



MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
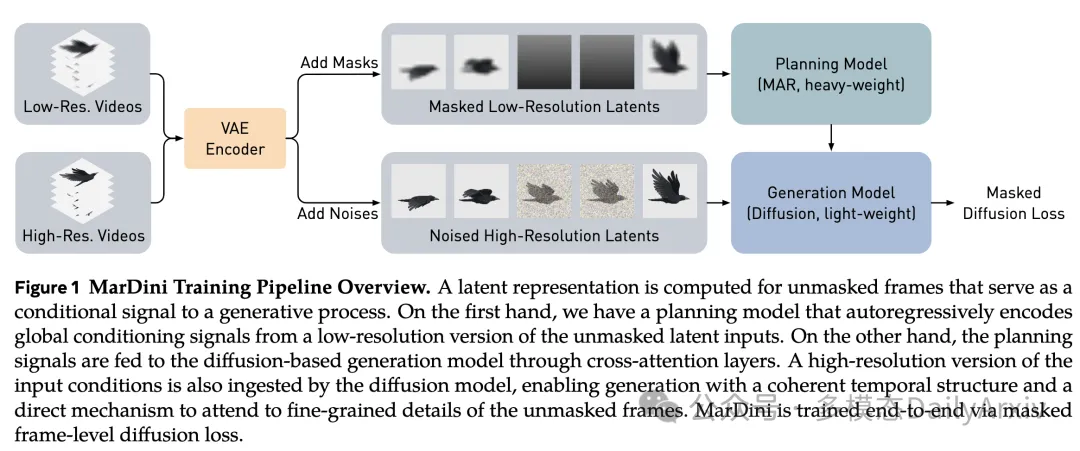
翻译摘要: 我们介绍MarDini,这是一个新的视频扩散模型系列,将掩模自回归(MAR)的优势融入统一的扩散模型(DM)框架中。在这里,MAR处理时间规划,而DM专注于空间生成在一个不对称网络设计中:i)基于MAR的规划模型包含大部分参数,使用低分辨率输入为每个掩模帧生成规划信号;ii)一个轻量级生成模型使用这些信号通过扩散去噪生成高分辨率帧。MarDini的MAR使视频生成能够根据任意数量的掩模帧在任何帧位置进行条件化:一个单一模型可以处理视频插值(例如,掩模中间帧)、图像到视频生成(例如,从第二帧开始掩模)和视频扩展(例如,掩模一半帧)。高效的设计将大部分计算资源分配给低分辨率规划模型,使得计算昂贵但重要的时空注意力在规模上可行。MarDini为视频插值设定了新的最先进水平;同时,在几个推理步骤内,它能够高效地生成与更昂贵的高级图像到视频模型相媲美的视频。
地址:https://arxiv.org/pdf/2410.20280
Diff-Instruct*: Towards Human-Preferred One-step Text-to-image Generative Models
作者:Weijian Luo, Colin Zhang, Debing Zhang, Zhengyang Geng

翻译摘要: 在本文中,我们介绍了Diff-Instruct*(DI*),这是一种无数据方法,用于构建与人类偏好一致且能够生成高度逼真图像的一步文本到图像生成模型。我们将人类偏好对齐视为在线强化学习使用人类反馈(RLHF),目标是最大化奖励函数,同时使生成器分布保持接近参考扩散过程。与传统的RLHF方法依赖KL散度进行正则化不同,我们引入了一种新颖的基于分数的散度正则化,导致性能显著提高。尽管直接计算这种散度是不可行的,但我们证明可以通过推导一个等效但可计算的损失函数来有效计算其\emph{梯度}。值得注意的是,以稳定扩散V1.5作为参考扩散模型,DI*在很大程度上优于\emph{所有}先前领先的模型。当使用0.6B PixelArt-α模型作为参考扩散时,DI*在仅进行一次生成步骤时实现了新的美学评分6.30和图像奖励1.31的记录,几乎是其他具有相似大小的模型得分的两倍。它还实现了28.70的HPSv2评分,建立了一个新的最先进的基准。我们还观察到DI*可以改善生成图像的布局并丰富颜色。
链接:https://arxiv.org/html/2410.20898v1
MovieCharacter: A Tuning-Free Framework for Controllable Character Video Synthesis

