







在图神经网络中,信息的传递和特征的转变,用户可以自定义的。当然在DGL中,也有高级别的API供调用。
现在来看一个网页排名简单的模型。每一个节点都有相同的PV值,PV=0.01, 每一个节点首先会均匀分散自己的PV值给周围的节点。各节点新的PV值等于周围节点的聚合,同时受到阻尼因子的调节。因此,每一次迭代,节点PV值的变化如下:
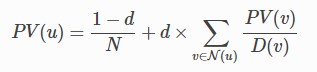
其中,d为阻尼因子,N为节点数。N为节点的邻接节点,D为节点的输出度(deg)
目的:查看10次迭代之后,各节点的PV值
首先,导入需要的模块
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
import dgl
import torch
import dgl.function as fn
一、构建图
N = 100 #节点数量
DAMP=0.85 #公式中的d
K = 10 #迭代次数
g = nx.nx.erdos_renyi_graph(N, 0.1) #随机erdos_renyi图
g = dgl.DGLGraph(g)
#可视化
nx.draw(g.to_networkx(), with_labels=True, nodes_size=50)
plt.show()

初始化节点PV值和输出度:
g.ndata['PV'] = torch.ones(N)/N #初始数据每个节点均为0.01
g.ndata['deg'] = g.out_degrees(g.nodes()).float() #每个节点输出度
print(g.ndata)

二、信息传递、聚合的四种方法
(1)完全用户自定义模式
分为四步:
1. 节点的输出PV值函数
def pagerank_message_func(edges):
'''
信息输出函数
:param edges: 图g的边对象,多条边(边对象具有src, dst, data三个属性, 分别代表边的起始节点,终止节点,边特征)
这里只对输出节点进行迭代PV值
:return:
'''
return {'PV': edges.src['PV'] / edges.src['deg']}
2. 节点PV信息聚合函数
def pagerank_reduce_func(nodes):
'''
信息的聚合(衰减)函数
:param nodes: 输入的节点对象
:return:
'''
megs = torch.sum(nodes.mailbox['PV'], dim=1)
pv = (1-DAMP)/N + DAMP*megs
return {'PV': pv}
3. 节点输出函数、信息聚合函数导入图
#对信息传递函数和信息聚合(衰减)函数进行注册在g网络中。
g.register_message_func(pagerank_message_func)
g.register_reduce_func(pagerank_reduce_func)
4. 向前传播
#信息正向传播
def pagerank_naive(g):
#阶段一:信息沿着节点发出所有信息
for u, v in zip(*g.edges()):
g.send((u,v)) #输入的是边
#阶段二:接收信息,计算新的PV值
for v in g.nodes():
g.recv(v) #输入的是终止节点
(2) 适合大图的批量处理方法
与(1)中的方法类似,也需要先定义好信息传播函数、信息聚合函数,并将这两个函数传入图g中。有差别的是第四步。将第四步替换成以下内容:
ef pagerank_batch(g):
g.send(g.edges())
g.recv(g.nodes())
批量出的原理:
“您可能想知道是否有可能在所有节点上并行执行reduce,因为每个节点可能有不同数量的传入消息,
并且您无法真正将不同长度的张量真正“堆叠”在一起。 通常,DGL通过按传入消息的数量对节点进行分组并为每个组调用reduce函数来解决该问题。”
(3)使用dgl中level 2的API
与(1)类似,前三步,万全相同,只是修改第四步,如下:
#DGL中可以使用更高级的API更新图 (level-2 APIs)
def pagerank_level2(g):
g.update_all()
(4) 从头到尾直接使用更高效的内置函数
#还有一种更有效的方法,使用dgl的内置函数。该方法执行起来更快。
def pagerank_builtin(g):
'''
1. fn.copy_src: 构建信息输出函数,将起始节点的信息传播出去
2. fn.sum:信息聚集
:param g: 图对象
:return:
'''
g.ndata['PV'] = g.ndata['PV']/g.ndata['deg']
g.update_all(message_func=fn.copy_src(src='PV', out='m'),
reduce_func=fn.sum(msg='m', out='m_sum'))
g.ndata['PV'] = (1-DAMP)/N + DAMP * g.ndata['m_sum']
三、进行N次迭代
#进行K次迭代
for k in range(K):
pagerank_builtin(g)
print(g.ndata['PV'])
















 3183
3183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









