







1.SFT 监督微调
1.1 SFT 监督微调基本概念
SFT(Supervised Fine-Tuning)监督微调是指在源数据集上预训练一个神经网络模型,即源模型。然后创建一个新的神经网络模型,即目标模型。目标模型复制了源模型上除了输出层外的所有模型设计及其参数。这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。微调时,为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。在目标数据集上训练目标模型时,将从头训练到输出层,其余层的参数都基于源模型的参数微调得到。
1.2 监督微调的步骤
具体来说,监督式微调包括以下几个步骤:
- 预训练: 首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练;
- 微调: 使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好;
- 评估: 使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
1.3 监督微调的特点
监督式微调能够利用预训练模型的参数和结构,避免从头开始训练模型,从而加速模型的训练过程,并且能够提高模型在目标任务上的表现。监督式微调在计算机视觉、自然语言处理等领域中得到了广泛应用。然而监督也存在一些缺点。首先,需要大量的标注数据用于目标任务的微调,如果标注数据不足,可能会导致微调后的模型表现不佳。其次,由于预训练模型的参数和结构对微调后的模型性能有很大影响,因此选择合适的预训练模型也很重要。
1.4 常见案例
- 样例 1
在计算机视觉中,低层的网络主要学习图像的边缘或色斑,中层的网络主要学习物体的局部和纹理,高层的网络识别抽象的语义,如下图所示。因此,可以把一个神经网络分成两块:
- 低层的网络进行特征抽取,将原始信息变成容易被后面任务使用的特征;
-
输出层的网络进行具体任务的预测。输出层因为涉及到具体任务没办法在不同任务中复用,但是低层的网络是具有通用型的,可以应用到其他任务上。

下图表示的是将预训练模型的前 L-1 层的参数复制到微调模型,而微调模型的输出层参数随机初始化。在训练过程中,通过设置很小的学习率,从而达到微调的目的。
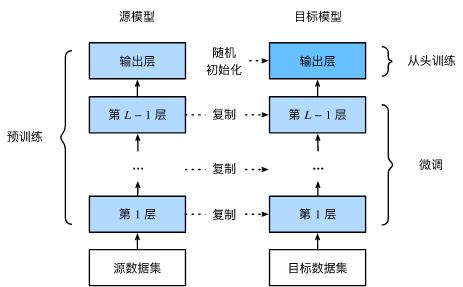
-
样例 2
BERT 模型是 Google AI 研究院提出的一种预训练模型,通过预训练 + 微调的方式于多个 NLP 下游任务达到当时最先进水平,如实体识别、文本匹配、阅读理解等。与样例 1 一样,BERT 模型微调时,将预训练好的模型参数复制到微调模型,而输出层参数随机初始化。
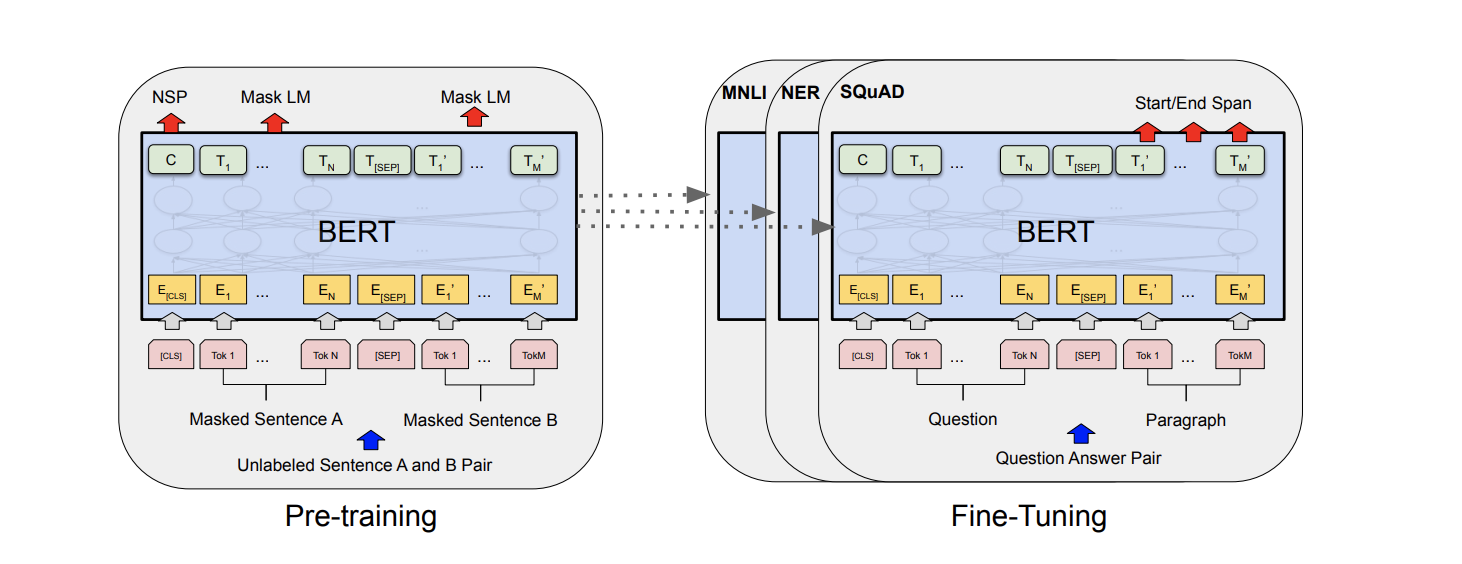
1.5 SFT 监督微调的主流方法
随着技术的发展,涌现出越来越多的大语言模型,且模型参数越来越多,比如 GPT3 已经达到 1750 亿的参数量,传统的监督微调方法已经不再能适用现阶段的大语言模型。为了解决微调参数量太多的问题,同时也要保证微调效果,急需研发出参数高效的微调方法(Parameter Efficient Fine Tuning, PEFT)。目前,已经涌现出不少参数高效的微调方法,其中主流的方法包括:
- LoRA
- P-tuning v2
- Freeze
2. LoRA 微调方法
2.1 LoRA 微调方法的基本概念
LoRA(Low-Rank Adaptation of Large Language Models),直译为大语言模型的低阶自适应。LoRA 的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型参数参与微调类似的效果。
随着大语言模型的发展,模型的参数量越来越大,比如 GPT-3 参数量已经高达 1750 亿,因此,微调所有模型参数变得不可行。LoRA 微调方法由微软提出,通过只微调新增参数的方式,大大减少了下游任务的可训练参数数量。
2.2 LoRA 微调方法的基本原理
神经网络的每一层都包含矩阵的乘法。这些层中的权重矩阵通常具有满秩。当适应特定任务时,预训练语言模型具有低的 “内在维度”,将它们随机投影到更小的子空间时,它们仍然可以有效地学习。
在大语言模型微调的过程中,LoRA 冻结了预先训练好的模型权重,并将可训练的秩的分解矩阵注入到 Transformer 体系结构的每一层。例如,对于预训练的权重矩阵W0,可以让其更新受到用低秩分解表示后者的约束:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
�0+△�=�0+��
其中:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











