







使用LLaMA-Factory进行模型量化
以下实验基于微调后模型进行量化。针对基座模型的直接量化,可以使用与部署中使用的数据类型紧密匹配的公开通用数据集作为校准数据集量化(任意数据集)该部分可以参考使用llm-compressor。
量化方法
LLaMA-Factory 支持多种量化方法,包括:
- AQLM
- AWQ
- GPTQ
- QLoRA
- …
GPTQ 等后训练量化方法(Post Training Quantization)是一种在训练后对预训练模型进行量化的方法。
量化导出
使用GPTQ和AWQ等后训练量化方法对模型进行量化时,需要进行以下步骤:(即使直接使用AutoAWQ和AutoGPTQ对qwen进行量化都需要进行以下步骤)
- 对模型进行微调
- 构建校准数据集
- 将微调后模型进行量化导出
以下是量化导出时使用的yaml文件以及其中的基础参数
### examples/merge_lora/llama3_gptq.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct #预训练模型的名称或路径
template: llama3 #模型模板
### export
export_dir: models/llama3_gptq # 导出路径
export_quantization_bit: 4 #量化位数[8, 4, 3, 2]
export_quantization_dataset: data/c4_demo.json #量化校准数据集
export_size: 2 #最大导出模型文件大小
export_device: cpu #导出设备,还可以为cuda
export_legacy_format: false #是否使用旧格式导出
当使用参数export_quantization_bit时直接使用auto-gptq
校准数据集
格式需要严格参考以下形式:
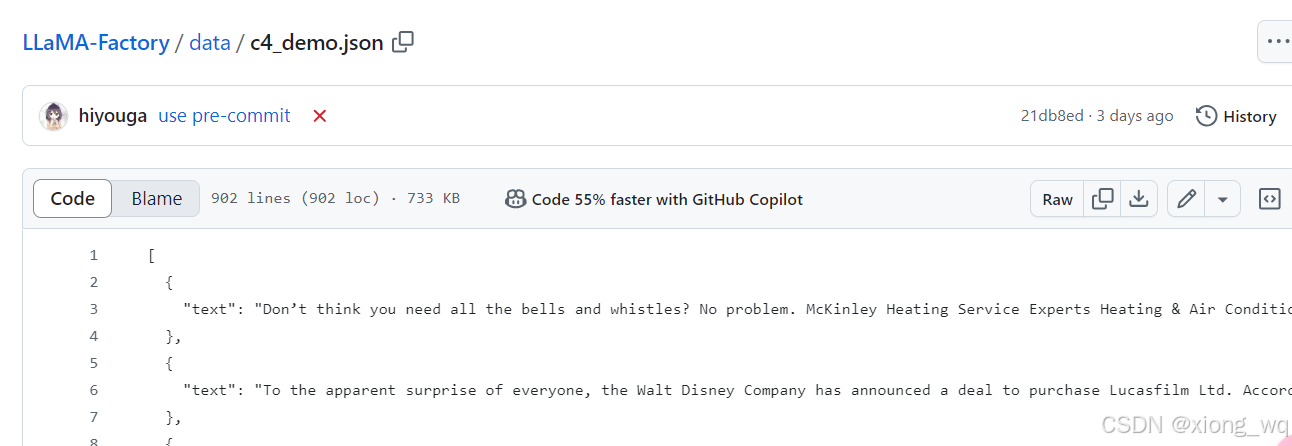
- 使用训练集进行构造
- 构造方式:instruction+input+ouput=>text
- 校准数据集不用很大,默认只会用 128 个样本
- 格式转换代码路径:/project/LLaMA-Factory_test2/datasets_convert_quanti_datasets.py
llamafactory对校准数据集进行采样时,如果样本长度太短会爆出以下错误:

解决方法:设置export_quantization_maxlen稍小一些即可
### model
model_name_or_path: model_path_dir
template: qwen
### export
export_dir: save_dir
export_quantization_bit: 4
export_quantization_maxlen: 300
export_quantization_dataset: /datasets/demo.json
export_size: 2
export_device: cuda
export_legacy_format: false
注意事项
由于GPU硬件支持参数精度有规定,在部署量化模型时需要考虑设备性能。

















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









