






MochiEdit:基于文生视频的视频编辑工具

ComfyUI-MochiEdit简介
在之前的文章已经介绍过最新的最大文生视频模型 Genmo Mochi。近期社区也开始了围绕Genmo Mochi 生态工具研发。今天的文章就是介绍其中一个:ComfyUI-MochiEdit,这是一款使用 Genmo Mochi 编辑视频的 ComfyUI插件,能够实现根据用户提示词编辑和修改视频主体,而不改变周围环境影响的视频编辑工具。同时也包含了Mochi GGUF4位和8位量化版本,以及sageattention注意力能够极大的加速文生视频速率,24G显存从原来需要30分钟一个视频提升到10分钟内。
-
• 插件地址:https://github.com/logtd/ComfyUI-MochiEdit
-
• Genmo Mochi:https://genmo.ai/play
ComfyUI-MochiEdit ComfyUI体验
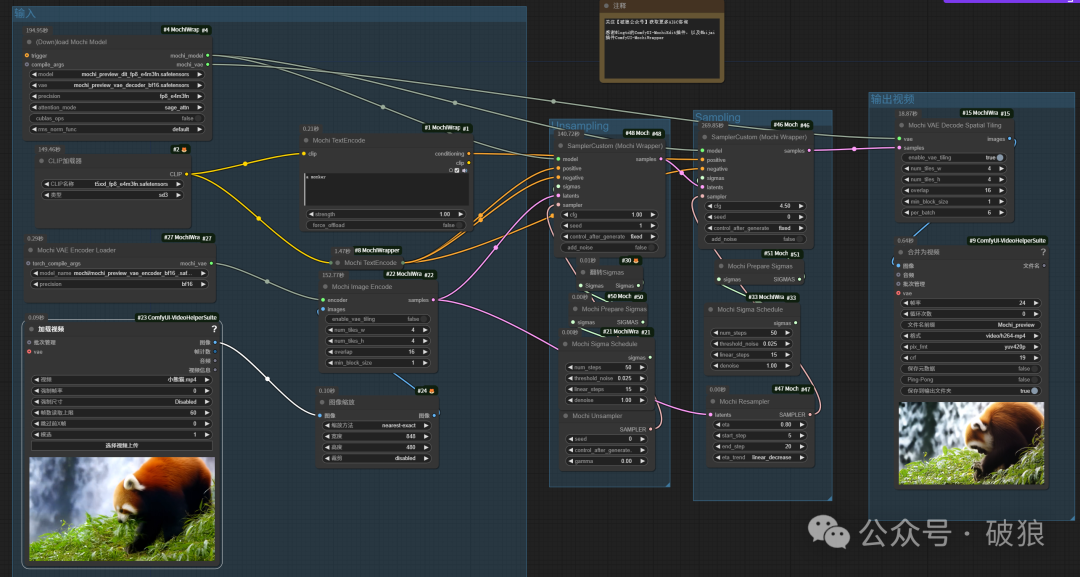
首先通过ComfyUI插件管理器搜索安装ComfyUI-MochiEdit插件。同时还需要安装对应的ComfyUI-MochiWrapper依赖插件(如已经安装别忘了本地git pull更新)。模型将会在首次运行时候下载。关于ComfyUI-MochiWrapper安装,
