






一、Architecture
1.1 你所设计的芯片的架构是什么样的?
1.2 各block的划分基于什么原则?
1.3 你负责的block的clk/reset架构是什么样的?对clk特性(例如transition、duty cycle)有无特殊要求?
二、FE
2.1 RTL
2.1.1 spyglass
2.1.1.1 lint/cdc/rdc的环境如何搭建?
2.1.1.2 lint/cdc/rdc check时遇到哪些vio?如何fix?
三、ME
3.1、Synthesis
3.1.1、input file
3.1.1.1、db和ndm有什么区别?
3.1.1.2、能不能在综合log中看出rtl中有哪些不正确之处
3.1.2、env setting
3.1.2.1 save_block的作用机理?
3.1.2.2 dont use cell一般包括哪些?
(1)对于部分频率要求不高的block,会将elvt的cell设dont ues。
(2)对于驱动较大的cell会设置dont ues。
(3)对于逻辑复杂的cell会设置dont ues。
(4)对于ck cell会设置dont ues。
(5)physical cell,例如tie cell。
(6)Delay cell。
(7)size 过大或过小的cell。
(8)对于congestion 敏感的设计还需要将多pin 的小size cell 禁用掉。
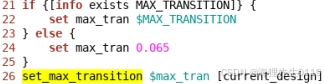
3.1.2.3 time drc的参数包括哪些、怎么确定值?
set_input_transition:经验值。
![]()
set_driving_cell:设置driving cell会使input transition更准,如果环境中存在driving cell就用driving cell,否则用set_input_transition值。
![]()
![]()
set_load:经验值。
![]()
se_max_transition:经验值。
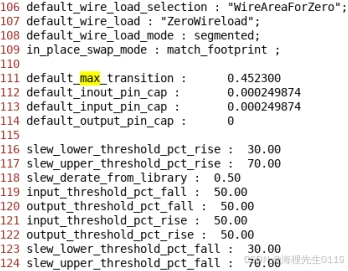
lib中的设定值:
3.1.2.4 哪些instance需要设置set_dont_tuch?
(1)前端rtl中例化的cell,需要设置dont touch。
3.1.2.5 综合阶段有哪些high fanout signal,如何处理?
3.1.2.6 综合阶段有哪些优化选项?
3.1.2.7 compile_fusion有哪些stage?到哪个stage是logic综合?
3.1.2.8 综合阶段的clk uncertainty如何设置?
3.1.2.9 综合时如何防止网表中生成assign语句?
3.1.3、output file
3.1.4、check list
3.1.4.1、综合网表的QoR需要检查哪些内容?如何fix?什么条件下满足release标准?
3.1.4.1.1 combinational loop
3.1.4.1.2 clk gating覆盖率
3.1.4.1.3 multi driven net
3.1.4.1.4 flaoting input pin
3.1.4.1.5 综合网表的sta相关check有哪些?如何fix?
3.1.5、timing vio
3.1.5.1、reset/set line什么时候修timing以满足recovery/remove check?
在place阶段,工具会插buf/inv以fix drc,在route_opt阶段会修timing以满足recovery/remove check。
注:综合阶段因为reset/set line是ideal的,所以不做recovery/remove check。
3.1.5.2、综合阶段会修哪些类的timing?不需要修哪些类的timing?
3.1.5.2.1、综合阶段会修哪些类的timing?
(1)setup check;
3.1.5.2.2、不需要修哪些类的timing?
(1)hold check;
(2)recovery/remove check;
(3)cts;
3.1.6、fix timing
3.1.7、signoff
3.1.7.1 综合的scenario如何选取?
foundary推荐。
3.1.8、others
3.2、Formal
3.2.1、Formality
3.2.1.1、input file
3.2.1.1.1 svf作用是什么?里面包含哪些内容?
3.2.1.2、env
3.2.1.2.1 APR阶段新增的inout 型的feedthrough pin怎么处理?
3.2.1.2.2 对于大型、hierarchical soc,应该采用怎样的formal策略以保证function一致性?
3.2.1.2.3 undriven pin怎么处理?
3.2.1.2.4 如果APR阶段做了寄存器复制,做formal时怎么处理?
3.2.1.2.5 如果APR阶段将某block的input port的tie cell放到其他block内?做formal时怎么处理?
3.2.1.2.6 如果某个block中暂时缺少某个module,做formal时应怎么处理?
3.2.1.2.7 SYN2DFT的formal,需要哪些设置?
3.2.1.2.8 formal对于clk gating怎么处理的?
3.2.1.2.9 formal时要怎样设置upf?upf是怎样影响formal结果的?
3.2.1.3、output file
3.2.1.3.1、遇到过的fail情况有哪些?如何解决的?
3.2.1.3.2、有没有遇到过abrot/inconclusion情况?如何解的?
3.2.1.3.3、有没有遇到过由于unmatch导致的fail?如何解的?
3.2.1.3.4、做完formal后除了检查fail/succeed外,还需要检查其他吗?
3.2.1.4、others
3.2.1.4.1 formal原理是什么?时序逻辑的功能一致性怎么保证?
3.2.1.4.2 哪些pin是compare pin?
3.2.1.4.3 三态门怎么处理?
3.2.1.2 SYN2APR时,怎么设置svf
在后端placement/cts/route阶段都会生成svf,根据实际经验,在做SYN2APR时不读svf也可以过。
3.2.2、Lec
3.3、STA
3.3.1、input file
3.3.2、env setting
3.3.2.1、如何在PT里面减少SI悲观度?
(1)设physical_exclusive, 这个是大家最常用的,比如两种功能时钟不会同时出现,那么物理上是没必要让Aggressor 和victim上同时出现这两个时钟的arrival window的
(2)设timing_enable_auto_mux_clock_exclusivity, 这个变量能够让工具在分析时自动去推断mux后面的点如何处理 I0/I1 的时钟关系,当然它会在特定的条件下才成立,比如select不为静止,两端入口必须为时钟,clock不能定义在mux output等等。
(3)Set_case_analysis static, 这个是当你知道某一类信号为静止的时候,比如特殊场景的IO和测试信号,选通信号等可以设置,这样他就不会作为aggressor 去干扰别人了。
(4)还有一些设置包括all_path_edge的边沿分析timing window 法,hyperscale去除子模块和顶层差异化防止子模块过修法,下次慢慢道来。
3.3.2.2、jtag简介?
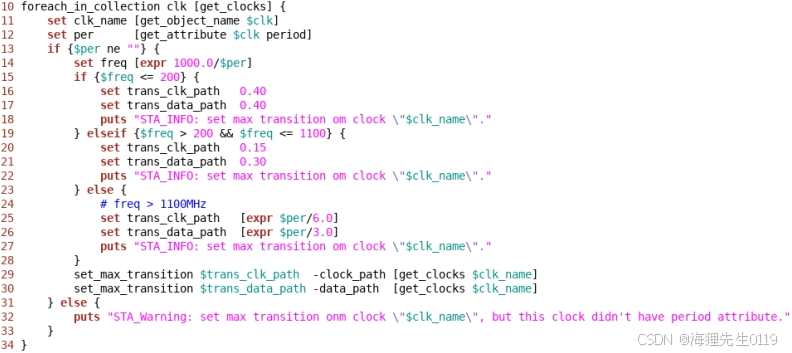
3.3.2.3、set_input_transition/set_load/set_max_transition/set_max_capacitance/clock net max fanout如何设置?
3.3.2.3.1 set_input_transition如何设置?
![]()
3.3.2.3.2 set_load如何设置?
![]()
3.3.2.3.3 set_max_transition如何设置?
最终STA的clock max transition收敛指标一般由两方面因素确定:一是clock实际的工作频率,二是标准单元库中pin的自带约束。
实际项目中,clock max transition收敛标准一般会使用1/6周期与60%库约束两者中的最小值。有时候根据clock具体的时序情况还可以将库的约束放松,比如放松到库约束的80%,或者直接使用库约束,但是通常不会放松1/6周期指标。
3.3.2.3.4 set_max_capacitance如何设置?
通常情况下,一般不做额外的clock max capacitance设置,直接使用标准单元库中提供的max capacitance约束。
从另一个角度看,在加严max transition约束的同时,也相当于是在变相地加严max capacitance约束。在PR工具完成clock tree后,由于clock net的max transition要严于单元库中的约束,因而最终实际的net capacitance值通常也会明显小于库里的约束。
3.3.2.3.5 clock net max fanout如何设置?
在STA最终的检查指标中,一般不会有max fanout的检查。其实,设置clock net max fanout约束的主要目的是为了指导工具做clock tree,弥补其他DRV约束的不足,让clock tree的质量更符合要求。从实际情况分析,其主要有以下两方面的考量:
其一、规避一些clock sink net的EM问题。在创建clock tree的过程中,由于clock sink点通常分布比较集中,工具可以在满足max transition与max capacitance的条件下,让一个驱动net驱动大量的sink点。这种驱动net的负载电容一般非常大,并且sink net通常会使用底层default rule绕线,因而容易出现EM问题。
其二、平衡clock tree的cell delay与net delay,维持不同corner下的clock skew。对于一个clock cell的驱动负载来说,如果net本身的寄生占比大,不同corner下cell delay与net delay之间的比重也越相近。因此,如果一个clock net绕线短并且驱动点多,那么该clock net的cell delay与net delay就会相差大,在不同corner下就会越不平衡。
通常clock net的max fanout一般建议在20到30之间,过大的约束达不到预期的效果,过小的约束又会导致clock cell增加,而不利于clock tree功耗,并且也不会带来明显的实际好处。
3.3.2.4、sta工具如何创建path group?如何通过path group优化时序?
3.3.2.4.1、sta工具如何创建path group?
(1)工具默认创建path group,工具默认创建path group规则可以总结为:
如果timing path end point的capture clock相同,那么这些timing path就会属于同一个path group,而path group的名字就是capture clock的名字。
(2)可以直接通过工具提供的application直接创建:
1)time.use_special_default_path_groups,将这个application设置成true后,工具分别对异步path与gate path创建**async_default**与**clock_gating_default**两个path group。
需要注意的是,这里的异步path group是指那些到reg的异步控制pin的timing check,并不是指两个异步clock之间的timing check,再说异步clock之间也不会有timing check。
2)time.enable_io_path_groups,将这个application设置成true后,工具会对IO创建**in2reg_default **、**reg2out_default **、**in2out_default **三个path group。
需要注意的是,这些path group名字的前后缀都带有**,并且不能使用命令来修改这些path group。比如说,不能通过命令往这些path group添加与删除path,同样也不能使用remove_path_groups命令删除这些path group。从某种程度上来说,这些通过application设置生成的path group同样也属于默认的path group。
(3)通过group_path命令创建:
3.3.2.4.2、如何通过path group优化时序?
