。
-
生成查询(Query)、键(Key)、值(Value)向量
通过线性变换生成查询、键和值向量。
其中, 是可训练的权重矩阵。
-
计算注意力得分
通过对查询向量 Q 和键向量 K 进行点积计算,得到注意力得分,每个得分衡量查询和键之间的相似度。
为了避免得分值过大,减缓梯度消失或爆炸问题,将得分进行缩放
-
应用Softmax函数
对注意力得分应用 Softmax 函数,得到注意力权重:
-
计算注意力输出
将注意力权重与值相乘,得到自注意力的输出:
import torch
import torch.nn as nn
def scaled_dot_product_attention(Q, K, V, mask=None):
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention_weights = torch.nn.functional.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, V)
return output, attention_weights
# 示例
Q = torch.rand(10, 64) # 查询矩阵
K = torch.rand(10, 64) # 键矩阵
V = torch.rand(10, 64) # 值矩阵
output, attn_weights = scaled_dot_product_attention(Q, K, V)
print(output.shape)
4.多头自注意力机制
多头自注意力机制是对自注意力机制的扩展,通过并行地执行多个自注意力操作(称为“头”),使模型能够捕捉不同子空间的信息,提高了模型的表达能力。
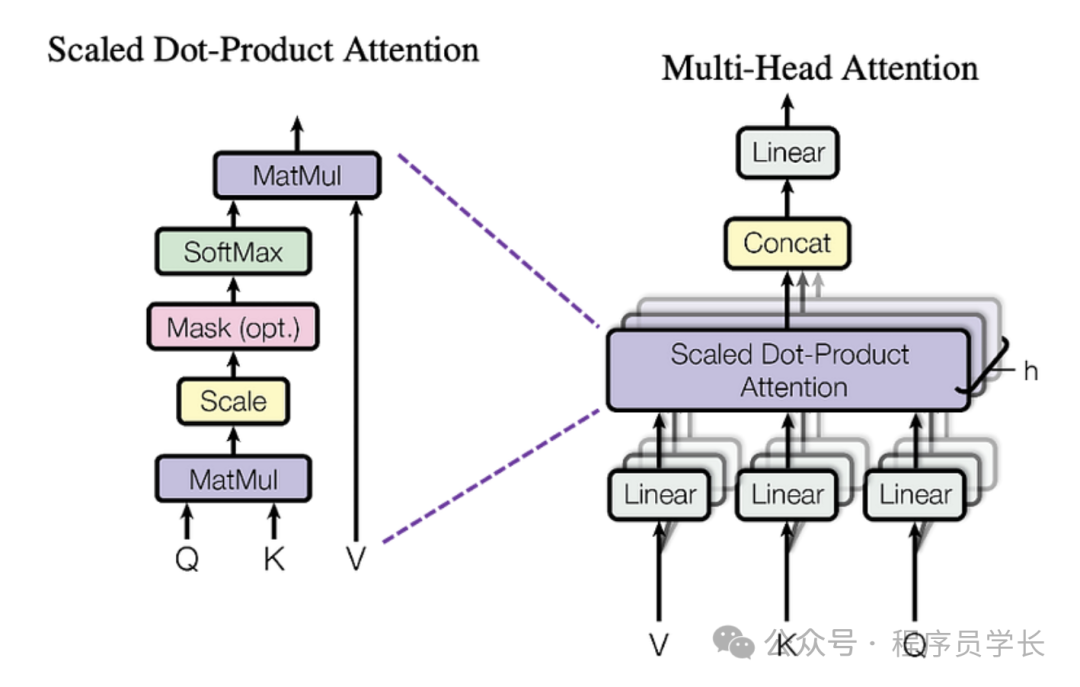
-
将输入映射到多个头,每个头独立执行自注意力
-
将所有注意力头的结果拼接并通过线性变换
其中:
是每个头的权重矩阵
是输出的线性变换矩阵。
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadAttention, self).__init__()
assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"
self.num_heads = num_heads
self.head_dim = embed_size // num_heads
self.W_q = nn.Linear(embed_size, embed_size)
self.W_k = nn.Linear(embed_size, embed_size)
self.W_v = nn.Linear(embed_size, embed_size)
self.W_o = nn.Linear(embed_size, embed_size)
