







 本文分析了DETR模型训练中的瓶颈,提出TSP-FCOS和TSP-RCNN方法。TSP-FCOS结合FCOS和编码器DETR,优化了目标检测过程,通过特征选择和受限匹配加速训练。TSP-RCNN则在两阶段策略中提升精度,尤其在处理不同尺度目标时。实验表明,新方法显著提高DETR的收敛速度和准确性。
本文分析了DETR模型训练中的瓶颈,提出TSP-FCOS和TSP-RCNN方法。TSP-FCOS结合FCOS和编码器DETR,优化了目标检测过程,通过特征选择和受限匹配加速训练。TSP-RCNN则在两阶段策略中提升精度,尤其在处理不同尺度目标时。实验表明,新方法显著提高DETR的收敛速度和准确性。
最近整理Transformer和set prediction相关的检测&实例分割文章,感兴趣的可以跟一下:
- DETR: End-to-End Object Detection with Transformers
- Deformable DETR
- Rethinking Transformer-based Set Prediction for Object Detection
- Instances as Queries
- SOLQ: Segmenting Objects by Learning Queries Bin
| paper | https://arxiv.org/abs/2011.10881 |
|---|---|
| code | none |
1. 摘要
最近提出的DETR是Transformer-based的方法,它将目标检测看作set prediction问题,并达到了SOTA的性能,但训练需要极长的时间。而这篇文章研究了DETR训练中优化困难的原因:Hungarian loss和Transformer cross-attention 机制等问题。 为了克服这些问题,我们提出了两种解决方案,即TSP-FCOS和TSP-RCNN。 实验结果表明所提出的方法不仅比原始DETR训练更快,准确性方面也明显优于DETR。
2. DETR收敛慢的原因分析
2.1 Does Instability of the Bipartite Matching Af- fect Convergence?
在模型早期,模型的GT分配就是约等于随机分配的,这造成了早期训练时的不稳定性。
-
为了验证上述猜想原因,本文提出了一种新的DETR训练策略,即蒸馏匹配。也就是说,使用预先训练好的DETR作为教师模型,其预测的二分匹配指导学生模型的ground-truth标签分配。
-
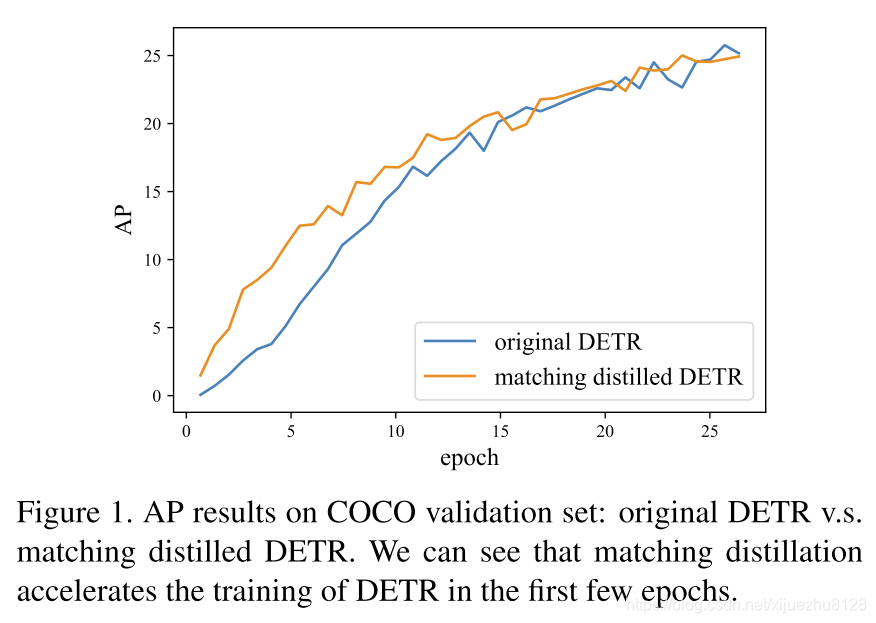
下图显示了前25个epoch的结果。可以看到,蒸馏匹配策略确实有助于在前几个epoch的DETR收敛。然而,这种影响在约15个epoch之后就变得无关紧要了。这意味着DETR的二分匹配部分的不稳定性只部分地导致了收敛速度慢(特别是在早期训练阶段),但这并不是其收敛慢的主要原因。