(1)将大的path group分成一些小的path group,以让工具去优化每个group里面的最差timing path。
(2)在使用group_path命令创建或者修改path group的时候,通过-critical_range选项就可以让工具优化最差path后面的timing path。当CLK group里面最差path优化不下去的时候,工具仍然会继续优化slack在WNS与WNS+0.3之间的其他timing path。这样虽然对group的WNS没有帮助,但是对整个group timing的TNS非常有帮助。
(3)对某些关键path group的-weight设较大的值。
3.3.2.5、sta工具如何创建path group?如何通过path group优化时序?
3.3.2.6、timing path上为什么没有反标上寄生参数?
(1)spef和netlist不匹配;
(2)可能一些net确实没有实际绕线,他们自然也不会出现在spef中。比较常见的是芯片的PAD。做顶层的话,你会习以为常。
(3)net比较短,以下值太大,导致RC值因为太小而被过滤掉了,此时可将以下值注释掉,然后重跑starrc。
3.3.2.7、pocv机理?
3.3.2.8、voltage、temperature 的varition怎么反映在sta中?
3.3.2.9、hyperscale原理怎样的?在跑sta时应怎样设置?
3.3.2.10、setup/hlod的clk uncertainty应分别怎么设置?
3.3.3、output file
3.3.4、check list
3.3.4.1 Noise 问题
3.3.4.1.1 Noise violation应该如何修复?nosie violation一般容易出现在什么样的path上?
答:
(1)
1)降低侵害网络drive cell驱动力;
2)增大受害网络drive cell驱动力;
3)减少线的并行长度,增加并行线的间距;
4)使用shiled net进行隔离。
(2)一般容易出现在clock path上,因为clock path的翻转率高。
3.3.4.2 Max transition问题
3.3.4.2.1 PT Timing signoff发现存在max transition violation,而且它的driver已经是最大强度驱动了,请问应该如何修复这类transition violation?
降低fanout或者中间插buffer减少net长度。优先去解决max fanout导致的问题。
3.3.4.3 Max capacitiance问题
3.3.4.3.1 Max capacitiance violation需要怎么修复?
(1)解max fanout;
(2)增加drive cell驱动力;
(3)减少drived cell驱动力;
(4)减小net上的loading,如减小net长度;
(5)可通过插buffer方式解决或者防止net有detour;
(6)从高层走线,增加net宽度。
3.3.5、timing vio
3.3.5.1、PT跑完发现setup存在100ps violation,但PR跑完却没有timing violation,请分析原因,并提出优化方法。
pt和pr抽取的rc会有差异,因此计算出来的cell delay和net delay是有mismatch的。因此,在跑pr时,可以下严一点constraint,如clock uncertainty比pt多设一点。另外,可以调整rc factor,将pr和pt抽出来的rc的variation尽量降低。
3.3.6、fix timing
3.3.6.1 如何判定可以进入timing eco阶段?
drc fix ok,然后timing vio在10-15%以内。
3.3.6.2 fix timing flow
先fix block级,然后将block设置为hyperscale,在跑sub system再跑top级。
3.3.6.3 各阶段fix timing的手段
(1)首先fix block timing vio,采用先auto fix再手修的方法。
(2)将auto fix ok的block设置hyperscal,然后集成到sub system中。再用同样的方式修sub system。
(3)采用类似(2)的方法修top。
3.3.6.4 如何选用eco buf
3.3.6.5 Max transition、leakage优化、hold time、setup time violation修复的顺序是?
答:
(1)先把max transition修掉,如果max transition有violation,意味着其超出了查找表范围之外,所以计算得到的delay都不是很准的。
(2)其次是把setup修复了,因为setup相对来说,需要减少cell delay,不是很好优化。
(3)其次修复hold。因为hold修复相对比较简单,增加cell delay即可。
(4)最后把leakage修复一下。因为leakage相对来说不是硬性指标,肯定要在timing修完善的情况下,再去修power。
3.3.6.6 auto timing fix flow
3.3.6.6.1 auto timing fix flow采用什么顺序?
(1)修几轮setup,每一轮的eco cmd根据timing结果而定。
(2)修hold。
3.3.6.6.2 对于被多个sub-sys例化的block,应该怎么fix timing?
(1)可将该block timing clean,再由其他sub-sys例化。
(2)可在各sub-sys中分别收敛该block的timing,然后做unify。
3.3.6.6.3 在一个sub-sys中,如果其中一个block存在较大的timing vio,修其他的block是否有意义?
正常需要将sub-sys下的所有block都clean,再进行下一轮收敛。
3.3.7、signoff
3.3.7.1、PT Timing Signoff了哪几个corner? 为什么?
对于老工艺来说,由于其工艺相对比较成熟,process variation不是那么大。Signoff一般是setup:ss125_cworst, hold是ffm40_cbest。但是对于先进工艺,由于其process variation很大,所以导致其signoff corner特别多,加上温度翻转效应,所以其signoff corner一般来说setup:ss125_cworst, ssm40_cworst等, hold基本上全corer都要signof。
3.3.7.2、sta signoff要检查哪些项目?如何fix?
3.3.8、others
3.3.7.1、为什么innovus跑出来的timing结果和pt有时会相差很大?
因为rc引擎不同,导致抽取的rc参数不同,进而导致net的load不同,最终导致cell delay/net delay不同。
3.3.7.2、综合后的sdc能够直接进行APR吗?
综合用到的sdc很多命令在APR的时候是不适用的。
比如set_wire_load_model,这条命令是让工具根据wire load模型去计算net上的delay。由于综合的时候,并没有进行布局布线,net的长度也不知道。通过wire load模型,工具可以根据fanout数量去估算net的长度,进而去计算delay。而这种估算模型,在实际的布局布线是非常不准确的。因此,在APR的时候,需要将这个命令去除掉,采用工具自带的rc引擎去抽取net上的RC,计算net delay。
另外像set_clock_latency,这条命令是设置clock tree的latency。但在APR时,我们会做CTS,clock tree会变成一个实际值,而不是命令涉资的set_clock_latency,因此这条命令也是不需要的。
还有其他一些命令,如set_max_transition, set_max_capacitance, set_timing_derate,这些设置约束的命令,其实在APR的不同阶段也是不一样的,也不可以采用综合时设定的值。
3.3.7.3、检查timing path的注意事项?
(1)检查input file是否正确;
(2)用report_annotated_parasitics确认反标成功与否;
(3)检查timing path中net是否有数值;
3.4、LowPower
3.4.1、input file
3.4.1.1、upf
3.4.1.1.1、如何编写upf
3.4.1.1.2、如何确定iso cell放在lunch block还是 destination block?
3.4.2、env
3.4.3、output file
3.5、Power Analysis
3.5.1、input file
3.5.1.1、wave form file
3.5.1.1.1、wave form file怎么生成
netlist+sdf生成wave form file
3.5.1.1.2、在做full chip的Power Analysis时,怎样选取各block跑哪些wave form file
跑各block的典型应用场景下的wave form file,然后将所有block的功耗相加。
3.5.1.1.3、你跑的block有哪些典型应用场景
跑cpu core时,跑了以下的case:
Dhrystone: 主要测试处理器的整数运算和逻辑运算的功耗测试。
Cache_miss: cache读取的miss场景的功耗测试。
Gemm: 矩阵乘法/累加测试,同时将大型矩阵分解为小型矩阵算法,simd向量化。
maxpwr:通过使用整数和浮点数的运算来测试ap最大功率消耗。
didt: 测试多次从低功率到高功率的快速转变过程。
saxpy_simd: 测试执行浮点数。
3.5.1.1.4、能不能在verdi中看懂波形
3.5.2、env
3.5.3、output file
3.6、sdc
3.6.1、input file
3.6.1.1、如何生成sdc
3.6.1.2、不同阶段sdc怎么生成的
(1)syn
根据rtl编写sdc,用该sdc做syn。
(2)apr
1)采用syn工具生成的sdc作为apr sdc;
2)根据生成的网表手写sdc作为apr sdc;
(3)signoff sdc
手写sdc作为signoff sdc,该sdc需要满各种场景,例如某port的clk有不同频率,signoff sdc需包含所有频率的clk而不能只选取频率最高的clk。
apr sdc一般不能作为signoff sdc,因为apr sdc一般只包括频率最高的clk。
3.6.2、env
3.6.3、output file
四、DFT
五、BE
5.1、Floorplan
5.1.1、input file
5.1.1.1 为什么要创建电压区域的保护带?设置多大合适的?
5.1.1.2 在进行APR时, init阶段我们需要读入那些文件?
(1)techlef:记录该工艺中使用的metal以及via信息,可以在进行pr过程中按照工艺drc要求来进行,从techfile中我们可以获取部分design rule信息(包括spacing / width / enclosure / thickness / antenna)
(2)ndm:记录stdcell,ip,io,mem相关的ndm;
(3)netlist:是由前端rtl通过综合生成的网表;
(4)sdc:Synthesis Design Constrained,记录一些设计约束(clock / generate clock / input_delay / output_delay / input_transition / output_load / max_delay / min_delay等等)
(5)upf:
(6)top层信息:def、feedthrough、tap cell。
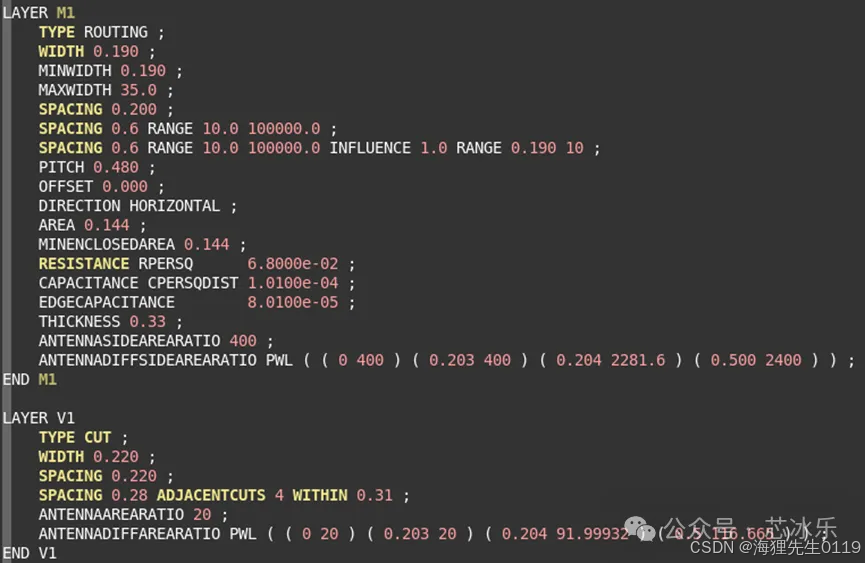
5.1.1.3 在def中怎么看block的面积?
divided by 2000 = 1um。
1.15*1.436=1.65mm2。
5.1.1.4 ndm有什么性质?
