










腾讯联合浙大提出了一种定制化视频生成框架-CustomCrafter,它能够基于文本提示和参考图像生成自定义视频,同时保留运动生成和概念组合的能力。通过设计一系列灵活的模块,使得模型实现了无需额外视频,通过少量图像学习,就能生成高质量的个性化视频。

上图为 CustomCrafter 可视化结果。CustomCrafter允许自定义主体身份和运动模式 通过保留运动生成和概念组合能力来生成带有文本提示的所需视频。
相关链接
论文地址:http://arxiv.org/abs/2408.13239v1
项目主页:https://customcrafter.github.io/
论文阅读

CustomCrafter:具有保留动作和概念合成功能的定制视频生成
摘要
定制视频生成旨在通过文本提示和主体参考图像生成高质量的视频。然而,由于它只在静态图像上进行训练,主体学习的微调过程会破坏视频扩散模型 (VDM) 组合概念和生成运动的能力。为了恢复这些能力,一些方法使用类似于提示的额外视频来微调或引导模型。这需要在生成不同运动时频繁更改引导视频甚至重新调整模型,这对用户来说非常不方便。
在本文中,我们提出了 CustomCrafter,这是一个新颖的框架,它保留了模型的运动生成和概念组合能力,而无需额外的视频和微调来恢复。为了保留概念组合能力,我们设计了一个即插即用模块来更新 VDM 中的一些参数,增强了模型捕捉外观细节的能力和对新主体的概念组合能力。对于运动生成,我们观察到 VDM 倾向于在去噪的早期阶段恢复视频的运动,而在后期阶段专注于恢复主体细节。因此我们提出动态加权视频采样策略,利用主体学习模块的可插拔性,在去噪前期降低该模块对运动生成的影响,保留VDM的生成运动的能力;在去噪后期恢复该模块,修复指定主体的外观细节,从而保证主体外观的逼真度。实验结果表明,我们的方法相比之前的方法有明显的提升。
方法

CustomCrafter 整体回顾。对于主题学习,我们采用 LoRA 构建空间主题学习模块,该模块更新所有 Spatial Transformer 模型中注意力层的 Query、Key 和 Value 参数。在生成视频的过程中,我们将去噪过程分为两个阶段:运动布局修复过程和主题外观修复过程。通过在运动布局修复过程中降低空间主题学习模块的影响,并在主题外观修复过程中恢复它来修复主题的细节。

与以前的工作相比,CustomCrafter 方法的特点是可以更好地学习主体的外观,同时保留概念组合能力和运动生成能力,只需要一个阶段的训练,而无需额外的视频。DWV 采样策略是我们的动态加权视频采样策略。

视频去噪过程的可视化。运动在去噪过程的早期阶段形成,主体的外观在后期阶段显现。
效果
与 SOTA 的比较



对包含主题和动作的定制视频生成进行定性比较。 在没有其他视频指导的情况下,我们的方法在概念组合方面表现明显优于其他方法。

对包含主题和动作的定制视频生成进行定性比较。在没有其他视频指导的情况下,我们的方法在概念组合方面表现明显优于其他方法。
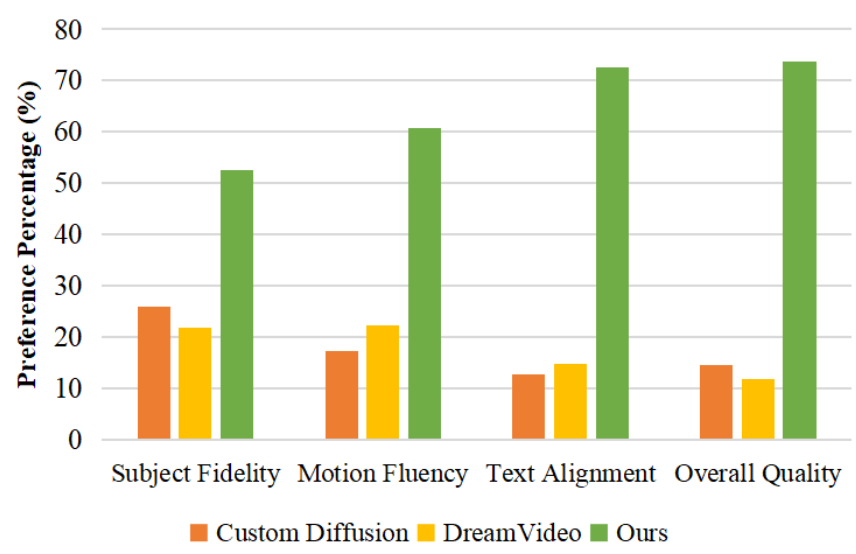
用户研究。CustomCrafter与其他比较方法的比较做到最好人类偏好。
结论
在本文中,我们介绍了 CustomCrafter,一种用于定制视频生成的新框架。这种方法不需要额外的视频来修复运动生成能力。我们首先设计了一个空间主题学习模块,它更新了空间注意力以完成对主题外观特征的学习。同时,我们提出了一种动态加权视频生成,它改进了模型的推理过程以恢复 VDM 的运动生成能力。通过定性和定量实验,我们证明了我们的方法比现有方法更好,保留了 VDM 结合概念和生成运动的能力。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