-
• ComfyUI-MochiEdit插件:https://github.com/logtd/ComfyUI-MochiEdit
-
• ComfyUI-MochiWrapper插件:https://github.com/kijai/ComfyUI-MochiWrapper
-
• t5xxl_fp8模型: 与SD3、Flux会使用想用,需放置目录ComfyUI/models/clip。地址:https://huggingface.co/mcmonkey/google_t5-v1_1-xxl_encoderonly/resolve/main/t5xxl_fp8_e4m3fn.safetensors?download=true
-
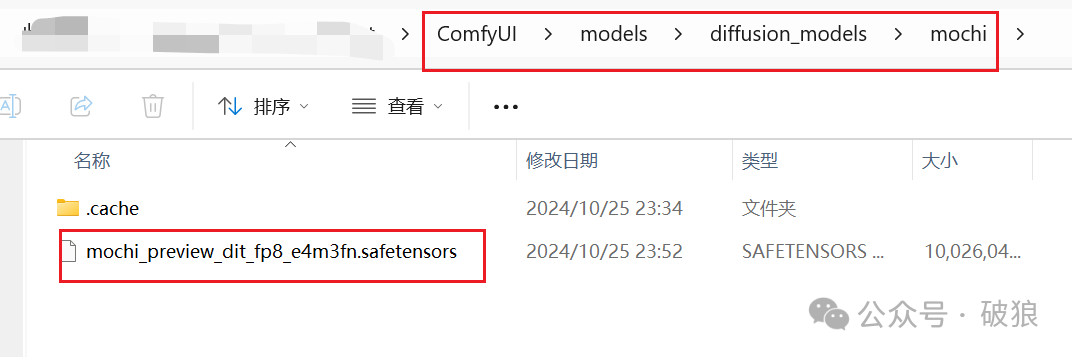
• mochi模型: 下载模型放置目录ComfyUI/models/diffusion_models/mochi。地址:https://huggingface.co/Kijai/Mochi_preview_comfy/tree/main
-
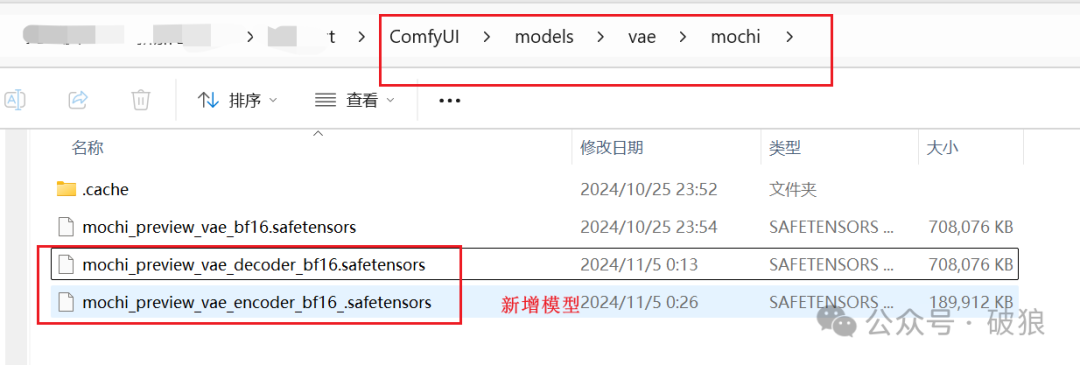