5.1.2、env setting
5.1.2.1 设计导入后我们需要对high fanout net进行处理么?
不需要,在place阶段会对high fanout net进行减fanout处理;
5.1.2.2 你这个floorplan定义的芯片长度宽度多少?为什么这样确定?模块面积是如何估算的?
5.1.2.2.1 你这个floorplan定义的芯片长度宽度多少?
![]()
![]()
5.1.2.2.2 为什么这样确定?
根据top层提供数据。
5.1.2.2.3 模块面积是如何估算的?
根据uti = std_cell_area/(design_area - macro_area - blockage_area),uti=41-51%(init_floorplan stage,经验值,综合网表)。得到各block的面积。
如果是dft 网表,还要增加5%的面积。
ps:post APR 要少过60% (因为没有DFT)。
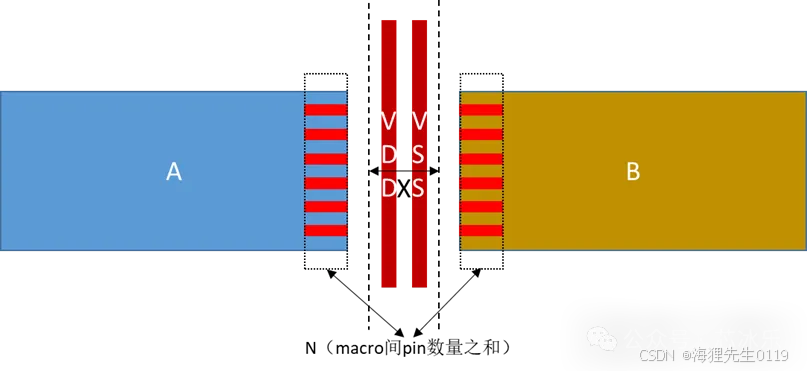
5.1.2.3 Macro间的channel要留多少?依据是什么?在placement前需要对channel做哪些处理呢?
5.1.2.3.1 Macro间的channel要留多少?
为了方便macro之间方便走线,同时为了解macro端口处max transition问题,会预留相应的channel;这些channel处需要打上soft blockage or hard blockage,这是因为只在这个区域内摆上buffer解transtion问题,而不允许其他逻辑或时序cell进入,为了保证这些buffer能正常工作,因此在这个channel区域内要留一组电源线位置;
channel预留的大小可通过如下公式得到的值进行参考:
L=N*P/i+X,其中N为两个macro相对的pin的数量,P为layer的pitch值,i为使用的layer的层次,而X为两根power线以及两侧spacing距离;如下channel计算示意图所示:
| lower left X of block placement : | 0.102*n |
| lower left Y of block placement : | 0.42*n |
| x spacing between sram back to back : | 0.765+0.102*n |
| x spacing to stdcells region : | 0.051, 0.765 |
| y spacing to stdcells region : | 0 |
| y spacing to sram without stdcells region : | 0 |
5.1.2.3.2 依据是什么?
根据台积电guide要求设置。
5.1.2.3.3 在placement前需要对channel做哪些处理呢?
5.1.2.4 Macro为何还要加Halo或hard blockage? placement blockage和routing blockage的本质区别是什么?
有些ip会在application note有距离stdcell要求;在很多数模混合相关macro中,对噪声比较敏感,为了避免数字信号线对其影响,需要预留一定spacing距离;同样考虑到噪声,模拟会在macro外面围一圈DNW,也需要空出一定空间。
placement blockage是针对place stdcell来进行约束的,而routing blockage是针对routing来进行约束。
5.1.2.5 Macro能否旋转90度或180度?为什么?
在传统工艺下(40nm以上),macro是可以进行旋转的,但是到40nm后,需要保持poly方向一致,就不能进行旋转;具体规则可参考drc rule。
5.1.2.6 IO port端口处出现min area drc,应该如何规避和修复?
出pin的时候需要控制pin metal的长度,使之满足drc要求;在pr过程中发现此类drc,可以通过补画一根相同layer的metal来解。
5.1.3、output file
5.1.4、check list/check method
5.1.4.1 在进行init过程后,我们需要做哪些检查?
(1)查看log中是否存在error,若有需要分析原因;
(2)使用check timing命令,查看生成的报告中是否存在漏设的约束;
(3)查看是否存在floating pin(若有需要和前端确认)
(4)查看初始利用率;
(5)查看初始timing结果,是否存在较大violation;
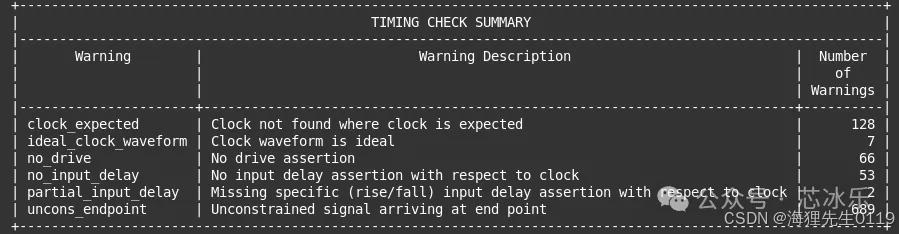
5.1.4.2 在init阶段使用check_timing作用是什么?
主要检查timing约束是否到位,相关report内容如下:
可重点关注一些pin未接clock(clock expected),需跟前端确认是否是漏定义clk等。
5.1.4.3 一个好的floorplan评价标准是什么?
(1)各个模块cell的分布符合data flow。
(2) congestion map 和cell density适度。
place后通过GUI的congestion map来查看工具预估的overflow是否在可绕线范围。具体多少数值,不同工艺,不同design情况都不太一样,需要自己积累项目经验(case by case)。同时,通过cell desity分布图我们也可以预估某些地方是否可能出现density过高导致绕线或者timing等方面的风险;如果你的cell desity很低,congestion map也特别好,显然也是不恰当的,因为明显浪费芯片面积。
(3)routing drc相对clean
如果你的一个floorplan满足前面几点条件,但是route后发现实际绕线存在很多的routing drc(short, double pattern drc,diff net space等)。可能有的人会说,如果route前congestion map和cell density map都比较好,为何会绕不出来?其实答案很简单,route之前的map都是工具估算出来的,实践证明,有时候是存在这种现象的(吐槽下)。如果真的出现这种情况,也只能吐血了,一切重来。因此,从这里就能看到floorplan的重要性。
(4)没有base layer的DRC
实际项目中,我相信有的时候会出现memory的poly orientaion 和std cell 的poly方向不一致的情况(90nm以下工艺)。出现这种情况怎么办呢?答案是显而易见的,天空飘过两个字 “重做”。还有比如tapcell加的不够等等,这里就不一一列举。
5.1.4.4 你这个floorplan定义的芯片长度宽度多少?为什么这样确定?模块面积是如何估算的?
5.1.5、debug/fix method
5.2、Power Mesh
5.2.1、input file
5.2.2、env setting
5.2.2.1 power mesh阶段如何做pg?需考虑哪些因素?
5.2.3、output file
5.2.4、check list/check method
5.2.5、debug/fix method
5.2.5.1 插不上PG VIA怎么办?
create_pg_vias有个选项-show_phantom,翻译成中文叫:幽灵现身。加上这个选项后,如果有打不上的via,这个命令会生成一个error file,告诉你某个地方打不上孔是因为什么原因。
create_pg_vias -show_phantom
例如,我想把这个地方加一个VIA78,把M7,M8的power mesh连接起来。
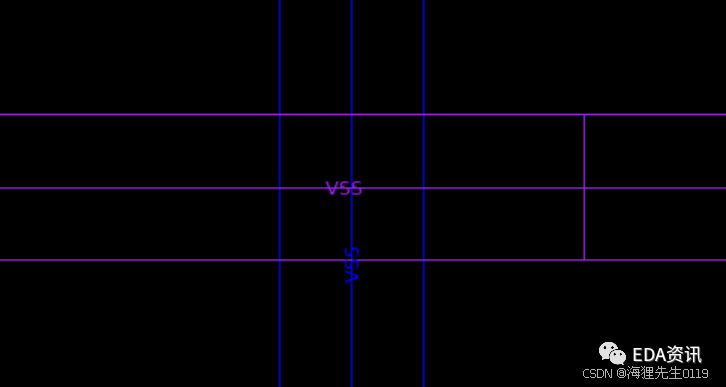
现在用这个命令
icc2_shell> create_pg_vias \
-nets VSS \
-within_bbox {{{297 1025} {298 1026}}} \
-from_layers M7 \
-to_layers M8
Log:
Instantiating vias for 1 intersections starts
Starting via DRC checking ...
Committed 0 vias.
Error: DRC violations prevented new vias to be inserted. (PGR-051)
从log里看,via没有插入成功,原因是有DRC violation。但是是什么DRC 呢?不知道。这个时候就可以用“显示幽灵这个”功能了
icc2_shell> create_pg_vias \
-nets VSS \
-within_bbox {{{297 1025} {298 1026}}} \
-from_layers M7 \
-to_layers M8 \
-show_phantom
log:
Instantiating vias for 1 intersections starts
Starting via DRC checking ...
Committed 0 vias.
Error: DRC violations prevented new vias to be inserted. (PGR-051)
Number of phantom vias: 1
仔细看log,这时有一个幽灵孔出现了。这时,再开打error brower研究一下。
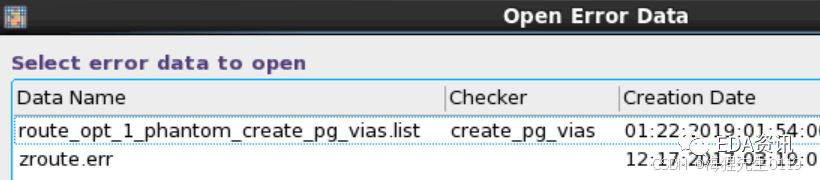
选择checker是“create_pg_vias”那个error data,打开之,就能看到幽灵孔了,选择幽灵孔,可以看具体原因。

从中可以发现,有DRC是因为via78和"routing objects" overlap了。奇怪了,via78这层明明啥也有没有啊,和谁overlap了?
打开别的东西看看,咦,在via78发现了routing blockage 。

5.3、place/place_opt
5.3.1、input file
5.3.1.1 为什么一种工艺都会提供两种或多种高度site的std cell库?
5.3.1.2 一个design里面可不可以使用不同高度的std cell?
5.3.2、env setting
5.3.2.1 create_placement、place_opt、compile_fusion之间有什么异同?
