







参考文档:常用Python PDF库对比
上文中:列举了几个常用的Python中PDF的模块。
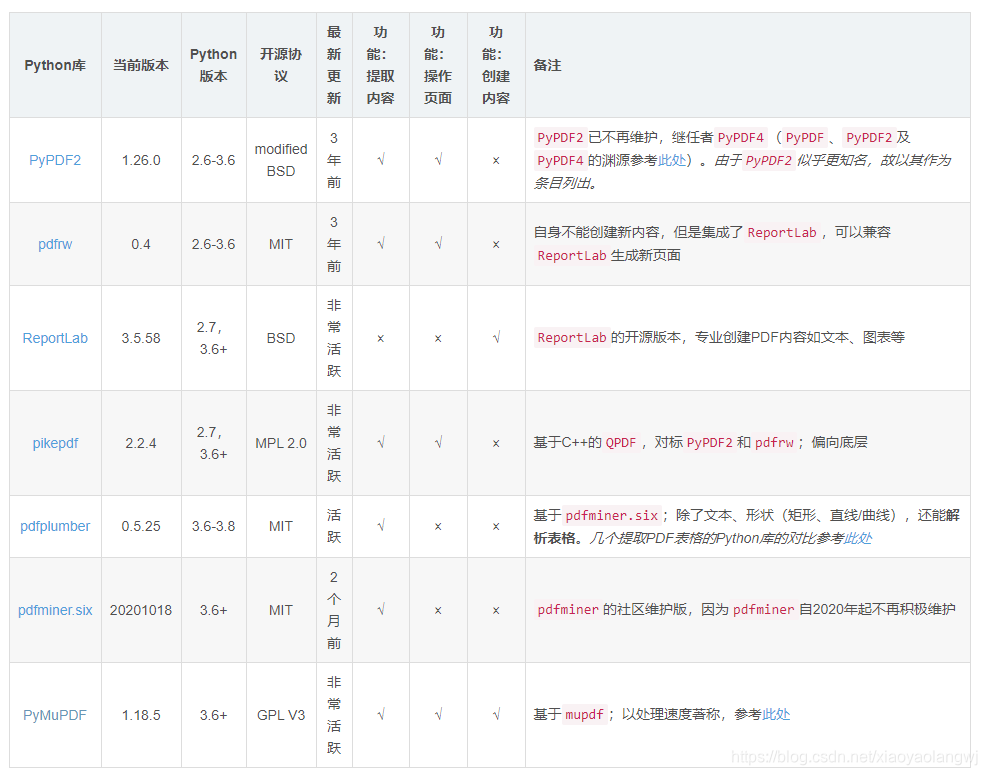
我自己的应用场景是将发票金额提取,并用金额去命名pdf文件名。
经过个人测试:PyMuPDF模块效果显著。
Talk is cheap,I show you the code。
import os
import fitz
import shutil
'''
支持滴滴行程单。
# PyMuPDF模块:https://pymupdf.readthedocs.io/en/latest/tutorial.html#extracting-text-and-images
'''
root_dir = "./"
out_dir = "./output"
if not os.path.exists(out_dir):
os.mkdir(out_dir)
def fapiao_read(text):
if "¥" in text:
print(text.split("¥")[-1].split("\n")[0])
money = text.split("¥")[-1].split("\n")[0]
elif "¥" in text:
print(text.split("¥")[-1].split("\n")[0])
money = text.split("¥")[-1].split("\n")[0]
return money
def xingchengdan_read(text):
print(text.split("合计")[1].split("元")[0].split()[0])
money = text.split("合计")[1].split("元")[0].split()[0]
return money
Repeat_name_list = []
for file in os.listdir("./"):
if file.endswith(".pdf"):
src = os.path.join(root_dir, file)
doc = fitz.open(src) # or fitz.Document(filename)
page = doc.load_page(0)
text = page.get_text("text")
if "¥" in text or "¥" in text:
if "敏感信息脱敏" in text and "敏感信息脱敏" in text:
money = fapiao_read(text)
out_file_name = "电子发票" + money + "元"
else:
continue
else:
money = xingchengdan_read(text)
out_file_name = "电子发票" + money + "元行程单"
Repeat_name_list.append(out_file_name)
if out_file_name in Repeat_name_list:
repeat_num = Repeat_name_list.count(out_file_name)
if repeat_num == 1:
out_file_name = out_file_name
else:
out_file_name = out_file_name + "(" + str(repeat_num-1) + ")"
dst = os.path.join(out_dir, out_file_name+".pdf")
shutil.copy(src, dst)
这个仅仅支持所有电子发票的pdf,同时支持滴滴发票和行程单的提取。其他pdf暂未考虑。因为我也用不到。
备注:据我观察人民币的“¥”符号,在发票中,有两种表现。代码中已经列出。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