翻译摘要: 这篇论文提出了一种名为MovieCharacter的简单而有效的人物视频合成框架,旨在简化合成过程并确保高质量的结果。该框架将合成任务分解为可管理的不同模块:人物分割和跟踪、视频对象去除、人物动作模仿和视频组合。通过利用现有的开源模型和整合成熟的技术,MovieCharacter能够在不依赖大量资源或专用数据集的情况下实现令人印象深刻的合成结果。实验结果表明,该框架提高了人物视频合成的效率、可访问性和适应性,为更广泛的创意和交互式应用铺平了道路。
地址:https://arxiv.org/pdf/2410.20974
Kandinsky 3: Text-to-Image Synthesis for Multifunctional Generative Framework
作者: Vladimir Arkhipkin, Viacheslav Vasilev, Andrei Filatov, Igor Pavlov, Julia Agafonova, Nikolai Gerasimenko, Anna Averchenkova, Evelina Mironova, Anton Bukashkin, Konstantin Kulikov, Andrey Kuznetsov, Denis Dimitrov
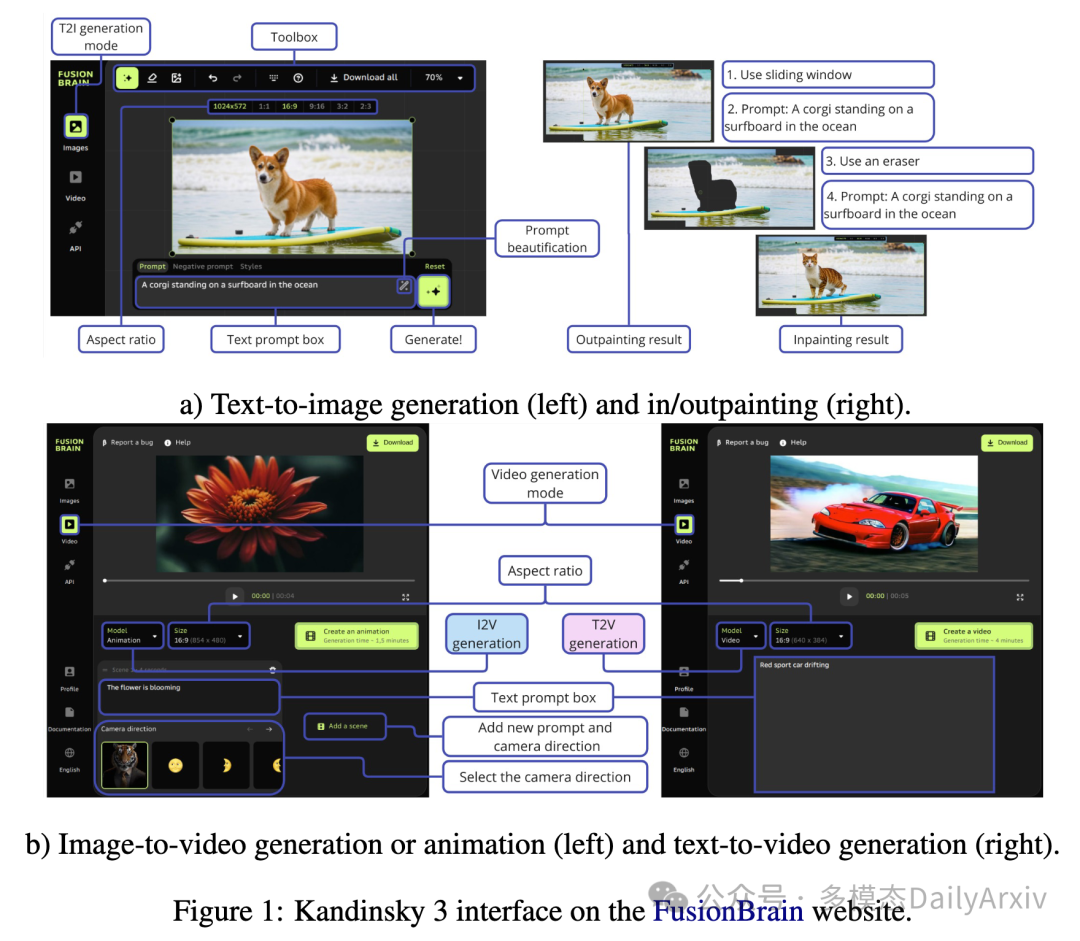 翻译摘要: 文本到图像(Text-to-image, T2I)扩散模型因推出多种图像处理方法,如编辑、图像融合、图像修复等,而深受欢迎。同时,图像到视频(Image-to-video, I2V)和文本到视频(Text-to-video, T2V)模型也是基于T2I模型构建的。我们介绍了Kandinsky 3,这是一种基于潜在扩散的新型T2I模型,实现了高水平的质量和照片级真实感。这种新架构的关键特点是其适配多种生成任务的简单性和高效率。我们拓展了基础T2I模型以适应各种应用,并创造了一个多功能的生成系统,包括文本指导的图像修复/扩绘、图像融合、文本图像融合、图像变体生成、I2V和T2V生成。我们还呈现了一个提炼版本的T2I模型,在不降低图像质量的情况下,评估了反向处理的4个步骤,速度是基础模型的3倍。我们部署了一个用户友好的演示系统,在这个系统中所有的特性都可以在公共领域测试。此外,我们还发布了Kandinsky 3及其扩展模型的源代码和检查点。人类评估表明,Kandinsky 3在开源生成系统中展示了最高的质量评分之一。
翻译摘要: 文本到图像(Text-to-image, T2I)扩散模型因推出多种图像处理方法,如编辑、图像融合、图像修复等,而深受欢迎。同时,图像到视频(Image-to-video, I2V)和文本到视频(Text-to-video, T2V)模型也是基于T2I模型构建的。我们介绍了Kandinsky 3,这是一种基于潜在扩散的新型T2I模型,实现了高水平的质量和照片级真实感。这种新架构的关键特点是其适配多种生成任务的简单性和高效率。