5.3.2.2 如何使congestion的分布更合理?
5.3.2.3 如何使pipeline register自动均匀的摆放?
从2018.06-SP4开始,工具通过“place.coarse.balance_registers”这个app option支持coarse placement自动识别pipelie register和自动摆放。这个app option是OBD(on-by-default),也就是你什么都不做,工具自动帮你搞掂pipeline register。
工具怎么判断哪些是pipeline register:
判断的标准是:窄的扇入/扇出logic(A narrow logic core)
那什么是窄的扇入/扇出logic?必须满足以下几个条件:
-
扇入
-
最多,3个timing startpoints
-
最多,2个side outputs
-
-
扇出
-
最多,3个timing endpoints
-
最多,2个side inputs
-
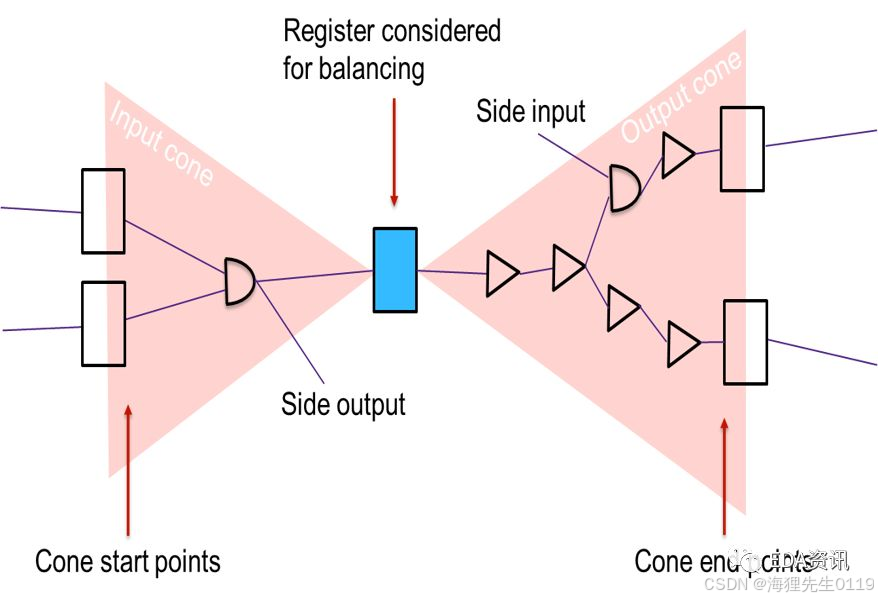
5.3.2.3 Placer要考虑绕弯的路线?
很简单,只需要把这个app option设成true
place.coarse.detect_detours
从2018.06-SP4开始,这个选项默认就是true了。兄弟你也不用设置啥了。
而且,从2018.06-SP4开始,支持多个core来做detect detours这个事情,runtime大大提速,基本看不到对runtime的影响。
5.3.2.4 Placement阶段如何通过group_path命令优化timing?
(1)通过设置group_path -critical_range xx。当CLK group里面最差path优化不下去的时候,工具仍然会继续优化slack在WNS与WNS+0.3之间的其他timing path。这样虽然对group的WNS没有帮助,但是对整个group timing的TNS非常有帮助。
(2)通过设置application
1)place.coarse.tns_driven_placement
这是设置tns timing模式的coarse placement参数。将它设置成true后,coarse place算法就不只会优化path group的WNS,同样会尽量地减少整个design timing的TNS。
2)place_opt.flow.optimize_icgs_critical_range
这是用来设置ICG EN端timing优化的参数,是place_opt.flow.optimize_icgs更为具体的控制参数,它的有效值在0.0与1.0之间。
将值设为X后,如果一个ICG的EN端slack在EN_WNS与EN_WNS*(1-X)的范围内,工具就会考虑是否将这个ICG cell进行split。由此可知,如果设置的值越大,工具考虑split的ICG cell就越多。
3)place_opt.flow.optimize_layers_critical_range
这是一个控制优化net layer来优化timing的参数,有效值在0到1.0之间。如果将值设定为X,工具就会对slack在WNS与X*WNS范围的path的net进行layer优化。如果这个值越小,进行layer优化的net数量就越多。因此,更小的值对TNS更有帮助,但是会占用更多的route资源。
4)place_opt.flow.optimize_ndr_critical_range
这个参数和上面介绍的参数类似,主要区别在于控制的优化方式不一样,它控制的是通过给net加NDR来优化timing。有效值同样在0到1.0之间,参数值越小,使用ndr优化的net数量就越多,需要的绕线资源就越多。这两个参数实际上都是在控制优化net绕线与牺牲route资源的力度,除非实际需要,一般情况下不宜设置过小。
5.3.2.5 layer怎么理解?
5.3.2.6 如何加Keepout Margins?加Keepout Margins有什么好处?
5.3.2.6.1 如何加Keepout Margins?

其中第一个就是我们常用的来给hard macro加的outer keepout margin,通过create_keepout_margin命令,给出四条边需要加的宽度以及macro的名字,就可以给该macro加keepout margin了。
中间的也是一个给hard macro加的outer keepout margin的方式,只是它的宽度并不是直接给定的,而是根据macro边上pin的数量来计算keepout margin的宽度,也就是说pin越多所加的宽度就越宽,对于那些没有pin的边就使用最小的margin宽度。这是非常合理的一个创建方式,既考虑了route的DRC问题又节省了更多的面积给std cell。
最后一个是创建一个inner keepout margin,主要是对hierarchical cell而言,一般不使用。
5.3.2.6.2 加Keepout Margins有什么好处?
(1)Base DRC方面
由于hard macro是一个已经设计好的design,里面会有具体的gds layer。如果std cell紧靠着hard macro摆放的话,就非常有可能导致std cell与hard macro的base layer DRC不满足要求,当然这样也可能导致metal layer的DRC不满足要求,如果在hard macro上加上一定宽度的keepout margin,在macro周围就会有一圈空地,这样就不会引起base DRC问题。
(2)Route方面
给hard macro加keepout margin除了base DRC的原因之外,还有另外一个重要的原因是route DRC。
一般macro的四周会有需要route的pin,由于macro内部已经占掉了一部分绕线资源,大部分情况下,这些macro的pin都是要从侧面连出的。如果std cell离macro非常近的话,macro四周的绕线资源就会更少,从而macro pin 附近就容易出现congestion问题。尤其是对于pin非常密集的memory macro来说,congestion可能会更加严重。
同样的道理,给hard macro加keepout margin后,在macro周围就不会有std cell来占用route资源,就可以基本上消除这些route congestion。
5.3.2.7 Placement Blockages三要素?
(1)作用阶段
(2)作用对象
(3)作用强度
5.3.2.8 macro channel是否需要摆放一定密度的std cell?
(1)作用阶段
(2)作用对象
(3)作用强度
5.3.2.9 综合阶段已经做了place,那apr flow的compile阶段做什么工作?
5.3.2.10 power strap对place有什么影响?
5.3.2.11 什么是site、row、orientation?
5.3.2.12 placement阶段有哪些drc的要求?
5.3.2.12.1 std cell水平之间有距离要求?
根据执行过程中报出的drc,将std cell设置水平间距的要求。

5.3.2.12.2 std cell垂直方向有距离要求?
5.3.3、output file
5.3.4、check list/check method
5.3.4.1 placement阶段做哪些检查?
5.3.4.1.1 timing
5.3.4.1.2 congestion
5.3.4.1.3 DRC
5.3.4.1.3.1 legalize之PG net checks
PG net checks就是检查cell内部的pin、route、routing blockage与cell附近PG net、user route之间的DRC。这些route DRC是真实的DRC,只能通过移动cell或者修改PG net才能fix,因而必须在placement阶段处理掉这些问题。下面是一个简单的示意图:
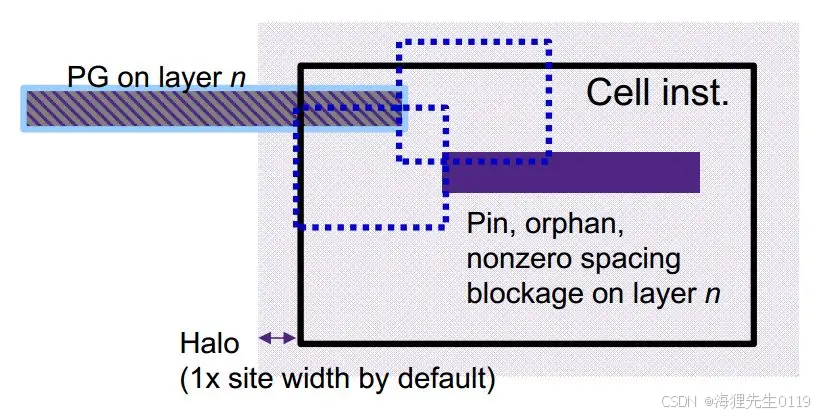