def forward(self, Q, K, V, mask=None):
batch_size = Q.shape[0]
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
attn_output, _ = scaled_dot_product_attention(Q, K, V, mask)
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
return self.W_o(attn_output)
# 示例
embed_size = 512
num_heads = 8
multihead_attention = MultiHeadAttention(embed_size, num_heads)
Q = torch.rand(2, 10, embed_size)
output = multihead_attention(Q, Q, Q)
print(output.shape) # 输出: torch.Size([2, 10, 512])
5.前馈神经接网络
在每个编码器和解码器层中,前馈神经网络对每个位置的表示进行独立的非线性变换,进一步提升模型的表达能力和复杂性。
它由两个线性层和一个非线性激活函数(ReLu)组成。
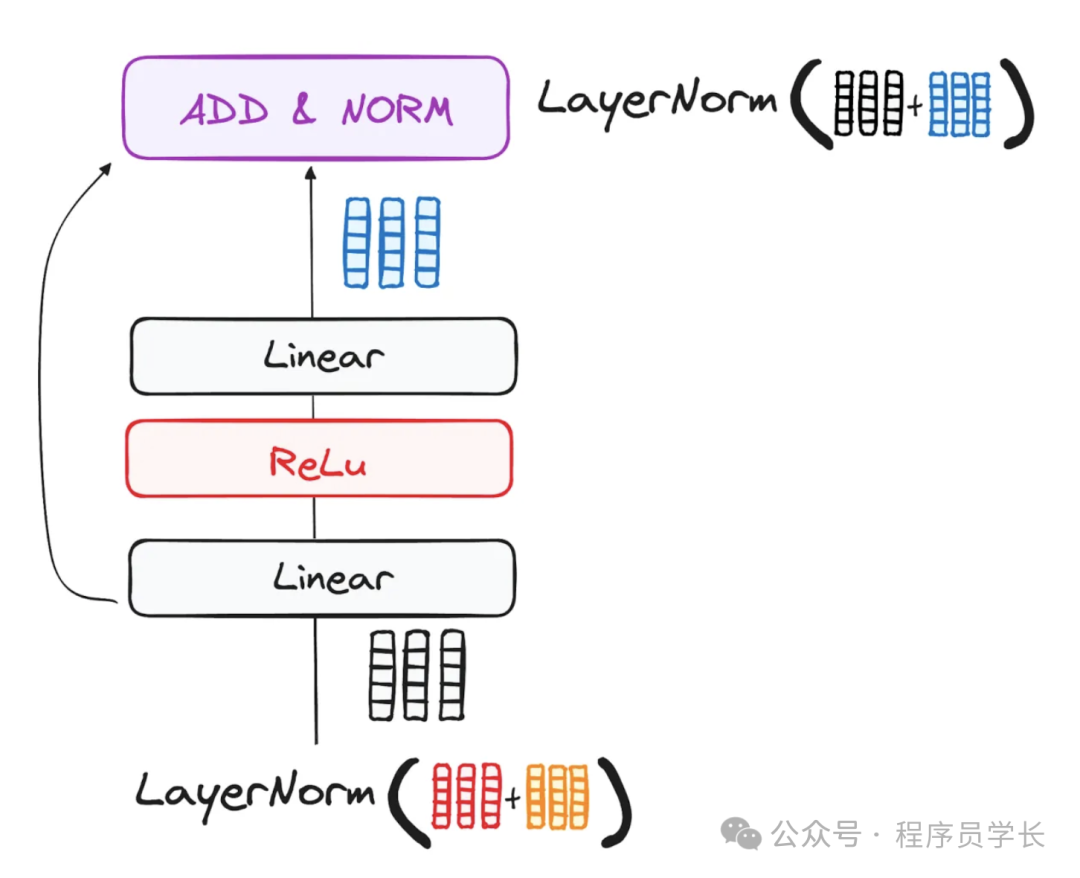
其数学形式为:
其中,, 是可学习的权重矩阵, 是偏置项。
class FeedForwardNetwork(nn.Module):
def __init__(self, embed_size, hidden_dim):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(embed_size, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, embed_size)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
6.残差连接与层归一化
每个子层后都采用残差连接和层归一化,以缓解梯度消失问题,加速训练,并提高模型性能。
残差连接
残差连接通过将子层的输入直接加到子层的输出上,缓解了深层网络中的梯度消失问题,并促进了信息的流动。
其中 表示子层的输出(如多头注意力或前馈网络)。
class ResidualConnection(nn.Module):
def __init__(self, size):
super(ResidualConnection, self).__init__()
self.norm = nn.LayerNorm(size)
def forward(self, x, sublayer):
