







本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:终于把RT-DETR搞懂!替代YOLO的更快实时目标检测算法及Pytorch实现【附论文及源码】
导读
YOLO通过非极大值抑制过滤重叠边界框,增加了计算延迟。RT-DETR的出现改变了这一现状,RT-DETR取消了NMS后处理,结合强大的主干网络、混合编码器和创新的查询选择器,提供了快速且高效的端到端目标检测解决方案。
论文链接:https://arxiv.org/pdf/2304.08069
源码链接:https://github.com/lyuwenyu/RT-DETR
引言
目标检测一直面临着一个重大挑战-平衡速度和准确性。像YOLO这样的传统模型速度很快,但需要一个名为非极大值抑制(NMS)的后处理步骤,这会减慢检测速度。NMS过滤重叠的边界框,但这会引入额外的计算时间,影响整体速度。这就是DETR(https://arxiv.org/pdf/2005.12872)(检测Transformer)的用武之地。
RT-DETR是基于DETR架构的端到端对象检测器,完全消除了对NMS的需求。通过这样做,RT-DETR显着减少了之前基于卷积神经网络(CNN)的对象检测器(如YOLO系列)的延迟。它结合了强大的主干、混合编码器和独特的查询选择器,可以快速准确地处理特征。
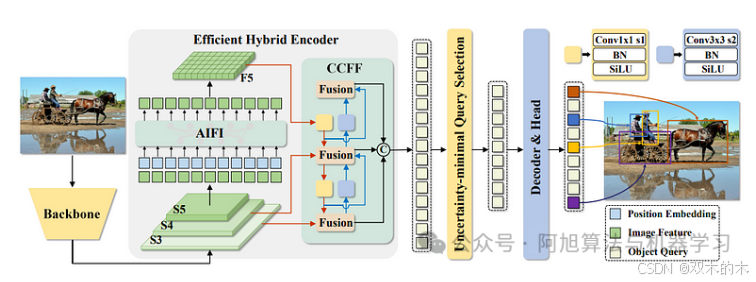
RT-DETR架构概述,来源:https://arxiv.org/pdf/2304.08069
RT-DETR架构的关键组成
-
主干:主干从输入图像中提取特征,最常见的配置是使用ResNet-50或ResNet-101。从主干,RT-DETR提取三个级别的特征- S3,S4和S5。这些多尺度特征有助于模型理解图像的高级和细粒度细节。
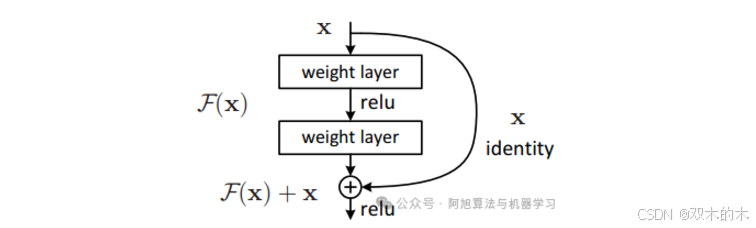
残差构建块,来源:https://arxiv.org/pdf/1512.03385
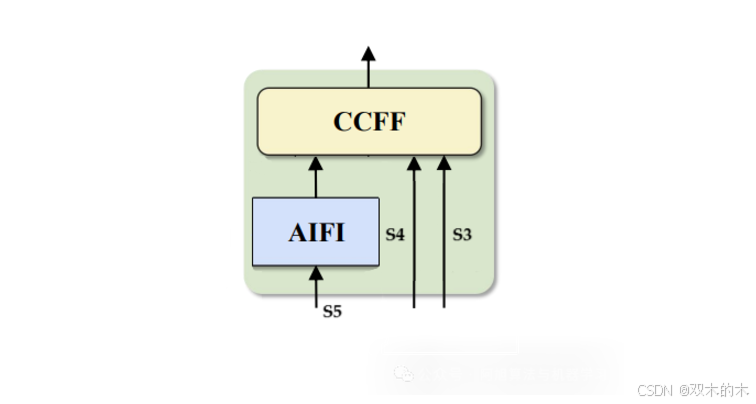
2.混合编码器:
img
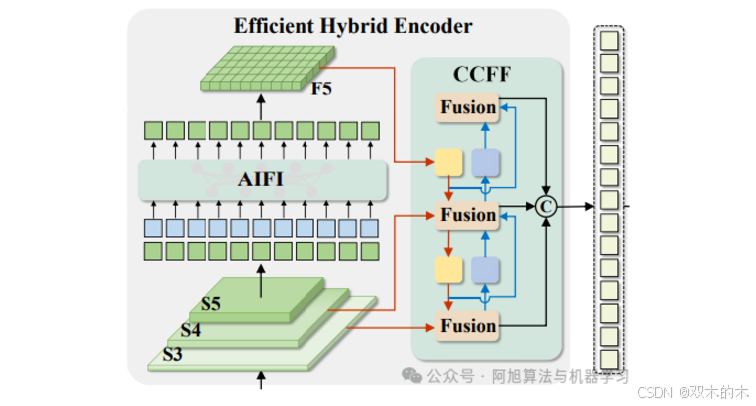
混合编码器
该混合编码器包括两个主要部分:基于注意力的尺度内特征交互(AIFI)和跨尺度特征融合(CCFF)。以下是每个部分的工作原理:
-
AIFI:这一层只处理主干中的S5特征图。由于S5代表最深的层,因此它包含关于图像中完整对象及其上下文的最丰富的语义信息-这使得它非常适合基于变换的注意力来捕捉对象之间有意义的关系。虽然S3和S4包含有用的低级别特征,如边缘和对象部分,但对这些层施加注意力将在计算上昂贵且效率较低,因为它们尚未表示需要彼此相关的完整对象。
以下是AIFI的PyTorch实现。代码分为三个主要部分:
-
处理关注后要素的前馈层(***FFLayer***)
-
实现多头自关注的Transformer编码器层
-
主要的AIFI模块,通过适当的特征投影和位置编码将所有内容联系在一起
import torch
import torch.nn as nn
class FFLayer(nn.Module):
'''
Feed-forward network: two linear layers with a non-linear activation
in between
'''
def __init__(self,
embedd_dim:int,
ffn_dim:int,
dropout:float,
activation:str) -> nn.Module:
super().__init__()
self.feed_forward = nn.Sequential(
nn.Linear(embedd_dim, ffn_dim),
getattr(nn, activation)(),
nn.Dropout(dropout),
nn.Linear(ffn_dim, embedd_dim)
)
self.norm = nn.LayerNorm(embedd_dim)
def forward(self,x:torch.Tensor)->torch.Tensor:
residual = x
x = self.feed_forward(x)
out = self.norm(residual + x)
return out
class TransformerEncoderLayer(nn.Module):
def __init__(self,
hidden_dim:int,
n_head:int,
ffn_dim:int,
dropout:float,
activation:str = "ReLU"):
super().__init__()
self.mh_self_attn = nn.MultiheadAttention(hidden_dim, n_head, dropout, batch_first=True)
self.feed_foward_nn = FFLayer(hidden_dim,ffn_dim,dropout,activation)
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(hidden_dim)
def forward(self,x:torch.Tensor,mask:torch.Tensor=None,pos_emb:torch.Tensor=None) -> torch.Tens 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