下面我们从几个方面来了解PG net checks内容以及一些注意事项:
1、PG net checks的rule来自technology file,如果发现在某些地方明显已经有DRC violation了,但是工具legalize check却没有发现问题,我们可以从technology file中得知工具是否已经获取正确的DRC rule。
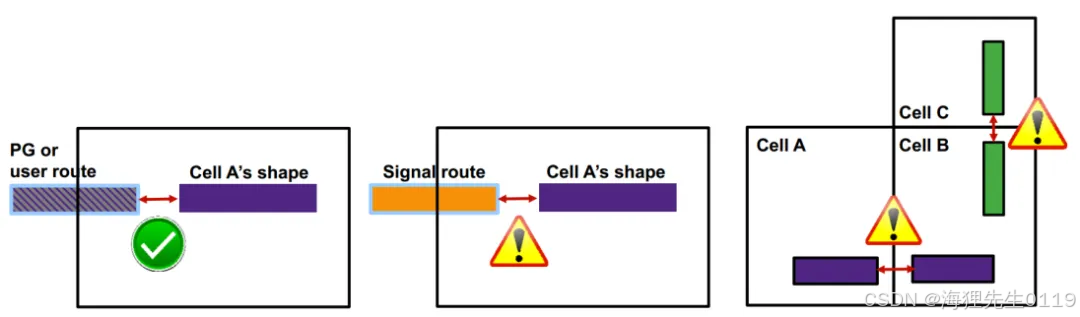
2、PG net checks仅仅check 在cell shape与PG route、user route之间的DRC。也就是说,对于那些不是PG net并且shape_use属性不是user_route的shape,工具不会check它们与cell内部shape之间的DRC。同样,对于cell与cell之间内部的shape,工具也是不做check的。如下图所示,工具不会做带感叹号部分的PG net checks。
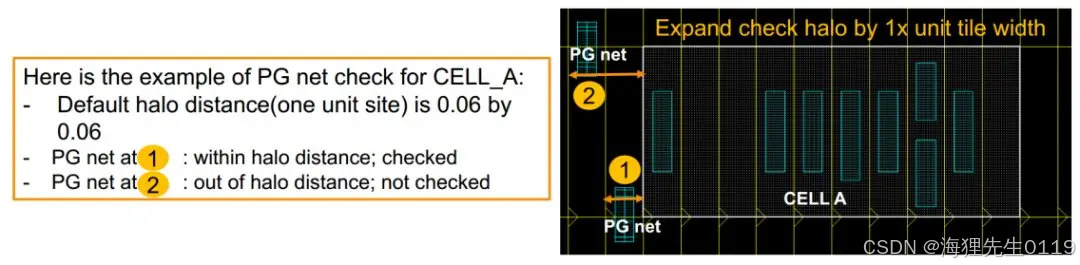
3、PG net checks的范围是从cell往外1倍site距离的区域。也就是说,工具会检查处于一倍site宽度区域内的PG net,不会检查区域外的PG net。如下图所示,工具会对PG net 1的shape做检查,不会对2 shape做检查。
4、默认情况下,check_legality只会给出一个violation的summary报告。但是,我们可以通过check_legality -verbose命令来查看详细的violation报告。需要注意的是,工具为了节省时间也只会给出第一条详细的报告。在后续章节中,会介绍怎么来debug所有的violation。下面是一个实际使用实例:

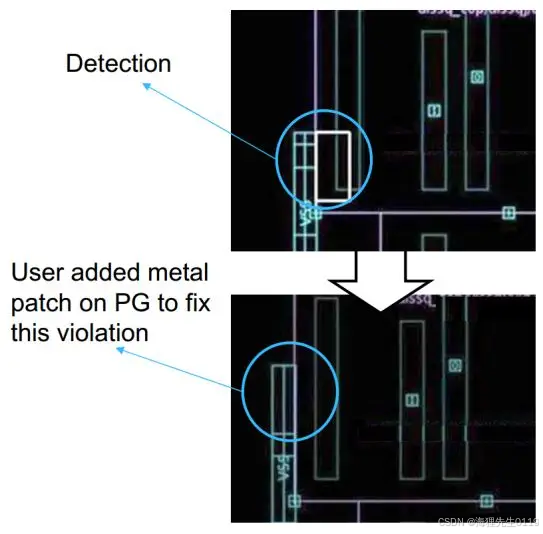
5、对于某些大量的PG net check violation来说,可能是PG不合理造成的,工具不可能通过移动cell来fix所有的violation,这时就需要调整PG来fix。
如下实例,在PG net与pin之间会有DRC问题,我们可以加长PG net或者修改cell内部的pin来处理这种问题。当然,实例中的这种问题,一般只会在先进工艺中才有这种类型的DRC rule。
5.3.4.1.3.2 legalize之Under PG Net Checks
Under PG Net Checks是check在PG net下面的cell pin,避免一些特殊的pin摆放在PG Net下面,造成route DRC问题。
下面我们从几个方面来了解一下为什么在legalize的时候需要做cell pin的Under PG Net Checks:
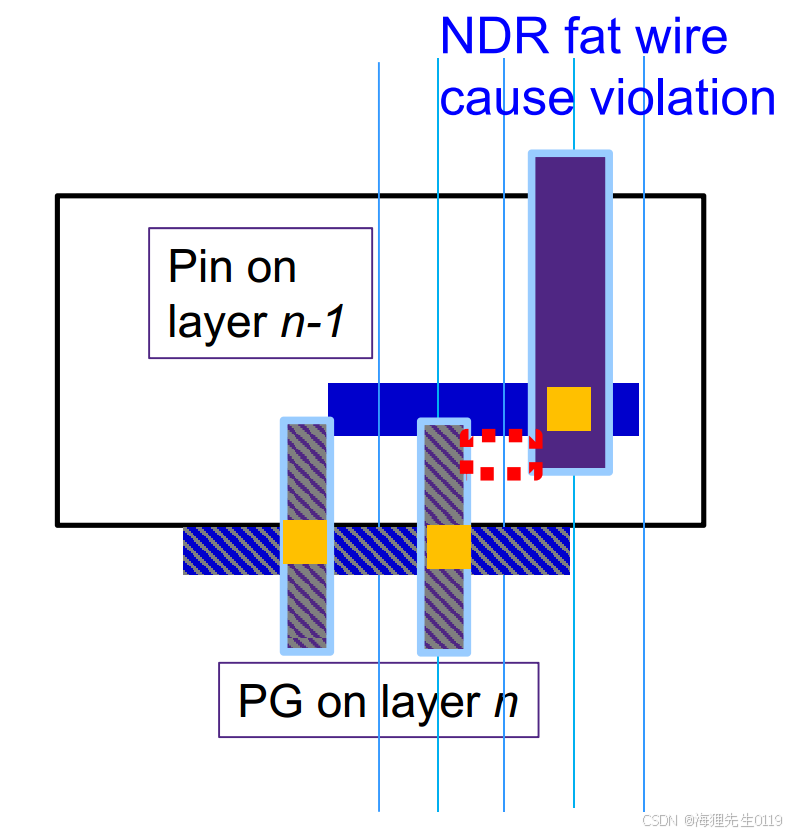
A、由于design的特殊要求,有些net的route会使用NDR rule,连接相应的pin可能就会需要更多的绕线资源。比如项目中的clock net,我们会加大绕线space来减小clock net上的寄生。因此,连接这些clock pin的shape与PG net shape之间就需要更多的space来满足要求。
B、在route约束中,有一种叫做via ladders的约束,它是用来约束route工具怎么来连接一个cell pin的。比如说,通过设置via ladders约束可以使一个pin shape上连出两个连接点,这样可以加强pin连接的EM能力。这种via ladders约束同样需要更多的绕线资源来满足要求,因而也需要在cell pin与PG net之间预留足够的space。
C、由于PG Net会占用一些上层绕线资源,使处在下面的std cell容易出现route问题,对于出pin数量非常多的cell来说,route DRC问题可能会更加严重。因此,需要Under PG Net Checks来预防这种问题。
如下图所示,NDR rule约束中需要使用宽的走线来连接pin,而宽走线默认的space rule也会不一样。这时候legalize的Under PG Net Checks就会考虑这种特殊的space rule,如果存在问题就会移动cell,时这些pin的route不会出现DRC问题。
通过下面的application设置,可以防止一些特殊lib cell pin摆放在PG Net下面:
![]()
其中,place.legalize.avoid_pins_under_preroute_layers用来指定需要做Under PG Net Checks的layers,place.legalize.avoid_pins_under_preroute_libpins用来设置需要check的lib cell pin,需要注意的是这两个application是需要一起使用的。
place.legalize.avoid_pins_under_preroute_width_threshold是用来设置需要做check的PG Net宽度,因为对于某些特别窄的PG来说不会占用太多的绕线资源,基本上不会引起太多的绕线问题。下面是设置实例:
![]()
我们也可以通过下面的application,直接阻止带有NDR rule的pin摆放在PG Net下面。
![]()
需要注意的是,工具在所有的Under PG Net Checks中,都只会检查带有via region的cell pin,对于不带via region的cell pin是不做检查的。下面简单介绍一下via region的概念:
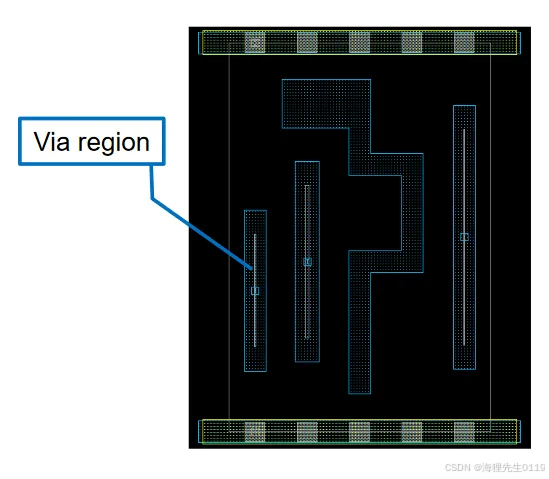
如上图所示,via region是lib cell pin shape的一个属性,在物理上它表示一块区域,用来指导工具在绕线的时候可以将via的中心坐标摆放在区域内。via region主要的目的是指导route工具对pin进行连接,这样可以加快route DRC的收敛速度。
需要注意的是,图中pin宽度使用的是最小线宽,能够打via中心位置其实就是一条直线,因而这种pin的via region就是一个非常窄的长条形。图中的via region看起来非常接近一根直线,其实工具识别这种via region后就是一条直线区域。
总之,Under PG Net Checks是工具在legalize的时候专门检查PG Net下面的cell pin,这样能够较早地预防绕线问题。
5.3.4.1.3.3 legalize之Pin Access Checks
Pin Access Checks有点类似于Under PG Net Checks,它会预测cell在后续route阶段可能的绕线方式,然后给出一些预测性的route DRC结果,尽量使每一个cell pin都能顺利地完成route。
实际绕线过程中,工具将每个pin的route难易程度分为容易、困难、不可能三种情况。Pin Access Checks会识别那些route不可能的情况,然后尝试着来修复这些情况,使这些pin能够绕线。需要注意的是,Pin Access Checks允许容易与困难两种难易程度的情况存在。
Pin Access Checks也可以认为就是Layer Access Checks。如下图所示,主要包括Pin access count、Pin extension、Track capacity三方面的内容。
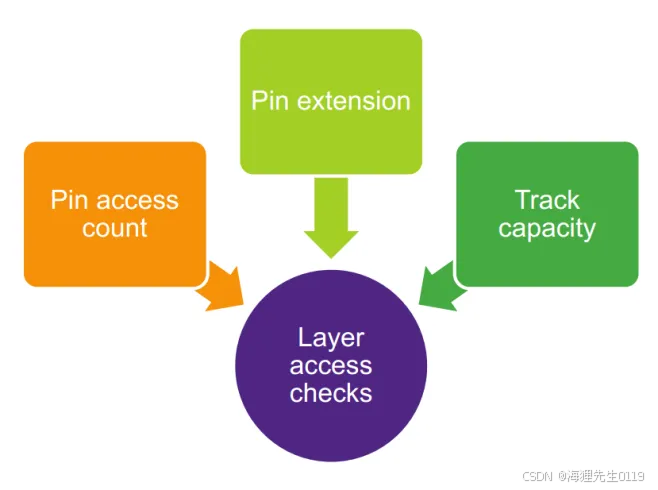
Pin access count
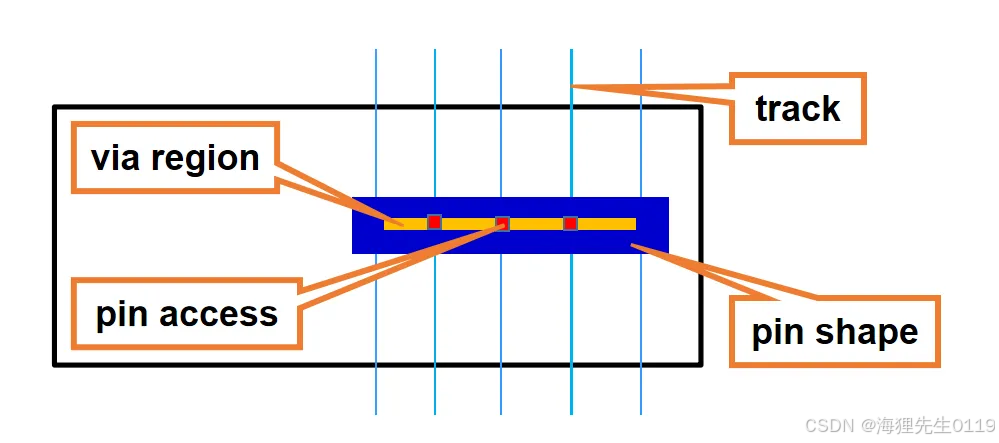
如上图所示,pin access就是pin shape的via region与相应track交叉的地方,而pin access count就是交叉的个数。比如说,如果pin shape的layer是M1,那么pin access就是pin shape via region与M2 track交叉的地方。上图中的pin的access count是3。
显然可知,一个pin的access count值越大,那么连接这个pin的route方式就越多,route灵活性就越大。这种类型的pin在route的时候就不太容易引起DRC问题。