2.2 Are the Attention Modules the Main Cause?
DETR使用了Transformer模块,其中Transformer注意力在初始化阶段几乎是统一的,但在训练过程中逐渐变得越来越稀疏(fcous),趋于收敛。本节验证DETR的Transformer attention 模块的稀疏性对其收敛的影响。
- 此处重点关注Transformer decoder中的cross attention部分的稀疏性动态变化,因为cross attention模块是解码器中的object query从编码器中获取object info的关键模块。不精确的cross attention可能无法从图像中提取准确的上下文信息,从而导致较差的定位,特别是对小目标。
- 具体如何评估cross attention的稀疏性呢?本文收集了不同训练阶段cross attention的attention map。由于attention map可以被视为概率分布,此处使用负熵作为稀疏性的度量。具体地说,给定一个 n × m n \times m n×m的attention map,我们首先计算每个位置 i ∈ [ n ] i \in [n] i∈[n]的稀疏性 1 m ∑ j = 1 m P ( a i , j ) l o g P ( a i , j ) \frac{1}{m}\sum^{m}_{j=1} P(a_{i,j})logP(a_{i,j}) m1∑j=1mP(ai,j)logP(ai,j),最后将所有n个结果取平均得到最终负熵的结果。
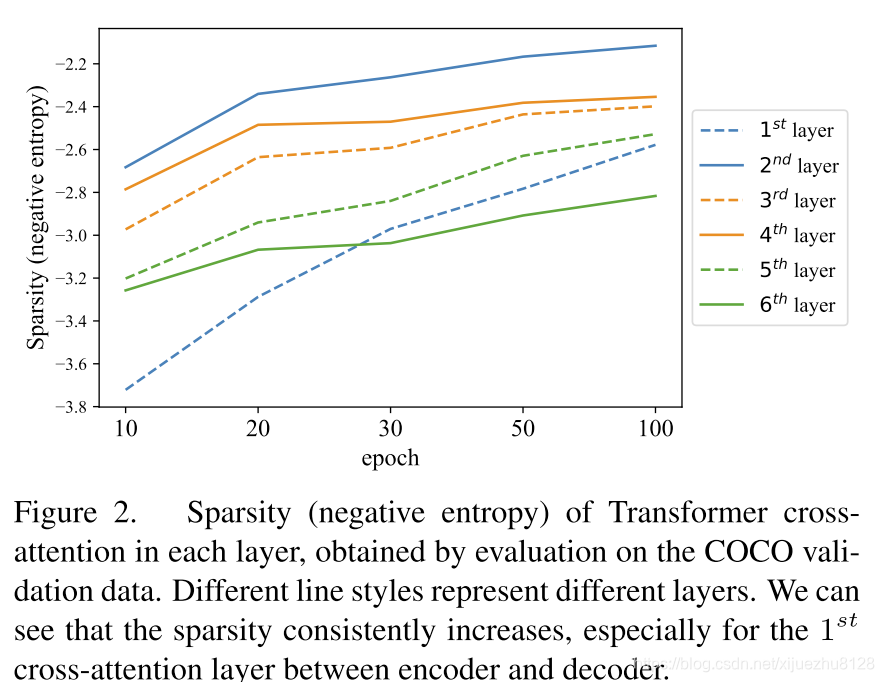
- 下图显示了不同epoch时期的稀疏度。可以看到,cross attention的稀缺性持续增加,甚至在100个epoch训练后也没有达到峰值。这意味着与之前讨论过的早期二分匹配不稳定因素相比,DETR的cross attention部分是收敛缓慢的更主要因素。
2.3 Does DETR Really Need Cross-attention?
那么能否将cross attention模块从DETR中移除,以更快地收敛,但又不破坏其目标检测能力呢?