我们拓展了基础T2I模型以适应各种应用,并创造了一个多功能的生成系统,包括文本指导的图像修复/扩绘、图像融合、文本图像融合、图像变体生成、I2V和T2V生成。我们还呈现了一个提炼版本的T2I模型,在不降低图像质量的情况下,评估了反向处理的4个步骤,速度是基础模型的3倍。我们部署了一个用户友好的演示系统,在这个系统中所有的特性都可以在公共领域测试。此外,我们还发布了Kandinsky 3及其扩展模型的源代码和检查点。人类评估表明,Kandinsky 3在开源生成系统中展示了最高的质量评分之一。
Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines

翻译摘要: 搜索引擎通过文本使我们能够检索未知信息。然而,传统方法在理解不熟悉的视觉内容方面存在不足,比如识别模型从未见过的对象。这一挑战对于大型视觉-语言模型(VLMs)尤其明显:如果模型没有接触过图片中描绘的对象,它在生成对用户有关该图像的问题的可靠答案时会遇到困难。此外,因为新的对象和事件不断涌现,频繁更新VLMs由于重大的计算负担并不切实际。为了解决这一限制,我们提出了一种新颖的框架——Vision Search Assistant,它促进了VLMs和网络代理之间的协作。这种方法利用了VLMs的视觉理解能力和网络代理的实时信息获取能力,通过网络进行开放世界的检索增强生成。通过这种协作整合视觉和文本表征,即使图像对系统而言是新颖的,模型也能提供知情的回应。在开放集和封闭集QA基准上进行的大量实验表明,Vision Search Assistant显著优于其他模型,并且可以广泛应用于现有的VLMs。
What Factors Affect Multi-Modal In-Context Learning? An In-Depth Exploration
作者:Libo Qin, Qiguang Chen, Hao Fei, Zhi Chen, Min Li, Wanxiang Che
翻译摘要: 最近,多模态上下文学习(MM-ICL)取得了显著成功,能够在各种任务中实现卓越性能,而无需额外的参数调整。然而,MM-ICL 的有效性规则仍未得到充分探讨。为了填补这一空白,本研究旨在探讨研究问题:“什么因素影响了MM-ICL的性能?”为此,我们对MM-ICL的三个核心步骤进行了广泛实验,包括演示检索、演示排序和提示构建,使用了6个视觉大型语言模型和20种策略。我们的研究结果突出了:(1)演示检索需要多模态检索器的必要性,(2)演示内部排序比演示间排序更重要,(3)通过提示中的介绍性说明增强任务理解。我们希望这项研究可以作为未来研究中优化MM-ICL策略的基础指南。
链接:https://arxiv.org/abs/2410.20482
Face-MLLM: A Large Face Perception Model
作者: Haomiao Sun, Mingjie He, Tianheng Lian, Hu Han, Shiguang Shan