• mochi encoder vae模型: 下载模型放置目录ComfyUI/models/vae/mochi。地址:https://huggingface.co/Kijai/Mochi_preview_comfy/resolve/main/mochi_preview_vae_encoder_bf16_.safetensors?download=true
-
• mochi decoder vae模型: 下载模型放置目录ComfyUI/models/vae/mochi。地址:https://huggingface.co/Kijai/Mochi_preview_comfy/resolve/main/mochi_preview_vae_decoder_bf16.safetensors?download=true

ComfyUI-MochiEdit工作流
ComfyUI-MochiEdit工作流已上传LIBLIB平台可下载地址:https://www.liblib.art/modelinfo/dad42ec6e9c14c699c047087fc3182c6?versionUuid=b9cfeb49c22249cfb91d437a17a92cfa
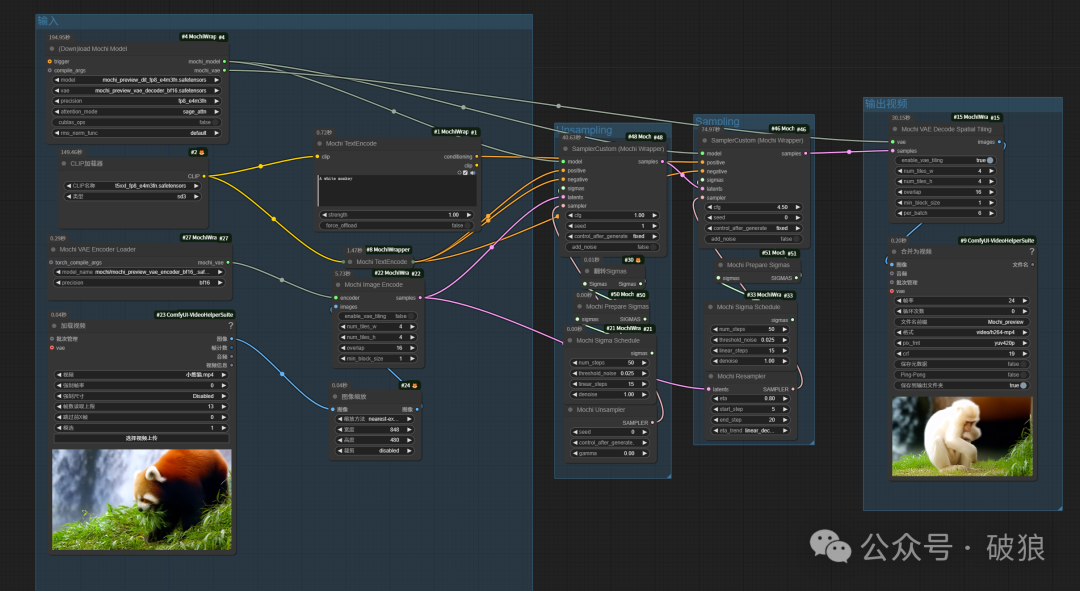

注意:工作流包含:Mochi Unsampler逆采样器、 Mochi Prepare Sigmas噪音调整、SamplerCustom (MochiWrapper)采样器、Mochi Resampler重采样等核心节点。详情参考插件主页。安装sageattention(https://github.com/thu-ml/SageAttention)可以极大的加速视频生成,命令如下:
`pip install sageattention`
如使用整合包不清楚如何安装,可使用ComfyUI的插件管理器安装:
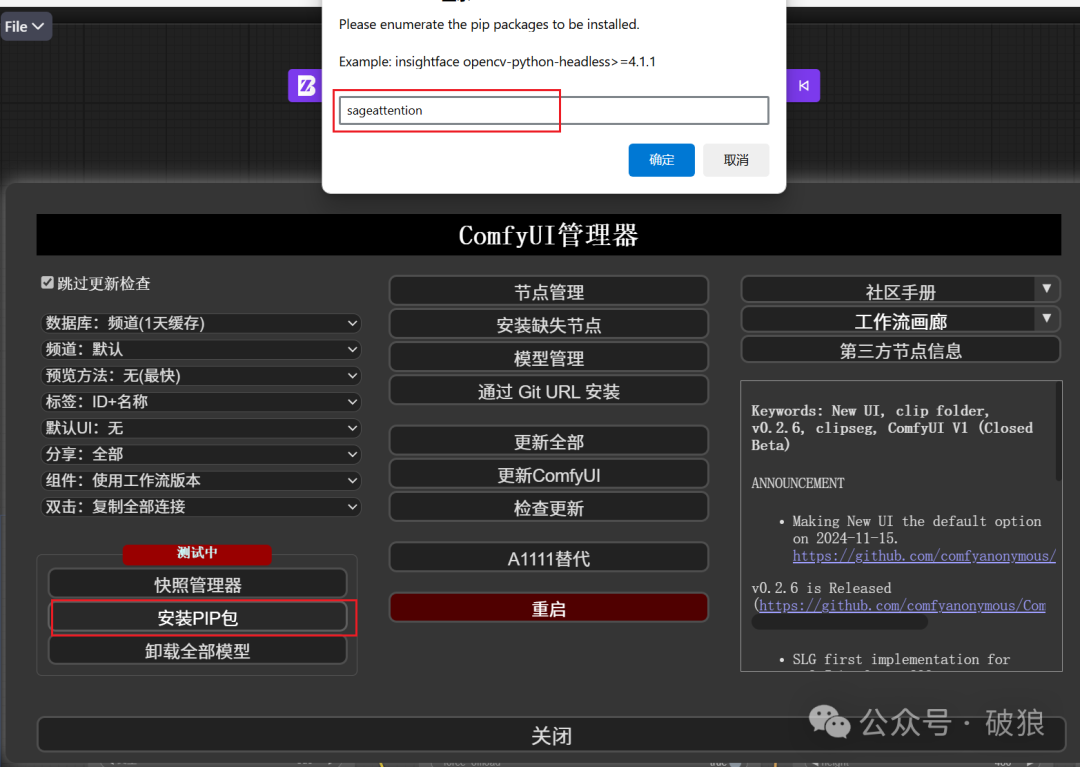
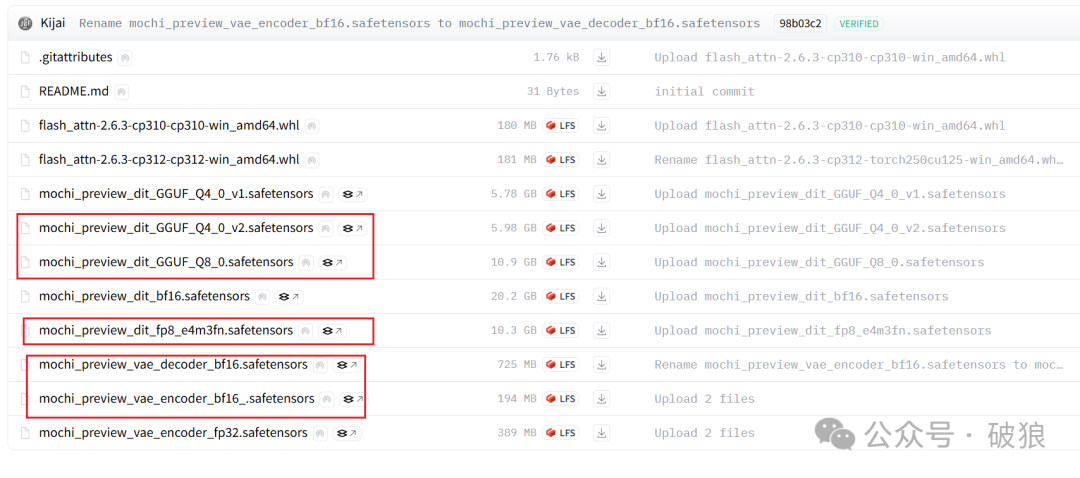
对于低显存机器也可以使用GGUF4或GGUF8模型,速率会更快,24G大约10分钟内(相比之前30分钟节约了20分钟时间):
Mochi Resampler核心采样节点
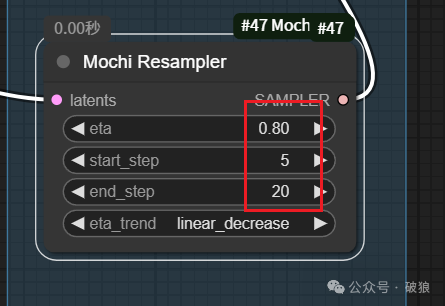
Mochi Resampler 采样节点 是创建一个采样器,并且可以将噪声转换成视频,主要调整eta强度和start_step开始步数。