- 在原始的DETR中,解码器负责产生每个object query的检测结果(cls & bbox)。
- 作为对比,本文引入的仅包含编码器的DETR版本,其直接使用Transformer编码器的输出进行对象预测。
- 具体地说,对于 H / 32 , W / 32 H/32, W/32 H/32,W/32的特征图,每个像素特征均被送入检测头以预测检测结果(cls & bbox)。
- 下图给出了原始DETR和仅编码器的DETR的mAP曲线。
-
- 总体曲线(左上角)显示,仅编码的DETR和原始的DETR一样好。这意味着我们可以将cross attention部分从DETR中移除,而不会产生太多性能退化。
-
- 从剩余的曲线中我们可以看到,仅编码器的DETR在小目标和部分中等目标上比原始的DETR性能更好,但在大对象上性能不佳。一个潜在的解释是,一个大目标可能包含太多潜在匹配的特征点,这对于只使用编码器的DETR中的滑动点方案是很难处理的。另一个可能的原因是,单一特征图对预测不同尺度的目标不鲁棒。
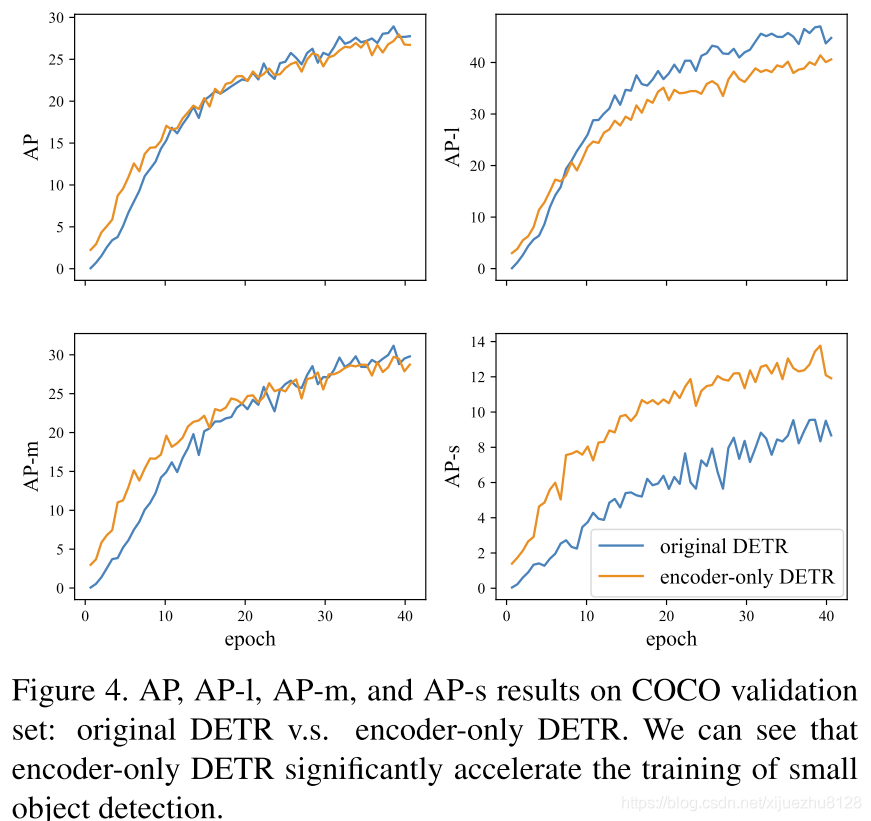
实际我觉得这里的改进并没有太有用,此处想说明只有encoder的DETR收敛更快,但是从训练曲线来看,只是刚开始快了一些,后续达到的精度与原始的DETR在40epoch处差不多。
3. 本文提出的方法
根据我们上一节的分析,为了加快DETR的收敛速度,我们需要同时解决DETR的二分匹配部分的不稳定性问题和Transformer中的cross attention问题。