翻译摘要: 尽管多模态大型语言模型(MLLM)在广泛的视觉-语言任务上取得了令人瞩目的结果,但它们感知和理解人脸的能力鲜有探索。在这项工作中,我们对现有MLLM在人脸感知任务上的表现进行了全面评估。量化结果显示现有MLLM在处理这些任务上存在困难。主要原因是缺乏包含对人脸细致描述的图像-文本数据集。为了解决这个问题,我们设计了一套实用的数据集构建流程,并在此基础上进一步构建了一种新颖的多模态大型人脸感知模型,即Face-MLLM。具体而言,我们用更详细的人脸描述和面部属性标签重新注释了LAION-Face数据集。此外,我们还使用适合MLLM的问答式重新构建了传统的人脸数据集。在这些丰富的数据集配合下,我们开发了一种新颖的三阶段MLLM训练方法。在前两个阶段,我们的模型分别学习视觉-文本对齐和基本的视觉问答能力。在第三阶段,我们的模型学习处理多个专业的人脸感知任务。实验结果表明,我们的模型在五个著名的人脸感知任务上超越了之前的MLLM。此外,在我们新引入的零样本面部属性分析任务上,我们的Face-MLLM也展现了卓越的性能。
LARP: Tokenizing Videos with a Learned Autoregressive Generative Prior
作者: Hanyu Wang, Saksham Suri, Yixuan Ren, Hao Chen, Abhinav Shrivastava
翻译摘要: 我们提出了LARP,这是一种新颖的视频分词器,旨在克服当前针对自回归(AR)生成模型的视频分词方法的局限性。与直接将局部视觉块编码成离散令牌的传统分块式分词器不同,LARP引入了一种整体的分词方案,使用一组学习得到的整体查询来收集来自视觉内容的信息。这种设计让LARP能够捕获更全局的和语义化的表征,而不仅仅局限于局部块级别的信息。此外,它通过支持任意数量的离散令牌提供了灵活性,使其能够基于任务的具体需求进行自适应和高效的分词。为了使离散令牌空间与下游自回归生成任务保持一致,LARP在训练期间集成了一款轻量级的自回归变换器作为先验模型,该模型预测其离散潜在空间上的下一个令牌。通过在训练期间纳入先验模型,LARP学习了一个不仅优化用于视频重建而且在更有利于自回归生成的方式结构化的潜在空间。此外,这个过程为离散令牌定义了一个顺序,逐步在训练期间推动它们朝着最佳配置发展,从而确保在推理时间内实现更平滑和更准确的自回归生成。全面的实验表明,LARP的强大性能,在UCF101类条件视频生成基准测试中取得了最先进的FVD成绩。LARP增强了AR模型与视频的兼容性,并开启了构建统一的高保真多模态大型语言模型(MLLMs)的潜力。
Attention Overlap Is Responsible for The Entity Missing Problem in Text-to-image Diffusion Models!