return x + self.norm(sublayer(x))
层归一化
层归一化用于标准化每一层的输入,提升模型的稳定性和训练速度。
不同于批归一化,层归一化在每个样本的特征维度上进行归一化。
其中, 和 分别是输入 x 的均值和方差, 和 是可训练的缩放和平移参数, 是一个小常数以防止除零。
class LayerNormalization(nn.Module):
def __init__(self, embed_size, eps=1e-6):
super(LayerNormalization, self).__init__()
self.gamma = nn.Parameter(torch.ones(embed_size))
self.beta = nn.Parameter(torch.zeros(embed_size))
self.eps = eps
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
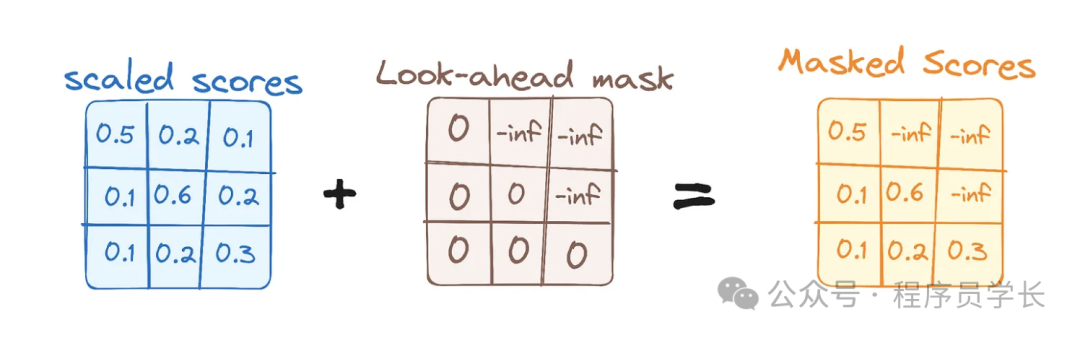
7.掩蔽多头自注意力机制
掩蔽多头自注意力机制(Masked Multi-Head Self-Attention)是应用于 Transformer 解码器的一个关键机制,它的主要目的是防止模型在训练时看到未来的 token,确保解码器在每一步只能访问当前及之前的输入,保持自回归特性。
在标准的自注意力机制中,注意力权重由以下公式计算。
为了在解码器中引入掩蔽机制,注意力分数在计算时会加入一个掩码矩阵 M。
其中,M 是掩蔽矩阵。
如果如果
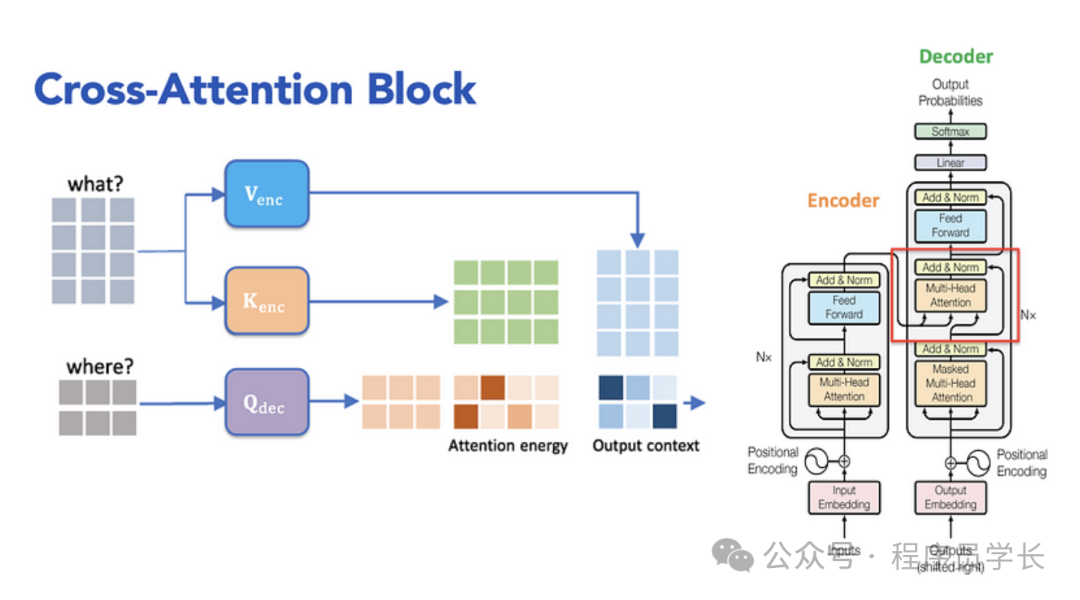
8.编码器-解码器注意力机制
编码器-解码器注意力机制是解码器中的一个关键部分,它负责在解码过程中将编码器的输出信息引入,以帮助解码器在生成目标序列时利用源序列的全局信息。
具体来说,在计算自注意力时,将解码器中的查询向量 (Query) 与编码器输出的键 (Key) 和值 (Value) 向量进行注意力计算,实现信息的传递和融合。
Transformer 的优势
Transformer 相较于传统的 RNN 和 CNN 具有以下优势。
-
并行计算
由于不依赖于序列的前后关系,Transformer 能够充分利用GPU的并行计算能力,加速训练过程。
-
长距离依赖建模
自注意力机制能够直接捕捉序列中任意两位置之间的依赖关系,解决了 RNN 在处理长序列时的梯度消失问题。
-
灵活性
Transformer 不仅适用于序列到序列的任务(如翻译),还可以扩展到其他任务,如文本生成、问答系统等。

















 5405
5405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