具体地说,为了利用仅采用编码器的DETR的加速收敛的潜力,我们需要克服它在处理不同尺度目标方面的弱点。因此,下面提出了基于Transformer的set prediction与FCOS (TSP-FCOS)。然后在TSP-FCOS的基础上,进一步应用两阶段策略,提出了基于Transformer的set prediction与RCNN(TSP-RCNN)。
3.1 TSP-FCOS
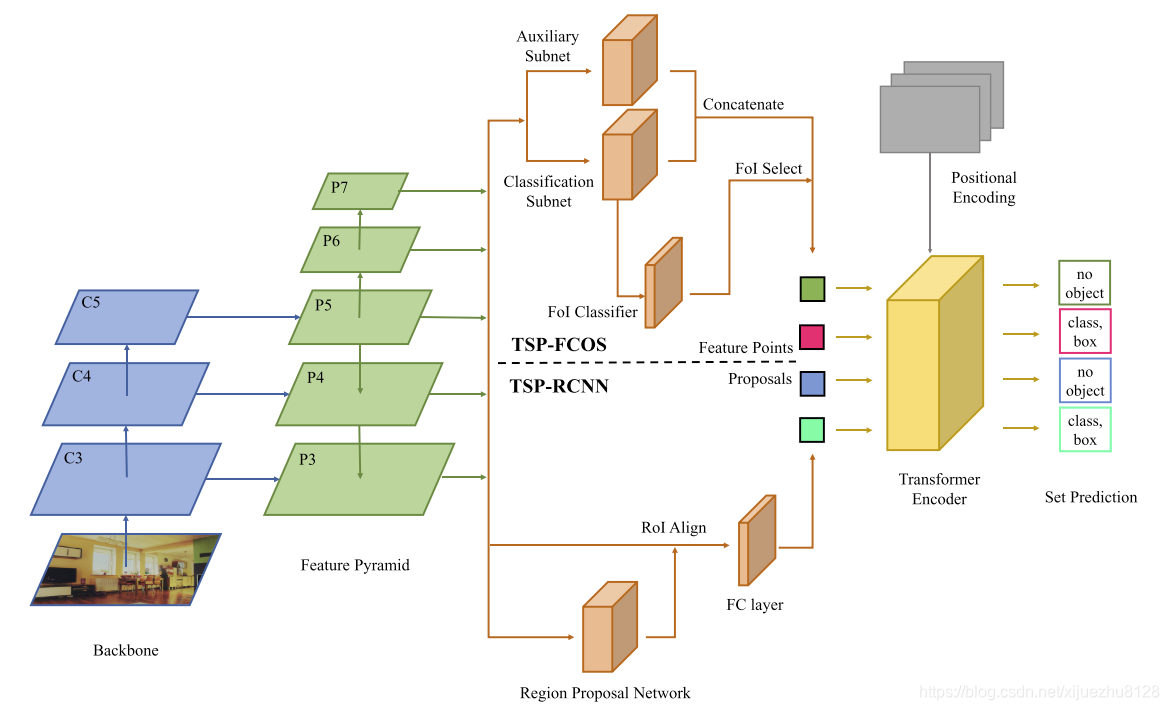
TSP-FCOS结合了FCOS和仅编码器的DETR的优点。
3.1.1 Backbone and FPN
- 我们遵循FCOS设计backbone和FPN,其可以产生多层次的特征,可以帮助仅采用编码器的DETR检测各种尺度的目标。
3.1.2 Feature extraction subnets
- 此处类似FCOS,在FPN各个分辨率特征图上设计共享的head;
- 该head包含分类head和辅助head;
- 这两个head的输出特征被concat起来然后被FOI classifier进行筛选。
3.1.3 Feature of Interest (FoI) classifier
- 在Transformer的self-attention中,计算复杂度是序列长度的二次方。
- 因此所以为了避免高复杂度,不直接使用FPN上的所有像素。
- 而是设计了一个二元分类器来选择一部分像素特征,将其称为感兴趣特征(Features of Interest, FoI)。具体哪些像素应该被选择(FoI GT)是依据FCOS的正负样本assignment指定的。