Pin extension
很多情况下,pin上面已经被一些绕线占据,直接在pin上面进行via连接会有一些route DRC问题。为了将这样的pin连接出来,工具需要将pin延长,然后连接pin的延长部分,这样才能避开pin上面的绕线。我们称这种将pin延长的方式为Pin extension。具体实例如下:
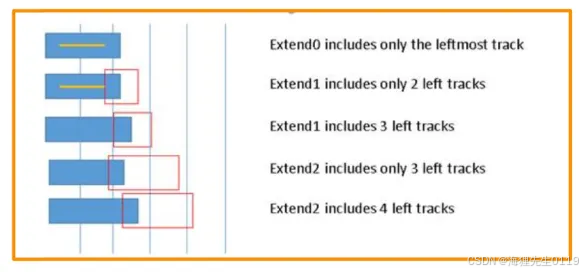
如上图所示,可以通过application来控制pin的延长大小,这样每个pin就可以获取额外的一些pin access count。针对不同的pin延长值,工具计算出来pin的access count值也会不一样。总之,设置pin extension能够保证得出的pin access count符合实际的route情况。
Track capacity
我们可以将track capacity理解为track的容量。从上面的介绍中可以知道:Pin access count与Pin extension是通过连接pin方式的多少来判断这个pin是否有绕线困难。而track capacity就是考虑一些pin平均的access count,从整体上来衡量连接这些pin是否会遇到绕线问题。如果每个pin平均不到一个track,那么就有可能遇到route DRC问题。具体实例如下:
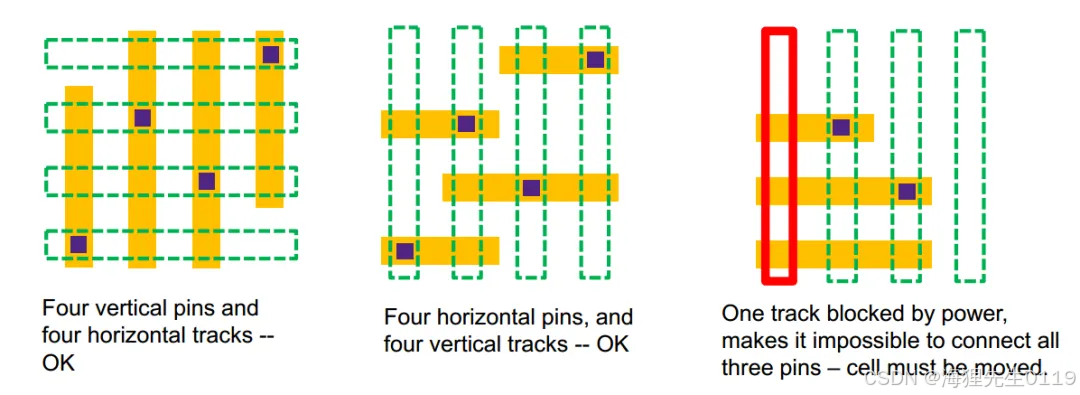
在图一中,一共有4个竖直的pin,4个pin上面也有4个横向的高层track,每个pin可以分到一个track。因此,这种情况是可以满足track capacity检查的。
图二的情况与图一类似,区别在于是4个横向的pin,上面依然有4个竖向的高层track。因此,这种情况也是满足track capacity检查的。
在图三中,有3个横向的pin,但是pin上对应的3个竖向track有一个被PG占据了,有效的track只剩下2个,平均每个pin不足一个track。因此,这种情况不满足track capacity检查。为了避免这种情况,工具在legalize的时候就需要移动cell。
5.3.4.1.3.4 legalize之Track and Color Alignment Checks
5.3.4.1.3.5 legalize之Advanced Layer Rule Checks
5.3.5、debug/fix method
5.4、cts/cts_opt
5.4.1、input file
5.4.1.1、cts时选取什么类型的buf?
综合考虑IR Drop、驱动能力、rise/fall一致性,选取D4-D16的cell。根据最终结果,可以酌情采用更大驱动的cell。

5.4.2、env setting
5.4.2.1、cts做balance时,以哪个scenario为准
当用多个corner做时钟树时,工具会选用一个主corner并兼顾所有corner做tree,cts auto log中会以以下方式报告。
![]()
5.4.2.2、如何判断common point不合理,以及如何修改common point
5.4.2.3、同一clk domain是否还需再细分group
5.4.2.4、长tree的原理?
5.4.2.5、什么样的reg/clk、mem/clk会被在“ CTS STEP: Clock Tree Initialization”阶段被工具自动设置clock balance point settings,如下所示:

5.4.2.6、CTS spec如何确定?
5.4.2.7、clock信号的一些特殊性质?clock cell如何选取?
5.4.2.7.1 clock信号的一些特殊性质?
在介绍选择clock cell考虑事项之前,首先需要了解clock信号的一些特殊性质,大概可以总结为以下几点:
其一、Clock信号波形完整性要求高,比如要求占空比稳定、周期波动小等等;
其二、Clock信号质量的好坏影响范围大,越接近clock源头,其影响越大;
其三、Clock信号翻转率高,功耗大;
在实际选择clock cell过程中,很多考虑因素均是出自于clock信号的特殊性。或者说,如果不是因为clock信号的特殊性,就可以放松很多clock cell的选择指标,从而获取更好的整体PPA。
5.4.2.7.2 clock cell如何选取?
针对clock信号的特殊性,clock cell选择时需要考虑很多事项,可以大概分为以下几个方面:
(1)Cell的OCV特性是否好;
(2)Cell的驱动能力是否合适;
从根本上讲,决定clock cell的驱动大小实际上是在功耗与时序之间做权衡。cell驱动能力大一些,其clock信号质量就好一些,有利于时序,但是会增加功耗。cell驱动能力弱一些,其clock信号质量就差一些,不利于时序,但是会降低功耗。下面总结几点确定cell驱动的相关注意事项:
1)inverter cell驱动不能过大,过大的cell容易引起IR问题;
2)需要有小驱动的inverter cell,可以在clock tree balance过程中用来增加delay;
3)针对库中提供的所有驱动大小,通常会做一定的保留,后期可以根据实际需要size大;
其四、不同工艺、不同库之间存在较大的区别,不能简单地依据以往经验通过X2、X4这些标识来选择驱动能力;
其五、对于clock tree上的其他功能逻辑cell,应该保证有多种驱动大小;
实际项目中,如果标准单元库最大提供X24的cell,那么建议最大使用X16的cell。针对clock的主干部分,有些时候为了保证信号高质量,也可以单独使用驱动更大的cell。但是不管怎么样,最终应该保证不会出现大量的clock cell IR问题;
总之,从后端的实际好处来看,选择驱动合适的clock cell可以减轻后期ECO工作,主要是减少clock cell相关的DRV问题,比如Clock SI、Clock Tran、Clock Cell IR等等。
需要注意的是,clock cell的驱动大小应该与clock DRV配套设置。否则,哪怕clock cell的驱动大小合适,最终的clock tree质量以及整体PPA也达不到最佳指标。
(3)Cell不同沿的延时一致性是否好;
由于clock信号波形完整性要求高,因此在选择clock cell时,应该选择上升延时与下降延时一致性好的cell。一般的标准单元库都会提供这种特性的cell,cell的名字里面通常会有CK这种类似的关键字。
在信号的传输过程中,如果所经过cell的上升延时与下降延时相差越大,信号经过后的波形失真也就越严重。如下图所示:
(4)Cell的IREM与功耗特性是否好;
总之,以上四方面是选择clock cell的过程中需要考虑的关键因素,只有考虑了这些点,才能保证选取的clock cell是合理的。后面将通过一些实际的考虑指标以及相关问题,详细介绍怎么选择clock cell。
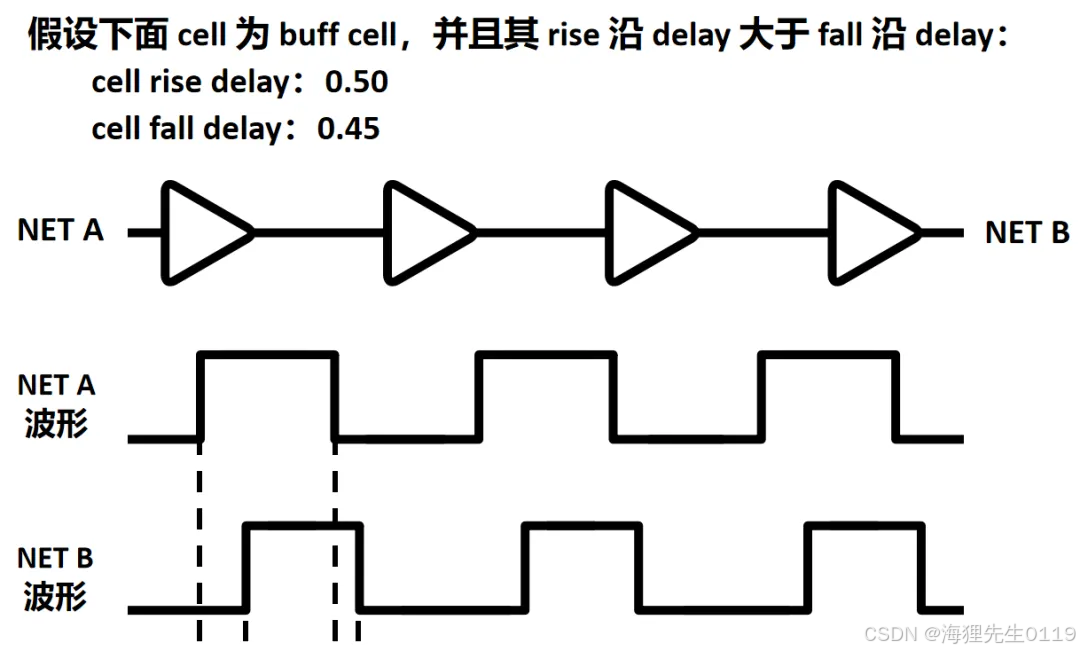
由于cell的rise沿延时大于fall沿延时,clock信号每经过一个cell,其高电平宽度就要变窄。这种波形失真会随着信号的传输累积下来,越往后越严重。对于上图中的情况,由于每级cell相差0.05,从A到B经过了4级cell,因而信号到B处就会相差0.2。
这种由cell不同沿延时不一致引起的clock信号失真,其主要影响有以下几点:
1)不利于clock sink pin的min pulse width约束;
2)不利于特殊IP clock pin信号的占空比需求;
3)不利于不同沿之间timing path的时序收敛;
总之,这些不利因素最终限制了clock 的最高频率,同样也限制了后端clock tree的最大理论长度。由于design的规模越大,其clock tree最终实现也需要更长,因而也间接地限制了design的规模,这也是超大规模芯片需要采取先进clock tree结构的原因之一。
