






目录
前言
在当今数字化浪潮汹涌澎湃的时代,数据已然成为驱动各领域发展的核心燃料,尤其是在人工智能领域,大规模且高质量的数据对于训练精准有效的模型起着决定性作用。然而,如何从浩瀚无垠的网络世界中高效地抓取并整理出符合需求的数据,一直是困扰众多开发者和研究人员的难题。
Crawl4AI 的应运而生,恰似一盏明灯,为这片数据采集的“迷雾之海”照亮了前行的道路。它是一款专为大型语言模型(LLM)和 AI 应用量身定制的开源网页爬虫及数据抓取工具,以其卓越的数据提取能力、高度的定制化特性以及出色的性能表现,在 AI 数据采集领域崭露头角,为广大用户提供了一个强大且便捷的解决方案。
一、Crawl4AI概述
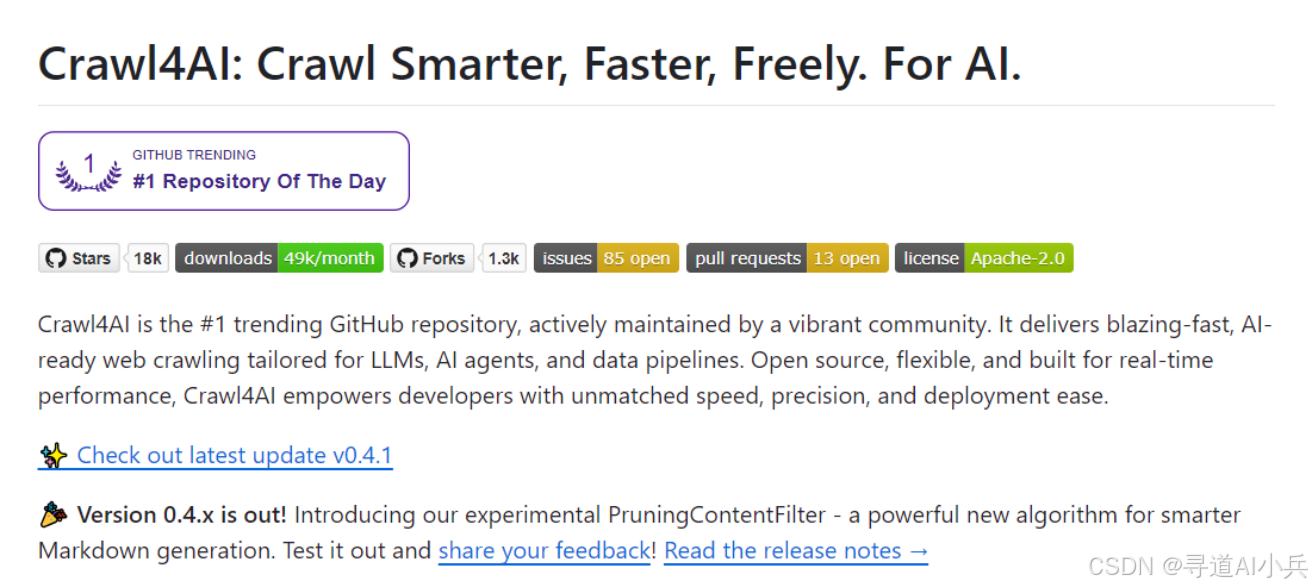
Crawl4AI 作为一款开源利器,在 GitHub 上拥有极高的关注度,采用 Apache - 2.0 license 授权。目前已斩获 14.7k stars 和 1k forks 的亮眼成绩,这充分彰显了其在开发者社区中的受欢迎程度和影响力。它致力于帮助开发者轻松突破网络数据采集的瓶颈,无论是为了丰富语言模型的语料库,还是为其他 AI 研究项目提供坚实的数据基石,Crawl4AI 都展现出了无与伦比的价值和潜力。
二、Crawl4AI技术原理
- 异步编程架构提升效率:Crawl4AI 巧妙地运用 Python 的
asyncio库,构建起高效的异步编程模型。这一架构使得它能够在同一时间内并行处理多个网页请求,如同开启了多条数据采集的“高速公路”,极大地提高了爬虫的整体并发性能,从而显著缩短数据抓取的时间成本。- 专业库协同实现精准抓取:借助
aiohttp等先进的异步 HTTP 客户端库,Crawl4AI 能够精准地向目标网页发送请求,并顺利获取丰富的网页数据。随后,通过BeautifulSoup、lxml等强大的解析库,对获取到的 HTML/XML
内容进行深度剖析,如同拥有一双敏锐的“数据之眼”,能够精准地识别和提取出其中有价值的数据元素,如文本、图片、视频、音频等多媒体信息,以及内外部链接、元数据等关键内容。- 正则表达式助力精细筛选:正则表达式在 Crawl4AI 中扮演着数据“过滤器”的重要角色。它能够依据特定的模式规则,对提取到的数据进行精细筛选和验证,确保所获取的数据完全符合用户的特定需求,如同一位严谨的“数据管家”,只保留最精华、最有用的数据部分。
- JavaScript 引擎攻克动态页面:为了应对日益复杂的网页环境,尤其是那些包含大量动态加载内容的页面,Crawl4AI 集成了 JavaScript 引擎(如 Selenium 或 Pyppeteer)。这使得它能够像一位智能的“网页舞者”,灵活地执行网页中的
JavaScript 代码,成功地渲染出动态加载的页面内容,从而将隐藏在其中的宝贵数据一一挖掘出来,实现全方位的数据采集。
三、Crawl4AI功能特点
1、全方位数据提取大师
Crawl4AI 犹如一位数据提取的“全能大师”,具备智能化的数据提取能力,能够自动识别并解析网页中的各种元素。无论是深藏在网页角落的文本段落,还是绚丽多彩的图片、引人入胜的视频、悦耳动听的音频等多媒体数据,亦或是那些看似不起眼却至关重要的内外部链接和元数据,都无法逃脱它的“数据抓取之网”,能够被精准地提取出来,为后续的分析和处理提供丰富的素材。