-
•
latents:原始视频的 latents。 -
•
eta:生成应该与原始视频对齐的强度。 -
• 更高的值会使生成更接近原始视频。
-
•
start_step:原始视频应该引导生成的起始步骤。 -
• 较低的值(例如 0)将更紧密地跟随,但不允许添加额外的物体,如帽子。
-
• 较高的值(例如 6)将允许放置新的物体,如帽子,但可能不跟随原始视频。较高的值也可能导致不良结果(模糊)。
-
•
end_step:停止引导生成更接近原始视频的步骤。 -
• 较低的值将导致视频输出中的差异更大。
-
•
eta_trend:eta(引导强度)应该保持恒定,增加还是减少随着步骤的进展。linear_decrease 是大多数变化推荐的设置。
01. 换主体-猴子
`A monkey`
02.换主体-小鸟觅食
`A little bird`
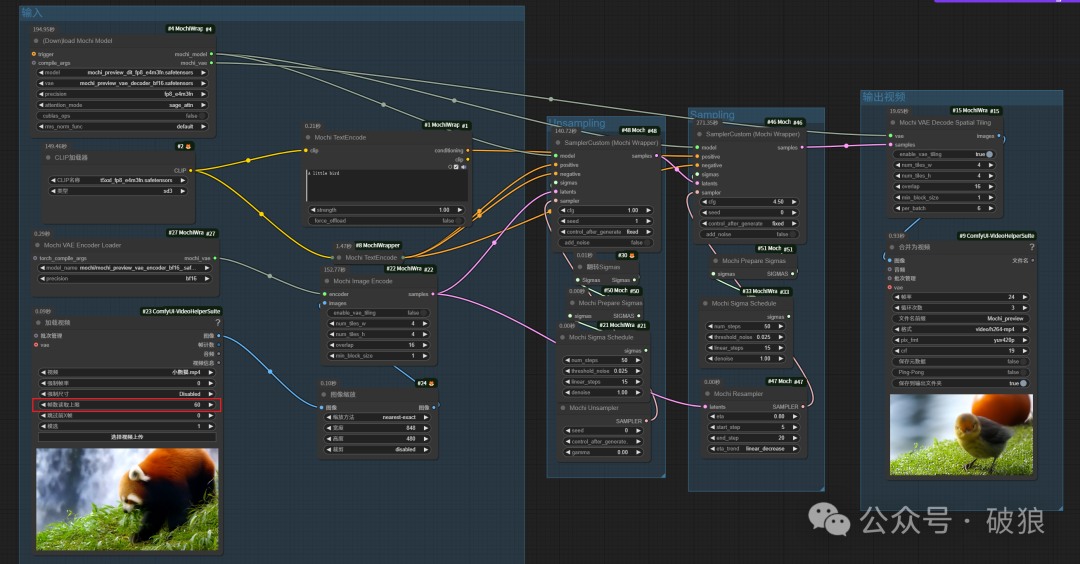
03.人物转绘-动漫
原本期望视频转动漫人物,人物主体变了,但是动漫风格没成功,可能是因为数据集缺失或者提示语问题,后续将继续研究。
`An anime girl`
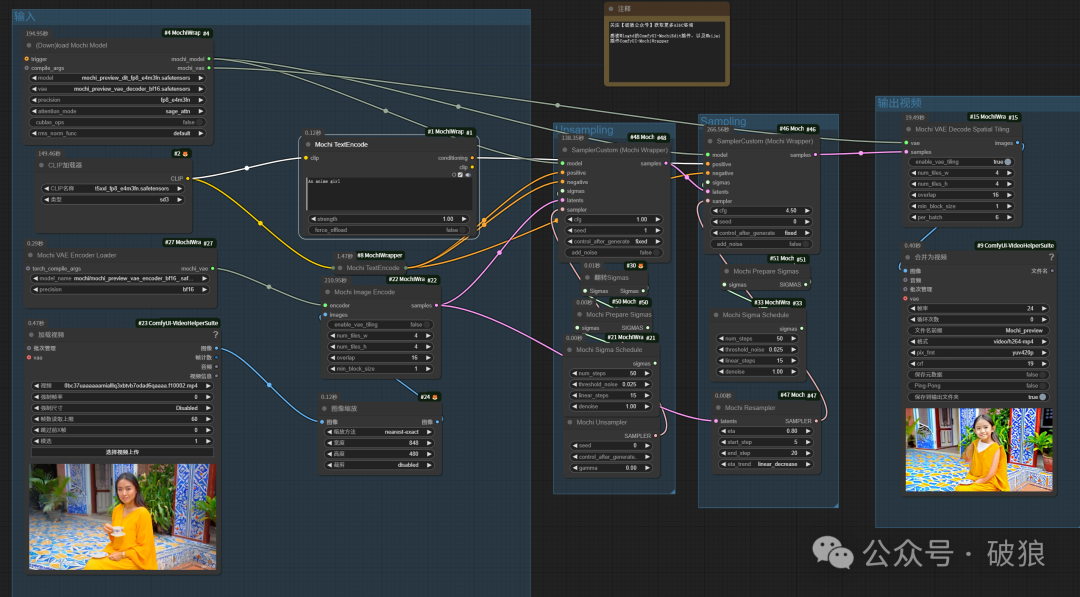