实际上,这种由不同沿延时不同所引起的波形失真现象,只会发生在那些不改变信号相位的cell上,也就是那些输入沿与输出沿方向相同的cell。对于clock tree来说,通常就是mux、clock gate、buffer这些cell。
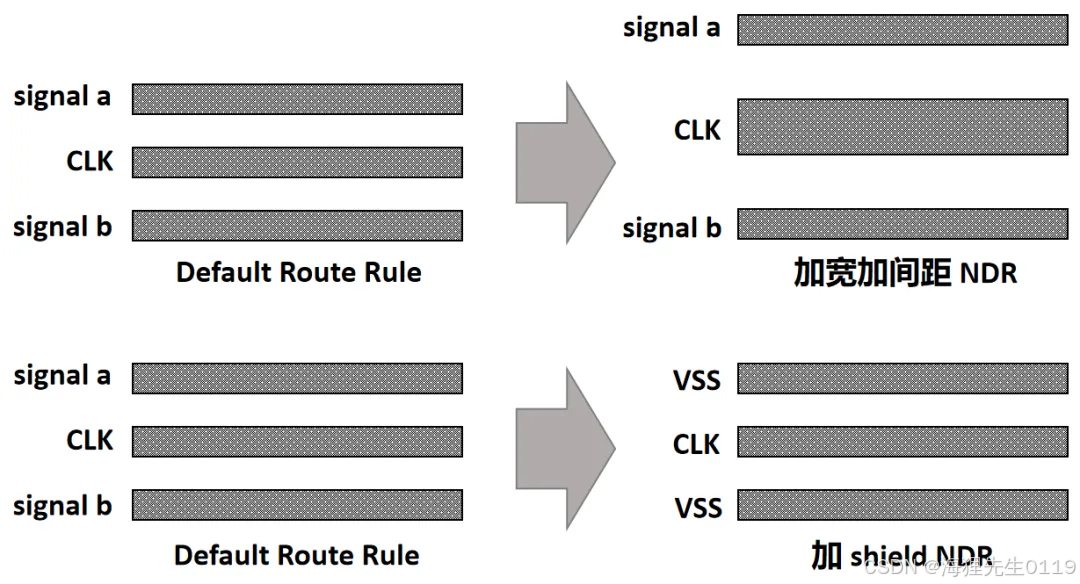
5.4.2.8、NDR route rule包括哪些内容?如何设置ndr?clock NDR相关注意事项?
5.4.2.8.1、NDR route rule包括哪些内容?
由于clock net的特殊性,通常会使用NDR的rule来绕线。根据NDR不同的约束内容又可以细分为:绕线宽度、绕线距离、加屏蔽线、绕线层次四种约束,实际NDR可以根据使用需求任意组合这四种约束。下面为两种NDR的简单示意图:
5.4.2.8.2、如何设置ndr?
实际项目中,通常会依据一定的考虑顺序来确定clock net合适的NDR,其主要思路如下:
(1)首先,需要确定绕线层次。clock net通常会使用中高层来绕线,如果绕线层次充足,每个走线方向最好提供两层金属。比如说,如果当前工艺一共有6层走线层,那么clock net可以使用3、4、5三层金属绕线。
(2)然后,考虑当前工艺是否真的需要其他NDR约束。由于clock NDR的主要目的是减少clock net上的SI delay,因而,一般只有在net delay相比于cell delay不能忽略的时候,才会考虑给clock net设置NDR。比如说,110nm工艺中的clock net一般就不会使用NDR,就算使用也不会带来实在的好处。
(3)接着,考虑绕线间距。经过上面的权衡,如果clock net确实需要使用NDR,那么首先考虑的应该是2倍间距,然后是3倍间距。在大多数情况下,2倍间距基本满足SI需求,并且也能接受额外占用的绕线资源。
(4)最后,考虑是否使用屏蔽线。通常只有在加大间距达不到预期效果时,才会考虑是否加屏蔽线,由于屏蔽线会占用较多的绕线资源,通常也只在clock tree主干net上使用。
(5)需要注意的是,通常不建议加大clock net的走线宽度。如果加大走线宽度是为了解决大量的EM问题,这时候应该检查clock DRV设置以及clock cell选择是否合理,而不是简单地加大走线宽度。如果加大走线宽度是为了更小的clock net delay,可能效果不会很明显,通常只有在cell驱动非常大的时候效果才会好。
5.4.2.8.3、clock NDR相关注意事项?
最后,结合前面介绍的内容与后端实际情况,对clock NDR的常用设置以及注意事项总结如下:
(1)clock net通常使用中高层绕线,只有当绕线层次明显不够时才不会做限制;
(2)一般只有在先进工艺中,才会考虑加大间距以及宽度,或者使用屏蔽线;
(3)首先应该考虑是否加大绕线间距,然后再是考虑是否使用屏蔽线;
(4)不建议加大绕线宽度,至少不建议加大整个clock tree net的绕线宽度;
(5)为了节省绕线资源,提前避免没必要的route DRC,clock tree的不同部分应该设置各自合适的NDR;
(6)在制定NDR的走线间距与宽度时,应该确保工具在绕线过程中既能满足绕线间距的要求,又能保证绕线在track上,避免绕线资源浪费。
(7)针对不同频率的clock,可以根据实际效果采用不同的NDR方案。
总之,clock NDR会给后端带来许多好处,同时也会占用更多的绕线资源,应该根据实际情况权衡其中的利与弊,最终确定具体方案。
5.4.2.9、CTS spec之clock DRV设置?
5.4.2.9.1、clock net max transition?
最终STA的clock max transition收敛指标一般由两方面因素确定:一是clock实际的工作频率,二是标准单元库中pin的自带约束。
实际项目中,clock max transition收敛标准一般会使用1/6周期与60%库约束两者中的最小值。有时候根据clock具体的时序情况还可以将库的约束放松,比如放松到库约束的80%,或者直接使用库约束,但是通常不会放松1/6周期指标。
需要注意,实际PR中在CTS阶段会适当地加严一些clock transition,因为最终STA实际的clock transition通常会变差一些。
针对时序紧张的情况,有时候可以将reg CLK pin的max transition适当地加严,从而获得更小的lib setup timing,预留更多的delay margin给data路径。
5.4.2.9.2、clock net max capacitance?
通常情况下,一般不做额外的clock max capacitance设置,直接使用标准单元库中提供的max capacitance约束。
从另一个角度看,在加严max transition约束的同时,也相当于是在变相地加严max capacitance约束。在PR工具完成clock tree后,由于clock net的max transition要严于单元库中的约束,因而最终实际的net capacitance值通常也会明显小于库里的约束。
5.4.2.9.3、clock net max fanout?
在STA最终的检查指标中,一般不会有max fanout的检查。其实,设置clock net max fanout约束的主要目的是为了指导工具做clock tree,弥补其他DRV约束的不足,让clock tree的质量更符合要求。从实际情况分析,其主要有以下两方面的考量:
其一、规避一些clock sink net的EM问题。在创建clock tree的过程中,由于clock sink点通常分布比较集中,工具可以在满足max transition与max capacitance的条件下,让一个驱动net驱动大量的sink点。这种驱动net的负载电容一般非常大,并且sink net通常会使用底层default rule绕线,因而容易出现EM问题。
其二、平衡clock tree的cell delay与net delay,维持不同corner下的clock skew。对于一个clock cell的驱动负载来说,如果net本身的寄生占比大,不同corner下cell delay与net delay之间的比重也越相近。因此,如果一个clock net绕线短并且驱动点多,那么该clock net的cell delay与net delay就会相差大,在不同corner下就会越不平衡。
通常clock net的max fanout一般建议在20到30之间,过大的约束达不到预期的效果,过小的约束又会导致clock cell增加,而不利于clock tree功耗,并且也不会带来明显的实际好处。
5.4.2.9.4、clock net max net length?
在后端最终的检查指标中,net max length通常不做严格的把控,大概会约束在400um或者500um的样子,具体根据实际工艺而定。
与max fanout一样,clock net max length约束的主要目的也是为了指导工具做clock tree,弥补其他DRV约束的不足,让clock tree的质量更符合要求。其主要有以下两方面考量:
其一、保持不同corner下clock tree net delay与cell delay的比重。由于先进工艺的绕线电阻显著增加,不同corner下net delay与cell delay的比重差距也会增加。控制好clock net走线长度,就可以控制好net的最大电阻,就可以缩小不同corner下的delay比重差距,从而有利于保证所有corner下的clock skew,最终有利于时序。
其二、获取更好的功耗特性或者时序特性。对于特定的驱动cell来说,在满足DRV的情况下,都会存在一个利于时序或者功耗的最佳驱动距离。因此,通过实际测试数据来设置clock net max length约束,可以获取最优的功耗特性或者是时序特性。
通常clock net的max length约束大概在120um到200um之间。过小的约束会使clock cell增加,不利于功耗,由于其他DRV约束的限制,过大的约束一般达不到预期的效果。
5.4.2.9.5、clock DRV相关总结?