2、多格式输出适配多样需求
深知不同用户和应用场景对数据格式有着多样化的需求,Crawl4AI 贴心地支持将提取到的数据转换为 JSON、HTML、Markdown 等多种结构化格式。这就像一位贴心的“数据翻译官”,能够根据用户的要求,将采集到的数据灵活地翻译成不同的“语言”,使其能够无缝对接后续的分析工具和 AI 模型训练流程,极大地提高了数据的可用性和兼容性。
3、高度定制化满足个性需求
Crawl4AI 赋予用户极高的定制化权力,如同一位“私人数据裁缝”。用户可以根据自己的独特需求,自由地定制认证信息、请求头内容、在爬取前对页面进行个性化修改、灵活切换用户代理,甚至可以定制 JavaScript 脚本的执行策略。同时,它还提供了多种数据提取策略,包括基于主题的精准提取、基于正则表达式的精细筛选、基于句子的智能分块,以及利用 LLM 或余弦聚类的高级提取策略,能够满足从简单到复杂的各种数据采集任务需求。
4、异步架构优化性能表现
凭借其先进的异步架构设计,Crawl4AI 在性能方面表现卓越。特别是在与 Playwright 多浏览器的异步协作下,它能够像一台高效运转的“数据采集引擎”,以更低的资源占用实现更快速的数据抓取。在与众多收费爬虫服务的对比测试中,Crawl4AI 脱颖而出,其爬取速度更快,能够加载 JavaScript 并提取出更多有价值的数据,为用户带来了极致的使用体验。
5、动态内容处理专家
在处理动态网页内容方面,Crawl4AI 堪称一位“专家级选手”。无论是隐藏在 iframe 框架内的神秘数据,还是那些采用延迟加载技术的内容,它都能够轻松应对。通过提供自定义页面超时等实用功能,Crawl4AI 能够根据不同网页的特点和网络环境,灵活地调整数据采集策略,确保每一份数据都能够被完整地采集到手,不错过任何一个有价值的信息片段。

四、Crawl4AI 应用场景
- AI 研究创新驱动力:
在 AI 研究领域,Crawl4AI 无疑是研究人员的得力助手。它能够帮助研究人员快速获取海量的网页数据,为语言模型的训练提供充足的“弹药”。这些丰富的数据资源能够助力研究人员深入探索语言模型的奥秘,挖掘出更多的语言规律和语义信息,从而推动 AI 研究在自然语言处理、机器翻译、智能问答等多个方向取得创新性的突破,为 AI 技术的发展注入源源不断的动力。 - 数据科学分析好帮手:
对于数据科学家和分析师而言,Crawl4AI 是一把开启数据宝藏的“金钥匙”。它能够高效地从网页这个巨大的数据“金矿”中提取出有价值的数据,无论是用于市场趋势分析、用户行为研究,还是进行风险预测、产品推荐等数据分析任务,Crawl4AI 所采集到的数据都能够为分析工作提供丰富的素材和精准的依据,帮助数据科学家们挖掘出数据背后隐藏的深刻洞察,做出更加明智的决策。 - 开发者项目加速器:
在开发各种 AI 驱动的应用程序时,开发者们常常需要大量的网络数据来丰富应用的功能和提升用户体验。Crawl4AI 则成为了他们的“项目加速器”。开发者可以轻松地将其集成到自己的应用程序中,实现自动化的信息采集功能。例如,在开发一款智能新闻聚合应用时,Crawl4AI 能够快速抓取各大新闻网站的最新消息,并将其整合到应用中,为用户提供一站式的新闻阅读服务;在开发一款电商价格监测应用时,它可以实时监控竞争对手的产品价格和促销信息,为商家提供及时的市场动态反馈,从而帮助开发者们更快地打造出功能强大、竞争力强的 AI 应用产品。 - 商业竞争情报收集利器:
在商业领域的激烈竞争中,信息就是胜利的关键。Crawl4AI 成为了企业收集竞争情报的“秘密武器”。例如,电商企业可以利用它实时监控竞争对手的产品价格、库存情况、促销活动等信息,从而及时调整自己的营销策略,保持竞争优势;市场研究公司则可以借助 Crawl4AI抓取社交媒体、新闻网站等平台上的海量数据,进行舆情分析,深入了解消费者的需求、偏好和市场趋势,为企业的产品研发、品牌推广等商业决策提供有力的支持,帮助企业在市场竞争的“战场”上抢占先机。
五、快速使用Crawl4AI
1、便捷安装方式多样
Crawl4AI 为用户提供了多种便捷的安装途径。如果您习惯使用 pip 包管理器,只需在命令行中输入 pip install crawl4ai,即可轻松完成安装,就像在应用商店中一键下载安装应用程序一样简单。
此外,如果您更倾向于使用 Docker 容器化部署,也可以通过 Docker 镜像来运行。首先构建 Docker 镜像,执行命令 docker build -t crawl4ai.,然后运行容器 docker run -d -p 8000:80 crawl4ai;或者直接从 Docker Hub 拉取最新的镜像,运行 docker pull unclecode/crawl4ai:latest 和 docker run -d -p 8000:80 unclecode/crawl4ai:latest,即可快速搭建起 Crawl4AI 的运行环境,开启数据采集之旅。
2、简单示例快速上手
以下是一个简单的 Crawl4AI 使用示例,让您能够快速领略其强大功能。
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.example.com")
print(result.markdown)
if __name__ == "__name__":
asyncio.run(main())
结语
Crawl4AI 的出现,无疑为 AI 数据采集领域带来了一场革命性的变革。它以其强大的功能、灵活的定制化选项、出色的性能表现以及广泛的应用场景,成为了广大开发者、研究人员、数据科学家以及商业用户在数据采集道路上的得力伙伴。无论是在推动 AI 研究的前沿探索,还是助力商业决策的精准制定,Crawl4AI 都发挥着不可替代的重要作用。随着技术的不断发展和社区的持续支持,相信 Crawl4AI 将在未来的日子里不断进化和完善,为我们带来更多的惊喜和价值,助力更多的用户在数字化浪潮中乘风破浪,驶向成功的彼岸。
项目地址:https://github.com/unclecode/crawl4ai

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!



















 1979
1979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











