









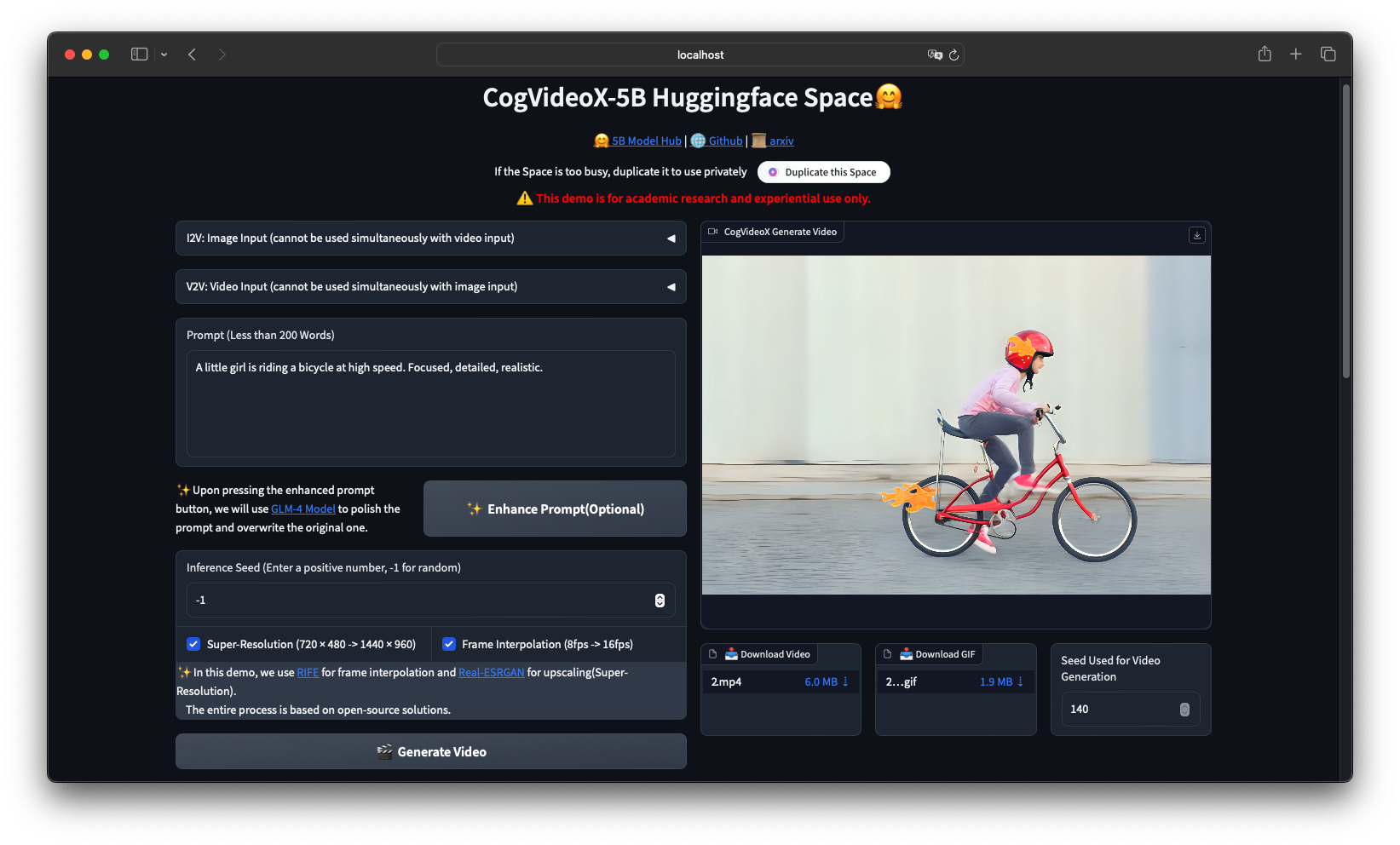
CogVideoX 系列近期开源了图生视频模型 CogVideoX-5B-I2V 。该模型可以将一张图像作为背景输入,结合提示词一起生成视频,能够生成具有较高视觉效果的动态视频,具有更强的可控性,非常适合从静态图像中提取内容并制作视频场景。至此,CogVideoX系列模型已经支持文本生成视频,视频续写,图片生成视频三种任务。