作者: Arash Marioriyad, Mohammadali Banayeeanzade, Reza Abbasi, Mohammad Hossein Rohban, Mahdieh Soleymani Baghshah
翻译摘要: 文本到图像扩散模型,例如Stable Diffusion和DALL-E,能够根据文本提示生成高质量、多样化且逼真的图像。然而,它们有时在准确描绘提示中描述的特定实体方面存在困难,这种限制在组合生成中被称为实体缺失问题。尽管先前的研究表明,在去噪过程中调整交叉关注图可以缓解这个问题,但它们并未系统地研究哪些目标函数可以最好地解决它。本研究检查了可能导致实体缺失问题的三个潜在原因,聚焦于交叉关注的动态:(1)对某些实体的关注强度不足,(2)关注扩散过广,以及(3)不同实体间关注图的过度重叠。我们发现,减少实体间关注图的重叠可以有效地最小化实体缺失的比率。具体来说,我们假设与特定实体相关的token在去噪过程中竞争对某些图像区域的关注,这可能导致token之间的关注分散,并阻碍每个实体的准确表征。为了解决这个问题,我们引入了四个损失函数,交集重叠率(IoU)、质心距离(CoM)、Kullback-Leibler(KL)散度以及聚类紧致性(CC),来在去噪步骤中调节关注重叠而无需重新训练。在广泛的基准测试中的实验结果显示,这些提出的无需训练的方法显著提升了组合准确性,在视觉问答(VQA)、标注分数、CLIP相似度和人类评估中超越了以前的方法。值得注意的是,这些方法使人类评估分数比最好的基线提高了9%,展示了在组合一致性上的显著改进。
Guide-LLM: An Embodied LLM Agent and Text-Based Topological Map for Robotic Guidance of People with Visual Impairments
作者: Sangmim Song, Sarath Kodagoda, Amal Gunatilake, Marc G. Carmichael, Karthick Thiyagarajan, Jodi Martin
翻译摘要: 为视觉障碍人士(PVI)提供导航服务是一个重大挑战。虽然传统的辅助工具,如白手杖和导盲犬,非常宝贵,但它们在传递详细的空间信息和精确指引至目的地方面有所不足。最近在大型语言模型(LLMs)和视觉-语言模型(VLMs)方面的发展,为增强辅助导航提供了新的途径。在本文中,我们介绍了Guide-LLM,这是一个基于LLM的具体化代理,旨在帮助PVI在大型室内环境中导航。我们的方法采用了一种新颖的基于文本的拓扑地图,它使得LLM能够利用简化的环境表示来规划全局路径,重点是直线路径和直角转弯,以便于导航。此外,我们利用LLM的常识推理来进行危险检测,并根据用户偏好进行个性化路径规划。模拟实验表明,该系统在指导PVI方面的有效性,强调了它作为辅助技术重大进步的潜力。结果凸显了Guide-LLM提供高效、适应性强和个性化的导航帮助的能力,指向了这一领域里令人充满希望的进步。
Mini-Monkey: Alleviating the Semantic Sawtooth Effect for Lightweight MLLMs via Complementary Image Pyramid
作者: Mingxin Huang, Yuliang Liu, Dingkang Liang, Lianwen Jin, Xiang Bai
翻译摘要: 最近,在多模态大型语言模型(MLLMs)中对高分辨率图像的缩放受到了广泛关注。大多数现有方法采用滑动窗口式的裁剪策略来适应分辨率的提高。然而,这种裁剪策略很容易切断对象和连接区域,引入了语义不连续性,因此阻碍了MLLMs识别小型或不规则形状的对象或文本,导致了我们称为“语义锯齿效应”的现象。这一效应在轻量级MLLMs中尤为明显。为了解决这个问题,我们引入了一个补充图像金字塔(CIP),一个简单、有效且即插即用的解决方案,旨在减缓高分辨率图像处理中的语义不连续性。特别是,CIP动态构建图像金字塔为基于裁剪的MLLMs提供补充的语义信息,使他们能够在所有级别上丰富地获取语义。此外,我们引入了一个尺度压缩机制(SCM)来通过压缩冗余的视觉标记减少额外的计算负担。我们的实验表明,CIP可以在不同的架构(如MiniCPM-V-2、InternVL2和LLaVA-OneVision)、不同的模型容量(1B$\rightarrow$8B)以及不同的使用配置(无需训练和微调)中始终提高性能。利用所提出的CIP和SCM,我们引入了一个轻量级MLLM,名为Mini-Monkey,它在通用多模态理解和文档理解方面都取得了显著的表现。在OCRBench上,2B版本的Mini-Monkey甚至超过了8B模型InternVL2-8B达12分。此外,训练Mini-Monkey成本很低,仅需八个RTX 3090 GPU。代码可在 https://github.com/Yuliang-Liu/Monkey 获取。