最后,结合上面的内容与后端实际情况,简单地总结几点clock DRV设置相关的注意事项:
其一、所有的DRV约束是相互关联的,如果其中一个加严,其它的DRV实际结果也会变化;
其二、从实际clock tree的约束对象来看,max fanout主要针对的是sink net,max length则主要针对的是root net与internal net;
其三、为了获取更好的功耗指标与时序指标,可以尝试在clock tree上不同的位置设置不同的DRV约束;
其四、在尝试寻找合理的DRV约束过程中,应该准确地分析具体是哪个DRV约束不合理,不能盲目地加严或者放松某个DRV约束;
其五、合理的DRV约束应该保证每个的corner下的DRV violation数量在一定范围内,一般保证每种类型的DRV violation数量不超过30。
总之,clock DRV设置主要是在功耗与时序两方面做权衡,一个合理的设置可以在较低的功耗下获取最优的时序指标,而一个不合理的设置可能既不利于功耗,也没给时序带来实在的好处。
5.4.2.10、CTS如何忽略MACRO内部的latency?
通过在macro/CK设置set_clock_balance_points。
fc_shell> set_clock_balance_points -clock [get_clocks *] -delay 0 [get_flat_pins my_macro/CK]
该命令适用于以下情况:
一是macro的 lib的clock latency比较大的情况,cts为了skew小,可能会给寄存器的时钟树上插额外的buffer.,让它和macro 做平,这样会增加不必要的功耗。
二是macro lib的max latency和min latency得skew本身就很大,比如250ps,这时候寄存器的skew怎么做会比250ps要大。
5.4.3、output file
5.4.4、check list/check method
5.4.4.1、在做CTS之前需要进行哪些检查?
①是否完成了placement
②power和groud是否pre-routed
③预估的congestion是否acceptable
④预估的timing是否acceptable
⑤预估的maxtransition/capacitance是否没有violations
⑥High fan-out net
5.4.5、debug/fix method
5.4.6、Others
5.4.6.1、cts和cts opt有什么区别?
5.5、route/route_opt
5.6、insert filter cell
5.6.1、如何控制各种filler的比例?
在物理设计的最后阶段,空余的地方需要插filler。
有些时候,需要控制各种filler cell的比例。怎么实现呢?
create_stdcell_filler 有个选项叫 -utilization,可以控制lib cell list里的filler在空余面积里占的比例。举个栗子:
create_stdcell_filler -lib_cells {FILL_A} -utilization 30
则工具会在当前空余处,找30%的面积来填FILL_A
但是,如果需求更复杂点呢。比如,要求FILL_A占20%比例,FILL_B占25%比例,剩下的地方用别的filler填满。
怎么做?答案很简单,三步走
create_stdcell_filler -lib_cells {FILL_A} -utilization 20
create_stdcell_filler -lib_cells {FILL_B} -utilization 25
create_stdcell_filler -lib_cells {FILL_others}
三步有点麻烦,也有点浪费时间。
有没有更简单的方法?
有的,从ICC2 2018.06-SP2开始有个新的选项叫做-type_utilization,用它来控制各种cell的比例,简直太方便了,一次搞定。
还是上面那个例子,方法如下:
create_stdcell_filler \
-lib_cells {FILL_A FILL_B FILL_others} \
-type_utilization {FILL_A 20 FILL_B 25} \
-fill_remaining
记得-fill_remaining要加上哦,不然只插FILL_A, FILL_B就结束了
5.7、LVS
5.7.1、input file
5.7.1.1 LVS(Layout Verus Source)检查的数据准备有哪些?
得准备cdl格式的网表文件、gds、lvs_rule_deck。并需要将lvs_rule_deck相关信息配置好,如pg name,layout path,cdl path。还有一些参数配置,如是否要打开split gate等。
5.7.2、env setting
5.7.3、output file
5.7.4、check list/check method
5.7.5、debug/fix method
5.7.*、others
5.7.*.1 V2LVS的作用是什么?
V2LVS是一个能够生成cdl格式的小工具。在跑lvs的时候,工具不认pr工具产生的netlist。另外这个工具可以将std的cdl给merge进来。而netlist中是不包括std cell内部device的。
5.7.*.2 LVS为何要打text? 它的目的是什么?
打上text,相当于在版图上定义了port。跑lvs的时候,工具识别到了顶层的text信息,就认为在此处有一个port。如果不打text,与port连接的这些net在版图上识别不到port存在,lvs自然是跑不过了。
那么,有的童鞋会问,除了port,其他net需要打text吗?感兴趣的童鞋可以加入知识星球了解。https://t.zsxq.com/ccmNw
5.8、IR Drop
5.8.1、input file
5.8.2、env setting
5.8.3、output file
5.8.4、check list/check method
5.8.4.1、在做ir drop之前需要进行哪些检查?
5.8.4.2、如果你的设计存在IR drop和congestion问题,你该如何去修复?
①、增加strap width
②、增加strap 数量
③、使用合适的blockage
5.8.5、debug/fix method
5.8.*、others
5.9、DRC Check
5.9.*、others
5.9.*.1、既然PR工具中都检查过DRC了,为何还要在Calibre再做DRC检查呢?
PR工具的drc是根据techlef检测的。而techlef只是一个简单的drc约束文件。有很多的drc在里面是没有的。如一些特殊pattern的drc check,这个目前techlef没法描述。而calibre中的drc rule文件就很全,由于其强大的polygon trace能力。其检查drc的能力也要比PR工具更强。另外,PR工具没法检查base layer的drc。
5.9.*.2、Calibre跑完DRC后你是在calibre中修DRC还是在PR工具中修DRC? 为什么?
一定要在PR工具内修。因为修完drc后,还需要重新跑一下timing。
5.9.*.3、为什么数字IC后端项目物理验证阶段做DRC检查前要先做merge?
因为PR工具产生的gds都是空架子,里面不包含底层的device信息。只包含metal层的信息。所以,需要对PR工具产生的GDS进行merge操作,将std cell或者一些macro底层的gds信息给merge进来,才能跑drc。
5.9.*.4、Calibre DRC的步骤包含哪些内容?
把PR产生的gds与std cell、memory、macro等gds进行merge。然后配置drc rule deck文件。最后,再去跑drc。
5.*、Others
5.*.1、Others
5.*.1.1 scenario在BE哪个阶段设置?怎么设置setup/hold scenario?
在init design阶段设置scenario,
设置了分别用于setup/hold的scenario,此后每个阶段都用该设置。
在compile/place_opt/cts_auto阶段也要设置用于hold的scenario,以用于CCD优化。
在cts_opt阶段要追加设置clk propagate、clk latency,如下所示:
![]()
用如下命令设置setup/hold scenario:

5.*.1.1 各physical only cell的用途?在哪个stage insert?
六、Foundary
七、Package
八、Test
九、Others
9.1、Scripts
9.1.1、tcl
9.1.1.1、正则表达式的用法
9.1.1.2、subst的用法
9.1.1.3、proc里嵌套proc的用法
9.1.1.4、lappend/concat的用法?
9.1.1.5、array的用法?
9.1.1.5.1、创建数组
(1)基本创建
set myArray(0) "value0"
set myArray(1) "value1"
(2)使用 array set命令创建数组
set pairs {a 1 b 2 c 3}
array set newArray $pairs
9.1.1.5.2、访问数组元素
(1)直接访问
set myValue $myArray(0)
puts $myValue ;# 将会输出 "value0"
(2)遍历数组
foreach index [array names myArray] {
puts "Index: $index, Value: $myArray($index)"
}
9.1.1.5.3、访问数组元素
9.2、sdc
9.2.1、sdc flow
9.2.2、clock
9.2.2.1、create_clock
9.2.2.2、create_generated_clock
9.2.2.3、set_clock_groups
9.2.2.4、set_clock_latency
9.2.2.5、set_clock_uncertainty
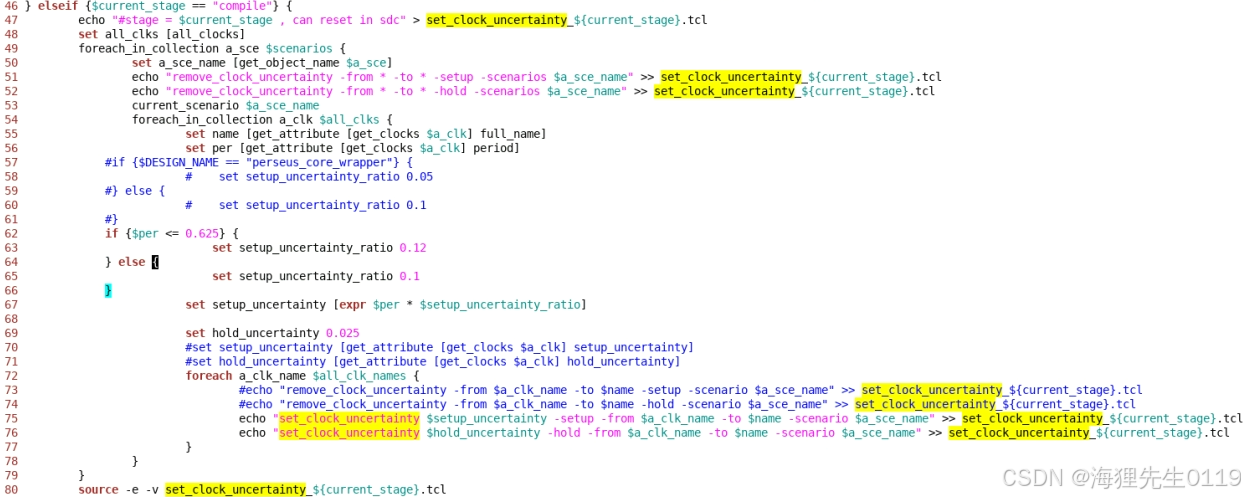
9.2.2.5.1、各stage的set_clock_uncertainty的value如何设置?
9.2.2.5.1.1 syn
9.2.2.5.1.2 sta
9.2.2.5.1.3 apr
(1)init design/floorplan
![]()
(2)power mesh
无需设set_clock_uncertainty。
(3)compile/place_opt
![]()

(4)cts_auto/cts_opt/route_auto

(5)route_opt

9.2.2.5.2、如果是multicycle path,各stage的set_clock_uncertainty的value如何设置?
9.2.2.5.2.1 syn
9.2.2.5.2.2 sta
9.2.2.5.2.3 apr
(1)init design/floorplan
(2)power mesh
(3)compile/place_opt
(4)cts_auto/cts_opt/route_auto
(5)route_opt

















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