增加更详细的提示词,这里采用joy反推并手工改写为3D动漫风格提示词,以及调整参数为eta:0.83,6步开始,有了一些显著变了满足了风格,但是质量完全不足够。在这里视频就不放出来吓人啦。
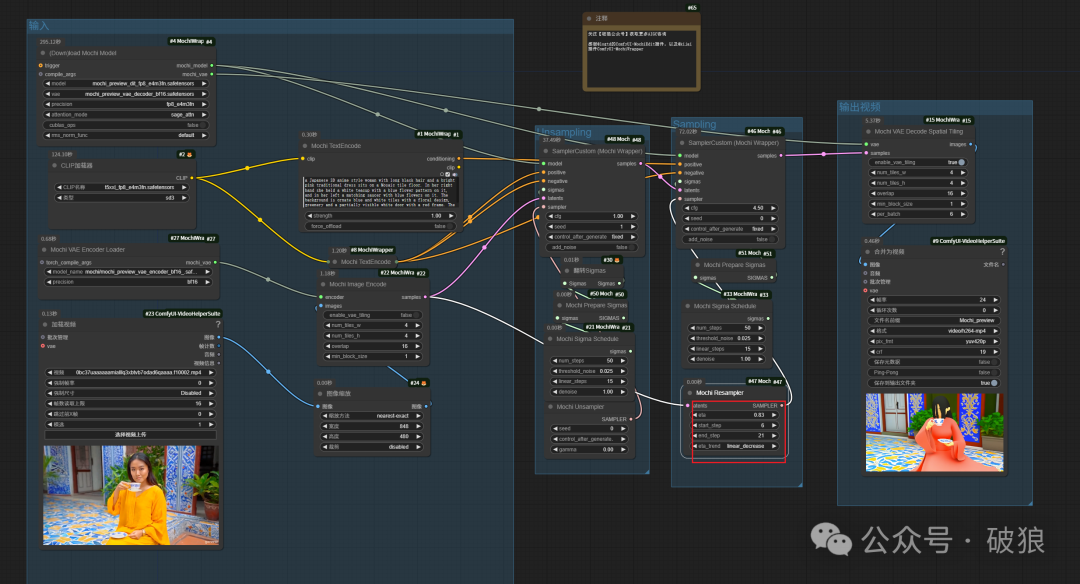
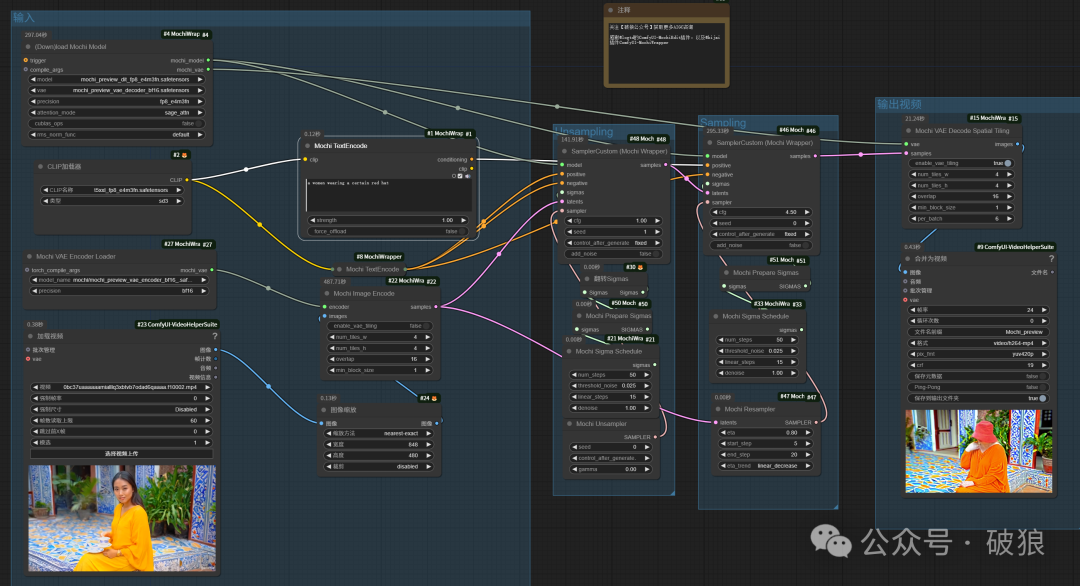
04.增加帽子
能够显著根据提示带上帽子,但是人物脸庞被遮住。
`a women wearing a certain red hat`
利用Mochi实现的MochiEdit工具将会是一个潜力不错的视频编辑工具,特别在视频转绘等方面,当前的功能体验并为达到期望,但相信随着AI视频模型的发展,这一领域将会越来越强大。
另外,近期发布的治愈微观昆虫世界,不少同学开始了精彩的案例写真创意,笔者在LIBLIB平台已发布独立写真工作流,感兴趣者体验:https://www.liblib.art/modelinfo/493781c57d2348bc812448efe6461984?versionUuid=102c8bda0e804e648bd829ec128d4992
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