- FoI分类后,得分最高的一部分特征被选为FoI,并输入Transformer编码器。
3.1.4 Transformer encoder
- 在FoI选择步骤之后,Transformer编码器的输入是一组FoI及其对应的position encoding。
- 编码器的输出通过一个共享的FFN,该网络预测每个FoI的cls & bbox。
3.1.5 Faster set prediction training
- 匈牙利二分匹配损失会导致在训练的早期阶段收敛缓慢,因此,本文设计了一种新的二分匹配方案,用于TSP- FCOS的快速set prediction训练。
- 具体地说,一个特征点只有在其所属对象的边界框内且在分配的FPN level时,才能被分配给一个目标。这是受到FCOS的ground-truth assignment规则的启发。接下来,执行一个受限制的匹配过程,以确定最优匹配。
3.2 TSP-RCNN
略。
此处重点在于理解本文的设计目的,暂时略过二阶段的算法设计,重点理解给予一阶段检测算法FCOS和Transformer以及set prediction结合的思路。
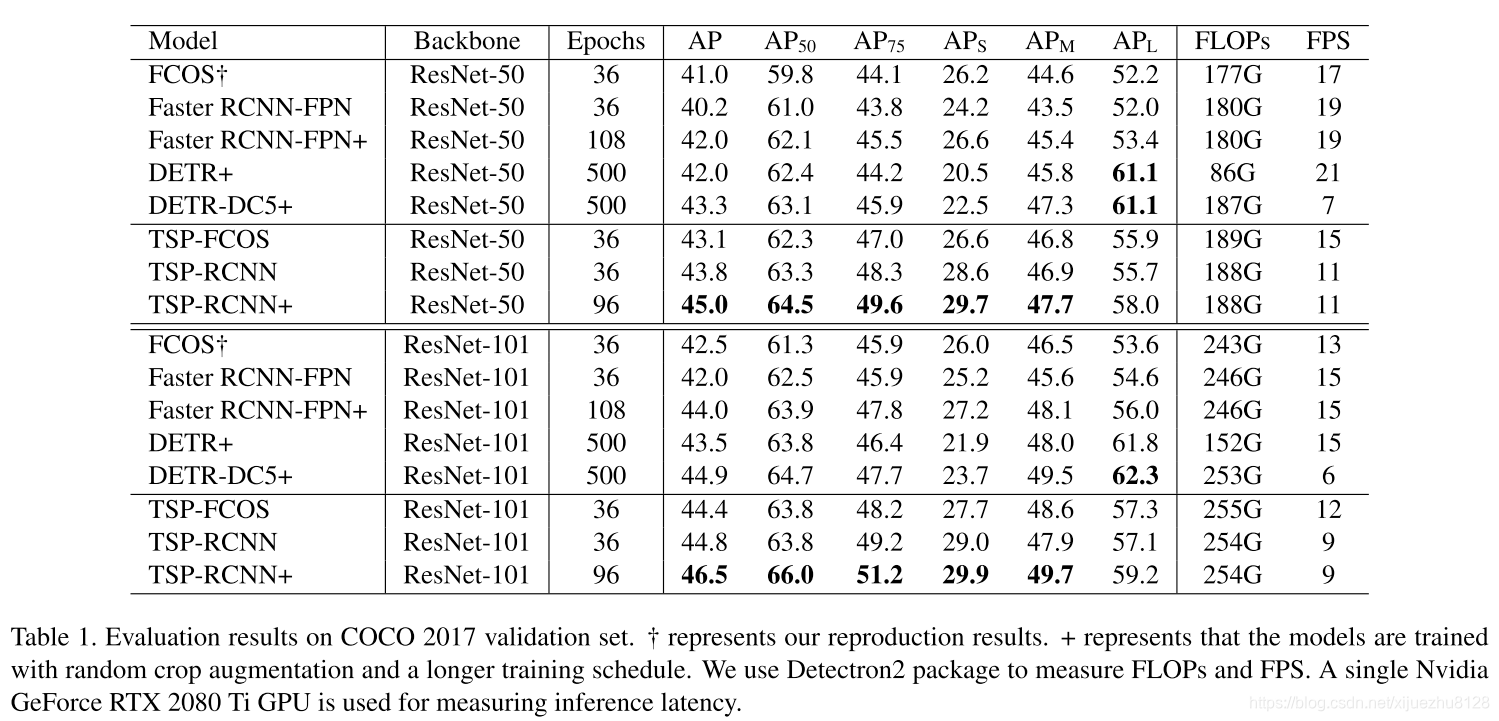
4. 实验结果
在实验中,每次从FoI分类器中选择得分最高的700个特征位置作为Transformer编码器的输入。



















 8218
8218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