此外,ComfyUI-CogVideoXWrapper是一个整合了 CogVideoX 模型的 UI 工具,支持图像到视频(Image-to-Video)和文本到视频(Text-to-Video)功能,允许用户通过 ComfyUI 界面轻松进行视频生成,并提供了多种优化和实验性功能。大家可以通过一下链接使用。
相关链接
Github:https://github.com/THUDM/CogVideo
ComfyUI:https://github.com/kijai/ComfyUI-CogVideoXWrapper
模型下载:https://huggingface.co/THUDM/CogVideoX-5b-I2V
模型特点
-
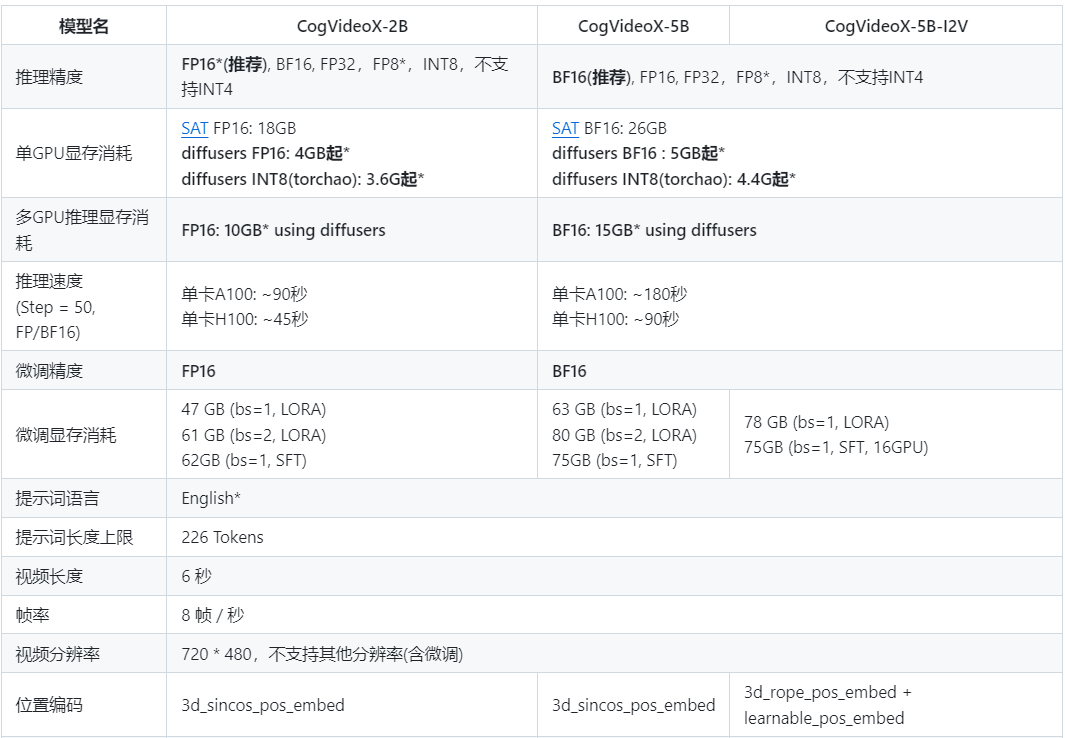
CogVideoX-5b-I2V 是一个图像到视频(Image-to-Video)的版本,通过将静态图像和文本描述结合,生成动态视频。支持 BF16 精度,能够在图像的基础上生成符合描述的动画效果。
-
推理性能:单 GPU A100 的推理时间约为 180 秒,支持多 GPU 推理和量化推理。模型内置多种优化策略,如模型 CPU 卸载、切片和拼接,以减少显存使用,提高推理速度。
-
量化推理支持:使用 PytorchAO 和 Optimum-quanto 可以对模型进行量化,以降低显存需求,使模型能够在低显存 GPU(如免费的 T4 Colab)上运行,并显著提升推理速度。
-
应用场景:支持的最大视频长度为 6 秒,每秒 8 帧,分辨率为 720 x 480,适合用于广告、短视频制作、动态场景建模等应用。
-
快速上手:提供了详细的模型使用指南和代码示例,用户可以通过 Huggingface diffusers 库部署模型,并使用静态图像和英语描述生成视频内容。
ComfyUI使用
-
ComfyUI已支持官方的 CogVideoX-5b 和 CogVideoX-5b-I2V 模型,分别用于文本生成视频和图像生成视频。同时支持实验性图像到图像(img2img)转换,尝试用于视频到视频(vid2vid)工作流。
-
性能优化:集成了 onediff 技术,使采样时间减少约 40%。在 4090 GPU 上,每 49 帧的采样时间仅需 4.23 秒,但需要安装 Linux、torch 2.4.0、onediff 和 nexfort。
-
无限视频生成:通过时间拼接(temporal tiling)功能实现无限视频生成,为用户提供更灵活的创作选择。
-
实验性功能:支持多种实验性功能,如自动下载模型、使用 ComfyUI 的 T5 文本编码器,提供临时解决方案以减少显存需求。内置的 VAE 解码阶段显存需求较大,但整体采样过程占用显存仅 5-6GB。
-
安装与使用:需要 diffusers 0.30.3 及更高版本,提供了安装和配置指南。用户可以根据 README 中的说明快速上手,并在 ComfyUI 中直观地操作



















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