Improving Generalization in Visual Reasoning via Self-Ensemble
作者: Tien-Huy Nguyen, Quang-Khai Tran, Anh-Tuan Quang-Hoang
翻译摘要: 视觉推理的认知能力需要整合多模态感知处理以及对世界的常识性和外部知识。近年来,提出了大量的大型视觉-语言模型(LVLMs),这些模型在不同领域和任务中展示了卓越的能力和非凡的常识推理能力。然而,训练这些LVLMs需要大量昂贵的资源。最近的方法,不是从头开始在各种大型数据集上训练LVLMs,而是专注于探索利用许多不同LVLMs的能力的方法,例如集成方法。在这项工作中,我们提出了自集成(self-ensemble),一种改进模型泛化和视觉推理能力而无需更新任何参数的无需训练的方法。我们的关键洞察是,我们意识到LVLM本身可以进行集成,无需其他任何LVLMs,这有助于释放它们的内部能力。在各种基准测试上的大量实验证明了我们的方法在SketchyVQA、外部知识VQA和分布外VQA任务上实现了最先进的(SOTA)性能。
CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
作者: Emanuele Frascaroli, Aniello Panariello, Pietro Buzzega, Lorenzo Bonicelli, Angelo Porrello, Simone Calderara
翻译摘要: 随着变换器(Transformers)和视觉语言模型(Vision-Language Models, VLMs)如CLIP的出现,对大型预训练模型进行微调最近已成为持续学习中的普遍策略。这导致了开发出众多的提示策略来适应基于变换器的模型,同时不引发灾难性遗忘。然而,这些策略经常会损害预训练CLIP模型原有的零样本(zero-shot)能力,并且难以适应与预训练数据显著不同的领域。在这项工作中,我们提出了一种简单且新颖的方法:持续生成训练用于增量式提示学习(Continual Generative training for Incremental prompt-Learning),以在适应CLIP的同时减轻遗忘。简而言之,我们使用变分自编码器(Variational Autoencoders,VAEs)来在视觉编码器的嵌入空间内学习以类别为条件的分布。然后,我们利用这些分布来抽样新的合成视觉嵌入,并在后续任务中训练对应的特定类别文本提示。通过在不同领域的广泛实验,我们展示了这种生成式回放方法可以适应新任务的同时,通过为持续学习场景量身定制的新评价指标,提升零样本能力。值得注意的是,进一步的分析揭示了我们的方法可以与联合提示调整的方法弥合差距。代码库可在 https://github.com/aimagelab/mammoth 上获取。
Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction
作者: Qintong Zhang, Victor Shea-Jay Huang, Bin Wang, Junyuan Zhang, Zhengren Wang, Hao Liang, Shawn Wang, Matthieu Lin, Wentao Zhang, Conghui He
翻译摘要: 文档解析对于将非结构化和半结构化的文件(如合同、学术论文和发票)转换为结构化的、机器可读的数据至关重要。文档解析能从非结构化输入中提取可靠的结构化数据,为众多应用提供巨大便利。特别是随着最近大型语言模型取得的成果,文档解析在知识库构建和训练数据生成中发挥着不可或缺的作用。本综述提供了对当前文档解析状态的全面回顾,涵盖了关键方法论,从模块化流水线系统到由大型视觉-语言模型驱动的端到端模型。详细检查了核心组成部分,如布局检测、内容提取(包括文本、表格和数学表达式)以及多模态数据集成。此外,本文讨论了模块化文档解析系统和视觉-语言模型在处理复杂布局、集成多个模块和识别高密度文本时所面临的挑战。它强调了开发更大更多样化数据集的重要性,并概述了未来研究的方向。
AutoBench-V: Can Large Vision-Language Models Benchmark Themselves?
