






代码:https://github.com/Megvii-BaseDetection/YOLOX
论文:https://arxiv.org/abs/2107.08430
速度和检测效果与yolov5对比:

首先还是backbone部分,YOLOX在backbone和neck部分与YOLOV4和V5基本一致。都是CSPDarknet53+FPN+PAN结构。

通过不同stage的输出feature map进行一个特征融合。FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,从不同的主干层对不同的检测层进行融合。这里结构简单。代码也简单。3 4 5 stage输出结果打成list输出就是FPN结构。对FPN输出的结果依次上采样cat后就是PAN结果。输出依然是三组Feature map,对应8 16 32倍下采样。
这里注意PAN的上采样操作将低分辨feature map提升到高分辨率然后cat
,一般来说分割算法会是conv+二次线性插值。而这里采用的是最近邻插值
最近邻插值我是这么理解的,一个是速度更快,另一个就是为了方便部署。根据我对目前各个嵌入式板的理解。基本上都对双线性插值算子支持很差。所以一般来说为了上板都得插值这块换成最近邻插值
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
一个一个来说YOLOX的改进:


base anchor需要设计长宽比(当然yolov5有自适应anchor)
x = self.stems[k](x) #FPN输出的feature map
cls_x = x
reg_x = x
cls_feat = cls_conv(cls_x) #分类卷积层 其实就是两个卷积
cls_output = self.cls_preds[k](cls_feat) #分类分支 输出类别
reg_feat = reg_conv(reg_x) #置信度分支,输出前景的概率
reg_output = self.reg_preds[k](reg_feat) #回归分支 其实就是两个卷积
obj_output = self.obj_preds[k](reg_feat) #回归分支 输出xywh
注意这里一共有三个分支:
回归分支:
预测anchor中心点坐标(xy)和wh
置信度分支:
预测该anchor是前景概率,最后输出后处理时通过置信度阈值卡框
分类分支:
输出类别概率。
回归分支本质还是一个conv层:
self.reg_preds.append(
nn.Conv2d(
in_channels=int(256 * width),
out_channels=4,
kernel_size=1,
stride=1,
padding=0,
)
)
分类分支本质也是一个conv层,输出xywh通过后面解码层解码
self.cls_preds.append(
nn.Conv2d(
in_channels=int(256 * width),
out_channels=self.n_anchors * self.num_classes,
kernel_size=1,
stride=1,
padding=0,
)
)
这一套分类回归解耦其实就是Retinanet的分类回归分支
结果:

增加解耦头后map提升了一个点,这个其实除了所谓的简化训练难度,我觉得也有一部分两个分支各两个卷积层增加了参数,从fps来看也确实是牺牲了一定实时性得来的
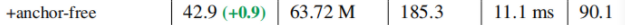
这个anchor-free本质上更多的是回归策略。yolox是通过直接预测xywh解码得到对应的检测框,而包括yolov5在内其他的各类base anchor是通过构造base grid然后对应步长滑窗得到基础网格,通过长宽比的anchor在基础网络上的位置得到初始anchor,预测anchor的偏移量来反向解码得到预测结果。
yolox这里说自己是anchor free感觉还是比较牵强,实际上对比yolov5和yolox在anchor阶段生成的结果来看。其实就是yolox并不需要yolov5的多种长宽比的框。也就是说yolox是直接输出框中心点xy和wh,完全靠回归预测框结果
而yolov5是虽然回归框也是输出xy和wh,但是不需要靠先验的长宽比来增加anchor数量。换句话说yolox通过优化后面的正负样本选择策略,避免了因为anchor数量减少和缺少长宽比先验导致的性能下降。
其实yolov5/yolox在anchor生成阶段都是一个办法。
区别只是
yolov5通过多种长宽比多更多的框
yolox直接每个点预测一个框(比如输入640x640,8倍下采样那一层就是80x80,每个点预测一个框,相比yolov5成倍数降低,yolox和yolov5一样输出三层80x80 40x40 20x20)
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。

通过合理的图像增强,mao提升2.4个点,在yolov4和yolov5中得到了很好地验证,这当然是合理的
数据增广方面同样采用Mosaic和Mix-up策略进行数据增广
multi positives+SimOTA:
目标检测的性能提升有一个很有效的方法就是正负样本策略,从去年的atss到paa。各种消融实验都很好地证明了通过优化算法的正负样本选择可以让模型性能有一个很好地提升
multi positives主要计算网格中心是否在gt bboxes框中,以gt bboxes框的中心为中心,2.5为半径(需乘上网格的stride,相当于5个网格大小的矩形框)的矩形框(中心框)中,只要满足其中一个即为前景anchor(fg_mask)记为is_in_boxes_anchor,两个都满足的anchor记为is_in_boxes_and_center(既在gt bboxes框中又在中心框中,这种框的cost要比其他前景anchor的cost要低很多,其他前景anchor的cost要加上10000)。
center_radius = 2.5 #2.5的半径
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
simOTA流程:
1、确定正样本候选区域。
2、计算anchor与gt的iou。
3、在候选区域内计算cost。
4、使用iou确定每个gt的dynamic_k。
5、为每个gt取cost排名最小的前dynamic_k个anchor作为正样本,其余为负样本。
6、使用正负样本计算loss。
其中:
dynamic_k确定方式:
①获取与当前gt有top10最大iou的prediction结果。
②将这top10 iou进行sum,就为当前gt的dynamic_k。dynamic_k最小取1。
相比之下yolov5的正负样本选择策略是这样的:
参考这里
Yolov5采用的是基于宽高比例的匹配策略。具体而言,对每一个groundtruth框,分别计算它与9种anchor的宽与宽的比值、高与高的比值,在宽比值、高比值这2个比值中,取最极端的一个比值,作为groundtruth框和anchor的比值。
yolov5共有3个预测分支(FPN、PAN结构),共有9种不同大小的anchor,每个预测分支上有3种不同大小的anchor。
Yolov5算法通过以下3种方法大幅增加正样本个数:
(1)跨预测分支预测:假设一个groundtruth框可以和2个甚至3个预测分支上的anchor匹配,则这2个或3个预测分支都可以预测该groundtruth框,即一个groundtruth框可以由多个预测分支来预测。
(2)跨网格预测:假设一个groundtruth框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据groundtruth框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个groundtruth框可以由3个网格来预测;
(3)跨anchor预测:假设一个groundtruth框落在了某个预测分支的某个网格内,该网格具有3种不同大小anchor,若groundtruth可以和这3种anchor中的多种anchor匹配,则这些匹配的anchor都可以来预测该groundtruth框,即一个groundtruth框可以使用多种anchor来预测。
结论:
旷世的yoloX在yolo各种有效组件基础之上,通过对检测器各种细节进行尝试。最后拿出了一个效果比yolov5略好的yolo模型。从整个代码来看,简洁,清晰。同时易于部署。但是从精度上来看相比yolov5并没有非常明显的进步,期待后续旷世的维护更新。















 4198
4198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