作者: Han Bao, Yue Huang, Yanbo Wang, Jiayi Ye, Xiangqi Wang, Xiuyin Chen, Mohamed Elhoseiny, Xiangliang Zhang
翻译摘要: 大型视觉-语言模型(LVLMs)已成为推进视觉和语言信息整合的关键,促进了一系列复杂应用和任务的发展。然而,评估LVLMs面临重大挑战,因为评估基准总是需要大量人力成本来构建,并且一旦构建完成,就缺乏灵活性,保持静态。尽管在文本模态中已经探讨了自动评估,视觉模态的评估仍然不够深入。因此,在这项工作中,我们提出了一个问题:“LVLMs能否成为自动评估基准的途径?”。我们介绍了AutoBench-V,一个自动化框架,用于按需提供评估服务,即基于模型能力的特定方面对LVLMs进行基准测试。在接收到一个评估能力要求后,AutoBench-V利用文本到图像模型生成相关的图像样本,然后利用LVLMs编排视觉问答(VQA)任务,以高效和灵活的方式完成评估过程。通过对五种评估能力要求(即用户输入)中的七种流行LVLMs进行广泛评估,该框架展现出了其有效性和可靠性。我们观察到以下几点:(1)我们构建的基准准确反映了不同任务难度;(2)随着任务难度的提高,模型之间的性能差距加大;(3)尽管模型在抽象层次理解方面表现强劲,但在细节推理任务上表现不佳;(4)构建具有不同难度水平的数据集对于全面和彻底的评估至关重要。总体而言,AutoBench-V不仅成功地利用LVLMs进行自动化基准测试,而且还揭示了LVLMs作为评判者在各个领域具有显著的潜力。
SAM 2: Segment Anything in Images and Videos
作者: Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer
翻译摘要: 我们提出了 Segment Anything Model 2 (SAM 2),这是一个基础模型,旨在解决图像和视频中可以通过提示进行的视觉分割问题。我们构建了一个数据引擎,该引擎可以通过用户交互改进模型和数据,以此收集到目前为止最大的视频分割数据集。我们的模型是一个简单的变换器(Transformer)架构,具备流式内存,用于实时视频处理。在我们的数据上训练的 SAM 2 在广泛的任务上展现出强大的性能。在视频分割方面,我们观察到准确度更高,与之前的方法相比,需要的交互次数减少了3倍。在图像分割方面,我们的模型比 Segment Anything Model (SAM) 更准确,速度快了6倍。我们相信,我们的数据、模型和洞察将成为视频分割和相关感知任务的一个重要里程碑。我们将发布我们的主要模型、数据集以及用于模型训练和我们演示的代码。
Enhancing Action Recognition by Leveraging the Hierarchical Structure of Actions and Textual Context
作者: Manuel Benavent-Lledo, David Mulero-Pérez, David Ortiz-Perez, Jose Garcia-Rodriguez, Antonis Argyros
翻译摘要: 行动的顺序执行和它们由不同抽象层级组成的层级结构,在行动识别任务中的特点尚未被完全探索。在本研究中,我们提出了一种新颖的方法来通过利用行动的层级组织以及结合包括地点和先前行动在内的文本化上下文信息来提高行动识别的效果,以反映行动的序列上下文。为了实现这一目标,我们引入了一个为行动识别量身定制的新型变换器(transformer)架构,它利用了视觉和文本特征。视觉特征通过RGB和光流数据获得,而文本嵌入则代表上下文信息。此外,我们定义了一个联合损失函数,用于同时对模型进行粗粒度和细粒度的行动识别训练,从而利用行动的层级性质。为了展示我们方法的有效性,我们扩展了丰田智能家居未修剪(TSU)数据集,引入了行动层级,创建了层级TSU数据集。我们还进行了消融研究以评估集成上下文和层级数据的不同方法对行动识别性能的影响。结果表明,当使用相同的超参数进行训练时,所提出的方法比预训练的最先进方法性能更好。此外,结果还显示,在使用实际预测中获得的上下文信息时,相比于等效的细粒度RGB版本,所提出的方法的top-1准确率提高了17.12%,而当使用真实上下文信息时准确率提高了5.33%。
OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup
作者: Xize Cheng, Siqi Zheng, Zehan Wang, Minghui Fang, Ziang Zhang, Rongjie Huang, Ziyang Ma, Shengpeng Ji, Jialong Zuo, Tao Jin, Zhou Zhao
翻译摘要: 近年来,在视觉和语言领域,规模扩大带来了巨大的成功。然而,在音频领域,研究人员在扩大训练数据时遇到了一个主要挑战,因为大部分自然音频都包含了多种干扰信号。为了解决这一局限性,我们引入了全模态声音分离(OmniSep),这是一个新颖的框架,能够基于全模态查询隔离出清晰的音轨,包括单一模态和多模态组成的查询。具体来说,我们引入了查询混合(Query-Mixup)策略,它在训练过程中混合来自不同模态的查询特征。这使得OmniSep能够同时优化多个模态,有效地将所有模态纳入统一框架进行声音分离。我们进一步通过允许查询积极或消极地影响声音分离,来增强这种灵活性,便于根据需要保留或移除特定的声音。最后,OmniSep采用了一种被称为查询增强(Query-Aug)的检索增强方法,它能够实现开放词汇的声音分离。在MUSIC、VGGSOUND-CLEAN+和MUSIC-CLEAN+数据集上的实验评估显示了OmniSep的有效性,它在文本查询、图像查询和音频查询的声音分离任务中实现了最先进的性能。有关样本和更多信息,请访问演示页面:\url{https://omnisep.github.io/}。
SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
作者: Ming Dai, Lingfeng Yang, Yihao Xu, Zhenhua Feng, Wankou Yang
翻译摘要: 视觉定位是一项常见的视觉任务,它涉及将描述性句子锚定到图像的对应区域。大多数现有方法使用独立的图像-文本编码,并且采用复杂的手工制作模块或编解码器结构来进行模态交互和查询推理。然而,当处理复杂的文本表达时,它们的性能会显著下降。这是因为前者范式仅利用有限的下游数据来拟合多模态特征融合。因此,当文本表达相对简单时才有效。相反,鉴于文本表达的广泛多样性和下游训练数据的独特性,现有的融合模块——从视觉语言上下文中提取多模态内容——尚未得到充分研究。在本文中,我们提出了一个简单而健壮的基于Transformer的视觉定位框架SimVG。具体来说,我们通过利用现有的多模态预训练模型并整合额外的对象标记,从而将视觉语言特征融合从下游任务中解耦,以促进下游任务和预训练任务的深度整合。此外,我们在多分支同步学习过程中设计了一种动态权重平衡蒸馏方法,以增强简化分支的表示能力。这个分支仅由一个轻量级的MLP组成,旨在简化结构并提高推理速度。在六个广泛使用的VG数据集上的实验,即RefCOCO/+/g、ReferIt、Flickr30K 和 GRefCOCO,证明了SimVG的优越性。最后,所提出的方法不仅在效率和收敛速度上取得了改进,而且在这些基准测试上取得了新的最先进的性能。代码和模型将可在以下网址获得:\url{https://github.com/Dmmm1997/SimVG}。
MemeCLIP: Leveraging CLIP Representations for Multimodal Meme Classification
作者: Siddhant Bikram Shah, Shuvam Shiwakoti, Maheep Chaudhary, Haohan Wang
翻译摘要: 文本嵌入图片的复杂性在机器学习中提出了一个巨大的挑战,因为它需要对它们所传达的多种表达形式进行多模态理解。虽然之前的多模态分析研究主要关注诸如仇恨言论及其子类别的单一方面,但本研究扩大了关注面,包括多方面的语言学:仇恨、仇恨的目标、立场和幽默。我们引入了一个新的数据集PrideMM,包含5,063幅与LGBTQ+骄傲运动相关的文本嵌入图片,从而解决了现有资源中的重大缺口。我们利用单模态和多模态基线方法对PrideMM进行了广泛的实验,为每项任务建立了基准。此外,我们提出了一种新颖的框架MemeCLIP,它能够在保留预训练的CLIP模型知识的同时进行高效的下游学习。我们的实验结果表明,MemeCLIP在两个实际数据集上的性能比之前提出的框架都要好。我们进一步比较了MemeCLIP和零样本GPT-4在仇恨分类任务上的性能。最后,我们通过定性分析误分类样本来讨论我们模型的不足之处。我们的代码和数据集可在以下地址公开获取:https://github.com/SiddhantBikram/MemeCLIP。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









